eve baprata um algoritmo
Texto
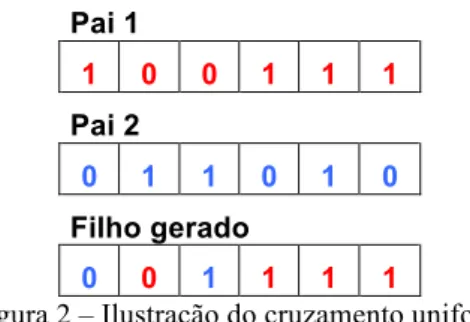
Imagem

Documentos relacionados
Como vantagens do modelo proposto, pode-se destacar: (i) permitir uma maior compreensão da dinâmica operacional do sistema modelado, se comparado com outros modelos de simulação;
Para a obtenção das variáveis, cabe observar os seguintes aspectos básicos: (i) O comportamento dos intervalos de chegada de cada conjunto de navios é refletido pelo
Neste contexto, o presente trabalho procura contribuir para a otimização da localização de Plantas de Produção de BDM - PPBDM nos municípios englobados pela Cadeia de
Ao longo deste texto, que apresentou uma visão geral da problemática da gestão das infra- estruturas no meio urbano, pôde-se perceber a complexidade de se avaliar e gerir as
De acordo com Ogden (1992), nenhuma área urbana pode existir sem um robusto, sustentável e confiável fluxo de bens, seja este fluxo interno ou externo à urbe. O acesso da população
O objetivo deste artigo é reportar a elaboração de um modelo de avaliação de desempenho operacional em pátios portuários, baseado nas redes de Petri coloridas,
A Análise Envoltória de Dados ( Data Envelopment Analysis - DEA) é uma técnica advinda da Pesquisa Operacional que, por intermédio de modelos de programação matemática,
Como sugestões para futuros estudos, para melhoria da eficácia e da eficiência da abordagem em foco, podem ser citadas: incorporação de uma heurística para o reparo de
