WAGNER ROGÉRIO FERREIRA PINHEIRO
AVALIAÇÃO DE KRIGAGENS ATRAVÉS DE INDICADORES LOCAIS PARA A AGRICULTURA DE PRECISÃO
Dissertação apresentada à Universidade Federal de Viçosa, como parte das
exigências do Programa de
Pós-Graduação em Estatística Aplicada e Biometria, para obtenção do título de Magister Scientiae.
VIÇOSA
Ficha catalográfica preparada pela Seção de Catalogação e Classificação da Biblioteca Central da UFV
T
Pinheiro, Wagner Rogério Ferreira, 1985-
P654a Avaliação de krigagens através de indicadores locais para 2013 a agricultura de precisão / Wagner Rogério Ferreira Pinheiro.
– Viçosa, MG, 2013.
ix, 67f. : il. (algumas color.) ; 29cm.
Inclui anexos.
Orientador: Gérson Rodrigues dos Santos.
Dissertação (mestrado) - Universidade Federal de Viçosa. Referências bibliográficas: f. 53-57.
1. Geologia - Métodos estatísticos. 2. Análise espacial (Estatística). 3. Agricultura de precisão. 4. Sistemas de informação geográfica. 5. Geologia - Processamento de dados. 6. Mapas de zoneamento. I. Universidade Federal de Viçosa. Departamento de Estatística. Programa de Pós-Graduação em
WAGNER ROGÉRIO FERREIRA PINHEIRO
AVALIAÇÃO DE KRIGAGENS ATRAVÉS DE INDICADORES LOCAIS PARA A AGRICULTURA DE PRECISÃO
Dissertação apresentada à Universidade Federal de Viçosa, como parte das
exigências do Programa de
Pós-Graduação em Estatística Aplicada e Biometria, para obtenção do título de Magister Scientiae.
ii
Penso no que faço, com fé. Faço o que devo fazer com amor. Eu me esforço para ser cada dia melhor, pois bondade também se aprende. Mesmo quando tudo parece desabar, cabe a mim decidir entre rir ou chorar, ir ou ficar, desistir ou lutar. Porque descobri, no caminho da vida que o mais importante é decidir.
iii
iv AGRADECIMENTOS
Agradeço a Deus por sempre fazer com que eu perceba a sua presença em todos os dias de minha vida nos momentos mais felizes ou mais tristes. Aos meus avós, Epitaciano Ferreira e Maria Enoi Ferreira pelo empenho, dedicação e incentivo dispensados ao longo de minha vida. A minha mãe Ângela Pinheiro e minha irmã Giselly Pinheiro que sempre acreditaram em mim e incentivaram minhas decisões. Aos meus familiares mais próximos, em especial a minha prima Nelly Ferreira e minha tia Anilce Ferreira.
Agradeço a todos os professores do Programa de Pós-Graduação em Estatística Aplicada e Biometria da Universidade Federal de Viçosa – UFV, pelos ensinamentos que aqui me transferiram. Em especial ao meu orientador Gerson Rodrigues dos Santos que teve um papel significativo nessa fase da minha formação acadêmica, me ensinando não somente com suas explicações e orientações, mas, também com exemplos dia após dia, além da colaboração, incentivo, generosidade, compreensão e firmeza com que norteou meus estudos.
Agradeço as secretárias Anita Paiva e Carla Zinato pela diligência, eficiência, zelo e atenção dedicados a mim nas horas em que as solicitei. Não posso deixar de registrar aqui meus agradecimentos, mais que especiais, aos amigos afetuosos de todas as horas por todas as experiências vividas em Viçosa. Agradeço imensamente a vocês estimados amigos Renata Maciel, Camila Azevedo, Lidiane Ferreira, Cássio dos Reis, Bruno Caetano e Diego Paiva, com atenção especial à Maria de Fátima Almeida. Agradeço ainda ao Wellington que foi peça fundamental no processo de elaboração desse trabalho. Muito obrigado, vocês são pessoas iluminadas.
Com um carinho todo especial agradeço a família Figueira primeiramente na pessoa de minha amiga e irmão Priscila Figueira pelo privilégio de ter permitido que eu fizesse parte de sua vida. Agradeço ainda, sua Darcirene Figueira e seu Pai José Maria Figueira, por toda a compreensão, atenção, cuidado e carinho que me proporcionaram. Meus sinceros agradecimentos.
v
SUMÁRIO
LISTA DE TABELAS ... vi
LISTA DE FIGURAS ... vii
RESUMO ... viii
ABSTRACT ... ix
1. INTRODUÇÃO ... 1
2. REFERENCIAL TEÓRICO ... 5
2.1 O uso da informação espacial na agricultura ... 5
2.1.1 Agricultura de Precisão (AP) ... 6
2.1.2 O mapa e sua importância na agricultura ... 7
2.2 Sistema de Informações Geográficas (SIG) ... 8
2.2.1 Imagem Raster ... 9
2.3 Funções algébricas de mapas ... 12
2.3.1 Álgebra de mapas ...13
2.4 Exatidão ou acurácia de mapas ... 15
2.4.1 Matriz de confusão ou de erros ...16
2.4.2 Índice Kappa ...18
2.5 Geoestatística ... 20
2.5.1 Semivariograma ...21
2.5.2 Modelos teóricos de Semivariograma ...23
2.5.3 Índice de dependência espacial ...25
2.5.4 Krigagem ...26
2.5.5 Validação cruzada ...28
2.6 Relações bidimensionais ... 29
3. MATERIAL E MÉTODOS ... 32
3.1 Simulações ...32
3.2 Recursos Computacionais ...34
3.3 Comparação entre os mapas temáticos ...35
4. RESULTADOS E DISCUSSÃO ... 37
4.1 Análise exploratória ...37
4.2 Ajuste do semivariograma experimental ...38
4.3 Validação ...42
4.4 Mapas temáticos ...44
4.5 Comparação entre os mapas temáticos obtidos...48
5. CONCLUSÕES ... 52
6. REFERÊNCIAS BIBLIOGRÁFICAS ... 53
vi LISTA DE TABELAS
Tabela 1: Representação matemática de uma matriz de confusão. ...17
Tabela 2: Índice Kappa e o correspondente desempenho da classificação. ...19
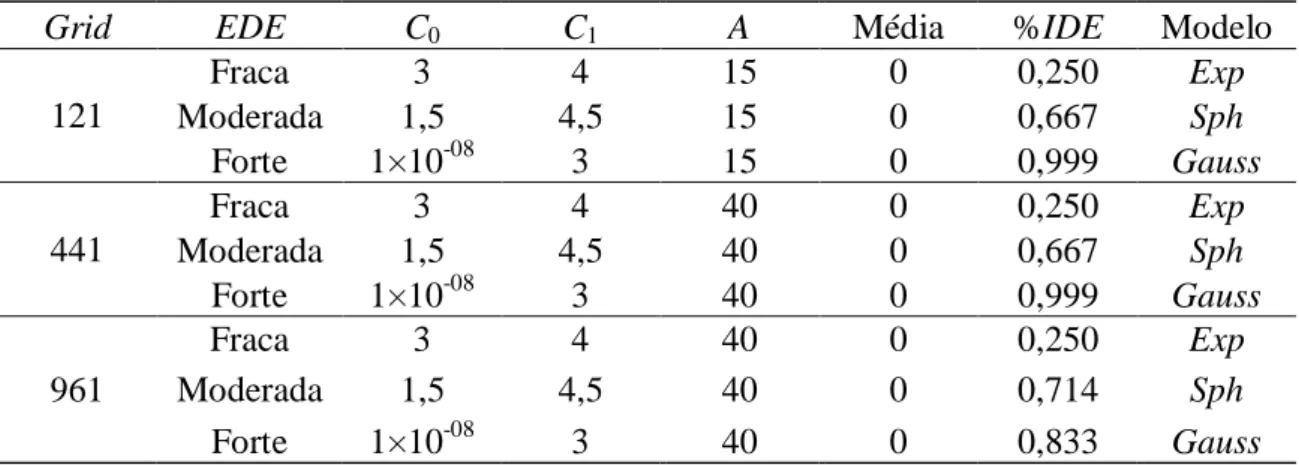
Tabela 3: Descrição da malha amostral (Grid), dos parâmetros e modelos utilizados nas simulações de dados...33
Tabela 4: Medidas estatísticas dos dados simulados para os diferentes grids (50×50, 100×100 e
150×150) e estrutura de dependência espacial. ...38
Tabela 5: Estimativa dos parâmetros dos modelos semivariográficos ajustados aos dados com fraca DE e diferentes grids. ...38
Tabela 6: Estimativa dos parâmetros dos modelos semivariográficos ajustados aos dados com
moderada DE e diferentes grids. ...40
Tabela 7: Estimativa dos parâmetros dos modelos semivariográficos ajustados aos dados com forte DE e diferentes grids. ...41
Tabela 8: Erro médio (ME), erro quadrático médio padronizado (RMSS) e coeficientes da regressão da validação cruzada da krigagem ordinária nos dados com fraca DE e diferentes grids ...43
Tabela 9: Erro médio (ME), erro quadrático médio padronizado (RMSS) e coeficientes da regressão da validação cruzada da krigagem ordinária nos dados com moderada DE e diferentes grids ...43
Tabela 10: Erro médio (ME), erro quadrático médio padronizado (RMSS) e coeficientes da regressão da validação cruzada da krigagem ordinária nos dados com forte DE e diferentes grids ...44
vii LISTA DE FIGURAS
Figura 1: Representação gráfica de um mapa rasterizado. [Fonte: Adaptado de ARCGIS, 2012] ...10
