Este trabalho implementa uma metodologia de medição de desempenho baseada em simulação sem a necessidade de um ambiente de execução real, nem do código-fonte do programa avaliado. Portanto, é necessário o uso de ferramentas de previsão de desempenho de sistemas para avaliar a viabilidade de aquisição de novos equipamentos.
Objetivos
Esta alternativa implica custos associados, como a aquisição de novos equipamentos de hardware e a contratação de pessoal qualificado para a sua manutenção. A importância da utilização do sistema é ainda mais importante na computação de alto desempenho, visto que o custo do novo hardware é muito alto.
Organiza¸ c˜ ao da monografia
Além disso, a abordagem torna programas complexos obtidos automaticamente sem a intervenção do programador em todo o código. Nesse escopo, a análise de desempenho fornece ferramentas para avaliar os sistemas, identificando assim se os recursos estão sendo utilizados de forma otimizada ou para detectar seus gargalos.
Medidas de desempenho
Medidas de desempenho em sistemas paralelos
Verifica a velocidade de um programa em execução em paralelo em relação a uma referência. Assim, a equação abaixo relaciona o aumento da velocidade em função de sua execução sequencial.
- M´ etodos anal´ıticos
- M´ etodos baseados em benchmarking
- M´ etodos baseados em simula¸ c˜ ao
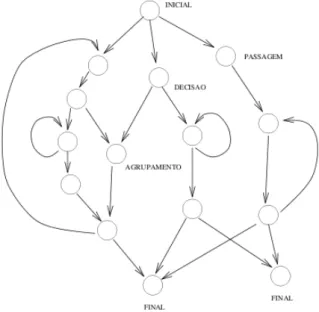
- Descri¸ c˜ ao da metodologia
- M´ odulos funcionais do m´ etodo
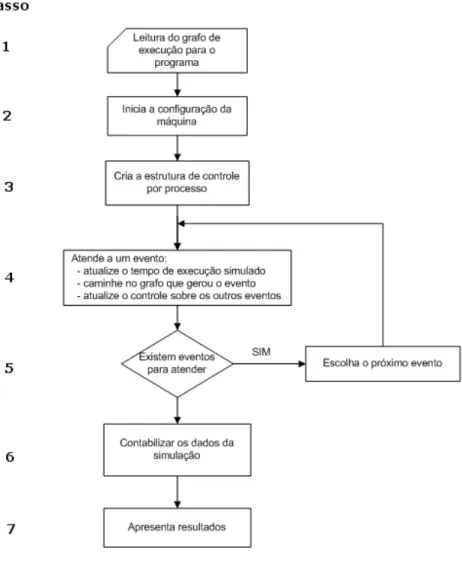
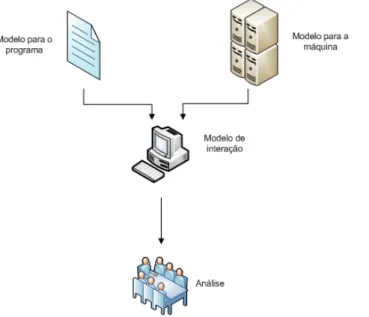
A precisão obtida pela reconstrução do código executável em um gráfico de execução é óbvia. Nesta etapa, obtém-se a configuração da máquina e o ambiente de execução, conforme descrito na subseção “Descrição da metodologia”.
Considera¸ c˜ oes finais
A decisão é tomada selecionando o evento com o menor tempo de ocorrência entre todos os eventos da implementação. No protótipo descrito, funções de distribuição de probabilidade uniforme, normal e exponencial foram usadas para simular esse processo de tomada de decisão. Por fim, foi exposto o método proposto por [7] por meio da previsão de desempenho através da simulação de grafos de execução.
Atualmente, um protótipo dessa ferramenta foi implementado em C por [7], mas essa implementação foca na arquitetura de processadores MIPS e foca na simulação de programas paralelos em PVM5. O próximo capítulo detalha a implementação em Java deste modelo, agora utilizando a plataforma x866 e focando na previsão de desempenho em um ambiente MPI7.

