F
ACULDADE DEE
NGENHARIA DAU
NIVERSIDADE DOP
ORTOCaracterização de um corpus
jornalístico português
Henrique Teixeira de Sousa
Mestrado Integrado em Engenharia Informática e Computação Orientador: Sérgio Nunes
Caracterização de um corpus jornalístico português
Henrique Teixeira de Sousa
Mestrado Integrado em Engenharia Informática e Computação
Aprovado em provas públicas pelo Júri:
Presidente: Gabriel David Arguente: Nuno Escudeiro Vogal: Sérgio Nune
Resumo
Nesta dissertação procede-se ao processamento e caracterização de um arquivo de artigos de notícias do jornal online português JornalismoPortoNet (JPN), um corpus textual com conteúdo de vários autores e tópicos. Um corpus representa um conjunto de textos no qual se pode efetuar uma análise estatística ou verificação de hipóteses, sobretudo na área da linguística. O crescente poder computacional facilita o processamento de grandes corpora (pesquisa, tratamento, seleção, etc.). Este corpus tem como objetivo ser uma representação de texto jornalístico do JPN, cole-cionando os títulos, subtítulos, autores, notícias relacionadas, categorias e datas de publicação, para além de incluir uma pequena parte referente à opinião do leitor (comentários às notícias). O arquivo é anotado quanto às partes da fala usadas, num primeiro processo de tratamento do seu conteúdo. Posteriormente é realizada uma análise aprofundada sobre a composição morfológica e categórica dos artigos de notícias, bem como uma investigação sobre os relacionamentos entre notícias, os hábitos de publicação do jornal e as diferenças entre o grande leque de autores de experiência variada. A análise morfológica revelou as diferenças em termos de partes do discurso do texto jornalístico quando comparado com outros tipos de textos, nomeadamente literários e políticos: o texto jornalístico do JPN apresenta mais nomes próprios e menos adjetivos e advér-bios. Em termos lexicais o jornal é principalmente composto por palavras referentes à cidade do Porto, fazendo-se também um estudo quanto aos n-gramas presentes nos textos. Categoricamente o jornal aborda o tema da cidade do Porto, principalmente tópicos relacionados com a Univer-sidade do Porto, focando-se também na Cultura, na Ciência e Tecnologia, no País, no Mundo e noutros. A análise às relações entre notícias destaca ainda alguns artigos com maior importância num determinado tópico ou assunto. Finalmente é também analisada a receção do público face ao conteúdo jornalístico, tanto em visualizações como em comentários dos leitores, revelando a na-tureza apreciadora da maioria dos comentários que incidem sobretudo nos artigos de de Desporto e de Ciência e Tecnologia.
Abstract
In this dissertation we process a news article archive from the portuguese online journal Jor-nalismoPortoNet (JPN), a text corpus with content from several authors and topics. A corpus represents a group of texts in which one can perform statistical analysis or hypothesis testing, mainly in the field of linguistics. The growing computing power eases the processing of large corpora (searching, treatment, selection, etc.). This corpus has the objective of being a represen-tation of the journalistic text practiced by JPN, collecting titles, subtitles, authors, related news, categories and dates of publishing, while including a small part referring to the reader’s opinion (news comments). The corpus will be annotated in respect to the Part-of-Speech tags used. Fol-lowing this, an deep analysis is performed about the morphological and categorical composition of the news articles, including research about relationships between news, the publishing habits of the journal and the differences between the huge array of authors with varying experience. The morphological analysis revealed the differences in terms of the parts-of-speech used in the jour-nalistic text compared to other types of text, namely literary and political: JPN’s jourjour-nalistic text presents more parts of names and less adjectives and adverbs. In respect to the lexical analysis, the journal is composed mainly of words related to the city of Porto; we also perform a study regarding the ngrams present in the text. Categorically the journal discusses the city of Porto, mainly topics related with the University of Porto, also focusing on Culture, Science and Technology, Portugal and the World. The news relation analysis also highlights some articles of bigger importance in certain subjects or topics. Finally, the publics reception to the journalistic material, be it in page visualization or readers’ comments, revealing the congratulatory aspect of most comments, which target mostly articles in the Sports and Science and Technology categories.
Agradecimentos
Gostaria de agradecer a todos os que contribuíram direta e indiretamente para a realização desta dissertação, principalmente ao meu orientador, o professor Sérgio Nunes, por me ter acon-selhado, guiado e revisto todo o meu trabalho. À minha família dedico também um especial agradecimento pelo apoio prestado, assim como aos meus amigos e colegas de curso pelo compa-nheirismo que sempre mostraram ao longo deste percurso pessoal e académico.
