An Intelligent Association Rule Mining
Model for Multidimensional Data
Representation and Modeling
S.VEERAMALAI * AND A.KANNAN**
Department of Information Science and Technology, College of Engineering, Guindy, Anna University - Chennai
Chennai‐600025, Tamil Nadu, India Abstract:
This paper presents a new algorithm called Fuzzy-T ARM (FTA) to classify the breast cancer dataset. In this work, ARM is used for reducing the search space of the Multidimensional breast cancer dataset and Fuzzy logic is used for intelligent classification. The dimension of input feature space is reduced the instances from one third by using ARM. The FTA has applied to the Wisconsin breast cancer dataset to evaluate the overall system performance. This research demonstrated that the ARM can be used for reducing the dimension of feature space and the proposed model can be used to obtain fast automatic diagnostic systems for other cancer diseases.
Key words: Data Mining, Fuzzy, Association Rule Mining, Data classification. 1. Introduction:
Data classification process using knowledge obtained from known historical data has been one of the most intensively studied subjects in statistics, decision science and computer science. It has been applied in problems of medicine, social science management and engineering. Various problems such as disease diagnosis, image recognition, and credit evaluation using classification techniques [1]. An Association rules is a well established data mining technique used to discover co-occurrences of items mainly in multidimensional data. One of the application areas of analyzing database and pattern recognition is automated diagnostic systems. The aim of these studies in the medical domain is to assist the doctors in making diagnostic decisions.
The algorithm proposed in this paper aims to find association rules (with strong support and high confidence) in large datasets. In this work, Classification Association Rule Mining (ARM) [4] is used to find the relationships among the data items present in Multidimensional databases. In order to implement this effectively the data collection that has been used in our experiments is taken from the data on high incidence of malady in Human life especially from developed countries since it has increased significantly in these countries in the last years.
In reality, only a small amount of these data are used from the [9] large dataset because, in many cases, for testing while the large portion of the data is used for training.
2. Problem Statement
Due to tremendous advances and achievement in biomedical, bioinformatics, biological and clinical data is being mined at tremendous speed. Biological data volume and complexity increases exponentially [7]. Thus the biological data stored at data warehouse in the format of multidimensional data [11]. Bio medical data analysis and integration becomes very difficult due to data complexity, distribution, volume of data. Most commercial data mining products provide large number of modules and tools for performing various data mining tasks but few provide intelligent assistance for addressing many important decisions that must be considered during the mining process.
medical data from data warehouses. Mostly analysis products do not provide the intelligent assistant in decision making process.
Our proposed system is needed that assists which provide the intelligent assistant in decision making process and can help researchers in mining to precede their research work.
3. Related Works
The traditional association rule mining algorithms to recognize frequent events in form of itemsets were widely-used example of association rule mining is Market Basket Analysis (Agrawal et al., 1993) were among the first to address the problem of pattern Classification by using breast cancer dataset[14] from the database. The work on association rules was extended from patterns [1,2,11] ,the authors explored data cube-based [2] rule mining algorithms on multidimensional databases, where each tuple/transaction consisted of multi-dimensional data features.In the area of multi-dimensional data sets [11], authors discussed a multidimensional data model, in which the multidimensional data was viewed as a value in the multidimensional space. Based on this model, efficient data mining have been performed using data cubes[2] based on aggregates of dimensions were computed in [9,10]. Rule mining is another well studied data mining problem and over the years many techniques have been designed to construct decision trees for mining the patterns in the data [8].However, it is necessary to perform classification in addition to association rule mining for effective decision making. Therefore, this paper focuses on the integration of ARM with Fuzzy rule mining for better decision.
4. System Architecture:
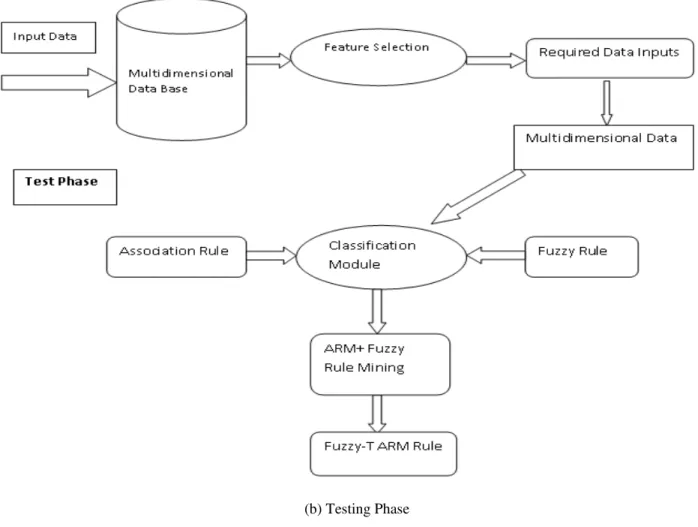
The architecture of the proposed system is shown in Fig 1.0 The proposed system is mainly divided into two phases: the training phase and the test phase. Data cleaning and feature extraction are common for both the training set of data and the test set [2]. In the training phase, features are selected from the dataset, represented in the form of feature vectors. Next, the features are discretized into intervals and the processed feature vector is merged with the keywords related with the trained Multidimensional data [11].
