TÍTULO
Nome completo do Candidato
Subtítulo
Criação de Clusters de Clientes de um Banco através do
Self-Organizing Maps Hierárquico (HSOM)
Inês Capote Coelho
Comparação entre HSOM e SOM
Instituto Superior de Estatística e Gestão de Informação Universidade Nova de Lisboa
CRIAÇÃO DE CLUSTERS DE CLIENTES DE UM BANCO ATRAVÉS
DO SELF-ORGANIZING MAPS HIERÁRQUICO (HSOM)
por
Inês Capote Coelho
Trabalho de Projeto apresentado como requisito parcial para a obtenção do grau de Mestre em Estatística e Gestão de Informação, Especialização em Gestão de Conhecimento e Business Intelligence
Orientador: Professor Doutor Fernando Bação
Coorientador: Professor Doutor Roberto Henriques
RESUMO
Um dos maiores desafios no processo de clustering está na multidimensionalidade da maioria dos problemas. A descrição de um fenómeno, necessita, normalmente, de um número elevado de variáveis, afetando assim, a eficiência dos algoritmos de clustering. Muitos destes algoritmos são sensíveis a variáveis divergentes, ou seja, com diferentes distribuições. Estas caracterizam-se por apresentar grandes diferenças quanto à tendência geral, o que lhes confere um maior peso na solução final de clustering.
Como forma de contornar este aspeto, surge o HSOM (Hierarchical Self-Organizing Map), o qual permite agrupar as variáveis em vários temas, produzindo assim uma segmentação final onde cada um dos temas usados terá um impacto semelhante na mesma.
Este Trabalho de Projeto vai debruçar-se sobre esta temática e envolve dois principais objetivos. O primeiro numa vertente teórica que visa explicar o método SOM (Self Organizing Maps) juntamente com o HSOM, dando a conhecer o modo como funcionam. O segundo, numa vertente prática, tendo o intuito de aplicar o método HSOM na construção de clusters, com base em clientes de um Banco, agrupando as variáveis nos seguintes temas: Marketing, Produção, Risco e Sociodemográficos.
Com isto, o objetivo final será a construção de uma interface interativa e de fácil utilização que segmente os clientes, de modo a facilitar à obtenção de informação sobre os mesmos, auxiliar as análises futuras e diferenciar as ofertas nas campanhas de marketing direto.
Neste âmbito, tanto o HSOM (com sete clusters) como o SOM (com cinco clusters) são concretizáveis. O HSOM permite reduzir a dimensionalidade dos problemas, a construção de uma estrutura natural do problema e exige menos esforço computacional usando diferentes SOMs para cada nível hierárquico.
PALAVRAS-CHAVE
ABSTRACT
Dimensionality is one of the biggest challenges faced by clustering process. Usually, the description of a phenomenon requires a large number of variables, which affects the clustering algorithms efficiency. Many of these algorithms are sensitive to variables with large differences between their scales which gives them a bigger weight on the final clustering solution.
HSOM (Hierarchical Self Organizing Maps) deals with this problem by grouping several variables in different subjects, producing a final segmentation where each subject has similar impact.
This project focuses on this subject and has two main goals. Explaining SOM and HSOM methods by introducing them in a theoretical way is the first one. The second one is applying the HSOM and SOM methods in a customer bank database in order to build clusters by grouping the available variables in different subjects – Marketing, Performance, Risk and Socio-demographic.
Thus will be possible to build an interactive and user friendly interface which will allow segmenting customers, making easier information search, supporting future analysis and creating different offers in direct marketing campaigns.
In this context, HSOM (with seven clusters) and SOM (with five clusters) are achievable. The HSOM reduces the dimensionality of the problems, require less computational effort and construct a natural structure of the problem, using different SOMs for each hierarchical level.
KEYWORDS
ÍNDICE
1. Introdução ... 9
1.1.Contextualização ... 9
1.1.1.Data Mining ... 10
1.2.Objetivo do Estudo ... 11
1.3.Banco em análise ... 12
1.4. Rationale / Lógica ... 12
1.5.Formulação das Questões ... 14
1.6.Organização do Trabalho de Projeto ... 14
2. Revisão da Literatura ... 16
2.1.Contextualização ... 16
2.1.1.Redes Neuronais Artificias (RNAs) ... 17
2.2.Self-Organizing Map Hierárquico (HSOM) ... 22
2.2.1.Definição ... 22
2.2.2.Taxonomia ... 23
2.2.3.Razões para utilizar o HSOM em vez do SOM ... 27
2.3.Balanço Final ... 28
3. Metodologia ... 29
4. Extração e Pré-processamento dos dados ... 32
4.1.Extração da base e pré-requisitos dos dados ... 32
4.1.1.Pressupostos da extração da base de clientes ... 32
4.2.Análise descritiva das variáveis ... 33
4.3.Análise dos dados e pré-processamento de dados ... 34
4.3.1.Estatísticas Descritivas ... 34
4.3.2.Correlações ... 36
4.4.Escolha das variáveis finais ... 36
5. Resultados práticos ... 40
5.1.SOM standard ... 40
5.2.SOMs Temáticos ... 45
5.3.HSOM ... 50
6.2.Comparação entre HSOM e SOM em termos teóricos ... 59
6.3.Respostas Finais às questões propostas ... 60
7. Conclusões ... 61
8. Limitações e Recomendações para Trabalhos Futuros ... 63
9. Bibliografia ... 64
ÍNDICE DE FIGURAS
Figura 1- Self Organizing Map´s espaço de output (duas dimensões) e espaço de
entrada (três dimensões) ... 19
Figura 2 - Fase de Treino do SOM ... 20
Figura 3 - Processo de desdobramento do SOM durante o processamento ... 20
Figura 4 - Exemplo de um SOM “dobrado” ... 21
Figura 5 – Estruturado HSOM ... 22
Figura 6 - Taxonomia do HSOM ... 23
Figura 7 - Tipos de HSOMs: a) Aglomerativo b) Por Divisão ... 24
Figura 8 - GHSOM a refletir a estrutura hierárquica dos dados de entrada ... 26
Figura 9 – Fases do Processo de investigação e elaboração ... 29
Figura 10- Planícies de componentes da nDiasUltResposta e perc_Resp_prop_camp . 37 Figura 11- Matriz U da variável maxTax ... 38
Figura 12- Matriz U da variável minTax ... 38
Figura 13- Matriz U da variável nAtivos ... 38
Figura 14- Matriz U do SOM standard ... 40
Figura 15- Resumo dos Clusters do SOM Geral ... 44
Figura 16- Resumo do SOM temático do Marketing ... 46
Figura 17- Resumo do SOM temático da Produção ... 47
Figura 18- Resumo do SOM temático do Risco ... 48
Figura 19- Resumo do SOM temático Sociodemográfico ... 49
Figura 20- Matriz U do HSOM ... 50
Figura 21- Resumo dos Clusters gerados pelo HSOM ... 55
Figura 22- Matriz U do SOM com o mapeamento dos clusters do HSOM ... 56
Figura 23- Distribuição dos clusters do HSOM pelos grupos gerados pelo SOM ... 57
Figura 24- HSOM vs SOM em termos práticos ... 57
ÍNDICE DE TABELAS
Tabela 1- Descrição das variáveis ... 33
Tabela 2 - Análise Univariada das variáveis ... 34
Tabela 3- Variáveis Finais ... 36
Tabela 4- Diferentes abordagens das variáveis iniciais ... 36
Tabela 5- Médias das variáveis dos grupos gerados pelo SOM Standard ... 41
Tabela 6- Médias das variáveis dos grupos gerados pelos SOMs temáticos... 45
ÍNDICE DE FIGURAS EM ANEXO
Anexo 1- Gráfico distribuição de Rendimentos ... 66
Anexo 2- Análise de outliers para variável Monetary ... 66
Anexo 3- Planícies de Componentes das variáveis de Marketing ... 66
Anexo 4- Planícies de Componentes das variáveis de Produção ... 67
Anexo 5- Planícies de Componentes das variáveis de Risco ... 67
Anexo 6- Planícies de Componentes das variáveis Sociodemográficas ... 67
Anexo 7- Bloxpot das variáveis no SOM Standard com linha que une a média de cada variável ... 68
Anexo 8- Bloxpot das variáveis de Marketing no HSOM com linha que une a média de cada ... 68
Anexo 9- Bloxpot das variáveis de Produção no HSOM com linha que une a média de cada ... 69
Anexo 10- Bloxpot das variáveis de Risco no HSOM com linha que une a média de cada ... 69
Anexo 11- Gráfico Linear das variáveis Sociodemográficas no HSOM ... 69
LISTA DE SIGLAS E ABREVIATURAS
AG Algoritmos Genéticos
BMU Best Matching Unit
CNPD Comissão Nacional de Protecção de Dados
CRM Customer Relationship Management
DM Data Mining
DW Data Warehouse
GHSOM Growing Hierarchical Self-Organizing Map
HSOM Hierarchical Self-Organizing Map
MLP Perceptrões multicamada
RFM Recency Frequency Monetary
RNAs Redes Neuronais Artificais
1. Introdução
1.
