Saul Emanuel Delabrida Silva (vejleder) - PhD - Federal University of Ouro Preto Andrea Gomes Campos Bianchi (Cosupervisor) - PhD - Federal University of Ouro Preto. Reinaldo Silva Fortes (eksaminator) - Læge - Federal University of Ouro Preto Jadson Castro Gertrudes (eksaminator) - Læge - Federal University of Ouro Preto.
Justificativa
Objetivos
Objetivo Principal
Objetivos Específicos
Organização do Trabalho
Neste capítulo é apresentada uma contextualização do tema reconhecimento de emoções e visão computacional, começando com a exposição de trabalhos relacionados que abordaram estes temas em geral, até aqueles que os abordaram em contextos específicos, como a utilização de um estudo do imitação . das emoções em pessoas com autismo. A seguir, há uma fundamentação teórica dos conceitos que serão discutidos ao longo deste trabalho, com o objetivo de proporcionar ao leitor uma melhor compreensão do método utilizado.
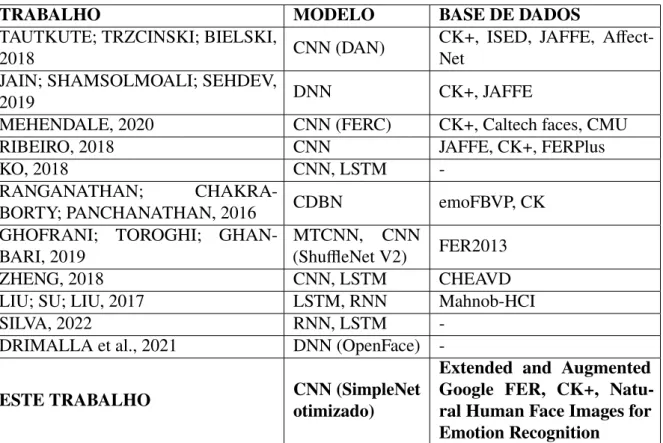
Trabalhos Relacionados
Os autores apresentam um modelo baseado em Convolutional Deep Belief Network (CDBN) para desenvolver uma abordagem multimodal para o reconhecimento de emoções. Também usando a CNN, Ghofrani, Toroghi e Ghanbari (2019) mostram um modelo que usa uma rede neural convolucional multitarefa (MTCNN) para reconhecer rostos e cortar seus limites corretos na primeira etapa, e uma arquitetura ShuffleNet V2 para reconhecer emoções em o segundo passo. Para enfrentar o problema do reconhecimento de emoções em vídeo, a pesquisa de Zheng (2018) propõe um modelo baseado em LSTM, que se baseia no mecanismo de atenção, extraindo características faciais por meio do MTCNN.
Em relação aos trabalhos que utilizam o reconhecimento de emoções em contextos específicos, trata-se, primeiramente, do artigo de Silva (2022). Portanto, parece que o trabalho apresentado neste artigo é semelhante ao trabalho apresentado acima no uso de redes neurais para desenvolver um modelo para extração de características faciais e reconhecimento de emoções.
Fundamentação Teórica
Reconhecimento de emoções
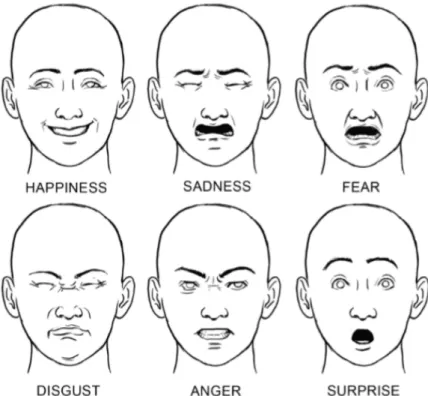
Assim, tendo em conta as bases de dados utilizadas neste trabalho, centra-se no reconhecimento das sete emoções principais definidas por Ekman e Friesen: felicidade (felicidade), tristeza (tristeza), medo (medo), repugnância (repulsa), raiva ( raiva), surpresa (surpresa) e desprezo (desprezo).
Aprendizagem em profundidade
No entanto, outros autores identificam diferentes classificações de emoções.Matsumoto (1992), por exemplo, extrai de Ekman e Friesen a descoberta de 1986 de que o desprezo (desprezo) é outra emoção universal e fornece mais evidências para tal afirmação por meio de pesquisas. com pessoas de diferentes culturas. Ou seja, é uma área que permite ao software treinar através de redes neurais múltiplas camadas que contenham grande quantidade de dados relevantes para a tarefa que deseja realizar. Tal formação ocorre por meio de uma hierarquia de conceitos, em que os conceitos considerados complexos são construídos a partir dos mais simples (GOODFELLOW; BENGIO; . COURVILLE, 2016).
