Universidade do Minho
Escola de Engenharia
Amadeu José Freitas Barroso Andrade
Análise de complexidade de programas em
ferramentas de apoio à decisão
Amadeu José F
reitas Barr
oso Andr
ade
Análise de comple
xidade de programas em ferrament
as de apoio à decisão
Amadeu José Freitas Barroso Andrade
Análise de complexidade de programas em
ferramentas de apoio à decisão
Universidade do Minho
Escola de Engenharia
Trabalho efetuado sob orientação do
Professor Doutor Cláudio Manuel Martins Alves
Dissertação de Mestrado
iii
A
GRADECIMENTOS
Deixo o meu agradecimento a todas pessoas que tornaram este projeto possível, em especial: À minha família, que sempre me apoiou.
Ao meu orientador, o professor Cláudio Alves, pela oportunidade de trabalhar sob a sua orientação e por todo o tempo que dedicou a aconselhar-me.
À SISCOG, pela oportunidade de realizar este projeto com o seu apoio.
Ao Ricardo Nogueira, por ter sido o impulsionador deste projeto e ter-se mostrado sempre disponível para ajudar.
v
R
ESUMO
Na área do desenvolvimento de software, o processo de análise de código é um processo extremamente delicado, pois é suscetível a erros e que varia consoante a experiência do programador, tornando-se por vezes um processo complexo e demorado se for feito sem a ajuda de ferramentas informáticas.
O trabalho desenvolvido nesta dissertação usou a linguagem LISP como base e visa proporcionar uma nova forma de apoio aos analistas-programadores durante a análise do código produzido e também para servir de apoio à equipa de testes na contabilização do número de casos de testes a desenhar. Aqui é também apresentado um estudo sobre todos os conceitos teóricos relativos à complexidade ciclomática e tudo que esta envolve, fazendo a ligação desta métrica de análise com os testes de software e os grafos de controlo de fluxo.
Palavras-Chave: Complexidade ciclomática, testes de software, grafos de controlo de fluxo, análise de software.
vii
A
BSTRACT
In the field of software development, the process of code analysis is a very delicate process because it is error-prone and varies with the experience of the developer, making it a complex and time consuming process if done without the support of the appropriate software tools.
The work described in this thesis was done using LISP and aims to provide a new form of support for the anlyst-programmer during the analysis of the code produced and also to provide support to the tests team making it possible to know the number of test cases that need to be designed.
It is also presented a study of all the theoretical concepts related to cyclomatic complexity and all the related issues, linking this analysis metric with the software testing process and with the control flow graphs.
ix
Í
NDICE 1. Introdução ... 1 1.1 Contextualização e Enquadramento ... 1 1.2 Motivação e objetivos ... 3 1.3 Apresentação da empresa ... 3 1.4 Estrutura da dissertação ... 52. Complexidade ciclomática de programas ... 7
2.1 Complexidade em geral ... 7
2.2 Definição e caracterização da complexidade ciclomática ... 8
2.3 Aspetos positivos da complexidade ciclomática ... 15
2.4 Aspetos negativos da complexidade ciclomática ... 16
3. Testes de software ... 19
3.1 Introdução aos testes de software ... 19
3.2 Testes de caixa branca e testes de caixa preta ... 19
3.3 Testes e complexidade ciclomática ... 21
4. Grafos de controlo de fluxos ... 23
4.1 Introdução à teoria de grafos e grafos de controlo de fluxo ... 23
4.1.1 Conceitos da teoria de grafos ... 24
4.2 Complexidade ciclomática e os grafos ... 25
5. Implementação ... 29
5.1 Abordagens ponderadas ... 29
5.2 Linguagem de programação e ferramentas externas de apoio ... 29
5.2.1 LISP ... 30
5.2.2 GNU Emacs e SLIME ... 31
5.2.3 Allegro CL IDE ... 31
5.2.4 Analisador de código: code walker ... 31
5.2.5 Gestor de bibliotecas LISP: Quicklisp ... 33
5.2.6 Biblioteca de grafos: CL-Graph ... 34
5.3 Estrutura do código ... 35
5.4 Decisões de implementação ... 36
5.4.1 Definição genérica ... 36
5.4.2 Operador lógico: and e or ... 36
5.4.3 Condicional simples: if ... 38
5.4.4 Condicional simples: cond ... 39
5.4.5 Condicional simples: when e unless ... 40
5.4.6 Condicionais compostos ... 41
5.4.7 Iterador: dolist ... 43
5.4.8 Iterador: do/do* ... 45
5.4.9 Operadores especiais: let e let* ... 47
5.4.10 Operadores especiais: labels e flet ... 48
5.4.11 Operadores especiais: multiple-value-bind ... 49
5.4.12 Outros ... 49
5.5 Relatório ... 49
6. Estudo de casos ... 51
6.1 Caso I – Definição de cálculo de compensações ... 51
6.2 Caso II – Definição de expansão de partilha de equipamento ... 53
6.3 Caso III – Definição de processamento de licitações ... 56
7. Conclusões ... 61
7.1 Síntese dos resultados alcançados ... 61
7.2 Trabalho futuro ... 63
Bibliografia ... 65
Anexo I – Relátorio gerado para o caso I ... 73
Anexo II – Grafo do caso de estudo II ... 74
Anexo III – Grafo do caso de estudo III (original) ... 77
xi
L
ISTA DE
F
IGURAS
Figura 1 - Logótipo da SISCOG. ... 4
Figura 2 - Exemplo de um if. ... 10
Figura 3 - Exemplo de grafo de controlo de fluxo. ... 11
Figura 4 - Grafo de controlo de fluxo da métrica original. ... 11
Figura 5 - Grafo de controlo de fluxo com a alternativa 1. ... 12
Figura 6 - Grafo de controlo de fluxo com a alternativa 2. ... 13
Figura 7 - Linguagens de programação usadas na SISCOG. (SISCOG, 2013). ... 30
Figura 8 - Exemplo de um if e um cond em LISP. ... 32
Figura 9 - Exemplo de um macroexpand. ... 32
Figura 10 - Resultado do macroexpand. ... 32
Figura 11 - Exemplo de um grafo em linguagem DOT. ... 34
Figura 12 - Estrutura geral do código implementado. ... 35
Figura 13 - Grafo de um and/or. ... 37
Figura 14 - Grafo de um and/or com nodos intermédios. ... 38
Figura 15 - Grafo de um if simples. ... 39
Figura 16 - Grafos da macro cond. ... 40
Figura 17 - Grafo de um when/unless. ... 41
Figura 18 - Pseudo-código de um if com recurso aos operadores and/or. ... 41
Figura 19 - Grafos de um if com recurso aos operadores and/or. ... 42
Figura 20 - Grafos do dolist. ... 44
Figura 21 - Grafo de um do/do*. ... 45
Figura 22 - Grafo 2 de um do/do*. ... 46
Figura 23 - Grafo de um let/let*. ... 47
Figura 24 – Definição do cálculo de compensações. ... 52
Figura 25 - Grafo do caso de estudo I. ... 52
Figura 26 - Exemplo de parte do grafo do caso de estudo II. ... 55
Figura 27 - Condições do when no caso de estudo II. ... 56
Figura 28 - Exemplo de parte do grafo da definição original do caso III. ... 58
Figura 29 - Grafos das definições criadas. ... 59
Figura 31 - Anexo II - Grafo do caso de estudo II (Parte 1). ... 74
Figura 32 - Anexo II - Grafo do caso de estudo II (Parte 2). ... 75
Figura 33 - Anexo II - Grafo do caso de estudo II (Parte 3). ... 76
Figura 34 - Anexo III - Grafo do caso de estudo III, original (Parte 1). ... 77
Figura 35 - Anexo III: Grafo do caso de estudo III, original (Parte 2). ... 78
Figura 36 - Anexo IV - Grafo do caso de estudo III, refatorizada (Parte 1). ... 79
xiii
L
ISTA DE
T
ABELAS
Tabela 1 - Fórmulas da complexidade ciclomática. ... 10
Tabela 2 - Análise do valor da complexidade ciclomática (Enescu, Mancas, Manole, & Udristoiu, 2008). ... 13
Tabela 3 - Ferramentas utilizadas no projeto. ... 30
Tabela 4 - Formas retornadas pelo code walker. ... 33
Tabela 5 - Grupos de palavras reservadas. ... 36
xv
L
ISTA DE
A
BREVIATURAS
,
S
IGLAS E
A
CRÓNIMOS
AAAI - American Association for Artificial Intelligence AST - Abstract Syntax Tree
IDE – Integrated Development Environment
1. I
NTRODUÇÃO
1.1 Contextualização e Enquadramento
O trabalho realizado e que irá ser descrito nesta dissertação, foi um projeto realizado numa empresa portuguesa, SISCOG, na área de desenvolvimento de sistemas de apoio à decisão. Um dos objetivos centrais deste projeto foi a construção de uma ferramenta que permitisse a análise automática da complexidade de programas de código LISP, sendo um passo no processo de melhoria contínua pelo qual a empresa se rege.
