Mitzi Araujo Vidal
OBFUSCATION AND ANONYMIZATION METHODS FOR
LOCATIONAL PRIVACY PROTECTION
Obfuscation and Anonymization methods for
locational privacy protection
A systematic literature review
Dissertation supervised by Marco Painho, PhD
NOVA Information Management School, Universidade Nova de Lisboa, Lisbon, Portugal
Co-supervised by Christian Kray, PhD
Institute for Geoinformatics (IFGI),
Westfälische Wilhelms-Universität, Muenster, Germany
Joaquín Huerta, PhD
Institute of New Imaging Technologies, Universitat Jaume I, Castellón, Spain
Acknowledgements
I am grateful to the Erasmus Mundus program for the opportunity and funding to attend the course M.Sc in Geospatial Technologies. I also would like to express my sincere gratitude to the administrative personal in both of the Geoinformatics Institute and NOVA IMS to help us with the bureaucratic affairs.
I would like to thank my supervisors Professors Christian Kray, Marco Painho and Joaquín Huerta for their feedback.
I am also grateful to my classmates of MSc Geospatial Technologies for the enriched and supportive environment during this Master’s course.
Finally, I would like to express my love and gratitude to my family and friends, their encouragement and support throughout this period.
Obfuscation and Anonymization methods for
locational privacy protection
A systematic literature review
Abstract
The mobile technology development combined with the business model of a ma-jority of application companies is posing a potential risk to individuals’ privacy. Because the industry default practice is unrestricted data collection. Although, the data collection has virtuous usage in improve services and procedures; it also undermines user’s privacy. For that reason is crucial to learn what is the privacy protection mechanism state-of-art.
Privacy protection can be pursued by passing new regulation and developing preserving mechanism. Understanding in what extent the current technology is capable to protect devices or systems is important to drive the advancements in the privacy preserving field, addressing the limits and challenges to deploy mechanism with a reasonable quality of Service-QoS level.
This research aims to display and discuss the current privacy preserving schemes, its capabilities, limitations and challenges.
Keywords
Locational Privacy Obfuscation Techniques Anonymization
Acronyms
PET Privacy Enhancing Techniques
LPPM location-privacy preserving mechanism SLR Systematic Literature Review
GL Grey Literature
GDPR General Data Protection Regulation
PIPEDA Personal Information Protection and Electronic Documents Act TA trusted authority
TTP trusted third party CA certificate authority QoS quality of service
CTPP collaborative trajectory privacy preserving POIs points of interest
ACM Association for Computing Machinery
IEEE Institute of Electrical and Electronics Engineers dblp Digital Bibliography Library Project
GPA Global Passive Adversary LPA Local Passive Adversary PIR Private Information Retrieval GPS Global Positioning System
RFID Radio Frequency Identification RS Reported server
DDoS Denial of Service RA Registration Authority
HISP-NC Homogenous Injection for Sink Privacy with Node Compromise
pro-tection
TVM Temporal Vector Map
DPMM Dynamic Pseudonym based Multiple Mix-zones FGCS Future Generation Computer Systems
INDEX OF TEXT
Acknowledgements . . . iii ABSTRACT. . . iv Keywords . . . v Acronyms . . . vi 1 Introduction 1 1.1.Scope of the research. . . 21.2.Aim and Objectives . . . 5
1.3.What Locational Privacy actually mean? . . . 7
1.4.How to preserve Locational Privacy? . . . 9
1.5.How Systematic Literature Review (SLR) can contribute to locational privacy . . . 9
1.6.Overview of Locational Data Protection Legislation . . . 11
1.7.Contributions. . . 13
1.8.Thesis Outline . . . 13
2 Systematic Literature Review 14 2.1.Theoretical Background . . . 14
2.3.Data Extraction and Data Synthesis . . . 27
3 Results 29 3.1.Articles Metadata . . . 31
3.2.CONCERNS Addressed . . . 34
3.3.SOLUTIONS and TRENDS. . . 36
3.4.Risk Assessment and Architecture . . . 40
3.5.General Discussion of the findings . . . 41
4 Conclusions and future work 44 References 60 APPENDIX-B: Search Strings. . . 74
APPENDIX-C: Data Extraction Form . . . 78
APPENDIX-D: Search Strings Results . . . 78
APPENDIX-E: Description of the Online Libraries . . . 79
APPENDIX-F: Threats Addressed by Solutions . . . 80
APPENDIX-G: Publication . . . 84
INDEX OF TABLES
3.1 Quality check-list Synthesis . . . 30
3.2 Addressed Issues . . . 35
3.3 Aims and Solutions Synthesis. . . 39
INDEX OF FIGURES
1.1 Locational Privacy in Mobile Networks . . . 4
2.1 Shades of Grey Literature (From J. Adams et al.2016). . . 21
2.2 Review Methodology . . . 22
2.3 Types of Artefacts . . . 28
3.1 Results of Selection and Exclusion Criteria . . . 29
3.2 Quality check-list Categories . . . 31
3.3 Author’s Institutions Country . . . 32
3.4 Publications from the selected articles . . . 33
3.5 Solution’s aims. . . 36
Chapter 1
Introduction
The societies are facing a shift in the computational paradigm, from desktops to mobile phones, from common devices to internet of things, pushing the capabil-ities to a ubiquitous computing, or pervasive computing. The plethora of appli-cations uses personalization, collects a tremendous amount of data and applies machine learning algorithms to them. The majority of this data is locational and private whose owners are not aware of their collection, transferring and analysing. The improvement of the mobile technologies and the pervasiveness of the computing, along with increasingly more sophisticated and personalized services has become a concern to the user’s privacy. This technology could be misused and applied to dataveillance. Location and trajectory are sensitive data which can disclose critical information, such as living and consumption habits, health conditions, social, sexual, religious behaviour, political views, work and home ad-dresses (Gao et al.2015). The localization and its historical recording, nowadays, is a means of profit for many companies. Hence many of them see the protec-tion of the user’s locaprotec-tional privacy as a potential danger to monetizaprotec-tion and a challenge to their business model (Herrmann 2016).
The locational privacy is under attack not only by adversaries and criminals but also by the government and big corporations. Institutions which continuously try to gain more and more personal and intimate data from the individuals.
Se-curity breaches along with the company’s business model are the current most common threats to the locational privacy. There are several privacy preserving techniques called privacy enhancing techniques PET for general personal data and locational data focused Locational Privacy Protection Mechanism LPPM that aim to provide anonymization, pseudonymization, unlinkability and unob-servability (Pfitzmann et al. 2010) of the data subjects.
Two different and complementary approaches are responses to the challenges of privacy erosion: the regulatory-enable solutions and the technology-enable so-lutions (Bouguettaya et al. 2003)to privacy preserving mechanisms. In order to reduce the intrusions from both attackers and companies tools and solutions applied to preserve privacy have been developed which can be classified in dis-tinct classes. The main classes of solutions according to Y. Sun et al. (2017) are Data Anonymization and Data Obfuscation while for Fang et al. (2017) are Data Anonymization, Data Perturbation (or Obfuscation) and Data Encryption. Bettini et al. (2015) add two other classes to latter author’s definitions: Access Control and Privacy Preserving Data Mining.
1.1
Scope of the research
The research title Obfuscation and Anonymization methods for locational privacy protection - A systematic literature review has highlighted expres-sions which are key concepts to define the scope. The methods chosen and the reason for that choice, a clear definition of locational privacy and the methodolog-ical instructions and restrictions, respectively. The selected studies will account only technology-enable solutions (Bouguettaya et al.2003) and consider the Bet-tini et al. (2015) classification for the Privacy preserving mechanism. Restrained to only two of the classes defined: Data Anonymization and Data Perturbation. Studies with techniques which only fell into the other categories, namely: Data Encryption, Access Control and Privacy Preserving Data Mining are out of scope. Conversely, studies with combined technologies will be selected only if any of the
techniques were classified in one of the two scope classes. If the study applies encryption in combination with data perturbation or data anonymization tech-niques; it will be included as a relevant study.
