Portanto, este trabalho tem como objetivo construir uma representação de alto nível de um conjunto de imagens. O problema da interpretação de imagens pode ser definido como a extração de significado de uma imagem.
MOTIVAÇÃO
CONTRIBUIÇÃO
A Seção 2.4 explica redes neurais, especialmente redes neurais convolucionais que se tornaram um padrão de fato em visão computacional. Finalmente, a Seção 2.7 apresenta uma conclusão sobre as diferentes técnicas apresentadas e a relação destas técnicas com este trabalho.
REPRESENTAÇÃO GLOBAL
A abordagem global mais simples para o reconhecimento de objetos é através do histograma de cores, onde diferentes classes normalmente têm diferentes distribuições de histograma de cores. Por exemplo, o trabalho apresentado em (ARBELAEZ et al., 2012) utiliza o histograma de cores no espaço HSV juntamente com descritores de textura e forma na segmentação de objetos.
REPRESENTAÇÃO LOCAL
DETECTORES
- ABORDAGENS BASEADAS NO DETECTOR DE HARRIS
- ABORDAGENS BASEADAS EM LAPLACIANO
- ABORDAGENS BASEADAS NO HESSIANO
Os pontos identificados na imagem serão maximizados se a segunda derivada da vizinhança tiver comportamento semelhante ao kernel aplicado. Outra abordagem para este problema é baseada no operador Hessiano (GRAUMAN; LEIBE, 2011), cujo objetivo é detectar pontos de interesse que são pontos máximos e mínimos no gradiente de uma imagem.
DESCRITORES
- SIFT
- SURF
- MSER
- ASIFT
- Descritores Binários
- Outras abordagens
O conceito básico do ASIFT é extrapolar o algoritmo SIFT gerando imagens sintéticas da imagem original sob várias transformações afins. Outro exemplo é encontrado em (KE; SUKTHANKAR, 2004) que segue o princípio SIFT, mas aplica PCA ao espaço gradiente para obter uma representação mais discriminativa do ponto de interesse.
ASSOCIAÇÃO DE DESCRITORES
O objetivo dos descritores binários é fornecer uma representação concisa dos atributos, o que reduz bastante os custos de processamento e armazenamento. De acordo com o foco da aplicação, há uma ampla gama de descritores a serem investigados, como descritores densos que consideram locais e escalas fixas (C. LIU et al., 2008; TOLA; LEPETIT; FUA, 2010).
APLICAÇÕES UTILIZANDO ATRIBUTOS DE BAIXO NÍVEL
DETECÇÃO DE OBJETOS
Esses descritores são exemplos de atributos usados em aplicações de recuperação de imagens. Deve-se notar que esta lista não é exaustiva, pois um conjunto separado de atributos pode ser definido para cada tarefa.
CLASSIFICAÇÃO ATRAVÉS DE BOW
Depois, na fase de treinamento, para cada imagem existente no banco de dados, é criada uma pirâmide contendo diferentes escalas em cada nível. A seguir, um índice invertido é utilizado para verificar quais imagens do banco de dados compartilham o maior número de atributos.
ATRIBUTOS EXTRAÍDOS DE MANEIRA NÃO SUPERVISIONADA
Um dos pontos principais entre a classificação de imagens utilizando redes neurais é a seleção de características, ou seja, as características para o classificador são aprendidas, já que a extração de características ocorre de forma implícita, principalmente nas camadas convolucionais. Como o foco deste trabalho é a recuperação de imagens, sendo portanto necessária a extração de características da imagem, optou-se pela utilização de redes neurais.
REDES NEURAIS CONVOLUCIONAIS
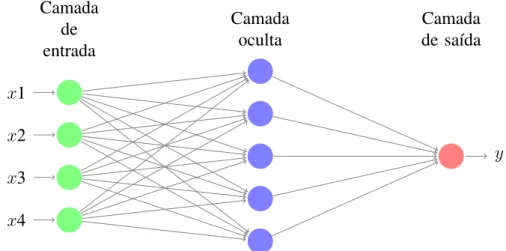
Um fator importante ao considerar o modelo apresentado na Figura 2 é a existência de apenas um neurônio. O modelo apresentado na Figura 3 contém três camadas, cada uma contendo um número distinto de neurônios.

