Por
Íris Daniela Gouveia Pereira Pinto Carvalho
Orientador:Doutor Pedro Miguel Mestre Alves da Silva
Co-orientador: Doutor Carlos Manuel José Alves Serôdio
Dissertação submetida à
UNIVERSIDADE DE TRÁS-OS-MONTES E ALTO DOURO para obtenção do grau de
MESTRE
em Engenharia Electrotécnica e de Computadores, de acordo com o disposto no DR – I série–A, Decreto-Lei n. 74/2006 de 24 de Março e no
Regulamento de Estudos Pós-Graduados da UTAD DR, 2. série – Regulamento n. 470/2011
Pedro Miguel Mestre Alves da Silva
Professor Auxiliar do Departamento de Engenharias da Escola de Ciência e Tecnologia da Universidade de Trás-os-Montes e Alto Douro
Carlos Manuel José Alves Serôdio
Professor Associado com Agregação do Departamento de Engenharias da Escola de Ciência e Tecnologia da Universidade de Trás-os-Montes e Alto Douro
Quero agradecer às pessoas que de alguma forma me ajudaram a tornar possível a realização da presente dissertação, em especial:
Ao Professor Doutor Pedro Miguel Mestre Alves da Silva e ao Professor Dou-tor Carlos Manuel José Alves Serôdio, orientador e co-orientador deste trabalho respetivamente, pela constante ajuda, motivação, imprescindíveis orientações e ideias inovadoras.
Aos meus colegas e amigos do curso de Engenharia Electrotécnica e de Compu-tadores da Universidade de Trás-os-Montes e Alto Douro pela sua amizade ao longo do meu percurso académico, mas também pela força e sugestões para este trabalho.
Aos meus pais, à minha avó e ao André por todo o apoio incondicional, encora-jamento, carinho e paciência durante a elaboração desta dissertação.
A todos, um sincero obrigado!
para o preenchimento dos requisitos parciais para obtenção do grau de Mestre em Engenharia Electrotécnica e de Computadores
Resumo —A utilização de tecnologia Java, através da implementação e aplicação de máquinas virtuais, é muito vasta pois apresenta uma grande vantagem. Eli-mina a necessidade de programar individualmente dispositivos computacionais distintos, com especificações diferentes, tornando compatíveis e homogéneos sis-temas que integram dispositivos diferentes como computadores, impressoras e telemóveis. Também as redes de sensores e atuadores sofisticadas, usadas em agricultura de precisão por exemplo, podem beneficiar da utilização de máqui-nas virtuais. Neste tipo de sistemas, a implementação de máquimáqui-nas virtuais está restrita, por norma, ao uso de microcontroladores tradicionais com reduzidas ca-pacidades de processamento e memória. A máquina virtual está, portanto, sujeita a uma arquitetura fixa.
Uma alternativa a este tipo de implementação de redes de sensores consiste subs-tituir o microcontrolador por um dispositivo semicondutor programável que per-mite desenvolver hardware, denominado por FPGA (Field Programmable Gate Ar-ray). Para além de possuir mais memória e uma maior capacidade de processa-mento, é mais versátil do que um microcontrolador. É de esperar que a FPGA, ao permitir criar hardware à medida das necessidades do programador, leve a uma implementação da máquina virtual de acordo com os requisitos e funcionalida-des pretendidas. A arquitetura do hardware é criada de propósito para a máquina virtual.
Na presente dissertação é desenvolvida uma máquina virtual Java (JVM - Java Virtual Machine) numa FGPA para avaliar se esta pode constituir uma boa alter-nativa à utilização de microcontroladores em algumas aplicações.
in partial fulfillment of the requirements for the degree of Master of Science in Electrical and Computers Engineering
Abstract — The use of Java technology, through the implementation and appli-cation of virtual machines, is very wide because it presents a great advantage. It eliminates the need for programming individually distinct computing devices, with different specifications, resulting on compatible and homogeneous systems that integrate different devices such as computers, printers and mobile phones. Also sophisticated networks of sensors and actuators, used in precision agricul-ture, may benefit from the use of virtual machines. In this kind of systems, the implementation of virtual machines is usually restricted to the use of traditional microcontrollers with limited processing capabilities and memory range. Thus, the virtual machine is subjected to a fixed architecture.
An alternative to this kind of implementation for sensors networks consists on replacing the microcontroller by a programmable semiconductor device, which allows the development of hardware, called FPGA (Field Programmable Gate Array). Besides the fact that this device has more memory and a greater proces-sing capability, it is also more versatile than a microcontroller. It is expected that the FPGA, since it allows to create customized hardware, leads to a virtual ma-chine implementation suited to the requirements and needed functionalities. The hardware architecture is built for the virtual machine.
In this dissertation, it is developed a Java Virtual Machine (JVM) using a FPGA to evaluate whether this may be a good alternative to the use of microcontrollers in some applications.
1 Introdução 1
1.1 Motivação e objetivos . . . 2
1.2 Organização da dissertação . . . 3
2 Sistemas Distribuídos 5 2.1 Evolução dos sistemas computacionais . . . 5
2.2 Da computação local aos sistemas distribuídos . . . 8
2.2.1 Objetivos dos sistemas distribuídos . . . 9
2.3 Soluções para a heterogeneidade dos sistemas distribuídos . . . 10
2.3.1 Middleware . . . 12
2.3.2 Máquinas Virtuais . . . 14
3 A Máquina Virtual Java 17 3.1 Tecnologia Java . . . 17
3.1.1 Linguagem de programação Java . . . 18
3.1.2 Plataforma Java . . . 18
3.2 Vantagens de usar Java . . . 20
3.3 Máquina Virtual Java . . . 21
3.3.1 Ficheiro class . . . 22
3.3.1.1 magic . . . . 23 xiii
3.3.1.2 minor_versione major_version . . . 23 3.3.1.3 constant_pool_counte constant_pool[] . 23 3.3.1.4 access_flags . . . . 28 3.3.1.5 this_classe super_class . . . . 28 3.3.1.6 interfaces_counte interfaces[] . . . 29 3.3.1.7 fields_counte fields[] . . . 29 3.3.1.8 methods_counte methods[] . . . 31 3.3.1.9 attributes_counte attributes[] . . . . 32
3.3.2 Áreas de dados em execução . . . 40
3.3.2.1 pcregister . . . 40
3.3.2.2 Stacks da máquina virtual Java . . . 40
3.3.2.3 Heap . . . 41
3.3.2.4 Method area . . . 41
3.3.2.5 Runtime constant pool . . . 42
3.3.2.6 Stacks de métodos nativos . . . 42
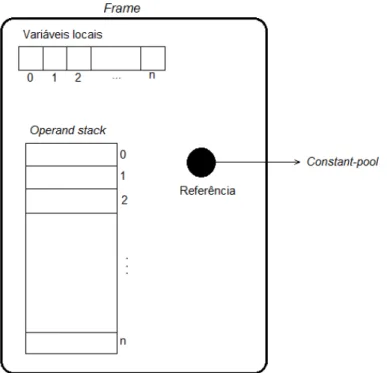
3.3.3 Frames . . . 42
3.3.3.1 Array de variáveis locais . . . 43
3.3.3.2 Operand stack . . . 44
3.3.3.3 Dynamic linking . . . 44
3.3.3.4 Invocação normal de métodos . . . 44
3.3.3.5 Invocação abrupta de métodos . . . 45
3.3.4 Conjunto de instruções . . . 45
3.3.4.1 Formato das instruções . . . 46
3.3.4.2 Tipos de valores e a máquina virtual Java . . . 46
3.3.4.3 Operações efetuadas . . . 47
3.3.5 Loading, Linking e Initializing . . . 48
3.3.5.1 Start-up da máquina virtual Java . . . 49
4 Field-Programmable Gate Array 51
4.1 Linguagens de descrição de hardware . . . 53
4.1.1 VHDL . . . 55
4.1.2 Verilog . . . 56
4.1.3 Comparação entre VHDL e Verilog . . . 56
4.2 Ambiente de desenvolvimento Xilinx . . . 57
4.2.1 Definição do sistema a implementar . . . 58
4.2.2 Synthesis . . . 58
4.2.3 Implement Design . . . 59
4.2.4 Generate Programming File . . . 59
4.2.5 Programação da FPGA . . . 59
4.2.6 Simulação . . . 60
4.3 Caracterização das FPGA Spartan-3E e Spartan-3A . . . 60
4.3.1 Spartan-3E . . . 61
4.3.1.1 Configuração da FPGA e da Platforma Flash ROM 63 4.3.2 Spartan-3A . . . 65