Figura 2: Representação gráfica da codificação de um mapa de polígonos para um mapa raster. [Fonte: Adaptado de ARCGIS, 2012] ...11
Figura 3: Representação gráfica de como se realiza a localização dos pixels no mapa raster. [Fonte: Adaptado de ARCGIS, 2012] ...12
Figura 4: Representação das operações aritméticas pixel a pixel executadas em diferentes bandas. [Fonte: Adaptado de Meneses et al. 2012] ...14
Figura 5: Representação gráfica de um caso hipotético onde atua a geoestatística e a estatística clássica...20
Figura 7: Representação gráfica de um semivariograma e seus parâmetros Alcance (a), Efeito Pepita (C0), Contribuição (C1) e Patamar (C C0 C1). ...23
Figura 6: Representação dos modelos de semivariogramas usualmente utilizados (Esférico, Guassiano e Exponencial). ...25
Figura 8: Escala de correlação linear entre variáveis. [Fonte: Adaptado de Ramos et al. 2013]...30
Figura 9: Esquema esperado para relação de concordância entre mapas. ...31
Figura 10: Semivariogramas experimentais e modelos ajustados para os dados com fraca DE. ...39
Figura 11: Semivariogramas experimentais e modelos ajustados para os dados com moderada DE. ...40
Figura 12: Semivariogramas experimentais e modelos ajustados para os dados com forte DE. ...41
Figura 13: Mapas temáticos para o grids de 50×50 e diferente estrutura de dependência espacial (Fraca, moderada e forte). ...45
Figura 14: Mapas temáticos para o grid de 100×100 e diferente estrutura de dependências espacial (Fraca, moderada e forte). ...46
Figura 15: Mapas temáticos para o grid de 150×150 e diferente estrutura de dependências espacial (Fraca, moderada e forte). ...47
Figura 16: Representação esquemática para a obtenção da correlação local (ri) entre mapas temáticos. ...49
Figura 17: Mapas de correlação local, em diferentes grids, para a comparação entre os mapas temáticos no caso com fraca dependencia espcial...51
Figura 18 Mapas rasterizados oriundos dos mapas temáticos obtidos por krigagem ordinária para dados que apresentaram os diferentes tipos de dependência espacial em estudo no grid de 50×50. ...65
Figura 19: Mapas rasterizados oriundos dos mapas temáticos obtidos por krigagem ordinária para dados que apresentaram os diferentes tipos de dependência espacial em estudo no grid de 100×100. ...66
viii
RESUMO
PINHEIRO, Wagner Rogério Ferreira, M.Sc., Universidade Federal de Viçosa, fevereiro de 2013. Avaliação de krigagens através de indicadores locais para a agricultura de precisão. Orientador: Gérson Rodrigues dos Santos. Coorientadores: Nerilson Terra Santos e Antônio Policarpo Souza Carneiro.
ix
ABSTRACT
PINHEIRO, Wagner Rogério Ferreira, M.Sc., Universidade Federal de Viçosa, February, 2013. Evaluation krigings by means of local indicators for precision agriculture. Advisor: Gérson Rodrigues dos Santos. Co-Advisor: Nerilson Terra Santos and Antônio Policarpo Souza Carneiro.
1
1.
INTRODUÇÃO
A agricultura entendida como um sistema produtivo é nomeada por Agronegócio ou Agribusiness. Este termo abrange as atividades agrícolas, pecuárias e florestais,
compreendendo a produção de alimentos, fibras e energia. Segundo Batalha (2001), corroborado por Lourenço e Lima (2009), costuma-se dividir o agronegócio em três partes que podem, por sua vez, subdividir-se em outras atividades pontuais.
A primeira parte trata da execução agropecuária ou de “dentro da porteira” que representam o produtor rural de pequeno, médio ou grande porte. Na segunda parte, evidenciam-se os negócios à montante ou “da pré-porteira”, e são representados pelas indústrias e comércios que fornecem insumos para a produção rural. Por fim, na terceira parte, estão os negócios à jusante, ou de “pós-porteira”, que envolvem a compra, transporte, beneficiamento e venda dos produtos agropecuários, até chegar ao consumidor final (LOURENÇO e LIMA, 2009).
O agronegócio constitui um complexo conjunto de atividades abrangendo aspectos que vão desde o processo inicial de cultivo nas atividades envolvidas (agricultura, pecuária e florestal) até a distribuição e comercialização do produto final. Podendo, também, ser considerado como uma gama de relações comerciais efetuadas com produtos agrícolas envolvendo plantio, industrialização e comercialização daquilo que é cultivado.
Um dos componentes que apresenta relevada importância no agronegócio é o uso econômico e viável do solo, não apenas no sentido da sua composição química e orgânica, mas também geográfica. Na intenção de entender, por exemplo, como fatores relativos a composição de nutrientes e manejo adequado do solo, podem implicar na produtividade de determinado cultivo influenciando no modo com o qual se distribui, interage e se comporta espacialmente.
2 aspectos próprios para o tipo de área que se dispõe. Tudo na intenção de utilizar o solo, destinado a determinado cultivo da maneira mais adequada.
Fraisse (1998) destaca que antes mesmo da revolução industrial e do processo de mecanização da atividade agrícola, os agricultores já se mostravam capazes de reconhecer a variabilidade espacial de certas características físico-químicas e biológicas das áreas cultivadas. Permitindo o emprego de esforços a áreas de menor ou maior fertilidade de maneira diferenciada.
Esse tipo de manejo, sistematizado segundo características observadas do solo, que era realizado antes mesmo de equipamentos de alta tecnologia, pode ser considerado também uma forma, embora empírica, de agregar maior precisão à atividade agrícola trazendo como consequência o aumento da produtividade da cultura na área destinada para plantio.
Conforme o exposto, identifica-se inicialmente, os conceitos que nortearam o que nas ultimas décadas definiu-se por Agricultura de Precisão que, de acordo com Ormond (2006), é um conjunto de técnicas de gerenciamento sistêmico e otimizado, para o enfoque agrícola, por meio do domínio da informação, com a utilização de uma série de tecnologias, tendo como base as informações sobre o posicionamento geográfico.
Este conjunto de ferramentas presentes na agricultura de precisão, frequentemente faz uso do GNSS (Global Navigation Satelite System), do SIG (Sistema de Informações Geográficas) que advém da tradução de Geografical Information System (GIS), de instrumentos e de sensores para medidas ou detecção de parâmetros ou de alvos de interesse no agroecossistema (solo, planta, insetos e doenças), de Estatística Espacial e da mecatrônica sendo, portanto, abrangente, sistêmico e multidisciplinar.
