Universidade Federal do Rio Grande do Norte Centro de Ciências Sociais Aplicadas Departamento de Ciências Administrativas Programa de Pós-Graduação em Administração
PREVISÃO DO ÍNDICE BOVESPA POR MEIO DE REDES NEURAIS ARTIFICIAIS: Uma análise comparada aos métodos tradicionais de séries de tempo
RENATA LAÍSE REIS DE SOUZA
Renata Laíse Reis de Souza
PREVISÃO DO ÍNDICE BOVESPA POR MEIO DE REDES NEURAIS ARTIFICIAIS: Uma análise comparada aos métodos tradicionais de séries de tempo
Dissertação apresentada ao Programa de Pós Graduação em Graduação em Administração (PPGA) da Universidade Federal do Rio Grande do Norte (UFRN), para a obtenção do título de Mestre em Administração.
Orientador: Prof. Dr. Anderson Luiz Rezende
Mól.
RENATA LAÍSE REIS DE SOUZA
PREVISÃO DO ÍNDICE BOVESPA POR MEIO DE REDES NEURAIS ARTIFICIAIS: Uma análise comparada aos métodos tradicionais de séries de tempo
Dissertação apresentada em defesa da obtenção do título de Mestre em Administração no Departamento de Administração, na Universidade Federal do Rio Grande do Norte.
COMISSÃO EXAMINADORA:
Prof. Dr. Anderson Luiz Rezende Mól - Orientador
Prof. Dr. Vinicio de Souza e Almeida - Examinador
Prof. Dr. Rodrigo José Guerra Leone - Examinador
Aos meus pais, fonte de tudo que sou e que tenho.
AGRADECIMENTOS
Diante da realização de mais um objetivo de vida, tornar-me Mestre em Administração, desejo agradecer esta realização:
À Deus, pai eterno, por todos os desafios, oportunidades e pessoas que colocou em minha vida e por todas as bênçãos que derramou sobre mim não apenas no decorrer deste curso mas durante toda a minha vida.
À minha família, em especial meus pais e irmãos, pelo incentivo e por sempre terem se esforçado para que eu tivesse as melhores condições para meu desenvolvimento e crescimento – não apenas como estudante, mas também como pessoa – e se preocupado comigo, zelando para que eu conseguisse cumprir com mais este objetivo em minha vida. À minha prima Virgínia pela preocupação e auxílio na busca por contatos que me auxiliassem no desenvolvimento do meu trabalho. E ao meu sobrinho Pedro Henrique por ter enchido meus dias de luz e alegria, mesmo nos momentos mais estressantes destes últimos anos.
Ao meu querido Victor, por ter estado ao meu lado me fornecendo apoio, compreensão, carinho, amor e amizade imprescindíveis para que eu continuasse seguindo em frente e me esforçando para conseguir realizar um bom trabalho.
Aos meus preciosos amigos, que contribuíram para que eu mantivesse minhas responsabilidades e me esforçasse para atingir minhas metas, e que também não me permitiram esquecer que preciso saber aproveitar a vida e os frutos de meus esforços. Principalmente as minhas amigas de longa data Almog, Amanda, Fabienne e Carmem, que mesmo com minha ausência de contato permanecem torcendo pelo meu sucesso, e meus amigos do Yujô Fest, que, além da companhia e afeto, me ajudaram a enfrentar esse último ano com um objetivo a mais a complementar meu tempo, me auxiliando para que não ficasse desesperada em momentos em que a dissertação andava a passos mais lentos. Aos amigos Fábio, Lucas Matheus e Matheus pelo auxílio durante a última etapa de meu trabalho.
Ao Professor Dr. Anderson Mól, por ter me apresentado ao tema desta dissertação, por ter aceitado ser meu orientador durante o curso, e por sua paciência, compreensão e auxílio ao desenvolver este trabalho tão importante.
Ao professor André Luiz, do Departamento de Estatística da UFRN, por ter me auxiliado na exploração inicial dos modelos aplicados às séries temporais e na compreensão de alguns testes de análise destes modelos. E ao professor Adrião, do Departamento de Engenharia da Computação e Automação da UFRN, e, em especial, ao Carlos Padilha e colegas do laboratório de Sistemas Inteligentes da UFRN, sem os quais não teria conseguido realizar a bendita modelagem com as Redes Neurais Artificiais.
Aos professores Dr. Luciano Sampaio, Dr. Vinicio de Souza e Almeida e Dr. Rodrigo Leone por suas preciosas contribuições ao trabalho feito, realizadas por meio de sua participação em minhas bancas examinadoras de Qualificação e de Defesa desta dissertação.
“Penso noventa e nove vezes e nada descubro; deixo de pensar, mergulho em profundo silêncio - e eis que a verdade se me revela.”
Resumo
Nas organizações, a previsão constitui a base para a tomada de decisões estratégicas, táticas e operacionais. Na economia financeira, diversas técnicas têm sido usadas a fim de prever o comportamento de ativos no decorrer das últimas décadas. Assim, existem diversos métodos para auxiliar na tarefa de previsão de séries temporais, entretanto, técnicas de modelagem convencionais como modelos estatísticos e aqueles baseados em modelos matemáticos teóricos têm produzido previsões insatisfatórias, aumentando o número de estudos em métodos mais avançados de previsão. Dentre estes, as Redes Neurais Artificiais (RNA) são um método relativamente recente e promissor para a previsão em negócios que se revela uma das técnicas que tem causado muito interesse no ambiente financeiro e tem sido utilizado com sucesso em uma ampla variedade de aplicações de sistemas de modelagem financeiro, provado em muitos casos sua superioridade sobre os modelos estatísticos ARIMA-GARCH (OLIVEIRA,2007). Nesse contexto, o presente trabalho teve por objetivo analisar se as RNAs são um método mais adequado para a previsão do comportamento de Índices em Mercados de Capital do que métodos tradicionais de análise de séries temporais. Para tanto, foi desenvolvido um estudo quantitativo que, a partir de índices econômico financeiros, elaborou dois modelos de RNA do tipo feedfoward de aprendizado supervisionado, cujas estruturas consistiram em 20 dados na camada de entrada, 90 neurônios em uma camada oculta e um dado como camada de saída (índice Ibovespa). Estes modelos utilizaram BackPropagation, função de ativação de entrada baseada na tangente Sigmoid e uma função de saída linear. Visto o intuito de analisar a aderência do Método de Redes Neurais Artificiais à realização de previsões do Ibovespa, optou-se por realizar tal análise por meio da comparação de resultados entre este e o Método de previsão em séries temporais GARCH, desenvolvendo-se um modelo GARCH (1,1). Uma vez aplicadas ambas as metodologias (RNA e GARCH) e desenvolvidos os modelos, realizou-se a análise dos resultados obtidos comparando-se os resultados das previsões com os dados históricos e estudando-se os erros de previsão por meio do MSE, RMSE, MAE, Desvio Padrão, U de Theil e teste abrangente da previsões. Verificou-se que os modelos deVerificou-senvolvidos por meio de RNAs apreVerificou-sentaram menores MSE, RMSE e MAE que o modelo de controle e o teste U de Theil indicou que os três modelos estudados apresentam erros menores que os de uma previsão ingênua. Embora a RNA baseada em retornos tenha apresentado valores dos indicadores de precisão inferiores aos da RNA baseada em preços, o teste abrangente de regressões rejeitou a hipótese de que este modelo seja superior que aquele, indicando que os modelos de RNA apresentam um nível semelhante de precisão. Concluiu-se que, para a série de dados estudada neste trabalho, as Redes Neurais artificiais se mostram um modelo mais adequado de previsão do que os modelos tradicionais de séries temporais, representado neste pelo método GARCH.
