Universidade Federal do Rio Grande do Norte
Centro de Ciências Exatas e da Terra
Departamento de Informática e Matemática Aplicada
Pós-Graduação em Sistemas e Computação
Uma Análise da aplicação do Modelo de Rede Neural
RePART em Comitês de Classificadores
Araken de Medeiros Santos
Universidade Federal do Rio Grande do Norte
Centro de Ciências Exatas e da Terra
Departamento de Informática e Matemática Aplicada
Pós-Graduação em Sistemas e Computação
Uma Análise da aplicação do Modelo de Rede Neural
RePART em Comitês de Classificadores
Araken de Medeiros Santos [email protected]
Documento submetido ao Programa de Pós-Graduação em Sistemas e Computação do Departamento de Informática e Matemática Aplicada da Universidade Federal do Rio Grande do Norte, como parte dos requisitos necessários para obtenção do Grau de Mestre em Sistemas e Computação.
Orientadora: Profa. Dra. Anne Magály de Paula Canuto
Catalogação da Publicação na Fonte. UFRN / SISBI / Biblioteca Setorial Especializada do Centro de Ciências Exatas e da Terra – CCET.
Santos, Araken de Medeiros.
Uma análise da aplicação do modelo de Rede Neural RePART em Comitês de classificadores / Araken de Medeiros Santos. – Natal, 2008.
168 f. : il.
Orientadora: Profa. Dra. Anne Magály de Paula Canuto.
Dissertação (Mestrado) – Universidade Federal do Rio Grande do Norte. Centro de Ciências Exatas e da Terra. Departamento de Informática e Matemática Aplicada. Programa de Pós-Graduação em Sistemas e Computação.
1. Redes neurais artificiais – Dissertação. 2. Fuzzy artmap – Dissertação. 3. RePART – Dissertação. 4. Comitês de Classificadores – Dissertação. 5. Artmap-IC - Dissertação. I. Canuto, Anne Magály de Paula. II. Título
iii
"A vida é mais simples do que a gente pensa; basta aceitar o impossível, dispensar o indispensável e suportar o intolerável."
Kathleen Norris.
"Uma vida não questionada não merece ser vivida."
iv
v
AGRADECIMENTOS
A Deus;
À minha mãe, por abdicar de seus sonhos em prol dos sonhos de seus filhos;
À toda a minha família, por sempre me apoiar em todos os meus projetos de vida;
À minha noiva Vanêssa, pelo apoio e compreensão nas horas em que tive que abdicar de sua companhia para tornar esse sonho possível;
À minha orientadora Anne Magály, pela paciência, compreensão, colaboração e acima de tudo, pela amizade e disponibilidade, decisivas durante este trabalho;
Aos amigos, porque os são;
vi
RESUMO
O RePART (Reward/Punishiment ART), modelo neural que se constitui numa variação do modelo Fuzzy Artmap, foi proposto objetivando minimizar problemas inerentes aos modelos da classe Artmap, tais como: proliferação de categorias e má classificação. Por essa razão, o RePART faz uso de mecanismos adicionais, como: um parâmetro contador de instância, um processo de recompensa/punição e um parâmetro de vigilância variável. O parâmetro contador de instância busca minimizar o problema de má classificação, resultante da sensibilidade à ruídos, freqüentemente presente nos modelos da classe Artmap. O uso da vigilância variável tem como objetivo minimizar o problema de proliferação de categorias, diminuindo a complexidade da rede, quando utilizado em aplicações com um grande número de padrões de treinamento. A proposta do RePART visou a minimização desses problemas e foi mostrado que o RePART obteve desempenho superior que alguns modelos da classe Artmap. Neste trabalho é proposta a realização de uma investigação do desempenho do modelo RePART em comitês de classificadores. Nesta investigação será realizada uma análise com comitês utilizando diferentes tamanhos, estratégias de aprendizados e estruturas. Os resultados obtidos com esta investigação servirão como meio de descoberta das vantagens e desvantagens de cada um dos modelos abordados em comitês. Com isso, poderá ser dado um embasamento ainda mais amplo à utilização do RePART em outras aplicações de reconhecimento de padrões.
vii
ABSTRACT
RePART (Reward/Punishment ART) is a neural model that constitutes a variation of the Fuzzy Artmap model. This network was proposed in order to minimize the inherent problems in the Artmap-based model, such as the proliferation of categories and misclassification. RePART makes use of additional mechanisms, such as an instance counting parameter, a reward/punishment process and a variable vigilance parameter. The instance counting parameter, for instance, aims to minimize the misclassification problem, which is a consequence of the sensitivity to the noises, frequently presents in Artmap-based models. On the other hand, the use of the variable vigilance parameter tries to smoouth out the category proliferation problem, which is inherent of Artmap-based models, decreasing the complexity of the net. RePART was originally proposed in order to minimize the aforementioned problems and it was shown to have better performance (higer accuracy and lower complexity) than Artmap-based models. This work proposes an investigation of the performance of the RePART model in classifier ensembles. Different sizes, learning strategies and structures will be used in this investigation. As a result of this investigation, it is aimed to define the main advantages and drawbacks of this model, when used as a component in classifier ensembles. This can provide a broader foundation for the use of RePART in other pattern recognition applications.
viii
LISTA DE FIGURAS
Figura 2.1 - Neurônio biológico ... 11
Figura 2.2 – Neurônio Artificial – Modelo MCP ... 12
Figura 2.3 -Aprendizagem supervivionada ... 13
Figura 2.4 – Aprendizagem Não-Supervisionada ... 14
Figura 2.5 - Aprendizagem Competitiva ... 14
Figura 2.6 - Aprendizagem por Reforço ... 15
Figura 2.7 – Esquema do ART1 ... 17
Figura 2.9 – As operações do modelo neural RePART ... 34
Figura 3.1 - Processo de combinação de decisão de um comitê classificador. ... 37
Figura 6.1 – Erro Médio e Desvio Padrão dos classificadores individuais ... 70
Figura 6.2 – Erro Médio e Desvio Padrão dos classificadores individuais aplicados à base SatImage. ... 72
Figura 6.3 – Erro Médio e Desvio Padrão dos comitês com 3 classificadores base (Média de todas as estratégias de boosting por combinador) aplicados à base de Câncer de mama. ... 74
Figura 6.4 – Erro Médio e Desvio Padrão dos Comitês com 3 classificadores base (Média de todos os combinadores por estratégia de boosting) aplicados à base de Câncer de mama. ... 75
Figura 6.5 – Erro Médio e Desvio Padrão dos Comitês com 3 classificadores base (Média de de todas as estratégias de boosting e métodos de combinação) aplicados à base de Câncer de mama. ... 76
Figura 6.6 – Erro Médio e Desvio Padrão dos comitês com 3 classificadores base (Média de todas as estratégias de boosting por combinador) aplicados à base SatImage. . 78 Figura 6.7 – Erro Médio e Desvio Padrão dos Comitês com 3 classificadores base (Média de todos os combinadores por estratégia de boosting) aplicados à base SatImage. ... 79
Figura 6.8 – Erro Médio e Desvio Padrão dos Comitês com 3 classificadores base (Média de de todas as estratégias de boosting e métodos de combinação) aplicados à base SatImage. ... 80
Figura 6.9 – Erro Médio e Desvio Padrão dos comitês com 6 classificadores base (Média de todas as estratégias de boosting por combinador) aplicados à base de Câncer de mama. ... 81