O trabalho desenvolvido nesta dissertação visa proporcionar uma nova forma de apoio aos analistas-programadores durante a análise do código produzido e também para servir de apoio à equipa de testes na contabilização do número de casos de testes a desenhar, pois é uma área onde é gasta uma grande quantidade de esforço dos recursos da empresa.
Partindo dos testes de software em ferramentas de apoio à decisão, na engenharia de software, os testes são, tradicionalmente, uma das principais técnicas a contribuir para uma maior fiabilidade e qualidade do software (Del Grosso, Antoniol, Merlo, & Galinier, 2008), sendo por isso usadas em várias empresas de desenvolvimento de software. Estes testes podem incidir numa vertente de análise de eficiência ou numa vertente de resolução e/ou prevenção de erros. Neste projecto, o foco principal foi a segunda vertente pois é aquela em que existe um maior número de recursos da empresa envolvidos. Na procura do erro são desenhados casos de teste na tentativa de cobrir o máximo possível de funcionalidades de um programa. Um caso de teste é considerado bom quando tem uma alta probabilidade de mostrar um erro não descoberto até ao momento. Erro esse que pode ser categorizado como erro fatal, que bloqueia por completo o funcionamento do programa, ou ser apenas uma falha subtil, que origina uma alteração do output, sem causar a falha do programa (Kanewala & Bieman, 2014). Se o teste não encontra erros serve para demonstrar o âmbito no qual o programa funciona e serve portanto para validar que o programa cumpre os requisitos. Existem vários tipos de testes, mas o foco deste projeto foram os testes de caixa-branca e os testes de caixa-preta, pois são os mais usados na SISCOG.
Os testes de caixa-preta são tipicamente utilizados para isolar possíveis comportamentos erróneos do sistema, tais como resultados, interfaces e rendimento. Por seu lado, os testes de caixa-branca, são utilizados para verificar o software antes de integrá-lo no sistema, sendo baseados em
estruturas de controlo e correcção algorítmica. Nos testes de caixa-branca surge o método dos caminhos básicos que engloba um grafo de fluxo e a sua complexidade ciclomática.
No que toca à complexidade de programas e sua medição, pode-se começar por referir que a complexidade do software é sempre indesejada, já que é uma das razões fundamentais para o diminuição da qualidade do software (Madi, Zein, & Kadry, 2013) e está directamente ligada à produtividade dos recursos que trabalham na manutenção do software (Gill & Kemerer, 1991), pois quanto mais complexo é um sistema, mais difícil é de manter, o que por sua vez vai acarretar custos maiores (Gill & Kemerer, 1991; Coleman, Ash, Lowther, & Oman, 1994) para as empresas.
Neste contexto, surgem então as métricas de complexidade de software. Desde 1976 têm sido usadas diferentes métricas para avaliar a complexidade de um sistema, acompanhar o progresso e avaliar a efetividade do software (Suresh, Pati, & Rath, 2012; Fenton & Neil, 1999). Estas fornecem uma forma de descrever quantitativamente os projetos de software, assim como uma forma de avaliar os métodos e ferramentas usadas nesses projetos, com o intuito de aumentar a produtividade e qualidade dos mesmos (Gill & Kemerer, 1991). Neste conjunto de métricas destaca-se a complexidade ciclomática de McCabe. Esta métrica é considerada como um dos melhores indicadores da fiabilidade do sistema (Suresh et al., 2012), sendo por isso escolhida como o principal foco desta dissertação.
A complexidade ciclomática surgiu em 1976 (McCabe, 1976), como uma abordagem para a medição da complexidade de um sistema, através do cálculo do seu valor ciclomático. Para isso foram necessárias algumas definições e teoremas da teoria de grafos, sendo o valor da complexidade ciclomática calculado através do número de arestas e nós de um grafo de controlo de fluxo (Suresh et al., 2012). O seu principal propósito, segundo Gill and Kemerer (1991), é identificar módulos de software que vão ser difíceis de testar ou manter. Além desta avaliação da complexidade dos módulos de um sistema, a complexidade ciclomática pode também ser usada para estimar o número de casos de teste necessários para atingir uma máxima cobertura do código (Suresh et al., 2012), estudando para isso o número de caminhos possíveis de um programa. No estudo de McCabe (1976), este refere que apesar de ser possível definir um conjunto de expressões algébricas que fornecessem o número total de caminhos possíveis através de um programa estruturado, usar este número não se tornaria prático, optando-se então por seguir o método dos caminhos básicos, que quando combinados gerariam todos os caminhos possíveis.
Estas informações foram o ponto de partida deste projecto, que teve como resultado final a criação de uma ferramenta automática de análise de complexidade.
1.2 Motivação e objetivos
No desenvolvimento de software, a análise do código produzido ou existente é um processo suscetível a erros e que varia com a experiência do programador, tornando-se por vezes num processo complexo se for feito sem a ajuda de ferramentas informáticas.
O objetivo deste projeto centrou-se na análise automática da complexidade de ferramentas informáticas dedicadas especificamente ao apoio à decisão e teve início com uma pesquisa bibliográfica, em que se realizou um levantamento dos conceitos chave para a resolução do problema e das principais técnicas e ferramentas que poderiam servir de suporte para a realização do mesmo.
Como este projeto pretendeu-se em particular avaliar a estrutura de ferramentas informáticas através da medida da sua complexidade ciclomática. Usando como base programas reais em uso numa empresa do sector, foi desenvolvida uma ferramenta de avaliação automática. A análise dos resultados obtidos com esta ferramenta permite avaliar o número de casos necessários para testar efetivamente estes programas, assim como avaliar quantitativamente a qualidade de partes do software produzidas pela empresa.
A motivação para este estudo assentou na sofisticação de algumas das rotinas (nomeadamente as de otimização) que compõem estas ferramentas, na dificuldade em delinear processos de teste efetivos, no reduzido número de estudos dedicados a este assunto na literatura, e na criticidade dos erros que podem ocorrer neste tipo de ferramentas.
1.3 Apresentação da empresa
A SISCOG é uma empresa criada em 1986, dedicada ao desenvolvimento de software, que fornece sistemas de apoio à decisão com o intuito de otimizar o planeamento de recursos e gestão de companhias de transporte, com um maior ênfase na ferrovia e metropolitanos.
Utilizando uma combinação de técnicas de inteligência artificial e investigação operacional (Morgado & Martins, 1998; Morgado, Martins, & Haugen, 2003), a empresa foi criando e desenvolvendo os seus produtos, que neste momento são o CREWS, o ONTIME e o FLEET.
Estes produtos surgiram na tentativa de cobrir grande parte do processo de planeamento e gestão dos clientes, fornecendo ferramentas para que estes consigam otimizar de forma precisa, efetiva e rápida os seus recursos operacionais e trabalho diário.
O CREWS é o produto usado no planeamento e gestão de pessoal, oferecendo aos utilizadores diferentes níveis de suporte à decisão, como o modo manual, que apenas valida todas as restrições do problema e faz os cálculos necessários enquanto os utilizadores constroem os planos dos recursos, o modo semi-automático, que aponta uma direção para atingir uma boa solução e por fim, o modo automático, que fornece uma solução otimizada. Este produto, foi premiado em 1997 e 2003 com o "Innovative Application Award" dado pela AAAI e laureados pelo "The Computerworld Honors Program" em 2006.
O ONTIME é usado para a criação de horários e cobre todo este processo, que vai desde a criação de horários anuais até aos ajustes feitos no dia-a-dia. Neste produto é possível planear e gerir a alocação de dois importantes recursos para as viagens das companhias: espaço (rotas, linhas, etc) e tempo (tempo de saída e chegada).
O FLEET, por sua vez, é usado para o planeamento e gestão de material motor. Este cria o escalonamento otimizado para veículos, considerando o número de passageiros expectável, especificações da frota e restrições operacionais. Produz também planos cíclicos de longo-prazo, planos de calendário de curto-prazo, lida com a manutenção planeada de veículos e fornece suporte à decisão para as operações do dia-a-dia.