Conteúdo
1 Introdução 1
1.1 Contexto . . . 1
1.1.1 Processamento de Linguagem Natural . . . 1
1.1.2 Corpus . . . 1
1.1.3 As abordagens linguísticas no uso de corpora . . . 2
1.1.4 JornalismoPortoNet . . . 2 1.2 Motivação e Objetivos . . . 2 1.3 Estrutura da Dissertação . . . 3 2 Revisão Bibliográfica 5 2.1 Corpora . . . 5 2.1.1 Corpora Internacionais . . . 5 2.1.2 Corpora Portugueses . . . 7 2.1.3 Anotação de Corpora . . . 8 2.1.4 Esquemas de Anotação . . . 10
2.1.5 Anotação Embutida e Anotação Autónoma . . . 10
2.1.6 Níveis de Anotação . . . 11
2.2 Análise do Arquivo de Notícias . . . 12
2.3 Tecnologias . . . 13
3 Processamento do arquivo de Notícias 15 3.1 JPN . . . 15
3.2 Processamento e anotação do arquivo . . . 15
3.2.1 Autores e Editores . . . 16 3.2.2 Notícias Relacionadas . . . 16 3.2.3 Exemplo . . . 17 4 Caracterização do Arquivo 21 4.1 Vista geral . . . 21 4.2 Análise Jornalística . . . 22 4.2.1 Hábitos de Publicação . . . 22 4.2.2 Vídeo Artigos . . . 23
4.3 Análise dos Visitantes . . . 23
4.3.1 Acessos e Visitantes . . . 25
4.3.2 Visualizações de Páginas . . . 25
4.3.3 Atividade . . . 25
4.3.4 Pesquisas . . . 25
CONTEÚDO
4.3.6 Comentários . . . 26
4.4 Análise Morfológica e Lexical . . . 28
4.4.1 POS Tags . . . 29
4.4.2 POS tags nos comentários . . . 33
4.4.3 Frases . . . 34
4.4.4 Léxico . . . 35
4.4.5 N-Gramas . . . 37
4.5 Análise Categórica . . . 38
4.5.1 POS Tags nas Categorias . . . 38
4.5.2 Léxico nas Categorias . . . 39
4.5.3 Popularidade das Categorias . . . 41
4.6 Análise de Autores . . . 43
4.6.1 POS Tags . . . 43
4.6.2 Categorias . . . 44
4.7 Relações entre Notícias . . . 45
4.7.1 Categorias . . . 46
5 Conclusões e Trabalho Futuro 57 5.1 Trabalho Futuro . . . 59
Lista de Figuras
4.2 Total número de artigos por mês . . . 22
4.3 Total número de artigos por hora . . . 23
4.4 Percentagem de vídeo artigos ao longo dos anos . . . 24
4.5 Percentagem de vídeo artigos por categoria . . . 24
4.6 Visitantes por mês . . . 26
4.7 Visualizações de páginas por hora . . . 26
4.8 Visualizações de páginas por dia da semana . . . 27
4.9 Browsers mais usados (Maio 2014) . . . 28
4.11 Horas até ao primeiro comentário após a publicação da notícia . . . 29
4.12 Frequência de cada etiqueta POS no arquivo . . . 30
4.13 Evolução das POS tags . . . 32
4.14 Percentagem de POS tag por cada secção . . . 33
4.15 Percentagem de POS tag nos comentários . . . 34
4.17 Média TTR ao longo dos anos . . . 36
4.18 Categorias mais frequentes . . . 42
4.19 Evolução das categorias ao longo dos anos . . . 44
4.20 Distribuição de nomes comuns, partes de nome e preposições nas categorias . . . 45
4.21 Distribuição de adjetivos, advérbios e verbos nas categorias . . . 46
4.22 Distribuição de demonstrativos, dígitos, quantidades e relativos nas categorias . . 47
4.23 Categorias mais populares (visualizações por artigo) . . . 49
4.24 Comentários por artigo nas diversas categorias . . . 50
4.25 POS Tags por grupo de autor . . . 51
4.26 Categorias por autor . . . 52
4.27 Grafo das relações entre notícias . . . 53
4.28 Nós com maior valor de centralidade . . . 54
Lista de Tabelas
2.1 Alguns corpora disponíveis . . . 9
2.2 Resumo das Tecnologias . . . 14
3.1 Marcadores XML de cada artigo no Corpus do JPN . . . 18
3.2 LX-Suite Tagset . . . 19
4.1 Frases de pesquisa mais utilizadas . . . 27
4.2 Unidades e tipos de algumas partes de discurso no JPN . . . 30
4.3 Comparação das etiquetas POS com outros corpora . . . 31
4.4 Uso e evolução percentual de algumas tags . . . 31
4.5 Palavras e o seu uso percentual em cada sub corpora . . . 37
4.6 Concordância da palavra “Porto” no JPN . . . 38
4.7 Colocações (%) da palavra ’Porto’ em diferentes corpora . . . 39
4.8 Nomes Comuns mais usados no arquivo do JPN . . . 39
4.9 Adjetivos mais usados no arquivo do JPN . . . 39
4.10 Colocações (%) da palavra “Porto” nos títulos das notícias do JPN . . . 40
4.11 Alguns adjetivos comuns nos comentários . . . 40
4.12 Alguns bigramas . . . 41
4.13 Alguns trigrams e a sua comparação com outros corpora . . . 41
4.14 Pentagrams mais frequentes . . . 42
4.15 Pentagrams mais frequentes nos comentários . . . 43
4.16 Adjetivos/Nomes comuns mais usados na categoria Desporto . . . 48
4.17 Adjetivos/Nomes comuns mais usados na categoria Cultura . . . 48
4.18 Adjetivos/Nomes comuns mais usados na categoria Mundo . . . 48
Capítulo 1
Introdução
1.1
Contexto
A área da linguística atravessou um período de grande crescimento na segunda metade do século XX, aliada ao avanço do poder computacional e da facilidade de acesso e recolha de infor-mação. Mais que o estudo do uso e significado da língua, a linguística debruça-se sobre a delicada relação entre a linguagem e as voláteis estruturas sociais ao longo da história, contribuindo para a compreensão da mente humana.
