Métodos de classificação supervisionada utilizados para identificar fraudes em fornecedores no estado do Rio de Janeiro. Além disso, os dados das licitações estão disponíveis no Portal da Transparência do Estado do Rio de Janeiro.1.
Evolução do processo de auditoria
Por fim, será apresentada a metodologia Cross Industry Standard Process for Data Mining (CRISP-DM) como ferramenta para desenvolvimento de modelos para análise de dados. Por outro lado, a amostra utilizada hoje fornece garantia sobre dados históricos e não avalia processos de negócios.
O processo licitatório
A estimativa de compra para propostas de engenharia deve ser de até R$ 3,3 milhões e para aquisição de outros serviços até R$ 1,43 milhão; Os critérios de seleção podem ser menor preço, melhor técnica, melhor preço e técnica, melhor rendimento ou maior desconto. A Lei 8.666/1993 determina também os casos em que há possibilidade de exceção e desvinculação de ofertas, ambas modalidades de contratação direta.
Na isenção, apesar da possibilidade de concorrência, a lei lista os casos em que o procedimento licitatório é dispensado. Apesar das diversas medidas de controle estabelecidas por lei ao longo dos anos, não é incomum ouvir falar de casos de corrupção descobertos em concursos públicos. Segundo publicação do Ministério do Planejamento, sanções administrativas em licitações e contratos. São as consequências de um ato ou conjunto de atos, praticados por licitantes e empreiteiros da Administração Pública, que causem danos à Administração ou violem normas de cumprimento obrigatório.

Fraude e definição de indicadores
Eles participaram de um jogo onde tinham que informar o número do dado para ganhar o prêmio. Esta experiência mostra que mesmo que as pessoas tenham tendências desonestas, podem ser implementados controlos para as inibir. Alguns desses controles podem ser preventivos, como o Código de Ética, e outros podem ser detetivescos quando apropriado.
Dessa forma, os concorrentes podem estabelecer um rodízio para o vencedor, o que dificulta a detecção pela análise de um único processo licitatório (MORAIS, 2016). Aviso Direcional ou Cláusulas Restritivas: Você pode incluí-las para fornecedores-alvo que atendam aos critérios estabelecidos. Essa análise pode ser realizada em massa na base de dados utilizando o banco de dados de CNPJ divulgado pela Receita Federal.
Lei de Benford
Quando a base de dados não se enquadra nesta teoria, ou seja, se a frequência de registros estiver fora do esperado, é necessário analisar seus desvios. Nigrini (2012) sugere que a lei de Benford deve ser usada como ponto de partida e que os dois primeiros dígitos seriam o teste preferido, a menos que o conjunto de dados seja pequeno. Um teste qui-quadrado de aderência pode ser realizado para avaliar a hipótese de que o banco de dados obedece à lei de Benford.
Quando o resultado do teste qui-quadrado for superior ao valor crítico para o nível de significância determinado, a hipótese de cumprimento da lei de Benford deve ser rejeitada. Como exemplo de sua aplicação em estudos brasileiros, Cella e Zanola (2018) propuseram a análise da lei de Benford sobre o ranking de transparência dos municípios do estado de Goiás e a base dos gastos comprometidos. A pesquisa mostrou que os municípios que mais cumprem a lei são também aqueles considerados mais transparentes, segundo ranking divulgado pelo MPF.
Aprendizado de máquina
A aprendizagem supervisionada ocorre quando existe o objetivo de prever a variável dependente com base nas variáveis independentes. A aprendizagem semissupervisionada é utilizada quando o banco de dados está desequilibrado, ou seja, há poucos exemplos de dados rotulados e muitos exemplos de dados não rotulados. No aprendizado por reforço, uma máquina aprenderá por meio de testes, recompensas quando uma meta for alcançada e punições quando ocorrer uma falha.
Essa abordagem é utilizada em jogos onde o objetivo é vencer uma partida e, a partir de movimentos corretos e incorretos, a máquina aprenderá a jogar. Nesta pesquisa, será utilizada uma abordagem de aprendizagem supervisionada utilizando algoritmos de classificação. Os dados de marcação para identificar se um fornecedor é sancionado ou não estão disponíveis no portal de Transparência do Governo do Estado do Rio de Janeiro.

Algoritmos de classificação
- Regressão logística
- KNN
- Redes neurais artificiais
- Random forest
- Máquina de vetor suporte (SVM)
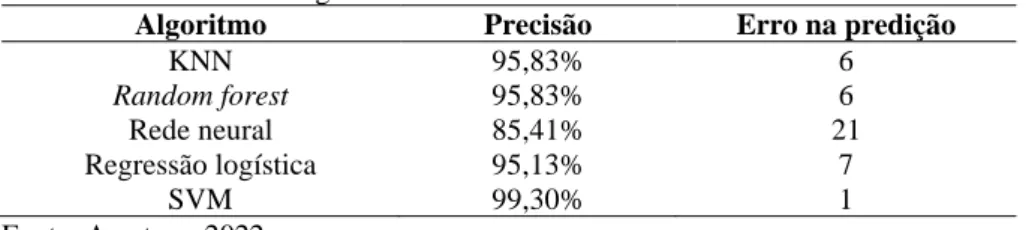
Uma das vantagens da regressão logística é que basta saber se ocorreu um evento (por exemplo, uma compra ou não, o sucesso ou o fracasso de um negócio) e depois utilizar o valor dicotômico como variável dependente. O experimento propôs uma arquitetura baseada em regras de associação e regressão logística para construção de um conjunto amostral para detecção de transações fraudulentas. Consequentemente, apesar da utilização do algoritmo, a pesquisa constatou que o modelo de regressão logística é mais eficaz para prever fraudes contábeis.
Ele recebe dados de entrada que são processados em neurônios localizados nas camadas subsequentes até entregarem o resultado final à camada de saída. Foram utilizados dados de solicitações de reembolso classificadas como legítimas ou suspeitas pelos auditores. Os resultados preditivos foram comparados com a regressão logística e mostraram que ambos os modelos obtiveram desempenho médio superior ao da regressão logística.

