DESEMPENHO E DISPONIBILIDADE EM
SISTEMAS DE FLUXO DE TRABALHO
CIENTÍFICO INTENSIVOS EM DADOS
DESEMPENHO E DISPONIBILIDADE EM
SISTEMAS DE FLUXO DE TRABALHO
CIENTÍFICO INTENSIVOS EM DADOS
Dissertaçãoapresentada aoCurso de
Pós-Graduação em Ciênia da Computação
da Universidade Federal de Minas Gerais
omo requisito parial para a obtenção
do grau de Mestre em Ciênia da
Com-putação.
TÚLIO COELHO TAVARES
FOLHA DE APROVAÇO
Desempenho e Disponibilidade em Sistemas de Fluxo de
Trabalho Cientío Intensivos em Dados
TÚLIO COELHO TAVARES
Dissertação defendidae aprovada pelabana examinadora onstituída por:
Prof. Renato Antonio C. Ferreira Orientador
Universidade Federalde Minas Gerais
Prof. Dorgival Olavo Guedes Neto
Universidade Federalde Minas Gerais
Prof.Wagner Meira Junior
Universidade Federalde Minas Gerais
Prof.Franiso José da Silva e Silva
1 Introdução 1
1.1 Objetivo . . . 4
1.2 Contribuições doTrabalho . . . 4
1.3 Coneitos . . . 5
1.4 Organização doTexto . . . 7
2 Trabalhos Relaionados 8 2.1 Anthill . . . 8
2.1.1 Dependênia de Dados . . . 10
2.1.2 Tolerâniaa Faltas noAnthill . . . 11
2.2 Mobius . . . 11
2.2.1 Mako. . . 12
2.3 Sistemas de Fluxo de TrabalhoCientío . . . 12
2.3.1 Sistemade FluxodeTrabalhoCientíoomSuporteaBano de Dados XML . . . 13
2.3.2 Chimerae Pegasus . . . 14
2.3.3 Sistemaom Reuso de Componentes . . . 15
2.4 DISC ePhoenix . . . 16
2.5 Grid Datafarm . . . 17
2.6 MapRedue . . . 17
2.7 FTOP . . . 18
2.7.1 Sumário . . . 20
3 Disponibilidade em Sistemas Distribuídos 21 3.1 Modelos de Faltas . . . 21
3.1.1 Modelo de FaltasFalhae Pára (Fail-stop) . . . 22
3.1.2 Modelo de Queda . . . 23
3.1.3 Modelo de FaltaporOmissão . . . 23
3.2.2 Message Logging . . . 27
3.2.3 Tolerâniaa Faltas emHardware . . . 28
3.2.4 Métodos Espeíos de Apliação . . . 29
3.2.5 Repliação Ativa . . . 29
3.2.6 Sumário . . . 29
4 Sistema de Fluxo de Trabalho Cientío Proposto 31 4.1 Requisitos Cobertos . . . 31
4.2 Arquitetura Proposta . . . 32
4.2.1 Gerente de Metadados do Fluxos de Trabalho (GMFT) . . . . 34
4.2.2 Gerente de Armazenamento de Dados emMemória(GADM) . 35 4.2.3 Gerente de Armazenamento Persistente (GAP) . . . 36
4.3 Apliação Exemplo: Análise de Plaentasde Rato . . . 37
4.3.1 Sumário . . . 39
5 Implementação 41 5.1 Dados e Operações dos Componentes do Sistema . . . 42
5.2 Aumento daDisponibilidade doSistema . . . 45
5.2.1 Modelo de Faltase Método de Tolerâniaa Faltas Adotados . 45 5.2.2 Protoolo de Controle . . . 48
5.2.3 Meanismode Reuperação . . . 50
5.2.4 Sumário . . . 55
6 Experimentos 56 6.1 Ambiente Experimental . . . 56
6.2 Resultados . . . 57
6.2.1 Resultados sem Inserção de Faltas . . . 57
6.2.2 Resultados om Inserção de Faltas. . . 59
6.2.3 OutrasApliações. . . 63
7 Conlusão e Trabalhos Futuros 65 7.1 TrabalhosFuturos. . . 65
1.1 Fluxo de Trabalho de uma apliação om quatro diferentes tarefas de
análise de imagens. . . 2
1.2 Propagação: Falta->Erro ->Falha [VR01℄ . . . 6
2.1 Visão domodelo de programação lter stream. . . 10
2.2 A arquitetura do ComponenteMakodo Mobius. . . 13
4.1 OrganizaçãodosComponentesdoSistemade FluxodeTrabalhoCientío. 34 4.2 Fluxo de trabalhodaapliaçãodividido emestágios. . . 39
4.3 Instâniasdosltrosduranteaexeuçãodouxodetrabalhodaapliação exemplo. . . 40
5.1 Camadas das entidadespresentes naexeução dos uxos de trabalho. . . 42
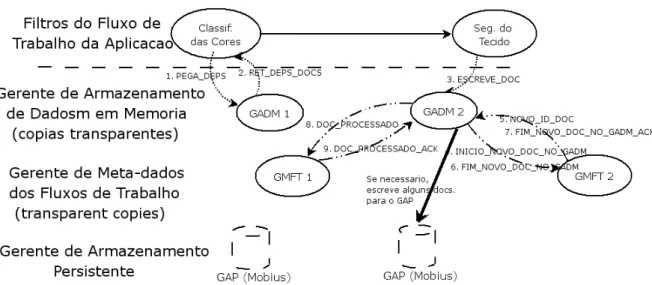
5.2 ComuniaçãoentreosomponentequandooltroClassiaçãodasCores lê um doumento. . . 50
5.3 Comuniação entre os omponentes quando o ltro Classiação das Cores envia um doumento para oltro Segmentação do Teido. . . 51
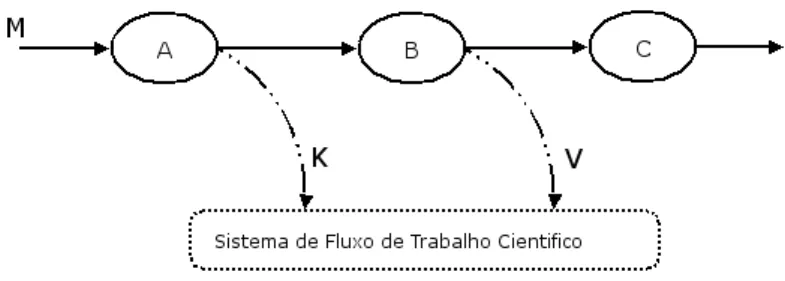
5.4 Exemplo da reuperação do sistema após uma falha. Existem
M
dou-mentospara serem proessados da base de dados iniial, eK
eV
dou-mentosdos uxos intermediários. . . 525.5 Exemplo de reuperação dos ltros do uxo de trabalho da apliação biomédia. . . 53
6.1 Tempo de exeução doltro PP/PF sem inserção de faltas.. . . 57
6.2 Speed-up. . . 58
6.3 Exeução doltro Normalização doHistogramasem inserçãode faltas. . 59
6.4 Exeução dos ltros Classiação das Cores e Segmentação do Teido sem inserção de faltas. . . 60
da apliação;6 - três faltasem ltros daapliação . . . 61
6.7 TempodeexeuçãodoltroNormalizaçãodoHistograma,rodandoem8
máquinas, em6 enáriosdiferentes: 1- sem falta; 2- uma faltano ltro
daapliação; 3- umafaltanoGADM; 4-uma faltanoWMFT; 5-duas
faltas emltros daapliação; 6 -três faltasemltros da apliação. . . . 61
6.8 Tempo de exeuçãodos ltrosClassiação das Corese Segmentaçãodo
Teido, rodando em 6 máquinas,em 6enários diferentes: 1- sem falta;
2 - uma falta no ltro da apliação; 3 - uma falta no GADM; 4 - uma
faltanoGMFT; 5- duasfaltasemltros daapliação; 6-três faltasem
6.1 Perentual do tempo, durante a exeução do segundo estágio da
Introdução
À medida que a Ciênia da Computação vem evoluindo e alançando diversas
áreasdeonheimento,oproessodeanálisede dadostem-setornadoumaatividade
extremamentesignianteemváriaspesquisasientías. Entremuitasáreaspodem
itar-seasiêniasnaturais,taisomoabiologiaeageograa, ujosdadossão
obti-dos porinstrumentos omomirosópios,telesópios, ousensores limátios,oupor
simulaçõesnumérias. Como um exemplo, onsidere-seo desenvolvimentode novas
terapiaspara tratar doenças. Um laboratóriobiomédio omeçará eventualmente a
pesquisa nonívelmoleulareelular, então onduziráum grandenúmero de
exper-imentosem animais e, mais tarde, vai transferir sua pesquisa para paientes. Para
alançarosuesso emada um desses passos,os ientistas preisamusar ambientes
omputaionaisparaanalisarimagens,porexemplo,deélulasoudeórgãos,obtidas
por meiode mirosópiosde altaresolução.
Para ajudar ospesquisadores emsuas análises,foramintroduzidososSistemas
deFluxodeTrabalhoCientío[FVWZ02,DBG
+
03,ABJ
+
04,LAB
+
05,BLNC06,
HRL
+
05℄. Fluxos de TrabalhoCientíos são proessos nos quais tarefas são
estru-turadasbaseadasnosoneitos,teorias,experimentosedadosusadospelosientistas
paraonseguirematransformaçãodedadosbrutosemresultadospubliáveis[ABJ
+
04℄.