Abstract
Forecast is the basis for making strategic, tactical and operational business decisions. In financial economics, several techniques have been used to predict the behavior of assets over the past decades.Thus, there are several methods to assist in the task of time series forecasting, however, conventional modeling techniques such as statistical models and those based on theoretical mathematical models have produced unsatisfactory predictions, increasing the number of studies in more advanced methods of prediction. Among these, the Artificial Neural Networks (ANN) are a relatively new and promising method for predicting business that shows a technique that has caused much interest in the financial environment and has been used successfully in a wide variety of financial modeling systems applications, in many cases proving its superiority over the statistical models ARIMA-GARCH. In this context, this study aimed to examine whether the ANNs are a more appropriate method for predicting the behavior of Indices in Capital Markets than the traditional methods of time series analysis. For this purpose we developed an quantitative study, from financial economic indices, and developed two models of RNA-type feedfoward supervised learning, whose structures consisted of 20 data in the input layer, 90 neurons in one hidden layer and one given as the output layer (Ibovespa). These models used backpropagation, an input activation function based on the tangent sigmoid and a linear output function. Since the aim of analyzing the adherence of the Method of Artificial Neural Networks to carry out predictions of the Ibovespa, we chose to perform this analysis by comparing results between this and Time Series Predictive Model GARCH, developing a GARCH model (1.1).Once applied both methods (ANN and GARCH) we conducted the results' analysis by comparing the results of the forecast with the historical data and by studying the forecast errors by the MSE, RMSE, MAE, Standard Deviation, the Theil's U and forecasting encompassing tests. It was found that the models developed by means of ANNs had lower MSE, RMSE and MAE than the GARCH (1,1) model and Theil U test indicated that the three models have smaller errors than those of a naïve forecast. Although the ANN based on returns have lower precision indicator values than those of ANN based on prices, the forecast encompassing test rejected the hypothesis that this model is better than that, indicating that the ANN models have a similar level of accuracy . It was concluded that for the data series studied the ANN models show a more appropriate Ibovespa forecasting than the traditional models of time series, represented by the GARCH model.
LISTA DE FIGURAS
Figura 1: Modelo não linear de neurônio artificial. ... 27
Figura 2: Rede feedforward de uma única camada de neurônios. ... 28
Figura 3: Rede feedforward de múltiplas camadas ... 28
Figura 4: Funcionamento de uma RNA feedfoward. ... 29
Figura 5: Rede feedforward de múltiplas camadas e redes recorrentes. ... 30
Figura 6: aprendizado supervisionado. ... 31
Figura 7: Estrutura Inicial da RNA ... 38
Figura 8: Estrutura Final da RNA ... 38
Figura 9: Arquitetura da Rede Neural Artificial ... 39
Figura 10: comportamento da série de preços (IBOV) e de retornos do Ibovespa (RIBOV). 41 Figura 11: Gráfico de distribuição e estatísticas descritivas da série RIBOV. ... 42
Figura 12: Comportamento da RNA (preços) em comparação com os dados históricos – etapa de treinamento. ... 46
Figura 13: Comportamento da RNA em comparação com os dados históricos – etapa de utilização. ... 47
Figura 14: Comportamento do erro e seu desvio padrão (RNA – preços). ... 47
Figura 15: Comportamento do erro e seu desvio padrão (RNA – preços, após conversão de seus resultados para retornos). ... 48
Figura 16: Comportamento da RNA (retornos) em comparação com os dados históricos – etapa de treinamento. ... 48
Figura 17: Comportamento da RNA (retornos) em comparação com os dados históricos – etapa utilização. ... 49
Figura 18: Comportamento do erro e seu desvio padrão (RNA – retornos). ... 49
Figura 19: Representação gráfica dos resultados obtidos pelo modelo GARCH (1,1) ... 51
LISTA DE QUADROS
LISTA DE TABELAS
Tabela 1: Teste de estacionariedade. ... 41
Tabela 2: Autocorrelação e autocorrelação parcial da série RIBOV. ... 42
Tabela 3: Resultados do Modelo ARMA (1,1) para geração de resíduos para estudo. ... 43
Tabela 4: Testes de efeitos ARCH. ... 43
Tabela 5: Resultados do Modelo GARCH para previsão do RIBOV. ... 50
Tabela 6: Teste de Efeitos ARCH, após a modelagem do GARCH (1,1). ... 50
Tabela 7: RMSE, MAE e Desvios Padrão dos erros de previsão dos modelos. ... 52
LISTA DE SIGLAS E ABREVIATURAS
ADF – Dickey-Fuller Aumentado (Teste de)
AR – Autoregressive Model (Modelo Auto Regressivo)
ARCH – Autoregressive Conditional Heterocedasticity Model (Modelo Autoregressivo de Heterocedasticidade Condicional)
ARIMA – Autoregressive Integrated Moving-Average Model (Modelo Auto-regressivo Integrado de Médias Móveis)
ARMA – Autoregressive-Moving-Average Model (Modelo Auto-regressivo de Médias Móveis )
BM&F Bovespa – Bolsa de Valores, Mercadorias e Futuros de São Paulo
GARCH – Generalized Autoregressive Conditional Heterocedasticity Model (Modelo de Heterocedasticidade Condicional Auto-Regressiva Generalizada)
IBOVESPA – Índice Bovespa
IBRA – Índice Brasil Amplo BM&F BOVESPA
IBrX – Índice Brasil BM&F BOVESPA
IBrX-50 – Índice Brasil 50 BM&F BOVESPA
ICO2 – Índice Carbono Eficiente BM&F BOVESPA
ICON – Índice BM&F BOVESPA de Consumo
IDIV – Índice de Dividendos BM&F BOVESPA IEE – Índice de Energia Elétrica BM&F BOVESPA
IFNC – Índice BM&F BOVESPA Financeiro
IGC – Índice de Ações com Governança Corporativa Diferenciada BM&F BOVESPA
IGCT – Índice BM&F BOVESPA de Governança Corporativa Trade
IMAT – Índice de Materiais Básicos BM&F BOVESPA
IMOB – Índice BM&F BOVESPA Imobiliário
INDX – Índice do Setor Industrial BM&F BOVESPA
ISE – Índice de Sustentabilidade Empresarial BM&F BOVESPA
ITAG – Índice de Ações Tag Along Diferenciado BM&F BOVESPA
ITEL – Índice Setorial de Telecomunicações BM&F BOVESPA
MA – Moving-Average Model (Modelo de Médias Móveis)
MAE – Mean Absolute Error (Erro Médio Absoluto) MLCX – Índice BM&F BOVESPA Mid-Large Cap
MSE – Mean Squared Error (Erro Quadrado Médio) RIBOV – Série de Retornos diários do Ibovespa
RMSE – Root Mean Squared Error (Raiz do Erro Quadrado Médio) RNA – Rede Neural Artificial
SMLL – Índice BM&F BOVESPA Small Cap
SUMÁRIO
1 INTRODUÇÃO ... 15
1.1 CONTEXTUALIZAÇÃO E PROBLEMA ... 15
1.2 JUSTIFICATIVA ... 18
1.3 OBJETIVOS ... 20
1.3.1 OBJETIVO GERAL: ... 20
1.3.2 OBJETIVOS ESPECÍFICOS ... 20
2. REDES NEURAIS ARTIFICIAIS (RNAs) ... 21
2.1 CONSIDERAÇÕES INICIAIS ... 21
2.2 AS REDES NEURAIS ARTIFICIAIS ... 23
2.2.1 O NEURÔNIO ARTIFICIAL ... 26
2.2.2 ARQUITETURA DE RNA ... 27
2.2.3 APRENDIZAGEM ... 30
2.2.4 IMPLEMENTANDO UMA RNA ... 32
2.2.4.1 DEFINIÇÃO DA REDE E ESCOLHA DO SOFTWARE ... 32
2.2.4.2 OBTENÇÃO DE DADOS ... 32
2.2.4.3 TREINAMENTO ... 32
2.2.4.4 ETAPA DE TESTES (UTILIZAÇÃO DA RNA) ... 33
2.2.4.5 MANUTENÇÃO ... 33
3 METODOLOGIA ... 34
3.1 TIPO DA PESQUISA ... 34
3.2 AMOSTRAGEM ... 34
3.3 COLETA DE DADOS ... 35
3.4 TRATAMENTO DOS DADOS ... 36
3.4.1 TRATAMENTO DOS DADOS PARA A RNA ... 36
3.4.2 TRATAMENTO DOS DADOS PARA O MODELO DE CONTROLE... 39
3.5 PROCEDIMENTO DA ANÁLISE DOS RESULTADOS ... 43
4 RESULTADOS E ANÁLISE ... 46
4.1 REDES NEURAIS ARTIFICIAIS ... 46
4.1.1 RNA BASEADA EM PREÇOS ... 46
4.1.2 RNA BASEADA EM RETORNOS ... 48
4.2 MODELO DE CONTROLE - GARCH (1,1) ... 49
4.3 ANÁLISE DOS RESULTADOS ... 52
5 CONSIDERAÇÕES FINAIS ... 54
1 INTRODUÇÃO
Este capítulo discorre sobre o contexto no qual se insere este trabalho, apresentando o problema e justificativa de pesquisa, bem como os objetivos gerais e específicos que nortearam o desenvolvimento da mesma.
