Monografia apresentada ao Curso de Ciência da Computação da Universidade Federal de Ouro Preto como parte dos requisitos para obtenção do título de Bacharel em Ciência da Computação. Monografia apresentada ao Curso de Ciência da Computação da Universidade Federal de Ouro Preto como requisito parcial para obtenção do título de Bacharel em Ciência da Computação. Rafael Alves Bonfim de Queiroz (Orientador) - Doutor - Universidade Federal de Ouro Preto Aline Silva de Miranda (Co-Orientadora) - Doutor - Universidade Federal de Minas Gerais Valéria de Carvalho Santos (examinadora) - Doutora - Universidade Federal de Ouro Preto.
Este trabalho apresenta uma análise exploratória de dados de traumatismo cranioencefálico por meio do uso de aprendizado de máquina para identificar os atributos mais importantes na previsão do resultado de variáveis-alvo. Vários algoritmos de aprendizado de máquina foram estudados e aplicados à análise de dados clínicos. Assim, este trabalho surgiu da necessidade identificada de realizar uma análise exploratória de dados de traumatismo cranioencefálico.
Para tanto, classRandomForestRegressor da biblioteca cikit-learndo Python foi utilizado para regressão de dados, determinando a pontuação média de cada um dos atributos na previsão do resultado e, portanto, identificando os atributos importantes. Este trabalho traz uma análise exploratória de dados de lesões cerebrais traumáticas por meio de aprendizado de máquina para identificar os atributos mais importantes na previsão do resultado de variáveis-alvo.

Problema abordado
Justificativa
Objetivos
Assim, este trabalho visa identificar atributos-chave para a definição de um modelo de predição incorporando dados clínicos de traumatismo cranioencefálico.
Organização do Trabalho
Traumatismo Cranioencefálico
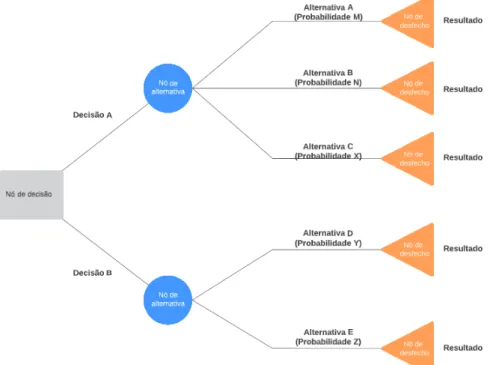
Árvores de Decisão
Neste exemplo, é possível observar que a árvore consiste em um conjunto de regras começando na raiz da árvore (decisão) e terminando em um nó folha (resultado). O principal objetivo ao utilizar árvores de decisão é separar os dados em grupos menores e cada vez mais homogêneos em relação ao resultado desejado. Os preditores usados em cada ponto da árvore são determinados pelo algoritmo, assim como o tamanho da distribuição da amostra.
A profundidade da árvore também deve ser definida e controlada para evitar o overfitting 1, que é uma das maiores desvantagens das árvores de decisão, pois dificulta a generalização. 1 overfitting: quando o modelo fica superajustado, ou seja, aprende demais com os dados e não consegue generalizar com novos dados.
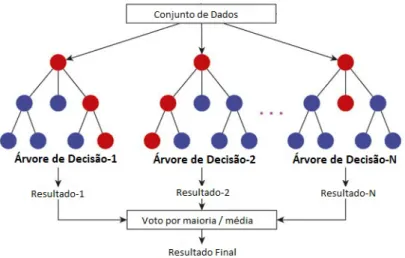
Métodos baseados em comitê de classificadores
Floresta Aleatória
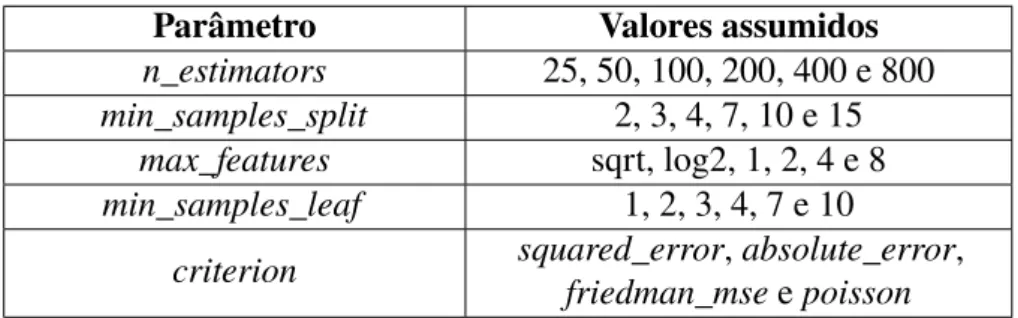
- n_estimators
- min_samples_split
- min_samples_leaf
- max_features
- criterion
Para construir um RF, é necessário ajustar o tamanho dos nós, o número de árvores e o número de características das amostras antes de treinar o modelo. No caso de classificação, o resultado considera o resultado com maior número de ocorrências e, no caso de regressão, a média desses resultados. A entropia usa a probabilidade de um determinado resultado para decidir se deve ou não fazer a separação.