VALIDAÇÃO DOS RESULTADOS DA RECUPERAÇÃO
REPRESENTAÇÃO DE CONHECIMENTO
Além da expressividade, outra propriedade importante no desenvolvimento de uma ontologia é a especificidade, ou seja, quão específicos são os conceitos representados por uma ontologia. A utilização de uma ontologia geral como base para a estruturação do conhecimento reduz, portanto, o esforço, uma vez que grande parte dos conceitos necessários podem já ter sido definidos, mesmo que haja uma curva de aprendizado para compreendê-los efetivamente. ).

CONCLUSÃO
O problema de interpretação de imagens é definido pela extração automática da semântica presente em uma imagem. O domínio deste trabalho refere-se às relações espaciais que existem em uma imagem, além disso, a interpretação do que é extraído na análise quantitativa (seção 4.1) é realizada através de uma ontologia, sendo a ontologia SUMO (Adam PEASE; Ian NILES; J.LI, 2002). Além disso, o SUMO se baseia em uma ontologia cuja construção foi feita manualmente por meio do mapeamento de toda a WordNet (A. PEASE; I. NILES, 2003), permitindo uma correlação entre o que é expresso em linguagem natural e a própria ontologia.
RECUPERAÇÃO DE IMAGENS
Finalmente, a tarefa de recuperação de imagens é altamente dependente do contexto, o que significa que não existe uma técnica única atual (WAN et al., 2014). Outra técnica de recuperação de imagens é a criação de um hash semântico, conforme proposto em (SALAKHUTDINOV; G. HINTON, 2009), aplicado a imagens (XIA et al., 2017). Esta abordagem é uma abordagem de busca pelo vizinho mais próximo considerando um conjunto de imagens (R. XIA et al., 2014).
SEGMENTAÇÃO SEMÂNTICA
O estado da arte neste campo é, portanto, a utilização de redes neurais, o que também pode ser confirmado pelos resultados de Zhou et al. Inspirados em resultados da área de processamento de linguagem natural (PNL), trabalhos recentes investigaram a relação entre os diversos objetos que compõem uma imagem (SOCHER et al., 2011). Os avanços na interpretação de imagens também buscam estabelecer relações espaciais entre estruturas encontradas em imagens, onde tais estruturas geralmente são objetos ou partes de objetos (C. HUDELOT; J. ATIF; I. BLOCH, 2008).
REPRESENTAÇÃO DO CONHECIMENTO
Relação espacial é um conceito com propriedades exclusivas e cuja principal característica é a criação de uma conexão entre outros conceitos de caráter especial representados por objetos ou partes de objetos (C. HUDELOT; J. ATIF; I. BLOCH, 2008). Neste trabalho serão consideradas apenas as relações intrínsecas, pois a base de conhecimento será construída com imagens digitais. Trabalhos recentes investigaram as relações entre diferentes objetos presentes em uma imagem com o objetivo de traduzir informações existentes em expressões de linguagem natural (KARPATHY; JOULIN; Li FEI-FEI, 2014; MALINOWSKI; FRITZ, 2014).

RECUPERAÇÃO DE IMAGENS ATRAVÉS DA SEMÂNTICA
ABORDAGENS DE COMPARAÇÃO
Assim, em (LAN et al., 2012) é proposto um formato de consulta para expressar buscas com o objetivo de recuperar imagens cujos objetos compartilhem uma relação espacial específica. Por fim, o trabalho em (SIDDIQUIE et al., 2014) constrói uma representação dos objetos identificados e faz uma associação entre os diferentes modelos envolvendo objetos e relacionamentos. Assim, a partir de um conjunto de modelos, construídos por meio de imagens sintéticas representando uma relação espacial, o método descrito em (SIDDIQUIE et al., 2014) associa cada par de objetos identificados a um desses modelos e consequentemente estabelece uma relação espacial.