1.1 CONTEXTUALIZAÇÃO E PROBLEMA
Tendo em vista a complexidade crescente do ambiente em que as organizações estão inseridas, torna-se necessária a busca de informações além de suas fronteiras de maneira prospectiva, à procura de obtenção de vantagem competitiva (ALMEIDA; DUMONTIER, 1996).
Nas organizações, a previsão constitui a base para a tomada de decisões estratégicas, táticas e operacionais, tendo um papel importante para realizar em economia e finanças, uma vez que essas são ciências de decisão preocupadas com os efeitos das decisões (PANDA; NARASIMHAN; 2006).
De acordo com Morettin e Toloi (2006, p7), etimologicamente a palavra previsão, que tem origem das palavras prae e vidare, “sugere que se quer ver uma coisa antes que ela
exista”. Essencialmente, a previsão supõe que “as condições presentes e passadas determinam
em algum grau o futuro de tal forma que pode haver muitas interações e complexas relações
entre as variáveis envolvidas” (OLIVEIRA, 2004, p.1).
Complementando, Ribeiro (2009) destaca que para que seja possível prever os valores futuros com base em valores passados, faz-se necessária a disponibilidade de uma memória histórica de dados ocorridos anteriormente. Entretanto, o conjunto de dados, por si só, não permite a previsão dos valores futuros, de forma que, para isso, faz-se necessária a utilização de algoritmos, técnicas ou métodos de previsão de séries temporais, que podem envolver cálculos simples ou procedimentos complexos (RIBEIRO, 2009).
ao contrário das séries determinísticas, nas quais os valores futuros de uma série
temporal são determinados exatamente por alguma função matemática, nas séries temporais estocásticas (não-determinísticas), os valores futuros podem ser descritos apenas em termos de uma distribuição de probabilidade à série temporal (OLIVEIRA, 2007).
Existem diversos métodos para auxiliar na tarefa de previsão de séries de tempo, como por exemplo: modelos de Suavização Exponencial, modelos auto-regressivos (AR), de Médias Móveis (MA), Modelos ARIMA, ARCH e GARCH.
Os métodos lineares são fáceis de serem desenvolvidos e implementados, além de serem, relativamente, simples de entender e interpretar. Porém, mesmo tendo dominado os processos de previsão por várias décadas, apresentam sérias limitações no fato de não serem capazes de capturar todas as relações não-lineares nos dados (ZHANG, 2004). Segundo Oliveira (2007), as técnicas de modelagem convencionais têm produzido previsões insatisfatórias, onde suas principais desvantagens seriam, em suma, seu alto grau de subjetividade com respeito à estrutura do modelo e sua base de informação limitada (ZHANG, 2004; OLIVEIRA, 2004; OLIVEIRA, 2007).
Por outro lado, o recente avanço da capacidade de processamento dos computadores deu grande impulso ao uso de métodos quantitativos em Administração (ALMEIDA; PASSARI, 2006) e permitiu que tecnologias de Inteligência Computacional, como Redes Neurais, Lógica Nebulosa e Algoritmos Genéticos, proporcionassem a criação de metodologias avançadas de previsão (PALIT; POPOVIC, 2005). Desta forma, modelos financeiros que exigem forte desempenho computacional agora podem ser explorados de maneira mais fácil.
Este é o caso das Redes Neurais Artificiais (RNAs), que se mostram um método relativamente recente e promissor para a previsão em negócios (ZHANG, 2004) e tem recebido muita atenção nos campos de economia e finanças (CARVALHAL; RIBEIRO, 2007; THAWORNWONG; ENKE, 2004).
Embora desenvolvidas originalmente com o propósito de entender o funcionamento do cérebro humano, a constante interação dos pesquisadores através de disciplinas que tentavam aplicar as atividades neurológicas do cérebro a funções de classificação tornaram-nas uma tendência multidisciplinar (WALLACE, 2008).
mais variadas situações que envolvem problemas reais de diversas áreas, incluindo Finanças e Economia (OLIVEIRA; MONTINI; BERGMAN, 2008).
Existem aplicações de RNAs encontradas nas áreas de Finanças, Gestão de Pessoas, Marketing, Médica, Engenharia e muitas outras. Esta tecnologia de informação baseada no funcionamento do cérebro humano propõe o uso de um enorme volume de dados disponíveis, que muitas vezes são pouco ou mal utilizados, transformando-os em informação útil à tomada de decisões (BOSAIPO, 2001).
Na área da Administração Financeira, as RNAs têm sido usadas para prever falência, taxa de câmbio, taxa de juros, preço de futuros, retorno acionário, volume de negociação, índice do Mercado de Capitais, preço da oferta pública inicial, valor da propriedade e outros (ZHANG, 2004). Além disso, estudos que utilizam este modelo têm obtido sucesso em uma ampla variedade de aplicações de sistemas e modelagem financeiros (OLIVEIRA, 2007), provando em muitos casos “sua superioridade sobre os modelos estatísticos ARIMA-GARCH (MEDEIROS et al, 2006; MEDEIROS, 2007).
A previsão em Mercado de Ações torna-se difícil porque este é influenciado por fatores diversos como eventos políticos, condições econômicas gerais e as expectativas dos investidores (OH; KIM, 2002).
Os preços das ações podem variar por fatores relacionados à empresa ou por fatores externos, como o crescimento do país, do nível de emprego e da taxa de juros (BM&F BOVESPA, 2011). Tendo isto em vista, a Bolsa de Valores, Mercadorias e Futuros de São Paulo (BM&F BOVESPA) – principal instituição brasileira de intermediação para operações financeiras, com o intuito de orientar as decisões de investimento, criou alguns índices que buscam retratar a situação dos investimentos realizados durante os pregões. Esses índices são indicadores de desempenho de um conjunto de ações, ou seja, mostram a valorização de um determinado grupo de papéis ao longo do tempo.
Atualmente existem 21 Índices da BM&F BOVESPA, onde cada um mostra o comportamento de um grupo diferente de ações. Destes, o Índice de maior destaque é o Ibovespa (Índice Bovespa), que tem por finalidade básica “servir como indicador médio do comportamento do mercado. Para tanto, sua composição procura aproximar-se o mais possível da real configuração das negociações à vista (lote-padrão) na BM&F BOVESPA” (BM&F BOVESPA, 2011, s/n).
80% do número de negócios e do volume financeiro verificados no Mercado à Vista (lote-padrão) da BM&F BOVESPA.
Dentre os estudos que utilizam Redes Neurais para previsão no Mercado Financeiro, costuma-se focalizar os preços dos ativos, como os trabalhos de Kalyvas (2001) e Oliveira (2007), entretanto, ao se trabalhar com previsão de Índices, como o trabalho de Carvalhal e Ribeiro (2007), passa-se a trabalhar com o comportamento não de um ativo em especial, mas sim do comportamento de um segmento do mercado.
Nesta conjuntura, este trabalho enfoca a seguinte questão- problema:
Seriam as Redes Neurais Artificiais um método aderente para a previsão do
comportamento do Índice Bovespa?
1.2 JUSTIFICATIVA
Novas tecnologias de informática frequentemente tornam mais competitivas as empresas que delas souberam tirar proveito antes da concorrência, uma vez que o uso desses sistemas lhes permitem tanto reduzir custos quanto oferecer um serviço diferenciado aos clientes. (ALMEIDA, 1995, p.47).
A capacidade de prever o futuro apuradamente é fundamental para muitos processos de decisão em planejamento, programação, aquisição, formulação da estratégia, definição de políticas e operações da cadeia de suprimentos (ZHANG, 2004). No campo da Administração Financeira, a maioria das empresas administra seus recursos com alocação de parte dos ativos em investimentos de diversos tipos, procurando garantir melhores receitas e lucros para seus acionistas e, para isto, boas técnicas de previsão e de auxílio à tomada de decisões são imprescindíveis.
Ao longo das últimas décadas, muitas tendências importantes mudaram o ambiente dos Mercados Financeiros e diversas técnicas têm sido usadas a fim de prever o comportamento de ativos.
comportamento geral do mercado por meio de um único indicador. Desta forma o presente estudo tem sua relevância teórica justificada, uma vez que trabalha métodos de previsão em Mercado de Capitais, com base em Índices de Mercado, contribuindo para o desenvolvimento dos estudos em Finanças no Brasil.
