SINAPAD Sistema Nacional de Processamento de Alto Desempenho Sistema de Gerenciamento de Banco de Dados SGBD. É evidente que o uso de computadores na análise de dados biológicos influenciou as ciências biológicas de todas as maneiras.

Definições
Está dividido nas seguintes seções: 4.1 Caracterização do ambiente de estudo, 4.2 Detalhamento e mapeamento do curso atual e 4.3 Identificação de oportunidades de melhoria. Está dividido nas seguintes seções: 1.1 Definições, 1.2 Breve histórico, 1.3 A Bioinformática no Brasil, 1.4 Bases de dados biológicas públicas e 1.5 Desafios da Bioinformática.
Breve histórico
Bioinformática no Brasil
O subcampo de desenvolvimento de ferramentas computacionais incluiria a criação de software para análise de sequências, bem como a criação e manutenção de bancos de dados biológicos. A aplicação dessas ferramentas e bancos de dados seria nas áreas de análise, estruturas e funções de sequências de DNA [4].
Bancos de dados biológicos públicos
Segundo Xiong [4], os bancos de dados biológicos podem ser divididos em três categorias: primários, secundários e especializados. Bancos de dados especializados são bancos de dados que contêm informações muito específicas sobre um determinado assunto.

Desafios da bioinformática
Porém, tudo isso exigirá avanços crescentes em hardware, software, modelagem e análise de dados. O armazenamento desses dados biológicos em bancos de dados públicos tornou-se cada vez mais comum e, como resultado, esses bancos de dados cresceram exponencialmente [5].
Conceitos básicos
Proteínas
Para melhor compreensão da pesquisa, este capítulo apresenta alguns conceitos da biologia molecular, com ênfase no sequenciamento de DNA. Ele está dividido nas seguintes seções: 2.1 Conceitos Básicos, 2.2 Sequenciamento de DNA, 2.3 Alinhamento de Sequência, 2.4 Sequenciamento de Próxima Geração (NGS) e 2.5 Sistema HLA.
Ácidos Nucleicos
Fluxo da informação em sistemas biológicos
Sequenciamento de DNA
Hoje, existem inúmeras bases de dados focadas em pesquisas biológicas que podem ser acessadas de qualquer lugar via Internet [34]. Um exemplo desta categoria é o banco de dados Flybase, que é utilizado para analisar o genoma da Drosophila.
Alinhamento de sequências
No alinhamento global, duas sequências a serem alinhadas são consideradas semelhantes em todo o seu comprimento. O alinhamento é, portanto, realizado do início ao fim com o objetivo de encontrar o melhor alinhamento possível ao longo de todo o comprimento entre as duas linhas. Este método é mais aplicável para alinhar duas sequências intimamente relacionadas de comprimentos aproximados.
Por outro lado, o alinhamento local não pressupõe que as duas sequências em questão compartilhem semelhanças ao longo de todo o seu comprimento. A Figura 6 apresenta um exemplo de alinhamento de duas sequências de nucleotídeos de tamanhos diferentes e destaca as diferenças entre os alinhamentos locais e globais. Os métodos de palavras, usados pelos algoritmos FASTA e BLAST, alinham duas strings muito rapidamente, primeiro procurando por pequenas partes idênticas das strings (palavras) e depois combinando-as em um alinhamento através da dinâmica do método de programação aplicado.

Sequenciamento de nova geração (NGS)
Além disso, esta tecnologia é frequentemente considerada ineficiente em comparação com outras tecnologias de sequenciamento NGS, uma vez que múltiplas sequências podem ser produzidas com Illumina, SOLiD ou Ion Torrent. O processo SOLiD começa com uma etapa de PCR em emulsão semelhante à usada pelo 454, mas usa uma abordagem de sequenciamento pós-ligação, diferentemente do sequenciamento pós-síntese usado em outras plataformas. A Ion Torrent entrou no mercado em 2010 com a Personal Genome Machine (PGM), alegando ser a primeira empresa a realmente introduzir o sequenciamento NGS viável e acessível para laboratórios menores [37].
O sistema Ion Torrent difere de todos os outros sistemas na forma como a incorporação de base é detectada. Pacific Biosciences (PacBio) usa uma abordagem de sequenciamento em tempo real de molécula única. O sistema de sequenciamento PacBio não envolve nenhuma etapa de amplificação, o que o distingue de outros sistemas de sequenciamento NGS [37].