INTRODUÇÃO
“Clustering constitutes one of the most popular and important tasks in data analysis. This is true for any type of data” (Henriques et al., 2012)
“The size and dimensionality of the existing and future databases stress the need for efficient and robust clustering algorithms. This need has been successfully
addressed in the context of general-purpose knowledge discovery. “ (Henriques et al.,
2012)
Um dos métodos de clustering existente para dar resposta a estes desafios é o SOM (Self-organing Maps), que por sua vez permite a criação e processamento de um outro método, o HSOM (Hierarchical Self-Organizing Map).
O SOM e o HSOM são os métodos de clustering que serão estudados e aplicados neste Trabalho de Projeto.
Este capítulo está organizado em seis subcapítulos: subcapítulo 1.1 onde será feita uma contextualização do tema em que o trabalho está inserido, incluindo o Data Mining, seguido do subcapítulo 1.2 onde será descrito o objetivo do estudo ao pormenor. No subcapítulo 1.3 estará descrito o banco em análise, seguido do subcapítulo 1.4 onde será abordada a lógica do Trabalho de Projeto. No 1.5 serão apresentadas as questões que são propostas a responder e por fim, no subcapítulo 1.6 será descrita a organização do Trabalho de Projeto.
1.1.CONTEXTUALIZAÇÃO
A capacidade de aquisição de dados de forma automática (sem qualquer intervenção humana) é cada vez mais uma realidade, acelerando a digitalização da nossa sociedade. Com a nossa sociedade a sofrer uma pro re a “d al a o” as empresas terão mais oportunidades e possibilidades de aprender mais sobre os seus clientes (Bacao, 2006).
integrado de dados com elevado detalhe e resumidos. Está organizado por áreas de negócio e user- friendly para um gestor e/ou um analista (Kimball and Margy, 2002).
1.1.1. Data Mining
Uma vez que o Datawarehouse tem como objectivo proporcionar ao utilizador final um repositório de dados de fácil utilização e com um grande valor acrescentado na área da análise da informação, existem condições para realizar e aplicar o Data Mining.
Sendo cada vez maior a dificuldade em desenvolver vantagens competitivas num mercado globalizado e em constante expansão, a ideia de transformar os dados dos clientes e do negócio em novo conhecimento torna-se muito apelativo e interessantes para o mundo empresarial. Atualmente é visto como uma melhor forma de desenvolver vantagens competitivas de longo prazo.
Assim, os dados podem ser transformados em informação, e a informação armazenada ao longo dos anos pelas organizações permite-lhes desenvolver conhecimento sobre a sua atividade, o seu funcionamento e os seus clientes. O Data Mining (DM) irá auxiliar as organizações a extrair esse conhecimento que tanto desejam. Uma definção possivel para DM é“ he analy of (of en large) observational data sets to find unsuspected relationships and to summarize the data in novel ways
ha are bo h under andable and u eful o he da a owner” (Hand et al., 2001).
O Data Mining é uma área que tem vindo a sofrer um elevado crescimento nos últimos anos, sendo considerada uma das tendências mais marcantes no mercado dos sistemas de informação (Bacao, 2006).
Com clientes cada vez mais exigentes, mais sensíveis ao preço e menos compreensivos para com eventuais ineficiências, é inevitável que as organizações inovem e se diferenciem através da antecipação do comportamento dos consumidores e do conhecimento do ambiente competitivo em que atuam.
Dentro do Data Mining existem as Redes Neuronais Artificias (RNAs) que irão auxiliar a ordenar, classificar e analisar os dados. O seu principal objetivo é simular o processo de aprendizagem do cérebro humano.
Por sua vez, o Self-Organizing Map (SOM), método que vai ser abordado neste Trabalho de Projeto, “one of he be -known unsupervised-learn n neural ne work” (Kohonen, 1982a).
1. Introdução
can be effectively utilized to visualize and explore properties of the data. When the number of SOM units is large, to facilitate quantitative analysis of the map and the data, similar units need to be grouped, i.e., clustered. (Vesanto and Alhoniemi, 2000)
O SOM tem sido utilizado em diversas áreas para a análise de agrupamento ou classificação automática de dados.
1.2.OBJETIVO DO ESTUDO
Neste contexto, através do Data Mining, o Trabalho Projeto que é proposto realizar surge fundamentalmente na necessidade que as organizações têm de gerir a relação com o cliente, mais precisamente através da segmentação de grandes bases de dados de clientes.
A segmentação é um aliado precioso das empresas, que lhes permite segmentar os seus clientes em grupos homogéneos para que a sua gestão seja feita, tanto quanto possível, com base no seu comportamento, características ou importância, separadamente. Com este tipo de metodologias, o gestor pode diferenciar o serviço, a comunicação, os produtos para segmentos específicos de clientes.
O presente Trabalho de Projeto irá estudar e aplicar um método de Data Mining muito popular, o SOM. Segundo (Henriques, 2010), o SOM é uma técnica utilizada principalmente na visualização, abstração de dados e tarefas de clustering. A principal vantagem é que permite aos usuários investigar a estrutura de dados e, portanto, permite uma melhor compreensão dos dados.
Além do SOM, a técnica que igualmente irá ser abordada e utilizada no clustering
será o HSOM, sendo este uma extensão do convencional (single-layer) SOM. Uma vez que o SOM é sensível a variáveis com diferentes distribuições, o que lhes confere um maior peso na solução final de clustering, a utilização do HSOM irá permitir agrupar as variáveis em estudo dos diferentes temas definidos, produzindo assim uma segmentação final, onde cada um dos temas terá um impacto semelhante na mesma.
terá como base quatro grupos de variáveis nos seguintes temas: Marketing, Produção, Risco e Sociodemográficos.
De acordo com os objetivos expostos, o Trabalho de Projeto propõe a construção de um interface interativo e de fácil utilização a partir dos clusters criados. Deste modo, será possível:
Segmentar os clientes, e a redução da dimensionalidadereduzir a dimensão dos problemas que vão surgindo no dia-a-dia;
Realizar queries de um modo rápido, eficiente e produtivo com o propósito de obter informação detalhada que caracterize os diferentes grupos de clientes criados;
Obter uma visão única dos mesmos, auxiliando análises futuras e diferenciar as ofertas nas campanhas de marketing direto;
Gerir a multidimensionalidade e ter acesso a diferentes perspetivas dos clientes num único quadro.
1.3.BANCO EM ANÁLISE
Como já foi mencionado, o Trabalho de Projeto vai debruçar-se sobre os dados de um Banco.
Atualmente, o Banco em análise desenvolve a sua atividade nas diferentes áreas de crédito ao consumo a particulares, apresentando soluções de financiamento adequadas aos segmentos A, B e C integrando diversas modalidades: crédito clássico, cartões de crédito, entre outros. Além disso, disponibiliza ainda linhas de crédito para apoio à atividade dos seus parceiros comerciais.
Em 2001 houve uma grande aposta no segmento C por parte do Banco, especializando-se em soluções financeiras para clientes finais, onde tem vindo a reforçar a sua penetração.
Com uma clara aposta num elevado nível de serviço, flexibilidade, rapidez de decisão, simplicidade de processos e gama alargada de produtos, o Banco tem vindo a consolidar a sua posição nestas áreas de negócio, demonstrando um crescimento sustentado dos seus resultados.
1.4.RATIONALE/LÓGICA
1. Introdução
experiência, diariamente surgem-me dúvidas no que diz respeito ao tratamento de dados, redução da dimensionalidade dos problemas e seleção das melhores técnicas, procedimentos e ferramentas para os resolver.
Tal como quase todas as organizações que exercem atividade neste mundo globalizado e altamente competitivo, o Banco em análise depara-se igualmente com a necessidade de extrair informação importante e gerar conhecimento a partir da grande quantidade de dados recolhidos diariamente.
