Aplicação de mineração de dados para recomendar parâmetros para KOIN-OR Branch and Cut [manuscrito] / Rafael de Sousa Oliveira Martins. Esta situação pode ser resolvida aplicando o processo de Knowledge Discovery in Databases (KDD). Segundo Han (2005), há um grande aumento de dados coletados pela sociedade, empresas, ciência e engenharia, medicina e outros aspectos da vida cotidiana.
Essa situação pode ser resolvida aplicando o processo de Knowledge Discovery in Databases (KDD), que segundo Fayyad, Piatetsky-Shapiro e Smyth (1996) é o processo que visa descobrir o conhecimento valioso, relevante e desconhecido no banco de dados de dados . A base de dados utilizada neste trabalho foi um conjunto de problemas de programação linear inteira resolvidos por COIN-OR Branch and Cut (CBC), utilizados no Grupo de Otimização e Algoritmos (GOAL/UFOP) da Universidade Federal de Ouro Preto. Assim, o trabalho atual é apresentado para usar o processo de mineração de dados com a tarefa de classificação e regressão para recomendar quais parâmetros usar, de forma confiável, dado um novo problema a ser executado no CBC.
Objetivos
Objetivo Geral
Este grupo desenvolve pesquisas nas áreas de otimização mono e multiobjetivo, inteligência computacional, mineração de dados, processamento e recuperação de informações e algoritmos. Esses problemas envolvem uma variedade de problemas do mundo real, como alocação de tempo, programação de projetos, roteamento de veículos, logística reversa, arte, medicina, engenharia e economia. COIN-OR Branch and Cut (CBC) é um solucionador de Programação Inteira Mista de código aberto escrito em C++, que possui uma multiplicidade de parâmetros.
Os parâmetros utilizados nos problemas desenvolvidos no GOAL/UFOP são utilizados de forma empírica.
Objetivos Específicos
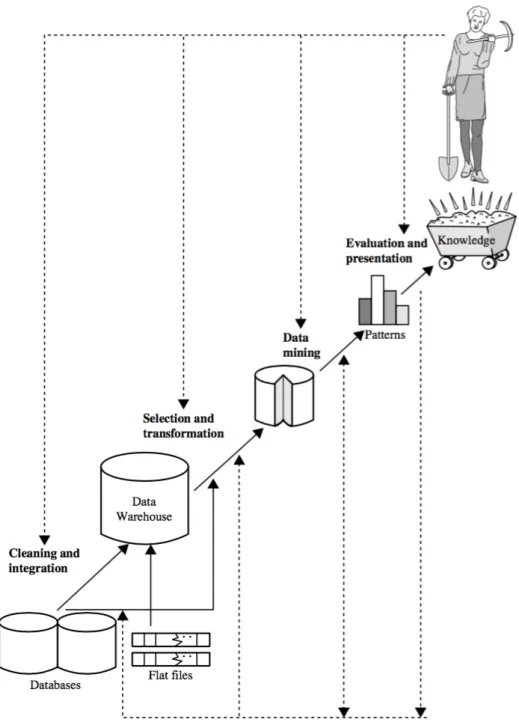
Descoberta de Conhecimento em Base de Dados
Mineração de Dados
Classificação
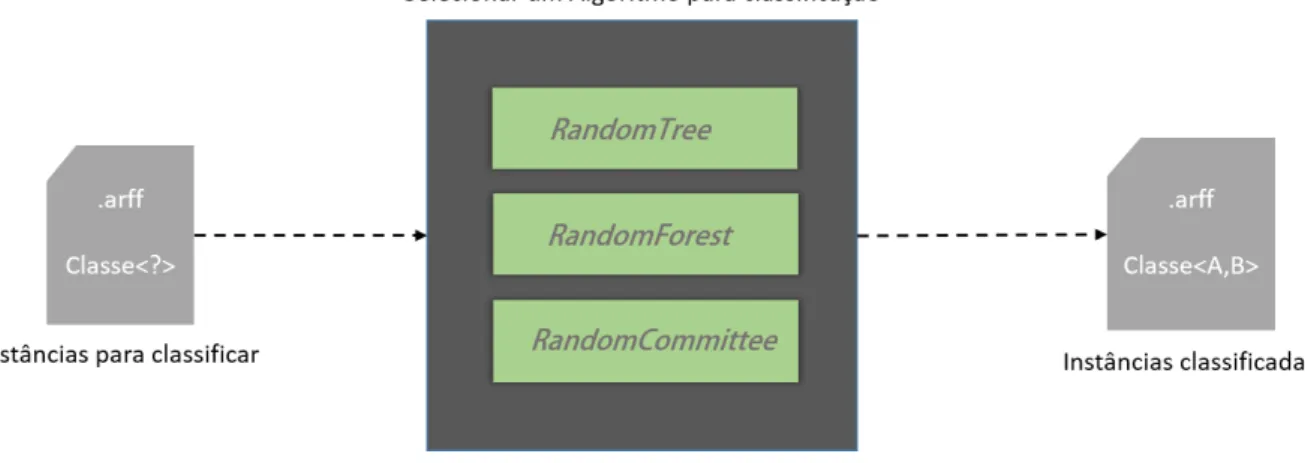
A classificação é uma tarefa de mineração de dados que visa encontrar uma função que permita que cada registroXi de um banco de dados seja associado corretamente a um único rótulo categórico Yj, denominado classe, que forma um par (X,Y). A ferramenta WEKA possui uma coleção de algoritmos de aprendizado de máquina, que inclui os algoritmos de tarefa de classificação. Como existem muitos tipos de algoritmos de classificação, alguns deles foram selecionados para serem aplicados ao problema descrito neste trabalho.
Regressão
WEKA
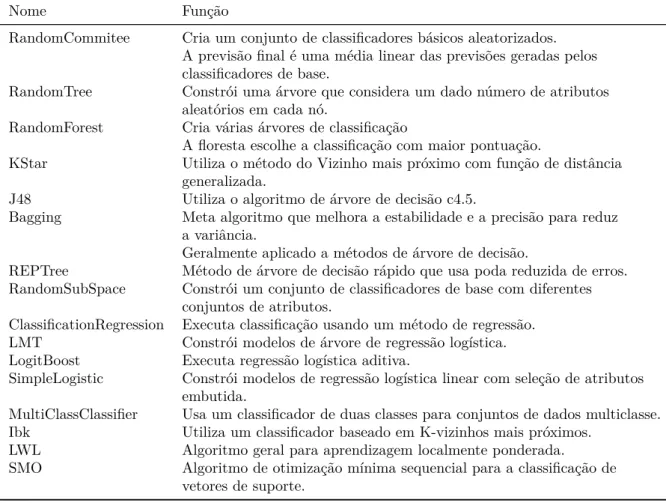
Algoritmos
RandomTree Constrói uma árvore que considera um determinado número de atributos aleatórios em cada nó.
