Examples of kernel methods include ridge kernel regression, support vector machines, and smoothing convolutions. In this work, we propose RFFNet, a new approach for adapting kernel methods that is scalable and interpretable.
Summary of contributions
We show that ARD kernels correspond to spectral densities that have the kernel relevances as "scale" parameters. Through this, we show that it is possible to decouple λ from the RFF map that approximates evaluations of an ARD kernel and therefore easily estimate λ with data.
Relation to prior work
In practice, it is expected that if the relevance vector λ is estimated using available data, λi will automatically be set to zero for irrelevant features. On the other hand, unlike standard random Fourier function applications, our framework effectively uses ARD kernels.
Organization
This chapter covers the basic definitions, facts, and notation of the supervised learning framework, optimization, and kernel method theory. In particular, we highlight the origin of the scalability and interpretability bottlenecks for common kernel methods.
Supervised learning
RLM is a modification of the Structural Risk Minimization (SRM) paradigm (MOHRI; ROSTAMIZADEH; TALWALKAR, 2018) and seeks to control the complexity of functions in H by introducing a regularization function that penalizes complex hypotheses in H. The loss and the regularization function is then jointly minimized on the training sample, generating an optimal estimatef∗ as.
Optimization
A primer on convex optimization
The focus will be on descent methods, a family of optimization procedures that includes the widely used gradient descent methods. Taking the search direction at the k-th iteration ∆x(k) as the negative gradient, ∆x(k)=−∇f(x(k)), the iteration scheme in (2.5) reduces to . 2.6), which is the defining rule of the gradient descent method. Note that, in this context, gradient descent has a slower convergence rate and requires O(1/√ . ε) iterations to find a point x such that with ∥∇f(x)∥2 ≤ε.
In this case, the gradient descent updates for the target must be modified to account for the roughness of h (PARIKH; BOYD, 2013). If we assume that g is L-smooth and we fix a constant step size t(k) ≤ 1/L, then proximal gradient descent has a convergence rate of O(1/k) matching the rate of gradient descent. Today, stochastic gradient descent algorithms are dominant in the optimization for machine learning scene.
Kernel methods
Many machine learning algorithms have optimization problems or closed-form solutions for optimal estimates that can only be written in terms of inner products of feature maps. Instead of constructing feature maps and adding feature spaces, one defines an expression for the inner product specified only in terms of the original features. Mercer's theorem (MERCER, 1909) guarantees that every PSD kernel implicitly defines a (possibly infinite) vector feature map such that this kernel is of the form given in (2.19).
This property allows us to interpret kernels as representing the inner product of vector maps of functions in the original input space. Let K be the kernel matrix of the kernel evaluated on the predictors of the training sample {xi : i ∈ [n]}, i.e. Kij = k(xi, xj). Thus, inversion becomes prohibitive for large data sets: this is the origin of the scalability problem of kernel methods.
Random Fourier features
In the following theorem, we show how to construct the vector feature map that approximates PSD kernels that satisfy the conditions of Theorem 5. First, from the fact that the kernel is real-valued, that is, Im k = 0, we obtain. Examples of cores and their corresponding spectral mass densities are given in Table 1.
The asymptotic nature of Theorem 6 cannot guide us to choose the dimensions of the random features to guarantee a good approximation of the kernel. The first point to derive sensible bounds on learning with RFF is to realize that bounding the kernel matrix approximation is not central. We formally define ARD kernels and show how to construct a random Fourier function map that is independent of the function relevances.
