Dissertação aprovada, como requisito parcial, para obtenção do título de Mestre em Ciência da Computação, Programa de Pós-Graduação em Computação, Centro de Desenvolvimento Tecnológico, Universidade Federal de Pelotas. A Ciência da Computação é uma área dentro da área maior das Ciências Exatas e da Terra, mas ainda não existe uma subárea da Ciência da Computação dedicada à Inteligência Artificial.
Classificação automática de artigos
Durante o desenvolvimento deste trabalho, foram realizadas buscas nas principais bases de dados acadêmicas para encontrar trabalhos relacionados. O trabalho utilizou metadados de referências já catalogadas em bibliotecas convencionais existentes, visando derivar probabilisticamente a classe mais adequada para o documento.
Desambiguação de autores
Estudos de comunidades científicas em bases digitais
Estudos com dados da plataforma Lattes
Objetivos Específicos
Crie um conjunto de dados de produções científicas de vários subcampos da computação, incluindo o subcampo de inteligência artificial, e contendo o título e o nome do subcampo para cada publicação. Crie um conjunto de dados de produções científicas de diferentes especialidades em inteligência artificial, contendo o título e o nome da especialidade para cada publicação. Desenvolva e avalie algoritmos para classificar se uma publicação pertence ao subcampo de inteligência artificial ou não, usando o conjunto de dados objetivo específico 1;.
Desenvolver e avaliar algoritmos para classificar a especialidade de IA a que pertence uma publicação, utilizando o conjunto de dados do Objetivo Específico 2.
Coleta de dados
Conjunto de dados Subáreas
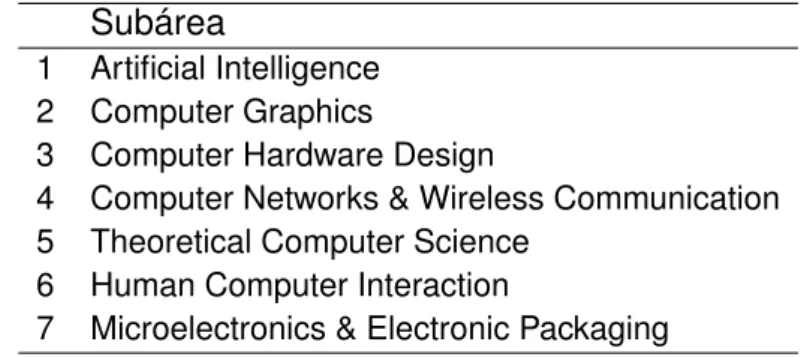
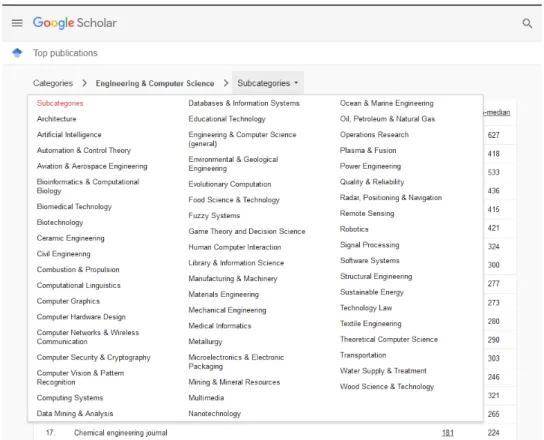
Neste caso, foram selecionados alguns veículos de cada subárea da Tabela 1, que também são subcategorias dentro da página. Os veículos editoriais selecionados e a subárea a que se enquadram podem ser vistos na Tabela 15 do Anexo A. No caso específico dos veículos editoriais da subárea Inteligência Artificial, a seleção foi um pouco diferente.
Assim, foram selecionados apenas alguns veículos da subcategoria “Inteligência Artificial” (Figura 2), pois muitos da lista eram de áreas específicas da IA. 5 European Conference on Artificial Intelligence 6 International Journal on Artificial Intelligence Tools 7 Simpósio Brasileiro de Inteligência Artificial 8 Brazilian Conference on Intelligent Systems.
