O desenvolvimento de soluções de processamento paralelo baseadas no framework Hadoop tem sido amplamente utilizado como uma alternativa eficiente para processamento de grandes volumes de dados. O Capítulo 1 fornece uma visão bibliográfica de soluções disponíveis na literatura que podem ser utilizadas para processamento de imagens utilizando o framework Hadoop.
Hadoop Image Processing Interface
Este capítulo apresenta algumas soluções disponíveis na literatura que podem ser utilizadas para processamento distribuído de imagens utilizando o framework Hadoop. O Hadoop, que será descrito na Seção 2.4, permite a utilização do modelo de programação MapReduce em projetos que se enquadram no escopo da computação distribuída e processamento de dados em larga escala em clusters de computadores.
InterImage Cloud Platform
O método primeiro produz fragmentos, blocos, imagens de sensoriamento remoto, que são distribuídas pelas unidades de processamento de uma matriz e segmentadas de forma independente. O principal problema abordado em (HAPP et al., 2016) foi a eliminação de artefatos (segmentos com bordas retas), resultantes de segmentações independentes de placas.
Hadoop Streaming
Para tanto, são propostas estratégias de pós-processamento que combinam essencialmente segmentos que tocam as bordas dos ladrilhos para ressegmentar as regiões da imagem cobertas por esses segmentos. O método proposto por (HAPP et al., 2016) visa, portanto, segmentar imagens grandes e dividi-las em pequenas partes, o que não é o caso deste trabalho, pois, como será visto mais adiante, imagens menores serão submetidas para distribuição. processamento. e neste caso não há problema de segmentos com artefatos introduzidos pelo processo.
Hadoop Pipes
Hadoop Libhdfs
Processo de Biolixiviação
Microscópio Eletrônico de Varredura
Segmentação de Imagens Digitais
Crescimento de Regiões
As técnicas de segmentação por crescimento de regiões visam dividir as imagens em regiões homogêneas, de acordo com alguns critérios de homogeneidade. As técnicas de crescimento de regiões normalmente começam a crescer a partir de sementes, pixels ou grupos de pixels que representam regiões iniciais.
Hadoop
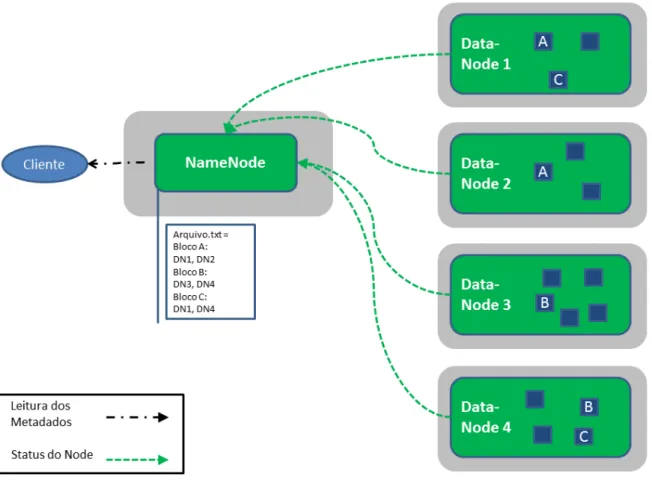
Hadoop Distributed File System (HDFS)
Os blocos de conteúdo importados para o HDFS são replicados para DataNodes de acordo com o fator de replicação configurado. Os blocos de dados geralmente são armazenados no disco rígido (HD) ou no disco de estado sólido (SSD) dos DataNodes.
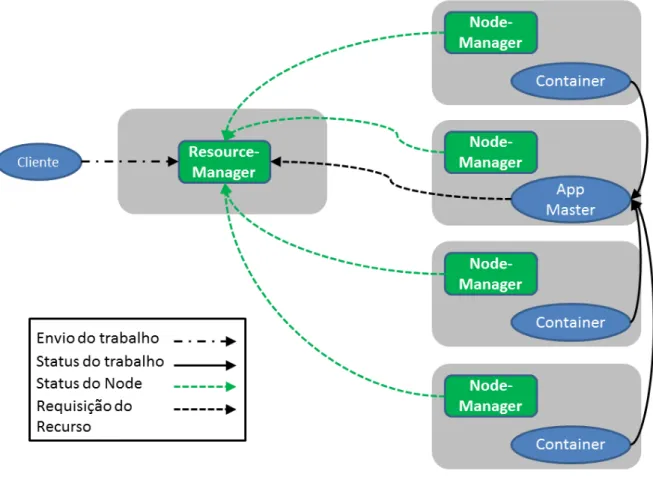
Hadoop YARN
O ResourceManager solicita alocação de recursos para cada aplicativo em execução e gerencia filas de processamento. Os containers são onde serão executadas as tarefas da aplicação, o NodeManager é responsável por gerenciar os recursos alocados nos containers como número de núcleos, memória, disco, rede e reportar o status dos recursos ao ApplicationMaster.
Modelo MapReduce
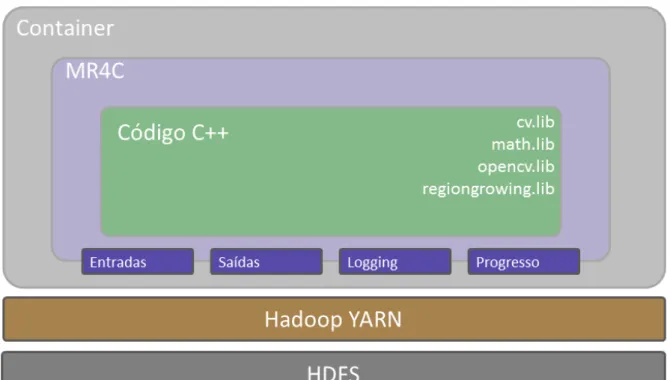
MR4C
Conjuntos de Dados (Datasets)
O MR4C nos permite trabalhar com arquivos individuais, ou também referindo-se a um diretório contendo muitos arquivos e agrupando-os como um conjunto de dados (KENNEDY-BOWDOIN, 2015).
Identificador de elementos (keyspace)
Configuração
OpenCV
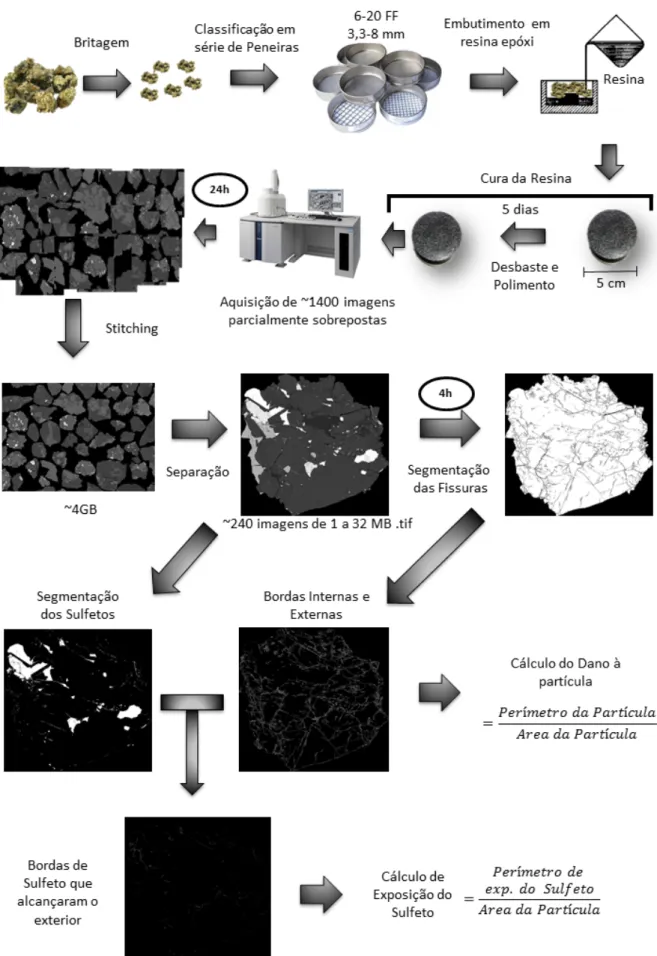