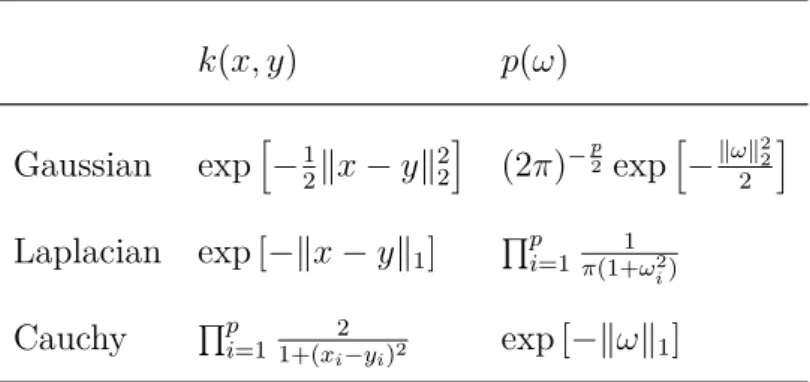
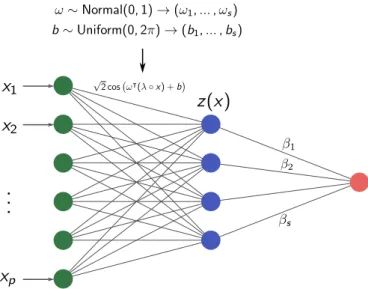
Random Fourier features for ARD kernels
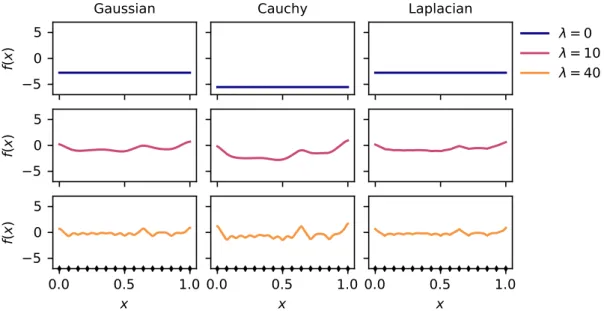
In this chapter we describe RFFNet, our approach for scalable and interpretable kernel methods, the utilization of ARD kernels and the framework of random Fourier features described in section 2.3 and section 2.4 respectively. Proposition 4 also reveals that pλ depends on λ in a very specific way: the relevances appear as a vector scaling parameter for the density associated with the equally weighted version of the kernel. That is, if we want to sample from pλ, we can first sample from p and then scale the sample by λ1.
Theorem 5 uses this last observation to show that the RFF map approximating an ARD kernel does not depend on λ. In fact, we can construct the RFF associated with the ARD kernel with λ =1p and obtain an approximation to the ARD kernel with arbitrary λ simply by introducing a data scaling with λ. Although the example is based on the ARD Gauss kernel, the above results also hold for the ARD Laplace and ARD Cauchy kernel, since the spectral measurements associated with the unweighted Laplace and Cauchy kernel are also a factor if ( 3.3) (see Table 1).
Approximate kernel machines
Overview of RFFNet
Optimization algorithm
We note, however, that we replaced the Adam gradient iterations with simple gradient descent for clarity and brevity.
Extensions
Recently, there has been extensive discussion on how to improve the empirical evaluation of new machine learning (ML) methods (SCULLEYet al., 2018; HENDERSON et al., 2017). It is argued that the remarkable practical success of machine learning has not been accompanied by the adoption of rigorous standards for evaluating ML methods. The implicit consensus in the field is that new methods should always outperform previous "competitors" on benchmark datasets or established tasks.
Recent machine learning methods rely on complex models, non-convex optimization procedures, and training heuristics (for example, early stopping and learning rate decay), which are theoretically not well understood. First, we describe the computer setup where RFFNet was evaluated and give some implementation details of the library. Next, we provide a description of the baseline algorithms compared to RFFNet and how hyperparameters were set during validation.
Computing infrastructure
Implementation details
Baselines and tuning methodology
We tuned the shape and rate parameters for Gamma prior to the distribution of the precision of the linear model coefficients. KRR uses a single bandwidth for the kernel, therefore it does not output a feature importance measure. We set the maximum depth of the trees (integer sampled between 3 and 20), the step size shrinkage (float sampled between 0 and 1), the minimum loss reduction required to split a leaf node further (float sampled between 10−5 and 100), and the minimum child weight (integer taken between 0 and 10).
The number of times the function is used to split the data into all trees was considered as a measure of feature importance. We used the library's default model, which includes a univariate concatenation for each feature; thus, no interactions were modeled in this case. For RFFNet, we considered the absolute value of the relevance parameter λ as a feature importance measure.