Figura 6.10 – Erro Médio e Desvio Padrão dos Comitês com 6 classificadores base (Média de todos os combinadores por estratégia de boosting) aplicados à base de Câncer de mama. ... 83
Figura 6.11 – Erro Médio e Desvio Padrão dos Comitês com 6 classificadores base (Média de de todas as estratégias de boosting e métodos de combinação) aplicados à base de Câncer de mama. ... 84
Figura 6.12 – Erro Médio e Desvio Padrão dos comitês com 6 classificadores base (Média de todas as estratégias de boosting por combinador) aplicados à base SatImage. . 86 Figura 6.13 – Erro Médio e Desvio Padrão dos Comitês com 6 classificadores base (Média de todos os combinadores por estratégia de boosting) aplicados à base SatImage. ... 87
Figura 6.14 – Erro Médio e Desvio Padrão dos Comitês com 6 classificadores base (Média de de todas as estratégias de boosting e métodos de combinação) aplicados à base SatImage. ... 87
ix
Figura 6.16 – Erro Médio e Desvio Padrão dos Comitês com 12 classificadores base (Média de todos os combinadores por estratégia de boosting) aplicados à base de
Câncer de mama. ... 91
Figura 6.17 – Erro Médio e Desvio Padrão dos Comitês com 12 classificadores base (Média de todas as estratégias de boosting e métodos de combinação) aplicados à base de Câncer de mama. ... 91
Figura 6.18 – Erro Médio e Desvio Padrão dos comitês com 12 classificadores base (Média de todas as estratégias de boosting por combinador) aplicados à base
SatImage. ... 93
Figura 6.19 – Erro Médio e Desvio Padrão dos Comitês com 12 classificadores base (Média de todos os combinadores por estratégia de boosting) aplicados à base
SatImage. ... 95
Figura 6.20 – Erro Médio e Desvio Padrão dos Comitês com 12 classificadores base (Média de todas as estratégias de boosting e métodos de combinação) aplicados à
base SatImage. ... 95
Figura 6.21 – Erro Médio e Desvio Padrão dos comitês com 24 classificadores base (Média de todas as estratégias de boosting por combinador) aplicados à base de
Câncer de mama. ... 98
Figura 6.21 – Erro Médio e Desvio Padrão dos comitês com 24 classificadores base (Média de todas as estratégias de boosting por combinador) aplicados à base de
Câncer de mama. ... 98
Figura 6.22 – Erro Médio e Desvio Padrão dos Comitês com 24 classificadores base (Média de todos os combinadores por estratégia de boosting) aplicados à base de
Câncer de mama. ... 99
Figura 6.23 – Erro Médio e Desvio Padrão dos Comitês com 24 classificadores base (Média de todas as estratégias de boosting e métodos de combinação) aplicados à
base de Câncer de mama. ... 99
Figura 6.24 – Erro Médio e Desvio Padrão dos comitês com 24 classificadores base (Média de todas as estratégias de boosting por combinador) aplicados à base
SatImage. ... 101
Figura 6.25 – Erro Médio e Desvio Padrão dos Comitês com 24 classificadores base (Média de todos os combinadores por estratégia de boosting) aplicados à base
SatImage. ... 102
Figura 6.26 – Erro Médio e Desvio Padrão dos Comitês com 24 classificadores base (Média de todas as estratégias de boosting e métodos de combinação) aplicados à
base SatImage. ... 103
Figura 6.27 – Erro Médio e Desvio Padrão dos comitês com 48 classificadores base (Média de todas as estratégias de boosting por combinador) aplicados à base de
Câncer de mama. ... 105
Figura 6.28 – Erro Médio e Desvio Padrão dos Comitês com 48 classificadores base (Média de todos os combinadores por estratégia de boosting) aplicados à base de
Câncer de mama. ... 107
Figura 6.29 – Erro Médio e Desvio Padrão dos Comitês com 48 classificadores base (Média de todas as estratégias de boosting e métodos de combinação) aplicados à
base de Câncer de mama. ... 107
Figura 6.30 – Erro Médio e Desvio Padrão dos comitês com 48 classificadores base (Média de todas as estratégias de boosting por combinador) aplicados à base SatImage. ... 109
Figura 6.31 – Erro Médio e Desvio Padrão dos Comitês com 48 classificadores base (Média de todos os combinadores por estratégia de boosting) aplicados à base SatImage. ... 111
Figura 6.32 – Erro Médio e Desvio Padrão dos Comitês com 48 classificadores base (Média de todas as estratégias de boosting e métodos de combinação) aplicados à
x
Figura 6.33 – Erro Médio e Medidas de Diversidade dos comitês Heterogêneos e
Homogêneos aplicados à base de Câncer de mama. ... 115
Figura 6.34 – Erro Médio e Medidas de Diversidade dos comitês Heterogêneos e
Homogêneos aplicados à base SatImage. ... 115
Figura 6.35 – Erro Médio e Medidas de Diversidade das Variantes do Boosting aplicados
à base de Câncer de mama. ... 117
Figura 6.36 – Erro Médio e Medidas de Diversidade das Variantes do Boosting aplicados
à base SatImage. ... 117
Figura 6.37 – Erro Médio e Medidas de Diversidade dos comitês com 3, 6, 12, 24 e 48 classificadores base aplicados à base de Câncer de mama. ... 119
Figura 6.38 – Erro Médio e Medidas de Diversidade dos comitês com 3, 6, 12, 24 e 48 classificadores base aplicados à base SatImage. ... 119
Figura 6.39 – Erro Médio e Medidas de Diversidade comitês com 0, 33, 66 e 100% de classificadores RePART aplicados à base de Câncer de mama. ... 121
xi
LISTA DE TABELAS
Tabela 6.1 – Erro Médio (EM) e Desvio Padrão (DP) ... 69
dos classificadores individuais aplicados à base de Câncer de mama. ... 69
Tabela 6.2 – Valor p obtidos ao aplicar o teste de hipótese (Base de Câncer de mama). .. 70
Tabela 6.3 – Erro Médio (EM) e Desvio Padrão (DP) ... 71
dos classificadores individuais aplicados à base SatImage ... 71
Tabela 6.4 – Valor p obtidos ao aplicar o teste de hipótese (Base SatImage). ... 71
Tabela 6. 5 – Erro Médio (EM) e Desvio Padrão (DP) dos comitês com 3 classificadores base aplicados à base de Câncer de mama. ... 73
Tabela 6.6 – Erro Médio (EM) e Desvio Padrão (DP) dos comitês com 3 classificadores base aplicados à base SatImage. ... 77
Tabela 6.7 – Erro Médio (EM) e Desvio Padrão (DP) dos comitês com 6 classificadores base aplicados à base de Câncer de mama. ... 81
Tabela 6. 8 – Erro Médio (EM) e Desvio Padrão (DP) dos comitês com 6 classificadores base aplicados à base SatImage. ... 85
Tabela 6. 9 – Erro Médio (EM) e Desvio Padrão (DP) dos comitês com 12 classificadores base aplicados à base de Câncer de mama. ... 89
Tabela 6. 10 – Erro Médio (EM) e Desvio Padrão (DP) dos comitês com 12 classificadores base aplicados à base SatImage. ... 93
Tabela 6. 11 – Erro Médio (EM) e Desvio Padrão (DP) dos comitês com 24 classificadores base aplicados à base de Câncer de mama. ... 97
Tabela 6. 12 – Erro Médio (EM) e Desvio Padrão (DP) dos comitês com 24 classificadores base aplicados à base SatImage. ... 101
Tabela 6. 13 – Erro Médio (EM) e Desvio Padrão (DP) dos comitês com 48 classificadores base aplicados à base de Câncer de mama. ... 105
Tabela 6. 14 – Erro Médio (EM) e Desvio Padrão (DP) dos comitês com 48 classificadores base aplicados à base SatImage. ... 109
Tabela 6. 15 – Erro Médio (EM), Desvio Padrão (DP) e Medidas de Diversidade dos
comitês Homogêneos, Heterogêneos (2) e Heterogêneos (3). ... 113
Tabela 6. 16 – Erro Médio (EM), Desvio Padrão (DP) e Medidas de Diversidade das
Variantes do Boosting. ... 116
Tabela 6. 17 – Erro Médio (EM), Desvio Padrão (DP) e Medidas de Diversidade dos
comitês com 3, 6, 12, 24 e 48 classificadores base. ... 118
Tabela 6. 18 – Erro Médio (EM), Desvio Padrão (DP) e Medidas de Diversidade dos
comitês com 0, 33, 66 e 100% de classificadores RePART. ... 121
