Universidade Federal do Rio Grande do Norte Departamento de Computac¸˜ao e Automac¸˜ao
Programa de P´os-graduac¸˜ao em Engenharia El´etrica e de Computac¸˜ao
Alan Paulo Oliveira da Silva
Uma Implementa¸c˜
ao da An´
alise de Componentes
Independentes em Plataforma de Hardware Reconfigur´
avel
Alan Paulo Oliveira da Silva
Uma Implementa¸c˜
ao da An´
alise de Componentes
Independentes em Plataforma de Hardware Reconfigur´
avel
Disserta¸c˜ao de Mestrado apresentada ao Programa de P´os-gradua¸c˜ao em Engenharia El´etrica e de Com-puta¸c˜ao da UFRN, como parte dos requisitos para a obten¸c˜ao do grau de MESTRE em Ciˆencias.
Orientador: Profa. Dra. Ana Maria Guimar˜aes Guerreiro
Co-orientador: Prof. Dr. Adri˜ao Duarte D´oria Neto
Alan Paulo Oliveira da Silva
Uma Implementa¸c˜
ao da An´
alise de Componentes
Independentes em Plataforma de Hardware Reconfigur´
avel
Disserta¸c˜ao de Mestrado apresentada ao Programa de P´os-gradua¸c˜ao em Engenharia El´etrica e de Com-puta¸c˜ao da UFRN, como parte dos requisitos para a obten¸c˜ao do grau de MESTRE em Ciˆencias.
Aprovado em de junho de 2010
BANCA EXAMINADORA
Profa. Dra. Ana Maria Guimar˜aes Guerreiro
Prof. Dr. Adri˜ao Duarte D´oria Neto
Prof. Dr. Gl´aucio Bezerra Brand˜ao
Resumo
A Separa¸c˜ao Cega Fontes (BSS) refere-se ao problema de estimar sinais origi-nais a partir de misturas lineares observadas sem nenhum tipo de conhecimento acerca das fontes ou do processo de mistura. A An´alise de Componentes Independentes (ICA) ´e uma t´ecnica aplicada principalmente ao problema do BSS e dentre os algor´ıtmos que imple-mentam essa t´ecnica, o FastICA ´e um algor´ıtmo iterativo de alto desempenho e de baixo custo computacional que utiliza medidas de n˜ao-gaussianidade baseadas em estat´ıstica de alta ordem para estimar as fontes originais. O grande n´umero de aplica¸c˜oes onde ICA se mostra ´util reflete a necessidade da implementa¸c˜ao dessa t´ecnica em hardware e o para-lelismo natural do FastICA favorece a implementa¸c˜ao desse algor´ıtmo em plataforma de hardware digital.
Este trabalho prop˜oe a implementa¸c˜ao do FastICA em uma plataforma de hardware reconfigur´avel para a viabiliza¸c˜ao de sua utiliza¸c˜ao em problemas de separa¸c˜ao cega de fontes, mais especificamente em um prot´otipo de hardware embarcado em uma placa Field Programmable Gate Array (FPGA) para a monitora¸c˜ao de leitos em ambientes hospitalares. As implementa¸c˜oes ser˜ao realizadas atrav´es de modelos em Simulink e a sintetiza¸c˜ao dos mesmos ser´a feita com o aux´ılio do software DSP Builder da Altera Corporation.
Abstract
Blind Source Separation (BSS) refers to the problem of estimate original signals from observed linear mixtures with no knowledge about the sources or the mixing process. Independent Component Analysis (ICA) is a technique mainly applied to BSS problem and from the algorithms that implement this technique, FastICA is a high performance iterative algorithm of low computacional cost that uses nongaussianity measures based on high order statistics to estimate the original sources. The great number of applications where ICA has been found useful reflects the need of the implementation of this technique in hardware and the natural paralelism of FastICA favors the implementation of this algorithm on digital hardware.
This work proposes the implementation of FastICA on a reconfigurable hard-ware platform for the viability of it’s use in blind source separation problems, more speci-fically in a hardware prototype embedded in a Field Programmable Gate Array (FPGA) board for the monitoring of beds in hospital environments. The implementations will be carried out by Simulink models and it’s synthesizing will be done through the DSP Builder software from Altera Corporation.
Agradecimentos
A todos os meus entes queridos e amigos, pelo encorajamento e apoio.
Aos professores Ana Maria e Adri˜ao, pela orienta¸c˜ao e oportunidade de realizar este trabalho.
Aos professores do Programa de P´os-gradua¸c˜ao em Engenharia El´etrica e de Computa¸c˜ao pelos ensinamentos, orienta¸c˜ao e contribui¸c˜ao para nosso enriquecimento pessoal e profissional.
Sum´
ario
Lista de Figuras 6
1 Introdu¸c˜ao 9
1.1 Motiva¸c˜ao . . . 11
1.2 Objetivos . . . 12
1.3 Estado da Arte . . . 13
1.4 Organiza¸c˜ao do Trabalho . . . 15
2 An´alise de Componentes Independentes 16 2.1 Defini¸c˜ao do Modelo . . . 16
2.2 Restri¸c˜oes . . . 17
2.3 Ambiguidades de ICA . . . 19
2.4 Pr´e-processamento dos Dados . . . 20
2.4.1 Centraliza¸c˜ao . . . 20
2.4.2 Branqueamento . . . 21
2.5 N˜ao-gaussianidade e independˆencia . . . 24
2.6 Medidas de N˜ao-gaussianidade . . . 26
2.6.1 Kurtosis . . . 26
2.6.2 Negentropia . . . 27
2.7 Algoritmo FastICA . . . 29
2.8 Calculando mais de uma componente independente . . . 31
2.8.1 Ortogonaliza¸c˜ao deflacion´aria . . . 32
2.8.2 Ortogonaliza¸c˜ao sim´etrica . . . 32
3 FPGA e Linguagem de Descri¸c˜ao de Hardware 38
3.1 Hist´orico . . . 38
3.2 Funcionamento interno . . . 41
3.2.1 Blocos l´ogicos configur´aveis . . . 42
3.3 Linguagem de Descri¸c˜ao de Hardware . . . 45
3.4 Projeto em N´ıvel de Sistema . . . 46
4 Implementa¸c˜ao do FastICA em FPGA 48 4.1 Projeto do Modelo do Hardware . . . 49
4.2 Modelos Sintetiz´aveis . . . 55
5 Resultados 68 5.1 An´alise Hardware-Software . . . 75
6 Conclus˜ao 81
Lista de Figuras
1.1 Sinais estimados por ICA a partir das misturas . . . 11
2.1 Distribui¸c˜ao de probabiliade gaussiana . . . 19
2.2 Fun¸c˜ao densidade de probabilidade conjunta dex1 e x2 . . . 23
2.3 Fun¸c˜ao densidade de probabilidade conjunta das vari´aveis brancas . . . 24
2.4 Sinais do lado esquerdo: sinais originais gerados manualmente. Sinais do lado direito: misturas geradas a partir de uma transforma¸c˜ao linear dos sinais originais utilizando a matrizA . . . 34
2.5 Componentes independentes obtidas utilizando a matriz de separa¸c˜ao W calculada pelo algoritmo FastICA . . . 35
2.6 Sinais do lado esquerdo: sinais de voz originais. Sinais do lado direito: misturas obtidas a partir da transforma¸c˜ao linear entre a matriz de mistura A e os sinais originais . . . 36
2.7 Componentens independentes obtidas com a matriz de separa¸c˜aoW calcu-lada pelo algoritmo FastICA . . . 37
3.1 Arquitetura interna de um CPLD: pinos de entrada e sa´ıda interligados aos dispositivos GAL atrav´es de uma switch matrix que realiza tamb´em a interliga¸c˜ao dos dispositivos entre s´ı . . . 41
3.2 Arquitetura interna de um FPGA: blocos l´ogicos configur´aveis (CLBs) formados por lookup tables, flip-flops e multiplexadores s˜ao interligados atrav´es de diversas switch matrixes . . . 42
3.3 Implementa¸c˜ao de uma fun¸c˜ao l´ogica combinacional de 3 bits em uma Loo-kup Table com oito posi¸c˜oes de mem´oria: fun¸c˜ao l´ogica (esquerda), tabela da verdade (centro) e mapeamento em lookup table (direita) . . . 43
3.5 Dois CLBs (lookup tables,flip-flops e multiplexadores) interconectados por uma switch matrix(implementada atrav´es de multiplexadores) . . . 44
4.1 Diagrama de alto-n´ıvel de todo o processo, onde o FastICA ´e executado uma vez para cada componente a ser calculada . . . 48
4.2 Hardwares de uma itera¸c˜ao principal do algor´ıtmo FastICA para os casos de 3 (A) e 2 (B) componentes independentes . . . 51
4.3 Hardwares de uma itera¸c˜ao principal do algor´ıtmo FastICA para os casos de 3 (A) e 2 (B) componentes independentes . . . 51
4.4 Hardware da ortogonaliza¸c˜ao deflacion´aria para duas componentes inde-pendentes . . . 52
4.5 Hardware da ortogonaliza¸c˜ao deflacion´aria para trˆes componentes indepen-dentes . . . 53
4.6 Hardware do c´alculo dos dados de sa´ıda para trˆes (A) e duas (B) componentes 54
4.7 Componentes independentes calculadas na simula¸c˜ao com dados reais de eletroencefalograma, ap´os a redu¸c˜ao de dimens˜ao atrav´es do PCA . . . 55
4.8 Blocos dispon´ıveis no softwareDSP Builder utilizados no desenvolvimento do hardware . . . 56
4.9 Modelo sintetiz´avel que realiza a itera¸c˜ao principal do FastICA para 2 componentes . . . 58
4.10 Modelo sintetiz´avel que realiza a itera¸c˜ao principal do FastICA para 3 componentes . . . 59
4.11 Hardware necess´ario para propagar os sinais da entrada de um bloco l´ogico 59
4.12 Modelo sintetiz´avel que realiza a ortogonaliza¸c˜ao necess´aria no FastICA, para 2 componentes . . . 60
4.13 Modelo sintetiz´avel que realiza a ortogonaliza¸c˜ao necess´aria no FastICA, para 3 componentes . . . 61
4.14 Modelo sintetiz´avel que realiza a normaliza¸c˜ao e o c´alculo de convergˆencia do sistema para 2 componentes . . . 62
4.15 Modelo sintetiz´avel que realiza o c´alculo da sa´ıda do sistema para 3 com-ponentes . . . 63
4.16 Modelo sintetiz´avel do algoritmo FastICA para o c´alculo de 2 componentes independentes . . . 64
4.17 Modelo sintetiz´avel do algoritmo FastICA para o c´alculo de 3 componentes independentes . . . 65
4.18 Bloco SignalCompiler do DSP Builder . . . 66
4.19 Fun¸c˜oes do bloco SignalCompiler . . . 66
5.1 Componentes independentes calculadas pelo hardware direcionado ao pro-blema da Cocktail Party . . . 69
5.2 Componentes independentes calculadas pelo modelo sintetiz´avel para trˆes componentes para os sinais propostos no experimento computacional em [Haykin, 2001] . . . 71
5.3 Sinais reais de eletroencefalograma utilizados . . . 73
5.4 Componentes independentes calculadas pelo modelo sintetiz´avel para trˆes componentes, com sinais reais de eletroencefalograma como entrada do modelo . . . 74
5.5 Observa¸c˜ao da influˆencia do ac´umulo do erro num´erico nas simula¸c˜oes em software . . . 77
9
1 Introdu¸c˜
ao
Na ´area da engenharia el´etrica e de comunica¸c˜oes os sinais s˜ao quantidades variantes no tempo ou no espa¸co que podem possuir diferentes naturezas, tais como sinais el´etricos, ac´usticos, de r´adio e etc. Esses sinais podem ser emitidos por uma fonte f´ısica, por exemplo, ´areas do c´erebro humano emitindo sinais el´etricos, pessoas falando em uma mesma sala emitindo sinais ac´usticos de voz ou telefones celulares emitindo sinais de r´adio.