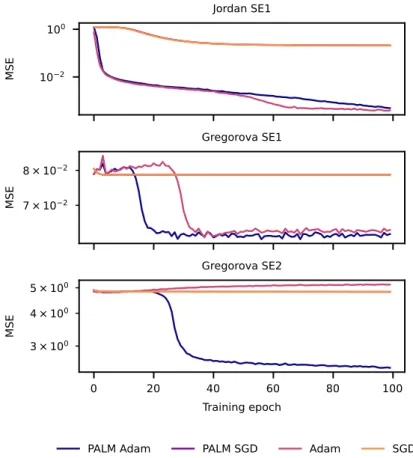
Ablation study of optimizers
Visualizing optimization trajectories
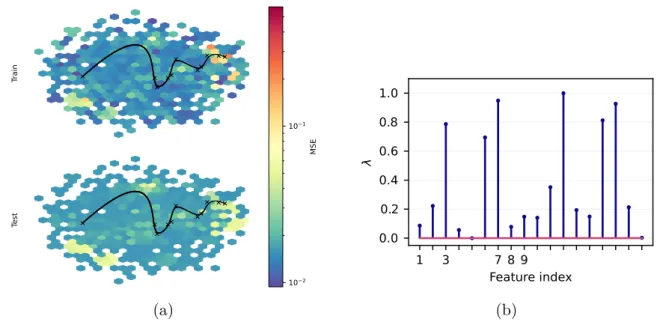
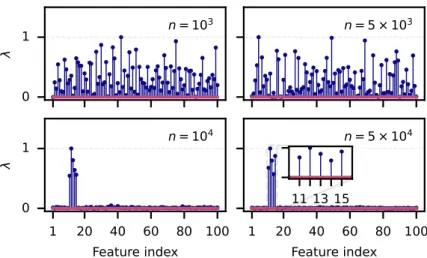
Specifically, in Figure 4 we observe that successful training resulted in a pattern of feature importance that matches features and 9 that are active in the regression function of the dataset. In this example, we see that the goodness-of-fit pattern does not fit the covariates that appear in the regression function of Gregor's SE1 data set. The trajectories were classified according to the x-coordinate and do not reflect the temporal evolution of the parameters in the landscape.
Note that the largest feature correlations match the features that appear in the Gregorova SE1 regression function (see Table 2). The trajectories were sorted by x coordi- night and do not reflect the temporal evolution of parameters in the landscape. In this case, the feature importance does not match the features that appear in the Gregorova SE1 regression function (see Table 2).
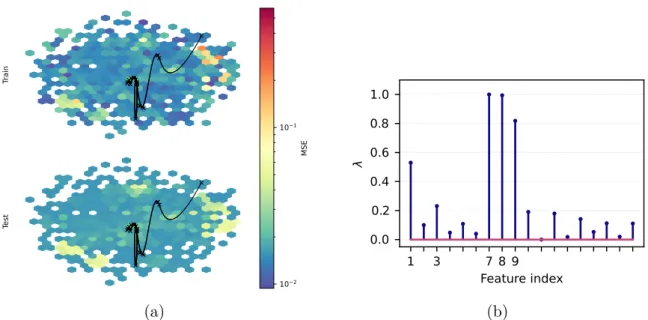
Simulations
Greogorova SE1
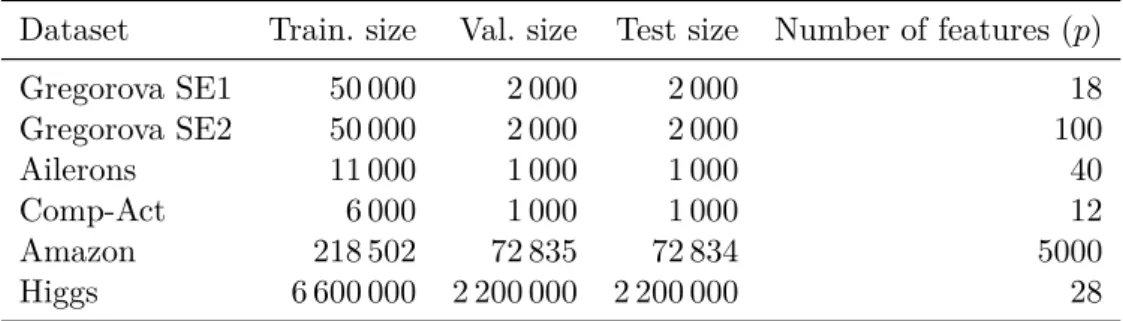
In this chapter, we describe the numerical experiments performed on simulated and real datasets to validate RFFNet. A description of the data processing steps followed for each data set is available in Appendix B. For each experiment, we discuss the results and interpret them using domain knowledge where possible.