As Redes Neurais estão propondo soluções interessantes a problemas de várias áreas de Administração, Como Finanças, Marketing, Vendas e Compras, ou mesmo Gestão de Pessoas. É uma tecnologia relativamente recente, e diversas áreas de aplicação estão por ser exploradas. (CARVALHAL; RIBEIRO, 2007; ALMEIDA, 1995).
Segundo Oliveira et al (2008, p.132):
Do ponto de vista teórico, o processamento de sinais não-lineares (LAPEDES; FABER 1987), a incorporação do tempo na rede neural (ELMAN, 1988) e o modelamento não-linear para previsão de séries temporais caóticas (CASDAGLI, 1989) têm sido aplicados como ferramenta na tomada de decisão em finanças (HAWLEY et al., 1990; REFENES,1993), análise de mercado (FISHMAN et al., 1991), modelamento não-linear e previsão (CASDAGLI; EUBANK.,1992; AZZOF, 1993; CLEMENTS; HENDRY, 1999). Mais recentemente tem havido a preocupação de comparar e relacionar a tecnologia de redes neurais com a abordagem estatística tradicional (CHENG; TITTERINGTON, 1994; RIPLEY, 1993, 1994, 1996; MEDEIROS et al., 2006), sob a perspectiva econométrica (KUAN; WHITE, 1994), de engenharia financeira (ABU-MOSTAFA et al., 2001) e macroeconômica (TERASVIRTA et al., 2005).
Diversas pesquisas na área da Administração Financeira vêm sendo realizadas abrangendo variados tópicos, como: vendas no varejo (ALMEIDA; PASSARI, 2006), previsões de avaliação de crédito (STEINER et al, 1999; LEMOS et al, 2005; KUMAR; BUTTACHARYA, 2006), estudos no Mercado Financeiro (DUTTA et al, 2006), Mercado de Ações (LAM;LAM, 2000; OH; KIM, 2002; KIM; LEE, 2004; PANDA, NARASIMHAN, 2006) e Índices de ações (CARVALHAL, RIBEIRO, 2007).
Desta forma, verifica-se a relevância deste método, a qual é reforçada uma vez que as Redes Neurais Artificiais virem sendo aplicadas a inúmeras situações, como diagnósticos médicos, inspeções de produtos, exploração de petróleo, controle aéreo (GATELY, 1996), bem como em áreas financeiras, onde têm encontrado aplicações em predição de ações, fraude em cartões de crédito, predição de falência, preço de arbitragem e etc.
Paulo. Quanto à relevância metodológica, esta se deve ao uso de modelos estatísticos ainda pouco utilizados em trabalhos específicos da área de Administração no Brasil – as RNAs, aspirando-se contribuir para a evolução dos estudos em Administração Financeira por meio da utilização de modelos que viabilizem estudos com resultados mais precisos.
Do ponto de vista prático, a realização desta pesquisa justifica-se na medida em que seus resultados possam servir de parâmetro de decisão para investimentos de empresas ou acionistas. Desta forma, contribui com informações para uma gestão de capital mais eficiente. Ademais, no âmbito dos estudos em Mercado de Capitais, a presente pesquisa oferece a avaliação de um método ainda pouco utilizado no mercado e pode vir a validar uma forte ferramenta para predição do comportamento de ativos, função cada vez mais importante visto a crescente complexidade das inter-relações em Mercados Financeiros.
Por fim, a realização deste estudo justifica-se também por ser de interesse pessoal da pesquisadora, a qual é, atualmente, Especialista em Administração Financeira e, tendo esta área como parte integrante de sua vida, considera que esta pesquisa terá grande importância para seu desenvolvimento, agregando conhecimento para uso próprio no decorrer de sua vida acadêmica e profissional.
1.3 OBJETIVOS
1.3.1 OBJETIVO GERAL:
Investigar se o método de Redes Neurais Artificiais resulta em melhor ajuste na
previsão do comportamento do Índice Bovespa, comparativamente aos métodos
tradicionais de Séries de Tempo.
1.3.2 OBJETIVOS ESPECÍFICOS
- Desenvolver modelos utilizando RNAs voltados à predição do comportamento do Índice Bovespa;
- Aplicar um modelo de previsão de séries temporais ARCH-GARCH como modelo de controle para a avaliação da adequação do modelo de Rede Neural Artificial;
2. REDES NEURAIS ARTIFICIAIS (RNAs)
Este capítulo trata do referencial bibliográfico utilizado como base para este trabalho. Desta forma, apresentam-se algumas considerações acerca de séries temporais e previsões financeiras para, então, explanarem-se os princípios sobre as Redes Neurais Artificiais e como elas podem ser utilizadas e implementadas.
2.1 CONSIDERAÇÕES INICIAIS
De acordo com Lima et al (2010, p.189), uma série temporal pode ser conceituada
como “qualquer conjunto de variáveis estocásticas equiespaçadas e ordenadas no tempo {Xt}nt-1 = {X1, X2, ..., Xn}”. Onde, qualquer
sinal que depende do tempo e é medido em instantes particulares no tempo pode ser representado por uma série temporal (ENDERS,2003). Conforme Morettin (2002), o que se chama de série temporal é uma parte de uma trajetória, dentre muitas que poderiam ter sido observadas, de um processo estocástico. (LIMA et al, 2010, p.189)
Segundo o autor, o objetivo principal da análise de séries temporais é a realização de previsões. E, para isto, utiliza-se uma metodologia que estabelece mecanismos onde “valores futuros de uma série possam ser previstos com base apenas em seus valores presentes e passados. As técnicas desse processo de previsão fundamentam-se na exploração da
correlação temporal que pode existir entre os valores exibidos pela série” (LIMA et al, 2010, p.189).
Uma vez que os modelos utilizados para descrever séries temporais são processos estocásticos, ou seja, controlados por leis probabilísticas, os modelos de previsão analisam as propriedades estocásticas destas séries com base nos valores passados das próprias variáveis e do termo estocástico (termo de erro). Onde
ao contrário das séries determinísticas, nas quais os valores futuros de uma série temporal são determinados exatamente por alguma função matemática, nas séries temporais estocásticas (não-determinísticas), os valores futuros podem ser descritos apenas em termos de uma distribuição de probabilidade à série temporal (OLIVEIRA, 2007).
propostos são modelos paramétricos (com número definido de parâmetros) e na segunda os modelos propostos são modelos não-paramétricos (MORETTIN; TOLOI, 2006)
Independente da classificação para os modelos de séries temporais, pode-se considerar um número muito grande de modelos diferentes para descrever o comportamento de uma série em particular. A construção destes modelos depende de vários fatores, tais como o comportamento do fenômeno ou o conhecimento a priori que temos de sua natureza e do objetivo da análise (MORETTIN; TOLOI, 2006). Na prática, depende, também, da existência de métodos apropriados de estimação e da disponibilidade de programas (softwares) adequados.
Normalmente as séries temporais podem conter cinco características: Tendência, sazonalidade, algum ponto de influência discrepante, uma variância que se altera no tempo – heterocedasticidade condicional e, não linearidade (OLIVEIRA, 2007). Tipicamente, uma série temporal econômica apresenta pelo menos duas ou três dessas características.
Muitos modelos financeiros dependem de entendimento de séries temporais para predizer a funcionalidade dos Mercados Financeiros e utilizam inferências estatísticas para fins de prospecção. As séries temporais são uma forma especial de dados onde os valores passados podem influenciar os valores futuros. E a relação entre variáveis influenciadas pelo tempo, em finanças, pode ser caracterizada por tendências, ciclos, e o comportamento não-estacionário entre pontos de dados que servem a um propósito de previsão ou informação para o modelo (WALLACE, 2008)
O nível de sucesso destes métodos de previsão varia de estudo para estudo e depende dos conjuntos de dados subjacentes e a forma que estes métodos são aplicados a cada vez. No entanto, nenhum deles foi provado ser a ferramenta de previsão consistente que o investidor gostaria de ter (KALYVAS, 2001).
Na literatura, diferentes métodos têm sido aplicados de forma a prever retornos de ações no mercado. Estes métodos podem ser agrupados em quatro categorias principais: 1) métodos de análise técnica, 2) métodos de análise fundamentais, 3) previsões tradicionais de séries temporais e 4) métodos de aprendizado de máquina.
Os modelos de previsão em séries temporais podem ser estacionários, como os modelos ARMA, ou não estacionários, como os modelos ARCH e GARCH. Entretanto, embora modelos lineares venham sendo utilizados no passado para extrair essas relações, existem relações não-lineares entre diversas variáveis financeiras. Desta forma, métodos como as Redes
mapear valores futuros de séries temporais, de modo a extrair estruturas ocultas e das relações que
podem governar os dados (WALLACE, 2008).
2.2 AS REDES NEURAIS ARTIFICIAIS
As origens das Redes Neurais Artificiais
remontam a cerca de 50 anos em estudos matemático-estatísticos, mas só obtiveram grande interesse a partir da década de 1980 com a evolução dos computadores, que possibilitaram não só processamento de número muito maior de simulações, como também a aceitação do modelo de computação paralela em computadores mais rápidos, permitindo, então, a construção dos algoritmos. (BIALOSKORSKI NETO
et al, 2006, p.61)
De acordo com Gately (1996) mesmo perante a existência de computadores com poder para se começar pesquisas práticas em Redes Neurais artificiais disponíveis desde o final da década de 1970, apenas a partir de 1986, com o desenvolvimento da retro-propagação, tornou-se possível que Redes Neurais Artificiais resolvestornou-sem problemas científicos, de negócios e industriais do dia-a-dia.
Além do fator tecnológico, Wallace (2008) aponta que o relativamente recente aumento no interesse e uso de modelos neurais tem origem em seus modelos não-lineares, que podem ser treinados para mapear valores passados e futuros das relações entre entradas e saídas, adicionando valor analítico através da possibilidade de extração de relações entre os dados que não seriam tão óbvias utilizando outras ferramentas de análise (WALLACE, 2008).
De uma forma mais geral, uma Rede Neural Artificial pode ser considerada “uma
máquina projetada para modelar a maneira como o cérebro realiza uma tarefa particular ou função de interesse; sendo normalmente implementada utilizando-se componentes eletrônicos
ou simulada por uma programação em um computador digital” (HAYKIN, 2001, p.28). Ou, em outras palavras, “um software que imita a habilidade do cérebro humano de classificar
padrões ou de fazer previsões e decisões baseado em experiências passadas” (GATELY, 1996, p.3).
De acordo com Wallace (2008), ela é basicamente, uma técnica de processamento de dados que liga cursos de entradas com a saída, seu uso pode ser caracterizado por quatro tipos de aplicações:
1. Classificação por linha de entrada (Input stream)
2. Associação com a saída dados os agrupamentos de setores de entrada
3. Codificação de entrada por saída produzida dentro de um subespaço dimensional reduzido;
4. Simulação de saída a partir dos relacionamentos e interconexões das entradas (inputs)
O sucesso das aplicações das Redes Neurais Artificiais pode ser atribuído às suas características únicas e poderosa capacidade de reconhecimento de padrões. Diferente da maioria das técnicas tradicionais de previsão, os modelos de RNAs auto-organizados possuem a vantagem de não exigirem do usuário a aplicação de nenhuma teoria acerca da organização destes dados, e podem fornecer subsídios para a atualização ou mesmo formulação de novas teorias acerca do assunto em questão. Em outras palavras, a novidade das Redes Neurais reside na sua capacidade para modelar processos não-lineares, sem suposições a priori sobre a natureza do processo de geração, permitindo seu emprego como alternativa aos modelos tradicionais (THAWORNWONG; ENKE, 2004; ZHANG, 2004; WALLACE, 2008; BRIESCH; RAJAGOPAL, 2010; LIMA et al, 2010).
Estas características:
são particularmente interessantes para situações concretas de previsão em que os dados são abundantes e facilmente disponíveis, mas o modelo teórico ou a relação subjacente não é conhecido. Além disso, uma RNA tem uma capacidade de aproximação funcional universal e são capazes de captar qualquer tipo de relação complexa. Como o número de possíveis relações não-lineares em dados de negócio geralmente é grande, RNAs têm a vantagem de aproximá-los bem. (ZHANG, 2004, p.vi)
Como todo modelo, as RNAs possuem pontos fortes e fracos em comparação com outros métodos. Sendo um de seus pontos fortes, a habilidade de facilmente acomodar relações lineares e não-lineares, visto que o pesquisador não precisa especificar formas funcionais com antecedência.
aplicação de RNAs em previsões de séries de tempo – como a possibilidade de utilização de diversas variáveis e capacidade de aprender sozinha sobre as relações entre as variáveis, alguns pontos fracos.
Destaca-se que parte dos pontos fracos apontados no quadro 1 referem-se a uma nova perspectiva, ou mesmo consequência, de diferenças entre os modelos já mencionadas. Este é o caso, por exemplo, da ausência da necessidade de uma noção prévia das relações entre as variáveis e seu embasamento teórico, previamente destacada como um ponto positivo das RNAs, que passa a ser apontada como desvantagem através da analogia das mesmas com
“caixas pretas”, uma vez que seus resultados podem ser obtidos sem a necessidade de se basearem na teoria.
Quadro 1: Comparação entre RNAs e Modelos Lineares Gerais.
Fonte: Adaptado de Briesch e Rajagopal, 2010, p.382.
De acordo com Oliveira, Montini e Bergman (2008), as RNAs constituem uma ferramenta flexível amplamente utilizada para a análise de séries temporais e sua aplicação tem sido feita em diversas áreas, como Finanças e Economia. Segundo os autores, “estas redes fornecem uma grande variedade de modelos matemáticos não-lineares, úteis para resolver diferentes problemas em que são empregadas convencionalmente técnicas estatísticas” (OLIVEIRA; MONTINI; BERGMAN, 2008, p.132).
trabalho, optou-se pela utilização do termo Rede Neural Artificial (RNA) ou, ocasionalmente, apenas Redes Neurais.
2.2.1 O NEURÔNIO ARTIFICIAL
Basicamente, as características das RNAs são formuladas através do estudo da célula fundamental do cérebro, o neurônio, e reproduzidas através de algoritmos que procuram simular o funcionamento de um conjunto de neurônios (HAYKIN, 2001).
Trabalhando analogicamente com o cérebro humano, as Redes Neurais empregam uma interligação maciça de células computacionais simples denominadas “neurônios” ou
“unidades de processamento” (HAYKIN, 2001). E, segundo Haykin (2001), assemelham-se ao cérebro em dois aspectos:
1.O conhecimento é adquirido pela rede a partir de seu ambiente através de um processo de aprendizagem; e
2. Forças de conexão entre neurônios, conhecidas como pesos sinápticos, são utilizadas para armazenar o conhecimento adquirido.
Através dos neurônios e suas ligações, de forma computacional, as informações interligam-se por uma rede na qual cada unidade recebe e combina uma série de entradas numa única saída, que dá entrada a uma nova unidade até a saída final da rede, ou a resposta ao problema (BIALOSKORSKI NETO et al, 2006).
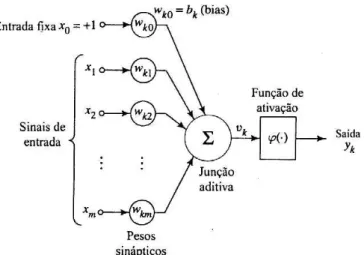
A estrutura de um neurônio, como ilustrada na figura 1, permite um conjunto de valores como entradas (x1, x2, ..., xm) para a produção de uma saída única (yk). Tais entradas
são ponderadas por respectivos pesos sinápticos (wk1, wk2, ...wkm) e somadas ao valor de um
bias bk aplicado externamente. O bias bk tem o efeito de aumentar ou diminuir a entrada
líquida da função de ativação, dependendo se ele é positivo ou negativo. Em seguida uma
Figura 1: Modelo não linear de neurônio artificial. Fonte: Haykin, 2001, p.38.
A função de ativação ϕ(.)define a saída de um neurônio, a regra para o mapeamento das entradas somadas do neurônio até sua saída, introduzindo a capacidade de processar a não-linearidade na rede (OLIVEIRA et al, 2008). Segundo Oliveira et al (2008) e Haykin (2001), a função de ativação mais comum utilizada na construção de RNAs é a sigmoide,
definida por uma função “de estreitamento crescente que exibe um balanceamento adequado entre comportamento linear e não linear” (HAYKIN, 2001, p.40). A função sigmoide pode ser expressa por:
Onde g é o ganho, ou parâmetro de inclinação da função sigmoide.
