Com essas informações, será possível criar conexões entre essas diferentes fontes de dados e fornecer informações mais ricas aos usuários, por meio da fusão de informações díspares. Uma aplicação para mapear e mesclar dados de produtos na web foi desenvolvida e avaliada em diferentes cenários.
Acronyms
Introduction
- Motivation
- Challenges
- Identity Problem
- Mapping Problem
- Duplicated Data Problem
- Solution Overview
- Use Case Scenarios
- Pharmaceutical Products
- Cinematographic Works
- Contributions
- Document Structure
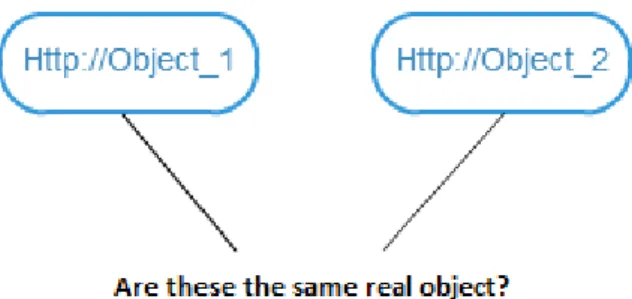
As we identified which different entities refer to the same real-world objects, we became aware that duplicate data existed in the scope of products. After that, we need to identify entries from separate data sources that refer to the same real-world object and merge their information.
Background
- The Semantic Web
- Resource Description Framework
- SPARQL Protocol And RDF Query Language
- Linked Data
- Linked Open Data Project
- Summary
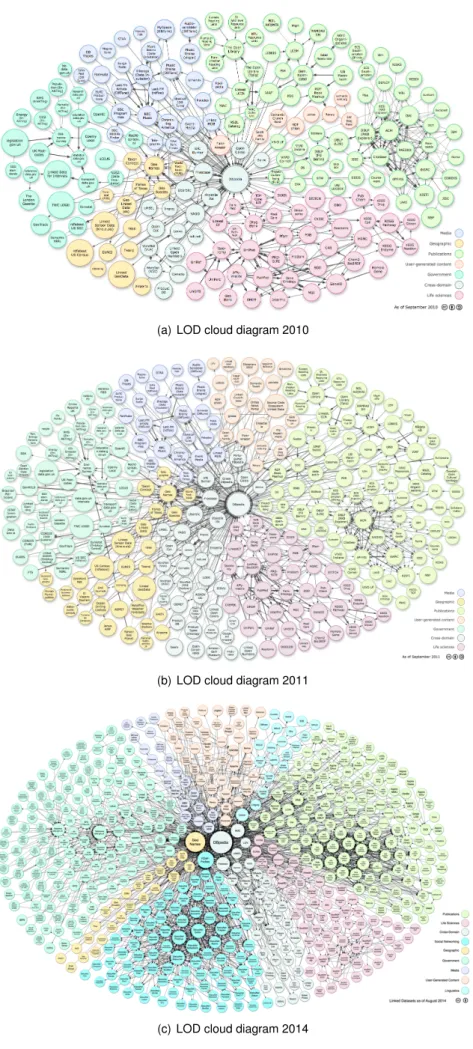
One example of this reality is the Linked Open Data project which will be described in more detail in the next section. In the beginning, LOD was a project with the aim of transforming unstructured data in the Web into structured data.
Related Work
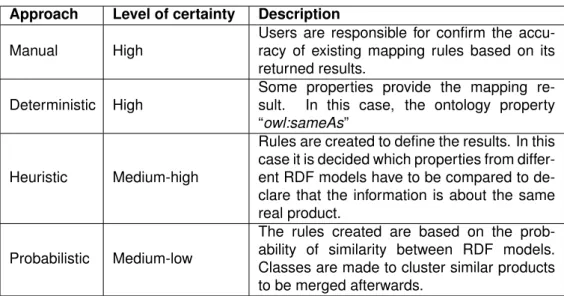
- Manual Approach
- Deterministic Approach
- Heuristic Approach
- Probabilistic Approach
- Summary
Validity - user feedback is classified as valid, invalid or unknown depending on conflicts arising in the process or in the latter case due to the absence of entities within the data sources. This approach is able to identify when two sources are the same by traversing datasets based on the information stored in the ontology by merging the data without any conflict and using the same data structure. 27] use this approach to determine whether two product references identify the same real-world product, so they perform product entity matching based on machine learning and probabilistic classifiers.
Finally, when all products are categorized, they use a heuristic approach to decide whether two products refer to the same real object. For this purpose, for each category and for each pair of objects they verify if the manufacturer is the same and if so, the objects are merged. In addition, map validation does not apply in this case due to the dynamic search in the various data sources at each execution of the system and due to the user's choices not being saved for later searches in the system.
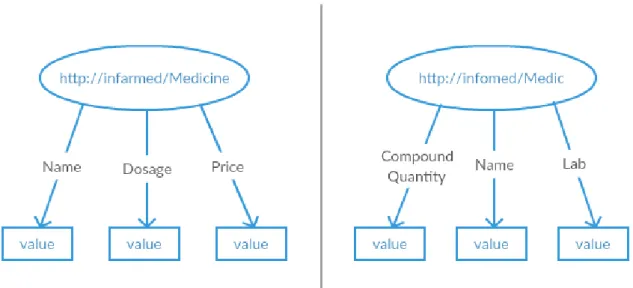
In this case, it is decided which properties of different RDF models should be compared to declare that the information is about the same real product.
Solution
Architecture
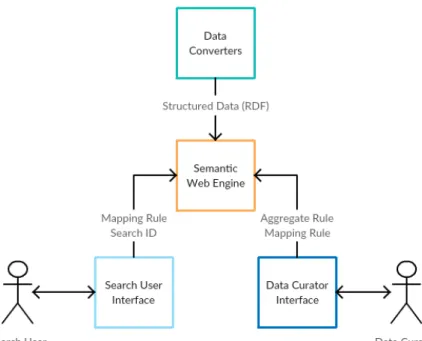
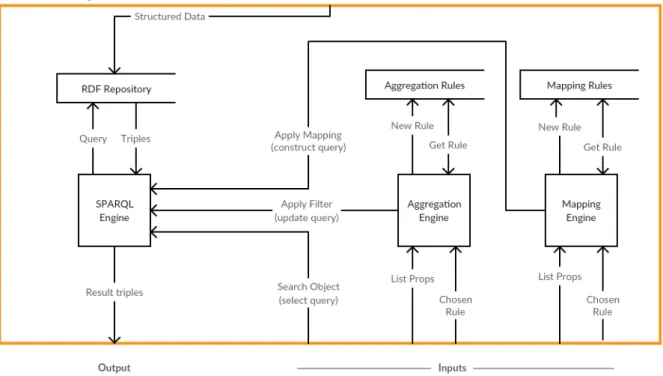
Once all data is standardized, this engine sends the RDF triples to the Semantic Web Engine. It is also responsible for getting all the stored information about a particular rule chosen by the user and creating a query that will then be applied to the RDF repository by the SPARQL Engine. Finally, the SPARQL Engine is responsible for making all queries to the Repository and returning the respective results.
After receiving input from the user, the user interface is responsible for communicating with the Semantic Web Engine and returning the results of the requested information to the user. This second user can now choose which mapping rule to apply to the data and perform searches in the updated repository. In relation to the Semantic Web Engine, depending on the input, a specific sub-engine (SPARQL, Aggregation or Mapping) will be called.
Whenever a query needs to be made to the repository, the SPARQL engine is invoked, even when the input comes from within the Semantic Web Engine.
Technologies
The data curator, despite being an expert user and responsible for creating such rules, also has the ability to query the repository to see how the data changed and to ascertain whether the created rules are working as they should. After the Data Curator step, the Research User can run the application and will be informed how the data filtering was done by the Curator, since he is the only one with the ability to decide which two entities represent an integral copy of the information . . In the case of creating or applying an aggregation rule, it will be the aggregation engine that will handle the input.
The meaning of RDF data, on the other hand, is part of the data itself, in other words, wherever there is data, the details (i.e. metadata) are always readily available. As before, we continue to choose technologies recommended for the W3C, so we chose the SPARQL Query Language to query the data held in RDF format. Since our goal was to link information from disparate datasets, SPARQL turned out to be the most obvious way to achieve this, as it can be used to express queries across different data sources, whether the data is stored natively as RDF or viewed as RDF via middleware [11].