No processo de extra¸c˜ao da informa¸c˜ao ´e comum que dois ou mais sinais fontes se misturem, de forma que os sinais captados pelos sensores s˜ao misturas dos sinais origi-nais. Em situa¸c˜oes reais, as ´unicas informa¸c˜oes acerca dos sinais em quest˜ao s˜ao os dados captados pelos sensores, ou seja, os dados provenientes de misturas dos sinais originais. ´E nesse contexto que surge o problema da Separa¸c˜ao Cega de Fontes (Blind Source Separa-tion - BSS), que consiste em estimar os sinais originais tendo somente a informa¸c˜ao das suas misturas. O termo “Cega”refere-se ao fato de que n˜ao se tem informa¸c˜ao alguma acerca dos sinais originais nem do processo de mistura que gerou os sinais captados.
A An´alise de Componentes Independentes (ICA) ´e uma t´ecnica aplicada prin-cipalmente na separa¸c˜ao cega de fontes. O modelo b´asico de ICA sup˜oe que as fontes originais s˜ao estatisticamente independentes, e com base nesse princ´ıpio estima as compo-nentes de forma que estas sejam as mais independentes poss´ıveis. Isso ´e poss´ıvel atrav´es da maximiza¸c˜ao da n˜ao-gaussianidade das misturas, com base no resultado do teorema do limite central que diz que a soma de duas vari´aveis aleat´orias n˜ao-gaussianas possui distribui¸c˜ao mais pr´oxima da gaussiana em rela¸c˜ao as vari´aveis originais. Mais detalhes sobre esse processo s˜ao abordados no Cap´ıtulo 2.
1 Introdu¸c˜ao 10
A ICA tamb´em ´e ´util em aplica¸c˜oes onde t´ecnicas cl´assicas de filtragem seletiva n˜ao apresentam bons resultados, como por exemplo no caso do sinal fonte e o ru´ıdo possu´ırem a mesma frequˆencia.
Outra aplica¸c˜ao interessante ´e o c´alculo das componentes independentes em sinais biol´ogicos. Esses sinais s˜ao captados em um mesmo indiv´ıduo e podem representar a press˜ao arterial, batimento card´ıaco e sinais de EEGs e MEGs (eletroencefalogramas e magnetoencefalogramas, respectivamente), entre outros. Os sinais de EEG e MEG s˜ao extra´ıdos por sensores no escalpo humano (EEGs s˜ao medi¸c˜oes do campo el´etrico no escalpo, enquanto MEGs s˜ao medi¸c˜oes do campo magn´etico) e podem conter influˆencias de sinais de atividade muscular e cerebral de v´arias origens como por exemplo, movimentos oculares e batimento card´ıaco, portanto, uma an´alise mais precisa desses dados requer um tratamento pr´evio que pode ser alcan¸cado pelo ICA.
A ICA tamb´em ´e utilizada no processamento de imagens em aplica¸c˜oes como compress˜ao e extra¸c˜ao de ru´ıdo. T´ecnicas cl´assicas de processamento de imagens como Fourier e a transformada Cosseno realizam suas aplica¸c˜oes atrav´es de representa¸c˜oes li-neares nos dom´ınios das respectivas transformadas, mas pode ser interessante estimar representa¸c˜oes lineares atrav´es do pr´oprio dado. Isso pode ser alcan¸cado atrav´es do ICA.
A t´ecnica ICA foi introduzida no in´ıcio da d´ecada de 80 por J. H´erault, C. Jutten e B. Ans em uma abordagem neurofisiol´ogica de codifica¸c˜ao de movimento, onde dados a velocidade e posi¸c˜ao de uma articula¸c˜ao de corpo humano, pode-se medir a contra¸c˜ao muscular gerada por esse movimento.
1.1 Motiva¸c˜ao 11
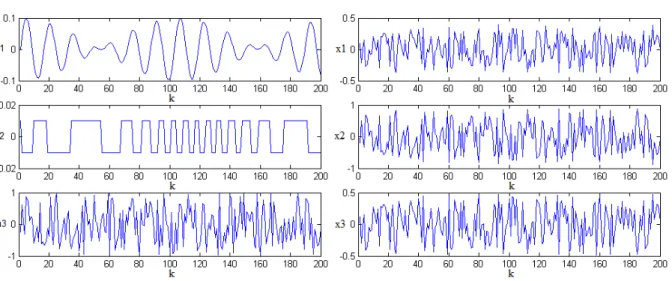
Figura 1.1: Sinais estimados por ICA a partir das misturas
Desde ent˜ao, houve um aumento significativo no n´umero de trabalhos e con-ferˆencias relacionadas a ICA e a separa¸c˜ao cega de fontes.
A tecnologia FPGA (Field Programmable Gate Array) ´e uma plataforma de hardware digital reprogram´avel que pode implementar algoritmos de processamento di-gital de sinais com uma alta capacidade de reprograma¸c˜ao. Mais detalhes sobre essa tecnologia ser˜ao discutidos no Cap´ıtulo 3.
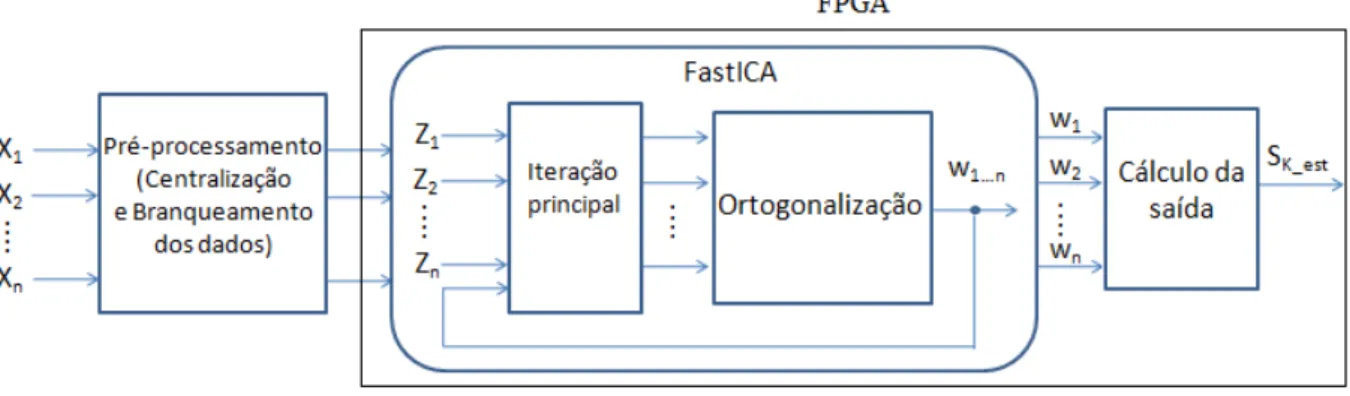
Neste trabalho propomos implementa¸c˜oes embarcadas em uma placa FPGA do algoritmo FastICA, com o objetivo de realizar a separa¸c˜ao cega de fontes de sinais captados em ambiente hospitalar com base na suposi¸c˜ao de que os sinais fontes s˜ao es-tatisticamente independentes. Na figura 1.1, temos um esquema de como esses sinais podem ser processados atrav´es da t´ecnica ICA, em uma plataforma reconfigur´avel. Todos os sensores (press˜ao, card´ıaco, pulso e canais de EEG) captam seus respectivos sinais em um mesmo indiv´ıduo, por´em, ainda podemos supor que os sinais s˜ao independentes j´a que s˜ao provenientes de diferentes ´org˜aos do corpo humano.
Ser˜ao utilizados sinais gerados manualmente e sinais de ´audio para validar os hardwares propostos, al´em de sinais biol´ogicos reais para validar os hardwares propostos.
1.1
Motiva¸c˜
ao
1.2 Objetivos 12
d´ecada de 90 houveram avan¸cos significativos em rela¸c˜ao a algoritmos e a aplica¸c˜oes reais onde o ICA poderia ser utilizado, de tal forma que o interesse acerca dessa t´ecnica tem aumentado significativamente. Uma das poss´ıveis ´areas de pesquisa ´e o estudo e imple-menta¸c˜ao de algoritmos que realizam o ICA em plataformas de hardware, como ASICs (Application-specific integrated circuits) ou FPGAs, uma vez que em muitas aplica¸c˜oes, existe a necessidade de executar esses algoritmos em campo.
Por´em, projetar hardware para fins gen´ericos ´e uma tarefa dif´ıcil, de tal forma que os algoritmos implementados nessas plataformas s˜ao voltados para aplica¸c˜oes es-pec´ıficas. A plataforma FPGA possui uma alta capacidade e facilidade de reconfigura¸c˜ao, o que favorece o desenvolvimento de modelos independentes espec´ıficos para determina-dos casos, de tal forma que reconfigurar os dispositivos para alternar entre aplica¸c˜oes pode ser feito facilmente em laborat´orio ou mesmo em campo com o aux´ılio de compu-tadores m´oveis, al´em disso, os FPGAs oferecem vantagens como o paralelismo inerente `a sua arquitetura, o cont´ınuo desenvolvimento desses dispositivos program´aveis e baixo custo NRE (Non-recurring engineering: valor relativo a o per´ıodo anterior `a fabrica¸c˜ao em massa do produto, este valor envolve gastos com pesquisa, desenvolvimento, projeto e testes).
