Em última análise, este trabalho mostrou-nos que é possível controlar um quadricóptero utilizando técnicas de Aprendizagem Reforçada. Para trabalhos futuros, além de testar a estabilidade de RL, recomenda-se também tentar a otimização de busca de grade de parâmetros para o controle de Aprendizado Reforçado e normalização de minilote.
Introduction
The terrorist attacks on the US in 2001 led to the so-called 'war on terror' and a decisive shift in the military strategy of the US and its allies. In the first two months of operations in Afghanistan, approximately 525 targets were targeted with lasers by Predators, and according to Pete Singer, author of Wired for War, the generals who once had no time for such systems couldn't get enough of them. .”[8]. Goldman estimates that global militaries will spend $70 billion on drones by 2020, and that these drones will play a critical role in resolving future conflicts and replacing the human pilot.
A section of the main rotor rotates above the fuselage and pushes the washed air against it, reducing the effective lift. In early quadcopters, the motor is usually mounted somewhere in the middle of the helicopter fuselage and drives the 4 rotors via belts or shafts. Therefore, designing a position controller with superior performance is one of the most common and important endeavors undertaken by researchers worldwide these days.
References show that most existing methods are complex to design and implement or require large computing resources.

Background
Quadcopter Mathematical Modelling
- Newton-Euler Equations
- Aerodynamical Effects
The angular velocity of the rotor 𝒊, denoted by 𝒊, creates a force 𝒇𝒊 in the direction of the rotor axis. In which the lift constant at 𝒌, drag content is 𝒃 and rotor moment of inertia is 𝑰𝑴. The torque 𝝉𝑩 consists of the torques 𝝉𝝓, 𝝉𝜽 and 𝝉𝝍 in the direction of the corresponding body frame angles.
In the body frame, the force required to accelerate the mass 𝑚𝑽𝑩̇ and the centrifugal force ѵ × (𝑚𝑽𝑩) are equal to gravity 𝑹𝑻𝑮 and the total thrust of the rotors . Thus, only the gravitational force and the magnitude and direction of thrust are contributing to the acceleration of the quadcopter. In the body frame, the angular acceleration of inertia 𝑰ѵ̇, the centripetal forces ѵ × (𝑰ѵ) and the gyroscopic forces 𝜞 are equal to the external torque 𝝉.
In which 𝑨𝒙, 𝑨𝒚 and 𝑨𝒛 are the drag force coefficients for velocities in the corresponding directions of the inertial frame.
Quadcopter Control Theory
- PD Control
- PID Control
For Cartesian position control, the procedures are the same, but the dynamic mathematical model refers to the outer loop control (Figure 1.10). Torques are related to the angular velocities by 𝝉 = 𝑰𝜽̈, so let's set the torques proportional to the output of our controller, with 𝝉 = 𝑰𝒖(𝒕). Note that this equation ignores the fact that the thrust will not point straight up.
In this case, the thrust required to keep the quadcopter aloft by projecting the thrust (𝒎𝒈) onto the inertial 𝒛 axis, is. In this case, the thrust component pointing along the positive z-axis will be equal to (𝒎𝒈). PID control is PD control with a second term added that is proportional to the integral of the process variable.
The equations remain identical to those presented in the PD case, but with an additional term in the error:.
Reinforced Learning
- Elements of Reinforced Learning
In addition to the agent and the environment, one can identify four main sub-elements of a reinforcement learning system: a policy, a reward signal, a value function, and possibly a model of the environment. In general, policies can be stochastic, but for specific control tasks, the policy is taken as deterministic. A reward signal defines how good or bad the system/environment (quadcopter) was at taking the sent action from the policy.
At each time step, the environment sends the reinforcement learning agent a single number as a reward. In a biological system, we can think of rewards as analogous to the experiences of pleasure or pain, and the reward sent to the agent at any time depends on the agent's current action and the current state of the agent's environment. A value function gives the expected reward in the long term, it means how good the given state is for the future reward.
Given a state and action, the model could therefore predict the resulting next state and the next reward.
