Carlos Alberto de Araújo Padilha
Algoritmos Genéticos Aplicados a um
Comitê de LS-SVM em Problemas de
Classificação
2
Carlos Alberto de Araújo Padilha
Algoritmos Genéticos Aplicados a um
Comitê de LS-SVM em Problemas de
Classificação
Dissertação de Mestrado apresentada ao Programa de Pós-Graduação em Enge-nharia Elétrica e Computação da Universi-dade Federal do Rio Grande do Norte, para a obtenção de Título de Mestre em Enge-nharia Elétrica e Computação, na Área de Sistemas Inteligentes.
Orientador: Adrião Duarte Dória Neto Co-orientador: Jorge Dantas de Melo
Algoritmos Genéticos aplicados a um comitê de
LS-SVM em problemas de classificação
Carlos Alberto de Araújo Padilha
Prof. Dr. Adrião Duarte Dória Neto (Orientador) . . . DCA/UFRN
Prof. Dr. Jorge Dantas de Melo (Co-Orientador) . . . DCA/UFRN
Profa. Dra. Anne Magaly de Paula Canuto (Examinadora Interna) . . . . DIMAp/UFRN
Agradecimentos
Primeiramente, gostaria de agradecer a Deus por me ajudar e proteger todos os dias da minha vida.
Agradecimento especial para minha família, meu pai José, minha mãe Raimunda e meus irmãos Dudu e Ana Maria, e minha querida namorada Paula pelo amor e incentivo para que eu me torne cada dia uma pessoa melhor em todos os sentidos e atingir os meus objetivos profissionais.
Aos professores Adrião Duarte Dória Neto e Jorge Dantas de Melo, meu orientador e co-orientador respectivamente, pela oportunidade de orientação oferecida e pelo grande exemplo como profissionais e como pessoas.
Aos companheiros do LABSIS, pela convivência diária, pela grande amizade e pelas conversas que sempre resultam em idéias mirabolantes.
Resumo
2
das respostas de cada máquina ponderadas pelos pesos. Foram utilizados vários proble-mas de classificação, tidos como benchmarks, para avaliar o desempenho do algoritmo e comparamos os resultados obtidos com outros classificadores.
3
Abstract
The pattern classification is one of the machine learning subareas that has the most outstanding. Among the various approaches to solve pattern classification problems, the Support Vector Machines (SVM) receive great emphasis, due to its ease of use and good generalization performance. The Least Squares formulation of SVM (LS-SVM) finds the solution by solving a set of linear equations instead of quadratic programming imple-mented in SVM. The LS-SVMs provide some free parameters that have to be correctly chosen to achieve satisfactory results in a given task. Despite the LS-SVMs having high performance, lots of tools have been developed to improve them, mainly the development of new classifying methods and the employment of ensembles, in other words, a combina-tion of several classifiers. In this work, our proposal is to use an ensemble and a Genetic Algorithm (GA), search algorithm based on the evolution of species, to enhance the LS-SVM classification. In the construction of this ensemble, we use a random selection of attributes of the original problem, which it splits the original problem into smaller ones where each classifier will act. So, we apply a genetic algorithm to find effective values of the LS-SVM parameters and also to find a weight vector, measuring the importance of each machine in the final classification. Finally, the final classification is obtained by a linear combination of the decision values of the LS-SVMs with the weight vector. We used several classification problems, taken as benchmarks to evaluate the performance of the algorithm and compared the results with other classifiers.
Sumário
Lista de Figuras 3
Lista de Tabelas 4
Lista de Algoritmos 5
1 Introdução 6
1.1 Motivação . . . 6
1.2 Objetivos . . . 10
1.3 Estado da Arte . . . 10
2 Máquina de Vetor de Suporte 14 2.1 Teoria do Aprendizado Estatístico . . . 14
2.1.1 Princípio da Minimização do Risco Empírico . . . 15
2.1.2 Dimensão V-C . . . 16
2.1.3 Minimização do Risco Estrutural . . . 17
2.2 Classificação de Padrões Linearmente Separáveis . . . 17
2.3 Classificação de Padrões Não-Linearmente Separáveis . . . 21
2.4 Máquinas de Vetor de Suporte Não-Lineares . . . 22
Sumário 2
3 Máquinas de Comitê 27
3.1 Introdução. . . 27
3.2 Comitês de Especialistas . . . 28
3.3 Comitês com Rede de Passagem. . . 31
4 Algoritmos Genéticos 33 4.1 Componentes . . . 35
4.1.1 Representação do Cromossomo . . . 35
4.1.2 Seleção . . . 35
4.1.3 Cruzamento . . . 36
4.1.4 Mutação . . . 40
4.1.5 Atualização . . . 40
4.2 Caracteristicas . . . 41
5 Método proposto 43 5.1 Seleção de Atributos e Criação de um Comitê . . . 44
5.2 Aplicação do Algoritmo Genético . . . 44
6 Resultados 49
7 Conclusões e Perspectivas 54
Lista de Figuras
2.1 Modelo de aprendizagem supervisionada. . . 15
2.2 Hiperplano de separação ótimo. . . 18
2.3 (a) Ponto de dado se encontra na região de separação no lado correto do hiperplano (b) Ponto de dado se encontra na região de separação, mas no lado errado. . . 21
3.1 Máquina de comitê do tipo média de ensemble. . . 29
3.2 Diagrama de blocos do modelo de mistura de especialistas. . . 31
4.1 Estrutura de funcionamento de um AG tradicional. . . 34
4.2 Operador de cruzamento de um ponto. . . 38
4.3 Operador de cruzamento multiponto com dois pontos de corte. . . 39
4.4 Operador de cruzamento uniforme. . . 39
Lista de Tabelas
2.1 Funções típicas usadas como kernel . . . 24
4.1 Exemplos de representações de indivíduos em diferentes problemas . . . . 35
6.1 Bases de dados utilizadas . . . 51 6.2 Comparação entre o método proposto (MP), o trabalho anterior (TA),
um único classificador RBF, SVM treinada com AG e o AdaBoost. As
melhores taxas médias de reconhecimento (%) são mostradas em negrito. . 52 6.3 Comparação entre os resultados obtidos pelo uso de cada técnica
isolada-mente no comitê de LS-SVM, denominados RSM-LS-SVM (utiliza a
sele-ção aleatória de atributos) e AG-LS-SVM (uso de um AG), e o método
proposto. As melhores taxas médias de reconhecimento (%) são mostradas
Lista de Algoritmos
4.1 Algoritmo da seleção por máscara . . . 37
Capítulo 1
Introdução
1.1
Motivação
A classificação de padrões é uma área de pesquisa que objetiva associar objetos ou padrões a um certo número de categorias ou classes (Theodoridis e Koutroumbas,2008). Assim, dado um conjunto de classes c1, c2, ..., cn e um padrão x, o sistema de classificação de
padrões associa o padrão x a uma das classes. Esses padrões podem ser sinais de voz, imagens de face, impressões digitais ou qualquer medida, dependendo da aplicação, que necessitam ser classificados.
reconhe-7 1.1. Motivação
cimento biométrico, sensoriamento remoto por imagens multiespectrais e reconhecimento de fala.
O projeto de sistemas de classificação de padrões é dividido essencialmente em três fases: 1) aquisição de dados e pré-processamento, 2) representação dos dados, e 3) tomada de decisões (Jain e Duin,2000). Uma forma comumente utilizada para se representar um exemplo do domínio do problema é a de um vetor que contém informações importantes sobre o problema. Para se gerar esse vetor a partir do mundo real é necessário um pré-processamento e as técnicas mais utilizadas para tal são a extração de características e a seleção de características. Técnicas de pré-processamento são úteis porque além de poder minimizar ou eliminar problemas existentes em um conjunto de dados, elas podem tornar os dados mais adequados para serem utilizados pelo algoritmo de classificação. Segundo Jain e Duin (2000), destacam-se quatro abordagens para a tomada de decisão em classificações de padrões:
• Casamento (template matching);
• Abordagem sintática;
• Abordagem estatística;
• Redes neurais;
Capítulo 1. Introdução 8
Inspiradas no cérebro humano, as redes neurais são máquinas constituídas de unidades de processamento simples que trabalham de maneira maciçamente paralela e distribuída para a realização de uma tarefa. Segundo Haykin(1999), elas se assemelham ao cérebro em dois aspectos: o conhecimento é adquirido a partir de seu ambiente atraves de um processo de aprendizagem e os pesos sinápticos (as forças de conexão entre neurônios) são utilizados para armazenar tal conhecimento.
Apesar das redes neurais serem largamente aplicadas em problemas de classificação de padrões, as Máquinas de Vetor de Suporte (do inglês, Support Vector Machines ou SVM) por definirem um superfície ótima de separação entre classes do problema, é uma das áreas de pesquisa que recebem grande destaque.