O FPGA possibilita n˜ao s´o a implementa¸c˜ao deste algor´ıtmo, mas tamb´em de outras funcionalidades necess´arias para o desenvolvimento do prot´otipo de hardware para o monitoramento de leitos em ambientes hospitalares. Dentro desse contexto, surgiu a ne-cessidade do desenvolvimento e implementa¸c˜ao do ICA em uma plataforma reconfigur´avel para complementar as pesquisas desenvolvidas no LAHB (Laborat´orio de Automa¸c˜ao Hos-pitalar e Bioengenharia da UFRN) com a principal finalidade de compor um hardware para controle e monitoramento de sinais vitais em leitos hospitalares.
1.2
Objetivos
Este trabalho tem como objetivo o desenvolvimento e implementa¸c˜ao da t´ecnica ICA para a separa¸c˜ao cega de fontes de misturas provenientes de sinais fontes, embar-cada em uma plataforma de hardware reconfigur´avel, que poder´a ser utilizada em diversas aplica¸c˜oes, principalmente com sinais biom´edicos.
1.3 Estado da Arte 13
em Simulink1
voltados para diferentes aplica¸c˜oes relacionadas com a utiliza¸c˜ao do algo-ritmo que implementa a An´alise de Componentes Independentes, FastICA, no problema da separa¸c˜ao cega de fontes.
Os modelos ser˜ao simulados e sintetizados em uma placa FPGA Cyclone II EP2C35 da Altera Corporation2
atrav´es do software DSP Builder disponibilizado pela Altera em seu DSP Development Kit. Este software possui um conjunto de blocos es-pec´ıficos para a gera¸c˜ao de modelos em Simulink e a sintetiza¸c˜ao dos mesmos em um dispositivo reconfigur´avel, como por exemplo, um FPGA. Al´em disso, o DSP Builder tamb´em possui blocos direcionados para a visualiza¸c˜ao dos testes realizados na placa de hardware em ambiente Simulink.
O algoritmo FastICA foi previamente implementado e testado de diferentes formas em ambiente MATLAB3
com o objetivo de compreender seu funcionamento.
Trˆes modelos principais ser˜ao implementados, um voltado para aplica¸c˜ao de extra¸c˜ao de ru´ıdo, outro voltado para resolver o problema da Cocktail Party e outro onde ser˜ao utilizados sinais reais de eletroencefalograma cedidos pelo Instituto Internacional de Neurociˆencias de Natal Edmond e Lily Safra4
(IINN-ELS).
1.3
Estado da Arte
Nos ´ultimos anos o n´umero de estudos relacionados `a implementa¸c˜ao de algorit-mos que realizam o ICA em plataformas de hardware tem aumentado significativamente. Em 2001, Nordin, Hsu e Szu propuseram um projeto em FPGA do algoritmo FastICA para aplica¸c˜oes de processamento de imagens hiper-espectrais (HSI), usadas geralmente em problemas de reconhecimento de ´areas geogr´aficas remotamente. Eles traduziram parte do c´odigo dispon´ıvel gratuitamente no FastICA Package5
para MATLAB em m´odulos em linguagem C e realizaram simula¸c˜oes ([Nordin, Hsu and Szu, 2001]).
1
Simulink ´e um ambiente gr´afico e interativo que fornece um conjunto de bibliotecas contendo blocos que podem ser customizados de acordo com as necessidades do usu´ario para projetar, simular, implemen-tar e tesimplemen-tar sistemas de processamento de sinais.
2
http://www.altera.com/
3
MATLAB ´e um ambiente de linguagem de computa¸c˜ao t´ecnica de alto n´ıvel para desenvolvimento de algoritmos, visualiza¸c˜ao e an´alise de dados e computa¸c˜ao num´erica.
4
http://natalneuroscience.com/
5
1.3 Estado da Arte 14
Du e Qi publicaram uma nova implementa¸c˜ao em paralelo do ICA em FPGA ([Du and Qi, 2004]) para realizar a redu¸c˜ao da dimens˜ao em imagens hiper-espectrais com o objetivo de reduzir o tempo computacional necess´ario para se processar grandes volumes de dados como nos problemas de HSI. Embora bons resultados tenham sido obtidos, uma compara¸c˜ao com o algoritmo FastICA, que ´e um algoritmo iterativo r´apido e simples, pode ser interessante.
Em 2005, Charoensak e Sattar propuseram a implementa¸c˜ao de um modelo em Simulink para resolver o problema da separa¸c˜ao cega de fontes utilizando um algoritmo ICA baseado em uma rede de Torkkola modificada. O modelo foi simulado e sinteti-zado em uma placa FPGA Virtex-E da Xilinx atrav´es de seu software System Generator ([Charoensak and Sattar, 2005]).
Em [Kim, Park, Kim, Choi and Lee, 2003], foi proposto uma implementa¸c˜ao de um algoritmo ICA para resolver o problema da separa¸cao cega de fontes e cancelamento adaptativo de ru´ıdo em FPGA.
Em [Costa, 2006], Costa propˆos a implementa¸c˜ao do algoritmo FastICA em ambiente de rede Foudation Fieldbus, tanto por blocos funcionais padr˜oes de uma rede Foundation Fieldbus com treinamento online via OPC como em tecnologia embarcada utilizando um DSP com o objetivo de extra¸c˜ao de ru´ıdos de sinais provenientes de uma planta de medi¸c˜ao de vaz˜ao.
Em 2006, Shyu e Li propuseram uma implementa¸c˜ao em FPGA do algoritmo FastICA em linguagem de descri¸c˜ao de hardware (HDL). Tamb´em foi implementada uma aritm´etica de ponto flutuante com o objetivo de agilizar as opera¸c˜oes realizadas com os n´umeros em representa¸c˜ao num´erica de ponto flutuante e diminuir a alta necessidade de hardware em opera¸c˜oes desse tipo ([Shyu and Li, 2006]). Embora o projeto puramente em HDL possa ser dif´ıcil, ´e poss´ıvel ter um maior controle de uso de hardware e minimizar as suas necessidades.
1.4 Organiza¸c˜ao do Trabalho 15
1.4
Organiza¸c˜
ao do Trabalho
16
2 An´
alise de Componentes Independentes
Neste cap´ıtulo, discutiremos conceitos b´asicos da t´ecnica An´alise de Compo-nentes Independentes (ICA), sua defini¸c˜ao como um modelo estat´ıstico de vari´aveis laten-tes e algumas restri¸c˜oes necess´arias para que o modelo possa ser um estimador. Tamb´em discutiremos a rela¸c˜ao de ICA com a t´ecnica chamada An´alise de Componentes Principais (PCA), al´em de introduzir um princ´ıpio simples e intuitivo de estimativa do modelo ICA apresentado e um algoritmo baseado em itera¸c˜ao de ponto-fixo utilizado na estimativa do modelo, bem como suas propriedades.
2.1
Defini¸
c˜
ao do Modelo
Para definir ICA, ´e utilizado um modelo estat´ıstico de vari´aveis latentes, ou seja, vari´aveis n˜ao observadas diretamente, mas sim inferidas atrav´es das propriedades de outras vari´aveis observadas. Sejam n vari´aveis aleat´orias observadas x1, ..., xn, que
significam para n´os as misturas captadas pelos sensores em uma abordagem de Separa¸c˜ao Cega de Fontes. Cadaxi´e modelado como uma combina¸c˜ao linear denvari´aveis aleat´orias
s1, ..., sn, tal que:
xi =ai1s1+ai2s2+...+ainsn, para todo i, j = 1, ..., n (2.1)
onde os aij s˜ao os coeficientes de mistura. Por defini¸c˜ao, as componentes si s˜ao estatisti-camente independentes.
Como uma combina¸c˜ao linear, o modelo tamb´em pode ser escrito como:
xi = n
X
j=1
aijsj (2.2)
Adotando um modelo matricial e denotando a matriz formada pelos coeficien-tes de mistura por A, temos que:
x=As (2.3)
2.2 Restri¸c˜oes 17
Para ilustrar o modelo, n´os podemos considerar duas vari´aveis aleat´orias x1 e
x2, pelo modelo temos que:
x1 =a11s1+a12s2 (2.4)
x2 =a21s1+a22s2 (2.5)
Na nossa abordagem de Separa¸c˜ao Cega de Fontes, osxi s˜ao as misturas obser-vadas, aij s˜ao os coeficientes da matriz de mistura esi s˜ao as componentes independentes, de tal forma que:
x1 x2 =
a11 a12
a21 a22
s1 1, s
2
1, ..., sk1
s1 2, s
2
2, ..., sk2
(2.6)
O problema da estimativa do modelo ICA apresentado ´e estimar as componen-tes independencomponen-tes, dado que n˜ao se tem conhecimento acerca dos coeficiencomponen-tes de mistura e das componentes independentes, ou seja, estimar uma matriz de separa¸c˜aoW composta por vetores linha wi, onde i= 1, ..., n tal que:
s=W x (2.7)
Como a matriz A ´e desconhecida, n˜ao se pode determinar uma matriz W tal que a eq. (2.7) seja satisfeita, mas n´os podemos encontrar um W∗ tal que:
y=W∗x (2.8)
onde ks−yk=min.
Esse ´e o modelo b´asico de ICA, por´em, em muitas aplica¸c˜oes seria mais rea-lista assumir que nas medi¸c˜oes dos sensores (microfones no Cocktail-party problem) est´a presente tamb´em ru´ıdo, o que significaria adicionar um termo para o ru´ıdo no modelo. Para fins de simplicidade, s˜ao omitidos quaisquer termos relacionados a ru´ıdos no mo-delo b´asico, j´a que este ´e suficiente em muitas aplica¸c˜oes. Ainda assim, momo-delos mais complexos s˜ao introduzidos em [Hyv¨arinen, Karhunnen and Oja, 2001].
2.2
Restri¸
c˜
oes
2.2 Restri¸c˜oes 18
1. ´E preciso assumir que as componentes independentes s˜ao estatisticamente independentes.
