UNIVERSIDADEFEDERALDO RIO GRANDE DO NORTE
UNIVERSIDADEFEDERAL DORIOGRANDE DONORTE
CENTRO DETECNOLOGIA
PROGRAMA DEPÓS-GRADUAÇÃO EMENGENHARIAELÉTRICA E DECOMPUTAÇÃO
SISTEMA INTELIGENTE PARA O PROCESSAMENTO DE
IMAGENS DIGITAIS INTRABUCAIS OCLUSAIS
Ramon Augusto Sousa Lins
Orientador: Prof. Dr. Adrião Duarte Dória Neto
Dissertação de Mestrado apresentada ao Programa de Pós-Graduação em Engenharia Elétrica e de Computação da UFRN (área de concentração: Engenharia de Computação) como parte dos requisitos para obtenção do título de Mestre em Ciências.
UFRN / Biblioteca Central Zila Mamede Catalogação da publicação na fonte.
Lins, Ramon Augusto Sousa
Sistema inteligente para o processamento de imagens digitais intrabucais oclusais / Ramon Augusto Sousa Lins.– Natal, RN, 2015
63 f. : il.
Orientador: Prof. Dr.Adrião Duarte Dória Neto
Dissertação (Mestrado) – Universidade Federal do Rio Grande do Norte. Cen-tro de Tecnologia. Programa de Pós-Graduação em Engenharia Elétrica e de Computação.
1. Sistemas inteligentes – Dissertação. 2. Processamento digital de imagens – Dissertação. 3. Saúde bucal coletiva – Dissertação. 4. Transformadawatershed
– Dissertação. 5. Descritores de Fourier – Dissertação. I. Dória Neto, Adrião Duarte II. Universidade Federal do Rio Grande do Norte. III. Título.
A ciência sem religião é manca, a
Agradecimentos
Agradeço primeiramente a Deus, por me conceder o privilégio de galgar este título tão desejado.
A minha amada, companheira de todas as horas Isabel Pinheiro, por me encorajar e in-centivar em todos momentos difíceis desta árdua caminhada, você é o amor da minha vida.
Aos meus pais Luciano e Sandra por toda estrutura e apoio que dispensaram por toda minha vida. Tenho um imensurável orgulho por ser filho deles, Deus em sua infinita sabedoria escolheu os melhores pais do mundo para ter como meus. Amo muito vocês.
Aos meus familiares que de alguma forma (sempre se tem uma forma) ajudaram-me nesta caminhada, em especial ao meu irmão Ranyer que sempre me deu apoio nas minhas decisões.
Aos amigos medalhas que em momentos de apatia conseguiam de alguma forma elevar meu estado de espírito.
Aos amigos do Laboratório de Sistemas Inteligentes (LABSIS) que de alguma forma sempre me ajudaram e contribuíram para o enriquecimento deste trabalho, em especial ao Keylly, por conseguir me ajudar nas situações mais difíceis deste projeto.
Agradecer em especial ao professor Adrião Dória, por me abrir as portas do fantástico universo da inteligência artificial e pelo apoio dispensado para este trabalho tornar-se possível.
Ao pessoal do departamento de odontologia por todo apoio prestado, em especial ao pro-fessor Luiz Noro idealizador deste projeto.
Resumo
Diversas são as áreas em que imagens digitais são utilizadas na solução de problemas do dia a dia. Na medicina a utilização de sistemas computacionais têm aprimorado os diagnósticos e interpretações médicas. Na odontologia não é diferente; cada vez mais os procedimentos assistidos por computadores têm auxiliado os dentistas em suas tarefas. Inserido nesse contexto, uma das área da odontologia conhecida como saúde bucal cole-tiva é responsável pelo diagnóstico e tratamento da saúde oral de uma população. Para este fim, são realizadas inspeções visuais bucais com intuito de obter informações sobre as condições de saúde bucal de uma dada população. A partir do levantamento de infor-mações, também conhecido como levantamento epidemiológico, o dentista pode planejar e avaliar tomadas de ações para os diferentes problemas identificados. Esse procedi-mento possui fatores limitantes, como por exemplo o número limitado de profissionais habilitados para realização dessas tarefas, diferentes interpretações de diagnósticos en-tre outros fatores. Diante deste contexto surgiu a ideia de utilizar técnicas de sistemas inteligentes no apoio à realização de levantamentos epidemiológicos. Com isso, foi pro-posto neste trabalho o desenvolvimento de um sistema inteligente capaz de segmentar, contar e classificar dentes a partir de imagens fotográficas digitais intrabucais oclusais. O sistema proposto faz uso combinado de técnicas de aprendizado de máquina e proces-samento digital de imagens. Primeiramente foi realizada uma segmentação baseada em cores das regiões de interesse, dentes e não dentes, presentes nas imagens através do uso de Máquina de Vetores de Suporte (SVM - Support Vector Machine, do inglês). A partir
da identificação dessas regiões foram utilizadas técnicas baseadas em operadores morfo-lógicos como erosão e transformada watershed para contagem e detecção de fronteiras
dos dentes, respectivamente. Com a detecção de fronteira dos dentes foi possível calcu-lar os descritores de Fourier para suas formas e os descritores de posição. Em seguida os dentes foram classificados quanto aos seus tipos através do uso de SVMs a partir do método um-contra-todos usado em problemas multiclasses. O problema de classificação para múltiplas classes foi abordado de duas maneiras diferentes. Na primeira abordagem foram consideradas três tipos de classes: molar, pré molar e não dentes, enquanto que na segunda abordagem foram consideradas cinco tipos de classes: molar, pré molar, ca-nino, incisivo e não dentes. O sistema mostrou-se eficiente na segmentação, contagem e classificação de dentes presentes nas imagens.
Abstract
Several are the areas in which digital images are used in solving day-to-day problems. In medicine the use of computer systems have improved the diagnosis and medical inter-pretations. In dentistry it’s not different, increasingly procedures assisted by computers have support dentists in their tasks. Set in this context, an area of dentistry known as pu-blic oral health is responsible for diagnosis and oral health treatment of a population. To this end, oral visual inspections are held in order to obtain oral health status information of a given population. From this collection of information, also known as epidemiolo-gical survey, the dentist can plan and evaluate taken actions for the different problems identified. This procedure has limiting factors, such as a limited number of qualified pro-fessionals to perform these tasks, different diagnoses interpretations among other factors. Given this context came the ideia of using intelligent systems techniques in supporting carrying out these tasks. Thus, it was proposed in this paper the development of an in-telligent system able to segment, count and classify teeth from occlusal intraoral digital photographic images. The proposed system makes combined use of machine learning techniques and digital image processing. We first carried out a color-based segmenta-tion on regions of interest, teeth and non teeth, in the images through the use of Support Vector Machine. After identifying these regions were used techniques based on morpho-logical operators such as erosion and transformed watershed for counting and detecting the boundaries of the teeth, respectively. With the border detection of teeth was possi-ble to calculate the Fourier descriptors for their shape and the position descriptors. Then the teeth were classified according to their types through the use of the SVM from the method one-against-all used in multiclass problem. The multiclass classification problem has been approached in two different ways. In the first approach we have considered three class types: molar, premolar and non teeth, while the second approach were considered five class types: molar, premolar, canine, incisor and non teeth. The system presented a satisfactory performance in the segmenting, counting and classification of teeth present in the images.