3 No âmbito agrícola uma maneira amplamente utilizada de projeção cartográfica são os mapas temáticos que segundo Druck et al. (2004) descrevem a distribuição espacial de uma grandeza geográfica, expressa de forma qualitativa, como os mapas de pedologia e a aptidão agrícola de uma região. Estes dados, obtidos a partir de levantamento de campo, são inseridos no sistema por digitalização ou a partir de classificação de imagens. Em suma, a finalidade dos mapas temáticos é facilitar a navegação do usuário que procura informações sobre temas definidos.
Existem diversas formas de dependência para um determinado conjunto de dados, uma delas é a espacial. Das ciências que visão o tratamento sistemático dessa dependência no espaço, destaca-se a Estatística Espacial que condensa um extenso conjunto de técnicas capazes, dentre outros funções, de modelar a dependência de um evento de forma geográfica (DRUCK et al., 2004; CRESSIE, 1993; BAILEY e GATRELL, 1996).
Deste modo, conceitos pertencentes à Estatística Espacial apresentam grande contribuição no que tange as questões relativas à agricultura de precisão e consequentemente ao agronegócio. Desses conceitos, salienta-se o de exatidão ou acurácia das características espaciais contidos num mapa temático obtido por meio de um determinado processo de interpolação, captação de imagem de satélite, entre outros.
A exatidão ou acurácia dos mapas temáticos são uma forma de garantir mapas que nortearão decisões adequadas respeitando características próprias da área destinada ao cultivo agrícola. Essa etapa ocorre no processo inicial do agronegócio (“dentro da porteira”), onde se encontram também a agricultura de precisão, com a finalidade de obter mapas de fertilidade do solo que originarão referencias sobre a produtividade e consequentemente lucratividade da área.
4 Pode-se destacar como exemplo o estudo realizado por Batista (2012). Neste estudo foram comparados mapas temáticos de zonas de manejo por meio de diferentes modelos de dependência espacial. Batista (2012) conclui que os diferentes modelos não influenciam na definição do mapa temático, pois as krigagens foram similares (considerando zonas de manejo), segundo a estatística Kappa que apresentou para cada comparação índices superiores a 0,80 o que representa concordância muito boa de acordo com a Tabela de classificação de desempenho Kappa.
Assim, a necessidade de identificar pontualmente a comparação entre mapas temáticos se faz extremamente importante para a tomada de decisão dos responsáveis envolvidos no
processo inicial do agronegócio. Uma alternativa válida para esse “problema” se origina dos
mesmos elementos utilizados para o cálculo da estatística Kappa, os pixels. Os pixels apresentam boas características por permitirem o uso de álgebras das quais podem ser extraídas informações não somente globais (como no Kappa) mas também pontuais.
O presente trabalho parte da hipótese de que há uma relação algébrica que possa evidenciar os pixels, que neste contexto, representam áreas em menores porções que em por sua vez não são captadas em índices generalizados de concordância entre uma imagem de referência e uma classificada. Essas relações algébricas permitem obter estatísticas pontuais de similaridade entre os mapas. A intenção inicial do trabalho é de que haja uma relação “um para um” entre os pixels do mapa de origem e os do mapa classificado. Como objetivos específicos pode-se destacar:
Identificar e comparar de forma global e local quadrantes que apresentam similaridade entre os mapas temáticos obtidos;
Evidenciar as diferenças entre as krigagens de diferentes modelos de dependências espaciais;
Obter mapas temáticos com maior detalhamento prestando suporte a tomada de decisão dos agentes envolvidos no sistema produtivo agrícola.
5
2.
REFERENCIAL TEÓRICO
Neste capítulo são apresentados os procedimentos metodológicos utilizados para análise espacializada no contexto agrícola. Com destaque para os principais conceitos do tema em estudo e as características das técnicas utilizadas com o devido rigor teórico.
2.1 O uso da informação espacial na agricultura
Câmara et al. (2007) evidenciam que na perspectiva moderna de gestão do território, toda ação seja de planejamento, ordenação ou monitoramento do espaço deve incluir a análise dos diferentes componentes de ambiente considerando o meio físico-biótico, a ocupação humana, e seu inter-relacionamento. No planejamento agrícola, essa abordagem é cada vez mais evidente.
São apontados por Câmara et al. (2007), pelo menos quatro grandes dimensões dos problemas ligados aos Estudos Ambientais que envolve também a agricultura, onde é grande o impacto do uso da tecnologia de Sistemas de Informação Geográfica, como o Mapeamento Temático, Diagnóstico Ambiental, Avaliação de Impacto Ambiental e Ordenamento
Territorial. Destes, os mais utilizados na agricultura são os Mapeamentos Temáticos.
Os Mapeamentos Temáticos visam caracterizar e descrever a organização do espaço, como base para que sejam estabelecidas ações e estudos futuros. Esses levantamentos temáticos, a exemplo: os levantamentos geológicos, geomorfológicos, de solos, de cobertura vegetal, entre outros. Recebem relevada importância na agricultura. Porém, para que esses estudos sejam realizados de forma adequada, necessita-se de uma abordagem de geoprocessamento que combine ferramentas de análise espacial, processamento de imagens, Geoestatística e modelagem numérica de terreno (CÂMARA et al., 2007).
6 oriundos da agricultura de precisão pois considera o rendimento das culturas quanto a variabilidade espacial.
2.1.1 Agricultura de Precisão (AP)
De acordo com Coelho (2005), desde meados da década de 1980, um grande número de termos tem sido usado para descrever o conceito da AP, são eles:
(i) Agricultura por metro quadrado (Reichenberg e Russnogle, 1989);
(ii) Agricultura com base em tipos de solos (Carr et al. 1991; Larson e Robert, 1991);
(iii) Aplicação de insumos a taxas variáveis – VRT (Sawyer, 1994);
(iv) Variável espacial, precisão, prescrição, ou manejo específico de culturas (Schueller, 1991); por fim,
(v) Manejo por zonas uniformes (Pierce e Sadler, 1997).
Ainda segundo Coelho (2005), o manejo de solos usando AP, tem por definição a propriedade de identificar e analisar características de solo, histórico de cultivo, clima e outras variáveis do sistema de produção, em diferentes locais dentro do campo. Muito embora sejam encontradas inúmeras definições para a agricultura de precisão, todas elas caminham em uma só direção que é a utilização de métodos de maneira pontual na área destinada ao plantio.
São, portanto, englobados na AP aspectos da variabilidade dos solos, clima, diversidade de culturas, performance de máquinas agrícolas e insumos (físicos, químicos e biológicos) naturais ou sintéticos, usados na produção das culturas. Com base nesses princípios, Pierce e Nowak (1999) utilizam a seguinte definição:
“Agricultura de Precisão é a aplicação de
princípios e tecnologias para manejar a variabilidade espacial e temporal, associada com todos os aspectos da produção agrícola, com o objetivo de aumentar a produtividade na
7 Vale ressaltar que a AP, tem por princípio básico o manejo da variabilidade do solo e cultura no espaço e no tempo, como mencionado anteriormente. Com tudo, sem essa variabilidade, o conceito de agricultura de precisão tem pouco significado e de acordo com Mulla e Schepers (1997) nunca teria evoluído.
2.1.2 O mapa e sua importância na agricultura
Joly (1990) utiliza a seguinte definição quando se refere a um mapa.
“Um mapa é uma representação geométrica
plana, simplificada e convencional, do todo ou de parte da superfície terrestre, numa relação de similitude conveniente denominada escala”
Para ser eficiente, o mapa, deve ser de fácil leitura. A percepção deve ser a mais instantânea possível, de modo que em um tempo curto seja possível lê-lo e entendê-lo de acordo com os princípios da cartografia. Por meio deles, pode-se ter uma imagem geral sobre uma configuração geográfica e obter dados usados para informação e orientação de decisões (JOLY, 1990).
A leitura de mapas na agricultura, por meio do geoprocessamento, objetiva descrever como se configura uma determinada área, na intenção de conhecer aspectos relacionados à vegetação, clima, presença de rios e lagos, além das riquezas do solo que a área destinada para o plantio oferece, relacionando produtividade e lucratividade da cultura segundo a área que se dispõe, por exemplo.
