Uma proposta para a construção de gráficos de controle por meio de componentes principais
Texto
Imagem

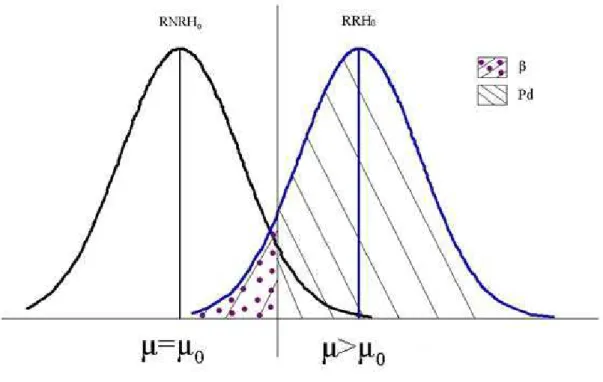
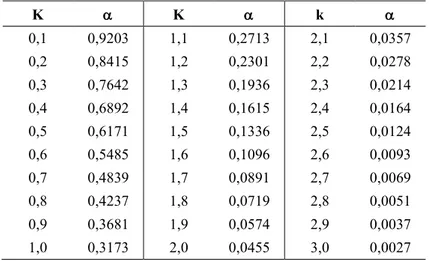


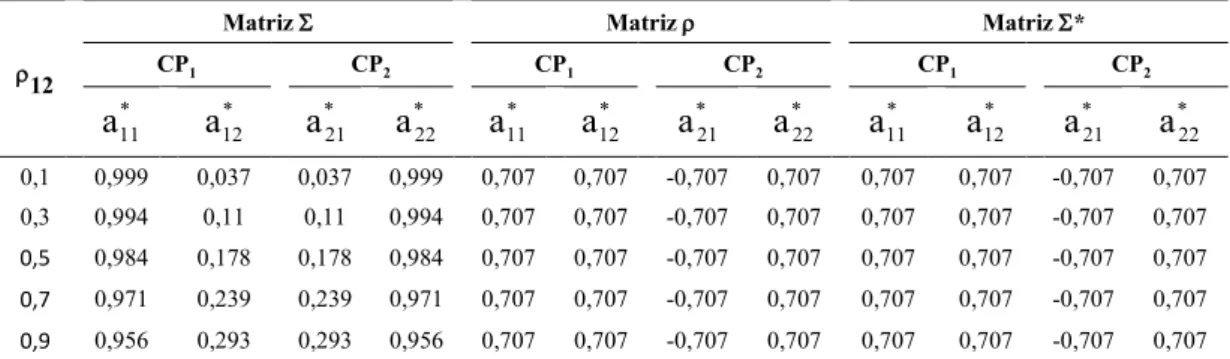
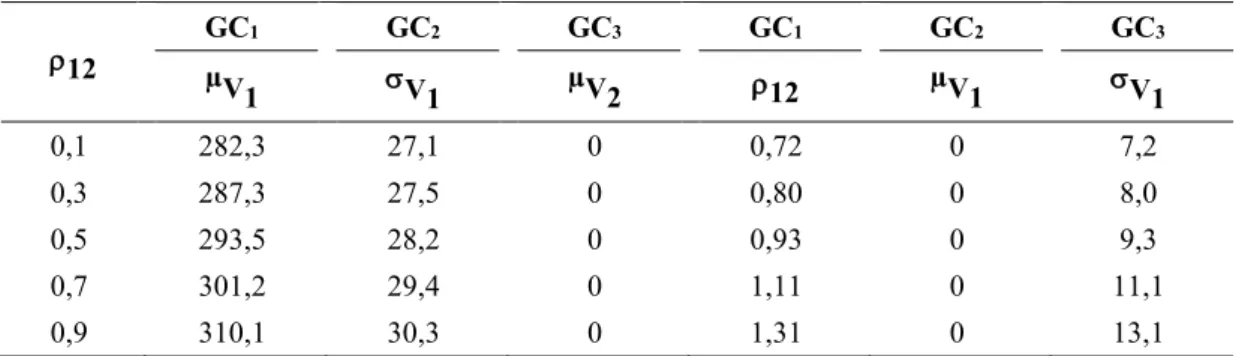

Outline
Documentos relacionados
Por exemplo, a nível das novas áreas (em particular a AP) não é fácil porque pede muito mais trabalho dos professores e pede uma nova postura da parte do professor (que passa a
Os doentes paliativos idosos que permanecem nas instituições privadas são encaminhados pelos hospitais em que estavam ou internados pelos próprios familiares
transientes de elevada periodicidade, cujos poros de fusão, de maior diâmetro, se mativeram abertos durante mais tempo. A expressão das quatro isoformas de HCN foi confirmada
29 Table 3 – Ability of the Berg Balance Scale (BBS), Balance Evaluation Systems Test (BESTest), Mini-BESTest and Brief-BESTest 586. to identify fall
For teachers who received their training in different periods, four different basic professional identities were identified: a) identity centred on an education of austerity
Especificamente as questões levantadas buscam avaliar qual o contributo das espécies mais representativas da área amostral (Bolbochenous maritimus (L.) Palla,
Se para as fibras monomodo, o recurso a técnicas de correcção de erros nomeadamente os códigos turbo é suficiente para se obter uma performance muito mais elevada, no caso das