Sumário
Sumário i
Lista de Figuras iii
Lista de Tabelas iv
Lista de Algoritmos v
Lista de Símbolos e Abreviaturas vi
1 Introdução 1
1.1 Motivação . . . 2
1.2 Objetivos . . . 3
1.3 Estado da Arte . . . 4
1.4 Principais Contribuições do Trabalho . . . 4
1.5 Organização do trabalho . . . 4
2 Processamento Digital de Imagens 6 2.1 Introdução . . . 6
2.2 Definições básicas . . . 7
2.2.1 Imagens, dados e entradas . . . 7
2.3 Filtragem . . . 8
2.3.1 Filtro de mediana . . . 8
2.4 Processamento Morfológico de Imagens . . . 9
2.4.1 Erosão . . . 9
2.4.2 Dilatação . . . 10
2.4.3 Abertura . . . 10
2.4.4 Reconstrução morfológica . . . 10
2.5 Segmentação baseada em morfologia . . . 11
2.5.1 TransformadaWatershed . . . 11
2.6 Representação e descrição . . . 12
2.6.1 Transformada de Fourier . . . 12
2.6.2 Transformada Discreta de Fourier . . . 12
2.6.3 Descritores de Fourier . . . 13
3 Máquinas de Vetores de Suporte 16
3.1 Introdução . . . 16
3.2 Máquina de Vetores de Suporte . . . 18
3.2.1 SVMs Lineares . . . 18
3.2.2 SVMs Não Lineares . . . 19
3.2.3 SVMs para Múltiplas Classes . . . 21
3.3 Considerações . . . 23
4 Sistema Desenvolvido 24 4.1 Introdução . . . 24
4.2 Metodologia . . . 24
4.3 Aquisição de imagem . . . 26
4.4 Pré-processamento . . . 26
4.4.1 Adaptação de escala . . . 26
4.4.2 Conversão RGB para YCbCr . . . 26
4.4.3 Ajuste de Contraste . . . 27
4.5 Segmentação . . . 28
4.5.1 Segmentação baseada em cores . . . 28
4.5.2 Operadores morfológicos . . . 29
4.5.3 TransformadaWatershed . . . 31
4.6 Representação e interpretação dos dados . . . 33
4.6.1 Contagem . . . 33
4.6.2 Classificação . . . 35
5 Resultados 39 5.1 Introdução . . . 39
5.2 Avaliação do algoritmo de classificação para segmentação baseada em cores . . . 39
5.2.1 Amostragem aleatória . . . 39
5.3 Desempenho do algoritmo de segmentaçãowatershed . . . 40
5.4 Desempenho do algoritmo de erosões sucessivas . . . 40
5.5 Avaliação do algoritmo de classificação para abordagem com três classes 40 5.5.1 Amostragem aleatória . . . 40
5.5.2 Desempenho do classificador ótimo . . . 41
5.6 Avaliação do algoritmo de classificação para abordagem de cinco classes 43 5.6.1 Amostragem aleatória . . . 43
5.6.2 Desempenho do classificador ótimo . . . 44
5.7 Considerações . . . 45
6 Conclusões e Trabalhos Futuros 46
Lista de Figuras
2.1 Elementos estruturantes básicos e em arranjos retangulares. . . 9 2.2 Fronteira digital e sua representação como uma sequência complexa. . . . 14 2.3 Exemplos de reconstrução de descritores de Fourier para diferentes
coe-ficientes para uma fronteira que representa um quadrado. . . 15
3.1 Métodos de aprendizados. . . 16
Lista de Tabelas
3.1 Sumário dos principais Kernels utilizados nas SVMs. . . 20
5.1 Resultados da segmentação por cores dos dentes presentes nas imagens dentais. . . 39 5.2 Resultados da segmentaçãowatersheddos dentes presentes nas imagens
dentárias. . . 40 5.3 Resultado da classificação dos tipos de dentes presentes nas imagens dentais. 41 5.4 Matriz de confusão . . . 42 5.5 Matriz de confusão para três classes . . . 42 5.6 Matriz de confusão do classificador 1 para abordagem de três classes. . . 43 5.7 Matriz de confusão do classificador 2 para abordagem de três classes. . . 43 5.8 Matriz de confusão do classificador 3 para abordagem de três classes. . . 43 5.9 Resultados da classificação do tipo dos dentes presentes nas imagens dentais 44 5.10 Matriz de confusão para cinco classes . . . 44 5.11 Matriz de confusão do classificador 1 para abordagem de cinco classes. . 44 5.12 Matriz de confusão do classificador 2 para abordagem de cinco classes. . 45 5.13 Matriz de confusão do classificador 3 para abordagem de cinco classes. . 45 5.14 Matriz de confusão do classificador 4 para abordagem de cinco classes. . 45 5.15 Matriz de confusão do classificador 5 para abordagem de cinco classes. . 45
Lista de Algoritmos
3.1 Determinação do hiperplano ótimo no espaço característica. . . 21
3.2 Classificador multiclasse . . . 22
4.1 Pré-processamento da imagem. . . 27
4.2 Segmentação baseada em cores por SVM . . . 29
4.3 Segmentação por operadores morfológicos . . . 30
4.4 Segmentação por transformadawatershed . . . 32
4.5 Erosões sucessivas . . . 34
Lista de Símbolos e Abreviaturas
AM Aprendizado de Máquinas
DCA Departamento de Computação e Automação
EM Espectro eletromagnético
fdp Função Densidade de Probabilidade
IA Inteligência Artificial
JPEG Joint Photographic Experts Group
MATLAB MATrix LABboratory
MLP Multilayer Perceptron
OOA One-Against-All
PDI Processamento Digital de Imagens
PNG Portable Network Graphics
RBF Radial Basis Function
RNA Rede Neural Artificial
SUS Sistema Único de Saúde
SVM Support Vector Machine
UFRN Universidade Federal do Rio Grande do Norte
Capítulo 1
Introdução
A visão é o mais avançado dos nossos sentidos e exerce um importante papel na per-cepção humana. Através dela, o homem consegue interagir adequadamente com o meio em que vive. No entanto, diferentemente dos seres humanos que são limitados à banda visual do Espectro eletromagnético (EM) os computadores digitais cobrem quase que todo espectro EM [Gonzalez e Woods 2010]. A partir do espectro de energia utilizado as imagens podem ser categorizadas por: raios gama, raios-X, bandas ultravioleta, visível, infravermelha, micro-ondas e de rádio.
A utilização de imagens na solução de problemas no “mundo real ” é uma abordagem cada vez mais utilizada no dia a dia. Neste contexto, o processamento inteligente de imagens surge com o objetivo de fornecer ao computador a capacidade de percepção do homem, de forma que a máquina possa interagir com o ambiente, entender os dados e tomar decisões da melhor maneira possível.
Diversas são as aplicações nessa área, dentre elas podem ser citadas as aplicações que abordam alguns dos problemas típicos de percepção, são eles: reconhecimento automá-tico de caracteres, sistema de visão computacional industrial para inspeção e montagem de produtos, reconhecimento militar, análise de imagens biomédicas, processamento au-tomático de impressões digitais, rastreamento de resultados de imagens radiográficas e amostras de sangue, processamento computacional de imagens aéreas e de satélites para previsão do tempo e avaliação ambiental entre outros.
Dentre as área citadas, a engenharia biomédica consiste na aplicação da ciência e tec-nologia na solução de problemas que acontecem na medicina e na biologia [Mudry 2003]. Muito se argumenta que a resolução de problemas na biomédica recai, em grande parte, na dificuldade em formular soluções em termos de engenharia. Porém, o constante avanço dos algoritmos computacionais têm contribuído para que soluções na engenharia biomé-dica, em específico na análise de imagens biomédicas, siga em contínua expansão. Cada vez mais estes sistemas desenvolvidos têm aprimorado diagnósticos e suas interpreta-ções. Na odontologia não é diferente, procedimentos assistidos por computador como por exemplo implantes dentários, planejamento ortodôntico entre outros, utilizam ima-gens dentárias digitais, como radiografias, fotografias e tomografia computadorizada, no auxílio dessas tarefas.
INTRODUÇÃO
de levantamentos epidemiológicos. Para este fim, o dentista realiza uma inspeção visual bucal a fim de produzir informações sobre as condições da saúde bucal da população bra-sileira, subsidiando o planejamento e avaliando as ações tomadas nos diferentes níveis de gestão do Sistema Único de Saúde (SUS). Esse procedimento comumente realizado pelos dentistas possui fatores limitantes, como por exemplo o número limitado de profissionais habilitados para realização desta tarefa, diferentes interpretações de diagnósticos entre outros fatores.
Com o intuito de auxiliar o levantamento epidemiológico, foi proposto neste trabalho, o desenvolvimento de um sistema inteligente capaz de realizar tarefas básicas da inspeção visual bucal de contagem e classificação dentária a partir de imagens fotográficas digitais intrabucais oclusais.
Anteriormente a este trabalho foi desenvolvida uma metodologia para aquisição de imagens, que se ajustou às limitações enfrentadas pelos agentes de saúde em campo, além de favorecer o seu processamento. Para tanto, foram realizadas diversas medições de angulação de inclinação e distância da câmera de aquisição.
Dando continuidade ao trabalho anteriormente desenvolvido, o sistema proposto neste trabalho faz uso combinado de técnicas de Inteligência Artificial (IA), em particular Aprendizado de Máquina (AM), e Processamento Digital de Imagens (PDI). Primeira-mente é feita uma segmentação baseada nas cores das regiões de interesse, dentes e não dentes, presentes nas imagens através do uso de Máquina de Vetores de Suporte (SVM -Support Vector Machine, do inglês ). A partir da identificação dessas regiões os dados
são representados e descritos de acordo com as necessidades das etapas de contagem, de-tecção de fronteiras e classificação. Nas etapas de contagem e dede-tecção de fronteiras dos dentes, são utilizadas técnicas baseadas em operadores morfológicos como por exemplo erosão e transformadawatershed, respectivamente. Com a detecção de fronteira dos
den-tes foi possível calcular os descritores de Fourier 1 para suas formas e os descritores de posição. Em seguida os dentes foram classificados quanto aos seus tipos através do uso de SVMs a partir do método um-contra-todos usado em problemas multiclasses. O pro-blema de classificação para múltiplas classes foi abordado de duas maneiras diferentes. Na primeira abordagem foram consideradas três tipos de classes: molar, pré molar e não dentes, enquanto que na segunda abordagem foram consideradas cinco tipos de classes: molar, pré molar, canino, incisivo e não dentes. A utilização da abordagem de três classes apresentou resultados melhores e como boa parte dos problemas dentários acontecem nos dentes molares e pré molares, esta abordagem pode ser útil.
1.1
Motivação
Um dos grandes desafios da estratégia de saúde da família é baseada no referencial epidemiológico, que busca satisfazer o princípio da equidade no acesso às ações de saúde previstas no SUS [Sisson 2007], ou seja, oferecer tratamento proporcional e prioritário ao nível do problema bucal. Na área da saúde bucal, esta referência é obtida principalmente através de vários índices e indicadores destinados a auxiliar no estudo de doenças orais
1Será dada sua devida definição no capítulo 2
INTRODUÇÃO
em populações humanas [Roncalli 2006]; especialmente cárie, doença periodontal, má oclusão, uso e necessidade de prótese, fluorose e lesões orais.