Posto isto, através deste Trabalho de Projeto tenciono especializar-me numa das ferramentas de análise para dados de elevada dimensionalidade e de visualização, como descreve Kohonen, o SOM. Por sua vez, como já foi explicado, o HSOM será o principal foco.
De maneira a colocar em prática os objetivos anunciados, optei por utilizar dados do Banco onde trabalho, porque:
São dados aos quais me sinto bastante familiarizada;
Com o auxílio dos meus orientadores e da revisão bibliográfica, tenciono aprender e consolidar os meus conhecimentos, nos meios e técnicas para ultrapassar as dificuldades que sinto diariamente em lidar com os dados do Banco (por exemplo, campos mal preenchidos no sistema, valores omissos,
outliers, entre outros);
Estou a construir um projeto que para além de ser benéfico e enriquecedor pessoalmente, também o será profissionalmente, uma vez que tenciono dar continuidade ao mesmo no meu local de trabalho.
A seleção dos temas para a segmentação dos clientes foi com base nas necessidades de negócio, e no que melhor contribui para os diferenciar e caracterizar.
As análises apenas irão incidir nos clientes ativos (com contratos a decorrer) de créditos pessoais, porque internamente é considerado o tipo de cliente mais importante ao qual não queremos perder contacto, tenciona-se conhecer cada vez melhor e estabelecer uma relação de confiança para que não se tornem inativos. Está provado internamente que é mais prejudicial angariar um novo cliente do que manter os já existentes.
As principais vantagens/utilidades que o interface irá trazer para o Banco são: Segmentar os clientes (construção de clusters) com diversos temas
Realização de queries que permitem o acesso rápido e eficiente à informação dos clientes presentes nos segmentos para a realização de análises e relatórios;
Auxiliar na diferenciação das ofertas aos clientes nas campanhas de marketing direto de acordo com o perfil verificado;
Ajuda a destetar padrões de respostas a campanhas de marketing direto; O cluster a que cada cliente pertence poderá vir a ser uma variável
importante para os modelos preditivos (Por exemplo: Modelo de Propensão de resposta a campanhas e de Churn).
Posto isto, além de o tema do Trabalho de Projeto ser do meu agrado pessoal e aplicável à minha vida profissional, acredito que com as pesquisas para a revisão bibliográfica presente no próximo Capítulo 2 Revisão da Literatura e com a parte prática presente no Capítulo 4, irei ficar mais especializada no tema e sentir-me mais apta e convicta nas funções que desempenho na minha atividade profissional.
1.5.FORMULAÇÃO DAS QUESTÕES
As questões que se propõe responder com o Trabalho de Projeto são as seguintes:
O SOM e o HSOM são instrumentos adequados para construir um interface com as grandes bases de dados do Banco em análise?
Neste contexto, o HSOM apresenta uma visão diferente relativamente ao SOM?
1.6.ORGANIZAÇÃO DO TRABALHO DE PROJETO
A organização deste Trabalho de Projeto está feita do seguinte modo:
Capítulo 1 – Diz respeito a um capítulo introdutório. É composto por uma breve contextualização do tema, é definido o problema de investigação, os objetivos da dissertação, a lógica e a formulação de questões.
Capítulo 2 – Neste capítulo é feita a revisão da literatura, onde serão abordados os conceitos teóricos das ferramentas que se encontram por de trás do Interface a desenvolver, o SOM e o HSOM.
1. Introdução
Capítulo 4 – É neste capítulo que está documentado o modo como se procedeu na extração e pré-processamento de dados.
Capítulo 5 – Neste capítulo será documentado a parte prática do Trabalho de Projeto com respetivas fases percorridas, escolhas, análises e respetivas conclusões.
Capítulo 6 – É onde é feita a discussão final dos resultados obtidos, em termos práticos e teóricos, e onde se responde às questões propostas.
Capítulo 7–Aqui irão resumir-se as principais conclusões da pesquisa.
Capítulo 8–Expõe as limitações encontradas no decorrer do Trabalho de Projeto e dá recomendações para futuras pesquisas.
Capítulo 9– Apresentação da bibliografia do Trabalho de Projeto.
Capítulo 10–Anexos de consulta facultativa.
2.
REVISÃO DA LITERATURA
Como já foi mencionado, os métodos aplicados no Trabalho de Projeto serão o SOM que por sua vez dará origem ao HSOM, onde este último terá maior destaque.
Este capítulo é composto por três subcapítulos: o 2.1 onde é feita uma contextualização dos métodos utilizados, começando por abordar um dos maiores desafios do clustering (a praga da dimensionalidade), seguido das Redes Neuronais Artificiais e do SOM. A subsecção do SOM apresenta um maior detalhe, uma vez que tem uma definição completa do método, o modo como funciona e por fim os problemas que podem surgir com a sua utilização. No subcapítulo 2.2 é abordado detalhadamente o método HSOM, explicando o seu funcionamento, apresentando uma taxonomia para a sua classificação, os métodos utilizados para cada taxonomia e as vantagens relativamente ao SOM. Por fim, no capítulo 2.3 serão mencionadas algumas das principais conclusões entre os diferentes métodos (SOM e HSOM).
De maneira a sintetizar as áreas do conhecimento conceptual sobre os temas abordados será utilizada uma de revisão de literatura conceptual.
2.1.CONTEXTUALIZAÇÃO
Como já foi discutido, a quantidade de dados disponíveis das organizações aumenta diariamente e vão surgindo ferramentas para os analisar.
Um dos aspetos mais desafiadores do clustering é a elevada dimensionalidade de muitos dos problemas. Geralmente descrever fenómenos implica o uso de muitas variáveis. O aumento da dimensionalidade terá um impacto significativo no desempenho de algoritmos de clustering e na qualidade dos resultados, porque:
Vai aumentar o espaço de busca que afeta a eficácia do algoritmo de cluster, devido ao efeito normalmente designado a "praga da dimensionalidade" (Bellman, 1961).
Haverá uma análise mais complexa do output gerado. Os grupos vão ser mais difíceis de caracterizar, devido à contribuição de múltiplas variáveis para a estrutura final (Henriques, 2010).
2. Revisão da Literatura
Além disso, à medida que a dimensionalidade do problema aumenta, ou seja, o número de variáveis, maior é a probabilidade de as variáveis estarem correlacionadas entre si.
A maioria destes algoritmos, nos quais se enquadram os Self Organizing Maps (Kohonen, 2001), são sensíveis a variáveis divergentes (Henriques, 2010). Estas caracterizam-se por apresentar grandes diferenças quanto à tendência geral, o que lhes confere um maior peso na solução final de clustering.
Deste modo, se existirem algumas variáveis deste tipo numa segmentação, elas serão responsáveis pela partição final, ficando as restantes com um papel secundário. Apesar de ser ter procedido à normalização das variáveis, este problema não fica resolvido, apenas suavizado.
É aqui que surge a necessidade de utilizar o método HSOM. Com esta técnica será possível utilizar um maior número de variáveis, agrupá-las em vários temas, produzindo assim uma segmentação final onde cada um dos temas terá um impacto semelhante na mesma.
Assim, com este método, haverá menos sensibilidade às variáveis divergentes, porque estas terão um impacto direto sobre o seu próprio tema.
2.1.1. Redes Neuronais Artificias (RNAs)
As Redes Neuronais Artificias (RNAs) têm como principal objetivo simular o processo de aprendizagem do cérebro humano. É constituído por um sistema de processamento, composto por um grande número de elementos interconectados (unidades ou neurónios), onde trabalham juntos para resolver problemas específicos. A sua capacidade de aprendizagem torna-os muito adequados para diferentes aplicações específicas, tais como, reconhecimento de padrões ou dados classificação (Gurney, 1997). De acordo com (Carpinteiro, 2000) o modelo neural artificial é capaz de desempenhar eficientemente classificação (redes neuronais não-supervisionadas) e discriminação (redes neuronais supervisionadas).
2.1.1.1. Self Organizing Map (SOM)
As RNAs possuem muitos modelos. Em 1982, Teuvo Kohonen desenvolveu um tipo de Rede Neuronal, o Self Organizing Map (SOM) (Kohonen, 1982b). Atualmente a principal referência do autor sobre o tema é (Kohonen, 2001) .
Como já foi mencionado, o SOM é uma rede não-supervisionada. Estes mapas também podem ser referidos como Self-organizing feature maps – SOFMS “Kohonen
neural ne work ” (Fu, 1994), “topology preserving feature maps” (Kohonen, 1995), ou
algumas variantes destes termos. Kohonen descreve o SOM como “uma ferramenta de análise para dados de elevada dimensionalidade e de visualização”. E a o a características mais interessantes do SOM, contudo, tem sido utilizado em inúmeras outras tarefas como: classificação, Data Mining (DM) (Kohonen, 2001), amostragem, clustering (Vesanto and Alhoniemi, 2000), redução da dimensionalidade, entre outras.