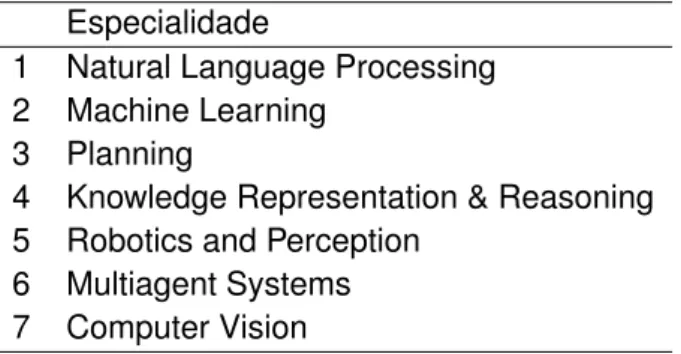
Conjunto de dados Especialidades
Assim como na definição do conjunto de subáreas, o próximo passo após a definição da especialidade foi a seleção dos veículos de publicação. Nesse caso, os veículos não foram extraídos das principais listas de publicações do Google Acadêmico, pois as especialidades selecionadas não eram propriamente categorias ou subcategorias do ranking de veículos na plataforma. Em vez disso, os volumes de publicação foram pesquisados pelos nomes das especialidades no Google Scholar, e os resultados da pesquisa foram analisados manualmente.
Nesta análise do manual, foram pesquisados e lidos sites de veículos de publicação para encontrar aqueles que melhor se adequassem às especialidades oferecidas de acordo com a descrição selecionada. Uma abordagem semelhante para definir assuntos de veículos foi adotada por Alwahaishi; Martinovic; Snáshel (2011).
Scripts de extração desenvolvidos
Para isso, foi feita uma busca no histórico de chamadas de trabalhos do Congresso da AAAI. Os temas mais frequentes no período foram criados como especialidades para este estudo e são apresentados na Tabela 3. Para recuperar os dados do DBLP, foram desenvolvidos programas de consulta API automatizada.
Porém, o nome do veículo no DBLP é representado por um campo de texto (lugar) que pode ser uma sigla ou uma abreviatura, por isso é necessário saber qual abreviação representa cada veículo. Além do título em inglês e do nome do veículo lançado, foram extraídos dados de tipo e ano.
Limpeza dos dados
Assim, foram desenvolvidos dois scripts: um para download dos dados pertencentes ao dataset Subáreas e outro para o dataset Especialidades. A tarefa dos scripts criados era baixar os dados referentes aos conjuntos de subáreas e especialidades para salvá-los em arquivos no formato de valores separados por vírgula (CSV). Nesse sentido, foram baixados todos os registros encontrados com o campo local pertencente ao conjunto de siglas definido neste trabalho.
Produções com títulos que incluam o nome do veículo: um problema encontrado nos dados extraídos foi a presença de registros que, embora não sejam do tipo editorial, são anais ou algum outro tipo de editorial e não representam simplesmente uma obra. Depois de executar os processos de limpeza de dados listados, o número de exemplos foi reduzido em relação ao tamanho inicial do conjunto.
Definição de conjuntos de treino e teste
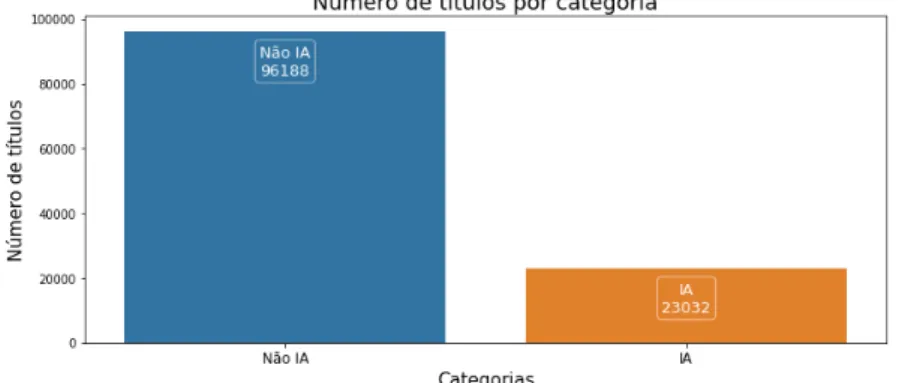
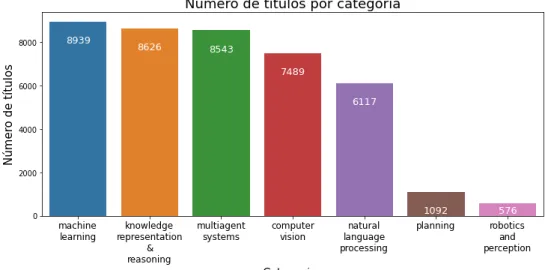
Outros exemplos de cabeçalhos não identificados: mesmo após as etapas anteriores, ainda havia alguns registros de cabeçalhos sem a devida classificação de tipo. Nessas circunstâncias, o número de registros gerados e a distribuição entre categorias no subdomínio e conjuntos de recursos foram mostrados respectivamente na Figura 3 e na Figura 4. Esse recurso é necessário para garantir um número adequado de exemplos de classes minoritárias tanto no treinamento quanto no teste.