1.1.1 Processamento de Linguagem Natural
O Processamento de Linguagem Natural (PLN) é um campo da Informática que se desenvol-veu a partir do estudo da linguagem e do nascimento da linguística computacional no contexto da inteligência artificial [LHL+03]. O PLN preocupa-se com o tratamento da linguagem humana, principalmente na sua forma natural como em emails, páginas web, livros, artigos de notícias, etc. Os problemas abordados em NLP são vários e possuem níveis de complexidade diferentes: sistemas de resposta automática, sumarização de textos, tradução, reconhecimento de voz, classi-ficação de documentos, análise de sentimento, etc.
1.1.2 Corpus
Entende-se por corpus, no plural corpora, um conjunto de dados naturalmente ocorridos de uma linguagem, criado geralmente com um propósito particular e representativo tanto de uma linguagem em geral (e.g. Português), como o uso da linguagem num domínio mais específico (e.g. poesia portuguesa). Nos últimos anos, resultante da evolução tecnológica e do crescimento da abordagem computacional da linguística, é geralmente chamado de corpus todo o conjunto de material existente em forma eletrónica e que pode ser processado por computadores [MXT06]. As razões para a utilização de um corpus são várias: modelação e estudo da distribuição linguística de
Introdução
uma linguagem, treino de classificadores, arquivo e outros tópicos de pesquisa e desenvolvimento linguístico. Desde os anos 70 verificou-se uma abordagem ao estudo da linguagem cada vez mais centrada no uso de corpora no campo da linguística, o que levou à construção dos primeiros conjuntos de textos.
1.1.3 As abordagens linguísticas no uso de corpora
As duas grandes abordagens ao estudo da língua com o uso de corpora diferem na importância colocada nos textos para a criação e validação de teorias sobre a linguagem em questão [GLM97]. Na abordagem baseada em corpus (corpus-based), as teorias, ideias e modelos de linguagem são testados e provados com o uso de corpora. Por sua vez, a abordagem guiada por corpus (corpus-driven) entrega-se em absoluto à “integridade dos dados como um todo"[Bak06], em que novas teorias e ideias são completamente refletidas no texto, desde que este possua um tamanho consi-derável. Por outras palavras, o estudo intensivo do corpus revela novas ideias e teorias sobre a linguagem em questão, enquanto que a abordagem baseada em corpus delega ao corpus apenas uma tarefa de validação de teoremas.
1.1.4 JornalismoPortoNet
O JPN (JornalismoPortoNet) [Rei15b] é um jornal digital de informação geral da Licenciatura de Ciências da Comunicação da Universidade do Porto, ativo desde 2004. Um jornal multimé-dia e com atualização permanente, o JPN conta com a contribuição de diversos colaboradores, “acompanhando a evolução das novas tecnologias de comunicação e pondo em prática as mais modernas técnicas de expressão jornalística na Internet"[Rei15a]. O jornal publica artigos em diversas categorias, desde a Cultura e Economia, até ao Desporto e Educação, e conta com ar-tigos de exposição e entrevistas com personalidades relevantes. Desde o ano 2008 até ao ano 2012, arrecadou por quatro vezes consecutivas o prémio de “Melhor Ciberjornalismo Académico” nas competições “Prémios de Ciberjornalismo”, promovidas pela equipa de investigação ObCiber [RBZ14].
1.2
Motivação e Objetivos
A necessidade de novos corpus faz-se sentir com a evolução da linguagem (como por exemplo, neologismos), e a evolução dos temas discutidos pela sociedade. Surge deste modo a oportunidade de processar um vasto corpus português para contribuir e promover avanços na área da linguística computacional e para analisar as ideias na presente sociedade. Pretende-se assim colecionar e processar os artigos de notícias do arquivo online do jornal JPN. Este corpus será composto por documentos que contêm tanto o corpo da notícia bem como o seu título, subtítulo, autor, notícias relacionadas, categoria e data de publicação, de forma a permitir o estudo de outros tipos de características (p. ex. frequência de notícias ao longo dos anos). Uma anotação ao nível gramatical é adicionada permitindo uma investigação mais profunda quanto à composição morfológica dos
Introdução
textos jornalísticos do jornal, comparando-se com outros tipos de textos e arquivos de notícias. Juntamente com esta análise ao arquivo é feita também uma análise aos acessos ao site do JPN bem como ao conteúdo dos comentários dos leitores e aos seus hábitos de publicação.
1.3
Estrutura da Dissertação
Para além da introdução, esta dissertação contém mais 4 capítulos. No Capítulo 2, é descrito o estado da arte e são apresentados trabalhos relacionados. No Capítulo 3 é esclarecida a estrutura do arquivo bem como o processamento efetudo nos artigos. No Capítulo 4 são apresentadas as análises efetuadas sobre o corpus, assim como algumas reflexões sobre a sua implicação e natu-reza. No Capítulo 5 conclui-se a dissertação e pondera-se sobre possíveis extensões ao corpus e algumas das suas aplicações futuras.
Capítulo 2
Revisão Bibliográfica
Neste capítulo é descrito o estado da arte e as mais recentes inovações e projetos no campo da linguística computacional e na oferta de corpora nacionais e internacionais.
