Algoritmo Q-learning
Algoritmo SARSA
Algoritmo TD(λ)
Algoritmo Q(λ) do Watkins
Algoritmo Q(λ) Naive
Algoritmo SARSA(λ)
Algoritmo TD(λ) implementado
MOTIVAÇÃO
Uma das motivações para este trabalho é que os robôs humanoides ainda têm muito que evoluir em relação aos humanos. O que motivou este trabalho é que atualmente no Centro Universitário da FEI e também em outras universidades os valores dos parâmetros do piso são ajustados manualmente e a estabilidade do piso robótico é verificada pela observação do piso.
OBJETIVO
ROBOCUP
A equipe RoboFEI compete na KidSize Humanoid League (mostrada nas Figuras 1 e 2) e na Small Size League pela RoboCup. Atualmente, na categoria humanóide KidSize, os robôs podem ter entre 40 e 90 centímetros de altura, e o número de jogadores é de no máximo quatro e no mínimo de um (ROBOCUP, 2015a).

ROBÔS HUMANOIDES
Na competição RoboCup existem vários tipos de robôs humanóides, entre eles está o NAO (Figura 5a) da Aldebaran Robotics (ALDEBARAN, 2015). O robô DARwIn-OP tem sido usado por algumas equipes da liga humanóide RoboCup Kid-Size.

ORGANIZAÇÃO DA DISSERTAÇÃO
Na geração de marcha para robôs humanóides são apresentadas algumas técnicas que são aplicadas no gerador de marcha. Este capítulo está dividido em quatro seções: cinemática de robôs humanóides; geração de marcha para robôs humanóides; aprendizagem por reforço; e trabalhos relacionados.

CINEMÁTICA DOS ROBÔS HUMANOIDES
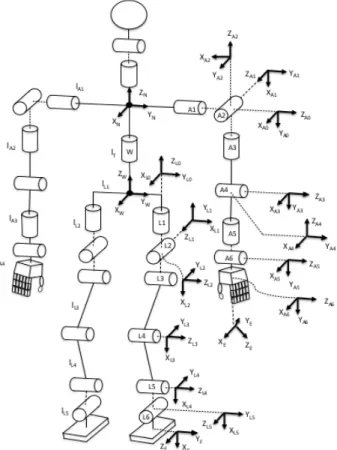
A seção geração de caminhada para robôs humanóides apresenta algumas técnicas que são aplicadas no gerador de caminhada para criar uma caminhada que mantenha o equilíbrio dinâmico e estático do robô. A orientação dos eixos coordenados cartesianos utilizados no robô humanóide DARwIn-OP (HA; TAMURA; ASAMA, 2011) e em outros robôs humanóides (ALI et al., 2010) utiliza os ângulos de Tait-Bryan.
GERAÇÃO DE CAMINHADA PARA ROBÔS HUMANOIDES
- Andar Passivo - Passive Dynamics Walking (PDW)
- ZMP - Zero Moment Point
- Gerador de Caminhada do DARwIn-OP
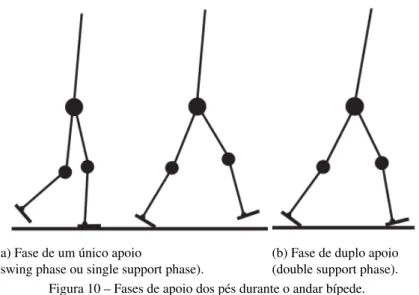
Na Figura 14 pode-se observar que a gravidade atua sobre a perna após a fase de extensão da perna. Quando o robô está na fase de suporte único, o CoP (Centro de Pressão) é o ponto na sola do pé onde se encontra a resultante das forças de pressão sobre o solo.
APRENDIZADO POR REFORÇO
- Processo Markoviano de Decisão
- Q-Learning
- SARSA
- Diferenças Temporais λ (TD(λ))
- Q(λ)
- SARSA(λ)
- Aprendizado por Reforço com Heurística
De acordo com a equação 10, pode-se observar que a qualidade do ajuste aumenta em 1 para o estado visitado, e para todos os outros estados decai pelo fator g. a) λ é o fator que quebra a característica de adequação (0≤λ ≤1) determinando quantas recompensas serão consideradas no futuro; Este tipo de aptidão é cumulativa porque aumenta 1 cada vez que o estado é visitado e diminui gradativamente cada vez que o estado não é visitado em proporção ao fator γλ, conforme mostrado na Figura 19. Portanto, se λ for igual a 1, o O algoritmo passa a se comportar de forma semelhante ao método de Monte Carlo, porém, se γ também for igual a 1, então os traços de aptidão não diminuem mais ao longo do tempo (a cada passo), pois a proporção de g será 1.
V(S) é o valor do estado em que o agente se encontra; r é o reforço por transição de estado. a) V(s) é um valor que se refere a um estado pertencente ao espaço de estados;. 13 para todos os estados e todas as ações. a) λ é um fator que reduz a propriedade de aptidão (0≤λ ≤1) que determina quantas recompensas futuras serão consideradas; O Algoritmo 5 mostra o algoritmo ingênuo Q(λ), onde a única diferença entre o Algoritmo 4 e o Algoritmo 5 é o reset do traço de aptidão quando a ação A0 do estado S0 difere da ação ótima A*.
Neste método, o recurso de fitness foi combinado com Sarsa, e em Q(λ), o uso do recurso de fitness aumenta a eficiência do algoritmo.
TRABALHOS RELACIONADOS
Esta proposta mantém as principais propriedades dos algoritmos de aprendizagem por reforço, mas acaba minimizando o tempo necessário para convergência. Uma diferença relatada pelos autores é que no robô real, a cada episódio, eles colocavam manualmente o robô e a bola nas posições corretas, resultando em mais ruído do que no simulador. Por outro lado, é difícil transferir a política aprendida no simulador para o robô real, conforme explicado por Farchy et al.
Ao longo deste capítulo, foi realizada uma revisão teórica da cinemática de robôs humanóides, geração de marcha de robôs humanóides e aprendizagem por reforço, e também foram apresentados alguns trabalhos relacionados. Abordagens essenciais formam a base do próximo capítulo, que se concentra no aprendizado por reforço para otimizar os valores dos parâmetros do piso. 3 APRENDIZAGEM POR REFORÇO PARA OTIMIZAR VALORES DE PARÂMETROS NO CHÃO EM UM ROBÔ HUMANÓIDE.
A primeira seção descreve o objetivo deste trabalho; como é composto o MDP do problema e como o aprendizado por reforço é aplicado no simulador.