As entradas tratam dos dados a serem processados, enquanto as saídas tratam da previsão ou classificação final feita pelo modelo. Além disso, os dados das camadas visíveis são aqueles que podem ser observados, enquanto os dados das camadas invisíveis são abstratos e são valores que o modelo usa apenas para definir conceitos importantes a partir dos dados de entrada.
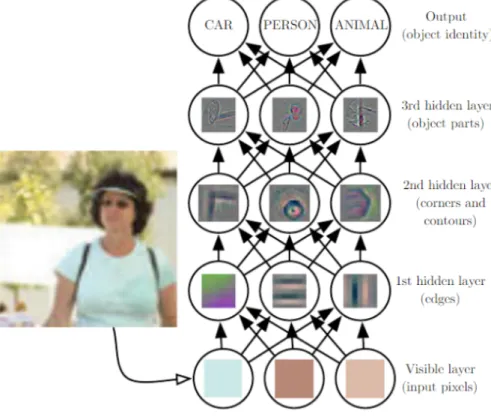
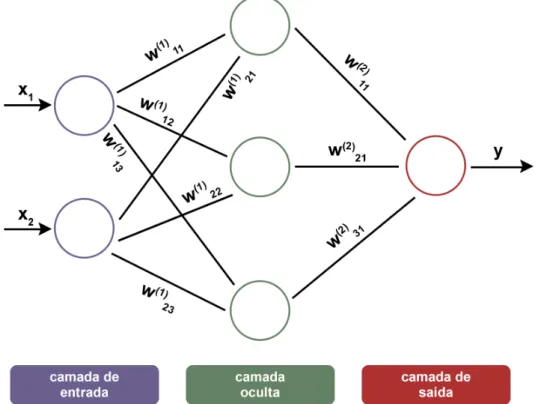
Redes neurais artificiais
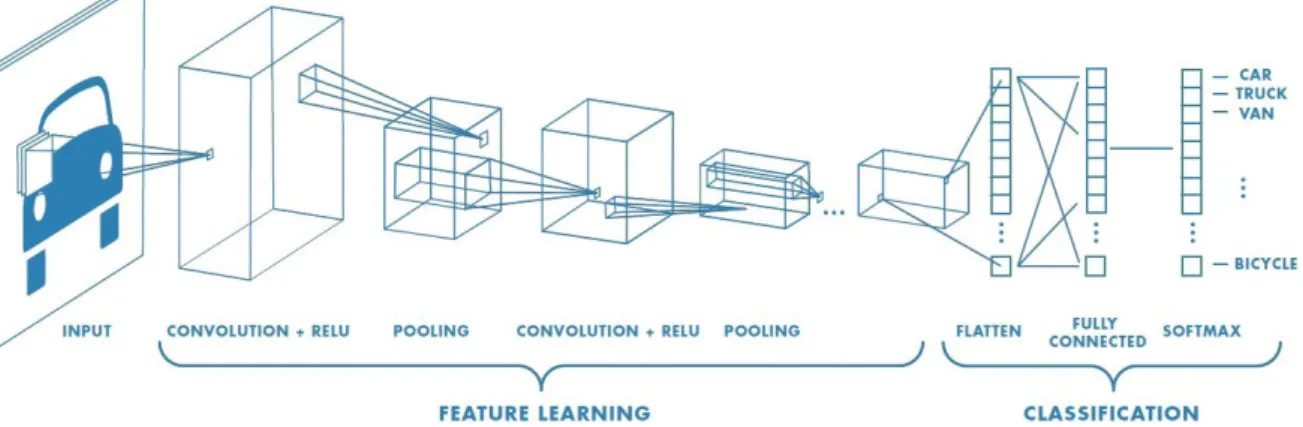
- Redes neurais convolucionais (CNN)
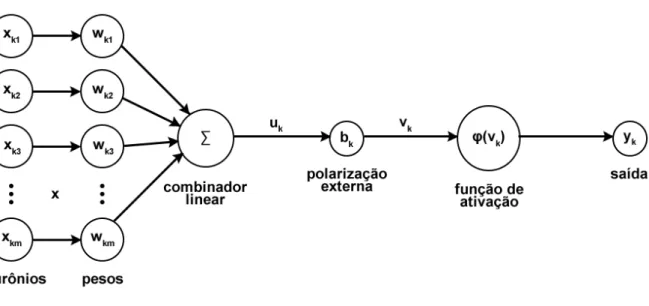
Além disso, as redes neurais podem ser categorizadas em diferentes tipos, cada um adequado para diferentes problemas e fontes de dados. As redes neurais convolucionais são um tipo especializado de rede neural projetada para processar dados que estão na forma de várias strings. Inicialmente, há uma fase voltada para a análise das bases de dados selecionadas para treinamento e teste do modelo a ser desenvolvido, descrito na seção 3.1.