2.1
Corpora
2.1.1 Corpora Internacionais
Os primeiros corpora linguísticos surgiram num contexto académico tendo como objetivo o estudo da linguagem. Um dos primeiros e mais importantes corpus é o Brown Corpus [FK79], da Universidade de Brown, publicado em 1963, com cerca de um milhão de palavras em inglês, de obras publicadas em 1961. Sujeito a diversas análises computacionais, tornou-se um dos corpora mais citados no campo da linguística. O corpus está dividido em 500 exemplos, cada um com aproximadamente 2000 palavras, extraídos de várias áreas, desde fontes jornalísticas (Política, Desporto, Sociedade) e religiosas até material educativo e de ficção.
Todas as palavras do Brown Corpus são ainda anotadas com uma etiqueta indicativa da classe específica da palavra. Estes etiquetas pertencem a um conjunto de 82 etiquetas (tags) e estão divi-didos em seis tipos: partes da fala (POS-tagging), etiquetas de função (determinantes, preposições, etc), etiquetas de certas palavras importantes (neste caso not e os verbos be e have), etiquetas de pontuação com importância sintática, etiquetas sobre morfemas da língua inglesa (indicadores de possessão, pluralidade, passado, presente, particípio passado, comparação e superlativo), e final-mente etiquetas com a função de indicar se uma palavra é estrangeira ou parte de uma citação. O Brown Corpus foi uma peça importante na abordagem à linguística com base em corpora, sendo usado em estudos de POS-tagging, identificação e delimitação de frases.
Um dos mais usados e detalhados corpora construídos a partir da agência de notícias Reuters, o RCV1 (Reuters Corpus Volume 1) [RSW02] é composto por cerca de 800 000 notícias extraídas entre agosto de 1996 e agosto de 1997. Os artigos do RCV1 foram manualmente anotados catego-ricamente (relativamente ao tópico da notícia), usando um conjunto de 126 códigos, organizados
Revisão Bibliográfica
hierarquicamente. Um artigo pode ser anotado com mais do que um código. Adicionalmente, cada artigo está anotado no que diz respeito à indústria (de um conjunto de 870 códigos) e às regiões mencionadas na notícia. Esta última anotação está separada em três categorias: países, grupos geográficos e grupos económicos (p. ex. GSEVEN). O corpus recebeu muita atenção nas áreas de extração de informação e classificação de documentos. Mais antigo que o RCV1 é o cor-pus Reuters-21578 [Lew97], um corcor-pus muito popular entre a comunidade de processamento de linguagem natural, com 21 578 artigos da Reuters do ano de 1987. Este corpus foi usado em proje-tos de classificação de texto [Joa98] e representação de conhecimento [Wu04] e mapas neuronais [Wer00].
Com o avanço dos anos foram surgindo cada vez mais corpora, em especial os chamados corpora nacionais, que visam agregar dados que refletem o uso da linguagem nacional de um país (Britânico, Americano, Polaco, etc). Esta evolução foi acompanhada com o aumento do tamanho dos corpora, atingindo as 100 milhões de palavras em certos exemplos (British National Corpus [Bur95]), ou até as 400 milhões de palavras no caso do Corpus of Contemporary American English [Dav08]. Estes corpora reúnem uma grande quantidade de material, focando-se na diversidade de textos e fontes, contribuíndo para o equilíbrio final do corpus, como diz McEnery et al.: “the representativeness of a corpus, especially a general corpus, depends primarily upon how balanced the corpus is, in other words, the range of text categories included in the corpus” [MXT06].
O British National Corpus (BNC) (Aston and Burnard 1998) [Bur95] representa um impor-tante exemplo dos corpora nacionais, composto por mais de 100 milhões de palavras, com textos extraídos de várias fontes jornalísticas, fictícias e académicas do século XX. O corpus possui uma parte escrita (90%) e uma parte falada (10%), sendo esta última a transcrição de conversações informais em diferentes contextos. O BNC foi automaticamente anotado com POS-tags usando a ferramenta CLAWS [Gar87], e está codificado de acordo com a iniciativa TEI [IV95] para re-presentar as diversas propriedades estruturais do texto (títulos, parágrafos, listas, etc). O trabalho efetuado no BNC é extenso e abrange diferentes vertentes da linguística: desambiguação de pa-lavras [Eva01] [SW01], o uso de diversas formas verbais e expressões na língua inglesa [Mal00] [SV00] [Deu03], delimitação de frases [SG00], identificação de entidades [MTU+01] e categori-zação de textos [SFK00].
Um importante corpus desenvolvido após o Brown Corpus é o London-Lund Corpus of Spoken English [Sva90], publicado em 1990. O corpus é composto por 500 000 palavras transcritas de conversações inglesas e apresenta um avançado esquema de anotação que, para além de anotar as partes da fala, marca o uso de diferentes tipos de expressões (p. ex. expressões de cumprimento, atenção, formalidade, agradecimento, etc). O North American News Text Corpus [Gra95] foi criado pelo LDC (Linguistic Data Consortium2) e apresenta textos de diversas fontes jornalísticas Norte Americanas, nos anos 1996 e 1997. O corpus foi usado maioritariamente para o estudo de analisadores sintáticos (parsing) automáticos [MCJ06].
O corpus da revista Norte Americana TIME [Dav07] é composto por mais de 275 000 textos diretamente retirados dos arquivos da TIME entre 1923 e 2006. O corpus é POS-tagged e tem
Revisão Bibliográfica
vindo a ser usado para estudar a evolução lexical do língua inglesa [Mil09]. Outro corpus impor-tante no que diz respeito à tarefa de identificação de entidades nomeadas é o RSS-500 [RUH+14] , construído a partir de quase 1500 feeds de RSS das principais fontes noticiosas internacionais no ano de 2011. O RSS-500 foi manualmente anotado relativamente as entidades presentes no texto.
