Neste contexto, investigamos como o Faststep [1], um método recente para fatoração de matrizes e agrupamento de grafos, pode ser adaptado para resolver esses problemas. Palavras-chave: ciência de redes, redes complexas, agrupamento de grafos, agrupamento hierárquico de grafos, compressão de grafos.
Problem
Context
Information about communities or even better hierarchical communities, can be useful to increase the compression rate. Based on this, it is possible to deduce the quality of a clustering algorithm just by analyzing how much the graph can be compressed using this information.
Document Outline
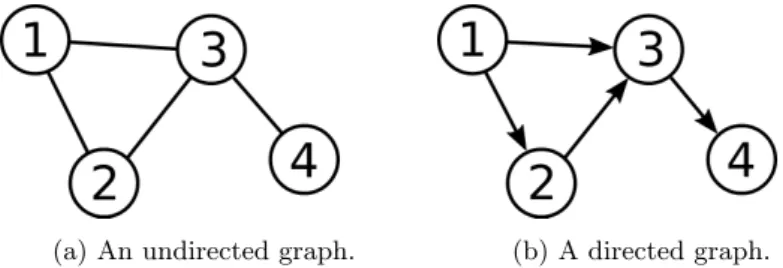
Graph representation
Adjacency lists store for each vertex a list of its neighbors, i.e. the nodes connected to i by an edge. The second array (R), of size O(n), stores, for each position i, the position where the elements in rowstart in the first array.
FastStep Algorithm
- FastStep formal goal
- Complexity
- Obtaining the clusters
- Results
A simple implementation of the algorithm would take O(T nmr2), where T is the number of iterations required, and the dimensions of the Boolean matrix and the rank of the decomposition (width of both On and B, as mentioned earlier). This algorithm works in quadratic time proportional to the size of the matrix; grows linearly in O(nm). As we can see in equation 2.6, calculating the gradient for each element of the matrix Aik requires O(nm) time.
However, given the sparsity of M and the symmetry of the error function—the error of misrepresenting one is equal to misrepresenting zero—we can |P(t)| remains small and on the order of O(rE). But when the number of communities we want to find approaches a ton, the complexity of the method becomes quadratic.
Label Propagation
Extensions to Label Propagation
In this algorithm, let us consider, for a given node x, that its neighbors have labels λi, with between 1 and K,K as the number of distinct labels in the neighborhood of x. In the simple LP algorithm, the new label λi is chosen such that ki is maximal. Large networks require special storage considerations, as they usually cannot fit into the memory of a computer with standard resources.
The sequence obtained by LLP is used in the Webgraph library, which can be used, among other things, as an efficient framework for graph compression [9]. LLP works by performing successive iterations of APM, with different γ values, and storing an ordering of the nodes using both the order from the previous iteration and the clustering obtained in the current iteration.
Modularity Maximization
Definitions
Algorithms
The agreed roughness algorithm starts from singleton clusters and merges clusters iteratively, choosing the merge with the highest modularity gain. Several modifications of the algorithm were proposed with other priority criteria for mergers and with changes to the purely greedy merger strategy. Here we can choose the best move in each iteration, i.e. the one with the highest modularity increase.
Modularity optimization may fail to identify modules smaller than a scale dependent on the total number of connections in the network, as shown by Fortunato et al [18]. Therefore, modularity optimization methods are considered to have a resolution limit: communities smaller than a certain size, which varies according to the graph under consideration, may not be found by the methods and these communities are therefore included in larger ones.
Louvain Method
The method can then run in near-linear time, if we can consider that the degree of a node is constant and does not depend on the size of the graph. The number of hierarchy levels resulting from the algorithm is small, which implies a few steps of the algorithm to reach its conclusion. It is also important to note that the order in which nodes are repeated in step 1 of the algorithm is relevant for obtaining different results.
Although the order does not seem too important to obtain clustering with higher modularity values, it can affect the computation time of the algorithm. The authors claim that the algorithm could partially avoid the resolution limit of maximizing modularity because it is very unlikely that in step 1 of the algorithm all nodes from one community would move to another.
Classical Hierarchical Algorithms
- Betweenness-based divisive algorithm
- Initial validation of the results
- Comparison Metrics
- Succinct representation as clustering metric
Usually, the first pass (running step 1 followed by step 2 at the beginning of the algorithm) is the heaviest computational task and takes most of the computing time. An important part of the evaluation is also the comparison of the results with those obtained by reference algorithms. We can also have an idea of the distribution of the Jaccard distances in subsection 4.3.
