Este modelo é integrado à biblioteca de código aberto transformadores, disponibilizada pelo grupo Hugging Face (WOLF et al., 2020). Atualmente, a ferramenta NILC Metrix (LEAL et al., 2021; LEAL et al., 2022a) é um dos recursos mais completos para geração de métricas de análise linguística e psicolinguística para o PB. Os métodos de AD tiveram sua origem em dados de imagem (BAYER et al., 2021).
No entanto, como apontado por Feng et al. 2021), é possível se inspirar nos métodos AD em imagens para textos. Especificamente no domínio PLN, Bayer et al. 2021) aponta que as pesquisas feitas para DA são recentes e escassas até 2019. Enquanto isso, o estudo de Longpre et al. 2020) levanta a hipótese de que os métodos AD aplicados à PNL só podem ser benéficos e eficientes se introduzirem novos padrões linguísticos.
Além disso, uma conclusão importante na análise de Lee et al. 2021) é que conjuntos de dados menores se beneficiam mais do uso de atributos linguísticos do que da incorporação de palavras. A versão mais recente da ferramenta NILC-Metrix (LEAL et al., 2021) (com 200 métricas) foi considerada, assim como as abordagens de aprendizado de transferência com a adição de métricas de rastreamento ocular. No contexto dos trabalhos sobre legibilidade, destaca-se o projeto PorSimples no NILC (ALUÍSIO et al., 2008).
9 Tarefas que são generalizáveis e consequentemente não criadas para nenhuma tarefa específica (LONGPRE et al., 2020).
Métodos Propostos para o Aumento de Dados para AAL
Substituição por Sinônimo (SS)
Esses grupos foram combinados para criar um léxico suplementar (ou contexto de palavras), composto por 12.564 palavras, incluindo verbos, adjetivos, advérbios e substantivos, com informações sobre (a) o sinônimo mais simples, (b) a forma infinitiva, (c) gênero e (d) número. A metodologia de construção desse léxico de unidades e sinônimos levou em consideração a combinação de cada palavra e seu grupo de sinônimos apresentados no TeP 2.0, em suas formas infinitivas (da base lexical - PortiLexicon), com a frequência de cada palavra correspondente no CorPop , também. em sua forma infinitiva dada por PortiLexicon. Foi desenvolvido a partir da análise de dados sobre o nível de alfabetização dos leitores brasileiros e as características que podem constituir um padrão de simplicidade textual em um corpus adequado a esses leitores (PASQUALINI, 2018), estando diretamente relacionado aos objetivos motivacionais desta pesquisa ; .
Considera dados de frequência para cada uma das palavras consideradas mais simples ou comuns do vocabulário popular brasileiro10. Posteriormente, informações de gênero e número de palavras do PortiLexicon foram incluídas para facilitar o SS e garantir coerência e coerência textual. 10 Segundo um dos principais pontos de análise de Wilkens et al., 2014), ao contrário da crença popular, o comprimento da palavra não é um bom indicador para categorizar palavras simples e complexas, mas a frequência de uso é.
Embora esse comportamento limite o número de possíveis substituições, a redução na complexidade do processo de substituição é significativa. Isso porque uma mudança de flexão em uma única palavra pode implicar em uma mudança de flexão em várias palavras dependentes em diferentes frases do texto. Portanto, a partir do léxico criado, cada um dos textos do corpus de treinamento é escaneado, onde todas as palavras dos textos foram verificadas por meio do tokenizador da biblioteca NLTK (BIRD et al., 2009).
Apenas signos identificados no corpus que não sejam nomes próprios dados pela biblioteca Spacy (HONNIBAL; MONTANI, 2017) são passíveis de substituição por seus respectivos sinônimos. Devido ao fato de existirem diferentes contextos de sinônimos expressos pelo Tep 2.0, uma mesma palavra pode ser substituída por mais de um sinônimo. Nesse sentido, a metodologia proposta considerou uma seleção inspirada no algoritmo da roleta genética11 (SHUKLA et al., 2015).
É importante ressaltar que, por se tratar de uma estratégia utilizada para AD, é fundamental que o SS desenvolvido consiga manter o rótulo inicial do texto, ou seja, Portanto, no caso de um texto simples original, os sinônimos com maior frequência no CorPop tiveram uma porção maior da roda, e os de menor frequência tiveram uma porção relativamente menor. No caso do algoritmo da roleta, ele é inspirado na teoria da seleção natural, na qual são selecionados os indivíduos mais adaptáveis e com maior probabilidade de reprodução.
Retrotradução (RT)
Metodologia Experimental
Coleta de Corpora
Enriquecimento de dados para teste: Para avaliar se os resultados obtidos com as técnicas de aumento de dados podem ser generalizados para outro domínio, foram buscados dados de textos originais e simplificados pareados de outros domínios do conhecimento para teste. Dentre as obras identificadas na Seção 3, o único repositório ativo e acessível desse gênero foi o disponibilizado por Wilkens et al. Textos coletados online Wilkens et al. 2016), não foram considerados devido à possibilidade de imprecisões na anotação disponível, pois foram caracterizados por meio de um modelo de classificação automática que estaria sujeito à propagação de erros.
Sobre os textos da camada de enriquecimento, devido à limitação da ferramenta NILC-Metrix de 2000 palavras para processamento e o tempo para processar embeddings para textos muito longos, apenas as primeiras 2000 palavras dos textos foram consideradas para capturar a representação dos atributos .
Classificação
Devido ao baixo número de textos no corpus alvo, o método leave one-out (LOO)12 é utilizado para treinar e validar os resultados do classificador. Assim, considerando o corpus inicial com i = 84 textos, o modelo foi treinado 84 vezes, cada vez um texto específico foi excluído do conjunto de treinamento e utilizado apenas para avaliar o modelo. Vale ressaltar que além do texto em si, o par anotado com o rótulo oposto também foi desconsiderado durante o treinamento, para evitar que os textos da prova vazassem durante o treinamento e causassem ajustes demais na classificação.
No caso do treinamento com AD, os textos ampliados relacionados ao texto deletado, bem como seu par oposto, também não são considerados nessa rodada.
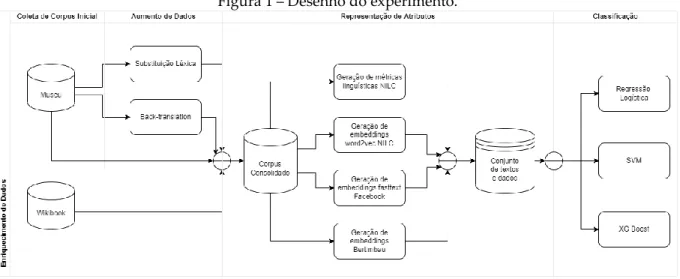
Representação de Atributos
Quanto às abordagens contextualizadas, foi utilizada a biblioteca Transformers, disponibilizada pelo grupo Hugging Face (WOLF et al., 2020), carregada com o modelo BERTimbau pré-treinado disponibilizado sob o nome neuralmind/bert-base portuguese -cased (SOUZA et al., 2020) com 768 dimensões. Especificamente para o modelo BERTimbau, existe uma limitação de processamento no número de tokens, portanto não é possível converter uma string com mais de 512 tokens por vez. Ao final do processamento das sentenças, é realizada uma média aritmética entre os vetores gerados para representar cada um dos textos do corpus.
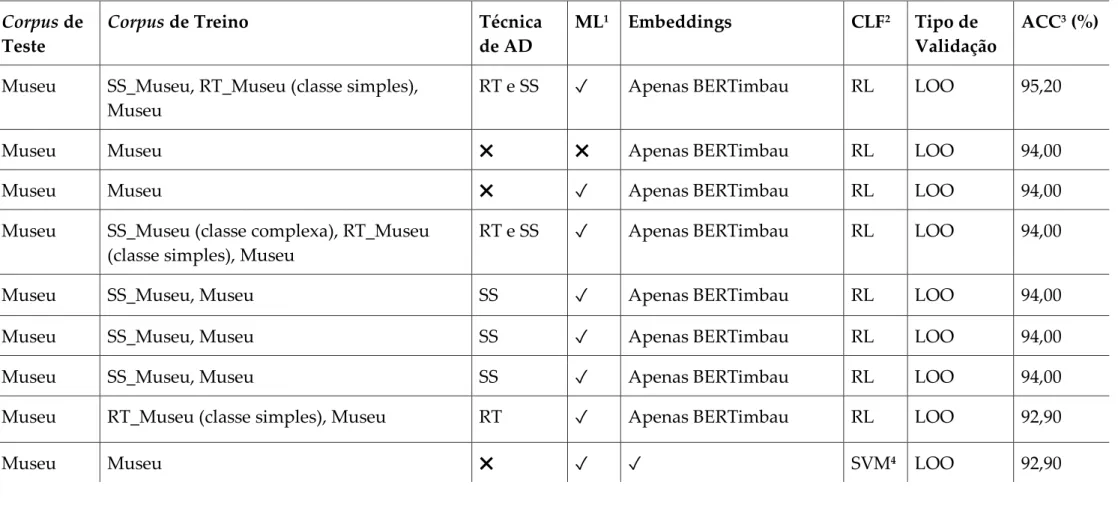
Para avaliar externamente as técnicas de DA propostas neste trabalho, 75 combinações de métodos e conjuntos de texto foram consideradas para treinar um modelo de classificação de legibilidade supervisionada (Tabela 1), visando AAL. Observa-se, na Tabela 1, que o limiar que define os agrupamentos dos modelos desenvolvidos é altamente variável, portanto, pequenas alterações na seleção de atributos ou textos utilizados para treinamento afetam significativamente o resultado. Ressalta-se que, devido ao baixo número de textos considerados neste experimento, o viés em tal análise está diretamente relacionado à volumetria dos dados.
Em termos holísticos, os textos reforçados com RT apresentaram maior nível de manutenção da estrutura gramatical do que aqueles reforçados com SS. Por outro lado, em relação às avaliações quantitativas, vale ressaltar que o aumento com SS promoveu melhores resultados do que o RT, mas não melhor do que a linha de base dada pelo modelo não aumentado. Dessa forma, o melhor resultado obtido para o conjunto inicial de textos do Museum Corpus foi de 94,0%.
Este resultado foi ligeiramente melhorado ao combinar a métrica NILC-Metrix com os embeddings contextualizados, para o modelo treinado com incremento com RT para a classe simples e SS para ambas as classes. Notadamente, os modelos treinados com dados boosted apresentaram desempenho igual ou ligeiramente melhor do que os treinados sem boost, porém apresentaram maior generalização quando introduzidos em outros domínios linguísticos, como pode ser observado nos resultados com os corpora de Wilkens et al. Além disso, em comparação com trabalhos anteriores, embora não seja possível estabelecer uma ligação direta entre o presente trabalho e Imperial (2021), haja vista que os corpora utilizados diferem entre si, em uma análise genérica de textos em idiomas com menos recursos, os resultados obtidos foram significativamente superiores aos apresentados por Imperial (2021) para a língua filipina.
Comparado com os resultados em PB, foi possível confirmar a generalização do modelo treinado com textos do corpus do museu ao testar o classificador com o mesmo corpus utilizado e desenvolvido no trabalho de Wilkens et al. Usando a combinação de textos aumentados, incorporações BERTimbau e métricas NILC-Metrix propostas aqui, obteve-se 84,4% de precisão para o classificador, o que é maior do que a precisão do classificador treinado sem aumento. Portanto, pode-se argumentar que o treinamento de um classificador com um conjunto reduzido avaliado por especialistas em legibilidade e aumentado com técnicas simples de AD promoveu resultados mais controlados em comparação com o uso de técnicas massivas como o WaC proposto por Wilkens et al.
Embeddings CLF 2 Tipo de Validação
Wikilivros RT_Museu (aula simples), Museu RT ✓ BERTimbau RL somente Por opção 80,50 Wikilivros SS_Museum, BT_Museu, Museu RT e SS ✖ BERTimbau RL somente Por opção 80,50 Wikilivros SS_Museu (classe complexa), . Wikibooks SS_Museum (aula simples), Museu SS ✓ BERTimbau RL apenas Por opção 79,20 Wikibooks RT_Museum (aula simples), Museu RT ✖ BERTimbau RL apenas Por opção 76,60 Wikibooks SS_Museum (classe complexa), RT_Museum. Proceedings of the NAACL HLT 2010 Fifth Workshop on Innovative Use of NLP for Building Educational Applications, 2010.
The Rastros Project: Contributions of natural language processing to the development of an eye tracking corpus with predictability rates for Brazilian Portuguese.