Segundo (Kaski et al., 1998, Kaski and Kohonen, 1996), o principal objetivo do SOM é “extrair e ilustrar” as estruturas essenciais do conjunto de dados, através de um mapa resultante de um processo de aprendizagem não-supervisionada.
Por ser uma ferramenta interessante, útil para resolver problemas difíceis do mundo real e com capacidade de organizar grandes conjuntos de dados de acordo com as semelhanças que apresentam. Atualmente existem inúmeras publicações sobre o tema aplicado a diversas temáticas (estatística, análise financeira, física experimental, química e medicina).
O SOM de Kohonen é inspirado na forma como nós acreditamos que o cérebro humano funciona(Henriques, 2010). Segundo (Kohonen, 2001) o “SOM um do modelos mais realista do funcionamento do c rebro b oló co”.
Como funciona o Self Organizing Map
“E e camen e o SOM pode er o como uma ma r de un dade (neurón o )
também designado por espaço de output ou mapa topológico “ (Bacao, 2006), em oposição tem-se o espaço original dos dados, designado por espaço de input.
2. Revisão da Literatura
respeito à visualização. Qualquer acréscimo de dimensão traduz-se na incapacidade de visualização do espaço de output (Bação et al., 2005).
Deste modo, de maneira a promover as mesmas distâncias entre as unidades do espaço de output, utiliza-se por vezes as grelhas hexagonais (Kohonen et al., 1995).
Contudo, é de destacar que existem alguns autores que usaram SOMs 3D (Gorricha, 2009, Keim et al., 2004, Seiffert and Michaelis, 1995).
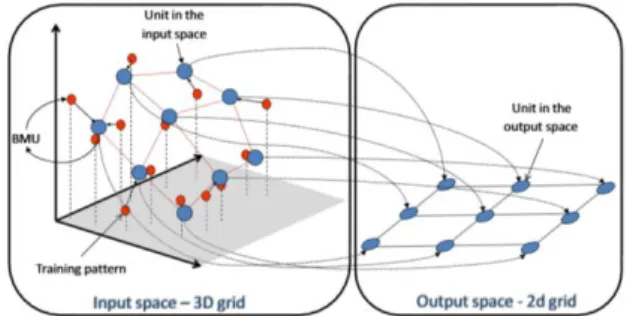
A Figura 1 ilustra um exemplo de um SOM de duas dimensões com 3 x 3 unidades adaptado das três dimensões do espaço de input, onde os círculos azuis representam as unidades do SOM (neurónios), por outro lado os círculos vermelhos representam os padrões de input.
Figura 1- Self Organizing Map´s espaço de output (duas dimensões) e espaço de entrada (três dimensões)
Fonte: elaborado por (Henriques, 2010)
Esse mapeamento tenta preservar as relações topológicas, ou seja, os padrões que estão próximos no espaço de entrada serão mapeadas para as unidades que estão próximas no espaço de saída, e vice-versa.
A iteração da fase de treino do SOM está apresentada na Figura 2 , onde um padrão de treino (ponto vermelho) é apresentado à rede e a unidade mais próxima está marcada (BMU).
Esta unidade move-se na direção do padrão de input (representada pela seta vermelha), dependendo da taxa de aprendizagem. Os vizinhos são selecionados no espaço de output (a intensidade do azul representa o grau de vizinhança), com base no BMU e na função de vizinhança. Os vizinhos também são atualizados para o padrão de
input (Henriques, 2010).
Figura 2 - Fase de Treino do SOM
Fonte: elaborado por (Henriques, 2010)
Independentemente da qualidade da fase de treino haverá sempre alguma distância residual entre o padrão de treino e a sua unidade representativa. Esta diferença é conhecida como erro de quantização (Henriques, 2010).
Posto isto, segundo (Bacao, 2006), normalmente é possível que o processo de treino do SOM seja composto por duas grandes fases:
1ª fase- E a fa e normalmen e denom nada como “fase de desdobramento” (unfold n pha e) onde a un dade o “e palhada ” de mane ra a cobr r o e pa o de
input. Depois desta fase, a forma genérica da rede no espaço de input fica definida; 2ª fase- U ualmen e de nada “ajustamento fino” ou “af na o” (f ne un n
phase). Durante esta fase o SOM procura minimizar o erro de quantização.
A Figura 3 apresenta a evolução de uma rede ao longo do processo de treino.
2. Revisão da Literatura
Os padrões de input, não visualizáveis na Figura 3, encontram-se distribuídos uniformemente ao longo do retângulo. Contudo, é possível observar a fase de desdobramento da rede, que começa com todas as unidades agrupadas no centro do plano, nos três retângulos da par e uper or e u da da fa e de “af na o” representada pelos três retângulos da parte inferior da figura. No fim do processo a rede cobre completamente o espaço (Bacao, 2006).
Contudo, o desdobramento do mapa pode não ser bem-sucedido e acaba por
f car “dobrado”. Na Figura 4 encontra-se um exemplo disso, onde estão visíveis as
con equênc a de um mau re no na “fa e de de dobramen o”.
Figura 4 - Exemplo de um SOM “dobrado”
Fonte: elaborado por (Kohonen, 1995)
Problemas com o SOM
Como já foi mencionado, o objetivo do SOM é ajustar os neurónios no espaço de input, de modo a que a rede represente o melhor possível o conjunto de dados de treino. Um dos problemas relacionados com esta adaptação é o facto de que a rede tende a subestimar regiões com alta densidade e superestimar as áreas de baixa densidade (Bishop et al., 1997). Esse problema é normalmente chamado de fator de ampliação (Cottrell et al., 1998). Um teorema básico para o caso de dados unidimensionais mostra que a densidade das unidades é proporcional à densidade dos padrões de treino com um fator de ampliação de 2 / 3 (Ritter and Schulten, 1986, Bauer et al., 1996).
O uso de Algoritmos Genéticos (AG) a fim de estimar os parâmetros de treino de um SOM (Silva and Rosa, 2002).
Um algoritmo que calcula os parâmetros de aprendizagem durante o treino de SOMs automaticamente, usando um filtro de Kalman (Haese and Goodhill, 2001).
2.2.SELF-ORGANIZING MAP HIERÁRQUICO (HSOM)
Nesta secção, irá ser abordado o Self-Organizing Map Hierárquico (HSOM). Como já foi mencionado, este foi o método selecionado para agrupar as variáveis do Banco em vários temas a fim de obter uma segmentação final. O objetivo será explorar o mesmo conjunto de dados a partir de diferentes perspetivas temáticas. Além disso, é de destacar que caso existam variáveis divergentes, estas vão apenas ter impacto no tema a que pertencerem, fazendo com que o HSOM seja menos sensível às mesmas.
Existem muitos tipos de Hierarquias de SOM, contudo, à semelhança da Tese de (Henriques, 2010), neste capítulo irei abordar uma taxonomia do HSOM para classificar os métodos existentes de acordo com a sua estrutura e objetivos.
2.2.1. Definição
É sabido que o HSOM é uma extensão do SOM convencional (Barbalho et al., 2001).
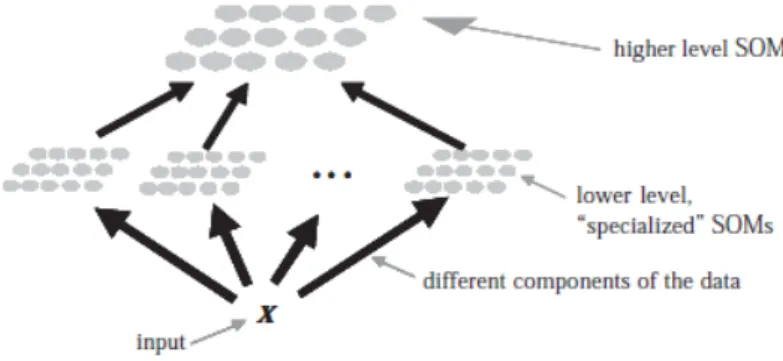
Os HSOMs “are often used in application fields where a structured decomposition into smaller and layered problems is convenient. One or more than one SOMs are located at each layer, u ually opera n on d fferen hema c ar able ” (Bação et al., 2005) (Figura 5).
