This work consists of the exploration of the computational power of NVIDIA GPUs in cryptography through the use of the CUDA technology, which was created to facilitate the development of general computation using the parallel processing presented on GPUs. In addition, a comparison is made between the CPU and the parallel version written in CUDA of the AES and MD5 cryptography algorithms.
INTRODUÇÃO
- C ONSIDERAÇÕES INICIAIS
- M OTIVAÇÃO E ESCOPO
- O BJETIVOS E METODOLOGIA
- O RGANIZAÇÃO DA MONOGRAFIA
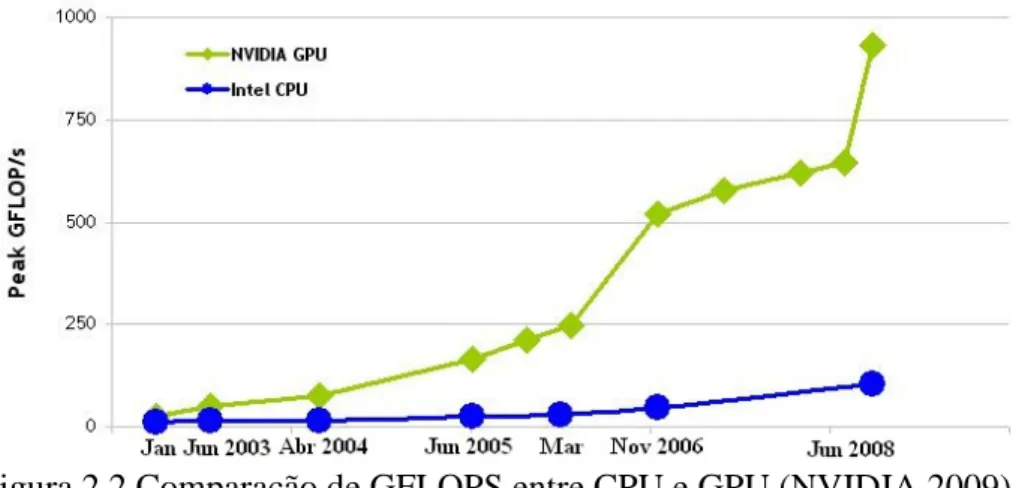
Devido a esse enorme poder computacional, surgiu uma nova tendência de processamento paralelo chamada General Purpose computing on Graphics Processing Units (GPGPU), que utiliza a GPU não apenas para aplicações gráficas, mas também para computação geral, geralmente associada à Unidade Central de Processamento. (CPU) (OWENS et al. 2007). Para isso, o processamento paralelo encontrado nas GPUs pode ser utilizado em conjunto com a arquitetura CUDA.
FUNDAMENTAÇÃO TEÓRICA
C ONSIDERAÇÕES I NICIAIS
C OMPUTAÇÃO DE ALTO DESEMPENHO
- M AXIMIZAÇÃO DO DESEMPENHO
- D ESENVOLVIMENTO NOS MICROPROCESSADORES
- P ROCESSAMENTO COM COPROCESSADORES
No caso dos processadores, é importante saber quanto tempo leva para executar um determinado conjunto de instruções. No entanto, usar um barramento de expansão implica em limitações de largura de banda e comunicação com atrasos significativos.