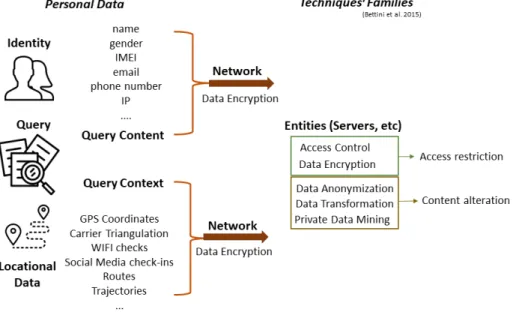
Instead of use the general concept of privacy which are intimately related to personal or personally identifiable information (PII) data, only the dimension related to data which has a spatial dimension will be used on this thesis. The Data transmitted in location-based applications are classified by Chunguang et al. (2015) there are of three kinds, namely: location privacy, query privacy, and identity privacy. Query privacy present two dimensions query content and query context. There are intensive work on the mobile application development on use of context to improve the user experience and performance. However, it is a double-edged sword as a potential source of background knowledge to malicious entities. Long et al. (2015) show the distinction between content-based and context-based queries. The former is well understood and documented, predominantly related to Identity Privacy and query privacy content whereby Data encryption technology is commonly applied. The latter threat presents a challenge, because locational privacy is a problem with a context-based nature, with an extensive flow of in-formation coming from different sensors and devices, similarly to query context providing background and a priori knowledge to services.
The cryptography approach is predominantly applied to identity and query content problems, including secure/private network transportation, however is less appropriate to address the context and locational types of information. The hostile environment of the Mobile Networks requires assumptions and designs which account to untrustworthy behaviour or compromised entities in a LBS scheme. Using just cryptography between an untrusted entity is not a rational system design. The untrusted or semi-trusted Server which provide the service will have access to both context and precise locational data, therefore the cryp-tography approach alone present limited resources in this case.
The reason for query context exclusion from scope resides on its characteris-tics. Dey (2001) defines context as "any information that can be used to
char-acterise the situation of an entity that is considered relevant to the interaction between a user and an application, including the user and applications them-selves". To Rosenberger et al.2018, context is built from gathering and combine different types of information and interpret them with a higher level of abstraction to understand the situation of the users and its relation with a given application. The majority of the data preserving mechanisms focus on unlikability and anonymity, decoupling the identity from attributes, relationships, location posi-tions and traces, and creating pseudonyms. In most of the cases the techniques just applied identity privacy, such anonymization whereby all the locational data and its context are just striped of the actual owner identification by pseudonyms.
Figure 1.1: Locational Privacy in Mobile Networks
In most of the cases the techniques just applied identity privacy, such anonymiza-tion. All the locational data and its context are just striped of the actual owner identification by pseudonyms. The hostile environment of the Mobile Networks requires assumptions and design decisions because entity related to the LBS can
be either compromised or be untrustworthy. Using cryptography between an un-trusted entity is not a rational system design. The unun-trusted or semi-un-trusted Server to provide the service will have access to both context and precise lo-cational data, for this reason the cryptography approach alone present limited resources in this case.
The definition of privacy used on this thesis is a subset of what is understood by the concept of locational privacy. It is defined as "the ability to prevent other parties from learning one’s current or past location" (Beresford et al. 2003).
The Vehicular Networks were removed from scope. Therefore, the studies related to vehicular networks in the pool of selected studies would implicate in more time to extract, synthesise and report the information since its nature and characteristics other than the ones from the Mobile Networks.
Another approach to classify the mobile user data problems was given by (Heurix et al. 2015) such as Identity Management, Network Traffic Anonymiza-tion and Anonymous Databases are themes out of the scope of this work. The thesis focus is on locational data and how the entities on the architecture treat and process them, the network security in not on scope, but the majority of the studies uses encryption for the data transportation. The post-treatment and private Data mining is not on scope of this research.
The privacy identity or query content privacy which has no locational data it is not scope of the thesis. For the same reason the techniques such as Data Access and private data mining are not in scope since they interrelated more to users’ identity than to locational data. This work will focus exclusively on location privacy even though some query context has locational nature.
1.2
Aim and Objectives
The main objective is to provide a state-of-art of the obfuscation and anonymiza-tion technologies for preserving locaanonymiza-tional privacy. In order to achieve this aim four dimensions of the topic were distinguished and research questions were
re-spectively composed as following:
RQ1 - CONCERNS: What are the addressed concerns for applying
obfusca-tion and anonymizaobfusca-tion techniques to protect locaobfusca-tion privacy?
RQ2 - SOLUTIONS: What are the proposed solutions in obfuscation and
anonymization techniques to protect location privacy?
RQ3 - TRENDS: What are the existing research directions within obfuscation
and anonymization techniques in location privacy?
RQ4 - RISK AND ARCHITECTURE: How architecture affects the
solu-tions, service quality with the use obfuscation and anonymization techniques to protect location privacy?
1.3
What Locational Privacy actually mean?
The ubiquity of devices and steadily information acquisition place oneself’s pri-vacy in danger. The pervasiveness of sensors, the huge amount of environment, human motion and behaviour information recording is now part of daily lives. Due to the massive access to personal data, along with the possibility of track-ing and profiltrack-ing, individuals, institutions and governments are concerned in how to preserve privacy, but there is no consensus regarding its meaning (Birnhack
2011).
In order to protect privacy, the concept need to be clearly explained, since its definition is imprecise and have a variety of understanding in different study fields, such as: philosophy, sociology, law, political science, human rights and more recently within the information technologies.
According to Kounadi et al. (2014) location privacy can be compromised by new geospatial technologies, lenient laws regarding privacy and as by a scientist’s and publisher’s negligence. Three dimensions of data treatment: data acquisition, data publication and regulation. For this author privacy definition relies on the combination of the correctness and uncertainty concepts. Meaning that the level of location privacy could be a combined measure of position accuracy and its mensuration uncertainty.
The common understanding of privacy is in terms of control over personal information. Westin (1967) defined privacy as "the desire of people to choose freely under what circumstances and to what extent they will expose themselves, their attitude and their behaviour to others." In (Tavani et al. 2001) is possible to find Charles Fried and Dag Elgesem statements, the former defines it as not a simply absence of information about an individual in the minds of others, rather than the control over information about oneself, the latter defines it as a personal ability to consent to the dissemination of personal information. In privacy theory, Tavani et al. (2001) argues the existence of three components: conceptualization, justification and management. Moor 1997 as cite in Tavani et al.2001states that
privacy best definition is access restriction rather than control of information. Both Dwork (2006) and Solove (2006) addresses the concept in terms of its vi-olations. The former has concerns about: (i)Defining what constitutes a preserve privacy failure (ii)Defining the objectives and the power of an adversary against privacy (iii) Identifying the possible background and a priori information the ad-versary can hold. While the latter proposed a privacy taxonomy with four basic groups of harmful activities: (1) information collection (Harms: Surveillance, In-terrogation),(2)information processing (Harms: Aggregation, Identification, Inse-curity, Secondary Use, Exclusion), (3)information dissemination (Harms: Breach of Confidentiality, Disclosure, Exposure, Increased Accessibility, Blackmail, Ap-propriation, Distortion), and (4)invasion (Harms: Intrusion, Decisional Interfer-ence).
In Ethics and Law, there are two definitions of Privacy: Normative Privacy and descriptive privacy. The former is delimited by law in effect and the latter the effective and actual restriction to any information (Tavani et al.2001).