Métricas de Avaliação dos Algoritmos
Parâmetros de Avaliação dos Resultados do WEKA
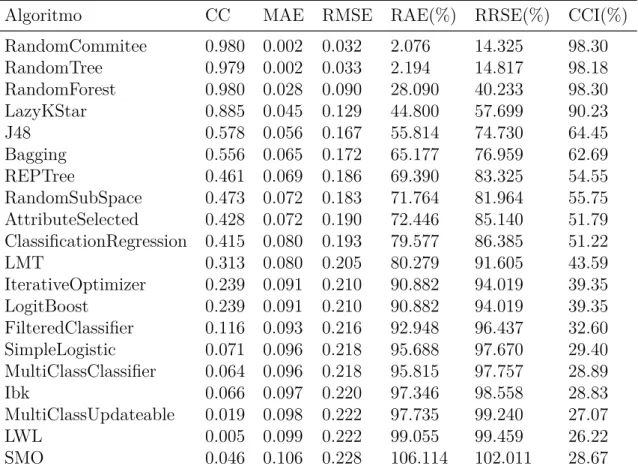
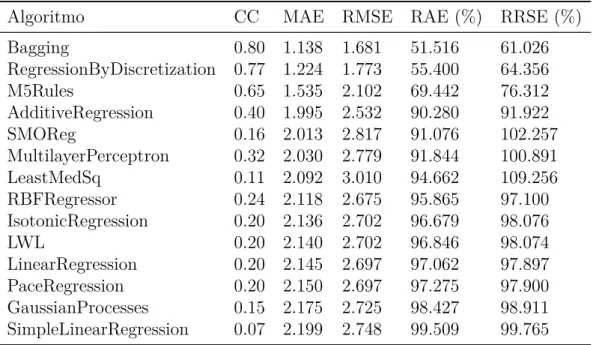
A métrica do coeficiente de correlação ou estatística kappa (coeficiente de correlação) mostra a razão entre o valor real e o valor estimado de uma classificação, portanto esse valor varia estritamente entre −1≥θ,θˆ≤1. Quanto mais próximos de zero estiverem os valores de θ e ˆθ, a relação é basicamente inexistente, e quanto mais próximo dos extremos a relação é muito forte, sendo no caso negativo uma relação inversa muito forte. A métrica MAE não leva em consideração se o erro foi superestimado ou subestimado e é caracterizada pela média dos erros cometidos pelo modelo de previsão ao longo de uma série de execuções.
Para calcular, subtraia o valor previsto do valor real em cada período de execução. A soma dos erros de previsão ao quadrado é determinada e dividida pelo número de erros usados no cálculo. Vale ressaltar que a diferença média entre MAE e SE RM pode ser comparada em relação ao valor da variável.
A métrica RRSE, segundo Witten, Frank e Hall (2011), refere-se a uma medida um pouco diferente, onde o cálculo do erro é feito em relação ao que teria sido um simples preditor utilizado. A métrica RAE, segundo Witten, Frank e Hall (2011), é apenas o erro absoluto total, com o mesmo tipo de normalização do RSSE. Os atributos acima são usados para a tarefa de regressão e para a tarefa de classificação, adicionando a porcentagem de instâncias classificadas corretamente.
Programação Linear Inteira
COIN-OR
Esta situação pode ser resolvida aplicando o processo Knowledge Discovery na base de dados, conforme descrito na seção 2.1. Neste trabalho são utilizadas técnicas de descoberta de padrões através da análise do comportamento histórico dos dados, permitindo que novas instâncias de problemas sejam executadas de forma eficiente no CBC.
Trabalhos Relacionados
O trabalho propõe uma nova perspectiva no trabalho de modificação de configurações de parâmetros metaheurísticos. Os resultados empíricos indicam que a eficácia das configurações de parâmetros pode realmente estar relacionada a um problema de informação específico (por exemplo, assinatura de partícula), para o qual o método de ajuste baseado em regressão geralmente parece promissor. Esta seção explica o pré-processamento dos dados, avaliação e seleção do algoritmo, além de apresentar a biblioteca criada.
