1200200172zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
11111" 1111111111 111/1111 "''''' 11nmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAI1I11IjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
MÉTODOS DE
DISCRIMINAÇÃO
ENTRE GRUPOS
APLICAÇÃO AO PROBLEMA DA CONCESSÃO DE CRÉDITO
Banca examinadora
zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAProf. Orientador Abraham Laredo Sicsú
Prof. João Carlos Douat
FUNDAÇÃO GETULIO VARGAS
ESCOLA DE ADMINISTRAÇÃO DE EMPRESAS DE SÃO PAULOjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
NELSON LERNER BARTH
MÉTODOS DE
DISCRIMINAÇÃO ENTRE GRUPOS
Aplicação ao Problema da Concessão de Crédito
Dissertação apresentada ao Curso de Pós-Graduação da FGV/EAESP (Área de Concentração "Sistemas de Informação") como requisito para obtenção de título de Mestre em Administração.
Orientador: Praf. Dr. Abraham Laredo Sicsú
SÃO PAULOzyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
2002
Fundação Getulio Va,.gas ~.,:,,:.-i'~""'t.~.ol\ Escola de Adminislração ..; ~,rte Empre~a~ de sse Paulo
f.-i)
Biblioteca ~ONMLKJIHGFEDCBA
BAR1H, Nelson Lemer. Métodos de discriminação entre grupos: aplicação ao problema da concessão de crédito. São Paulo: EAESPIFGV, 2002.
155 p. (Dissertação de Mestrado apresentada ao Curso de
Pós-Graduação da EAESPIFGV, Área de Concentração: Sistemas de
Informação).
Resumo: Apresenta métodos quantitativos próprios para a
discriminação entre grupos, baseados em Análise Discriminante Linear, Regressão Logística, Redes Neurais e Algoritmos Genéticos, dentro do contexto do problema da análise de crédito.
Palavraschaves: Métodos Quantitativos Discriminação entre Grupos Análise Discriminante Linear Regressão Logística Redes Neurais
-Algoritmos Genéticos - Análise de Crédito - Credit Scoring
-Inadimplência - Instituições Financeiras - Empresas.ONMLKJIHGFEDCBA
SP-00025076-0
SUMÁRIO
I. Introdução _
1.1. Tema _
1.2. Diferentes aspectos da concessão do crédito _
1.3. Justificativa da escolha do tema _
1.4. Metodologia _
1.5. Estrutura da dissertação _
1.6. Recursos computacionais utilizados _
11. Conceituação _
11.1. Amostra de casos históricos _
11.2. Modelos preditores de inadimplência _
11.3. Variáveis discriminantesONMLKJIHGFEDCBA
---11.4. Poder discriminador _
11.5. Amostras de desenvolvimento e de controle _
11.6. Classificação _
11.7. Casos históricos de créditos negados _
11.8. Transformações de variáveis _
m.
Métodos quantitativos tradicionais _111.1. Análise Discriminante Linear _
111.1.1. Função Discriminante Linear _
111.1.2. Determinação dos pesos _
111.1.3. Determinação do ponto de corte _
m.1.4. Escolha das variáveis que comporão o modelo _
111.1.5.Pressupostos para o uso da técnica 42 ill.1.6. Observações sobre tamanho das amostras 44
IlI.2. Regressão Logística 46
111.2.1. Modelo da Regressão Logística 47 111.2.2. Escolha das variáveis que comporão o modelo 50 111.2.3. Determinação do ponto de corte 50 111.2.4. Uso de funções polinomiais 52 111.2.5.Observações sobre tamanho das amostras 53
IV. Métodos alternativos 54
IV.1. Redes Neurais 54
IV.1.L Elementos de uma Rede Neural 55 IV. 1.2. Tipologia das Redes Neurais 59 IV.L3. "Formas de aprendizado" das Redes Neurais 59 IV. 1.4. Topologias das Redes Neurais 60 IV. 1.5. Algoritmos de aprendizado nas Redes Neurais 64
IV.1.6. Ponto de corte 67
IV.1.7. Validação do modelo: treinamento de Redes Neurais 68 IV. 1.8. Observações sobre Redes Neurais e Regressões 70 IV. 1.9. Requisitos para o uso da técnica 70
IV.1.10. Fundamentação estatística 71
IV.1.H. Interpretação dos resultados 72
IV.2. Algoritmos Genéticos 74
IV.2.1. Algoritmos Genéticos e a evolução de Darwin 74
IV.2.2. Conceitos 75
IV.2.3. Seleção, reprodução e evolução 78 IV.2.4. Algoritmos Genéticos para modelos não-lineares 90
IV.2.5. Caráter otimizador 91
IV.2.6. Convergência e calibração dos parâmetros 91
IV.2.7. Validação do modelo preditor 95zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
.
IV.2.8. Interpretação dos resultados 95 IV.2.9. Implementação denmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAs o ftw a r e dos Algoritmos Genéticos 96
V. Comparação entre os métodos 97
V.1. Estudos empíricos 97
V.1.l. Primeiro estudo na Centrale dei Bilanci em Turim 97 V.1.2. Segundo estudo na Centrale dei Bilanci em Turim 101 V.1.3. A pesquisa de ADYA e COLLOPY 103 V.2. Análise crítica das comparações entre métodos encontradas na literatura __ 106
V.2.1. Algumas conclusões fortes mencionadas na bibliografia 107 V.2.2. Algumas conclusões vulneráveis mencionadas na bibliografia_ 110
VI. Exemplos práticos comparativos _
VI.1. Exemplo com uma amostra de 46 empresas, _ VI. 1.1. Uso de Análise Discriminante Linear _
VI.1.2. Uso de Regressão Logística _
VI. 1.3. Uso de Redes Neurais _
VI.1.4. Uso de Algoritmos Genéticos _
VI.1.5. Resultados comparativos _
VI.2. Exemplo com amostra de 1452 empresas _ VI.2.1. Transformações de variáveis _ VI.2.2. Aplicação dos diferentes métodos discriminantes _
VI.2.3. Curvas ROC _
VI.2.4. Resultados comparativos _
VIT.Epilogo, _
Apêndice: Bibliografia. _
Agradecimentos
zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAo
zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBApresente trabalho não teria sido possível sem o apoio de muitas pessoas que, cada qual de uma forma, deram sua contribuição. Assim sendo, gostaria deagradecê-las:
• à Célia, que incentivou meu lado acadêmico e que me apOIOUnos
momentos de desânimo;
• aos meus pais, Tomas e Sara, pela minha capacidade de concentração;
• ao Prof. Dr. Abraham Laredo Sicsú, meu Orientador, pela sua
orientação detalhada, rigorosa, exigente e construtiva;
• ao Andre Laredo que, mesmo sem ter tomado consciência do fato
durante sua vida terrena, contribuiu para esta dissertação;
• ao Prof. Wilton de Oliveira Bussab, pelas suas contribuições em
estudos que antecederam esta dissertação;
• aos meus sócios Nelson Bardelli dos Santos, Paulo K. Endo e Victor
Ramon A. Perez, por existirem (em particular, ao primeiro, pela ajuda
na preparação de algumas figuras);
• à CAPES, ao CEB e à SERASA, pelos apoios financeiros que foram
fundamentais para este trabalho.
Obrigado,
Nelson Lemer Barth
.
BA"M a n is s till th e m o s t e x tra o rd in a ry c o m p u te rzyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAof a li. "
JOHN F. KENNEDY
"N e v e r s p e a k m o re c /e a r/y th a n y o u th in k . "
JEREMY BERNSTEINjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
I.
INTRODUÇÃO
1.1.
TEMA
o
zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAtema da Dissertação de Mestrado é a descrição e a comparação de vários métodos quantitativos próprios para a discriminação entre grupos, métodos estesdisponíveis para suporte à decisão na concessão de crédito.
A teoria que justifica a inadimplência creditícia com certeza envolve
conceitos econômicos, psicológicos e sociológicos. Entretanto, para a análise de
fichas cadastrais, de histórias creditícias ou de demonstrativos financeiros com
vistas a se conceder um crédito a uma pessoa fisica ou jurídica, é necessário
estabelecer um modelo de previsibilidade de inadimplência.
A literatura apresenta inúmeros relatos de utilização de métodos
quantitativos para o estabelecimento de modelos preditores para a concessão de
crédito a partir da análise de uma amostra de casos onde se conhecem as
contábeis etc.) e os resultados finais obtidos com a operação de crédito
-adimplência ou in-adimplência. Por
exemplo, citam-se BOGGESS,
1967,
SINKEY, 1975, KLINGEL e PRESS, 1976, ALTMAN et al., 1979, PERRY e
CRONAN, 1986, ALTMAN et al., 1994, SAUNDERS, 1996 e VARETTO,
1998.
Vários destes
métodos utilizam técnicas
"tradicionais" de
Análise
Multivariada tais como Análise Discriminante e Regressão Logística (descritas em
HAlR et al., 1998, p. 239-325 e SHARMA, 1996, caps. 8 e 10), entre outras.
Existem, entretanto, outras técnicas, ditas "alternativas", que visam também
resolver o mesmo tipo de problema. Citam-se, entre estas últimas, as Redes
Neurais (pATTERSON, 1996, ALTMAN et al., 1994 e COATS e FANT, 1993) e
os Algoritmos Genéticos (BAUER, 1994 e VARETTO, 1998).
A descrição destes métodos em uma linguagem acessível e um estudo
comparativo dos mesmos, evidenciando-se as vantagens e desvantagens na
aplicação ao problema da concessão de crédito, com certeza é de grande utilidade
e interesse para as áreas da Gestão Bancária ou para as instituições que se
dedicam
àquestão da concessão do crédito, quer seja para pessoas fisicas ou para
pessoas jurídicas.
