Utiliza, portanto, o processo de mineração de textos para buscar jurisprudência relativa à “parte especial” (artigos 121 a 128) do direito penal, diretamente dos Diários Eletrônicos da Justiça de Santa Catarina. Nesse sentido, o trabalho proposto buscou desenvolver uma ferramenta de mineração de textos para auxiliar os profissionais do direito na busca por jurisprudência.
PROBLEMA DE PESQUISA
Solução Proposta
Este trabalho propôs o desenvolvimento de uma ferramenta web para busca de jurisprudência em Diários Eletrônicos de Justiça utilizando processos de mineração de texto, que visa reduzir resultados ambíguos ou fora do contexto de busca, e tenta contribuir para ajudar profissionais do direito a encontrar subsídios necessários no preparação de teses e defesas. Como os processos de mineração de textos podem ajudar advogados na preparação de teses e defesas.
Delimitação de Escopo
Assim, considerou-se a criação de um dicionário de termos jurídicos na área do direito penal, mais concretamente a “Parte Especial” (artigos 121.º a 128.º) do Código Penal, em conjunto com um especialista na área do direito. usado para implementar a solução. Foi desenvolvida uma ferramenta web na qual o usuário pode inserir uma data ou intervalo de datas e os termos que se referem à jurisprudência que deseja encontrar. Com essa ferramenta ele realiza os processos de mineração de textos e, utilizando o dicionário de termos jurídicos, realiza a busca nos Diários Eletrônicos de Justiça disponíveis no site do TJSC em formato PDF, buscando encontrar documentos textuais que se refiram à jurisprudência examinada.
Justificativa
O processo de mineração de textos faz uso de uma série de técnicas e algoritmos que já são utilizados em soluções das mais diversas áreas do conhecimento humano (ARANHA, 2007; BARBOSA, 2013; PASSINI, 2012; RAHMAN, 2011; RAMOS, BRASCHER, 2009) , que possibilitam a utilização de conhecimentos já adquiridos e compartilhados para a elaboração deste trabalho. Nota-se que este trabalho, baseado no conhecimento disponível, pode dar sua parcela de contribuição quando a mineração de textos for aplicada ao campo jurídico, área que tem buscado auxílio tecnológico para a realização de seu trabalho.
OBJETIVOS
Objetivo Geral
A solução proposta neste trabalho pode atender juristas interessados em textos jurisprudenciais relacionados à área do Direito Penal, tratando de crimes contra a pessoa e contra a vida, e auxiliá-los fornecendo conhecimentos derivados dos textos processados foram extraídos.
Objetivos Específicos
METODOLOGIA
Metodologia da Pesquisa
Procedimentos Metodológicos
Na fase de análise e avaliação dos resultados foram utilizados dois métodos de verificação dos resultados: subjetivo, utilizando o conhecimento de um especialista na área, e objetivo, com indicadores estatísticos que indicam a qualidade dos resultados alcançados. Isto abre oportunidades para criar novas ferramentas de acesso e conversão de dados em informação.
DESCOBERTA DE CONHECIMENTO
Seleção de dados: Visa selecionar dados relacionados ao domínio do problema, área onde serão aplicados os processos de descoberta de conhecimento no banco de dados (SILVA, 2011). A fase de seleção é realizada por meio de um banco de dados ou conjunto de bancos de dados estruturados.
MINERAÇÃO DE DADOS
A mineração de dados pode ser considerada uma importante ferramenta na busca por conhecimento, quando o objetivo é obter vantagem competitiva nas organizações. A mineração de texto ou descoberta de conhecimento em texto surge assim para preencher esta lacuna.
MINERAÇÃO DE TEXTO
- Coleta de Textos
- Pré-processamento
- Extração de Padrões
- Análise e Avaliação dos Resultados
- Ontologia
A MT pode ser dividida em quatro etapas: coleta de texto, pré-processamento, extração de padrões e avaliação dos achados e validação dos resultados. A coleta de dados da Internet pode ser realizada de forma automatizada por meio do uso de crawlers (HEATON, 2002).

