Uma estrutura para analisar e identificar grupos de mulheres na computação e suas características por meio de técnicas de mineração de dados. Monografia apresentada ao Curso de Engenharia de Computação da Universidade Federal de Ouro Preto como requisito parcial para obtenção do título de Bacharel em Engenharia de Computação. Portanto, este trabalho buscou construir uma estrutura para a análise e identificação de grupos e características de mulheres pertencentes ao campo da tecnologia da informação por meio de técnicas de mineração de dados.
A partir de um banco de dados fictício preenchido com um questionário dividido em questões de cunho pessoal, sobre a motivação para a escolha de um estudo, sobre situações de preconceito enfrentadas durante a graduação e questões para análise comportamental, foi possível utilizar técnicas de mineração de dados como etapa. descobrir conhecimento em bancos de dados, para obter conhecimento útil.
O problema de pesquisa
Apesar de seu legado até então inédito, com a redescoberta de sua obra, a vida de Lovelace passou a ser questionada. Portanto, é possível perceber que, apesar de sua contribuição essencial para o desenvolvimento e evolução das áreas relacionadas à informática, a presença feminina era cada vez mais rara, o que torna necessário entender o motivo e o que foi feito pode ser feito para reverter tal situação.
Objetivos
Metodologia
Organização do trabalho
Lei Geral de Proteção de Dados
Trabalhos relacionados
A análise estatística dos dados proposta pelos autores foi desenvolvida utilizando a linguagem de programação Python, utilizando bibliotecas de apoio para visualização dos dados coletados. Apesar das semelhanças com este trabalho, os dados foram tratados e analisados por meio do software Excel e não pela linguagem de programação Python.
Metodologia DISC
Métodos e Ferramentas
Coleta de dados a partir de questionários
Knowledge Discovery in Databases e mineração de dados
- SentiStrength
- Principal Component Analysis ou PCA
- Clusterização
Crie um conjunto de dados de destino, selecionando os dados que deseja recuperar ou foque em um subconjunto de variáveis ou amostra de dados, onde a detecção será aplicada. A redução e projeção de dados são alcançadas descobrindo fontes úteis de representação de dados, dependendo do objetivo da análise. Os objetivos do processo KDD devem ser combinados com um método específico de extração de dados.
A mineração de dados consiste na busca de padrões de interesse em uma determinada forma de representação ou em um conjunto de representações, incluindo regras ou árvores de classificação, regressão e agrupamento. Segundo Jolliffe e Cadima (2016), conjuntos de dados que possuem alta dimensionalidade podem dificultar sua interpretação. Os autores afirmam ainda que preservar o máximo de variabilidade possível significa encontrar novas variáveis que sejam funções lineares daquelas do conjunto de dados original, que maximizaram sucessivamente a variância e foram não correlacionadas entre si.
Abdi e Williams (2010) afirmam que os objetivos da aplicação PCA são extrair as informações mais relevantes de um conjunto de dados; reduzir o tamanho de um conjunto de dados, preservando apenas informações importantes; simplificar a descrição de um conjunto de dados e analisar a estrutura de observações e variáveis. Essa matriz pode, portanto, ser utilizada para obter informações relevantes sobre o conjunto de dados, como outliers e variáveis com maior expressividade para os dados originais. Este capítulo descreve o desenvolvimento do trabalho, incluindo a criação do questionário, a construção da base de dados fictícia e a criação de um framework com as técnicas de mineração de dados relevantes.

Construção do questionário e desenvolvimento da base de dados
Todas as perguntas deste questionário são de preenchimento obrigatório, podendo ser de múltipla escolha, onde algumas permitem a seleção de mais de uma alternativa ou o acréscimo de uma resposta pessoal, a partir da marcação das alternativas “outras” ou questões abertas, que refletem os efeitos de uma resposta curta à pergunta proposta.
Criação e pré-processamento dos dados
Situação Preconceito Você já sofreu e/ou presenciou uma cena de preconceito/discriminação contra mulheres no curso. Baixa presença Em sua opinião, qual a explicação para a baixa presença de mulheres na informática? Obstáculo de trabalho Na sua opinião, as mulheres enfrentam algum tipo de obstáculo para continuar com o computador.