Tabela A.1 – Erro Médio (EM) e Desvio Padrão (DP) e Medidas de Diversidade das
variantes do boosting s base aplicados à base de Câncer de mama. ... 147
Tabela A.2 – Erro Médio (EM), Desvio Padrão (DP) e Medidas de Diversidade das
variantes do boosting s base aplicados à base SatImage. ... 147
Tabela A.3 – Erro Médio (EM) e Desvio Padrão (DP) e Medidas de Diversidade das
variantes do boosting s base aplicados à base de Câncer de mama. ... 148
Tabela A.4 – Erro Médio (EM) e Desvio Padrão (DP) e Medidas de Diversidade das
xii
LISTA DE SIGLAS
ART: Adaptive Resonance Theory
ART-EMAP: ART with spatial and temporal Evidence integration dor dynamic predictive Mapping
Artmap: Predictive ART
Artmap-IC: Artmap Instance Counting dART: Distributed ART
DCS –LA: Dynamic classifier base on local accuracy class
DCS –MCS: Dynamic classifier selection base on multiple classifier behaviour DCS-DT: Dynamic classifier selection using also decision
FAMR: Fuzzy Artmap with Relevance Factor
FASEAM: Fuzzy Adaptive System Ellipsoid Artmap Fuzzy ART: Fuzzy Adaptive Resonance Theory Fuzzy MLP: Fuzzy Multi-Layer Perceptron GNC: Growing Neural Gas
GSC: Growing Cell Structures IA: Inteligência Artificial MLP: Multi-Layer Perceptron PROBART: Probability ART
PSFAM: Probabilistic Simplified Fuzzy Artmap PTAM: Polytope Artmap
RePART: Reward and Punishment ART RNA: Redes Neurais Artificiais
SFAM: Simplified Fuzzy Artmap SF-ART: Supervised Fuzzy ART SMC: Sistema Multiclassificador
xiii
SUMÁRIO
CAPÍTULO 1 ... 1
1.1. INTRODUÇÃO ... 2
1.2 MOTIVAÇÃO ... 5
1.3 OBJETIVO ... 6
1.4 ESTRUTURA ... 7
CAPÍTULO 2 ... 8
2.1. INTRODUÇÃO ... 9
2.2. NEURÔNIOS BIOLÓGICOS ... 10
2.3. NEURÔNIOS ARTIFICIAIS: MODELOMCP ... 11
2.4. APRENDIZAGEM ... 13
2.5. REDESNEURAIS ARTIFICIAIS ... 15
2.5.1. REDES BASEADAS NA SIMILARIDADE ... 15
2.5.1.1. Redes ART (Adaptive Resonance Theory) ... 16
2.5.1.2. Rede Fuzzy ART ... 18
2.5.1.3. Redes Artmap ... 20
2.5.1.4. Redes Fuzzy Artmap ... 23
2.5.1.5. Artmap-IC ... 24
2.5.1.6. RePART ... 25
CAPÍTULO 3 ... 35
3.1. INTRODUÇÃO ... 36
3.2. COMITÊSNEURAIS ... 38
3.2.1. A ESTRUTURA DE UM SISTEMA MULTI-NEURAL ... 40
3.2.1.1. Abordagem Baseada em Ensemble ... 40
3.2.2. DIVERSIDADE ... 42
3.2.2.1. Medidas Pairwise ... 43
A) Q-Estatístico ... 43
B) Medida de Desacordo ... 44
C) Medida de Duplo-Falso ... 45
3.2.2.2. Medidas Non-Pairwise ... 45
A) Medida de Entropia ... 45
3.2.3.BOOSTING ... 46
3.2.4. MÉTODOS DE COMBINAÇÃO ... 48
3.2.4.1. Soma ... 49
3.2.4.2. MLP ... 49
3.2.4.3. RBF ... 50
3.2.4.4.Naive Bayesian ... 50
3.2.4.5. Máquinas de Vetor de Suporte (Support Vector Machine) ... 51
xiv
3.2.4.7. K-NN ... 53
CAPÍTULO 4 ... 54
4.1. COMITÊS ... 55
4.2. TÉCNICAS DE TREINAMENTO ... 57
4.3. TEORIA DA RESSONÂNCIA ADAPTATIVA ... 58
CAPÍTULO 5 ... 60
5.1 INTRODUÇÃO ... 61
5.2. BASES DE DADOS ... 62
5.3. MÉTODOS E EXPERIMENTOS ... 62
5.3.1. BOOSTING ... 63
5.3.2. METOTOLOGIA DE AVALIAÇÃO ... 63
5.3.2.1. VALIDAÇÃOCRUZADA ... 63
5.3.2.1. TESTE DE HIPÓTESE ... 64
5.3.4. EXPERIMENTOS ... 64
CAPÍTULO 6 ... 67
6.1. CLASSIFICADORES INDIVIDUAIS ... 69
6.1.1. BASE DE DADOS DE CÂNCER DE MAMA ... 69
6.1.2. BASE DE DADOS DE SATIMAGE ... 70
6.2. COMITÊS COM 3 CLASSIFICADORES BASE ... 72
6.2.1. BASE DE DADOS DE CÂNCER DE MAMA ... 72
6.2.2. BASE DE DADOS DE SATIMAGE ... 76
6.3. COMITÊS COM 6 CLASSIFICADORES BASE ... 80
6.3.1. BASE DE DADOS DE CÂNCER DE MAMA ... 80
6.3.2. BASE DE DADOS DE SATIMAGE ... 84
6.4. COMITÊS COM 12 CLASSIFICADORES BASE ... 88
6.4.1. BASE DE DADOS DE CÂNCER DE MAMA ... 88
6.4.2. BASE DE DADOS DE SATIMAGE ... 92
6.5. COMITÊS COM 24 CLASSIFICADORES BASE ... 95
6.5.1. BASE DE DADOS DE CÂNCER DE MAMA ... 96
6.5.2. BASE DE DADOS DE SATIMAGE ... 100
6.6. COMITÊS COM 48 CLASSIFICADORES BASE ... 104
6.6.1. BASE DE DADOS DE CÂNCER DE MAMA ... 104
6.6.2. BASE DE DADOS DE SATIMAGE ... 108
6.7. ANÁLISE DOS RESULTADOS ... 112
6.7.1. COMITÊS HETEROGÊNEOS VS. COMITÊS HOMOGÊNEOS ... 113
6.7.2. VARIANTES DO BOOSTING:AGGRESSIVE, CONSERVATIVE E INVERSE ... 115
6.7.3. NÚMERO DE CLASSIFICADORES BASE ... 118
6.7.4. INFLUÊNCIA DO REPART ... 120
xv
7.1. CONSIDERAÇÕES FINAIS ... 124
7.2. TRABALHOS FUTUROS ... 125
REFERÊNCIAS BIBLIOGRÁFICAS ... 127
ANEXO 1 – TABELAS DE RESULTADOS DAS TRÊS VARIAÇÕES DO BOOSTING ... 147
Capítulo 1
Introdução
1.1. Introdução
A busca pela modelagem de sistemas inteligentes artificiais é o principal objetivo da Inteligência Artificial (IA). Dentre as diversas abordagens dadas ao estudo da IA destaca-se a área de redes neurais artificiais [Rezende, 2003; Braga et al., 1998].
As Redes Neurais Artificiais (RNAs) são sistemas baseados em alguns princípios organizacionais do cérebro humano, tentando reproduzir as funções das redes biológicas, buscando implementar seu comportamento e sua dinâmica. Vários modelos de RNAs têm sido propostos, adotando as mais variadas técnicas de aprendizagem e por muitas vezes combinando algumas das técnicas existentes com outras áreas da IA. Como exemplo, podemos citar o modelo neural Fuzzy Artmap [Carpenter et al., 1992], que se fundamenta na combinação dos Sistemas Fuzzy [Rezende, 2003, Shi and Mizumoto, 2000a, Shi and Mizumoto, 2000b] com o modelo neural Artmap [Carpenter et al., 1991]. Este modelo de rede emprega um processo de aprendizagem baseado na similaridade entre o padrão de entrada e os pesos dos neurônios da camada de saída.
Os algoritmos de aprendizagem podem ser divididos em dois grupos principais: por minimização do erro e os baseados na similaridade. Nos algoritmos com aprendizagem baseada na minimização do erro, o processo se fundamenta na adaptação através da diminuição do erro entre a saída desejada e saída da rede, tendo como principal exemplo o algoritmo
backpropagation [Werbos, 1989]. O backpropagation é um dos algoritmos mais utilizados no processo de treinamento de redes neurais artificiais, em especial do modelo Multi-Layer Perceptron [Rumelhart et al., 1986]. Dentre os modelos neurais cujo aprendizado é baseado na similaridade, podemos destacar os modelos fundamentados na Teoria da Ressonância Adaptativa (ART, do inglês
Grossberg, 1987a] foi o primeiro passo rumo ao desenvolvimento da Teoria da Ressonância Adaptativa. Subsequentemente, vários outros modelos de RNAs baseados nesta teoria foram desenvolvidos, tais como: ART-2 [Carpenter and Grossberg, 1987b], ART-3 [Carpenter and Grossberg, 1990], Fuzzy ART [Carpenter and Grossberg, 1991] e Artmap [Carpenter et al., 1991].
O modelo Artmap original, diferentemente do modelo ART, usa um processo de aprendizagem supervisionada, uma vez que tanto a entrada quanto a saída desejada são conhecidas. Este modelo incorpora dois módulos ART-1 [Carpenter and Grossberg, 1987a] bem como um módulo de mapeamento, sendo este último utilizado para formar associações entre as saídas de ambos os módulos ART. Vários modelos têm sido propostos tendo como base o modelo Artmap. Como exemplos podemos citar o Fuzzy Artmap [Carpenter et al., 1992], ART-EMAP [Carpenter and Ross, 1995], Artmap-IC [Carpenter and Markuzon, 1998], dART [Carpenter, 1997], Gaussian Artmap [Williamson, 1996], SFAM [Kasuba, 1993], PROBART [Srinivasa, 1997],
Cascade Artmap [Tan, 1997], PSFAM [Jervis et al., , 1999], RePART [Canuto, 2001], SF-ART [Akhardeh and Varri, 2005], FASEAM [Peralta et al., 2005], PTAM [Gomes et al., 2005], entre outros.