2.1.2 Corpora Portugueses
No domínio dos corpora portugueses, o estudo e criação de corpora começa no início dos anos 90 [OS98], com várias coleções relativamente pequenas como a Natura – Público [OS98], com 6 milhões de palavras, e a Natura – Minho [OS98], com 2 milhões de palavras. Uma coleção de artigos de notícias e conteúdo jornalístico é o DiaCLAV [SS02], com 6,7 milhões de palavras de vários jornais online regionais do centro de Portugal (Diário de Coimbra, Diário de Leiria, Diário de Aveiro e Viseu Diário), de junho de 1999 a setembro de 2000. No que diz respeito a corpora de grandes dimensões, a oferta de corpora brasileiros era consideravelmente mais elevada, com corpora como o NILC/São Carlos [NGM+96], com 31 milhões de palavras. O CETENFolha [dTE] é outro corpus brasileiro baseado no NILC/São Carlos composto por textos jornalísticos do jornal “Folha de S. Paulo"do ano de 1994, com 24 milhões de palavras na sua primeira edição.
Surge no começo do novo milénio um dos mais importantes corpus da língua Portuguesa, o CETEMPúblico [RS00], composto por notícias do jornal Público 3 durante um período de seis anos (1994 a 2000) e com um tamanho de 180 milhões de palavras. Diversos projetos de inves-tigação em programação de linguagem natural utilizam o CETEMPúblico como corpus de geral utilização tanto para o teste e validação de algoritmos como para o treino de técnicas de apren-dizagem automática: extração de relações [OSG09], sistema de respostas automático [Cos06], analisadores morfológicos [Vic13] e correção automática [MS04b].
O CINTIL - International Corpus of Portuguese [BBF+06], com 1 milhão de palavras é com-posto por uma metade de textos jornalísticos e outra metade por transcrições de conversas formais e informais em português. O corpus é também POS-tagged e foi construído como um recurso de teste e validação para um conjunto de ferramentas (segmentador, analisador sintático, anotador, etc.) do grupo da fala e linguagem da Faculdade de Ciências da Universidade de Lisboa4. O Corpus do Português [Dav09] composto por textos portugueses e brasileiros do século XIV até ao seculo XX, possui 45 milhões de palavras e é outro importante corpus, especialmente no domínio da análise histórica da língua portuguesa [dA10] [Mä13]. Mais moderno é o Reference Corpus of Contemporary Portuguese Online[GHM12], desenvolvido no Centro de Linguística da Universi-dade de Lisboa e que agrega mais de 312 milhões de palavras, com textos em português europeu assim como outras variantes (português brasileiro, português angolano, etc), desde a segunda me-tade do século XIX até ao ano 2008. O corpus é anotado com as etiquetas de POS usadas no CINTIL [BBF+06] e foi usado para teste de um sistema de anotação automático da modalidade dos verbos portugueses [QMHG14].
3http://www.publico.pt
Revisão Bibliográfica
O WPT 03 [MS04a] é um corpus criado no âmbito da criação de um motor de pesquisa web português e é composto por mais de 3,7 milhões de documentos, onde cerca de 70% são escritos em português. O corpus foi usado para a realização de uma caracterização da web portuguesa, comparando a presença de termos em relação a outro corpus (CETEMPúblico) e analisando o tamanho dos documentos [MS04a]. Em 2005, o corpus foi atualizado e aumentado (WPT 05).
Diversos outros corpora portugueses foram criados desde o nascimento da área da linguística computacional, diferenciando-se sobretudo no tipo de textos colecionados e na variante da Língua Portuguesa nestes presente. Alguns destes corpora a que não se deu tanta relevância são coleções e grupos de corpora, como o Floresta Sintá(c)tica [FRB08], um treebank português, assim deno-minado por ser sintaticamente anotado, resultando em estruturas tipo árvores que especificam a organização sintática das frases dos seus textos. Apenas uma parte da anotação sintática do corpus foi revista por linguistas. O Floresta está também anotado morfologicamente, e é composto por textos do CETEMPúblico e do CETEMFolha, e os seus diferentes sub corpora (Bosque, Amazó-nia, Floresta Virgem e Selva) somam no total aproximadamente 7 milhões de palavras. Outros corpora portugueses são o BIG Corpus PT [Bat14], o CHAVE, composto por textos do Público e do Folha de São Carlos, o Colónia, com textos históricos desde o século XVI e o Avante!, composto essencialmente de textos políticos do semanário Avante! de 1997 a 2002.
Na Tabela 2.1 são apresentados os principais em mais relevantes corpora portugueses disponí-veis.
2.1.3 Anotação de Corpora
Um dos aspetos mais importantes da linguística de corpora e onde ocorreram diversas ino-vações nos últimos anos é a anotação. A anotação consiste na sinalização, normalização e adi-ção de informaadi-ção linguística a um corpus, com o objetivo de o enriquecer com valor linguístico [GLM97]. Pode ser considerada a prática de adicionar informação interpretativa e linguística a um corpus eletrónico. O facto de ser interpretativa é de extrema importância: as anotações resultam de uma análise subjetiva do texto, não representando uma verdade linguística absoluta. A anotação é acima de tudo meta linguística: oferece informação sobre a linguagem usada. As razões para ano-tar um corpus consistem principalmente na facilidade de extração de informação, que por vezes só se torna acessível depois de se construir/descobrir informação adicional sobre o texto. Outro ponto forte da anotação é a característica de ser reutilizável e multifuncional: sendo um processo muitas vezes oneroso, um texto anotado poupa trabalho a um investigador, revelando-se por vezes a mesma anotação útil na resolução de diferentes problemas.