4.3.2.1 Configuração . . . 66
4.4 Comparação entre FPGA, ASIC e CPLD . . . 70
4.4.1 FPGA e ASIC . . . 70
4.4.2 FPGA e CPLD . . . 71
5 Conceção, Implementação e Testes 73 5.1 Estudo inicial e módulo de pré-processamento . . . 74
5.1.1 Pré-processamento . . . 78
5.2 Testes genéricos com FPGA e kit de desenvolvimento . . . 82
5.2.1 Módulo EPP . . . 82
5.2.3 Armazenamento de dados . . . 86 5.3 Implementação da máquina virtual Java em hardware . . . 89 5.3.1 Organização e identificação de dados através de simulações 90 5.3.2 Construção da frame e simulação de execução de instruções 93 5.3.3 Implementação em hardware . . . 97 5.3.4 Avaliação da velocidade de execução da máquina virtual
Java em FPGA . . . 102
6 Conclusões e trabalho futuro 105
A A.1 - Opcodes 109
2.1 O primeiro transístor . . . 7
2.2 Modelo da localização das camadas de middleware num sistema distribuído . . . 13
2.3 Organização das máquinas virtuais num computador . . . 15
3.1 Estrutura interna de uma frame . . . 43
3.2 Formato de um opcode . . . 46
4.1 Estrutura interna genérica de uma FPGA . . . 53
4.2 Código VDHL para implementação de uma porta OR . . . 56
4.3 Código Verilog para implementação de uma porta OR . . . 57
4.4 Estrutura interna da Spartan-3E . . . 62
4.5 Diagrama de blocos da Nexys2 . . . 63
4.6 Adept em ambiente Windows . . . 64
4.7 Adept em ambiente Linux . . . 64
4.8 Placa Nexys2 depois da FPGA ser programada . . . 65
4.9 Estrutura interna da Spartan-3A . . . 66
4.10 Localização da porta JTAG/USB e das memórias não-voláteis . . . 67
4.11 Configuração dos jumpers . . . 68
4.12 Escolha do modo de configuração no iMPACT . . . 68 xvii
4.13 Escolha de um ficheiro para a SPI Flash no iMPACT . . . 69
4.14 Starter Kit depois da FPGA ter sido programada . . . 69
5.1 Ficheiro de teste Teste.java . . . 74
5.2 Parte do ficheiro class resultante . . . 75
5.3 Bytecodes presentes no ficheiro Teste.class . . . 75
5.4 Localização dos opcodes no ficheiro class . . . 77
5.5 Output da leitura do ficheiro class . . . 78
5.6 Exemplo de um message digest . . . 79
5.7 Ficheiro de teste JavaApplication2.java . . . 81
5.8 Ficheiro file1.class resultante do pré-processamento . . . 81
5.9 Ficheiro file2.class resultante do pré-processamento . . . 81
5.10 Ficheiro string.txt resultante do pré-processamento . . . 82
5.11 Máquinas de estados para a EPP . . . 83
5.12 Código Verilog para a escrita de endereços . . . 84
5.13 Demonstração do funcionamento da EPP . . . 84
5.14 Receção de dados do ficheiro class na FPGA, via porta série . . . 86
5.15 Criação de uma Distributed RAM com o Core Generator . . . 88
5.16 Criação de um clock com o Core Generator . . . 88
5.17 Transmissão dados via porta série . . . 90
5.18 Configuração da constant pool . . . 91
5.19 Estrutura geral dos dados da máquina virtual Java . . . 92
5.20 Simulação de parte da constant_pool . . . 93
5.21 Simulação de parte da tabela dos métodos . . . 94
5.22 Estrutura da frame . . . 95
5.23 Identificação do pc register . . . 95
5.25 Print do resultado e respetivo método . . . 96
5.26 Bytecodes do ficheiro JavaApplication2.class . . . 97
5.27 Output da execução das instruções do ficheiro JavaApplication2.class 97 5.28 Ficheiro de teste JavaApplication3.java . . . 98
5.29 Bytecodes presentes no ficheiro JavaApplication3.class . . . 98
5.30 Resultado da simulação para o ficheiro JavaApplication3.class . . . 98
5.31 Interface de dados do ecrã LCD . . . 100
5.32 Sinais da interface do LCD . . . 100
5.33 Conjunto de comandos do LCD . . . 101
5.34 Debug sobre os bytecodes no LCD . . . 101
5.35 Invocação dos métodos setBit() e resetBit() . . . 102
5.36 Execução dos métodos setBit() e resetBit() . . . 102
5.37 Ficheiro de teste para avaliação da velocidade de execução . . . 103
5.38 Bytecodes correspondentes aos métodos estáticos e à operação de soma . . . 103
A.1 Opcodes organizados por tipos de dados . . . 109
B.1 Escrita de endereços . . . 111
B.2 Escrita de dados . . . 111
3.1 Tipos de constantes presentes na constant_pool. . . 24 3.2 Interpretação das access_flags presentes no ficheiro class. . . 28 3.3 Tipos de campos e correspondentes entradas da constant_pool. 34 5.1 Resultados obtidos para a execução da máquina virtual Java. . . 104
Sigla Expansão
API Application Programming Interface
ASCC Automatic Sequence Controlled Calculator
ASCII American Standard Code for Information Interchange ASIC Application Specific Integrated Circuits
BPI Byte Peripheral Interface
CLB Configurable Logic Block
CPLD Complex Programmable Logic Device
DCM Digital Clock Manager
DDR Double Data-Rate
DSP Digital Signal Processing
ENIAC Electronic Numeric Integrator And Calculator
FPD Field-Programmable Device
FPGA Field-Programmable Gate Array
Gbps Gigabits per second
IBM International Business Machines
Java EE Java Enterprise Edition Java ME Java Micro Edition Java SE Java Standard Edition
IDL Interface Definition Language
I/O Input/Output (Entrada/Saída)
IOB Input/Output Block
IrDA Infrared Data Association
JRE Java Runtime Environment
Kbps Kilobits per second
Sigla Expansão
LAN Local Area Network
LUT Look-Up Table
NCD Native Circuit Description
NGC Native Generic Circuit
NGD Native Generic Database
OTP One-Time Programmable
PDA Personal Digital Assistant
PLA Programmable Logic Array
PMOD Peripheral Module
PROM Programmable Read-Only Memory
RAM Random Access Memory
ROM Read Only Memory
SDK Software Development KIT
SPI Serial Peripheral Interface
SRAM Static Random Access Memory
UCF User Constraint File
UTF-8 Unicode Transformation Format de 8 bits
VHDL VHSIC Hardware Description Language
VHSIC Very-High-Speed Integrated Circuit VLSI Very Large Scale Integration
Introdução
É difícil dissociar a vida quotidiana no século XXI de toda a tecnologia que nos rodeia. Esta é utilizada constantemente, de tal forma que por vezes nem nos apercebemos dela. A tecnologia computacional está presente em todo o lado, a todo o momento, é manipulada pelas pessoas, acabando por estar associada ao seu dia-a-dia. A evolução dos sistemas computacionais ao longo das últimas dé-cadas permitiu que isto ocorra pois temos dispositivos cada vez mais pequenos, fáceis de usar, eficientes, baratos, rápidos e seguros. Tal aconteceu e continua a acontecer porque, através da investigação na área da ciência da computação, surgiram sofisticados métodos para gerir recursos computacionais, possibilitar a comunicação, escrever aplicações, criar chips e bases de dados [1].
Tomando como exemplo os computadores, estes evoluíram de sistemas comple-xos no que diz respeito à interação com os utilizadores, com grandes dimensões e capacidade de processar dados muito aquém dos padrões atuais, para máquinas com microprocessadores que aumentaram imenso a sua capacidade de processa-mento e a sua rapidez, além de reduzirem muito o tamanho destes dispositivos [2]. Hoje em dia encontramos computadores que cabem na palma da mão sob a forma de smartphones por exemplo. No seguimento da inovação a nível de hard-ware, encontramos hoje em dia dispositivos semicondutores com mais funcionali-dades que um microcontrolador. As FPGA são dispositivos semicondutores que permitem criar hardware personalizado, podendo ser programadas múltiplas ve-zes de acordo com os requisitos que o utilizador deseja. Não estão restritas a uma
pré-determinada função de hardware [3]. As FPGA permitem aliar o desempenho do hardware à flexibilidade do software.