(b) Testing Phase
Fig 1.0 Architecture of the Proposed System. a) Training Phase b) Testing Phase
5. Association Rules Mining:
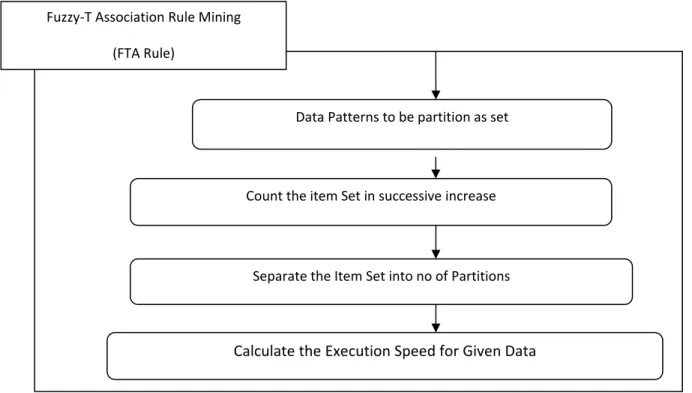
Fig: 1.1 The proposed FTA algorithm
Algorithm: - The Proposed algorithm uses a partition-approach to generate FTA rules.
Input:- The dataset is logically divided into p disjoint horizontal partitions P1, P2, …, Pp. Each partition is as large as can fit in available main memory. For ease of exposition, we assume that the partitions are equal-sized, though each partition could be of any arbitrary size as well.
We use the following notations:
• E = fuzzy dataset generated after pre-processing • Set of partitions P = {P1, P2, …, Pp}
• td[it] = tid list of item set it,
• µ = fuzzy membership of any item set• count[it] = cumulative µ of item set it over all partitions in which it has been processed• d = number of partitions (for any particular item set.
Output:-The Proposed FTA Rule mining algorithm has Performance analysis based on,for each remaining item set ‘it’ proposed Rule Mining calculate average value of remaining data and Compare the performance analysis of Fuzzy-ARM & FTA Algorithm.
Fuzzy‐T Association Rule Mining
(FTA Rule)
Data Patterns to be partition as set
Count the item Set in successive increase
Separate the Item Set into no of Partitions
FTA Rule Mining Algorithm:
6. Experimental Result:
Table: 1 Performance Analysis of Fuzzy ARM & FTA using Wisconsin breast Cancer Dataset
Fig: 1.2 Performance Analysis Graph of Fuzzy ARM & FTA using Wisconsin breast Cancer Dataset Data Attribute Names
No. of
Instances
Fuzzy
Efficiency
(%)
Fuzzy ARM
Efficiency (%)
FTA Rule Mining
Efficiency (%)
Clump Thickness 9 92.85 94.5 96.98
Uniformity of Cell Size 9 89.08 90.08 91.88
Uniformity of Cell Shape 9 91.5 92.47 95.1
Marginal Adhesion 9 91.3 92.6 93.2
Single Epithelial Cell Size 9 91.5 92.8 93.78
Bare Nuclei 9 92.51 93.1 94
Bland Chromatin 9 92.32 93.2 93.6
Normal Nucleoli 9 93.5 94.05 95.05
Mitoses 9 93.12 94.2 94.95
Class
Begin-B,
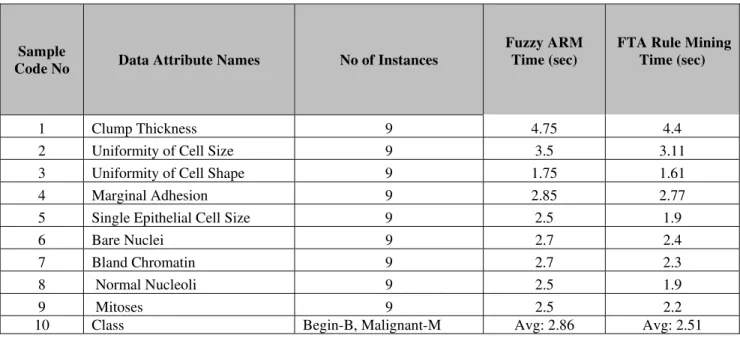
Table: 2 Time Efficiency of Fuzzy ARM & FTA Rule using Wisconsin breast Cancer Dataset
Fig: 1.3 Time Efficiency Graph of Fuzzy ARM & FTA using Wisconsin breast Cancer Dataset
7. Conclusion
We have presented a novel FTA algorithm, for very huge datasets, as an alternative to fuzzy ARM. Through our experimental results the Performance Analysis tables shown that the proposed algorithm is 5-8 times faster than fuzzy ARM. This considerable speed up has been achieved because novel properties like two-phased tid list-style
Sample
Code No Data Attribute Names No of Instances
Fuzzy ARM Time (sec)
FTA Rule Mining Time (sec)
1 Clump Thickness 9 4.75 4.4
2 Uniformity of Cell Size 9 3.5 3.11
3 Uniformity of Cell Shape 9 1.75 1.61
4 Marginal Adhesion 9 2.85 2.77
5 Single Epithelial Cell Size 9 2.5 1.9
6 Bare Nuclei 9 2.7 2.4
7 Bland Chromatin 9 2.7 2.3
8 Normal Nucleoli 9 2.5 1.9
9 Mitoses 9 2.5 2.2
processing using partitions, tid lists represented in the form of byte-vectors, effective compression of tid lists, and a tauter and quicker second phase of processing. In this work, the proposed method of FTA has two stages were applied and average values were calculated. The performance comparison and correct classification rates are tabulated and the best classification performance was obtained with FTA with nine inputs and its correct classification rate is 96.47%. The correct classification rate of Fuzzy with eight inputs is 92.48% and the correct classification rate of Fuzzy-ARM is 94.56% was obtained. So, we can use FTA for best classification performance and Fuzzy-ARM for using input parameters at minimum number.