Figura 5 – Estruturado HSOM
Fonte: elaborado por (Bação et al., 2005)
2. Revisão da Literatura
“Mul -Layer SOMs” (Luttrell, 1989, Ichiki et al., 1991) “Mul -Resolution
SOM ”(Graham and D'Eleuterio, 1991) ou “Tree-SOM ” (Sauvage, 1997).
Segundo (Henriques, 2010), estes métodos variam na forma como os SOMs interagem uns com os outros e com os dados originais.
De acordo com (Henriques, 2010), considera-se um HSOM quando em algum momento, um dos SOMs recebe como entrada as saídas de outro SOM. Deste modo, este tipo de estrutura assemelha-se a um tipo de rede neuronal designado por Perceptrão multicamada (MLP). Contudo, é de destacar que os HSOMs têm algoritmos de treino e tipos de interação entre as camadas bastante diferentes.
Para se estar perante um verdadeiro HSOM, as diferentes interações entre os SOMs têm de estar no treino. Este tipo de interações é onde os outputs de um SOM são utilizados para treinar outro SOM (Henriques, 2010).
Contudo, no HSOM muitas configurações diferentes são possíveis, podendo variar no número de camadas utilizadas, as conexões podem ser realizadas de diversas maneiras, assim como a informação enviada em cada conexão.
Na próxima subsecção será apresentada uma taxonomia do HSOM para classificar os métodos existentes de acordo com seus objetivos e estrutura.
2.2.2. Taxonomia
Por considerar que a Tese de Doutoramento do Professor Doutor Roberto Henriques está muito completa e resume praticamente tudo o que é importante no que diz respeito à Taxonomia do HSOM, toda esta secção referente à taxonomia terá como base a mesma, (Henriques, 2010).
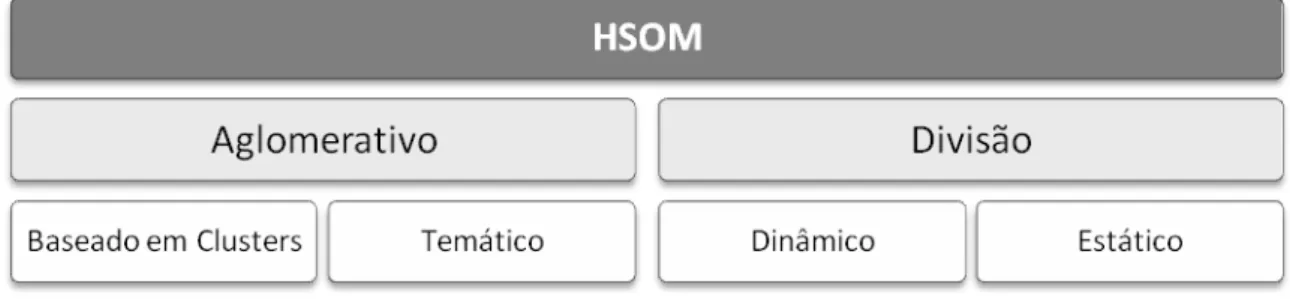
Assim sendo, segundo (Henriques, 2010), a taxonomia existente para classificar os métodos do HSOM é composto por Aglomerativo e Divisão (Figura 6).
Por sua vez o Aglomerativo é dividido por Baseado em Clusters e Temático. Na Divisão existe uma repartição por Dinâmica e outra por Estática. Estas divisões dependem do tipo de abordagem adotada.
Segundo (Henriques, 2010), na Figura 7 é possível perceber melhor como se comportam os dois tipos de HSOM em análise:
a) HSOM Aglomerativo b) HSOM por Divisão
Figura 7 - Tipos de HSOMs: a) Aglomerativo b) Por Divisão
No SOM Aglomerativo (Figura 7) normalmente têm-se muitos SOMs na primeira camada (isto é, a camada que está diretamente conectada com os padrões de dados originais) para depois se unir os outputs num nível mais elevado do SOM. Geralmente, neste tipo de HSOM, o primeiro nível tem uma representação mais detalhada dos dados e à medida que se vai subindo na estrutura, o principal objetivo é a criação de clusters mais gerais que forneçam de uma forma mais simples e assertiva de ver os dados.
Por outro lado, no HSOM por divisão (Figura 7) tem-se um único SOM na primeira camada, e mais na segunda. O primeiro nível é conhecido por ser menos preciso e de usar pequenas redes. O principal objetivo desta camada é criar partições em bruto, que serão mais detalhados e precisos à medida que se vai subindo nos níveis de HSOM.
Nas próximas secções serão apresentadas as diferentes categorias das divisões apresentadas.
2.2.2.1. HSOM Aglomerativo baseado em Clusters
2. Revisão da Literatura
Segundo (Henriques, 2010), nesta arquitetura apenas as coordenadas do primeiro nível do SOM são passadas como entrada para a camada superior (normalmente mais pequena e simples de utilizar). Cada unidade do nível superior do SOM é BMU para diversas unidades do primeiro nível. Neste caso, o nível superior agrupa as unidades de nível inferior, e o resultado final é semelhante ao uso de um SOM standard.
A grande vantagem deste método é que se irá obter os mesmos dados com diferentes níveis de detalhe (através dos dois SOMs mapeados), sem ter que treinar o nível superior diretamente com os padrões originais. Assim como, utilizar o nível superior para detetar padrões de entrada que, por ser mal interpretado no primeiro nível, exijam uma maior atenção (Henriques, 2010).
O nome proposto para esta classe (HSOM baseado em "clusters") decorre do fato de o primeiro nível de SOM usar os padrões por completo para obter as agregações, sendo as informações sobre esses grupos a entrada para o segundo nível do SOM. Assim, dependendo da informação do cluster que é passada, o HSOM baseado em clusters pode ser semelhante ou muito diferente do SOM standard (Henriques, 2010).
2.2.2.2. HSOM Aglomerativo Temático
O nome Temático advém pelo facto de no espaço de entrada as variáveis serem agrupadas de acordo com alguns critérios, formando diversos temas. O tipo de padrões de saída enviados a partir do nível mais baixo do SOM para o nível superior, pode variar.
De acordo com (Henriques, 2010), ao realizar um agrupamento multidimensional, esta estrutura apresenta várias vantagens, tais como a redução do esforço computacional. Além disso, esta partição também permite a criação de grupos temáticos que poderá ser muito interessante para o analista. Assim, obtendo as diferentes perspetivas de agrupamento apresentadas no primeiro nível, vai haver a possibilidade de as mesmas serem comparadas com a solução global do Cluster. Deste modo, o usuário irá ter uma melhor compreensão e exploração dos padrões emergentes.
variáveis agrupadas nos quatro temas já anunciados: Marketing, Produção, Risco e Sociodemográficos.
2.2.2.3. HSOM por Divisão Dinâmica
Este método, também conhecido como HSOM em crescimento (GHSOM) (Dittenbach et al., 2002), é caracterizado pela auto adaptação da estrutura de dados. Como o próprio nome indica, permite o crescimento da estrutura durante a fase de aprendizagem (Henriques, 2010).
De acordo com (Dittenbach et al., 2002), o GHSOM proporciona uma adaptação à sua arquitetura durante o processo de treino, de acordo com as necessidades específicas dos dados de entrada.A referência também menciona que este modelo de rede neural é composto por SOMs independentes, cada uma dos quais pode crescer de tamanho durante o processo de formação, até que um critério de qualidade em matéria de representação de dados é satisfeito (Figura 8).
Figura 8 - GHSOM a refletir a estrutura hierárquica dos dados de entrada
Fonte: elaborado por (Dittenbach et al., 2002)
É de salientar que é permitido dois tipos de crescimento: um horizontal onde há um aumento do número de unidades de cada SOM, e um vertical, onde é o número de camadas no HSOM que aumenta (Henriques, 2010).
2. Revisão da Literatura
2.2.2.4. HSOM por Divisão Estática
Por fim, nesta secção irá ser abordado o HSOM com uma estrutura estática, onde o número de níveis e as conexões entre SOMs são pré-definidos de acordo com o objetivo do usuário.
Segundo (Henriques, 2010), as principais vantagens deste método são:
Redução do esforço computacional, devido ao pequeno número de unidades de primeiro nível (e apenas algumas das unidades de nível superior serão utilizados em cada caso);
A possibilidade de obter detalhe a diferentes níveis para diferentes áreas do SOM.