O mais recente esforço na construção do perfil epidemiológico de saúde bucal dos brasileiros veio de um processo amplo que visa a construção de uma base de dados per-manente sobre os principais indicadores de saúde bucal em 177 municípios brasileiros, com a perspectiva de examinar cerca de 50.000 pessoas [Roncalli et al. 2012]. Apesar da grande contribuição de estudos para a compreensão da condição de saúde bucal da população, há uma limitação para o planejamento local de saúde, como levantamentos epidemiológicos que identificam a extensão do problema mas não identificam as necessi-dades específicas de uma determinada população [Assaf et al. 2007].
Devido as limitações atuais em criar este perfil epidemiológico, a maior parte das ações desenvolvidas no atendimento odontológico e realizados em unidades de saúde da família ainda são impulsionados pela demanda, ou seja, é o paciente que busca atendi-mento e define o problema que querem resolver. É preciso também considerar que o acesso aos serviços odontológicos no Brasil é limitado e desigual [Fernandes LS 2005, Hugo et al. 2007].
Como uma maneira de diminuir os desafios enfrentados pelos dentistas na condução dos exames clínicos, surgiu a ideia de utilizar técnicas de sistemas inteligentes no processo de inspeção visual bucal básico a fim de auxiliar o levantamento do perfil epidemiológico da população brasileira.
1.2
Objetivos
Este trabalho teve origem em um projeto de pesquisa coordenado pelo Professor Dr. Luiz Noro do departamento de odontologia com participação do Professor Adrião Duarte do Laboratório de Sistemas Inteligentes do Departamento de Engenharia da Computação e Automação - DCA, ambos da Universidade Federal do Rio Grande do Norte - UFRN. Esse projeto contou com a participação de vários pesquisadores de ambos departamen-tos. Dando continuidade a esse trabalho e seguindo nessa mesma linha de pensamento procurou-se neste projeto alcançar os seguintes objetivos:
Geral:
– Desenvolver um sistema inteligente capaz de fazer a segmentação, contagem e classificação dos dentes a partir de imagens digitais intrabucais oclusais, obtidas através de câmeras compactas convencionais.
Específicos:
– Auxiliar o dentista na realização de levantamentos epidemiológicos em saúde bucal coletiva tornando esse processo mais ágil, eficiente e de baixo custo; – Contribuir com a coleta de informações básicas de inspeção visual bucal a
partir de imagens fotográficas digitais intrabucais oclusais;
INTRODUÇÃO
1.3
Estado da Arte
Recentemente diversos trabalhos envolvendo o uso de processamento inteligente de imagens na solução de problemas na odontologia vêm sendo divulgados.
Em Arifin et al. (2012), uma contagem e classificação de dentes é realizada com foco na odontologia forense. Os dentes molares e pré molares são contados e classificados a partir de imagens radiográficas interproximais através do uso de SVM com detecção da distância mesiodistal dos dentes.
A segmentação individual de dentes para extração de suas características é sempre uma etapa importante em processamento de imagens dentais. Em Choorat et al. (2011), a segmentação é baseada na estimação dos ângulos de orientação dos dentes presentes nas imagens através do uso de filtros de Gabor. O contorno dos dentes é realizado em seguida por meio do método de contornos ativos.
Ainda na segmentação de imagens radiográficas, Niroshika et al. (2013) trata o pro-blema de detecção de contorno por meio de contornos ativos para regiões com cantos pon-tiagudos. Sua metodologia é incorporar a priori conhecimentos significativos dos cantos pontiagudos dos dentes de maneira que eles não sejam suprimidos.
Outra abordagem para segmentação de dentes é proposta em Sepehrian et al. (2013), porém neste caso são utilizadas imagens obtidas por tomografia computadorizada. A seg-mentação é baseada na transformadawatershedonde restrições anatômicas são impostas
a fim de evitar problemas de supersegmentação.
Em Gottlieb et al. (2014), é proposto um sistema inteligente capaz de detectar e pon-tuar o nível de lesão de cárie a partir de imagens fotográficas oclusais da superfície de um único dente. São utilizados algoritmos de extração de características baseados na estatística das cores, transformadaswavelete transformadas de Fourier.
1.4
Principais Contribuições do Trabalho
Como principais contribuições deste trabalho podem ser consideradas:
• Proposta de um sistema inteligente para inspeção bucal básica para contagem e
classificação de dentes;
• Implementação de um sistema inteligente capaz de auxiliar o levantamento epide-miológico de uma comunidade brasileira;
• Uso de técnicas consolidadas nas áreas de aprendizado de máquinas e
processa-mento digital de imagens;
• Elaboração de análise estatística dos resultados, através do uso de matriz de
confu-são e teste de performance de classificação.
1.5
Organização do trabalho
No Capítulo 2 será mostrado a fundamentação teórica das técnicas de PDI utilizadas neste trabalho. O Capítulo 3 versará sobre o modelo preditivo baseado em otimização
INTRODUÇÃO
Capítulo 2
Processamento Digital de Imagens
O interesse na utilização de técnicas de PDI provém basicamente de duas necessida-des reais: melhoria das informações visuais para interpretações humanas e processamento de dados de imagens. O processamento de dados geralmente tem como objetivo se ade-quar às diversas funcionalidades existentes, transmissão, armazenamento, representação, descrição entre outras aplicações.
2.1
Introdução
O processamento digital de imagens é constituído de diversos passos fundamentais aplicados a diferentes propósitos e objetivos variados. De maneira geral esse processo possui uma base de conhecimento comum para cada passo que pode ser divido [Gonzalez e Woods 2010] da seguinte maneira:
• Aquisição de imagens; • Filtragem e realce;
• Processamento de imagens coloridas;
• Compressão;
• Processamento morfológico; • Segmentação;
• Representação e descrição; • Reconhecimento de objetos;
Nem todos os passos precisam ser seguidos, seu uso varia de acordo com a necessidade do problema.
A aquisição de imagens caracteriza-se pela obtenção de uma imagem em formato digital. Em geral, neste estágio é necessário que um pré-processamento seja feito, como por exemplo o redimensionado de imagens para adequação dos dados de entrada.
A filtragem e realce de imagens é um processo de manipulação de imagens de forma que o seu resultado seja o mais adequado possível para uma aplicação específica. As técnicas de realce são relacionadas desde o início ao tipo de problema encontrado.
PROCESSAMENTO DIGITAL DE IMAGENS
A compressão lida com a redução de armazenamento de uma imagem, ou largura de banda necessária para transmissão. A utilização de imagens digitais geralmente faz uso de alguma técnica de compressão de dados na forma de extensões de arquivos, como por exemplo a extensão Joint Photographic Experts Group (JPEG) ,Portable Network Graphics(PNG) entre outras existentes.
O processamento morfológico caracteriza-se pela extração de componentes de ima-gem para representação e descrição de forma.
Na segmentação ocorre a divisão da imagem em suas partes ou objetos constituintes. Em geral, quanto mais precisa for a separação das suas regiões de interesse, melhor são as chances de sucesso no reconhecimento de objetos.
A representação e descrição geralmente partem do estágio da segmentação, cuja saída normalmente são dados primários em forma de pixels, correspondendo a representação
por fronteiras ou regiões completas. De forma intuitiva as representações por fronteiras se caracterizam por informações externas do objeto e as regiões completas pelas informações internas do objeto. A descrição que também é conhecida como seleção de características, resultam em informações que podem ser utilizadas para diferenciar uma classe de objeto de outra.
O reconhecimento é o processo que faz uso de descritores para que os objetos sejam classificados ou rotulados de acordo com a base de conhecimento envolvida.
Neste capítulo é dado ênfase aos três principais processos utilizados no desenvolvi-mento do sistema proposto: o processadesenvolvi-mento morfológico, a segmentação e a represen-tação e descrição. As etapas de aquisição e processamento de imagens coloridas são abordadas no capítulo 4 de modo que venha a facilitar o entendimento da metodologia utilizada.
2.2
Definições básicas
2.2.1
Imagens, dados e entradas
Uma imagem expressa por f(x,y) pode ser definida por um conjunto de elementos representados no espaço 2-D∈Z2. Cada elemento representa um vetor bidimensional de
coordenadas(x,y)de umpixelbranco ou preto para uma imagem binária, dada a
conven-ção utilizada. Imagens em níveis de cinza são representadas no espaçoZ3, coordenadas do pixele seu valor discreto. Dimensões maiores podem conter outros atributos de imagem,
como por exemplo, cor e frequência.
O menor elemento de uma imagem é opixelque será aqui referido como peq. Um pixel pnas coordenadas x e y possui 4 vizinhos horizontais e verticais definidos como:
(x+1,y),(x−1,y),(x,y+1),(x,y−1) (2.1)
PROCESSAMENTO DIGITAL DE IMAGENS
Outros vizinhos existentes são os vizinhos diagonais que são definidos como:
(x+1,y+1),(x+1,y−1),(x−1,y−1),(x−1,y+1) (2.2) esses pontos, junto com a vizinhança-4 são chamados de vizinhança-8 e podem ser refe-renciados comoN8(p).