ALGORITMOS DE MINERAÇÃO DE TEXTO
Stemmers ou lematização
Palavras que não foram alteradas na primeira etapa ou na segunda etapa devem ser tratadas na quarta etapa, onde são retirados os demais sufixos (os, a, i, o, á, í, ó). O primeiro passo trata de palavras no plural, geralmente identificadas pelo “s” no final da palavra, mas algumas palavras devem aparecer na lista de exceções (ex.: simples, lápis,...).
Descoberta de Conhecimento em Texto
Assim, probabilidade “a priori” são as estimativas iniciais e probabilidade “a posteriori” são os resultados possíveis encontrados com base na probabilidade “a priori” (ZEMBRZUSKI, 2010). A probabilidade “a posteriori” de uma hipótese é alcançada por cálculos que envolvem a probabilidade “a priori” da hipótese, a probabilidade “a priori” da evidência e a probabilidade entre causa e efeito (ZEMBRZUSKI, 2010). Para responder à questão proposta, pelo raciocínio bayesiano, primeiro são considerados os valores da hipótese, portanto em média 1% das mulheres de 40 anos têm câncer e 99% não fazem “a priori” da hipótese.

CENÁRIO NACIONAL DA JUSTIÇA BRASILEIRA
Justiça Catarinense
Em Santa Catarina, de acordo com o artigo 77 da Constituição do Estado, os órgãos que integram o Poder Judiciário do Estado são o Tribunal de Justiça, os Tribunais do Júri, os Desembargadores e Desembargadores, o Tribunal Militar, os Juizados Especiais e as Turmas de Justiça. Apelo. , Juízes de Paz e demais órgãos instituídos em lei (SANTA CATARINA, 1989). O Tribunal de Justiça, com sede na capital do Estado de Santa Catarina, tem jurisdição sobre todo o seu território e é composto por cinquenta (cinquenta) juízes, nomeados na forma do artigo 82 da Constituição do Estado, ou seja, provenientes de os magistrados profissionais, advogados e membros do Ministério Público (SANTA CATARINA, 1989). O poder judiciário é enfatizado na Constituição da República Federativa do Brasil com capítulo próprio (Capítulo III, artigos 92 a 126) e no artigo 5º, inciso XXXV, que descreve que “a lei não proibirá danos ou ameaças por parte do poder judiciário”. excluir da avaliação do Judiciário”. para a direita” (BRASIL, 2000).
Área Penal
Além das normas definidas na Constituição Federal, a organização da Justiça nos Estados orienta-se pelas normas contidas na Lei Orgânica do Poder Judiciário Nacional (Lei Complementar nº 35, de 14 de março de 1979) e pelas disposições do as Constituições Estaduais (ALVES, 2010). Dentre as áreas jurídicas citadas acima, este trabalho tem como objetivo criar uma ferramenta que auxilie os profissionais do direito a encontrar jurisprudências relacionadas aos crimes na parte específica do Direito Penal, artigos 121 a 128, do Código Penal Brasileiro. Além disso, estudos voltados para a área penal, a Parte Especial do Código Penal Brasileiro, artigos 121 a 128, em síntese, tornam mais aplicável e prática a demonstração da funcionalidade da ferramenta de busca de jurisprudência no Tribunal de Justiça de Santa Catarina.
Jurisprudência
O direito penal é o segmento do ordenamento jurídico que tem a função de selecionar os comportamentos humanos mais graves e prejudiciais à coletividade, capazes de pôr em risco os valores básicos da convivência social e classificá-los como infrações penais, obrigando-os a praticá-los, em consequentemente, as sanções correspondentes, além de estabelecer todas as regras complementares e gerais necessárias à sua aplicação justa e justa. Já a criminologia visa explicar a razão, a essência e o alcance das normas jurídicas, de forma sistemática, estabelecendo critérios objetivos para o seu estabelecimento e evitando a arbitrariedade e a aleatoriedade que resultariam da falta de padrões e da subjetividade ilimitada nas mesmas. . aplicativo. Portanto, a principal razão para a escolha desta área deve-se ao facto de ser um tema muito polémico e preocupante, pois afecta a liberdade, noticiado e comentado todos os dias pelos meios de comunicação (redes de televisão, jornais, sites de notícias, ..), e utilizado por inúmeros profissionais do direito (juízes, advogados, estagiários,..) que atuam na área criminal.