Relativamente aos produtos FLEET e ONTIME, a empresa encontra-se neste momento a fazer grandes desenvolvimentos.
1.4 Estrutura da dissertação
Esta dissertação está dividida em 7 capítulos, que serão descritos em seguida.
No primeiro capítulo é feita uma introdução onde é apresentada a contextualização e enquadramento do tema, é feita a apresentação da empresa, assim como a motivação e os objetivos do projeto. Este capítulo acaba com a descrição da estrutura do relatório.
No segundo capítulo é introduzida a métrica da complexidade ciclomática, sendo exposto o estudo geral feito sobre o tema. Este estudo é o resultado da revisão de literatura existente e cobre aspectos como a sua definição, utilização, cálculo e análise dos seus resultados. São também apresentadas algumas críticas a esta métrica.
No terceiro capítulo é introduzido o tema dos testes de software, onde são abordados os testes de caixa branca e caixa preta, assim como a sua ligação à complexidade ciclomática.
No quarto capítulo é apresentada uma revisão sobre os grafos de controlo de fluxo, começando por uma breve introdução à teoria de grafos direcionada para o número ciclomático e acabando na ligação entre os grafos de controlo de fluxo e a complexidade ciclomática.
No quinto capítulo é apresentado o processo de desenvolvimento da ferramenta informática, desde a linguagem de programação utilizada até aos elementos principais e cálculos efetuados pela ferramenta.
No sexto capítulo mostram-se exemplos práticos de utilização da ferramenta, apresentando e analisando os casos de estudos selecionados.
No último capítulo são retiradas conclusões do trabalho realizado e apresentam-se propostas para trabalho futuro.
2. C
OMPLEXIDADE CICLOMÁTICA DE PROGRAMAS
Neste capítulo será exposto o estudo geral feito sobre a métrica da complexidade ciclomática. Este estudo é o resultado da revisão de literatura existente e cobre aspectos como a sua definição, críticas, utilização, cálculo e análise dos resultados.
2.1 Complexidade em geral
Antes de abordar a parte da complexidade ciclomática, vou começar por introduzir o tema da complexidade em geral, passando uma visão geral sobre o que é a complexidade de software e como é que esta tem vindo a ser definida na engenharia de software.
A complexidade de software é tradicionalmente um indicador direto da qualidade e do custo do software (Banker, Srikant, Kemerer, & Zweig, 1993; Basili & Perricone, 1983; Curtis, Sheppard, & Milliman, 1979; Gill & Kemerer, 1991; Munson & Khoshgoftaar, 1992; Wilkie & Hylands, 1998; Jay et all., 2009), pois quanto maior a complexidade de um programa, maior é a probabilidade de este ter falhas, o que consequentemente se traduz numa menor eficiência do mesmo (Gaur, 2013; Khalid, ul Haq, & Khan, 2013; Yadav & Khan, 2012; Bandara, Wikramanayake, & Goonethillake, 2009).
Na engenharia de software, o conceito genérico de complexidade foi investigado por vários autores, resultando daí uma grande variedade de definições que correspondem às diferentes visões de complexidade dos mesmos. De seguida irei expor alguns conceitos, compilados no artigo de Abram, Lopez, and Habra (2004):
Em IEEE (1990), pode-se encontrar o conceito de complexidade como sendo o grau de dificuldade em entender e verificar o desenho ou implementação de um sistema ou componente, sendo aqui definido que a complexidade é uma propriedade da implementação do desenho, mas que está também relacionada com o esforço necessário para perceber e verificar a implementação do desenho.
Em Evans and Marciniak (1987), a complexidade é baseada na estrututura do sistema e na definição de algumas das suas caraterísticas, sendo então determinada por fatores intrínsecos ao sistema, como o número e complexidade das interfaces, o número e complexidade dos ramos condicionais, pelo grau de encadeamento e pelos tipos de estruturas de dados. Quanto maior o número de fatores e relações de um sistema, maior é a interação entre os seus elementos, o que torna o sistema mais complexo.
Em Whitmire (1997), o conceito de complexidade tem um âmbito mais abrangente, pois considera alguns tipos de complexidade, como a complexidade computacional e psicológica. Estes conceitos de complexidade computacional e complexidade psicológica, são baseadas nas noções propostas por Whitmire (1997) e Henderson-Sellers (1996), sendo a primeira definida em termos de recursos de hardware necessários para executar o software e, a segunda, baseada em fatores como o problema complexo que foi resolvido, as caraterísticas do software utilizadas e o conhecimento e experiência do programador sobre o problema e domínio da solução.
Analisando estas definições, pode-se concluir que a complexidade é algo que a indústria de software deve evitar, sendo por isso a questão da avaliação da complexidade uma área crítica no desenvolvimento do software. Nesta área é gasto muito esforço na tentativa de identificar técnicas e métricas para avaliar a complexidade do software e dos seus módulos (Munson & Khoshgoftaar, 1989), mas que também permitam o acompanhamento do progresso e avaliação da efetividade do software (Fenton & Neil, 1999). Estas métricas são então consideradas como fatores decisivos na medição da qualidade de um produto de software.
Segundo Gill and Kemerer (1991), sem o recurso às métricas, as tarefas de planeamento e controlo do desenvolvimento de software iriam permanecer estagnadas, já que estas competências são adquiridas apenas através do ganho de experiência, e esta, não é facilmente transferível para um próximo sistema ou para futuros melhoramentos. Por seu lado, com o uso das métricas, os projetos de software podem ser quantitativamente descritos e os métodos e ferramentas usadas nesses projetos para melhorar a produtividade e qualidade podem ser avaliados.
Sendo a métrica da complexidade ciclomática um dos melhores indicadores da fiabilidade de um sistema (Suresh et al., 2012), irei aborda-la de seguida.
2.2 Definição e caracterização da complexidade ciclomática
Sabendo que os problemas de testabilidade e manutenção nasceram do fato de as empresas passarem metade do tempo de desenvolvimento em testes (Boehm, 1973) e do custo excessivo em manter os sistemas (Cammack & Rogers, 1973), a métrica da complexidade ciclomática surgiu como uma técnica matemática que fornece uma base quantitativa para a modularização de um sistema de software, permitindo identificar quais os módulos desse software é que vão ser difíceis de testar ou manter (McCabe, 1976).
Em McCabe, Wallace and Watson (1996), esta métrica é descrita como tendo dois propósitos. Um deles é ser usada durante todas as fases do ciclo de vida do software, na tentativa de manter o software fiável, testável e gerível; o outro é dar o número recomendado de casos de teste para o software. Pelo mesmo caminho, em Shuman (1990) e Suresh et al., (2012), a métrica da complexidade ciclomática é descrita como fornecedora de um meio para quantificar a complexidade do software e a sua utilidade tem vindo a ser sugerida no processo de desenvolvimento e de testes de software.
Para o cálculo desta, é necessário recorrer à teoria de grafos (McCabe, 1976; McCabe et al., 1996), pois esta métrica calcula a complexidade de um módulo baseada no seu grafo de controlo de fluxo, isto é, todas as instruções de um módulo são transformadas em nodos do grafo, com os caminhos do grafo a representarem a sua ligação/sequência, sendo depois representada por um único número (Madi et al., 2013).
Sendo os grafos tão importantes para a medição da complexidade ciclomática, todos os pormenores relativos a estes vão ser abordados num capítulo em separado (4. Grafos de controlo de fluxos).
Originalmente, a fórmula de cálculo desta métrica, foi definida por McCabe (1976) como sendo: V(G) = E – N + 2
Onde:
V(G), é o valor da complexidade do grafo G; E, é o número de caminhos do grafo; N, é o número de nodos.
A complexidade ciclomática pode também ser definida por meios alternativos, sendo as formas mais usuais (McCabe, 1976; Sarwar, Ahmad, & Shahzad, 2012; Pressman, 2010; Jovanović, 2006) as seguintes:
Fórmula Explicação
Original V(G) = E – N + 2 V(G), é o valor da complexidade
ciclomática do grafo G;
E, é o número de caminhos existentes no grafo.
N é o número de nodos existentes no grafo.
Alternativa 1 V(G) = P + 1 V(G), é o valor da complexidade
ciclomática do grafo G;
P é o números de pontos de decisão do grafo.
Alternativa 2 V(G) = R V(G), é o valor da complexidade
ciclomática do grafo G;
R, é o número de regiões do grafo (região exterior e regiões interiores fechadas).
Tabela 1 - Fórmulas da complexidade ciclomática.