2.3
Filtragem
O processo de filtragem pode ser realizado no domínio espacial, próprio plano da ima-gem, ou no domínio da transformada, onde primeiramente ocorre uma transformação, em seguida o processamento nesse domínio e obtêm-se a transformada inversa para retornar ao domínio do espaço.
A filtragem espacial consiste em mover uma janela w(s,t) por uma imagem f(x,y)
substituindo o pixel x,y, posição arbitrária na imagem, em função de um operador T
definido como:
g(x,y) =T[f(x,y)] (2.3) Basicamente a filtragem pode ser definida em linear e não linear. A filtragem linear de uma imagem com dimensõesi x j, com um filtro de dimensõesm x npode ser definida
pela expressão:
g(x,y) =
a
∑
s=−ab
∑
s=−bw(s,t)∗f(x+s,y+t) (2.4)
onde o tamanho da janela é definido por m=2a+1 en=2b+1, sendo a e b números inteiros positivos, de maneira que todo x e y seja percorrido [Gonzalez e Woods 2010].
Para gerar um filtro não linear é preciso especificar além das dimensões da janela, as operações a serem executadas. Existem diversos tipos de operadores mas neste capítulo será levado em consideração apenas o filtro de mediana, utilizado no sistema proposto explicado no capítulo 4.
2.3.1
Filtro de mediana
No filtro da mediana o valor de umpixel é substituído pela mediana dos valores em
sua vizinhança, levando em consideração o próprio valor dopixeloriginal. Dessa maneira
o filtro da mediana faz com que ospixelsmais distintos se assemelhem aos pixels mais
próximos.
A utilização de filtros de mediana 2-D com m x n pontos pode distorcer seriamente
a descontinuidade em uma imagem. Uma maneira de amenizar esse problema é filtrar a imagem ao longo da direção horizontal com um filtro 1-D e em seguida filtrar o resultado na vertical novamente por um filtro 1-D [Lim 1990].
PROCESSAMENTO DIGITAL DE IMAGENS
2.4
Processamento Morfológico de Imagens
A palavra morfologia geralmente denota um ramo da biologia que lida com forma e a estrutura dos animais e das plantas. Usamos a mesma palavra aqui no contexto da morfologia matemática como uma ferramenta para extrair componentes das imagens que são úteis na representação e na descrição da forma de uma região [Gonzalez e Woods 2010].
Os conceitos de reflexão e translação de conjuntos são fundamentais na morfologia. Segundo Gonzalez e Woods (2010) a reflexão de um conjuntoB, indicado por ˆB, pode ser
definida como:
ˆ
B={w|w=−b, parab ∈ B} (2.5)
e a translação de um conjuntoBno pontoz= (z1,z2)indicada por(Bz), é definida como:
Bz={c|c=b+z, parab ∈ B} (2.6)
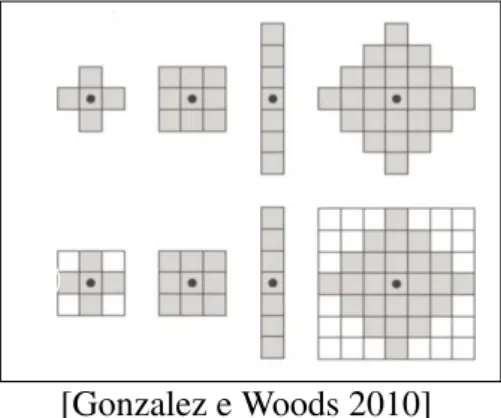
A reflexão e translação são utilizadas para formular operações nos elementos estrutu-rantes, pequenos conjuntos utilizados na busca de propriedades de interesse definidos na figura 2.1.
Figura 2.1: Elementos estruturantes básicos e em arranjos retangulares.
(A)
(B)
[Gonzalez e Woods 2010]
2.4.1
Erosão
O processo de erosão pode ser visto como uma varredura de um elemento estruturante
B em um determinado conjunto A. Segundo Gonzalez e Woods (2010), esta varredura
pode ser definida pela equação 2.7 mostrada seguir, [Gonzalez e Woods 2010]:
A⊖B={z|(B)z⊆A} (2.7)
de forma queBtransladado por z, deve estar contido emA. Os elementos que não
satis-fazem esta condição são eliminados gerando um novo conjunto de elementos do conjunto
PROCESSAMENTO DIGITAL DE IMAGENS
2.4.2
Dilatação
Como no processo de erosãoAeBpodem ser vistos como conjuntos deZ2. Segundo
[Gonzalez e Woods 2010], a dilatação pode ser definida como:
A⊕B={z|[(Bˆ)z ∩A]⊆A} (2.8)
de maneira que a reflexão deBtransladado porzeAse sobreponham pelo menos por um
elemento.
De forma contrária a erosão que diminui ou afina os objetos, a dilatação aumenta ou engrossa os objetos de acordo com o tamanho do elemento estruturante utilizado.
2.4.3
Abertura
Uma outra operação morfológica bastante utilizada é a operação de abertura. A aber-tura elimina regiões salientes suavizando os contornos dos objetos. DefinindoAeBcomo
nas seções anteriores, o processo de abertura pode ser definido [Gonzalez e Woods 2010] como:
A◦B= (A⊖B)⊕B (2.9)
em que, esse processo morfológico pode ser visto como a erosão deAporB, seguido de
uma dilatação porB.
2.4.4
Reconstrução morfológica
Os processos morfológicos descritos até agora levam em consideração o uso combi-nado de uma imagem de entrada e um elemento estruturante. Diferentemente, na recons-trução morfológica, que faz parte de um conjunto de operadores comumente definidos como geodésica, são utilizadas duas imagens nas suas transformações. A partir da com-binação de duas imagens novas primitivas morfológicas podem ser alcançadas.
Segundo Vicent (1993), a partir de imagens binárias, a reconstrução pode ser feita a partir da extração de componentes conectados, conjuntos de pixelsque compartilham
mesmas propriedades, de uma imagem binária A (Máscara) marcadas por uma imagem
bináriaC⊆A. Em termos de mapeamento, isso significa que∀p∈D(Domínio discreto), C(p) =1⇒A(p) =1. Com isso, sendo {A1,A2, ...,An}os componentes conectados de
A, a reconstrução morfológicaρA(C)em imagens binárias é definida como:
ρA(C) =
[
C∩Ak6=/0
Ak (2.10)
onde, a reconstrução pode ser vista como a união dos componentes conectados da máscara que contém pelo menos umpixeldos marcadores.
PROCESSAMENTO DIGITAL DE IMAGENS
2.5
Segmentação baseada em morfologia
A segmentação subdivide uma imagem em regiões de interesse de acordo com a ne-cessidade do problema. Quanto maior o grau de complexidade da imagem, maior o grau de dificuldade da segmentação. A maioria dos algoritmos de segmentação baseiam-se nos valores de intensidade: descontinuidade e similaridade. A primeira ideia é baseada na di-visão de uma imagem levando em consideração as mudanças bruscas de intensidade. A segunda ideia utiliza o grau de similaridade de um conjunto de elementos que satisfazem critérios predefinidos. A segmentação pode ser efetuada por meio de técnicas em mor-fologia, fazendo uso combinado de vários atributos positivos das segmentações citadas anteriormente.
2.5.1
Transformada
Watershed
A transformada watershed foi proposta por Beucher e Lantuejoul (1979) como um
modelo geofísico de decaimento da chuva em um terreno. A idéia é que uma gota de chuva caindo em uma superfície irá gotejar através do caminho de descida mais íngreme até um mínimo [Beare e Lehmann 2006].
Baseada na morfologia matemática, a transformada watershedé inspirada na
detec-ção de superfícies em bacias hidrográficas. As imagens são segmentadas a partir de um gradiente, onde os níveis de cinza formam uma superfície de captação. Estas superfícies sofrem um processo de inundação uniforme a partir de seus mínimos regionais. A partir do momento em que as inundações começam a se misturar, barreiras são erguidas para evitar que isto aconteça, estas barreiras são conhecidas como linhas dewatershed.
A existência de muitos mínimos regionais podem levar a um problema de superseg-mentação. Para que isto não aconteça utilizam-se marcadores. Neste caso, um conjunto de marcadores é detectado para cada objeto presente na imagem, inclusive o fundo da imagem. Em seguida o processo de inundação é feito a partir dos mínimos regionais idênticos aos dos marcadores. Após a inundação, a imagem é segmentada de maneira que cada parte contenha apenas um marcador.
Esta definição intuitiva pode ser definida de forma mais rigorosa. Segundo Meyer (1994), o gradiente pode ser visto como relevos topográficos. Assim, considerandof uma
função distância a partir deℜ2emℜ, supp(f) como suporte de f, T o intervalo de ℜ eγ
uma função continua deT em supp(f). Sendo (T, γ) o caminho contido no suporte de f
eΓ(p,q)o conjunto de todos os caminhos entre os pontos p e q, a distância topográfica
entre dois pontos no espaço continuo é defnida como:
DT(p,q) = in f
γ∈Γ(p,q) Z
γ|∇
f(γ(s))|ds (2.11)
onde o módulo do gradiente da funçãof representa a variação topográfica def.