Conceitos b´ asicos
Java
Graças à tecnologia desenvolvida pela Sun Microsystems, é possível compilar um programa em um sistema operacional do tipo Unix e executá-lo em um ambiente Microsoft Windows. Isso ocorre devido à geração de byte codes e não de códigos binários nativos do processador - como acontece em outras linguagens, esses byte codes são interpretados por uma Java Virtual Machine (JVM) que os traduz para a arquitetura onde o programa será executado. Além das funcionalidades que uma linguagem orientada a objetos fornece como herança, encapsulamento e polimorfismo, o Java fornece coleta de lixo automática (coletor de lixo), assim o programador não precisa se preocupar em liberar alocação manual de memória quando não estiver usando um objeto, isso é feito automaticamente pela JVM feito quando um objeto não é referenciado.
Por causa dessas e outras características, desenvolver projetos mais robustos e confiáveis torna-se uma tarefa mais fácil para o programador. Isso possibilita a utilização das classes de um projeto desenvolvido para desktop em, por exemplo, um ambiente web.
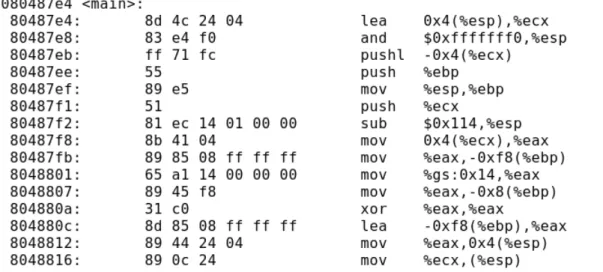
Disassembler
Esses símbolos, também conhecidos como mnemônicos, auxiliam o programador assembly no desenvolvimento de programas de baixo nível, pois não é necessário lembrar os códigos (opcodes) das instruções. Com essas informações em mãos, é possível reconstruir o código executável em instruções conhecidas e assim obter um gráfico de execução do programa, que é um dos objetivos deste trabalho. Com este programa é possível obter, além dos mnemônicos, os opcodes das instruções com seus endereços lógicos e também o nome dado às funções pelo programador.
Gera¸ c˜ ao do grafo de execu¸ c˜ ao
- Leitura do c´ odigo execut´ avel
- Interpreta¸ c˜ ao das instru¸ c˜ oes de m´ aquina
- Agrupamento de instru¸ c˜ oes
- Interface gr´ afica do Gerador do grafo de execu¸ c˜ ao
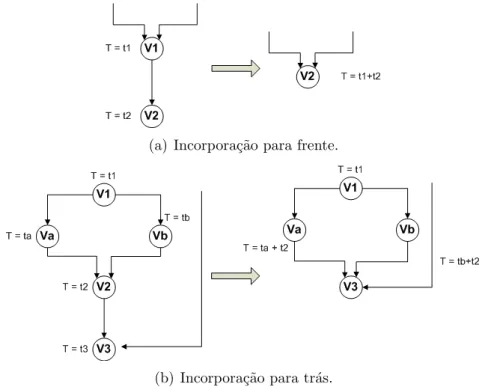
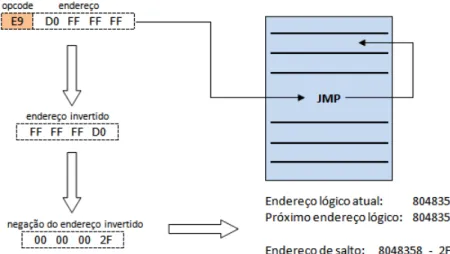
Cada arquivo é nomeado com a data atual (número de milissegundos desde 1970, devido à convenção de data do Java), seguida do endereço lógico da função e uma extensão. ˜.gttxt”(GraspTool TeXT). Dados como o nome do arquivo criado, o endereço lógico inicial e o nome da função são armazenados na estrutura mostrada na figura 3.2 para uso em fases posteriores. No caso de instruções de salto, é necessário calcular seu endereço de salto, que está em seu código de instrução, e assim identificar se o salto é para frente ou para trás, o endereço lógico atual.