Segue um exemplo para ajudar na compreensão da Tabela 1, ilustrando assim todas as alternativas possíveis para definir a complexidade ciclomática.
Usando um pequeno exemplo de um “if” simples:
Começamos por desenhar o grafo de controlo de fluxo:
Figura 3 - Exemplo de grafo de controlo de fluxo.
Com a fórmula original, V(G) = E- N + 2, em que contamos o número de caminhos, representados na Figura 4 por nodo origem à nodo destino, e o número de nodos, representados por um único número, temos:
V(G) = 5 – 5 + 2
V(G) = 2 à O valor da complexidade ciclomática é 2.
Com a alternativa 1, V(G) = P + 1, em que P é o número de pontos de decisão, ou seja, é a contagem dos nodos onde existe uma condição, sendo estes caracterizados por terem 2 ou mais caminhos a sair de si. Temos então:
Figura 5 - Grafo de controlo de fluxo com a alternativa 1.
V(G) = 1 + 1
V(G) = 2 à O valor da complexidade ciclomática é 2.
Por fim, com a alternativa 2, V(G) = R, em que R é o número de regiões. Quando se está a calcular regiões, estas regiões são as áreas cercadas por caminhos e nodos (na Figura 6 denominada por região fechada), e a área exterior ao grafo (na Figura 6 considerada região exterior):
Figura 6 - Grafo de controlo de fluxo com a alternativa 2.
V(G) = 1 + 1, em que somamos o número de regiões (a exterior e a fechada) V(G) = 2 à O valor da complexidade ciclomática é 2.
Como podemos observar pelos exemplos em cima, independentemente da fórmula escolhida, o valor da complexidade ciclomática é sempre o mesmo.
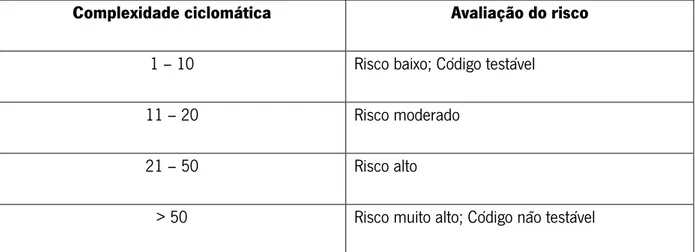
No que toca à análise dos resultados, a seguinte tabela mostra como é avaliado o risco de não se conseguir testar todo o código, com base na complexidade ciclomática.
Complexidade ciclomática Avaliação do risco
1 – 10 Risco baixo; Código testável
11 – 20 Risco moderado
21 – 50 Risco alto
> 50 Risco muito alto; Código não testável
Segundo Enescu, Mancas, Manole, and Udristoiu (2009), analisando a Tabela 2, concluiu-se que o número da complexidade ciclomática calculada de um programa deve estar no intervalo de 1 a 10 para o programa ser considerado simples e apenas aí o software é considerado como estando quase livre de risco. Se o valor se encontra entre 11 e 20, então o risco é considerado moderado e o programa começa a ser considerado como algo complexo. Se o número ciclomático cair no intervalo de 21 a 50, o módulo é considerado de alto risco, sendo o programa considerado muito complexo. Por fim, se o valor ciclomático for maior que 50, o programa/módulo é considerado não testável e de muito alto risco.
Em McCabe et al. (1996), foram analisadas as razões sobre o porquê de se dever limitar o valor da complexidade ciclomática a 10, mas tal como em várias outras métricas da indústria de software, não há um consenso quanto a um número fixo de complexidade ciclomática que sirva a todas as empresas, no entanto, o valor de 10 é considerado como bom ponto de partida (McCabe, 1976).
Algumas das principais razões apontadas a favor do limite do valor da complexidade ciclomática são que módulos excessivamente complexos são mais propensos a erros, são difíceis de perceber, são mais difíceis de testar e também mais difíceis de modificar (Gaur, 2013; Khalid, ul Haq, & Khan, 2013; Yadav & Khan, 2012; Bandara, Wikramanayake, & Goonethillake, 2009). Então, ao limitar a complexidade em todas as fases de desenvolvimento de software, está-se a evitar os grande parte dos problemas associados à alta complexidade de software.
Segundo McCabe et al. (1996), várias organizações conseguiram implementar limites à complexidade como parte dos seus programas de software. No entanto, o número exacto a ser usado, permanece ainda sem consenso. O limite original de 10 tem evidências de suporte significativas (McCabe, 1976), mas anos mais tarde, na publicação de McCabe et al. (1996), foi reportado que limitar esse número a 15 foi igualmente usado com sucesso. Segundo essa publicação, limitar o valor acima de 10 deve ser reservado a projetos com, por exemplo, desenvolvedores experientes, onde existe um desenho formal, uma linguagem de programação moderna, programação estruturada, orientações de código e um plano de testes compreensivo.
A Hewlett Packard, pode ser usada como exemplo de uma empresa que usou e limitou o número da complexidade ciclomática acima de 10, pois segundo Grady (1992), na Hewlett Packard, qualquer módulo com complexidade acima de 16, deve ser redesenhado, mostrando que até esse valor a complexidade é aceitável.
2.3 Aspetos positivos da complexidade ciclomática
A métrica da complexidade ciclomática sempre foi relacionada com qualidades de software (Nystedt, 1999) como a reutilização, manutenção (Geoffrey, 1991), segurança (Chowdhury, 2009), previsão de falhas de software (Shimeall, 1990) e como um bom guia para o desenvolvimento de casos de teste (McCabe, 1976).
Em Butler (1983), esta métrica é descrita como o melhor método para analisar e limitar a complexidade de programas de software, sendo que ao contrário da maioria das métricas de complexidade que são mais discriminatórias, esta é facilmente calculada por uma análise estática (Fenton & Neil, 1999).
Existem vários estudos que reforçam os aspectos positivos da complexidade ciclomática. Muitos deles focam-se na análise entre a correlação da complexidade ciclomática com a incidência de erros no software, como são os casos de Walsh (1979), Schneidewind (1979), Ward (1989), Meals (1981), Henry, Kafura and Harris (1981), Gollhofer, Shimeall and Leveson (1983) e Shuman (1990). Nestes estudos podem ser encontrados vários aspectos positivos para a utilização da complexidade ciclomática.
Em Walsh (1979), foram analisados oito módulos de um programa de larga escala com funcionalidades relacionadas. Neste estudo, foi medida a relação entre a ocorrência de erros e o valor da complexidade ciclomática. Para a realização do estudo, os módulos a serem testados foram divididos em dois grupos, um com o valor de complexidade ciclomática menor que 10 e outro onde era maior. O objetivo era comparar a incidência de erros entre os dois grupos. No fim, o autor conclui que havia uma incidência de erros 21% maior no grupo com maior complexidade ciclomática.
Em Schneidewind (1979), foram analisados quatro programas, todos com um número diferente de instruções, com o intuito de examinar a correlação entre a incidência de erros e a complexidade ciclomática. Da análise da estrutura destes programas, o autor concluiu que quanto maior a complexidade ciclomática, maior a ocorrência de erros.
Em Ward (1989), foram analisados dois programas de larga escala, com milhares de linhas de código, para estudar a correlação entre erros e complexidade ciclomática. Neste estudo foi encontrada uma correlação estatística de 0.8 (numa escala entre -1 e 1) entre a complexidade e a densidade dos erros.
Em Meals (1981), foram usadas ferramentas automáticas de medição de complexidade, para analisar três programas independentes e de larga escala. O objetivo era determinar se existia uma correlação entre complexidade ciclomática e a história de erros conhecida. Dois desses três programas
mostraram uma correlação entre a incidência de erros e a complexidade ciclomática, apesar de não ter sido dado nenhum coeficiente. A conclusão foi que a complexidade ciclomática é um indicador útil de secções do código propensas a erros.
Em Henry, Kafura and Harris (1981), foi levado a cabo o estudo de um programa de larga escala. Foi encontrada uma forte correlação, 0.95 (numa escala entre -1 e 1) entre procedimentos que continham erros e a complexidade ciclomática.
Em Gollhofer, Shimeall and Leveson (1983), foi analisada a complexidade de 27 programas independentes. Nove porcento dos módulos tinham complexidade superior a 10, sendo que estes mesmos módulos tinham 47% do total de erros. Os autores concluiram que existe uma forte correlação entre a complexidade ciclomática (quando maior que 10) e a incidência de erros.
Por fim, em Shuman (1990), foram analisadas múltiplas versões de programas relativamente largos e complexos, sendo encontrada uma correlação entre erros e a medida de complexidade ciclomática.