CONSIDERAÇÕES FINAIS
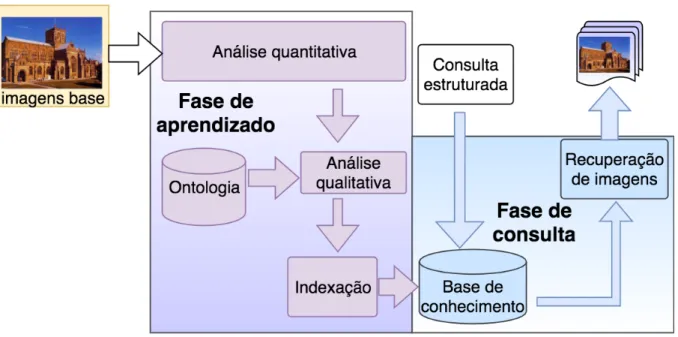
Este método visa integrar informações de baixo nível com informações de alto nível. A aquisição de informação de baixo nível é conseguida através de métodos numéricos descritos na secção 4.1. A representação formal utilizada responsável por fornecer informações de alto nível sobre o domínio é apresentada na seção 4.2.
ANÁLISE QUANTITATIVA
SEGMENTAÇÃO DE OBJETOS
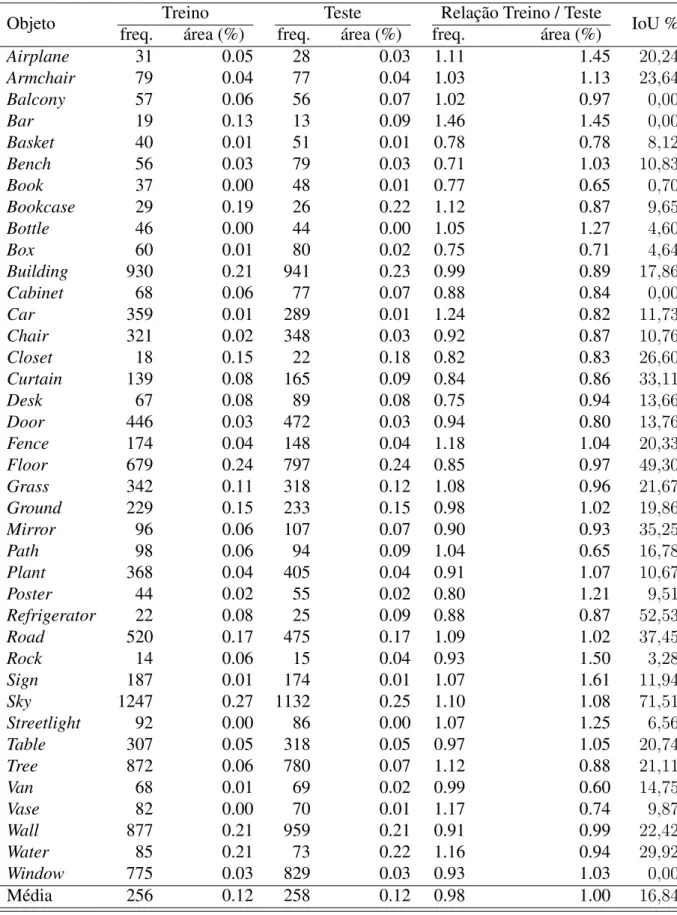
Para construir o modelo de segmentação, as imagens foram todas normalizadas para escalar de acordo com o tamanho original utilizado (ZHOU et al., 2016). Além disso, foram utilizados os pesos de Zhou et al. 2016) para inicializar o modelo adotado neste trabalho. Neste trabalho, para realizar a segmentação de objetos, foi utilizada uma rede neural com arquitetura idêntica à definida em (ZHOU et al., 2016), por representar o estado da arte no campo de aplicações de segmentação semântica.

DETECÇÃO DE RELAÇÕES TOPOLÓGICAS
O RCC modela um conjunto de relações mereotopológicas através da relação de conexão primitiva entre pares de regiões. Por fim, com base na área (ax, ay, az) das imagens (Ix, Iy, Iz), ou seja, a contagem de valores maiores que zero e, segundo um conjunto de regras pré-definidas, uma relação. é designado pela KBR. As regiões obtidas a partir das imagens são mapeadas para um conjunto de relações definidas por prefixos espaciais através de um método de classificação supervisionada.

CRIAÇÃO DE ÍNDICE
ANÁLISE QUALITATIVA
Assim, ao considerar a figura 11 e a fórmula 4.2, seria de grande valia se o sistema fosse capaz de identificar que a mesma relação entre SkyA e BuildingA também vale para SkyA e GrassA, desde que exista a relação expressa na fórmula 4.3. A Fórmula 4.6 representa que existe um carro numa estrada2, porém, o fato representado por esta fórmula não é eterno, portanto é necessário estabelecer que a relação apresentada na fórmula 4.6 não é constante ao longo do tempo. Ao analisar a fórmula 4.9, percebe-se que o ponto de vista do observador não é levado em consideração.