Em seguida, há a etapa de pré-processamento (Seção 3.2) Nela o foco foi ajustar as imagens dos bancos de dados para que todas sigam o mesmo padrão, ou seja, a mesma dimensão (pixels) e também os mesmos rótulos (labels). Com os resultados obtidos nos testes, foi definida a melhor configuração dos bancos de dados no sistema.
Caracterização das bases de dados
Extended and Augmented Google FER
Este conjunto de dados é uma versão expandida do conjunto de dados Google FER 2013, contendo mais dados e uma nova classe, Contempt. Além disso, pôde-se observar que além das imagens de pessoas reais, há também desenhos que representam expressões faciais e algumas figuras que não possuem rostos ou não correspondem às emoções da turma. No entanto, considerando a grande quantidade de dados, parece que os dados errôneos, por representarem uma pequena parte do total de dados, não afetam negativamente o conjunto de dados.
Abaixo, na Figura 3.1, estão exemplos de diferentes expressões faciais armazenadas no banco de dados.
Extended Cohn-Kanade (CK+)
Natural Human Face Images for Emotion Recognition
As imagens possuem apenas um canal de cor e, portanto, estão em tons de cinza e possuem dimensões de 48 x 48 pixels.
Pré-processamento
Tais características foram escolhidas considerando que o modelo de classificação deve ser capaz de reconhecer emoções em diferentes rostos, que podem estar em locais com pouca ou muita luz ou em diferentes posições. Já os demais guias não passam por essa etapa para aumentar o número de imagens, pois não é necessário. As três últimas funções desenvolvidas são responsáveis por pré-processar apenas o banco de dados CK+.
Tendo em vista que a base original possui diretórios separados para as imagens e seus tags, e estes são armazenados em arquivos de texto, foi necessário criar uma função responsável por percorrer os diretórios, salvando o caminho para as imagens e seus respectivos tags. Em seguida foi criada uma função responsável pela nova estrutura do banco de dados, onde cada classe possui seu próprio diretório, e por fim foi criada uma função para selecionar as imagens que são consideradas as únicas relevantes, levando em consideração que as primeiras imagens do banco de dados são expressões faciais neutras.
Definição do modelo
Arquiteturas bases para definição do melhor modelo
Dessa forma, os parâmetros focam nas transformações geométricas, visando simular rostos que não estão totalmente posicionados na frente da câmera, e nas transformações de brilho. As imagens formadas pelo gerador são armazenadas no diretório de treinamento com o prefixo 'aug_' em seu nome de arquivo. Vale ressaltar que a implementação dessas funções foi baseada nos algoritmos de Sinha (2019), conforme apresentado em seu repositório na plataforma GitHub.
No artigo que a define, a arquitetura regular desta CNN é apresentada com os componentes da Figura 3.4, enquanto funções de Batch Normalization são introduzidas no código, a fim de aumentar a velocidade de operação e precisão da rede por meio da normalização.
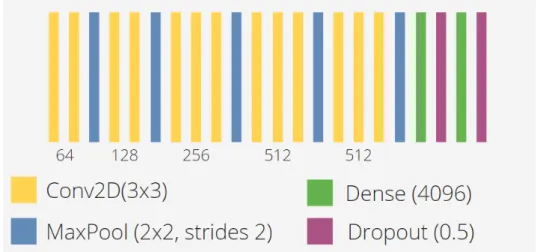
Definindo os melhores hiperparâmetros do modelo
Treino e teste do modelo
Além disso, também é realizado um teste com o modelo VGG16 definido na biblioteca Keras e outro teste com o modelo desenvolvido pelo autor com o banco de dados MNIST (composto por um grande número de dígitos, 0 a 9, desenhados à mão), para determinar se os resultados Os problemas observados durante a execução do código foram causados pelos dados ou pelos modelos. Desta forma, os resultados obtidos neste teste e os apresentados anteriormente são salvos em um arquivo de texto e apresentados com mais detalhes no Capítulo 4. Este capítulo apresenta os resultados obtidos com a realização das etapas definidas no desenvolvimento, com o objetivo de possibilitar uma análise adequada do desempenho dos modelos construídos.
Portanto, as seções a seguir detalham e discutem os resultados dos testes de diferentes configurações de banco de dados e, por fim, é feita uma comparação desses resultados com os obtidos em trabalhos relacionados. Além disso, vale ressaltar também que os resultados foram coletados em um microcomputador com processador Intel(R) Core(TM) i7-9700F de 3,00 GHz, 16 GB de RAM e sistema operacional de 64 bits.