Reinforcement Learning Algorithms
- Model-Free Reinforced Learning
- Policy optimization or policy-iteration methods
- Q-learning or value-iteration methods
- Hybrid
- Model-Base Reinforced Learning
- Learn the Model
- Given the Model
Model-based RL uses experience to construct an internal model of transitions and immediate outcomes in the environment. In policy optimization methods, the agent directly learns the policy function that maps state to action. Asynchronous: Multiple agents are trained in its own copy of the environment, and the model form of these agents is aggregated into a master agent.
The reason behind this idea is that the experience of each agent is independent of the experience of the others. The idea is that PPO improves the stability of Actor training by limiting the policy update at each training step. PPO became popular when OpenAI made a breakthrough in Deep RL when they released an algorithm trained to play Dota2 and they won against some of the best players in the world.
As it sounds simple, these methods combine the strengths of Q-learning and policy gradients, learning the policy function that links state to action and the action value function that returns a value for each action.

Talking about Reward
- Discounted Reward
- Average Reward
In most cases, the function 𝒈 is the sum of the rewards received, as explained in the following items. The resulting estimate of 𝑱 is called the value function and two definitions exist for it. Depends only on the state 𝒙 and assumes that the policy 𝝅 is followed from this state.
Also depends on state 𝒙, but makes action 𝒖 chosen in this state a free variable instead of having it generated by policy 𝝅. As an alternative to the discounted reward setting, the approach is to use the average return. For a given policy 𝝅, the state value function 𝑽𝝅(𝒙) and state action value 𝑸𝝅(𝒙, 𝒖) are then defined as.
The Bellman equations for the average reward – in this case also called the Poisson equations – are Equation 35.
Talking about Stochastic Policy Gradient Theorems
- Theorem 1 (Policy Gradient)
- Theorem 2 (Policy Gradient with Function Approximation)
An additional assumption is that 𝒉 must actually be an approximation that is linear with respect to some parameter 𝒘 and feature 𝝍, i.e.
Talking about Deterministic Policy Gradients
In addition, it also shows that the deterministic policy gradient is the limiting case, as the policy variance tends to zero, of the stochastic policy gradient. Policy evaluation methods estimate the value function of the action 𝑸𝝅(𝒔, 𝒂) or 𝑸𝒘 (𝒔, 𝒂) = 𝒉𝒘( A simple and attractive computational method is to move the policy along the gradient of 𝑸.
Specifically, for each visited state 𝑠, the policy parameter 𝒌+𝟏 is updated in proportion to the gradient 𝛁𝑸𝒘𝒌(𝒔, 𝝅(𝒔)).
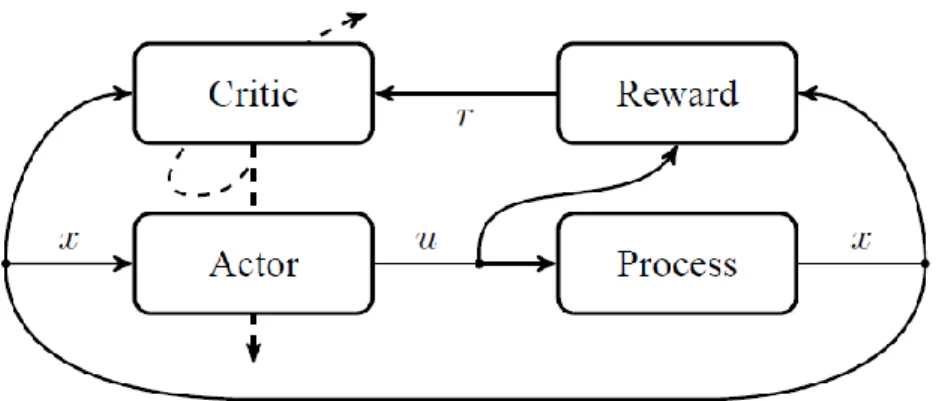
Actor-Critic Reinforced Learning
- Critic-Only Methods
- Actor-only Methods and the Policy Gradient
- Actor-Critic Algorithms – Stochastic
- Actor-Critic Algorithms – Deterministic
This is reflected in the state-of-the-art limits on the quality of least squares time difference (LSTD) solutions, which always include a term depending on the distance between the true-valued function and its projection onto the approximation space. Instead, most actor-only algorithms work with a parameterized family of policies and optimize costs defined directly in the policy's parameter range. Given that both Equation 27 and Equation 33 are functions of the parameterized policy 𝝅𝝑 are actually functions of 𝝑, the gradient of the cost function with respect to 𝝑 is described by .