O RePART é uma versão mais avançada do modelo Artmap, mais especificamente do modelo Fuzzy Artmap. Neste modelo, são empregados mecanismos adicionais para melhorar o desempenho e a operabilidade do processo de aprendizagem e teste do Fuzzy Artmap. As principais melhorias são: um mecanismo de vigilância variável durante o processo de aprendizagem e um processo de recompensa/punição durante a fase de teste [Canuto et al., 1999b]. Desde que foi proposto, algumas pesquisas vêm sendo realizadas acerca do desempenho e comportamento do modelo RePART em diferentes tarefas de reconhecimento de padrões, como por exemplo em [Canuto et al., 1999a, Canuto et al., 1999b, Canuto et al., 2000a, Canuto et al., 2001, Canuto and Santos, 2004, Santos and Canuto, 2004].
significantemente menor que os modelos Fuzzy Artmap e Artmap-IC. Adicionalmente, pôde-se verificar que o modelo RePART comporta-se semelhantemente ao MLP, uma vez que as diferenças apresentadas nos resultados das duas redes não se mostraram significantes do ponto de vista estatístico. Contudo, tais pesquisas abordam somente o desempenho do RePART em sistemas classificadores simples, não contemplando seu desempenho em comitês de classificadores, também chamados de ensembles ou sistemas multiclassificadores (SMCs).
Comitês de classificadores exploram a idéia de que diferentes classificadores podem oferecer informações complementares sobre os padrões a serem classificados, melhorando a efetividade do processo de reconhecimento como um todo. As melhorias obtidas pela combinação ou integração das saídas de múltiplos classificadores em problemas de reconhecimento de padrões complexos têm sido objeto de intensas pesquisas, como, por exemplo, em [Canuto et al., 2007, Canuto et al., 2005a, Canuto et al., 2005b, Canuto et al., 2005c, Kuncheva, 2004, Skurichina and Duin, 2002].
A maioria dos comitês de classificadores combina o mesmo tipo de classificadores (comitês homogêneos), com variações no conjunto de treinamento, parâmetros iniciais e/ou configuração, como por exemplo, em [Bhattacharya and Chaudhuri, 2005], no qual são utilizados comitês compostos unicamente de classificadores neurais. Contudo, recentemente vêm sendo realizadas algumas investigações nas quais são analisados os benefícios do uso de diferentes tipos de classificadores (comitês heterogêneos), como por exemplo em [Canuto et al., 2007, Canuto et al., 2005a, Canuto et al., 2005b, Canuto et al., 2005c].
desempenho geral do sistema quando suas saídas são combinadas. Sendo assim, é intuitivamente aceito que os classificadores para serem combinados devem apresentar diversidade, uma vez que não há nenhuma vantagem a ser obtida da combinação de um conjunto de classificadores idênticos [Canuto et al., 2005c, Canuto et al., 2005b].
Com isso, surgiu a necessidade de analisar o desempenho do RePART, quando utilizado em comitês de classificadores Para atender a esta necessidade, neste trabalho serão analisados os desempenhos de diversas configurações de comitês (heterogêneos e homogêneos) aplicados sob diferentes níveis de diversidade em diferentes tarefas de reconhecimento de padrões.
1.2 Motivação
Em [Canuto et al., 1999a, Canuto et al., 1999b, Canuto et al., 2000a, Canuto et al., 2001, Canuto and Santos, 2004, Santos and Canuto, 2004], foram realizadas pesquisas acerca do desempenho do RePART, aplicado individualmente em diversas tarefas de reconhecimento de padrões. Nestes trabalhos, comparou-se o desempenho de diferentes configurações do RePART com outros modelos neurais, tais como o Fuzzy Artmap [Carpenter et al., 1992], Artmap-IC [Carpenter and Markuzon, 1998] e MLP [Haykin, 1998]. Adicionalmente, foi utilizado um método estatístico para comparações de algoritmos de aprendizagem de máquina, através da análise da significância estatística das diferenças nos resultados obtidos por dois classificadores.
Contudo, com o aumento do uso de sistemas classificadores nas mais diversas tarefas, surge a necessidade de sistemas cada vez mais eficazes. Por este motivo, pode-se verificar um crescente interesse da comunidade científica por pesquisas acerca da combinação ou integração de classificadores com o objetivo de obter melhorias no desempenho.
A partir daí, a principal motivação para este trabalho é analisar o comportamento do RePART quando utilizado em comitês de classificadores. O principal objetivo desta análise é dar um embasamento mais amplo à utilização deste modelo neural, uma vez que o mesmo na maioria dos casos analisados apresentou um desempenho superior a outros modelos da classe ART.
1.3 Objetivo
Como mencionado anteriormente, o objeto de estudo deste trabalho é uma investigação do desempenho do modelo de rede neural RePART em comitês de classificadores. Para tanto, os comitês analisados neste trabalho serão treinados utilizando três variações da técnica de construção de comitês (estratégias de aprendizado) conhecida como boosting [Freund, 1995]: agressive boosting, conservative boosting e inverse boosting [Kuncheva and Whitaker, 2002]. Por ser bastante apropriado para a geração de diversidade em comitês, o boosting é muito utilizado pela comunidade científica.
Deste modo, ao final deste trabalho espera-se contribuir com os seguintes tópicos, no universo analisado:
x Definir o número de classificadores base apresenta melhor acurácia em comitês utilizando modelos da família Artmap;
x Definir a quantidade de diferentes tipos de classificadores base apresenta melhor acurácia;
x Definir a variação boosting que apresenta melhor acurácia quando aplicados a comitês utilizando modelos da família Artmap;
x Definir a existência de relacionamento entre diversidade e acurácia em comitês utilizando modelos da família Artmap;
x Definir o impacto, em termos de acurácia, que a utilização do modelo RePART tem em comitês utilizando modelos da família Artmap.
1.4 Estrutura
Este trabalho está dividido em seis capítulos e está estruturado da seguinte forma:
x No Capítulo 2 é apresentada uma introdução às redes neurais artificiais, à teoria da ressonância adaptativa (ART) e aos modelos neurais que serão utilizados;
x O Capítulo 3 trata dos comitês, especialmente os comitês de classificadores neurais, apresentando suas principais características;
x O Capítulo 4 apresenta o estado da arte acerca de comitês e dos modelos neurais que serão utilizados no trabalho proposto;
x No Capítulo 5 é apontada a metodologia dos experimentos realizados;
x No Capítulo 6 são apresentados os resultados experimentais, assim como uma análise com diferentes níveis de abstração;
Capítulo
2
Redes Neurais
2.1. Introdução
A principal motivação para o estudo de redes neurais artificiais é o reconhecimento de que o cérebro processa informações de uma forma inteiramente diferente de um computador digital convencional. Dados incompletos e inconsistentes podem ser processados pelo cérebro por meio do uso da experiência adquirida, podendo-se afirmar que o mesmo é tolerante a falhas [Haykin, 1998].
As Redes Neurais Artificiais (RNAs) são modelos matemáticos que procuram assemelhar-se às estruturas neurais biológicas. Elas têm capacidade computacional adquirida por meio de aprendizagem e generalização. O processo de aprendizagem está normalmente associado à capacidade de se adaptar aos seus parâmetros como conseqüência da sua interação com o mundo externo [Müller et al., 1990].
Dentre os vários atrativos para a solução de problemas através de RNAs, podemos destacar a capacidade de aprender e generalizar a informação aprendida e a forma como estes problemas são representados internamente pela rede. Outro forte atrativo é o fato do paralelismo natural inerente à arquitetura das RNAs criar a possibilidade de um desempenho superior ao dos demais modelos existentes.
Uma rede neural pode ser vista como um sistema composto de diversas unidades funcionais simples (neurônios artificiais) que ligadas de maneira apropriada podem gerar comportamentos interessantes e complexos, determinados pela estrutura das ligações (topologia) e pelos valores das conexões (pesos sinápticos). Há um vasto número de modelos de redes neurais artificiais na literatura [Haykin, 1998, Lin and Lee, 1996, Mehrotra et al., 1998] que podem ser diferenciados de acordo com os seguintes parâmetros:
x Modelo das interconexões e estrutura topológica (uma camada ou várias camadas, parcial ou totalmente conectada);
x Modelo do algoritmo de aprendizagem (supervisionado ou não-supervisionado).