Como podemos observar por estes estudos, várias autores consideram existir uma forte correlação entre a complexidade ciclomática e a incidência de erros.
Mais recentemente, em McCabe, McCabe Jr., and Fiondella (2012), os autores concluíram que a complexidade ciclomática permite um escrutínio mais compreensivo da estrutura e do fluxo de controlo de código, fornecendo capacidades de deteção significativamente melhores.
Mesmo sendo esta uma das métricas mais populares (Fenton & Neil, 1999; Sarwar, Shahzad, & Ahmad, 2013) no que se refere à medição da complexidade de software, tem também algumas críticas associadas que passarei a expor de seguida.
2.4 Aspetos negativos da complexidade ciclomática
A complexidade ciclomática tem vindo a sofrer alguns ajustes de modo a tornar-se uma métrica mais completa e consensual (Curtis, 1983; Hansen, 1978; Harrison & Magel, 1981; Iyengar, Parameswaran, & Fuller, 1982; Magel, 1981; Myers, 1977; Oviedo, 1980; Stetter, 1984; Woodward, Hennell, & Hedley, 1979) mas, mesmo sendo esta bastante usada e amplamente citada tanto em estudos, como artigos ou mesmo livros (Arthur, 1985; Cobb, 1978; De Marco, 1982; Dunsmore, 1984; Harrison, Magel, Kluczny, & De Kock, 1982; Schneidewind, 1979; Tanik, 1980, Pressman, 1987; Wiener & Sincovec, 1984), encontra-se também sujeita a várias críticas.
Em Jay et all. (2009), os autores concluíram que a complexidade ciclomática, por si só, não tem poder explanatório suficiente, e que esta métrica mede a mesma propriedade que a métrica das linhas de código. Vários estudos (Curtis, Sheppard, Milliman, Borst, & Love, 1979; Kitchenham, 1981; Paige, 1980; Wang & Dunsmore, 1984; Basili & Hutchens, 1983) indicam mesmo que a métrica das linhas de código tem melhor performance que a complexidade ciclomática.
Em Shepperd (1988), a complexidade ciclomática é colocada em causa tanto no campo teórico como no campo empírico, sendo concluído que há uma grande dificuldade em avaliar a métrica de McCabe e o trabalho empírico associado devido à inexistência de um modelo explícito onde a complexidade ciclomática é baseada.
Em Baker & Zweben (1980), Oulsnam (1979) e Prather (1984), é argumentado que a complexidade ciclomática de um programa pode aumentar quando são usadas técnicas na melhoria da estrutura interna de um programa, sendo que essas técnicas são bastante consensuais na indústria de software.
Em Garg (2014), o autor concluiu que apesar das grandes vantagens obtidas através da análise do número da complexidade ciclomática, este não calcula o número exacto da complexidade do software porque não tem em conta a interação entre duas classes de objetos.
Em Vinju and Godfrey (2012), foram analisados oito sistemas Java de código aberto e recolhidas evidências empíricas, de que a complexidade ciclomática não avalia corretamente a compreensibilidade dos métodos, pois tanto é possível que esta seja subestimada como sobrestimada. Em Sarwar et al. (2013), é citado que a métrica de McCabe tem várias limitações, sendo um dos principais problemas o encadeamento de condições. Neste estudo, é exemplificado que a complexidade ciclomática calcula o mesmo valor de complexidade para uma construção simples e para uma construção encadeada, sendo que no segundo caso o valor deveria ser maior já que o programa se torna mais complexo.
Numa outra análise sobre o encadeamento de condições, em Solichah, Hamilton, Mursanto, Ryan, and Perepletchikov (2013), os autores comentam que a complexidade ciclomática tem incompletudes no que toca à medição da complexidade de um grafo de controlo de fluxo, já que esta métrica, quando existem dois grafos de programas, sendo que um deles tem um controlo de fluxo sequencial e o outro tem um controlo de fluxo encadeado, calcula o mesmo valor de complexidade para os dois e o segundo caso deveria trazer um maior valor de complexidade.
Como se pode ver pelos estudos em cima, apesar da complexidade ciclomática de McCabe ser bastante aceite na indústria de software, ainda existem vários estudos que lhe apontam falhas.
3. T
ESTES DE SOFTWARE
Neste capítulo será feita uma introdução aos testes de software, mostrando algumas abordagens de testes e fazendo a sua ligação com a complexidade ciclomática.
3.1 Introdução aos testes de software
Os testes de software podem ser definidos como o resultado da execução de um software e comparação entre o comportamento observado e o comportamento esperado, sendo o seu principal objetivo a detecção de erros (Myers, 1989). A medição objetiva da qualidade de teste é uma das questões-chave nos testes de software (Zhu et al., 1997), já que um importante problema na gestão dos testes de software é assegurar que antes de qualquer teste, os objetivos desses testes são conhecidos e aceites, e que esses objetivos são definidos em termos que possam ser medidos. Esses objetivos devem ser quantificáveis, razoáveis e atingíveis (Ould & Unwin, 1986).
Os testes podem ser considerados como uma das principais técnicas a contribuir para uma maior fiabilidade e qualidade do software (Del Grosso et al,. 2008), mas tal como as outras fases do desenvolvimento de software, são atividades bastante exigentes em termos de recursos humanos, fazendo com que seja necessário e quase obrigatório um processo continuo de procura de técnicas com o objetivo de tornar o processo de testes o mais eficiente possível. Embora a procura dessas técnicas consuma grande parte do tempo da investigação dos testes, é também importante fazer software que possa efetivamente ser testado, visto que quando não são detetados erros na execução dos testes, isto pode significar duas coisas, ou que a qualidade do software é alta ou que o processo de testes é de baixa qualidade (McCabe et al., 1996).
No que toca aos processos de teste de software, existem várias abordagens no que toca à tentativa de controlar a qualidade do software a ser testado. De seguida falarei de duas das mais usadas, os testes de caixa branca e os testes de caixa preta.
3.2 Testes de caixa branca e testes de caixa preta
Na procura do erro são desenhados casos de teste na tentativa de cobrir o máximo possível de funcionalidades de um programa. Um caso de teste é considerado bom quando tem uma alta probabilidade de mostrar um erro não descoberto até ao momento. Erro esse que pode ser categorizado como erro fatal, que bloqueia por completo o funcionamento do programa, ou ser apenas
uma falha subtil, que origina uma alteração do output, sem causar a falha do programa (Kanewala & Bieman 2014). Se o teste não encontra erros, serve para demonstrar o âmbito no qual o programa funciona e portanto serve para validar que o programa cumpre os requisitos.
Na literatura de testes de software, é normal encontrar os conceitos de testes de caixa branca e testes de caixa preta. Estes são os testes mais usados na SISCOG.
Os testes de caixa preta pressupõem que o programa que está a ser testado seja uma “caixa preta”, ou seja, é assumido que não há conhecimento sobre a forma como o programa está implementado (Zhu et al., 1997). Este tipo de teste é tipicamente utilizado para isolar possíveis comportamentos erróneos do sistema, tais como resultados, interfaces e rendimento. Uma das abordagens usadas no desenvolvimento de testes de caixa preta é o teste baseado na especificação. Esta abordagem utiliza os requisitos como forma de testar as funcionalidades, já que a especificação dos requisitos é convertida em casos de teste, sendo que cada requisito resulta em pelo menos um caso de teste. Segundo McCabe et al. (1996), apesar desta abordagem ser bastante usada, ela não pode ser considerada uma solução completa, pois para além dos documentos de requisitos serem propensos a erros, o código contempla muitos mais detalhes do que os requisitos, pois este são normalmente escritos de uma forma muito mais abstrata. Devido a este motivo, foi argumentado que um caso de teste que seja desenvolvido a partir de um requisito pode originar várias falhas no que toca à cobertura total do programa.
Por seu lado, nos testes de caixa branca, existe o acesso a detalhes sobre o programa a ser testado, sendo que os testes são feitos de acordo com esses detalhes (Zhu et al., 1997). Estes, são utilizados para verificar o software antes da sua integração no sistema, sendo baseados em estruturas de controlo e correção algorítmica. Neste tipo de testes, de caixa-branca, surge então o método dos caminhos básicos criado por McCabe (1976). Com o uso deste tipo de testes, o erros são mais facilmente detetados mesmo quando existem falhas na especificação do software, pois sabe-se que toda a implementação do software é tida em conta. Um dos problemas destes testes, segundo McCabe et al. (1996), é que quando um ou mais requisitos do software não são implementados, os testes de caixa branca podem não detetar os erros que resultam dessa omissão. Portanto, tanto os testes de caixa branca como os de caixa preta são importantes para um processo de testes efetivo.