OportunidadesTrabalho Na sua opinião, as mulheres têm as mesmas oportunidades que os homens na computação. Como primeiro passo no pré-processamento dos dados recolhidos, verificou-se a existência de erros no conjunto de dados para que os mesmos pudessem ser corrigidos. Salienta-se que, como o banco de dados foi criado com o objetivo de desenvolver uma estrutura para análise de dados, não há dados duplicados ou respostas ausentes, fator que deve ser observado quando se utiliza dados coletados de forma orgânica.
Assim, cada alternativa desse tipo de consulta foi transformada em um atributo para o banco de dados a fim de construir uma matriz de incidência baseada na estratégia bag-of-words. Para lidar com dados reais de linguagem natural, todos os caracteres não ASCII foram removidos e todo o texto foi convertido em letras minúsculas. Vale ressaltar também que o pré-processamento desenvolvido para este trabalho está pronto para aplicação em dados reais.

Aplicação do SentiStrength
O módulo nativo re2 da linguagem de programação Python, que é usado para processar expressões regulares, foi usado para remover caracteres não portugueses. Além disso, todas as palavras de parada, palavras que não são relevantes para o tratamento do texto e pontuação foram removidas. É importante ressaltar que a utilização da análise de humor em português não é tão precisa quanto a análise em inglês, tendo em vista que os valores obtidos para uma mesma frase nem sempre foram os mesmos, como pode ser observado na Tabela 2. PT-BR Análise em PT-BR Sentença em EN Análise em EN.
Sim, experimentei uma situação de preconceito durante uma hora em que minhas perguntas foram ignoradas, mas se colegas do sexo masculino fizessem perguntas iguais e/ou semelhantes, suas perguntas eram respondidas sem mais comentários. Situação tendenciosa durante uma hora em que minhas perguntas foram ignoradas, mas se colegas do sexo masculino fizessem perguntas iguais e/ou semelhantes, suas perguntas eram respondidas sem mais comentários. Sim, uma colega foi completamente ignorada durante uma aula em que queria fazer perguntas. foi completamente ignorada durante uma aula em que ela queria fazer perguntas. Sim, uma colega foi ignorada durante as práticas de um sujeito por ser mulher.
Frase em PT-BR Análise em PT-BR Frase em EN Análise em EN Sim, sofri bullying. durante uma hora para fazer perguntas, meus colegas me perguntaram e nada aconteceu. Sedei durante uma aula para fazer perguntas aos meus colegas homens e nada aconteceu com eles. Sim, já senti que os professores homens me olhavam diferente durante as aulas. Sim, um colega foi observado desajeitadamente por várias horas pelo mesmo professor. obscenamente observado ao longo de várias horas pelo mesmo professor.
Transformação dos dados
É importante ressaltar que, como o banco de dados utilizado foi criado a partir de dados fictícios, as correlações obtidas não refletem a opinião dos alunos de uma determinada universidade ou campus. Dada a elevada dimensionalidade do conjunto de dados obtido, deverá ser utilizada a técnica PCA, com o objetivo de reduzir o número de variáveis analisadas e identificar as variáveis que melhor representam a variabilidade dos dados. Decidimos usar 9 componentes principais, pois há uma notável diferença de nível para esse número de componentes na Figura 6.
Para usar tal algoritmo, é necessário escolher antecipadamente o número ideal de clusters que melhor define o conjunto de dados. Assim, o número ideal de clusters é encontrado quando ao adicionar outro cluster não é possível obter uma melhor modelagem do banco de dados. A análise inicia para um número de clusters de k = 2, onde são realizadas iterações para k aumentando em uma unidade até que o ganho de informação, representado pela soma dos quadrados intra-cluster (WCSS), sofra um queda abrupta, representada por um canto agudo no gráfico.