Resultados obtidos nos testes das bases de dados
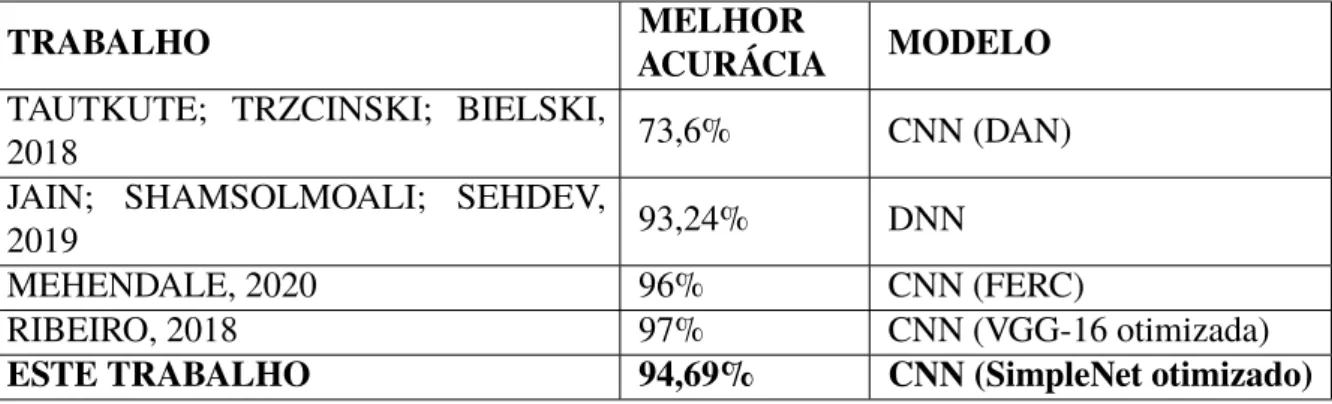
Dessa forma, foi possível obter uma precisão de teste de 90,94%, o que indicou que as alterações feitas resolveram o problema de overfitting. Através de vários experimentos foi possível observar uma melhora na acurácia do teste de 90,94% para 93,75% e, em outra modalidade, para 94,68% com a base CK+, e uma melhora de 33,09% para 46,09% com a base Natural Human Facial Images, justificando assim a relevância desta etapa durante o desenvolvimento de um modelo de classificação. Tais resultados, apresentados na tabela 4.1, mostram que a base de dados CK+ isoladamente possui os melhores valores de acurácia e perda, enquanto a base de dados Natural Human Face Images possui os piores valores de acurácia e perdas.
Em relação às combinações de bases, é importante ressaltar que o uso do Early Stopping pode ter afetado negativamente o resultado, como mostra o uso desse callback no banco de dados CK+, que resultou em uma acurácia do teste de 86,25%. Conforme apontado anteriormente, a configuração do teste com a base CK+ apresentou dois valores de acertos diferentes quando executados duas vezes, mostrando que usar a validação cruzada e calcular a média das acurácias nela obtidas potencialmente resultaria em lei difere do apresentado na Tabela 4.1 , onde apenas uma execução de teste foi realizada para cada configuração.
Comparação com trabalhos relacionados
Em relação ao trabalho de Mehendale (2020), obteve-se 96% de acerto a partir de uma validação cruzada de 25 dobras, mas o banco de dados CK+ foi complementado com outros bancos de dados, considerando que o autor obteve apenas 45% de acerto usando apenas esta base para usar. O segundo atingiu 98,01% na base CK+, mas seu desenvolvimento não contou apenas com o uso de um modelo CNN para classificação, mas outras etapas também foram realizadas durante o pré-processamento, como a aplicação do CLAHE (contraste limited adaptive histogram equalization) para aumentar a visibilidade das imagens. Diante das observações apresentadas nesta seção, conclui-se que o modelo desenvolvido e exposto nesta monografia possui um desempenho adequado em relação aos demais modelos desenvolvidos, sendo superior ao de Tautkute, Trzcinski e Bielski(2018) e Jain, Shamsolmoali e Sehdev (2019), mas inferior a Mehendale (2020) e Ribeiro (2018).
Este capítulo explica as conclusões obtidas no final deste trabalho, com uma breve descrição dos objetivos alcançados e dos resultados alcançados na secção 5.1. Além disso, na Seção 5.2, o capítulo também apresenta propostas para a continuação deste trabalho, tendo em vista o que foi alcançado até o momento.
Conclusões
Trabalhos Futuros
Primeiramente, os hiperparâmetros do modelo podem ser encontrados para o banco de dados CK+, ao invés da versão reduzida utilizada anteriormente no trabalho. Em segundo lugar, o pré-processamento pode ser estendido adicionando novas etapas, como o uso do CLAHE, e outros bancos de dados, como o AffectNet, também podem ser usados. Além disso, o uso da validação cruzada também é importante, pois permitiria uma melhor análise do desempenho do modelo.
Let's keep it simple by using simple architectures to outperform deeper and more complex architectures.arXiv preprint arXiv. Efficient facial emotion recognition model using deep convolutional neural network and modified trilateral joint filter. Soft Computing, Springer, v.