Métricas de avaliação
Precisão
Este algoritmo visa encontrar o hiperplano ideal, em que os limites (a distância entre os vetores de suporte e o hiperplano) serão os maiores. O kernel no SVM consiste no conjunto de funções matemáticas utilizadas para definir o hiperplano ideal, que pode ser linear, radial, polinomial ou sigmóide.
Matriz de confusão
Curva ROC
Metodologia CRISP-DM
Neste capítulo descreveremos o método e as etapas para a elaboração da pesquisa, começando pela população e pela amostra, seguida pela coleta e tratamento dos dados, que teve como produto final a construção de um banco de dados para o desenvolvimento de o modelo (investigação de características e definição de indicadores), utilizando algoritmos.
População e amostra
Ao final do processo de elaboração das bases de dados, observou-se a seguinte relação entre a população total das bases de dados originais e a amostra utilizada no estudo (Tabela 3).
Coleta de dados
Foi realizado um filtro na base de fornecedores e foram considerados apenas aqueles que possuíam CNPJ (a base também continha pessoas físicas como fornecedores), que atuam no Brasil e que assinaram pelo menos um contrato ou participaram de licitação estudaram durante o cut-off período. Um baixo capital social, comparado ao serviço contratado, pode indicar que o prestador não possui a estrutura necessária para atender o que é demandado. Diferença em anos entre a data de registro do fornecedor no banco de dados do Governo do Estado do RJ e a data de criação da empresa na Receita Federal.
Indica se a empresa está ativa na Receita Federal “0” ou possui outro status como encerrado, inelegível ou suspenso “1”. Número de contratos assinados com o fornecedor cujos números iniciais falharam no teste de Benford (valor acima do limite superior). Quanto maior o número de contratos que falharam no teste de hipótese da Lei de Benford, maior será a indicação de que os valores dos contratos foram manipulados.
Tratamento dos dados
- Verificação de dados ausentes
- Balanceamento das bases
- Divisão da base entre treino e teste
- Normalização da base de dados
- Aplicação dos algoritmos
A base de dados de prestadores do estado do Rio de Janeiro é desequilibrada, pois apenas 240 prestadores foram homologados, de um universo de 6.067, correspondendo a apenas 4% do total. Para solucionar esse problema, foi utilizada a técnica de subamostragem no banco de dados, que consiste em selecionar uma amostra da classe majoritária para que haja o mesmo número de registros da base minoritária. Após o rebalanceamento do banco de dados, os dados foram divididos entre bases de treinamento (70%) e de teste (30%), com o objetivo de que o algoritmo pudesse aprender com 70% dos registros, e então aplicar esse conhecimento a 30% dos registros. ausente.
A normalização do banco de dados é uma técnica usada para evitar que os algoritmos se desviem para variáveis de ordem de magnitude maiores. Para melhorar o desempenho dos algoritmos SVM e de rede neural, o comando MinMaxScaler, que escala todos os atributos do banco de dados no intervalo [0, 1], foi utilizado para normalizar os dados. Nesse processo, a validação cruzada é realizada para garantir que não haja overfitting do modelo, o que ocorre quando um modelo tem um desempenho muito bom na classificação de casos no banco de dados de treinamento, mas não consegue classificar corretamente o banco de dados de teste.

Análise descritiva da base de dados
O tamanho da empresa é um atributo importante a ser verificado, pois existem licitações exclusivas para participantes ME e EPP. Os tipos de sanções aplicadas aos fornecedores foram, na maioria dos casos, multas (47%), seguidas de advertências (37%). Em relação ao valor dos contratos com fornecedores (Gráfico 10), constatou-se que a maioria era de até R$ 100 mil.
Há também vários fornecedores que se registaram na base de dados, mas que até à data não conseguiram vencer nenhuma licitação. Observou-se também que o tipo de ofertas mais frequente foi o leilão eletrónico, representando 85% do total (Gráfico 11). A matriz de correlação (Figura 10) foi executada para determinar quais variáveis têm a maior correlação com a variável sanção.

Teste de hipótese – Lei de Benford
Portanto, pode-se supor que as bases dos contratos firmados pelo governo do estado do Rio de Janeiro não passaram no teste de hipótese de conformidade com a lei de Benford. Para esta figura foi calculado o escore z, que representa o número de vezes que a frequência base está acima do desvio padrão observado. Esse fato pode explicar o número de registros acima do esperado na faixa encontrada, pois os usuários podem estar realizando compras no limite para evitar um processo de locação mais complexo.

Resultados
Enquanto resultados menores que 1 indicam que quanto menor o valor, menor a probabilidade de ocorrência de fraude. Além disso, pode-se observar que os resultados são diferentes dos coeficientes da regressão logística. Para a rede neural, que apresentou o pior resultado entre os algoritmos avaliados, uma opção para melhorar seu desempenho seria utilizar a matriz de correlação, os coeficientes de regressão logística ou os resultados de feature_importances e assim fazer uma seleção de atributos.
Beskikbaar by: