UNIVERSIDADEFEDERALDO RIO GRANDE DO NORTE
UNIVERSIDADEFEDERAL DORIOGRANDE DONORTE CENTRO DETECNOLOGIA
PROGRAMA DEPÓS-GRADUAÇÃO EMENGENHARIAELÉTRICA E DECOMPUTAÇÃO
Modelo para Reconstrução 3D de Cenas
baseado em Imagens
Alessandro Assi Marro
Orientador: Prof. Dr. Luiz Marcos Garcia Gonçalves
Dissertação de Mestrado apresentada ao
Programa de Pós-Graduação em Engenharia Elétrica e de Computação da UFRN (área de concentração: Engenharia de Computação) como parte dos requisitos para obtenção do título de Mestre em Ciências.
UFRN / Biblioteca Central Zila Mamede Catalogação da Publicação na Fonte
Marro, Alessandro Assi.
Modelo para Reconstrução 3D de cenas baseado em imagens / Alessandro Assi Marro. – Natal, RN, 2014.
50 f. : il.
Orientador: Prof. Dr. Luiz Marcos Garcia Gonçalves.
Dissertação (Mestrado) – Universidade Federal do Rio Grande do Norte. Centro de Tecnologia. Programa de Pós-Graduação Engenharia Elétrica e da Computação.
1. Recontrução 3D - Dissertação. 2. SURF - Dissertação. 3. Structure from motion - Dissertação. I. Gonçalves, Luiz Marcos Garcia. II. Universidade Federal do Rio Grande do Norte. III. Título.
Agradecimentos
Ao meu orientador, professor Luiz Marcos, sou grato pela orientação.
Ao meu grande amigo Bruno Marques pelas grandes idéias e confusões, mas sem o qual não teria conseguido.
Resumo
Reconstrução 3D é o processo pelo qual se faz possível a obtenção de um modelo grá-fico detalhado em três dimensões de alguma cena objetivada. Para a obtenção do modelo gráfico que detalha a cena, faz-se uso de sequências de imagens que a fotografam, assim é possível adquirir de forma automatizada informações sobre a profundidade de pontos característicos, ou como comumente chamados,features. Esses pontos são portanto des-tacados utilizando-se alguma técnica computacional sobre as imagens que compõem o
datasetutilizado. Utilizando pontos característicos SURF (Speeded-Up Robust Features) este trabalho procura propor um modelo para obtenção de informações3Dsobre pontos principais detectados pelo sistema. Ao termino da aplicação do sistema proposto sobre sequências de imagens é objetivada a aquisição de três importantes informações: a posi-ção3D dos pontos característicos; as matrizes de rotação e translação relativas entre as imagens; o estudo que relaciona a baselineentre as imagens adjacentes e o erro de pre-cisão do ponto3D encontrado. Resultados de implementações são mostrados indicando resultados consistentes. O sistema proposto também segue restrições deSoftwarelivre, o que é uma contribuição significativa para esta área de aplicação.
Abstract
3D Reconstruction is the process used to obtain a detailed graphical model in three dimensions that represents some real objectified scene. This process uses sequences of images taken from the scene, so it can automatically extract the information about the depth of feature points. These points are then highlighted using some computational technique on the images that compose the used dataset. Using SURF feature points this work propose a model for obtaining depth information of feature points detected by the system. At the ending, the proposed system extract three important information from the images dataset: the 3D position for feature points; relative rotation and translation matrices between images; the realtion between the baseline for adjacent images and the
3Dpoint accuracy error found.
Sumário
Sumário i
Lista de Figuras iii
Lista de Tabelas iv
1 Introdução 1
1.1 Motivação . . . 1
1.2 Proposta do Trabalho . . . 2
1.2.1 Estrutura do Texto . . . 2
2 Referencial Teórico 4 2.1 Modelo e Parâmetros de Câmera . . . 4
2.1.1 Parâmetros Extrínsecos . . . 4
2.1.2 Parâmetros Intrínsecos . . . 5
2.2 Aerofotogrametria . . . 5
2.3 Extração de Pontos Caractísticos . . . 6
2.4 Mínimos Quadrados e Decomposição em Valores Singulares . . . 6
2.5 Geometria Epipolar . . . 7
2.6 Recuperando Relações entre Poses de Câmeras entre Duas Imagens . . . 8
3 Trabalhos Relacionados 11 4 O Problema 14 4.1 Solução Proposta . . . 15
4.1.1 Fase de correspondência . . . 16
4.1.2 Recuperar matrizesFeE. . . 16
4.1.3 Determinação das Matrizes de Projeção . . . 17
4.1.4 Triangulação e Pontos3D . . . 18
5 Implementações 19 5.1 Softwaree Bibliotecas Utilizadas . . . 19
5.2 Filtragem de Pontos . . . 24
6 Experimentos e Resultados 26 6.1 Comprovações Visual e Numérica . . . 26
6.3 Metodologia dos Testes Realizados . . . 27
6.4 Resultados experimentais . . . 29
6.4.1 Matching . . . 30
6.4.2 Nuvem de Pontos . . . 32
6.4.3 OEstudo . . . 34
Lista de Figuras
2.1 Imagem representativa sobre a geometria epipolar existente entre pares de
imagens adjacentes. . . 8
2.2 Ambiguidade gerada durante a fase de triangulação para cada matriz de projeção encontrada. Podemos perceber que a solução ideal é aquela en-contrada no item (a). . . 10
4.1 Sistema de visão estéreo. . . 15
5.1 Algumas imagens que compõem odataset . . . 21
6.1 O dispositivo kinect e seus sensores. . . 27
6.2 (a) Visualização de uma das imagens que compõe odataset obtida pelo Kinect. (b) Seu respectivo modelo3Dtambém gerado pelo Kinect. . . 28
6.3 Ilustração da cena imageada. . . 29
6.4 Resultados de matching para imagens com linha de base pequena. Pri-meiro caso com 273 correspondências encontradas. . . 31
6.5 Resultados dematchingpara imagens com linha de base e rotação relativa grandes. Segundo caso com 30 correspondências encontradas. . . 31
6.6 Imagem tirada de frente da nuvem de pontos encontrada (pontos verdes) e da nuvem do Kinect. . . 32
6.7 Imagem mais próxima da nuvem de pontos encontrada (pontos verdes) e da nuvem do Kinect. . . 33
6.8 Imagem tirada lateralmente à nuvem de pontos encontrada (pontos ver-des) e da nuvem do Kinect. . . 33
6.9 Comparação entre triangulações para linha de base diferentes. . . 34
6.10 Comparação entre linha de base e o Erro Médio encontrado para os pontos 3Dtriangulados. . . 35 6.11 Comparação entre erro e linha de base para um único ponto3Dencontrado. 35
Lista de Tabelas
3.1 Bibliografia . . . 13 6.1 Tabela que apresenta os dados obtidos a partir das execuções realizadas. . 30
Capítulo 1
Introdução
1.1
Motivação
A busca por uma forma de mapear regiões tem sido alvo de estudos realizados por di-versas instituições que realizam pesquisas nas áreas de Visão Computacional e Robótica. Em especial, a construção de mosaicos a partir de imagens tem sido uma das solução ado-tada para resolver o problema de mapeamento, visto que, para mapear regiões de grande dimensão, são necessárias várias imagens.
Apesar da grande contribuição que as diversas metodologias existentes para a constru-ção de mosaico nos propõe, visualmente, convém ressaltar que o processo de mapear uma região não se resume a uma simples visualização em duas dimensões (2D) da mesma, mas sim se faz necessário uma representação mais detalhada, em alto-relevo, dos componentes que fazem parte do ambiente mapeado, ou seja, uma visualização3D.
A idéia aqui tratada não é inovadora, mas sim incremental ao estado da arte. É fá-cil encontrar na Iternet empresas e softwares (a maioria pago) que realizam esse tipo de processamento, sobre imagens, visando a realização da reconstrução3Ddo ambiente ma-peado. APix4D, uma empresa suiça, realiza o procedimento de mapeamento3Dde uma área qualquer de maneira completa e precisa, conforme afirmação da empresa. Porém, a
Pix4Dé privada e o estudo realizado por ela para a definição da metodologia não é di-vulgado, assim como seuSoftwarenão é aberto, além de ser pago. Há outras empresas e softwares similares, mas não com metotologia aberta, reproduzível.
Dados os fatos apresentados, pode ser dito que esta dissertação de mestrado procura suprir dois aspectos importantes para a pesquisa relacionada com a reconstrução de mo-delos 3Dpara cenas mapeadas por imagens. A primeira é a geração de um modelo de
CAPÍTULO 1. INTRODUÇÃO 2 de base (do inglês,baseline) maior entre imagens gera uma aquisição de pontos triangu-lados mais precisa. Essa afirmação será analisada durante as seções que seguem neste documento, também como contribuição do presente trabalho.
1.2
Proposta do Trabalho
Como introduzido acima, a contribuição principal deste trabalho é a criação de um modelo de estudo que seja o mais completo possível, com o desenvolvimento de um sistema baseado emSoftwareaberto que consiga obter informações aproximadas de pro-fundidade para pontos de interesse selecionados entre as imagens utilizadas. Por sua vez, essas informações adquiridas são utilizadas para realizar, posteriormente, uma reconstru-ção aproximada, em um sistema de referência global, em três dimensões, da região que se quer mapear.
Para desenvolver o que é proposto acima, é preciso obter imagens da cena. É im-portante ressaltar que além dessas imagens, em trabalhos como o de Irschara [Irschara et al. 2011] e o de Wu [Wu 2013] se fazem necessárias informações de posição e orien-tação para cada imagem, obtidas por sensores externos como GPS e IMU. Até o presente momento, o trabalho não exige informações provenientes desses sensores. A idéia prin-cipal da metodologia desenvolvida nesta dissertação é utilizar técnicas de Visão Compu-tacional entre pares de imagens para extrair informações de posição e orientação relativas que serão posteriormente utilizadas para a obtenção de informações3Dde pontos princi-pais. Basicamente, utilizamos pontos de interesse entre pares de imagens, identificados como correspondentes, e através de cálculos provenientes de metodologias como SfM e Reconstrução Estéreo é possível adquirir a posisão e orientação relativas entre os centros de projeção das câmeras. A partir destes dados, faz-se possível a reconstrução do ponto
3Dem questão a partir da técnica de triangulação.
Durante o processo descrito acima, será feito também um estudo sobre a relação do tamanho da linha de base entre pares de imagens e a precisão do ponto3Dadquirido.
Ou seja, ao término deste trabalho, temos uma metodologia para a extração de infor-mação3Daplicada à sequências de imagens.
1.2.1
Estrutura do Texto
No Capítulo 2, são apresentados os conceitos básicos que circundam os procedimentos a serem usados para desenvolver este trabalho. O problema de construção de mosaico, já conhecido na literatura, é apresentado, bem como é feita uma revisão de alguns tópicos das áreas de Visão Computacional e Fotogrametria necessários ao entendimento do texto. No Capítulo 3 são mostradas as metodologias distintas utilizadas por outros pesqui-sadores para solucionar o problema de SfM, que conseguimos levantar numa procura exaustiva em periódicos, conferências e na Internet.
CAPÍTULO 1. INTRODUÇÃO 3 O Capítulo 5 discorre sobre a especificação do ambiente de execução utilizado e a explicação sobre os módulos implementados, incluindo seus detalhamentos.
No Capítulo 6 serão apresentados uma série de experimentos e os resultados obtidos, assim como a analise apresentada nesta seção. A metodologia experimental usa dados (imagens) obtidos com câmeras embarcadas em robôs (aéreos), pela equipe do projeto NVANT (Desenvolvimento de Protótipos de Veículos Aéreos não Tripulados) ou dados obtidos de repositórios disponíveis publicamente.
Capítulo 2
Referencial Teórico
O presente Capítulo apresenta e discute o ferramental teórico necessário para o enten-dimento desta monografia. Apresentamos aspectos relacionados ao modelo matemático de câmera usado e os seus parâmetros (intrínsecos e extrínsecos), alguns conceitos bá-sicos de aerofotogrametria e também discorremos sobre o procedimento metodológico conhecido para a construção de um mosaico (incluindo toda a matemática necessária, tal como o método dos mínimos quadrados).
2.1
Modelo e Parâmetros de Câmera
Neste trabalho, usamos o modelo de projeção perspectiva mais conhecido como câ-merapinhole[Trucco & Verri 1998]. O modelopinholedescreve a projeção de um ponto
3Dno mundo,Q= [X,Y,Z]t, em um plano2Dna imagem,q= [u,v]t.
Algoritmos de visão computacional que realizam uma reconstrução 3Dde uma cena
qualquer, têm como base equações capazes de relacionar as coordenadas dos pontos3D
da cena real às suas respectivas representações no plano 3D da imagem. Existem dois
conjuntos de parâmetros envolvidos neste processo que devem ser considerados, os in-trínsecoseextrínsecos. O primeiro é necessário para relacionar as coordenadas dospixels
na imagem às suas respectivas coordenadas noframede referência da câmera. Já os pa-râmetros extrínsecos são responáveis por definir a posição e orientação da câmera em relação aoframede referência do mundo.
2.1.1
Parâmetros Extrínsecos
Oframede referência de câmera possibilita uma maneira simples de formular as equa-ções fundamentais de projeção perspectiva. Por ser geralmente desconhecida, é um pro-blema comum determinar a posição e orientação da câmera baseando-se apenas em in-formações provenientes de técnicas de visão computacional, porém torna-se complicado proceder desta forma. Osparâmetros extrínsecos são capazes de facilitar esse procedi-mento a partir de duas relações principais. A primeira baseia-se em um vetor de translação
3D, chamado deT, que descreve a transformação relativa aos doisframesde referência, de
câmera e mundo; já a segunda é uma matriz de rotação 3×3,R, ortogonal que relaciona
CAPÍTULO 2. REFERENCIAL TEÓRICO 5
2.1.2
Parâmetros Intrínsecos
Correspondem ao conjunto de parâmetros responsáveis por informar as características óticas, geométricas e digitais da câmera. Para uma câmera pinhole três conjuntos de parâmetros são necessários.
• Distância focal,f.
• A transformação entre os sistemas de coordenadas da câmera e do pixel na imagem. • Os parâmetros de distorção das lentes.
x=−xim−oxsx (2.1) y=−yim−oysy (2.2)
A Equação 2.1 e 2.2 relaciona as coordenadas(xim,yim)de um ponto na imagem, em
pixels, com as coodenadas(x,y)do mesmo ponto representado no sistema de coodenadas
da câmera. Para isso, é necessário estabelecer os valores de quatro variáveis:ox,oy,sx,sy.
As duas primeiras são as coordenadas dopixelno centro da imagem, em coordenadas de imagem. As duas últimas representam o tamanho dopixel, em milímetros, nas direções horizontal e vertical, respectivamente.
Portanto, neste caso, temos que o conjunto que representa os parâmetros intrínsecos é composto porf,ox,oy,sx,sy.
2.2
Aerofotogrametria
Aerofotogrametria refere-se, de maneira genérica, ao processo de cobertura aerofo-tográfica de uma determinada região para fins de mapeamento. A Fotogrametria, mais especificamente, é a ciência que permite executar, através de fotografias de alta resolu-ção, medições precisas sobre uma determinada área a qual se deseja mapear ou adquirir alguma informação. Naturalmente que, por analogia, a Aerofotogrametria nada mais é do que o processo fotogramétrico com imagens adquiridas por alguma fonte a uma al-titude mais elevada que a do terreno, normalmente a partir de câmeras embarcadas em aeronaves.
O processo fotogramétrico utiliza alguns outros conceitos indispensáveis para adquirir uma maior precisão e, por consequência, resultados melhores.
• Georreferenciamento: Processo que torna as coordenadas de imagens ou qualquer
CAPÍTULO 2. REFERENCIAL TEÓRICO 6 a outros pontos ao redor, tais como interseção de estradas, pontas de montanhas, ou até mesmo símbolos fábricados. A obtenção de suas coordenadas pode ser realizada por algum processo de medição em campo, por exemplo através do uso de aparelhos GPS.
• Sobreposição (ouoverlap) entre imagens: A taxa de sobreposição entre duas
ima-gens adjacentes representa a região de ambiguidade, entendendo-se por ambigui-dade a região nas cenas adjacentes que se repete. Existem dois tipos de sobrepo-sição, a frontal (também conhecida como longitudinal) e a lateral. A primeira é utilizada para determinar a porcentagem de similaridade entre imagens espaçadas sobre o eixo que determina o sentido de vôo de um avião de aerofotogrametria; já a segunda determina a similaridade entre imagens espaçadas perpendicularmente ao sentido de vôo (lateralmente). Em procedimentos aerofotogrametricos mais acura-dos (ressalva, muito caros), a sobreposição frontal é geralmente de 70% e a lateral de 30%.
2.3
Extração de Pontos Caractísticos
Procedimentos que extraem características de imagens são alvos de estudo na área da Visão Computacional. Essas características (features) são projeções na imagem de marcos visuais presentes na cena visualizada. Uma vez detectadas, as características podem ser utilizadas para formar a base para o reconhecimento de objetos, para a calibração de câmeras e principalmente, para caso do nosso trabalho, para a construção de mosaicos, entre outras aplicações.
O detector de pontos característicos conhecido comoSURFé um desses
procedimen-tos [Bay et al. 2008]. Ele possui a importante propriedade de detecção de ponprocedimen-tos diprocedimen-tos serem invariantes à escala além da invariância à rotações no plano. Este detector utiliza uma aproximação de uma matriz hessiana calculada a partir dos valores de intensidade dos pixels de uma região da imagem, fazendo com que os resultados sejam obtidos com uma maior rapidez.
A hessiana é a matriz formada pelas convoluções das derivadas parciais de segunda ordem do gaussiano com a imagem. Sendo Lxx(x,σ) a convolução com a imagem da
derivada parcial de segunda ordem do gaussiano na direção x na posiçãox com desvio
padrãoσ, a hessiana é definida como na Equação 2.3.
H(x,σ) =
!
Lxx(x,σ) Lxy(x,σ)
Lyx(x,σ) Lyy(x,σ)
"
(2.3)
2.4
Mínimos Quadrados e Decomposição em Valores
Sin-gulares
CAPÍTULO 2. REFERENCIAL TEÓRICO 7 dimensãon. Neste trabalho, nos deparamos com situações como a apresentada porAx=0
durante a etapa responsável por calcular as matrizes de projeções para cada câmera do par de imagens associado, como será apresentado nos próximos capítulos deste documento. Para resolver tal problema, usa-se a solução de sistemas lineares através de mínimos qua-drados [Trucco & Verri 1998] de forma a encontrar algum valor para o vetor xque não
seja a solução trivialx=0, pois esta não interessa. A idéia é encontrar somente a direção
dexque minimizeAx=0. Procedendo com a minimização do quadrado da norma deAx,
devemos encontrar o autovetorenque minimize∥Ax∥2. Desenvolvendo a equação, temos
∥Ax∥2=
=xtAtAx =etnAtAen
=etnenλ
=λn,
o que significa que o autovetor de interesse é o associado com o menor autovalorλn.
Para encontrar o autovetor que procuramos, utiliza-se uma fatoração na matriz de dados A chamada de decomposição em valores singulares, mais conhecida como SVD
(Singular Value Decomposition). Como resultado desta fatoração, encontramos três ma-trizes:U eVt, matrizes estas ortogonais de tamanhosm×men×n, respectivamente; e a
matriz diagonal de tamanhom×n,D. Os valores da diagonal principal da matrizDestão organizados na formaσ1≥σ2≥σ3≥...≥σn, assim como os autovetores à direita deV.
Colocado isto, fica fácil ver que a solução que satisfaz a equaçãoAx=0 porSVDé obtida
pelo último vetor coluna deVt, associado ao menor autovalorλn.
2.5
Geometria Epipolar
Uma das contribuições principais desta dissertação de mestrado é justamente encon-trar informações 3Dde pontos característicos selecionados nas imagens. Essas coorde-nadas3Dpodem ser recuperadas com informações presentes em duas ou mais imagens. No caso estudado aqui, tem-se duas imagens de uma cena capturadas pelo mesmo sensor, com diferentes posições e orientações globais, porém com bastante sobreposição entre elas. De qualquer maneira, este método só se faz possível uma vez que se tenha diferen-tes projeções em imagens aplicadas a um mesmo ponto3Dpresente na cena. Claro, não podem ser muito diferentes as posições e orientações com que as imagens são capturadas, pois neste caso não se teria muitos pontos da cena aparecendo nas duas imagens (condição necessária e suficiente para a estereofotogrametria).
A geometria epipolar garante que essa restrição seja alcançada ao utilizar os parâ-metros internos da câmera e as correspondências obtidas entre as imagens para recupe-rar informações da estrutura 3D da cena fotografada. Essas correspondências formam um conjunto de pares de pontos característicosxi↔xi′ que relacionam as projeções do
CAPÍTULO 2. REFERENCIAL TEÓRICO 8 deseja obter.
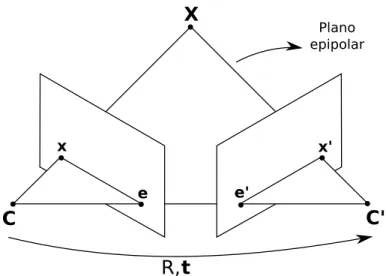
Figura 2.1: Imagem representativa sobre a geometria epipolar existente entre pares de imagens adjacentes.
A geometria epipolar, apresentada pela Figura 2.1, determina que dado um ponto no mundoX e as suas projeções xex′, adquiridas pelos respectivos centros de projeção da
primeira e segunda imagens,CeC′, existe um plano epipolar que contém todos os demais
pontos que, ao serem reprojetados nas imagens, geram pontos não característicos.
De maneira resumida, a lógica da geometria epipolar pode ser expressa matematica-mente pela definição de duas importantes matrizes, aessenciale afundamental[Hartley & Zisserman 2004] [Hartley & Sturm 1997] [Trucco & Verri 1998]. A matriz essencial
Ede dimensão 3×3 relaciona pontos em sistemas de coordenadas de câmera através dos
parêmetros extrínsecosRet. A matriz fundamental, por sua vez, relaciona pontos em co-ordenadas de imagens. Esta, também sendo uma matriz 3×3, torna possível extrair dados codificados por ela, a rotaçãoRe a translaçãot relativas entre as duas poses de câmeras que representam as imagens utilizadas para a extração dos pontos característicos.
2.6
Recuperando Relações entre Poses de Câmeras entre
Duas Imagens
Como já vimos em seções anteriores deste capítulo, é possível calcular a matriz funda-mentalF a partir de pontos característicosxi↔xi′extraídos de duas imagens diferentes.
Para isso, podemos utilizar o algoritmo dos 8 pontos [Hartley & Zisserman 2004]. A partir da matrizF encontrada, podemos relacionar o par de imagensI eI′.
Pelo menos oito correspondências entre features são necessárias para se obter uma
solução que seja única. A matriz fundamentalF pode ser então computada, a menos de um fator de escala.
CAPÍTULO 2. REFERENCIAL TEÓRICO 9
E=KtFK (2.4) A matriz E possui informações sobre os parâmetros extrínsecos R e t relativa entre os centros de projeção entre as imagens relacionadas. Para realizar a extração destes parâmetros extrínsecos, utiliza-se a fatoração SVD, vista anteriormente. Assumindo-se duas matrizes de projeção (uma para cada imagem), tais como P= [I|0] e P′= [R|t],
temos quatro possíveis soluções a serem consideradas.
• P′= [UWVt|+t];
• P′= [UWVt| −t];
• P′= [UWtVt|+t];
• P′= [UWtVt| −t];
onde
W =
⎡
⎣
0 −1 0 1 0 0 0 0 1
⎤
⎦.
CAPÍTULO 2. REFERENCIAL TEÓRICO 10
(a) (b)
(c) (d)
Capítulo 3
Trabalhos Relacionados
Várias abordagens para o problema de construção de mosaicos foram propostas nos últimos anos. Os trabalhos apresentados nesta seção foram desenvolvidos através de di-versas técnicas da computação, sendo algumas delas no âmbito da programação estocás-tica, visão computacional, rede neural, entre outras.
É importante esclarecer, por questões de preferências quanto a nomenclatura utilizada, que os autores que se fazem referenciados nesta seção, nomeiam a metodologia utilizada por este trabalho comoSfM(do inglêsStructure from Motion) ou Reconstrução Baseada
no Movimento, o que é uma preferência partilhada pelo autor desta dissertação. Basi-camente, o processo matemático envolvido entre a metodologia de SfM e Reconstrução Estéreo é o mesmo, mas as duas metodologias se diferenciam em sua essência. SfM supõe a existência de movimentos da câmera ou da cena, o que não ocorre com a Reconstrução Estéreo, a qual não admite a necessidade da verificação da existência de movimento.
Um dos exemplos de metodologia para o problema abordado nesta pesquisa é a de-senvolvida por Rong Liu [Liu et al. 2009]. Nela, são utilizadas tecnologias de localização e informações espacial como dispositivos GPS -Global Point System, GIS -Geographic Information System, além de sensores para o controle e monitoramento remoto. Infor-mações provenientes do sistema de fotogametria digital construído por este trabalho são cruciais para a criação do, como denomina o artigo, DEM - Digital Elevation Model. Desta maneira, a partir dos dados adquiridos pelos sensores, pelo sistema de fotogametria e pelo GIS, Rong Liu tem o objetivo de gerar modelos 3D de infraestruturas urbanas. Pon-tos de controle localizados em coordenadas conhecidas são utilizados durante o processo de ortorretificação das imagens adquiridas. Tal método não possibilita apenas uma melhor precisão na localização das imagens, mas também tais pontos podem ser utilizados para correção do erro final acumulado pelo processo de reconstrução3D.
O trabalho apresentado por Irschara [Irschara et al. 2011] [Irschara n.d.] possui uma abordagem clássica de reconstrução baseada em imagens e geolocalização. Neste, utiliza-se a informação prévia de sistemas de posicionamento global e unidades de medição inercial para acelerar a metodologia de SfM. É proposta uma estratégia de seleção para
CAPÍTULO 3. TRABALHOS RELACIONADOS 12 melhora no processamento dematchingspara encontrar pontos característicos entre ima-gens. Além disto o algoritmo proposto por Irschara faz uso da técnica de otimização de ajuste de blocos, denominada deSBA(do inglêsSparse Bundle Adjustment). Ele propõe
uma função para o cálculo do custo do erro pela reprojeção dos pontos 3Dencontrados de forma a atenuar o fator que relacionaoutliers. A aplicação do método de otimização
SBAé realizado apenas uma vez ao final do procedimento de reconstrução. Imagens são
capturadas por um veículo aéreo conectado com sensoresGPS eINS(do inglês Inertial Navigation System).
Em contrapartida com a linha de raciocínio proposta por Irschara, temos o trabalho de Wu [Wu 2013]. Apesar de realizar reconstruções baseadas em imagens com auxílio de sistemasGPSeINS, seu trabalho segue um fluxo alternativo. Ao contrário dos traba-lhos apresentados anteriormente, neste existem dois métodos de otimização, o Full BA
e oPartial BA, que são aplicados em intervalos fixos de iteração. O Full BA aplica a
cadanintervalos do sistema o algoritmoSBA a todas as imagens, classificandooutliers
e ajustando matrizes de rotaçãoRe de translaçãot relativas entre os centros de projeções das imagens. Para pontos triangulados a partir de novas imagens, por sua vez, é aplicada a técnica dePartial BAque realiza a mesma correção de matrizes e classificação de pontos
com erros elevados. Esse segundo método não é aplicado a todas as imagens inseridas no sistema, o que gera uma otimização mais frequente e com um custo menor. Além disto, após a classificação dosoutliersé realizada uma Re-triangulação comthresholdmais rela-xado, o que filtra pontos com erro de reprojeção elevado, mas não remove completamente todos os pontos nesta classificação da solução final.
Em uma outra abordagem [Sharma et al. 2009] temos como metodologia de registro entre imagens o uso de Redes Neurais Auto-Organizáveis. O trabalho propõe um algo-ritmo baseado em rede neural que encontra o maioroverlappingentre pares de imagens. Os dados de entrada da rede neural são as bordas detectadas através da aplicação do al-goritmo de Sobel sobre as imagens. O objetivo principal deste trabalho é provar que ao utilizar redes auto-organizáveis de Kohonen é possível a construção de mosaicos de forma eficiente. O uso de tal rede é motivado pela sua característica principal, sua forma [Sharma et al. 2009]. Como redes de Kohonen são espaciais a topologia dos pixels na imagem seria preservada, assim como sua informação.
Apesar do que é afirmado pelos trabalhos comentados anteriormente neste capítulo, o trabalho de Saeed Yahyanejad [Yahyanejad et al. 2011] apresenta detalhes que são im-portantes durante todas as etapas que envolvem a metodologia utilizada emSfM. Neste,
veículos aéreos de pequeno porte navegam a altitudes baixas para que imagens do terreno ao qual se quer mapear sejam obtidas. O foco deste trabalho reside na atenção especial que é dada a três fontes principais de erro. Segundo o autor a primeira ocorre quando os pontos de controle (GCP), espalhados pelo terreno, estão desnivelados. Isto pode vir a acarreta futuramente em uma fraca homografia. A segunda fonte de erro é ocasionada por falhas na calibração da câmera. Por último, a falta de um modelo de projeção bem definido acarreta em modelos de transformação inapropriados.
CA
PÍ
T
U
L
O
3.
T
RA
B
A
L
H
O
S
RE
L
A
CI
O
N
A
D
O
S
13
Trabalho Ambiente Features Informaçõesa priori
[Liu et al. 2009] Simulado Não informado GPS e INS / GCPs [Irschara et al. 2011] Externo SIFT GPS e IMU
[Wu 2013] Externo Não informado GPS
[Sharma et al. 2009] Interno Featuresauto-organizáveis de Kohonen Duas imagens(M×N eP×N) [Yahyanejad et al. 2011] Externo Não informado GPS e GCPs
Capítulo 4
O Problema
Visão estéreo refere-se à capacidade de inferir informações sobre estruturas 3D a par-tir de duas ou mais imagens de uma cena com sobre-posição entre elas, capturadas de diferentes pontos de vista. Neste trabalho, nos restringimos a modelos fotogramétricos constituídos, cada um deles, por duas imagens consecutivas, claro, tomadas de pontos de vistas diferentes. O problema de reconstrução estéreo é geralmente dividido em dois sub-problemas, o daCorrespondência(oumatching) e o daReconstrução3D propriamente
dita. Dadas as duas imagens, o primeiro sub-problema consiste em determinar pares de pixels (ou de elementos), sendo um em cada imagem, que sejam correspondentes à pro-jeção de um mesmo ponto (ou elemento) na cena. Esta etapa é resolvida geralmente de forma automatizada, com o uso de um computador, com programas que buscam por si-milaridades entre pixels ou elementos. Pode-se usar para isso as características locais da imagem tal como a variação do nível intensidade na vizinhança ou determinadas estru-turas que se sobressaem na imagem. Uma vez determinadas as correspondências entre (idealmente todos) os pares de pixels (ou elementos) nas duas imagens e tendo o conhe-cimento de uma possível informação sobre a geometria do sistema (posição e orientação relativa e absoluta entre as câmeras), a reconstrução, por sua vez, consiste em determinar a localização 3D de cada ponto em um sistema de coordenadas global. O problema de visão estéreo encontra-se bem definido atualmente e pode ser encontrada uma vasta literatura a respeito, incluindo livros textos [Marr 1982, Trucco & Verri 1998, Szeliski 2010].
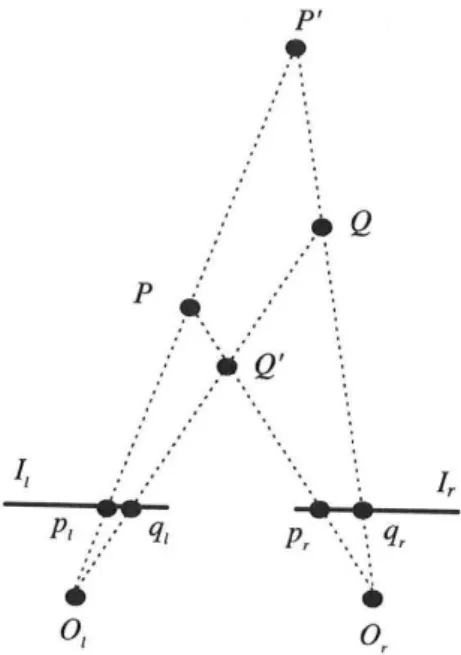
A Figura 4.1 ilustra o processo do cálculo da profundidade (reconstrução) por tri-angulação, sendo determinada a posição de P e Q no espaço em três dimensões. Este procedimento depende da solução para o seguinte problema:
• Se(pl,pr)e(ql,qr)é um par de pontos correspondentes nas imagens esquerda (ql)
e direita (qr), respectivamente, a interseção dos raios Olpl−Orpr e Olql−Orqr
leva às projeções dePeQno espaço.
No caso, para as sequências de imagens usada em nossos experimentos, a distância entre os centros de projeção em cada imagem e a seguinte (linha de base) é pequena, o que configuraria mais um problema de reconstrução a partir de movimento (SfS - Structure from Motion). Neste caso, similarmente, realizar a operação de recontrução3Dsignifica,
CAPÍTULO 4. O PROBLEMA 15
Figura 4.1: Sistema de visão estéreo.
entre as câmeras pode ser aumentada ou, com o mesmo efeito geométrico, imagens podem ser puladas na sequência, aumentando a linha de base e generalizando o problema. Porém, claro, deve haver um balanceamento entre a distância de cada tomada para a seguinte e a diferença observada nas respectivas imagens, ou seja, as imagens não podem ser muito diferentes, caso contrário não seria possível encontrar correspondências.
Tendo posto isto, fica fácil ver que a forma de abordar o problema da visão estéreo neste traballho é uma generalização do problema demotion, como posto acima. A busca por correspondência torna-se um pouco mais complexa, pois envolve imagens possivel-mente com certa diferença visual entre elas, incluindo oclusões em alguas poucas regiões. Entretanto, ainda assim, é possível usar os conceitos abordados anteriormente para cada par de imagens que possua muitas características em comum correspondentes ao conjunto de características presentes na cena ou região mapeada, a qual queremos reconstruir. Isto pode ser melhor entendido a seguir, quanto tratamos da solução proposta.
4.1
Solução Proposta
A solução proposta neste trabalho consiste em um sistema para encontrar informações
CAPÍTULO 4. O PROBLEMA 16 que esta seja precisa e que o erro acumulado referente a solução final seja coerente com o método aplicado, quanto ao estudo proposto. A metodologia encontrada para solucionar o problema abordado se resume, basicamente, em algumas etapas principais:
• Computar pontos característicos (feature) e correspondências (matches) entre um par de imagens sobre uma cena estática.
• Recuperar a matriz fundamental e essencial,FeE.
• Extrair o par de matrizes de projeção a partir da matrizEencontrada.
• Realizar a triangulação dematchespara obter pontos3DXi.
4.1.1
Fase de correspondência
Após a escolha de um par de imagens corrente da sequência de imagens que cobre a região de interesse, com superposição, é preciso realizar a primeira etapa do processa-mento que é a extração pontos característicos (ou features) e o matching. Para realçar e localizar as features nas imagens, utilizamos a técnica descrita no Capítulo 2 na Se-ção 2.3, baseada em SURF, que descreve a forma de se encontrar pontos supostamente invariantes à transformações de escala e rotação do plano. Como explicado, este detector faz uso da aproximação da matriz hessiana da imagem na vizinhança do ponto, dado pela Equação 2.3.
Encontrados os pontos de interesse e seus respectivos descritores, o próximmo passo é a comparação e determinação de uma estimativa dematching para esses. A busca por correspondências pode ser realizada comparando-se os vetores descritores de pontos de interesse encontrados na fase anterior, dois a dois, até que se encontre o par cujos des-critores sejam o mais similar possível. Ressaltando que os desdes-critores são ditos serem invariantes a rotação e escala. Esta comparação pode ser feita através do uso de alguma métrica como por exemplo a distância euclideana ou outra medida qualquer de simila-ridade. Ao final desta fase têm-se pontos de interesse determinados com os respectivos
matchesentre eles.
4.1.2
Recuperar matrizes F e E
Após a obtenção das features e dosmatches, a próxima etapa é responsável por en-contrar as matrizesFe Ea partir destes pontos de interesse. Como já foi no Capítulo 2
na Seção 2.6, é possível calcular a matriz fundamentalFa partir de oito pares de pontos
característicos utilizando-se a técnica conhecida como o algoritmo dos 8 pontos [Hartley & Zisserman 2004]. Ao final, obtem-se uma matrizFúnica, a menos um fator de escala,
que relaciona o par de imagens Ie I′. Segundo Nistér [Stewénius et al. 2006], a matriz
fundamental real não-zero encontrada só é válida se satisfizer a seguinte equação:
CAPÍTULO 4. O PROBLEMA 17 Tendo encontrado a matrizFválida, fica fácil obter a matriz essencialE. Utilizando a
matriz de parâmetros intrínsecos da câmera e a matriz fundamental conseguimos encon-trar a matriz essencial desejada, de acordo com a Equação 4.2:
E =KTFK (4.2) Ainda segundo Nistér, a matrizEé uma matriz essencial válida se e somente se
satis-fizer a seguinte equação:
2EETE−trace(EET)E=0. (4.3)
Ao termino desta fase, tem-se as matrizes essencial e fundamental que relacionam as imagens tanto a nível de sistema de coordenadas de imagem quanto a nível de sistema de coordenadas de mundo.
4.1.3
Determinação das Matrizes de Projeção
Observando o modelo mostrado na Figura 4.1, pode-se concluir que, para realizar a triangulação necessária objetivando-se a obtenção de pontos3D, são necessárias duas matrizes que possibilitam, unicamente, a reprojeção do ponto 2D na imagem para um ponto3Dno mundo. Cada uma destas matrizes de projeção refere-se aa uma das câmeras associada à imagem.
Assumindo que a origem do sistema de coordenadas de mundo é definido como sendo a localização de onde foi tomada a primeira imagem, ou seja, este é o ponto origem (0,0,0) do sistema de coordenadas de mundo, pode ser concluído que, a matriz de projeção da primeira câmera é dada porP= [I|0].
Ao se calcular a matriz essencial que relaciona informações sobre parâmetros extrín-secos na etapa anterior, consegue-se extrair as matrizes R e t relativas entre os centros
de projeção de câmeras. Como já descrito no Capítulo 2, durante a Seção 2.6, ao se usar a fatoração SVD, obtem-se quatro possíveis soluções a serem consideradas, tal como mostrado na Figura 2.2.
• P′= [UWVt|+t];
• P′= [UWVt| −t];
• P′= [UWtVt|+t];
• P′= [UWtVt| −t];
Apenas uma destas soluções é a correta, que gera pontos3Dà frente de ambas as câ-meras. Segundo Hartley e Zisserman [Hartley & Zisserman 2004] um ponto3Dqualquer só pode estar à frente de uma determinada câmera se e somente se a sua profundidade for positiva, como mostra a Equação 4.4.
CAPÍTULO 4. O PROBLEMA 18 Antes de continuar com os cálculos que detalham de forma simplificada a Equa-ção 4.4, primeiramente um conceito deve ser abordado. A matriz que representa infor-mações de posição e orientação e parâmetros intrínsecos de câmera pode ser chamada de matriz de projeção de câmera. Segundo a Equação 4.5, a matriz de projeção depende da matriz de intrínsecosKe da matriz de rotaçãoRe o vetor de translaçãot.
P=K[R|t] = [M|p] (4.5)
A funçãodepthpresente na Equação 4.4 é então descrita pela Equação 4.6, na qualP
representa a matriz de projeção associada. SendoX= (X,Y,Z,T)T um ponto3Dqualquer
eP= [M|p]a matriz de câmera e supondoPX =w(x,y,1)T então definimos a
profundi-dade do pontoXcomo sendo:
depth(X,P) = sign(det(M))w
T∥m3∥ (4.6)
parawsendo a coordenada homogênea emPX=w(x,y,1)T em3sendo a última linha
deM.
4.1.4
Triangulação e Pontos
3D
Dados dois pontos homólogosxiexj, observados nas imagensIieIj, respectivamente,
e as matrizes de projeçãoPiePj, o ponto3DX, associado ao parxi↔xj, pode ser obtido
através da solução da Equação 4.7.
AX=0 (4.7)
O pontoX pode ser estimado utilizando raios de reprojeção no espaço3D, portanto,
na maioria dos casos,xiexj não são precisos, dados seus erros de detecção. Desta forma
os raios de reprojeção não conseguiriam intersectar o pontoXperfeitamente.
Uma solução possível para a Equação 4.7 pode ser encontrada usando o método dos mínimos quadrados, na qualAé definida pela Equação 4.8 [Hartley & Zisserman 2004].
A=
⎡
⎢ ⎢ ⎣
P(3)x−P(1)
P(3)y−P(2)
P′(3)x′−P′(1)
P′(3)y′−P′(2) ⎤
⎥ ⎥ ⎦
(4.8) Assim, aplicando a decomposição SVD à matriz A, encontra-se o ponto 3DXcomo
Capítulo 5
Implementações
A partir do formalismo apresentado no Capítulo 4, conseguimos ter uma idéia con-creta do problema tradicional de reconstrução estéreo, onde a posição das tomadas varia de forma suave (ou seja, com disparidade pequena entre os píxels correspondentes), mas discreta, e como uma solução particular deste foi adotada para o problema de reconstrução estéreo abordado no presente trabalho, com possibilidade de disparidades maiores entre pontos homólogos. Assim, o objetivo principal deste capítulo é unicamente mostrar o de-senvolvimento e implementação da solução proposta computacionalmente, descrevendo os algoritmos principais que a compõem.
5.1
Software
e Bibliotecas Utilizadas
O código fonte dos algoritmos implementados foi concebido em linguagem C++, uti-lizando a biblioteca de rotinas em Visão Computacional OpenCV [Bradski & Kaehler 2008] no sistema operacional OS X 10.9. O uso desta biblioteca agilizou o desenvolvi-mento das rotinas de mais alto nível que compõem o sistema proposto, uma vez que algo-ritmos de visão e rotinas comuns de manipulação de imagens e matrizes já encontram-se prontas para serem utilizadas. Como descrito anteriormente, a solução para o problema proposto é composta porcincofases principais seguintes:
• Escolher par de imagensIieIj.
• Computarfeaturesematchesentre as imagens.
• Encontrar as matrizes fundamentalF e essencialE.
• Extrair as matrizes de projeção.
• Realizar a triangulação e reconstrução propriamente dita.
A implementação computacional dessas fases pode ser melhor entendidas no Algo-ritmo 1, responsável por controlar todas as outras rotinas do sistema. A primeira etapa a ser feita é a responsável por escolher um par de imagens dentre as que compõem odataset
utilizado. A primeira imagem dodataset é usada como sendo a imagem principal - ou
CAPÍTULO 5. IMPLEMENTAÇÕES 20 para escolher a imagem secundária - outraincomo é normalmente nominada. É possí-vel visualizar que, a cada iteração do laço, uma imagemtrainé escolhida. As operações responsáveis pelo processamento total do sistema são então executadas utilizando como par de imagens(Ii,Ij), as escolhidas para seremqueryetrain, respectivamente. É
impor-tante ressaltar que uma limitação do sistema é não dar suporte para que todas as imagens dodatasetsejam, em alguma iteração, imagensquery. Desta forma, todos os pontos3D
encontrados, localizam-se no sistema de referência da primeira imagem, e não no sistema global de referência. Isto nos permite arbitrar um sistema de coordenadas genérico, com origem na primeira imagem.
Algorithm 1Controlador Entrada:
Ii Ij⊂I[]
Saída:Nuvem de Pontos Comece:
1: Para toda ImagemIjfazer:
2: C←Computar_Correspondencias(Ii,Ij); 3: Encontrar_Matriz_F_E(C);
4: Extrair_Matriz_Projecao();
5: Triangular_Pontos(); 6: Fim-Para
Após a escolha das imagens, quatro rotinas são executadas:Computar_Correspondencias,
Encontrar_Matriz_F_E,Extrair_Matriz_ProjecaoeTriangular_Pontos.
A primeira rotina, cuja implementação pode ser vista no Algoritmo 2, recebe como entrada o par de imagens(Ii,Ij)e retorna como valor de saída o conjunto que contém as
correspondências entre asfeatures detectadas. Neste pseudocódigo, faz-se uso de roti-nas previamente implementadas pelo pacote do OpenCV, como já foi dito anteriormente. Para a detecção defeatureutiliza-se o método SURF por este ter a propriedade de detec-ção de pontos invariantes à escala, além de invariância à rotações no plano. Este fator é importantíssimo para o bom funcionamento do sistema, uma vez que esta fase é de ex-trema importância para os demais procedimentos que serão realizados. Ou seja, caso não se tenham correspondências corretas entre features, a nuvem de pontos 3D encontrada certamente apresentarárá um erro de precisão considerável.
A Figura 5.1 justifica a importância de se utilizar um detector invariante à rotação no plano. O conjunto de correspondências é então calculado pelomatcher Força Bruta, também implementado pelo pacote OpenCV.
CAPÍTULO 5. IMPLEMENTAÇÕES 21
Algorithm 2Computar_Correspondencias Entrada:
ImagemIi
ImagemIj
Saída:CorrespondênciasC Comece:
1: (K pts,D)←SURF.detectAndCompute(Ii);
2: (K pts′,D′)←SURF.detectAndCompute(I j);
3: C←BF.matcher(K pts,D,K pts′,D′);
4: RetorneC;
(a) (b)
(c) (d)
CAPÍTULO 5. IMPLEMENTAÇÕES 22 corretos. Além disso, esta rotina procura filtrar possíveis correspondências incoerentes, utilizando o método RANSAC [Fischler & Bolles 1987]. Este método utiliza conceitos estatísticos para identificar falsas correspondências entrefeatures introduzidas pelo mé-todo da Força Bruta. Com o intuito de validar a matriz fundamental calculada, é realizada a verificação exposta pela Equação 4.1. Caso se tenha uma matrizF inválida, o sistema interrompe a iteração corrente e parte para um novo par de imagens, trocando a segunda imagem do par. Isto pode ocorrer em duas possíveis situações. Uma é quando o par de imagens foi tomado com uma diferença muito pequena entre seus pontos de vista, isto é, quase não houve deslocamento de uma tomada para a outra, configurando neste caso o problema deSfMideal. Neste caso, descarta-se a segunda imagem e toma-se a próxima
imagem na sequência refazendo-se os cálculos. Claro, presume-se que a próxima imagem foi tomada com um deslocamento maior da primeira imagem do par. A segunda situação é quando o par de imagens é muito diferente (linha de base muito grande), neste caso não se consegue convergir para uma matriz. No caso ideal, a matriz será encontrada sem maiores problemas. Parte-se do princípio que as imagens da cena foram tomadas obede-cendo restrições fotogramétricas que permitem obter imagens com uma distância entre as tomadas considerada ideal. Um bom planejamento do sistema de voo pode resultar em imagens como esta, como discutimos no trabalho inicial desta dissertação [Assi Marro & Garcia Goncalves 2013].
Algorithm 3Encontrar_Matriz_F_E Entrada:CorrespondênciasC Saída:MatrizesFeE
Comece:
1: (F,status)←cv2.findFundamentalMat(C, RANSAC);
2: Sedet(F)̸=0
3: Finalizar rotina; Ir para próximo par de imagens; 4: C←inlier←C[status=1]
5: E=KTFK
6: Se 2EETE−trace(EET)E ̸=0
7: Finalizar rotina; Ir para próximo par de imagens;
8: Retorne(F,E);
Após o cálculo da matriz F, calcula-se a matriz essencialE usando a Equação 4.2. Para a obtenção da matriz essencial, faz-se necessário o uso da matriz de parâmetros intrínsecos correspondente à câmera utilizada. Uma validação também é realizada paraE, de acordo com a Equação 4.3. Caso se tenha uma matrizEinválida, o sistema interrompe a iteração e parte para um novo par de imagens.
A terceira rotina, apresentada no Algoritmo 4, é responsável por obter as matrizes de projeção válidas, associadas a cada imagem do par. Assumindo que a rotina passada rea-lizou a validação da matrizEe que foi constatado que esta é de fato uma matriz essencial, o algoritmoExtrair_Matriz_ProjecaoutilizaE, a matriz de parâmetros intrínsecosK e os
CAPÍTULO 5. IMPLEMENTAÇÕES 23 par(Ii,Ij)de imagens.
Algorithm 4Extrair_Matriz_Projecao Entrada:
Matriz EssencialE
Matriz de IntrínsecosK
CorrespondênciasC
Saída:Matrizes de ProjeçãoPeP′ Comece:
1: W ←
⎡
⎣
0 −1 0 1 0 0 0 0 1
⎤
⎦
2: P←K ⎡
⎣
1 0 0 0 0 1 0 0 0 0 1 0
⎤
⎦
3: (U,s,VT)←SVD(E)
4: t←U[:,3]T
5: P1′= [UWVT|+t];
6: P2′= [UWVT| −t];
7: P3′= [UWtVT|+t];
8: P4′= [UWtVT| −t];
9: Para todoPk′em[P1′,P2′,P3′,P4′]fazer
10: X←Triangular_Ponto(Ci,P,Cj,Pk′)
11: SeDepth(X,P)>0&Depth(X,Pk′)>0
12: P′←Pk′
13: Retorne(P,P′)
14: Fim-Para
Tendo o valor deW tal como definido no Capítulo 2 eP= [I|0]- estando no sistema de referência da primeira imagem fica fácil de entender esta afirmação, uma vez que, para uma dada matriz de projeção qualquer, em um sistema de visão estéreo, esta é uma composição de matrizes de rotação R e vetor de translação t relativos entre os centros de projeção das câmeras associadas ao sistema estéreo. Como esta composição estéreo fica referenciada no sistema de coordenadas da primeira câmera, naturalmente que ot = [0,0,0]se localiza na própria origem do centro de projeção da primeira câmera e que a
rotação associada ao sistema é a própria rotação da câmera, portantoR=IeP= [Ri|ti] =
[I|0]-.
A matriz de projeção da segunda câmera pode ser obtida através da decomposição
SVD da matriz essencial encontrada. A matriz essencial relaciona informações sobre parâmetros extrínsecos e a partir dela pode-se extrairR et relativas entre os centros de
CAPÍTULO 5. IMPLEMENTAÇÕES 24 par de matrizes que obtiver, ao final da avaliação, mais pontos3Dcom profundidades po-sitivas, em ambas as câmeras, será o par a ser utilizado durante a triangulação final, rotina esta chamada pelo sistema. A triangulação é realizada pela execução do Algoritmo 5.
Algorithm 5Triangular_Ponto Entrada:
Ponto na primeira Imagemxi
Matriz de Projeção da primeira ImagemP
Ponto na segunda Imagemxj
Matriz de Projeção da segunda ImagemP′ Saída:Ponto 3DX
Comece:
1: A←Montar A segundo Equação 4.8
2: (U,s,VT)←SVD(A)
3: X←Última coluna deV.
4: RetorneX
5.2
Filtragem de Pontos
É importante ressaltar que, durante a fase dematching, é possível que, para pares de imagens diferentes, um mesmo ponto localizado na imagem query seja correspondido para pontos localizados em imagens train diferentes. A fase de triangulação, por sua vez, não é responsável por identificar quando correspondências se referem a um mesmo ponto na imagemquery. Desta forma, a triangulação é realizada e pontos 3Dreferentes a um mesmo ponto 2D na imagem são encontrados. Tendo dito isto, faz-se necessário a aplicação de um filtro que recupera todos estes pontos triangulados e determina quais deles se referem a um mesmo ponto2Dna imagem.
Como existem erros durante as fases que antecedem a de triangulação, pontos 3D
distintos encontrados para um mesmo ponto 2D na imagem possuem erros de precisão em suas coordenadas tridimensionais. O método de filtragem implementado leva isso em consideração e, após encontrar pontos3D semelhantes, calcula o erro de precisão e escolhe o que obtiver menor valor, ou seja, o mais preciso. Esta ideia pode ser vista no Algoritmo 6.
CAPÍTULO 5. IMPLEMENTAÇÕES 25
Algorithm 6Filtrar_Pontos_3D Entrada:
Pontos 3DX[]
Saída:Novos Pontos 3DX[] Comece:
1: (X1,X2, ...,Xn)= Encontrar Pontos 3D semelhantes
2: Para todoX em(X1,X2, ...,Xn)fazer
3: E= Encontrar Erro paraX 4: Comparar ErrosE
5: SalvarX com menorE
Capítulo 6
Experimentos e Resultados
Sendo este um projeto que tem como objetivo a reprodução de cenas reais em modelos
3Dvirtuais, é de suma importância que o resultado obtido tenha aspecto semelhante ao da cena real, a qual se deseja reproduzir. Para melhor localização do que está sendo discutido durante o decorrer da apresentação deste capítulo, foram criados fatores que serão recuperados nas futuras seções. Para o fator que apresenta amostras visuais dos resultados, dá-se o nome deComprovação Visual. Por outro lado, para que se tenham
resultados mais precisos do que somente o que é percebido pelo olho humano, devem ser obtidos resultados numéricos que confirmem a precisão do modelo 3D encontrado. Para este fator, dá-se o nome de Comprovação Numérica. Esses fatores serão melhor
discutidos na Seção seguinte.
6.1
Comprovações Visual e Numérica
Ambos fatores de teste apresentados já tornam possível a composição de um trabalho concreto nesta área, pois ambos apresentam a nuvem de pontos que será utilizada para compor o modelo final da reconstrução e a comprovação numérica de que aquela dada nuvem realmente reconstroi a cena real. Apesar disso, um terceiro fator foi introduzido neste trabalho, o Estudo. Baseando-se nos resultados obtidos e nos estudos realizados
utilizando as mais diversas refências bibliográficas, este capítulo apresenta uma análise comparativa entre o tamanho da linha de base que existe entre os centros de projeção para cada imagem do par e a média dos erros obtidos pela triangulação realizada sobre os pares de pontos característicos, obtidos pela etapa de matching, para aquele mesmo par de imagens.
6.2
Ambiente de Execução
CAPÍTULO 6. EXPERIMENTOS E RESULTADOS 27 Como já colcoado no Capítulo 5, o código dos algoritmos implementados foi con-cebido em linguagem C++, utilizando a biblioteca de rotinas de Visão Computacional OpenCV1[Bradski & Kaehler 2008] no sistema operacional OS X 10.9. O uso da bibli-oteca OpenCV traz vantagens no desenvolvimento de algoritmos. Esta biblibibli-oteca apre-senta rotinas comuns para ler e exibir imagens, calibração de câmeras, acesso apixelsem imagens, filtragens e implementações de algoritmos, como por exemploSVD, já imple-mentadas e prontas para serem utilizadas.
6.3
Metodologia dos Testes Realizados
A metodologia aplicada aos experimentos se baseia nos três fatores apresentados. Para que haja umaComprovação Visuale umaComprovação Numéricaé necessário
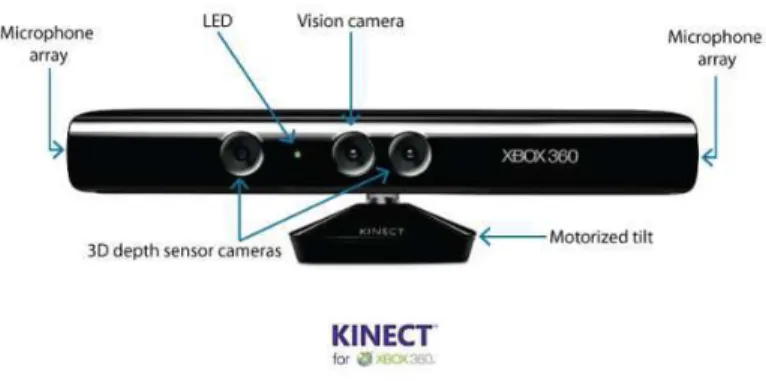
encon-trar algum modo que tanto apresente um modelo3Dque sirva como base comparativa para aquela nuvem de pontos obtida quanto seja uma reconstrução da cena real com o mínimo de erro possível. Para isto, foi utilizado o dispositivo criado pela Microsoft, denominado de Kinect, para obter a posição 3D dos pontos na cena.
O Kinect é um sensor de movimentos desenvolvido pela Microsoft junto com a em-presaPrime Sense para o console Xbox 360. O Kinect apresenta os principais sensores necessários para o desenvolvimento dos experimentos aqui apresentados. A sua câmera
VGAcom resolução 640×480 possibilita a captura das imagens que serão utilizadas pelo algoritmo apresentado no Capítulo 5. Além disso, um projetor e outro receptor infraver-melhos são localizados em cada lado da câmera. O Kinect é capaz de obter informações de profundidade da cena a partir destes sensores, o que torna a obtenção de uma recons-trução3Dda cena possível.
Figura 6.1: O dispositivo kinect e seus sensores.
Segundo Khoshelham e Elberink [Khoshelham & Elberink 2012], o Kinect é capaz de realizar a reconstrução de uma determinada cena com erro menor que um centímetro por pixel em caso de estar posicionado a menos de 2,5 metros do centro da cena. Tal
CAPÍTULO 6. EXPERIMENTOS E RESULTADOS 28 estudo permitiu que a utilização do Kinect fosse confiável em nosso trabalho uma vez que nenhuma imagem aqui utilizada foi obtida com distância maior que a especificada.
Tendo dito isto, é fácil de entender que ao utilizar o Kinect, os fatores referentes à
Comprovação VisualeComprovação Numéricasão facilmente analisados. O modelo
3D encontrado pelo Kinect serve como base comparativa para a nuvem de pontos en-contrada, tanto visualmente quanto numericamente, uma vez que para analisar o erro de precisão de um determinado ponto3Dbasta calcular a distância euclidiana deste para o seu respectivo na nuvem gerada pelo Kinect.
Além disso, dados como a matriz de parâmetros intrínsecos da câmera do Kinect já são previamente disponibilizados. A Equação 6.1 mostra os valores intrínsecos da câmera imbutida no dispositivo.
K=
⎡
⎣
525 0 319.5
0 525 239.5
0 0 1
⎤
⎦ (6.1)
(a) (b)
Figura 6.2: (a) Visualização de uma das imagens que compõe odatasetobtida pelo Ki-nect. (b) Seu respectivo modelo3Dtambém gerado pelo Kinect.
O fatorEstudo, por sua vez, é composto por duas informações a serem extraídas. A
primeira é o erro médio e este pode ser encontrado a partir do erro de cadapixel 3D en-contrado. Como dito anteriormente, este erro pode ser calculado utilizando-se a distância Euclidiana entre o ponto gerado pelo sistema proposto e o seu respectivo gerado pelo Ki-nect. Tendo comoPum ponto3Dencontrado eP′o ponto3Dgerado pelo Kinect, o erro
de precisão unitário paraPé determinado como mostra a Equação 6.2.
E=)(Px−Px′)2+ (Py−Py′)2+ (Pz−Pz′)2 (6.2)
Tendo obtido o erro unitário para cada ponto gerado a partir da triangulação das cor-respondências para um dado par de imagens, é trivial obter o erro médio necessário, como mostra a Equação 6.3.
Em=∑ n i=1Ei
CAPÍTULO 6. EXPERIMENTOS E RESULTADOS 29 Como colocado, ideia é usar a tecnica deste traballho com imagens obtidas a partir de câmeras embarcadas em veículos aéreos não tripulados cuja distância de cada cena tomada é superior a 30 metros, em alguns casos muito superior, portanto não sendo pos-sível de se utilizar o kinect nesta situação. Mas convém observar que a nuvem de pontos fornecida pelo kinect pode ser usada para verificar se a técnica de reconstrução apresen-tada é válida. Caso o resultado fornecido pela nossa técnica e com o uso do kinect, pelas equações acima, esteja dentro de um erro considerado razoável, a reconstrução pode ser validada.
A outra informação necessária para realizar o Estudoé o valor da linha de base
en-tre as imagens. Para isto basta calcular a distância relativa enen-tre os centros de projeção referentes às imagens dos pares que foram utilizados.
6.4
Resultados experimentais
Os resultados foram obtidos utilizando-se umdatasetcom 181 imagens tiradas de uma única cena. A cena éindoor e foi montada com itens presentes no laboratórioNatalnet. Nenhuma das imagens que compõem odatasetfoi retirada a uma distância maior que 2 metros do centro da cena. A composição de Figuras 6.3 mostra a cena fotografada.
(a) (b)
(c) (d)
Figura 6.3: Ilustração da cena imageada.
CAPÍTULO 6. EXPERIMENTOS E RESULTADOS 30 que foram de fato utilizadas para compor a solução final da nuvem de pontos, devido às restrições aplicadas pelas Equações 4.1 e 4.3. Além disto, a quantidade de pontos que compõem a solução final é um outro fator a ser analisado. A Tabela 6.1 mostra os dados obtidos.
Número Total de Imagens Número de Imagens Utilizadas Quantidade Pontos na Nuvem
20 11 298
50 27 304
181 107 319
Tabela 6.1: Tabela que apresenta os dados obtidos a partir das execuções realizadas. A partir dos dados apresentados pela Tabela 6.1 algumas conclusões podem ser afir-madas. A primeira é que grande parte das imagens utilizadas não dispuseram de qualidade suficiente para que as matrizes fundamental ou essencial encontradas fossem considera-das váliconsidera-das. No último caso, 181 imagens foram utilizaconsidera-das inicialmente, mas apenas 107 passaram na etapa de validação da matriz fundamental/essencial. Isso se dá pelo fato de que os casamentos entrefeaturesencontrados foi de baixa qualidade e muitos deles po-dendo ser falsos casamentos. Como já havia sido dito nos capítulos anteriores, a matriz fundamental é encontrada a partir dosmatchesencontrados.
Por outro lado, ao analisar a quantidade de pontos encontrada para compor a nuvem final, chega-se à conclusão que muitos destes pontos foram repetidos. Segundo o que foi apresentado no Capítulo 5, Seção 5.2, ao realizar a filtragem de pontos, muitos destes são removidos por serem pontosduplicados. Ao analisar mais detalhadamente este fato, pode-se chegar à conclusão que o motivo de se ter tantos pontos 3D duplicados é qua fase de matching não deve ter encontrado matches mais espaçados. As imagens, mais uma vez, não contribuem para uma das fases cruciais do algoritmo. Apesar disso, esta é uma das limitações enfrentadas, pois geralmente as câmeras embarcadas em aviões de pequeno porte não possuem resolução alta.
6.4.1
Matching
Como foi descrito nos Capítulos 4 e 5 a primeira fase do algoritmo é a de encontrar
features e matches. Foram utilizados os algoritmos de SURF e Matching Força Bruta para encontrar pontos característicos e correspondências entre estes, respectivamente. Os resultados para esta primeira fase podem ser vistos na Figura 6.4.
Para o primeiro caso, mostrado na Figura 6.4, as imagens apresentam pouca variação entre sí. Tanto alinha de basequanto a orientação relativa entre ambas são muito peque-nas. Este fator influencia positivamente a obtenção de um resultado coerente durante esta primeira fase. Esta afirmação pode ser comprovada ao se observar a Figura 6.5. Na cena considerada, ocorre uma variação substancial no posicionamento de ambas as imagens. A
CAPÍTULO 6. EXPERIMENTOS E RESULTADOS 31
Figura 6.4: Resultados dematching para imagens com linha de base pequena. Primeiro caso com 273 correspondências encontradas.
CAPÍTULO 6. EXPERIMENTOS E RESULTADOS 32
6.4.2
Nuvem de Pontos
Apesar de tudo que já foi dito nas seções anteriores deste capítulo, dados que compro-vem os fatores determinados -Comprovação Visual,Comprovação NuméricaeEstudo
- ainda não foram apresentados.
Os resultados obtidos para o fator Comprovação Visualpodem ser vistos nas
Figu-ras 6.6, 6.7 e 6.8.
Figura 6.6: Imagem tirada de frente da nuvem de pontos encontrada (pontos verdes) e da nuvem do Kinect.
A nuvem encontrada pelo algoritmo aqui proposto é representada pelos pontos ver-des, localizados de forma esparsa. Para efeitos visuais, foram inseridas linhas brancas que servem como base comparativa entre o ponto3Dencontrado pelo algoritmo e o seu representante na nuvem encontrada pelo Kinect. Essa linha é calculada usando a distância Euclidiana, como já foi apresentada anteriormente neste capítulo. A Figura 6.6 aparenta apresentar nuvens bem próximas na maioria dos pontos. De fato, os pontos da nuvem adquirida, em grande parte, apresentam erros na casa do centímetro, se comparados às localizações dos seus respectivos na nuvem do Kinect.
CAPÍTULO 6. EXPERIMENTOS E RESULTADOS 33
Figura 6.7: Imagem mais próxima da nuvem de pontos encontrada (pontos verdes) e da nuvem do Kinect.
CAPÍTULO 6. EXPERIMENTOS E RESULTADOS 34 Apesar das nuvens não parecerem tão próximas quanto àquelas apresentada na Fi-gura 6.6, o erro médio calculado para a nuvem encontrada fica em torno deEm=4.7806
centímetros, com desvio padrão médio deDp=8.8016 e variância médiavar=0.7747.
Tendo apresentado estes dados, é possível realizar a demonstração referente à Compro-vação VisualeComprovação Numérica.
6.4.3
O Estudo
Segundo Hartley e Sturm [Hartley & Sturm 1997] e outros autores [Irschara et al. 2011, Wu 2013], uma maior linha de base entre imagens gera uma triangulação mais precisa, o que acarreta na obtenção de um ponto3Dcom maior precisão. Esta afirmação pode ser melhor visualizada na Figura 6.9.
Figura 6.9: Comparação entre triangulações para linha de base diferentes.
Na prática, esta hipótese pode não vir a se confirmar, uma vez que o processo não depende unicamente do procedimento que realiza a triangulação. Ao contrário, para re-alizar a reconstrução3Dde uma determinada cena é extremamente necessário uma série de condições a favor. A reconstrução depende daresolução das imagens, da precisão dos algoritmos dematching, da precisão dos valores intrínsecos da câmera, de uma
vali-dação adequada para as matrizes fundamental e essencial, da capacidade de extração
dematrizes de projeçãoa partir da matriz essencial, datriangulação, e da precisão na
técnica utilizada paraaferir erro de triangulação, entre outros fatores.
Tendo dito isto, apresentamos os Gráficos 6.10 e 6.11. O Gráfico 6.10 mostra o erro médio dos pontos3Dencontrados em relação à linha de base entre o par de imagens que foram utilizadas para aferir a triangulação. Já o Gráfico 6.11 mede o comportamento do erro de precisão para apenas um ponto, que se repete em diversos pares de imagens, em relação a linha de base dos pares utilizados para sua triangulação.
CAPÍTULO 6. EXPERIMENTOS E RESULTADOS 35
Figura 6.10: Comparação entre linha de base e o Erro Médio encontrado para os pontos
3Dtriangulados.
processo de reconstrução, estejam em seu perfeito estado. Caso contrário, todas as trian-gulações possíveis de serem realizadas devem ser levadas em consideração, apesar destas serem passíveis de erro elevado.
CAPÍTULO 6. EXPERIMENTOS E RESULTADOS 36
Capítulo 7
Conclusão
Ao concluir as análises feitas durante o decorrer deste documento e tendo como re-sultado o sistema que foi implementado até o momento, é possível perceber que o fruto desta Dissertação de Mestrado foi uma metodologia parcialmente completa para extração de informações tridimensionais baseada em técnicas de Visão Computacional aplicadas sobre conjuntos de imagens.
Apesar de caracterizarmos a aplicação desenvolvida por este trabalho como uma me-todologia quase completa, esta pode ser considerada como finalizada para os objetivos que foram propostos desde o início do projeto. Todos os procedimentos necessários apli-cados ao problema de reconstrução para que o objetivo final de obtenção de informações
3Dforam implementados e, como os resultados apresentados no Capítulo 6 mostram, é possível adquirir uma nuvem de pontos aproximada àquela escolhida para comprovar a precisão do sistema proposto.
Este trabalho não envolve apenas medidas matemáticas e números que representam er-ros de precisão. Também devem ser levados em consideração aspectos visuais. Ao serem mostrados os resultados obtidos, procurou-se estabeler uma comparação direta entre as nuvens de pontos. O uso do Kinect como ferramenta de análise para medir a eficiência da metodologia proposta mostrou-se bastante útil, não apenas para comprovar que a nuvem de pontos encontrada é próxima à que se deseja obter, mas como também para facilitar esse importante aspecto visual, o qual espera-se ter sido apresentado adequadamente.
Dito isso, uma contribuição importante deste trabalho se refere às etapas propostas e à análise do estudo sobre a relação do tamanho da linha de base entre pares de imagens e a precisão do ponto3Dadquirido.
7.0.4
Trabalhos Futuros
Como colocado no Capítulo 5, a aplicação desenvolvida neste documento realiza pro-cedimentos para encontrar informações3Dde pontos característicos para pares de ima-gens. Durante todo o capítulo 5, determinou-se que uma das limitações do sistema era o de realizar todo o procedimento unicamente para apenas uma imagem determinada como
query. Desta forma, todos os pontos3Dencontrados estariam no sistema de referência da imagem em questão, o que facilita os cálculos para uma solução de uma nuvem inicial.
CAPÍTULO 7. CONCLUSÃO 38 sejam, em algum momento, imagensquery. Desta forma, a nuvem de pontos encontrada seria muito mais densa do que a atual.
Um outro quesito a ser incorporado é o método de otimização SBA, como método
Referências Bibliográficas
Assi Marro, A. & L.M. Garcia Goncalves (2013), A path planning method for multi-uav system,em‘Robotics Symposium and Competition (LARS/LARC), 2013 Latin American’, pp. 129–135.
Bay, Herbert, Andreas Ess, Tinne Tuytelaars & Luc Van Gool (2008), ‘Speeded-up robust features (surf)’,Comput. Vis. Image Underst.110(3), 346–359.
Bay, Herbert, Tinne Tuytelaars & Luc J. Van Gool (2006), Surf: Speeded up robust fe-atures, em ‘European Conference on Computer Vision - ECCV 2006’, Springer, pp. 404–417.
Bradski, Gary Rost & Adrian Kaehler (2008), Learning opencv, 1st edition, O’Reilly Media, Inc.
Cyganek, B. & J. Paul Siebert (2009),An Introduction to 3D Computer Vision Techniques and Algorithms, John Wiley & Sons.
Fischler, Martin A. & Robert C. Bolles (1987), ‘Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography’, pp. 726–740.
Garage, Willow (n.d.), ‘Opencv library’. http://opencv.willowgarage.com.
Hartley, R. I. & A. Zisserman (2004), Multiple View Geometry in Computer Vision, secondaedição, Cambridge University Press, ISBN: 0521540518.
Hartley, Richard I & Peter Sturm (1997), ‘Triangulation’, Computer vision and image understanding68(2), 146–157.
Irschara, A., C. Hoppe, H. Bischof & S. Kluckner (2011), Efficient structure from mo-tion with weak posimo-tion and orientamo-tion priors, em ‘Computer Vision and Pattern Recognition Workshops (CVPRW), 2011 IEEE Computer Society Conference on’, pp. 21–28.
Irschara, Arnold (n.d.), Towards fully automatic photogrammetric reconstruction using digital images taken from UAVs.
Khoshelham, Kourosh & Sander Oude Elberink (2012), ‘Accuracy and resolution of ki-nect depth data for indoor mapping applications’,Sensors12(2), 1437–1454. URL:http://www.mdpi.com/1424-8220/12/2/1437