Na fórmula, pi representa a frequência relativa da classe observada no conjunto de dados e C representa o número de classes. Na fórmula, N é o número de dados, fi é o valor retornado pelo modelo e yi é o valor atual dos dados que estão sendo testados em um determinado nó. O parâmetro n_estimators define o número de árvores que serão construídas e conseqüentemente formarão a floresta que produzirá os resultados da classificação ou regressão.
Min_samples_split é o parâmetro que controla o número de amostras necessárias em um nó para que ele seja considerado uma divisão de árvore. O parâmetro max_features é o que define o número máximo de atributos que o modelo levará em conta para a construção de uma árvore e consequentemente para a divisão de uma nova árvore.
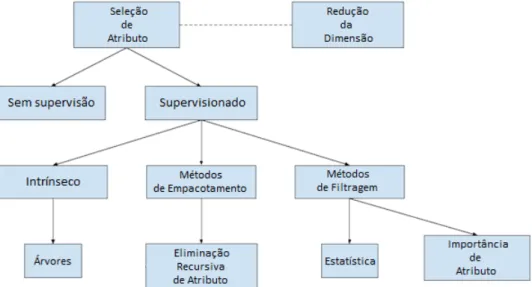
Importância e Seleção de Atributos
Com ele é possível ajustar o número mínimo de atributos que os nós folha de cada árvore devem compor. Por afetar diretamente o resultado de cada árvore, um baixo número de nós folha tornará o modelo menos preciso e mais propenso a falhas. O critério definido é utilizado para definir como serão feitas as variáveis e os limites para a distribuição das amostras.
De acordo com Brownlee(2020), a seleção de atributos refere-se a técnicas para selecionar o subconjunto de atributos de entrada mais relevantes para a variável prevista. O objetivo de usar a seleção de recursos é reduzir as variáveis de entrada no modelo de previsão, eliminando o uso de dados irrelevantes. Modelos supervisionados são aqueles que usam variáveis alvo para identificar quais variáveis podem melhorar o modelo.
Já os modelos não supervisionados são aqueles que não dependem da variável alvo para selecionar os atributos.
Modelo de Regressão
Um objetivo importante da análise de regressão é a estimativa de parâmetros desconhecidos (β's) no modelo de regressão (MONTGOMERY; PECK; . VINING, 2021). Para realizar esse ajuste ao modelo de dados, existem várias técnicas bem conhecidas para estimar os parâmetros.
Trabalhos Relacionados
Em Molaei et al.(2016), foi definido um conjunto de características para avaliar a necessidade de realização de tomografia computadorizada em pacientes com TCE. No trabalho de Matsuo et al.(2020), foi feita uma análise comparativa do uso de nove algoritmos de ML usados na previsão de casos de TCE para um conjunto de dados de 232 casos usando vários parâmetros possíveis. Devido ao pequeno conjunto de pacientes (dados), esse pré-tratamento foi necessário para que não fosse necessário excluir amostras (dados do paciente), ou seja, todos os biomarcadores aberrantes foram removidos das amostras.
As variáveis-alvo a serem analisadas estão associadas à Escala Hospitalar de Ansiedade e Depressão (HADS) (ZIGMOND; SNAITH, 1983). Assim, seria possível reduzir as características observadas para predizer o desfecho para novos casos. Para determinar a pontuação de importância para cada atributo, os atributos sem outliers que já foram obtidos são considerados para atribuir um valor significativo aos atributos de entrada com base em quão úteis eles são na previsão de uma variável de destino.