3.3 Testes e complexidade ciclomática
Sabendo que os testes na SISCOG baseiam-se essencialmente na prevenção de erros, com a complexidade ciclomática podemos estimar o número de casos de testes necessários para cobrir todos os caminhos possíveis de uma definição. Assim sendo, a métrica da complexidade ciclomática não pode ser só vista como um meio para quantificar a complexidade de software, já que também pode e tem vindo a ser utilizada no apoio ao processo de testes de software (McCabe et al., 1996; Zhu, Hall, & May, 1997; Gold, 2013).
O valor da complexidade ciclomática indica o número de caminhos possíveis de execução de um programa, sendo este conjunto de caminhos conhecido como caminhos básicos. A sua lógica consiste essencialmente em gerar os casos de teste de forma a que estes passem por um número mínimo de caminhos entre a entrada e a saída do programa, sem o risco de ocorrerem redundâncias. Baseados no número de caminhos encontrados, os casos de testes são gerados manualmente ou através de um processo automático, de modo a cobrir todos os caminhos executáveis, o que vai assegurar que é atingida a máxima cobertura do código (Suresh et al., 2012).
De uma forma simples, pode-se explicar a forma de cálculo do número de casos de teste através da complexidade ciclomática da seguinte forma:
• Desenhar o grafo de controlo de fluxo;
• Determinar o número de caminhos independentes (complexidade ciclomática); • Identificar esses caminhos;
• Para cada caminho, gerar os casos de teste (manualmente ou com uma ferramenta); • Por fim,
o Executar cada caso de teste;
o Comparar os resultados obtidos com os resultados esperados.
Para assegurar então a máxima cobertura, todos os caminhos do programa devem ser testados. Isto implica que, um programa com um número de complexidade alto, vai necessitar de um maior esforço ao nível dos testes, já que quanto maior o número de complexidade, maior o número de caminhos existentes no código.
Ao identificarmos o número de casos de testes e as zonas do código onde o esforço dos testes deve ser concentrado, além da poupança de tempo e dinheiro, talvez se consiga ter um sistema mais fiável (Shuman, 1990), já que os testes se podem centrar em áreas que são mais suscetíveis a erros.
4. G
RAFOS DE CONTROLO DE FLUXOS
Neste capítulo é feita uma breve introdução à teoria de grafos e aos grafos de controlo de fluxo, expondo alguns conceitos essenciais para posteriormente facilitar a compreensão da ligação entre a complexidade ciclomática e os grafos.
4.1 Introdução à teoria de grafos e grafos de controlo de fluxo
A teoria de grafos é o estudo dos grafos, que são considerados como estruturas matemáticas usadas para modelar pares de relações entre objetos. Um grafo é um conjunto de nodos ligados por caminhos, podendo ser direcionado, em que o caminho indica a direção de ligação dos nodos, ou não-direcionado, significando que não há qualquer distinção entre os dois nodos associados pelo caminho (Berge, 1973).
Usando a notação de grafo pode-se usar grafos de controlo de fluxo para descrever todos os caminhos que podem ser executados por um programa. Estes grafos têm sido objeto de vários estudos ao longo dos anos (Jalote, 2005; Kosaraju, 1973; McCabe, 1976; Paige, 1977; Rapps and Weyuker, 1982; Tan, 2006; White, 1981; Zhu et al., 1997) e são largamente usados na análise de software (Fenton, Whitty, & Kaposi, 1985; Kosaraju, 1973; McCabe, 1976; Paige, 1975).
São também conhecidos por grafos de programas que representam o controlo de fluxo do programa, isto é, são grafos que descrevem a estrutura lógica de módulos software (McCabe et al., 1996; Zhu et al., 1997). Esses módulos de software correspondem a uma única função ou sub-rotina, que têm um único ponto de entrada e outro de saída, e podem ser usados como componente de desenho através de um mecanismo de chamada/retorno (McCabe et al., 1996).
Os grafos de controlo de fluxo, consistem num conjunto de nodos e caminhos, sendo que os nodos representam as instruções do programa e os caminhos representam o controlo de fluxo entre essas instruções (Gold, 2010).
De seguida abordarei alguns conceitos fundamentais que são necessários para o estudo da complexidade ciclomática.
4.1.1 Conceitos da teoria de grafos
Para o estudo elaborado neste projeto são necessários alguns conceitos da teoria de grafos. Estes conceitos foram retirados de Berge (2001), Cardoso (2009) e Abran (2010):
Grafo
“Um grafo G, é um par (V (G), A(G)), onde V (G) é um conjunto não vazio de elementos chamados vértices, e A(G) é uma família finíta de pares não ordenados de pares de elementos, não necessariamente distintos, chamados arestas.”
Grafo simples
“Um grafo simples G, é um par (V (G), A(G)), onde V (G) é um conjunto não vazio de elementos chamados vértices, nodos ou pontos, e A(G) é um conjunto finito de pares não ordenados de elementos distintos de V (G), chamados arestas ou linhas; V (G) é o conjunto dos vértices e A(G) é o conjunto das arestas.”
Grafo direcionado
“Um grafo direcionado (ou digrafo) D, é um par (V (D), A(D)), onde V (D) é um conjunto não vazio de elementos chamados vértices, e A(D) é uma família finita de pares ordenados de elementos de V (D), chamados arcos. Se D não tem laços e se os arcos de D são todos distintos, então D é um grafo direcionado simples.”
Caminho
“Um caminho de comprimento l em G, de vi a vj, é a sequência finita de vértices em G,
vi = u0, u1, . . . , ul = vj, tais que ut−1 e ut são adjacentes para 1 ≤ t ≤ l, sendo que os vértices são distintos (excepto, possivelmente, u0 = ul).”
Grafo ligado
“Um grafo G é ligado se, para todo o x e para todo o y (vértices), existe um percurso que liga x e y. Um grafo que não é ligado pode ser dividido em componentes ligados.”
Ciclo simples
“Um ciclo que tem o comprimento mínimo de 3 e no qual apenas o vértice inicial e final podem aparecer repetidos, todos os outros aparecem apenas uma vez.”
Grafo fortemente ligado
“É um grafo direcionado que tem um caminho de cada vértice para todos os outros vértices.” Número ciclomático
“É o menor número de arestas que devem ser removidas de um grafo para que o mesmo não apresente ciclos.”
Tendo então presentes estes conceitos, mostrarei de seguida como McCabe se apoiou na teoria de grafos e no número ciclomático para realizar o seu estudo da complexidade ciclomática.
4.2 Complexidade ciclomática e os grafos
A medida de McCabe é baseada na teoria de grafos (McCabe, 1976; McCabe et al., 1996), pois o seu trabalho apoiou-se em alguns conceitos de medida presentes na teoria de grafos e na transposição desses conceitos para o domínio da medida de software (Abran, 2010).
Segundo McCabe (1976), a abordagem seguida no estudo da medida da complexidade centrou-se na medição e controlo do número de caminhos existentes num programa. Um dos problemas imediatamente detetado, foi durante a medição do número total de caminhos possíveis, no caso de existir um caminho no sentido inverso, isto é, para trás, estavamos perante a possibilidade de obter um número infinito de caminhos. Por este motivo, o uso do número total de caminhos foi descartado, pois não era considerado uma abordagem realista. Então, a abordagem escolhida para a definição da complexidade ciclomática passou a focar-se no número de caminhos básicos através de um programa, que quando combinados geram todos os caminhos possíveis.
Por outras palavras, a complexidade ciclomática expõe que para qualquer grafo de fluxo existe um conjunto de caminhos de execução, de tal modo que cada caminho de execução pode ser expresso como uma combinação linear dos mesmos. Um conjunto de caminhos é considerado independente se nenhum deles for uma combinação linear dos outros. De acordo com McCabe (1976), um caminho deve ser testado, se ele for independente dos caminhos que foram testados. Por outro lado, se um
caminho é uma combinação linear dos caminhos testados, ele pode ser considerado redundante (Zhu et al., 1997).
De acordo com a teoria de grafos e segundo Berge (1973), o número ciclomático é definido como o número de ciclos fundamentais (ou básicos) num grafo ligado e não-direcionado ao que McCabe et al. (1996) acrescentou que era também o número de caminhos independentes através de um grafo direcionado fortemente ligado, podendo ser calculado por:
v(G)= E - N + P onde:
E, é o número de caminhos; N, é o número de nodos;
P, é o número de componentes separados.