Enquanto que no início da linguística de corpus a anotação era um processo manual, efetuado por especialistas em linguística, nos dias de hoje o processo de anotação é geralmente automático. A anotação de corpora deve seguir as seguintes máximas [Lee93]:
1. Deve ser sempre possível regressar/visualizar os dados originais, o que se pode revelar difícil devido à normalização, como por exemplo, depois da extensão de um pronome composto “da” (de + a).
Revisão Bibliográfica Nome T amanho a Interv alo T emporal Observ ações/Anotações T ipo de T exto Língua inglesa Bro wn Corpus (1963) [FK79] 1 000 1961 (1 ano) POS-tags Vários BNC (1998) [Bur95] 100 000 40 anos POS-tags Vários RCV1 (1997) [RSW02] 170 000 b 1996-1997 (1 ano) Cate goria de T extos e Re giões Mencionadas Jornalístico Reuters-21578 (1996) [Le w97] 4 600 1996-1997 (1 ano) Cate gorias (Pessoas, Locais, Or g anizações) Jornalístico LLCSE (1990) [Sv a90] 500 1959–1989 (30 anos) T ranscrição de con v ersações, P artes da fala Informal, Con v ersação N ANT Corpus (1997) [Gra95] 90 400 1994-1997 (3 anos) Não anotado Jornalístico TIME Corpus (2007) [Da v07] 100 000 1923-2006 (83 anos) POS-tags Jornalístico Língua portuguesa Natura -Público (1994) [OS98] 6 000 1991-1994 (3 anos) Não anotado Jornalístico Natura -Minho (1994) [OS98] 2 000 1991-1994 (3 anos) Não anotado Jornalístico DiaCLA V (2000) [OS98] 6 700 1999-2000 (1 ano) POS-tags Jornalístico NILC/São Carlos (1996) [NGM + 96] 31 000 1994 (1 ano) Corpus brasileiro, não anotado Jornalístico CETEMPúblico (2000) [RS00] 180 000 1994-2000 (6 anos) POS-tags Jornalístico CETENF olha (2002) [dTE] 24 000 1994 (1 ano) POS-tags Jornalístico Floresta Sintá(c)tica (2002) [FRB08] 7 000 1994-2006 (6 anos) Anotação Sintática e Morfológica Jornalístico WPT -03 (2004) [MS04a] 1 600 600 199? -2003 ( 10 anos) Não anotado W eb CINTIL (2006) [BBF + 06] 1 000 2006 (1 ano)? POS-tags, lema e a fle xão das classes abertas Vários Corpus do Português (2006) [Da v09] 45 000 Séc, XIV -Séc. XX ( 600 anos) Vários RCCP (2012) [GHM12] 312 000 1800-2008 ( 200 anos) POS-tags Vários T abela 2.1: Alguns corpora disponív eis aem milhares de pala vras bAssumindo a média de 213 pala vras por artigo [NWM06], com 800 000 artigos
Revisão Bibliográfica
2. A anotação deve ser extraível do texto
3. A anotação deve ser devidamente documentada
4. Deve ser mencionado como foi criada a anotação (automática, manual), por quem foi criada, e de que tipo é.
5. O utilizador deve ser avisado que a anotação é falível.
6. O esquema de anotação deve-se basear o mais possível em princípios e conceitos largamente reconhecidos na comunidade científica.
7. Nenhum esquema de anotação tem o direito de se auto-considerar como um standard da área.
2.1.4 Esquemas de Anotação
Um esquema de anotação pode ser definido como “an explanatory system supplying informa-tion about the annotainforma-tion practices followed, and the explicit interpretainforma-tion, in terms of linguistic terminology and analysis, for the annotation” [Lee04]. Quando a anotação incide sobre áreas profundamente estudadas como a estrutura gramática ou sintática de uma frase, o esquema de anotação pode e deve ser baseado num conjunto consensual de categorias, com as quais a maioria dos linguísticas concorda. O uso de um esquema de anotação que reflita e se conforme com as te-orias e designações mais aceites resultará num corpus mais acessível e num esquema de anotação significativamente mais re-utilizável.
O esquema de anotação varia conforme o tipo de anotação a aplicar e, enquanto que corpora mais antigos utilizavam uma anotação mnemónica colocada junto da palavra/token, hoje em dia é mais comum a utilização de sistemas de anotação mais complexos e verbosos como o SGML/XML [MXT06].
2.1.5 Anotação Embutida e Anotação Autónoma
Outra importante discussão referente à anotação de corpora é a colocação e posição de ano-tações no texto do corpus disponibilizado. A primeira, e mais simples, abordagem refere-se à mistura de textos com a anotação, resultando na clássica anotação embutida, presente na maioria dos corpora (BNC, Brown Corpus). Um exemplo é “Hoje/ADV fui/V a/DA Lisboa/PNM”, onde as partes-do-discurso são aglutinadas à palavra correspondente.