No Brasil, o processo de abordagem agrícola georreferenciada, se dá inicialmente com o uso do mapeamento de um imóvel rural referenciando os vértices de seu perímetro ao Sistema Geodésico Brasileiro, definindo sua área e sua posição geográfica. Tudo para regularizar o registro dos imóveis rurais, obedecendo a legislação vigente (Lei 10.267/01 e Decretos 4.449/02 e 5.570/05)
8 estimativa da área plantada (para o estudo utilizou-se: área plantada de soja) é uma das principais informações empregadas na previsão de safras agrícolas.
Antunes et al. (2012) objetivaram, portanto, estimar a área plantada com soja por meio da normalização da matriz de erros (oriunda dos pixels) gerada a partir da classificação supervisionada de mapa temático em formato de imagens TM/Landsat-51. No trabalho apresentado por Antunes et al. (2012), nas classificações digitais, as áreas são estimadas por contagem de pixels de toda a região em estudo, sem a necessidade de amostragem. Outras aplicações de análises por meio de mapas são de relevada importância no contexto agrícola.
2.2 Sistema de Informações Geográficas (SIG)
De acordo com Abreu (2012), historicamente, percebe-se a evolução técnica no domínio das ferramentas cartográficas (Sistemas de Coordenadas, de Projeção Cartográfica, Métodos de Posicionamento, Processos de Representação). Nesta evolução, destacam-se os Sistemas de Informações Geográficas (SIG).
Abreu (2012) esclarece, ainda, que seu surgimento é recente, por volta dos anos 60, com o CGIS (Canada Geographical Information System). Porém, ainda hoje, não há uma definição única para o SIG. Um dos conceitos que nos últimos anos frequentemente é citado nas literaturas é o proposto por Chrisman (2007), onde o autor define que os SIGs são
“Sistemas de computadores e periféricos, programas, dados, pessoas, organizações e
instituições com o propósito de coletar, armazenar, analisar e disseminar informações sobre
áreas da Terra”.
Uma definição mais modesta e igualmente referenciada é a de Aronoff (1999) citado por Abreu (2012) o qual define que SIG são sistemas computacionais usados para armazenar e manipular informações geográficas. Abreu (2012) destaca, também, que independentemente da definição, o SIG é a principal ferramenta de apoio a diagnóstico, planejamento e tomada de decisão quando a informação é passível de ser geoespacializada.
1
9 Existe, para informações geoespacializadas segundo Soares Filho (2000), entes que compõem um modelo em Geoprocessamento e são considerados como discretos ou contínuos complexo. Uma outra definição dado aos que Soares Filho se refere como entes, são os de modelos de campo e de objeto. Em suma, os modelos de campo compreendem a fenômeno contínuo no espaço (teor de algum mineral no solo, temperatura, etc.), e o modelo de objeto representa uma coleção de dados distintos e identificáveis no campo (mapa raster, por exemplo).
Para exemplificar os entes citados por Soares Filho (2000), pode-se destacar como entes discretos indústrias, propriedades e vias urbanas, e como entes contínuos complexos o relevo, teor de minério no solo, temperatura entre outros. A representação dos entes discretos se dá por um dos três modos de implantação cartográfica, ou seja, o ponto, a linha ou a área.
Já os contínuos são representados por superfícies matemáticas, grades regulares ou irregulares e pelo formato raster2. Como vantagem da estrutura raster, Soares Filho (2000) cita que, neste formato, o espaço geográfico está uniformemente definido e sua estrutura se aproxima mais da arquitetura dos computadores, o que facilita avaliações matemáticas, lógicas de múltiplas camadas e maior capacidade analítica permitindo o uso de técnicas de processamento de imagem.
2.2.1 Imagem Raster
Segundo Levine (1993) um arquivo de imagem raster é um vetor de pontos, onde cada um destes pontos é chamado de pixel. Cada pixel é armazenado com um número que representa sua cor. Já Gonzalez (1992), define que um arquivo raster pode ser considerado como sendo uma matriz cujos índices de linhas e de colunas identificam um ponto (pixel) na imagem, e o correspondente valor do elemento da matriz identifica a cor naquele ponto. Os elementos dessa matriz digital são chamados de elementos da imagem, elementos da figura, célula, pixel ou pels, estes dois últimos, abreviações de picture elements (elementos de figura).
2
10 2.2.1.1Características de um mapa raster
O conjunto de dados raster representam características geográficas, dividindo o
“mundo” em pequenas células quadradas ou retangulares dispostos em um grid. Cada célula tem um valor atribuído a uma cor, este valor é utilizado para representar uma característica da localização, tal como a temperatura, a altitude, ou um valor espectral, por exemplo. A Figura 1 apresenta uma representação gráfica de um mapa rasterizado (ARCGIS, 2012).
Imagem do espaço
Colunas
L
in
h
a
s
Coordenadas Espaciais
Figura 1: Representação gráfica de um mapa rasterizado. [Fonte: Adaptado de ARCGIS, 2012]
11 Figura 2: Representação gráfica da codificação de um mapa de polígonos para um mapa raster. [Fonte: Adaptado de ARCGIS, 2012]
Os rasters podem ser utilizados para representar toda a informação geográfica (características, imagens e superfícies) existentes em um mapa temático, e eles têm um rico conjunto de operadores em geoprocessamento. Além de ser um tipo de dado universal para a realização de imagens em SIG, o raster também pode ser utilizadas como um poderoso recurso, permitindo que todos os objetos geográficos sejam passiveis de serem modelados e analisados algebricamente.
Quatro propriedades geográficas são estendidas para os conjuntos de dados raster. Estes tornam-se úteis para georreferenciamento e contribui para explicar como os arquivos de dados raster são estruturados. Estes conceitos são importantes para entender como os rasters são
armazenadas e gerenciadas em uma base de dados.
As propriedades geográficas para um raster incluem tipicamente:
O seu sistema de coordenadas;
Uma coordenada de referência ou localização x, y;
Um tamanho de célula;
12
Imagem do espaço
Colunas
L
in
h
a
s
Coordenadas Espaciais
GRID (x,y)
Tamanho da célula Linhas 8
Colunas 8
Valores das células listados
Figura 3: Representação gráfica de como se realiza a localização dos pixels no mapa raster. [Fonte: Adaptado de ARCGIS, 2012]
Vale ressaltar que o conjunto de dados raster têm uma maneira especial de definir a localização geográfica. Uma vez que as células ou pixels pode exatamente ser georreferenciada, é fácil ter uma lista ordenada de todos os valores das células em um raster. Isto significa que cada conjunto de dados de quadriculação tem um registro de cabeçalho que prende as suas propriedades geográficas, e o corpo do conteúdo é simplesmente uma lista ordenada dos valores das células.
2.3 Funções algébricas de mapas
As funções de mapas utilizadas no SIG podem ser dividas em consulta, reclassificação, análise de proximidade, contiguidade, modelos digitais de elevação, operações algébricas não cumulativas e operações algébricas cumulativas. A implementação dessas funções exige certos procedimentos metodológicos que determinam o controle da qualidade dos resultados (SILVA, 2003).
13 Silva (2003) afirma que todo conjunto de mapa observacional pode ser manipulado na sua forma digital produzindo produtos, tais como: imagem de falsa cor, modelos de elevação digital, mapas de declividade e aspecto, ou seja, permitem tratamento numérico via processamento digital de imagem e geram os chamados mapas analíticos.
Outras definições, decorrentes das funções aplicadas aos mapas, são as de mapas integrados e mapas fundidos, que envolvem uma gama de procedimentos tais como:
(i) Álgebra cumulativa: Corresponde a operações tipo adição, subtração, multiplicação e divisão entre as matrizes que correspondem aos arranjos dos dados espaciais contidos em mapas de georreferenciamento.
(ii) Álgebra não cumulativa: Permite cruzamento e integração de mapas por meio de modelos lógicos como simultaneidade Booleana, possibilidade fuzzy e probabilidade Bayesiana.