Da mesma forma que as máquinas evoluíram, o mesmo verificou-se nos sistemas computacionais, nomeadamente na sua forma, devido ao facto de serem consti-tuídos pelas máquinas que estão em constante evolução, e no seu funcionamento. Antes existiam apenas sistemas de computação local, mas devido aos avanços dos protocolos de transporte, entre outros, chegamos à era dos sistemas distribuídos. O aparecimento da Internet possibilitou que este tipo de sistemas se tornasse glo-bal. Hoje em dia um dispositivo computacional tem que ser capaz de comunicar com outros dispositivos, criando sistemas computacionais complexos pela diver-sidade de plataformas que englobam. Considerando que cada uma delas tem um hardware específico e a nível de software é desenvolvido com uma linguagem de programação diferente, produzindo código binário executável diferente e tam-bém é distinta na forma como lida com os dados, seria de esperar que a comuni-cação entre diferentes plataformas computacionais não fosse possível por serem incompatíveis. Da necessidade de tornar estas plataformas compatíveis entre si, foram desenvolvidos mecanismos que resolvem os problemas de incompatibili-dade entre dispositivos e de heterogeneiincompatibili-dade dos sistemas distribuídos, como é o caso das máquinas virtuais e tecnologias de middleware [4].
1.1
Motivação e objetivos
Assim como as máquinas virtuais e tecnologias de middleware são aplicadas a sis-temas distribuídos mais complexos, também são uma solução para sissis-temas mais simples como redes de sensores, que possuem na sua constituição microcontro-ladores com especificidades diferentes, tornando estas redes heterogéneas. Es-tes sistemas de sensores podem ser encontrados na agricultura, nomeadamente numa área denominada por agricultura de precisão. Por definição, este conceito está normalmente associado à utilização de equipamento de alta tecnologia, seja hardware ou software, para avaliar ou monitorizar as condições de uma determi-nada parcela de terreno, aplicando depois os diversos factores de produção em conformidade [5]. Na Universidade de Trás-os-Montes e Alto Douro tem-se apos-tado nesta área de investigação, havendo muitas publicações sobre este tema de
investigadores desta instituição. Várias dessas publicações referem-se à imple-mentação de uma máquina virtual Java especializada em aquisição de dados e tarefas de atuação em redes de sensores e atuadores, ou seja, sistemas com pou-cos recursos tendo por base microcontroladores de 8 bits [4]. A utilização de tecnologia Java neste projeto está relacionado com a sua capacidade de ser um re-curso que permite desenvolver aplicações que são independentes da tecnologia alvo.
Esta dissertação tem como objetivo o desenvolvimento de uma máquina virtual Java em FPGA para avaliar se este dispositivo pode constituir uma alternativa viável à utilização de microcontroladores para implementação de uma máquina virtual Java. Numa primeira fase de testes gerais com FPGA foi utilizada a FPGA Spartan-3E, que está integrada na placa de desenvolvimento Nexys2 da Digilent. Posteriormente, foi também usado o Spartan-3A Starter Kit, que inclui um ecrã LCD que permite acompanhar mais facilmente a execução da máquina virtual Java implementada e que pode atuar como meio para receber resultados de ins-truções da máquina virtual Java.
1.2
Organização da dissertação
A presente dissertação está organizada em seis capítulos.
Este Capítulo engloba uma introdução ao tema e a explicação da motivação e objetivos do trabalho.
No Capítulo 2 apresenta-se o estado de arte relativo aos temas das camadas de middleware e máquinas virtuais.
No Capítulo 3, é realizada uma análise à tecnologia Java que engloba a máquina virtual Java, sendo abordada a The Java Virtual Machine Specification, Second Edition que serve de base à implementação deste tipo de máquinas virtuais.
No Capítulo 4 é analisada a FPGA de um modo geral mas também as placas de desenvolvimento, com as respetivas FPGA, utilizadas na elaboração da presente dissertação, que constituem o meio de implementação da máquina virtual Java.
A conceção do projeto, a implementação da máquina virtual Java, os testes e res-petivos resultados estão contidos no Capítulo 5, assim como as conclusões e con-siderações sobre o trabalho futuro.
Sistemas Distribuídos
Este capítulo tem como objetivo descrever a evolução dos sistemas computacio-nais, desde as suas origens até aos sistemas distribuídos de hoje em dia. Dá-se relevo às questões e problemas inerentes a este tipo de sistemas e respetivas so-luções, como as máquinas virtuais e camadas de middleware.
2.1
Evolução dos sistemas computacionais
Vivemos no tempo da revolução do computador e na era da informação. O desen-volvimento do computador, como resposta às necessidades militares criadas pela Segunda Guerra Mundial, causou profundas mudanças na forma como são con-duzidos os negócios, como é feita a investigação científica e como são passados os momentos de lazer. No entanto, a história da computação nasceu muito antes da época da Segunda Grande Guerra, nos anos 40 do século passado. Desde os primórdios da civilização que a humanidade colmatou a sua necessidade de pro-cessar informação e realizar cálculos através da tecnologia, com inovações que, à luz da época atual podem parecer primitivas e rudimentares, mas que eram avançadas no contexto histórico, intelectual e social em que se inseriram [6]. Uma dessas invenções tem o nome de abaco, que se presume ter sido criado na zona do Médio Oriente antes do auge de civilizações como a Romana e a Grega, sendo aperfeiçoado por estas posteriormente. Esta calculadora primitiva consistia num aparelho com várias colunas nas quais eram colocados seixos. Cada coluna repre-sentava uma potência de 10 [7]. O abaco era utilizado por estas civilizações para
auxílio na contagem de mercadorias e realização de cálculos mais complicados. No caso dos Romanos, até foi desenvolvido um sistema numérico singular em que letras representam algarismos, para além de outras civilizações que também desenvolveram os seus próprios mecanismos e sistemas numéricos [6].
Com a evolução humana cresceu a complexidade de problemas, como por exem-plo na Matemática, e a necessidade de criar dispositivos que ajudassem a resolvê--los. No século XIX, Charles Babbage descreveu uma máquina analítica a vapor, que originou o conceito de computador programável. Não foi construída durante o tempo de vida de Babbage, mas cientistas atuais afirmam que teria funcionado. Estava desenhada para ser programada através de cartões perfurados e teria apli-cado um sistema numérico de base decimal, com memória para guardar 1000 nú-meros até 50 dígitos [6] [8]. Em 1931, Vannevar Bush e um grupo de estudantes do MIT (Massachusetts Institute of Technology) elaboraram uma calculadora chamada Bush Diferential Analizer capaz de resolver equações diferenciais. Este computa-dor ocupava uma sala inteira e era puramente mecânico [8]. É considerado a base para a criação do famoso computador ENIAC, o primeiro computador a válvu-las construído durante a Segunda Guerra Mundial, por John Mauchley e John Presper Eckert para o Exército Norte-Americano, para cálculo de trajetórias de bombas [9].
Paralelamente em 1944, a IBM construiu a sua primeira mainframe1, a ASCC, que era uma máquina eletromecânica, e também criou o computador RAMAC 305 em 1956, que utilizava discos de alumínio cobertos com óxido de ferro para ar-mazenar informação. Esta era codificada magneticamente, permitindo o acesso aleatório aos dados armazenados nos discos. Foi este o primeiro passo para o de-senvolvimento da atual memória RAM, que é o núcleo das memórias dos com-putadores atuais [8] [10]. Enquanto algumas empresas fabricavam mainframes, outras apostavam em computadores mais pequenos, baratos e úteis para a po-pulação em geral. A invenção do transístor em 1948, por John Bardeen, Walter Brattain e William Shockley nos laboratórios Bell em Nova Jérsia, permitiu que o computador pessoal se tornasse uma realidade [11]. No intervalo de tempo de uma década, os transístores evoluíram da sua forma primitiva, como se pode 1Segundo a IBM, uma mainframe é um computador ao qual outros computadores se podem
ligar para usufruir dos recursos que esta fornece. O termo refere-se apenas a hardware, nomeada-mente a armazenamento, circuitos de execução e unidades periféricas.
verificar na figura 2.1, e tornaram obsoletas por completo as válvulas nos compu-tadores, mas a inovação envolvendo transístores ainda evoluiria mais.
Figura 2.1: O primeiro transístor [11].
A partir da junção de vários transístores numa placa de silício nasceu o circuito integrado, que aumentou a capacidade de processamento dos computadores, di-minuiu o seu tamanho e tornou-os mais baratos. Nos anos 80, com o surgimento da tecnologia VLSI foi possível agrupar milhares de transístores numa pastilha de silício, criando o atual chip. A velocidade de processamento dos computado-res aumentou consideravelmente e o tamanho diminuiu ainda mais, assim como o preço, permitindo que as pessoas adquirissem estes dispositivos. A era do com-putador pessoal tornou-se, assim, numa realidade [9].