As SVM são máquinas de aprendizado estatístico linear propostas inicialmente por Vapnik (1998) e que se baseiam no princípio de minimização do risco estrutural. O treinamento das SVM busca maximizar a margem de separação entre as classes, encon-trando um hiperplano ótimo. Em problemas de classificação e regressão não-lineares é utilizado o método conhecido como função kernel, que fornece um mapeamento do es-paço de entrada em outro eses-paço, sendo este de alta dimensionalidade, chamado eses-paço de características.
As Máquinas de Vetor de Suporte por Mínimos Quadrados (Least Squares Support Vector Machines, LS-SVM) propostas por Suykens e colaboradores (Suykens e Van-dewalle,1999) são modificações das SVM, que ao invés de usarem a programação
quadrá-tica usada nas SVM (que é de grande complexidade matemáquadrá-tica e exige grande esforço computacional), usam um sistema de equações lineares e a função custo por Mínimos Quadrados. Dessa forma, proporcionam menor custo computacional em relação às SVM e sem perder a qualidade das soluções, uma vez que os princípios que ambas se baseiam são os mesmos.
LS-9 1.1. Motivação
SVM, seja através do desenvolvimento de novos métodos de treinamento (Osuna et al., 1997), otimização (Yang, 2009) ou através da criação de comitês (Lima et al., 2009),
mas pode-se observar que as mesmas costumam atuar em apenas um ponto específico do problema, seja focando apenas no processo de otimização, parametrização ou na divisão das tarefas entre os múltiplos classificadores. Pensando nisso, a idéia é atuar em mais de um ponto, como na parametrização e na divisão das tarefas entre classificadores.
As LS-SVMs possuem alguns parâmetros livres que aparecem em suas formulações, parâmetro(s) do kernel utilizado (caso de problemas não-lineamente separáveis) e o pa-râmetro de regularização C, que precisam ser corretamente selecionados para alcançar resultados satisfatórios em uma determinada tarefa de regressão ou, nesse caso, classifi-cação de padrões. Assim, para encontrar tais valores pensou-se em utilizar técnicas de busca chamadas de Algoritmos Genéticos (AG).
Algoritmos Genéticos (AG) são métodos de otimização inspirados na evolução bioló-gica. Utilizando eventos naturais como inspiração, são gerados mecanismos de mutação e cruzamento, que fazem a busca pela solução ótima. Nessa metaheurística, o conjunto de soluções possíveis é chamado de população, e cada solução do problema é chamada de cromossomo. Um cromossomo é constituído por um conjunto de valores numéricos ou por uma sequência de bits. A otimização é feita a partir de uma função matemática chamada função de aptidão ou fitness, que mede a capacidade de sobrevivência daquele indivíduo. Então a população é sujeita a diversos níveis de mutação, seleção e cruza-mento, simulando o princípio da “sobrevivência do mais apto”, até que um certo nível da função fitness seja atingido, ou até que uma quantidade limite de gerações tenha transcorrido. Então o cromossomo “mais apto” é a resposta do AG para o problema.
Capítulo 1. Introdução 10
de recursos computacionais. Para resolver essa questão foram desenvolvidos os comitês de máquinas. Basicamente, o comitê funde o conhecimento adquirido por um conjunto de máquinas, chamadas de especialistas, para chegar a uma decisão global que é teorica-mente superior àquela que seria alcançada por qualquer uma delas isoladateorica-mente.
1.2
Objetivos
O objetivo deste trabalho é aprimorar o poder de classificação de uma LS-SVM através do uso da teoria de comitês e Algoritmos Genéticos.
Objetivos específicos:
• Verificar o uso de um comitê para que cada classificador fique responsável pela classificação de uma porção do problema.
• Estudar o uso de Algoritmos Genéticos na parametrização das LS-SVMs, para que estas consigam bons resultados individualmente, e na avaliação da importância de cada uma delas para a resposta final do comitê.
• Mostrar uma abordagem para a combinação de Algoritmos Genéticos e Comitês de Máquinas, visando o aprimoramento do poder de classificação de LS-SVMs.
• Realizar testes comparativos com outras técnicas clássicas.
1.3
Estado da Arte
Vários trabalhos encontrados na literatura procuram aprimorar o desempenho de uma SVM ou LS-SVM, através do uso de técnicas de otimização e/ou do uso de comitês.
11 1.3. Estado da Arte
otimização, e mostrou bom desempenho quando comparadas com outras duas técnicas de seleção de componentes de um comitê.
Lima (2004) fez o uso de um comitê para combinar SVMs com diferentes tipos de
kernel. A seleção dos componentes é feita via o critério baseado em Perrone e Cooper (1993) e a combinação deles é feita por voto majoritário.
Sun e Huang (2004) propuseram o uso de um comitê de LS-SVMs para aumentar a performance de uma única LS-SVM. Para a construção desse comitê foi utilizado o algoritmo Bagging (Breiman, 1996), porque é mais adequado que o algoritmo de Boos-ting (Schapire, 1999) em problemas com alto ruído. Ao contrário da forma tradicional de agregar as respostas das máquinas a qual considera todas as respostas, a aborda-gem dos autores podem excluir um classificador cujo desempenho individual degrade o desempenho global. Os resultados mostram a efetividade e a eficiência do método.
O trabalho de Liu e Zhu (2006) propõe o uso do algoritmo de Boosting para criar um comitê de LS-SVMs cujas saidas são combinadas através de lógica fuzzy, resultando na resposta geral do comitê. Nos testes realizados, o desempenho do método proposto é superior em termos de acurácia aos resultados atingidos por uma única SVM e por um comitê de SVMs usando votação como técnica de integração das respostas das máquinas.
EmYang(2009) foi proposto a utilização de Algoritmos Imunológicos para encontrar os valores dos parâmetros de uma LS-SVM usandokernel de Função de Base Radial (do inglês, Radial Basis Function ou RBF). Os parâmetros são codificados como os genes dos anticorpos. Seus resultados mostram que há melhora significativa na performance e ela é comparável com a acurácia de outros métodos existentes como o multi-fold cross-validation e grid-search.
Já Xie (2009), usa Algoritmos Genéticos para encontrar os parâmetros de uma LS-SVM com kernel híbrido construído para tentar absorver as vantagens de cada tipo de
Capítulo 1. Introdução 12
Kapp et al.(2010) propõem uma abordagem para a realização de aprendizagem incre-mental de forma adaptativa com um comitê de SVMs. A idéia principal é acompanhar, evoluir e combinar hipóteses ótimas ao longo do tempo, baseada na otimização de proces-sos dinâmicos e seleção do comitê. A partir dos resultados experimentais, demonstram que a estratégia proposta é promissora, uma vez que supera uma variante classificador único da abordagem proposta e outros métodos de classificação frequentemente utilizados para a aprendizagem incremental.
No trabalho de Yang e Shi(2010), foi proposto um comitê de SVM em 3 "estágios". Primeiro, utilizam a técnica Fuzzy C-means para clusterizar o espaço de entrada dos dados e criam subconjuntos de dados. Em seguida, as SVMs são construídas com base no algoritmo PSO (Particle Swarm Optimization ou, em português, otimização por exame de partículas ) que irá otimizar os parâmetros de seuskernels. Por fim, utilizam a lógica
Fuzzy para agregar as saidas das máquinas do comitê para obter uma resposta final. Lu e Wang(2011) propuseram uma técnica envolvendo um comitê de SVMs para si-mular a predição de chuva. Primeiro, utilizam oBagging para gerar diferentes conjuntos de treinamento para cada máquina. Então, treinam as SVMs usando diferentes tipos de
kernel para obter as respostas baseadas em cada conjunto de treino. Em seguida, a téc-nica PLS (Partial Least Square) para selecionar os componentes do comitê. Finalmente, criam uma v-SVM (Schölkopf et al.,2000) usando o aprendizado das máquinas treinadas previamente.
Zhang e Niu (2011) propuseram uma nova técnica híbrida chamada SACPSO que é a junção do simulated annealing (SA) com a técnica PSO, também visando a seleção automática dos parâmetros de uma LS-SVM usando kernel RBF. O SA emprega uma certa probabilidade para aprimorar a capacidade do PSO de escapar de mínimos locais, tem uma rápida convergência e alta precisão computacional. As simulações mostram que o resultado do método hibrido é melhor que o do PSO sozinho.