The taxonomy of Pfitzmann et al. (2010) is a pivotal contribution in how to generate understanding to a complex concept as privacy that can be evaluated and improved. It defines a vocabulary which expresses levels and dimensions to the conceptualization: Anonymity, Unlinkability, Undetectability, Unobservabil-ity and their variations:
• Anonymity of a subject is a level of indistinguishability within a set of subjects from an attacker perspective. Its level varies according to the a priori knowledge from an attacker. The higher the background knowledge the lower the anonymity.
• Unlinkability is an impossibility of fairly distinguish whether items of in-terest are related from an attacker’s perspective.
• Undetectability is an impossibility of fairly distinguish whether items exist or not from an attacker’s perspective.
• Unobservability from an item of interest means that all subjects involved cannot sufficiently distinguish whether it exists or not. In addition, anonymity of the subject involved with it.
• A pseudonym is an alias to the subject’s real names.
• An identity is any subset of attributes of an individual person which uniquely identifies him within any set of persons.
1.4
How to preserve Locational Privacy?
Privacy and more particularly locational privacy need to be protected with both Regulatory and technological enabled solutions (Bouguettaya et al.2003). These approaches are complimentary. Nonetheless, complex and diverse. For that rea-son, the objective of this work is to know the state-of-the art the technological solutions without disregarding the regulatory implications. Because the regula-tions should orient the early stages of the applicaregula-tions and system development. Data Anonymization and Obfuscation classes of techniques are examples of how to preserve geoprivacy. Some families of techniques are worth to mention in Mobile Networks. Asuquo et al. (2018) lists some of them: (a)Mix-zones in Mobile Networks, (b) Obfuscation-based Approaches in Mobile Networks, (c) Location Cloaking in Mobile Networks, (d) Dummy-based techniques In Mobile Networks, (e) Caching Schemes in Mobile Networks, (f) Coordinate Transformation in Mo-bile Networks(g) Information Access Control in MoMo-bile Networks.
1.5
How Systematic Literature Review (SLR)
can contribute to locational privacy
Shokri et al. (2011) advocates that the location privacy research is in its infancy added to the fact that humans are naturally poorly performers of risk estimation, privacy level evaluation is a challenge. It presents some shortcoming, commonly
the adversary model of the systems are not appropriately addressed and formal-ized. The Attack capabilities Model and measurements of the adversary’s success in his attacks, accuracy, certainty and correctness of estimations of the user’s location and trajectory are missing. Adding to that, some current used metrics such entropy and k-anonymity for quantifying location privacy are inappropriate and there is no privacy benchmark for location information. (Shokri 2013)
For that reason, it is required a formal and standardized way of evaluate and understand the development and advances of the privacy preserving mechanism field of study. The systematic literature review is the method found to identify experiments, suggested models and schemes as primary studies using the practices of the Evidence-based software engineering. Using the Evidence-based paradigm will drive the findings/extraction and reporting will allow a consistent and robust knowledge of the given questions related to local privacy preservation with ob-fuscation and anonymization methods. The definition and the details regarding the review will be thoroughly explained in the following chapters.
Software development and IT systems has Design Science Research as one paradigm analysis which builds artefacts that follow the engineer cycle. Design Science Research is a research approach introduced to Information Systems to tackle properly the practical and dynamic nature of such artefact like algorithms, HCI Human-Computer Interfaces, schemes and languages Kanellis et al. (2008). This research approach is a rigorous process to build solving problems mechanism, evaluate what was projected and working, finally communicate the results. Its objective is to generate applicable useful knowledge for a problem of solving, the improvement of existing systems and the creation of new solutions or tools (Lacerda et al.2013). Since software artefacts do not provide sufficient statistical basis for confirming or rejecting a hypothesis, the credibility level of the studies depends on the validity of the conclusions drawn Basili et al. 1999.
Carver et al. (2016) define the subjects types which can be evaluated in or-der to establish a baseline to measure advancements in security science, such as Algorithm/theory, Model, Language, Protocol, Process, Tool. Identifying the
novelty of subjects or if they are the basis of prior ones help the understanding the relevant and prospective subjects. The authors suggest the following questions related to the evaluation of the subjects: "Q1: What types of artefacts are being evaluated (e.g. algorithm, language, model, process, protocol, or tool)?
RQ2: How are the artefacts being evaluated (case study,experiment, survey, proof, discussion)?
RQ3: Are there trends in the type of artefact and the evaluation method used to evaluate it?"
These questions on the subjects evaluation approach from (Carver et al.2016), add to the contributions of (Basili et al.1999) and (Lacerda et al.2013) from De-sign Science can be helpful to build the Review Protocol and the Data extraction and Data Synthesis.
1.6
Overview of Locational Data Protection
Leg-islation
In the recent history some countries have been passing legislation in order to preserve privacy which clearly stablish it as a basic right or more specifically to protect and regulate how to treat personal data from the access, acquisition, stor-age and processing. Other countries are passing laws and policy to preserve the privacy rights of its citizens, and locational data is one object from this regulation. Some countries have explicitly laws protecting privacy and private information. Privacy is mention in the Universal Human rights, in Constitutional texts of some countries with just mentions or clearly protection such as USA, Portugal, Brazil, etc. In some countries privacy is not mentioned on their constitution but it is present in other legislations, like Canada, New Zealand, Germany, etc.
In 25th May 2018 entered into effect The General Data Protection Regulation of the European Union to protect personal data, the GDPR, which is one of the tools import to cope with the threats of one’s privacy. It regulates the acquisition,
storage and transferring of personal data requiring from the user its consent as well as the users the knowledge of the data acquisition and its purposes as well as the possibility to manage it through the access, erasure and portability requisition. The regulation consists of 11 Chapters to lay down the rules to processing and traffic of the personal data of the individuals of the European Union(“Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive
95/46/EC (General Data Protection Regulation)” 2016).
In Brazil, the law to regulate personal Data was approved in August 2018 and will enter into effect in 2020, it was inspired by GDPR.
1.7
Contributions
• Visualise the state-of-art of locational privacy preserving technologies present on the works from technological information community;
• Give an overview of at what extent the current technologies are capable to address the locational privacy threats issue, its limitation and challenges, identifying the trends in research in privacy preserving field;
• Analyse the trend on the schemes proposed in follow distributed architec-ture, avoiding to rely on Trusted Third Party and giving more control to the user and running more procedures on client side.
1.8
Thesis Outline
The rest of the thesis is organised as follows: the chapter 2 presents a review of the Systematic Literature Review methodology as a theoretical background the Methodology used is explained and how the Review was performed described. The chapter 3 presents the results and discussions related to the Data collected and synthesized. Finally, thechapter 4bring some conclusions, limitations, future improvements and suggestions from the acquired knowledge.
Chapter 2
Systematic Literature Review
2.1
Theoretical Background
The systematic review has been widely used in medical research and just recently applied in the field of computer science and software development (Kitchenham
2007, Kitchenham 2004). The procedures were adapted from the heath studies to the computer studies. Condensing and transposing the rules and strategies used in the medical research to the software development context. There is a plethora of empirical studies and documents. In order to understand clearly the distinctions between the studies and documents produced in medical research which were adapted to computer science, there is a following list with some suc-cinct definition (Kitchenham2007) of: Meta-analysis, Primary study, Secondary study, Sensitivity analysis, Systematic literature review, Systematic review pro-tocol, Systematic mapping study and Tertiary study.
• Primary study - An empirical proposition to answer a problem.
• Meta-analysis - Secondary study where the synthesis is made based in quan-titative analysis.
• Sensitivity analysis - Analysis to verify bias in Meta analysis and Systematic literature review.
• Systematic literature review (SLR)- A secondary study with a well-defined methodology and reproducible.
• Systematic review protocol - A plan for a systematic literature review.
• Systematic mapping study - General and wide vision of the primary studies, commonly providing a classification.
• Tertiary study - A study which review secondary studies about a same topic.