Duas ou mais vari´aveis aleat´orias s˜ao ditas estatisticamente independentes se a informa¸c˜ao contida nos valores de qualquer uma delas n˜ao fornece informa¸c˜ao alguma acerca dos valores de qualquer uma das outras. A independˆencia estatistica pode ser defi-nida formalmente atrav´es das fun¸c˜oes densidade de probabilidade das vari´aveis aleat´orias. Sejamp(y1, y2) a fun¸c˜ao densidade de probabilidade conjunta (fdp) das vari´aveis aleat´orias
y1 ey2 epi(yi) a fun¸c˜ao densidade de probabilidade marginal deyi, ou seja, a fun¸c˜ao
den-sidade de probabilidade de yi quando somente esta ´e considerada. ´E dito que y1 e y2
s˜ao estatisticamente independentes se e somente se a fun¸c˜ao densidade de probabilidade conjunta for fator´avel da seguinte maneira:
p(y1, y2) = p1(y1)p2(y2) (2.9)
Uma propriedade importante da independˆencia de vari´aveis aleat´orias ´e que, dado duas fun¸c˜oes h1 e h2, n´os sempre teremos que:
E{h1(y1)h2(y2)}=E{h1(y1)}E{h2(y2)} (2.10)
2. As componentes independentes precisam ter distribui¸c˜oes de probabilidade n˜ao-gaussianas.
No modelo ICA, n˜ao ´e assumido que as distribui¸c˜oes de probabilidade das componentes independentes s˜ao conhecidas, por´em, ´e preciso assumir que elas sejam n˜ao-gaussianas. As distribui¸c˜oes gaussianas s˜ao sim´etricas (Fig. 2.1). N˜ao h´a uma dire¸c˜ao de maior concentra¸c˜ao de valores que possa ser privilegiada na estimativa do modelo ICA, isso significa que as distribui¸c˜oes gaussianas possuem cumulantes de alta ordem iguais a zero, mas essas informa¸c˜oes de alta ordem s˜ao importantes na estimativa do modelo ICA. Embora seja assumido que as distribui¸c˜oes das componentes independentes sejam n˜ao-gaussianas, certamente as distribui¸c˜oes das misturas observadas ser˜ao.
Nas se¸c˜oes 2.5, 2.6 e 2.7, entraremos em detalhes sobre como essas restri¸c˜oes se relacionam e como o modelo ICA ´e estimado fazendo uso delas, al´em de introduzir um algoritmo de ponto-fixo baseado nos conceitos de independˆencia estat´ıstica e n˜ao-gaussianidade para estimar o modelo ICA.
2.3 Ambiguidades de ICA 19
Figura 2.1: Distribui¸c˜ao de probabiliade gaussiana
´e quadrada e, portanto, pode possuir inversa. Se esse n˜ao for o caso, haver˜ao misturas redundantes que poder˜ao ser omitidas no modelo.
2.3
Ambiguidades de ICA
Existem algumas ambiguidades decorrentes do modelo ICA b´asico. Elas s˜ao as seguintes:
1. N˜ao ´e poss´ıvel determinar as variˆancias das componentes independentes.
Como tanto A quanto s s˜ao desconhecidos, qualquer escalar α multiplicado em alguma das componentes independentes poderia ser cancelado dividindo a coluna correspondente ai de Apelo mesmo escalar. Uma poss´ıvel solu¸c˜ao ´e fixar as energias das vari´aveis aleat´orias e um m´etodo simples de se fazer isso ´e considerar que suas variˆancias sejam unit´arias, ou seja,E{s2
2.4 Pr´e-processamento dos Dados 20
2. N˜ao se pode determinar a ordem das componentes independentes.
Isso se d´a novamente por A e s serem desconhecidos, j´a que sendo assim, podemos trocar livremente a ordem dos termos na soma (2.2) e obter o mesmo resultado na combina¸c˜ao linear. Uma solu¸c˜ao para essa ambiguidade ´e adicionar uma matriz de permuta¸c˜ao P e sua inversa no modelo tal que:
x=AP−1
P s (2.11)
de forma que as componentes independentes P s ser˜ao as componentes originais si, em outra ordem. A matriz AP−1
ser´a a nova matriz de mistura a ser estimada.
2.4
Pr´
e-processamento dos Dados
Antes de aplicar o modelo ICA para a estimativa das componentes indepen-dentes, ´e recomend´avel realizar algumas etapas de pr´e-processamento no conjunto de misturas observadas. Nessa se¸c˜ao, iremos discutir algumas t´ecnicas de pr´e-processamento que tornam as misturas observadas melhor condicionadas e a estimativa do modelo mais simples. Al´em disso, veremos que caso a dimens˜ao dos dados seja muito grande, pode ser ´util calcular o PCA a fim de diminuir essa dimens˜ao para um intervalo previamente estabelecido.
2.4.1
Centraliza¸c˜
ao
Esse ´e o pr´e-processamento mais b´asico, embora tenha uma boa contribui¸c˜ao em simplificar a teoria envolvida no modelo ICA e os algoritmos para estimar o modelo.
Sem perda de generalidade, n´os podemos assumir que as componentes inde-pendentes e as misturas observadas possuem m´edia zero. Para que isso seja estritamente verdade, as misturas observadas passam pela fase de centraliza¸c˜ao, que significa subtrair das misturas a sua m´edia. Denotando as misturas observadas originais porx, as misturas centralizadas xc s˜ao tais que:
xc =x−E{x} (2.12)
Dessa forma, as componentes independentes tamb´em ter˜ao m´edia zero j´a que
E{s}=A−1
2.4 Pr´e-processamento dos Dados 21
O modelo continua sendo estimado da mesma forma, pois n˜ao h´a altera¸c˜ao alguma na matriz de mistura, al´em disso, ap´os a matriz de mistura ser estimada (consi-derando que as misturas observadas passaram pela fase de centraliza¸c˜ao), a m´edia sub-tra´ıda pode ser reconstru´ıda adicionando a W∗E{x} (lembrando que W = A−1
e W∗ ´e uma aproxima¸c˜ao ´otima de W) as componentes independentes de m´edia zero, ou seja, as componentes independentes que foram estimadas no modelo.
2.4.2
Branqueamento
A fase de branqueamento, apesar de ser um pouco mais dif´ıcil de ser calculada do que a centraliza¸c˜ao, ainda ´e um procedimento simples de ser implementado al´em ajudar a de diminuir significativamente a complexidade do problema. Sendo assim, o branqueamento ajuda a resolver o problema para o qual ICA ´e proposto. Esse pr´e-processamento ´e aplicado nas misturas centralizadas.
O branqueamento ´e uma propriedade um pouco mais poderosa em rela¸c˜ao `a descorrela¸c˜ao. Duas vari´aveis aleat´orias y1 e y2 s˜ao descorrelacionadas se sua covariˆancia
for igual a zero, ou seja:
cov(y1, y2) = E{y1y2} −E{y1}E{y2}= 0 (2.14)
Se duas vari´aveis aleat´orias forem independentes, necessariamente elas ser˜ao descorrelacionadas. Essa afirma¸c˜ao pode ser verificada se n´os tomarmosh1 =y1 eh2 =y2
na eq. (2.10)). Dessa forma, temos que:
E{y1y2}=E{y1}E{y2} (2.15)
que implica em descorrela¸c˜ao das vari´aveis aleat´orias.
Por outro lado, descorrela¸c˜ao n˜ao implica independˆencia. Se n´os tomarmos duas vari´aveis aleat´orias discretas com uma distribui¸c˜ao tal que o par possui probabilidade 1/4 para os seguintes valores: (0,1), (0,-1), (1,0) e (-1,0). N´os temos que as duas vari´aveis s˜ao descorrelacionadas, por´em, a condi¸c˜ao da eq. (2.10) ´e violada como podemos ver em (2.16), portanto, y1 e y2 n˜ao s˜ao independentes.
E{y2 1y
2
2}= 0 6=
1
4 =E{y
2 1}E{y
2
2} (2.16)
2.4 Pr´e-processamento dos Dados 22
al´em de serem descorrelacionadas possuem variˆancia unit´aria, ou seja, possuem matriz de covariˆancia igual a matriz identidade:
Cy =E{yyt}=I (2.17)
O processo de branqueamento consiste em aplicar uma determinada trans-forma¸c˜ao linear em uma vari´avel aleat´oria x, obtendo assim uma nova vari´avei aleat´oria
z, a qual ´e branca:
z =V x (2.18)
Um m´etodo popular para se realizar o branqueamento ´e a decomposi¸c˜ao por auto-valor (EVD do inglˆes Eigenvalue Decomposition) da matriz de covariˆancia:
E{xxt}=EDEt (2.19)
tal que E ´e a matriz ortogonal dos auto-vetores associados aos auto-valores da matriz de covariˆancia E{xxt} e D ´e a matriz diagonal de auto-valores da matriz de covariˆancia. A matriz de transforma¸c˜ao utilizada no branqueamento (geralmente chamada pormatriz de branqueamento) ´e definida por:
V =ED−1/2
Et (2.20)
Pela defini¸c˜ao do modelo ICA b´asico, n´os temos que:
z = V As (2.21)
= A′s (2.22)
A utilidade do branqueamento reside no fato de que a nova matriz de mis-tura A′
´e ortogonal, ou seja, como A′−1
= A′t
(no caso de matrizes ortogonais), a es-timativa da matriz de mistura se restringe ao espa¸co de matrizes ortogonais. Ao inv´es de estimar os n2
parˆametros da matriz de mistura original, somente ´e preciso estimar os parˆametros da matriz ortogonal A′−1
, o que significa n(n −1)/2 parˆametros. Para exemplificar essa propriedade, ser´a reproduzido a seguir um experimento realizado em [Hyv¨arinen, Karhunnen and Oja, 2001]. Consideremos duas vari´aveis aleat´orias x1 e x2
com distribui¸c˜oes uniformes p(si), tal que:
p(si) =
1
2√3 se si ≤
√
3
2.4 Pr´e-processamento dos Dados 23
Figura 2.2: Fun¸c˜ao densidade de probabilidade conjunta de x1 ex2
Os valores da distribui¸c˜ao uniforme foram escolhidos de tal forma que a fun¸c˜ao densidade de probabilidade conjuta das duas vari´aveis aleat´orias seja propositalmente quadrada (Fig. 2.2).