As principais vantagens das redes neurais artificiais sobre sistemas convencionais são [Lin and Lee, 1996]:
x Mapeamento não-linear da entrada-saída: RNAs são aptas a aprender arbitrariamente mapeamentos não-lineares da entrada-saída diretamente do conjunto de treinamento;
x Generalização: capacidade que permite às RNAs um desempenho satisfatório (produzir saídas adequadas) em resposta a dados desconhecidos (não pertencentes ao conjunto de treinamento, mas que estejam em sua vizinhança);
x Adaptatividade: RNAs podem automaticamente ajustar sua estrutura (número de neurônios ou conexões) para otimizar seu comportamento;
x Tolerância à falhas: característica que permite a rede continuar apresentando resultados aceitáveis no caso de falha de alguns neurônios (unidades computacionais básicas das redes neurais artificiais).
Nas seções seguintes serão apresentadas as principais definições aplicadas à estrutura de uma rede neural artificial [Haykin, 1998].
2.2. Neurônios Biológicos
dendritos e o axônio. Os dendritos têm por função receber as informações ou impulsos nervosos, oriundos de outros nodos (neurônios), e conduzi-las até o corpo celular, onde a informação é processada e novos impulsos são gerados, e então repassados aos neurônios a ele conectados. O ponto de contato entre a terminação axônica de um neurônio e o dendrito de outro é chamado de sinapse [Braga et al., 1998, Haykin, 1998]. A Figura 2.1 mostra a estrutura básica de um neurônio biológico.
Figura 2.1 - Neurônio biológico
2.3. Neurônios Artificiais: Modelo MCP
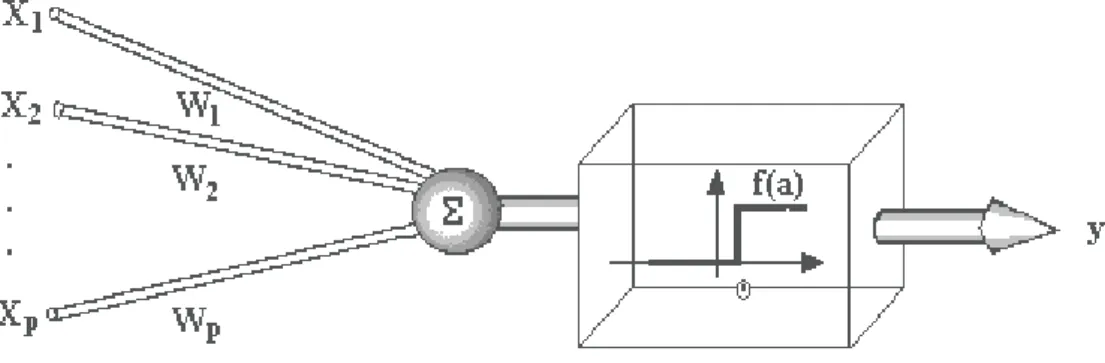
A fascinação criada em torno do funcionamento do cérebro e dos neurônios biológicos levou a estudos visando encontrar a melhor forma de construção de neurônios artificiais, projetando-os de modo a capturar algumas características importantes do neurônio biológico.
Um dos trabalhos pioneiros acerca de neurônios artificiais, cujas variações ainda são amplamente utilizadas nos dias de hoje, foi desenvolvido pelo neurofiologista Warren McCulloch e o lógico Wafter Pitts, em 1943. O modelo de neurônio proposto por [McCulloch and Pitts, 1943], comumente chamado como MCP, é uma simplificação do que se sabia naquela época, a respeito do neurônio biológico. Nesse modelo, um neurônio biológico é interpretado como sendo um circuito de entradas binárias combinadas por uma soma ponderada (com pesos) produzindo uma entrada efetiva. Assim, cada neurônio possui n terminais de entrada, representando os dendritos, e apenas um terminal de saída, representando o axônio. O comportamento das sinapses é emulado por meio de pesos associados aos terminais de entrada, cujos valores podem ser positivos ou negativos, dependendo das sinapses serem excitatórias ou inibitórias [Haykin, 1998]. A Figura 2.2 representa a estrutura do modelo MCP, na qual Xi representa a saída do neurônio i e wi representa o
peso do neurônio i.
Figura 2.2 – Neurônio Artificial – Modelo MCP
2.4. Aprendizagem
As Redes Neurais Artificiais possuem a capacidade de aprender por exemplos e fazer interpolações e extrapolações do que aprenderam. A aprendizagem é realizada por meio do ajuste dos parâmetros de uma rede neural através de uma forma continuada de estímulo pelo ambiente no qual a rede está operando, determinando, assim, a intensidade das conexões entre os neurônios [Braga et al., 1998].
Os diversos métodos para treinamento podem ser agrupados em dois paradigmas principais: aprendizagem supervisionada e aprendizagem não-supervisionada. Outros dois paradigmas bastante conhecidos são os de aprendizagem por reforço, que é um caso particular de aprendizagem supervisionada, e aprendizagem por competição, que consiste numa forma particular de aprendizagem não-supervisionada.
Na aprendizagem supervisionada, como pode ser observado na Figura 2.3, a entrada e a saída desejadas para a rede são fornecidas por um supervisor externo. O objetivo é ajustar os parâmetros da rede, de forma a encontrar um mapeamento entre os pares de entrada e saída fornecidos, assim como a saída produzida pela rede.
Figura 2.3 -Aprendizagem supervivionada
-ҙ
+
6
PROFESSOR
Quanto à aprendizagem não-supervisionada, não há um supervisor para acompanhar o processo de aprendizagem. Neste paradigma, a aprendizagem ocorre através da modificação repetida dos pesos sinápticos das conexões do sistema em resposta às entradas. A Figura 2.4 apresenta a estrutura dessa aprendizagem.
Figura 2.4 – Aprendizagem Não-Supervisionada
Na aprendizagem por competição, que é um caso especial de aprendizagem não-supervisionada, a idéia básica é que, dado um padrão de entrada, faz-se com que as unidades de saída disputem entre si para serem ativadas. A Figura 2.5 ilustra o funcionamento da aprendizagem competitiva.
Figura 2.5 - Aprendizagem Competitiva
A aprendizagem por reforço é um caso especial de aprendizagem supervisionada. A principal diferença entre esses dois processos é que, na aprendizagem supervisionada, a medida de desempenho é baseada no conjunto de respostas desejadas, usando um critério de erro conhecido, enquanto que na aprendizagem por reforço, o desempenho é baseado em qualquer medida possível de ser fornecida ao sistema. A única informação de realimentação fornecida à rede é se uma determinada saída está correta ou não, isto é, não é fornecida à rede a resposta correta para o padrão de entrada. O funcionamento da aprendizagem por reforço é ilustrado na Figura 2.6.
ESTADO DO
MEIO EXTERNO RESPOSTA
Figura 2.6 - Aprendizagem por Reforço
2.5. Redes Neurais Artificiais
Há uma vasta literatura sobre as várias classes de redes neurais tais como em [Braga et al., 1998; Haykin, 1998]. Dentre elas, destacam-se as redes com aprendizagem baseada na correção do erro e as redes com aprendizagem baseada na similaridade.
2.5.1. Redes Baseadas na Similaridade
Nas redes com aprendizagem baseada na similaridade, o processo de aprendizagem é baseado na similaridade entre o padrão de entrada e os pesos dos neurônios existentes. A principal vantagem das redes com aprendizagem baseada na similaridade é a capacidade de aprender novos padrões sem sofrer dano nos padrões previamente aprendidos.
Na literatura, há um grande número de modelos de redes neurais cujo processo de aprendizagem é baseado na similaridade, dentre os quais podemos destacar as redes baseadas na Teoria da Ressonância Adaptativa, tais como ART-1 [Carpenter and Grossberg, 1987a], ART-2 [Carpenter and Grossberg, 1987b], ART-3 [Carpenter and Grossberg, 1990], Fuzzy ART [Carpenter and Grossberg, 1991], Artmap [Carpenter et al., 1991], Fuzzy Artmap [Carpenter et al., 1992], ART-EMAP [Carpenter and Ross, 1995], Artmap-IC [Carpenter and Markuzon, 1998], dART [Carpenter, 1997], Gaussian Artmap [Williamson, 1996], SFAM [Kasuba, 1993], PROBART [Srinivasa, 1997], Cascade Artmap [Tan, 1997], PSFAM [Jervis et al., 1999] e o RePART [Canuto, 2001].
REFORÇO/ PENALIDADE
AÇÃO
RNA
2.5.1.1. Redes ART (Adaptive Resonance Theory)
A Teoria da Ressonância Adaptativa (ART, do inglês Adaptive Resonance Theory) surgiu com uma análise do processamento cognitivo de informação pelo homem em um ambiente de entrada complexo. Tal teoria surgiu como resultado da tentativa de compreender como sistemas biológicos são capazes de continuar aprendendo, sem comprometer a estabilidade de padrões previamente aprendidos.