A evolução continua mais propriamente a nível da forma como utilizamos os computadores, com o surgimento da computação distribuída [9]. No que diz respeito a novas arquiteturas, estão a ser desenvolvidas alternativas aos semicon-dutores, como a computação molecular e a computação quântica. A primeira foi proposta por Leonard Adleman e é baseada no ADN e biologia molecular, tendo sido já implementado um computador molecular capaz de identificar atividade cancerígena dentro de uma célula e libertar um medicamento para combater essa atividade [12]. No que diz respeito à computação quântica, esta surgiu quando, na década de 90 do século XX, os cientistas aperceberam-se que a física
quân-tica poderia ter aplicações extraordinárias na ciência computacional. No entanto, um computador quântico não se define apenas como uma máquina cujas ope-rações são manipuladas pela mecânica quântica, uma vez que esta governa o comportamento de todos os fenómenos físicos. Sendo assim, o mais comum dos computadores também opera segundo as leis da mecânica quântica mas não é considerado um computador quântico. Define-se, então, computador quântico como uma máquina cuja operação explora transformações especiais do seu es-tado interno. As leis da mecânica quântica permitem que estas transformações peculiares aconteçam dentro de condições cuidadosamente controladas [13]. A unidade de quantidade de dados de um computador quântico é o qubit, que é construído usando partículas com dois estados de spin [12].
2.2
Da computação local aos sistemas distribuídos
Antes da existência das redes de computadores, o computador estava associado ao conceito de computação local, com a utilização de uma mainframe, que se de-fine como um sistema centralizado com apenas uma máquina (computador), ou seja, este computador tem uma única plataforma de hardware, apenas um sistema operativo, um ambiente de execução, os seus periféricos e alguns terminais remo-tos. Este cenário mudou radicalmente com a criação das redes de computadores de alta velocidade, obtendo-se um grande avanço tecnológico. As LAN permitem que centenas de máquinas localizadas no mesmo edifício estejam ligadas entre si, de forma a que pequenas quantidades de informação possam ser transferidas en-tre as diferentes máquinas em apenas alguns segundos. Extrapolando para uma visão global, as WAN possibilitam a interligação de milhões de máquinas espa-lhadas pelo mundo com velocidades que variam desde os 64 Kbps até a alguns Gbps [2].
Houve, portanto, uma passagem do conceito de computação local para com-putação global, onde diferentes dispositivos são capazes de comunicar entre si, quer estejam lado a lado ou em continentes diferentes. Este novo paradigma denomina-se por sistema de computação distribuída. Por definição, um sistema distribuído é um conjunto de computadores independentes que se apresenta aos utilizadores como um único sistema coerente. Há dois aspetos importantes a
re-ter a partir desta afirmação, o facto de estes computadores serem autónomos e o facto dos utilizadores pensarem que só estão a lidar com um único sistema [2]. Seria espectável que tal não acontecesse uma vez que sistemas deste tipo englo-bam vários elementos computacionais espalhados ao longo da rede. Estes com-ponentes têm distintas plataformas de hardware, assim como diferentes sistemas operativos, protocolos de comunicação e implementações, ou seja, a tecnologia varia de máquina para máquina. Também ao nível de software existem diferenças entre os diferentes nós de um sistema distribuído, uma vez que cada nó pode ter aplicações implementadas em linguagens de programação distintas, produzindo assim códigos executáveis não compatíveis entre si [4]. Existe, portanto, uma heterogeneidade no seio dos sistemas distribuídos. Esta heterogeneidade pode ainda ser classificada como heterogeneidade de dados, se as plataformas de um sistema distribuído diferirem entre si no tipo de dados ou no formato usado para encapsular esses dados, ou uma heterogeneidade de comportamento, que é rela-tiva às diferenças entre os protocolos que os componentes usam para comunicar entre si [14].
2.2.1
Objetivos dos sistemas distribuídos
Os objetivos dos sistemas distribuídos são [2]:
- Tornar os recursos da rede disponíveis - deve ser fácil aos utilizadores o acesso aos recursos remotos e estes devem ser partilhados de forma eficiente e controlada;
- Transparência da rede - é importante esconder o facto de, nos sistemas dis-tribuídos, os processos e recursos estarem distribuídos fisicamente por vá-rias máquinas. Um sistema distribuído capaz de se apresentar como se fosse apenas um computador é denominado por sistema transparente;
- Grau de abertura - um sistema distribuído aberto é um sistema que ofe-rece serviços de acordo com as regras standard que descrevem a sintaxe e a semântica desses serviços. Nos sistemas distribuídos, os serviços são espe-cificados através de interfaces, descritas normalmente numa IDL;
- Escalabilidade - a conectividade mundial através da Internet tornou-se num acontecimento banal como enviar uma carta pelo correio. Neste aspeto, a escalabilidade torna-se num dos mais importantes objetivos a atingir pe-los programadores de sistemas distribuídos. Estes podem ser escaláveis ao nível do tamanho, geograficamente ou administrativamente;
- Evitar erros - apesar de se comportar como um único computador, um sis-tema distribuído possui falhas inerentes ao facto dos seus componentes es-tarem dispersos pela rede. Peter Deutsch, da Sun Microsystems, formulou sete falácias que são assumidas pelos programadores que desenvolvem este tipo de sistemas e que devem ser evitadas [2]:
1. A rede é confiável; 2. A rede é segura;
3. A sua topologia não muda; 4. A latência é zero;
5. A largura de banda é infinita; 6. O custo de transporte é zero; 7. Só existe um administrador; 8. A rede é homogénea.
A oitava falácia foi adicionada posteriormente por James Gosling, também da Sun Microsystems, uma vez que muitos programadores tinham tendên-cia para se iludirem com o facto da rede parecer homogénea quando, na realidade, não o é [15]. Analisando estas falácias, conclui-se que se relacio-nam com propriedades únicas aos sistemas distribuídos, pelo que no desen-volvimento de aplicações não distribuídas, estes problemas não se colocam [2].
2.3
Soluções para a heterogeneidade dos sistemas
dis-tribuídos
Partindo da definição de sistema distribuído apresentada, é fácil deduzir que os diferentes componentes, que constituem um sistema desta natureza, têm que
co-laborar entre si. A variedade de componentes pode ir desde mainframes de alta--performance até pequenos nós em redes de sensores, mas note-se que as carac-terísticas de cada elemento e a forma como estão interligados não são do conhe-cimento dos utilizadores ou programadores de alto nível, visto que o sistema se comporta de forma homogénea. Estas diferenças dentro de um sistema distri-buído e a sua própria organização interna estão escondidas, possibilitando aos utilizadores tirar partido do sistema de forma consistente e uniforme, indepen-dentemente de onde e quando as interações ocorrem. Tal como um sistema dis-tribuído deve ser apresentado como algo homogéneo aos utilizadores, também o deve ser aos programadores. Estes só se devem preocupar com programação de alto nível, sendo os detalhes de implementação escondidos [2].
De forma a suportar esta homogeneidade “aparente” dos sistemas distribuídos, é necessário conciliar as diferenças de implementação entre os vários nós de uma rede, ou seja, é preciso atingir uma interoperabilidade entre esses nós, que se de-fine como a capacidade pela qual implementações de dois ou mais componentes de uma rede, criados por diferentes fabricantes, podem co-existir e trabalhar jun-tos tendo apenas como base os seus respetivos serviços, especificados por um standard comum [14]. Uma das técnicas utilizadas para esconder a heterogenei-dade dos sistemas distribuídos é colocar uma camada de software abaixo das ca-madas de alto nível, onde utilizadores e programadores interagem, e acima das camadas dos sistemas operativos e comunicações. Esta camada de software é de-nominada por middleware. Outra forma de homogeneizar os sistemas distribuídos é através de virtualização. A utilização de máquinas virtuais permite aos progra-madores desenvolver aplicações independentemente da plataforma alvo [2]. Portanto, a chave para gerir a complexidade dos sistemas de computadores é a sua divisão em níveis de abstração separados por interfaces bem definidas. Es-ses níveis permitem que os detalhes de implementação de componentes de baixo nível de um sistema possam ser ignorados ou simplificados, facilitando assim o desenho de componentes de alto nível. Os detalhes do disco rígido de um com-putador, por exemplo, que é dividido em sectores, são abstraídos pelo sistema operativo, para que o disco se apresente à aplicação de alto nível como um con-junto de ficheiros de tamanho variável. Um programador de aplicações desta natureza pode criar, escrever e ler ficheiros sem ter conhecimento sobre a forma
como o disco está construído e organizado [16]. Da mesma forma, o programa-dor pode abstrair-se do sistema operativo alvo da sua aplicação, utilizando uma máquina virtual.
