Porém, devido ao aumento do número de documentos informatizados, é necessário encontrar uma forma eficiente de encontrar e localizar esses documentos. Ao utilizar técnicas de recuperação de informações, bons resultados podem ser obtidos no processo de recuperação de documentos.
PROBLEMATIZAÇÃO
Formulação do Problema
Solução Proposta
OBJETIVOS
Objetivo Geral
Objetivos Específicos
METODOLOGIA
ESTRUTURA DO TRABALHO
Apresenta conceitos fundamentais que abrangem desde a documentação e ficheiros até às técnicas necessárias ao tratamento destes documentos e à sua respetiva pesquisa e recuperação. As opiniões de diferentes autores são aqui apresentadas para que possam ser identificadas as técnicas mais adequadas para resolver o problema.
ARQUIVOS
Processo Documentário
As principais fases do processo documental, ou seja, análise, indexação, pesquisa e recuperação da informação, são apresentadas na Figura 1. Para Araújo Júnior (2007), o processo documental torna-se muito mais fácil quando se consegue aliar a prática do indexador ao conhecimento dos usuários. necessidades e requisitos de informação, porque através da compreensão ou análise imediata, as palavras-chave e descritores serão representativos do processo de busca e recuperação de informação.
CIÊNCIA DA INFORMAÇÃO
Portanto, a documentação e a biblioteconomia tradicional nada mais são do que aplicações específicas da ciência da informação. Segundo Ramos (2008), a ciência da informação é um campo do conhecimento que visa estudar a informação em sua amplitude e sob múltiplas perspectivas.
MINERAÇÃO DE TEXTOS
Coleta de Documentos
Essa base pode ser estática, nos casos mais simples, ou dinâmica, onde os dados são atualizados a todo momento através da coleta de novas informações. A coleta pode ser feita adicionando novos conteúdos, removendo conteúdos antigos ou substituindo conteúdos (ARANHA, 2007).
Pré-Processamento
Segundo Aranha (2007), nesse processo um dicionário pode ser utilizado para identificar termos específicos quando as palavras que se deseja utilizar para criar o índice estão pré-determinadas, evitando o uso de palavras desconhecidas e de um dicionário não controlado. Na construção da stop word devem ser incluídas palavras como artigos, preposições, pronomes e outras classes de palavras auxiliares.
TESAURO
- Origem
- Conceito
- Função
- Organização
No momento da indexação, o assunto é representado: o documento é analisado, o seu conteúdo é identificado e “traduzido” de acordo com os termos do tesauro e a política de indexação que foi estabelecida. Relação de equivalência: permite destacar termos que possuem significado equivalente em uma determinada área (sinônimos).
INDEXAÇÃO
RECUPERAÇÃO DA INFORMAÇÃO
Modelos Quantitativos
Como resultado, obtém-se um conjunto de documentos, organizados de acordo com o grau de similaridade de cada documento em relação à expressão pesquisada (FERNEDA, 2003). A semelhança entre cada documento e uma expressão de pesquisa é normalmente usada ao organizar os documentos resultantes. Portanto, ao utilizar o modelo vetorial, o resultado de uma busca deve ser um conjunto de documentos, ordenados pelo grau de similaridade entre o documento e a expressão de busca.
Tomando como exemplo um limite de 0,6, uma expressão de pesquisa retornará apenas documentos com pontuação de similaridade maior ou igual a 60%.

Modelos Dinâmicos
Um sistema de recuperação de informação procura rotineiramente documentos relevantes para satisfazer uma determinada expressão de pesquisa através de termos de indexação. Nestes sistemas, existem termos de pesquisa de um lado e documentos do outro, com termos de indexação no meio. Os termos de pesquisa (t1, t7, t3, t9) iniciam o processo de inferência ativando os termos de índice correspondentes.
Após receber esses estímulos, os termos de indexação enviam novos sinais aos documentos e repetem o processo.