2.3.1 Álgebra de mapas
Cordeiro et al. (2007) relatam que o tema “álgebra de mapas” foi popularizado a partir
dos livro “Geographic Information System and Cartographic Modeling” (Tomlin, 1990)3. Esta foi a primeira abordagem em que se buscou explorar de uma maneira formal as propriedades dos dados em SIG, usualmente representados por mapas.
Cordeiro et al. (2007) cita, ainda, que ferramentas como o GRID (ArcInfo), o IDRISI e o IDL, foram essencialmente concebidas sob tal paradigma, no qual operações de modelagem são representadas por sequências de operações primitivas descritas através de uma linguagem que procura respeitar as propriedades dos tipos de dados envolvidos.
Segundo Meneses et al. (2012), as operações aritméticas entre bandas é uma das mais simples formulações algorítmicas de processamento de imagens e que pode ter resultados expressivos. A facilidade para executar as operações aritméticas de soma, subtração, multiplicação e divisão é uma notável demonstração das vantagens do uso de processamento de imagens multiespectrais.
3
14 O processo algébrico é executado pixel a pixel por meio de uma regra matemática pré-definida envolvendo, normalmente, no mínimo duas bandas do mesmo sensor ou bandas de datas de aquisição diferentes que resulta em outro mapa com os resultados do processo algébrico utilizado (Figura 4).
Figura 4: Representação das operações aritméticas pixel a pixel executadas em diferentes bandas. [Fonte: Adaptado de Meneses et al. 2012]
De acordo com Silva (2003), as principais operações matemáticas para modificar os dados não espaciais compreendem a operações lógicas, aritméticas, trigonométricas, estatísticas e multivariadas. A saber:
Operações lógicas: São baseadas na definição de hipóteses falsas (0) e
verdadeiras (1) e podem resultar em união, intersecção, negação e exclusão.
Operações aritméticas: Correspondem aos resultados obtidos com adição,
subtração, multiplicação, exponenciação, logarítmica (natural ou na base 10), truncamento e radiciação.
Operações trigonométricas: Podem relacionar seno, co-seno, tangente ou seus
inversos.
Operações estatísticas: Compreendem média, moda, mediana, desvio padrão,
variância, mínimo, máximo, entre outras.
Operações Multivariadas: Podem ser modelos de regressão, análise fatorial,
15 No ANEXO II está contido um quadro que apresenta as operações comumente utilizadas no geoprocessamento.
2.4 Exatidão ou acurácia de mapas
De acordo com Vieira (2000), no processo de análise dos dados do sensoriamento remoto, por exemplo, um passo fundamental é a avaliação da precisão temática. Na intenção de saber quão confiáveis são os dados provenientes dos mapas temáticos, derivados da classificação ou interpolação de uma análise espacial. Uma forma de captar essa exatidão se dá por meio da matriz de confusão onde é possível derivar medidas e consequentemente verificar erros oriundos do processo de atribuição dos pixels a determinadas classes.
A avaliação do processo de alocação dos pixels, no contexto cartográfico, que se vale da chamada matriz de confusão ou matriz de erros é denominada de exatidão ou acurácia e usa medidas estatísticas de concordância. Onde, para o caso cartográfico ou de sensoriamento remoto, faz referência a concordância e omissão entre o número de pixels que foi classificado por um processo de interpolação, com o número de pixels da imagem usada como referência.
Congalton (1991) relata que o uso do coeficiente Kappa é satisfatório na avaliação da precisão de uma classificação temática, pelo fato de levar em consideração toda a matriz de confusão no seu cálculo, inclusive os elementos de fora da diagonal principal, os quais representam as discordâncias na classificação, diferentemente da exatidão global, por exemplo, que utiliza somente os elementos diagonais (concordância real).
Porém, Foody (1992) observou que o grau de concordância por chance poderia estar sendo superestimado, pelo fato de incluir também a concordância real, e por causa disso a magnitude de Kappa não refletiria a concordância presente na classificação, apenas descontada a casualidade, ou seja, leva em consideração duas vezes o total de acertos. Na tentativa de corrigir essa deficiência no cálculo do índice Kappa, Ma e Redmond (1995) propuseram um outro índice para a medição da precisão da classificação, o índice Tau.
16 de validação. Dado que esses índices levam em consideração ou o número total de classes ou o número total de padrões de validação; ou mesmo se houver discrepância entre os valores amostrados, para validação, entre as classes estabelecidas.
No estudo realizado por Figueiredo e Vieira (2007), os autores concluíram que as diferenças entre os três índices (Exatidão Global, Kappa e Tau) não são constantes ao longo dos níveis de desempenho da classificação. No geral, a diferença entre os índices Kappa e Tau foi muito pequena. Os autores chegaram a conclusão que embora a Exatidão Global apresente um valor mais alto, os coeficientes de concordância Kappa e Tau são mais consistentes por envolver no valor final todas as células da matriz de confusão.
2.4.1 Matriz de confusão ou de erros
A acurácia é normalmente expressa em termos de índices que são calculados a partir de matrizes de erros que expressam a concordância entre a imagem classificada e o conjunto de amostras de referência. A matriz de erros compara, classe por classe, a relação entre os dados de verdade terrestre (dados de referência) e os correspondentes resultados da classificação. O número de linhas e o número de colunas dessa matriz devem ser iguais ao número de classes espectrais do estudo. Erros de omissão (exclusão) e de comissão (inclusão) de cada classe são calculados a partir dessa matriz.
Segundo Antunes et al. (2007), corroborado por Jupp (1989); Congalton e Green (1999), De Wit e Clevers (2004); Serra e Pons (2008), Peña-Barragán et al. (2011), a matriz de erros ou confusão, bem como as métricas de exatidão global e o índice Kappa, vem sendo utilizada para determinar a acurácia de classificações digitais mediante a utilização de imagens de satélites.
Essa matriz permite avaliar o desempenho da classificação realizada para uma classe individual, particularmente quando um pequeno número de classes de uso do solo é de interesse, como, por exemplo, na estimativa de área de uma cultura agrícola (ANTUNES et al. 2012 apud CEBALLOS-SILVA e LÓPEZ-BLANCO, 2003).
17 relativa, inferida por um classificador (ou regra de decisão), comparado com a categoria atual verificada no campo (CONGALTON, 1991).
De acordo com Figueiredo e Vieira (2007), normalmente abaixo das colunas representa-se o conjunto de dados de referência que é comparado com os dados do produto da classificação que são representados ao longo das linhas. Os elementos da diagonal principal indicam o nível de acerto, ou concordância, entre os dois conjuntos de dados. A Tabela 1 apresenta a representação de uma matriz de confusão.
Tabela 1: Representação matemática de uma matriz de confusão.
Classificação Dados de Referência
n
i1
2
p1
x
11x
12x
1px
12
x
21x
22x
2px
2p
x
p1x
p2x
ppx
pi
n
x
1x
2x
pN
As medidas derivadas da matriz de confusão são: a exatidão global, precisão de classe individual, precisão de produtor, precisão de usuário, índice Kappa, entre outros. Um resultado com 100% de acurácia significa que todos os pixels da imagem foram classificados de forma correta, segundo um conjunto de dados que compõe a verdade terrestre. Um resultado com 50% de acurácia significa que, em teoria, metade dos pixels da imagem foi classificada corretamente essa classificações são apresentadas pela matriz de confusão.
18 2.4.2 Índice Kappa
Desde a introdução da estatística kappa, por Cohen (1960), estudos e pesquisas têm sido realizados para medir a concordância entre avaliadores corrigida pelo acaso. Cohen, originalmente, formulou kappa para uso onde dois observadores designam cada indivíduo a uma das categorias de uma escala nominal. Nessa abordagem as discordâncias observadas entre as avaliações possuem pesos iguais.
Modificações desse coeficiente foram propostas para uso em outras situações. Cohen (1968) mostrou como a concordância pode ser medida quando se atribui uma ponderação à discordância. Esse índice kappa ponderado foi estudado por inúmeros autores [Cicchetti (1981); Cicchetti e Fleiss (1977) e Fleiss, Cohen e Everitt (1969)].
Recentemente, têm sido desenvolvidas diferentes abordagens que utilizam de modelagem estatística para medir a concordância entre dois avaliadores, como é o caso do geoprocessamento. A modelagem estatística facilita e enriquece a análise, pois, especifica o tipo e a quantidade de concordância presente nos mapas.