2.2.3. Razões para utilizar o HSOM em vez do SOM
De acordo com (Henriques, 2010) existem principalmente dois motivos para utilizar um SOM hierárquico (HSOM) em vez de um SOM standard:
Um HSOM pode ser mais adequado para modelar um determinado problema, pela sua própria natureza (estrutura hierárquica);
Um HSOM pode exigir menos esforço computacional do que o SOM standard para alcançar determinados objetivos.
Conforme o primeiro motivo, o HSOM é geralmente o mais adequado para lidar com problemas que apresentam uma hierarquia ou estrutura temática. Assim sendo, nestes casos o HSOM pode mapear a estrutura natural do problema, usando diferentes SOMs para cada nível hierárquico. Esta separação do agrupamento global, não só pode representar a verdadeira natureza dos fenómenos, mas também pode proporcionar uma fácil interpretação dos resultados, permitindo ao usuário ver o cluster que foi realizado em cada nível.
De acordo com a segunda razão, a redução do esforço computacional é uma grande vantagem do HSOM. O mesmo pode ser alcançado de duas maneiras:
1. Através da redução da dimensionalidade das entradas para cada SOM; 2. Reduzindo o número de unidades em cada SOM.
O ganho de velocidade também pode ser conseguido através de menos unidades em cada SOM.
Além destes dois pontos principais, é de salientar que segundo (Henriques, 2010), ao contrário do SOM standard, os outliers identificados pela HSOM não são outliers devido a valores extremos em uma ou poucas variáveis, mas sim valores estranhos nos diversos temas.
2.3.BALANÇO FINAL
Neste capítulo, começou-se por abordar o que são Redes Neuronais Artificiais (RNAs), assim como definir e caracterizar o SOM. Estas secções iniciais serviram para contextualizar o tema principal do Trabalho de Projeto, o HSOM. Sendo assim, neste capítulo também foi definido o que é um SOM Hierárquico, e as maneiras pelas quais os SOMs com diferentes níveis podem interagir.
O HSOM Aglomerativo Temático foi o selecionado para ser utilizado no Trabalho de Projeto por melhor se adequar a atingir o objetivo proposto.
Além disso, foi notório que o HSOM provou ser um valioso complemento para o SOM standard. Sumariamente, conclui-se que o HSOM apresenta as seguintes vantagens:
Permite a criação de clustering com vários níveis temáticos.
É menos sensível a outliers resultantes de uma ou poucas variáveis; Permite a utilização de um maior número de variáveis sem diminuição no
desempenho. Com o aumento da dimensionalidade, um SOM standard é menos eficiente na deteção de padrões, e leva mais tempo para treinar; Permite o uso de SOMs maiores. A redução do esforço computacional
3. Metodologia
3.
METODOLOGIA
De maneira a tingir os objetivos propostos para este Trabalho de Projeto, foi estabelecida e seguida uma metodologia de pesquisa/investigação de trabalho.
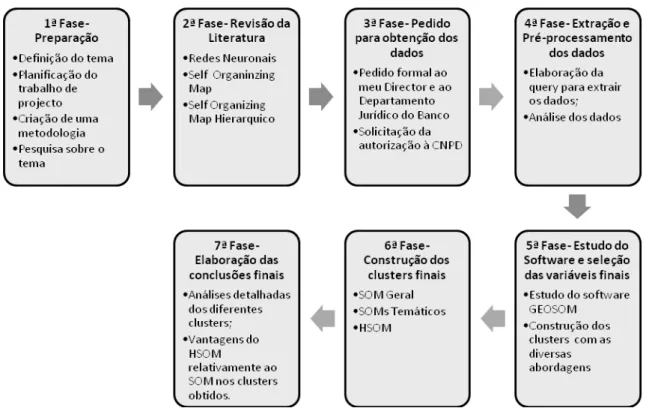
O processo de investigação e elaboração considerado para o Trabalho de Projeto é composto por seteprincipaisetapas (Figura 9).
Figura 9 – Fases do Processo de investigação e elaboração
Analisando cada uma das fases de forma mais detalhada, tem-se que na 1ª Fase
é onde tudo começa, podendo mesmo designar-se a fase preliminar. Após a definição do tema com o auxílio dos orientadores do Trabalho de Projeto, os Seminários de Metodologias de Investigação auxiliaram a planificação e criação de uma metodologia de pesquisa e de estruturação. As pesquisas iniciais sobre o tema prosseguiram após esta fase.
documentação do ISEGI: Biblioteca do Conhecimento Online e ISI Web of Knowledge, bem como no Google Académico (Google Scholar).
No que diz respeito ao espaço temporal da pesquisa, vai desde 1982. Este foi o ano que Kohonen desenvolveu a ferramenta SOM e quando tudo começou (Kohonen, 1982a). Visto não ter sido há muitos anos, optou-se por efetuar a pesquisa desse ano até aos dias de hoje. Contudo, surge uma referência bibliográfica referente a 1961. A mesma aparece devido à necessidade de abordar a "praga da dimensionalidade" (Bellman, 1961).
Numa 3ª Fase iniciou-se o processo de solicitação da autorização dos dados para aplicar nas análises do trabalho. A decisão para o tema do Trabalho de Projeto sempre teve o apoio dos orientadores, do meu diretor e da área jurídica do Banco. Contudo, como se trata de dados sensíveis bancários dos nossos clientes, a autorização não passa apenas pelo consentimento do Banco. Assim, em Setembro de 2011 procedeu-se à elaboração do requerimento para obter a autorização de utilização dos dados por parte da CNPD (Comissão Nacional de Proteção de dados). Em Março de 2012 obteve-se a autorização para utilizar os dados dos clientes do Banco, tendo obteve-sempre como prossuposto que não haveria qualquer identificação dos mesmos.
Só após a 3ª Fase concluída se pode avançar para a 4ª Fase de extração e pré-processamento dos dados. Aqui foram elaboradas as queries de extração dos dados, tendo sempre em atenção a não identificação do cliente, para tal, foi criado um número de cliente fictício. Após o final do Trabalho de Projeto, uma vez que o objetivo será implementar estas segmentações no Banco, a correspondência com o original apenas poderá ser feita internamente.
Ainda nesta fase, foram elaborados os estudos dos dados através de análises univariadas e multivariadas, subcapítulo 4.3- Análise dos dados e pré-processamento de dados do capítulo 5-Resultados práticos, com o apoio do software SAS Guide e SAS Miner.
3. Metodologia
Após seleção das variáveis finais, avançou-se para a Fase 6, onde foram processadas as diferentes segmentações finais propostas: SOM Geral, SOMs Temáticos e HSOM.
Por fim, na 7ª Fase procedeu-se à elaboração das conclusões finais com as análises detalhadas das diferentes segmentações obtidas, assim como, a comparação entre os dois métodos, ou seja, HSOM e SOM.
4.
EXTRAÇÃO E PRÉ-PROCESSAMENTO DOS DADOS
Este capítulo destina-se a apresentar o modo e os pressupostos que foram definidos para extrair a base, as variáveis que serão estudadas, assim como, a análise dos dados e pré-processamento dos mesmos. Por fim, serão apresentadas também as variáveis finais para entrar no estudo, com as respetivas abordagens percorridas.
4.1.EXTRAÇÃO DA BASE E PRÉ-REQUISITOS DOS DADOS
Após o processo de autorização interna para utilização dos dados por parte do Banco, e externa por parte da CNPD, seguiu-se a extração da base e escolha das variáveis possíveis de entrar na análise.
Como já foi mencionado, existem quatro grupos temáticos de estudo: Marketing, Produção, Risco e Sociodemográficas. O número total de variáveis elegíveis dos distintos temas para entrar na análise eram 111. De modo a reduzir este número, e por consequência reduzir a dimensionalidade do problema, começou-se por selecionar apenas as que em termos de negócio são mais relevantes, restando apenas 31. De maneira a simplificar a demonstração de resultados, apenas serão representadas e incluídas nas futuras análises de dados deste capítulo, este último grupo mais reduzido de variáveis.
4.1.1. Pressupostos da extração da base de clientes
Em Agosto de 2011 as campanhas de marketing baseadas na venda de crédito pessoal no Banco foram extintas. Posto isto, de maneira a trabalhar com os dados próximos da realidade que existia antes desta medida, foi decidido extrair os clientes primeiros titulares com contratos de crédito a decorrer à data de 31 de Agosto de 2011, ou seja, clientes considerados ativos a esta data.
É de salientar que na temática do Marketing as variáveis relacionadas com as campanhas de decorrem desde 1 de Junho de 2006, data à qual as campanhas começaram a ter um maior fluxo no Banco.
