PODA ESTÁTICA PARA ÍNDICES INVERTIDOS
Instituto de Ciênias Exatas
Programa de Pós-Graduação em Ciênia da Computação
PODA ESTÁTICA PARA ÍNDICES INVERTIDOS
BASEADA EM LOGS
Dissertação apresentada ao Curso de
Pós-Graduação em Ciênia da Computação da
UniversidadeFederaldeMinasGeraisomo
requisitoparialparaaobtençãodograude
Mestre emCiênia daComputação.
FOLHA DE APROVAÇO
Poda Estátia para Índies Invertidos Baseada em Logs
CHARLES ORNELAS ALMEIDA
Dissertaçãodefendida e aprovada pelabana examinadora onstituída por:
Ph. D. Nivio Ziviani Orientador
Universidade Federal de Minas Gerais
Ph. D. Edleno Silva de Moura Co-orientador
Universidade Federal doAmazonas
Ph. D. Berhier Ribeiro de Araújo Neto
Universidade Federal de Minas Gerais
Ph. D. Renato Antnio Celso Ferreira
O resimento inexorável do volume de doumentos na World Wide Web oloa
um grandedesao para as máquinas de busa, não apenas om relação a eáiamas
tambémom relaçãoaeiênia deespaço ede tempo. Esta dissertaçãoapresentaum
novo métodode ompressão om perda (poda) para arquivos invertidos queonsidera
o aspeto eiênia sem desonsiderar a eáia. O método proposto é baseado na
análise de logs de onsultas passadas para obter uma grande redução no espaço
ou-pado pelo índie. O método pode ser utilizado em qualquer máquina de busa para
melhorar sua eiênia emtermos de tempo de proessamento e espaço oupado pelo
índie, pratiamente sem perdas naqualidadedos resultados daonsulta.
Experimen-tosutilizandouma máquinadebusa realmostramqueaténiaapresentada reduzos
ustosde armazenamentodoíndieematé50%omrelaçãoaoíndiesem ompressão.
Uma onsequênia dessa redução no tamanho do índie é que o tempo de
proessa-mentode umaonsultapode ser reduzido a aproximadamente45% dotempooriginal,
sem perda na preisão média. Considerando a qualidade do ranking produzido, o
es-paçooupadopeloíndieeotempode respostaaonsultas,estudosomparativosom
os dois melhores algoritmos de ompressão de índies onheidos na literatura
mos-tram que o algoritmo proposto é bastante ompetitivo. Por exemplo, tanto a urva
de similaridade entre os rankings quanto a preisãomédia das respostas doalgoritmo
proposto e o melhor algoritmodentre os dois onsideradosna omparação semantêm
aproximadamente iguais para os diferentes níveis de poda. Quanto ao tempo de
res-posta o algoritmo proposto é mais rápido do que o melhor algoritmo dentre os dois
onsiderados naomparação.
Palavras-have: poda, ompressão de índies, máquinas de busa, busa na Web,
The relentless growth of the volume of douments in the World Wide Web poses
a great hallenge for searh engines, not only regarding searh eetiveness but also
time and spae eieny. This thesis presents a new lossy ompression (pruning)
methodfor inverted les that addresses the eieny issue withoutdisonsideringthe
eetiveness. The proposed methodisbasedonloganalysis ofpast queriestoobtaina
greatredutioninthesize oftheindies. Themethodanbeused inanysearhengine
to improve itseieny in terms of query proessing time and spae oupied by the
index, with nearly noost interms of the qualityof query results. Experimentsusing
areal searhengineshowthatthe tehniquepresented redues the storageosts ofthe
index by upto50%overtraditionallosslessompressionmethods. Oneonsequeneof
this redution inthe size ofthe indexisthat the queryproessingtimean beredued
to nearly 45% of the original time, with no loss in average preision. Considering the
quality of the ranking, the spae oupied by the index and the query answer time,
omparative studies with the two best known stati pruning methods show that the
proposed algorithm is ompetitive. For example, both the similarity plot between
the rankings and the average preision of the answers of the proposed algorithmand
the best algorithm among the two onsidered are very lose for all dierent levels of
pruning. For the query answer time the proposed algorithm is faster than the best
algorithmamong the two onsidered.
ADeus,aimadetudo,quemedeuasalvaçãopormeiodeJesusCristo,meuSenhor.
A Ele eu agradeço pelo amor, miseriórdia, bondade e longanimidade imensuráveis,
dispensados amimaada dia. A Eleeu louvoe dou graçaspelapresença onsoladora
e animadora, que me fez não desistir, mesmo em situações além de minhas próprias
forças, memostrandoassimqueeleéaminhaforçaequepormimmesmo,nadaposso.
Ameus paisJorgelinoeMariaOlinta,meusirmãosSávioeIgoreminhanamorada
Talita, meus amores. A eles dedio todo o meu afeto por terem me aompanhado
durante os momentos mais difíeis de minha vida. Agradeço pelo arinho, por
om-partilharem as alegriase dores eprinipalmenteporsuas onstantes orações.
A meu orientador, professor Nivio, pelo suporte sempre eiente. A ele agradeço
o inentivoonstante eas muitas horas de dediação, queforamdeterminantes para a
exeução desse trabalho.
A meu o-orientador, professor Edleno, que apesar da distâniafísia sempre
par-tiipoude perto deste trabalhopormeio de inúmerasvideoonferênias.
Aos demais membros da bana examinadora, professores Berthier e Renato, por
suas rítiase ontribuiçõesvalorosas.
Aos amigos do Laboratóriopara Tratamentoda Informaçãoos de agora, Álvaro,
Anísio, Bruno, Claudine, Maro Cristo, Maro Modesto e Thierson e os de outras
époas,Cláudio,Cristiane, Dilú,Pável,TâniaeWesleyporompartilhardias,noites
1 Introdução 1
1.1 Motivação . . . 1
1.2 Trabalhos Relaionados. . . 3
1.3 Contribuições . . . 4
1.4 Organização daDissertação . . . 5
2 Coneitos Básios 7 2.1 ArquivosInvertidos . . . 7
2.2 ModeloEspaço Vetorial . . . 7
2.3 Métodos de Poda . . . 9
2.3.1 PodaDinâmia . . . 9
2.3.2 PodaEstátia . . . 11
2.4 Avaliaçãode Resultados . . . 14
2.4.1 Preisão e Revoação . . . 15
2.4.2 Similaridade de Rankings . . . 16
3 Algoritmo de Poda Proposto 19 3.1 Extração de Informação dos Logs . . . 20
3.2 O Proesso de Poda. . . 21
3.3 Desrição doAlgoritmo . . . 22
4 Resultados Experimentais 25 4.1 Ambiente de Exeução eColeçõesde Teste . . . 25
4.2 Impato naOrdenação daResposta . . . 26
4.3 Qualidade daResposta . . . 28
4.4 Tempo de Exeução. . . 29
5 Conlusões e Trabalhos Futuros 31
Introdução
1.1 Motivação
Máquinas de busa preisas e eientes são um reurso valioso atualmente dadas
as grandes proporções da Web. Em novembro de 2004, a máquina de busa Google 1
anuniou que sua base de dados possuía mais de 8 bilhões de doumentos 2
. Outras
máquinas de busa de esala globaltambémtêm bases de dados om bilhõesde
dou-mentos. Apesar dessesaltos números,essas basessão apenasuma pequenaamostrade
um universo ainda maior (Raghavan eGaria-Molina, 2001).
Para reuperar informação relevante para seus usuários de forma eiente as
má-quinas debusautilizamum tipode índiehamadode arquivoinvertido(Baeza-Yates
e Ribeiro-Neto,1999). O arquivoinvertido assoiaada termo queaparee naoleção
om os doumentos em que ele oorre. Para tratar de busas por frases ou busas
em proximidade, o arquivo invertido guarda também informação de onde ada termo
aparee dentrodos doumentos. Otamanhodestes índieséproporionalaotamanho
da base de dados de texto armazenadapelosistema de busa, portanto o índietoma
dimensõesmuito grandes quando usadospara busa em todaa Web.