Gestão de Precisão
A expressão t2 pode ativar o documento dn, que, dependendo do nível de ativação, pode até fazer parte do conjunto de documentos restaurados (FERNEDA, 2003). Segundo Pinheiro (2008), a grande característica das redes neurais é a sua alta automação, uma vez que seu usuário final ou desenvolvedor não precisa saber muito sobre como elas funcionam, sobre modelagem preditiva ou mesmo sobre o banco de dados que utiliza. lá. Claro, esta é uma aproximação aproximada do que foi feito, mas define claramente a facilidade de construção de redes neurais em uma ampla variedade de campos.
Uma medição objetiva do desempenho dos componentes de um sistema de recuperação de informação, considerada acurácia, é muito importante na detecção e correção de falhas em um processo de recuperação de informação, além de servir de parâmetro para testes de novas tecnologias relacionadas ao recebimento de informações. melhoria de processos (ARAÚJO JÚNIOR, 2007).
FERRAMENTAS SIMILARES
CONSIDERAÇÕES
O número de ferramentas de recuperação de informação e mineração de textos ainda está muito aquém do potencial que esta área tem. Vale destacar o surgimento de formas de melhorar o processo de recuperação de informação, o que torna muito relevante o surgimento de novos trabalhos nesta área, especialmente em português. Atualmente o número de ferramentas aplicadas à nossa linguagem é pequeno, mas diversos trabalhos estão sendo desenvolvidos nesta área, onde técnicas podem ser estudadas e discutidas, aumentando a base de conhecimento necessária para desenvolver essas ferramentas.
Esta modelagem inclui requisitos funcionais e não funcionais, diagramas de casos de uso, diagramas de classes e diagramas de sequência.
REQUISITOS FUNCIONAIS
REQUISITOS NÃO FUNCIONAIS
CASOS DE USO
Pesquisa de documentos: permite pesquisar documentos através de expressões fornecidas pelo usuário; Pesquisar com todas as palavras: permite uma pesquisa que retorna qualquer uma das palavras da expressão pesquisada; Pesquisar palavra semelhante: permite pesquisar palavras foneticamente semelhantes à que você deseja;
Realizar pesquisa avançada: permite realizar uma pesquisa avançada sem conhecer as expressões, através da tela de pesquisa avançada.
DIAGRAMA DE CLASSES DO SISTEMA
Filtrar número de resultados: permite ao usuário selecionar o número máximo de resultados a serem exibidos; Pesquisa por ordem exata das palavras: permite pesquisar pelo termo utilizado pelo usuário, levando em consideração a ordem das palavras; Pesquisa curinga: permite pesquisar substituindo um caractere desconhecido por um curinga que substituirá um ou mais caracteres;
Pesquisa de distância máxima: permite escolher a distância máxima entre os termos que você irá pesquisar;
DIAGRAMAS DE SEQUÊNCIA
Desta forma, podem ser demonstrados os principais métodos e atributos das principais classes, correspondentes aos processos de indexação e busca. Após o processo de indexação do sistema, esses índices gerados tornam-se pesquisáveis. Modelar a ferramenta facilita o processo de identificação das funcionalidades do sistema, além de ajudar no entendimento de seus processos.
Com a ajuda deste importante mecanismo, tornou-se possível compreender melhor a interação entre o usuário e o sistema, o relacionamento entre as classes e a sequência de processos e trocas de mensagens.
FERRAMENTAS AUXILIARES
Apache Lucene
No processo de indexação, Lucene armazena os dados de entrada em uma estrutura de dados chamada índice invertido, que permite aos usuários realizar pesquisas rápidas por palavras-chave e encontrar documentos que correspondam a uma determinada consulta. Neste caso, o analista converte os dados do texto em uma unidade fundamental de busca, chamada Nesta análise, os dados do texto passam por diversas operações: extrair palavras, remover palavras comuns, etc.
A análise converte dados de texto em tokens e esses tokens são incluídos como termos no índice Lucene (SONAWANE, 2009).

Apache POI
O Lucene possui diversos tipos de analisadores, entre eles o BrazilianAnalyzer, que realiza o processamento dos termos de acordo com o idioma português brasileiro, removendo stopwords e sufixos se necessário. A pesquisa no Lucene, além de suportar vários tipos de consulta eficientes, incluindo análise de expressão e uso de operador, calcula uma pontuação para cada documento que corresponde a uma determinada consulta e retorna apenas documentos relevantes classificados por essas pontuações. Como o arquivo Biguaçu só funciona com arquivos no formato ".Doc", optou-se por utilizar esta ferramenta no desenvolvimento da aplicação.
Também seria facilmente adaptado para funcionar com tipos de arquivos mais recentes, como o formato ".Docx", se necessário.
LUKE
Como pode ser visto na Figura 26, Lucas permite uma visualização simples de todos os termos do índice. A Figura 25 mostra como Luke fornece acesso aos termos de índice, classificando-os por número de ocorrência. Também é possível acessar a quantidade de termos em cada campo do documento, como título e conteúdo.
Luke (2010) teve um papel importante no desenvolvimento deste projeto, pois facilitou o processamento e visualização dos índices, possibilitou a verificação detalhada dos termos e auxiliou na análise da solução.