A S UNIDADES DE PROCESSAMENTO GRÁFICO
- A ARQUITETURA DA SÉRIE 8 DA NVIDIA
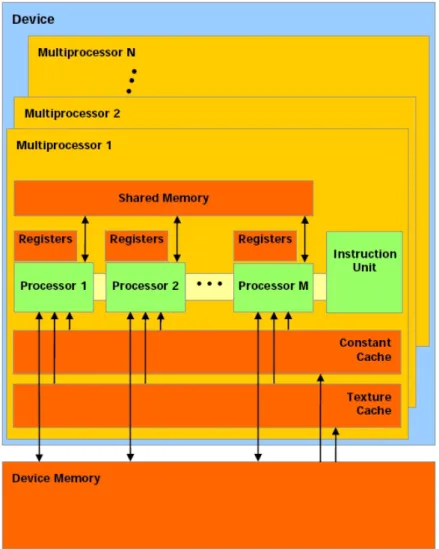
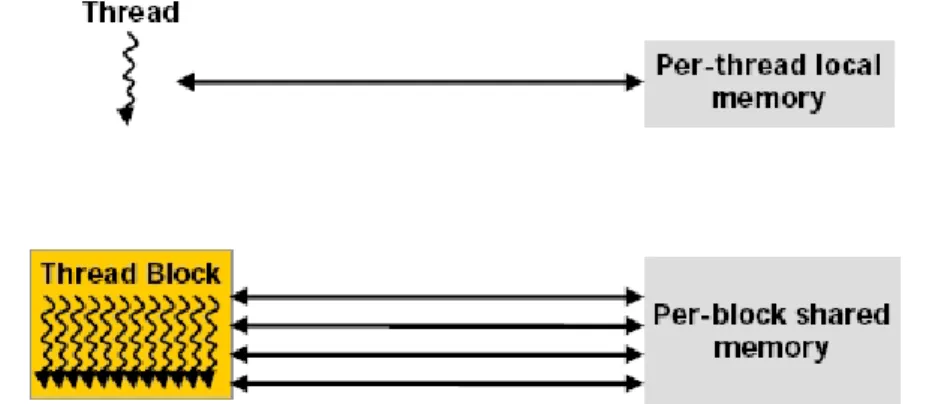
- H IERARQUIA DE MEMÓRIA
- G ERENCIAMENTO DE THREADS
- E SCOLHA DE DADOS
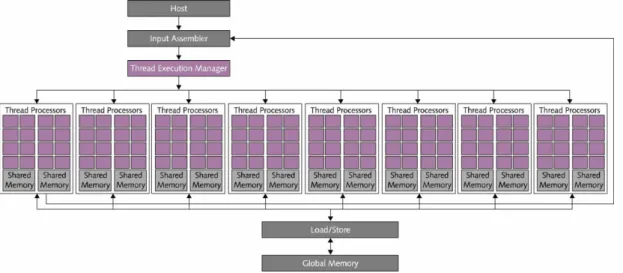
A Figura 2.6 mostra que os processadores de thread ou processadores de fluxo são agrupados em grupos de 8, cada um chamado de multiprocessador. Os fatores para análise incluem o tamanho de todo o conjunto de dados; a quantidade máxima de dados locais que podem ser compartilhados por um bloco de threads; o número de processadores de fluxo de GPU e o tamanho das memórias on-chip.

P ARADIGMA DE PROGRAMAÇÃO
- E XTENSÕES
- G RUPOS DE EXTENSÕES
Os grupos de encadeamentos são executados em rodízio, garantindo que cada encadeamento obtenha seu tempo de execução sem interferir nos outros. Dada a função VectorSubtract acima, que possui a diretiva __global__, é possível especificar o número de blocos de encadeamento e também o número de encadeamentos por encadeamento. bloco que irá executá-lo. É possível identificar qual é o índice de encadeamento atual de dentro de um kernel por meio da variável interna threadIdx.
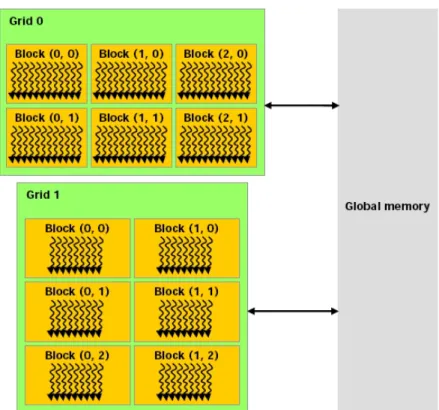
Ao reescrever o código da Figura 2.11, é possível especificar que cada thread em execução calcule a subtração de um par de posições, conforme mostrado na Figura 2.14. O caso multithreaded mais comum é usar uma sequência unidimensional de threads, como um conjunto de threads de 1 a N. Os diferentes blocos de threads são organizados em um nível superior de abstração, em grades de uma ou duas dimensões , onde cada bloco de threads se comporta como se fosse um elemento de um array.