As redes ART surgiram com o intuito de solucionar o dilema da estabilidade-plasticidade. Tal dilema envolve a questão de como projetar um sistema capaz de prover adaptação contínua em resposta a padrões significativos, ao mesmo tempo em que é indiferente a padrões irrelevantes. Em outras palavras, um sistema capaz de aprender conhecimentos novos preservando o conhecimento previamente adquirido e evitando que um novo conhecimento se sobreponha a conhecimentos prévios.
Uma rede neural ART pode ser qualificada como uma RNA incremental, ou seja, uma RNA capaz de aumentar a sua complexidade à medida que novos padrões são apresentados. Desse modo, não é necessário recomeçar seu treinamento do ponto inicial cada vez que aparecem novos padrões de entrada, preservando, por conseguinte, o conhecimento adquirido anteriormente [Braga et al., 1998].
O modelo ART tenta controlar o grau de similaridade entre padrões, colocando-os em um mesmo grupo quando a similaridade entre o padrão apresentado e um padrão protótipo anteriormente aprendido pela rede ultrapassar um determinado patamar (limiar de vigilância). Tais redes são bastante apropriadas para aplicações em reconhecimento de padrões [Carpenter and Grossberg, 1987a].
1990]. O primeiro modelo da família ART apresentado foi o ART1 [Carpenter and Grossberg, 1987a].
F2
F1
b
w
F0 A = (a, ac)
a xa ya
Figura 2.7 – Esquema do ART1
A arquitetura básica do modelo ART1 envolve três camadas de nodos (Figura 2.7):
x Uma camada F0, que armazena o vetor de entrada corrente e
transmite-o para a próxima camada, adicionando seu complemento no final da cadeia. A entrada codificada em complemento é definida da seguinte forma:
I = (a, ac), (2.1)
em que:
ac(x+N) = (1-a(x)) (2.2)
x Uma camada intermediária, F1, que processa os dados recebidos da
camada F0;
x Uma camada de saída, F2, que agrupa os padrões de treinamento em
Essas duas últimas camadas estão conectadas através de conexões que ligam cada nodo (neurônio) de uma camada a todos os nodos da outra. O primeiro conjunto, representado por conexões feedforward, w, assume valores reais e segue da camada de entrada para a camada de saída. O segundo conjunto, que contém as conexões de feedback, b, assume valores binários e conecta os nodos da camada de saída aos nodos de entrada. As conexões
feedforward e feedback são também conhecidos como filtros adaptativos por adaptarem dinamicamente seus valores para possibilitar a aprendizagem de novos padrões. Entre a camada intermediária e a camada de saída existe um mecanismo de reset, responsável por verificar a semelhança entre um vetor de entrada e um dado vetor protótipo, utilizando um limiar de vigilância [Braga et al., 1998].
O algoritmo de aprendizagem da rede ART1 é não-supervisionado, podendo ser ativado a qualquer momento, permitindo que a rede aprenda novos padrões continuamente. Quando um novo padrão de entrada não se enquadra a qualquer grupo de padrões já existente este mecanismo provoca a formação de um novo grupo. Tal característica resolve o problema da estabilidade-plasticidade. Há dois tipos de treinamento para a rede ART1: aprendizagem rápida, no qual os pesos feedforward são ajustados para seus valores ótimos em poucos ciclos, e aprendizagem lenta, no qual os pesos são ajustados lentamente em vários ciclos de treinamento, possibilitando um ajuste melhor dos pesos da rede para os padrões de treinamento [Carpenter and Grossberg, 1987a].
Vários modelos de redes neurais pertencentes à família ART foram propostos subseqüentemente ao modelo ART1, como por exemplo, o ART2 [Carpenter and Grossberg, 1987b], ART3 [Carpenter and Grossberg, 1990],
Fuzzy ART [Carpenter and Grossberg, 1991] e Artmap [Carpenter et al., 1991].
2.5.1.2. Rede Fuzzy ART
que ao invés de usar a teoria dos conjuntos clássica como no ART1, utiliza a teoria dos conjuntos fuzzy [Zadeh, 1965].
Essencialmente, o processo de aprendizagem do Fuzzy ART é executado em três passos:
Logo que a entrada (I) codificada em complemento é recebida pela camada F1, a saída (Tj) de todos os neurônios da camada F2 é calculada pela
Equação 2.3. Nesta equação ao invés do operador AND booleano utilizado pelo ART original, utiliza-se o operador AND fuzzy, dado por:
,
j j j
w w I T
D (2.3)
em que:
D é um parâmetro escolhido pelo usuário, normalmente com magnitude baixa.
Assim que o neurônio vencedor (neurônio com a maior saída) é encontrado, submete-se a análise para verificar se sua similaridade com o vetor de entrada é mais alta que o mínimo de similaridade permitida, definida pelo parâmetro de vigilância. O grau de casamento entre o neurônio da camada F2 e o vetor de entrada I é dado pela função de casamento (F),
definida como:
, )
,
( ȡ
I w I w I
F j j t (2.4)
Esta função avalia a extensão a que I pertence à classe representada por
j
w . A decisão se o casamento é bom o bastante é feita comparando a função
de casamento (F) ao parâmetro de vigilância (U).
Se a função de casamento é maior ou igual à vigilância, seu peso wj é
Se a função de casamento é menor que a vigilância, um novo neurônio é criado para aprender este novo padrão de entrada.
Logo que as condições de casamento são satisfeitas, um estado de ressonância é ativado, o que permite ocorrer aprendizagem na seção pertinente da matriz de pesos. A equação de aprendizagem é definida da seguinte forma:
1
ant , j ant
j novo
j ȕ I w ȕ w
w (2.5)
em que:
ant j
w é o j-ésimo peso corrente do neurônio vencedor;
novo j
w é o j-ésimo peso novo do neurônio vencedor;
E é a taxa de aprendizagem.
Na equação acima, os novos pesos são calculados levando em
consideração o peso já existente (wjant ) e a similaridade entre o peso e o
padrão de entrada (I wjant ), de acordo com uma certa taxa de aprendizagem E.
2.5.1.3. Redes Artmap
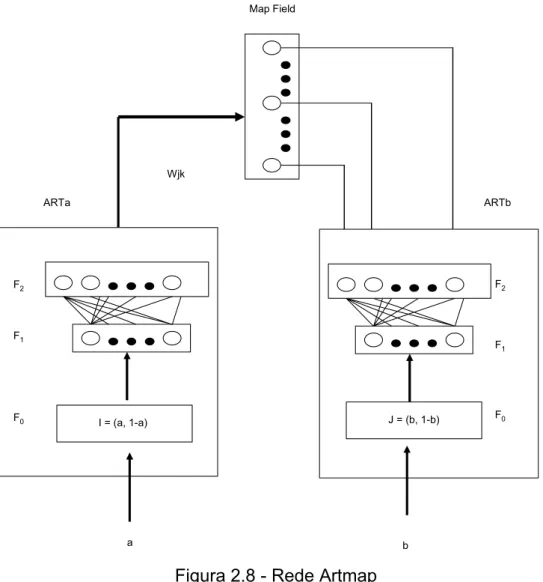
O modelo de rede neural Artmap [Carpenter et al., 1991], diferentemente do modelo ART, usa um processo de aprendizagem supervisionada, uma vez que tanto a entrada quanto a saída desejadas, são conhecidas.
O modelo Artmap emprega um processo de aprendizagem baseado na similaridade entre o padrão de entrada e os pesos dos neurônios da camada de saída em ARTa.
Vários modelos de redes neurais têm sido propostos tendo como base o modelo Artmap. Como exemplos podemos citar o Fuzzy Artmap [Carpenter et al., 1992], ART-EMAP [Carpenter and Ross, 1995], Artmap-IC [Carpenter and Markuzon, 1998], dART [Carpenter, 1997], Gausian Artmap [Williamson, 1996], SFAM [Kasuba, 1993], PROBART [Srinivasa, 1997], Cascade Artmap [Tan, 1997], PSFAM [Jervis et al., 1999] e o RePART [Canuto, 2001].
x Módulo de mapeamento (Map Field)
Cada neurônio no módulo ARTa é conectado a todos os neurônios do módulo de mapeamento (associação 1-para-muitos), tendo seus pesos inicialmente ajustados para 0. Durante a fase de aprendizagem, o peso que liga o neurônio vencedor em ARTa e o neurônio correspondente no módulo de mapeamento é ajustado para 1.
Durante a fase de reconhecimento, assim que os dois módulos ART produzem suas saídas, faz-se uma associação entre essas saídas. Em seguida, levando-se em consideração a saída do módulo ARTa, a qual pode ser definida conforme equação a seguir, calcula-se o vencedor no módulo de mapeamento:
), (
) (
1
¦
Nk k
U Max I
W (2.6)
em que:
¦
M jj jk
k w T
U
1
jk
w é o peso do
j-ésimo neurônio da camada F2 do módulo ARTa para o
k-ésimo neurônio do módulo de mapeamento;
j
T é a saída do
j-ésimo neurônio da camada F2 do módulo ARTa.