Ap´os o branqueamento, a fun¸c˜ao densidade de probabilidade conjunta das vari´aveis brancas ´e uma vers˜ao rotacionada da fun¸c˜ao das vari´aveis originais, como visto em (Fig. 2.3). Isso se d´a porque em um espa¸co bidimensional, uma transforma¸c˜ao ortogo-nal (z =A′
s) ´e determinada por um ´unico parˆametro, que ´e o ˆangulo da rota¸c˜ao, ou seja, ao inv´es de estimarmos todos os 4 parˆametros de uma matriz 2x2, estimamos somente um parˆametro de rota¸c˜ao, caso as vari´aveis tenham passado pelo processo de branqueamento.
Em algumas aplica¸c˜oes onde a massa de dados ´e muito grande, pode ser ´util extrair as componentes principais dos dados antes de realizar o branqueamento, por meio da t´ecnica PCA. A solu¸c˜ao para o problema do PCA de uma massa de dadosx´e dada em termos dos autovetores e1, ..., en da matriz de covariˆancia Cx, onde Cx =E{xxt} ([Oja,
1983]). Os autovetores s˜ao ent˜ao ordenados de acordo com seus respectivos autovalores, tal que d1 ≥ d2 ≥, ..., ≥ dn. Os menores autovalores s˜ao ent˜ao descartados de acordo
2.5 N˜ao-gaussianidade e independˆencia 24
Figura 2.3: Fun¸c˜ao densidade de probabilidade conjunta das vari´aveis brancas
2.5
N˜
ao-gaussianidade e independˆ
encia
Nesta se¸c˜ao, iremos discutir a rela¸c˜ao entre as restri¸c˜oes de n˜ao-gaussianidade e independˆencia estat´ıstica das componentes independentes, assim como a maneira como ICA se utiliza dessas restri¸c˜oes para estimar o modelo.
´
E poss´ıvel mostrar que para componentes independentes com distribui¸c˜oes de probabilidade gaussianas (eq. 2.24), a matriz de mistura n˜ao surte efeito algum nas distri-bui¸c˜oes das misturas (eq. 2.25), ou seja, as distridistri-bui¸c˜oes s˜ao identicas, o que significa que n˜ao h´a meios de se estimar a matriz de mistura tendo somente as informa¸c˜oes fornecidas pelas misturas observadas. Isso tamb´em acontece se n´os tornarmos as componentes in-dependentes brancas, por meio do branqueamento. Na verdade, ´e at´e mais f´acil entender porque n˜ao podemos estimar a matriz de mistura no caso de componentes independentes gaussianas se as componentes forem brancas.
p(s1, s2) =
1
2πexp(− s2
1+s 2 2
2 ) (2.24)
p(x1, x2) =
1
2πexp(− x2
1 +x 2 2
2 ) (2.25)
2.5 N˜ao-gaussianidade e independˆencia 25
matriz de mistura e consequentemente recuperar as componentes baseando-se somente nas informa¸c˜oes fornecidas pelas misturas observadas. O Teorema do Limite Central nos d´a uma id´eia de como isso ´e poss´ıvel.
O teorema do limite central ´e um resultado cl´assico da teoria de probabilidade. O teorema afirma que, se n´os considerarmos uma sequˆencia de vari´aveis aleat´orias esta-tisticamente independentes e igualmente distribu´ıdasx1, x2, ..., xk, a soma yk =x1+x2+
...+xk converge para uma distribui¸c˜ao gaussiana sek → ∞. Na pr´atica, n´os n˜ao temos
k → ∞, mas baseados no teorema do limite central, n´os podemos dizer que a soma de duas vari´aveis aleat´orias estatisticamente independentes e igualmente distribu´ıdas geral-mente tem uma distribui¸c˜ao que ´e mais pr´oxima de uma gaussiana do que qualquer uma das distribui¸c˜oes das vari´aveis originais. Dessaf forma, o Teorema do Limite Central pode ser utilizado para estimar as componentes independentes da seguinte forma.
Pelo modelo ICA b´asico, n´os temos que:
s =A−1
x (2.26)
Portanto, para se estimar uma das componentes independentes, n´os podemos considerar uma combina¸c˜ao linear das misturas observadas y, tal quey =bx, ondeb´e um vetor linha a ser determinado. Pelo modelo, n´os temos tamb´em que y=bAs, ou seja, y´e uma combina¸c˜ao linear das componentes independentes com o vetor bA. Se denotarmos esse vetor por q, temos que:
y=bx=qs=X i
qisi (2.27)
Se n´os observarmos a eq. (2.26) e considerarmos que b corresponde a uma das linhas de A−1
, ent˜ao a combina¸c˜ao linear bx teria como resultado uma das componentes independentes. Consequentemente, se n´os consideramos q = bA e b como uma linha da inversa de A, q ser´a necessariamente um vetor com somente um elemento igual a 1 e todos os outros iguais a zero. Se n´os estamos considerando que as componentes independentes s˜ao estatisticamente independentes, pelo teorema do limite central n´os podemos afirmar que qualquer combina¸c˜ao linear das componentes ter´a distribui¸c˜ao mais pr´oxima da gaussiana do que as distribui¸c˜oes de qualquer uma das componentes, portanto,
y = qs ser´a sempre mais gaussiana do que qualquer si a menos que qs resulte em uma das componentes independentes.
2.6 Medidas de N˜ao-gaussianidade 26
at´e que y se igualasse a uma das componentes independentes, mas na pr´atica somente os valores das misturas observadas x s˜ao conhecidas. Por outro lado, n´os sabemos tamb´em queqs=bx, ent˜ao, se n´os pudermos calcular um vetorbque maximize a n˜ao-gaussianidade de bx, esse vetor seria necessariamente igual ao vetor bA, ou seja, y = bx = qs ser´a equivalente a uma das componentes independentes.
Embora a rela¸c˜ao entre independˆencia e n˜ao-gaussianidade tenha sido esclare-cida (com o aux´ılio do teorema do limite central), outra quest˜ao precisa ser discutida. A combina¸c˜ao linear y=bx seria equivalente a uma das componentes independentes se n´os pud´essemos calcular um vetor b que maximize a n˜ao-gaussianidade de bx. Mas como a n˜ao-gaussianidade pode ser medida? Essa quest˜ao ser´a discutida na se¸c˜ao (2.6).
2.6
Medidas de N˜
ao-gaussianidade
Para utilizar a n˜ao-gaussianidade na estimativa do modelo ICA, n´os precisamos ter uma medida quantitativa da n˜ao-gaussianidade de uma vari´avel aleat´oria y. Apesar de existirem outros m´etodos relacionados com n˜ao-gaussinidade de vari´aveis aleat´orias que podem ser utilizados para estimar o modelo ICA, como M´axima verossimilhan¸ca e Informa¸c˜ao m´utua, nessa se¸c˜ao iremos nos restringir a discutir duas importantes medidas
de n˜ao-gaussianidade utilizadas neste trabalho: a Kurtosis e a Negentropia.
2.6.1
Kurtosis
Uma medida cl´assica de n˜ao-gaussianidade ´e a Kurtosis, tamb´em chamada de Cumulante de Quarta-ordem. A fun¸c˜ao Kurtosis de uma vari´avel aleat´oria y ´e dada da seguinte forma:
kurt(y) = E{y4
} −3(E{y2
})2
(2.28)
Se n´os assumirmos que y possui variˆancia unit´aria (se a vari´avel for branca, por exemplo), ent˜ao a fun¸c˜ao ´e simplificada da seguinte forma:
kurt(y) =E{y4
} −3 (2.29)
A eq. (2.29) nos mostra que a fun¸c˜ao kurt ´e uma vers˜ao normalizada do momento de quarta ordem E{y4
2.6 Medidas de N˜ao-gaussianidade 27
Usando o valor absoluto da kurtosis, chega-se na medida de n˜ao-gaussianidade. O quadrado do valor absoluto da kurtosis tamb´em pode ser utilizado. Para o caso de uma vari´avel gaussiana, o resultado da fun¸c˜ao kurtosis ´e, na maioria das vezes, igual a zero. Para vari´aveis n˜ao-gaussianas, o valor absoluto (ou seu quadrado) da kurtosis ´e diferente de zero.
A raz˜ao pela qual a kurtosis ´e amplamente utilizada ´e pela sua simplicidade. Na pr´atica, a kurtosis pode ser calculada utilizando somente o momento de quarta ordem e al´em disso, para duas vari´aveis aleat´orias independentes s1 e s2, temos as seguintes
propriedades de linearidade:
kurt(s1+s2) =kurt(s1) +kurt(s2) (2.30)
kurt(αs1) = α 4
kurt(s1) (2.31)
Apesar de sua simplicidade, a kurtosis possui algumas desvantagens na pr´atica. A quest˜ao ´e que somente algumas amostras de uma vari´avel aleat´oria podem ter uma maior influˆencia no valor absoluto da kurtosis em rela¸c˜ao a todas as outras amostras. Se n´os considerarmos uma vari´avel aleat´oria com 1000 amostras (com m´edia zero e variˆancia unit´aria) com valores que variam entre 0 e 1 e algum agente externo contribuisse para que uma amostra possuisse valor igual a 10, o valor da kurtosis seria igual a pelo menos 104
/1000−3 = 7, ou seja, a kurtosis ´e uma medida de n˜ao-gaussianidade simples mas n˜ao robusta.
2.6.2
Negentropia
Nessa se¸c˜ao, ser´a apresentada uma segunda medida de n˜ao-gaussianidade, cha-mada Negentropia. A negentropia se baseia na quantidade de informa¸c˜ao te´orica de uma vari´avel dada pela entropia diferencial, tratada simplesmente por entropia.
2.6 Medidas de N˜ao-gaussianidade 28
probabilidade py(η) ´e definida da seguinte forma:
H(y) =−
Z
py(η)log(py)dη (2.32)
Um resultado fundamental da teoria da informa¸c˜ao ´e que uma vari´avel gaussi-ana possui a maior entropia dentre todas as vari´aveis aleat´orias de igual variˆancia. Isso sig-nifica que distribui¸c˜oes gaussianas s˜ao as mais aleat´orias e desestruturadas dentre todas as distribui¸c˜oes, ou seja, n´os podemos utilizar a entropia como medida de n˜ao-gaussianidade.
A negentropia ´e uma vers˜ao normalizada da entropia, de tal forma que a negentropia ´e sempre n˜ao-negativa e zero para uma vari´avel gaussiana. A negentropia J
de uma vari´avel aleat´oria y´e definida da seguinte forma:
J(y) =H(ygauss)−H(y) (2.33)
onde ygauss ´e uma vari´avel aleat´oria com distribui¸c˜ao gaussiana e mesma matriz de cor-rela¸c˜ao (e portanto, covariˆancia) que y.