TERMINOLOGIA
Linguagem Especializada
Portanto, um conceito é a organização metálica do conhecimento, uma unidade de pensamento ou conhecimento, que pode ser explicada e compartilhada na comunidade especializada por meio de uma unidade lexical especializada denominada termo. Na extração de texto, a quantidade de palavras (“n”) que formam uma unidade lexical, seja ela um termo ou não, determina o seu “peso”. Portanto, uma unidade lexical simples ou termo simples tem peso igual a um, enquanto uma unidade lexical composta por duas palavras tem peso igual a dois e assim por diante (VIEIRA, 2010).
AGRUPAMENTO E CATEGORIZAÇÃO DE DOCUMENTOS
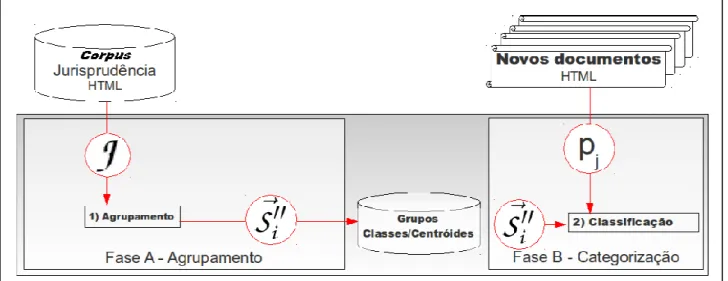
O algoritmo proposto por Furquim (2011) pressupõe um relacionamento um-a-um entre os conjuntos gerados e as classes utilizadas no treinamento dos classificadores. O processo proposto foi implementado em um exemplo composto por um corpus, uma base lexical, um analisador sintático e um rótulo. Segundo especialistas que avaliaram os resultados do agrupamento e categorização propostos por Furquim (2011), uma ferramenta de busca como essa pode reduzir significativamente o tempo gasto na busca de jurisprudências.
UMA ARQUITETURA PARA DESCOBERTA DE CONHECIMENTO A
Silva (2012) define “trabalho” como o processo de geração da frequência comum dos conceitos e cálculo do coeficiente de correlação. Outro ponto enfatizado pelo autor é que a única informação utilizada pelo modelo de correlação proposto é o número de páginas em que se encontra determinado termo, ou seja, a. Segundo Silva (2012), classes e domínios foram definidos como genéricos porque o serviço de consulta não possui semântica.

APRENDIZADO NÃO SUPERVISIONADO DE HIERARQUIAS DE
Na clusterização incremental de termos, Marcacini (2011) adotou uma estratégia semelhante à do algoritmo Leader, mas sem utilizar parâmetro com valor mínimo de similaridade (threshold). A atualização do agrupamento incremental de documentos ocorre juntamente com a atualização do agrupamento incremental de termos. Desta forma, quando uma iteração de agrupamento de termos é processada, o agrupamento incremental de documentos também é atualizado.
ANÁLISE COMPARATIVA
Os resultados mostram que o IHTC apresentou melhores resultados de recuperação de descritores em cinco das oito coleções de textos avaliadas. Porém, vale ressaltar que o trabalho de Furquim (2011) foi pensado para atender uma área específica e assim poderia alcançar desempenho e resultados superiores ao trabalho desenvolvido por Marcacini (2011). Portanto, o trabalho proposto por Silva (2012) pode apresentar desempenho superior ao utilizar processamento distribuído através de uma estrutura de grade computacional.

CONSIDERAÇÕES SOBRE OS TRABALHOS RELACIONADOS
A utilização de métodos de aprendizagem não supervisionada propostos por Marcacini (2011) pode ser uma alternativa para aumentar a capacidade do algoritmo de busca proposto neste trabalho. Assim, a partir de uma ontologia que abrange apenas os artigos 121 a 128 do Código Penal Brasileiro, um algoritmo de aprendizagem não supervisionado pode ser implementado e abranger um número maior de artigos. Este trabalho teve como objetivo desenvolver uma ferramenta de busca de jurisprudência em textos que possa auxiliar os profissionais do direito.