Para calcular o dano das partículas, é necessário submeter as imagens das partículas ao algoritmo de segmentação de fissuras (Figura 10) e depois ao algoritmo de identificação de bordas internas e externas (Figura 11). Para calcular a exposição ao sulfeto, é necessário submeter as imagens das partículas ao algoritmo de segmentação de sulfeto (Figura 12), e utilizar o resultado do algoritmo de identificação de bordas interna e externa (Figura 11) aplicado ao resultado do algoritmo.
Base de dados
O terceiro processo utilizou o britador de mandíbulas e a prensa de rolos de alta pressão (HPGR) abaixo de 20 Bar e o quarto processo utilizou o britador de mandíbulas e a prensa de rolos de alta pressão (HPGR) abaixo de 50 Bar. Isso se refere aos rejeitos de minério que passaram pelo segundo processo de prensagem que utilizou o britador de mandíbulas e a fragmentação eletrodinâmica Selfrag.
Algoritmo Sequencial de Segmentação de Fissuras
As sementes para áreas de crescimento são inicializadas marcando todos os pixels nas bordas dos conjuntos de pixels como sementes com intensidade igual a zero. Os pixels recém-mesclados são usados como sementes na próxima iteração de áreas de crescimento. Os itens abaixo descrevem as variáveis do Algoritmo 1. i) l, lv: coordenadas de linha de um pixel (ii) c, cv: coordenadas de coluna de um pixel. iii) S, S0: conjuntos de sementes para áreas de cultivo.
Distribuição das imagens com o HDFS
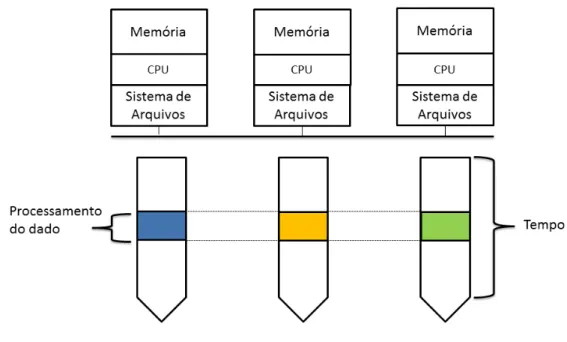
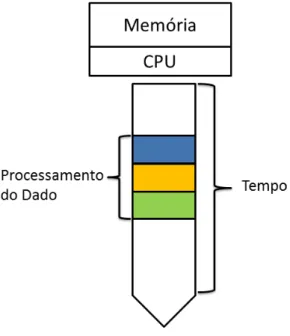
Mais especificamente, o HDFS distribui imagens entre nós de processamento, o MR4C encapsula o processamento sequencial de análise e instanciação de partículas individuais e informa o sistema distribuído sobre os parâmetros de execução, enquanto o YARN permite a execução e gerencia toda a alocação de recursos. O programa de balanceamento, que é executado antes do envio das imagens para o HDFS, lista as imagens na pasta de entrada em ordem de tamanho e as renomeia, adicionando um número de identificação ao início de seus nomes. Este processo se repete até que todas as imagens na pasta de entrada tenham sido renomeadas.
Encapsulamento do processamento com MR4C
Para que ocorra o equilíbrio, esse número de ID começa com um e vai aumentando até atingir o número de tarefas a serem utilizadas na configuração da aplicação. Em seguida, ele chama a função de segmentação de slice renderizando cada imagem e, com base no resultado obtido, chama novamente a função convert para transformar o objeto em um Hadoop DataFile, possibilitando que a imagem processada seja armazenada em formato TIF no HDFS. O arquivo JSON mencionado acima foi utilizado como referência para os parâmetros de entrada da aplicação, como o local onde foi armazenado o conjunto de imagens a serem processadas na estrutura de diretórios do HDFS, bem como a extensão do formato dos dados. .
Distribuição e Execução do processamento com YARN
Assim, o Hadoop transfere o processamento para o nó de processamento onde os dados estão armazenados, o que significa que não há necessidade de transferir uma grande quantidade de dados pela rede. Desta forma, as partículas podem ser processadas em paralelo, o que permite reduzir o tempo de processamento. É importante ressaltar que as definições dos parâmetros da aplicação MR4C afetam diretamente o desempenho de execução da aplicação e podem, se configuradas corretamente, reduzir o tempo de processamento.