A locally optimal solution of the costs 𝑱 can then be found by using standard optimization techniques. The main advantage of the actor-only approach is their strong convergence property, which is naturally inherited from gradient descent methods. The role of the critic is to evaluate the current policies prescribed by the actor.
The difference between the right and left sides of the Bellman equation, whether it is for the reduced reward setting or the mean reward setting, is called the Temporal Difference (TD) error and is used to update the critic.
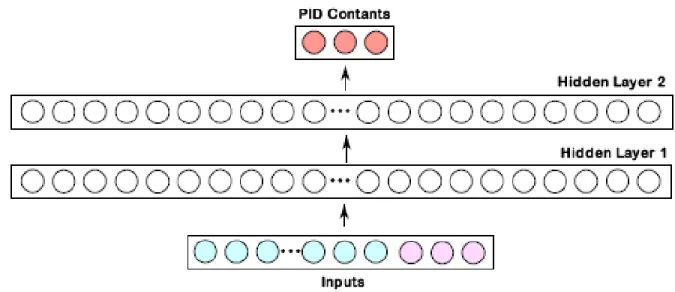
Neural Network – Function Approximator
- What is a Fully Connected Deep Network?
- Dropout Regularization
In general, the environment may be partially observed, so the entire history of the observation, pairs of actions 𝒔𝒌 = (𝑥1, 𝑢1, … , 𝑢𝑘−1, 𝑥𝑘) may be required to describe the state. A challenge in using neural networks for reinforcement learning is that most optimization algorithms assume that the samples are independently and identically distributed. As a quick implementation note, note that the equation for a single neuron is very similar to a dot product of two vectors (recall the discussion of the fundamental tensor).
Dropout is a form of adjustment that randomly reduces a portion of the nodes that feed into a fully connected layer. Here, dropping a node means that its contribution to the corresponding activation function is set to 0. The basic design principle is that the network will be forced to avoid "co-adaptation".
As a result, other neurons will be forced to "pick up" and also learn useful representations.
Methodology
Quadcopter Simulation – RL Environment
RL Reward method
Actor and Critic – Structure and Training
Transitions were sampled from the environment according to the exploration policy and the tuple (𝑥𝑘, 𝑢𝑘, 𝑟𝑘, 𝑥𝑘+1) was stored in the replay buffer. Because DDDPG is an off-policy algorithm, the replay buffer can be large, allowing the algorithm to benefit from learning across a set of uncorrelated transitions. Since the network 𝑄(𝑥, 𝑢|𝜃𝑄) being updated is also used to calculate the target value, the Q update is prone to divergence.
A copy of the players' and critics' networks, 𝑄′(𝑥, 𝑢|𝜃𝑄′) and 𝜋′(𝑥, 𝜃𝜋′) respectively, was made, which are used to calculate the target values. This means that the target values are limited to changing slowly, which greatly improves the stability of the learning. However, when learning from low-dimensional observations of feature vectors, different components of the observation may have different physical units (such as positions versus velocities) and the extents may vary across environments.
For the targets, a copy of the actor and critic networks was created, which was then used to calculate the target values.
Results
PID Controlled Response
Conclusions
In Proceedings of the 12th International Conference on Computer Engineering and Systems (ICCES), Cairo, Egypt, pp. Neural network control system for UAV altitude dynamics and its comparison with the PID control system. In Proceedings of the IEEE International Conference on Computer, Communication and Control Technology., Langkawi, Malaysia, sat.
Attitude and pitch control of quadrotor by discrete PID control and nonlinear model Predictive control. In Proceedings of the International Conference on Information and Communication Technologies (ICICT), Karachi, Pakistan, Dec. Simple nonlinear control of quadcopter for collision avoidance based on geometric approximation in static environment.
In Proceedings of the 6th International Conference on Industrial and Information Systems, Peradeniya, Sri Lanka, geleden.