Por outro lado, a proporção de aessos a sites provindos de máquinas de busa
quase dobrou de 2002 para 2003 3
. Essa tendênia é mundial, sendo que no Brasil a
proporção aumentou ainda mais,indo de 8% para 19%. Embora oaesso diretoainda
sejaresponsávelpelamaiorpartedotráfegoaum site,essa modalidadereseu menos,
era de 30%. É até mesmo omum ao públio da Internet utilizar sua máquina de
busapreferidaomobookmark,ouseja,emvezdeentrar,porexemplo,omoendereço
www.ufmg.br no navegador, ointernauta entra oma palavra-have ufmg na máquina
1
http://www.google.om
2
http://www.google.om/googleblog/2004/11/go ogles-index-nearly-doubles.html
3
omoresposta 4
.
A ombinação entre quantidade resente de informação e de usuários faz om
que haja uma demanda por estruturas de índie mais ompatas e eientes para
máquinasde busa. Máquinas debusa naWeb requeremum uso extremode reursos
omputaionais,devendoserapazesderesponderamilharesdeonsultasporsegundo.
Uma únia onsulta pode ler entenas de megabytes de dados e onsumir dezenas de
bilhões de ilos de CPU (Barroso et al., 2003). Além disso, a resposta às onsultas
deve apresentar os doumentos em ordem de relevânia para o usuário. Logo, uma
utilizaçãomaisraionaldosreursosomputaionaisenvolvidosnomeanismodebusa
éimportantepara quese possa atender rapidamentea todas as requisições.
Outra tendênia que motiva a riação de índies mais ompatos é o advento dos
omputadores de bolso. Atualmente eles já são apazes de armazenar oleções de
doumentos de tamanho moderado, de tal forma que a apaidade de se fazer busa
indexada é desejável. No entanto, sua apaidade de armazenamento limitada impõe
severas restrições de tamanho aos índies.
Aompataçãode índies(Zivianietal.,2000;Carmeletal.,2001;deMoura etal.,
2005)éumartifíioquereduznão somenteosustosde armazenamentoomotambém
melhoraotempode resposta àsonsultas. Omaior ustoenvolvidonoproessamento
de uma onsulta é o tempo gasto para ler do diso as porções de índie neessárias
parao mputo daresposta. Dessaforma,índies menores impliammenosleitura de
diso,que por sua vez impliamtemposde resposta menores.
Esta dissertaçãopropõe,implementaeavaliaumanovaténiade ompataçãode
arquivosinvertidosbaseadaemlogs. Oslogs 5
deumamáquinadebusapodemseruma
boafonte de informação para guiara redução do tamanhodos índies. Uma formade
fazeraompatação doíndie éeliminar entradasque não são de interesse para o
pú-blioqueutilizaamáquina debusa. Oslogs podemser usadosparaestimarquaissão
osinteressesde pesquisa dos usuários,ajudandoadeterminarqueinformaçãopode ser
desartadados índiessemqueosusuáriosperebammudançasnosresultadosobtidos.
Experimentos apresentados om o método proposto indiam que é possível melhorar
o desempenho de um sistema de busa reduzindo tanto os ustos de armazenamento
doíndie omo o os ustos de proessamento da onsultas, sem perda signiativa na
qualidadedareposta.
4
http://www.google.om/help/features.html#luky
5
Uma abordagem para a ompatação de arquivos invertidos é a ompressão sem
perdas(de Mouraetal.,2000;Zivianietal.,2000). Essa téniaéhamadasem perda
porque nenhuma informação é desartada do arquivo invertido. As ténias de
om-pressãoutilizadasemarquivosinvertidospartemdoprinípiodequenúmerospequenos
podemser representados de formamais ompatapormeio de odiaçõesespeías.
Como a listade doumentos que ontém um determinado termoda oleçãoé
armaze-nadaemordemasendente, elapodeseronsideradaomoumaseqüêniadeintervalos.
Assim, o primeiro doumento da lista, digamos 5, é representado normalmente, o
se-gundo, digamos 11, é representado omo 6, ou seja, 11 menos o anterior 5, e assim
suessivamente. Umavez queo proessamento dalistade oorrênias de uma palavra
énormalmentefeitodeformaseqüenial, onúmerooriginaldodoumentopodesempre
ser reomputado pela soma dos intervalos. A lista de oorrênias omposta agora de
inteiros menores pode então ser representada em menos bits usando uma odiação
adequada.
Outra abordagem, onheida omo poda (Persin et al., 1996; Carmel et al.,2001;
de Moura etal.,2005),desarta determinadasentradasdoarquivoinvertido
tornando-o menor,porém perdendo informação. Essas duasténias são omplementares,sendo
possível apliar uma poda num arquivo invertido para seleionar as entradas mais
importantes e em seguida omprimir o arquivo invertido podado. Possivelmente não
se obtém a mesma taxa de ompressão que seria obtida omprimindo um arquivo
invertido não podado, porém o resultado da ombinação das duas abordagens aaba
sendo melhor quea apliaçãode apenas uma delas.
Exemplos de métodos de poda são a remoção de stopwords 6
e Indexação
Semân-tia Latente(LSI) 7
(Deerwester et al.,1990). Ambas as ténias foram originalmente
propostas om oobjetivode removerinformaçãoruidosadoíndie,eliminando termos
que deterioram a preisão. No entanto, outro efeito ausado por essas ténias é a
redução dotamanho doíndie. Oproblema destasténias é queelas desartamlistas
de oorrêniasinteirasde determinadostermos. Assim, onsultasontendotaistermos
terão de ignorá-los ou retornar uma resposta vazia. Em ambos os asos, o usuário do
sistema de busa não ará satisfeito.
Um tipo de poda menos drástia e mais eaz é a que elimina apenas asentradas
menos importantes das listas de oorrênias. Umexemplo é a poda de Persin (Persin
et al., 1996), que é apliada no momento em que a onsulta é proessada.
Normal-6
Remoçãodoarquivoinvertidodasentradasdetermosmuitofreqüentesedepouovalor
semân-tio, omoporexemplo,preposições,artigos,algunspronomes,et.
7
mais raro para o termo mais freqüente na oleção. Porém, o proessamento de ada
termo é terminado assim que determinada ondição é atingida, mesmo que sua lista
de oorrênias não tenha sido inteiramente lida e proessada. Isso reduz o tempo de
proessamentodas onsultas, entretanto, asentradasdas listas de oorrênias quenão
foramlidas ainda fazem doparte doíndie, que não diminui de tamanho.
EnquantoométododePersinpropõequeapodasejafeitaduranteoproessamento
da onsulta, o método de Carmel (Carmel et al., 2001) propõe que essa poda seja
feita estatiamente, logo depois que o índie é onstruído. Assim omo o método
de Persin, somente as entradas menos importantes de ada lista de oorrênias são
podadas, mas essa poda impliaremover literalmenteessas entradas do índie emvez
de simplesmente não proessá-las. Podar o índie estatiamente, além de reduzir o
tempo de proessamentodas onsultas reduz tambémotamanho doíndie.
Um problema que é omum tanto à poda de Persin quanto à poda de Carmel é
que a poda é feita sem levar em onta o relaionamento entre os termos. Essa
es-tratégiaaaba deteriorando a qualidade das respostas, prinipalmentepara onsultas
onjuntivas. Emonsultasdessetipoéneessário quetodosostermosprourados
este-jampresentes nos doumentosda resposta, mas omo a podaé feitatratando de ada
termoindividualmente,muitos doumentos queseriambons andidatos aabamsendo
desartados. Por exemplo, suponhamos que o doumento
d
seja um bom andidatopara responder à onsultapelos termos
ta
etb
,mas aopodar alistade oorrênias dotermo
ta
,o doumentod
foi desartado. Assim, mesmoque odoumentod
tenhasidopreservado na lista de oorrênias do termo
tb
, esse doumento não será dado omoresposta à onsulta.
Um trabalho reente que leva em onta a relação entre os termos é o método de
poda estátia baseada em loalidade, o Lbpm (de Moura et al., 2005). Esse método
determinaquaissão asentradasindividualmentemaisimportantesnalistade
oorrên-ias dos termos, mas preservatambémasentradas de termos que oorrem próximos a
estes dentrodos doumentos. A prinipal diferençaentre o métodoLbpm e ométodo
proposto nesta dissertação é que o Lbpm proura predizer quaistermos serão
pesqui-sados em onjunto utilizando o onteúdo dos doumentos, enquanto o nosso método
olha para asonsultas já submetidas para fazer essa predição.
1.3 Contribuições
A prinipal ontribuição desta dissertação é a apresentação de um novo método
de busapara melhorarsua eiênia emtermosde tempo de proessamento e espaço
oupadopeloíndie,pratiamentesemperdasnaqualidadedosresultadosdaonsulta.