DESCRIÇÃO DO MODELO DE APRENDIZADO
- Descrição dos parâmetros do andar
- Definição dos parâmetros utilizados no aprendizado
Este capítulo está dividido em três seções: a descrição do modelo de aprendizagem; descrição do robô; e descrição do simulador. O modelo de piso do robô DARwIn-OP no simulador possui os mesmos parâmetros do robô real. A velocidade foi usada no tutorial como forma de medir o impacto criado pela configuração dos parâmetros, e a queda do robô determinará a instabilidade do piso.
Para saber se o robô está parado ou caindo, a posição Zglobal do robô é verificada pelo controlador Supervisor. O robô corre paralelo ao controlador de movimento no simulador, portanto, a partir do momento em que o robô está em execução, uma thread executa todo o algoritmo de caminhada, enquanto o controlador de movimento fica disponível para realizar as ações. O robô DARwIn-OP utiliza um gerador de marcha através de três osciladores acoplados, estes osciladores realizam movimentos de trajetória senoidal que são sincronizados no tempo, de modo que o movimento do chão do robô seja um chão com estabilidade dinâmica, conforme descrito na seção 2.2.3.
V simuladorju Webots datoteka config.ini robota DARwIn-OP nima parametrov balance_angle_smooth_gain, balance_angle_gain, lean_fb_gain, lean_fb_accel_gain, lean_turn_gain, start_step_factor.
DESCRIÇÃO DO ROBÔ
- Descrição do hardware
- Descrição do software
Contudo, foi realizada uma análise do posicionamento do centro de gravidade do robô durante o seu deslocamento, para fins de equilíbrio. Uma das contribuições científicas desses robôs (Newton, B1 e B2) é que eles não possuem o microcontrolador que os robôs das outras equipes do RoboCup utilizam como interface de comunicação entre os servos e o PC, conforme mostra a Figura 28, ali. é apenas um conversor USB/RS-485 para comunicação com os motores e um conversor USB/RS-232 para comunicação com a IMU, conforme mostrado na Figura 29. Memória compartilhada é a memória que pode ser acessada simultaneamente por múltiplos processos, tornando-a comunicação entre eles é possível.
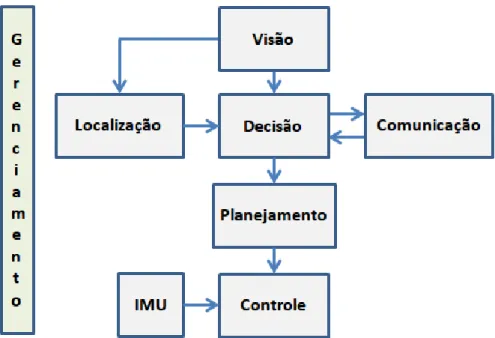
O controlador é responsável por realizar todos os movimentos do robô, como: andar; ascender; virar; entre outras coisas, chutar a bola. O código fonte para comunicação entre o computador e a IMU foi baseado no código de comunicação com a IMU utilizado no ROS (Robot Operating System). O padrão de comunicação entre o computador e a IMU é o protocolo de comunicação serial RS-232, que está implementado.
Na arquitetura de software, o programa que lê a IMU é um processo que é responsável apenas por essa leitura, a comunicação entre os demais processos se dá através de memória compartilhada.