Eles são entrados nos dados e podem ser modelados omo redes de proessos
baseadasemuxosdedados(dataowproessnetworks)[LP95℄,ummodelode
om-putação que suporta exeução de proessos onorrentes om omuniação baseada
em uxos. Os uxos de trabalho podem ser desritos omo um grafo direionado
ílio ouaílio no qual osnodos representam omponentes de proessamento da
apliação, e as arestas representam os uxos de dados troados entre esses
ompo-nentes. Emum exemploespeíodeuma apliaçãode análisedeimagens
biomédi-as,umuxodetrabalhopodeservistoomoomostradonagura1.1. Esseexemplo
mu-danças do fenótipo induzidas por manipulações do genótipo. Nessa gura podem
ver-se ver quatro diferentes omponentes de um uxo de trabalho ientío. Cada
um delesestá relaionadoauma tarefade análisede imagens,eessas tarefas devem
ser apliadasem seqüeniaaos slides.
Figura 1.1: Fluxo de Trabalho de uma apliação om quatro diferentes tarefas de
análisede imagens.
Os Sistemas de Fluxo de Trabalho Cientío foram riados para prover aos
i-entistas um ambiente no qualeles podem realizardiversas atividades. Entre várias
delas podemos itar: desrever e riar omponentes baseados nas tarefas que eles
querem exeutar em seus experimentos; organizar esses omponentes em uxos de
trabalhobaseados nasemântia dasua apliação; exeutar esses uxos de trabalho
sob bases de dados; e também monitorara exeução pelo exame, por exemplo, de
dadosintermediáriosriadosduranteela. Algumasdas idéiasintroduzidasporesses
sistemassão juntar omponentes taisomoretornode dados, omputaçãoe
visuali-zação, emum únio pipeline,e tornar reusáveisesses omponentes . A reutilização
deomponentes introduzofatodequeomponentespodemfazerpartedossistemas
de uxo detrabalho, douxo de trabalhode uma outraapliação,ouaté mesmode
omponentesexternosaessados,porexemplo,viaserviçosweboudegrid[BLNC06℄.
Os desaos para o projeto e a implementação desses sistemas são muitos,
prin-ipalmentedevido às araterístiasdas apliaçõesquegeram osuxos de trabalho
ientíos. Elassãoonsideradasapliaçõesintensivasemdados eproessamentoas
quais riam uma enorme quantidade de dados durante a exeução e exeutam por
longos períodos. Um exemplo é oprojetoLarge Hadron Collider (LCD) doCERN.
Começandonesteanode2006,esseprojetogerarádadosnaesaladepetabytes a
par-tirde quatrograndes detetoresde partíulasubterrâneos aadaano[CER℄.
Proje-tosomooGridDatafarm[TMM
+
02℄estãosendorealizadosparaodesenvolvimento
de sistemas de uxo de trabalho ientío que proessem os dados eientemente
em ambientes distribuídos. Alguns dos desaos para projetar esses sistemas são:
uxos de trabalhoemambientes distribuídos,eotimizaroreuso de omponentes de
diferentes uxos.
Comoossistemasdeuxode trabalhoientíoestãosendoonstruídospara
ex-eutarapliaçõesporlongos períodos,aprobabilidadedeoorrerumafalhadurante
a exeução tem aumentado bastante [KKL05℄ e não tem reebido tanta atenção.
Dessa forma, é desejável que esses sistemas possuam meanismos que aumentem
a sua disponibilidade [HRL
+
05, LAB
+
05℄. A nalidade desses meanismos é a de
que o trabalho (proessamento) realizado anteriormente ao momento da falha não
seja perdido, ou seja, para que não haja a neessidade de omeçar a exeução das
apliações do seu iníio. Embora muitos sistemas distribuídos já tenham tratado
esse problema, ainda éum desao prover meanismos quelidem om grandesbases
distribuídasequegereniem troasmaiçasde dadosentre asapliaçõesaumbaixo
usto.
Esse desao se torna ainda maior quando os sistemas de uxo de trabalho são
tratados. Esses sistemasdisponibilizamosresultadosintermediáriosdaexeuçãode
um uxo de trabalho para serem inspeionados pelos seus usuários, ou até mesmo
para servirem de entrada para outros uxos de trabalho ou para o próprio uxo
que os gerou, para que parte desse possa ser reexeutada sob novos parâmetros.
Essa tarefa é bastanteara; para que sejarealizada, háa neessidade douso de um
sistemade armazenamento persistente distribuído,onde dados intermediáriosserão
salvos em bases de dados riadas sob demanda. Na gura 1.1, por exemplo, uma
base de dados diferente seria riada para ada oleção de imagens:
I
1
,I
2
eI
3
. Éinteressanteobservarqueotamanhodessas imagenspode ser daordem de entenas
oumilharesde megabytes,fazendoom queas basesde dadossejammuito grandes.
Este trabalho investiga o uso de meanismos que, de forma transparente,
au-mentem a disponibilidade de sistemas de uxo de trabalho ientío, de tal forma
que o trabalho a ser refeito após uma falha no sistema seja mínimo. Esses
mea-nismos prouram utilizar omo base araterístias próprias desses sistemas, omo
adisponibilizaçãode resultadosintermediários,para aonstruçãode um sistemade
armazenamento dos dados neessários para a reuperação dos sistemas após uma
falha. Dopontodevistadeeiênia,esse sistemadeveser apazdeesalargrandes
basesde dados,edeveproverum armazenamentoassínronodos dadosde talforma
que não haja neessidade do travamento da exeução dos uxos de trabalho para
1.1 Objetivo
Ossistemasde uxo detrabalhoientíoestão sendoonstruídos paraexeutar
apliaçõesporlongos períodos de tempoquelidem om quantiasde dados adavez
maiores. Apossibilidadede falhasoorreremduranteasexeuçõesdessasapliações
temaumentadobastante,fazendoomqueotrabalhorealizadoanteriormenteàfalha
seja todo perdido. Introduzir meanismos apazes de aumentar a disponibilidade
desses sistemas é neessário, entretanto esses meanismos não podem introduzir
grandeoverhead nesses sistemas.
Oobjetivodestetrabalhoéprojetar,desenvolver, eanalisarmeanismosque
au-mentem a disponibilidade em sistemas de uxo de trabalho ientío, de tal forma
queotrabalhoperdidoporumafalhasejamínimo. Esses meanismosdevemser
a-pazesdegereniargrandes quantidadesde dadosqueserãoutilizadosparareuperar
esses sistemas, eo impatointroduzido poreles deve ser pequeno.
1.2 Contribuições do Trabalho
As ontribuiçõesdeste trabalho são:
•
Aumentodadisponibilidadedossistemasdeuxodetrabalho: omasténiasintroduzidas nesses sistemas, eles serão apazes de se reuperar quando uma
falhaaonteer emalgum dos seus omponentes ouaté mesmonos nodos nos
quaiseles estão proessando.
•
Melhoranadinâmiadaexeução dos sistemasde uxo de trabalho: uma vezque o proesso de disponibilização de resultados intermediários é beneiado
om as ténias para aumento da disponibilidade desses sistemas, há uma
melhoranadinâmiaexeução dos uxos de trabalho. Como osdados podem
serompartilhadosentreváriosuxos,essamelhorapodeseraindamaior,pois
eles não preisamser omputadosnovamente.
•
Gereniamento e armazenamento eiente de dados repliáveis: para que oimpatodas téniasqueaumentemadisponibilidadedossistemasde uxode
trabalhosejapequeno,háneessidadede umgereniamentoearmazenamento
eientedos dados quepodem ser utilizadosparareuperaro sistemade uma
1.3 Coneitos
Três termosquegerambastanteonfusão,quandoadisponibilidadeemsistemas
é disutida, são: falta (fault), falha (failure) e erro (error). Vários autores tem-se
oupado da nomenlatura e oneitos básios da área. Os oneitos apresentados
aqui são derivados dos trabalhos de Avizienis e Laprie [Lap85, AL86, ALR01℄ e
Andersone Lee [AL81℄.
A falha do sistema oorre quando o serviço forneido se desvia das ondições
menionadasnasua espeiação,ouseja,nadesriçãodoserviçoesperado. A
ons-truçãode um sistema onável onsisteemprevenir a oorrênia de falhas. A falha
oorreporqueosistemaestavainorreto: umerroéapartedoestadodosistemaque
podeonduziràfalha,istoé,aoforneimentodeumresultadoquenãoestádeaordo
om o serviço espeiado. Dessa forma a falha pode ser observada externamente
omo o efeitode um erro. A ausa de um erro éuma falta. Umafalta pode existir
muito antes de produzir efeitos: diz-se inativa. Exposto em outros termos,um erro
éa manifestação de uma faltanosistema, euma falhaé amanifestação de um erro
noserviço.
Umdefeitonoódigode umprogramadoréonsideradoumafalta. A
onseqüên-iadessa faltaserá um erro (latente) nosoftware esrito,por meiode instruçõesou
dados errados. Quando ativado o módulo no qual o erro reside, ou seja, quando
um padrão de entrada zer utilizar a instrução, seqüenia de instruções ou dados
errados, o erro tornará efetivo. Quando esse erro efetivoproduz dados errados, que
afetem o serviço dosistema,a falha oorre.