13 1.3. Estado da Arte
Capítulo 2
Máquina de Vetor de Suporte
A Máquina de Vetor de Suporte (SVM, Support Vector Machine) foi proposta por Vap-nik (1998) e consiste de uma máquina de aprendizado estatístico e, mais precisamente, uma implementação do método de minimização estrutural de risco (SRM,Structural Risk Minimization). Seu método de treinamento é capaz de contruir um hiperplano de sepa-ração ótima que maximiza a margem de sepasepa-ração entre as classes, no caso de padrões linearmente separáveis. Em problemas nao-linearmente separáveis sao utilizadas funções de núcleo or kernels, que fazem um mapeamento do espaço de entrada em um outro espaço, sendo este de alta dimensionalidade, chamado espaço de características, onde os padrões são linearmente separáveis com alta probabilidade de acordo com o teorema de Cover (Cover,1965).
2.1
Teoria do Aprendizado Estatístico
15 2.1. Teoria do Aprendizado Estatístico
conta o desempenho do classificador e a sua complexidade, com a finalidade de obter um bom desempenho de generalização. Nas subseções a seguir, será mostrada a estrutura da aprendizagem supervisionada, a dimensão V-C e os princípios da minimização do risco empírico e da minimização estrutural de risco.
2.1.1 Princípio da Minimização do Risco Empírico
Um modelo de aprendizagem supervisionada é composto de três componentes interrela-cionados, como na Figura 2.1.
Figura 2.1: Modelo de aprendizagem supervisionada.
SegundoHaykin(1999), os componentes desse modelo podem ser descritos matema-ticamente como:
• Ambiente: Fornece o vetor de entradax gerado com um função de distribuição de probabilidade fixa, cumulativa e desconhecida p(x).
• Professor: Fornece uma resposta desejadad para cada vetor de entrada x que lhe é fornecido pelo ambiente. O vetor de entrada e a resposta desejada se relacionam através da equação:
Capítulo 2. Máquina de Vetor de Suporte 16
onde v é um termo de ruído. Como d depende de x que depende da função p, podemos escreverp(x,d).
• Sistema de aprendizagem: Provê o mapeamento entrada-saida através da função y = F(x,w), onde y é a saída real produzida pelo sistema de aprendizagem e w, um conjunto de parâmetros livres.
O problema da aprendizagem supervisionada é encontrar a função que se aproxime da função f através do conjunto de entrada e saida desejada. Utiliza-se também um função de perda dada por:
L(x,d,f) =
⎧
⎪ ⎨
⎪ ⎩
0, sed=f(x); 1, sed̸=f(x).
(2.2)
O valor esperado de perda é definido pelo funcional de risco:
R(f) =
∫︁
L(x,d,f)dp(x,d) (2.3)
Porém, como a função de distribuição de probabilidade p é normalmente desconhe-cida, o cálculo do funcional só é aplicado para dados do conjunto de entrada, que é a única informação disponível. Assim, o funcional de risco é calculado como:
Re =
1
N
N
∑︁
i=1
L(xi,di,fi) (2.4)
Onde N é a quantidade de exemplos do conjunto de entrada.
2.1.2 Dimensão V-C
17 2.2. Classificação de Padrões Linearmente Separáveis
da classe à qual os exemplos pertençam.
EmHaykin (1999), exemplifica-se que, para o plano cartesiano, a dimensão V-C de uma reta é 3, porque três pontos no plano sempre podem ser classificados corretamente por uma reta, independente da classe que pertençam.
2.1.3 Minimização do Risco Estrutural
O princípio da minimização do risco estrutural é baseado no fato de que a taxa de erro de generalização de uma máquina de aprendizagem é limitada pela soma da taxa de erro de treinamento e por um valor que depende da dimensão V-C.
Seja um espaço de hipóteses de uma estrutura aninhada de nmáquinas:
M1 ⊂M2 ⊂ · · · ⊂Mn (2.5)
Assim, as dimensões V-C dos classificadores de padrões individuais satisfazem a con-dição:
h1 ≤h2≤ · · · ≤hn (2.6)
Implicando que a dimensão V-C de cada classificador de padrões é finita. Então, o método de minimização estrutural de risco objetiva encontrar uma estrutura de rede tal que o decréscimo da dimensão V-C ocorra à custa do menor aumento do erro de treinamento.
2.2
Classificação de Padrões Linearmente Separáveis
Capítulo 2. Máquina de Vetor de Suporte 18
realiza esta separação é:
wTx+b= 0 (2.7)
Onde w é o vetor de pesos ajustáveis, x é o vetor de entrada e b é o bias. Assim, pode-se escrever que:
⎧ ⎪ ⎨
⎪ ⎩
wTxi+b≥0, paradi= +1;
wTx
i+b <0, paradi=−1.
(2.8)
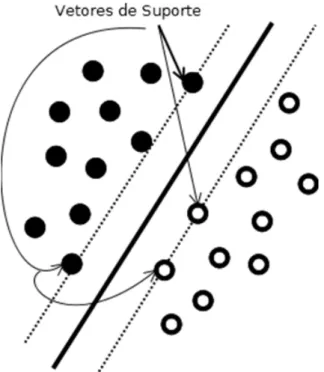
A margem de separação, representada por ρ, é a distância entre o hiperplano e o ponto de dado mais próximo ao mesmo. O objetivo de uma máquina de vetor de suporte é encontrar um hiperplano para o qual a margem de separaçãoρ seja máxima. Sob esta condição, a superfície de decisão é referida como o hiperplano ótimo. A Figura2.2ilustra a construção de um hiperplano ótimo para um espaço de entrada bidimensional.
19 2.2. Classificação de Padrões Linearmente Separáveis
Observando a Figura 2.2, vê-se que há dois outros hiperplanos em tracejado que serviram de base, pois passam por pontos que são amostras de treinamento. Esses pontos são chamados de vetores de suporte. Sendo então o hiperplano de separação ótimo descrito por:
wT0x+b0 = 0 (2.9)
Ondew0 eb0 são os valores ótimos do vetor peso e do bias, respectivamente. Sendo,
então, a distância entre um vetor de suporte e o hiperplano ótimo dada por:
r= |w
T
0x(s)+b0|
‖w0‖
(2.10)
Da equação acima, verifica-se que para maximizar a margem de separação entre as classes, o que corresponderia a 2r, deve-se minimizar a norma do vetor de pesos do hiperplano ótimo. Então, a função custo é dada por:
Φ(w) = 1 2‖w‖
2 (2.11)
Sujeita às restrições: di(wTxi+b)≥1 parai= 1,2, ..., N.
Segundo Haykin (1999), este problema de otimização com restrições é chamado de problema primordial, pois a função de custo Φ(w) é uma função convexa de w e as restrições são lineares em relação a w. Utilizando-se a teoria dos multiplicadores de Lagrange (Cristianini e Shawe-Taylor,2000), o problema pode ser representado por:
J(w, b, α) = 1 2‖w‖ 2− N ∑︁ i=1 αi [︀
di(wTxi+b)−1
]︀
(2.12)
Onde as variáveis auxiliares não-negativas αi são chamadas de multiplicadores de
Capítulo 2. Máquina de Vetor de Suporte 20
a b e maximizada em relação a α. Assim, diferenciando J(w,b,α) em relação w e b e igualando os resultados a zero, tem-se:
∂J
∂w = 0 =⇒w=
N
∑︁
i=1
αidixi=0 (2.13)
∂J
∂b = 0 =⇒
N
∑︁
i=1
αidi= 0 (2.14)
O vetor solução w é definido em termos de uma expansão envolvendo os N exem-plos de treinamento. Entretanto, apesar dessa solução ser única devido à convexidade lagrangiana, o mesmo não pode ser dito sobre os coeficientes αi. Para tal, é possível
construir um outro problema chamado de problema dual, que tem o mesmo valor ótimo do problema primordial, mas com os multiplicadores de Lagrange fornecendo a solução ótima. Assim, substituindo as equações2.13e2.14na equação2.12, obtém-se o problema dual, que é a maximização de:
Q(α) =
N
∑︁
i=1
αi−
1 2 N ∑︁ i=1 N ∑︁ j=1
αiαjdidjxTixj (2.15)
Sujeito às restrições:
1. ∑︀N
i=1αidi = 0
2. αi ≥0 parai= 1,2, ..., N
Uma vez determinados os multiplicadores de Lagrange ótimos, representados porα0,i,
pode-se calcular o vetor peso ótimow0 da seguinte forma:
w0 =
N
∑︁
i=1
α0,idixi (2.16)
21 2.3. Classificação de Padrões Não-Linearmente Separáveis
b0= 1−wT0x(s) (2.17)
2.3
Classificação de Padrões Não-Linearmente Separáveis
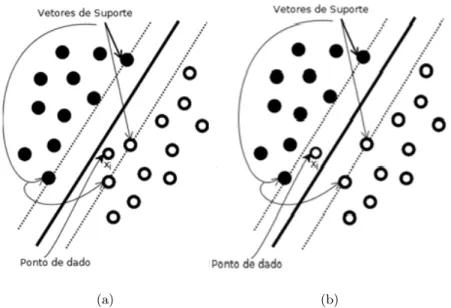
Para o caso de padrões não-linearmente separáveis, não é possível construir uma superfície de separação sem que se cometam erros de classificação. Neste caso, precisa-se encontrar o hiperplano ótimo que minimize a probabilidade de erro de classificação, calculada como a média sobre o conjunto de treinamento. Para tal, é necessário adicionar variáveis ao problema, chamadas de “variáveis soltas” ξi, escalares não-negativos, que medem o desvio
de um ponto de dado da condição ideal de separabilidade de padrões, para gerar uma margem suave de decisão para a SVM. Para 0 ≤ ξi ≤ 1, o ponto de dado se encontra
dentro da região de separabilidade, mas no lado correto do hiperplano. Já paraξi >1, o
ponto se encontra no lado errado do hiperplano. Os dois casos estão ilustrados na Figura 2.3.