O índice kappa simples, introduzida por Cohen (1960), é uma medida de concordância dada por
1 2
2
ˆ
1
q
q
k
q
onde 1
1 p
ii i
x
n
q e 1
2 2
p i i i
x x
n
q são obtidos na matriz de confusão, apresentada na Tabela 1
da seção 2.4.1.
19 Tabela 2: Índice Kappa e o correspondente desempenho da classificação.
Índice Desempenho
< 0,0 Péssimo
0,0 <
k
≤ 0,2 Ruim0,2 <
k
≤ 0,4 Razoável0,4 <
k
≤ 0,6 Bom0,6 <
k
≤ 0,8 Muito bom 0,8 <k
≤ 1,0 ExcelenteFonte: Adaptado de Fonseca (2000).
Contudo, de acordo com Batista (2012), o valor do Índice Kappa por si só, não tem a capacidade de dizer se existe uma concordância ou não entre dois mapas. É preciso avaliar a significância estatística do valor obtido para o mesmo. Para tanto, é razoável, realizar um teste estatístico para a significância do índice Kappa.
Neste caso a hipótese testada é avaliada pelo teste Z e se por ventura o valor da estatística de teste for igual a 0 (zero), indicará concordância nula, ou se for maior do que zero, indicará concordância maior do que o acaso (teste monocaudal: H0:k 0; H1:k 0). Pode-se encontrar em literaturas especializadas [Thompson (2001); Conover (1999); Agresti (1990); Siegel e Castellan (1988); Landis e Koch (1977)] um contexto explicativo indicando que a obtenção de um valor negativo para a estatística de teste utilizada para avaliar a significância do índice Kappa, não tem interpretação cabível e pode resultar num paradoxal nível crítico (valor de p) maior do que um.
A estatística do teste Z utilizada de acordo com Congalton e Green (2009) é dada por
ˆ (0,1). ˆ ( ) Z N Var k k k
A obtenção de variâncias, segundo Agresti (2002), é fundamentada no método delta. A variação, por este método, é obtida a partir da expressão
2 2
1 1 1 1 2 3 1 4 2
2 3 4
2 2 2
(1 ) 2(1 )(2 ) (1 ) ( 4 )
1
ˆ
( )
(1 ) (1 ) (1 )
Var
n
q q q q q q q q q
k
q q q
20
1 2 3
( )
p
ii i i
i
x x x
n
q e 4 1 1 3
( )
. p p
ij j i
i j
x x x
n q
2.5 Geoestatística
A geoestatística se vale da teoria das variáveis regionalizadas4. Nesta teoria, segundo Matheron (1963) citado por Silva et al. (2011), a diferença nos valores de uma dada variável tomados em dois pontos no campo depende da distância entre eles. Andriotti (2003) cita que um ponto importante a ser destacado nessa teoria é a relevância dada as relações espaciais existentes entre as observações que compõe uma amostra.
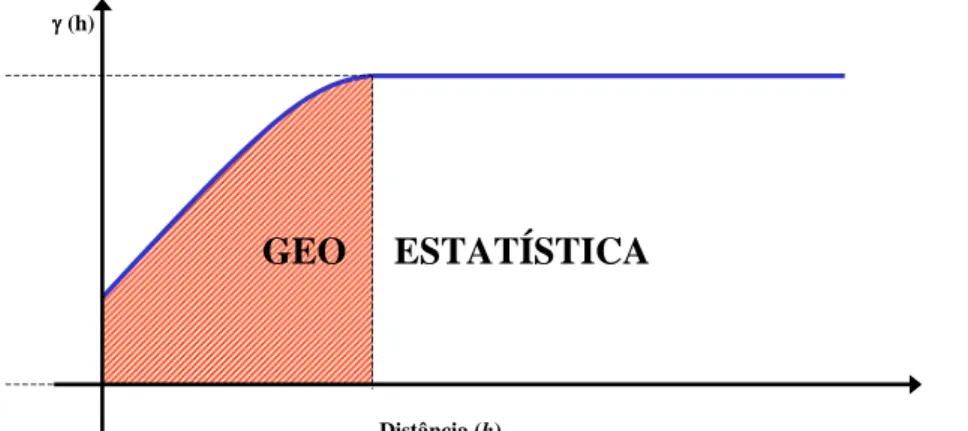
Estas relações espaciais são captadas por meio do semivariograma. A geoestatística estuda essa estrutura entre os dados, modelando as influências do ponto de vista geográfico. A medida que a distância aumenta as relações espaciais entre os dados fica cada vez mais fraca, podendo então ser analisadas por métodos estatísticos clássicos. A Figura 5 apresenta graficamente o exposto.
(h)
GEO ESTATÍSTICA
Distância (h)
Figura 5: Representação gráfica de um caso hipotético onde atua a geoestatística e a estatística clássica.
É importante destacar que os ramos da estatística, tato a estatística dita Clássica como a Geoestatística, ambos abordam variáveis aleatórias. No entanto, para a Estatística Clássica uma variável é considerada aleatória quando o valor da mesma é independente e identicamente distribuído obtido através de observações ou experimentos (CASELLA e
4
21 BERGER, 2010; MOOD, GRAYBILL e BOES, 1974), e cada valor está associada a uma certa probabilidade se valendo da Teoria das Probabilidades.
Ao passo que a Geoestatística está baseada na Teoria das Variáveis Regionalizadas (SANTOS, 2010), que considera aspectos aleatórios e estruturados do fenômeno em estudo. Andriotti (2003) cita que o fenômeno é aleatório no sentido de que os valores das medições feitas podem variar consideravelmente entre si e estruturado segundo uma certa lei no espaço considerando que os valores das observações não são independentes da sua localização geográfica, por tanto, dependentes espacialmente como indica a parte hachurada da Figura 5 e sem a possibilidade de realizar nova amostragem o mesmo ponto.
De acordo com Andriotti (2003), na década de 1970, a Geoestatística experimentou grandes avanços na conceituação teórica e nos campos de atividade em que se mostrou útil, tendo ocorrido naquele ano um notável crescimento da utilização dessa técnica no mundo todo. Isso ocorreu dado os avanços computacionais.
Santos (2010), a propósito, cita em seu trabalho que durante um longo período o principal obstáculo encontrado pela Geoestatística era a pequena capacidade de processamento dos computadores dado os cálculos envolvidos na aplicação dessa metodologia. O que explica os avanços que Andriotti (2003) referiu-se.
Atualmente ela tem aplicação rotineira em pesquisas nas mais diversas áreas de atuação. No contexto agrícola Vieira (2000), evidencia que sua utilização na agricultura de precisão apresenta aplicabilidade na pesquisa da variabilidade espacial dos atributos do solo e das plantas, bem como obter estimativas utilizando o princípio da variabilidade espacial e na identificação inter-relações destes atributos no espaço, além de permitir estudar padrões de amostragem adequadas.
2.5.1 Semivariograma
22 regionalizada) é definida a partir da comparação de valores tomados simultaneamente em dois pontos, segundo uma determinada direção procedimento exercido pelo semivariograma.
Santos (2010), explica que o nível de dependência espacial entre duas variáveis regionalizadas é representado por
2
2 ( )g h E Y x[ ( ) Y x( h)] var[ ( )Y x Y x( h)].
Segundo Vieira (2000), dentre todos os estimadores de semivariâncias o mais utilizado é o baseado no método de momentos proposto por Matheron (1963), e dado por
( )
2
1
1
ˆ( ) [ ( ) ( )]
2 ( )
N h
i i
i
h Y x Y x h
N h g
onde gˆ( )h é o estimador da semivariância na distância h, N h( ) é o número de pares de valores médios, Y x( )i e Y x( i h) separados por um vetor distância.