Ainda que a heterogeneidade dos sistemas distribuídos obrigue a trabalho extra por parte dos técnicos, que desenvolvem aplicações para que um sistema desta natureza se apresente homogéneo aos utilizadores, também pode ser encarada como uma vantagem. Um trabalho desenvolvido por [17] apresenta uma teoria que defende a heterogeneidade como sendo uma mais-valia para estes sistemas em determinadas situações, tendo em conta alguns factores prévios. É conside-rado que dependendo do contexto em que um sistema se insere, o seu ambiente e a carga de trabalhos, a heterogeneidade pode influenciar o desempenho de um sistema de forma positiva. Explora-se um exemplo simples para ilustrar a situa-ção: existem dois sistemas multi-core paralelos, o sistema homogéneo A com dez processadores de 1000 MHz e o sistema B, mais heterogéneo que o primeiro, com um processador de 5,5 GHz e nove de 500 MHz. Se a carga de trabalhos consistir em dez tarefas que levam 1 segundo a ser executadas num processador de 1 GHz, então o sistema A completa as tarefas em 1 segundo. No sistema B há a hipótese de colocar pelo menos uma das tarefas num processador mais lento ou todas no processador mais rápido; em qualquer um dos casos, o tempo de execução passa para o dobro do tempo do sistema A, ou seja, aproximadamente 2 segundos. En-tão, o sistema A tem um desempenho melhor apesar de ambos os sistemas terem a mesma capacidade. Mas se por outro lado, a carga de trabalhos for agregada numa tarefa única e maior, não estando dividida em várias, o sistema B consegue ser cinco vezes mais rápido que o A. Neste caso, a heterogeneidade de B foi uma vantagem para o desempenho do sistema. Este trabalho visou o estudo de uma framework teórica chamada Price of Heterogeneity, que mede o efeito do pior caso em cenários de heterogeneidade crescente.
2.3.1
Middleware
O middleware define-se como uma camada de software acima do sistema operativo, níveis de hardware e comunicações mas abaixo das camadas onde utilizadores e programadores operam, fornecendo a abstração necessária ao programador sobre a heterogeneidade inerente aos sistemas distribuídos e facilitando o
desenvolvi-mento de aplicações de alto nível. O middleware esconde os aspetos heterogéneos do hardware, da rede, do próprio sistema operativo e das linguagens de progra-mação, fornecendo transparência à rede. Esta tecnologia é muitas vezes referida, de forma informal, como a canalização dos sistemas distribuídos uma vez que liga diferentes partes de uma aplicação distribuída através de “túneis” e permite a passagem de dados por eles [18]. A figura 2.2 ilustra a localização genérica das camadas de middleware nos componentes de sistemas distribuídos.
Figura 2.2: Modelo da localização das camadas de middleware num sistema distri-buído [18].
Contudo, as abstrações fornecidas pelo middleware restringem a estrutura dos da-dos que os componentes de um sistema trocam e os protocolos de coordenação pelo qual eles comunicam entre si. Sendo assim, torna-se impossível que compo-nentes que tenham implementações de tecnologias de middleware diferentes con-sigam operar uns com os outros. Portanto, a interoperabilidade que é necessário atingir entre componentes, também o é para as camadas de middleware. Existem entidades de software intermediárias, designadas por mediators, que são usadas para realizar as traduções necessárias entre os dados trocados e para coordenar apropriadamente os protocolos dos componentes [14].
2.3.2
Máquinas Virtuais
As máquinas virtuais são máquinas de computação abstratas mas que têm o seu próprio conjunto de instruções e manipulam áreas de memória tal como uma máquina real [19]. Permitem que os programadores não precisem de ter conhe-cimento sobre as especificidades das plataformas a programar, desde que cada plataforma tenha uma implementação da máquina virtual. Assim, basta que o código seja escrito uma vez para que possa ser executado em todas as platafor-mas, o que constitui uma forma de esconder a heterogeneidade entre estas. A virtualização também permite que o programador desenvolva as suas aplica-ções utilizando uma linguagem de programação mais conveniente e adaptada aos humanos, ou linguagem de alto nível, e não em código de máquina, que é mais difícil de usar pois traduz-se em instruções muito básicas ou de baixo nível, para que o computador as execute diretamente [16]. Designa-se a linguagem de alto nível por L1 e a linguagem de máquina por L0, para melhor se perceber a in-teração entre elas. Portanto, é necessário que um programa escrito em L1 seja exe-cutado numa máquina que só executa L0, o que pode ser conseguido através de duas abordagens. A primeira consiste em substituir cada instrução do programa em L1 pelas instruções equivalentes em L0, o que resulta num novo programa constituído apenas por instruções em L0. Esta técnica denomina-se por tradução. Na segunda hipótese, escreve-se um programa em L0 que aceite como dados de entrada programas escritos em L1, examina-se uma instrução de L1 de cada vez e executa-se a sequência de instruções em L0 equivalente a essa instrução direta-mente. Chama-se interpretação a esta abordagem, sendo o programa escrito em L0 denominado por interpretador. Ambas as abordagens são semelhantes uma vez que o computador executa instruções em L1 executando as instruções equi-valentes em L0. A diferença entre elas é o facto de na tradução ser criado um novo programa que é executado pelo computador, sendo o primeiro descartado. Na interpretação, assim que uma instrução do programa em L1 é descodificada, é executada imediatamente, não existindo a criação de um novo programa. As duas abordagens são habitualmente empregues em conjunto [9].
Estes conceitos de tradução e interpretação são substituídos por um termo mais simples, que consiste em imaginar a existência de um computador hipotético ou uma máquina virtual M1 cujo código de máquina correspondente seja L1. Da
mesma forma se pode corresponder L0 a uma máquina virtual M0, que neste caso é a máquina real, sendo L0 a linguagem de máquina do dispositivo. No en-tanto, se a linguagem L1 continuar a ser mais adaptada às máquinas do que aos humanos, a solução é criar mais uma linguagem L2, cujo conjunto de instruções seja mais conveniente ao lado humano, correspondente a uma máquina virtual M2. Então, o programa inicial será escrito em L2, de alto nível, que é traduzido ou interpretado por L1, que por sua vez é manipulado por L0, de baixo nível, que resulta na execução do código diretamente na máquina real. Esta situação pode ser alargada hipoteticamente até à criação de uma linguagem Ln, com a respec-tiva máquina virtual Mn, criando uma série de camadas ou níveis, em que cada linguagem usa a anterior como a base para a sua implementação. A linguagem mais em baixo é a mais simples e a do topo é a mais sofisticada [9]. A figura 2.3 ilustra uma situação que se pode encontrar num computador, com a existência de várias máquinas virtuais. Desta forma, a pessoa que escreve programas para o nível n, ou seja, para a máquina virtual n, não necessita de saber como são os níveis inferiores.
Figura 2.3: Organização das máquinas virtuais num computador [9].
A estrutura da máquina irá assegurar que os programas em Ln são de alguma forma executados. Mas se o programador quiser desenvolver uma nova máquina virtual terá que estudar as camadas inferiores para poder desenvolver uma
má-quina cujos programas escritos na linguagem correspondente possam ser tradu-zidos ou interpretados pelas máquinas virtuais inferiores [9]. É de referir que, embora se tenha usado o computador como dispositivo base para ilustrar a exis-tência das máquinas virtuais, estas podem ser encontradas em diversos dispositi-vos, como telemóveis, impressoras, etc, o que vai de encontro ao seu propósito no âmbito dos sistemas distribuídos: tornar homogéneas as diferentes plataformas que os constituem.
A Máquina Virtual Java
Neste capítulo aborda-se uma tecnologia indispensável no seio dos sistemas dis-tribuídos, a tecnologia Java. É também analisada um das peças fundamentais que serve de base a esta dissertação, a máquina virtual Java.
3.1
Tecnologia Java
O Java é uma tecnologia (linguagem de programação e plataforma de computa-ção) lançada pela primeira vez pela Sun Microsystems, em 1995. Está presente em mais de 850 milhões de computadores pessoais e em milhões de dispositivos em todo o mundo, incluindo computadores, telemóveis e aparelhos de televisão [20]. A tecnologia Java permite que sistemas construídos com plataformas de compu-tação diferentes atuem como uma entidade homogénea, onde todos os elementos são compatíveis entre si, não só ao nível do código executado como também na forma como comunicam, armazenam e gerem os dados [4].