EXEMPLO TRABALHADO
Na Fig. 13, a imagem gerada pela rede neural 13a e a imagem segmentada são sobrepostas à imagem original 13b. Todas as imagens mostradas na Figura 14 são enviadas ao classificador para avaliação das propostas. Incorporar esta imagem na base de conhecimento do SUMO consiste em criar fórmulas que instanciem os objetos detectados, conforme mostrado na Figura 13, e apresentar as proposições encontradas para cada um dos pares mostrados na Figura 14.

CONCLUSÃO
Um conjunto de dados público conhecido como SUN09 (CHOI et al., 2010) foi utilizado para realizar os testes. Esse conjunto de anotações contém tags triplas, que em (LAN et al., 2012) são chamadas de consultas estruturadas. Assim, o conjunto de dados utilizado para executar os testes é um subconjunto do SUN09 que contém todas as consultas estruturadas.
PROCEDIMENTO DE TESTES
Este conjunto de dados consiste em mais de 12.000 imagens contendo diferentes classes de objetos em diferentes cenas. O segundo conjunto de anotações fornecido em (MALINOWSKI; FRITZ, 2014) (conjunto 2) expande o conjunto 1 ao incluir um maior número de preposições, representando sete classes distintas: acima, oposto, atrás, abaixo, em, frente, dentro, esquerda, certo, um abaixo. Além disso, o primeiro conjunto de dados pode ser considerado mais simples para um classificador cujo objetivo é detectar preposições, uma vez que a probabilidade de um acerto aleatório é n1 = 0,5, sendo n o número de classes, ou seja, inferior e superior.
TESTES COM CONJUNTO DE DADOS 1
SEGMENTAÇÃO DE OBJETOS REFERENTE AO CONJUNTO DE DA-
Além disso, o primeiro conjunto de dados cobre menos possibilidades de análise espacial, em contraste com o segundo conjunto de dados que contém mais preposições e, portanto, expressa mais características do arranjo espacial dos objetos. Todas as classes agrupadas estão listadas na Tabela 15 com a frequência com que aparecem no conjunto de dados (LAN et al., 2012), já considerando esse agrupamento. Este critério de seleção de objetos foi escolhido porque o conjunto total de objetos originalmente existentes no conjunto de dados SUN09 possui 6.481 elementos.
ATRIBUIÇÃO DE PREPOSIÇÕES ESPACIAIS
Os valores da Tabela 5 foram atualizados de acordo com o conjunto de treinamento, significando que a segmentação foi realizada por rotulagem manual ao invés de utilizar o modelo gerado conforme descrito na Seção 5.2. Assim, para um total de 41.193 pares de objetos combinados existentes no conjunto de teste, o classificador alcançou uma precisão de 88% para a proposta acima, considerando 14.364 amostras da classe acima. Nesta seção, tentamos avaliar o classificador da proposta considerando o cenário oferecido pelo conjunto de dados 1.

AVALIAÇÃO DA RECUPERAÇÃO DE IMAGENS
Além disso, a tabela 6 apresenta os valores obtidos, considerando os índices positivos e negativos. Porém, o conjunto de preposições utilizado neste experimento é limitado, pois possui apenas duas preposições. Assim, foi realizada uma análise adicional sobre um conjunto de dados que expressa mais situações entre pares de objetos, conforme apresentado na próxima seção.