2.5.1.1Caracterização dos parâmetros do semivariograma
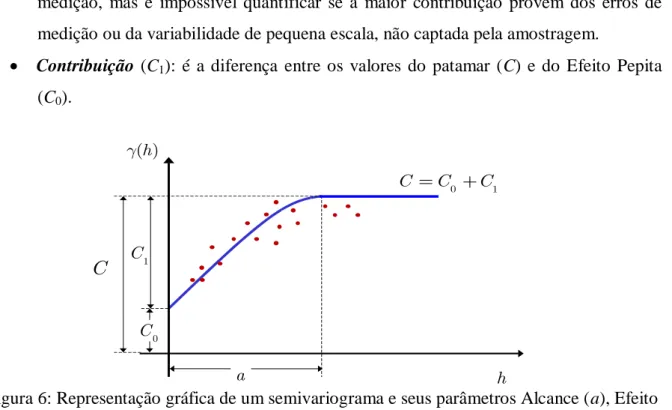
Por meio do semivariograma deve-se obter os parâmetros da estrutura de dependência espacial, úteis no processo de predição geoestatística (SANTOS, 2010). A Figura 6 apresenta graficamente os seguintes parâmetros:
Alcance (a): É a distância dentro da qual os valores amostrais apresentam-se
correlacionadas espacialmente. É o raio de dependência espacial.
Patamar (C): é o valor do semivariograma correspondente ao valor do alcance (a), ou
seja, é o valor constante atingido por gˆ( )h quando a distância entre os dados, h, cresce. Deste ponto em diante, considera-se que não existe mais dependência espacial entre as amostras.
Efeito Pepita (C0): é o valor da semivariância para a distância zero, representa a
23 medição, mas é impossível quantificar se a maior contribuição provém dos erros de medição ou da variabilidade de pequena escala, não captada pela amostragem.
Contribuição (C1): é a diferença entre os valores do patamar (C) e do Efeito Pepita
(C0).
C
0
C
1
C
a h
V
0 1
C C C
( )h
g
Figura 6: Representação gráfica de um semivariograma e seus parâmetros Alcance (a), Efeito Pepita (C0), Contribuição (C1) e Patamar (C C0 C1).
O chamado semivariograma experimental é construído, de acordo com Andriotti (2003), segundo uma linha, um plano ou em três dimensões. Para sua construção, são plotados sobre o eixo das ordenadas os valores estimados das semivariancias [gˆ( )h ] e sobre o eixo das abscissas o espaçamento para cada distância (h) entre as observações de campo.
2.5.2 Modelos teóricos de Semivariograma
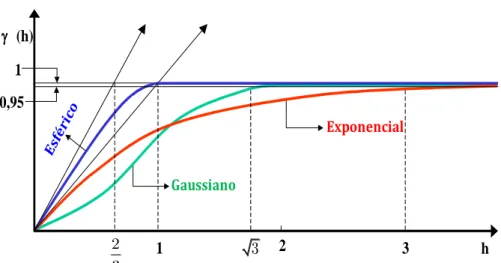
Para a análise geoestatística é necessário utilizar um modelo que “melhor” se ajuste aos
dados, geralmente os modelos são predefinidos e classificados de acordo à característica de atingir ou não o patamar (C C0 C1). Os modelos usuais são: Esférico, Exponencial e Gaussiano.
24
3
0 1
0 1
0 , 0
3 1
( ) , 0
2 2
, h
h h
h C C h a
a a
C C h a
(ii). O modelo exponencial também apresenta comportamento linear à origem, e sua expressão é
3
0 1
0 , 0
( )
1 , 0
h a
h
h
C C e h
onde dh representa a distância máxima. O alcance, nesse modelo, tem significado puramente analítico, sendo o patamar só alcançado assintoticamente quando h .
(iii). O modelo de Gauss ou parabólico é o modelo que reflete mais regularidade da variável estudada, tendo tangente horizontal na origem, presença de efeito pepita (C0), e sua expressão é dada por
2
3
0 1
0 , 0
( ) .
1 , 0
h a
h
h
C C e h
25
1 2 3
(h)
1
0,95
h Gaussiano
Exponencial
3 2
3
Figura 7: Representação dos modelos de semivariogramas usualmente utilizados (Esférico, Guassiano e Exponencial).
Vale salientar que os cálculos de Geoestatística dependem do valor do modelo do semivariograma para cada distância (h) especificada (VIEIRA et al., 1981). Sendo assim, é importante que o modelo ajustado represente a tendência do semivariograma em relação à distância. Desse modo, as estimativas da krigagem serão mais exatas e, portanto, mais confiáveis (CAMARGO, 1997).
2.5.3 Índice de dependência espacial
Conforme critérios estabelecidos por Zimback (2001) o índice de dependência espacial (IDE) é dado por
0
100 C
IDE
C C
e a classificação quanto ao grau de dependência espacial da variável em estudo assume os seguintes intervalos: fraco para valores de IDE < 25%; moderado entre 25% ≤ IDE ≤ 75% e forte para IDE >75%.
26 teórico ajustado, pois a escolha do modelo deve ser coerente com o que se espera na prática para o índice esperado do fenômeno em estudo.
Supondo que o modelo escolhido apresente um IDE conforme o esperado, a fase seguinte consiste em predizer os valores para os pontos que não foram amostrados. Isto pode ser realizado pela krigagem.
2.5.4 Krigagem
Conhecido o semivariograma da variável, e havendo dependência espacial entre as amostras, podem-se interpolar valores em qualquer posição no campo de estudo, sem tendência e com variância mínima (VIEIRA, 2000; SILVA et al., 2011).
O método de interpolação, na Geoestatística, chama-se krigagem e tem como base os dados amostrais da variável regionalizada e as propriedades estruturais do semivariograma obtido a partir destes dados o que permite visualizar o comportamento da variável na região através de um mapa temático (SILVA et al., 2011).
Existem diferentes tipos de Krigagem. Segundo Silva (2003), inicialmente esse método estatístico de interpolação pode dar uma impressão de complexidade, porém, o autor explica que os diferentes tipos de krigagem são técnicas de regressão que diferem apenas dos tipos peculiares de funções obtidas a partir dos dados que estão sendo combinados para obtenção da estimativa.
Para o presente trabalho será utilizado o método de Krigagem Ordinária que utiliza um estimador linear não-viciado com mínima variância, ou seja, estimador do tipo Best Linear Unbiased Estimator (BLUE), para interpolação do atributo medido em posições não
amostradas (ANDRIOTTI, 2003; ISAAKS e SRIVASTAVA, 1989). O valor interpolado de uma variável regionalizada Z x( )0 , num local x0, pode ser determinado por
0
1
ˆ( ) n ( )
i i i
27 onde Z xˆ( )0 representa o valor estimado para o local x0não amostrado, Z x( )i são os valores obtidos por amostragem no campo e li são os pesos associados ao valor médio na posição xi.
De acordo com Silva et al. (2011) a “melhor” estimativa de Z xˆ( )0 é obtida quando
1) O estimador é não tendencioso, ou seja, E Z xˆ( )0 Z x( )0 0;
2) A variância da estimativa é mínima, logo, Var Z x[ ( )ˆ 0 Z x( )]0 mínimo.
Segundo Silva et al. (2011), para que Zˆ seja uma estimativa não tendenciosa de Z, a soma dos pesos das amostras deve ser igual a 1 ( li 1). Para obter a variância mínima sob a condição o sistema de Krigagem resultante é dado por
0 1
( , ) ( , )
n
i i j i
i
x x x x
l g m g
onde m é o multiplicador de Lagrange. O sistema de equações da Krigagem contém n 1
equações e n 1 incógnitas e uma única solução produz n pesos
l
e um multiplicador de Lagrangem
.De acordo com Silva et al. (2011), em notação matricial chamando de Aa matriz de
variâncias dos valores amostrados envolvidos na estimativa de Z xˆ( )0 ,
l
a matriz coluna quecontém os pesos
l
ie o multiplicador de Lagrange e b a matriz coluna das variâncias entre os valores amostrados e o ponto a ser estimado, tem-sel
A
b
logo
-1
l
A b
e a variância da estimativa sE2 é dada por
2
.
t E
28 As matrizes
A
,b
el
são dadas por1 1 1 2 1
2 1 2 2 2
1 2
( , )
( , )
( ,
)
1
1
( , )
( , )
( ,
)
1
( , )
( , )
( ,
)
0
1
1
1
n
n
n n n n
x x
x x
x x
x x
x x
x x
x x
x x
x x
g
g
g
g
g
g
g
g
g
A =
1 2 ( , ) ( , ) ( , ) 1 n n n n x x x x = x x g g g b 1 2 n = l l l l mSilva et al. (2011) ressalta que (1) a matriz
A
é simétrica e possui diagonal principal igual a zero, ou igual ao valor do efeito pepita, (2) os valores 1 que aparecem na matrizA
eb são consequência do multiplicador de Lagrange e (3) o sistema deve ser resolvido para
cada estimativa Zˆe para cada variação do número de amostras envolvidas na estimação.