1.2.
DIFERENTES ASPECTOS DA CONCESSÃO DO CRÉDITOzyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAAnalisa-se nesta seção o contexto onde se insere o objeto de estudo da
dissertação.
o
problema da determinação de um modelo preditor de inadimplência é
complexo e pode ser dissecado em algumas questões distintas (a dissertação se
concentrará somente na questão 4, isto é, a questão relacionada com o método
quantitativo a ser utilizado):
1. Em primeiro lugar, é preciso estabelecer um critério para se interpretar o
resultado da operação de crédito. Sob que aspectos o cliente será
considerado bom ou mau pagador? Pagamento em dia pode ser sinal de
sucesso na operação. Entretanto, se o cliente atrasar 2 dias, poderá
haver dúvidas sobre como classificar o cliente. E, se houver atraso de
um mês, mas houver complementação com juros de mora sem
questionamentos, tais dúvidas sobre a classificação aumentarão. O
estabelecimento de tal critério é pré-requisito para a determinação do
modelo de previsibilidade de inadimplência.
2. Existe o problema da escolha de um conjunto restrito de informações
sobre o candidato
àobtenção do crédito, informações estas a serem
coletadas para a decisão sobre a concessão do crédito. Não importa qual
o conjunto restrito de informações que se selecione (em função da
o fato de que ser o candidato um potencial adimplente ou inadimplente
dependerá das informações selecionadas no questionário, no balanço ou
no histórico creditício, mas também dependerá de uma série de
informações que não estão acessíveis (HOADLEY, 1996).
Acrescenta-se ainda que algumas destas informações não coletadas, que
certamente constituem fatores responsáveis pelo resultado do crédito
concedido, dependem de questões conjunturais, independentes do
candidato em si (conjuntura econômica do país na época, conjuntura do
setor econômico específico etc.).
3. É necessário escolher ou definir um critério para a determinação do
"melhor" método preditor de inadimplência ("função objetiva", na
nomenclatura de HOADLEY, 1996). Por exemplo, tal critério pode ser a
porcentagem de acertos na previsão ou os custos oriundos de predições
incorretas.
4. É necessário selecionar uma "família de técnicas" para a previsão de
inadimplência (exemplo: Análise Discriminante). Diferentes "famílias de
técnicas" apresentam vantagens e desvantagens: poder preditor,
flexibilidade, custos, demanda de processamento computacional, rapidez
e, finalmente, interpretabilidade das influências das diversas variáveis
observáveis nos candidatos a crédito.MLKJIHGFEDCBA
I
Salienta-se ainda que o sucesso da aplicação de um determinado método
quantitativo para o desenvolvimento de um modelo para análise de crédito não
depende apenas das qualidades intrínsecas do método do ponto de vista teórico.
Os resultados também serão influenciados pelos seguintes fatores:
~ treinamento do profissional na utilização do método quantitativo;
~ disponibilidade de boas ferramentas denmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAs o ftw a r e próprias para a aplicação do referido método.jihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
1.3.
JUSTIFICATIVA DA ESCOLHA DO TEMAA análise preditora de inadimplência tem sido objeto de estudos, conforme
citações mencionadas na seção 1.1. Empresas que concedem empréstimos
(bancos, comércio atacadista, comércio varejista, instituições de fomento etc.),
bem como instituições cuja missão é a própria análise de crédito, necessitam de
instrumentos para que possam de maneira razoavelmente objetiva classificar os
potenciais tomadores do crédito, quer sejam pessoas juridicas ou pessoas fisicas,
de acordo com a probabilidade de inadimplência futura. Conforme AL TMAN e
HALDEMAN (1995, p. 11), "[...] a desconfiança sobre a consistência das
tais pontuações [...] têm gerado grande interesse em modelos objetivos' e
reprodutíveis/ ".
Existem vários estudos que comparam,
àluz de alguns critérios, os
diferentes métodos quantitativos discriminantes quando aplicados ao problema da
concessão do crédito. Um sistematização destes estudos pode ser útil para que a
escolha de um determinado método para um problema específico possa ser
realizada de uma maneira mais objetiva.
A probabilidade de inadimplência, por sua vez, influencia a determinação
dos juros a serem incorporados na operação de crédito. No Brasil, onde as altas
taxas de juros são notórias por várias razões (não contempladas pelo escopo desta
dissertação), tomam-se relevantes todos os estudos relacionados com fatores que
podem influenciar na definição de tais taxas de juros.
A contribuição da dissertação é oferecer uma visão geral sobre diversos
métodos de discriminação entre grupos utilizados como ferramentas preditoras
para a concessão de crédito, desmistificando alguns jargões e mitos sobre o
zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA1Para ALTMAN e HALDEMAN (1995, p. 13), "objetivo significa alguma forma de
processo estatístico ou mecânico que produza uma classificação creditícia que seja independente da opinião humana".
2 A expressão "reprodutível" está sendo utilizada para caracterizar um processo (ou um modelo) para o qual existe a possibilidade de aplicá-lo inúmeras vezes a um determinado caso específico, alcançando-se sempre as mesmas conclusões. Uma pontuação de crédito por critérios subjetivos pode não ser "reprodutível", pois o resultado pode depender fortemente da pessoa que a executou.
assunto, e permitindo aos Administradores de Empresas julgar sobre as vantagens
e desvantagens de cada um dos tipos de ferramentas disponíveis.
Salienta-se que temas como Redes Neurais e Algoritmos Genéticos são
comumente alvos de paixões, devido às associações interessantes com outros
campos do conhecimento, correndo-se o risco de se despir do rigor científico na
sua escolha como método. Conforme GOODE e HATT (1968, pág. 87), "existe
razão para suspeitar de qualquer analogia com outra ciência, quando os modelos
aplicados são claramente compreendidos no quadro de referência teórico original,
mas não são relacionados com o novo quadro de referência". Em contrapartida,
com relação aos Algoritmos Genéticos, são comuns as resistências ao
entendimento da aplicação de conceitos darwinistas a entes não-biológicos.
Sem prejuízo do rigor dos conceitos, nesta dissertação dá-se preferência
para uma linguagem fluída, mais apegada à intuição, sem a utilização de fórmulas,
jargões, notações complexas ou teoremas matemáticos que exijam excessivo
poder de abstração. Pretende-se com esta forma gerar uma contribuição para os
profissionais Administradores de Empresas, que poderão adquirir um
entendimento básico e comparativo de cada uma destas técnicas. Sempre que
possível, é efetuado um paralelo com situações hipotéticas de análise de crédito.jihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
1.4.
BAM E T O D O L O G I AEsta dissertação tem um caráter exploratório. Utiliza-se tipicamente a
~ fa m ilia r iz a r e e le v a r o c o n h e c im e n to e a c o m p r e e n s ã o d e u m p r o b le m a e m p e r s p e c tiv a ;
~ a u x ilia r a d e s e n v o lv e r a fo r m u la ç ã o m a is p r e c is a d o p r o b le m a d e p e s q u is a ;
~ a c u m u la r a p r io r i in fo r m a ç õ e s d is p o n ív e is r e la c io n a d a s a u m p r o b le m a d e p e s q u is a c o n c lu s iv a a s e r e fe tu a d a fu tu r a m e n te ;
~ a ju d a r n o d e s e n v o lv im e n to o u n a c r ia ç ã o d e h ip ó te s e s e x p lic a tiv a s d e fa to s a s e r e m v e r ific a d o s n u m a p e s q u is a c a u s a l;
~ a ju d a r n o d e s e n v o lv im e n to o u n a c r ia ç ã o d e q u e s tõ e s d e p e s q u is a r e le v a n te s p a r a o o b je tiv o p r e te n d id o ;
~ a u x ilia r n a d e te r m in a ç ã o d e v a r iá v e is r e le v a n te s a s e r e m c o n s id e r a d a s n u m p r o b le m a d e p e s q u is a c o n c lu s iv a ;
~ c la r ific a r c o n c e ito s ; [...]
~ v e r ific a r s e p e s q u is a s s e m e lh a n te s já fo r a m r e a liz a d a s , q u a is o s m é to d o s u tiliz a d o s e q u a is o s r e s u lta d o s o b tid o s ;
~ e s ta b e le c e r p r io r id a d e s p a r a fu tu r a s p e s q u is a s .zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
MATTAR (1993, pág. 86) afirma que "os métodos empregados [em
pesquisas exploratórias] se dividem em: levantamento em fontes secundárias,
levantamentos de experiências, estudos de casos selecionados e observação
informal". Esta dissertação se baseia em "levantamento em fontes secundárias"
(revisão bibliográfica) e em "estudos de casos selecionados" (aplicação dos
métodos quantitativos de discriminação em grupos a algumas amostras de dados
de concessão de crédito).
Tendo esta dissertação natureza teórico-empírica, compreendem-se duas
etapas para sua elaboração: revisão bibliográfica e uma pesquisa. Na parte de
revisão bibliográfica, elabora-se um estudo de artigos, livros e materiais que
tratam do assunto, a fim de recolher, selecionar, analisar, articular e sintetizar
contribuições existentes sobre o tema. O texto é, complementarmente, ilustrado
com o auxílio de exemplos simples de aplicação dos métodos de discriminação
em grupos em problemas de concessão de crédito.
Na parte da pesquisa comparativa, os métodos quantitativos abordados no
decorrer da dissertação são aplicados a algumas amostras de casos reais,
ocorridos no passado, em que se conhecenmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAa p o s te r io r i as variáveis observáveis (dados de fichas cadastrais, de demonstrativos financeiros etc.) e o resultado final
em termos de adimplência / inadimplência.