4. Extração e pré-processamento dos dados
Uma vez que apenas restam 10% da população, realizou-se um teste de homogeneidade para as duas populações em questão, de modo a provar estatisticamente que as conclusões retiradas para a amostra ao longo do trabalho de projeto poderão ser generalizadas para toda a população.
A hipótese de homogeneidade é dada por :
Uma vez que todas as variáveis em questão têm o p-value superior ao nível de
n f cânc a do e e (α= 0 05) conclu -se que não se rejeita H0. Ou seja, as bases são
homogéneas e será possível realizar o trabalho de projeto sobre a amostra extraída.
4.2.ANÁLISE DESCRITIVA DAS VARIÁVEIS
A Tabela 1 apresenta as 31 variáveis em estudo. Apesar de as variáveis binárias poderem provocar um elevado enviesamento na constituição dos clusters, decidiu-se manter, uma vez que enriquecem a análise nos distintos temas, como será possível concluir no decorrer do Trabalho de Projeto.
Temas Variáveis Tipo Unidades Descrição
nCampAlvo Intervalar - Número de campanhas alvo desde Junho 2006
nDiasUltResposta Intervalar Dias Número de dias desde a última resposta a uma campanha
perc_RespProp_Camp Intervalar % (Número de propostas de resposta à campanha) / (nCampAlvo >=3)
clv Intervalar € Customer Lifetime Value do Banco
RFM Intervalar - Recency Frequency e Monetary
Recency Intervalar Meses Antiguidade do cliente no Banco
Frequency Intervalar - Número de contratos realizados
Monetary Intervalar € Valor total financiado de todos os contratos do cliente
n_B_Activos Intervalar - Número de contratos activos no negócio B
n_A_Activos Intervalar - Número de contratos activos no negócio A
n_C_Activos Intervalar - Número de contratos activos no negócio C
nLiquidados Intervalar - Número de contratos liquidados
antUltProposta Intervalar Meses Antiguidade da última proposta carregada
maxPrazo Intervalar Meses Prazo máximo do total de contratos do cliente
maxTaxa Intervalar % Taxa máxima do total de contratos do cliente
minTaxa Intervalar % Taxa mínima do total de contratos do cliente
nActivos Intervalar - Número total de contratos activos
nPropostasNFinanciadas Intervalar - Número de propostas não financiadas (não passaram a contrato)
nMeses_FimProxCtr Intervalar Meses Número de meses restantes para o fim do próximo contrato
escIncumprimento_B Ordinal - Escalão de incumprimento no negócio B
escIncumprimento_A Ordinal - Escalão de incumprimento no negócio A
escIncumprimento_C Ordinal - Escalão de incumprimento no negócio C
sCapitalVencidoNPago Intervalar € Soma do capital vencido (em incumprimento) não pago
maxNDiasInc Intervalar Dias Número máximo de dias em incumprimento
minNMesesUltAtraso Intervalar Meses Mínimo número de meses desde o último atraso
iInc Binária 0-1 Indicador se está em incumprimento
idade Intervalar Anos Idade
antProfissaoAct Intervalar Meses Antiguidade da profissão actual
rendimentos Intervalar € Rendimentos
Flag_CasaPropria Binária 0-1 Flag se tem casa própria
Flag_Reformado Binária 0-1 Flag se é reformado Marketing
Produção
Risco
4.3.ANÁLISE DOS DADOS E PRÉ-PROCESSAMENTO DE DADOS
Neste subcapítulo o objetivo é realizar a análise dos dados (análise univariada e correlações), de maneira a ganhar sensibilidade aos mesmos e efetuar o pré-processamento mais indicado (valores omissos e outliers).
Deste modo, a análise de dados será um grande contributo para auxiliar na próxima seção referente à escolha das variáveis finais.
Com o pré-processamento efetuado reduziu-se a base de 20.000 registos para 19.828.
4.3.1. Estatísticas Descritivas
Na Tabela 2, é possível observar as principais estatísticas referentes às 31 variáveis elegíveis para as análises.
Tabela 2 - Análise Univariada das variáveis
Para desenvolver um modelo robusto é essencial eliminar ou tratar valores que possam causar um enviesamento dos resultados do estudo a realizar. Neste caso, é
Temas Variáveis Média Desvio-Padrão Mínimo Máximo % Valores omissos
nCampAlvo 9 7 1 34 36%
nDiasUltResposta 941 510 110 2,159 90%
perc_RespProp_Camp 0% 0 0% 100% 36%
clv 1 218 € 3,868 -65454 31 € 47316 68 € 0%
RFM - - - - 0%
RECENCY 43 37 0 199 0%
FREQUENCY 1 1 1 11 0%
MONETARY 9 470 € 11,485 150 € 292 413 € 0%
n_B_Activos 1 1 0 4 0%
n_A_Activos 0 1 0 3 0%
n_C_Activos 0 0 0 2 0%
nLiquidados 0 0 0 3 0%
antUltProposta 25 19 0 144 0%
maxPrazo 58 27 3 120 0%
maxTaxa 11% 7 0% 49% 0%
minTaxa 9% 6 0% 36% 0%
nActivos 1 0 1 4 0%
nPropostasNFinanciadas 1 1 0 19 0%
nMeses_FimProxCtr 31 30 -123 123 0%
escIncumprimento_B 2 3 0 7 41%
escIncumprimento_A 2 3 0 7 58%
escIncumprimento_C 2 3 0 7 85%
sCapitalVencidoNPago 512 € 2,203 0 € 48396 38 € 0%
maxNDiasInc 117 274 0 999 0%
minNMesesUltAtraso 7 12 0 73 80%
iInc 1 0 0 1 30%
idade 44 14 0 81 0%
antProfissaoAct 129 100 2 701 19%
rendimentos 1 012 € 1,876 - € 110 523 € 0%
Flag_CasaPropria - - 0 1 0%
Flag_Reformado - - 0 1 0%
Risco
Sociodemográficas Marketing
4. Extração e pré-processamento dos dados
No que diz respeito aos valores omissos, através da análise da Tabela 2 verifica-se que existem 9 variáveis com uma percentagem superior a zero. As três variáveis correspondentes ao tema Marketing procedeu-se à substituição dos mesmos para o número zero, uma vez que, os clientes que tinham valores omissos, era porque nunca receberam campanha. Na temática do Risco, as três variáveis correspondes aos escalões de incumprimento acabaram por ser excluídas por terem uma elevada percentagem de omissos e por apresentarem uma elevada correlação com outra variável do grupo (ver próxima subseção referente às correlações e o subcapítulo referente à escolha das variáveis finais). As restantes duas variáveis do risco com presença de valores omissos (minNMesesUltAtraso e iInc com 80% e 30% respetivamente) substituí-se novamente pelo número zero, à semelhança do Marketing, porque significa que os clientes nunca se encontraram nas respetivas situações. Por fim, na temática Sociodemográfica, onde apenas existe uma variável nestas condições (antProfissaoAct com 19%), corresponde aos clientes que não trabalham, substituindo igualmente por zero.
Como já foi mencionado, segundo (Henriques, 2010), ao contrário do SOM standard, os outliers identificados pela HSOM não são outliers devido a valores extremos em uma ou poucas variáveis, mas sim valores estranhos nos diversos temas. Contudo, por uma questão de coerência e lógica, foi decidido efetuar o tratamento dos
outliers de três variáveis através do SAS Enterprise Miner. Para a variável
antUltContrato definiu-se um valor máximo de 150 meses, uma vez que, numa perspetiva de regras negócio não faz sentido analisar clientes que realizaram o último contrato há mais de 12 anos. Na variável rendimentos, o valor máximo delineado foi de
5.000€ a ra da anál e da Tabela 2 é possível ver que a média é aproximadamente
1.000€ e com um alor máx mo er f cado per o de 100.000€. Através do gráfico do
4.3.2. Correlações
Uma vez que a possível existência de variáveis muito correlacionadas (e que, consequentemente poderiam expressar a mesma informação) foi analisada a matriz de correlações de Pearson (Anexo 12) apenas com as variáveis intervalares. Através desta análise, é possível verificar onde se localizam as maiores correlações, de modo a serem excluídas as variáveis consideradas redundantes. Foi estabelecido o critério de que se a correlação fosse acima de 50% uma das variáveis à partida seria excluída, salvo exceções em que seria pertinente manter ambas devido à contribuição que teriam para a interpretação da segmentação.
Ao longo do próximo subcapítulo, a utilização desta matriz será bastante útil e decisiva.