Existe, portanto uma distinção entre linguagem Java e plataforma Java. A lingua-gem de programação Java é utilizada para desenvolver aplicações Java como ap-plets, servlets e componentes JavaBeans. A plataforma de computação Java define-se como um conjunto pré-definido de clasdefine-ses Java que existe em qualquer insta-lação Java, estando estas classes disponíveis para uso por parte dos programas escritos na referida linguagem de programação. Esta plataforma engloba um am-biente Java chamado JRE, e pode ser aumentada com extensões standard opcionais [21].
3.1.1
Linguagem de programação Java
É uma linguagem orientada a objetos que tem uma sintaxe semelhante às lingua-gens C e C++. Os criadores da linguagem Java esforçaram-se para que esta fosse uma linguagem poderosa, mas ao mesmo tempo tentaram evitar a complexidade presente em outras linguagens orientadas a objetos como C++, bem como ten-taram eliminar aspetos que tornavam as outras linguagens confusas e inseguras [19]. Por ser simples, os programadores podem escrever código robusto, dimi-nuindo as dificuldades de análise, optimização e transformação dos programas [22]. É eficiente e leve, porque é uma linguagem que é compilada para bytecodes, o que a torna mais rápida do que as linguagens puramente interpretadas [23]. Sendo uma linguagem orientada a objetos pura, até o mais pequeno bloco de código constitui uma classe, o que resulta num ambiente de programação bem definido e estruturado no qual todos os conceitos e operações estão mapeados em classes e em transações entre elas. Isto constitui uma vantagem para o desen-volvimento de sistemas em geral, mas beneficia especialmente quem desenvolve sistemas distribuídos. Tanto uma instância de uma classe como um objeto podem ser vistos como um agente computacional. O seu nível de sofisticação como um agente autónomo é determinado pela complexidade dos seus métodos e repre-sentações de dados, assim como também pelo seu papel dentro do modelo que define o sistema distribuído em que se insere. Um sistema distribuído implemen-tado em Java pode, portanto, ser visto como uma distribuição dos seus objetos de forma razoável, com as comunicações entre eles estabelecidas utilizando suporte para redes próprio do Java [24].
3.1.2
Plataforma Java
Como já foi referido na secção 3.1, todos os programas escritos em Java assentam num conjunto pré-definido de classes que constituem a plataforma Java. Uma classe Java é um módulo de código Java que define uma estrutura de dados e um conjunto de métodos que operam nesses dados. Estas classes estão organi-zadas por grupos relacionados conhecidos como packages, que estão estruturados por funcionalidades como entradas/saídas, networking, gráficos, interface com o utilizador, segurança, entre outras.
O termo plataforma, para um programador, é definido pelas APIs em que este se pode basear quando desenvolve os seus programas. Estas APIs são normal-mente definidas pelo sistema operativo do computador a que se destina o pro-grama. Assim, um programador que vai criar um programa para ser executado no sistema operativo Windows usa um conjunto de APIs diferente do conjunto que o mesmo programa necessita para ser executado num sistema Linux. Neste exemplo, os sistemas operativos Windows e Linux são duas plataformas distin-tas. Contudo, Java não é um sistema operativo, mas fornece APIs com dimensão suficiente para serem comparadas às que são fornecidas pelos sistemas operati-vos. Uma aplicação escrita na plataforma Java pode ser executada em qualquer sistema operativo desde que este suporte a plataforma. Isto significa que não é necessário criar versões distintas dos programas para Windows e para Linux, por exemplo. Um único programa em Java pode ser executado em todos os sis-temas operativos, constituindo a célebre frase da Sun Microsystems “Write once, run anywhere” (“escrever uma vez, executar em todo o lado”). A plataforma Java oferece aos programadores uma independência em relação às plataformas para as quais programam [21].
A plataforma Java contém, portanto, o JRE, que inclui tudo o que é necessário para executar programas em Java. Contudo, não inclui as ferramentas necessárias para desenvolver esses programas, como o compilador. Estas ferramentas estão disponíveis no pacote SDK, que também faz parte da plataforma Java. Existem também várias versões da plataforma Java, sendo as mais conhecidas as seguin-tes:
- Java SE - para aplicações e servidores em ambiente desktop;
- Java EE - usada para aplicações e servidores em contexto empresarial; - Java ME - para PDAs, telemóveis, ou seja, dispositivos móveis;
- Java Embedded - para aplicações embebidas; - Java Card - para aplicações com Smart Cards;
Com estas versões, a tecnologia Java oferece diversos suportes de acordo com as características dos dispositivos e com o tipo de serviço a ser implementado [25]. O núcleo da plataforma Java, que torna possível a execução de programas em Java em qualquer sistema operativo, é a máquina virtual Java. A secção 3.3 deste capítulo é relativa a este importante e fundamental elemento da plataforma Java.
3.2
Vantagens de usar Java
Um sistema completamente homogéneo no qual todos os seus componentes têm as mesmas características é muito difícil de conseguir, pois teriam que ser iguais ao nível das especificações da arquitectura dos processadores, potência de pro-cessamento, memória e tecnologias de comunicação. Por ser uma tecnologia que suporta múltiplas plataformas computacionais, o Java constitui uma solução para o problema da heterogeneidade de plataformas [25]. Esta característica torna a linguagem Java numa linguagem de programação móvel, que permite que um ficheiro class1 seja executado num largo espectro de processadores, desde mi-crocontroladores até super-computadores [23]. É também referida como sendo uma linguagem distribuída, pois foi criada tendo em conta as redes de computa-dores modernas, possuindo uma grande biblioteca para lidar com protocolos que operam sobre o TCP/IP, como o HTTP e o FTP. As aplicações Java podem aceder a objetos espalhados pela Internet através de URL, tão facilmente como quando acedem no sistema de ficheiros local. Com a tecnologia Java, a Internet e as redes embebidas podem ser encaradas como o ambiente de um computador, o que se torna útil em aplicações de controlo. A capacidade do Java em entregar progra-mas ao longo de uma rede ilustra o conceito de “escrever uma vez, executar em todo o lado” [22]. Tendo em conta a segurança, pois tratando-se de uma tecno-logia que opera em redes onde existem sempre programas maliciosos e hostis, o Java fornece uma framework baseada no modelo caixa de areia, que confina o uso de recursos do sistema para o proteger [23].
Para o projeto da presente dissertação, a escolha da tecnologia Java para desen-volver uma máquina virtual em FPGA deve-se ao facto de ser possível executar na FPGA um programa escrito em Java originalmente criado para um
dor ou microcontrolador, assim como ao facto de se poder integrar a FPGA numa rede onde todos os componentes suportem a tecnologia Java. Para além dessas razões, a implementação de uma máquina virtual Java está especificada num do-cumento aberto [19] a todos os programadores, o que facilita o desenvolvimento deste tipo de máquinas virtuais.
3.3
Máquina Virtual Java
Quando um programa Java é compilado, é convertido em informação simbólica, que inclui os bytecodes que constituem a linguagem de máquina da chamada má-quina virtual Java. Portanto, esta mámá-quina virtual interpreta e executa bytecodes, contendo estes as instruções que a máquina virtual terá que executar. É uma peça vital em qualquer instalação de tecnologia Java. Por definição, os programas Java são portáveis mas apenas para plataformas computacionais nas quais exista uma versão da máquina virtual Java. Existem implementações desta máquina virtual para Microsoft Windows, para plataformas da Apple e para sistemas Unix. Con-tudo, a máquina virtual Java não está apenas disponível para ambientes desktop. Existe também para dispositivos móveis [21], como telemóveis, que usam siste-mas operativos como Android, Windows Phone, Symbian e iOS.
O primeiro protótipo implementado da máquina virtual Java, pela Sun Microsys-tems, emulava o conjunto de instruções da máquina virtual Java em software alo-jado num dispositivo semelhante a um PDA. As implementações atuais, que fa-zem parte do Java 22 SDK e Java 2 Runtime Environment, emulam a máquina vir-tual Java de formas muito mais sofisticadas. Ainda assim, a máquina virvir-tual Java não assume nenhuma tecnologia particular de implementação, hardware anfitrião ou sistema operativo. Não é inerentemente interpretada mas pode ser implemen-tada compilando o seu conjunto de instruções para um conjunto de instruções de um CPU de silício. Também é possível implementá-la em microcódigo ou direta-mente em silício.
2Java 2 é o nome atual da plataforma Java, que passou a denominar-se assim a partir da sua
versão 1.2, uma vez que foram introduzidas muitas funcionalidades novas e importantes altera-ções.
A implementação da máquina virtual Java engloba vários aspectos, no entanto, a estrutura base dessa implementação, descrita em [19], especifica uma máquina abstrata. Os detalhes práticos da implementação ficam sempre à consideração do programador. As sub-secções seguintes analisam alguns aspetos da The Java Virtual Machine Specification [19].