(a) (b)
Capítulo 2. Máquina de Vetor de Suporte 22
Dessa forma, o problema primordial se torna a minimização de:
Φ(w,ξ) = 1 2‖w‖
2+C
N
∑︁
i=1
ξi (2.18)
Sujeito a:
1. di(wTxi+b)≥1−ξi
2. ξi≥0para todo i
Assim como foi feito na seção anterior, usando os mesmos artifícios matemáticos tem-se o problema dual, que é a maximização de:
Q(α) =
N
∑︁
i=1
αi−
1 2 N ∑︁ i=1 N ∑︁ j=1
αiαjdidjxTi xj (2.19)
Sujeito a:
1. ∑︀N
i=1αidi = 0
2. 0≤αi ≤C parai= 1,2, ..., N
Onde C é um coeficiente de regularização da SVM, escolhido pelo usuário, que esta-belece um equilíbrio entre a complexidade do modelo e o erro de treinamento.
2.4
Máquinas de Vetor de Suporte Não-Lineares
Como visto em seções anteriores, as máquinas de vetor de suporte são estruturas de na-tureza linear. A SVM forma um hiperplano, capaz de maximizar a margem de separação entre duas classes.
23 2.4. Máquinas de Vetor de Suporte Não-Lineares
hoje em dia. Portanto, se faz necessário encontrar alguma forma de permitir a uma SVM atuar em problemas de classificação de forma não-linear.
Para a resolução desse problema, são utilizadas estruturas denominadas núcleos ou
kernels. Esses núcleos geram um mapeamento entre o espaço de entrada e um espaço de alta dimensionalidade, chamado espaço de características, onde os padrões têm uma alta probabilidade de serem linearmente separáveis. O hiperplano gerado pela SVM nesse espaço de características, ao ser mapeado de volta ao espaço de entrada, se torna uma superfície não-linear.
Um kernel é uma função que recebe dois pontos xi e xj do espaço de entradas e
calcula o produto escalar desses dados no espaço de características. Dado por:
K(xi,xj) =φT(xi)φ(xj) (2.20)
Assim, utilizando a figura do kernel no problema de otimização do treinamento da SVM passa a ser a maximização de:
Q(α) =
N
∑︁
i=1
αi−
1 2 N ∑︁ i=1 N ∑︁ j=1
αiαjdidjK(xi,xj) (2.21)
Sujeito a:
1. di(wTxi+b)≥1−ξi
2. ξi ≥0 para todoi
Para garantir a convexidade do problema de otimização e que okernel apresente ma-peamento nos quais seja possível o cálculo de produtos escalares, okernel a ser utilizado precisa satisfazer as condições estabelecidas pelo teorema de Mercer (Mercer,1909). Os
Capítulo 2. Máquina de Vetor de Suporte 24
todo(i,j= 1,2,. . . ,n). Na Tabela 2.1 abaixo, são mostradas algumas funções comumente utilizadas como função kernel.
Tabela 2.1: Funções típicas usadas como kernel
Tipo deKernel Expressão Matemática Comentários
Polinomial (xT
i xj+ 1)p A potência
p é especificada a priori pelo usuário
RBF exp
(︂
− 1
2σ2‖xi−xj‖2
)︂ A larguraσ, comum a todos os
núcleos, é especificada a priori pelo usuário
Perceptron tanh(β0xT
i xj+β1)
O teorema de Mercer é satis-feito apenas para alguns valo-res deβ0 e β1
2.5
Máquinas de Vetor de Suporte por Mínimos Quadrados
Uma boa característica das SVM não-lineares é que elas conseguem resolver problemas não-lineares de classificação e regressão através de uma programação quadrática. Bus-cando simplificar o esforço computacional sem perder qualidade nas soluções, Suykens e Vandewalle (1999) propuseram uma modificação da SVM, levando a resolução de um conjunto de equações lineares ao invés da programação quadrática. A modificação da SVM chamada de Máquina de Vetor de Suporte por Mínimos Quadrados (Least Squares Support Vector Machine, LS-SVM), formula o problema de classificação como:
min
w,b,eJLS(w, b, e) =
1 2w
Tw+C1
2
N
∑︁
k=1
e2k (2.22)
Tal que:
dk
[︀
wTφ(xk) +b
]︀
= 1−ek, k= 1, ..., N. (2.23)
25 2.5. Máquinas de Vetor de Suporte por Mínimos Quadrados
proposta por Vapnik em dois pontos, simplificando o problema. Primeiro, ao invés de restrições de desigualdade, usa restrições de igualdade onde o valor 1 no lado direito é mais considerado como um valor alvo do que um valor limite. Sobre esse valor alvo, uma variável de erro ek é permitida de forma que erros de classificação podem ser tolerados
em caso de sobreposição de distribuições. Essas variáveis de erro funcionam de forma semelhante como as variáveis de folgaξk nas formulações de SVM. Segundo, a função de
perda quadrática é tomada para essa variável de erro.
O Lagrangiano é definido por:
L(w, b, e;α) =JLS(w, b, e)− N
∑︁
k=1
αk{dk[wTφ(xk) +b]−1 +ek} (2.24)
Ondeαk são os multiplicadores de Lagrange (os quais podem positivos ou negativos
agora devido às restrições de igualdade como decorre das condições Karush-Kuhn-Tucker (KKT) (Witzgall e Fletcher,1989)).
As condições de otimalidade são:
⎧ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎩ ∂L
∂w = 0−→w=
∑︀N
k=1αkdkφ(xk),
∂L
∂b = 0−→
∑︀N
k=1αkdk= 0,
∂L ∂ek
= 0−→αk =Cek, k= 1, ..., N,
∂L ∂αk
= 0−→dk
[︀
wTφ(x k) +b
]︀
= 1−ek= 0, k= 1, ..., N
(2.25)
Capítulo 2. Máquina de Vetor de Suporte 26 ⎡ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣
I 0 0 ZT
0 0 0 −DT
0 0 CI −I
Z D I 0
⎤ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎡ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ w b e α ⎤ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ = ⎡ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ 0 0 0 1 ⎤ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ (2.26)
Onde Z =[︀
φ(xi)Td1;...;φ(xN)TdN
]︀
,D= [d1;...;dN],
− →
1 = [1;...; 1],e= [e1;...;eN],
α= [α1;...;αN]. A solução é dada também por:
⎡
⎢ ⎣
0 −DT
D ZZT +C−1I
⎤ ⎥ ⎦ ⎡ ⎢ ⎣ b α ⎤ ⎥ ⎦= ⎡ ⎢ ⎣ 0 − → 1 ⎤ ⎥ ⎦ (2.27)
A condição de Mercer pode ser aplicada de novo para a matriz Ω =ZZT, onde:
Ωkl=dkdlφ(xk)Tφ(xl) =dkdlK(xk, xl) (2.28)
Onde K(xk, xl) é a funçãokernel.
Capítulo 3
Máquinas de Comitê
3.1
Introdução
Máquinas de comitê são estruturas que se baseiam em um princípio frequentemente uti-lizado: dividir para conquistar. Tal princípio diz que um problema complexo pode ser resolvido dividindo-o em um número de subproblemas mais simples de serem resolvi-dos e, posteriormente, combinando as soluções destes problemas como visto em Haykin (1999). Dessa forma, as máquinas de comitê são constituídas por um conjunto de máqui-nas chamadas de especialistas, cujas respostas são fundidas para chegar a uma decisão teoricamente superior àquelas alcançadas individualmente.