Outras ontribuiçõesespeías dotrabalho são:
•
Proposição,desriçãoeimplementaçãode umnovoalgoritmodeompressãoomperdabaseado naanálise de logs (apítulo 3).
•
Estudo omparativo doomportamento doalgoritmoproposto om doisalgorit-mos apresentados na literatura,o algoritmode Carmel (Carmeletal.,2001) e o
algoritmo Lbpm (de Moura et al., 2005) (apítulo4), onsiderando os seguintes
aspetos:
qualidadedo ranking produzido;
espaço oupadopelos índiesgerados pelos algoritmos;
tempo de resposta de ada algoritmo.
•
Estudo dos prinipaisalgoritmos de poda onheidos na literatura(apítulo 2),om modiação do algoritmo para poda dinâmia de Persin (Persin et al.,
1996), paratrataronsultas onjuntivas(seção2.3.1), estudodométodode
Car-mel (Carmeletal.,2001)(seção2.3.2),estudodométodoLbpm (deMoura etal.,
2005) (seção2.3.2)eestudo de medidasde similaridade de rankings para
utiliza-ção nos experimentos (seção2.4.2).
1.4 Organização da Dissertação
Esta dissertação está dividida em ino apítulos, dos quais este é o primeiro. O
apítulo 2 apresenta os oneitos básios neessários para o entendimento do texto,
bemomo as prinipaismedidas de relevânia utilizadas nos experimentosrealizados.
O apítulo3 apresenta o novo algoritmode podaproposto. O apítulo4 apresenta os
Coneitos Básios
2.1 Arquivos Invertidos
O esquema de indexação omumente utilizado pelos sistemas de reuperação de
informação é o arquivo invertido (Baeza-Yates e Ribeiro-Neto, 1999). Um arquivo
invertido é omposto por um voabulário e um onjunto de listas invertidas. O
vo-abulário ontém ada termo
t
presente na oleção de doumentos e o númeroft
dedoumentosontendo
t
. Existe uma lista invertida para adat
, onstituída dosiden-tiadores
d
dos doumentos ontendo o termo e da freqüêniafd,t
det
emd
. Logo,ada entrada de uma listainvertidaé um par
h
d, fd,t
i
de valores.2.2 Modelo Espaço Vetorial
O método de ordenação das respostas mais onheido e utilizado nos sistemas de
reuperação de informaçãoé o modelo espaço vetorial (Salton e MGill,1986). Nesse
modelo,ada termodovoabuláriorepresentaumadimensão. Doumentoseonsultas
são entãomapeadosemvetoresmultidimensionaisnesteespaçovetorial. Quantomaior
é o valor do osseno entre um vetor que representa uma onsulta e um vetor que
representaumdoumento,maioréasimilaridadeentreestaonsultaeestedoumento.
De forma prátia,a similaridadeentre odoumento
d
e aonsultaq
é denida porCq,d
=
P
t
simq,d,t
Wd
,
sendo
Wd
o tamanhodo doumentod
esimq,d,t
,a similaridadeparialentreq
ed
omrelação aotermo
t
, denida porem que
wx,t
é o peso det
no doumentod
ou na onsultaq
. AumuladoresAd
sãousados para manter os somatórios pariais
P
t
simq,d,t
de ada doumento. Osvaloresde
Wd
são previamenteomputados om a expressãoWd
=
s
X
t
w
2
d,t
e armazenados em diso. Vários métodos para alular
wx,t
são propostos (Wittenetal.,1999). Dentre eles, adotamos
wq,t
= 1
e
wd,t
= ln
fd,t
·
ln
N
ft
sendoN o número de doumentos naoleção.
Uma forma de garantir que nenhum doumento que ontenha todos os termos da
onsulta seja desartado prematuramente é não utilizar poda. O algoritmo 2.1 é o
método básio para proessar onsultas onjuntivas sem poda e om ordenação da
resposta.
No algoritmo básio,
A
(
d
)
.sim
aumula as similaridades pariais entred
eq
omrelação a
t
, ao passo queA
(
d
)
.cont
onta quantos dos termos da onsulta oorreramno doumento
d
. Ao nal do algoritmo, os doumentos prourados são aqueles emque
A
(
d
)
.cont
=
|
Q
|
, sendo|
Q
|
igual à quantidade de termos presente na onsulta 1.
Como estamos interessados apenas nos
k
melhores doumentos, reuperamos aquelesquepossuem os maioresvalores de similaridade
A
(
d
)
.sim
oma onsulta.para adadoumento
d
daoleção façaA
(
d
)
.sim
←
0
;A
(
d
)
.cont
←
0
;para adatermo
t
da onsultafaça Reupere alistainvertida det
nodiso;para adaentrada
h
d, fd,t
i
nalistainvertida façaA
(
d
)
.cont
←
A
(
d
)
.cont
+ 1
;A
(
d
)
.sim
←
A
(
d
)
.sim
+
simq,d,t
;Divida ada aumulador
A
(
d
)
.sim
porWd
;Identique os
k
aumuladoresom maior valorA
(
d
)
.sim
eA
(
d
)
.cont
=
|
Q
|
; Reupere osk
doumentos orrespondentes;Algoritmo2.1: Algoritmo básiopara onsultas onjuntivas
1
posta. Se partirmosdo pressuposto de que a ordenação da resposta dada pelafunção
de similaridadeutilizadaéboa,então aordenaçãodadapeloalgoritmobásiotambém
será boa. Apesar de ser eaz quanto à qualidade da resposta, o algoritmo básio
possuiumgrandeproblemade eiênia. Nessealgoritmo,aslistas invertidasde todos
os termos daonsulta têm que ser inteiramenteproessadas. No aso de máquinas de
busa, em que aoleção de doumentos éomposta de bilhõesde páginas Web, as
lis-tas invertidaspodem ser muito grandes. Isso fazom queo desempenho doalgoritmo
básio, emtermos de eiênia, seja muito ruim.
2.3 Métodos de Poda
Ténias de podaonheidasnaliteratura(Persin etal.,1996; Carmeletal.,2001)
podem ser muito bem apliadas quando não há a neessidade de que os doumentos
da resposta ontenham todos os termos da onsulta. Normalmente esses meanismos
funionam desartando alguns pares
h
d, fd,t
i
das listas invertidas durante oproessa-mento de uma onsulta (Persin et al., 1996) ou previamente, omo é o aso da poda
estátia (Carmel et al., 2001). No aso de onsultas disjuntivas, a eliminação
des-sas entradas não signia que o doumento em questão está desartado da resposta
pois outro par
h
d, fd,t
i
referente a outro termo nesse mesmo doumento pode aabarinluindo-o nas primeirasposições do onjunto resposta. Com isso, a podaaaba não
modiando muito o resultado das onsultas, mas garante um ganho signiativo de
desempenho.
O mesmoprinípio poderia ser usado para proessar onsultas onjuntivas,porém
a deisão por desartar uma entrada de uma lista invertida pode ser extremamente
arrisada. Nesse aso, desartar um par
h
d, fd,t
i
equivale a dizer que o termo nãooorreuno doumento emquestão. Essa pode ser uma esolha prematura mesmo que
a similaridade parial relativa à entrada desartada seja baixa, pois ao proessar as
outras listas invertidas, podemos desobrir que todos os outros termos da onsulta
oorreram naquele doumentoom altas similaridadespariais.
2.3.1 Poda Dinâmia
No métodode poda dinâmia,as listas invertidas são ordenadas pelo valor de
fd,t
e a similaridade parial relativa a um par
h
d, fd,t
i
é tratada de forma difereniada,dependendo da relação entre a freqüênia
fd,t
e duas freqüênias limiares, uma deinserção
fins
e outra de adiçãofadd
. Para o asofd,t
≥
fins
, ria-se uma entradaomputada,atualizandooaumulador
A
(
d
)
. Quandofins
> fd,t
≥
fadd
,a similaridadeparialsóatualizaoaumulador
A
(
d
)
,asoelejá existanaestruturade aumuladores.Apartir do momentoem quetemos
fadd
> fq,t
todoorestanteda listainvertidapodeser abandonado, uma vez que elaestá ordenada por
fd,t
. O algoritmo2.2 apresenta aestratégia de podade Persin.