O processamento realizado pelos neurônios, além de estar disposto em uma arquitetura paralela, também lança mão de uma propagação sequencial na qual os neurônios de camadas posteriores recebem como sinal de entrada o resultado do processamento ocorrido nas camadas anteriores (ZHANG et al, 2004; PANDA; NARASIMHAN, 2006). Estas operações consistem na multiplicação do valor de cada entrada pelo respectivo peso associado e na posterior soma para resultar em um valor (BOSAIPO, 2001). Nos modelos de Redes Neurais Artificiais, estas características são simuladas através da adoção de estado, função e limiar de ativação (BRAGA; CARVALHO; LUDERMIR, 2007).
A estrutura da Rede Neural, composta de interconexões de neurônios, pode variar quanto ao número de camadas, neurônios em cada camada, função de ativação dos neurônios em uma camada e a forma como as camadas são conectadas (totalmente ou parcialmente).
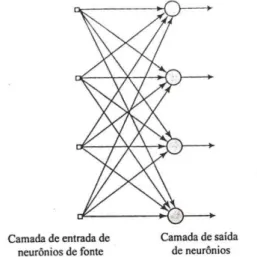
Existem basicamente três tipos de arquitetura de RNA: redes feedforward (alimentada adiante) de camada única, redes feedforward de múltiplas camadas e redes recorrentes.
As redes feedfoward, também conhecidas por redes alimentadas adiante ou acíclicas, podem ser de camada única (Figura 2) ou de múltiplas camadas (Figura 3). Onde a designação
“camada única” se refere à camada de saída dos neurônios, não sendo contabilizada a camada
de entrada dos neurônios uma vez que nela não é realizada qualquer computação.
Figura 2: Rede feedforward de uma única camada de neurônios. Fonte: Haykin, 2001, p.47.
As RNAs acíclicas de múltiplas camadas se distinguem pela presença de uma ou mais camadas ocultas, cujos nós computacionais são chamados correspondentemente de neurônios ocultos ou unidades ocultas (HAYKIN, 2001). A função desses neurônios é intervir entre a entrada externa e a saída da rede de uma maneira útil.
Convindo ressaltar que uma Rede Neural do tipo feedforward é especialmente adequada para realizar previsão de séries que apresentam volatilidade, devido ao tratamento da não-linearidade realizada pela utilização de funções sigmoides na camada de entradas (OLIVEIRA et al, 2008).
O funcionamento de um RNA do tipo feedfoward pode ser retratado pela figura 4, abaixo:
Figura 4: Funcionamento de uma RNA feedfoward. Fonte: Adaptado de Wallace, 2008, p.71.
Figura 5: Rede feedforward de múltiplas camadas e redes recorrentes. Fonte: Braga, Carvalho e Ludemir, 2007, p.11.
A escolha da estrutura da Rede Neural determina diretamente a qualidade do modelo obtido e diversas atividades são necessárias para a definição da arquitetura de uma RNA para a qual um problema específico deverá ser resolvido de forma ótima (RIBEIRO et al, 2009).
Na maior parte das aplicações de previsão, somente uma camada oculta é usada, embora algumas situações excepcionais justifiquem um número maior. Já o número de neurônios nas camadas de entrada e de saída depende da dimensionalidade dos dados, enquanto que o número de neurônios nas camadas intermediárias depende da complexidade do problema, de forma que quanto maior o número de neurônios nas camadas intermediárias, mais complexas são as funções mapeadas com a RNA. (RIBEIRO et al, 2009).
2.2.3 APRENDIZAGEM
De forma similar ao ser humano, as Redes Neurais Artificiais são capazes de aprender comportamentos através de exposição de exemplos dos mesmos (LEMOS et al, 2005). Nesta fase, as entradas são apresentadas e as redes aprendem a extrair informações relevantes a partir desses padrões, com isso, a rede pode gerar resultados e conduzir a conclusões lógicas ou não previstas através do modelo (WALLACE, 2008)
No contexto de Redes Neurais, aprendizagem pode ser definida como:
Esta definição, segundo Haykin (2001, p. 75), implica a seguinte sequência de eventos:
1. A rede neural é estimulada por um ambiente
2. A rede neural sofre modificações nos seus parâmetros livres como resultado desta estimulação
3. A rede neural responde de uma maneira nova ao ambiente, devido às modificações ocorridas na sua estrutura interna.
Os algoritmos de aprendizado podem ser classificados em três paradigmas distintos: aprendizado supervisionado, aprendizado não-supervisionado e aprendizado por reforço.
A aprendizagem supervisionada, também conhecida como aprendizagem com um professor, caracteriza-se pela existência de um professor ou supervisor, externo a rede que tem a função de monitorar a resposta da mesma para cada vetor de entrada. Como aponta Medeiros 2007, neste aprendizado, são sucessivamente apresentadas à rede conjuntos de padrões de entrada e seus correspondentes padrões de saída. De forma que, durante este processo, a rede realiza um ajustamento dos pesos das conexões entre os elementos de processamento, segundo uma determinada lei de aprendizagem, até que o erro entre os padrões de saída gerados pela rede alcance um valor mínimo desejado.
Figura 6: aprendizado supervisionado. Fonte: Dutta et al, 2006, p.286.
No aprendizado não-supervisionado a rede é autônoma, ela não necessita de um
“professor”, sendo o processo direcionado por correlações existentes nos dados de entrada.
Nele, a rede “analisa” os conjuntos de dados apresentados a ela, determina algumas propriedades
apenas pelos vetores de entrada, mas existe um crítico externo em substituição ao supervisor do aprendizado supervisionado.
2.2.4 IMPLEMENTANDO UMA RNA
Existem algumas etapas gerais a serem seguidas para a implementação de uma Rede Neural Artificial. Para que se possa compreender tal processo, abaixo expõe-se uma breve explanação sobre as mesmas.
2.2.4.1 DEFINIÇÃO DA REDE E ESCOLHA DO SOFTWARE
Processo pelo qual a RNA é desenvolvida teoricamente. Nessa etapa, são definidas questões primordiais, como os problemas que a rede deve solucionar, bem como as variáveis de relevância para a obtenção da resposta ao problema proposto.
Para o desenvolvimento de sistemas a base de Redes Neurais existe um certo número de pacotes para micro computadores voltados especificamente para este fim (Brainmaker, Neuroshell, Explorer, Matlab, Nestor e etc), entretanto também podem ser utilizados softwares estatísticos como Microsoft Office, Statistica ou SPSS.
2.2.4.2 OBTENÇÃO DE DADOS
O segundo elemento indispensável é a obtenção de dados, os quais poderão ser quantitativos ou qualitativos.
A fim de realizar o processo de experimentação através de Redes Neurais, três subconjuntos de dados devem ser selecionados: o de treinamento, o de validação e o de teste. O subconjunto de treinamento serve para treinar a rede, ou seja, é através desses dados que a rede neural é criada. O subconjunto de validação é utilizado para acompanhar o desempenho da rede a partir de uma mostra independente. Para testar a rede com um subconjunto de dados independente da criação do modelo, um terceiro subconjunto de teste deve ser selecionado (ZANETI JR; ALMEIDA, 1998).
Ressalta-se que em alguns modelos, o pesquisador pode optar por estudar os subconjuntos de validação e o de teste durante o mesmo processo.
Esta etapa é de fundamental importância para a validação da rede, pois é nela que a rede recebe os dados para treinamento, classificados como supervisionados ou não-supervisionados. No modo supervisionado, a rede recebe os valores de entradas e quais devem ser os resultados de saída, analisados previamente, e estabelece os pesos das correlações; já no modo não-supervisionado a rede analisa as diversas informações e determina semelhanças, aprendendo a utilizar essas informações em suas saídas (BIALOSKORSKI NETO et al, 2006).
Como mencionado anteriormente, existem dois tipos de paradigmas de aprendizado: supervisionado, o qual supõe a existência de um direcionador externo que orienta a rede para as saídas desejadas, e não supervisionado, no qual inexiste este direcionador, fazendo com que os resultados produzidos pela rede sejam considerados como sendo o melhor processamento possível obtido a partir dos dados disponíveis. A escolha do paradigma de aprendizado depende do tipo de aplicação a que a rede neural será utilizada e às limitações relativas à topologia da rede. (HAYKIN, 2001).
A otimização do processo de criação das redes através de algoritmos genéticos ou a difusão dos dados para melhor representação permitem aumentar a precisão dos modelos (ZANETI JR; ALMEIDA, 1998).