A idéia de combinar máquinas de aprendizagem para melhorar o desempenho final não é nova. Em Haykin (1999), nota-se que essa idéia remonta a Nilsson (1965); a estrutura de rede usada por ele consistia de uma camada de perceptrons elementares seguida de um perceptron de votação na outra camada. Entretanto, a partir da década de 90, a pesquisa nesta área teve grande impulso, devido à evolução computacional e do conseqüente surgimento de importantes trabalhos comoHansen, L. K. e Salamon(1990), Schapire (1989),Jacobs et al.(1991),Wolpert (1992) e Perrone e Cooper(1993).
Capítulo 3. Máquinas de Comitê 28
grandes categorias:
• Comitês de especialistas: Nesta classe de máquinas de comitê, as saídas dos espe-cialistas são combinadas por meio de um mecanismo que não envolve diretamente o sinal de entrada do problema. Esta classe ainda possui os seguintes métodos:
– Média de ensembles, onde as saídas dos especialistas são combinadas linear-mente para gerar uma saída global.
– Reforço, onde um algoritmo de baixa precisão é convertido em um algoritmo que consegue atingir uma precisão elevada.
• Comitês com rede de passagem. Nesta classe de máquinas de comitê, o sinal de entrada do problema está influenciando diretamente no mecanismo que combina as saídas dos especialistas em uma saída global. Entre os tipos de estruturas dinâmicas encontram-se:
– Mistura de especialistas, onde as saídas dos especialistas são combinadas por meio de uma rede de passagem.
– Mistura hierárquica de especialistas, onde as saídas dos especialistas são com-binadas por várias redes de passagem arranjadas de forma hierárquica.
3.2
Comitês de Especialistas
29 3.2. Comitês de Especialistas
dados aumenta quando o número de parâmetros ajustáveis é grande comparado com o tamanho do conjunto dos dados de treinamento.
Figura 3.1: Máquina de comitê do tipo média de ensemble.
Como as saídas dos especialistas correspondem a soluções do problema, para que haja um aumento da eficiência do classificador final é necessário que haja certa diversidade entre os especialistas, ou seja, certa discordância entre eles. A abordagem de máquinas de comitê por reforço é bastante diferente da média de ensemble. Na média de ensem-ble, todos os especialistas que constituem a máquina de comitê são treinados usando o mesmo conjunto de dados, mas podem se diferenciar por suas condições de inicialização usadas no treinamento. Já na abordagem por reforço, os especialistas são treinados com conjuntos de dados com distribuições distintas. Segundo Haykin(1999), o reforço pode ser implementado através de três modos básicos:
1. Reforço por filtragem: esta abordagem envolve filtrar os exemplos de treinamento por diferentes versões de um algoritmo de aprendizagem fraca. Ele assume, teori-camente, uma quantidade infinita de fontes de exemplos, com os exemplos sendo descartados ou não durante o treinamento e, se comparado com os outros dois modos, é o que menos requer memória.
Capítulo 3. Máquinas de Comitê 30
de acordo com uma determinada distribuição de probabilidade.
3. Reforço por ponderação: esta abordagem também trabalha com uma amostra de treinamento fixa como a anterior, porém assume que o algoritmo de aprendizagem fraca pode receber exemplos “ponderados”.
As abordagens mais importantes que são encontradas na literatura para se gerar comitês de especialistas são Bagging (Breiman,1996) e Boosting (Schapire,1989).
O método de Bagging (do inglês bootstrap aggregating) foi um dos primeiros algorit-mos criados para a geração de um comitê. Nesta abordagem, cada especialista é treinado com um conjunto de dados gerado através de uma amostragem com reposição dos dados de entrada, de modo que o conjunto de treinamento de cada especialista possua a mesma quantidade de exemplos. Como a probabilidade de cada exemplo ser escolhido é igual para todos, alguns podem ser repetidos e outros deixados de fora no treinamento geral. A combinação de resultados é feita através de uma votação simples onde a resposta com maior freqüência é a escolhida.
31 3.3. Comitês com Rede de Passagem
3.3
Comitês com Rede de Passagem
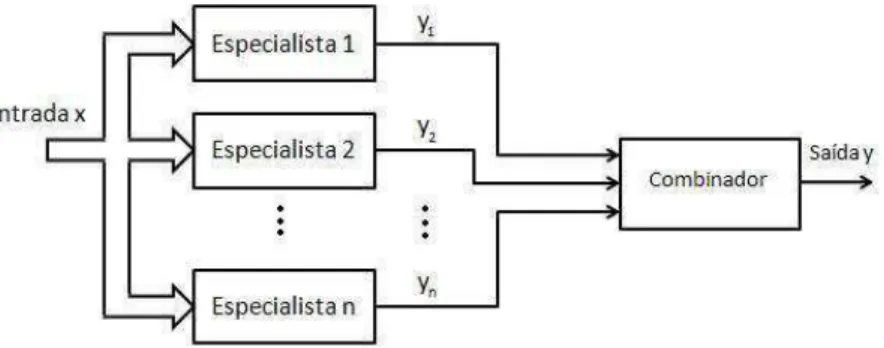
O modelo de mistura de especialistas proposto por Jacobs et al.(1991), visto na Figura 3.2, consiste de um conjunto de K especialistas e de uma unidade chamada de rede de passagem ou supervisora que desempenha o papel de decidir como as saídas dos módulos devem ser combinadas e qual padrão deve ser apresentado a um determinado especialista.
Figura 3.2: Diagrama de blocos do modelo de mistura de especialistas.
A resposta final é dada por:
y =
K
∑︁
i=1
yigi (3.1)
Capítulo 3. Máquinas de Comitê 32
gk=
exp(uk)
∑︀k
j=1exp(uj)
0≤gk≤1para todo k (3.2)
K
∑︁
k=1
gk= 1
Onde uk representa o produto interno do vetor de entrada x pelo vetor de pesos
sinápticos da rede de passagem. Assim, é dever da rede de passagem modelar a relação de probabilidade entre os especialistas, os padrões de entrada e a saída final do comitê.
Uma grande característica dessa abordagem é que a região onde cada especialista deve atuar não é definida previamente, portanto, a divisão de tarefas e cooperação entre os especialistas são feitas de forma interativa. O modelo de mistura hierárquica de especialistas é uma extensão do modelo de mistura de especialistas. Eles se diferenciam na medida em que o espaço de entrada é dividido em conjuntos aninhados de subespaços, com a informação sendo combinada e redistribuída entre os especialistas sob o controle de várias redes de passagem arranjadas em uma forma hierárquica como mostrado em Haykin(1999).
Capítulo 4
Algoritmos Genéticos
Algoritmos Genéticos (AG) compreendem o campo da Computação Evolutiva com nú-mero maior de aplicações e extensões. Os AG são métodos de otimização e busca ins-pirados nos mecanismos de evolução das espécies. Estes algoritmos seguem o princípio da seleção natural e sobrevivência do mais apto, declarado pelo naturalista e fisiologista inglês Charles Darwin em seu livro A Origem das Espécies. Foram propostos inicialmente porHolland(1975) e popularizados por um dos seus alunos,Goldberg(1989), como parte de suas tentativas em explicar processos ocorrendo em sistemas naturais e de construir sistemas artificiais baseados em tais processos.
Capítulo 4. Algoritmos Genéticos 34
gerações.
O Algoritmo Genético canônico (simples AG) pode ser visto como uma junção de três componentes: (a) a representação do cromossomo, comumente uma cadeia de bits ou um conjunto de valores em ponto flutuante; (b) seleção dos pais da próxima geração, usando a função de aptidão, através de uma roleta, torneio, ou outro método de seleção; (c) a síntese de novos indivíduos, usando operadores inspirados na biologia como o crossover e a mutação. A estrutura de funcionamento de um AG tradicional pode ser vista na Figura4.1.
Figura 4.1: Estrutura de funcionamento de um AG tradicional.
35 4.1. Componentes
4.1
Componentes
4.1.1 Representação do Cromossomo
A escolha da representação do cromossomo é a etapa mais importante para o desenvol-vimento de um AG, uma vez que ela será a principal responsável pelo desempenho do algoritmo. Um indivíduo se resume ao conjunto de genes onde a informação se encontra codificada (genótipo) e sua avaliação é baseada em seu fenótipo (conjunto de característi-cas observáveis no objeto resultante do processo de decodificação dos genes). O conjunto de todas as configurações que o cromossomo pode assumir forma o seu espaço de busca. Se o cromossomo representa n parâmetros de uma função, então o espaço de busca é
n-dimensional. A Tabela 4.1 mostra exemplos de representações de indivíduos. Tabela 4.1: Exemplos de representações de indivíduos em diferentes problemas
Genótipo Fenótipo Problema
101101 45 Otimização
nu-mérica
ABCDE
Inicie pela cidade A, passando em seguida pelas cidades B, C, D e
termine em E
Caixeiro viajante
C1R3C2R4
Se condição 1 (C1) execute a regra
3 (R3), se condição 2 (C2) execute
a regra 4 (R4)
Regras de apren-dizagem para agentes
4.1.2 Seleção
Capítulo 4. Algoritmos Genéticos 36
de seu meio. Ela é cumulativa devido às boas características serem mantidas de uma geração para a outra no processo de seleção. Essas duas propriedades combinadas ga-rantem a possibilidade de surgimento de organismos complexos como as formas de vida que hoje conhecemos.