Ordene o termos daonsultapor
ft
deresente;Smax
←
0
;para adatermo
t
da onsultafaça Compute osvalores defins
efadd
; Reupere alistainvertida det
nodiso;para adaentrada
h
d, fd,t
i
dalistainvertida faça sefd,t
≥
fins
entãoCrie um aumulador
A
(
d
)
seneessário;A
(
d
)
.sim
←
A
(
d
)
.sim
+
simq,d,t
;senão se
fd,t
≥
fadd
EA
(
d
)
já foi riado entãoA
(
d
)
.sim
←
A
(
d
)
.sim
+
simq,d,t
;termineo proessamento dalistainvertida atual;
Smax
←
max(
Smax, A
(
d
)
.sim
)
;Divida ada aumulador
A
(
d
)
.sim
porWd
;Identique os
k
aumuladoresom maior valorA
(
d
)
.sim
; Reupere osk
doumentos orrespondentes;Algoritmo2.2: Estratégia de podade Persin
A podade Persin dene osvaloresdas freqüênias limiaresde inserção por
fins
=
cins
·
Smax
fq,t
·
w
2
t
eadição por
fadd
=
cadd
·
Smax
fq,t
·
w
2
t
.
Nessa expressão,
Smax
orresponde àmaior similaridadeomputada durante oproes-samento das listas invertidas. As onstantes
cins
ecadd
são utilizadas para ontrolaro nível da poda. Elas devem ser ajustadas de aordo om a oleção de
doumen-tos (Persin et al.,1996), de forma a se obter o melhor balaneamento entre eonomia
de reursos omputaionais e qualidade daresposta.
AadaptaçãomaisingênuadapodadePersinpararesponderaonsultasonjuntivas
édiretaepode ser vistanoalgoritmo2.3. Nesse algoritmo,
A
(
d
)
.cont
éutilizadoomono algoritmo básio para ontar quantos dos termos da onsulta oorreram em ada
doumento. As similaridades pariais entre o doumento e a onsulta são somadas
do
i
-ésimo termo da onsulta referenia um aumuladorA
(
d
)
, sua similaridade só éomputada esomada se todos os termos anteriores tambémoorreram no doumento
d
,nesse asoA
(
d
)
.cont
=
i
.Ordene os termosda onsultapor
ft
deresente;Smax
←
0
;para adatermo
ti
daonsulta(0
≤
i
≤ |
Q
|
)
faça Compute osvaloresdefins
efadd
;Reupere alistainvertida de
ti
dodiso;para ada entrada
h
d, fd,t
i
dalistainvertida façase
i
6
= 0
E (A
(
d
)
não está noonjuntode aumuladoresouA
(
d
)
.cont < i
) entãoContinue;
se
fd,t
≥
fins
entãoCrie um aumulador
A
(
d
)
seneessário;A
(
d
)
.cont
←
A
(
d
)
.cont
+ 1
;A
(
d
)
.sim
←
A
(
d
)
.sim
+
simq,d,t
;senão se
fd,t
≥
fadd
EA
(
d
)
já foi riado entãoA
(
d
)
.cont
←
A
(
d
)
.cont
+ 1
;A
(
d
)
.sim
←
A
(
d
)
.sim
+
simq,d,t
;termineo proessamento dalistainvertida atual;
Smax
←
max(
Smax, A
(
d
))
;Divida adaaumulador
A
(
d
)
.sim
porWd
; Identique osk
aumuladoresom maior valorA
(
d
)
.sim
eA
(
d
)
.cont
=
|
Q
|
; Reupere osk
doumentosorrespondentes;
Algoritmo 2.3: Adaptação da estratégia de poda de Persin para onsultas
on-juntivas
Apesar do algoritmode Persin ser failmente adaptado para tratar onsultas
on-juntivas,existem muitospontosquedevemser investigados. Como nãoexiste nenhum
trabalho que estudou esta possibilidade, é neessário veriar se é possível enontrar
as onstantes
cins
ecadd
que balaneiam eonomia no proessamento e qualidade deresposta para o aso de onsultas onjuntivas. Esse estudo foi feito neste trabalho,
demonstrando que a adaptação desse algoritmo gera resultados muito ruins, mesmo
para podas muito pequenas, onformepode ser visto noapítulo 4.
2.3.2 Poda Estátia
Existem dois métodos de poda estátia propostos na literatura, o método de
Car-mel (Carmel et al., 2001) e o método Lbpm 2
(de Moura et al., 2005). O ponto de
2
mentodestetrabalhosurgiuoLbpm, queapresentou resultadosmelhoresqueométodo
de Carmel em termos de preisão de resultados. O método de poda estátia baseado
emlog,queestamospropondo,éomparadonoapítulo4om estesdois métodos, que
são desritos a seguir.
2.3.2.1 Poda Estátia de Carmel
A idéia do método de Carmel é usar o ranking da máquina de busa para
om-putara importâniade ada entrada nas listas invertidas edeterminar quais entradas
resultamemumaontribuiçãobaixaosuienteparaseremremovidassemprejuízoda
resposta. Para isso, submetemos individualmente ada termo do voabulário da
ole-ção omouma onsultaà maquinade busa. Oresultado disso é quepara ada termo
t
temos a lista resultanteR
(
t
)
de doumentos relaionados at
em ordem deresentede importânia,segundo os ritériosde ranking damáquina de busa.
A lista resultante
R
(
t
)
pode ser enarada omo um ranking para os doumentos,umavezquequantomaiorfor oranking dodoumento
d
emR
(
t
)
, maioréahanedeque
d
apareça nos resultados de uma onsulta ontendo o termot
. Apodade Carmelonsisteemtomarapenasosdoumentos queapareem napartedotopode
R
(
t
)
omosendo a nova lista de doumentos relevantes para o termo
t
. Cada entrada da listainvertida que representa a oorrênia de um termo
t
em um doumentod
é removidadoíndie se
d
não está presenteno topodeR
(
t
)
.A quantidade de entradas que ompõemo topo de
R
(
t
)
de ada termo édetermi-nadaporumparâmetro
δ
. Esteparâmetroapenaspreservaentradasqueorrespondemadoumentosem
R
(
t
)
ujoranking,dadopelamáquinade busa,épelomenosδ
vezeso maior ranking de todos os doumentos em
R
(
t
)
. O resultado é uma nova listaha-mada
Rδ
(
t
)
. Por exemplo, seδ
= 0
,
7
, ada doumento om ranking maior ou igual a70%
domaiorranking estaráemRδ
(
t
)
. Ovalordeδ
,entre0
e1
,édeterminadoexperi-mentalmente. Um bomvalorpara
δ
reduziráo tamanhodoíndieeonseqüentementeotempode resposta das onsultas,mas deverá preservarum número de elementosque
seja suiente para dar uma boa aproximação dos rankings das respostas de topo de
grandeparte das onsultas submetidasao sistema.
Oalgoritmo2.4desreve omopodar um arquivoinvertido usandoapodaestátia
de Carmel. O algoritmo toma omo entrada um arquivo invertido e o parâmetro
δ
, gerando omo saída um arquivo invertido podado. Assim omo nos algoritmosanteriores,
A
(
d
)
éo valoraumuladodas similaridades pariaisentre odoumentod
eaonsulta, mas para failitaro entendimento podemos vê-lo omo o ranking de
d
empara adatermo
t
noarquivoinvertido faça Reupere alistainvertida det
do diso;para ada entrada
h
d, fd,t
i
nalistainvertida façaA
(
d
)
←
ranking det
emrelação ad
;τt
←
δ
max(
A
(
d
))
;para ada aumulador
A
(
d
)
faça seA
(
d
)
> τt
entãoInsira
h
d, fd,t
i
emRδ
(
t
)
;Esreva
Rδ
(
t
)
nodiso;Algoritmo2.4: Algoritmode Carmel para podaestátia
Nossos experimentos indiamqueeste métodoé de fatoútilpara onsultas
disjun-tivas, mas seus ganhos não são tão signiativos em um enário onde a maioria das
onsultas são onjuntivas,omo de fato aontee nas máquinas de busa daWeb.
2.3.2.2 Poda Estátia Baseada em Loalidade (Lbpm)
Um ponto frao do método de Carmel é seu desempenho em termos de qualidade
das respostas para onsultas onjuntivas. Consultas desse tipo, bem omo onsultas
do tipo frase, requerem que entradas de determinados doumentos sejam preservadas
em listas invertidas de diferentes termos. Essa ondição não é satisfeita pelo método
de Carmel,quepodaaslistainvertidasdeadatermoindividualmente. Esseproblema
é desritode maneiramais detalhada no apítulo3.