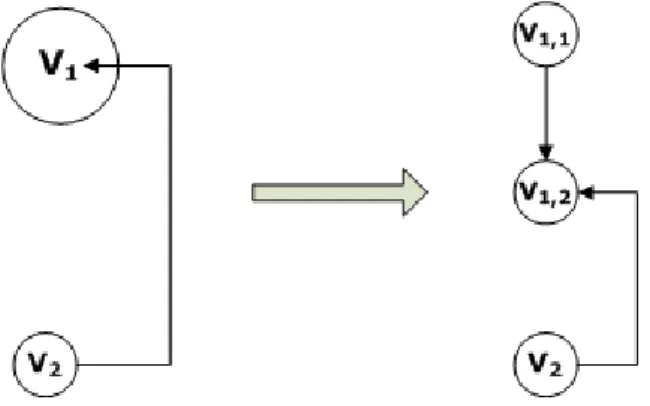
As outras arestas podem representar o endereço para uma chamada de função, o endereço de salto ou então o endereço para um vértice de comunicação. Após a obtenção do grafo de execução, é possível verificar detalhes dos vértices adicionados em um grafo, como por exemplo seus endereços inicial/final, número de ciclos gastos no vértice, tipo de instrução e próximo endereço.

Implementa¸ c˜ ao do Simulador
- Inicializa¸ c˜ ao do Simulador
- Motor de Simula¸ c˜ ao
- Simula¸ c˜ ao do paradigma Mestre/Escravo
- Simula¸ c˜ ao do paradigma SPMD
- Medidas de Desempenho Coletadas
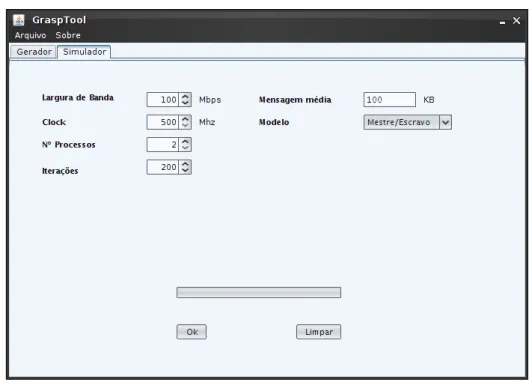
Uma vez fornecida a entrada, o usuário pode pressionar o botão "Ok" e o simulador procura os vértices de comunicação na floresta do grafo. Nesse caso, a função de distribuição de probabilidade exponencial é aplicada no processo de tomada de decisão. Após tomada a decisão, a referência ao próximo vértice a ser executado é ajustada para mais uma iteração do loop ou para a próxima instrução de execução.
Conforme mencionado na subseção 3.3.1, esse paradigma divide as tarefas entre dois tipos de processos: mestre e escravo. Assim, durante a simulação de um loop sob este paradigma, avalia-se se o loop possui um nó de comunicação.
Considera¸ c˜ oes finais
Desta forma, o usuário poderá verificar se esta função foi um obstáculo na simulação. Desta forma, cada vez que esta função é chamada, seu contador é incrementado e, enquanto a mesma função estiver no topo da pilha, os ciclos de máquina executados por ela são armazenados em outro acumulador de ciclos, específico para cada função. Por fim, a última medida explorada pelo simulador está relacionada ao loop de iteração, cujo princípio é informar ao usuário quantas vezes um determinado loop de iteração não foi executado.
Essa medida é importante para o usuário verificar se um determinado loop de iteração é o gargalo em seu programa. Vale ressaltar que uma das entradas fornecidas pelo usuário é o número máximo de vezes que um loop pode ser executado, portanto, loops que atingem esse limite superior são possíveis.
Testes sobre o modelo mestre/escravo
C´ alculo de uma integral
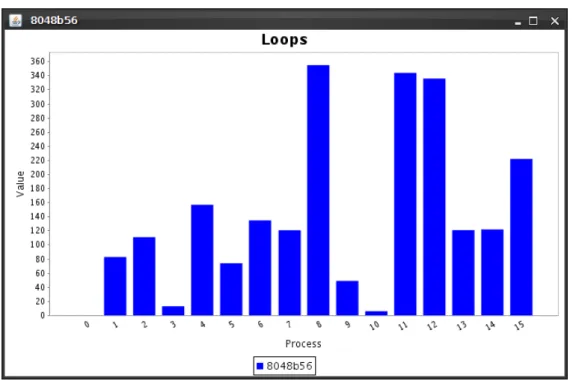
A Figura 4.2 mostra as estatísticas de execução do loop do programa para cada processo simulado em um dos cinco testes realizados. Sua implementação segue o comportamento da função de distribuição exponencial devido aos parâmetros fornecidos como limite e média das iterações. A precisão desses valores varia com as iterações do loop e estão fortemente relacionadas à eficiência da função de distribuição de probabilidade exponencial.