Especificação da tarefa dos modelos
A entrada para este modelo deve ser o título de um artigo de informática em inglês. Modelo de especialidade: deve realizar uma classificação multiclasse, ou seja, dentre todas as especialidades selecionadas, o modelo deve indicar qual é a correta para cada exemplo. A entrada para este modelo deve ser o título de um artigo de inteligência artificial em inglês.
Representações utilizadas
Spacy pt_core_web_sm: trata-se de um pipeline da biblioteca SpaCy treinado em inglês e que suporta diversas operações, entre elas, transformar uma frase ou documento em um vetor através do método vetorial. BERT: Bidirectional Encoder Representations from Transformers (BERT) (DEVLIN et al., 2018) é um modelo desenvolvido pelo Google que utiliza uma técnica de “embedding contextualizado” que permite ao modelo aprender representações para palavras em um contexto específico.
Seleção e treinamento dos modelos
Validação inicial
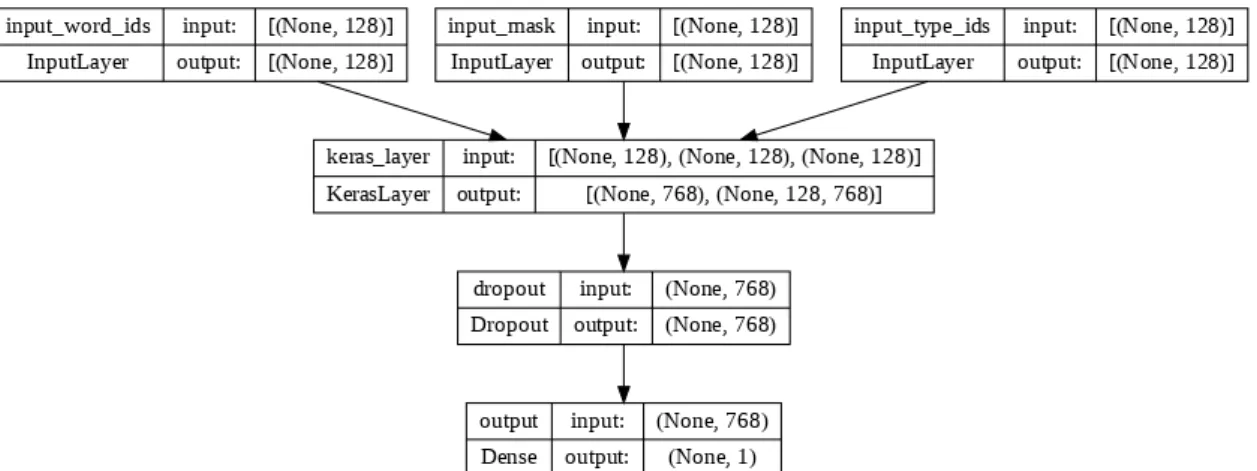
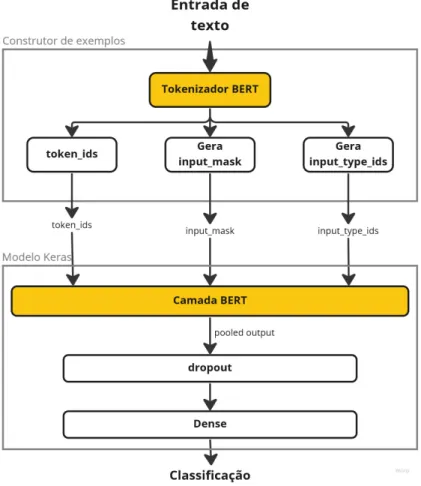
Um bom motivo para usar o modelo BERT é que ele pode ser treinado juntamente com um modelo de classificação para aprender as entradas de uma tarefa específica, um processo conhecido como ajuste fino. Para transformar os cabeçalhos neste formato, foi usado o exemplo do model package builder baixado do TensorFlow Hub. O vetor de saída é passado por uma camada de Dropout e então serve como entrada para o modelo de classificação.