TESTES COM CONJUNTO DE DADOS 2
- IDENTIFICAÇÃO DE OBJETOS
- IDENTIFICAÇÃO DE CENAS
- IDENTIFICAÇÃO DE PREPOSIÇÕES
- RECUPERAÇÃO DE IMAGENS
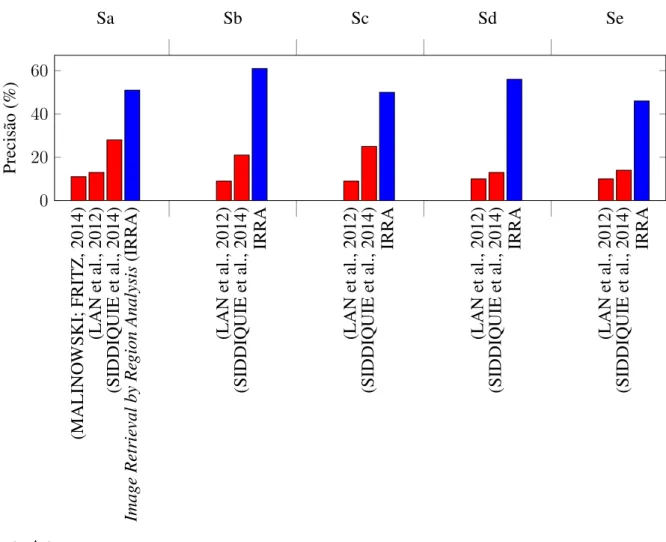
As próximas três colunas contêm os valores de precisão, recall e medida F da rede neural usando a representação implícita da topologia, ou seja, o modelo ilustrado na Figura 10a (arquitetura implícita). As próximas três colunas apresentam os valores do segundo modelo, distribuídos de forma idêntica, ou seja, existem medidas de precisão, recall e F. A Tabela 13 apresenta os valores obtidos na tarefa de recuperação de imagens considerando as 53 consultas de (MALINOWSKI; FRITZ, 2014).
EXPANSÃO DE CONSULTAS POR UMA REPRESENTAÇÃO FORMAL
Utilizando as mesmas bases e fórmulas definidas neste trabalho, foi possível por meio de um provador de teoremas (SCHULZ, 2013) construir inferências de acordo com as consultas originais. A Tabela 14 apresenta ambas as consultas: a consulta modificada na coluna da esquerda e a consulta original na segunda coluna. As colunas subsequentes são compostas de acordo com as consultas modificadas, na ordem da esquerda para a direita: a quantidade de imagens que foi possível realizar a derivação, quantas imagens no padrão ouro eram esperadas de acordo com a consulta original e por fim a métrica de média precisão.
CONCLUSÃO
Mas mesmo quando se utiliza um texto estruturado e o sistema não utiliza uma representação formal, não é possível abstrair novas relações. Esse fato tende a reduzir o recall, principalmente quando se trata de sistemas de recuperação de imagens, pois o escopo das consultas é estático. Ao considerar especificamente o SUMO, é necessário aprender a linguagem Knowledge Interchange Format (KIF) para representar os axiomas.
CONCLUSÃO
In this work, we deal with the semantic gap problem in image retrieval by representing the image with the spatial relationship between the objects that exist in the image itself. The presentation of knowledge is built according to the spatial arrangement of the identified structures in the images. To define a spatial relation in SUMO, it is necessary to create an instance of the classPositionalAttribute attribute.
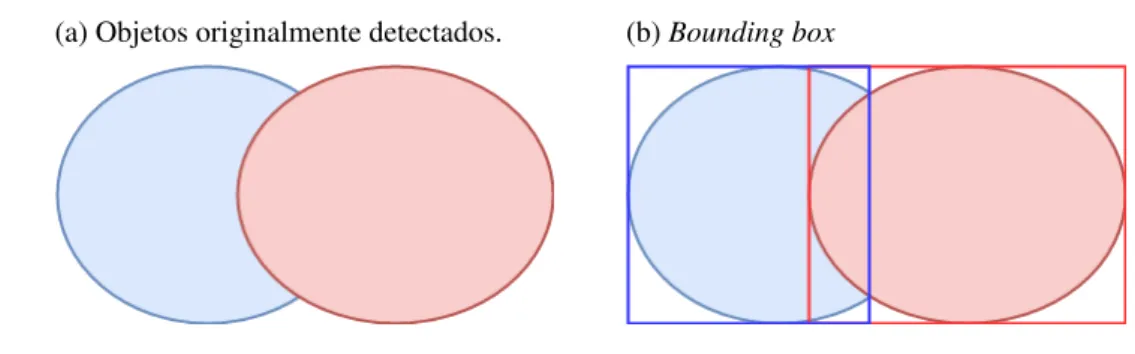
The overlap in this context is related to the shared area of the detected objects. On the importance of spatial relations and fuzzy representations for ontology-based image interpretation., in: Proceedings of the 7th International Conference on Advances in Pattern Recognition, ICAPR, Kolkata, India.