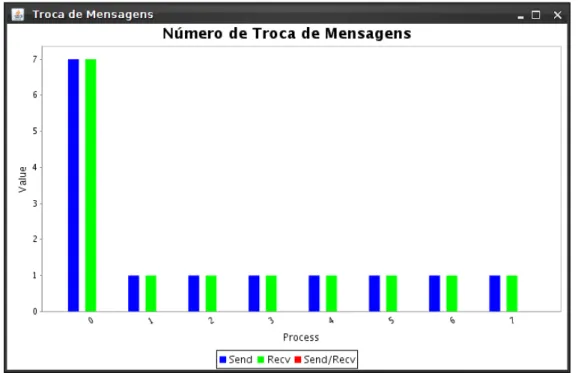
A Figura 4.3(a) mostra o número de chamadas para a função que calcula uma raiz quadrada em uma iteração da integral. Outra informação relevante nas chamadas de função está ligada ao número de ciclos de CPU gastos na execução da função.
M´ ultiplica¸ c˜ ao de matrizes
A tabela abaixo mostra os tempos médios obtidos na simulação e na execução real em cinco testes. A eficiência da ferramenta pode ser verificada pela taxa de erro do tempo médio de execução, ou seja, cerca de 4%. Como a execução dos loops na simulação não é determinística, seu comportamento varia, isso pode ser observado na mudança dos tempos de execução simulados.
Em geral, os resultados obtidos ficaram abaixo do tempo real de execução, o que pode ser explicado pela distribuição de probabilidade utilizada no momento da simulação e pelos parâmetros fornecidos. A Figura 4.6 mostra os ciclos de execução gastos em uma das cinco simulações executadas, esses valores fornecem os tempos de execução no ambiente simulado.
Conclus˜ oes
Perspectivas de trabalhos futuros
1] Amdahl, G.M.; "Validity of single-processor approach to achieve large-scale capabilities"; inAFIPS Conference Proceedings, vol J.; "Predi¸c˜ao de Desempenho de Programas Paralelos por Simula¸c˜ao do Grafo de execu¸c˜ao"; Tese (Doutorado) – Unicamp , 1997. Mudge; "Idtrace - a tracing tool for i486 simulation"; In MAS-COTS ’94: Proceedings of the Second International Workshop on Modeling, Analysis and Simulation On Computer and Telecommunication Systems, pages 419-420.
Construção de geradores de números aleatórios independentes para diferentes distribuições de probabilidade. Essa arquitetura inclui recursos comuns aos dispositivos de 16, 32 e 64 bits da Intel, por exemplo, tornando possível executar código compilado para um processador de 16 bits em um modelo de 64 bits para executar
Formato das instru¸ c˜ oes
Os grupos são divididos em bloqueio e repetição, substituição de segmento, operador e prefixos de endereço. Para cada instrução, um prefixo desses grupos pode ser usado e adicionado em qualquer ordem. Esses campos definem a operação da instrução, seu deslocamento e outras peculiaridades da instrução.
R/M: pode especificar um registro como um operando ou pode ser combinado com o campo mod para codificar um modo de endereçamento. Alguns endereços incluem um offset após o campo ModR/M ou SIB, se necessário este offset pode ser de 1, 2 ou 4 bytes.
Estrutura b´ asica
Fun¸ c˜ oes
As principais funções utilizadas em um ambiente paralelo estão relacionadas à troca de mensagens, descoberta do identificador do processo e número de processos em execução paralela. Seus parâmetros são: buffer a ser enviado, tamanho do buffer, tipo de mensagem (MPI INT, MPI FLOAT, MPI CHAR, etc.), classificação do processo de destino, tag indicando o canal de comunicação e o comunicador. Seus parâmetros são idênticos aos da função send, exceto pelo fato de que agora temos a origem da mensagem e não o destino.
Uma observação importante é quanto ao seu estado, quando a execução atingir esta função, o restante do código será executado somente após a chegada da mensagem, ou seja, esta função está bloqueando. O uso desta função torna o código mais claro e evita a duplicação de funções.
Exemplo
Outra mudança diz respeito ao status da mensagem recebida, com esta variável é possível obter informações sobre o resultado da comunicação.