SIMULADOR
- Simulador Webots
- Experimentos do desenvolvimento do sistema de controle
- Experimentos do andar do robô executando pontos em uma máquina de es-
- Experimentos com o robô utilizando o gerador de andar desenvolvido para o
- Experimento do pêndulo invertido no robô real utilizando Q-learning
- Discussão
A primeira seção apresenta experimentos relacionados ao desenvolvimento da marcha do robô e ao aprendizado por reforço aplicado a um robô real. Esta subseção apresenta alguns experimentos realizados com um robô real e os resultados de experimentos realizados durante o desenvolvimento do sistema de controle de um robô real (o robô é descrito no Capítulo 3, subseção 3.2.2). Na Tabela 3, mostrada no Capítulo 3, Subseção 3.2.2, você pode ver a velocidade do robô newtoniano, que era de 70 cm/min sem cinemática inversa, e na Figura 33 você pode ver o movimento de caminhada.
Neste experimento foi utilizado o código-fonte para geração da marcha do robô Jimmy (INTEL, 2015c) desenvolvido pela Intel. Como resultado, o caminhar do robô tornou-se mais estável, conforme mostrado na Figura 34, e a velocidade aumentou significativamente de 2 cm/s para 10 cm/s, conforme mostrado na Tabela 4, apresentada no Capítulo 3, Subseção 3.2. .2. Na Figura 31 mostrada na subseção 3.2.2, um modelo de malha fechada aplicado ao piso do robô (este circuito de controle não funciona quando o robô está parado) foi desenvolvido para estabilizar o piso do robô.
São experimentos realizados durante o desenvolvimento do sistema de controle do robô real e experimentos de aprendizagem por reforço aplicados ao robô real.
EXPERIMENTOS DO APRENDIZADO POR REFORÇO PARA OTIMIZA-
- Experimento de validação do algoritmo proposto
- Experimento utilizando uma função exponencial como recompensa positiva 88
- Experimento buscando novos parâmetros que aumentam a velocidade do
- Configurando o robô com os valores dos parâmetros extraídos do gráfico de
- Discussão
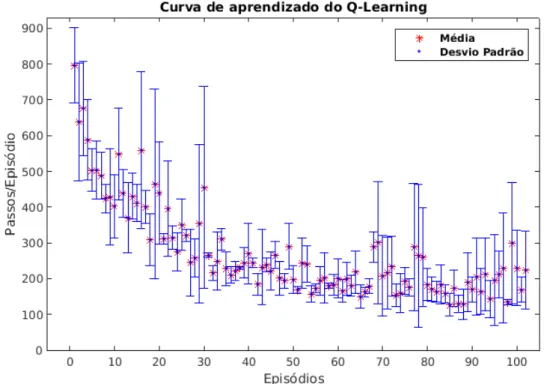
O gráfico da Figura 39 apresenta o valor de V(s) de todos os estados, este gráfico mostra que o algoritmo conseguiu encontrar os valores dos parâmetros que tornam o piso do robô estável. Porém, como o número máximo de passos por episódio era 30, o algoritmo executou 300.000 passos em aproximadamente 6.000 episódios. Neste experimento, todos os parâmetros do piso foram utilizados com os valores padrão do simulador.
No gráfico da Figura 51, os valores period_time = 600 e swing_right_lef t = 20 com referência ao ponto P2 estão dentro da faixa de melhores valores. Este experimento busca velocidades mais altas (em busca de novos valores de parâmetros) do que a velocidade de caminhada do robô usando os valores de parâmetros que vêm por padrão no simulador. O gráfico da Figura 53 mostra dois gráficos dos valores máximos de V(s) para cada valor period_time e swing_right_left.
A Tabela 9 representa o resultado da utilização dos valores dos parâmetros que o algoritmo encontrou como os melhores valores (valores dos parâmetros period_time = 625 e swing_right_lef t = 24 do ponto P2, e period_time = 675 e swing_right_left = 25 do ponto P3).

CONTRIBUIÇÕES
Este trabalho apresentou um algoritmo de aprendizagem por reforço para otimizar os valores dos parâmetros de um sistema de controle de marcha de um robô humanóide em um ambiente simulado. Neste caso, para otimizar os valores dos parâmetros do solo, basta conhecer os valores dos parâmetros. O controle é responsável por controlar todos os servo motores, pois é responsável por realizar todos os movimentos do robô, como: andar; subida; virar; chutar a bola, entre outras coisas.
Algumas técnicas de geração de marcha foram implementadas para o piso do robô e os resultados desses experimentos foram apresentados. Este controle faz parte da arquitetura de software do robô desenvolvida e apresentada por Perico et al. Desenvolvimento de um sistema de controle que não utiliza placa microcontrolada como interface de comunicação entre servomotores e PC.
Essa estabilidade pode ser visualizada pelos gráficos que mostram os valores de V(s) referentes aos valores dos parâmetros do gerador de malha.
TRABALHOS FUTUROS
AND MULTIAGENT SYSTEMS. Proceedings of the International Conference on Autonomous Agents and Multiagent Systems 2013. Knee-extended, heel-contact, toe-off human-like walking performed by a humanoid robot. Hardware and software aspects of the design and assembly of a novel humanoid robocup soccer robot.