Os diferentes métodos quantitativos são aplicados às amostras, no sentido
de se efetuar um estudo comparativo, levantando as vantagens, as desvantagens e
a aplicabilidade de cada método.
Dada a natureza sigilosa deste tipo de informação cadastral, financeira e
creditícia, os dados das amostras foram obtidos de forma convenientemente
disfarçada, a fim de proteger a confidencialidade das informações.jihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
1.5.
ESTRUTURA DA DISSERTAÇÃOO texto da dissertação está assim dividido:
~ um capítulo relativo à introdução, incluindo a definição do tema, os
>-
um capítulo próprio para a exposição de alguns conceitos e dealgumas definições operacionais, pré-requisitos para a clarificação
dos demais capítulos;
>-
um capítulo com itens pertinentes à revisão bibliográfica sobre osaSSIm denominados métodos quantitativos "tradicionais",
acompanhados de ilustrações baseadas em problemas simplificados
de concessão de crédito;
>-
um capítulo com itens pertinentes à revisão bibliográfica sobre osassim chamados métodos quantitativos "alternativos", também
acompanhados de ilustrações baseadas em problemas de concessão
de crédito;
>-
um capítulo dedicado à comparação entre os métodos, através decompilação bibliográfica;
>-
um capítulo próprio para apresentação de aplicação prática dosvários métodos quantitativos em situações relacionadaszyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAàanálise de crédito, para efeitos comparativos;
>-
um epílogo, incluindo a apresentação das limitações do estudorealizado e sugestões para estudos futuros.jihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
1.6.
RECURSOS COMPUTACIONAIS UTILIZADOSzyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAA aplicação prática (empírica) dos diversos métodos quantitativos, para
efeitos comparativos, é realizada utilizando-se programas de computador
nmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA (" s o ftw a r e " )próprios para cada uma das técnicas:
~
SPSS (Statistical Program for Social Sciences), para Análise
zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAI
Discriminante e Regressão Logística;
~
GeneHunter (Ward Systems Group), para Algoritmos Genéticos;
11.
CONCEITUAÇÃO
zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBANeste capítulo, apresentam-se alguns conceitos e definições operacionais
que serão necessários no decorrer desta dissertação.
Segundo GOODE e HATT (1968, p. 73), "uma definição operacional [...]
pode definir um fenômeno com maior definibilidade porque delineia as instruções
para se ter experiência igual a dos outros pesquisadores". Entretanto, os campos
da Estatística e das Ciências da Computação costumam apresentar seus conceitos
com unanimidade razoável em suas definições, o que simplifica em muito a tarefa
de adotar definições operacionais.
11.1.
AMOSTRA DE CASOS HISTÓRICOSo
modelo preditor de inadimplência creditícia é construído a partir daanálise de uma amostra de casos históricos de pessoas físicas ou jurídicas que
receberam créditos e cujas características (dados cadastrais, demonstrações
financeiras etc.) bem como os resultados finais obtidos com a operação de crédito
(adimplência ou inadimplência) são conhecidos.
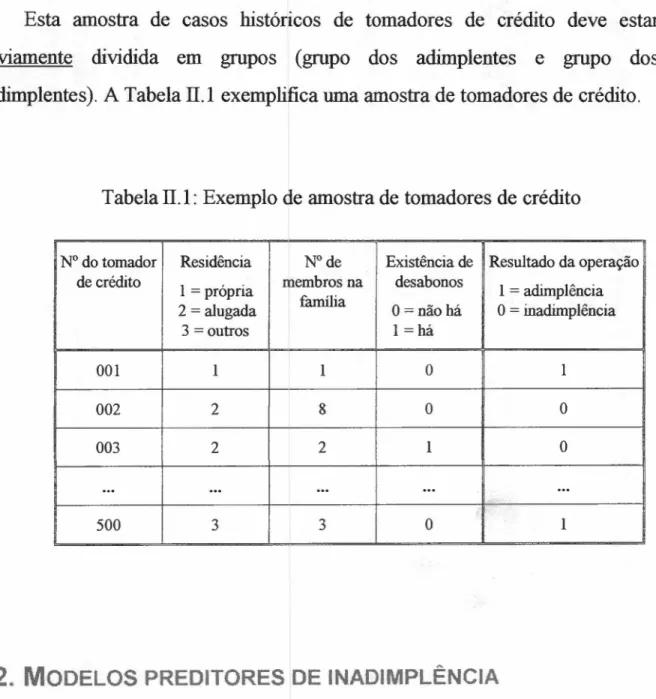
Esta amostra de casos históricos de tomadores de crédito deve estar
previamente dividida em grupos (grupo dos adimplentes e grupo dos
inadimplentes). A TabelazyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAlI.I exemplifica uma amostra de tomadores de crédito.
Tabela lI.I: Exemplo de amostra de tomadores de crédito
N° do tomador Residência N° de Existência de Resultado da operação de crédito
1 = própria membros na desabonos 1 = adimplência 2 = alugada família O = não há O = inadimplência
3 = outros 1 =há
001 1 1 O 1
002 2 8 O O
003 2 2 1 O
...
...
...
...
...
500 3 3 O 1jihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
11.2.
MODELOS PREDITORES DE INADIMPLÊNCIAOs modelos preditores de inadimplência são construídos com a ajuda das
famílias de técnicas apresentadas nesta dissertação, técnicas estas que utilizam as
características dos tomadores de crédito de ambos os grupos em que a amostra
o
modelo preditor de inadimplência assnn construído permitirá a
classificação de um novo aspirante a crédito em um dos grupos, ou seja, o
candidato
poderá
ser
considerado
"provável
adimplente"
ou
"provável
inadimplente".
o
candidato a crédito será considerado "provável adimplente" se suas
características forem mais parecidas com as dos tomadores conhecidos de crédito
que se mostraram adimplentes. Por outro lado, será considerado "provável
inadimplente" se suas características forem mais parecidas com as dos tomadores
conhecidos de crédito que se mostraram inadimplentes.
Apesar de existirem técnicas aplicáveis também a mais de dois grupos, por
exemplo a Análise Discriminante Múltipla (HAIR et al., 1998, p. 251-254),
limitar-se-á esta dissertação ao caso de dois grupos (provável adimplência
nmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAv e r s u sprovável inadimplência). Técnicas adequadas
àutilização de um número maior de
grupos poderiam ser utilizadas quando a instituição preferir dividir seus clientes
em mais do que duas categorias (por exemplo: risco alto de inadimplência, risco
médio de inadimplência e risco baixo de inadimplência).
jihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA11.3.
VARIÁVEIS DISCRIMINANTESCada uma das características observáveis nos candidatos a crédito
(exemplos: salário, tempo de residência, sexo, liquidez etc.) pode ser traduzida
por uma variável (denominada variável discriminante). Cada uma das variáveis
discriminantes, quando examinada individualmente, pode ser uma boa ou uma má
discriminadora entre os dois grupos.
N a Figura 11.1, ilustra-se uma hipotética variável discriminante X 1 que não
é capaz, por si só, de permitir a boa classificação de um tomador de crédito nos
dois grupos (adimplentes e inadimplentes). Examinado-se a distribuição de
probabilidades da variável XI, percebe-se que os valores de X 1 se superpõem nos
dois grupos. Por exemplo, a variável "idade do imóvel em que habita", tomada
isoladamente, pode não ser uma boa variável discriminante entre os grupos dos
inadimplentes e dos adimplentes se as distribuições de probabilidades desta
variável forem semelhantes nos dois grupos de tomadores de crédito.
Função densidade de probabilidade
de Xl Grupo dosinadimplentes Grupo dosadimplentes
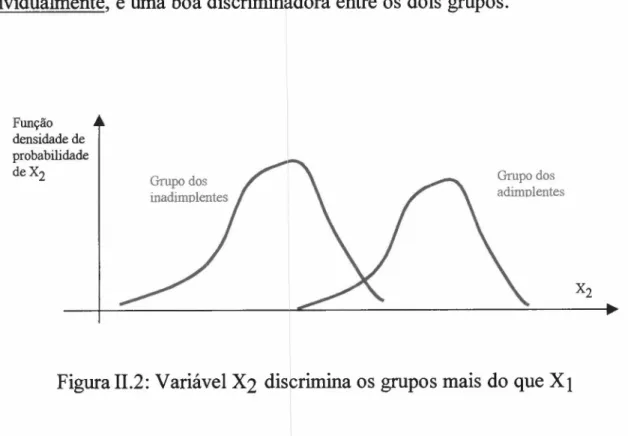
Já na Figura II.2, apresenta-se a variável discriminante X2 que,
individualmente, é uma boa discriminadora entre os dois grupos.
Função densidade de probabilidade deX2
Grupo dos inadimolentes
Grupo dos adimolentes
Figura 11.2:Variável X2 discrimina os grupos mais do quezyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAXj
Comparando-se, para os grupos dos adimplentes e dos inadimplentes, as
distribuições de probabilidades de uma série de variáveis discriminantes, cada
qual relacionada a uma característica observável nos candidatos, pode-se
determinar o conjunto de variáveis que deverão pertencer ao modelo de
previsibilidade de inadimplência. Se, por exemplo, tempo de residência é uma
variável que, por si só, discrimina bem os dois grupos, então pode-se considerar
que a mesma é uma forte candidata a ser incluída no modelo. Entretanto, na
realidade, a combinação de duas variáveis de pequeno poder discriminador pode
resultar em uma nova variável fortemente discriminante (SICSÚ, 1998, p. 58).
Assim, a análise das distribuições das variáveis discriminantes de forma isolada
pode levar a conclusões incorretas.jihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
11.4.