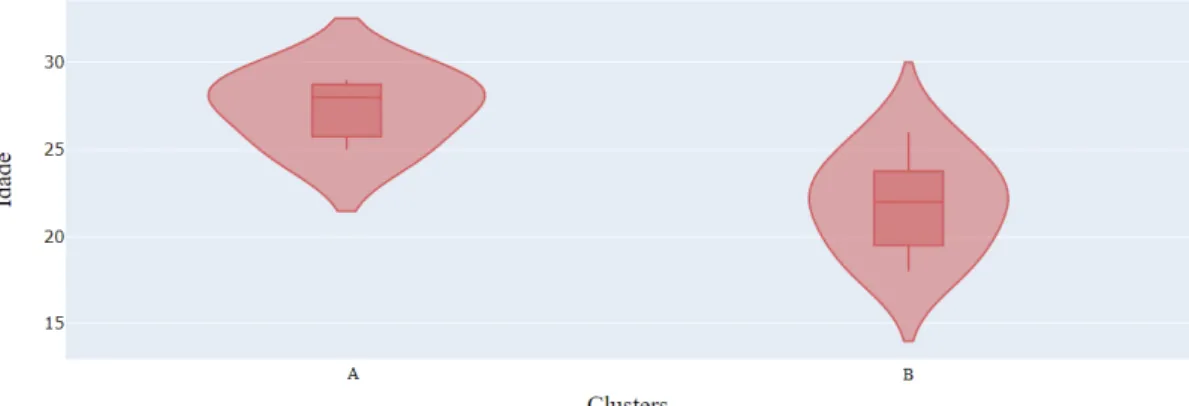
Nesse sentido, de acordo com os dois critérios utilizados, optou-se por adotar 2 clusters. É prudente ressaltar que toda a metodologia de seleção de grupos e componentes principais é apresentada no framework desenvolvido, o que possibilita a aplicação de um banco de dados real. Este capítulo descreve os resultados obtidos pela mineração do banco de dados fictício inserido no framework desenvolvido, que pode ser encontrado nos links a seguir1,2.

Análise dos resultados
É possível observar que na Figura 11, no cluster A, 100% dos respondentes cursaram o ensino médio apenas na rede privada. Além disso, conforme ilustrado na Figura 12, no cluster A, 100% das alunas cursaram o ensino médio em escolas públicas e privadas. Ainda sobre as percepções, para os dois clusters identificados nas Figuras 14 e 15, é possível perceber que para o cluster A, 100% dos respondentes gostam da infraestrutura do campus e 42,9% gostam dos professores que lecionam as disciplinas do curso.
No cluster A, 66,7% consideram continuar seus estudos para continuar na academia, sendo esse valor igual a 57,1% no cluster B. Por fim, entre os grupos de respondentes por características pessoais, na Figura 18, no cluster A, 33,3% dos alunos disseram que seus pais concluíram o ensino superior. Nos perfis identificados por Marston (1928), para a primeira questão analisada, ilustrada pela Figura 19, sobre preferências quanto à execução de atividades, no grupo A, 100% dos respondentes afirmaram preferir realizar atividades junto com alimentação, o que segundo o autor, corresponderia ao perfil S ou estabilidade.
No Grupo B, 57,1% dos alunos afirmaram preferir focar-se nas tarefas que têm em mãos, correspondendo ao Perfil C ou conformidade segundo Marston (1928). Por fim, para o humor médio dos textos sobre situações de preconceito enfrentadas ou presenciadas pelos entrevistados, foi realizada uma análise de acordo com o humor médio em cada cluster, conforme a Figura 21. Com isso, foi possível perceber o quão diferente Os respondentes podem ser classificados em grupos de acordo com o que consideram mais ou menos importante, e faz sentido destacar a análise sentimental de determinados textos obtidos por meio de perguntas abertas.
Como continuidade deste trabalho, será possível coletar dados reais com base no questionário elaborado no Anexo A, com o objetivo de proteger os respondentes de acordo com a LGPD. Esses riscos, caso ocorram, serão reduzidos da seguinte forma: os dados sensíveis não são coletados de acordo com a LGPD e a elaboração do questionário está de acordo com as normas de procedimentos a serem adotadas para pesquisas em ambientes virtuais UFOP ( Termo de Consentimento Livre e Esclarecido (TCLE) Informações pessoais Motivações para a escolha do curso Percepções durante o curso Análise comportamental