OLbpm éumavariaçãodométododeCarmel quetentapredizerquaisonjuntosde
termos oorremjuntosnasonsultas dos usuárioseusa essa informaçãopara preservar
doumentosem omum nas listas invertidasdestes termos.
Oprimeiropasso doLbpm onsisteemdeterminarquais oorrêniasde termossão
individualmenteimportantesparaadadoumento. Essepassopodeser feitopormeio
da poda de Carmel. Em seguida, essa informação é utilizada para determinar quais
são as sentenças signiativas de ada doumento, que são aquelas em que oorrem
as entradas seleionadas pelapodade Carmel. Essas sentenças são então ordenadas e
seleionadas paraomporumaoleção de doumentosmenorquea original,omposta
apenas das sentenças signiativas seleionadas omo mais importantes. Por m, a
novaoleção éindexada.
A seleção das sentenças signiativas mais importantes de ada doumento é feita
pormeiodoalgoritmo2.5. Seja
T
(
d
)
alistadostermossigniativosparaodoumentod
. Esta listaéobtidadesinvertendo aslistasinvertidasobtidaspelapodade Carmel.Seja
S
(
d
)
a listadas sentenças signiativasdo doumentod
. Considerando que umatermosemomumom
T
(
d
)
, oalgoritmoutilizaessafunção paraordenarassentençassigniativas.
Oalgoritmo2.5seleionasentençasatéquenãoexistammaissentençassigniativas
ouatéqueotamanhodonovodoumento,emnúmerode termos,atinjaaporentagem
p
do tamanho dodoumento original. O algoritmofaz uma ópia deT
(
d
)
emT
′
(
d
)
e
exeutaum laço, queaada passo,adiionaem
S
′
(
d
)
asentença
S
deS
(
d
)
quepossuiomaiornúmero de termosemomumom
T
′
(
d
)
. Otamanhode
S
′
(
d
)
é inrementado
dotamanhodasentença
S
seleionada. Emseguida,S
éremovidadeS
(
d
)
eostermosem
S
sãoremovidosdeT
′
(
d
)
,paraqueaseleçãodeadasentençade
S
′
(
d
)
sejabaseada
em diferentes onjuntos de termos. Caso as sentenças já seleionadas ubram todos
os termos em
T
(
d
)
,T
′
(
d
)
a vazio. Quando isso oorre,
T
(
d
)
é novamente opiadoem
T
′
(
d
)
iniiando assim uma nova rodada de esolhas baseada em todos os termos
signiativospara o doumento
d
.p
←
porentagem nal desejada;T
(
d
)
←
onjuntodos termosigniativosparad
;S
(
d
)
←
onjuntodas sentenças signiativas parad
;T
′
(
d
)
←
T
(
d
)
;
repita
Scomum
←
comum
(
S
(
d
)
, T
′
(
d
))
;
S
′
(
d
)
←
S
′
(
d
)
∪
Scomum
;
tamanho
←
tamanho
+
|
Scomum
|
;T
′
(
d
)
←
T
′
(
d
)
− {
x
|
x
∈
Scomum
∧
x
∈
T
′
(
d
)
}
;
S
(
d
)
←
S
(
d
)
−
Scomum
;se
T
′
(
d
) =
∅
então
T
′
(
d
)
←
T
(
d
)
;
até (
tamanho
≥
p
|
d
|
)OuS
(
d
) =
∅
; RetorneS
′
(
d
)
;
Algoritmo 2.5: AlgoritmoLbpm paraseleção das sentenças signiativas
Ao preservar as sentenças om o maior número de termos signiativos, o Lbpm
onsegue obter uma qualidade de respostas para onsultas onjuntivas melhor que a
obtidapelo método de Carmel, onformepode ser visto noapítulo 4.
2.4 Avaliação de Resultados
Para qualquer sistema de reuperação de informação o objetivo a ser alançado é
retornar doumentos relevantes às onsultas submetidas e no menor tempo possível.
ontudo,prejudiaraeáia. Istoé,umbommeanismodepodaéaquelequediminui
o tempo de resposta às onsultas de uma forma geral, mas que ontinue a retornar
doumentostão relevantes quanto osque seriam retornados sem ouso dapoda.
Enquanto uma melhora na eiênia pode ser failmente obtida, o problema de
manter a eáia é mais difíil. No entanto, não é inomum que uma poda bem feita
onsigamelhorarambososaspetos. Istopode pareerpouonatural,maséentendido
quando lembramos que bases de dados tão populares e aessíveis omo a Web estão
sujeitas a armazenar uma enorme quantidade de informação pobre ou mesmo inútil.
Ao podar esse tipode doumento estamosdiminuindo o tamanhoda base, e om isso
ganhando emeiênia, aomesmo tempoemque melhoramosaqualidade daoleção,
e om isso ganhamos emeáia.
A avaliaçãoda eiênia dosistemaéfeita sem maioresdiuldadesusando
métri-as omo tempo médio de resposta das onsultas, avaliandotempo de proessamento,
quantidade de memória e diso utilizada, dentre outros. Já a avaliação da eáia é
mais difíil, pois dizer se um doumento é relevante para uma dada onsulta é uma
tarefa subjetiva. A seguir apresentamos dois métodos que utilizamos para medir a
qualidade dos resultados obtidos depoisde feita a poda.
2.4.1 Preisão e Revoação
Uma maneira de veriar a relevânia dos doumentos reuperados é o álulo de
preisão e revoação (Baeza-Yates e Ribeiro-Neto, 1999; Witten et al., 1999). Essa
é a medida padrão utilizada para avaliar a qualidade da respostas de um sistema de
reuperaçãode informação,sendo largamenteutilizada.
R
C
R
C
r
= Recuperados
= Relevantes
= Coleção
r
Figura2.1: PreisãoRevoação
Na gura 2.1, onsidere que
C
seja a oleção de todos os doumentos da base eque para uma dada onsulta,
R
seja o onjunto dos doumentos relevantes er
seja oonjunto de doumentos reuperados. A preisãose denepor
P
=
|
R
∩
r
|
R
=
|
R
∩
r
|
|
R
|
.
Intuitivamente, a preisão nos dá uma medida de quão apurado foi o resultado,
pois nos diz quantos dos doumentos reuperados são realmente relevantes, enquanto
a revoação nos dá uma medida da obertura do resultado, pois nos diz quantos dos
doumentosrelevantes foramreuperados. Normalmenteessasduas medidassão
apre-sentadas omo um gráo de preisão em função da revoação ou omo a preisão
médiados dez pontos de revoação(Wittenetal.,1999). Nesta dissertaçãoutilizamos
apreisãomédia.
Para utilizaressa métria é neessário quese tenha avaliadode antemão quaissão
os doumentos relevantes para um onjunto de onsultas. Esse é um proesso
traba-lhosoe demorado uma vez que o julgamentoda relevânia ounão de um determinado
doumentodeveserfeitoporumapessoa. Porisso, muitasvezesasmedidasdepreisão
e revoação não são viáveis. Assim, outro método de avaliação de qualidade que tem
sido utilizadoé amedida de similaridade de rankings.
2.4.2 Similaridade de Rankings
A medida de similaridade onsiste em omparar dois rankings para veriar quão
pareidos eles são um do outro. No nosso aso, o objetivo da medida de similaridade
é veriar quão próximos são os rankings dados pelo índie podado em relação aos
rankings dados peloíndie original.