Sistema HLA
Transplante de Medula Óssea
O transplante de medula óssea é um tipo de tratamento sugerido para algumas doenças que afetam as células sanguíneas, como leucemia e linfoma. A medula óssea contém células-tronco hematopoiéticas, responsáveis pela produção de todo o sangue (glóbulos vermelhos, glóbulos brancos e plaquetas). Portanto, o termo “transplante de medula óssea” para estes procedimentos foi substituído por “transplante de células-tronco hematopoiéticas” [41].
REDOME é um registro nacional de doadores voluntários de medula óssea, um registro que coleta informações (nome, endereço, resultados de exames, características genéticas, etc.) de voluntários para doar medula óssea a pacientes que necessitam de transplante. É possível se cadastrar como doador voluntário de medula óssea em hemocentros de todos os estados do país. O Cadastro Nacional de Doadores Voluntários de Medula Óssea (REDOME) foi criado em 1993, em São Paulo, para coletar informações de pessoas dispostas a doar medula óssea para quem necessita de transplante.

Laboratórios diagnósticos
A acreditação é uma auditoria externa da capacidade de um laboratório em fornecer um serviço de alta qualidade. Segundo a Sociedade Brasileira de Patologia Clínica e Medicina Laboratorial (SBPC/ML) “o laboratório pode escolher o organismo acreditador, com base na sua credibilidade, experiência e conhecimento técnico de seus auditores. e a investigação aplicada como base para a prática laboratorial, com contribuições das áreas da medicina e da pediatria, bem como da bioquímica e da microbiologia [46].
Hoje, a medicina laboratorial participa de 70% das decisões clínicas, representando apenas 10% dos custos totais dos cuidados de saúde, e as tendências ainda mostram um aumento na utilização de exames laboratoriais, especialmente aqueles destinados à prevenção de doenças, o que mostra a grande importância deste medicamento. especialidade. no campo da saúde [48]. Os serviços de medicina laboratorial englobam diversas ações que incluem testagem, colheita de amostras, preparação de amostras, identificação de amostras, transporte e armazenamento de material biológico, processamento e análise de amostras, bem como interpretação e posterior elaboração de relatórios e pareceres. Existem três etapas no fluxo do processo de um laboratório clínico [48]: pré-analítica, analítica e pós-analítica.
Vantagens da tecnologia da informação
Os sistemas de tecnologia da informação também fornecem procedimentos confiáveis e padronizados para avaliação de laboratórios médicos [49]. Os desafios de gestão da informação aumentarão à medida que os avanços na genómica e na proteómica geram dados cada vez mais complexos e abundantes. As soluções de TI para a indústria de diagnóstico in vitro são normalmente concebidas para melhorar a usabilidade e a qualidade dos instrumentos e reagentes, em vez de abordar os desafios de gestão da informação a nível empresarial.
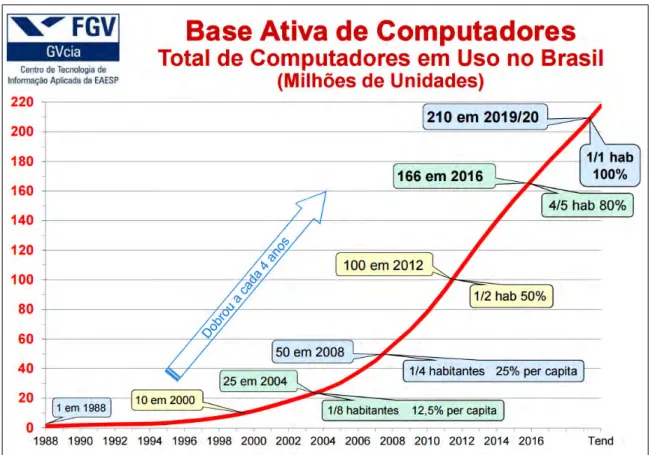
De acordo com a 27ª pesquisa anual, realizada em 2016 pelo Centro de Tecnologia da Informação Aplicada (GVcia) da Escola de Administração de Empresas de São Paulo da Fundação Getúlio Vargas (FGV/EAESP), que apresenta o cenário atual e o futuro da tecnologia baseada em TI mercado, o processo de automatização das empresas e da sociedade continua a crescer, mesmo numa situação muito desfavorável e com um declínio acentuado do consumo pessoal [53]. Segundo pesquisa da FGV, até o final de 2016, haverá 166 milhões de computadores, entre desktops, notebooks e tablets, em uso no Brasil, sendo 4 computadores para cada 5 habitantes, o equivalente a 80% per capita. A Figura 10 mostra a quantidade de computadores utilizados no Brasil ao longo dos anos, de 1988 a 2016, com previsão para 2019.