As bacias hidrográficasBH(mi′)dos mínimos regionaismi′ como conjunto de pontos x∈supp(f) que estão mais próximos de mi′ do que de outro mínimo regional para a distância topográfica são definidas como:
PROCESSAMENTO DIGITAL DE IMAGENS
Descrevendo as linhas dewatershedda funçãof como o conjunto de pontos do suporte
de f que não pertencem a nenhuma bacia hidrográfica como:
W sh(f) =supp(f)∩[∪
i′(BH(mi′))]
c (2.13)
Pode-se observar que o algoritmo de integração de imagens é na verdade um algoritmo usado para computar distâncias ponderadas, ou seja, é o mesmo que computar o caminho de custo mínimo entre os pixels [Verbeek e Verwer 1990]. O tamanho do caminho de
custo mínimo é na verdade a distância topográfica.
A segmentação viawatersheda partir de imagens gradientes produz dados primários
em forma depixelque representam fronteiras epixelscontidos em uma região.
2.6
Representação e descrição
A representação pode ser feita basicamente de duas maneiras: representar os dados primários em função de suas características externas (sua fronteira) ou em função de suas características internas (pixels de uma região). A escolha da representação é importante pois a partir dela diferentes algoritmos com diferentes graus de complexidade computaci-onal podem ser utilizados. A descrição é feita com base na representação escolhida. Por exemplo, uma região pode ser representada pela sua fronteira e ser descrita por coeficien-tes complexos (descritores de Fourier).
2.6.1
Transformada de Fourier
A transformada de Fourier pode ser apresentada de forma dividida de acordo com a natureza do sinal utilizado. Se o sinal é contínuo e periódico, tem-se a série de Fourier; se o sinal é discreto e aperiódico, tem-se a série discreta de Fourier; se o sinal é discreto e periódico, tem-se a transformada discreta de Fourier e se o sinal for contínuo e aperiódico, tem-se a transformada de Fourier [Martins 2014].
Utilizandotpara expressar variáveis espaciais contínuas eµpara variáveis de
frequên-cia contínua, a transformada de uma função contínua e aperiódica, expressa porF(µ)pode
ser definida como:
F(µ) =
Z ∞
−∞f(t)e
−j2πµtdt (2.14)
Inversamente, a função f(t)pode ser obtida utilizando a transformada de Fourier
in-versa, definida como:
f(t) =
Z ∞
−∞F(µ)e
j2πµtdµ (2.15)
2.6.2
Transformada Discreta de Fourier
Segundo Gonzalez e Woods (2010), a transformada discreta de Fourier (discrete Fou-rier transform - DFT, no inglês) de uma função amostrada de banda limitada se
esten-dendo de−∞a +∞é uma função periódica, contínua, que também se estende de −∞ a
+∞. Na prática, trabalha-se com um número finito de amostras K.
PROCESSAMENTO DIGITAL DE IMAGENS
Utilizando x e u para expressar variáveis discretas unidimensionais no domínio do
espaço e da frequência, a DFT pode ser definida como:
F(u) =
K−1
∑
x=0f(x)e−j2πKux (2.16)
Inversamente, a função f(x) pode ser obtida utilizando a transformada discreta de
Fourier inversa, definida como:
f(x) = 1
K
K−1
∑
u=0F(u)ej2πKux (2.17)
Esta operação é utilizada em diversos campos da engenharia mas exige um elevado custo computacional na prática.
2.6.2.1 Transformada Rápida de Fourier
Uma forma mais eficiente de se calcular a DFT e muito utilizada atualmente foi pro-posta por Cooley e Tukey (1965). Também conhecida como Transformada Rápida de Fourier (Fast Fourier Transform - FFT, em Inglês), a FFT não é um tipo diferente de
transformada de Fourier. É uma forma mais eficiente de se computar a DFT. O custo computacional gasto para realização de uma DFT depende do número de multiplicações e somas envolvidas, que neste caso é daO(N2), enquanto a FFT é daO(NlogN) opera-ções aritméticas. A principal característica deste algoritmo é que a DFT de N sequências pode ser reescrita em termos de duas DFT’s com tamanho N
2, também conhecida como decimação no tempo. Assim com o tamanho de N em potência de 2, é possível aplicar a decomposição recursivamente até que a DFT atinja pontos únicos.
2.6.3
Descritores de Fourier
PROCESSAMENTO DIGITAL DE IMAGENS
Figura 2.2: Fronteira digital e sua representação como uma sequência complexa.
[Gonzalez e Woods 2010]
A partir de um ponto qualquer (x0,y0), pares de coordenadas são encontradas percor-rendo a fronteira no sentido horário ou anti-horário. As coordenadas podem ser expres-sas na forma x(k) =xk e y(k) =yk. Com isso a fronteira pode ser representada como
a sequência de coordenadas s(k) = [x(k),y(k)], para k=0,1,2, . . . ,N−1 [Gonzalez e Woods 2010]. Cada par de coordenadas pode ser tratado como um número complexo de modo que:
s(k) =x(k) + jy(k). (2.18) Embora a forma de representação da fronteira tenha sido mudada, a sua natureza em si não foi alterada. Esta nova representação reduz um problema 2-D em um problema 1-D. Aplicando-se a DFT des(k), temos que:
a(u) =
N−1
∑
k=0s(k)e−j2πNuk (2.19)
estes coeficientes complexos são chamados de descritores de Fourier da fronteira.
Inversamente, os coeficientess(k)podem ser obtidos através da transformada inversa de Fourier da seguinte forma:
s(k) = 1
N
N−1
∑
u=0a(u)ej2πNuk (2.20)
Podem ser utilizados ainda os primeiros M coeficientes para reconstrução des(k). O
resultado é uma aproximação des(k)definida como: ˆ
s(k) = 1
M
M−1
∑
u=0a(u)ej2πMuk (2.21)
Embora apenas M termos sejam utilizados, k ainda varia de 0 a M-1, ou seja, ainda existe o mesmo número de pontos na fronteira aproximada, mas menos termos são utili-zados na reconstrução de cada ponto. Componentes de alta frequência são responsáveis
PROCESSAMENTO DIGITAL DE IMAGENS
pelos detalhes finos, e os componentes de baixa frequência determinam a forma global da imagem [Gonzalez e Woods 2010]. Com isso, quanto menor M, mais detalhes são perdidos na fronteira.
Poucos descritores de Fourier são suficientes para captar a essência de uma fronteira, esta é uma propriedade importante pois carrega informações sobre o formato da fronteira. Um exemplo é mostrado na figura 2.3 a seguir.
Figura 2.3: Exemplos de reconstrução de descritores de Fourier para diferentes coeficien-tes para uma fronteira que representa um quadrado.
[Gonzalez e Woods 1992]
Os descritores possuem propriedades importantes como translação, rotação, escala e ponto de partida. Por motivos de simplificação estas propriedades não serão aqui defini-das.
É importante que os descritores de Fourier de uma determinada fronteira sejam in-variantes a estas propriedades citadas no parágrafo acima. A inexistência de invariância destas propriedades podem acarretar em recuperações incorretas da fronteira desejada.
2.6.4
Considerações
Capítulo 3
Máquinas de Vetores de Suporte
A capacidade de aprendizado é uma característica fundamental para caracterizar o comportamento inteligente. Atividades como memorizar, observar e explorar situações com o intuito de aprender fatos, melhorar habilidades motoras/cognitivas por meio de práticas e organizar conhecimento novo em representações apropriadas podem ser consi-deradas atividades relacionadas ao aprendizado [Katti Facelli 2011].
3.1
Introdução
Aprender significa encontrar parâmetros que consigam definir uma função desconhe-cida. O processo de aprendizagem pode ser visto como um problema de otimização onde procura-se definir os parâmetros de uma função custo em função dos dados de entrada. A definição de parâmetros é também chamada de fase de treinamento da rede. Nesta fase diferentes algoritmos com diferentes graus de complexidade podem ser utilizados. Para que o treinamento seja cessado, um critério de parada deve ser definido.
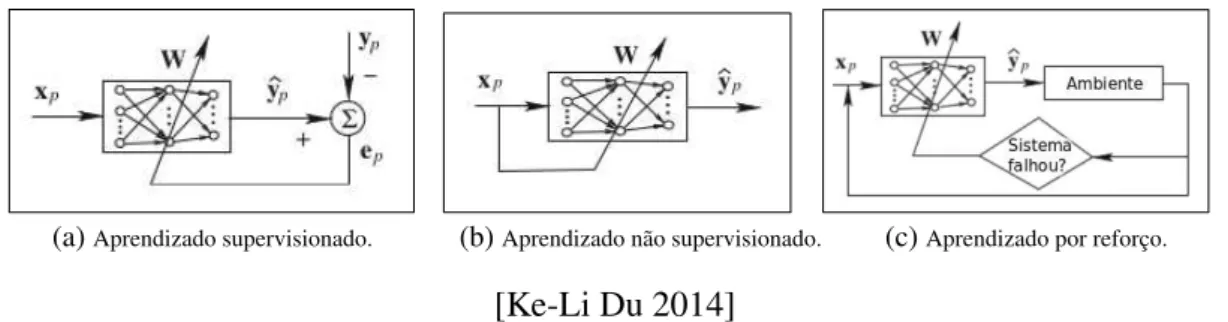
Os métodos de aprendizado podem ser basicamente divididos em: supervisionado, não supervisionado e por reforço. Esses métodos podem ser vistos na figura 3.1. Nelaxp
eyprepresentam a entrada e saída para pdados de treinamento, ˆypé a saída da rede para
pentradas eepé o erro da função.