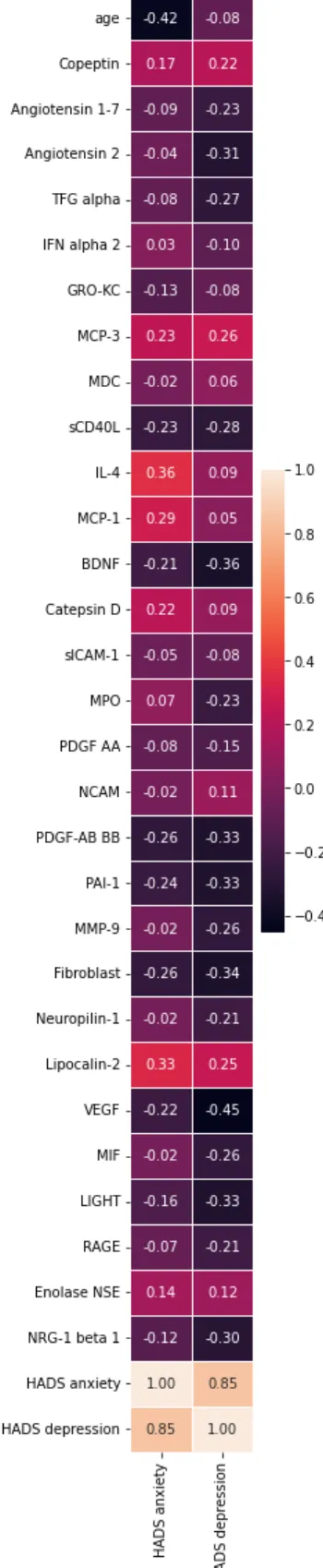
Nesta etapa, o algoritmo de regressão de RF é investigado utilizando o oscikit-learn (PEDREGOSA et al., 2011), uma ferramenta simples e eficiente para análise preditiva de dados em Python. Para uma melhor compreensão do conjunto de dados inicial e da relação entre os atributos (descrevendo a existência ou não de relação entre uma variável e outra), foi gerada uma matriz de correlação entre os atributos e as duas variáveis alvo (HADSanxiety e HADSdepression). Para avaliar a importância desses atributos, é necessário calcular o limiar (pontuação média para cada variável-alvo, que é a pontuação média geral de todos os atributos na predição daquela variável.
Esse processo é realizado por um profissional de saúde (por exemplo, médico) que é capaz de determinar se os atributos identificados como significativos são significativos para predizer variáveis. Assim, as variáveis em uma escala de 0,7 a 1 (positivo e negativo) e em tons de laranja (positivo) e roxo escuro (negativo) apresentam forte correlação. Variáveis entre 0,5 e 0,7 (positivo e negativo) e na tonalidade de vermelho (positivo) e violeta médio (negativo) apresentam correlação moderada.
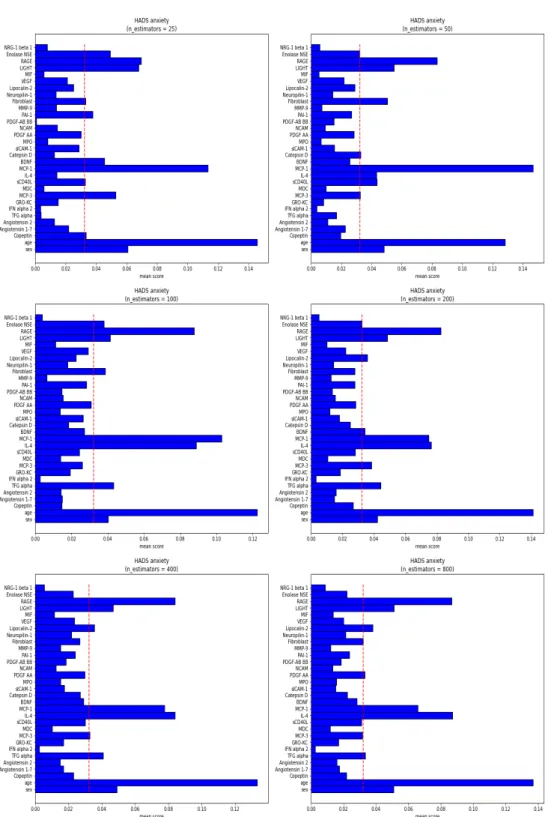
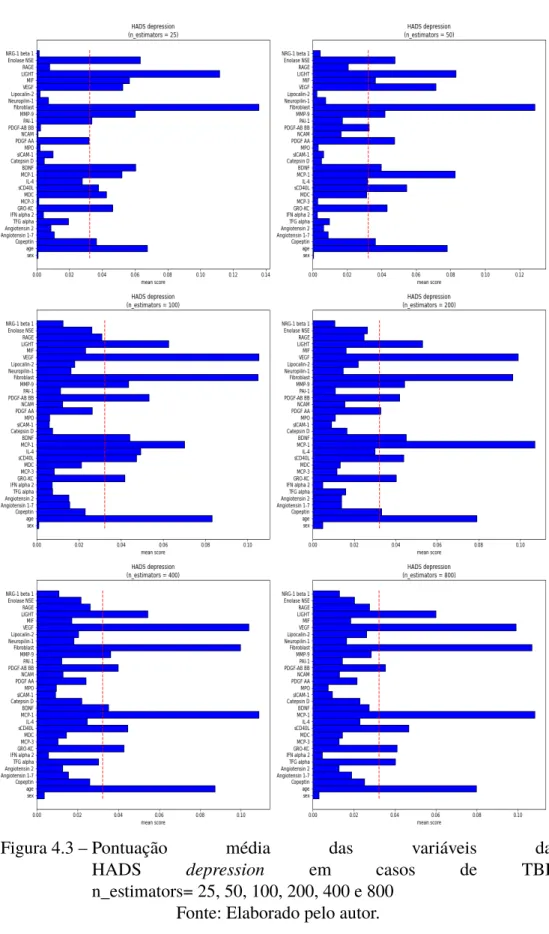
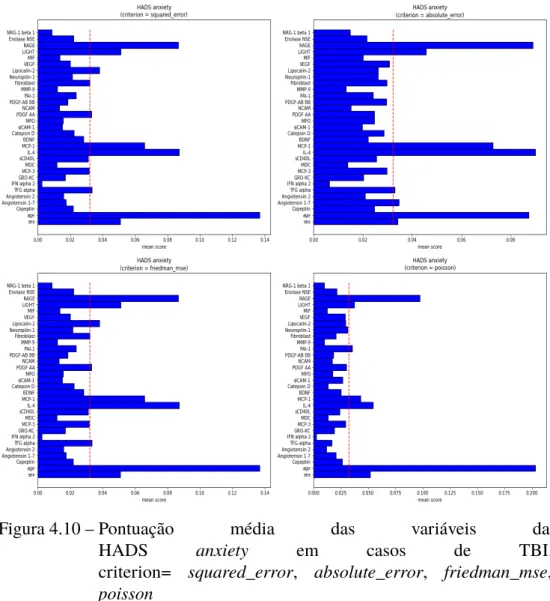
Para a análise dos resultados da execução do modelo para cada um dos parâmetros com os valores predeterminados, foram geradas 10 figuras contendo os gráficos dos escores de importância para cada característica, sendo 5 para a variável alvo HADSansiedade e 5 para a variável alvo HADS depressão. Além disso, foram geradas 10 tabelas, sendo 5 com as características mais importantes e outras 5 com o resultado dos escores R2, ambos para cada variável-alvo, com base nos parâmetros analisados. Vale ressaltar que, para fins de análise, são considerados apenas atributos e biomarcadores presentes em 80% ou mais dos casos.
Diante disso, todos os valores testados para o critério apresentaram boas medidas e o melhor desempenho nessa medida foi com o valor critério=absolute_error chegando a 84% para HADS ansiedade e os valores criterion=squared_error e critério=friedman_mse chegando a 82 % para HADS -depressão em ambos os casos. Com base em todos os resultados obtidos para a variação de cada parâmetro, existem atributos e biomarcadores que estão presentes em todos ou quase todos os casos, independentemente do parâmetro e do valor assumido. Por outro lado, existem outras características que possuem baixíssima importância no modelo, pois raramente aparecem com pontuação acima do limiar ou mesmo atingem esse valor em algum dos casos analisados.