3.3.1
Ficheiro class
O ficheiro que contém os bytecodes é de um formato binário particular, indepen-dente do hardware e do sistema operativo, o qual se denomina por ficheiro class. A implementação correta da máquina virtual Java baseia-se simplesmente em ser capaz de ler o ficheiro class e executar corretamente as operações nele especifi-cadas. Para além dos bytecodes, contém tabelas de símbolos e informação auxiliar adicional. Esta informação contida no ficheiro class define uma classe ou uma interface. Na The Java Virtual Machine Specification [19], o ficheiro class está re-presentado sob a forma de uma estrutura de dados semelhante às de linguagem C: ClassFile { u4 magic; u2 minor_version; u2 major_version; u2 constant_pool_count; cp_info constant_pool[constant_pool_count-1]; u2 access_flags; u2 this_class; u2 super_class; u2 interfaces_count; u2 interfaces[interfaces_count]; u2 fields_count; field_info fields[fields_count]; u2 methods_count; method_info methods[methods_count]; u2 attributes_count; attribute_info attributes[attributes_count]; }
Este tipo de ficheiro consiste numa stream de bytes de 8 bits. Quando existem dados com maiores quantidades, nomeadamente de 16 bits, 32 bits e 64 bits,
es-tas são construídas lendo dois, quatro e oito bytes consecutivos, respetivamente. Os dados de um ficheiro class são representados por tipos de dados próprios, sendo eles u1, u2 e u4. Cada um representa quantidades de um, dois ou quatro bytes.
A seguir, aborda-se cada elemento desta estrutura.
3.3.1.1 magic
É o magic number que identifica o formato de ficheiro class e tem sempre o valor 0xCAFEBABE, que são os primeiros quatro bytes do ficheiro.
3.3.1.2 minor_versione major_version
Estes valores são os números de versão menor e maior do ficheiro class, e juntos determinam a versão desse ficheiro.
3.3.1.3 constant_pool_counte constant_pool[]
O valor constant_pool_count indica o número de entradas presentes na ta-bela constant_pool mais um. O índice de uma entrada da constant_pool, à exceção das constantes do tipo long e double3, só é considerado válido se for maior que zero e menor que o valor de constant_pool_count, .
A constant_pool é uma tabela de estruturas que representam várias constan-tes de strings, classes, interfaces, campos, entre outros. As instruções da máquina virtual Java não são baseadas no layout de classes, instâncias de classes, inter-faces ou arrays. Em vez disso, as instruções referem-se a informação simbólica presente nesta tabela. Cada entrada da constant_pool é indicada pelo seu primeiro byte, ao qual se dá o nome de tag, que também fornece informação sobre o tipo de constante presente nessa entrada. A estrutura representativa da constant_poolé a seguinte:
cp_info { u1 tag;
u1 info[]; }
O conteúdo do parâmetro info varia de acordo com o valor da tag. A seguir a cada byte indicativo da tag seguem-se dois ou mais bytes de informação sobre o tipo de constante correspondente a essa tag. A tabela 3.1 ilustra os tipos de constantes que podem estar presentes na constant_pool, os valores que a tag pode assumir conforme o tipo de constante e o número de bytes de informação que cada constante terá. A descrição de cada constante é realizada a seguir.
Tabela 3.1: Tipos de constantes presentes na constant_pool.
Tipo de constante Tag Bytes de informação CONSTANT_Utf8 1 2 + x CONSTANT_Integer 3 4 CONSTANT_Float 4 4 CONSTANT_Long 5 4 + 4 CONSTANT_Double 6 4 + 4 CONSTANT_Class 7 2 CONSTANT_String 8 2 CONSTANT_Fieldref 9 2 + 2 CONSTANT_Methodref 10 2 + 2 CONSTANT_InterfaceMethodref 11 2 + 2 CONSTANT_NameAndType 12 2 + 2
x na tabela indica um número variável de bytes.
- CONSTANT_Utf8 - este tipo é usado para representar valores constantes de strings, ou seja, indicam o nome de métodos, nomes de variáveis os bytecodes e Strings. As strings UTF-8 estão codificadas de forma a que sequências de caracteres que contenham caracteres ASCII possam ser representadas usando apenas um byte por caracter. No entanto, podem ser representa-dos caracteres até 16 bits. Este tipo de constante segue a seguinte estrutura:
CONSTANT_Utf8_info { u1 tag;
u2 length;
O parâmetro length indica o número de bytes no array bytes (não o ta-manho da string resultante), que contém a string codificada.
- CONSTANT_Integer e CONSTANT_Float - Estes dois tipos de constan-tes seguem uma estrutura idêntica, estando apenas aqui representada a CONSTANT_Integer:
CONSTANT_Integer_info { u1 tag;
u4 bytes; }
Na CONSTANT_Integer, bytes indica o valor de uma constante do tipo int. Os bytes que representam esse valor estão guardados por ordem big--endian (byte mais significativo primeiro). Na CONSTANT_Float, o mesmo parâmetro representa o valor de uma constante do tipo float no formato IEEE 754 floating-point single. Os bytes de representação desse valor também estão guardados por ordem big-endian.
- CONSTANT_Long e CONSTANT_Double - representam constantes com ta-manho de 8 bytes. Mais uma vez, estes dois tipos de constantes seguem uma estrutura igual, de modo que só está aqui ilustrada uma delas:
CONSTANT_Long_info { u1 tag;
u4 high_bytes; u4 low_bytes; }
Os parâmetros high_bytes e low_bytes na CONSTANT_Long represen-tam juntos o valor de uma constante do tipo long, seguindo a seguinte fórmula ((long)high_bytes < < 32 + low_bytes, estando também orga-nizados por ordem big-endian. Já na CONSTANT_Double os dois parâmetros indicam um valor do tipo double no formato IEEE 754 floating-point double. Os bytes de cada parâmetro também seguem uma ordem big-endian. Todas as constantes que possuem 8 bytes de informação ocupam duas entradas
na tabela constant_pool do ficheiro class. Se uma destas constantes é o item do índice n da constant_pool, então o próximo item da tabela está localizado no índice n+2.
- CONSTANT_Class - usada para representar uma classe ou interface, tem a seguinte estrutura:
CONSTANT_Class_info { u1 tag;
u2 name_index; }
O item name_index deve ser um índice válido da tabela constant_pool. O conteúdo da entrada correspondente a esse índice deve ser uma estru-tura do tipo CONSTANT_Utf8_info, representando o nome válido de uma classe ou interface.
- CONSTANT_String - representa objetos constantes do tipo String. A sua estrutura é:
CONSTANT_String_info { u1 tag;
u2 string_index; }
O item string_index deve ser um índice da tabela constant_pool vá-lido, cuja entrada deve ser uma estrutura do tipo CONSTANT_Utf8_info representando a sequência de caracteres pela qual o objeto String está para ser inicializado.
- CONSTANT_Fieldref, CONSTANT_InterfaceMethodref e CONSTANT_-Methodref- tal como os nomes indicam, representam campos, métodos de interfaces e métodos, seguindo todas uma estrutura idêntica (aqui está ape-nas ilustrada uma delas):
CONSTANT_Fieldref_info { u1 tag;
u2 class_index;
O campo class_index deve ser um índice da tabela constant_pool válido. A entrada dessa tabela, indicada pelo índice anterior, deve ser uma estrutura do tipo CONSTANT_Class_info, que representa uma classe ou interface que contém a declaração do campo ou método. O class_index deve ser, de acordo com o tipo de constante:
1. Do tipo classe para a estrutura CONSTANT_Methodref_info; 2. Do tipo interface para CONSTANT_InterfaceMethodref_info; 3. Do tipo classe ou interface para CONSTANT_Fieldref_info;
O item name_and_type_index deve indicar um índice válido da tabela constant_pool, cuja entrada deve corresponder a uma estrutura do tipo CONSTANT_NameAndType_info. Esta entrada indica o nome e o descrip-tor4 do campo ou método. O descriptor deve ser um field descriptor, no caso de ser constante do tipo CONSTANT_Fieldref_info, senão deve ser um method descriptor. Se o nome do método presente numa estrutura do tipo CONSTANT_Methodref_info começar pelo símbolo ’<’, então o nome do método será <init>, que representa a instância do método de inicialização. Não deve retornar nenhum valor.
- CONSTANT_NameAndType - usada para representar um campo ou um mé-todo, sem indicar a qual tipo de classe ou interface pertence. A sua estrutura é apresentada a seguir.