A segunda abordagem centra-se na separação física do texto do corpus com a anotação, man-tendo apenas uma ligação entre os dois. Em comparação com a anotação embutida, a anotação autónoma (stand-alone) possui diversas vantagens como a criação de hierarquias sobrepostas, a possibilidade do uso de diferentes esquemas de anotação no mesmo texto e a facilidade de mani-pulação da anotação sem causar problemas em outros níveis. No entanto, a anotação autónoma carrega também um problema a nível de complexidade (algumas anotações poderão necessitar de várias ligações difíceis de estabelecer) e de compatibilidade com a maioria das ferramentas de
Revisão Bibliográfica
exploração de corpus (e.g. Wordsmith [Sco96] e Xaira [Bur06]) que são geralmente construídas para o uso com anotação embutida.
2.1.6 Níveis de Anotação
Os tipos de anotação distinguem-se normalmente pelo nível em que atuam no texto. A ano-tação de mais baixo nível, morfológica, encarrega-se do desdobramento de palavras compostas, com prefixos e sufixos. Ao nível gramatical são usadas diversas anotações, sendo a mais comum e desenvolvida a POS-tagging, que involve a anotação das partes do discurso presentes nas frases do texto. Esta anotação indica se uma palavra é um nome, um adjetivo, um pronome, ou outros, ajudando na desambiguação de algumas palavras incertas (p. ex. “Eu como um pão”, “voa como uma ave”). A enorme quantidade de estudos sobre o POS-tagging faz desta anotação uma das mais desenvolvidas e sofisticadas, atingindo níveis de sucesso de 97% [BS04].
Outras anotações a este nível são por exemplo o género, número e tipo de palavras, lemati-zação, e campos semânticos (família de palavras). A lematização define-se como o processo de agrupar diferentes formas de palavras num único item que pode ser analisado individualmente [MRS08]. As palavras “trabalhou, trabalho, trabalhoso” possuem o lema comum “trabalho”. No nível sintático estão presentes as anotações referentes à natureza sintática das frases, mais especi-ficamente a construção de árvores sintáticas (treebanks). Neste nível é abordada a clássica tarefa de parsing de uma frase, determinando o sujeito, predicado, etc.
Ao nível do discurso são aplicadas geralmente anotações de coreferência, atos da fala e ano-tação estilística. A anoano-tação de coreferência visa descobrir quando duas expressões se referem à mesma pessoa ou coisa. É assim essencial para determinar o sujeito de um pronome. Atos da fala correspondem à finalidade de um discurso, ou parte dele. Uma citação de um ator pode ser assim classificada conforme que tipo de ação o seu discurso impõe, seja assertividade, diretividade, ex-pressividade, etc. A estilística confina-se na anotação do tipo de texto presente: narração, discurso direto, discurso indireto, pensamento, etc.
Finalmente ainda existem as anotações que não se incluem num nível textual específico e são muitas vezes orientadas ao problema. Neste campo temos a EEM (extração de entidades mencionadas), que visa identificar pessoas, eventos, locais, organizações e outros presentes no texto. Enquanto que sistemas antigos usavam algoritmos baseados em regas criados manualmente, a maioria dos sistemas modernos usam técnicas de aprendizagem automática. A escolha do set de tipos de entidades é também importante, sendo a hierarquia de Sekine [SSN02] uma das mais usadas com mais de 200 tipos de entidades.
Um problema relacionado com a identificação de entidades é o de Ligação de Entidades (En-tity Linking). Um corpus anotado com Ligação de Entidades vem geralmente acompanhado de um dicionário de entidades, que são referenciadas no texto, muitas vezes por denominadores diferen-tes. É assim uma tarefa importante analisar o texto e desambiguar a que entidade se refere uma certa expressão. Este problema já foi abordado recorrendo a bases de conhecimento [ZLHZ10]. Para finalizar, é claro que o tipo de anotação necessário num corpus está altamente dependente do
Revisão Bibliográfica
uso final e do objetivo de pesquisa deste. No entanto, alguns tipos de anotações têm uma grande variedade de usos e podem servir de base para anotações mais complexas de nível mais alto.
2.2
Análise do Arquivo de Notícias
A segunda parte da dissertação incide sobre a construção de uma análise sobre o arquivo de notícias do JPN. O objetivo desta análise é tanto o de observar a evolução linguística do jornal como o de descobrir padrões e hábitos de publicação de um meio jornalístico online. O estudo do arquivo pode incidir sobre vários aspetos dos dados, pelo que apresentamos aqui algumas análises mais comuns.
A análise lexical do corpus centra-se sobre os léxicos e formas gramaticais mais presentes nos textos. É possível assim determinar se um jornal possui um texto fundamentalmente mais rico em adjetivos do que um texto não-jornalístico e também a riqueza lexical (número de palavras únicas) dos artigos. Esta análise pode ser estendida à pesquisa das palavras que são mais mencionadas no corpus num certo contexto, por exemplo, quantas vezes os países europeus são mencionados [WA07], ou quais as expressões mais utilizadas por certos autores.
Uma segunda análise possível refere-se à categoria das notícias no arquivo. Com o uso de classificadores é feita uma divisão quanto à categoria dos artigos, que podem abranger um tema mais genérico (desporto, atualidade, política, etc.) ou situar-se numa categoria específica (Epide-mia Ébola 2014, Mundial de Futebol 2010, etc.) [Cri13]. Esta categorização pode ser conseguida ao identificar palavras-chave (keywords) no texto, usando depois um classificador para distinguir o tipo de notícia, ou através do uso de grupos (clusters) [NMTM00].