A importância do mapeamento de processos
Pode-se assim dizer que o mapeamento de processos desempenha o papel essencial no desafio dos processos existentes, criando oportunidades para melhorar o desempenho da organização através da identificação de interfaces críticas e, acima de tudo, criando a base para a implementação de novas e modernas tecnologias de informação (TI). e integração de negócios [11]. No trabalho laboratorial de rotina, processar um grande número de amostras e inserir os resultados manualmente significa que é mais provável que os resultados fiquem fora dos limites especificados, o que significa que os desvios ocorrerão com mais frequência. Dada a relevância de conhecer tais processos produtivos, são utilizadas técnicas de modelagem de processos de negócios para representar as diversas tarefas necessárias na ordem em que ocorrem para executar e entregar o serviço.
O mapa de processos deve ser apresentado graficamente, para que os detalhes do processo possam ser expostos, para estimular a brevidade e a precisão em sua descrição, para chamar a atenção para as interfaces do mapa de processos e para fornecer uma análise do processo consistente com a linguagem do projeto [ 11]. Este capítulo faz uma apresentação do Laboratório de Histocompatibilidade e Criopreservação (HLA-UERJ) da Universidade do Estado do Rio de Janeiro, detalha o processo de tipagem HLA do atual HLA-UERJ e mostra oportunidades de melhorias e os recursos necessários para sua implementação. Está dividido nas seguintes seções: 4.1 Caracterização do ambiente de estudo, 4.2 Detalhamento e mapeamento do processo atual e 4.3 Identificação de oportunidades de melhoria.
Caracterização do ambiente de estudo
Laboratório HLA-UERJ
O HLA-UERJ possui o credenciamento do Instituto Nacional de Metrologia, Qualidade e Tecnologia (INMETRO), concedido com base no atendimento a requisitos de normas e documentos normativos [6].
Atividades do Laboratório HLA-UERJ
Exames de Tipificação HLA do HLA-UERJ
Detalhamento e mapeamento do processo atual
Em 1965, Dayhoff desenvolveu o primeiro banco de dados de sequências de proteínas, o Atlas de Sequência e Estrutura de Proteínas, reconhecido como o primeiro esforço para sistematizar o conhecimento da informação genética. Pearson e David Lipman desenvolveram o FASTA, um algoritmo capaz de realizar buscas mais rápidas por similaridade entre sequências em um banco de dados [21]. Em resposta ao tremendo crescimento nos ESTs gerados, o banco de dados dbEST foi criado no NCBI para armazenar todos os ESTs conhecidos publicamente [2].
Bases de dados primárias são aquelas que contêm dados originais, em sua forma bruta, sem qualquer processamento, submetidos pela comunidade científica. Bancos de dados secundários são aqueles que contêm dados que já foram processados, de forma informatizada ou manual, com base em informações de bancos de dados primários. Todos os anos, a revista Nucleic Acids Research publica uma lista atualizada de todos os bancos de dados biológicos disponíveis no mundo com seus respectivos URLs.
A consulta aos bancos DDBJ e EMBL é feita através do Sequence Retrieval System (SRS), que foi desenvolvido pela EBI para gerenciar bancos de dados biológicos primários e secundários. A Illumina produz a família de plataformas mais difundida porque uma maior quantidade de dados pode ser gerada de maneira mais econômica.
Identificação de oportunidades de melhoria
Proposta de arquitetura de alta disponibilidade
Procurando uma solução barata e como o número de usuários é reduzido, sugere-se hospedar tanto a camada de apresentação quanto a camada de aplicação na mesma máquina. No entanto, é preferível que a base de dados esteja alojada numa máquina separada, pois em caso de falha a base de dados permanece acessível a outros. A segregação do banco de dados também garante desempenho e segurança porque o tipo de processamento realizado pelo banco é diferente daquele do servidor de apresentação e aplicação. Em termos de segurança, o facto da base de dados ser segregada permite-lhe residir numa rede à qual apenas os servidores de apresentação e aplicação têm acesso.
O banco de dados utilizado pode ser o PostgreSQL, que, apesar de ser de uso gratuito, é tão poderoso e estável quanto as soluções comerciais [72]. Para garantir a sincronização de dados entre o nó primário e o nó secundário, sugere-se a utilização da solução DRBD (Distributed Replicated Block Device). O desenvolvimento de filtros de pesquisa de dados também será um recurso muito útil quando o banco de dados atingir dimensões maiores.
Disponível em:






