Extraktion textueller Informationen aus heterogenen PDF-Dokumenten
85
0
0
Texto
Imagem
![Abbildung 2.1: Ein PDF-Dokument-Modell [15]](https://thumb-eu.123doks.com/thumbv2/1library_info/14174471.3172512/16.892.362.531.459.889/abbildung-ein-pdf-dokument-modell.webp)
![Abbildung 2.2: Der logische Aufbau eines Dokuments [16].](https://thumb-eu.123doks.com/thumbv2/1library_info/14174471.3172512/17.892.215.703.753.1040/abbildung-der-logische-aufbau-eines-dokuments.webp)
![Abbildung 2.3: Links ist Seite eines Dokuments, rechts Klassifizierung ihrer Textblöcke [16].](https://thumb-eu.123doks.com/thumbv2/1library_info/14174471.3172512/18.892.121.788.629.1016/abbildung-dokuments-klassifizierung-textblöcke.webp)
![Abbildung 2.4: Darstellung der physischen Struktur des Dokuments als Baumstruktur [16].](https://thumb-eu.123doks.com/thumbv2/1library_info/14174471.3172512/19.892.203.707.193.575/abbildung-darstellung-physischen-struktur-dokuments-baumstruktur.webp)
+7
![Abbildung 3.1: Ein Ausschnitt einer zu analysierenden PDF-Datei [28].](https://thumb-eu.123doks.com/thumbv2/1library_info/14174471.3172512/25.892.177.721.157.1054/abbildung-ausschnitt-analysierenden-pdf-datei.webp)
![Abbildung 3.2: Eine zu analysierenden PDF-Datei durch tabula-py [36].](https://thumb-eu.123doks.com/thumbv2/1library_info/14174471.3172512/35.892.283.625.183.1182/abbildung-analysierenden-pdf-datei-tabula-py.webp)
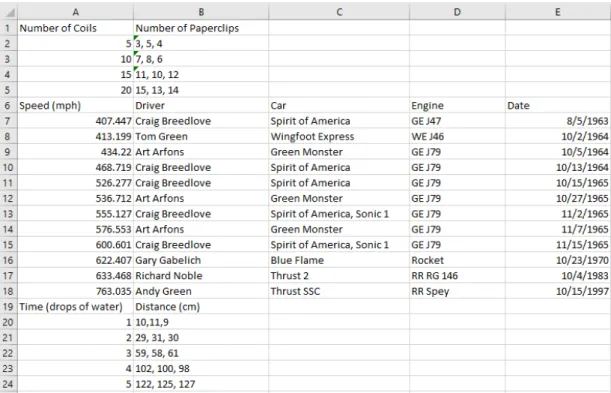
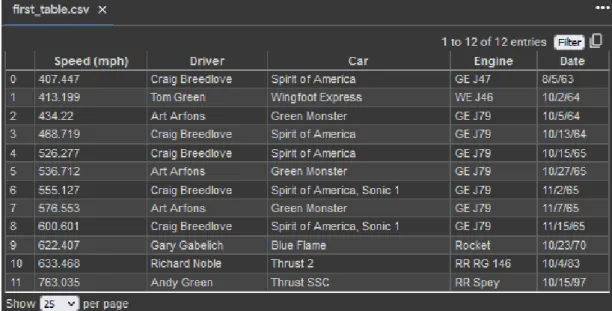
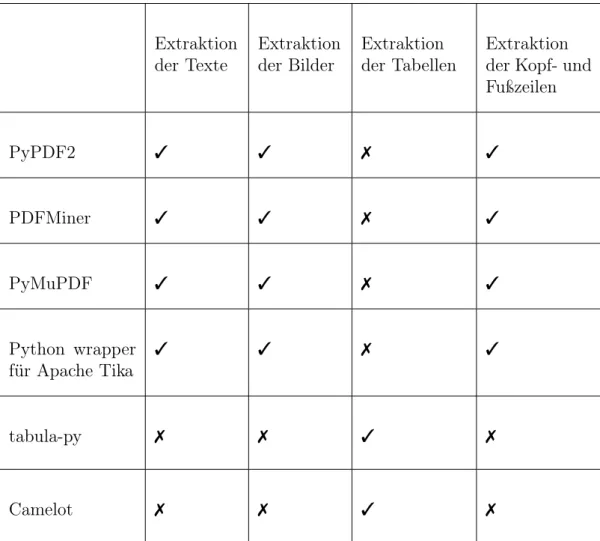
![Abbildung 3.5: Bearbeitung von PDF-Dateien mit Python-Bibliotheken [39]](https://thumb-eu.123doks.com/thumbv2/1library_info/14174471.3172512/40.892.115.857.364.921/abbildung-bearbeitung-von-pdf-dateien-mit-python-bibliotheken.webp)
Documentos relacionados
Thus, if the data values were in an Access relational table like Figure 10-2, the table declaration for Access could be used together with the read table command to read the members