Esses parâmetros são os mesmos ou estão na mesma faixa dos apresentados no artigo original (DEVLIN et al., 2018). O modelo de classificação utilizado com o BERT foi uma rede neural artificial, mais precisamente a implementação Dense da biblioteca Keras.
Busca de hiper-parâmetros
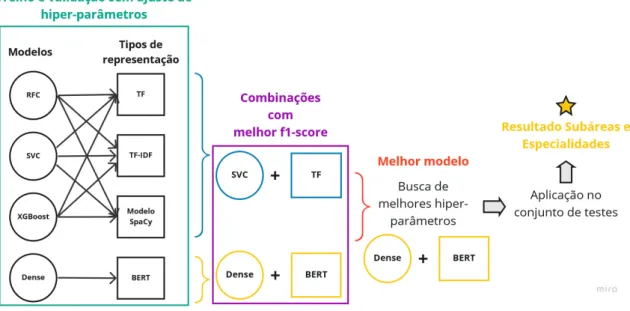
Ao final da validação, os melhores modelos foram selecionados para uma etapa posterior de busca de hiperparâmetros. O modelo scikit-learn com melhor desempenho na primeira etapa de validação foi selecionado para a pesquisa de hiperparâmetros. Assim, foi feita uma busca pelos melhores hiperparâmetros com o método GridSearchCV da biblioteca.
O objetivo final é determinar a melhor combinação de processamento de texto e modelo de aprendizado de máquina para o modelo de subdomínio e o modelo de recursos e medir seu desempenho em relação a algumas métricas. 2∗tp+f p+f n (6) Os resultados são divididos em subáreas do modelo e especificidades do modelo e organizados por etapas: validação inicial, busca de hiperparâmetros e teste.
Modelo de Subáreas
Validação inicial
Inicialmente, os modelos implementados no scikit-learn foram treinados e validados sem alterar os hiperparâmetros padrão da biblioteca. Já no caso da arquitetura desenvolvida para o BERT, foi criada uma base de pipeline na qual não foi realizada a busca pelos melhores hiperparâmetros. Este modelo base foi criado de acordo com a arquitetura apresentada na subseção 4.6.1, e a função de ativação base foi o sigmóide.
Nessas condições, de todas as combinações testadas, o modelo SVC com processamento TF e o modelo Denso com processamento BERT tiveram o melhor desempenho. O macro escore f1 foi utilizado nas análises por ser a média entre os escores f1 das turmas, sendo cada turma igualmente importante e, portanto, mais indicada para turmas desequilibradas.
Busca de hiper-parâmetros
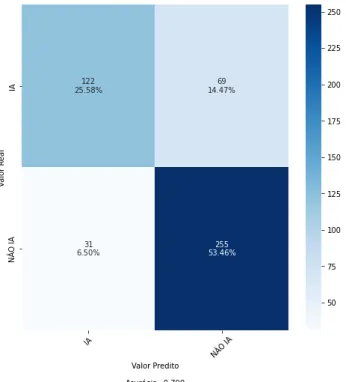
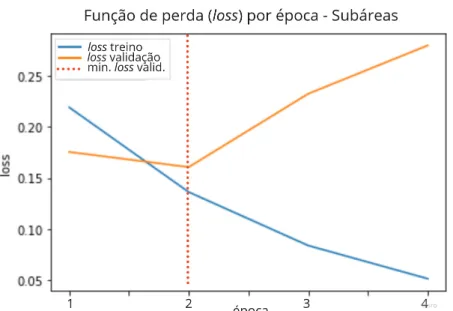
Durante o treinamento, observou-se que a melhor acurácia de eloss no conjunto de validação foi obtida treinando apenas 2 épocas (Figura 8 e Figura 9, respectivamente). Além disso, a função de ativação ReLu também foi testada, mas os resultados foram significativamente inferiores. A precisão do modelo foi de 93% e a pontuação macro f1 foi de 89%, os mesmos valores da etapa anterior, mas a precisão da classe IA melhorou.