The systematic review or systematic literature review is a formalised way to combine a set of empirical studies using the concept of evidence-based method as orientation. Focusing on aggregating empirical evidence of a defined question or problem according to Brereton et al. (2007). The main objective is to build a protocol which describes the source selection, inclusion and exclusion criteria, search methods and keywords (Felizardo et al. 2009). The SLR consists in three main parts Planning, Execution and Report.
In Kitchenham 2004, Kitchenham 2007 the authors define the aim of the SLR as a research topic evaluation applying a formal, replicable and well defined methodology, and it has several benefits: reduces bias, allow general conclusions from broader contexts. Complemented by a meta-analysis the pool of studies can detect more than individual studies alone. In (L. Feng et al. 2017) the authors understand the importance of SLR, but its performance manually is quite challenging, with intensive work and prone to bias and omissions.
Biolchini et al. (2005) as cited in (Felizardo et al.2009) states that the benefits of this type of research method rely on the fact that SLR has objectives clearly defined, a review protocol built which contains all items needed to perform the task, such as selection of sources, searching methods and keywords, inclusion and exclusion criteria and finally the quality assessment of primary studies. Hence,
the use of such a methodology in computer science and in software/application development can support the professionals to adopt a standard or techniques proven to be more effective: Consequently, improving the quality of their final products and services.
Garousi et al. 2017 suggests two new secondary studies which consider not only white Literature but also Grey Literature, the Multivocal Literature Review and Multivocal Literature Mapping. A Multivocal Literature Review (MLR) is a Systematic Literature Review (SLR) which includes materials called grey literature." Garousi et al. 2017
Mapping or Scoping Studies is another type of second study which do not focus in answer research questions but identify omissions in primary studies and which are the topic clusters that can be an object to SLR The process of search, the inclusion and exclusion criteria are explicitly defined in the protocol of SLR differently than the mappings. They are broader on scope of topics (Petersen et al. 2008) although, comprising by the same early steps of SLR, but they aim to classify the studies instead of performing data extraction and data synthesis. These are the essential difference between mapping studies and SLR. For Petersen et al. (2008) the following three stages of SLR are common to mapping studies: 1. identification of relevant primary studies; 2. selection of the appropriate primary studies following a set of inclusion/exclusion criteria; 3. Performing the quality assessment the selected studies (bias/validity).
Meta Analysis is a type of data synthesis techniques along with: narrative synthesis, quantitative synthesis, qualitative synthesis, thematic analysis. It is most appropriate to quantitative studies (Garousi et al.2017). Beside, the quan-titative approach, Meta-analysis can also be qualitative and reveal the biases, strengths, and weaknesses of existing studies Russo 2007.
The quality tool developed by Dybå et al. 2008 has been applied frequently to systematic reviews to measure the quality of empirical studies. It comprises 11 questions as follows:
expert opinion? 2.Is there a clear statement of the aims of the research? 3.Is there an adequate description of the context in which the research was carried out? 4.Was the research design appropriate to address the aims of the research? 5.Was the recruitment strategy appropriate to the aims of the research? 6.Was there a control group with which to compare treatments? 7.Was the data collected in a way that addressed the research issue? 8.Was the data analysis sufficiently rigorous? 9.Has the relationship between researcher and participants been con-sidered to an adequate degree? 10.Is there a clear statement of the findings? 11.Is the study of value for research and practice?"
The same way that Dybå et al. 2008, Carver et al. 2016 suggested a quality assessment tool for primary studies, but instead of 11 questions 10 were proposed, as it can be seen below. "QC 1 Is there is a clear statement of the aim of the research?
QC 2 Is the study put into a context of other studies and research? QC 3 Are system or algorithmic design decisions justified?
QC 4 Is the test data set reproducible?
QC 5 Is the study algorithm reproducible? QC 6 Is the experimental procedure thoroughly explained and reproducible?
QC 7 Is it clearly stated in the study which other algorithms the study’s algo-rithm(s) have been compared with?
QC 8 Are the performance metrics used in the study explained and justified? QC 9 Are the test results thoroughly analysed?
QC 10 Does the test evidence support the findings presented?"
On the Planning phase, the structure of the review will be shaped and task and subtasks assigned. All these components should be explained in detail.
To perform a review a guideline is needed, according to Pickard et al. 1998, Greenhalgh et al. 2005 there are three methods: Protocol driven, "Snowballing" and Personal knowledge. Protocol driven is a strategy to establish the detailed prescriptions for the review. It is driven by rules and criteria define beforehand
to serve as a guideline to perform the tasks and report it.
Snowballing is a cross-referencing method of studies. From the references from the fist batch of studies it is decided whether to pursue the references of the references. The Snowballing process includes studies in the selection. Green-halgh et al. (2005) Snowballing consists in pursuing references of references and electronic citation tracking which will result on finding high quality sources on uncommonly locations.
Personal Knowledge approach starts with resources requests to the experts in the field; it is the search criteria. The background knowledge of the experts and its connection with others from the field allow access to relevant and not indexed material. However snowballing and personal knowledge can provide high relevant studies, report them need a more attentive and through description. Because it is not a systematic way of acquiring material, the studies could be subject to selection bias.
To the general structure of the Planning phase is to develop a protocol for the review. Conversely, Greenhalgh et al. 2005 advocates that for complex evidence studies review along with the protocol driven search a snowballing method should be also applied.
Moher et al. 2015 discusses how the protocol driven guideline is restrictedly used in SLR despite of its usefulness. He also defines protocol as a document that presents an explicit plan for SLR which constitutes a detailed rationale and methodology.
Regarding protocol development the articles, Kitchenham2004,Biolchini et al.
2005, (Uzun et al. 2018), Moher et al. 2015 can offer examples of protocol to be applied. Some are more thorough than the others in relation of each subtasks documentation such as (Uzun et al. 2018) and Biolchini et al. 2005.
On the execution phase, the SLR chosen guideline is applied, either protocol-driven, snowballing or personal knowledge or a combination of the three. The basics tasks are described, keywords chosen in the planning phase will identify eligible papers, subsequently the criteria for selection and exclusion will be
ap-plied, added by the time frame criteria, quality assessment to establish the first amount of studies to be taken into account for further investigation.
The tasks to be performed defined in Review Protocol are: Keywords Def-inition, Search and Selection, Quality Assessment, Data Extraction and Data synthesis.
The report phase consists in the written description of the steps and respec-tive tasks in detail and reasonable justification. The guideline for its performance is given by the review protocol build in the planning phase of the research. On the report all conclusion drawn as well as the documented tasks will be interning in one document. This document should contain the bias and validity discussion. The report should contain all the steps taken with detailed procedures of each of its tasks. All unexpected issues should be reported as well as unexpected situa-tions and results. Limitasitua-tions, constrains, conflicts should be also be reported. Before proceeding to the reporting step the results obtained should be validated, it is a common approach to use checklist to evaluate the validity. Some useful questions applied were previously presented.
Issues
This methodology is subject to different types of biases: Selection bias, per-formance bias, attrition bias, detection bias and report bias Higgins et al. 2011. In consequence, the tasks and subtasks should follow well-defined guidelines, in-dividual or ad hoc decisions should to be avoided. However, in case it is needed it should be properly justified.
SLR presents some issues such as Publication Bias, Protocol Form adaptations and implementation, Grey Literature shortcomings with no controlled vocabulary, flawed and not indexed search tools, variety levels of quality and striving to evaluate.
2.2
Methodology
Since the scope of this study is the technological enabled solutions, understanding the locational privacy preserving tools and schemes state-the-art is imperative. In order to perform this task, the method selected was the systematic Literature review, addressing the current obfuscation and anonymization techniques, its structures and architecture, weakness and threats.
The aim of this research will be delimited in four dimensions: Concerns, Solu-tions, Trends and Risk Assessment and Architecture defined as research questions to assess the efficiency of the obfuscation and anonymization strategies. The pro-tocol of the Data extraction will be improved during the process of the reading the papers which will not be older than 5 years.
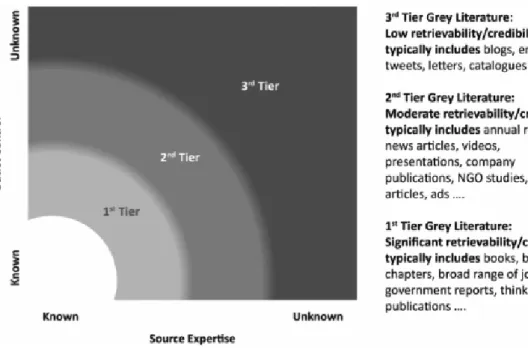
Even though there are relevant Phd Thesis been developed on the privacy preserving research, It was opted to keep only using the white literature instead of include what J. Adams et al. 2016 define as the first tier of Grey literature (GL) Figure 2.1. Grey Literature was not included in the research due to its challenging control and evaluation needs.
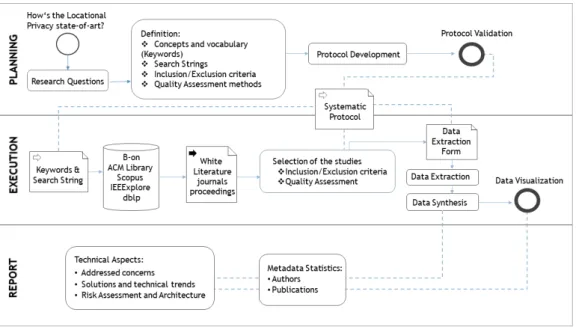
As verified at the Theoretical Background, Systematic Literature Review needs to be performed in three Steps: Planning, Execution and Report. The complete overview of the methodology applied to this SLR it is shown in Fig-ure 2.2.
On the Planning step, the aims and Research Questions will be defined and a Review Protocol built. The Review Protocol is pivotal to perform an SLR, this document contains all the actions thoroughly explained. It defines how the search and Selection will be performed, how the Data will be collected, aggregate, synthesised and report. On the Executing step, all activities planned on the previous step, Search and Selection, Data Extraction, Data Synthesis will be executed.
On the Reporting step, it will be following the guidelines of master thesis document.
Figure 2.1: Shades of Grey Literature (From J. Adams et al. 2016)
Review’s objectives
The Main objective is to provide a state-of-art of the obfuscation and anonymiza-tion technologies for preserving locaanonymiza-tional privacy.
RQ1 - CONCERNS: What are the addressed concerns for applying
obfusca-tion and anonymizaobfusca-tion techniques to protect locaobfusca-tion privacy?
RQ2 - SOLUTIONS: What are the proposed solutions in obfuscation and
anonymization techniques to protect location privacy?
RQ3 - TRENDS: What are the existing research directions within obfuscation
and anonymization techniques in location privacy?
RQ4 - RISK AND ARCHITECTURE: How architecture affects the
solu-tions, service quality with the use obfuscation and anonymization techniques to protect location privacy?
The Systematic Literature Review (SLR) performed on this research will pro-tocol based. The Review Propro-tocol structure will be the following:
Figure 2.2: Review Methodology
1.Question formularization
Review’s objectives Keywords and synonyms
2.Source selection
Sources searched to identify primary studies.
Criteria used to assess the quality of primary studies and their application
3.Studies Selection
Inclusion/exclusion criteria and their application
4.Data Extraction
Data extracted procedure from the primary studies
5.Results summarization
Data synthesis
Differences between studies revised Data combination and integration Conclusions based on evidence
Source selection To perform a systematic search strategy, there is a need to
strings. Several databases will be searched to guarantee a reasonable coverage on the topic.
The vocabulary assessment and keywords definition were orientated by the concepts list of (Wernke et al.2014). From this list, test were performed and new words were added and excluded.
Listed by (Wernke et al. 2014)
position dummies coordinate transformation spatial cloaking k-anonymity
spatial obfuscation mix zones
and conjoint with the following:
PET - Privacy-enhancing technologies geo-indistinguishability
The Keywords Definition took into account the usage of the spatial and loca-tion words to create the strings and test the searches. The following strings were tested against the digital databases.
“spatial cloaking” OR “location cloaking” *anonymity AND location or *anonymity AND spatial “spatial obfuscation” and “location obfuscation” “mix zones” and privacy
Privacy need to be added to mix zones because this expression is present in other knowledge fields beside privacy preserving. The words spatial and location were added to the string because just anonymity was generic, and the focus was locational data. For the same reason spatial and location were added to obfuscation and cloaking. There are other types of obfuscation, like authorship, code, etc.
The words and expression: coordinate transformation geomasking, Voronoi masking and point dummies were discarded because they were either too generic or exceedingly specific as Voronoi masking. The reason for the exclusion was a
great amount of irrelevant studies from the search results and the relevant ones were covered by the other keywords.
Once the aim and the research questions are defined the first step is to elab-orate a plan to search relevant studies to answer to the questions. The keywords and synonym were tested in the engine search of different Digital Libraries. Since the engines work differently some search strings were written slightly different in each case that can be verified in Appendix B. The search used broad contexts, in order to bring different platforms and architectures. For that reason, the time span criteria, relevancy and quality assessments were applied to constrain the studies selected. The final number of the studies pass through the steps of selec-tion, the search criteria and afterwards with the inclusion and exclusion criteria. Only two classes will be on scope: Data Anonymization and Data Perturba-tion classes of techniques, the articles which present combined technologies will be selected only if they use any of the techniques classified in one of the two aforementioned classes.
The keywords related to Data Perturbation Techniques and Data Anonymiza-tion were used to search the relevant studies on the Digital libraries, namely: Scopus, IEEExplorer, B-on, ACM Digital Library and dblp. The Libraries Sco-pus, ACM Library, B-on, IEEExplorer the string were applied entirely in one step. Conversely, dlpb the search string was done by steps because we did not allow customization on the queries. For that reason there were duplicates results even within the papers found by the aforementioned Libraries. The selection of the online database followed the criteria of been a wide spectrum and a variety of articles and publication indexed. The selection was performed sequentially, as follows: the Scopus, B-on, ACM, IEEExplorer, dbpl. The description can be seen in the Appendix E.
Criteria to assess the quality of primary studies
The quality criteria chosen is a combination of the Peer-reviewed Journals with studies with a high number of citations. Pursuing the quality assessment
prescriptions from Dybå et al. 2008, Carver et al. 2016 and Kitchenham et al.
2011. Added to the two aforementioned factors generating the quality check-list as following.
Quality Assessment check-list
QA1 - Are the aims of the study clearly stated?
QA2 - Is the proposed solution clearly explained and validated by an empirical evaluation?
QA3 - Is the architecture clearly described? QA4 - Is the threat model clearly described?
QA5 - Do the conclusions relate to the aim of the purpose of study?
QA6 - Does the report have implications in practice in a research area of privacy preserving mechanism?
The Extraction Form contains one entry QA which adds a number for the questions with a positive answer.
Studies Selection Inclusion/exclusion criteria:
Since the search was broad, more criteria other than then the keywords were necessary to narrow down the number of the studies, the relevance, reputation and quality criteria play a significant role in the selection of the studies in analysis. For this work the number citations, five years period of publications, from 2015 to 2018. Following are the inclusion and exclusion criteria in detail.