Este foi o princípio base usado por McCabe no seu estudo (McCabe, 1976), no qual este fez a transposição desta definição para o domínio da medida de software.
Segundo Abran (2010), na engenharia de software, o programa é modelado como um grafo de controlo de fluxo, que é uma estrutura abstrata usada pelos compiladores, em que os nodos representam os blocos básicos, e os caminhos direcionados representam os saltos de controlo de fluxo.
Sabendo que os grafos de controlo de fluxo de programas não são fortemente ligados, McCabe percebeu que os poderia tornar fortemente ligados adicionando um caminho virtual que liga-se o nodo de saída com o nodo de entrada (McCabe et al., 1996). Assim sendo, transformando o grafo de controlo de fluxo num grafo fortemente ligado, o número ciclomático do grafo pode ser aplicado na representação de programas (Abran, 2010). Nesta transposição, o número ciclomático, quando aplicado ao software calcula-se da seguinte maneira:
v(G) = E - N + P + 1
Mas sabendo que esta transposição de McCabe só se aplica a módulos individuais (McCabe, 1976), o número de componentes ligados, P, é sempre igual a 1, ficando então definida a fórmula de cálculo da complexidade ciclomática por:
McCabe (1976), sugeriu que, a fórmula, v(G) = E – N + 2, por associação, é a medida da complexidade de um programa, à qual ele chamou de complexidade ciclomática e interpretou como a quantidade de decisão lógica num módulo único de software (McCabe et al., 1996).
Por fim, no seu trabalho original, McCabe (1976) listou algumas propriedades da complexidade ciclomática:
• v(G) ≥ l.
• v(G) é o número máximo de caminhos linearmente independentes em G; é o tamanhos de um conjunto básico.
• Inserir ou apagar instruções funcionais em G não afeta v(G). • G tem apenas um caminho se, e apenas se, v(G) = 1.
• A inserção de um novo caminho em G, aumenta o v(G) uma unidade. • v(G) depende apenas da estrutura de decisão de G.
5. I
MPLEMENTAÇÃO
Neste capítulo será explicado todo o processo de desenvolvimento, mostrando qual a linguagem de programação usada, quais as ferramentas que serviram de suporte e explicando as decisões tomadas durante a implementação.
5.1 Abordagens ponderadas
Na discussão sobre que caminho seguir para a elaboração deste projeto, foram discutidas duas alternativas para a implementação da ferramenta.
A primeira passava pela criação de um parser, que é uma metodologia muito utilizada em ferramentas do género, tendo esta abordagem sido posteriormente abandonada muito por causa das particularidades do LISP. Entre algumas dessas particularidades que levaram a esta decisão, surgiu o fato de esta linguagem permitir a criação macros que, em LISP, podem ser vistas como extensões da linguagem e que podem, entre outras utilizações, permitir a definição de novos condicionais, iteradores, etc. Isto faria com que fosse impossível cobrir todos estes casos com a utilização de parsers.
A segunda, e que acabou por ser a escolhida, passava pela utilização de um code walker. Um code walker permite que todas as macros sejam totalmente expandidas, isto é, sejam transformadas em instruções básicas e nativas, removendo assim a limitação encontrada na primeira abordagem que tinha sido ponderada. Esta ferramenta retorna como resultado uma Abstract Syntax Tree, que é uma representação abstrata e simplificada, em forma de árvore, da estrutura semântica do código. Esta
Abstract Syntax Tree, foi então o ponto de partida para a análise proposta para este projeto, que passa pela criação do grafo e cálculo da sua complexidade ciclomática.
5.2 Linguagem de programação e ferramentas externas de apoio
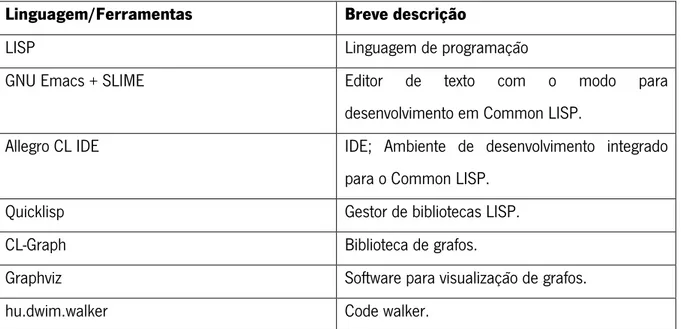
Aqui serão demonstradas todas as ferramentas utilizadas no desenvolvimento do projeto, sendo que a tabela seguinte serve como uma pequena introdução ao que vai ser falado nesta secção.
Linguagem/Ferramentas Breve descrição
LISP Linguagem de programação
GNU Emacs + SLIME Editor de texto com o modo para
desenvolvimento em Common LISP.
Allegro CL IDE IDE; Ambiente de desenvolvimento integrado para o Common LISP.
Quicklisp Gestor de bibliotecas LISP.
CL-Graph Biblioteca de grafos.
Graphviz Software para visualização de grafos.
hu.dwim.walker Code walker.
Tabela 3 - Ferramentas utilizadas no projeto.
5.2.1 LISP
Começando pela linguagem de programação usada, o LISP (McCarthy, 1960), abreviatura para List Processing, é uma linguagem criada por John McCarthy, no final dos anos 50 e que, como podemos ver pelo nome, tem como ideia principal usar listas como a estrutura para os dados e para o código.
Esta, é a linguagem de programação mais utilizada na SISCOG, sendo uma linguagem que está fortemente ligada ao mundo da inteligência artificial. Existem diversos dialetos LISP, sendo que o usado neste projeto foi o Allegro Common LISP.
5.2.2 GNU Emacs e SLIME
O GNU Emacs, criado por Richard Stallman, é um dos editores de texto mais conhecido, enquanto que o SLIME, criado por Luke Gorrie e Helmut Eller, é um modo do Emacs para o desenvolvimento em
Common LISP, que permite dotar o Emacs de um conjunto de funcionalidades adicionais que
melhoram a interacção entre o Emacs e o LISP.
Na SISCOG o Emacs é muito utilizado pois, para além de ser usado como editor de texto para os desenvolvimentos em LISP, é também através dele que os analistas-programadores lançam as aplicações da empresa em modo de desenvolvimento, criando uma ligação com o IDE Allegro CL que será abordado de seguida.
5.2.3 Allegro CL IDE
O Allegro CL é um ambiente de desenvolvimento criado pela Franz Inc. e que corresponde à implementação do LISP que é usada na SISCOG para desenvolver, compilar e distribuir as aplicações da empresa. Algumas das vantagens apontadas (SISCOG, 2013) pelos analistas-programadores são:
• IDE com trace dialog, profiler, class browser;
• Compilador rápido;
• Multiprocessamento simétrico (SMP).
5.2.4 Analisador de código: code walker
O code walker hu.dwim.walker, foi umas das ferramentas mais importantes para o desenvolvimento do projeto, já que através dele foi possível aceder às Abstract Syntax Tree que contêm toda a informação necessária para a construção do grafo.
Para que se perceba melhor as vantagens de se utilizar um code walker para LISP é necessário compreendermos quais os principais passos executados pelo compilador:
1) O texto é convertido em s-expressions (árvores de células cons, com símbolos, números, etc), sendo que isso é feito pelo reader do LISP.
2) As macros são expandidas. 3) O resultado é compilado.
O code walker baseado no resultado da fase 2, fornece uma Abstract Syntax Tree com o resultado de todas as macros totalmente expandidas. Isto foi também um dos pontos chaves para a utilização do code walker neste projeto, pois era importante ter as macros totalmente expandidas, já que em LISP as macros permitem extender a sintaxe da linguagem o que poderia criar problemas na análise do código.
Um exemplo da utilização de macros no LISP pode ser observado pelo facto de existirem na própria especificação da linguagem algumas macros para representar algumas instruções nativas, como por exemplo a instrução cond. Essa instrução pode ser representada na sua forma mais primitiva como um conjunto de instruções if encadeadas:
Figura 8 - Exemplo de um if e um cond em LISP.
Se se utilizar o macroexpand do LISP para ver a expansão da macro cond da Figura 8:
Figura 9 - Exemplo de um macroexpand.
Obtem-se o seguinte resultado:
Figura 10 - Resultado do macroexpand.
Como se pode observar pela Figura 10, o cond não é totalmente expandido para as suas
formas mais primitivas, pois, nem todas as suas as condições foram retornadas como if.