PODER DISCRIMINADORzyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAVárias são as possíveis definições operacionais para o poder discriminador
(ou poder discriminante) do modelo preditor de inadimplência.
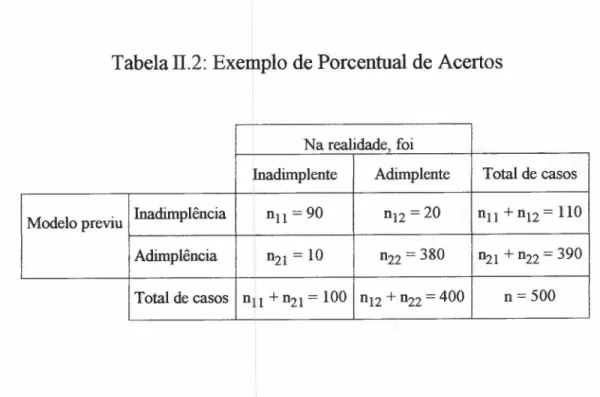
Freqüentemente, adota-se o Porcentual de Acertos ao se aplicar o modelo
preditor (previu-se adimplência e obteve-se adimplência, ou, previu-se
inadimplência e obteve-se inadimplência). No exemplo da Tabela II.2, obtém-se:
Porcentual de Acertos
=
(nIlzyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA+
n22) / n=
(90+
380) /500=
94%Tabela Il.2: Exemplo de Porcentual de Acertos
Na realidade, foi
Inadimplente Adimplente Total de casos
Modelo previu Inadimplência nll = 90 n12 = 20 n11+n12 = 110 Adimplência n21 = 10 n22 = 380 n21+n22 = 390 Total de casos n11+n21 = 100 n12+n22 = 400 n=500
o
Porcentual de Acertos obtido pela aplicação de um modelo preditor deinadimplência deve ser avaliado por comparação com alguns parâmetros. Se a
adimplentes e de inadimplentes, o Porcentual de Acertos deve ser superior a 50%
para haver alguma vantagem na aplicação do modelo, visto que, mediante
classificação aleatória nos dois grupos, espera-se obter acerto de 50%. HAIR et
alo (1998, p. 268-270) examina ainda qual seria este parâmetro de comparação
para o caso da amostra possuir proporções diferentes de adimplentes e de
inadimplentes. Por exemplo, se a amostra possuir 80% de adimplentes, a simples
classificação de todos os elementos da amostra como adimplentes geraria um
acerto de 80% (ou seja, neste caso, modelos preditores da inadimplência, para
serem úteis, deveriam apresentar Porcentual de Acertos superior a 80%).
Entretanto, desejando-se comparar os modelos preditores de inadimplência com a
classificação nos grupos de forma puramente aleatória, deve ser usado outro
critério, comparando-se a Taxa de Acertos obtida pelo modelo preditor com
CPROzyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA=p2
+
(1 - p)2 , onde p é a proporção de adimplentes na amostra conhecida.Assim, no caso de amostras com 80% de casos de adimplência, o modelo preditor
precisa obter Porcentual de Acerto superior a 68% (e não 80%) para ser
considerado útil.
Costuma-se dar o nome de Taxa de Acerto Total (TAT) ao Porcentual de
Acertos acima definido1
. Adicionalmente, pode-se definir:
1No decorrer desta dissertação, será também utilizada a nomenclatura Taxa de Erro
~ Taxa de Acertos dos Bons (TAB) como n22 / (n12zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
+
n22); no exemploda Tabela 1I.2, TAB = 380 /400 = 95%; e,
~ Taxa de Acertos dos Ruins (TAR) como n11 / (nll
+
n2Ü; no exemploda Tabela lI, TAR =90 /100 =90%.
Uma outra alternativa para definir o poder discriminador de um modelo
preditor de inadimplência seria utilizar a medida do custo do erro (custos
causados por conceder indevidamente os créditos somados aos custos causados
por rejeitar indevidamente os créditos). ALTMAN et al. (1977, p. 44-46)
apresenta algumas considerações sobre formas de dimensionamento dos custos
dos erros (de conceder e de não conceder crédito, ambos indevidamente ).1
De forma mais elaborada, OUQUE-RIBEIRO e SAL VATTO (1995)
enfatizam estratégias baseadas mais no potencial de lucro nas operações
creditícias do que na prevenção de perdas. Desta forma, um forte poder
discriminador de um modelo preditor de inadimplência estaria associado à sua
capacidade de maximizar lucros (e não simplesmente de maximizar acertos ou de
minimizar custosj.'
1 O detalhamento das formas de medida dos custos dos erros na previsão de
inadimplência não é objeto desta dissertação.
2 DUQUE-RIBEIRO e SALVATTO (1995) relatam técnicas para maximizar as rentabilidades nas operações de crédito tanto para o grupo de baixo risco como para o de alto
11.5.
AMOSTRAS DE DESENVOLVIMENTO E DE CONTROLEzyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBADenomina-se Amostra de De'senvolvimento a própria amostra de casos
históricos, onde se conhecem as características dos tomadores de crédito e os
resultados da operação (adimplência e inadimplência), com base na qual um
modelo preditor de inadimplência é construído.
Para se aferir a qualidade do modelo preditor, pode-se aplicá-lo à própria
amostra de desenvolvimento, verificando-se então o porcentual de acertos, o custo
total do erro ou outra medida qualquer. Entretanto, ao se testar o modelo usando a
própria amostra de desenvolvimento, pode-se concluir pelo seu bom desempenhozyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
I
quando, na realidade, o modelo pode, chegando-se a extremos, só funcionar bem
sobre esta única amostra. Na verdade, pode-se demonstrar ser viesado e otimista
o uso do porcentual de acertos obtido pela aplicação do modelo preditor sobre a
própria amostra de desenvolvimento como estimador do porcentual de acertos
quando da aplicação do modelo sobre novos aspirantes a crédito (EISENBEIS,
1977, p. 893).
De forma a se evitar tal viés, é conveniente repartir a amostra de casos
históricos em duas partes: a primeira, constituindo a Amostra de Desenvolvimento
(utilizada na construção do modelo preditor de inadimplência) e a segunda,
denominada Amostra de Teste (ou Amostra de Controle ou, ainda, Amostra de
Validação), própria para se medir a qualidade do modelo preditor.BA
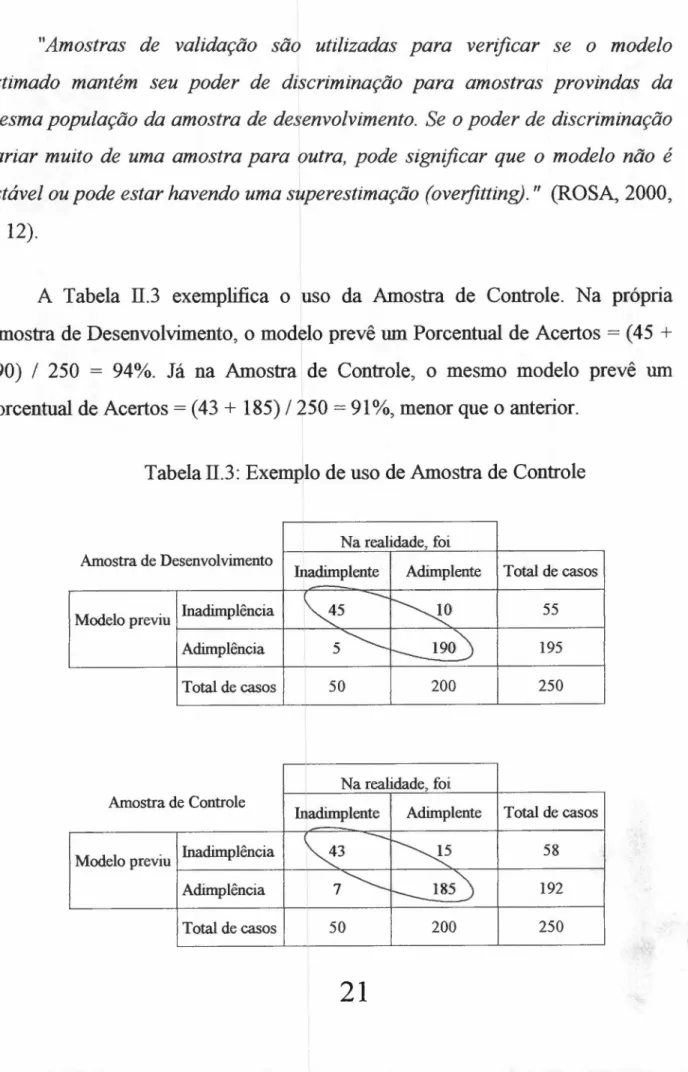
" A m o s tr a s d e v a lid a ç ã o s ã o u tiliz a d a s p a r a v e r ific a r s e o m o d e lo
e s tim a d o m a n té m s e u p o d e r d e d is c r im in a ç ã o p a r a a m o s tr a s p r o v in d a s d a
m e s m a p o p u la ç ã o d a a m o s tr a d e d e s e n v o lv im e n to . S e o p o d e r d e d is c r im in a ç ã o
v a r ia r m u ito d e u m a a m o s tr a p a r a o u tr a , p o d e s ig n ific a r q u e o m o d e lo n ã o é
e s tá v e l o u p o d e e s ta r h a v e n d o u m a s u p e r e s tim a ç ã o (o v e r fittin g )."zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA(ROSA, 2000,
p.12).