2.5.5 Validação cruzada
De acordo com Andriotti (2003) validação cruzada é o procedimento mediante o qual cada amostra é retirada do conjunto de dados e é feita uma krigagem para avaliar seu valor, o valor médio das diferenças será tão mais próximo de zero quanto melhor for a estimativa. De modo resumido a validação cruzada processa-se da seguinte maneira:
a) É extraído do conjunto de dados original o valor correspondente a um determinado ponto amostrado ( )Zi ;
b) Utilizados os dados remanescentes do conjunto de dados, estima-se o valor desse ponto cujo o valor foi retirado do conjunto obtendo-se o valor Zˆi;
c) Obtém-se o erro cometido nessa estimação (Zˆi Zi) e compara-se esse valor com
ˆ
(Zi Zi)/si ;
d) Repete-se os procedimentos descritos nos itens a, b e c para todas as observações disponíveis no conjunto de dados e procura-se observar se são verificadas as duas
29 seja aproximadamente zero e a de que o valor médio de [(Zˆi Zi)/ ]si 2 seja aproximadamente igual à unidade.
Deve haver também, ainda segundo Andriotti (2003), uma correlação entre os valores krigados e os valores originais do conjunto de dados, correlação esta representada por um de coeficiente de correlação linear em torno de 1.
2.6 Relações bidimensionais
Frequentemente, nos mais distintos ramos do conhecimento, há o interesse em analisar o comportamento conjunto entre duas ou mais variáveis aleatórias. Segundo Bussab (2005), os dados referentes às variáveis de interesse são dispostos em forma matricial, usualmente para o caso onde os dados são independentes e identicamente distribuídos (iid), as colunas desta matriz indicam as variáveis de interesse e as linhas, os indivíduos ou elementos. No contexto espacial os dados são igualmente representados de forma matricial, porém, os valores contidos nas linhas e colunas fazem referencia a posição a qual o mesmo se encontra.
Em análises estatísticas o primeiro passo é a identificação do tipo de variável a ser utilizada. Se a natureza da variável é métrica ou não métrica, o mesmo ocorre ao dado que foi observado, vale lembrar que mesmo em situações onde a observação é métrica ela pode ser passível de categorização e isso ocorre tanto em análises com abordagem da estatística clássica quanto da estatística espacial. Um exemplo de dados métricos porém que são categorizados na agricultura de precisão é a definição de zonas de manejo como indica Borem (2000) citado por Batista (2012).
Outro exemplo de categorização que ocorre em análises espaciais é realizado no cálculo do índice de exatidão Kappa apresentado na subseção 2.4.2, onde são estabelecidas classes iguais para os dois mapas em seguida os mesmos são comparados e como resultado o índice indica se há concordância entre os mapas. O referido índice realiza, então, uma associação entre os mapas avaliando suas concordâncias ou discordâncias.
30 que um dispositivo bastante útil para verificar associação entre duas variáveis métricas ou entre dos conjuntos de dados, é o diagrama de dispersão. Contudo se faz importante quantificar esse tipo de relação. Existe um vasto tipo de associação, para este trabalho será utilizada a relação mais simples que é a linear.
Uma ferramenta que quantifica a relação linear entre variáveis métricas é o coeficiente de correlação linear de Pearson (r). Esse coeficiente mede o grau de relação entre conjuntos de dados, Ramos et al. (2013) salienta que em termos quantitativos o seu valor varia na faixa de
1 r 1. Uma formulação simples do coeficiente pode ser representada por
1
2 2
1 1
( )( )
,
( ) ( )
n
i i
i
n n
i i
i i
x x y y
r
x x y y
onde
1
1 n
i i
x x
n , 1
1 n
i i
y y
n e n é o tamanho amostral. Ramos et al. (2013), indica uma
escala de referência para o grau de associação entre o conjunto de duas variáveis de interesse como apresentado na Figura 8.
Figura 8: Escala de correlação linear entre variáveis. [Fonte: Adaptado de Ramos et al. 2013]
Como apresentado na Figura 8, pode-se observar que para r 1 os pontos desenhados
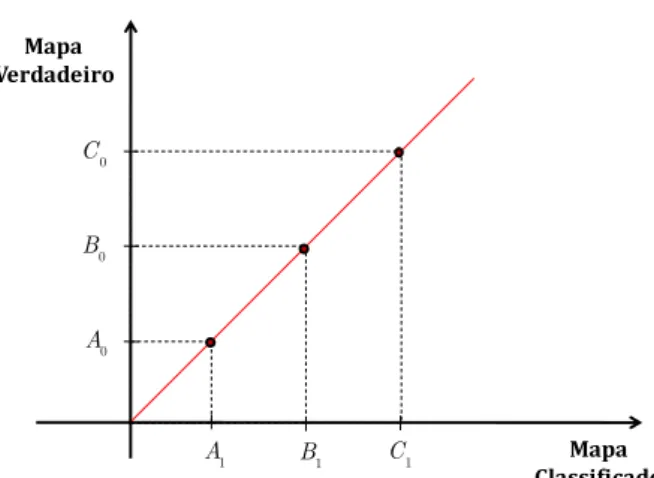
31 O presente estudo parte da premissa que haja uma relação linear entre os mapas iguais. Daí a utilização do coeficiente de correlação de Pearson para os valores interpolados em um mapa temático condensados em pixels como descrito na seção 2.2.1.
Mapa Verdadeiro
Mapa Classificado 0
A
1 A 0
B
1 B 0
C
1 C
Figura 9: Esquema esperado para relação de concordância entre mapas.
32
3.
MATERIAL E MÉTODOS
Neste capítulo são apresentados os recursos e metodologia utilizada neste estudo. Descreve-se a forma de obtenção dos dados por meio de simulações, os softwares e as estatísticas utilizadas para a obtenção dos objetivos propostos.
3.1
Simulações
Para a realização do estudo foram simulados 27 cenários espaciais distintos combinando três tamanhos de grids (todos regulares), três graus de dependência espacial e três diferentes modelos de semivariograma. Com o objetivo de obter um conjunto de valores que pudesse representar cada cenário, foram gerados inicialmente 300 conjuntos de valores distintos para os pontos que compõem os grids em estudo (ANEXO I), o procedimento utilizado foi o SIM2D contido no programa SAS (SAS Institute Inc, 1999), onde os tamanhos de grids regulares simulados foram de 50×50, 100×100 e 150×150. Os modelos de semivariograma utilizados foram o gaussiano, esférico e o modelo exponencial.
Quanto aos níveis de dependência espacial incorporados nas simulações, seguiu-se a definição do Índice de Dependência Espacial (IDE) proposta por Zimback (2001), onde foram utilizados valores de 25% para fraca, 66,70% para moderada e 99,99% para forte. Portanto, para cada nível de dependência espacial adotado, foram simulados 9 cenários diferentes (Totalizando os 27 cenários).
Para a simulação desses diferentes cenários, previamente, foi necessária a determinação dos parâmetros: alcance (a), efeito pepita (C0) e contribuição (C1), de modo que os valores
simulados se comportassem de maneira a representar cada cenário adotado. O que diferenciou-se entre eles foi o número de pontos observados, 121 pontos para o primeiro, 441 para o segundo e 961 para o terceiro cenário (grids de 50×50, 100×100 e 150×150, respectivamente).
![Figura 1: Representação gráfica de um mapa rasterizado. [Fonte: Adaptado de ARCGIS, 2012]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15378557.65469/21.892.265.673.405.660/figura-representação-gráfica-mapa-rasterizado-fonte-adaptado-arcgis.webp)