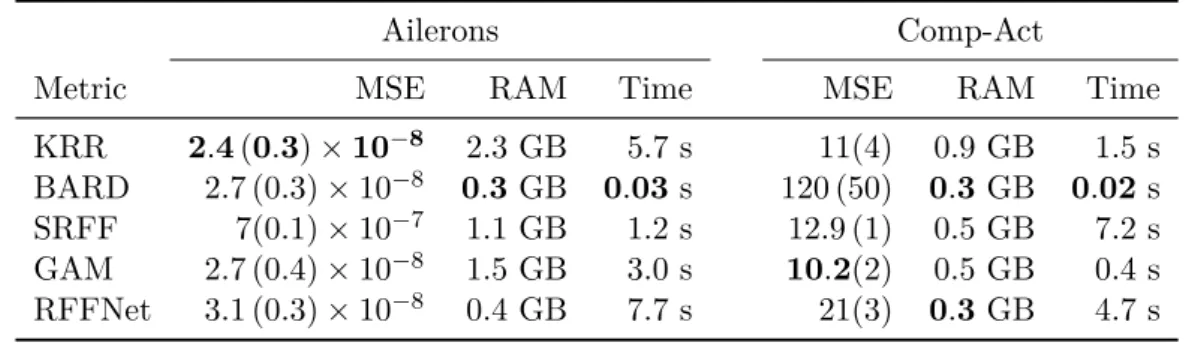
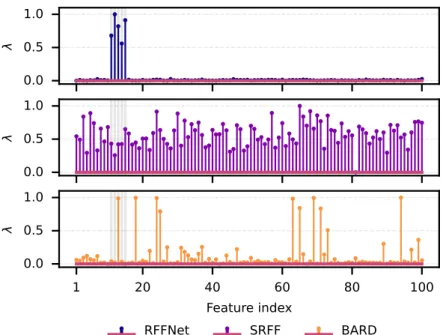
Compared to the full Kernel Ridge Regression (KRR) with fixed bandwidths, it trained faster, with less memory and to a lower MSE solution. In addition, Figure 7 shows that RFFNet is the only method to extract feature relevances that match the active features in the Gregorova SE1 dataset. With sample sizes greater than 104, RFFNet consistently assigns small weights to the irrelevant features.
Gregorova SE2
Real datasets
Amazon Fine Food Reviews
Again, RFFNet is the only method that outputs a fitness measure of features that match active features in Gregor's SE2 dataset. For this reason, we used the cross-entropy as the loss function. Table 5 shows that RFFNet performed worse than the baselines, although it consumed significantly less memory. Furthermore, Figure 10 shows that ten features (stem words) with higher importance (according to RFFNet) are indeed related to product quality (e.g. “disappointing”, “terrible”), while those with lower importance are not.
The derived words with the ten greatest relevancies are indeed associated with product quality, showing that the feature relevance provided by RFFNet is meaningful.
Higgs
Ailerons
Furthermore, Table 7 shows that the predictive performance of the method was greatly enhanced with RFFNet+, achieving MSE errors significantly smaller than base RFFNet (see Table 4), without affecting RAM and runtime. Differential private database publishing via kernel means embeddings. lt;https://proceedings.mlr.press/v80/balog18a.html>. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, 2016.
Increase the margin directly in combinatorial and non-decomposable statistics. lt;https://proceedings.mlr.press/v151/csillag22a.html>. Training Neural Networks as Learning Data Adaptive Kernels: Probable Representation and Approximation Benefits. Journal of the American Statistical Association, 2019. Umap: Uniform manifold approximation and projection for dimension reduction. functions of positive and negative type, and their relation the theory of integral equations.Philosophical Transactions of the Royal Society of London.