Qualificadores de função: especifique se a função é executada no host ou no dispositivo e pode ser chamada de qualquer um. Se nenhum outro qualificador for usado, a variável residirá no espaço de memória global, terá o tempo de vida do aplicativo e poderá ser acessada por todos os encadeamentos na rede e no host por meio da biblioteca de tempo de execução.

I NTRODUÇÃO À CRIPTOGRAFIA
- V ISÃO HISTÓRICA
- O BJETIVOS DA CRIPTOGRAFIA
- T IPOS DE CRIPTOGRAFIA
- F UNÇÃO CRIPTOGRÁFICA HASH
As palavras, caracteres ou letras da mensagem original são chamadas de mensagem ou texto simples, enquanto as do texto cifrado são chamadas de texto cifrado ou texto cifrado. Em 1854, a cifra de Viginére foi quebrada por Charles Babbage, e por muitos anos nenhum outro método de criptografia foi desenvolvido que fosse relativamente seguro (SINGH 2000). Com o desenvolvimento dos computadores mecânicos no início do século 20, máquinas de criptografia mecânica surgiram e tornaram os processos de criptografia de substituição e transposição mais complexos.
Antes do início da Segunda Guerra Mundial, a Alemanha desenvolveu uma máquina de cifra mecânica chamada Enigma, que usava métodos de substituição e transmissão tão complexos que a criptoanálise manual de suas mensagens era quase impraticável. Confidencialidade: Somente o destinatário original da mensagem deve ser capaz de extrair o conteúdo original de sua forma criptografada. Autenticação: O destinatário deve ser capaz de identificar o remetente e verificar se ele enviou a mensagem.
A chave pública pode ser distribuída livremente, mas a chave privada deve ser conhecida apenas pelo remetente da mensagem. Para determinar se houve alguma alteração em uma mensagem ou arquivo, basta comparar o valor de hash da mensagem antes e depois da transferência.
O ALGORITMO AES
- A SPECTOS PRINCIPAIS
- T RANSFORMAÇÃO S UB B YTES
- T RANSFORMAÇÃO S HIFT R OWS
- T RANSFORMAÇÃO M IX C OLUMNS
- T RANSFORMAÇÃO A DD R OUND K EY
- E XPANSÃO DE CHAVE
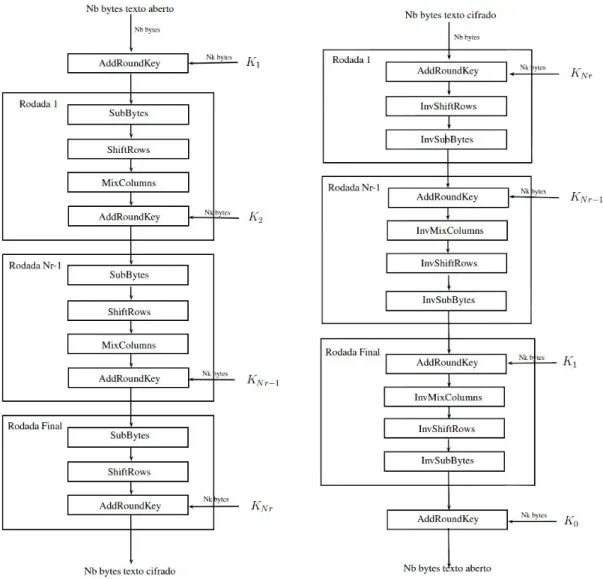
A chave primária é dividida em uma matriz de 4 linhas e Nk colunas, e cada chave de rodada é agrupada da mesma forma que o bloco de dados. Nesta etapa, cada byte de estado é substituído por outro em uma caixa S (caixa de substituição), denotada por SRD. Na figura 2.22 Ci é o número de posições que irão rodar na linha de um bloco com colunas Nb.
Seja S' o estado após esta transformação e o produto da matriz em GF (28), então S' será o resultado da multiplicação da matriz fixa C pela matriz S representando o estado conforme mostrado na Figura 2.24. A inversa dessa operação é chamada de InvMixColumns e é uma multiplicação usando a matriz fixa B, mostrada na Figura 2.25, da matriz inversa C, mostrada na Figura 2.26, usada na criptografia. Conforme mencionado anteriormente, as chaves usadas em cada rodada são geradas a partir da chave mestra.
