Additional Fault Detection Test Case Prioritization
Texto
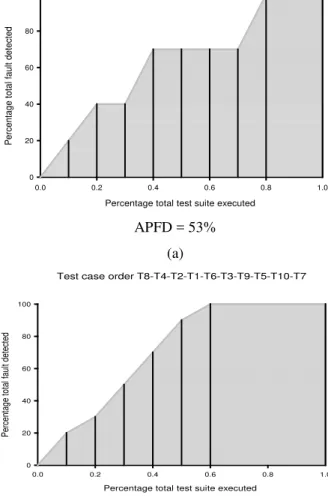
Imagem
![Table 1 shows test cost and fault severity of test cases and faults respectively [11]](https://thumb-eu.123doks.com/thumbv2/123dok_br/17205796.243091/4.918.469.855.140.432/table-shows-test-fault-severity-cases-faults-respectively.webp)
Documentos relacionados
dos impactos ambientais com restrições leves 1.5- Percepção dos Pressupostos Ecológicos com restrições leves 1.6- Valoração dos Recursos Humanos com restrições leves NIVELII
Ora, segundo o Filósofo, esta virtude não se confunde com as virtudes éticas, pois, se a estas últimas cabe a consideração dos fins verdadeiros, à sabedoria cumpre discernir os
Porcentagem de injúrias de Costalimaita ferruginea Coleoptera: Chrysomelidae nas regiões apical, mediana e basal de clones TP 361, VE 41, VCC 865, I1 44 de Eucalyptus urograndis
Segundo a Comissão Europeia existem atualmente na Europa mais de 12 mil espécies exóticas, mas apenas 15% são invasoras. Os prejuízos económicos causados pelas espécies
Figure 3.1 – Differences in the distribution of woodpigeon abundance (number of pigeons / 10 minutes of observation) on Terceira island, considering each dataset of abundance (All
30 Uma pesquisa também realizada em uma cidade no interior do Rio Grande do Sul, com escolares entre 9 e 11 anos de idade, revela que não foram observadas
Tipos valor não podem ser usados como classes base para criar novos tipos por- que estes são implementados usando classes chamadas “seladas”, a partir das quais não é
In the second part, a series of techniques of image processing were joined into a procedure that, upon the input of the disparity map obtained by the stereo