Figura 3.1: Métodos de aprendizados.
(a)Aprendizado supervisionado. (b)Aprendizado não supervisionado. (c)Aprendizado por reforço.
[Ke-Li Du 2014]
MÁQUINAS DE VETORES DE SUPORTE
procura de similaridade e associações a partir de um conjunto de dados. No aprendizado por reforço, figura 3.1c, o indivíduo aprende a partir da interação com o ambiente no qual está inserido [Sutton e Barto 1998].
Do ponto de vista estatístico, pode-se dizer que no método não supervisionado aprende-se uma função densidade de probabilidade (f.d.p) do conjunto de treinamento, p(x), en-quanto no supervisionado aprende-se a f.d.p dep(x/y)[Ke-Li Du 2014].
O aprendizado supervisionado pode ser associado ao ponto de vista do aprendizado de sala de aula onde existe a figura de um professor. Neste paradigma um conjunto de exemplos de entrada e saída representam o ambiente de forma que o professor, que possui um conhecimento prévio, forneça uma resposta desejada. A resposta do professor repre-senta a ação ótima a ser obedecida. Ela é comparada à saída do sistema e gera um sinal de erro que ajusta a função de modelagem do sistema de aprendizagem de forma adequada, ou seja, o conhecimento do professor é transferido para o modelo de aprendizagem da melhor forma possível. Normalmente este tipo de aprendizagem é capaz de realizar ta-refas de aproximações de funções bem como classificação de padrões. Este processo de aprendizagem pode ser visualizado na figura 3.1a.
Embora o aprendizado supervisionado seja visto como um processo associado à inte-ligência artificial, outras áreas têm contribuído muito para o seu avanço, como probabili-dade e estatística, teoria da computação, neurociência, teoria da informação entre outras. Diversos problemas reais podem ser resolvidos através do uso de técnicas de aprendiza-gem. Dentre os problemas existentes podemos citar:
• Reconhecimento de fala;
• Predição de taxa de cura de pacientes para diferentes doenças; • Detecção de fraude em cartões de crédito;
• Reconhecimento de objetos em imagens; • Condução de automóveis de forma autônoma; • Diagnóstico de doenças por análise de dados.
Atualmente existem diversos algoritmos de modelos preditivos para a solução destes problemas citados anteriormente. Segundo Katti Facelli (2011), o algoritmo preditivo é uma função que, dado um conjunto de exemplos rotulados, constrói um estimador. O rótulo ou etiqueta toma valores num domínio conhecido. Se esse domínio for um con-junto de valores nominais, tem-se um problema de classificação, também conhecido como aprendizado de conceitos, e o estimador gerado é um classificador. Se o domínio for um conjunto infinito e ordenado de valores, tem-se um problema de regressão, que induz um regressor.
Os modelos preditivos podem ser vistos como um conjunto diversificado de métodos baseados em diferentes conceitos matemáticos e probabilísticos, direcionados a resolução de um determinado problema. Dentre os métodos existentes temos:
• Métodos baseados em distâncias (ex: k-Nearest Neighbor);
• Métodos probabilísticos (ex:NaiveBayes);
• Métodos baseados em procura (ex: Árvores de decisão);
• Métodos baseados em otimização (ex: Redes Neurais-RN e SVM)
MÁQUINAS DE VETORES DE SUPORTE
3.2
Máquina de Vetores de Suporte
3.2.1
SVMs Lineares
A SVM é um classificador de padrões embasado na teoria de aprendizado estatístico, proposto por [Vapnick 1995], que busca encontrar uma superfície de separação ótima, minimizando os erros de classificação. Ela pode ser usada tanto para problemas linear-mente quanto não linearlinear-mente separáveis. Em um problema linearlinear-mente separável, uma SVM cria um hiperplano de separação de forma que a distância entre esse hiperplano e os pontos mais próximos dele, seja a maior possível. Dado um conjunto de pontos de treinamentoXcom n objetosx∈Xe suas respectivas classes de saída distintasy∈Y, em queY= {-1,+1} o hiperplano ótimo que separa a duas classes é dado pela expressão:
f(x) = w.x + b (3.1)
de forma que w.x é o produto escalar entre x ew, vetor normal ao hiperplano ótimo, e
b
||w|| é a distância do hiperplano à origem, para umb∈ℜ.
A partir da definição do hiperplano, o conjunto de entrada pode ser separado em duas regiões:
f(x) = (
w.x + b>0
w.x + b<0 (3.2)
Através do uso de uma função sinal sgn(f(x)), os pontos de X mais próximos do hiperplano canônico,w.x + b=0, formam as margens de separação (vetores de suporte)
e são definidos como:
|w.x + b| = 1 (3.3)
O problema é restringido de forma que não ocorram dados de treinamentos entre as margens de separação (SVM com margens rígidas). Na prática, fatores como ruídos,
outliersentre outros fatores tornam a tarefa de separação através de margens rígidas mais
difíceis. Para que o processo de separação torne-se mais maleável são inseridas variáveis de folgasξ. Essas folgas tornam as margens mais flexíveis (SVM com margens suaves), de forma que os vetores de suporte sejam definidos como:
y(w.x + b) −1+ξ≥ 0 (3.4)
Segundo Campbell (2000), a maximização da margem de separação dos objetos em relação aw.x + b=0 pode ser obtida pela minimização de ||w||. Com a inserção das variáveis de folga o problema de minimização é definido como [Burges 1998]:
min
w,b,ξ
1 2||w||
2+C n
∑
i=1ξi
!
(3.5)
onde C é um termo de regularização que impõe um peso à minimização dos erros no con-junto de treinamento em relação à minimização da complexidade do modelo [Katti Facelli 2011].
MÁQUINAS DE VETORES DE SUPORTE
O problema de minimização é um problema de otimização quadrático com restrições lineares e pode ser resolvido através do uso de multiplicadores de Lagrange. Com isso, o problema de maximização das margens suáveis para separação ótima dos dados é definido como [Katti Facelli 2011]:
max
α
n
∑
i=1αi−
1 2
n
∑
i,j=1αiαjyiyj(xi.xj) (3.6)
Restrições:
(
0≤αi≤C,∀i=1, ...,n
∑ni=1αiyi=0
(3.7)
sendoαo parâmetro denominado multiplicador de Lagrange.
3.2.2
SVMs Não Lineares
No caso de padrões não linearmente separáveis, deve ser feito um mapeamentoΦdo espaço de entradas X para o espaço de características ℑ. Segundo o teorema de Cover [Haykin 1999] para que esse mapeamento garanta com alta probabilidade a separação dos objetos, a transformação deve ser não linear e o espaço de características ter dimensão suficientemente alta.
No espaço de característica os dados podem ser linearmente separáveis, tornando pos-sível a utilização do modelo SVM linear com margens suaves. Mapeando o problema de otimização tem-se que:
max
α
n
∑
i=1αi−
1 2
n
∑
i,j=1αiαjyiyj(Φ(xi).Φ(xj)) (3.8)
Através do uso da função kernelKo produto escalar do espaço de entradas é calculado
no espaço de características [Herbrich 2001], com isso tem-se que:
K(xi,xj) =Φ(xi)Φ(xj) (3.9)
A única informação necessária para realização do mapeamentoΦestá na forma como o produto escalar do espaço de entrada será feito. Muitas vezes a função kernel é utilizada sem que se saiba como o mapeamento acontece.
Para que o produto escalar seja possível, deve-se seguir as condições estabelecidades pelo teorema de Mercer [Mercer 1909]. O teorema afirma que qualquer função kernel positiva semidefinida satisfaz a relação:
n
∑
i,j=1αiαjK(xi,xj)≥0 (3.10)
MÁQUINAS DE VETORES DE SUPORTE
Tabela 3.1: Sumário dos principais Kernels utilizados nas SVMs.
Tipo de Kernel FunçãoK(xi,xj) Comentários
Polinomial (xTi xj)p
A potênciapdeve ser
especi-ficada pelo usuário
Gaussiano (RBF) exp
1
2.σ2||xi−xj||
2 A largura σ
2 é especificada
pelo usuário
Sigmoidal tanh β0xixj+β1
Utilizado somente para
al-guns valores deβ0eβ1
Algumas características relativas aos Kernels citados na tabela anterior podem ser destacadas, são elas ([Burges 1998], [Haykin 1999]):
• Polinomial: Os mapeamentosΦtambém são polinomiais e possuem grau de com-plexidade crescente a medida em que p aumenta;
• Gaussiano (RBF): O mapeamento do espaço de característica possui dimensão
in-finita. Essa característica faz com que quase toda forma de mapeamento possa ser realizada;
• Sigmoidal: Chamada de Tangente Hiperbólico a função Kernel Sigmoidal é
tam-bém conhecida como Kernel Multilayer Perceptron (MLP). A função sigmóide
é usualmente utilizada como função de ativação de uma Rede Neural Artificial (RNA).
A obtenção de um classificador por meio do uso de SVM’s envolve a escolha de uma função kernel, seus parâmetros e o do fator de regularização C. As escolhas feitas são responsáveis pelos resultados obtidos, ou seja, pela geração das regiões de decisões obtidas pelo classificador.