VISÃO GERAL DA APLICAÇÃO
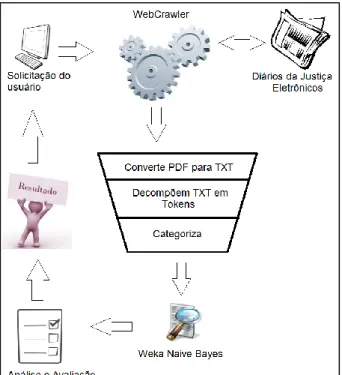
O processo de busca desenvolvido inicia-se com a solicitação do usuário, que informa o intervalo de datas em que deseja realizar a busca e o parâmetro pelo qual deseja encontrar a jurisprudência adequada. O processo de busca proposto incluiu as etapas de remoção de stopwords e lematização (lematização) conforme mostrado na Figura 6. Porém, essas etapas foram retiradas da ferramenta para que fosse possível utilizar a ontologia apresentada no Apêndice 1.

DEFINIÇÃO DA ONTOLOGIA
A primeira versão da ontologia desenvolvida consistia em vários termos compostos, conforme apresentado no Apêndice 2. Porém, durante o desenvolvimento da ferramenta de busca, houve a necessidade de alterar a ontologia; os motivos da mudança são apresentados na seção 4.7.
ANÁLISE DE REQUISITOS
Requisitos Funcionais
Requisitos não Funcionais
Regras de Negócio
MODELAGEM DA APLICAÇÃO
DETALHAMENTO DO DESENVOLVIMENTO
O documento processado pela biblioteca PDFBox e o tópico inserido pelo usuário são passados para um método que busca na ontologia e nas tabelas do thesaurus da base de dados termos relacionados ao tema. A partir desse processamento é criado um índice invertido com documentos, páginas, termos e sua importância. Com o índice invertido criado, o resultado é apresentado na página que o usuário utiliza para realizar a consulta.
DESCRIÇÃO DO EXPERIMENTO
Após categorizar os termos utilizando o padrão definido, a API Weka os analisa por meio de cálculos matemáticos e define um valor para o termo, dependendo da quantidade encontrada. A cada resultado foi atribuído um valor de relevância, ou seja, foram considerados suficientes, insuficientes ou insuficientes de acordo com o julgamento do perito. Com os resultados da análise dos especialistas, foi possível comparar a eficácia dos dois métodos de pesquisa.
RESULTADOS
A Tabela 4 apresenta os resultados comparativos entre a busca manual e a busca pela ferramenta. Com base nos resultados obtidos na busca realizada na edição DJE 1996, tanto manual quanto de ferramentas, constatou-se que os resultados não atingiram o objetivo de trazer termos mais relevantes ao assunto de interesse do usuário. Outros termos que compõem a ontologia e que prejudicaram os resultados foram os artigos do código penal, pois no texto do DJE são frequentemente encontrados valores numéricos que variam de 121 a 128, sem representar os artigos da lei que a ferramenta é tentando encontrar.

TRABALHOS FUTUROS
Uma abordagem de pré-processamento automático para mineração de textos em português: sob a perspectiva da inteligência computacional. Uma ferramenta de mineração de texto em banco de dados de um hospital universitário utilizando decomposições matriciais. Etapas do processo de mineração de textos – uma abordagem aplicada a textos em português brasileiro.
ONTOLOGIA VERSÃO FINAL
ONTOLOGIA VERSÃO INICIAL
TESAUROS
CÓDIGO PENAL ART. 121 A 128
Pena - reclusão de dois a seis anos, em caso de suicídio; ou pena de prisão de um a três anos se a tentativa de suicídio resultar em lesões corporais graves. 127 - as penas previstas nos dois artigos anteriores são aumentadas de um terço, se a gestante tiver sofrido lesão física grave em razão da interrupção da gravidez ou do meio utilizado para provocá-la; e são duplicados se a morte ocorrer por qualquer uma dessas causas. II - se a gravidez resultou de estupro e a gestante ou, se for incapaz, seu representante legal consentiu antes do aborto.
CÓDIGO FONTE DO WEBCRAWLER