Sabendo que a instrução cond faz nativamente parte da especificação do LISP e por esse
motivo, se a abordagem de utilização de um parser fosse seguida, esta instrução iria certamente ser considerada, não seria possível precaver todas as outras possibilidades que um programador de LISP
internamente e que fazem parte da API dos produtos da empresa, sendo que não seria viável conseguir uma cobertura total de todos estes casos através da utilização do parser.
Com a utilização do code walker, este problema não existe pois todas as macros são
totalmente expandidas, ou seja, todas elas estão nas suas formas primitivas, o que tomando os casos
dos condicionais como exemplo, faria com que todos eles, na Abstract Syntax Tree do resultado,
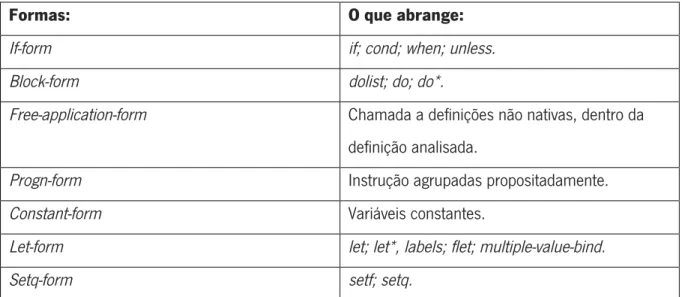
tivessem a mesma forma, ou seja, uma if-form. Na tabela seguinte podemos ver algumas das formas retornadas pelo code walker, assim como alguns exemplos do que estas abrangem:
Formas: O que abrange:
If-form if; cond; when; unless.
Block-form dolist; do; do*.
Free-application-form Chamada a definições não nativas, dentro da
definição analisada.
Progn-form Instrução agrupadas propositadamente.
Constant-form Variáveis constantes.
Let-form let; let*, labels; flet; multiple-value-bind.
Setq-form setf; setq.
Tabela 4 - Formas retornadas pelo code walker.
5.2.5 Gestor de bibliotecas LISP: Quicklisp
O Quicklisp é um gestor de bibliotecas para Common Lisp, que permite descarregar, instalar e carregar bibliotecas usando apenas comandos simples. Este gestor foi utilizado para descarregar a biblioteca hu.dwim.walker, que foi o code walker necessário para este projeto.
Para instalar o quicklisp usa-se o seguinte comando: (quicklisp-quickstart:install)
E para descarregar/carregar a biblioteca do code walker: (ql:quickload "hu.dwim.walker ")
5.2.6 Biblioteca de grafos: CL-Graph
O CL-Graph é uma biblioteca de Common LISP usada para a manipulação de grafos, e que contém, entres outros, uma série de algoritmos orientados a grafos.
No âmbito deste projeto, a utilização desta biblioteca foi feita de modo muito simplista, de acordo com as necessidades que foram identificadas, tendo sido usadas as seguintes definições desta biblioteca:
• add.vertex, para adicionar um vértice ao grafo; • delete.vertex, para apagar um vértice do grafo;
• iterate.vertexes, para percorrer os vértices existentes no grafo; • add.edge, para adicionar um caminho entre dois vértices; • delete.edge, para apagar um caminho entre dois vértices.
5.2.7 Graphviz
O Graphviz, abreviatura para Graph Visualization Software, é um software de código livre usado para o desenho de grafos que sejam especificados, entre outros, em scripts de linguagens DOT. Esta linguagem é usada para descrever grafos através de um formato simples de texto, sendo que esse texto é posteriormente usado pelo Graphviz para a criação de um ficheiro de imagem com o grafo correspondente.
Figura 11 - Exemplo de um grafo em linguagem DOT.
Neste projeto, esta ferramenta foi utilizada durante o processo de construção do relatório de complexidade e toda a implementação foi pensada para que esta operação fosse realizada de forma completamente automática, não sendo para isso necessária qualquer intervenção do programador.
5.3 Estrutura do código
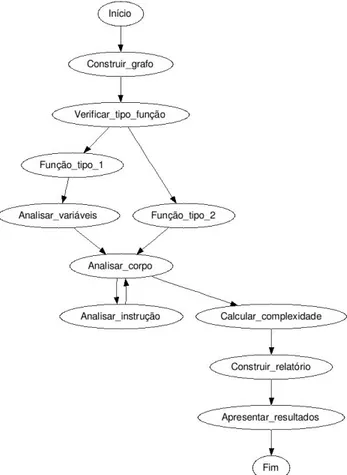
A estrutura do código foi pensada da seguinte forma:
Figura 12 - Estrutura geral do código implementado.
Este processo tem início com a construção do grafo. Numa primeira fase é feita uma verificação à definição que está a ser analisada, com o intuito de identificar se esta definição tem ou não variáveis e, em caso afirmativo, é chamada outra definição para lidar com essa variáveis, criando os nodos respetivos e ligando-os entre si, devolvendo como resultado a parte inicial do grafo com esta informação. Este passo é importante, porque em LISP podem existir pontos de decisão na definição das variáveis, o que faz com que a própria definição de variáveis possa influenciar a complexidade ciclomática de um programa.
Tendo a parte introdutória do grafo definida, começa-se a avaliar o corpo da definição, que corresponde a um ciclo onde se avaliam todas as instruções do corpo, transformando cada instrução num nodo do grafo e criando os respetivos caminhos entre instruções, representando assim a ordem de execução das mesmas. Quando este processo acaba, é calculada a complexidade ciclomática,
usando o número de nodos e caminhos do grafo calculado anteriormente. Findo este processo é gerado o relatório com todas estas informações.
De seguida irão ser abordadas com mais detalhe as decisões tomadas durante todo o processo de implementação.
5.4 Decisões de implementação
Depois de definida a forma sobre como o projeto se devia desenrolar e qual a estrutura do código, começou-se então com a construção da ferramenta com base nos casos mais simples possíveis e que serão descritos de seguida. Esses casos mais simples foram dando origem a casos cada vez mais complexos, podendo a ferramenta, no fim da implementação, lidar com definições de diferentes complexidades, isto é, desde as mais simples às mais complexas.
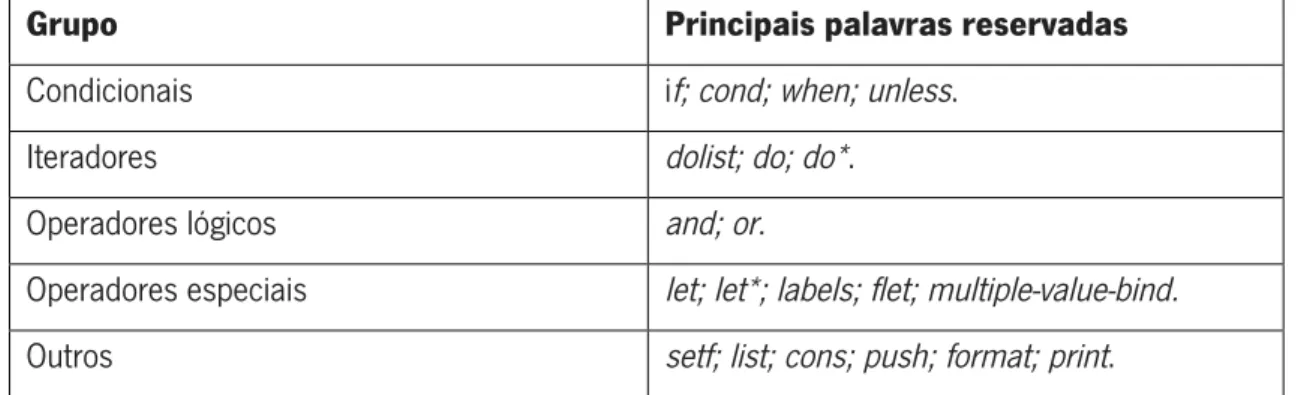
Os casos analisados de seguida encontram-se agrupados como mostra a seguinte tabela:
Grupo Principais palavras reservadas
Condicionais if; cond; when; unless.
Iteradores dolist; do; do*.
Operadores lógicos and; or.
Operadores especiais let; let*; labels; flet; multiple-value-bind.
Outros setf; list; cons; push; format; print.
Tabela 5 - Grupos de palavras reservadas.
5.4.1 Definição genérica
Foi criada uma definição genérica, para controlar o tipo da forma devolvida pelo code walker, identificando assim qual a definição que deve ser usada para determinada forma, ou seja, de cada vez que se vai construir um nodo do grafo, esta definição é chamada para verificar qual o seu tipo de forma, fazendo posteriormente a chamada da definição responsável por tratar esse tipo.
5.4.2 Operador lógico: and e or