De forma resumida o algoritmo 3.1 demonstra o que foi descrito até aqui [Katti Facelli 2011],[Vert 2001] .
MÁQUINAS DE VETORES DE SUPORTE
Algoritmo 3.1Determinação do hiperplano ótimo no espaço característica.
1: Dado um conjunto treino qualquerΦ(X) ={(Φ(xi),yi), ...,(Φ(xn),yn)}
2: Sejaα= (α1, ...,αn)a solução do problema de otimização com restrições
3: Maximizar:
n
∑
i=1αi−
1 2
n
∑
i,j=1αiαjyiyjK(xi,xj)
Sob as restrições:
0≤αi≤C,∀i=1, ...,n n
∑
i=1αiyi=0
4: Definindo o hiperplano ótimo em função deweb: w←
n
∑
i=1αiyiΦ(xi)
b← −12
min
i|yi=+1
(w.Φ(xi)) + max i|yi=−1
(w.Φ(xi))
5: Classificador dado por: g(x)←sgn
n
∑
xi∈SV
αiyiK(xi,x) +b
!
3.2.3
SVMs para Múltiplas Classes
A SVM foi originalmente desenvolvida para problemas binários (duas classes). Es-tender sua funcionalidade continua sendo objeto de pesquisas atuais. Diversos métodos foram propostos ao longos dos anos de maneira que a sua utilização em problemas de classificação de múltiplas classes seja hoje uma realidade. Basicamente dos diversos mé-todos existentes a maioria faz uso combinado de vários classificadores binários. Os dois métodos mais básicos conhecidos são:
• Um-Contra-Todos (OAA,One-Against-All, do inglês) : Consiste em construir
clas-sificadores binários que distinguem uma classe das demais.
• Um-Contra-Um (OAO, One-Against-One, do inglês): Consiste em construir um
classificador para cada par de classes.
Na estratégia um-contra-todos paracclasses são construídoscclassificadores. Usa-se
como exemplos contrários todas as outras classes existentes. A classificação de cada nova instância é feita através da metodologia em que o vencedor ganha tudo (winner-takes-all),
ou seja, o classificador com a maior saída atribui a classe correspondente.
Na estratégia um-contra-um paracclasses são construídosc(c−1)/2 classificadores. A classificação é feita por uma estratégia de votação onde a maioria vence (max-wins voting). Neste caso cada classificador atribui uma das duas classes para instância, a classe
MÁQUINAS DE VETORES DE SUPORTE
3.2.3.1 Um-Contra-Todos
Neste método são utilizados k modelos SVM sendo k o número de classes. O
i-ésimo modelo SVM é treinado com todos os dados de treinamento emiclasses rotuladas
positivas e o restante em classes rotuladas negativas. Assim, para um dado conjunto de treinamento n{(x1,y1), ...,(xn,yn)}, ondexi∈ℜd,i=1, ...,neyi∈ {1, ...,k}é a classe de
xi, o i-ésimo modelo SVM é resolvido da seguinte maneira [Chih-Wei Hsu 2002]:
min
wi,bi,ξi
1 2||w
i||2+C n
∑
j=1ξij
!
(3.11)
Após o problema de otimização 3.11 ser resolvido são encontradaskfunções de
deci-sões:
(w1)TΦ(x) +b1
...
(wk)TΦ(x) +bk
Com isso, pode-se dizer que x pertence a classe com maior valor entre as funções de
decisões, define-se assim que:
classe de x≡arg max
i=1,...,k((w
i)TΦ(x) +bi) (3.12)
De forma resumida o algoritmo 3.2 demonstra a abordagem de SVM multiclasses.
Algoritmo 3.2Classificador multiclasse
1: Dado um conjunto treino qualquerΦ(X) ={(Φ(xi),yi), ...,(Φ(xn),yn)}
2: Sejaα= (α1, ...,αn)a solução do problema de otimização com restrições
3: Maximizar:
n
∑
i=1αi−
1 2
n
∑
i,j=1αiαjyiyjK(xi,xj)
Sob as restrições:
0≤αi≤C,∀i=1, ...,n n
∑
i=1αiyi=0
4: Definindo o hiperplano ótimo em função deweb: w←
n
∑
i=1αiyiΦ(xi)
b← −12
min
i|yi=+1
(w.Φ(xi)) + max i|yi=−1
(w.Φ(xi))
5: Classificador dado por: g(x)←argmax
n
∑
xi∈SV
αiyiΦ(x) +b
!
MÁQUINAS DE VETORES DE SUPORTE
3.3
Considerações
Capítulo 4
Sistema Desenvolvido
4.1
Introdução
Conforme inicialmente mencionado no capítulo 1, na odontologia, em específico na saúde bucal coletiva, a inspeção visual bucal é realizada com o intuito de conhecer as condições da saúde bucal de uma dada população. Como tarefa básica inicial o sistema desenvolvido é capaz de fazer a contagem e classificação de dentes através do uso com-binado de técnicas de PDI e AM. A partir da segmentação baseada em cores por SVM a contagem é feita por meio de sucessivas erosões enquanto a classificação de dentes recai em um típico problema de reconhecimento de padrões. Antes da classificação ocorrer, a detecção de fronteira dos dentes é realizada por meio da transformadawatershed. Em
seguida descritores de forma e posição são calculados e utilizados na classificação indivi-dual dos dentes presentes nas imagens.
Este capítulo está organizado em função das etapas envolvidas neste processo, eviden-ciando em cada uma delas as principais técnicas utilizadas de acordo com as necessidades específicas.
4.2
Metodologia
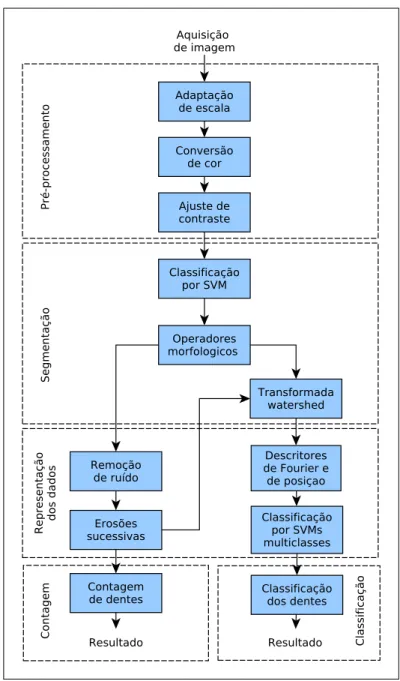
O sistema proposto pode ser definido basicamente em cinco etapas:
• Pré-processamento; • Segmentação;
• Representação dos dados; • Contagem;
• Classificação
SISTEMA DESENVOLVIDO
Figura 4.1: Diagrama de blocos do sistema implementado.
A partir do estabelecimento de uma padronização nas tomadas de fotos descrita na introdução, foi montado um banco de imagens com pacientes de diversas faixas etárias. Essas imagens são utilizadas como entrada do sistema onde cada uma passa por um pré-processamento adequando sua escala, modelo de cor e ajuste de contraste conforme a metodologia proposta explicada nas seções a seguir. Em seguida ela passa por diferentes processos de segmentação baseados em técnicas de AM (Classificação baseada em cores por SVM) e PDI (Operadores morfológicos e transformadawatershed) de maneira que
SISTEMA DESENVOLVIDO
4.3
Aquisição de imagem
Foram utilizadas 40 imagens a partir de câmeras compactas CANON, modelo A1300 comflashembutido. As fotografias utilizadas foram tomadas em duas situações: oclusal
superior e inferior, utilizando um espelho lateral específico e afastador labial em adultos. A fotografia oclusal é uma imagem bidimensional correspondente à distribuição de todos os dentes (terceiro molar direito até o terceiro molar da esquerda) na arcada dentária (superior ou inferior) vista de cima para baixo ou de maneira contrária como mostrada na figura 4.2a.
4.4
Pré-processamento
O pré-processamento de imagens é um procedimento utilizado com frequência em problemas de reconhecimento de padrões. Tem como intuito adequar os dados de entrada para diferentes objetivos, a fim de obter a melhor solução possível para o problema.
A imagem digital é representada por uma matriz depixels, que recebem um vetor de
valores RGB (vermelho, verde, azul), imagens coloridas, com valores que variam de 0 a 255 para 8 bits de profundidade, que podem ser normalizados de 0 a 1 [Gonzalez e
Woods 2010].
Nesta etapa, o dado de entrada é uma imagem fotográfica digital intrabucal oclusal no sistema de cor RGB. Existem ainda outros tipos de modelos de cores de imagens. Neste trabalho é utilizado o modelo de representação de cores YCbCr que será detalhada na seção 4.4.2.
4.4.1
Adaptação de escala
Devido as diferentes escalas resultantes do processo de aquisição da imagem, é re-alizado um procedimento de adaptação de escala, que reduz ou amplia a imagem auto-maticamente a partir de uma escala obtida em função das dimensões da imagem e das dimensões máximas de uma janela fixa de 600 x 600pixels, de modo que essa dimensão
fixa não seja ultrapassada.
Esse ajuste é realizado através do método de interpolação Bi-Cúbico, onde os valores dospixelsde saída são valores médios de uma janela 4x4pixelsda vizinhança do ponto.