Existem várias formas para efetuar a seleção, dentre as quais se destacam:
• Seleção porranking: os individuos da população são ordenados pelo seu grau de aptidão e então a probabilidade de escolha de um individuo é atribuída conforme a posição que ocupa.
• Seleção por roleta: cada individuo da população é representado proporcional-mente ao seu grau de aptidão. Logo, indivíduos com valores altos de aptidão ocupam grandes porções da roleta (maior probabilidade de ser um pai da próxima geração), enquanto aqueles de menor aptidão ocupam uma porção relativamente menor da roleta (menor probabilidade de ser um pai da próxima geração). Fi-nalmente, a roleta é girada certo número de vezes, dependendo do tamanho da população, e aqueles sorteados na roleta serão indivíduos na próxima geração.
• Seleção por torneio: usa sucessivas disputas para fazer a seleção. Esse método estabelece k disputas para selecionar k indivíduos, cada disputa envolvendo n in-divíduos selecionados aleatoriamente. O indivíduo com o maior valor de aptidão é selecionado na disputa, e deve permanecer na população para a próxima geração.
• Seleção uniforme: todos os indivíduos da população têm a mesma probabilidade de serem selecionados. Claramente, esta forma de selecionar indivíduos possui uma probabilidade muito remota de causar uma melhora da população.
4.1.3 Cruzamento
37 4.1. Componentes
aconteça, o operador precisa escolher pares de reprodutores, havendo assim a troca de partes de seus materiais genéticos. Segundo Lucas(2002), alguns dos principais métodos de escolha desses pares de reprodutores são:
• Escolha aleatória: os pares de individuos sao escolhidos ao acaso.
• Inbreeding: parentes são combinados, ou seja, individuos que possuem um ances-tral em comum são escolhidos.
• Line breeding: onde o indivíduo mais apto é o único que pode cruzar com os outros.
• Self-fertilization: o indivíduo é combinado consigo mesmo, ou seja, há uma espécie de "clonagem"desse individuo.
• Positive assortive mating: indivíduos semelhantes são combinados.
• Negative assortive mating: indivíduos diferentes são combinados.
Para realizar a operação do cruzamento, são definidos pontos na estrutura do cromos-somo para a troca do material genético. Baseada nestes pontos, uma seleção por máscara é criada para determinar para qual filho irá cada gene dos pais ao se combinarem. Seu funcionamento pode ser visto segundo o seguinte algoritmo:
1 semascara(i) = 0 então 2 f ilho1(i) =pai1(i); 3 f ilho2(i) =pai2(i); 4 senão
5 f ilho1(i) =pai2(i); 6 f ilho2(i) =pai1(i); 7 fim
Algoritmo 4.1: Algoritmo da seleção por máscara
Capítulo 4. Algoritmos Genéticos 38
• Cruzamento de um ponto: dados dois genomas p1 e p2 de comprimento l,
sorteia-se um número k qualquer tal que 0 < k < l, o primeiro filho f1 receberá
todos os genesp1de1atéke todos os genesp2dek+ 1atél, e o segundo filhof2 o inverso. Portanto, a máscara de cruzamento seria uma sequência de0s(zeros) de1
aték, sucedida por uma sequência de1s(uns) dek+ 1 atél. Dentre os operadores de cruzamento tradicionais, o de um ponto é o que normalmente apresenta o pior desempenho. A Figura4.2ilustra esse operador.
Figura 4.2: Operador de cruzamento de um ponto.
• Cruzamento multiponto: o cruzamento multiponto é uma generalização do ope-rador de um ponto. Um número fixonde pontos de corte é sorteado. Um operador comnpontos de cruzamento apresentaria uma máscara de cruzamento com n trocas em sua sequência de zeros e uns. A Figura4.3apresenta esse operador.
39 4.1. Componentes
Figura 4.3: Operador de cruzamento multiponto com dois pontos de corte.
• Cruzamento uniforme: para cada gene dos filhos, o operador de cruzamento uni-forme escolhe de qual dos pais este se origina. A máscara de cruzamento, portanto, é uma sequência qualquer de zeros e uns. A Figura 4.4mostra esse operador.
Capítulo 4. Algoritmos Genéticos 40
4.1.4 Mutação
A mutação opera sobre os indivíduos resultantes do processo de cruzamento e com certa probabilidade pré-estabelecida efetua algum tipo de alteração em suas estruturas. A mutação é fator fundamental para garantir a biodiversidade, assegurando assim que o espaço de busca possivelmente será explorado em uma parte significativa de sua exten-são. Este operador possui também um papel fundamental para evitar uma convergência prematura, que ocorre quando a população se estabiliza com uma média de adaptação pouco adequada por causa da pressão evolutiva e baixa diversidade. Alguns exemplos de operadores de mutação são:
• Mutação por troca (swap mutation): são sorteados n pares de genes, e os elementos do par trocam de valor entre si.
• Mutação creep: um valor aleatório é somado ou subtraído do valor do gene.
• Mutaçãoflip: cada gene que sofrerá mutação recebe um valor sorteado do alfabeto válido.
4.1.5 Atualização
41 4.2. Caracteristicas
4.2
Caracteristicas
Pela maneira particular como os AGs operam, podem-se destacar as seguintes caracte-rísticas:
• Busca codificada: SegundoLucas(2002), os AGs não trabalham sobre o domínio do problema, mas sobre representações de seus elementos. Tal fato impõe ao pro-blema que o conjunto de soluções viáveis para ele seja de alguma forma codificada em uma população de indivíduos.
• Generalidade: Uma vez que a representação e a avaliação das possíveis solu-ções são as únicas partes que requerem conhecimento dependente do domínio do problema, basta apenas a alteração destas para os AGs atenderem outros casos.
• Paralelismo explícito: o alto grau de paralelismo intrínseco aos AGs pode ser facilmente visto considerando que cada indivíduo da população existe como um ente isolado e é avaliado independentemente.
• Busca estocástica: diferentemente do que ocorre em outros métodos de busca de valores ótimos, os AGs não apresentam um comportamento determinístico. No en-tanto, a busca não se dá de forma completamente aleatória, pois as probabilidades de aplicação dos operadores genéticos fazem com que estes operem de forma previ-sível estatisticamente, apesar de não permitirem que o comportamento do sistema seja determinado com exatidão absoluta.
Capítulo 4. Algoritmos Genéticos 42
• Eficiência mediana: por constituir um método de busca cega, um AG tende a apresentar um desempenho menor se comparado com alguns tipos de busca heu-rística orientadas ao problema. Para solucionar isso, a tática mais utilizada é a hibridização como mostrada em (Weare et al., 1995), onde heurísticas de outras técnicas são incorporadas.
• Paralelismo implícito: ao se fazer uma busca por populações, a evolução de um AG tende a favorecer indivíduos que compartilhem certas características, sendo as-sim capaz de avaliar implicitamente determinadas combinações ou esquemas como sendo mais ou menos desejáveis, assim, efetuando uma busca por hiperplanos que é de natureza paralela (Goldberg,1989).
Capítulo 5
Método proposto
O principal objetivo do método proposto é aprimorar o desempenho de uma LS-SVM através da construção de um comitê de máquinas e uso de AG. A idéia surgiu com um trabalho anterior (de A. Padilha et al., 2010), onde propusemos o uso de um comitê e AG para aprimorar o desempenho das SVMs. Todas as SVMs eram treinadas com o mesmo conjunto de treinamento, seus parâmetros eram arbitrariamente escolhidos para que houvesse diversidade entre as máquinas e o AG era usado para encontrar um vetor de pesos que melhor representasse a importância de cada SVM na classificação final. De forma a usar essa idéia como base e aprimorá-la para construção deste trabalho, nós adentramos um pouco na teoria de comitês presente na literatura.
Em (Kuncheva e Whitaker,2003;Hansen, L. K. e Salamon,1990;Krogh e Vedelsby, 1995; Opitz e Shavlik, 1996) nós vemos que um comitê efetivo deve consistir de um
Capítulo 5. Método proposto 44
mais populares e usados pelas SVMs é o kernel RBF (Função de Base Radial), o qual tem um parâmetro conhecido como largura da Gaussiana,σ. As análises de desempenho realizadas por Valentini et al. (2004) mostram que uma sintonização apropriada desses parâmetros evitam ooverfitting. Portanto, é necessário que se faça uso de alguma técnica para gerar diversidade entre as máquinas do comitê e encontrar valores adequados para os seus parâmetros. Para tal, utilizou-se a técnica de seleção aleatória de atributos para gerar diversidade no comitê e um AG para encontrar parâmetros adequados para as máquinas.