Preprocessamento de Dados
Limpeza e Padronização dos Dados
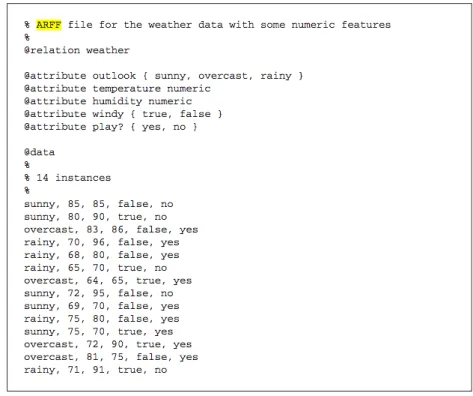
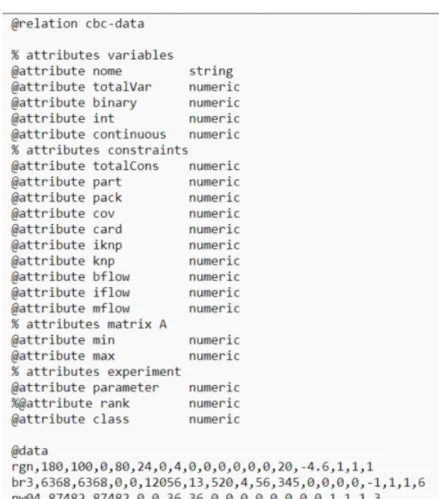
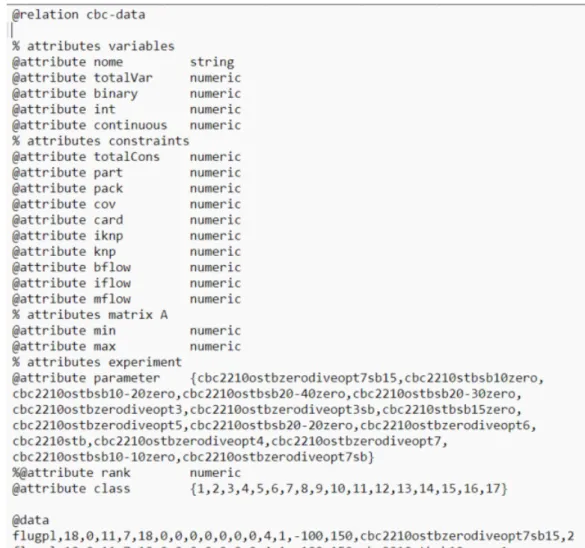
Da mesma forma, foram definidos dois arquivos .arff que diferem apenas em dois atributos: rank, que é o atributo de classe, e os parâmetros, que para tarefas de classificação são definidos como nominais e para tarefas de regressão são definidos como numéricos. Nesta tarefa, é criada uma função matemática que, dados os valores numéricos de novas instâncias, retorna o valor numérico da classe. Na classificação, os parâmetros e campos orank são nominais, ou seja, não possuem um valor numérico atribuído a eles, embora sejam especificados como numéricos.
O mapeamento de nominal para numérico mencionado anteriormente é feito simplesmente realizando uma categorização direta por posição de entrada, ou seja, o primeiro item do parâmetro é definido como número 1, o segundo item como número 2 e assim por diante, e para o atributo rank, que é o classificador, por ser numérico por padrão, apenas foi convertido diretamente para nominal, sendo o número 1 convertido para categoria 1. A partir do processo de criação do arquivo .arff, ele foi adicionado ao WEKA para pré-processamento, nome removido. Depois de limpar os dados e diferenciar a definição de ficheiros .arff, passamos à fase de aplicação de tarefas de data mining, nomeadamente classificação e regressão.
Avaliação de Desempenho dos Algoritmos
Na figura é apresentado o modelo simplificado da árvore de classificação gerada pelo algoritmo Random Tree, apresentando apenas os nós iniciais, pois o modelo é extenso.
Biblioteca
Pseudocódigo
O pseudocódigo consiste em um procedimento que seleciona entradas fornecidas por argumentos tratados por ArgParser4j 1 , que opera sobre argumentos passados como parâmetros no terminal ao executar a biblioteca. O pseudocódigo é dividido em duas funções, classificação e treinamento, que serão tratadas como módulos separados neste trabalho. O módulo de classificação recebe como parâmetros o modelo, a base de teste e o nome do arquivo de saída.