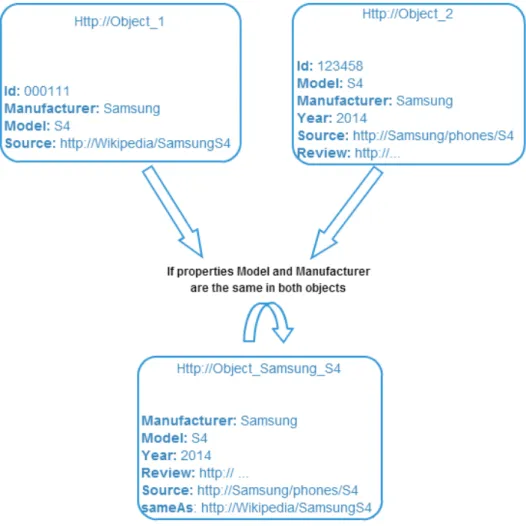
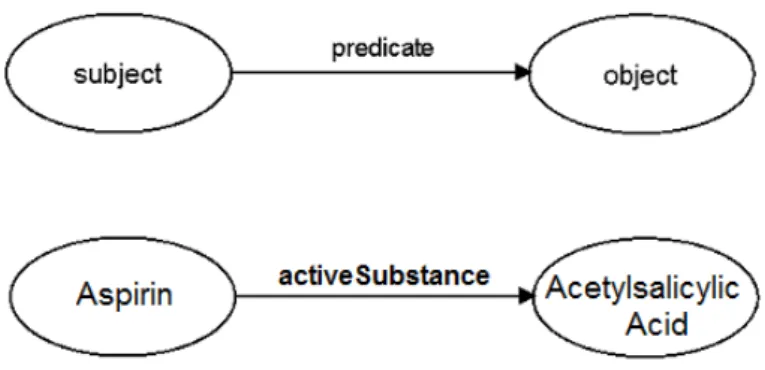
Since the data is obtained from different sources, this approach will be used to describe which RDF subjects represent the same real world object.
Implementation
- Gather information
- Filter information to remove duplicate values
- Map entities based on similarity
- Perform searches
In the code, the property request list of the "showAggregationCriteria(String rule)" function is executed as shown in Listing 4.4, after which a SPARQL query is constructed to apply the rule to the main repository. After the creation of all the desired mapping rules, the data curator has the opportunity to see the results generated by applying a specific mapping rule to the repository. An overview of the data sources is then presented to the general user, i.e. what classes exist;.
Next, the search user must select a mapping rule to be used in the system to retrieve the most complete information possible. For more details, the search UI presents the user with all available datasets where a search can be performed. This is done because of LOD's vision where existing schemes should be reused in the community.
Finally, the search user selects the mapping rule that best suits the search goals and performs searches through interaction with the Search User Engine.
Evaluation
Pharmaceutical Scenario
- Filtering Data
- Filtering Data From a Second Data Source
- Mapping Data From Two Data Sources
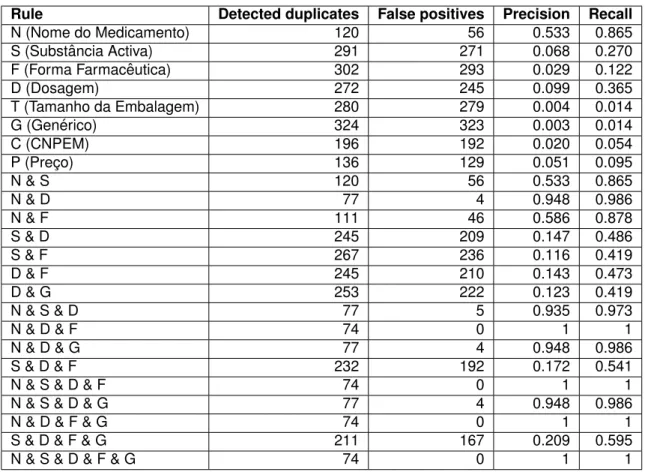
The obtained results were evaluated according to the number of duplicates, true positives, false positives, precision and recall. Regarding the number of duplicates found and the number of false positives, these two metrics reveal a directly proportional relationship, i.e. Similar to Infarmed, the metrics used were the number of duplicates found, true positives and false positives, and precision and recall values. .