Wjk
a b
F0
F1
F2
J = (b, 1-b)
F2
F1
F0
ARTa ARTb
Map Field
I = (a, 1-a)
Figura 2.8 - Rede Artmap
2.5.1.4. Redes Fuzzy Artmap
O modelo neural Fuzzy Artmap [Carpenter et al., 1992] possui, basicamente, a mesma estrutura abstrata apresentada pelo modelo Artmap [Carpenter et al., 1991]. No Fuzzy Artmap, similarmente ao modelo Artmap, entrada e saída desejadas são apresentadas aos módulos Fuzzy ARTa e ARTb, respectivamente, tendo-se as saídas destes módulos associadas no módulo de mapeamento. A diferença básica entre os dois modelos é que, enquanto o Artmap possui módulos ART, utilizando, portanto, a teoria dos conjuntos clássica, o Fuzzy Artmap possui módulos Fuzzy ART, ou seja, módulos ART que fazem uso da teoria dos conjuntos fuzzy.
O Fuzzy Artmap apresenta-se como um modelo bastante apropriado para uso em aplicações de classificação de padrões e em ambientes não-estacionários, uma vez que oferece um sistema de aprendizagem automática.
Assim como os demais modelos derivados do Artmap, o Fuzzy Artmap emprega um processo de aprendizagem baseado em associação, ou seja, a aprendizagem é baseada na similaridade entre a entrada e os pesos dos padrões anteriormente apresentados.
O uso deste tipo de aprendizagem oferece algumas vantagens [Canuto et al., 2000a], tais como:
x Fácil extração de conhecimento: em redes baseadas no modelo Artmap, a representação de associações de padrões é alcançada por neurônios individuais, facilitando, assim, a extração de regras e, conseqüentemente, permitindo uma melhor compreensão e interpretação de seu conhecimento;
x Rápida aprendizagem: modelos baseados no Artmap têm a habilidade de checar rapidamente a saída, aprendizagem estável, reconhecimento e predição, com um procedimento de treinamento que requer apenas uma iteração através dos dados.
Contudo, algumas desvantagens também são verificadas quando este modelo é aplicado [Canuto et al., 1999b], conforme abaixo:
x Proliferação de categoria: este problema surge durante a fase de aprendizagem, como conseqüência direta da sensibilidade a ruído presente nos modelos baseados no Artmap. Assim, caso a magnitude do ruído no padrão de entrada seja elevado, o Artmap pode gerar muitos neurônios, tornando a rede muito complexa;
x Má classificação: este efeito surge, também, como conseqüência da sensibilidade a ruído, só que desta vez, durante a fase de reconhecimento dos modelos baseados no Artmap. Nesta classe de redes neurais, durante a aprendizagem e reconhecimento, somente a melhor categoria de neurônio é escolhida como vencedora. Na fase de reconhecimento, um padrão de entrada com ruído pode levar a seleção de uma categoria de neurônio errada e, conseqüentemente, má classificação.
2.5.1.5. Artmap-IC
classificação causado pela sensibilidade a ruídos nos padrões de entrada durante a fase de reconhecimento.
O Artmap-IC usa um parâmetro contador de instância que distribui predição de acordo com o número de entradas do grupo de treinamento classificadas por cada neurônio da camada F2. Em outras palavras, é a
freqüência de ativação de um neurônio da camada F2 durante a fase de
aprendizagem. Durante a fase de reconhecimento, o contador de instância é usado com Ti (saída do i-ésimo neurônio do módulo ARTa) para encontrar os
neurônios vencedores da camada F2.
2.5.1.6. RePART
O modelo de rede neural RePART (Reward/Punishment ART) [Canuto, 2001] é mais um modelo que veio se somar ao grupo de modelos da família Artmap [Carpenter et al., 1991], mais especificamente da família Fuzzy Artmap [Carpenter et al., 1992]. Tal modelo integra propriedades de Sistemas Fuzzy [Rezende, 2003] e do modelo Artmap, ao mesmo tempo em que utiliza mecanismos adicionais, tais como um processo de recompensa/punição, um parâmetro contador de instância e vigilância variável. O uso do processo de recompensa/punição é adicionado ao processo de reconhecimento visando obter melhorias no desempenho da rede [Canuto et al., 1999b]. A vigilância variável tem como objetivo minimizar o problema de sensibilidade ao problema de ruído que ocorre normalmente nos modelos da família Artmap, melhorando a operabilidade destes modelos [Canuto et al., 2000a].
x Vigilância Variável
para definir a similaridade mínima permitida entre o padrão de entrada e os neurônios existentes durante a fase de aprendizagem [Canuto et al., 2000a]. Adicionalmente, a vigilância é o parâmetro mais importante que pode ser selecionado pelo usuário nos modelos baseados no Artmap.
A escolha do parâmetro de vigilância é muito importante para o desenvolvimento das redes baseadas no Artmap e conhecida como dilema da
bias/variância. Desse modo, quando o parâmetro de vigilância é ajustado para um valor muito baixo, a estrutura da rede tende a ser pequena demais, tornando a rede tendenciosa a certos padrões e, como conseqüência, ocasiona generalização excessiva. Por outro lado, se o parâmetro de vigilância é ajustado para um valor muito elevado, a complexidade da rede tende a ser excessivamente elevada, ocasionando uma pobre generalização. Na maioria das redes baseadas no modelo Artmap tem sido usado um parâmetro de vigilância fixo durante toda a fase de aprendizagem. Para amenizar o problema de proliferação de categorias e solucionar o dilema da bias/variância, adota-se o uso de uma vigilância variável que se ajusta dinamicamente durante o processo de aprendizagem para melhor representar os padrões. Uma abordagem alternativa é usar uma vigilância que inicialmente tem um valor elevado, o qual será decrementado à medida que a complexidade da rede vai aumentando. Tal abordagem é utilizada pelo modelo RePART [Canuto et al., 2001], sendo inspirado no processo de aprendizagem humana. Sendo assim, o parâmetro de vigilância no estágio inicial da rede é bem alto e é decrementado à medida que novos padrões são adicionados à rede [Canuto et al., 1999b].
O uso de vigilância variável pode ser tratado de duas formas: pode-se utilizar uma vigilância variável geral, na qual a mesma vigilância é associada com todos os neurônios e a variação de sua magnitude é a mesma para todos os neurônios. Alternativamente, pode-se utilizar uma vigilância variável individual, a qual é associada com cada categoria de neurônios (neurônios da camada de saída F2), levando-se em consideração sua média e freqüência de
ativação durante a fase de treinamento [Canuto, 2001].
ativação de cada neurônio, bem como o número de neurônios da camada F2
associados com sua classe correspondente. A escolha de uma vigilância individual deve-se ao fato de que os neurônios da camada F2 têm diferentes
comportamentos, armazenando diferentes números de padrões e, como conseqüência, têm diferentes saídas. Além disso, em algumas classes há mais variações intraclasses que em outras, levando a um diferente número de neurônios da camada F2 associados com cada classe, favorecendo algumas
classes na fase de reconhecimento [Canuto et al., 2000a].
É importante enfatizar que o uso da vigilância variável individual não força as classes a terem o mesmo número de neurônios. Forçar as classes a terem o mesmo número de neurônios não pode ser vista como uma decisão apropriada, uma vez que para cada classe há um diferente grau de dificuldade associado com a aprendizagem das suas características e particularidades. Portanto, o número de neurônios associados com uma classe tem uma influência sobre o parâmetro de vigilância individual dos neurônios da camada F2 [Canuto et al., 2001].
O processo de vigilância variável individual pode ser descrito como segue:
x Logo que o padrão de entrada é passado para a camada F1 em ARTa,
a vigilância de cada neurônio é calculada de acordo com a média e a freqüência de ativação. A vigilância variável individual é calculada por:
Vigi(t) = Vigi(t-1) + 'RFA + 'RIAA (2.8)
em que:
Vigi(t) é a vigilância do neurônio i no tempo t;
'RFA é a freqüência relativa de ativação – (RFA(t) - RFA(t-1));
'RIAA é a inversa da média relativa de ativação – ((1-RIAA(t))-(1-RIAA(t-1))).
¸ ¹ · ¨ © §
¦
k k TN N c c t RFA j k j ii( ) * 1.001* , (2.9)
e i i i c t T t
RIAA( ) ( ), (2.10)
em que:
i
c é a freqüência (contador de instância) do i-ésimo neurônio da camada F2;
k
N é o número de neurônios que foram assinalados para aprender a
classek;
k
TN é o número máximo de neurônios que podem ser assinalados para
aprender a classe k (número total de neurônios da camada F2);
) (t
Ti é a soma total das saídas ativadas do i-ésimo neurônio do padrão de treinamentot.