4.4.ESCOLHA DAS VARIÁVEIS FINAIS
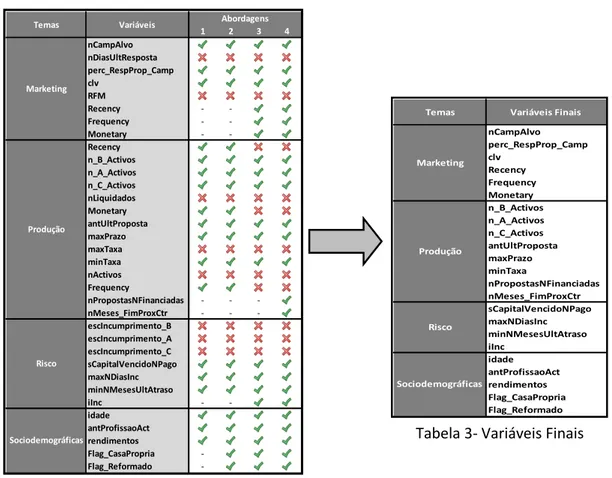
A escolha das variáveis não foi um processo simples nem rápido. Após várias tentativas e simulações de variáveis, das 31 variáveis selecionadas (Tabela 4) a análise restaram apenas 23 (Tabela 3).
nCampAlvo perc_RespProp_Camp clv Recency Frequency Monetary n_B_Activos n_A_Activos n_C_Activos antUltProposta maxPrazo minTaxa nPropostasNFinanciadas nMeses_FimProxCtr sCapitalVencidoNPago maxNDiasInc minNMesesUltAtraso iInc idade antProfissaoAct rendimentos Flag_CasaPropria Flag_Reformado Variáveis Finais Marketing Produção Risco Sociodemográficas Temas
1 2 3 4
nCampAlvo nDiasUltResposta perc_RespProp_Camp clv
RFM
Recency -
-Frequency -
-Monetary -
-Recency n_B_Activos n_A_Activos n_C_Activos nLiquidados Monetary antUltProposta maxPrazo maxTaxa minTaxa nActivos Frequency
nPropostasNFinanciadas - -
-nMeses_FimProxCtr - -
-escIncumprimento_B escIncumprimento_A escIncumprimento_C sCapitalVencidoNPago maxNDiasInc minNMesesUltAtraso
iInc -
-idade antProfissaoAct rendimentos Flag_CasaPropria -Flag_Reformado -Sociodemográficas
Temas Variáveis Abordagens
Marketing
Produção
Risco
4. Extração e pré-processamento dos dados
Figura 10- Planícies de componentes da nDiasUltResposta e perc_Resp_prop_camp
De seguida será descrito o processo de seleção das variáveis e os motivos de exclusão e/ou inclusão das mesmas nos diversos temas.
Na temática Marketing Como é possível observar através da Tabela 4, no Marketing foram necessárias três abordagens para chegar à solução final. Na primeira e seguintes abordagens optou-se por excluir a variável nDiasUltRespost e RFM. No que diz respeito ao primeiro caso,
uma vez que a taxa de resposta de campanhas de marketing é bastante reduzida, esta variável pouco acrescenta à análise. Observando as planícies de componentes (Figura 10) das variáveis nDiasUltRespostae perc_Resp_prop_camp
respetivamente, é possível concluir que na área onde estão representados os clientes que respondem às campanhas, não existe nenhuma diferenciação no que diz respeito ao número de dias desde a última resposta. Por outro lado, a variável RFM foi igualmente excluída de raiz por ser nominal e por estar muito relacionada com o conceito da variável CLV. Neste caso, optou-se por não excluir o CLV porque a RFM tinha a possibilidade de ser desmembrada e utilizá-las na temática produção. Na segunda abordagem apenas restavam três variáveis para este tema, foi assim que surgiu a necessidade de na terceira abordagem transferir as variáveis que compunham o RFM para a temática do Marketing, acrescentando bastante valor ao cluster como vai ser possível observar mais à frente no Capítulo 5 Resultados práticos. Posto isto, a versão final desta temática é composta por seis variáveis (nCampAlvo, perc_RespProp_Camp, clv, Recency , Frequency, Monetary).
No que diz respeito ao tema Produção, mais uma vez, através do Tabela 4, é possível concluir que nesta temática foram necessárias 4 abordagens, passando de 14 variáveis para 8 (n_B_Activos, n_A_Activos, n_C_Activos, antUltProposta, maxPrazo,
minTaxa, nPropostasNFinanciadas, nMeses_FimProxCtr). Na primeira abordagem
Figura 11- Matriz U da variável maxTax
Figura 12- Matriz U da variável minTax
Figura 13- Matriz U da variável nAtivos
teve taxas baixas, caso se verifique, significa que é sensível à mesma. Esta informação poderá enriquecer a análise. Por fim, ainda na primeira abordagem retirou-se o
nAtivos, por apresentar uma planície de componente pouco conclusiva (Figura 13).
Na terceira abordagem surgiu a necessidade da passagem das três variáveis que compõe o RFM (Recency, Frequency e Monetary) para o grupo do Marketing, deixando assim a necessidade de na quarta abordagem introduzir novas variáveis para melhor compor este tema. Surgiu então a nPropostasNFinanciadas que demonstra a intenção do cliente em fazer outro contrato com o Banco, independentemente de ter sido aprovado ou não, e a variáveis nMeses_FimProxCtr que enriquece por dizer quanto tempo mais o cliente irá ficar no Banco.
No Risco apenas restaram 4 variáveis viáveis para entrar na análise (sCapitalVencidoNPago, maxNDiasInc, minNMesesUltAtraso e iInc). Através do Tabela 4 épossível observar que as variáveis referentes aos escalões de incumprimento nos diversos negócios foram excluídas, isto porque, têm muitos valores omissos (Tabela 2) e porque estão correlacionadas com a variável maxNDiasInc (correlações superiores a 0,5, consultaro Anexo 12). Na segunda abordagem surge novamente a necessidade de adquirir mais variáveis, assim, na terceira abordagem, a variável iInc foi incluída, esta irá ter o papel semelhante às dos escalões de incumprimento não tendo a distinção por negócio.
Por fim, no tema das variáveis Sociodemográficas apenas foram necessárias duas abordagens. Este tema requereu mais cuidado, uma vez que muitas das variáveis possíveis de entrar eram nominais ou binárias, e como já foi dito, neste último caso, as variáveis poderão influenciar demasiado as partições do cluster. Assim, na primeira abordagem apenas estavam disponíveis três variáveis, as quais eram intervalares. Porém, na segunda abordagem houve a necessidade de arriscar a inserção de variáveis binárias e ver como se comportavam. Foi então decidido inserir a Flag_CasaPropria
4. Extração e pré-processamento dos dados
Flag_Reformado que além da estabilidade, também permite conciliar com a variável da antiguidade da profissão, de maneira a justificar quando os clientes têm idades mais elevadas com antiguidades reduzidas. Como será possível observar noCapítulo 5 de Resultados práticos, foram apostas ganhas e que acrescentaram valor às conclusões.
5.
RESULTADOS PRÁTICOS
Neste capítulo foram elaborados os resultados práticos do problema que foi proposto resolver com este Trabalho de Projeto, assim como as respetivas conclusões. Como é sabido, o principal objetivo deste Trabalho é a criação de clusters de clientes de um Banco, através do método SOM, com maior foco no HSOM. Contudo, também foi proposto analisar se neste contexto o HSOM apresenta os mesmos resultados relativamente ao SOM, assim como, comprovar algumas vantagens enumeradas na subseção 2.2.3 Razões para utilizar o HSOM em vez do SOM.
Assim, este capítulo é composto por um primeiro subcapítulo referente aos resultados práticos do SOM Geral, seguido dos SOMs temáticos, que irão suportar o HSOM presente no último subcapítulo.
5.1.SOM STANDARD
Neste subcapítulo, são analisados os grupos de clientes gerados através do SOM standard, ou seja, com todas as 23 variáveis selecionadas como input, sem estarem agrupadas por temas.
A seguinte Figura 14 ilustra a Matriz U do SOM standard e onde foi possível definir cinco clusters.
Figura 14- Matriz U do SOM standard
Assim, após definidos os cinco clusters a analisar com este método, foram elaboradas as médias das variáveis dentro de cada cluster, para que fosse mais simples caracterizar cada grupo (Tabela 5). Nesta Tabela cada cluster está caracterizado com a cor que corresponde na Matriz U (Figura 14), e as cores que acompanham os números refletem os valores elevados (verde), intermédios (amarelo) ou reduzidos (vermelho)
1 4
5