2.2.4.4 ETAPA DE TESTES (UTILIZAÇÃO DA RNA)
Após o treinamento, o método passa a fornecer dados confiáveis. Utilizando estimativas, pode-se entrar com novos dados para verificar como certa alteração teria efeito sobre determinada função, ou qualquer outro resultado para o qual a rede tenha sido treinada (BIALOSKORSKI NETO et al, 2006).
2.2.4.5 MANUTENÇÃO
3 METODOLOGIA
Este capítulo expõe os elementos da metodologia científica utilizados no presente trabalho. Nele serão descritos o tipo de pesquisa, bem como os procedimentos de coleta de dados, tratamento de dados e análise dos resultados.
3.1 TIPO DA PESQUISA
Este trabalho está baseado em teorias quantitativas de análise, sendo assim os modelos matemáticos e estatísticos são utilizados a fim de atender o objetivo da pesquisa. Segundo Markoni e Lakatos (1990), os estudos quantitativos são aqueles em que os pesquisadores estabelecem hipóteses e as testa por meio da mensuração de variáveis operacionais definidas, quantificando o resultado com o uso de variados métodos matemáticos e estatísticos. Sendo um tipo de pesquisa tradicionalmente aceito como tendo confiabilidade, fidedignidade e validade, desde que realizado seguindo uma metodologia rigorosa (MARKONI; LAKATOS, 1990).
Convém ressaltar que, visto este estudo ter por objetivo a análise da adequação do Método de Redes Neurais Artificiais à realização de previsões do Ibovespa, optou-se por realizar tal questão por meio da comparação de resultados entre este e o Método de previsão em séries temporais GARCH.
3.2 AMOSTRAGEM
Segundo a Bolsa de Valores oficial do Brasil, BM&F Bovespa (2011), os preços das ações podem variar por diversos motivos, logo, com o intuito de orientar as decisões de investimento, criaram-se alguns Índices que buscam retratar a situação dos investimentos realizados durante os pregões, retratando a valorização de um determinado grupo de papéis ao longo do tempo.
Materiais Básicos (IMAT), Índice Utilidade Pública (UTIL), Índice de Ações com Governança Corporativa Diferenciada (IGC), Índice de Governança Corporativa Trade (IGCT), Índice de Ações Tag Along Diferenciado (ITAG), Índice Mid-Large Cap (MLCX), Índice Small Cap (SMLL), Índice Valor Bovespa (IVBX-2), Índice Financeiro (IFNC) e Índice de Dividendos (IDIV).
Optou-se por se realizar previsões acerca do Índice Bovespa, adotando-o como indicador que melhor refletiria o comportamento geral do mercado objeto de estudo. Visto sua composição e que o mesmo é o mais relevante indicador do desempenho médio das cotações do Mercado de Ações Brasileiro, já que retrata o comportamento dos principais papéis negociados na BM&F Bovespa e também por sua tradição (BM&F BOVESPA, 2011, s/n).
3.3 COLETA DE DADOS
Os dados econômicos e financeiros necessários para o estudo consistiram basicamente de séries históricas e o acesso aos mesmos ocorreu através de consulta ao site da BM&F Bovespa – Bolsa de Valores, Mercadorias e Futuros de São Paulo.
Dentre os dados coletados, estão os valores diários dos 21 Índices da BM&F Bovespa listados no tópico acima, quando disponíveis, durante um horizonte de tempo que abrangeu desde o primeiro dia útil do ano de 2006 (dois de janeiro) até o último dia útil do mês de janeiro do ano de 2011, a saber, dia 31.
A coleta de outros Índices além do Ibovespa se justifica pelo fato de que tais dados foram inseridos como inputs nos modelos de previsão baseados em redes neurais. Isso ocorreu pois os modelos baseados em Redes Neurais Artificiais podem extrair relações interessantes ao seu modelo de previsão a partir do comportamento de outras variáveis e identificação de inter-relações no sistema e, portanto, considerou-se válida a inserção de dados referentes ao comportamento dos diferentes setores do mercado abordados pelos Índices por retratarem segmentos e portfólios distintos do mercado e por terem potencial para adicionar contribuições significativas às redes neurais modeladas visto que o Ibovespa pode ser considerado um reflexo do comportamento geral do mercado.
3.4 TRATAMENTO DOS DADOS
Uma vez coletados os dados, os mesmos foram tratados por meio de métodos estatísticos e financeiros de acordo com as necessidades dos modelos a serem utilizados (Redes Neurais e GARCH).
Criou-se, por exemplo, uma base de dados convertida na qual transformou-se os dados de valores diários (preços) em retornos diários. Onde, denotando observações sucessivas de uma variável tomada nos instantes t e t+1 a transformação da série de valores em uma série de retornos foi dada por:
Y t = Log(t+1) - Log(t)
Após esta etapa de adequação dos dados, desenvolveram-se modelos de previsão para o Ibovespa através dos métodos das Redes Neurais Artificiais e GARCH (modelo de controle).
Durante esta etapa foram utilizados os softwares MS Excel – para organização e tratamento inicial dos dados, Eviews – para modelagem do método GARCH e MATLAB (versão estudante) – para modelagem do método de RNA.
3.4.1 TRATAMENTO DOS DADOS PARA A RNA
Observou-se na base de dados utilizada que dois dos 21 Índices – ICON e ICO2 - não apresentavam dados referentes aos seus valores durante um longo período de tempo da série, optando-se por excluí-los dos parâmetros estudados para fins de tornar a inter-relação modelada pela RNA mais coesa, restando assim 19 parâmetros (Índices) para estudo. E, como mencionado anteriormente, a Rede Neural Artificial foi desenvolvida para realizar a previsão do período (dia) seguinte do Índice Bovespa.
Ressalta-se que visto a possibilidade da RNA de extrair informações dos comportamentos e relações dos demais Índices, este modelo se utiliza não apenas dos dados históricos do Ibovespa como também dos demais Índices disponíveis acerca do mercado a fim de que a rede tenha a possibilidade de criar um modelo mais acurado de previsão.
convertidos para retornos diários, para fins de padronização de resultados. E o outro tendo seus dados de entrada convertidos para retornos diários antes da modelagem da rede, gerando suas previsões já em forma de retornos. Entretanto, embora os dados de entrada e saídas sejam diferentes (preços – retornos), ambas utilizaram a mesma metodologia e estrutura.
Para a modelagem das Redes Neurais a base de dados foi dividida em dois grupos. Para o modelo baseado em preços, o grupo de treinamento consistiu nos dados referentes aos valores do período 1 ao período 1200, ou seja, de dois de janeiro de 2006 a 11 de novembro de 2010. Já o grupo de teste e validação foi composto pelos 50 períodos seguintes do banco de dados, abarcando o período de 12 de novembro de 2010 a 26 de janeiro de 2011. Já para o modelo baseado em retornos, o grupo de treinamento abarcou do período 2 (visto a perda da primeira observação AR se realizar a transformação da série de preços para retornos) ao 1196, enquanto que o grupo de teste e validação gerou previsões para os 50 períodos seguintes.
Depois de selecionados os dados, iniciou-se o estudo da melhor estrutura a ser utilizada na rede. Após uma analise inicial optou-se, para um melhor tratamento dos dados, por utilizar não apenas um período (n) para realizar a previsão do próximo (n+1), mas sim a carga histórica do período atual mais os quatro anteriores, como pode ser ilustrado através da figura7. Convém ressaltar que para cada período de tempo utilizado como entrada nas RNAs foram fornecidos os valores de cada um dos 19 parâmetros (Índices), esta ação está representada na figura abaixo pelos grupos de 19 entradas referentes a cada um dos períodos
Onde :
I = valor diário do Índice no período n = dia
X = entrada fornecida ao sistema para cada parâmetro
MLP = MultiLayer Perceptron (Perceptron de Múltipla Camada)
Figura 7: Estrutura Inicial da RNA Fonte: Dados da Pesquisa, 2011.
Entretanto, após tentativas de modelagem através desta estrutura e do nível de erro obtido, resolveu-se pela utilização da Análise dos Componentes Principais (PCA) para fins de reduzir o número de entradas e, assim, aumentar a relevância dos dados levados em consideração pela rede (MLP) em si. Desta forma conseguiu-se reduzir o número de entradas a serem fornecidas à rede de 95 para 20, como pode ser visualizado através da seguinte figura:
Figura 8: Estrutura Final da RNA Fonte: Dados de Pesquisa, 2011.