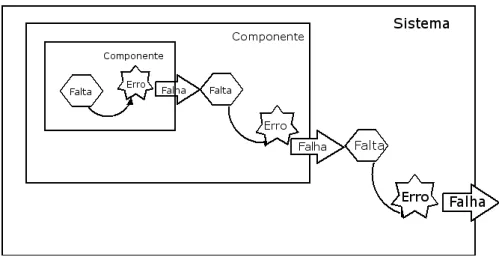
AdotandoanomenlaturadeLaprie[Lap85℄,umsistemapodeserdeompostoem
umonjuntode omponentesligadosuns aosoutrosparainteragirem,sendoqueum
omponentepodeser umoutrosistema. Essareursão énalizadaquandoosistema
é onsiderado atmio: qualquer outra estrutura interna não pode ser disernida,
ounão é de interesse epode ser ignorada. Dessa forma,omopodemosobservarna
gura1.2, oerrooorridoem um omponentepode sepropagarporoutrosde modo
queabeaoprojetistadosistemadeidiremqualdessesomponentes esseerrodeve
ser tratado.
Quando sistemas distribuídos são disutidos em vários trabalhos, muitas são as
nomenlaturas utilizadaspara os desreverem. Neste trabalho, assumimos que um
sistemadistribuídoéompostoporumonjuntodeproessosqueexeutamemnodos
de proessamento, que são ligados utilizando anais de omuniação. Quando os
sistemasde uxode trabalhosão menionadosnestetrabalho, pornaturezaestamos
Figura1.2: Propagação: Falta->Erro ->Falha [VR01℄
múltiplasamadasde formaindependente, adeisãodequaiserrosdevemser
propa-gadosequaiserrosdevemsertratadosemadaamadanãoéumadeisãomuitobem
entendida[TL02,LKL04℄. Oargumentom-a-m(end-to-end)[SRC84℄delaraque
olugarorretopara umafunionalidadeénopontonal, mas elapode ser oloada
emníveismaisbaixosporquestõesdedesempenho. Coloartodasasfunionalidades
opontonal aumentaa omplexidadee requer que desenvolvedores nais possuam
umonheimentodoquepode oorrernasamadasinferiores. Nossistemasdeuxo
detrabalho,ondeosdesenvolvedores(usuários)sãoespeialistasdeumdeterminado
domínio,esse argumentoiria exigirque os usuários possuíssem onheimento sobre
omo lidar om oserros.
Thain e Livny [TL02℄ desenvolveram uma teoria de propagação de erro. Eles
denemoesopodoerroomoaporçãodosistemaqueumerroinvalidaedesrevem
queumerro temqueser propagadoparaoproesso quegereniaesse esopo. Dessa
formaos erros que podem aonteer em um ambiente distribuído são do esopo do
sistema que está exeutando nesse ambiente, e não do esopo da apliação. Com
o auxíliodessa teoria, deidimos oloar a amadapara tratar os erros e aumentar
a disponibilidade do sistema de uxo de trabalho em amadas intermediárias que
podem gereniar esses erros.
Em todo o texto, quando menionarmos usuários, estamos nos referindo aos
usuáriosdosistemadeuxodetrabalho. Essesusuáriossãoosientistasdasdiversas
áreas de onheimento que desenvolvem suas apliações omo uxos de trabalho, e
1.4 Organização do Texto
Este trabalho está dividido em 7 apítulos. O restante dele está dividido da
seguinte maneira:
Capítulo 2 [Trabalhos Relaionados℄ Nesseapítuloostrabalhos relaionados
sãodesritosedisutidosemrelaçãoaotrabalhoapresentadonestadissertação.
Capítulo 3 [Disponibilidade em sistemas Distribuídos℄ Nesseapítuloserão
apresentados osmodelosde faltas,assim omo os meanismosde tolerânia a
faltasexistentes, para aumentar adisponibilidade dos sistemas distribuídos.
Capítulo 4 [Sistema de Fluxo de Trabalho Cientío Proposto℄ Nesse
apí-tuloserãoapresentadosalgunsdosrequisitosdossistemasdeuxo detrabalho
ientíos, assim omo a arquitetura dosistema proposta neste trabalho.
Capítulo 5 [Implementação℄ Baseado nos modelos e meanismos apresentados
no apítulo 3, apresentaremos aqueles que foram utilizados nos sistemas de
uxo de trabalho ientío. Nesse apítulo ainda detalharemos os
algorit-mos, os protoolos e as estruturas de dados utilizados na implementação dos
meanismos queaumentam a disponibilidadedo sistema de uxo de trabalho
ientío.
Capítulo 6 [Experimentos℄ Nesse apítuloserão desritos osexperimentos
rea-lizados para avaliar o desempenho do sistema, utilizando-se os meanismos
para aumentar sua disponibilidade, assim omo seu omportamento quando
falhassão inseridas durante asua exeução.
Capítulo 7 [Conlusão e Trabalhos Futuros℄ Nesse apítuloserão apresentas
Trabalhos Relaionados
Neste apítuloserão apresentadas sínteses dos prinipaistrabalhos relaionados
asistemas de uxo de trabalho ientíoe à disponibilidadeem sistemas
omputa-ionaisde largaesala. Naseção2.1,apresentamosoframework Anthillujomodelo
deprogramaçãoltro-uxopermitequeapliaçõessejamdeompostasemdiferentes
unidadesdeproessamento(ltros)que,ligadaspelosuxos,formampipelines
pare-idos om osdas apliaçõesdos sistemasde uxo de trabalho. Esse sistemafoi
uti-lizado omobase para aonstrução dosistema apresentado neste trabalhoe possui
ummeanismode tolerâniaafaltasquenãofoiaproveitadoaqui. Outroframework
utilizadofoi oMobius, apresentado na seção 2.2.
Na seção 2.3, apresentamos diferentes sistemas de uxo de trabalho ientío
que apresentam esforços para a implantação de meanismos que aumentem a sua
disponibilidade. Nasseções2.4e2.5,serãoapresentadostrêssistemasquesão
desen-volvidosparaexeutaremapliaçõesintensivasemdadosequeprovêem tolerâniaa
faltas. Finalmente, nas seções 2.6 e 2.7, apresentamos implementaçõesde
meanis-mos de tolerânia a faltasde dois sistemas de omputação distribuída, MapRedue
e PVM,respetivamente.
2.1 Anthill
O Anthill [FJG
+
05℄ é um ambiente para desenvolvimento e exeução de
apli-açõesdistribuídas esaláveis. Ele foi desenvolvido om o objetivo de atender
apli-ações não regulares, intensivas em proessamento e em entrada-e-saída (E/S) de
dados. Nesses tipos de apliação, os dados enontram-se distribuídos nos vários
nodos do sistema, e uma araterístia que o Anthill utiliza sabiamente é levar a
omputação aonde o dado se enontra, reduzindo a omuniação através da rede.
então seremproessados éfreqüentementeuma operaçãoineiente, prinipalmente
porque, à medida que o proessamento avança, os dados resultantes tendem a ser
muitas vezes menores que osdados de entrada [PFT
+
05℄.
Nesse ontexto, apliaçõesaseremparalelizadasnoAnthilldevemlevarem
on-sideração tanto o paralelismo de dados quanto o de tarefas, ou seja, a apliação
deveser dividida emetapas quesejampassíveisde exeuçãoemnodosdiferentes do
sistema, e ada uma dessas etapas irá exeutar parte das transformações sobre os
dados,iniiando-seomoonjuntodedadosdeentrada,atéqueseatinjaoonjunto
de dados de saída [PFT
+
05℄, formando um pipeline de tarefas ou transformações.
A estratégia do Anthill aplia os dois enfoques, agregando uma tereira dimensão
quepermiteexplorarograudeassinroniaexistenteentrediferentestarefas
indepen-dentesnosistemaaolongodotempo. Osbenefíiodessastrêsdimensõesombinadas
permite atingirspeedups elevados experimentalmente [VJF
+
04,FJG
+
05℄.
Alguns dosoneitos implementadosnoAnthillsão derivados doDatautter, um
sistemade exeuçãode apliaçõesdistribuídas,baseado nomodelo de programação
lter stream. Nesse modelo, oproessamento édividido emtarefas queoperam sob
osdadosqueuempelosistema. Cadaltroimplementaumatarefaquetransforma
osdados segundo aneessidade daapliaçãoe se omuniaom outros ltros pelos
anaisdeomuniação responsáveispelatransmissãoontínuadedados (streams ou
uxos). Dessaforma,riarumaapliaçãonoAnthilléumproessode deomposição
de proessamentoem ltros.
A gura 2.1 apresenta a visão desse modelo de programação baseado no lter
stream. Durante a exeução, o proesso denido para ada ltro é instaniado em
diferentes nodos do ambiente distribuído. A esses proessos dá-se o nome de ópias
transparentesouinstâniasdeumltro,omomostradonessagura. Dessaforma,o
proessamentopodeserdistribuídopormuitosnodos,eosdadosquedevemuirpor
aqueleltropodemserpartiionadospelassuasinstânias,produzindooparalelismo
de dados desejado.
O Anthill possui duas extensões do modelo lter stream original. Foiveriado
quemuitas apliaçõespreisavamompartilharerto estadoglobalsobre aevolução
da omputação, o que levou os autores a denir um broadast stream, que permite
esse padrãode omuniação para todas asinstânias de um ltro. Alémdisso,para
garantirumaloalidadedeproessamento,ouseja,paraquedadosqueompartilham
uma erta araterístia na semântia da apliação possam ser proessados pela
mesma instânia, foi riado o labeled stream. Esse tipo de omuniação permite
exatamente que a instânia de destino dos dados seja determinada em função de
Figura 2.1: Visãodo modelo de programaçãolter stream.