Reference:
[1] Murat Karabatak , M. Cevdet Ince “An expert system for detection of breast cancer based on association rules and neural network” Expert Systems with Applications 36 (2009) 3465–3469, journal homepage: www.elsevier.com/locate/eswa.
[2] Micheline Kamber, Jiawei Han, and Jenny Chiang, “Metaruleguided mining of multi-dimensional association rules using data cubes,” in Proc. of the KDD conf., 1997, pp. 207–210.
[3] Rouming Jin and Gagan Agrawal, “Efficient decision tree construction on streaming data,” in Proc. of the 9th ACM SIGKDD conf., New York, NY, USA, 2003, pp. 571–576.
[4] [Pudi, V., Haritsa, J.: ARMOR: Association Rule Mining based on Oracle. CEUR Workshop Proceedings, 90 (2003).
[5] Mangalampalli, A., Pudi, V.: Fuzzy Logic-based Preprocessing for Fuzzy Association Rule Mining. Technical Report IIIT/TR/2008/127, International Institute of Information Technology (2008).
[6] R. Agrawal and R. Srikant, “Fast Algorithms for Mining Association Rules,” Proc. 20th Int’l Conf. Very Large Data Bases (VLDB ’94), pp. 478-499, Sept. 1994.
[7] Chen G., Yan P., Kerre E.E.: Computationally Efficient Mining for Fuzzy Implication-Based Association Rules in Quantitative Databases. International Journal of General Systems, 33, 163-182 (2004).
[8] Huller Meier, E.: Fuzzy methods in machine learning and data mining: Status and prospects. Fuzzy Sets and Systems. 156, 387-406 (2005). [9] Coenen, F. P., Leng, P., & Ahmed, S. (2004). Data Structures for Association Rule Mining: T-trees and P-trees. IEEE Transactions on Data
and Knowledge Engineering, 16(6), 774–778. doi:10.1109/TKDE.2004.8
[10] Dino Pedreschi, Salvatore Ruggieri, and Franco Turini. Discrimination-aware data mining. In Proceedings of the Fourteenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2008.
[11] Ishibuchi H., Nakashima T., Murata T. (1999) Performance evaluation of fuzzy classifier systems for multidimensional pattern classification problems. IEEE Trans. SMC–B 29, 601–618.
[12] F. Tao, F. Murtagh, and M. Farid, “Weighted Association Rule Mining Using Weighted Support and Significance Framework,” Proc. ACM SIGKDD ’03, pp. 661-666, 2003.
[13] W. Deng, G. Wang, and Y. Wang, “Weighted Naive Bayes Classification Algorithm Based on Rough Set,” Computer Science, vol. 34, pp. 204-206, 2007.
[14] C. Merz, P. Murphy, and D. Aha, “UCI Repository of Machine Learning Databases,” Dept. of ICS, Univ. of California, http://www.ics.uci.edu/mlearn/MLRepository.html, 1997.
[15] .H. Witten and E. Frank, Data Mining: Practical Machine Learning Tools and Techniques, second ed. Morgan Kaufmann, http://prdownloads.sourceforge.net/weka/datasets-UCI.jar, 2005.
Authors
Dr. A. Kannan is currently working as a Professor in the Department of Information Science and Technology, Anna University, Chennai-600 025, Tamil Nadu. He has Published around seventy Technical Research Papers in various International Journals and Conferences. His areas of interest include Database Systems, Data Mining and Artificial Intelligence