Inclusion criteria:
IC1-Papers Published between 01/01/2015 and 30/11/2018; IC2-Number of citations
• Year of Publication 2015 >= 15
• Year of Publication 2016 >= 10
• Year of Publication 2018 (Jan-Jun) > 1
• Year of Publication 2018 (Jul-Nov) >= 1
Exclusion criteria:
EC1 - Articles which the full text is not available; EC2 - Duplicate Articles from different platforms; EC3 - Articles not written in English;
EC4 - Articles not related to locational privacy preserving mechanism; EC5 - Articles not related to obfuscation or anonymization techniques; EC6 - Articles not related to locational data;
EC7 - Articles from second studies
EC8 - Articles related with Vehicle Network
The Exclusion Criteria EC8 was established after the process of Data extrac-tion due to the diverse concepts and artefacts not adaptable to the realm of the Mobile Networks.
2.3
Data Extraction and Data Synthesis
After the preliminary study selection, the data extraction phase initiates. The crucial task of this phase is to collect data from the studies through reading and filling up the Extract Data Form present on Appendix C built and validated on the planing step. Not all entries are applicable to all artifacts. The broad conception of the extraction form enables the maximisation of information collection thus the data analysis and synthesis will be enriched. Most of the articles did not present all details of the experiments, the threat model, platform and settings. It was not possible to extract all information to fill all entries on the extraction form.
The extracting process started with reading and screening of the studies. The focus at the beginning was on the abstract, introduction and conclusion. The reading task was executed as following: abstract screening, text sections screening, full text screening, data form entry filling screening. If after the process of reading all full texts of the studies some entries in the Data Extraction Form were left empty by omission it will be corrected during Data form entry filling screening phase.
The reading process focused on the article’s sections: system design, experi-ment and evaluations, the information extraction of the proposed solution, system architecture, the risk assessment and threat model, techniques, the results and discussion, applicabilities, capabilities, limitations, constrains challenges level and comparison with others solutions. Development environment, architecture, com-mon threats and countermeasures encountered, concerns addressed and solutions as well as information journals metadata were also extracted.
On the entry Why not from the Data Extraction Form is a place to report the post excluded studies which exclusion was performed after the data extraction started during the reading process. The entry sections was helpful for study screening, showing quickly where to extract the Address Concern, Aims, solutions and the general overview of the study.
Differences between studies revised
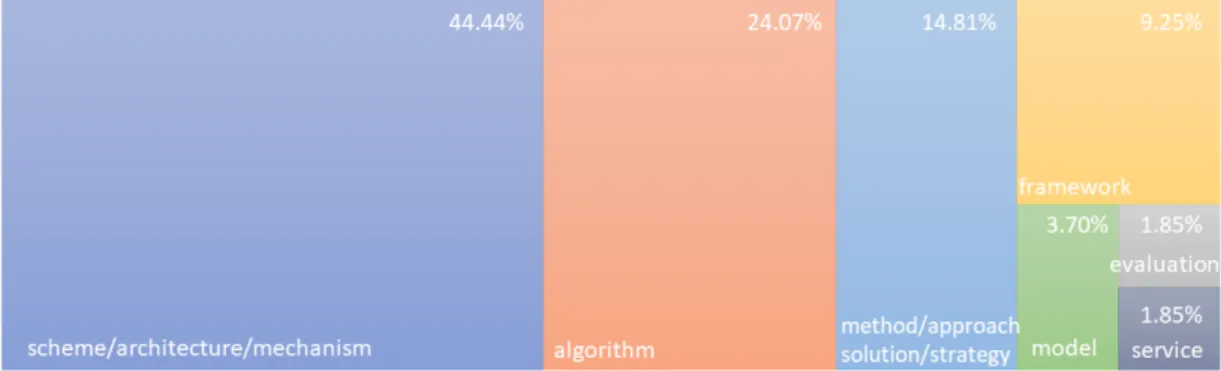
The selected artefacts present different implementation and characteristics. In the Figure 2.3 it is possible to observe that the 37 of 54 studies comprises mostly by schemes and algorithms.
Figure 2.3: Types of Artefacts
Data combination and integration
The data integration will follow the similar structure of the research questions. There will be four main sections: metadata and technical aspects separated by the dimension. The research question (RQ1) will have the title addressed concerns, the second title will be solutions and trends answering to questions two and three (RQ2 and RQ3), the third title risk assessment and architecture answering questions (RQ2 and RQ4).
To manage risk, organisations need the means to assess them. In software development, the threat Model provides the description of the risk in security Networks. Describing the targeted assets and procedures of the system, the ca-pabilities of the adversary and the policies to tackle them. On the Data extraction form, this information can be extracted. The entries used were type of artefact artefact, the threat model of the schemes and algorithms threat_model, the topol-ogy topoltopol-ogy, the presence of a trusted third party TTP.
Chapter 3
Results
The selection results can be seen inFigure 3.1which shows the number of the In-cluded, not included studies, and number of each study for a type of the exclusion criteria. On the Appendix D it is possible to see a more detailed table with the Selection Status results with the studies disaggregated for Digital library used.
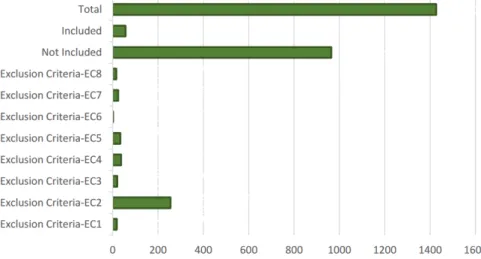
Figure 3.1: Results of Selection and Exclusion Criteria
From the 1427 articles after applying the inclusion and exclusion criteria 54 studies were selected.
From the total select studies, 43 from 54 present or should present system design and threat model. Because they are schemes, system architectures, service or algorithm with implementation described Figure 2.3. To total set of studies
not all the questions are applicable because they were just a simply improvement of a specific routine or algorithm but not a proposed scheme or mechanism.
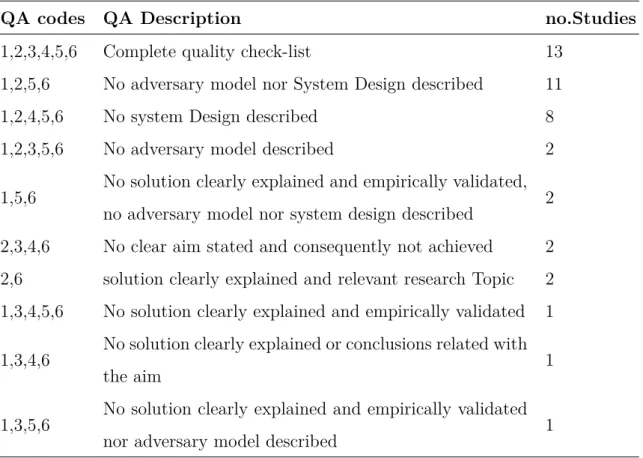
A quality assessment was performed using the checklist defined in the planning phase of the review. From the studies which all the six questions of the quality checklist should applied were aggregated in the following Table 3.1.
QA codes QA Description no.Studies
1,2,3,4,5,6 Complete quality check-list 13
1,2,5,6 No adversary model nor System Design described 11
1,2,4,5,6 No system Design described 8
1,2,3,5,6 No adversary model described 2
1,5,6 No solution clearly explained and empirically validated, no adversary model nor system design described 2 2,3,4,6 No clear aim stated and consequently not achieved 2 2,6 solution clearly explained and relevant research Topic 2 1,3,4,5,6 No solution clearly explained and empirically validated 1
1,3,4,6
No solution clearly explained or conclusions related with
the aim 1
1,3,5,6
No solution clearly explained and empirically validated
nor adversary model described 1
Table 3.1: Quality check-list Synthesis
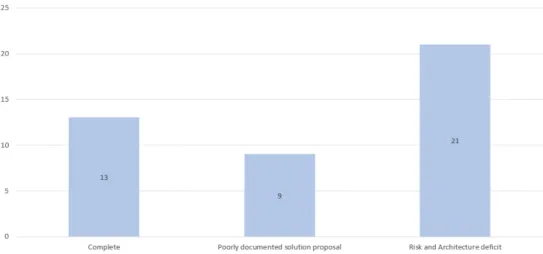
Eleven studies had neither a clear and detailed adversary model nor System Design described, adding to them the studies with either no clear and detailed adversary model or System Design described, two and eight respectively. It is around half of the studies has no clear description of the system design or privacy risk assessment/adversary model as it can be seen in fig:qa under the category of Risk and Architecture deficit.