A medida de similaridade que utilizaremos é baseada no método tau de
Ken-dall (Kendall e Gibbons, 1990), que é utilizado para omparar a similaridade entre
permutações de onjuntos. O método original assoia uma penalidade
S
(
i, j
) = 1
para ada par
i, j
de itens distintos do onjunto em quei
aparee antes dej
emumapermutação e
j
aparee antes dei
na outra permutação. A soma dessas penalidadespara todos os pares
i, j
dá uma penalidade nal entre0
(quando as permutações sãoidêntias) e
n
(
n
−
2)
/
2
(quandouma permutação éo inverso da outra).Quando omparamososrankings geradospeloíndiepodado omoíndieoriginal,
pode aonteer de um elemento estar presente em um ranking e não estar presente
nooutro. Dessa forma,utilizamosuma modiação dométodotau de Kendall (Fagin
etal.,2003). Nessa versão modiada, omparamosotopodas duas listas, queéonde
devem apareer os doumentos mais relevantes. Para ada par
i, j
, em quei
e/ouj
aparee no topo, istoé, entre os
k
primeiros elementos de pelomenos uma das listas,assoiamos as seguintes penalidades
S
(
i, j
)
:no métodooriginal. A saber, se
i
ej
estão namesma ordem, entãoS
(
i, j
) = 0
,do ontrário
S
(
i, j
) = 1
;•
Caso 2: sei
ej
apareem no topode uma lista(digamos, nalista 1)e apenasj
ou
i
aparee no topo da outra lista (lista 2), e sei
está à frente dej
na lista 1,então
S
(
i, j
) = 0
, do ontrárioS
(
i, j
) = 1
. Intuitivamente, sabemos quei
está àfrente de
j
na lista 2, uma vez quei
aparee no topo da lista 2 enquantoj
nãoaparee.
•
Caso 3: seapenasi
aparee no topode uma listae apenasj
aparee no topo daoutra lista, então
S
(
i, j
) = 1
. Intuitivamente, sabemos quei
está à frente dej
na primeiralistae que
j
está àfrente dei
na outralista.•
Caso4: sei
ej
apareemnotopodeumadaslistasmasnemi
nemj
apareemnotopo da outra lista, então
S
(
i, j
) = 1
/
2
. Intuitivamente, não temos informaçãosuiente para determinar se
i
ej
apareem na mesma ordem nas duas listas,então assoiamosuma penalidade neutra de
1
/
2
.A soma nal das penalidades será então um valor entre
0
(quando os dois rankingssão idêntios) e
k
(3
k
−
1)
/
2
(quando osdois rankings são disjuntos). Obtemos o valornormalizado
x
′
, entre
0
e1
, fazendox
′
= 1
−
2
x/k
(3
k
−
1)
. Assim, o valor
1
oorreAlgoritmo de Poda Proposto
As ténias de poda de Persin e de Carmel eliminam entradas das listas
inverti-das tratando ada termo de forma isolada. Essa abordagem funiona bem quando se
trabalha om onsultas disjuntivas, no entanto, não é boa para responder a onsultas
onjuntivas. Por exemplo, será que o onjunto de doumentos que melhor
respon-dem à onsulta trabalho bem omo os que melhor respondem à onsulta infantil
inlui osdoumentos que melhorrespondemàonsultaonjuntivaontendo ostermos
trabalho einfantil?
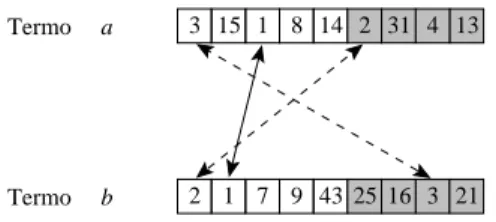
A gura 3.1 ilustra bem a situação derita aima. Ela mostra o mesmo exemplo
apresentado noartigoquepropõeoLbpm (deMoura etal.,2005). Alistainvertidado
termo
a
era originalmenteomposta pelos doumentos 3,15, 1, 8,14, 2,31, 4,e 13, ealistadotermo
b
, pelos doumentos 2,1,7,9,43,25,16,3e21. As áreassombreadasorrespondem aos doumentos que foram eliminados pela poda. Nesse enário, uma
onsulta onjuntiva ontendo os termo
a
eb
onterá apenas o doumento 1 omoresposta. Entretanto,osdoumentos2e3fariampartedarespostaseaonsultativesse
sido feitasobre oíndie original. Alémdisso, estes dois doumentossão possivelmente
importantes, já que eles apareem notopo das listade
a
edeb
individualmente. Esseexemplomostraqueumapodaquenãoleveemontaorelaionamentoentreostermos
pode desartar entradas importantes.
43
7
1
2
9
3 21
3 15
1
8
14
2
31
4
13
25 16
Termo
a
Termo
b
Figura 3.1: Informação perdida ao podar as listas invertidas dos termos
prourapredizer quaistermosapareeramemonjuntonasonsultasfeitaspelos
usuá-rios. Para desobrir os relaionamentosentre os termos nosso método faz uso de logs
de onsultas passadas damáquina de busa.
3.1 Extração de Informação dos Logs
Quando as pessoas usam máquinas de busa para reuperar algum tipo de
infor-mação,suas onsultas eos sites liados são armazenados emlogs. Tais dados trazem
informaçõesvaliosas: as onsultaspodemindiar relaçõesentre termose ossites
lia-dos indiamque,emuma primeiraanálise, ousuário damáquina de busa onsiderou
talsitepossivelmenterelevanteemrelaçãoasuaonsulta. Nessesentido,oslogs podem
ser vistosomo um registro doonheimento e dainteligêniade milhões de pessoas.
No aso espeío das onsultas, quando um usuário de uma máquina de busa
utilizaumonjuntode termospara fazerumapesquisa, podemosinferirque ostermos
utilizadospossuemalgum grau de relação entre si. Ou melhor,sabemos queo usuário
espera que existamdoumentosnaWeb que ontenhamos termos pesquisados. Logo,
ao fazer uma poda é importante que tais doumentos sejam preservados nas listas
invertidasdos termosenvolvidos naquelaonsulta. Éjustamentenessaobservação que
sebaseia onosso método.
Analisando o log estabeleemos que há um relaionamentoentre dois termos aso
elesoorramemumamesmaonsulta. Oproessamentodolog resultaemumarquivo
emque, para ada termo
t
, temos uma lista dos termos que possuem relaionamentoom
t
. Denimos esse onjunto de termos relaionados at
omoR
(
t
)
. Por exemplo,digamosqueotermo
a
o-oorraomostermosb
,c
ed
emdiferentesonsultas. Assim,depoisde proessarolog, alistade relaionamentos de
a
seriaR
(
a
) =
{
b, c, d
}
e,alémdisso, ambas as listas de relaionamento dos termos
b
,c
ed
onteriam uma entradapara otermo
a
.Antes de gerar as listas de relaionamento de ada termo, fazemos um
proessa-mento prévio no log a m de diminuir a quantidade de relaionamentos que vamos
levar emonsideração. Conforme mostramos na próxima seção, estas listas de
relai-onamentosservem para expandir a podade Carmel a m de ontemplar as onsultas
onjuntivas. O problemade onsiderar todos osrelaionementosdolog é quea
expan-são aabagerando listas invertidastão grandesquanto asoriginais,logo, seleionamos
apenas osrelaionamentosmais freqüentes.
Aseleçãodosrelaionamentos maisfreqüentesdolog éfeitautilizandooneitosda
de 1%. É importante salientar que a ferramenta utilizada em nossos experimentos 1
utiliza umoneito de suporte umpouodiferente(Borgelte Kruse,2002)dooneito
original (Agrawal et al., 1993). Também é importante dizer que o valor de suporte
foi esolhido de maneiraque aquantidade de pares de termospresentes nos onjuntos
fosse aproximadamente igual a
1
/
5
dos pares presentes no log do mês de janeiro, quefoi o mês utilizadopara o proesso de poda. Esse valorfoi esolhido empiriamente.
3.2 O Proesso de Poda
Uma vez obtidas as relações entre os termos o próximo passo é fazer a poda das
listas invertidas preservando asrelaçõesenontradas nolog. Para ada termo
t
, nossoobjetivo é determinar quais são os doumentos mais importantes que ontêm
t
, querseja individualmente, quer seja aompanhado dos termos aos quais
t
se relaiona.Esse proesso é omposto de duas etapas exeutadas para ada termo
t
:1. Enontrar as melhores entradas dalistainvertida de
t
individualmente;2. Expandir a lista invertida resultante de
t
, aresentando as entradas que sãoimportantes para ostermos aos quais
t
se relaiona.No nosso método, a etapa 1 do proesso de poda é obtida por meio da proposta
de Carmel. Chamemosde
Carmel
(
t
)
a funçãoque retornaalistainvertidapodadadotermo
t
pormeio dapodade Carmel ehamemos deOriginal
(
t
)
afunção queretornaa listainvertida originalde
t
.Seja
R
(
t
) =
{
r
1
, ..., rn
}
o onjunto dos termos que se relaionam omt
, obtido nafasedeproessamentodolog. Oresultadodaetapa2éobtidopelafunção
Expandido
(
t
)
denida por:
Expandido
(
t
) = [
n
[
i
=1
Carmel
(
ri
)
∪
Carmel
(
t
)]
∩
Original
(
t
)
.