We can then obtain the mutual information of clusters X and Y, which is given by I(X, Y) =H(X)−H(X|Y), where H is the Shannon entropy. We will use NMI in comparing different clusters for evaluating the developed algorithms.
Graph Clustering
Faststep
We decided to change the community selection method by directly using the values obtained in the matrix rows. Whenever the size of the larger subgraph is less than the current threshold, clustering is obtained. The entire community structure is stored in a tree, which is an auxiliary structure of the algorithm.
The complexity of this method is the same as Faststep (see equation 2.8), with the difference that the number of executions of the algorithm is greater, and cannot be directly estimated. The number of runs cannot be directly limited and depends on the configuration of the network.
Louvain Method
When all communities currently in the queue are less than the threshold, we can store this information as one valid cluster of the graph. The threshold can then be further reduced, allowing the method to continue, retrieving more clusters of higher granularities. This approach keeps all subgraphs in a heap, with the larger subgraph at the top.
The larger graph can then be removed from the top and split into two, which are added to the heap. One problem with this method is that it can cause clusters to be the same size as they are split into smaller ones based on the number of nodes they have.
Layered Label Propagation
The method was then adapted to use an iterative approach where communities are held in a queue and larger communities are split first.
Graph Compression
Implementation
Recursive Faststep implementation
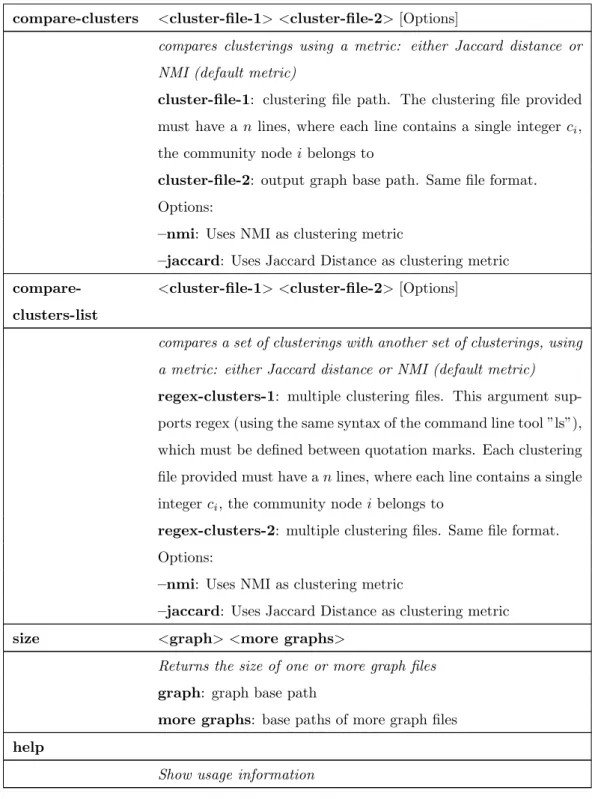
Command Line tool
Each line contains two space-separated integersri,0 andri,1, the endpoints of edge i of the graph. By default, the edges are interpreted as undirected and the vertices numbering starts at 1. This argument supports regex (using the same syntax of the "ls" command-line tool), which must be defined in quotes.
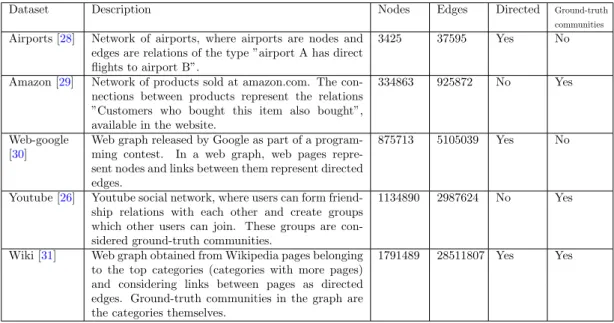
Another important aspect for their choice was the availability of ground truth communities, which allows us to see how the algorithms work in real situations. Airports [28] Network of airports, where airports are nodes and edges are relationships of the type "airport A has direct flights to airport B".
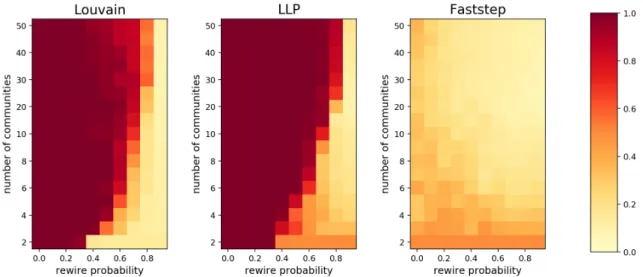
Detection of communities in artificial networks
The results of the tests were evaluated against the original communities using both NMI and Jaccard Distance, as defined in subsection 3.1. Each test was performed using 5 random networks with the defined parameters and the average of the obtained metric value was taken. Figures 4 and 5 present the results for the three algorithms considered, for the NMI and Jaccard Index metrics respectively.