Seja cada palavra denotada por wi, onde i é a posição da palavra no vetor, então um exemplo de vetor está na Figura 2.28. 32 Inicialmente, as primeiras Nk palavras do vetor são preenchidas com os bytes da chave primária.
M ODOS DE OPERAÇÃO DO AES
- M ODO ECB
- M ODO CBC
- M ODO CFB
- M ODO OFB
- M ODO CTR
Dessa forma, cada bloco de texto cifrado depende de todos os blocos de texto simples processados até aquele ponto. Este bloco também é XORed com outro bloco de texto simples para produzir um segundo bloco de entrada. Cada bloco de texto simples é XORed com o bloco anterior de texto cifrado para produzir um novo bloco de entrada.
No processo de descriptografia, o algoritmo de descriptografia é aplicado ao primeiro bloco de texto cifrado e o bloco resultante é XORed com VI para produzir o primeiro bloco de texto simples. No processo de criptografia CFB, o primeiro bloco de entrada é o VI e o algoritmo é aplicado ao VI para produzir o primeiro bloco de saída. O primeiro bloco de saída é XORed com o primeiro bloco de texto simples para produzir o primeiro bloco de texto cifrado.
O segundo bloco de saída é XORed com o segundo bloco de texto simples para produzir o segundo bloco de texto cifrado e assim por diante. Este bloco é então XORed com o primeiro bloco de texto cifrado para produzir o primeiro bloco de texto simples.

O ALGORITMO MD5
Um bloco de texto simples correspondente a um determinado bloco de texto cifrado pode ser obtido independentemente de outros blocos de texto simples se um contador de bloco apropriado for especificado. O algoritmo opera em cada bloco de 512 bits por vez, com cada bloco mudando de estado. O processamento de bloco consiste em quatro fases, e cada fase consiste em 16 operações semelhantes baseadas em funções não lineares, adição modular e rotação de bit à esquerda.
A Figura 2.37 ilustra uma operação dentro de uma fase, onde <<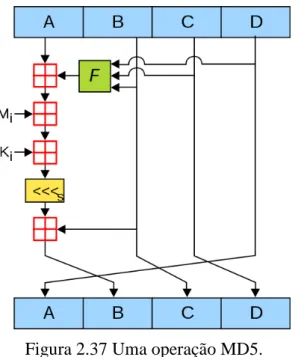
C ONSIDERAÇÕES FINAIS
PROJETO DESENVOLVIDO
- C ONSIDERAÇÕES INICIAIS
- D ESCRIÇÃO DO PROJETO
- AES NA GPU
- MD5 NA GPU
- T RABALHOS RELACIONADOS
- I MPLEMENTAÇÃO DO ALGORITMO
- A LGORITMO AES
- A LGORITMO MD5
- C ONSIDERAÇÕES FINAIS
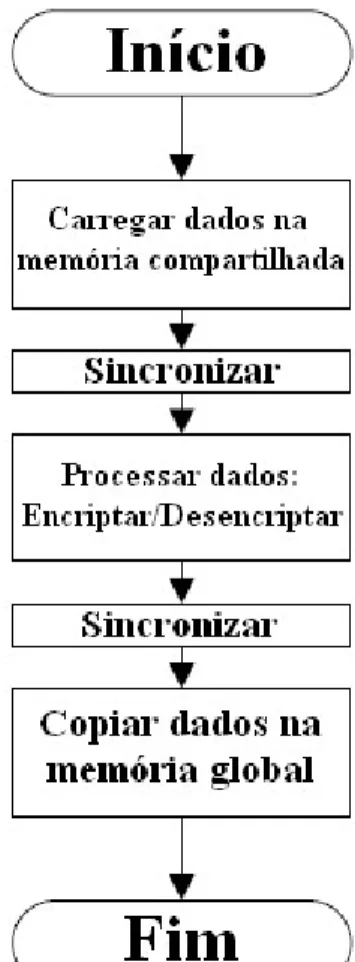
Para verificar o desempenho do algoritmo MD5, um sistema de verificação de senha de força bruta foi implementado. O sistema de força bruta funciona exatamente da mesma maneira, tenta todas as senhas possíveis e, eventualmente, a senha correspondente será encontrada. Como todos os threads acessam os dados da memória global antes de processá-los, é fácil ordenar os acessos para que seja feito o uso mais eficiente da largura de banda da memória.