Assim como a influência do número de cores, também deve ser verificada a influência da memória máxima por tarefa. Porém, é necessário identificar efeitos adversos do aumento do número de imagens para estudá-las, a fim de obter variação no tempo de processamento em relação ao aumento do volume de dados. Assim como as configurações por tarefa, a influência do número de tarefas também deve ser verificada.
Infraestruturada do cluster utilizado nos experimentos
Os nós de processamento possuem um recurso de processamento YARN, NodeManager, e um recurso de armazenamento HDFS, DataNode.
Base de dados utilizada nos experimentos
Validação do modelo distribuído
Influência do número de cores por tarefa
Analisando os resultados apresentados na Figura 18, observa-se que para a maioria dos casos, um núcleo por tarefa proporcionou o menor tempo de execução. Por exemplo, dado um experimento com configuração de quatro tarefas utilizando quatro cores, em um cluster com um nó de processamento que possui oito cores, no máximo duas tarefas serão processadas em paralelo. Como resultado dos resultados mostrados na Figura 18, apenas um núcleo por tarefa será utilizado em experimentos subsequentes.

Influência da memória máxima definida por tarefa
Analisando os resultados apresentados na Figura 19, nota-se que a redução da memória máxima na maioria dos casos resultou em menor tempo de execução. As exceções são os experimentos realizados para duas tarefas e 20 tarefas, para as quais alguns valores máximos de memória causaram comportamentos diferentes. Como resultado dos resultados apresentados na Figura 19, decidiu-se que para cada experimento subsequente seria realizada uma pré-avaliação para identificar a memória mínima alocada que permitiria a execução sem erros por insuficiência de memória.