5.1
Seleção de Atributos e Criação de um Comitê
Dado um probleman-dimensional, nós usamos a técnica de seleção aleatória de atributos para dividi-lo emM subconjuntos do espaço de atributos dos dados, sendo M fornecido pelo usuário, e os atributos de cada subconjunto são escolhidos de forma aleatória. Dessa forma, cada LS-SVM fica responsável pela classificação do problema baseado na infor-mação dada pelo seu subconjunto. Para evitar um grande desbalanceamento nas quan-tidades de atributos dada a cada máquina, foi fixado que, em média, todas as máquinas recebem metade dos atributos.
5.2
Aplicação do Algoritmo Genético
45 5.2. Aplicação do Algoritmo Genético
das LS-SVMs com esse vetor de pesos encontrado. A seguir, é mostrada a representação de cada individuo da população do AG como um vetor contendo os parâmetros ajustáveis das LS-SVMs e seus respectivos pesos.
cromossomoi = [σ1, σ2, ..., σM, C1, C2, ..., CM, w1, w2, ..., wM] (5.1)
OndeM é o número de LS-SVMs.
A função de aptidão do AG é a norma quadrada do erro do comitê calculada sobre um conjunto de pontos de validação. Essa função logicamente vai depender de todos os parâmetros e pesos que queremos encontrar e pode ser vista como:
Ψ(σ,C,w) =‖d−y‖2
d= [d1, ..., dN],y= [y1, ..., yN] (5.2)
yk=oTw, k= 1, ..., N
Onde d contém os padrões de saida, y contém as respostas finais do comitê, o é o vetor das saídas das LS-SVMs para um dado padrão de entrada xk e w é o vetor de
pesos.
Então, uma vez escolhida a função que depende das variáveis que queremos encontrar, nós podemos formular o problema de otimização para ser resolvido pelo AG dessa forma:
min
σ,C,wΨ(σ,C,w) =‖d−y‖
2 (5.3)
Sujeito a:
1. ∑︀M
i=1wi = 1
2. σi, Ci>0 e wi ≥0, parai= 1,2, ..., M
Capítulo 5. Método proposto 46
A população inicial do AG é gerada aleatoriamente com 20 indivíduos. Empregamos a seleção por torneio, onde em cada torneio dois individuos participam e o mais apto é escolhido. A escolha dos pares de individuos para fazer o cruzamento é feita de forma aleatoria e a função de cruzamento é o operador uniforme. A função de mutaçãocreep é utilizada sobre os genes que codificam os parâmetros das máquinas, um valor aleatório é adicionado ou subtraido ao valor do gene resultando em um novo valor dentro dos limites de valor mínimo das restrições do problema de otimização. Já sobre os genes que codificam os pesos, é utilizada a mutação de troca ou swap. O AG funciona por 100 gerações e em cada uma delas dois indivíduos da elite são mantidos para a próxima.
47 5.2. Aplicação do Algoritmo Genético
Capítulo 5. Método proposto 48
Entrada: S={(x1, d1), ...,(xN, dN);xk ∈ ℜn, dk∈ {−1,1}}, o conjunto de dados
Saída: A classificação final do comitê dos dados de teste 1 início
2 Gere de S o conjunto de treinamentoP e o conjunto de teste V;
3 Usando a seleção aleatória de atributos,P é dividido aleatoriamente em M subconjuntos de atributos;
4 Crie M LS-SVMs para fazer parte do comitê, cada uma delas terá como dados de entrada um dos subconjuntos;
5 Chame o AG para inicializar a população de nindivíduos; 6 enquantocritério de parada não atingido faça
7 Treine asM LS-SVM com os dados dos M subconjuntos e usando os valores de σ e C contidos nos ncromossomos;
8 Faça a combinação linear das respostas das M LS-SVMs com os pesosw contidos nos ncromossomos;
9 y(j)
k =o(j)Twparak= 1, ..., N ej= 1, ..., n;
10 y(j)= [y(j)
1 , y (j) 2 , ..., y
(j)
k ]T;
11 Calcule a função de aptidao de cada um dos individuos: 12 Ψ(j)(σ,C,w) =‖d−y(j)‖2;
13 Selecione os pais;
14 Faça o cruzamento dos selecionados; 15 Faça a mutação dos resultantes; 16 Atualizar a população;
17 fim
18 Recupere o individuo mais apto para usar no teste;
19 Avalie as LS-SVM usandoV e obtenha a classificação final: 20 Z(x) =o(op)Twop;
21 Sendo o(op) e w(op), respectivamente, as saídas e pesos otimizados das LS-SVMs;
22 fim
Capítulo 6
Resultados
Um estudo comparativo dos desempenhos obtidos pelo método proposto, o trabalho an-terior (de A. Padilha et al.,2010), uma rede de Função de Base Radial (RBF), uma única SVM treinada com AG (AG-SVM) e um comitê de SVMs treinado com o algoritmo Ada-Boost (Freund e Schapire, 1996) foi conduzido em alguns experimentos. A perfomance dessas redes foi comparada em termos da qualidade da generalização.
Os testes foram realizados usando 13 bases da dados, sendo as 11 bases (Breast Can-cer, Diabetis, Flare Solar,German,Heart,Image,Ringnorm,Splice,Thyroid,Twonorm
eWaveform) adquiridas deFirst(2001) e as outras duas (Hill-Valley,Libras Movement) do UCI Machine Learning Repository. Elas contém problemas de duas classes, exceto a base Libras Movement que contém 15 classes, que incluem vários tipos de problemas de classificação reais e artificiais que variam em relação ao número de dimensões, tipo dos atributos (dados contínuos, discretos ou uma mistura dos dois) e quantidade de padrões. O método proposto e os testes foram implementados usando o MATLAB R2011a.
A seguir, uma breve descrição de cada base utilizada:
Capítulo 6. Resultados 50
• Diabetisé outra base para diagnóstico de diabetes em mulheres com pelo menos 21 anos da linhagem do índios Pima que vivem no Arizona.
• Flare-Solar contém características capturadas de regiões ativas do sol para classi-ficação de tempestades solares.
• German é uma base que classifica pessoas descritas por um conjunto de atributos como tendo baixo ou alto risco de crédito.
• Heart tem informações para classificar se pacientes tem ou não doença cardíaca.
• Hill-Valley é uma base que contém pontos em um gráfico bidimensional formando colinas ou vales.
• Image é outra base que contém informações para a classificação de uma região 3x3 segmentada de imagens ao ar livre.
• Libras Movement é uma base composta por 15 classes que são referentes a tipos de movimento feito com a mão em LIBRAS (Língua Brasileira de Sinais).
• Ringnorm classifica um dado padrão como vindo de uma das duas distribuições normais sobrepostas.
• Splicereconhece duas classes de juntas de processamento numa sequência de DNA.
• Thyroid diagnostica se um paciente tem doença na tireoide.
• Twonorm classifica um dado padrão como proveniente de uma das distribuições normais, uma se encontra dentro da outra.
51
A Tabela 6.1mostra todas as bases de dados usadas e suas respectivas informações sobre o número de dimensões, quantidade de pontos de treinamento, quantidade de pontos de teste e número de partições.
Tabela 6.1: Bases de dados utilizadas
Base de dados Dimensões Treinamento Teste Partições
Breast Cancer 9 200 77 100
Diabetis 8 468 300 100
Flare-Solar 9 666 400 100
German 20 700 300 100
Heart 13 170 100 100
Hill-Valley 100 606 606 100
Image 18 1300 1010 20
Libras Movement 90 180 720 100
Ringnorm 20 400 7000 100
Splice 60 1000 2175 20
Thyroid 5 140 75 100
Twonorm 20 400 7000 100
Waveform 21 400 4600 100
A Tabela6.2mostra as taxas médias de reconhecimento e seus desvios padrão alcan-çados pela rede RBF, AG-SVM, AdaBoost, o trabalho anterior e pelo método proposto sobre todas as partições. Para tratar o problema Libras Movement que contém 15 clas-ses, foi necessário realizar uma adequação em relação ao uso de AG-SVM, AdaBoost e o método proposto. Para o uso do AG-SVM, foi utilizada a estratégia um-contra-um, ou seja, foi criado um classificador AG-SVM para cada par de classes e a resposta final dada por voto majoritário. Já para o uso do AdaBoost, trabalho anterior e do método, foi utilizada a estratégia um-contra-todos, criando um comitê para cada classe e a resposta final é dada pelo comitê que "responder"pelo ponto dado. Em todos os testes, os comitês podem conter até 10 LS-SVMs, ao final da seleção dos pesos das LS-SVMs, caso alguma não contribua efetivamente para a classificação final, seu peso é zero ou próximo de zero e, então, poderá ser removida do comitê sem perda da qualidade de resposta final.