A negentropia ´e uma medida de n˜ao-gaussianidade bem justificada pela teo-ria estat´ıstica e ´e por vezes considerada um estimador ´otimo de n˜ao-gaussianidade. O problema ´e que, como n´os podemos constatar pela pr´opria defini¸c˜ao, a negentropia ´e uma medida de dif´ıcil implementa¸c˜ao computacional, al´em de ser necess´ario ter conhe-cimento (ou ao menos uma estimativa) da fun¸c˜ao densidade de probabilidade. A seguir ser˜ao discutidas algumas boas aproxima¸c˜oes da negentropia que tornam a medida mais pratic´avel.
O primeiro m´etodo de aproxima¸c˜ao ´e utilizando cumulantes de alta-ordem. Dessa forma, n´os temos a seguinte aproxima¸c˜ao:
J(y)≈ 1 12E{y
2
}2
+ 1
48kurt(y)
2
(2.34)
Como podemos constatar na eq. (2.34), a aproxima¸c˜ao utilizando cumulantes de alta-ordem levam ao uso da kurtosis apresentada na se¸c˜ao (2.6.1). Como consequˆencia disso, essa aproxima¸c˜ao da negentropia n˜ao ´e t˜ao robusta, assim como a kurtosis.
Um m´etodo mais sofisticado ´e utilizar esperan¸cas de fun¸c˜oes n˜ao-quadr´aticas. N´os podemos utilizar quaisquer duas fun¸c˜oes n˜ao-quadr´aticas G1
eG2
tal queG1
´e ´ımpar e G2
´e par. Isso nos d´a a seguinte aproxima¸c˜ao:
J(y)≈k1(E{G 1
(y)})2
+k2(E{G 2
(y)} −E{G2
(v)})2
2.7 Algoritmo FastICA 29
onde k1 e k2 s˜ao constantes positivas e v ´e uma vari´avel aleat´oria gaussiana com m´edia
zero e variˆancia unit´aria.
Se n´os usarmos somente uma fun¸c˜ao n˜ao-quadr´aticaG, a aproxima¸c˜ao se torna a seguinte:
J(y)∝[E{G(y)} −E{G(v)}]2
(2.36)
A quest˜ao agora ´e a escolha de uma fun¸c˜ao n˜ao-quadr´atica G. A escolha de uma G que n˜ao cres¸ca t˜ao depressa resulta em estimadores mais robustos. As seguintes fun¸c˜oes tem provado serem boas escolhas:
G1(y) =
1
a1
log(cosh(a1y)) (2.37)
G2(y) = −exp(−
y2
2) (2.38)
onde a1 ´e uma constante, tal que: 1≤a1 ≤2.
2.7
Algoritmo FastICA
Nesta se¸c˜ao ser´a apresentado um bom algoritmo baseado em itera¸c˜ao de ponto-fixo que maximiza a n˜ao gaussianidade de wz (m´aximo local), onde z s˜ao as misturas observadas centralizadas e brancas e w ´e um vetor de coeficientes de separa¸c˜ao. ´E im-portante notar que o algoritmo encontra somente uma componente independente. Para estimar todas as componentes independentes, ´e preciso executar o algoritmo para cada componente. Esse algoritmo recebe o nome de FastICA.
O algoritmo FastICA pode ser derivado tanto para o caso de maximizar a n˜ao-gaussianidade utilizando o m´etodo kurtosis quanto o m´etodo negentropia. A diferen¸ca b´asica entre os algoritmos ser´a a itera¸c˜ao que calcular´a o novow. Abaixo segue o algoritmo utilizando o m´etodo negentropia:
1. Escolher um vetor de pesosw inicial (por exemplo, aleatoriamente).
2. w∗ ←E{zg(wtz)} −E{g′(wtz)}w.
3. w← w
∗
2.7 Algoritmo FastICA 30
4. Se n˜ao convergiu, voltar ao passo 2.
Como fun¸c˜ao g, as derivadas das fun¸c˜oes descritas nas equa¸c˜oes 2.37 e 2.38 podem ser utilizadas (equa¸c˜oes 2.39 e 2.40), pois resultam em boas aproxima¸c˜oes da negentropia. Al´em dessas fun¸c˜oes, pode-se utilizar tamb´em a derivada do momento de quarta ordem, que resultar´a no m´etodo kurtosis (equa¸c˜ao 2.41).
g1(y) = tanh(a1y) (2.39)
g2(y) = yexp(−
y2
2) (2.40)
g3(y) =y 3
(2.41)
As derivadas g′ s˜ao dadas por:
g′
1(y) = a1(1−tanh 2
(a1y)) (2.42)
g′
2(y) = (1−y 2
)exp(−y
2
2) (2.43)
g′
3(y) = 3y 2
(2.44)
A itera¸c˜ao utilizando o kurtosis, ´e dada da seguinte forma:
w∗ ←E{z(wtz)3
} −3w (2.45)
O crit´erio de convergˆencia ´e o novo e antigowapontarem para a mesma dire¸c˜ao (considerando que w e −w s˜ao iguais, como visto nas ambiguidades do modelo ICA).
Abaixo seguem algumas propriedades do algoritmo FastICA:
2.8 Calculando mais de uma componente independente 31
2. Contr´ario a algoritmos baseados em gradiente, n˜ao h´a nenhum parˆametro de taxa de aprendizagem para escolher, o que torna o FastICA mais simples.
3. O algoritmo encontra diretamente as componentes independentes de praticamente qualquer distribui¸c˜ao n˜ao-gaussiana usando qualquer medida de n˜ao-linearidade g, ao contr´ario de muitos algoritmos onde a medida de n˜ao-linearidade precisa ser escolhida especificamente.
4. O desempenho do algoritmo pode ser melhorado com a escolha adequada de uma medida de n˜ao-linearidade.
5. As componentes independentes podem ser estimadas uma a uma, o que diminui o custo computacional em casos onde somente algumas das componentes independen-tes precisam ser estimadas.
6. O algoritmo FastICA possui outras vantagens como: paralelismo, ´e distribuido, com-putacionalmente simples e requer pouco espa¸co de mem´oria.
2.8
Calculando mais de uma componente
indepen-dente
Como visto anteriormente, o algoritmo FastICA apresentado calcula somente uma componente independente. ´E poss´ıvel calcular todas as componentes executando o FastICA um n´umero de vezes igual ao n´umero de componentes independentes, al´em de variar o vetor w inicial, por´em, existe o risco de um mesmo m´aximo local ser calculado mais de uma vez. Para eliminar este problema, ´e utilizada a propriedade de que os vetores
wi s˜ao ortogonais no espa¸co branco. Isto se d´a devido a ortogonalidade da nova matriz de misturaA′
obtida ap´os o branqueamento. ComoA′−1
=A′t
, os vetoreswi s˜ao as linhas de
A′−1
e as colunas deA′t
, portanto, para evitar que um mesmo m´aximo local seja calculado mais de uma vez, ´e preciso ortogonalizar os vetores wi a cada itera¸c˜ao do algoritmo.
2.8 Calculando mais de uma componente independente 32
2.8.1
Ortogonaliza¸
c˜
ao deflacion´
aria
Um m´etodo simples e bastante conhecido na ´algebra linear de ortogonaliza¸c˜ao deflacion´aria ´e o m´etodo de Gram-Schmidt. A cada itera¸c˜ao o algoritmo FastICA calcula um novo vetor wp e para ortogonaliz´a-lo, basta subtrair as proje¸c˜oes (wpt)wj, onde j = 1, ..., p −1, dos p− 1 vetores calculados nas itera¸c˜oes anteriores e ent˜ao renormalizar
wp. Dessa forma as componentes independentes s˜ao calculadas uma a uma, ou seja, sequencialmente. Por esse motivo, o erro de ortogonaliza¸c˜ao ´e propagado para as pr´oximas componentes independentes.
Utilizando a ortogonaliza¸c˜ao deflacion´aria, os passos para a estimativa das componentes independentes s˜ao os seguintes:
1. Escolher um vetor de pesosw inicial (por exemplo, aleatoriamente).
2. Executar uma itera¸c˜ao do algoritmo FastICA.
3. Realizar a ortogonaliza¸c˜ao apresentada na equa¸c˜ao 2.46.
wp ←wp− p−1 X
j=1
(wptwj)wj (2.46)
4. Normalizar wp.
5. Se n˜ao convergiu, voltar ao passo 2.
6. p←p+ 1. Se p≤n, voltar ao passo 1.
2.8.2
Ortogonaliza¸
c˜
ao sim´
etrica
Na ortogonaliza¸c˜ao deflacion´aria, as componentes independentes s˜ao calcula-das uma a uma, por isso possui a desvantagem de propagar erros de estima¸c˜ao para as componentes subsequentes. Por esse motivo, pode ser interessante uma outra t´ecnica de natureza sim´etrica de ortogonaliza¸c˜ao onde as componentes n˜ao s˜ao mais calculadas se-quencialmente mas sim paralelamente, ou seja, como as componentes independentes s˜ao calculadas todas ao mesmo tempo, n˜ao h´a propaga¸c˜ao de erro de estima¸c˜ao.
2.9 Exemplo de aplica¸c˜ao do ICA 33
O algoritmo completo da estimativa das componentes independentes utilizando ortogonaliza¸c˜ao sim´etrica ´e dado a seguir:
1. Escolher um vetor de pesosw inicial (por exemplo, aleatoriamente).
2. Executar uma itera¸c˜ao do algoritmo FastICA para todos vetores wi em paralelo.
3. Realizar uma ortogonaliza¸c˜ao sim´etrica nos vetoreswi.
4. Se n˜ao convergiu, voltar ao passo 2.
A ortogonaliza¸c˜ao sim´etrica pode ser obtida pelo m´etodo cl´assico da raiz qua-drada de uma matriz. Dessa forma, a matrizW formada pelos vetoreswi´e ortogonalizada da seguinte maneira:
W ←(W Wt)−12W (2.47)
Uma outra maneira ´e executar o seguinte algoritmo iterativo:
1. W ← W
kW k.
2. W ← 3
2W − 1 2W W
tW.
3. SeW Wt n˜ao pr´oximo o bastante da matriz identidade, voltar ao passo 2.
2.9
Exemplo de aplica¸
c˜
ao do ICA
Ap´os a defini¸c˜ao de diversos aspectos que envolvem a an´alise de componen-tes independencomponen-tes, se torna necess´ario a visualiza¸c˜ao da t´ecnica como uma ferramenta para resolver o problema da separa¸c˜ao cega de fontes. Dessa maneira, nessa se¸c˜ao ser˜ao apresentados e discutidos alguns exemplos da utiliza¸c˜ao do ICA.