2.1.1 Dependênia de Dados
Quando asapliaçõesutilizamomodelode programaçãolterstream, elas
apre-sentamuma araterístiadesritaaquiomodependênia dedados. Para um ltro
gerarumasaída paraoutro,eletemqueprimeiroreeberuma quantiade dados
(al-gumasmensagenspelostream)eessesdadospodemser denidosomo dependênia
dasaída. Ostiposde dependênia são desritos a baixo:
•
1 para 1: essa é o tipo mais simples. Quando um ltro reebe umamen-sagem,elepodeproessarosdadosnessamensagemeenviaroresultadoparao
próximoltronopipeline. Dessaforma,amensagem de entradaé dependente
dade saída.
•
n para 1: um ltro tem que reebern
mensagens, de um ou mais streams,antesdegerarumasaída. O
n
podevariardeaordoomaapliaçãoetambémassumir diferentes valores durante a exeução de uma mesma apliação. A
mensagem de saída é dependente das
n
de entrada.•
n para m: esse tipoé similaraon para 1, entretanto,m
mensagens de saídapodem ser geradaspelo ltro,em um oumais streams de saída.
•
1 para n: esse é araterizado por um ltro que reebe uma mensagem deentrada egera várias de saída, usandoum oumais stream de saída.
liza para ontrolar todas as mensagens troadas durante a exeução dos uxos de
trabalho. Listas de dependênia de mensagens são riadas para ada mensagem
enviada. Osapítulos 4e 5 desrevemomo esse ontrole é realizado.
2.1.2 Tolerânia a Faltas no Anthill
OAnthillpossui um meanismode tolerânia afaltas desritoporCoutinho em
[Cou05℄. Esse meanismo é baseado no oneito de tarefa. A exeução de uma
apliação é denida omo a exeução de um onjunto nito e denido de tarefas.
Uma tarefa onstitui uma seqüenia de operações bem delimitadas, onde dados
podemserarmazenadosdeformaperene,detalformaquetarefasposteriorespossam
aessaresses dados,riando, assim, dependênia entre astarefas.
Coutinho deniu que a exeução de uma tarefa é atmia, o que lhe permitiu
que o grão da tolerânia a faltas fosse uma tarefa inteira. Ele utiliza meanismos
de hekpoint pararepliaros estadosdas tarefas, e,omo nãosão permitidas
men-sagensentre tarefas,essesmeanismosforamsimpliados,nãohavendoneessidade
de lidar om a omuniação entre as instânias dos ltros.
Emboraessaabordagemde tarefassejabastanteinteressante, elaimpõealgumas
onsideráveis restrições sobre o modelo de programaçãodas apliações. A primeira
restrição diz respeito à omposição da apliação em ltros. É esperado que as
apliações sejam ílias, ou seja, que exista um loop entre os ltros. A segunda
restriçãoé quantoà omplexidade de programação de apliações. Nesse modelo, os
programadoresdas apliaçõesdevem dividirseus programas emtarefas, divisão que
pode não ser simples.
2.2 Mobius
OMobius[HLOS04℄éumframework projetadoparaogereniamentoeientede
metadadosedadosemambientesdinâmiosedistribuídos. Eleprovêumonjuntode
serviçoseprotoolos genériosparasuportarariaçãoegereniamentode esquemas
de bases de dados, riação sob demanda de bases de dados, federação de bases
de dados existentes, e onsulta a dados em ambientes distribuídos. Seus serviços
empregam esquemas XML para representar denições de metadados e doumentos
XML para representare troar instânias de metadados.
O Mobius possui três omponentes prinipais:
ri-•
Mako (data instane management): um serviço que expõe e abstrai fontesde dados omo XML e permite a instaniação de armazenamentode dados e
gereniamentofederativo de armazenamentosexistentes distribuídos.
•
DTS(Data TranslationServie): um serviço que permite atradução eienteeonável de desriçõesde dados entre instituições.
Neste trabalho, o omponente Mako será desrito em mais detalhes devido ao
fato de ele ser o únio omponente utilizado na arquitetura do sistema de uxo de
trabalhoproposta eapresentada naseção 4.2.
2.2.1 Mako
O Mako provê serviços para ambientes grid para armazenar e onsultar dados
e metadados. Ele permite que dados sejam armazenados por meio de máquinas
heterogêneas e fraamente integradas. Ele também permite a usuários onáveis a
habilidade de atualizar,onsultar eapagar os dadosque eles armazenam. Bases de
dados podem ser instaniadas para um m espeío e podem ser, na prátia, de
qualquer tamanho eesala, resendo dinamiamentede aordoom a neessidade.
O Mako expõe os dados omo serviços XML através de um onjunto de
inter-faesbemdenidasbaseadasnoprotooloMako. Esseprotoolodenemétodospara
submeter, atualizar, remover e retornar doumentos XML. Na submissão, o Mako
assinala um identiador únio a ada doumento XML submetido. Doumentos,
ousubonjuntos dos doumentos XML, podem ser retornados ouremovidos
espei-andoseus identiadores únios, oupor meio de expressões XPath [BWC
+
03℄.
A arquitetura do Mako, omo mostrada na gura 2.2, ontém um onjunto de
ouvintes (listeners) que permitem a lientes omuniar-se om uma instânia do
Mako utilizando protoolos de omuniação tais omo TCP, SSL, ou GSI (Globus
Seurity Infrastruture). Os paotes são então transmitidos para um roteador de
paotes,oqualdeterminaseopaotepossuiumhandler noMakoe,sesim,transmite
o paote para o handler para proessar e enviar uma resposta para o liente. A
implementação atual provê suporte para expor bases de dados XML que suportam
a API do XMLDB e ontém uma implementação do MakoDB. O MakoDB é um
bano de dados XML onstruído sob o MySQL[htt ℄.
2.3 Sistemas de Fluxo de Trabalho Cientío
Hoje em diapodemos enontrar muitos sistemas de uxo de trabalho ientío
Figura2.2: A arquitetura do ComponenteMakodo Mobius.
esses sistemas tenham sido desenvolvidos para exeutar apliações intensivas em
dados, pouos deles apresentam a preoupação de aumentar sua disponibilidade.
Nestaseçãoapresentamososprinipaissistemaseprouramosdarumamaiorênfase
nos meanismos que aumentam asua disponibilidade.
2.3.1 Sistema de Fluxo de Trabalho Cientío om Suporte
a Bano de Dados XML
XMLtemsetornadoum padrãoparaarmazenamento,pesquisaetroade dados
emambientesomoWebeGrid. Umnúmerograndedeferramentastêmsido
desen-volvidas para riar, fazer parsing, validar e pesquisar doumentos XML. Com uma
propostabaseadaemXML,torna-sepossívelparaambos,lientesedesenvolvedores
de apliações, utilizar essas ferramentas. Em [HRL
+
05℄, Hastings entre outros
in-vestigaa apliaçãoefetiva dosuporte a bano de dados XML distribuído emuxos
de trabalho ientíos. Ele examina o uso de tenologias XML para tratar
assun-tos assoiados om omposição e gereniamento de uxos de trabalho, denições e
armazenamentode dados em ambientes distribuídos.
Naquele artigo, os autores desrevem um sistema de uxo de trabalho
no paradigma ltro-uxo, e outro middleware para armazenamento de dados
dis-tribuído. Aarquiteturaapresentadapermitequeapliaçõesdesenvolvidas utilizando
o primeiro middleware sejam exeutadas e possuam os seus dados intermediários
armazenados no segundo. Para que esse armazenamento seja realizado, há a
ne-essidade de os desenvolvedores das apliações expliitamente utilizarem em seu
ódigo uma API (Appliation Programming Interfae) para riar bases de dados
sob demanda, esrever e ler os dados. No nosso sistema, todoo gereniamento e o
armazenamentodos dados é realizadotransparentementeà apliação.
OutropontonegativoparaotrabalhoapresentadoporHastingséque,quandoos
dadosintermediáriossãoarmazenados,aexeuçãodaapliaçãotemqueserrealizada
em estágios, de tal forma que um estágio deve terminar seu proessamento por
ompletoerealizaroarmazenamentodosdadosparaentãoopróximoestágioutilizar
essesdadosomoentrada. Esseproblemaéresolvidononossotrabalhoutilizando-se
uma amada de armazenamento eiente em memóriaque permite que a exeução
daapliaçãoseja desaoplada datarefa de armazenamentode dados.
Os autores em [HRL
+
05℄ disutem que, utilizando os dados armazenados no
bano de dados distribuído, é possível aumentar a robustez do sistema, tornando-o
tolerantea faltas. Entretanto, meanismospara realizar essa tarefa, omo deteção
de faltas ereuperação,não são disutidos noartigo.
2.3.2 Chimera e Pegasus
O projeto Chimera [FVWZ02℄ tem desenvolvido um sistema de dados virtual
apaz de representar o proesso de derivação de dados, e dados já derivados, para
expliarsuaorigem. Seusautoresqueremserapazes derastrearomoasproduções
de dados são originadas, om preisão suiente para que esses dados possam ser
utilizadospara reexeutar apliações e gerar os dados novamente. Um atálogo de
dadosvirtuais(baseadoemumesquemade dadosvirtualrelaional)provêuma
rep-resentação ompata e expressiva de proedimentos utilizadospara gerar os dados,
assim omo invoações a esses proedimentos e bases de dados produzidas por
es-sas invoações. Um interpretador de linguagem de dados exeuta requisições para
onstruir e exeutaronsultas abanos de dados.