Again, the results showed a proportional relationship between the number of duplicates and the number of false positive returns. Therefore, as the number of copies found increases, so does the number of false positives. Regarding precision and recall, we also concluded that as the number of duplicates increases, precision decreases.
The third metric gives us the coverage of the rule in terms of the number of mappings within the expected set and is calculated using equation (5.4).
Cinematographic Scenario
The Distance metric is designed to help the curator construct better mapping rules by letting her/him know the distance between the new mapping rule and the expected result, namely that the lower the distance, the better the created rule .
User Validation
- Data Curator Users
- Task 1. Pair Properties
- Task 2. Filter Data Sources
- Task 3. Map Data Sources
- End-users
- Task 1. Simple Search
- Task 2. Map Disparate Data Sources
- Task 3. Complex Search
In this task, users had to understand what filtering by the property Nome do Medicamento means and what results are expected. In this task, users were asked to first filter each of the available data sources, then map those data sources by name, and finally check the results obtained. This exercise required users to create a new mapping rule with a special syntax that combined product information from each of the data sources that represent the same value for the name property.
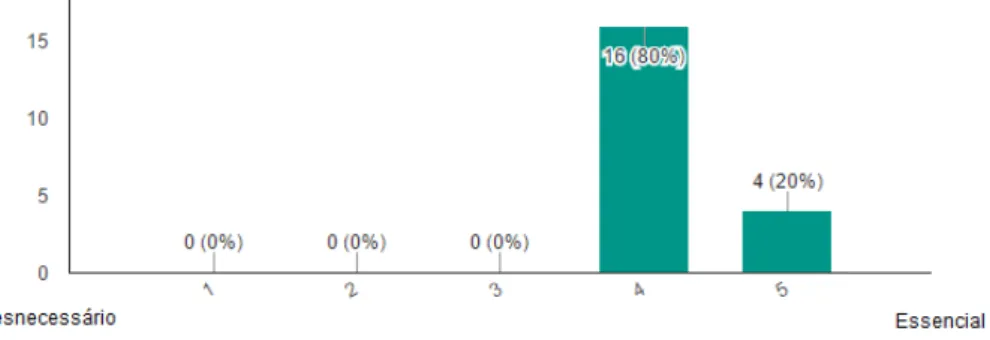
As expected, users found the latter task to be the most complicated of the three, while the former was the easiest. With this task, users could see the problem found in the first task solved, so according to the questionnaires, most users said that they did not need more information to understand which fields they should select to complete the tasks.
In addition, almost all users indicated that they wanted this application on all existing platforms (computer, tablet and smartphone) and the vast majority in the context of technological products.
Conclusion
Contributions
The main achievements of the present work were providing a way to address the Identity Problem, a way to deal with duplicate information within a database and the use of metrics to evaluate the rules designed to filter, a way to compiled information from various data sets and an application for user testing. The first problem, brought by the new era of the Web, where a lot of redundant data is kept in different data sources with different data structures and different identifiers for properties and products, was solved with the introduction of a Data Curator , an expert user, with sufficient knowledge. the ability to compare schemes of available data sources and with the developed mapping tool. To deal with duplicates, it was also the Data Curator who was responsible for creating the rules that would be used to aggregate information that takes the same values for a set of characteristics.
Similarly, to map different resources, the Curator user had to create rules that would make a correspondence between the properties of the different resources. A correlation between the number of matches returned by applying a rule and the maximum possible matches between two sources was also used as a metric. The developed application allows users to search for pharmaceutical products (and cinematographic works) and get all the information from two different sources in a unified way.
In addition to being able to search in the mapped results, users can also choose to search in each of the available sets (source 1, source 2 and mapped source) or all at the same time, this way they will never lose information even though it may not have been mapped.
Future Work
Bibliography
In Lecture Notes in Computer Science (including the subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), volume 5823 LNCS, pages. In Lecture Notes in Computer Science (including the subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), volume 5268 LNAI, pages.
Appendix A
Questionnaires
Search User Answers
Para consultas complexas, a opção sources deve explicar que existem 3 views relacionadas ao mapeamento realizado.
Data Curator Answers
Tamanho das imagens Pesquisa de imagens Imagem/imagens de tamanho grande e plano de fundo Tamanho de imagens transparentes e uso de imagem em tamanho real.