It can be argued that the communities and nodes of the test graphs represent a very homogeneous network with a low clustering coefficient relative to the number of edges in the graph. This test provides strong indications that Faststep may not perform well in subsequent tests, but we expect better results when using real networks.
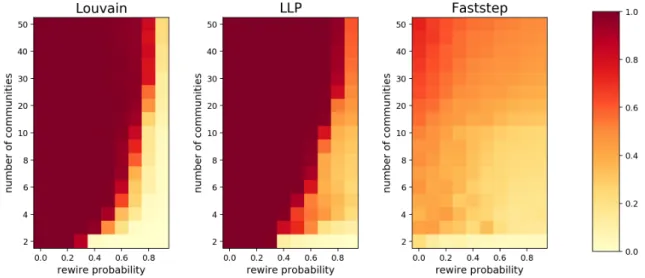
Detection of communities in networks with ground-truth communities
However, the other methods did much better at finding the known communities, implying that they can be partially approximated by using the structure of the graph, and Faststep simply fails to detect them. The methods used are Louvain method (left column), LLP (middle column) and Faststep (right column).
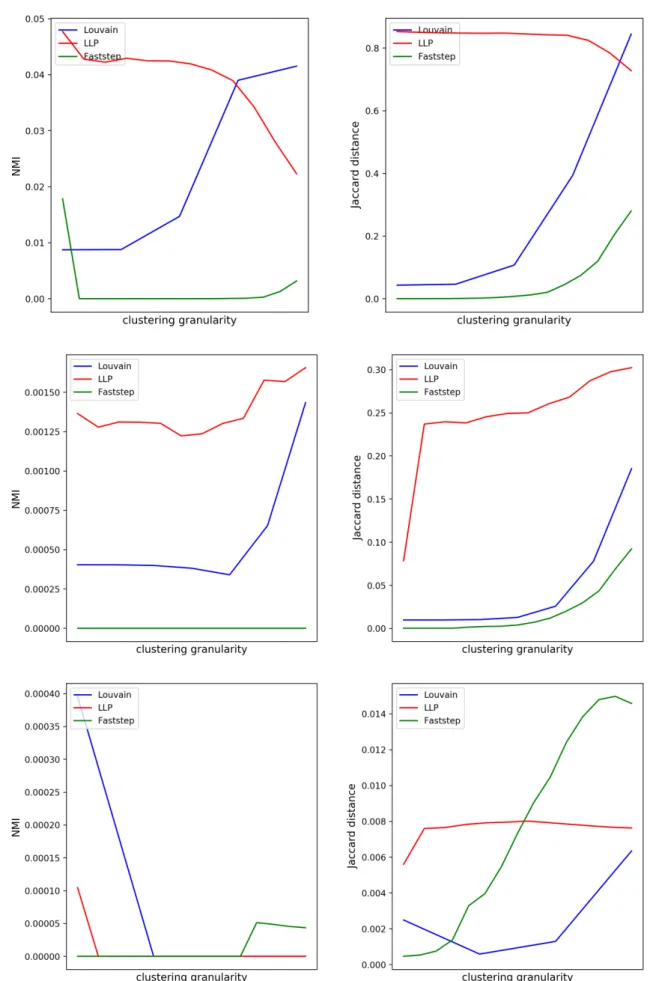
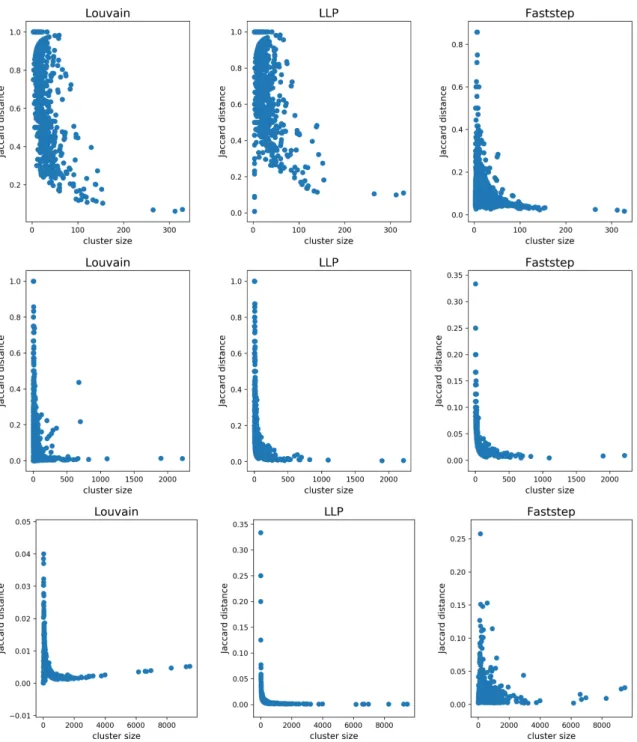
Comparison of clusterings obtained with different methods
Still, for the Jaccard metric, we can observe that the clusterings with more similarity are the high-granularity clusterings obtained by Leuven and the lower-granularity clusterings obtained by LLP, as discussed earlier. The similarity obtained using the Jaccard metric is quite low, while the similarity using the NMI is generally high, but is not of much use as there is no correlation between the granularities of the clustering and the value of the NMI obtained. We can still evaluate the clusterings of each algorithm independently, taking advantage of graph compression, which we do in the next test.