CONSTANT_NameAndType_info { u1 tag;
u2 name_index;
u2 descriptor_index; }
O item name_index deve ser um índice válido da tabela constant_pool. A entrada correspondente a esse índice deve ser uma estrutura do tipo 4Um descriptor é uma string que representa o tipo de método ou campo, estando no ficheiro
classsob a forma de uma string do tipo UTF-8. Um field descriptor indica o tipo de uma classe, instância ou variável local. Um method descriptor representa os parâmetros que um método aceita e o valor que ele retorna.
CONSTANT_Utf8_info, que representa tanto o nome de um campo como de um método, guardado como um simple name, isto é, como um identifica-dor único da linguagem de programação Java5 ou como nome do método especial <init>.
O parâmetro descriptor_index deve ser um índice válido da tabela constant_pool, cuja entrada correspondente a esse índice deve ser uma estrutura do tipo CONSTANT_Utf8_info, representando um field descriptor ou method descriptor válido.
3.3.1.4 access_flags
Este valor é uma máscara de flags usada para indicar permissões de acesso, assim como propriedades de uma classe ou interface. A interpretação de cada flag está descrita na tabela 3.2.
Tabela 3.2: Interpretação das access_flags presentes no ficheiro class.
Nome da flag Valor Interpretação
ACC_PUBLIC 0x0001 É declarada public, pode ser acedida a partir do exterior do seu package ACC_FINAL 0x0010 É declarada final, não são permitidas sub-classes
ACC_SUPER 0x0020 Lida com os métodos de super-classes invocados pela instrução invokespecial ACC_INTERFACE 0x0200 O ficheiro class define uma interface, e não uma classe
ACC_ABSTRACT 0x0400 É declarada abstract, pode não estar instanciada
3.3.1.5 this_classe super_class
O item this_class deve ser um índice válido da tabela constant_pool. A en-trada correspondente deve ser uma estrutura do tipo CONSTANT_Class_info, que representa a classe ou interface definida pelo ficheiro class em questão.
5Este identificador é o nome pelo qual está identificada uma entidade num programa Java,
Para uma classe, o item super_class deve corresponder a um índice da tabela constant_pool válido. Se este valor não for igual a 0, a entrada correspon-dente ao índice deve ser uma estrutura do tipo CONSTANT_Class_info, que indica a classe direta da classe definida pelo ficheiro class. Nem a super--classe direta nem alguma das suas supersuper--classes devem ser a classe final. Se o valor de super_class for igual a 0, então o ficheiro class especifica a classe Object, a única classe ou interface que não possui uma super-classe direta. Para uma interface, o valor de super_class deve ser um índice válido da tabela constant_pool, cuja entrada representa a classe Object.
3.3.1.6 interfaces_counte interfaces[]
O valor de interfaces_count é o número de super-interfaces diretas da classe ou interface. Cada valor do array interfaces deve ser um índice válido da ta-bela constant_pool. A correspondente entrada da constant_pool a cada valor de interfaces[i], onde 0 ≤ i < interfaces_count, deve ser uma es-trutura do tipo CONSTANT_Class_info, representando uma interface que é a super-interface direta da classe ou interface.
3.3.1.7 fields_counte fields[]
O item fields_count indica o número de estruturas do tipo field_info pre-sente no array ou tabela fields[]. A estrutura field_info representa todos os campos, tanto variáveis de classes como variáveis de instâncias, declarados pela classe ou interface.
field_info { u2 access_flags; u2 name_index; u2 descriptor_index; u2 attributes_count; attribute_info attributes[attributes_count]; }
Cada valor presente na tabela fields, isto é cada campo, deve ser uma estru-tura field_info, que fornece a descrição completa de um campo nesta classe
ou interface. A tabela fields inclui apenas os campos declarados nesta classe ou interface, não inclui campos que foram herdados de classes ou super-interfaces. O nome de um campo e o field descriptor devem ser únicos, não de-vendo haver dois ou mais campos com o mesmo nome e descriptor dentro da mesma classe. Os parâmetros de cada entrada desta tabela definem-se da se-guinte forma:
- access_flags - este valor é uma máscara de flags usada para indicar per-missões de acesso e propriedades de um campo. Cada campo pode ser de-clarado como public, private, protected, static, final, volatile e transient.
- name_index e descriptor_index - em ambos os casos, o valor de cada item deve ser um índice válido da tabela constant_pool, cuja entrada correspondente deve ser uma estrutura do tipo CONSTANT_Utf8_info. No caso de name_index a estrutura representa um nome válido para o campo, guardado como um simple name. Para o descriptor_index, in-dica um field descriptor válido.
- attributes_count - indica o número de atributos adicionais de um cam-po.
- attributes[] - cada valor da tabela attributes deve ser uma estru-tura do tipo attribute, descrita mais à frente neste documento. Um campo pode ter um número qualquer de atributos associados. Segundo a The Java Virtual Machine Specification, os atributos que podem aparecer na tabela attributes da estrutura field_info são: ConstantValue, Synthetice Deprecated. A implementação da máquina virtual deve ser capaz de reconhecer e ler corretamente atributos do tipo ConstantValue presentes na tabela attributes da estrutura field_info, devendo igno-rar todos os atributos presentes que não reconhece. Estes não estão defini-dos e, como tal, não podem afetar a semântica do ficheiro class, podendo apenas fornecer informação adicional.
3.3.1.8 methods_counte methods[]
O valor de methods_count representa o número de estruturas method_info presentes na tabela methods. Cada entrada da dessa tabela é um método, de-vendo portanto ser uma estrutura do tipo method_info. Define-se assim todos os métodos declarados na classe ou interface, incluindo instâncias de métodos, métodos de classes static, métodos de inicialização de instâncias e qualquer outro método de inicialização de classe ou interface. A tabela methods não in-clui métodos que tenham sido herdados de super-classes ou super-interfaces. A estrutura method_info é definida da seguinte forma:
method_info { u2 access_flags; u2 name_index; u2 descriptor_index; u2 attributes_count; attribute_info attributes[attributes_count]; }
- access_flags - é uma máscara de flags utilizada para indicar permissões de acesso e propriedades de um método. Cada método pode ser declarado como public, private, protected, static, final, synchronized, native, abstract e strictfp.
- name_index e descriptor_index - os valores destes dois parâmetros devem ser índices válidos da tabela constant_pool, aos quais correspon-dem entradas que devem ser estruturas do tipo CONSTANT_Utf8_info. Para o name_index esta estrutura representa um dos special names de mé-todos, nomeadamente o <init> ou <clinit>6, ou um nome válido de um método da linguagem Java, guardado como um simple name. No caso do descriptor_index, deve estar representado um method descriptor válido. 6Ao nível da máquina virtual Java, cada construtor aparece sob a forma de uma instância do
método de inicialização, que tem o special name <init>. Este método só pode ser invocado den-tro da máquina virtual através da instrução invokespecial e apenas em instâncias de classes que ainda não foram inicializadas. Uma classe ou interface tem no máximo um método de inicia-lização de classe ou interface, com o special name <clinit>, que é inicializado invocando esse método. A invocação deste método é implícita dentro da máquina virtual Java, nunca sendo di-retamente invocado por uma das instruções, mas apenas indidi-retamente como parte do processo de inicialização da classe.
![Figura 2.2: Modelo da localização das camadas de middleware num sistema distri- distri-buído [18].](https://thumb-eu.123doks.com/thumbv2/123dok_br/15942935.1096517/37.892.205.753.429.706/figura-modelo-localização-camadas-middleware-sistema-distri-distri.webp)

![Figura 4.1: Estrutura interna genérica de uma FPGA [26].](https://thumb-eu.123doks.com/thumbv2/123dok_br/15942935.1096517/77.892.254.700.168.442/figura-estrutura-interna-genérica-de-uma-fpga.webp)
![Figura 4.4: Estrutura interna da Spartan-3E [34].](https://thumb-eu.123doks.com/thumbv2/123dok_br/15942935.1096517/86.892.197.627.369.671/figura-estrutura-interna-da-spartan-e.webp)

![Figura 4.9: Estrutura interna da Spartan-3A [35].](https://thumb-eu.123doks.com/thumbv2/123dok_br/15942935.1096517/90.892.179.645.164.527/figura-estrutura-interna-da-spartan-a.webp)
![Figura 4.10: Localização da porta JTAG/USB e das memórias não-voláteis [37].](https://thumb-eu.123doks.com/thumbv2/123dok_br/15942935.1096517/91.892.170.785.287.537/figura-localização-porta-jtag-usb-memórias-não-voláteis.webp)