A Tabela II.3 exemplifica o uso da Amostra de Controle. Na própria
Amostra de Desenvolvimento, o modelo prevê um Porcentual de AcertoszyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA= (45
+
190) / 250 = 94%. Já na Amostra de Controle, o mesmo modelo prevê um
Porcentual de Acertos = (43
+
185) / 250 = 91 %, menor que o anterior.Tabela II.3: Exemplo de uso de Amostra de Controle
Na realidade, foi Amostra de Desenvolvimento
Inadimplente Adimplente Total de casosONMLKJIHGFEDCBA
~5
--
~Modelo previu Inadimplência 55
Adimplência 5~ ___ 190) 195
Total de casos 50 200 250
I
Na realidade, foi Amostra de Controle
Inadimplente Adimplente Total de casos
~3
-...
N
Modelo previu Inadimplência 58
Adimplência 7~
r--
185) 192Se a amostra de casos históricos de tomadores de crédito não possuir
tamanho suficiente para a separação entre Amostra de Desenvolvimento e
Amostra de Controle, existem técnicas que permitem efetuar a validação do
modelo preditor de inadimplência utilizando uma amostra única. Uma destas
técnicas,
denominada Jacknife, Método
U
ou Método
de Lachenbruch
(EISENBEIS, 1977, p. 893-895; ALTMAN et al., 1979, p. 25) sugere que se
construa o modelo preditor de inadimplência inúmeras vezes (na verdade,
MLKJIHGFEDCBAkvezes, onde
ké o tamanho da amostra de casos históricos). A cada vez, um dos
casos históricos é deixado de lado (ou seja, a técnica utilizada para a construção
do modelo preditor de inadimplência não o leva em consideração) e testa-se o
modelo obtido somente sobre este caso particular. Após repetir-se a operação
nmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAkvezes, poder-se-á verificar qual a porcentagem de acertos na previsão de
inadimplência dentre os
kcasos testados.
jihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA11.6.
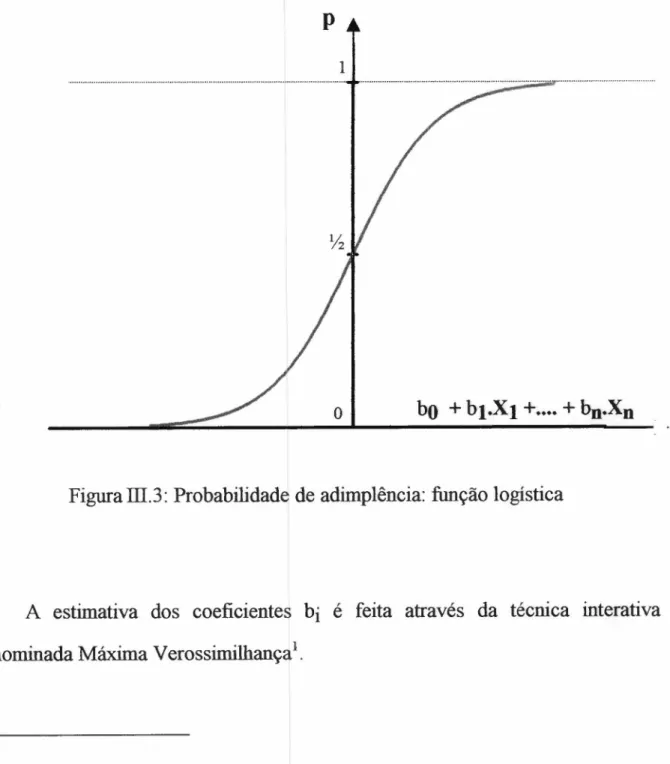
CLASSIFICAÇÃOOs modelos preditores, independentemente do método utilizado para
obtê-los, produzirão, ao se submeter um novo candidato a crédito, um resultado
numérico ("escore") que gerará uma classificação (como adimplente ou como
inadimplente). Este resultado numérico poderá ser, indiferentemente, o valor de
uma função discriminante, a probabilidade obtida de uma função logística, a
probabilidade obtida no neurônio de saída de uma Rede Neural ou o valor de uma
função gerada via Algoritmos Genéticos.
ONMLKJIHGFEDCBATal classificação será efetuada pela definição de um ponto de corte para o
resultado numérico mencionado. Abaixo do ponto de corte, considerar-se-á o
novo candidato como propenso à inadimplênciazyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA1.
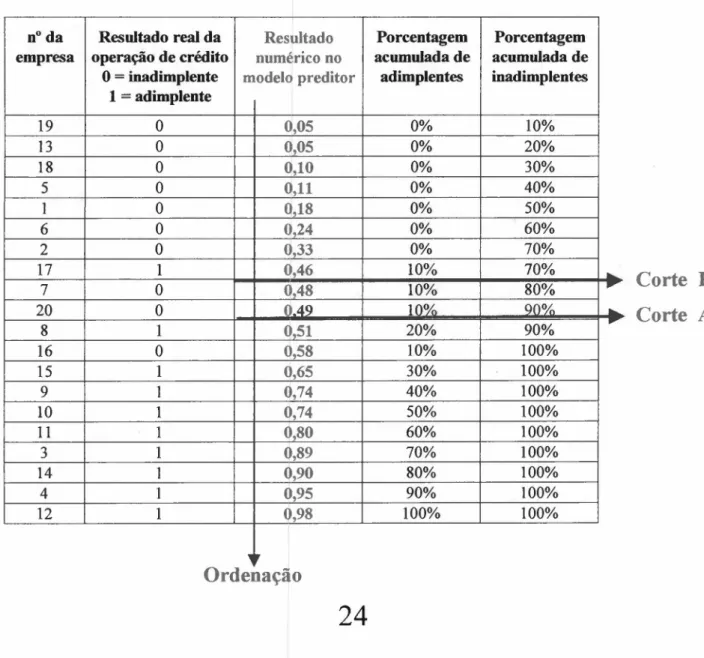
Um método empírico usado para resolver o problema de determinação do
ponto de corte começa pela ordenação da amostra de desenvolvimento em ordem
crescente do citado resultado numérico (resultado da função discriminante,
probabilidade resultante de uma Rede Neural etc.). A Tabela II.4 ilustra este
procedimento, apresentando 20 empresas constituintes da amostra de
desenvolvimento (10 inadimplentes e 10 adimplentes), devidamente ordenadas
pelo escore mencionado. As duas colunas :finais apresentam as porcentagens
cumulativas dos casos de real adimplência e inadimplência respectivamente.
Assim sendo, se for adotado o ponto de corte A, será entendido que futuras
empresas candidatas a crédito serão classificadas como potenciais adimplentes se
o modelo preditor gerar o referido escore superior a 0,50.
1 Entretanto, em certos modelos, o novo candidato é considerado como propenso à
Examinando-se a penúltima coluna, conclui-se que o ponto de corte A gera
10% como taxa de adimplentes classificados como inadimplentes.
Examinando-se a última coluna, conclui-Examinando-se que o ponto de corte A gera 100% - 90%zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA= 10%
como taxa de inadimplentes classificados como adimplentes. Diferentes pontos de
corte (por exemplo, o ponto de corte B) corresponderão portanto a diferentes
proporções entre acertos nas classificações de inadimplentes e acertos nas
classificações de adimplentes.
Tabela 11.4:Exemplo de uso do método empírico para classificação
n° da Resultado real da Resultado Porcentagem Porcentagem empresa operação de crédito numérico no acumulada de acumulada de
°
=inadimplente modelo preditor adimplentes inadimplentes 1=adimplente19 O 0,05 0% 10%
13 O 0,05 0% 20%
18 O 0,10 0% 30%
5 O 0,11 0% 40%
1 O 0,18 0% 50%
6 O 0,24 0% 60%
2 O 0,33 0% 70%
17 1 0,46 10% 70%
••
7 O Q,48 10% 80% ~
20 O 0.49 10% 90%
•..
8 1 0,51 20% 90% ~
16 O 0,58 10% 100%
15 1 0,65 30% 100%
9 1 0,74 40% 100%
10 1 0,74 50% 100%
11 1 0,80 60% 100%
3 1 0,89 70% 100%
14 1 0,90 80% 100%
4 1 0,95 90% 100%
12 1 0,98 100% 100%
."
Corte B
Corte
AOrdenação
Um fator importante a ser considerado na determinação do ponto de corte é
o custo do erro, visto que são diferentes o custo de não detectar um possível
inadimplente e o de não conceder um crédito por análise errônea. Por exemplo, se
o objetivo é minimizar o custo dos erros (e não maximizar o porcentual de
acertos) e o custo do erro de não prever uma inadimplência for maior, deve-se
então elevar o valor do ponto de corte de forma que o modelo passe a classificar
mais casos como inadimplentes.
Outro fator importante para a determinação do ponto de corte é a
probabilidadenmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAa p r io r i de classificação. Por exemplo, se existem poucos
inadimplentes para determinada operação creditícia, existe uma probabilidade a
p r io r i de que um futuro candidato se mostre um adimplente (neste caso, deve-se
baixar o valor do ponto de corte de forma que o modelo passe a prever
adimplência em mais casos).