Utilizandoo Chimera, pessoas podem riarou reriardados através do
onhei-mentoadquiridonorastreamento. Elaspodementão expliar denitivamenteomo
osdadosproduzidosforamriados,prátiaquegeralmentenão épossívelmesmoem
bano de dados uidadosamenteinvestigados. Elas podem ainda implementaruma
re-foramriados,geram novamentedados quando suas dependênias ouprogramas de
transformaçõesmudam,e/ouatémesmoriarépliasdedadosproduzidosemloais
remotos,quando sua riação for mais eienteque sua transferênia.
O Chimeraé aoplado a outros serviços de dados emgrid [CFK
+
99, KF98℄ que
permitema riaçãode novos dados pelaexeução de esalonadores de omputação,
obtidos de onsultas a bano de dados, e o gereniamento distribuído de dados
resultantes.
O Pegasus [DBG
+
03℄ pode riar sistemas de dados virtuais que salvam
infor-mações sobre a proesso de derivação dos dados e dados derivados, utilizando o
Chimera. Eletambémmapeiaosuxosde trabalhoabstratos doChimeraemuxos
de trabalhoonretos DAG queo esalonador DAGMan [FTFT01℄exeuta.
DiferentementedoChimera,osistemadeuxodetrabalhoientíoapresentado
neste trabalho foa o armazenamento de resultados pariais e a utilização desses
dados para aumento da disponibilidade desse sistema. Nós não armazenamosuma
grande quantidade de informação sobre a origem dos dados, mas somos apazes de
eientementearmazenarbasesdedadosgeradasduranteaexeuçãodasapliações.
2.3.3 Sistema om Reuso de Componentes
Em [BLNC06℄, Bowers apresenta uma arquitetura para a onstrução de
ompo-nentes reusáveis em sistemas de uxos de trabalho ientíos. A abordagem
pro-posta é baseada no enapsulamento de espeiações do omportamento genério
dos omponentes nos hamados templates. Ostemplates são omponentes distintos
e separados que podem ser reutilizados em outros uxos de trabalho. Eles são
es-peiaçõespariaiseontémburaos, hamadosframes,queatuamomoespaços
reservados para subomponentes denidos independentemente. Compor templates
om omponentes de uxo de dados existentes resultaem apliaro omportamento
assoiado ao omponente de tal forma que a separação entre o ontrole e os dados
douxo émantido, permitindoque omponentes de base dos uxos de dadossejam
troados failmente.
Aarquiteturaapresentadaéompostadetrêsamadas: asuperiorérepresentada
omoumaarmadura dentrodeumgrafodeuxodedadosedenotaumatarefa
par-tiular(porexemplo,transferênia dedados ouexeução remota). Essa armadura
superiorpode serenaixadaa umde váriostemplates (amadaintermediária),onde
ada um dene um omportamentode ontrole para uma tarefa. Um template tem
um oumais frames quepodemser enaixados paraa implementaçãode uma tarefa
O autor argumentaque, utilizandoomponentes onstruídos baseados nessa
ar-quitetura, é possível aumentar a onança do sistema, se esses omponentes
apre-sentarem meanismos de tolerânia a faltas. Por exemplo, quando um omponente
detransferêniadedados,quepossuimeanismosparafazeraretransmissãodos
da-dos quandoessa nãofor bemsuedida, fosseutilizado,poronseqüêniaaonança
do sistema estaria aumentando. Assim omo esse omponente, o autor apresenta
umoutroparaexeuçãoremotadetarefasquetambémpossuiummeanismomuito
simples de tolerânia a faltas. Ambosos meanismos não permitema reonstrução
dosistema apósuma falha, aqual minimizao trabalhoaser refeito.
2.4 DISC e Phoenix
Kola, em [KKF
+
04℄, analisa os problemas om os atuais sistemas que lidam
om apliações intensivas em dados em ambientes distribuídos, e usa o resultado
dessaanáliseparaprojetaroDISC.Umdosproblemasapresentadospelaanáliseéa
movimentaçãodosdadosomopartedaomputação,oqueaarretaareomputação
dos dados, quando a transferênia de dados falha. Para resolver esse problema ele
propõeuma estratégia de isolamentode faltaquedesaopla a loalizaçãodos dados
dasuaomputação. Aamadadearmazenamentoeienteparaarmazenarosdados
intermediáriosdasexeuçõesdas apliações, apresentado nestadissertação,também
resolveesse problema.
O DISC é apaz de difereniar as falhas que podem oorrer em grids de
om-putadoresomopersistentes etransientes, eautomatiamentereuperarfalhas
tran-sientes. Entretanto,essareuperaçãosegueinstruçõesantesforneidaspelosusuários,
ouseja, não são utilizadosmeanismos transparentes.
Em[LKL04℄, Kolapropõeo Phoenix. Esse sistemaprovêferramentas, para
am-bientes grid, que permitem tolerânia a faltas para apliações intensivas em dados
queoperemnessetipodeambiente. Essasferramentas,assimomooDISC,deforma
transparente à apliação, são apazes de detetar e lassiar as falhas, entre
tran-sientes e permanentes, e tratar ada falhatransiente damelhor forma possível que
foianteriormentedenida pelousuário. Diferentementedestetrabalhodemestrado,
queestámaispreoupadonoarmazenamentoeientedosdadosenareuperaçãodo
sistemaapósafalha,oPhoenixestámais preoupadonadeteção enalassiação
2.5 Grid Datafarm
Em[TMM
+
02℄,TatebeapresentaaarquiteturadoGridDatafarm(Gfarm). Esse
sistema de arquivos possui omo objetivo o gereniamentode grandes bases de
da-dos na esala de petabytes. O modelo apresentado obre apliações onde os dados
primários onsistem de um onjunto de objetos os quais são analisados
indepen-dentemente, e ele proura tirar proveito dessa loalidade de aesso para esalonar
o proessamento sobre os dados distribuídos, onseguindo uma boa esalabilidade.
Oautor disute a idéia de que, repliando osdados, ele automatiamenteonsegue
tolerânia a faltas. Entretanto, o Gfarm não provê transparênia na repliação e
no ontrole dos dados, exigindo que seus usuários tenhamonheimento e realizem
grandeparte do trabalho.
Um arquivo do Gfarm é onsiderado omo um arquivo de larga esala que é
dividido em fragmentos que são distribuídos entre os disos do sistema de arquivo
Gfarmequeserãoaessadosemparalelo. OGfarmapresentaumaAPIparariação,
visãoe aesso paraleloa esses arquivos:
•
gfs_pio_open:. Abre um arquivo determinado. Flags omo aGFARM_FILE_REPLICATION podem ser espeiadas para repliar o
ar-quivo em diso loalquando oaesso for remoto.
•
gfs_pio_reate:. Cria um arquivo Gfarm. Permissões de aesso, omoes-rita eleitura, podem ser espeiadas nariação.
•
gfs_pio_set_view_loal: Visão loalde um arquivo. Permite que ospro-essos aessem os própriosfragmentos doarquivo.
•
gfs_pio_set_view_index: Expliitamenteespeiaum fragmentode umarquivo.
•
gfs_pio_read: Bloqueia a aesso ao arquivo e realiza a leitura do númerode bytes espeiados de um fragmento.
•
gfs_pio_write: Bloqueia a aesso ao arquivo e realizaa esrita donúmerode bytes espeiados a um fragmento.
2.6 MapRedue
O MapRedue, proposto por Dean em [DG04℄, é um modelo de programação
Uma abstração foi riada para permitir que os usuários expressem omputações
simplesqueeles desejamrealizar,masesonde detalhes ompliadosde paralelismo,
tolerânia a faltas, distribuição de dados e balaneamento de argas em uma
bi-bliotea. Aabstraçãofoiinspiradaemprimitivasdemapear(map)ereduzir(redue)
presentes em Lisp eem muitas linguagens funionais. Osusuários espeiamuma
funçãode mapeamentoqueproessaum par have/valorpara gerarumonjuntode
pareshave/valorintermediários,euma funçãode redução queune todos osvalores
intermediários assoiados om a mesmahave intermediária.
Muitas são as similaridades do MapRedue, do Anthill e do Datautter.
Pro-gramas seqüeniais esritos utilizando o estilo neessário são automatiamente
pa-ralelizados e exeutados emgrandes aglomerados de omputadores. Esses sistemas
am responsáveis por detalhes omo exeução dos programas nos onjuntos de
máquinas,tratamento de falhas de máquina (om exeção do Datautter), e
geren-iamentodaomuniaçãoneessáriaentreosproessosdasmáquinas. OMapRedue
ainda possui funionalidades para partiionamento dos dados de entrada e
esalo-namento dos proessos.
O MapRedue também possui um gerente responsável por enviar o trabalho a
ser realizadopara os trabalhadores. Esses trabalhadoressão riados pela bibliotea
do MapRedue e quando estiverem oiosos, reeberão tarefas de mapeamento ou
redução. À medida que essas tarefas forem sendo ompletadas, os resultados
in-termediários vão sendo armazenados no diso loal de ada máquina. Utilizando
hamadas de proedimento remoto, esses dados podem ser aessados por
trabalha-dores de outras máquinas. O proesso de armazenamento de dados pode limitar a
eiênia desse ambiente, uma vez que ele é realizado diretamente no diso. Neste
trabalhopropomosumaamadade armazenamentode dadoseienteque
primeira-mentearmazenaosdadosemmemóriaparamaistardearmazená-losnodiso,oque
não aarreta o travamentodaapliação duranteesse proesso.