Tomando o exemplo anterior, em que o termo
a
se relaiona om os termosb
,c
ed
,teríamos:Expandido
(
a
) = [
Carmel
(
b
)
∪
Carmel
(
c
)
∪
Carmel
(
d
)
∪
Carmel
(
a
)]
∩
Original
(
a
)
.
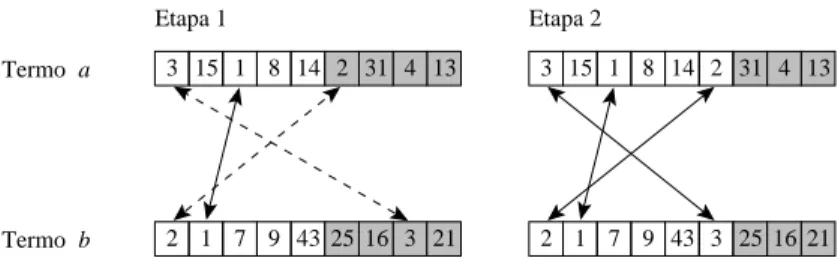
Dessa forma, ainda que determinadaentrada do termo
a
não esteja entre as melhoresindividualmente ela pode ser preservada aso apareça entre as melhores entradas de
algum dos termos que possuem relaçãoom
a
. 1onado usando essa ténia. Como os termos
a
eb
se relaionam, o doumento2
quenão estava entre osmelhores dotermo
a
passa a ser preservado, uma vez que eleestáentre os melhores doumentos do termo
b
. Similarmente, o doumento3
passa a serpreservado na listainvertida do termo
b
. A gura 3.2 mostra omo ariam as listasinvertidas desses termos apósas duas etapasdo proesso de poda.
43
7
1
2
9
3 21
3 15
1
8
14
2
31
4
13
25 16
2
1
7
9
43
21
15
1
8
14
31
4
13
3
2
16
25
3
Etapa 2
Etapa 1
a
Termo
Termo b
Figura3.2: Informação preservada aolevaremonta orelaionamento entre os termo
3.3 Desrição do Algoritmo
O algoritmo 3.1 mostra omo enontramos os relaionamentos entre os termos.
Lembramosque o primeiropasso da podaonsiste em seleionar os onjuntos de
ter-mos freqüentes maximais obedeendo um determinado suporte, onforme já foi dito
anteriormente. Então riamos uma uma lista para ada termo do voabulário da
o-leção. Em seguida, para ada onjunto freqüente maximal, tomamos seus termos aos
pares
h
ti, tj
i
, inserindoti
na lista detj
, asoti
ainda não esteja presente e vie-versa.Note que são desartados os termos que não fazem parte do voabulário da oleção,
logo, somente proessamos onjuntos que possuem pelo menos dois termos existentes
novoabulário.
Porm,gravamos emdisoalistadostermos
r
aosquaisada termot
serelaiona.O resultado é um arquivo pareido a um índie invertido, porém, em vez haver, para
ada termo
t
, a lista dos doumentos em quet
oorre, temos a lista de termosr
queoorreram nas mesmas onsultas que
t
.O algoritmo 3.2 mostra omo é feita a expansão das listas invertidas podadas na
etapa1. Oproessoonsisteemexluirdentreosdoumentosdalistainvertidaoriginal
do termo
t
aqueles doumentos que não oorrem nas listas invertidas, geradas pelopara adatermo
t
dovoabulário façaCrie uma listade relaionamentos
R
(
t
)
vazia;para adaonjuntofreqüente maximal
m
faça para ada par de termosti, tj
dem
façase
ti
etj
pertenem aovoabulárioentão Insirati
emR
(
tj
)
;Insira
tj
emR
(
ti
)
;para adatermo
t
dovoabulário faça EsrevaR
(
t
)
emdiso;Algoritmo3.1: Geração das listas de relaionamentodos termos
Exeute apodade Carmel; // algoritmo 2.4
Gere aslistas de relaionamentos; // algoritmo 3.1
para adadoumento
d
daoleção faça Crie um aumuladorA
(
d
) = 0
;para adatermo
t
dovoabulário faça Reupere alistainvertida sem podadet
;para ada entrada
h
d, fd,t
i
dalistainvertida sem podafaçaA
(
d
)
←
A
(
d
) + 1
;Reupere alistainvertida podadade
t
; // poda de Carmel para ada entradah
d, fd,t
i
dalistainvertida podadafaçaA
(
d
)
←
A
(
d
) + 1
;Reupere alistade relaionamentos de
t
; para ada termo relaionador
façaReupere a listainvertida podada de
r
; // poda de Carmel para ada entradah
d, fd,r
i
da listainvertidapodada façaA
(
d
)
←
A
(
d
) + 1
;Crie uma nova listainvertida
L
(
t
)
; para ada doumentod
façase
A
(
d
)
>
1
entãoInsira
h
d, fd,t
i
emL
(
t
)
;para adatermo
t
dovoabulário faça EsrevaL
(
t
)
emdiso;Resultados Experimentais
Nesteapítulosão desritososexperimentosrealizadosomonovométododepoda
propostoeomosdemaismétodosexistentesnaliteratura,visandoaavaliaçãodaidéia
de seutilizarlogs de onsultas passadas omo fonte de informaçãoparaa poda.
Com-paramos osmétodos emtermos de tempo de proessamento,preisãodos resultados e
diferença entre a resposta forneida pelo sistema antes da poda e depois da poda. A
seção 4.2 apresenta a omparação da diferença das respostas. A seção 4.3 apresenta
a omparação da preisão das respostas. A seção 4.4 apresenta a omparaçãao dos
temposde resposta dos três métodos de podaestátia avaliados.
4.1 Ambiente de Exeução e Coleções de Teste
Todososexperimentosdemedidadedesempenhoforamrealizadosemumamáquina
om 1gigabytes de memóriaprinipal, diso Serial ATA, proessador Intel Pentium 4
de 2.4 GHz esistema operaionalLinux om kernel versão 2.6.
Osexperimentosforamrealizados sobreaoleçãode doumentosWBR-99. A
ole-ção WBR-99 1
é omposta de um onjunto de doumentosoletados daWeb brasileira
no ano de 1999. Os doumentos foram tomados da base de dados da máquina de
busa TodoBR 2
.A WBR-99ontémaproximadamente6milhõesde doumentostanto
em formato de texto omo em formato indexado. Esta oleção onta ainda om um
onjunto de todas as onsultas submetidas ao TodoBR nomês de novembro de 1999,
sendo que para 50 destas onsultas existe um onjunto de doumentos relevantes. A
tabela 4.1apresentaos prinipaisdados sobre aoleção WBR.
O log de novembro de 1999 foi utilizado apenas nos experimentos de medida de
preisão. Para os experimentos de similaridade de ranking e de tempo de exeução,
1
http://www.linguatea.pt/Repositorio/WBR-99/
2
dejaneiro aoutubro de 2003. outrosdadossobre este log são mostrados natabela4.2.
ColeçãoWBR-99
Tamanhototal 20gigabytes
Tamanhodo texto 16gigabytes
Número de doumentos 5.939.061
Número de termos 2.669.965
Consultas avaliadas 50
Doumentos Avaliados 4.117
Tabela 4.1: Dadossobre a oleçãoWBR-99
Log de Consultas TodoBR-2003
Meses janeiro aoutubro
Total de onsultas 2.158.756
Média de palavrasporonsulta 3.4
Consultas om mais de um termo 65%
Conjuntivas 87%
Frases 12%
Disjuntivas 1%
Tabela 4.2: Dadossobre a oleçãoWBR-99
Para veriar a preisão dos resultados foram utilizados as 50 onsultas avaliadas
do log de novembro de 1999, enquanto que para veriar a similaridade dos rankings
foramutilizadosdois onjuntos de 1000 onsultas esolhidas aleatoriamentedo log de
fevereiro de 2003, sendo um onjunto omposto por onsultas disjuntivas e outro por
onsultas onjuntivas.