Como cada thread carrega um conjunto de dados da memória global que não necessariamente será usado, todos os threads devem ser sincronizados antes que a memória compartilhada possa ser usada. Como essas tabelas são constantes e comuns a todas as threads, é possível carregá-las na memória GPU persistente. Basta percorrer todas as palavras possíveis em um determinado alfabeto, transformar as palavras em hashes e compará-las com o hash desejado.
Os dados necessários para o funcionamento do algoritmo são copiados para a memória constante da GPU, tornando o acesso aos dados muito mais rápido. Assim, o programa percorre todas as combinações possíveis de palavras de quatro caracteres, usando todas as letras do alfabeto.
TESTES, RESULTADOS E AVALIAÇÃO DOS
- C ONSIDERAÇÕES INICIAIS
- H ARDWARE E S OFTWARE
- T ESTES REALIZADOS
- T ESTES DO AES
- T ESTES DO MD5
- C OMPARAÇÃO DE DESEMPENHO
- D ESEMPENHO DO ALGORITMO AES
- D ESEMPENHO DO ALGORITMO MD5
- C ONSIDERAÇÕES FINAIS
Esta seção mostra os resultados das implementações propostas dos algoritmos AES e MD5. Como o objetivo de qualquer cifra é criptografar os dados recebidos rapidamente, a métrica usada para desempenho é o tempo total de execução do algoritmo. Portanto, o tempo de execução do algoritmo na CPU apresentada nas figuras é um pouco maior do que o analisado, devido ao fato da CPU ter sido utilizada para outras aplicações enquanto o programa estava rodando.
Os testes do algoritmo MD5 consistem em um sistema de recuperação de força bruta da palavra original. O tamanho da mensagem começa em 16 bytes, o menor tamanho de bloco possível, e dobra até 32 MB, permitindo que você veja como o algoritmo se comporta à medida que o problema cresce. Todos os testes dos algoritmos MD5 na GPU foram realizados com 128 threads por bloco e 8192 blocos.
Como pode ser visto na tabela, o desempenho do algoritmo executado na GPU é quase 70 vezes superior ao algoritmo executado na CPU para a palavra de oito caracteres. A Figura 4.18 mostra como a versão da CPU leva muito mais tempo para chegar à palavra original à medida que cresce.
CONCLUSÃO
- I NTRODUÇÃO
- C ONCLUSÕES
- D IFICULDADES ENCONTRADAS
- T RABALHOS F UTUROS
A utilização de máquinas com múltiplas GPUs representa um enorme potencial a ser explorado na busca incessante por performance. Porém, com a utilização de senhas mais complexas, com mais caracteres, números ou mesmo símbolos, torna-se inviável o uso da CPU para recuperação de senha, o que aumenta muito o tempo de execução do algoritmo conforme aumenta a palavra ou alfabeto utilizado. Porém, uma solução plausível para esse problema é o uso de GPUs, que encurtam o tempo de recuperação para alguns minutos ou algumas horas, dependendo do tamanho e complexidade da palavra.
Outros algoritmos simétricos também podem ser implementados, juntamente com algoritmos de hash e algoritmos assimétricos, para criar uma estrutura de algoritmos criptográficos acelerados por GPU usando CUDA. A arquitetura CUDA também pode ser utilizada para testar a segurança de outros algoritmos, testando vulnerabilidades antes inviáveis com CPUs convencionais. KAHN, D.; "The Codebreakers: The Comprehensive History of Secret Communication from Ancient Times to the Internet", Scribner, 1996.
KEDEM, G.; ISHIHARA, Y.; "Brute Force Attack on Unix Passwords with SIMD Computer", Proceedings of the 8th USENIX Security Simposium, 1999. HARRISON, O.; WALDRON, J.; "AES Encryption Implementation and Analysis on Commodity Graphics Processing Units", Lesingnotas oor Rekenaarwetenskap, 2007.