O meanismo de tolerânia a faltas implementado no MapRedue é baseado
na reexeução de tarefas que estavam sendo ou foram exeutadas nas máquinas
que falharam. O gerente a responsável por notiar trabalhadores que estavam
aessando os dados nas máquinas que falharam para realizar a leitura nas novas
máquinasque estarão exeutando a tarefa novamente.
2.7 FTOP
OFTOP[BGS02℄éumabiblioteadehekpoint integradaomoPVM(Parallel
distribuídas exeutando sobre o PVM. Osdesenvolvedores das apliações preisam
inserir algumas hamadas a proedimentos em suas apliações para utilizarem o
meanismo de tolerânia a faltas, sendo que nenhuma modiação é neessária no
núleo dosistema operaional.
OFTOPassumequeumsistemadistribuídoonsistenumgrupodemáquinas
ro-dandoLINUX eonetadas através de uma LAN de altaveloidade. Em adauma
dessas máquinas há neessidade de um PVM exeutando. Todas elas podem
fal-har om exeção de uma que pode exeutar tanto o gerente que é responsável pelo
esalonamento de tarefas, assim omo pela oordenação dos protoolos de
hek-point e reuperação, quanto o armazenamento onante que onsiste dos arquivos
de hekpoint, logs de mensagens et. O modelo de faltas assumido é o de faltas
falha e pára, em que os proessos do sistema distribuído são notiados quando
uma faltaoorre (esse modeloé desrito emmais detalhes na seção 3.1.1).
No hekpoint, o estado de um proesso é ongelado e armazenado em um
ar-mazenamentoonável,doqualelepodeser reuperadonoaso defalhas. OFTOP
esolheuoprotoolodehekpointoordenadonãobloantenoqualosproessos
de-idem em realizar os hekpoints (maiores detalhes estão desritos na seção 3.2.1).
Esse protoolo permite que os proessos ontinuem seu proessamento durante a
realização dohekpoint,o que pode introduzirmenos overhead.
Salvar e reuperar o estado de proessos envolve o salvamento de GPRs,
re-gistradores de ponto utuante et, os quais podem depender da arquitetura. Em
vez de de aessar os módulos dependentes de linguagens de máquina para ada
arquitetura para efetuar essa tarefa, o FTOP lida om isso através de sinais. Os
meanismostratadores de sinaisdosistema operaionalrequisitamo salvamentodo
estadode exeução doproesso oqualpode ser maistarde restaurado,uma vez que
osinalfoitratado. OFTOPtratade arquivosabertossuportandoapenasoperações
de leituraeanexação(append). Operaçõesdeesritanão sãotratadasumavez que,
segundo os autores, elas não são omuns e envolvemum grande overhead.
A deteção de faltas é realizada utilizando-se meanismos presentes no PVM.
Proessos PVM oasionalmenteheam seus pares através de envios de mensagens
de ping. Quando um proesso PVM não responde, dado um tempo, o proesso que
odetetou avisa osdemais que houve falta nosistema.
A reuperação de faltas envolve a restauração de um estado sem faltas da
exe-ução. Um protoolo de duas fases foi implementado no FTOP para realizar essa
reuperação. Naprimeirafaseogerenteinformaaosproessosqueelesdevemvoltar
para seu último hekpoint salvo. Quando todos os proessos onseguem voltar
Durante esse protoolo de reuperação não é permitidoo envio e o reebimento de
mensagens pelos proessos.
Apesar de o FTOP apresentar um protoolo de hekpoint eiente, existem
alguns gargalos que tornam difíil utilizar omo base para onstrução de sistemas
de uxo de trabalho ientío. Primeiramente, os hekpoints são armazenadosem
uma só máquina doambiente distribuído, que se torna um grande gargalo, quando
arquivos muito grandes forem tratados. Segundo, ele não lida om operações de
esritadearquivos,oquetornaompliadogarantirqueosresultadosintermediários
salvosduranteaexeuçãodosuxosdetrabalhorealmentevãoapresentaroonteúdo
orretoduranteuma falta.
2.7.1 Sumário
Neste apítulo apresentamos os prinipais trabalhos relaionados a sistemas de
uxo de trabalho ientío e disponibilidade em sistemas de larga esala. Como
podemos pereber, os meanismos utilizados para aumentar a disponibilidade dos
sistemas de uxo de trabalho são bastante limitados. Pouo foi estudado até o
momento, o que faz om que haja uma grande arênia nessa área. Antes de
ap-resentarmos o sistema proposto neste trabalho, assim omo os meanismos para
aumentarasuadisponibilidade,nopróximoapítulovamos apresentarosprinipais
modelos de faltas e métodos de tolerânia a faltas que são utilizados em sistemas
Disponibilidade em Sistemas
Distribuídos
Aumentaradisponibilidadeemsistemasdistribuídossigniainluirmeanismos
detolerâniaafaltasnessessistemas,osquaispermitemqueproessossobrevivama
faltasqueoorramdentrodosistema,sejanos seus omponentessejanos nodos que
oexeuta. Sem tolerâniaafaltas,um sistemaexeutando emparalelo,emdiversos
nodos,poderiafalharinteiramenteseapenasumsimplesnodoexeutandopartedele
falhasse. A esolha de um método para ser utilizadopor um sistema deve ser feita
levando-seemonsideraçãosuas araterístiasdetalformaqueumoverhead muito
grandenão sejaintroduzido.
Nasseções3.1e3.2serãodesritososmodelosdefaltaseosmétodosdetolerânia
a faltas, respetivamente, enontrados na literatura, que geralmente são utilizados
omo base nos estudos de tolerânia a faltas.
3.1 Modelos de Faltas
Um modelo de faltasespeia as suposiçõesde um projetistasobre a natureza
das faltas que um sistema, ou omponente de um sistema, pode sofrer. Ele
a-rateriza o modo omo um omponente vai falhar, sem fazer nenhum relato sobre
asausas atuais da falta. Um modelo de faltasentão limitao número e ostiposde
faltas que um desenvolvedor de um sistema tem que anteipar e lidar. Nesta seção
serão apresentados os prinipais modelos de faltas assim omo alguns exemplos de
3.1.1 Modelo de Faltas Falha e Pára (Fail-stop)
O Modelo de Faltas Falha e Pára (Fail-stop), primeiramente apresentado por
Shlihting et al. em[SS83℄, permite que qualquer nodoou omponentedo sistema
falhe a qualquer momento, mas, quando a falha oorrer, ele essa a produção de
saídas e ainteraçãoom o resto dosistema, não sendo apaz de produzirrespostas
erradas ou maliiosas. Dessa forma, ada omponente está sempre trabalhando ou
não, e, quando um omponente falha, todos os outros tornam-se ientes da falha.
Este modelo representa faltas omuns omo travamento e queda do sistema, mas
não lidaom faltas mais sutis taisomo orrupção aleatóriade memória[Tre04 ℄.
Faltas do tipo Falha e Pára são geralmente muito simples de detetar, uma
vez que o omponente defeituoso do sistema essa suas operações. Desta forma, a
simpliidade desse modelo tem feito om que ele seja a base para muitos trabalhos
de tolerânia a faltas. De fato, embora a maioria das faltas não se enaixem nesse
modelo, o omportamento dessas demais faltas podem ser adaptadas para o
om-portamento Falha e Pára, usando-se meanismos ortogonais bem onheidos, tais
omoaredundâniamodulartripla[GR93℄ouarepliaçãodeestadoesperta[CL99℄.
Entretanto,quanto maioraomplexidade dafalta,maiorserá oimpatodasua
de-teção naexeução do sistema.
VáriossãoosexemplosqueproduzemfaltasdotipoFalhaePára nos sistemas.
Numa primeira ategoria podem itar-se as faltas que ausam a queda do sistema.
Nessa ategoria enontram-se faltas na apliação, omo as que surgem através de
errosdeprogramação,errosemsistemasoperaionais,exeçõesnãotratadaset,
as-simomoasfaltasnopróprionodo,oumáquina,omoqueimadafontedamáquina,
queda de energia et.
Umasegundaategoriade faltasenvolveaquelasqueproporionamotravamento
do nodo, ou máquina. Nesse aso, a máquina pára de realizar proessamentos e de
responder arequisiçõesexternas; por exemplo: pára de enviar paotes de rede, não
respondea interações de entradas padrãoet. Essas faltasgeralmentesão ausadas
porerros nosistema operaionaloupordefeitos de hipset. Em 2004,porexemplo,
foi desoberta uma vulnerabilidade no Kernel do Linux em que usuários, mesmo
nãopossuindoaessoprivilegiado,quandoompilavamalgunsprogramas utilizando
versões do GCC 3.0 a 3.3.2 rodando no Kernel 2.4.2x ou 2.6.x, faziam om que a
máquinatravasse [CAI04℄. Geralmentequando esse tipodefaltaoorre,háa
nees-sidadedaintervençãohumanaparareiniiaramáquina. Entretanto,existemalguns
sistemas que automatizam essa operação, reiniiando adequadamente a máquina,
omoéoasodoHPIntegratedLightsOut Standard(iLO)[L.P ℄,oLinuxNetworks
3.1.2 Modelo de Queda
OmodelodeQueda(Crash)podeseronsideradoumaextensãodomodeloFalha
ePára. Elepermitequequalquer nodoouomponentedosistemafalheaqualquer
momento, essando permanentemente a exeução de suas ações. Entretanto nesse
modelo não há garantia de que os outros omponentes do sistema irão detetar
a falta. Devido a essa araterístia, ele também é hamado de modelo de falta
sileniosa(fail-silent) [PVB
+
88℄.