O primeiro exemplo ´e um exerc´ıcio proposto como experimento computacional em [Haykin, 2001]. O experimento prop˜oe a utiliza¸c˜ao dos seguintes sinais e matriz de mistura:
2.9 Exemplo de aplica¸c˜ao do ICA 34
Figura 2.4: Sinais do lado esquerdo: sinais originais gerados manualmente. Sinais do lado direito: misturas geradas a partir de uma transforma¸c˜ao linear dos sinais originais utilizando a matriz A
2. u2(k) = 0,01sign(sen((500k) + 9cos(40k)))
3. u3(k) = ru´ıdo uniformemente distribu´ıdo no intervalo [-1, 1]
A=
0,56 0,79 −0,37
−0,75 0,65 0,86
0,17 0,32 −0,48
(2.48)
Os sinais originais e as misturas obtidas ap´os a transforma¸c˜ao linear s˜ao ilus-trados na figura 2.4.
As misturas s˜ao ent˜ao, dadas como entrada do algoritmo FastICA que ir´a iterativamente calcular proje¸c˜oes wi (vetores ou pontos no espa¸co), onde i = 1, ...n e
n = 3. Os vetores wi iniciais s˜ao obtidos aleatoriamente, o valor do erro ´e definido como 0,0001 e o n´umero m´aximo de itera¸c˜oes para cada componente independente foi definido como 500. A fun¸c˜ao g escolhida para medir a n˜ao-gaussianidade das componentes foi a
g3(y) =y 3
, vista na eq. (2.43).
2.9 Exemplo de aplica¸c˜ao do ICA 35
Figura 2.5: Componentes independentes obtidas utilizando a matriz de separa¸c˜ao W
calculada pelo algoritmo FastICA
Como pode ser observado, o FastICA obteve uma estimativa das componentes independentes satisfat´oria (Figura 2.5), embora seja poss´ıvel perceber aspectos discutidos na se¸c˜ao 2.3, onde foram detalhadas algumas ambiguidades da an´alise de componen-tes independencomponen-tes. A primeira delas trata da impossibilidade de determinar as energias (variˆancias) das componentes independentes, j´a que qualquer escalar multiplicado nas componentes independentes pode ser eliminado na matriz de mistura, j´a que ambos s˜ao desconhecidos. Por isso, percebemos altera¸c˜oes nas amplitudes dos sinais estimados em rela¸c˜ao aos sinais originais. Al´em disso, ´e ainda poss´ıvel inverter qualquer uma das com-ponentes independentes, j´a que as proje¸c˜oes wi e −wi possuem mesma dire¸c˜ao, embora estejam em sentidos contr´arios. O crit´erio de convergˆencia do algoritmo FastICA leva em considera¸c˜ao as duas proje¸c˜oes.
A segunda ambiguidade trata da ordem das componentes independentes. Como visto na se¸c˜ao 2.3, n˜ao ´e poss´ıvel estimar as componentes independentes e garantir que estas estejam ordenadas exatamente como os sinais originais, j´a que podemos trocar os ter-mos na equa¸c˜ao (2.2) livremente e ainda assim obter o mesmo resultado. Isto tamb´em se d´a pelo fato da matriz de mistura e das componentes independentes serem desconhecidos.
2.9 Exemplo de aplica¸c˜ao do ICA 36
Figura 2.6: Sinais do lado esquerdo: sinais de voz originais. Sinais do lado direito: misturas obtidas a partir da transforma¸c˜ao linear entre a matriz de mistura A e os sinais originais
A matriz de mistura A utilizada foi a mesma utilizada nos experimentos em [Charoensak and Sattar, 2005] para obter os sinais de mistura, tal que:
A=
0.6 1 1 0.6
(2.49)
A figura 2.6 ilustra os sinais de voz originais (lado esquerdo) e as misturas obtidas a partir da transforma¸c˜ao linear entre a matriz de mistura Ae os sinais originais (lado direito).
Da mesma forma que o exemplo anterior, os pontos wi iniciais s˜ao obtidos aleatoriamente, onde i = 1, ..., n e n = 2. O valor do erro foi definido em 0,0001, o n´umero m´aximo de itera¸c˜oes foi definido como 500 e a fun¸c˜ao escolhida para medir a n˜ao-gaussianidade das componentes foi a g3(y) =y
3
.
A primeira componente independente foi calculada ap´os 5 itera¸coes do algo-ritmo, enquanto a segunda foi calculada ap´os 2 itera¸c˜oes. A figura 2.7 mostra as com-ponentes indenpendentes obtidas e embora o algoritmo apresente boas estimativas, nova-mente ´e poss´ıvel observar a presen¸ca das ambiguidades do modelo ICA.
2.9 Exemplo de aplica¸c˜ao do ICA 37
Figura 2.7: Componentens independentes obtidas com a matriz de separa¸c˜aoW calculada pelo algoritmo FastICA
medi¸c˜ao da n˜ao-gaussianidade. Na maioria dos experimentos o algoritmo apresentou boas estimativas das componentes independentes.
38
3 FPGA e Linguagem de Descri¸
c˜
ao de
Hardware
A tecnologiaField Programmable Gate Array (FPGA) surgiu nos anos 80 como uma alternativa aos j´a comuns Dipositivos L´ogico Program´aveis e com o intuito de possi-bilitar a implementa¸c˜ao de circuitos l´ogicos complexos e de alta performace. Constitu´ıdos de interconex˜oes program´aveis e blocos l´ogicos que reunem aspectos de l´ogica combinaci-onal e sequencial, os FPGAs s˜ao considerados uma boa alternativa para a implementa¸c˜ao de circuitos l´ogicos de grande porte e ainda assim possuir uma grande capacidade de re-programa¸c˜ao. O termo Field Programmable refere-se ao fato de que, diferentemente de dispositivos projetados por seus manufaturadores, FPGAs s˜ao configurados no campo, ou seja, em um laborat´orio ou at´e mesmo j´a estando conectados a um sistema eletrˆonico.
Neste cap´ıtulo ser˜ao discutidos alguns aspectos dessa tecnologia, al´em de de-talhar o funcionamento interno dos FPGAs e a utiliza¸c˜ao de linguagens de descri¸c˜ao de hardware para a implementa¸c˜ao circuitos l´ogicos nesses dispositivos.
3.1
Hist´
orico
Os Dispositivos L´ogico Program´aveis (PLDs) foram introduzidos na metade dos anos 70 com o objetivo de implementar circuitos l´ogicos combinacionais que possu´ıssem aspectos program´aveis. Em contraste com os microprocessadores, que podem executar programas implementados em linguagens de programa¸c˜ao cl´assicas mas possuem um hard-ware fixo, os PLDs surgiram com o objetivo de levar a reprograma¸c˜ao a um n´ıvel de hardware. Isso significa que os PLDs s˜ao dispositivos utilizados para a implementa¸c˜ao de aplica¸c˜oes generalizadas, mas que o hardware pode ser reconfigurado para se adequar a um tipo espec´ıfico de circuito.
3.1 Hist´orico 39
o lan¸camento dos PAL foram introduzidos PLDs com circuitos flip-flops embutidos nas sa´ıdas dos dispositivos, os quais foram chamados de Registered PLDs. Dessa forma, se tornava poss´ıvel a implementa¸c˜ao de fun¸c˜oes sequenciais ao inv´es de puramente combina-cionais.
No in´ıcio dos anos 80, foi adicionado `as sa´ıdas dos PLDs l´ogica combinacio-nal extra, que continha portas l´ogicas e circuitos multiplexadores. Essa nova tecnologia tamb´em era program´avel, permitindo v´arios modos de opera¸c˜ao, al´em disso, permitia um sinal de retorno das sa´ıdas dos dispositivos para o circuito interno. Esse novo tipo de estrutura foi chamado de Generic PAL (GAL). Todos esses dispositivos (PAL, Registered PLD e GAL) s˜ao hoje conhecidos como SPLDs (Simple PLDs).
Rapidamente, diversos dispositivos GAL foram produzidos em um mesmo chip, possibilitando a implementa¸c˜ao de circuitos mais complexos e al´em disso, v´arias funcio-nalidades e propriedades (como suporte a diversos padr˜oes l´ogicos) foram adicionadas aos circuitos. Essa nova estrutura ficou conhecida como CPLD (Complex PLD). Os CPLDs s˜ao circuitos l´ogico program´aveis bastante populares, devido a caracter´ısticas como alta performance e baixo custo (em [Pedroni, 2004], ´e visto que CPLDs com pre¸co abaixo de um dolar podem ser encontrados no mercado).
Na metade dos anos 80, os FPGAs foram introduzidos no mercado pela Xilinx. Estes dispositivos diferem dos CPLDs em muitos aspectos, como por exemplo tecnologia de armazenamento (CPLDs utilizam mem´orias EEPROM e Flash, enquanto os FPGAs utilizam SRAM, portanto estes ´ultimos s˜ao mais vol´ateis), n´umero de propriedades em-butidas e custo. Al´em disso, os FPGAs foram desenvolvidos com o objetivo de suprir a cadˆencia de dispositivos l´ogico program´aveis direcionados para a implementa¸c˜ao de circuitos complexos e de grande porte.
Nos anos 90, os FPGAs se tornavam mais e mais sofisticados em termos de tamanho e caracter´ısticas adicionais. Nessa ´epoca, o principal mercado atingido por esses dispositivos foi o de telecomunica¸c˜oes e redes, e a principal aplica¸c˜ao era a de processa-mento de grandes blocos de dados. Como os FPGAs continuaram a crescer, no final dos anos 90 eles j´a eram utilizados em aplica¸c˜oes industriais e automotivas
veloci-3.1 Hist´orico 40
dade. Com isso, os FPGAs podem ser utilizados para implementar circuitos complexos e de grande porte em quase que qualquer aplica¸c˜ao, desde dispositivos de telecomunica¸c˜oes, dispositivos wireless definidos por software, radar, imagem e processamento digital de sinais ([Maxfield, 2004]). Mais especificamente, os FPGAs est˜ao se destacando em quatro grandes ´areas da engenharia e eletrˆonica: o projeto de prot´otipos de ASICs (Applica-tion Specific Integrated Circuit, circuitos integrados voltados para aplica¸c˜oes espec´ıficas),
processamento digital de sinais, microcontroladores e chips de comunica¸c˜ao em camada f´ısica.