SLR instructions understands quality assessment as one of the exclusion crite-ria. But instead of removing the studies, it was decided to have them analysed in
Figure 3.2: Quality check-list Categories
order to identify the most common relevant parameters and conditions overlooked in this type of research.
The studies which were listed as not having a clearly defined aim are generally the ones which the authors explained a general problem but not explicitly state that the aim of the proposed scheme or other artefact has a define design goal to be achieved.
3.1
Articles Metadata
In this section, the Metadata of the Studies will be discussed. The variables (en-tries) in the Data Extract Form considered are the ones related to the Publication media Information, such as Publication Date, publisher’ name, written language, authors’ names, Institutions and Digital Libraries. Nothing related to the study content itself. Because of the search criteria some information is already given and comon to all the studies, such as the language of the studies which is English and the period of publication that is from 01-01-15 to 30-11-18.
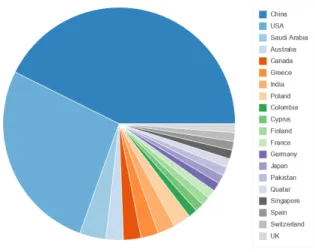
The major part of the author Institutions 43% are from the Republic of China, followed by USA with 27% as it can be seen in Figure 3.3. This massive number of studies is following a dominance trend of the technological sector in China,
growing with high rates in new technologies development, in the number of new start-ups finding no comparison in other countries, leaving even USA far behind. The amount of investment, a budget of some of these companies are massive. This phenomenon is so striking that the journalist Moritz 2018 in his article of the Financial Times from June 2018 states that "China is winning the global tech race".
Figure 3.3: Author’s Institutions Country
The most relevant publications found are: The Future Generation Computer Systems (FGCS) and Journal of Network and Computer Applications from the Elsevier Publisher, IEEE Access, IEEE IoT Journal (IoT-J) and IEEE Transac-tions on Knowledge and Data Engineering from IEEE Journals and Magazines were the top five of the Publications, FGCS with 6 and the others with 3 articles. The top ten publication with the respective studies can be seen in the Appendix F and the on the Figure 3.4. The number of journals with only one article selected is 24, which names are following: ACM Conference on Security and Privacy in Wireless and Mobile Networks, Applied Soft Computing, Computer Communi-cations, Computer Networks, Computers and Security,IEEE INFOCOM, IEEE International Conference on Recent Trends in Electronics, Information and Com-munication Technology, IEEE International Conferences on Big Data and Cloud Computing, IEEE Wireless Communications, International Conference on Data
Engineering, International Journal of Distributed Sensor Networks, International Journal of Geographical Information Science, Investigación en Innovación en las Ingeneirías, Journal of Transport Geography, Knowledge-Based Systems, Mul-timedia Tools and Applications, Personal and Ubiquitous Computing, Sensors, Soft Computing - A Fusion of Foundations, Methodologies and Applications, Telecommunication Systems, Transportation Research Part C: Emerging Tech-nologies, Tsinghua Science and Technology, Wireless Communications and Mobile Computing, Wireless Networks.
Figure 3.4: Publications from the selected articles
FGCS has its focus on distributed systems, collaborative environments, high performance and high performance computing, Big Data and Internet of Things presenting with an Eigenfactor of 0.008 and an Impact Factor of 4.639.
The Journal of Network and Computer Applications has its focus on computer networks and applications (design, standards,etc) studies. It presents an Impact Factor of 3.991 and an Eigenfactor of 0.008.
IEEE Access has its focus on the topics comprised by IEEE, emphasizing applications-oriented and interdisciplinary articles. It has an Impact factor of 3.557 and an Eigenfactor of 0.0186.
IEEE Transactions on Knowledge and Data Engineering has its focus on knowledge and data engineering aspects of computer science, artificial
intelli-gence, electrical engineering, computer engineering. It has an Impact Factor of 2.775 and Eigenfactor of 0.018.
IEEE Internet of Things Journal (IoT-J) has its focus on the latest advances on the various aspects of IoT. It has an Impact Factor of 5.863 and Eigenfactor of 0.00663.
Except from FGCS with 11% of the articles, there is no concentration on a specific journal. Since 44% of all studies are percentage of journal with only one single article. In addition, the journals with more numbers of studies presents high impact factors and a diverse scope of publication.
3.2
CONCERNS Addressed
The CONCERNS dimension was one of the four unfolded in research questions in order to display the state-of-art of locational privacy. Therefore, identify the cur-rent concerns and what extent they have been addressed is crucial. They can be related to defence to current threats, identification of new ones, limitation on pri-vacy preserving technology, improvement of existent techniques and mechanism, or suggestion of new methods. This dimension will be extracted from the follow-ing Data Form entries: addressed_concern and obs_addconcern, the Addressed Issues collected from the studies can be seen on Appendix A. The aggregated concerns categories are the following:
− Identification of new threats
− Mechanism proposal against a current threat
− Solve a limitation on privacy preserving mechanism/scheme
− Improvement of existent techniques or scheme
− Suggestion of a new method
The majority of the studies were focused on suggestion of new privacy pre-serving schemes with 40.7% or dealing with the current environment of known threats with 38.9% Table 3.2.
Concern Percentage
Suggestion of a new method 40.7%
Mechanism proposal against a current threat 38.9% Improvement of existent techniques or scheme 13% Evaluation or test of privacy preserving
mecha-nism/scheme 13%
Solve a limitation 7.41%
Identification of new threats 1.85%
Table 3.2: Addressed Issues
From the entry assessment_approach were captured the tools used to evaluate the artefacts. The types of assessment are: a case study, experiment, theoretical, analytical and empirical validations or a small example. From the 54 articles 44, i.e. 81.48%, performed experiments or simulations. The objective pursued was to provide a reasonable level of privacy with an acceptable user experience.
3.3
SOLUTIONS and TRENDS
On this section, the proposed solutions and trends observed on this four years will be discussed and further directions projected. The entries on the Data Extrac-tion form examined were: techniques,combined_techniques, aims, soluExtrac-tions and constraints.
The proposed solutions can be seen in Appendix A which lists the classes of techniques, Anonymization with 46.48%, Data perturbation with 40.85% and En-cryption with 12.68%. From the total of studies, 31.48% have combined types of techniques. K-anonymity, dummyfication, differential privacy are the most used techniques. It is worrisome, since k-anonymity perform poorly against continuous behaviour and moving objects, therefore is commonly used combined with others techniques.
The techniques and their families can be seen in Appendix F and the threats which the proposed solutions address can be seen in Appendix F. In Table3.3and in Figure 3.5 it is verified that the solutions in general aim to provide location and trajectory privacy 77.77% or protect against a specific attack 25.92%. The solutions are rather general than specific in dealing with privacy threats.
Figure 3.5: Solution’s aims
Threats like the inference attacks and continuous query are still a challenge to privacy preserving mechanism. Consequently, a low number of threats addressed
solutions it is an ill-advised direction.
For Shokri (2013), the recurrent menace to locational privacy is classified in: i)tracking attack, ii)inference attack, iii)disclosure attack, iv)user profiling. On Appendix F the threats addressed by the solution proposed on the select articles are listed in categories partially based on his classification. Most of them are historical attackers, they collect, analyse and integrate to other sources of data, such as context information or other’s entity data.