Um exemplo lássio de falha desse modelo é o travamento da apliação. Um
estudorealizadoporKolaetal. sobrefaltasemduasgrandesapliaçõesdistribuídas,
US-CMSeBMRBBLAST,mostrouqueessaéumadasfaltasmaisfreqüentes[KKL05℄.
Alguns dos proessos paravamindenidamente e nuna retornavam, o que era
bas-tante difíil determinar se o proesso estava fazendo algum progresso ou se estava
realmentetravado. Aausamaisomumeraotravamentonatransferêniadedados,
devidoàperdadoreonheimento depara quemoarquivoestavasendotransferido.
Numafraçãomenordos travamentosestavaumproblema nãoonheidoenvolvendo
oservidor NFS.
Outros exemplos de travamento de apliação que podem ser itados são
er-ros de programação omo loops innitos e deadlok que podem ser ausados em
apliações paralelas. Esses erros também são muito difíeis de detetar. Dessa
forma, ténias de veriação automátia de ódigo, omo ferramentas de análise
estátia de ódigo e veriação formal, prinipalmente o projeto Meta-Level
Com-pilation[AE02, YTEM04 ℄, têm ganhodestaque ultimamente[Cou05℄.
3.1.3 Modelo de Falta por Omissão
Umafalhaporomissãooorre quando,emresposta auma seqüêniade entrada,
o omponente nuna dá a saída espeiada, ou seja, um omponente do sistema
sempre vai produzir uma saída orreta em tempo ou nuna a produzirá [ES86℄.
As faltas do modelo de queda podem ser vistas omo uma sublasse das faltas por
omissão,de talformaqueelasoorremdepoisqueumomponentesistematiamente
omite responder a todos os eventos de entrada subseqüentes à primeiraomissão de
uma saída [CASD85 ℄.
As faltas por omissão são utilizadas para modelar omponentes omo uma rede
que oasionalmenteabandona paotes. Outros exemplos de faltasporomissão são:
a queda de um proessador, o olapso de um link, um proessador que de vez em
3.1.4 Modelo de Faltas Bizantinas
OModelodeFaltasBizantinas,iniialmenteapresentadoporLamportatravésdo
ProblemadosGeneraisBizantinos [LSP82℄,permitequeosomponentes dosistema
possuamumomportamentototalmentearbitrárioeinonsistente. Nessemodelo,os
nodos defeituosospodem ontinuarinteragindoom oresto dosistema,etambémé
permitidoqueelesolaboremomoobjetivodeelaborarsaídasmaliiosas. Osnodos
operandoorretamentenão podem detetar automatiamenteque algumdos nodos
falhou, muito menos saber quais nodos em partiular falharam, se a existênia da
falhaé onheida. Esse modelopode representar faltasaleatóriasnosistema,assim
omo ataques maliiososde um haker.
As faltas bizantinas geralmente são ignoradas devida à sua omplexidade de
deteção. Por ausa da diuldade natural de detetá-las, tem-se assumido que
essas faltas são extremamente raras, e os problemas assoiados na sua deteção e
tolerânia podem ser, na sua maior parte, ignorados [DHSZ03℄. É provado que
nenhuma garantiana deteção de faltaspode ser feitaem um sistema om 3
m
+ 1nodos emoperação normal quando mais que
m
nodos estão experimentando faltasbizantinas.
A losoa do projeto de aglomerados de omputadores de alto desempenho a
baixousto tem inueniado a utilizaçãode um hardware não tão preiso e seguro,
uma vez que um hardware om onança alta é muito aro. À medida que esse
hardware é integrado em um iruito para alançar o alto desempenho, a elevada
freqüêniadolok,assimomoasgeometriasmaisdensaseasvoltagensmaisbaixas
de forçaforneidas podem elevara taxaom aqualos iruitosentrem emolapso,
e onseqüentemente as faltasbizantinas podem vir a tornar-se mais omuns.
Exemplos de faltasbizantinas que podem ser itadas são: orrupção dos dados,
porexemplo,atravésdareversãodebitsdesaídaquepodemserausadasporeventos
taisomointerferêniaeletromagnétiaeradiaçãoexterna [DNR02℄;faltasausadas
por defeitos de hardware ousoftware devido ao envelheimento, danos externos ou
sabotagem,asquaisausamerros repetidosemomputaçõesparao restodotempo
de vida dosistema.
3.1.5 Modelo Fail-Stutter
O modelo fail-stutter [ADAD01 , KKL05℄ é uma extensão do modelo Falha e
Pára. Eletentamanteratradiionalidadedomodelo,ouseja,levaemonsideração
queosomponentes de umsistemade vez emquando falham,mastambémexpande
falta de desempenho é um evento no qual um omponente provê um desempenho
abaixodoesperado,masnãointerrompeoseufunionamento. Essaextensãopermite
queomodeloinluafaltastaisomoumbaixodesempenhonalatêniadeumswith
derede,quandorepentinamentealançaumtráfegodeargamuitoelevado. Embora
introduza muitas vantagens, esse modelo de faltasainda não tem sido muito aeito
peloomunidade [Tre04 ℄.
Algunsexemplosdessasfaltassão asqueoorremomosproessadores. Existem
faltasquefazem om que proessadoresde um mesmo tipopossam vir aapresentar
desempenho diferente quando testados sobre as mesmas ondições. Por exemplo,
geralmenteomasaramentode faltasé utilizadopara aumentara produçãode
pro-essadores,permitindoquehipsparialmentedefeituosossejamusados;oresultado
é que hips om araterístias diferentes são vendidos omo idêntios. Arpai et
al.[ADV95℄examinaramotamanhodaahe de umasérie de proessadores Viking
daSunedesobriram,entreoutrasoisas,queproessadoresqueeramvendidosom
espeiação de ahe nível 1de 16 KB tinhamna verdade 4KB.
Outros exemplos são as faltasque oorrem nos disos. Os disos também
apre-sentam um grau de masaramento de faltas. Como doumentado em [AD99℄, um
experimento de largura de banda mostra desempenho diferente entre alguns
dis-os 5400-RPM Seagate Hawk. Embora a maioria apresente 5.5 MB/s em leituras
seqüeniais, um diso apresentou apenas 5.0MB/s.
Algumas faltas de software tambémpodem ser enquadradas nesse modelo.
Vir-tualmente, todasasmáquinashojeemdiausamendereçosfísiosnoendereçamento
das ahes. A menosque aahe sejapequena osuiente, então ooset dapágina
não é utilizado nesse endereçamento, e a aloação de páginas vai afetar a taxa de
ahe-miss. Chen e Bershad mostraram que deisões de mapeamento de memória
virtual podemreduzir o desempenho de apliações ematé 50% [CB93℄.
Esse modelo também inluioutros tiposde faltasomo as de temporização que
oorrem quando um omponente dá a saída espeiada muito edo, muito tarde,
oununa [CASD85 ℄.
3.2 Métodos de Tolerânia a Faltas
Existemváriosmétodosquepodemserinorporadosasistemasdistribuídospara
torná-los tolerantes a faltas. Entre esses métodos, os mais disutidos na literatura
são os meanismos de hekpointing e de message logging. Além desses métodos,
tambémexistemalgunsoutrosquejáforamempregadosemsistemasdeomputação,
ativa et. Nessa seção serão apresentados esses métodos lássios individualmente.
Éinteressanteobservarquegeralmenteelessão ombinadoseentão empregadosnos
sistemas.
3.2.1 Chekpointing
Osmeanismosde hekpoints sebaseiamemprotoolosnosquaisadanodo
pe-riodiamentesalvaoseu estadoemalgumdispositivode armazenamentoestável. O
estadosalvoontéminformaçãosuienteparareiniiaraexeuçãodoproesso. Um
hekpoint global onsistenteé um onjunto de N hekpoints loais, um para ada
nodo,formandoumestadoonsistenteparaosistema. Qualquerum doshekpoints
globaispodemserutilizadosparareiniiaraexeuçãodonodoapósumafalha,sendo
desejável minimizaro trabalhogasto narestauração dosistema [EAWJ96 ℄.
Os protoolos de reuperação de falta baseados em hekpoints possuem
pou-as restrições e são bastante simples de serem implementados. Entretanto, esses
protoolos não garantem que a exeução anterior à oorrênia da falha possa ser
deterministiamenterestaurada depois dareuperação [EAWJ96 ℄.
Asténiasparareuperaçãodefaltabaseadasemhekpoints podemser
lassi-adasem três ategorias: hekpointing não oordenado, hekpointing oordenado,
e hekpointing induzidopelaomuniação. Analisamosada ategoria a seguir.
•
Chekpointing Não Coordenado: As ténias de hekpointing nãooor-denadopermitema ada nodoter uma autonomia máxima aodeidir quando
realizar hekpoints. A prinipalvantagem dessa autonomia é que ada nodo
pode tomar a deisão de armazenar o seu estado nomomentoque onsiderar
mais onveniente. Por exemplo, um nodopode reduziro overhead realizando
hekpoints, quando aquantidade de informaçãoa ser salvaé pequena [Di87℄.