4.2 Impato na Ordenação da Resposta
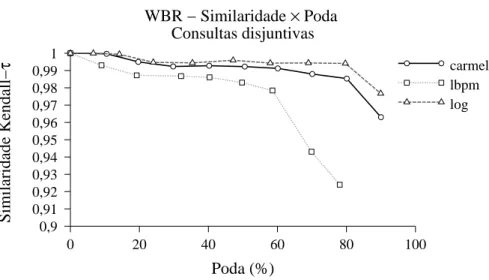
Os gráo das guras 4.1 e 4.2 mostram a similaridade entre os
20
primeirosre-sultados retornados pelo índie original e pelos índies podados em diferentes taxas
de poda. Utilizamos a versão modiada da medida de similaridade de Kendall tau
(videseção2.4.2) para omparar osresultados. Conformepode ser visto,a eáiado
métodode Carmel paraonsultas disjuntivasé muito boa,sofrendo uma perda muito
pequena, mesmo para uma podade
70%
do índie. Por outro lado, quando tratamosWBR − Similaridade × Poda
Consultas disjuntivas
Similaridade Kendall−
τ
0,9
0,91
0,92
0,93
0,94
0,95
0,96
0,97
0,98
0,99
1
Poda (%)
0
20
40
60
80
100
carmel
lbpm
log
Figura4.1: Comparaçãodasimilaridadedas respostasdisjuntivasparaostrês métodos
de poda estátiaavaliadossobre a oleçãoWBR-99
WBR − Similaridade × Poda
Consultas conjuntivas
Similaridade Kendall−
τ
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
Poda (%)
0
20
40
60
80
100
carmel
lbpm
log
Figura4.2: Comparaçãodasimilaridadedasrespostasonjuntivasparaostrêsmétodos
de poda estátiaavaliadossobre a oleçãoWBR-99
Estes gráos também mostram que nosso método dá resultados melhores que os
dométodode Carmel tantoparaasonsultasdisjuntivasquantoparaasonsultas
on-juntivas. Éimportantesalientarqueasonsultas utilizadasnesses experimentosforam
retiradas do log do mês de fevereiro, enquanto as onsultas que utilizamospara gerar
osíndiesutilizandonossométodoforamextraídasdolog domês de janeiro. Em
om-paração omo Lbpm, nosso métodoobtémresultados bem próximos,superando-o por
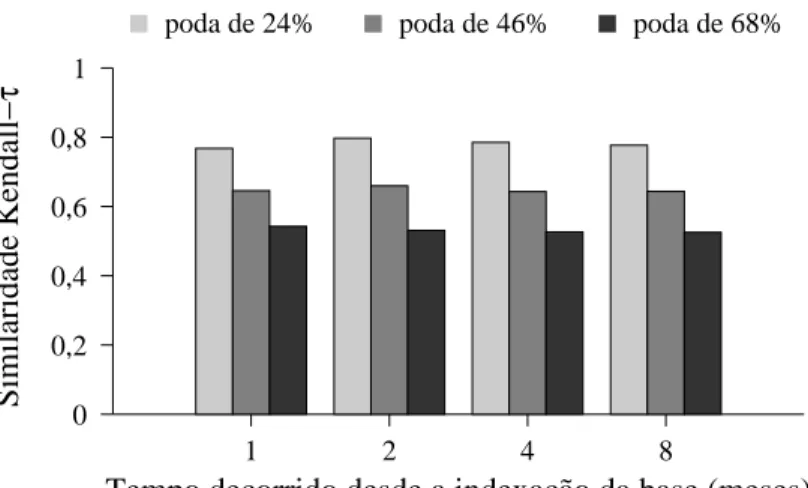
da resposta à medida em que aumentamos a distânia entre o momento em que foi
realizadaapodae o momento emque foramrealizadas as onsultas. Esta avaliação é
importanteporque namedidaemque esta diferençade tempoaumenta,espera-se que
haja uma relação ada vez menor entre as onsultas utilizadas para guiar o proesso
de podae as onsultas orrentes. Comoonseqüênia pode-se ter uma degradação da
qualidadedaresposta om o passar dotempo.
Os resultados desse experimento podem ser observados no gráo da gura 4.3.
Pode-se pereber que a similaridade das respostas varia pouo em um período de 9
meses. Isso signiaque o índie não preisa ser atualizado om periodiidademuito
freqüente para que oproesso de poda baseado emlogs dê bons resultados.
WBR − Similaridade
×
Envelhecimento do índice
Tempo decorrido desde a indexação da base (meses)
1
2
4
8
Similaridade Kendall−
τ
0
0,2
0,4
0,6
0,8
1
poda de 24%
poda de 46%
poda de 68%
Figura 4.3: Qualidade daresposta à medidaem queo índiepodado envelhee
4.3 Qualidade da Resposta
Alémdas diferençasna ordenação das respostas, outro fatorimportantea ser
ava-liadoé aqualidadedas mesmas. Osresultados deste experimentopodemser vistosno
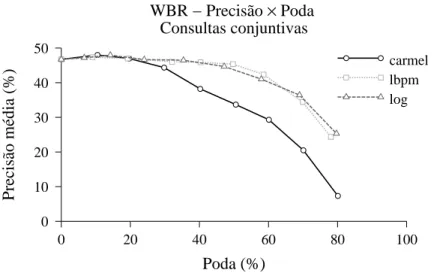
gráodagura 4.4.
Esta métria éimportantepor indiaro impatodosistema de podana qualidade
dos serviços prestados pelo sistema de busa aos seus usuários. O gráo mostra a
preisão média obtida om os diferentes métodos de poda estátia ao variarmos o
perentual de poda. Nota-se queos métodoLbpm e log forneem resultados similares
proesso de poda quanto o própriotexto dos doumentos.
WBR − Precisão
×
Poda
Consultas conjuntivas
Precisão média (%)
0
10
20
30
40
50
Poda (%)
0
20
40
60
80
100
carmel
lbpm
log
Figura 4.4: Comparaçãodapreisão para ostrês métodos de podaestátiaavaliados
4.4 Tempo de Exeução
Esta seção mostra as diferenças no tempo de exeução de onsultas em índies
geradospelosdistintosproessosdepoda. Aprimeiravista,nãohaveriarazãoparauma
variação no tempo de exeução ao utilizarmos níveis de poda similares em diferentes
métodos. Contudo, as estratégias de eliminaçãode entradas inueniam o tempo de
exeução assim omo inueniama qualidade das respostas.
Agura4.5mostraotempomédiodeexeuçãodasonsultasutilizandoadaumdos
três métodos experimentados quando variamos operentual de poda. A porentagem
do tempoé em relação aotempogasto utilizandoo índie sem poda. Noexperimento
foramutilizadasapenasonsultas onjuntivas,umavez queasmesmassão mais
popu-lares e apresentam usto de proessamentobemmaior que o de onsultas disjuntivas.
Como pode ser observado, o método de Carmel apresenta ganhos signiativos no
tempo de exeução mesmo om perentuais pequenos de poda. Contudo, a vantagem
de desempenho obtida pelo método de Carmel é anulada pelas perdas na qualidade
das respostas obtidas pelo método. Dentre os três métodos, o que apresenta melhor
relação entre usto e benefíio é o método baseado em logs, que apresenta tempos de
resposta melhores queo Lbpm om qualidadede resultadossimilares.
Uma expliação para as diferenças de tempo de exeução entre os métodos está
WBR − Tempo × Poda
Consultas conjuntivas
Tempo (%)
0
20
40
60
80
100
Poda (%)
0
20
40
60
80
100
carmel
lbpm
log
Figura4.5: Comparação dos tempos de proessamento para os três métodos de poda
estátiaavaliados
O método de Carmel normalmente elimina mais entradas de termos freqüentes que
os outros dois métodos. O Lbpm elimina entradas dos termos baseando-se em
o-oorrênias dos termos dentro dos textos. Por esta razão o método Lbpm tende a
preservarmais entradas de palavrasomuns, as quaissão onheidas omo stopwords.
Ométodobaseado em logstambémésusetívelaoproblema de preservar emdemasia
entradas de palavras omuns, ontudo, omo o mesmo é baseado em logs e não no
texto, aquantidade de ruídos inseridos nométodoé menor.
Para ilustrar o problema, veriando o tamanho das listas das 250 palavras mais
freqüentes daoleção WBR eum nível de podade 50%, perebemos queo métodode
Carmel preservou em média era de 119 mil entradas do índie, o método baseado
emlogsera de 200 mile ométodoLbpm erade 440 mil. Estes valores omprovam
que o Lbpm tende a preservar mais entradas de palavras omuns. O problema om a
preservaçãodestaspalavraséqueasmesmastambémostumamapareeremonsultas,