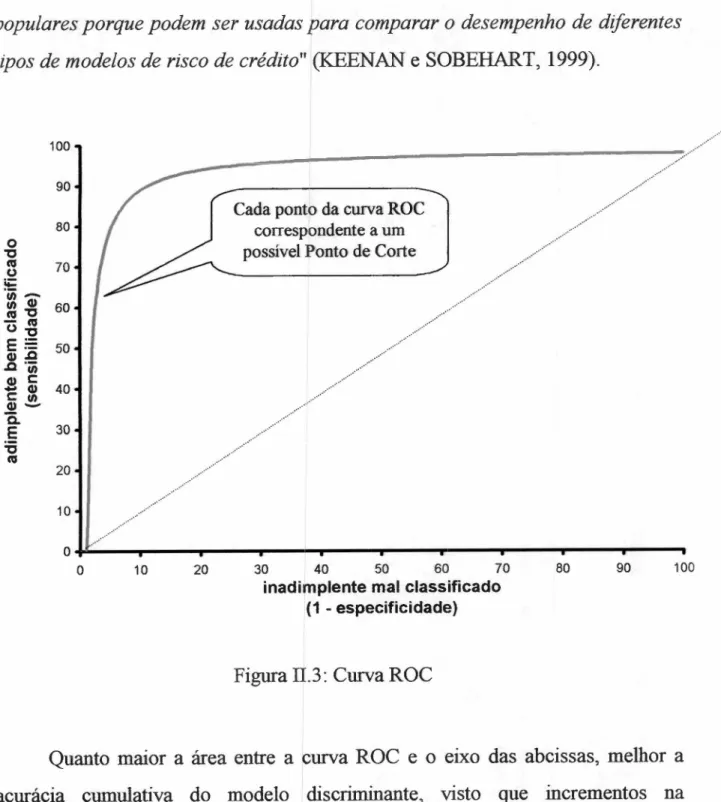
Um outro instrumento útil para a determinação do ponto de corte é a curva
ROCzyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA1 (R e c e iv e r O p e r a tin g C h a r a c te r is tic ouR e la tiv e O p e r a tin g C h a r a c te r is tic i,
1 Segundo TAPE (2001), a denominação ROC - Receiver Operating Characteristic é
originária do uso desta curva em um campo da ciência denominado Teoria da Detecção de Sinais, desenvolvida durante a 23 Guerra Mundial para fins de análise de imagens de radar.
Segundo o autor, somente após 1970 esta teoria foi reconhecida como útil também para a interpretação de resultados médicos.
apresentada em TAPE (2001). Também denominada Diagrama de Lorentz',
apresenta a proporção de "inadimplentes classificados como adimplentes" no eixo
das abcissas e a proporção dos "adimplentes hem classificados" no eixo das
ordenadas, conforme ilustrado na Figura 1I.3.
Utilizando-se a nomenclatura típica do uso da curva ROC, denomina-se
especificidade a relação
entre o número de inadimplentes corretamente
classificados e o número total de inadimplentes na amostra. Portanto, a relação
entre o número de inadimplentes mal classificados e o número total de
inadimplentes na amostra corresponde a (1 - especificidade), relação esta que
constitui o eixo das abcissas da curva ROC. Denomina-se sensibilidade a relação
entre o número de adimplentes corretamente classificados e o número total de
adimplentes na amostra, relação esta que constitui o eixo das ordenadas.
Cada ponto desta curva corresponde a uma definição distinta do ponto de
corte, facilitando a percepção dos erros que estarão sendo cometidos ao adotá-lo
(KEENAN e SOBEHART, 1999;
HANDe HENLEY, 1997, p. 529-530). Ainda
na nomenclatura usada com a curva ROC, sensibilidade e especificidade são
medidas que compõem a "acurácia cumulativa" do modelo preditor de
inadimplência.
nmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA" M e d id a s d e a c u r á c ia c u m u la tiv a tê m s e to m a d o c a d a v e z m a iszyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA1A denominação Diagrama de Lorenz ocorre em função da semelhança com a Curva de
Lorenz, desenvolvida por Max O. Lorenz para descrever a desigualdade social (DRISLANE e PARKINSON, 2001).jihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
p o p u la r e s p o r q u e p o d e m s e r u s a d a s p a r a c o m p a r a r o d e s e m p e n h o d e d ife r e n te s
tip o s d e m o d e lo s d e r is c o d e c r é d ito " zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA(KEENAN e SOBEHART, 1999).ONMLKJIHGFEDCBA
100zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
.... ...
90
__
---:7····
...•....•.., ....•...
....•...
80
Cada ponto da curva ROC correspbndente a um possível Ponto de Corte
...•...., ... o 'O ta U i;: 'in
-I/) CI) 60
ta 'OjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
õ.g
E.- 50Cl)Jl
Jl I/)
CI) c:: -c:: CI) 40
I/) CI)-õ.. E 'O ta 70 ... ..•.... ,.. -... ... ... ... ...•...•... ... ... .•.. 30 .... 20 ... ... ... ... .... 10 ... ...
o 10 20 30 40 50 60 70
inadimplente mal classificado
(1 - especificidade)
80 90 100
Figura Il.3: Curva ROC
Quanto maior a área entre a curva ROC e o eixo das abcissas, melhor a
acurácia cumulativa do modelo discriminante, visto que incrementos na
sensibilidade causam baixos decrementos da especificidade. A diagonal
sem nenhum poder discriminador (visto que, independentemente do ponto de
corte escolhido, o porcentual de adimplentes classificados como adimplentes será
sempre igual ao porcentual de inadimplentes classificados como adimplentes).jihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
11.7.
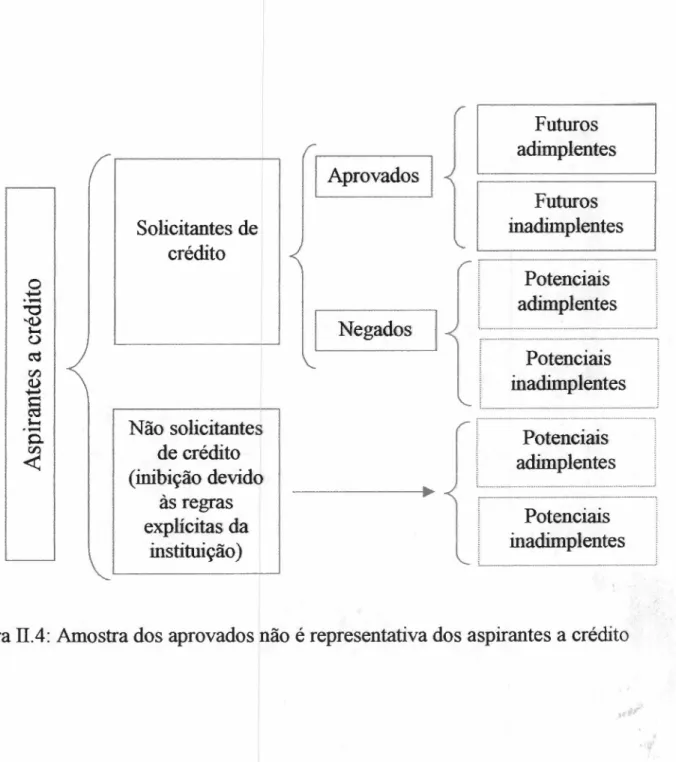
CASOS HISTÓRICOS DE CRÉDITOS NEGADOSTipicamente, as amostras utilizadas para desenvolver ou testar um modelo
preditor de inadimplência são constituídas por bons ou maus pagadores, mas
sempre por tomadores efetivos do crédito. Desta forma não estão representados
nestas amostras (conforme Figura II.4):
a) aspirantes para os quais o crédito foi negado;
b) pessoas fisicas ou jurídicas que nem tentaram obter o crédito por
julgarem que as regras da instituição não favoreceriam a
concessão.
EISENBEIS (1978, p. 215-216) reputa a questão acnna como muito
importante, por causa do viés introduzido no modelo preditor pelo fato da amostra
de desenvolvimento não ser representativa de uma população típica de aspirantes
a crédito. MAKUCH (1998, p. 65-66) apresenta algumas soluções para "corrigir"
tal viés, baseadas em artificios para tentar suprir a falta de informações sobre o
que aconteceria se tais aspirantes tivessem recebido seus créditos. Uma dessas
soluções é baseada na aplicação do modelo preditor aos aspirantes que tiveram
crédito rejeitado. Desta forma, tais aspirantes são classificados como prováveis
adimplentes ou prováveis inadimplentes e são então incluídos na amostra de
desenvolvimento como se tais resultados fossem reais (e não previstos). Com a
nova amostra de desenvolvimento, agora incluindo também os aspirantes que
tiveram crédito rejeitado, obtém-se um novo modelo preditor de inadimplência.
Solicitantes de
créditozyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
I
AprovadosFuturos adimplentes
Futuros inadimplentes
, ,
Não solicitantes de crédito (inibição devido
às regras explícitas da
instituição)
Negados
Potenciais
adimplentesnmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
i_ _ • .._ _ .•_• ._• .• .•_ • .• • •_ _• • • •_ _ .• ._ ._ . ..i
,--_._._---_._-Potenciais adimplentes ;, _ __.__
_
...•...•.•••.•....__.;Potenciais inadimplentes
~
Figura II.4: Amostra dos aprovados não é representativa dos aspirantes a créditoONMLKJIHGFEDCBA
11.8.
TRANSFORMAÇÕES DE VARIÁVEISzyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBADurante o processo de procura de um modelo preditor de inadimplência,
pode-se concluir que, dada uma variável X 1 correspondente a uma característica
dos solicitantes do crédito, uma outra variável do tipo X2 = X 1zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA2, X2 = In X 1,
X2 = l/XI etc. apresenta mais vantagens em participar do modelo do que a
variável Xj original. Isto acontece, por exemplo, quando a nova variável X2
possui maior poder discriminante que a variável original X 1 ou, ainda, quando a
nova variável possui distribuição mais próxima da normal (a ausência da
normalidade pode comprometer os resultados gerados por alguns dos métodos
discriminantes, conforme será examinado na seçãoMLKJIHGFEDCBAm .l.5 ).