Como o pipeline usando o modelo Denso em combinação com o BERT alcançou as melhores métricas, ele foi definido como o modelo Subáreas.
Testes
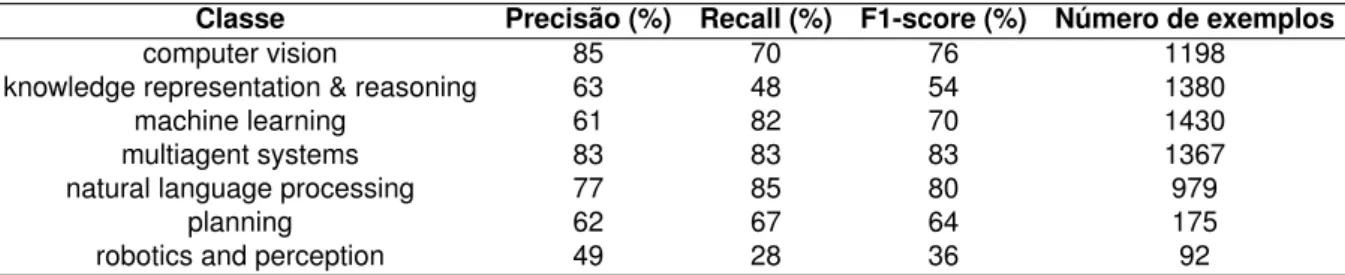
Os resultados do modelo foram equilibrados, com a medida menos robusta sendo a chamada para a classe IA. Ainda assim, o modelo foi capaz de classificar corretamente a maioria dos exemplos sem prejudicar significativamente as estatísticas das classes minoritárias. Uma certa taxa de erro também é esperada devido à forma como o conjunto de dados é construído.
Como os trabalhos envolvendo inteligência artificial não são publicados exclusivamente nos veículos associados à IA no conjunto de dados, pode haver títulos tratando da IA nos exemplos não-IA. Isso tende a fazer com que o modelo classifique um falso positivo, mas não é necessariamente um erro de classificação na prática; por exemplo.
Modelo de Especialidades
Validação inicial
Busca de hiper-parâmetros
Assim como no modelo de sub-regiões, durante o treinamento, as melhores métricas foram observadas ao treinar por duas épocas (Figura 11 e Figura 12).
Teste
No gráfico, pode-se perceber que a turma de aprendizado de máquina concentra o maior número de falsos negativos em quase todas as turmas. Dado que o aprendizado de máquina não é um tópico publicado exclusivamente nos veículos relacionados à especialidade no conjunto de dados, podemos entender que alguns dos erros podem não ser realmente erros. A análise consistiu em contabilizar a ocorrência de termos relacionados ao aprendizado de máquina em exemplos de representação e raciocínio do conhecimento classificados como aprendizado de máquina.
Com essa análise é possível entender que existem itens de aprendizado de máquina atribuídos à classe de representação e raciocínio do conhecimento em construção. Além disso, é provável que haja cruzamento entre essas duas especialidades e, como o aprendizado de máquina tem aplicações diferentes e está presente em diferentes especialidades, é provável que esse fenômeno ocorra em outras especialidades.
Teste com dados da plataforma Sucupira
A review of author name disambiguation techniques for the PubMed bibliographic database.Journal of Information Science, [S.l.], v.47, n.2, p. IEEE Transactions on Computers Computer Hardware Design IEEE Journal of Solid-State Circuits Computer Hardware Design IEEE International Solid-State Circuits Confe- . Computer Hardware Design Design Automation Conference (DAC) Computer Hardware Design IEEE Transactions on Computer-Aided Design by.
ACM Symposium on Theory of Computing Theoretical Computer Science IEEE Symposium on Foundations of Computer. Theoretical Computer Science ACM SIAM Symposium on Discrete Algorithms Theoretical Computer Science SIAM Journal on Computing Theoretical Computer Science Journal of the ACM (JACM) Theoretical Computer Science Theoretical Computer Science Theoretical Computer Science ACM/IEEE International Conference on Human. Human Computer Interaction IEEE Transaktioner på Affective Computing Human Computer Interaction ACM Symposium om brugergrænsefladesoftware.
International Conference on Machine Learning Machine Learning Journal of Machine Learning Research Machine Learning International Natural Language Generation Confe-.