Rows from top to bottom represent results for Airports, Amazon, Web-google, Wiki, and Youtube datasets. The rows from top to bottom represent the results for the Airports, Amazon, Web-google, Wiki, and Youtube datasets.
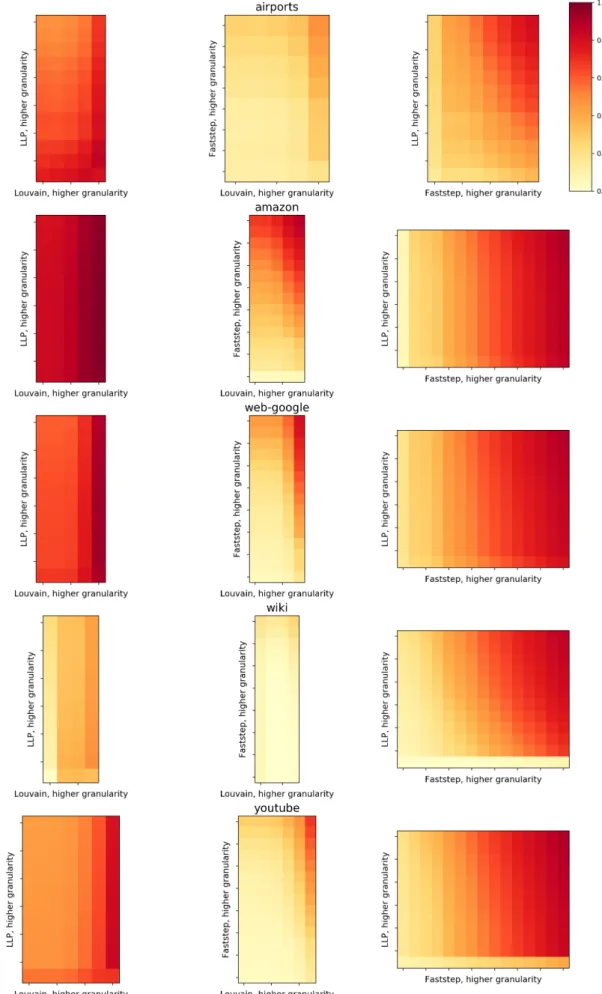
Compression Results
If two clusters are siblings in the hierarchical tree, we don't know which of them to go through first, but if one is the parent of the other, that ambiguity disappears. This problem could be easily overcome by exploiting the full hierarchical structure of the network generated internally by the method, which is not a direct output in the implementation provided by the authors. In the previous tests we already introduced several reasons why Faststep's performance would probably not be as good as the other algorithms.
That way, all nodes belonging to overlapping communities tend to be included in the first community created, while nodes with fewer edges but some proximity to this community being created are simply omitted. However, we can still detect some compression of the graphs, implying that Faststep actually finds meaningful communities related to graph rearrangement and/or compression, which remained a questionable assumption in the other tests performed.
Performance Evaluation
It could also be argued that we could have compromised cluster quality to improve runtime. In this way, much less importance is given to the running time of the algorithm. We compared its results with two state-of-the-art algorithms, LLP and the Louvain method.
Finally, we implemented a tool that allows the retrieval of graph groupings and rearrangements and the use of these groupings or rearrangements in the compression of the graph. These details of the method achieved worse results than we could have expected at the beginning of the work.