Quando se utilizam essas fórmulas, cada neurônio da camada F2 tem sua
própria vigilância que depende de sua freqüência relativa de ativação e da inversa de sua média relativa de ativação. A magnitude da mudança no valor da vigilância, por sua vez, depende de todos esses parâmetros mencionados. Em outras palavras, cada neurônio da camada F2 terá sua vigilância ajustada
com base no seu próprio conhecimento e comportamento.
O segundo termo da Equação 2.9, ¸¸¹
· ¨¨
© §
k k
TN N
001 , 1
, estimula classes com poucos neurônios a criar mais neurônios, assim como previne classes com muitos neurônios de criar neurônios adicionais, ou seja, a proliferação de neurônios.
O uso do inverso da média relativa de ativação (RIAA) tem como meta ajustar a vigilância de um neurônio de acordo com sua média de ativação. Caso um neurônio tenha uma média de ativação baixa, conseqüentemente tende a ter generalização excessiva. Neste caso, sua vigilância é incrementada, deixando o neurônio mais rigoroso na seleção. Por outro lado, se a média de ativação é alta, o neurônio é muito rigoroso e não é ativado muitas vezes.
x Recompensa/Punição (reward/punishment)
Por pertencer à família Artmap, o RePART herdou muitas características de funcionamento inerentes ao modelo Artmap. Uma delas é que cada neurônio no módulo ARTa armazena pesos que correspondem aos modelos padrões (templates) que representam um ou mais padrões de uma classe. Deste modo, a ativação de um neurônio detecta a similaridade entre o padrão de entrada e um modelo apresentado anteriormente. Sendo assim, todos os neurônios pertencentes à classe do padrão apresentado deverão ser considerados para que se alcance o melhor resultado na fase de reconhecimento. Em algumas tarefas, principalmente no reconhecimento de padrões, as informações de todas as regiões de uma classe serão consideradas, uma vez que podem ser importantes para que se consiga uma boa predição de um padrão não treinado [Canuto, 2001].
instância para definir a freqüência de ativação de cada neurônio da camada F2
[Canuto et al., 1999b]. Em adição ao grupo de vencedores, é usado um grupo de perdedores, fazendo com que cada neurônio da camada F2 pertença
obrigatoriamente ao grupo de vencedores ou ao grupo de perdedores de acordo com o valor da sua saída. Um mecanismo de recompensa/punição é utilizado como forma de recompensar o grupo de vencedores e punir o grupo de perdedores.
O parâmetro de recompensa é usado para os neurônios do grupo de vencedores no cálculo das saídas dos neurônios do módulo de mapeamento. A magnitude da recompensa depende da posição do neurônio no grupo de vencedores, com o primeiro vencedor (que é o neurônio com a maior saída), tendo a maior recompensa. A equação de recompensa é definida da seguinte forma:
R T N u m W in N u m W in k
j j j w § ©
¨¨ ·¹¸¸
§ ©
¨¨ * ·¹¸¸
2
, (2.11)
em que:
j
T é o valor de saída do j-ésimo neurônio;
NumWin é o número de neurônios do grupo de vencedores;
w j
k é a posição do j-ésimo neurônio no grupo de vencedores.
Um processo análogo é executado com o grupo de perdedores usando o parâmetro de punição. A intensidade da punição de um neurônio depende da sua posição em um senso inverso, com o primeiro perdedor (com a maior saída) tendo a menor punição. A equação de punição é definida da seguinte forma: 2 * ) (( ¸¸ ¹ · ¨ ¨ © § ¸ ¸ ¹ · ¨ ¨ © § NumLos k NumLos L W P l j j
em que:
W é a saída do último neurônio do grupo de vencedores (vencedor com a
menor saída);
j
L é a saída do j-ésimo neurônio perdedor;
NumLos é o número de neurônios do grupo de perdedores;
l j
k é a posição do j-ésimo neurônio no grupo de perdedores.
x Processo de Aprendizagem
Assim como no Artmap-IC [Carpenter and Markuzon, 1998], o processo de aprendizagem no modelo RePART [Canuto, 2001] funciona basicamente da mesma maneira que no modelo Artmap [Carpenter et al., 1991] original. A diferença básica reside no fato de que, logo que o padrão de entrada é recebido pela camada F1 do módulo ARTa, as vigilâncias de todos os
neurônios são calculadas.
x Processo de Reconhecimento
Durante a fase de reconhecimento, assim que os dois módulos ART tenham produzido suas saídas, uma associação entre estas saídas é empregada. Primeiramente, o neurônio vencedor do módulo de mapeamento é calculado, levando em consideração a saída do módulo ARTa [Canuto et al., 1999b].
x Classificação dos neurônios da camada F2de acordo com suas saídas,
do neurônio com maior saída (com maior grau de similaridade) para o neurônio com menor saída (com menor grau de similaridade);
x Divisão dos neurônios em dois grupos:
Vencedores: grupo composto dos primeiros NumWin neurônios mais similares;
Perdedores: grupo composto dos neurônios remanescentes.
Para a definição do número de neurônios vencedores pode-se usar ou o método da evolução empírica ou a regra do polegar. No método da evolução empírica, o grupo de treinamento original é dividido em um novo grupo de treinamento (N) e um grupo de verificação complementar. Na regra do polegar, o número de neurônios é dividido pelo número de possíveis classes de saída. O resultado será o número de neurônios vencedores [Canuto, 2001].
Para calcular a saída dos neurônios do módulo de mapeamento (map field), concede-se uma recompensa aos neurônios que pertencem ao grupo de vencedores. Da mesma forma, uma punição é aplicada aos neurônios que pertencem ao grupo de perdedores. A magnitude, tanto da recompensa como da punição, dependerá da classificação do neurônio no grupo de vencedores e perdedores, respectivamente [Canuto et al., 2001].
O cálculo da saída dos neurônios do módulo de mapeamento é dividido em duas partes, a primeira usando o grupo de vencedores e a segunda usando o grupo de perdedores. Logo que isso ocorre, o neurônio vencedor do módulo de mapeamento é a maior saída. A escolha do neurônio vencedor pode ser sumarizada da seguinte forma:
¦ ¦
¸¸ ¸ ¸ ¹ · ¨¨ ¨ ¨ © § ¸ ¸ ¸ ¹ · ¨ ¨ ¨ © § j j jk j j j j j jkk w R
T c T c w U * * * * (2.13) em que: jk
w é o peso do j-ésimo neurônio no módulo ARTa para o k-ésimo neurônio do módulo de mapeamento ;
j
c é o contador de instância do j-ésimo neurônio do módulo ARTa (freqüência de ativação);
j
T é a saída do j-ésimo neurônio do módulo ARTa;
representa o grupo de vencedores;
R é o parâmetro de recompensa (equação 2.11).
Um processo análogo é executado usando os neurônios da camada F2
remanescentes (grupo de perdedores) usando o parâmetro de punição:
¦ ¦
* * ¸¸ ¸ ¸ ¹ · ¨¨ ¨ ¨ © § ¸ ¸ ¸ ¹ · ¨ ¨ ¨ © § j j jk j j j j j jkk w P
T c T c w U * * * * (2.14) em que:
* representa o grupo de perdedores;
j
Figura 2.9 – As operações do modelo neural RePART
Depois que o neurônio vencedor do módulo de mapeamento é escolhido, uma associação entre este e o vencedor do módulo ARTb é criada. Cada neurônio do módulo de mapeamento é associado somente a sua classe correspondente no módulo ARTb (associação 1-para-1). Inicialmente, os pesos entre o módulo ARTb e o módulo de mapeamento são ajustados para 0. Quando uma associação ocorre, o peso correspondente é ajustado para 1.
Deste modo, devido as modificações propostas pelo RePART em [Canuto, 2001], pode-se usar sua saída como um mensurador de similaridade da entrada apresentada para todas as classes de padrões, sendo a melhor classe escolhida através do nó de saída do módulo de mapeamento, não impedindo que as outras classes tenham similaridade com o padrão de entrada, que pode ser definida pelos outros valores de saída, diferindo, portanto, das redes Fuzzy Artmap.
Padrão de Entrada
ARTa Map ARTb
Field
a b Wjk Wb
Recompensa vencedores e pune os perdedores
Perdedores
L
Vencedores
W
Cada neurônio F2
calcula sua própria vigilância
Identifica Classe
Procura a classe Vencedora comparando
o vencedor do ARTb com o vencedor do
MAP Field Divide todos os neurônios
em vencedores e perdedores Classe vencedora MAP Field