4.4.2
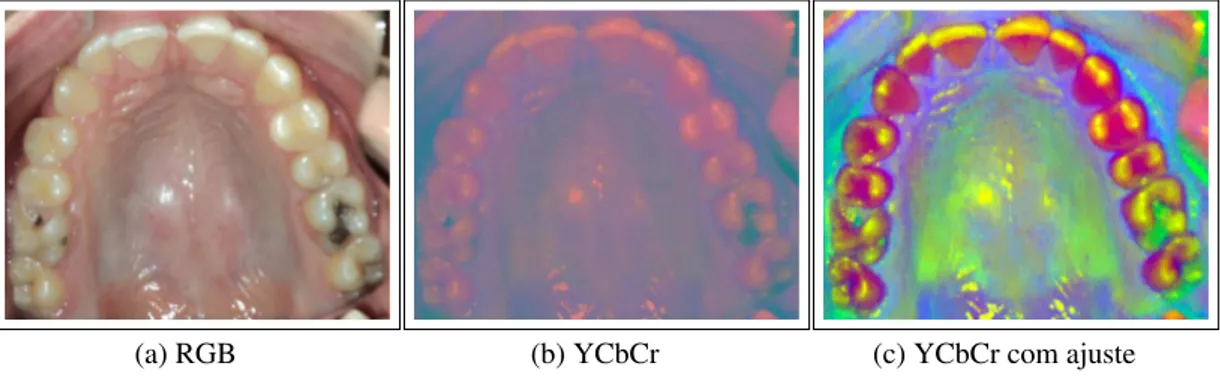
Conversão RGB para YCbCr
O modelo YCbCr possui redundâncias que podem ser eliminadas sem prejuízo a ima-gem, tornando os arquivos de imagens menores sem grandes perdas visuais. Outra ca-racterística importante está na componente Y que contém altas frequências de luminância em escalas de cinza que facilitam o processo de aprendizagem do sistema.
Neste modelo, o Y representa a luminância de uma imagem, enquanto o Cb repre-senta a crominância azul (B - Y) e o Cr a crominância vermelha (R - Y). O processo de conversão de RGB para YCbCr é dado pela seguinte equação:
SISTEMA DESENVOLVIDO Y Cb Cr =
0.29900 0.58700 0.11400 -0.16874 -0.33126 0.50000 0.50000 -0.41868 -0.08131
R G B (4.1) Y’ Cb’ Cr’ = Y Cb Cr + 0 128 128 (4.2)
Como descrito por Acharya e Tsai (2005), as componentes Cb e Cr podem resultar em valores negativos. Para que sua representação fique entre 0 e 255 é necessário adicionar o escalar 128 e fazer o seu arredondamento.
4.4.3
Ajuste de Contraste
Após a imagem ser redimensionada e convertida para o modelo YCbCr, aplica-se em cada componente um aumento de contraste para conseguir uma melhor discriminação de cores de seuspixels. O ajuste de contraste é feito através do mapeamento de cadapixels
da imagem de entrada em umpixelcorrespondente a um intervalo de [0,1].
De forma resumida a etapa de pré-processamento pode ser definida de acordo com o algoritmo 4.1 mostrado a seguir:
Algoritmo 4.1Pré-processamento da imagem.
1: Entrada: MatrizXi,j,3contendo os valores RGB para a imagem I de resolução i x j.
2: Saída: MatrizYi,j,3contendo os valores YCbCr com ajuste de contraste de I.
3: Redimensionar I a partir do método de interpolação Bi-Cúbico em função da escala
segundo a equação:
4: escala←(1−((dim−max)/dim)) 5: Onde:
max: dimensão máxima da janela fixa dim: dimensão da imagem original
6: Converter o modelo de cores segundo as equações lineares 4.1 e 4.2
7: Ajustar contraste da imagem no modelo YCbCr mapeada no intervalo [0,1]
SISTEMA DESENVOLVIDO
Figura 4.2: Imagem RGB convertida para o modelo YCbCr com ajuste de contraste.
(a) RGB (b) YCbCr (c) YCbCr com ajuste
Após a etapa de pré-processamento a imagem segue como entrada para etapa de seg-mentação descrita a seguir.
4.5
Segmentação
4.5.1
Segmentação baseada em cores
A partir da conversão e ajuste de contraste da imagem original, a segmentação é feita através do uso de um classificador binário por SVM. Cadapixelda imagem é classificado
como dente ou não dente, que para este problema foram configuradas como amostras variadas de cores de dentes e restaurações em uma classe, e gengiva, língua e outros elementos bucais em uma segunda classe. Após a criação do conjunto de treinamento um hiperplano ótimo é calculado de acordo com o algoritmo 3.1. Definido os parâmetros da rede um conjunto de dados de teste é utilizado como entrada do classificador. Os dados de saídas formam uma imagem binária com as regiões de interesse identificadas, dentes e não dentes, acrescida de ruídos e regiões indesejadas, ver a sub-imagem 4.4b. O processo de segmentação é apresentado no algoritmo 4.2 a seguir.
SISTEMA DESENVOLVIDO
Algoritmo 4.2Segmentação baseada em cores por SVM
1: Entrada: MatrizYi,j,3para imagem I .
2: Saída: MatrizBi,j contendo valores binários em 0 e 1 para imagem B.
3: Criar vetor xpnp,3, contendo valores de intensidade de pixels YCbCr de np pontos selecionados como dados positivos
4: Criar vetor xnnn,3, contendo valores de intensidade de pixels YCbCr de nn pontos selecionados como dados negativos
5: Criar vetor únicoxn,3a partir dexpnp,3exnnn,3
6: Criar vetor de saída desejadayn,3contenton=np+nnvalores rotulados:
7: yn,3←1, paraxpnp,3
8: yn,3← −1, paraxnnn,3
9: Separar uma fração dexn,3para treinamento e outra para teste
10: Determinar o hiperplano ótimo de acordo com o algoritmo 3.1 a partir dos dados de treinamento permutados aleatoriamente
11: Classificar os dados de teste permutados aleatoriamente de acordo com o passo 5 do
algoritmo 3.1
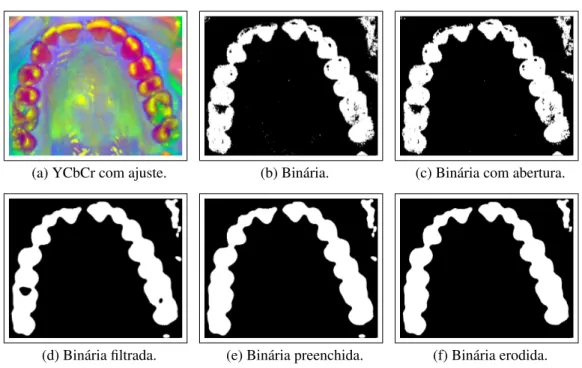
A saída do classificador passa por um processamento morfológico para que regiões indesejadas, como buracos de imagens e ruídos sejam reduzidas ou eliminadas como mos-trado a seguir.
4.5.2
Operadores morfológicos
Os operadores morfológicos são utilizados na extração de componentes das imagens, neste caso ospixelsde dentes, de maneira que possam ser utilizados adequadamente nas
subsequentes etapas de representação e descrição de suas formas.
A partir da imagem binária obtida é realizado um processo de abertura de imagem por um elemento estruturante em formato de disco com raio 1 extraindo-se o "background"da
imagem, de maneira que ospixelsmais representativos dos dentes sejam identificados.
Em seguida a imagem passa por um processo de filtragem onde é utilizado um filtro de mediana de dimensão 17 x 17.
Após a filtragem a imagem passa por um preenchimento de buracos. Segundo Soille (2002), buracos de imagens binárias são definidos como um conjunto de componentes de fundo que não são conectados às bordas da imagem. Seguindo esta ideia, podemos dizer que buracos são conjuntos de pixels de fundo (pretos) cercados porpixels de primeiro
SISTEMA DESENVOLVIDO
imagem filtrada.
Após o preenchimento de buracos, a imagem sofre um processo de erosão de ma-neira que ruídos e elementos indesejados sejam removidos. O algoritmo 4.3 apresenta o processo descrito envolvendo os operadores morfológicos.
Algoritmo 4.3Segmentação por operadores morfológicos
1: Entrada: Imagem binária B.
2: Saída: MatrizBCi,jpara uma imagem binária BC com ruído diminuído ou eliminado.
3: Criar um elemento estruturanteSEn,nem forma de disco plano para uma dado raioR:
4: Onde:
R: Inteiro positivo
n x n: Dimensão com valor inteiro positivo
5: Realizar processo de abertura de B por um elemento estruturante SEn,n segundo a
equação 2.9
6: Aplicar filtro da mediana segundo as definições da seção 2.3.1
7: Preencher os buracos da imagem segundo equação 2.10
8: Realizar processo de erosão da imagem por um elemento estruturanteSEn,nsegundo
equação 2.7
Todo procedimento descrito pode ser observado na figura 4.3, onde são representas as subetapas realizadas na identificação dos dentes presentes na imagem: a) YCbCr equa-lizada, b) Binária da saída do classificador baseado em cores, c) Binária com processo de abertura para retirada dobackground, d) Binária filtrada por um filtro de mediana, e)
Binária com buracos preenchidos e f) Binária com aplicação de erosão para eliminação de ruídos e regiões indesejadas.