Também é importante notar que foi possível observar que uma alta correlação de Pearson entre cada atributo e as variáveis-alvo (ver Figura 4.1) não correspondia necessariamente à importância dos atributos determinados pelos modelos de floresta aleatória. Isso é explicado pelo fato de que esses modelos de aprendizado de máquina também podem levar em consideração correlações entre atributos para implicar a variável de destino. No geral, as características coletadas que representam a maior significância para o modelo foram idade e LIGHT, MCP-1, TFG-alfa, IL-4, sCD40L, Fibroblasto, VEGF e PDGF-AB BB.
Conclusão
Trabalhos Futuros
BROWNLEE, J. Data preparation for machine learning: data cleaning, feature selection and data transformations in Python. Ten-year trends in traumatic brain injury: a retrospective cohort study of california emergency department and hospital readmissions and readmissions.BMJ open, British Medical Journal Publishing Group, v. Comparison of injury severity score, Glasgow coma scale, and revised trauma score in predicting traumatic infant mortality and prolonged icu stay: a cross-sectional retrospective study. Emergency Medicine International, Hindawi, v.
The economic burden of traumatic brain injury due to fatal traffic accidents in shahid rajaei trauma hospital, shiraz, iran. Archives of trauma research, Kowsar Medical Institute, v. Emergency Department evaluation of traumatic brain injury in the United States The Journal of head trauma rehabilitation, NIH Public Access, v. Machine learning to predict in-hospital morbidity and mortality after traumatic brain injury. Journal of neurotrauma, Mary Ann Liebert, Inc., publishers 140 Huguenot Street, 3rd Floor New .., v.
A machine learning based approach for identifying patients with traumatic brain injury in whom a head CT scan can be avoided. In: IEEE.2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). Problems with the analysis of survey data and a proposal. Journal of the American Statistics Association, Taylor &.