Por meio desta estrutura, pôde-se chegar a uma Rede Neural Artificial do tipo feedforward e de aprendizado supervisionado, cuja arquitetura, ilustrada pela figura 9, consistiu em 20 dados na camada de entrada, 90 neurônios em uma camada oculta e um dado na camada de saída (previsão do Ibovespa).
optou-se também por se utilizar a função de ativação de entrada como sendo a tangente Sigmoid e uma função de saída linear.
Figura 9: Arquitetura da Rede Neural Artificial Fonte: Dados de Pesquisa, 2011.
3.4.2 TRATAMENTO DOS DADOS PARA O MODELO DE CONTROLE
Para fins de estudo dos resultados obtidos pelos modelos de RNA gerados, realizou-se a modelagem de um modelo de controle baseado nos modelos tradicionais de análise de séries temporais. Visto as características dos dados estudados e do objetivo do modelo, optou-se pela utilização do método ARCH/GARCH para a modelagem deste modelo de controle.
O modelo
Enquanto séries temporais e modelos econométricos convencionais operam com a suposição de variância constante, o modelo ARCH (Autoregressive Conditional Heterocedasticity) desenvolvido por Engle (1982) considera ser a variância heterocedástica, ou seja, não é constante ao longo do tempo (BOLLERSLEV, 1986).
O modelo GARCH pode ser usado para descrever a volatilidade com menos parâmetros que um modelo ARCH. Neste modelo, a função linear da variância condicional inclui também variâncias passadas.
Assim sendo, a volatilidade dos retornos depende dos quadrados dos erros anteriores e também de sua própria variância em momentos anteriores. Segundo Bollerslev (1996, p.309), um modelo GARCH (p,q) é dada seguinte forma:
onde
Ressaltando-se que q representa a ordem do componente ARCH e p a ordem do componente GARCH.
O modelo GARCH utilizado neste trabalho foi um GARCH (1,1), versão mais simples e mais utilizada em séries financeiras, que pode ser representada por:
Tratamento de dados
Para a realização da modelagem GARCH, fizeram-se necessárias as observações de alguns testes e análises padrão, discutidos a seguir.
Primeiramente, com o intuito de se transformar a série de dados a ser trabalhada em uma série estacionária, realizou-se a conversão da mesma de valores diários (preços) do Ibovespa (IBOV) em uma série de retornos diários deste Índice por meio da equação especificada anteriormente.
-.15 -.10 -.05 .00 .05 .10 .15 20000 30000 40000 50000 60000 70000 80000
250 500 750 1000 1250
____IBOV ____ RIBOV
Figura 10: comportamento da série de preços (IBOV) e de retornos do Ibovespa (RIBOV). Fonte: Dados de Pesquisa, 2011.
Além da observação gráfica, optou-se por também realizar o teste de Dickey-Fuller Aumentado (teste de ADF) em ambas as séries, para verificação da existência ou não de raiz unitária – onde quanto mais negativo o número retornado da estatística de ADF, mais indicativo o teste se torna a rejeitar a hipótese nula de que existe raiz unitária. Por meio deste teste conclui-se que, diferentemente da série IBOV, a série de retornos não apresenta raiz unitária.
Tabela 1: Teste de estacionariedade.
Teste para Raiz Unitária Dickey-Fuller
Série Ibovespa
Série de retornos do Ibovespa
-2,112709 -36,04160
Fonte: Dados de Pesquisa, 2011.
Nota:
O valor crítico a 1% de significância* é de -3.965416;
* Valor crítico de MacKinnon para rejeição da hipótese de raiz unitária.
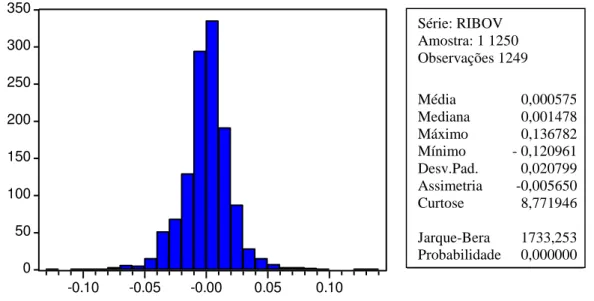
Por meio do estudo das estatísticas descritivas da série RIBOV (Figura11), analisou-se o nível de assimetria e curtose da mesma, bem como o indicador do teste de Jarque-Bera, verificando-se a rejeição da hipótese de normalidade, visto o valor retornado pelo teste de Jarque-Bera ser superior a 6, e observando-se que a série apresenta leptocurtose, demonstrada pelo excesso de curtose e assimetria negativa.
0 50 100 150 200 250 300 350
-0.10 -0.05 -0.00 0.05 0.10
Series: RIBOV Sample 1 1250 Observations 1249
Mean 0.000575 Median 0.001478 Maximum 0.136782 Minimum -0.120961 Std. Dev. 0.020799 Skewness -0.005650 Kurtosis 8.771046
Jarque-Bera 1733.253 Probability 0.000000
Figura 11: Gráfico de distribuição e estatísticas descritivas da série RIBOV. Fonte: Dados de pesquisa, 2011.
Observando-se as funções de autocorrelação (AC) e de autocorrelação parcial (FAC), vide tabela 2, verificou-se a presença de poucos dados fora do Intervalo Assintótico da série, indicando a existência de ruído branco e a não necessidade de se modelar a média da série, evitando-se assim, o aumento do erro embutido no modelo. Logo, o momento condicional da série necessitaria ser modelado segundo uma estrutura autoregressiva da família ARCH.
Tabela 2: Autocorrelação e autocorrelação parcial da série RIBOV.
Retornos RIBOV
a1 (p1)*
a2 (p2)
a3 (p3)
a4 (p4)
a5 (p5)
2/ ** -0,020(0,020) -0,043(0,043) -0,071(0,073) -0,003(0,009) -0,019(0,026) 0,056569
*ai e pi denotam os coeficientes de autocorrelação e autocorrelação parcial da i-ésima ordem,
respectivamente.
** Limite assintótico da função de autocorrelação
Fonte: Dados de Pesquisa, 2011.
Série: RIBOV Amostra: 1 1250 Observações 1249
Média 0,000575 Mediana 0,001478 Máximo 0,136782 Mínimo - 0,120961 Desv.Pad. 0,020799 Assimetria -0,005650 Curtose 8,771946
Embora tenha sido verificada a não necessidade da aplicação de um modelo ARMA, devido a sua característica heteroscedástica optou-se por realizar um modelo ARMA (1,1) com o intuito de se gerar a possibilidade da observação dos resíduos deste modelo, se viabilizando o estudo das variâncias (efeitos ARCH) da série estudada. Para este modelo, utilizou-se um filtro de correção de Newey-West tornando-o robusto à heteroscedasticidade e autocorrelação no processo do resíduo, obtendo-se os resultados ilustrados por meio da tabela 3, abaixo.
Tabela 3: Resultados do Modelo ARMA (1,1) para geração de resíduos para estudo. Equação de Variância
Coeficiente Erro Padrão Estatística-z P Valor AR (1)
MA (1)
0,737926 -0,790481
0,189690 0,173818
3,890165 -4,547755
0,0001 0,0000
Critério de Informação de Akaike - 4,911962
Critério de Informação de Schwarz - 4,903742
Máxima Verossimilhança 3067,064
Fonte: Dados de Pesquisa, 2011.
Uma vez de posse dos resíduos gerados por meio do Modelo ARMA (1,1), pôde-se aplicar o teste de ARCH de Engle (1982) para estudo dos mesmos (tabela 4).
Tabela 4: Testes de efeitos ARCH.
TESTE ARCH 1 lag 5 lags 10 lags 20 lags
F-statistic 51,55367 88,21203 64,54719 39,39459
p-valor 0,000000 0,000000 0,000000 0,000000
Fonte: Dados de pesquisa, 2011.
Conforme os p-valores, os testes para efeitos ARCH fornecem fortes evidências contra a hipótese nula de não haver heteroscedasticidade condicional na volatilidade dos modelos para a série estudada (RIBOV).
3.5 PROCEDIMENTO DA ANÁLISE DOS RESULTADOS
Os resultados obtidos por meio da implementação das RNAs e do modelo de controle (GARCH (1,1)) foram analisados estudando-se as previsões e erros obtidos em cada modelo de forma a se visualizar qual seria aquele mais aderente à base de dados utilizada.