Influência do número de nós de processamento
Analisando os resultados apresentados na Figura 20, nota-se que o aumento no número de nós de processamento proporcionou menor tempo de execução. Através destes resultados foi possível verificar que na faixa de número de nós avaliados, a proposta apresentou boa escalabilidade. A Figura 21 mostra o speedup utilizando o tempo de execução obtido para o cluster com apenas um nó de processamento como referência para cálculo.

Influência do número de imagens
Avaliando os resultados apresentados na figura 21, ficou evidente que os resultados apresentaram uma aceleração quase linear, atingindo o valor de 8,6, fazendo uma comparação com a execução utilizando um e nove nós de processamento. A Figura 23 mostra o speedup usando como referência os resultados de um nó de processamento do cluster, variando o número de imagens e o número de nós de processamento, enquanto o número de tarefas permanece igual ao número de imagens. No caso do processamento da base de dados Selfrag_120_0001, utilizando oito nós de processamento obteve-se um speedup de 7,4 enquanto o valor para o caso linear hipotético seria 8.

Influência do número de tarefas
Analisando os tempos de execução apresentados na Figura 24, percebe-se que dentre as configurações avaliadas neste experimento, o menor tempo de processamento foi obtido para 45 tarefas. Seu valor corresponde à razão entre o número de tarefas no tempo base e o número de tarefas em cada execução, sendo esse valor então multiplicado pelo resultado do tempo de execução no tempo base. Se o número de tarefas estiver configurado para exceder o limite de hardware, as tarefas que excedem o limite de recursos deverão aguardar a liberação dos recursos antes de poderem ser instanciadas.

Influência do tamanho da imagem
Analisando os resultados apresentados na Figura 25, o aumento do número de nós de processamento até o limite de sete nós gerou uma pequena diminuição no tempo de execução. As acelerações, que utilizam como referência o resultado para um cluster com apenas um nó, obtido para diferentes números de nós, são apresentadas na Figura 26. Avaliando os resultados apresentados na Figura 26, observou-se que os resultados apresentam uma aceleração muito abaixo do valor linear teórico, chegando ao valor de 1,2, o que faz uma comparação com o desempenho utilizando um e nove nós de processamento.

Execução sequencial do corte do mosaico
Este experimento tem como objetivo avaliar a influência do número de imagens em grande escala no desempenho do procedimento de segmentação de fissuras utilizando crescimento de regiões. O valor foi multiplicado pelo número de imagens de outras bases de dados e foi gerado um fator de crescimento linear baseado no tempo de processamento do Selfrag_180_0001. Em contrapartida, com a influência do número de cores e memória por tarefa, a variação no número de nós de processamento apresentou um ganho quase linear no tempo de execução.
Variando o número de tarefas também foi possível verificar que o aumento no número de tarefas produziu uma diminuição praticamente linear no tempo de execução até atingir o limite de recursos do cluster. Também foi possível perceber que neste caso houve uma ligeira diminuição no tempo de tratamento ao aumentar o número de nós de tratamento.