Entretanto, existem muitas desvantagens. Primeira: existe a possibilidade do
efeito dominó, que pode fazer om que todos os nodos voltem ao iniio da
sua omputação [Di87℄. Segunda: um nodo pode realizar um hekpoint sem
neessidade, fazendo om que hekpoints nuna sejam utilizados para o
es-tado global onsistente do sistema. Tereira: hekpoints não oordenados
forçam adanodoa manter váriasópias de seus estados anterioresemalgum
dispositivode armazenamento seguro eperiodiamenteinvoar um algoritmo
oletorde lixopara remover ópiasquenão serão mais utilizadas. Para
deter-minar um hekpoint global na reuperação, os nodos usam as dependênias
entre seus hekpoints que foram guardadas utilizando-se ténias disutidas
•
Chekpointing Coordenado: As ténias de hekpointing oordenadore-queremqueosnodosoordenemseushekpointsparaformarumestadoglobal
onsistente. Essas ténias simpliam a reuperação de faltas e não são
susetíveisaoefeitodominó. Umavantagemquepodemosdestaaréqueessas
téniasrequeremqueada nodomantenhaapenasum hekpoint emum
dis-positivode armazenamentoseguro,eliminandoaneessidadede umoletorde
lixo. Sua desvantagem prinipal,entretanto,é a grandelatênia envolvida no
envio de informações para armazenamentos estáveis, havendo neessidade de
umhekpoint globalantes desse envio. Para minimizaressa situaçãoexistem
ténias não bloantes que permitem ohekpointing oordenado [EAWJ96℄.
•
Chekpointing InduzidopelaComuniação: Asténiasdehekpointinginduzido pela omuniação evitam o efeito dominó, enquanto permitem que
os nodos tenham alguma independênia nas suas veriações. Entretanto os
nodos podem ser forçados a realizar veriações adiionais para garantir que
haverá suesso na reuperação da falha. Os hekpoints que um nodo realiza
independentementesão hamadosde hekpoints loais,enquantoaqueles que
um nodo é forçado a realizar são hamados de hekpoints forçados. Essas
ténias adiionam informações nas mensagens troadas entre os nodos. O
reeptor de ada mensagem usa as informaçõesadiionais para determinar se
há neessidade de realizar uma veriação forçada para ser inorporada ao
estado globaldosistema.
3.2.2 Message Logging
O meanismo de message logging é baseado na suposição de que a exeução de
um proesso emumnodoédeterminístiaentre asmensagensde entradareebidas,
ouseja, se dois nodos omeçam nomesmo estado e reebem a mesmaseqüênia de
mensagens, eles têm que produzir a mesma seqüenia de saída e têm que terminar
no mesmo estado. O estado do nodo é então ompletamente determinado por seu
estado iniiale pelaseqüênia de mensagens reebidas [Joh89℄.
Osprotoolosusados para messagelogging podem ser divididosem doisgrupos,
hamadosde message loggingpessimista e message logging otimista,de aordoom
ograu de sinronizaçãoimposto pelo protoolo na exeuçãodo sistema.
•
Message Logging Pessimista: Os protoolos pessimistas armazenam asmensagens sinronamente. O protoolo garanteque qualquer nododefeituoso
não tenhamfalhado, e previneos nodos de prosseguirematé que o
armazena-mentodasmensagenstenhasidoompletado. Essesprotoolossãopessimistas
porque assumemqueafalhapodeoorreraqualquermomento,possivelmente
antes que o armazenamento das mensagens neessárias seja ompletado. As
vantagens enontradas nesses protoolos é queeles são apazes de restaurar o
sistemadepoisde umafalhasemafetar osestadosdeoutrosnodosquenão
fal-haram. Entretanto,sua prinipaldesvantageméadegradaçãododesempenho
ausada pela sinronizaçãonoprotoolo de armazenamento de mensagens.
•
Message Logging Otimista: Em ontraste om os protoolos pessimistas,os otimistas operam assinronamente. O reeptor de uma mensagem não é
bloqueado, e mensagens são armazenadas após seu reebimento, por
exem-plo agrupando várias mensagens e esrevendo-as em um dispositivo de
ar-mazenamento seguro em uma só operação. Entretanto, o estado orrente de
um nodo só pode ser reuperado, se todas as mensagens reebidas
anterior-mente àoorrêniadafalha foramarmazenadasorretamente. Esses
protoo-lossãohamados de otimistasporqueassumem queoarmazenamentodeada
mensagem reebida pelo nodo será ompletado antes de o nodo falhar, e são
projetados para tratar esse aso mais efetivamente. Esses protoolos
otimis-taspossuemavantagemde signiantementereduzirooverhead ausado pelo
armazenamentode mensagens. Apesar de os protoolos otimistasrequererem
um proedimentomais omplexopara reuperar osistema de uma falha,esse
proedimento só é usado quando uma falta oorre. A prinipal desvantagem
dos protoolos otimistas é que a reuperação do sistema devido a uma falha
pode levar um tempo maior para ompletar, uma vez que mais nodos podem
partiipar [Joh89℄.
3.2.3 Tolerânia a Faltas em Hardware
Métodos de tolerânia a faltas inteiramente implementados em hardware
geral-menteapresentam um melhor desempenho doque aqueles implementados em
soft-ware [Car86,Sie86, Joh89℄. Doisexemplos lássiosde sistemasque utilizam
méto-dos de tolerânia a faltas em hardware são o sistema de telefone eletrnio ESS
desenvolvido pela AT&T [CG87℄ e o ARPANET Pluribus IMP [KEM
+
78℄. Tais
métodos de hardware, entretanto, são menos exíveis e não podem ser failmente
adiionados asistemas existentes.
Umamaneiradeonseguirtolerâniaafaltasemhardware éatravésda
barramentos,oufontes de energiaqueoperem simultaneamenteeemparalelo,
om-parando resultados das operaçõesrealizadas.
3.2.4 Métodos Espeíos de Apliação
Métodos de tolerâniaafaltasespeíosde apliação[SH82,RK06℄ sãoaqueles
desenvolvidos espeiamente para um programa partiular que os use. Esses
de-senvolvimentos requeremonheimentotantodaapliaçãoquantodoseu ambiente.
Cadatipode faltaquepossaviraoorrernosistemadeve seranteipada, esoluções
espeías para ada falta devem ser adotadas. A implementação desses métodos
podeseguiralgumaestruturageraltalomoousodebloosdereuperação[SS83℄,ou
pode ser estruturada espeialmentepara ada apliação. Entretanto esses métodos
não são transparentes e requerem que programas existentes sejam uidadosamente
modiados ou reesritos para serem tolerantes afaltas. Emontraste, métodos de
tolerânia afaltasque usam message logging ehekpointing são de propósito geral
epodemserapliadostransparentementeanovosprogramasexistentes. Emboraem
algunsasos osmétodos espeíosde apliaçãopossam ser onstruídos para serem
mais eientes do que os métodos de propósito geral, eles são limitadosa sua falta
de transparênia.
3.2.5 Repliação Ativa
A repliação ativa envolve a exeução onorrente de múltiplas ópias
indepen-dentes de adaproesso emnodos(proessadores) separados, detalformaqueada
réplia domesmo proesso reeba a mesma seqüênia de entrada, e é esperado que
produza a mesma seqüenia de saída. Se uma réplia falhar, as demais réplias
daquele proesso ontinuam a omputação sem interrupção. Exemplos de sistemas
queutilizam repliação ativainluemo sistema ISIS [BJ87℄e o WAFT [AM98℄.
O método de repliação ativa é bem adaptado para uso em sistemas de tempo
real,umavezqueareuperaçãodeumafalhaéessenialmenteimediata. Entretanto,
essa habilidade requer proessadores extras para serem dediados a ada programa
para suas réplias.
3.2.6 Sumário
Umavez queosmodelosde faltaseosmétodos detolerânia afaltasforam
estu-dados,esuas vantagens edesvantagens foramidentiadas, temosa baseneessária
distribuí-uxo de trabalho ientío, preisamos identiar as araterítias desses sistemas.
No próximo apítulo ( 4) apresentamos as prinipais araterístias assim omo a
arquitetura do sistema proposta neste trabalho, e posteriormente, no apítulo 5,
mostramos quais foram os modelos de faltas e os métodos de tolerânia a faltas
Sistema de Fluxo de Trabalho
Cientío Proposto
A visão de que ientistas tipiamente exeutam experimentos e de que esses
experimentos podem ser onsiderados oleções ordenadas de tarefas atuando sobre
dados e envolvendo uma variedade de atividades distintas motiva a exploração do
paradigma de uxo de trabalho ientío. Como foi dito anteriormente, o
geren-iamento, a manipulação e o armazenamento de grandes volumes de dados, assim
omoagarantiadedisponibilidade,nessesambientes,sãoosgrandesdesaosaserem
enfrentados.
Neste apítuloserão disutidos quaisdos requisitosneessários para os sistemas
que dão suporte à exeução de uxos de trabalho ientíos foram obertos neste
trabalho, e será desritaa arquitetura dosistema proposto.
4.1 Requisitos Cobertos
Para suportar uxos de trabalho ientíos omplexos, um sistema de uxo de
trabalhodevesatisfazerumagrandevariedadederequisitos [HRL
+
05,SM96℄. Esses
requisitosinlueminterfaesde usuárioelinguagenspara fáilomposiçãode uxos
detrabalho,esalonamento,exeuçãoemonitoramentodeuxosde trabalho,
geren-iamentode oleçõesde dados,onança e robustez. Osprinipaisrequisitos
trata-dos neste trabalhosão:
•
Composiçãodeuxosdetrabalho: jáqueapesquisaéumproessodeevoluçãoemudanças,pesquisadoresdevemserapazes deompor,registrar,eontrolar
diferentesversõesdeuxosdetrabalho. Asdeniçõeseinstâniasdessesuxos