PROCESSO DE COLETA DE DOCUMENTOS
PROCESSO DE INDEXAÇÃO
Desta forma, é criado um novo arquivo de índice para cada conjunto de documentos indexados, dentro de uma pasta nomeada para esse conjunto. Para indexar um conjunto de documentos foi implementado o método index, que é responsável por registrar na classe de entidade indexadora os atributos referentes ao nome da pasta onde os documentos estão localizados, o caminho dessa pasta e o caminho onde ela está localizada. o arquivo de índice é salvo. Este trecho de código mostra que a pasta do documento é percorrida na busca por arquivos e, quando uma pasta (pasta) é encontrada, o método usa recursão, que também percorre subpastas.
Então podemos ver que a pasta de documentos é percorrida na busca por arquivos, e quando uma pasta (pasta) é encontrada, o método é chamado novamente, que também percorre as subpastas.

PROCESSO DE PESQUISA
Este método utiliza a classe Document, que consiste em Fields – campos onde residem as informações dos documentos – e adiciona um novo documento. Neste método, após acessar o índice, é preparada uma coleção de resultados com o número máximo de resultados desejados e a busca é feita.
PROCESSO DE CONSULTA AO TESAURO
O método searchThesaurus divide o termo de pesquisa em tokens para verificar se cada token possui sinônimos correspondentes. Dessa forma, cada termo de pesquisa é separado para que você possa pesquisar possíveis sinônimos no banco de dados.

FUNCIONAMENTO DA FERRAMENTA
Neste caso, o sistema realizará uma busca que trará documentos contendo o termo “título” e pelo menos um dos termos “estrada” ou “servidão”. Documentos hospitalares E de construção contendo os termos Hospital e Construção Hospitalar OR Documentos de farmácia com pelo menos um dos termos. Luiz Gonzaga Junior”~1 Documentos contendo os termos exigidos com distância máxima de um termo entre cada um.
João^3 Joaquim Documentos contendo os termos pesquisados, mas com peso maior para o termo especificado.

RESULTADOS RELEVANTES
Tempo de Indexação
Para atingir esse tempo, além de utilizarmos a versão mais atual do Lucene, que possui desempenho muito melhor que as anteriores, também buscamos otimizar o processo de indexação, evitando qualquer esforço desnecessário na ferramenta nesse período. qualquer operação que não faça parte do processo quando é chamada. Assim, o processo de indexação, que é o único processo que seria capaz de consumir um tempo significativo para ser executado, está dentro do tempo aceitável para um bom desempenho da ferramenta.
Stopwords e Stemming
Com o processo de remoção de stopwords e radicais, percebe-se que o número de termos foi reduzido significativamente (cerca de 8%), otimizando assim o processo de indexação de documentos.
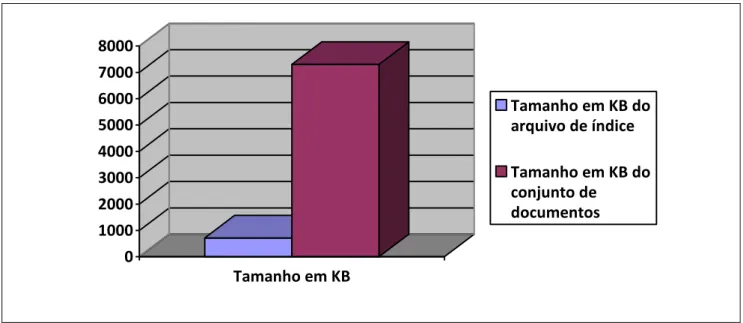
Tamanho do Índice
Desta forma, pode-se obter uma noção da qualidade do processo de indexação, uma vez que o arquivo de índice tem menos de 10% do tamanho do conjunto de documentos indexados. Além disso, foram abordados temas relevantes em um processo de recuperação de informações, como mineração de textos, uso de tesauros e a importância da indexação de documentos nesse processo. Muitos documentos contêm conteúdo que não é de interesse do processo de indexação e busca e devem ser tratados.
Procuramos solucionar todos esses problemas para que fosse obtido um resultado satisfatório quando a ferramenta fosse concluída, e para o contexto atual do Arquivo Público de Biguaçu, a ferramenta mostrou-se capaz de auxiliar e otimizar o processo de busca e recuperação de informações.