Prot´otipos de ASICs: FPGAs tˆem sido utilizados para implementar circuitos que eram implementados somente em ASICs, como forma de um prot´otipo, j´a que o tempo e custo de projeto de ASICs ´e bastante superior ao de FPGAs.
Processamento digital de sinais: Anteriormente, a maioria das aplica¸c˜oes em pro-cessamento digital de sinais eram implementadas em microprocessadores especiais chamados Digital Signal Processors (DSPs) mas com o aumento de caracter´ısticas adicionais em FPGAs tais como multiplicadores embutidos, mem´oria externa e ro-teamento aritm´etico dedicado, o n´umero de aplica¸c˜oes de DSPs implementadas em FPGAs vem crescendo continuamente. Al´em disso, aliar todas essas caracter´ısticas com o paralelismo dos FPGAs podem resultar em ganhos de desempenho nos FP-GAs em rela¸c˜ao aos DSPs ([Maxfield, 2004]).
Microcontroladores: A grande maioria de aplica¸c˜oes envolvendo fun¸c˜oes de controle s˜ao implementadas em dispositivos chamados Microcontroladores. Por´em, comoo custo dos FPGAs tem ca´ıdo gradualmente, al´em do fato que os FPGAs possuem mais que o necess´ario para a implementa¸c˜ao de fun¸c˜oes de controle, estes dispositivos est˜ao se tornando cada vez mais interessantes para a implementa¸c˜ao de aplica¸c˜oes em controle.
Comunica¸c˜ao em camada f´ısica: A utiliza¸c˜ao de FPGAs na comunica¸c˜ao entre ca-mada f´ısica e protoc´olos de caca-madas de mais alto n´ıvel j´a ´e tradicional. O que chama a aten¸c˜ao ´e que com o avan¸co dos FPGAs, hoje em dia um dispositivo pode conter multiplos transceivers de alta velocidade. Isso quer dizer que as fun¸c˜oes de rede e comunica¸c˜oes podem ser concentradas em um ´unico chip.
3.2 Funcionamento interno 41
Figura 3.1: Arquitetura interna de um CPLD: pinos de entrada e sa´ıda interligados aos dispositivos GAL atrav´es de uma switch matrix que realiza tamb´em a interliga¸c˜ao dos dispositivos entre s´ı
j´a se encontram inclu´ıdos, o surgimento desses dispositivos criou um novo mercado, a computa¸c˜ao reconfigur´avel. Esse novo mercado refere-se ao aproveitamento do paralelismo inerente e capacidade de reconfigura¸c˜ao dos FPGAs.
3.2
Funcionamento interno
O funcionamento interno de um FPGA difere em muitos aspectos dos CPLDs. Nos CPLDs, as fun¸c˜oes l´ogicas s˜ao implementadas atrav´es da uni˜ao de v´arios disposi-tivos GAL, que s˜ao constitu´ıdos de interconex˜oes program´aveis e portas l´ogicas AND seguidas de uma porta l´ogica OR. Al´em disso, ´e utilizada uma matriz de interconex˜oes program´aveis, chamada de switch matrix para customizar a interliga¸c˜ao dos dispositivos GAL entre s´ı e com os pinos de entrada e sa´ıda. Na figura 3.1, temos a ilustra¸c˜ao da arquitetura interna de um CPLD descrita de forma simplificada.
3.2 Funcionamento interno 42
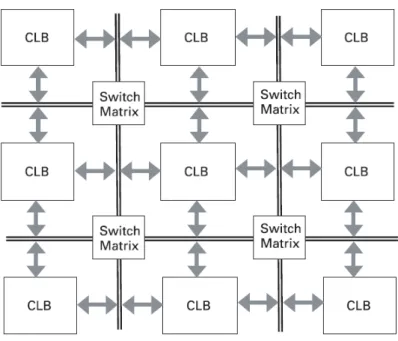
Figura 3.2: Arquitetura interna de um FPGA: blocos l´ogicos configur´aveis (CLBs) for-mados por lookup tables, flip-flops e multiplexadores s˜ao interligados atrav´es de diversas switch matrixes
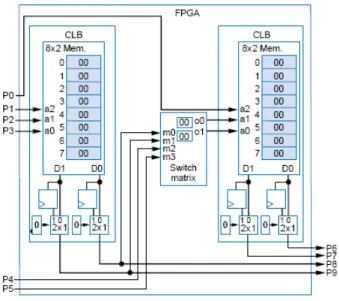
tables resulta nos Blocos L´ogicos Configur´aveis (CLBs) que fazem parte da arquitetura interna dos FPGAs. Para que fun¸c˜oes l´ogicas complexas e de grande porte possam ser implementadas, os CLBs s˜ao interligados atrav´es de diversas interconex˜oes program´aveis (Switch Matrix). Na figura 3.2, temos a ilustra¸c˜ao da arquitetura interna de um FPGA.
Outra diferen¸ca fundamental entre FPGAs e CPLDs est´a na tecnologia de armazenamento das interconex˜oes. Enquanto os CPLDs s˜ao n˜ao-vol´ateis (utilizam EE-PROM e Flash), a maioria dos FPGAs utilizam SRAM, e portanto, s˜ao vol´ateis. A vantagem de usar SRAM ´e a economia de espa¸co, mas como os FPGAs possuem uma grande quantidade de interconex˜oes, ´e necess´aria a utiliza¸c˜ao de uma ROM externa. Em-bora a maioria dos FPGAs sejam vol´ateis tamb´em existem os n˜ao-vol´ateis, que apesar de n˜ao serem t˜ao comuns, podem ser interessantes em aplica¸c˜oes onde a reprograma¸c˜ao n˜ao seja necess´aria.
3.2.1
Blocos l´
ogicos configur´
aveis
3.2 Funcionamento interno 43
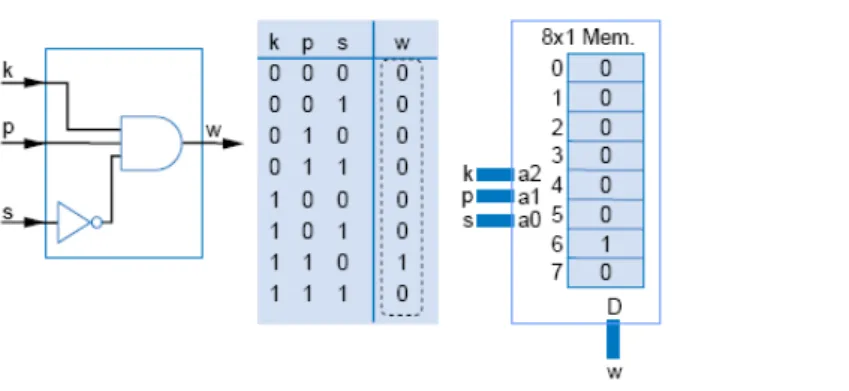
Figura 3.3: Implementa¸c˜ao de uma fun¸c˜ao l´ogica combinacional de 3 bits em umaLookup
Table com oito posi¸c˜oes de mem´oria: fun¸c˜ao l´ogica (esquerda), tabela da verdade (centro) e mapeamento em lookup table (direita)
As lookup tables s˜ao blocos constitu´ıdos por c´elulas de mem´oria que s˜ao utili-zados para implementar qualquer fun¸c˜ao l´ogica combinacional. Isso ´e poss´ıvel atrav´es do mapeamento dos resultados poss´ıveis de uma fun¸c˜ao l´ogica combinacional em cada c´elula de mem´oria em uma determinada posi¸cao. Na figura 3.3 temos a implementa¸c˜ao de uma simples fun¸c˜ao l´ogica combinacional de 3 bits em uma lookup table com 8 posi¸c˜oes de mem´oria. O n´umero de posi¸c˜oes de mem´oria necess´arias para a implementa¸c˜ao de uma fun¸c˜ao l´ogica combinacional ´e obtido atrav´es do seguinte c´alculo: 2n, onde n ´e o n´umero de bits de entrada da fun¸c˜ao l´ogica. As posi¸c˜oes de mem´oria nas quais s˜ao mapeados os re-sultados de uma fun¸c˜ao l´ogica s˜ao geralmente dadas pelo valor em decimal da combina¸c˜ao de bits de entrada que geram aquele resultado.
No caso de fun¸c˜oes l´ogicas combinacionais de at´e 3 bits as lookup tables fun-cionam muito bem. A desvantagem dessa abordagem aparece quando o n´umero de bits de entrada cresce, j´a que o n´umero de posi¸c˜oes de mem´oria necess´arios para armazenar os resultados da fun¸c˜ao l´ogica cresce em uma escala exponencial em rela¸c˜ao ao n´unero de bits de entrada. Para verificar essa desvantagem, basta utilizarmos o c´alculo das posi¸c˜oes de mem´oria descrito acima. Dessa forma, podemos perceber que para implementar uma fun¸c˜ao l´ogica de 8 entradas (relativamente simples) utilizando uma abordagem de lookup tables, seria necess´ario um total de 256 posi¸c˜oes de mem´oria. Para a implementa¸c˜ao de uma fun¸c˜ao l´ogica com 16 bits de entrada, seriam necess´arias 65.536 posi¸c˜oes de mem´oria.
3.2 Funcionamento interno 44
Figura 3.4: Implementa¸c˜ao de uma fun¸c˜ao l´ogica combinacional de 5 bits de entrada utilizando duas lookup tables de 8 posi¸c˜oes de mem´oria cada
Figura 3.5: Dois CLBs (lookup tables, flip-flops e multiplexadores) interconectados por uma switch matrix(implementada atrav´es de multiplexadores)
facilitar a visualiza¸c˜ao, o circuito foi dividido em duas partes, onde a primeira representa o circuito que resulta no bit x e a segunda representa o circuito que resulta no bit w. Em FPGAs recentes a concatena¸c˜ao de lookup tables ´e realizada atrav´es de interconex˜oes program´aveis, ou seja, uma ou mais switch matrixes, assim como a interconex˜ao de CLBs com o objetivo de alcan¸car o m´aximo em capacidade de reprograma¸c˜ao.
As lookup tables somente implementam l´ogica combinacional. Portanto nas sa´ıdas de cada bloco de mem´oria existem flip-flops, que s˜ao respons´aveis por implementar fun¸c˜oes l´ogicas sequenciais. A sele¸c˜ao entre as sa´ıdas dos flip-flops ou diretamente das lookup tables ´e feita atrav´es de multiplexadores.