Como a determinação de modelos preditores baseados em combinações
lineares de variáveis é mais fácil para vários dos métodos discriminantes, pode-se
utilizar uma técnica de linearização de variáveis. Por exemplo, em um modelo
preditor de inadimplência com 7 variáveis, se X 12 discrimina mais do que a
variável Xj ,ao invés de usar Xj no modelo preditor, rebatiza-se X 12 como sendo
uma nova variável X8, que será entãd introduzida no modelo.
Similarmente, pode-se introduzir no modelo preditor variáveis do tipo
X9 =X I.X 2, nos casos em que o efeito de uma variável na previsão de
inadimplência depende de outra variável, efeito este denominado Moderador ou
Interação (HAIR et al., 1998, p. 170-171). Um exemplo hipotético de interaçãoBA
ocorre na situação onde a influência de um aumento da renda na probabilidade de
adimplência é maior quando existem muitos filhos.
A presença de variáveis discriminantes categóricas (não-métricas) também
exige transformação. São exemplos: sexo, área de atuação da empresa, categoria
da profissão etc. Utiliza-se a técnica denmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAd u m m y v a r ia b le s para acomodar as variáveis não-métricas. Por exemplo, se a área de atuação da empresa pode ser
indústria, serviços ou comércio, criam-se 2 novas variáveis (se a variável
não-métrica original possui k estados, criam-se k - 1 novas variáveis, as chamadas
d u m m y v a r ia b le s ). Neste exemplo, as duas d u m m y v a r ia b le s poderiam ser "pertence à indústria" e "pertence ao comércio", assumindo os valores
apresentados na Tabela TI.5.
Tabela TI.5: Exemplo de variáveis dummy
Área de atuação da empresa
Indústria Comércio Serviços
1a variável dummy:zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA1 O O
"pertence àindústria"
2a variável dummy: O 1 O
Em certos casos, há vantaglns em categorizar variáveis originalmente
métricas, utilizando depois a técnic~ de
nmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAd u m m y v a r ia b le spara acomodá-las no
modelo (por exemplo, quando a variável discriminante influencia a possibilidade
de inadimplência de forma não miear). As categorias são determinadas por
tentativa e erro, aproveitando-se a experiência dos analistas de crédito.
111.
MÉTODOS QUANTITATIVOS TRADICIONAIS
111.1.
ANÁLISE DISCRIMINANTE LINEARBA1zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBANa Análise Discriminante baseada em uma Função Discriminante Linear,
constrói-se uma função através de combinação linear das variáveis discriminantes.
Nesta técnica, tenta-se construir a "melhor" Função Discriminante Linear em
termos de discriminação entre grupos,
Doravante, nesta dissertação, utilizar-se-á a expressão "Análise
Discriminante Linear" como sinônimo de "Análise Discriminante baseada em uma
Função Discriminante Linear", conforme denominação usual na literatura.
Entretanto, salienta-se que, a rigor, todas as técnicas apresentadas nesta
dissertação são técnicas de "análise discriminante".zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
1 A descrição do método Análise Discriminante Linear, bem como as respectivas
111.1.1. FUNÇÃO DISCRIMINANTE LINEARzyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
A Função Discriminante Linear' pode ser definida como:
onde Wi correspondem aos pesos atribuídos a cada uma das variáveis X], de
forma a maximizar o poder discriminador de Z. Os pesos wi são calculados para
que as distribuições de probabilidade de Z tenham pouca superposição entre os
dois grupos (adimplentes e inadimplentes), como na Figura ID.I. Dado um
aspirante a crédito, conhecendo-se os valores das variáveis X I a Xp e
calculando-se Z, pode-se classificá-lo em um dos dois grupos, conforme será visto
na seção ID.I.3.
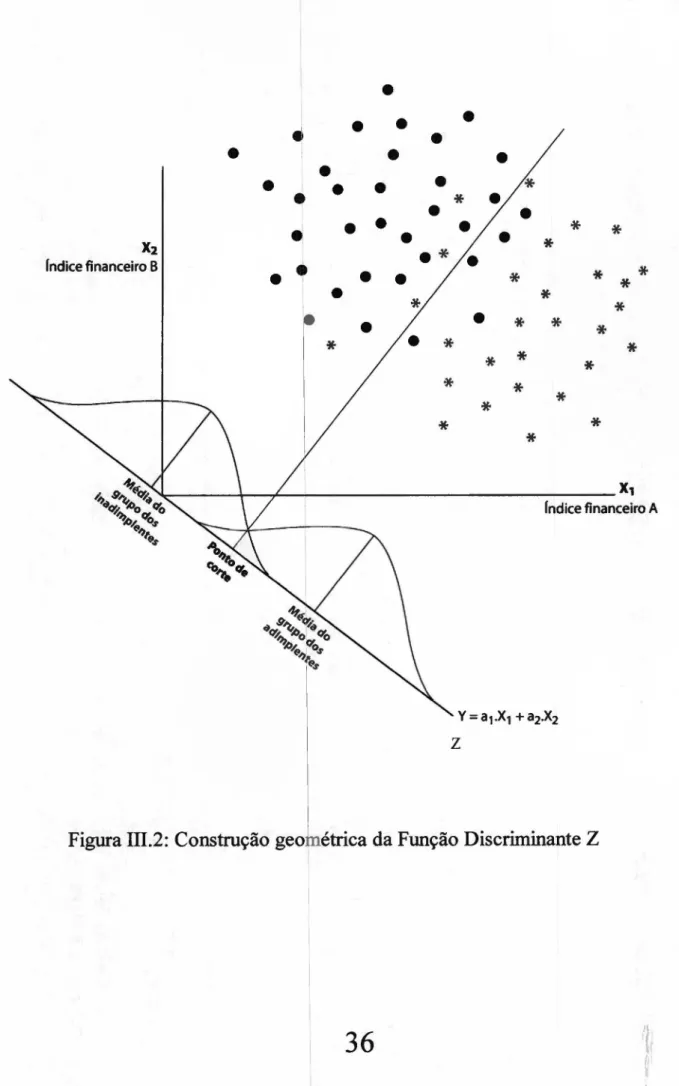
Uma representação geométrica da técnica matemática utilizada para a
escolha dos pesos Wi pode ser apresentada de forma simplificada em um exemplo
onde somente se consideram 2 variáveis, X] e X2. ilustra-se na Figura ID.2,
adaptada a partir de uma figura de AÁKER e DAY (1980, p. 470), uma amostra
de pessoas jurídicas que realizaram determinada operação de crédito. Para cada
um dos elementos desta amostra, conhecem-se os valores de duas variáveis X I ezyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
1 SHARMA (1996, p. 245) menciona que a Função Discriminante Linear também é
denominada Função Discriminante Linear de Fischer. Entretanto, trata-se de nomenclatura controversa, visto que HAIR et alo (1998, p. 263) utiliza este último nome para "funções de classificação" (que não serão detalhadas nesta dissertação).
X2 (índices financeiros). Determina-se o eixo Z que permita, para cada um dos
grupos, a mínima superposição entre as projeções dos elementos da amostras
sobre o referido eixo. Se o eixo das abcissas representa a variável X 1 e o eixo das
ordenadas representa a variável X2, o eixo Z representará uma combinação linear
das variáveis X 1 e X2.
Função densidade de probabilidade deZ
Grupo dos adimplentes
•
• •
•
•
•
•
•
•
I
•
•
•
,
• •
*
zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA*
•
•
•
• •
•
*
*
Xl
·1
•
•
*
rndice financeiro BjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
.*
•
•
•
*
*
•
I•
•
*
*
*
*
*
~
•
•
*
*
*
*
•
*
*
I
* *
*
*
*
I
*
*
*
*
*
I
..,~-9'"" .~MLKJIHGFEDCBA
.~ 'J I,
'*'oI"
Qó ~/(!fó., ~~ 1I
I
I
Figura Ill.2: Construção geométrica da Função Discriminante Z
z
BA111.1.2. DETERMINAÇÃO DOS PESOSzyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
o
cálculo dos pesos wi em Z
zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA=Wl.X 1
+
w2·X2
+
w3.X3
+ .... +
wp.Xp
objetiva minimizar a Taxa de Erro Global no modelo preditor, partindo-se das
seguintes premissas (SHARMA, 1996, p. 245 e 277-278; JOHNSON e
WICHERN, 1982, p. 461-520):
>-
Xj,X2, X3, ..., Xp possuem normalidade multivariada, isto é, cada
uma destas variáveis (individualmente) e qualquer combinação destas
variáveis possuem distribuição normal (HAIR et al., 1998, p. 70-73);
>-
variâncias
e
covariâncias
são
respectivamente
iguais
quando
examinadas em cada um dos grupos de adimplentes e de inadimplentes
(JACKSON, 1983, p. 92).
Existem vários produtos de
nmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAs o ftw a r eque permitem o cálculo dos
coeficientes wi, liberando o analista da necessidade de conhecer os procedimentos
matemáticos. Em particular, nesta dissertação, utiliza-se o
s o ftw a r eSPSS.
SHARMA (1996, p. 262-263) mostra que a Análise Discriminante Linear
pode ser também formulada como um problema de Regressão Linear Múltipla,
onde a variável dependente é binária
(Oou 1), representando o grupo de
classificação (inadimplentes e adimplentes). Os coeficientes calculados para a
equação de regressão serão os pesos Wi desejados. Assim sendo, pacotes de
disponibilizarem ferramentas para Regressão Múltipla, podem também ser usados
para o cálculo dos pesos wi. Entretanto, não permitem selecionar as variáveis com
poder discriminador significativo, conforme será examinado na seção TIL1.4.jihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
111.1.3. DETERMINAÇÃO DO PONTO DE CORTE
Tendo sido determinada a Função Discriminante Linear Z = wj.X 1zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
+
w2.X 2
+
W3·X3+ .... +
wn .Xp, esta poderá agora ser utilizada para classificarnovos candidatos a crédito. Utilizando-se os valores das variáveis Xi de um novo
candidato ao crédito, se Z for maior ou igual a um certo "ponto de corte",
classifica-se o candidato como de baixo risco de inadimplência. Se Z for menor
que o ponto de corte, classifica-se o candidato como de alto risco de
inadimplência.