Capítulo 6. Resultados 52
Tabela 6.2: Comparação entre o método proposto (MP), o trabalho anterior (TA), um único classificador RBF, SVM treinada com AG e o AdaBoost. As melhores taxas médias de reconhecimento (%) são mostradas em negrito.
Bases de dados RBF AG-SVM AdaBoost TA MP
Breast Cancer 72.4±4.7 69.6±4.7 73.1±4.7 74±5.8 74.1±0.1
Diabetis 75.7±1.9 73.5±2.3 76.5±1.7 76.4±0.3 76.3±0.8
Flare-solar 65.6±2.0 64.3±1.8 67.6±1.8 65.5±1.0 70.3±0.6
German 75.3±2.4 72.5±2.5 76.4±2.1 76.1±0.7 78±0.6
Heart 82.4±3.3 79.7±3.4 84±3.3 86±2.4 87±0.5
Hill-Valley 63.6±1.8 69.5±1.0 67.8±1.6 70.5±1.8 72.1±1.8
Image 96.7±0.6 97.3±0.7 97±0.6 92.5±0.5 96.3±0.1
Libras Movement 73.3±1.6 84.4±1.0 85.4±1.6 83.2±2.6 88.7±0.8
Ringnorm 98.3±0.2 98.1±0.3 98.3±0.1 97.7±0.6 97.5±0.3
Splice 90±1.0 89.9±0.5 89.1±0.7 89.5±0.5 90.1±0.1
Thyroid 95.5±2.1 95.6±0.6 95.2±2.2 94.6±2.7 94.7±0.6
Twonorm 97.1±0.3 97±0.3 97±0.2 97.2±0.4 97.9±0.2
Waveform 89.3±1.1 89.2±0.6 90.1±0.4 90.3±0.6 92.7±0.2
resultados alcançados pelos outros classificadores na maioria dos testes (9 dos 13) e sem-pre melhores em relação ao trabalho anterior. Os resultados do AdaBoost são melhores do que os alcançados pelos classificadores individuais de uma maneira geral, mostrando que o uso de vários classificadores frequentemente gera melhores taxas de reconhecimento. Entre os classificadores individuais, o AG-SVM tem frequentemente melhores resultados que a RBF. Um teste de significância (Teste t para duas médias) ao nível de 5% foi realizado comparando os resultados do método proposto com os resultados dos outros métodos (dois a dois), e mostrou que o método proposto tem o melhor desempenho entre todos os outros métodos.
Nas quatro bases de dados em que teve um desempenho inferior (Diabetis, Image,
clas-53
sificação destas bases, um outro teste foi realizado considerando o uso de cada técnica separadamente. Os resultados deste novo teste podem ser vistos na Tabela 6.3.
Tabela 6.3: Comparação entre os resultados obtidos pelo uso de cada técnica isolada-mente no comitê de LS-SVM, denominados RSM-LS-SVM (utiliza a seleção aleatória de atributos) e AG-LS-SVM (uso de um AG), e o método proposto. As melhores taxas médias de reconhecimento (%) são mostradas em negrito.
Bases de dados RSM-LS-SVM AG-LS-SVM Método Proposto
Breast Cancer 71.0±2.3 72.7±4.4 74.1±0.1
Diabetis 74.0±2.3 74.6±2.1 76.3±0.3
Flare-solar 65.2±2.2 65.6±1.6 70.3±0.6
German 71.7±1.7 75.3±2.5 78±0.6
Heart 79.4±2.4 83.3±4.2 87±0.5
Hill-Valley 60.1±1.9 70.3±1.8 72.1±1.8
Image 78.6±5.2 96.4±0.5 96.3±0.1
Libras Movement 75.4±2.4 86.3±1.2 88.7±0.8
Ringnorm 91.3±3.7 97.8±2.6 97.5±0.3
Splice 83.8±1.5 88.2±0.6 90.1±0.1
Thyroid 92.3±1.1 96.2±1.9 94.7±0.6
Twonorm 96.1±0.8 97.2±0.2 97.9±0.2
Waveform 83.3±0.7 89.7±0.5 92.7±0.2
Capítulo 7
Conclusões e Perspectivas
Neste trabalho, nós propusemos duas mudanças em relação ao nosso trabalho anterior (de A. Padilha et al.,2010), incorporamos o método de seleção aleatória de características para selecionar subconjuntos de atributos do problema original, gerando um certo grau de diversidade entre os componentes do comitê, e estendemos o uso do AG para encontrar bons valores para os parâmetros de cada LS-SVM (σ, C). O uso de tal técnica de busca global se deve ao fato que o espaço de busca desses parâmetros é realmente enorme em problemas complexos devido a grande extensão dos valores. Comparando os resultados obtidos pelo trabalho anterior e o presente método, podemos ver que o método atual obteve melhores resultados em todos os casos.
Nos testes realizados, foi feita uma comparação do método proposto com outros clas-sificadores individuais, uma rede RBF e uma SVM treinada com AG, e com o algoritmo AdaBoost e foi mostrado que o mesmo alcançou, de forma significativa, melhores resulta-dos para a maioria das bases de daresulta-dos. O AG aplicado ao comitê mostrou ter uma maior contribuição do que o método de escolha aleatória de atributos, dessa forma é possível explorar uma técnica otimizada para fazer essa seleção de características.
55
Referências Bibliográficas
Barbosa, H. J. C. (1996). Algoritmos genéticos para otimização em engenharia: uma introdução. Juiz de Fora. IV Seminários sobre Elementos Finitos e Métodos Numéricos em Engenharia.
Breiman, L. (1996). Bagging predictors. Machine Learning, 24(2):123–140.
Canuto, A. M. P. e Nascimento, D. S. C. (2012). A genetic-based approach to features selection for ensembles using a hybrid and adaptive fitness function. Em The 2012 International Joint Conference on Neural Networks (IJCNN), pgs. 1–8. IEEE.
Coelho, A., Lima, C., e Von Zuben, F. (2003). GA-based selection of components for heterogeneous ensembles of support vector machines. Em The 2003 Congress on Evo-lutionary Computation, 2003. CEC ’03., volume 3, pgs. 2238–2245. IEEE.
Coelho, A. L. V. (2004). Evolução, simbiose e hibridismo aplicados à engenheria de sistemas inteligientes moodulares: Investigação em redes neurais, comitês de máquinas e sistemas multiagentes. Tese de Doutorado. Universidade Estadual de Campinas.
Cover, T. M. (1965). Geometrical and Statistical Properties of Systems of Linear Ine-qualities with Applications in Pattern Recognition. IEEE Transactions On Electronic Computers, EC-14(3):326–334.
57 Referências Bibliográficas
Dawkins, R. (1996). A Escalada do Monte Improvável: uma defesa da teoria da evolução. Companhia das Letras, São Paulo.
de A. Padilha, C. A., Lima, N. H. C., Neto, A. D. D., e de Melo, J. D. (2010). An genetic approach to Support Vector Machines in classification problems. EmThe 2010 International Joint Conference on Neural Networks (IJCNN), pgs. 1–4. IEEE.
Eshelman, L. J., Caruana, R. A., e Schaffer, J. D. (1989). Biases in the crossover lands-cape. Em Schaffer, J. D., editor,Proceedings of the Third International Conference on Genetic Algorithms, pgs. 10–19. Morgan Kaufmann Publishers Inc.
Faceli, K., Lorena, A. C., Gama, J. a., e de Carvalho, A. C. P. L. F. (2011). Inteligência Artificial: Uma Abordagem de Aprendizado de Máquina. LTC, 1 edition.
First, G. M. D. (2001). Soft Margins for AdaBoost. Machine Learning, pgs. 287–320.
Freund, Y. e Schapire, R. E. (1996). Experiments with a New Boosting Algorithm.
Machine Learning, pages:148–156.
Goldberg, D. E. (1989). Genetic Algorithms in Search, Optimization, and Machine Le-arning. Artificial Intelligence. Addison-Wesley.
Hansen, L. K. e Salamon, P. (1990). Neural network ensembles. IEEE Transactions on Pattern Analysis and Machine Intelligence, 12(10):993–1001.
Haykin, S. (1999). Neural Networks: A Comprehensive Foundation, volume 13. Prentice Hall.
Holland, J. H. (1975). Adaptation in Natural and Artificial Systems, volume Ann Arbor. University of Michigan Press.