Aims no.studies Solutions
Trajectory and location protection 29
DQE S. Zhang, G. Wang, et al. 2018, Ma et al. 2018, Ye, Y. Li, et al. 2017, CTPP Peng, Liu, Meng, et al. 2017, LTPPM Gao et al.
2015, Chunguang et al. 2015, LLB G. Sun, Liao, et al. 2017 ,TVM Konstantinidis et al. 2015, Hara et al. 2016, J. Li et al. 2017, Seidl et al. 2016, MobiMix Palanisamy et al. 2015, 2SP-SP, Priv-2SP-SP Aïvodji et al. 2016 ,S. Zhang, Choo, et al. 2018,Ye, Chen, et al. 2018, Ye, Chen, et al. 2018,Lahe et al.2017,Peng, Liu, and G. Wang 2017,Chi et al. 2018,Y. Wang, Cai, Tong, et al. 2018,Schlegel et al. 2015,Ye, Y. Li, et al. 2017,HISP-NC Rios et al.2015,Yi et al.2016,Montazeri et al.
2017,Weiwei et al. 2016,Han, J. Wang, et al.2018,Chi et al. 2018,H. Zhu et al. 2018
Anonymity 13
DPMM Memon et al. 2017, PPVC Shahid et al. 2017, Chunguang et al. 2015, MobiMix Palanisamy et al.2015, DLP G. Sun, Chang, et al.
2017, Huang et al. 2018, Y. Zhang et al. 2016 ,DPkA J. Wang, Cai, et al.2018, Graph-based X. Li et al.2016, SCGuard To et al.2018, Al-Dhubhani et al.2018, Ttcloak Niu, X. Zhu, W. Li, et al.2015, k-Trustee Jin et al. 2018
Continued from previous page
Aims no.studies Solutions
Resistance to specific privacy attack 14
Niu, X. Zhu, Q. Li, et al. 2015 ,ASA Y. Sun et al.2017 ,DLP G. Sun, Chang, et al.2017, Y. Wang, Cai, Chi, et al.2018,TIS-BAD Wightman et al. 2015, ILLIA Zhao et al.2018, Chunguang et al.2015, LLB G. Sun, Liao, et al. 2017, CTPP Peng, Liu, Meng, et al. 2017, Y. Wang, Cai, Chi, et al. 2018, Schlegel et al. 2015, ILLIA Zhao et al. 2018, k-Trustee Jin et al. 2018, Han, J. Li, et al.2016
User-centric location privacy 3 G. Sun, Xie, et al. 2017 ,ESOT Ullah et al. 2018, L2P2 G. Sun, Liao, et al. 2017
Preserve Query Privacy 2 EPLQ L. Li et al. 2016,Yi et al. 2016
Privacy preserving Data publication 2 Terrovitis et al. 2017, Oksanen et al.2015
Protect Friend relationships and location 1 CenLocShare Xiao et al. 2018
Identify the influence of probing frequency 1 Freudiger 2015
MCS better than WSN 1 He et al. 2015
Node Location Privacy Protection 1 J. Wang, R. Zhu, et al. 2018
Table 3.3: Aims and Solutions Synthesis 39
3.4
Risk Assessment and Architecture
On this section, the Privacy Risk Assessment and Adversaries model will be discussed. Together with the dimensions of the solutions and the quality of service.
In security networks, the risk assessment buils threats or attack models. The manager define its policy and analyse the potential risks for system entities, assets and network to be exposed. The assumptions of the severity, extent of an attack and the capabilities of an adversary need to be reasonable, otherwise the protection and consequently mitigation will be ineffective. In computer security the adversary and threat Model can be classified as following: Global/Local, Active/Passive, Static/Adaptive and Internal/External. The entries on the Data Extraction Form for this type of information are: Internal_External, threat_model and topology.
Mobile Applications and services schemes can present a centralised or decentralised architecture. Each arrange has its advantages and drawbacks. The centralised structure simplify control, but generate bottlenecks or become a weak spot. On the other hand, distributed architecture reduce the extent of damage when an entity is compromised and remove the role of third trusted party.
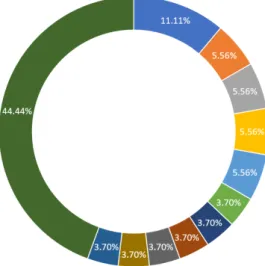
On Table 3.5 and Figure 3.4 it can be verified that 31.48% Implementation depen-dant or not informed, 27.78% Centralised, 40.74% Distributed. The existence of Trusted Third Party (TTP) entity percentages comprises 35.19% no TTP, 31.48% Implementation dependant or not informed, 22.22% TTP, 11.11% Semi trusted.
From the studies which were supposed to present a complete architecture described 30.23% succeed similar percentage, 25.58%, the studies without a clear description of the system design and threat model (Table 3.1).
On the entry metrics, the metrics used to evaluated the performance of the artefacts were captured as mostly computational, communication, storage cost and privacy level.
Privacy preserving mechanisms are highly complex, consuming massive resources ei-ther on device or Server, for this reason achieve a reasonable performance with privacy protection is hard. But with a rapid development of hardware, the accessibility to new technologies, the devices are become increasingly more powerful in terms of computation and storage. Thereof, potential usage on client-side and user centric applications with rea-sonable tradeoff between privacy and utility. Other consideration to be made regarding to QoS is the overhead and battery usage.
3.5
General Discussion of the findings
To perform an intensive working endeavour like SLR some limitations has to be taken into account, such as the time frame available, restrict resources and the manually executing of the tasks. The scope and selection criteria were affected by the restriction, whereas only four years articles will be investigated and Vehicular Networks excluded.
Bias is one of the risk in performing SLR, on this research it is worth to mention the difficulty on achieve the gold set of the studies. the total amount of studies existent that to be satisfied the criteria. the total amount is unknown, hence it is not possible to measure the bias of the selection of the studies.
Other limitation of the study rely on the Data extract Form filing up, since the process were mostly manual, with a significant amount of studies and entries. It possible an eventual omission of data on the Data Form.
Background knowledge, collusion and contextual data are not considered on the system design of the solutions. The assumptions, when present at the article are naïve assuming in some cases entities to be fully trusted.
Architecture Category TTP no.Studies
Users+LBS server distributed no 8
User+Anonymizer+LBS Server centralized Anonymizer 6
SN Server+query user (QU)+query user’s friends (Ufs) distributed no 1 User + Location-Storing Social Network Server (LSSNS) +
Cellular Tower (CT) centralized cellular towers 1
User+User’sfriends+LBS Server distributed no 1
User-centric architecture distributed yes 1
IoT devices+ obfuscation engine + LBS centralized no 1
nodes +access points (AP) +report server (RS)+App. Server
(AS) distributed no 1
users+location Anonymizer +LBS distributed no 1
User + LBS Server +Base Station +Satellites distributed trusted hardware 1
User+AP distributed no 1
user+Anonymizer+Function Generator+ LBS centralized Semi trusted 1
user+Annonymizer+Converter+LBS Sever centralized Semi trusted 1
Scheme Architecture Synthesis – Continued on next page
Continued from previous page
Architecture Category TTP no.Studies
User+OSN Server+LBS Server centralized Semi trusted 1
user+Pseudonym Identity Server+ LBS Server centralized no 1
User+semiTTP+Provider distributed Semi trusted 1
User+Social Network Server+Beacons distributed no 1
User+TTP+LBS centralized TTP 1
Users+CS+LBS centralized CS 1
users+ online social network server +LBS server and multiple
location servers (MLS) implementation distributed no 1
Users+CA +Plataform Server centralized PS 1
Users+Access Point+Operator distributed no 1
Users+Fog server+LBS server distributed no 1
Users+LBS server distributed Semi trusted 1
users+service providers+ query servers distributed semi QS 1
Implementation dependant or not informed 17
Table 3.4: Scheme Architecture Synthesis 43