O módulo de treinamento, por outro lado, recebe parâmetros como modelo, banco de dados de teste, nome do arquivo de saída e base de treinamento, além dos parâmetros, e esses argumentos para ambos os módulos são parcialmente recebidos como argumentos de biblioteca. Dois primeiros passos são seguidos tanto no módulo de classificação quanto no módulo de treinamento. Primeiro, o filtro é aplicado para remover o nome e o atributo rank é colocado como uma classe para o problema de classificação.
Em seguida, as instâncias classificadas são gravadas em um arquivo de saída, substituindo a classe no arquivo de entrada pela classe prevista pelo modelo. A partir da terceira etapa, o módulo de classificação lê o modelo armazenado na pasta da biblioteca. Feito isso, será definido o classificador para a base de teste, para validar o modelo treinado e escrever a solução em um arquivo .model.
A biblioteca possui um argumento específico que será exibido quando um argumento não corresponder ao conjunto, que exibe esta tela para auxiliar no uso da biblioteca.
Módulo de Treinamento
A Figura 7 é um exemplo da tela de ajuda que aparece na tela quando passada pelo argumento "-h" ou por um erro de argumento. Para que o fluxo seja completo e válido, devem ser disponibilizadas instâncias de treinamento para o modelo a ser gerado. Para executar a biblioteca, instale o Java Jdk 2 e execute o seguinte comando no terminal de comando do sistema operacional: "java -jar rp-cbc.jar –train A tarefa de classificação mostrou-se mais eficaz em recomendar os parâmetros que COIN-OR Branch and Cut devem utilizar na resolução de problemas de programação inteira. É possível inferir com boa precisão qual conjunto de parâmetros relacionados ao CBC levaria à melhor solução possível para um determinado problema. Este trabalho propõe uma recomendação de parâmetros para o solver COIN-OR Branch and Cut (CBC) para obter a melhor configuração de parâmetros para problemas de otimização e melhorar a eficiência em encontrar a solução ótima. Esta situação pode ser resolvida aplicando o processo de Knowledge Discovery in Databases (KDD). Os resultados obtidos foram satisfatórios, tornou-se possível encontrar um modelo de árvore geral, para diferentes tipos de problemas, em que a representação dos parâmetros é feita de forma confiável. Nesse modelo, x representa um conjunto de variáveis de decisão contínuas de dimensão n e um conjunto de variáveis de decisão completas de dimensão p. O resolvedor é escrito na linguagem C++ e possui um conjunto de bibliotecas que permitem ler, criar e tratar tais problemas. Essa situação pode ser resolvida com a aplicação do processo Knowledge-Discovery in Databases (KDD), que segundo Fayyad et al. A escolha dos parâmetros pode influenciar diretamente no desempenho do solver, tornando essa etapa uma atividade essencial na construção da solução . O comportamento histórico dos dados permite analisar as características das instâncias e configurações de parâmetros aplicados nas quais o melhor GAP foi obtido. Assim, por meio de um modelo de classificação, pode-se indicar com segurança a configuração dos parâmetros que um GAPideal retorna, próxima de zero. No problema em questão, os registros são as instâncias que possuem as características dos problemas de otimização combinatória e linear realizados no CBC. Neste trabalho, uma abordagem baseada em classificação foi apresentada para recomendar parâmetros a serem utilizados pela COIN-OR Branch e Cut na resolução de problemas.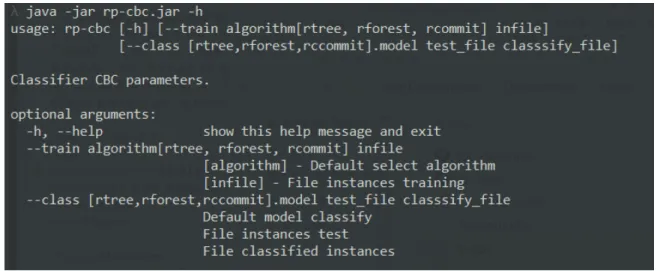
Módulo de Classificação