A determinação do ponto de corte pode ser feita empiricamente, conforme
descrito na seção ll.6. Alternativamente, desde que válidas as suposições de
normalidade multivariada e de igualdade das estruturas de variâncias e
covariâncias, demonstra-se (JOHNSON e WICHERN, 1982, p. 480-482) que a
seguinte fórmula de determinação do ponto de corte
Zo minimiza
a Taxa de ErroGlobal, levando em consideração as probabilidadesMLKJIHGFEDCBAap rio ri de classificação e os custos dos erros:
~
Zo
é o ponto de corte (seZ
zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA>ZO,
classifica-se no grupo de baixorisco de inadimplência),
~ ZI é o valor médio de Z calculado para aqueles tomadores de
crédito da amostra utilizada que são conhecidos já como
adimplentes,
~
Z
2 é o valor médio de Z calculado para aqueles tomadores decrédito da amostra utilizada que são conhecidos já como
inadimplentes,
~
PI
é a probabilidadeMLKJIHGFEDCBAap rio ri do candidato ser classificado comoadimplente,
~ P2 é a probabilidade a p rio ri do candidato ser classificado como
inadimplente (ou 1 -
PI);
~ C(1I2) é o custo do erro de se classificar o candidato a crédito
como de baixo risco de inadimplência sendo ele de alto risco; e
~ C(2/I) é o custo do erro de se classificar o candidato a crédito
111.1.4. ESCOLHA DAS VARIÁVEIS QUE COMPORÃO O MODELOzyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
AzyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBArestrição quanto ao número de variáveis (características observáveis nos candidatos a crédito) a serem introduzidas no modelo de Análise Discriminante é
dada pela disponibilidade e pelo custo de obtenção destas variáveis.
De início, as variáveis que potencialmente poderão compor o modelo são
escolhidas pelos analistas, mediante técnicas denmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAb r a in s to r m in g , aproveitando as experiências próprias na área. Os analistas escolherão as variáveis onde acreditam
existir poder discriminante.
É
necessário então efetuar-se uma seleção nesteconjunto inicial de variáveis, por questões de custo e simplicidade: devem ser
retiradas as variáveis que não possuam poder discriminante e aquelas que tragam
informações já contempladas por outras variáveis.
Várias técnicas são comumente utilizadas para a seleção das variáveis
preditoras que comporão a Função Discriminante Linear:
~ Na técnica denominada " fo r w a r d s e le c tio n " , a prunerra variável
escolhida para compor a função é a que possui o maior poder
discriminante' entre todas as variáveis disponíveis. Em seguida,
seleciona-se a segunda variável, aquela que, junto com a variável
1 Existem diferentes critérios, desenvolvidos pelos estatísticos, para medir a
contribuição das diversas variáveis ao poder discriminante do modelo. Apesar de tais critérios não constituírem objeto desta dissertação, cita-se, em particular, o Teste Wilks' Lambda, descrito em SHARMA (1996, p. 252, 253, 266).
inicialmente escolhida, gera a função com maior poder discriminador.
Repete-se o procedimento até que nenhuma outra variável disponível
agregue mais poder discriminante à função até então definida.
>-
Na técnica denominadanmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA" b a c k w a r d s e le c tio n " , a função começa comtodas as variáveis disponíveis. Em seguida, retira-se da função a
variável que menos diminui o poder discriminante do modelo.
Repete-se o procedimento até que a retirada de qualquer das variáveis
restantes na função cause diminuição significativa no poder
discriminante do modelo.
~ A técnica " s te p w is e fo r w a r d s e le c tio n " é uma combinação das anteriores. A cada passo, agrega-se uma nova variável ou retira-se uma
variável previamente escolhida (uma variável anteriormente agregadazyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAà função é dela retirada se sua eliminação não causar, significativa baixa
no poder discriminante do modelo). Essa eliminação decorre da
inclusão posterior de outras variáveis que agregam poder discriminador
ao modelo de forma tal que aquela variável pode ser excluída sem
prejuízo.
Salienta-se que, utilizando-se uma das técnicas acima, por exemplo, a
s te p w is e fo r w a r d s e le c tio n , uma variável com alto poder discriminante poderá
acabar fora do modelo gerado se for altamente correlacionada com uma outra
variável ou com uma combinação de variáveis anteriormente introduzidas. Um
"último salário" após já ter sido introduzida a variável "salário médio anual" (visto
que o poder discriminante de ambas é baseado em características semelhantes do
candidato a crédito).
A existência de correlação entre as variáveis discriminantes do modelo
preditor é natural e não afetará a capacidade preditora do modelo, mas, em sendo
alta, poderá piorar a capacidade de interpretação dos pesos wi (SHARMA 1996,
p. 254). É a chamada multicolinearidade das variáveis discriminantes.jihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
111.1.5. PRESSUPOSTOS PARA O USO DA TÉCNICA
Nos problemas reais de análise de crédito, costumam não ser válidas as
suposições utilizadas na dedução das fórmulas de cálculo dos pesos Wi e do ponto
de corte
Zo
(normalidade multivariada e igualdade das variâncias e covariânciaspara cada grupo).zyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBAÉ comum o uso de variáveis contínuas, que nem sempre
apresentam distribuição normal, e de variáveis categóricas, como sexo, região
geográfica, área de atuação etc., onde certamente não existe normalidade. Isto
significa que, nestes casos, o método Análise Discriminante Linear precisa ser
utilizado com reservas.
Entretanto, não é fácil determinar o grau de comprometimento no modelo
preditor de inadimplência nos casos em que não são válidas essas suposiçõeszyxwvutsrqponmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA1.
Sugere-se, portanto, que se utilize o método, determinando os pesos Wi e um
ponto de corte Zo. O teste de validação do modelo, realizado posteriormente,
poderá eventualmente ser satisfatório apesar de não serem válidas as premissas.
No lugar da fórmula apresentada na seção m.l.3 para a determinação do ponto de
corte, conviria utilizar o procedimento empírico descrito na seção II.6.
A eficiência do modelo preditor também pode ficar comprometida na falta
da igualdade das variâncias e covariâncias nos dois grupos". Um teste para aferir
a igualdade das matrizes de covariância é o M de Box (SHARMA, 1996, p. 264),
ressalvando-se que este teste é demasiadamente sensível, rejeitando a hipótese de
igualdade dessas matrizes no caso de amostras muito grandes, ainda que haja
apenas pequeníssimas diferenças (que não seriam comprometedoras).
Finalmente, a Análise Discriminante Linear exige relações lineares, ou seja,
os pesos Wi do modelo preditor de inadimplência devem estar multiplicando as
1A normalidade multivariada é condição suficiente para que o modelo se aplique, mas
não é estritamente necessária.
2 SHARMA (1996, p. 264) e H4JR et al. (1998, p. 259) mencionam ainda a possibilidade de uso de uma outra técnica de Análise Discriminante, baseada em Função Discriminante Quadrática, que pode ser melhor adequada no caso de desigualdade das referidas variâncias e covariâncias. Um exemplo de Função Discriminante Quadrática com duas variáveis
variáveis X] (e não Xi2, In X] etc.). Relações não-lineares não são refletidas na
função discriminante Z, a menos que as variáveis com efeito não-linear sejam
transformadas, conforme exposto na seção II.8 (HAIR et al., 1998, p.259-260).
Se, hipoteticamente, existir uma relação na qual o risco de inadimplência aumenta
com o quadrado da distância da instituição à moradia do cliente, a Função
Discriminante Linear não será apropriada, visto existir uma relação não-linear
com a variável "distância". Entretanto, pode-se introduzir no modelo a variável
"quadrado da distância", ou seja, através de linearização, pode-se introduzir
variáveis de influência não-linear no modelo preditor de inadimplência.jihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
111.1.6. OBSERVAÇÕES SOBRE TAMANHO DAS AMOSTRAS
o
tamanho mínimo da amostra de candidatos a crédito onde se conheceMLKJIHGFEDCBAap rio ri o resultado (inadimplência ou adimplência) pode ser determinado a partir de sugestões "práticas" apresentadas por HAIR et alo (1998, p.258):
~ utilizar proporções semelhantes para o número adimplentes e de
inadimplentes na amostra; ROSA (2000, p. 12) acrescenta quenmlkjihgfedcbaZYXWVUTSRQPONMLKJIHGFEDCBA
" ... q u a n d o s e u tiliz a u m a a m o s tr a p r o p o r c io n a l à p o p u la ç ã o , c o m o a q u a n tid a d e d e c lie n te s b o n s é s e m p r e m u ito m a io r d o q u e a d e r u in s , o m o d e lo fin a l a c a b a s e n d o e x c e le n te p a r a d is c r im in a r o s c lie n te s b o n s , p o r é m , in e fic ie n te p a r a d is c r im in a r o s r u in s ." ;
~ utilizar uma amostra de no mínimo 5 (pior caso) ou 20 elementos para
cada uma das variáveis discriminantes.BA
Entretanto, com as grandes bases de dados hoje disponíveis e manipuláveis
com ajuda dos computadores, não há Igrandes problemas em obtenção de amostras
bem maiores que as amostras mínimas aqui definidas.
Claramente, permanece mesmo assim a questão da confiabilidade nas
informações disponíveis, em função da qualidade das fichas cadastrais, da