A análise jornalística preocupa-se com características não relacionadas com o conteúdo dos textos, procurando descobrir padrões sobre os hábitos de publicação do arquivo: hora do dia mais comum para a publicação de novas notícias, autores mais ativos, etc. Esta é uma área onde ainda não foi efetuada investigação considerável e relevante, pelo que espera-se, com esta dissertação, contribuir para o avanço desta análise.
A análise geográfica tenta posicionar a notícia num ou mais locais no espaço, resultando num mapa capaz de indicar os locais com mais protagonismo no arquivo. Adicionalmente, esta análise poderá ser aliada à categoria de notícias para distinguir que tipos de notícias (entretenimento, educação, etc.) ocorrem mais em certas regiões, ou até estender este conceito para que tipo de regiões são mais associadas com uma certa palavra-chave (ex. “crime”) [GB].
Outra análise importante é a análise de entidades, focada nos atores, organizações e eventos dos arquivos, identificando relações e possíveis cumplicidades entre entidades e permitindo, por exemplo, a criação de uma rede de personalidades do corpus. Os métodos de extração e aná-lise de relações entre personalidades são vários, desde baseando-se na referência simultânea de duas personalidades no mesmo artigo (tornando-se a relação mais forte quanto mais vezes estes forem referenciados em conjunto), até à compreensão profunda do texto de forma a inferir uma relação exata entre atores [FSM+09]. Este tipo de análise já foi abordado em diversos trabalhos, destacando-se o português Sapo “Máquina do Tempo” [U/P15].
Revisão Bibliográfica
Finalmente a análise sentimental visa identificar a polaridade sentimental de um texto. Por outra palavras o seu objetivo é interpretar corretamente se o autor expressa uma posição positiva ou negativa sobre certo assunto. É importante saber o balanço emocional quando são expressas opiniões, o que, no contexto de um arquivo de notícias, pode acontecer numa entrevista. A posição emocional do texto é exposta recorrendo geralmente a certas palavras-chave que correspondem a posições negativas ou positivas [NAdL+12].
2.3
Tecnologias
No que diz respeito a tecnologias, é de destacar a grande oferta de ferramentas de anotação automática de textos, em diversas linguagens, principalmente para as tarefas de POS-tagging e le-matização. Nesta dissertação importam principalmente as ferramentas não comerciais, que podem ser assim usadas no propósito desta tese. Apresentamos de seguida algumas das mais importantes. A Linguateca [San11] é um centro de recursos linguísticos que se dedica a servir a comunidade de processamento computacional da língua portuguesa. A Linguateca apresenta serviços de acesso a recursos (corpora, publicações, informações), manutenção de comunicações entre vários inves-tigadores e participa ativamente na criação, disponibilização e promoção de projetos linguísticos portugueses. Um dos seus mais importantes projetos é o AC/DC (Acesso a Corpos/Disponibiliza-ção de Corpos) [SB00], que surge em 1999 e visa aglomerar e disponibilizar diversos corpora num único website, com uma interface comum e uma poderosa ferramenta de interrogação de corpora. Para além disso, o AC/DC anota automaticamente todos os corpora envolvidos no projeto, com o anotador PALAVRAS [Bic00]. O PALAVRAS é um analisador automático para o português cri-ado por Eckhard Bick, que pode ser uscri-ado para anotar um corpus com partes da fala e informações gramaticais.
O LX-Suite [BS06] foi desenvolvido pela Universidade de Lisboa e é distribuído gratuita-mente. Esta ferramenta disponibiliza serviços de segmentação de frases (LX-Chunker), um ato-mizador (LX-Tokenizer), um etiquetador com uma precisão de 96% (LX-Tagger), assim como um lematizador com precisão de 97.6% (LX-Lemmatizer).
No que diz respeito a exploradores de corpora, os mais utilizados são o Wordsmith [Sco96] e o Xaira [Bur06]. Estas ferramentas possibilitam a descoberta de concordância nas palavras do corpus, ou seja, esclarece quais as palavras colocadas à palavra em questão. Outra funcionali-dade é a identificação de palavras-chave (keywords) num texto específico, e a criação de listas de palavras de forma a analisar a sua frequência.O Stanford CoreNLP [MSB+14] é um projeto da Universidade de Stanford que agrega várias ferramentas de análise de linguagem natural. A cole-ção de ferramentas é escrita em Java e é capaz de atomizacole-ção, segmentacole-ção de frases, anotacole-ção de acordo com diversos tagsets, identificação de entidades e análise de sentimento. NLTK (Natural Languge Toolkit) [Bir06] é uma plataforma de processamento de linguagem natural construída em Python, capaz de diversas análises linguísticas (concordância, análise sintática, anotação, lemati-zação, etc.) e com uma grande coleção de corpora e outros recursos para o teste de algoritmos e
Revisão Bibliográfica
teoremas. Esta ferramenta destaca-se pela facilidade de uso ao mesmo tempo que mantém uma alta qualidade nos seus algoritmos de classificação e anotação.
O Rembrandt [Car08] é uma ferramenta de reconhecimento de entidades mencionadas para a língua portuguesa, capaz também de detetar relações entre as entidades no texto. Esta ferramenta usa a enciclopédia online Wikipédia para resolver as entidades mencionadas.
As tecnologias mencionadas podem ser consultadas na Tabela 2.2.
Nome Funcionalidade Licença Observações
Suportadas atualmente
LX-SUITE (2006) [BS06] Anotação POS Gratuita Ferramenta
CoreNLP (2013) [MSB+14] NER, POS tagging, etc Gratuita Biblioteca Java NLTK (2006) [Bir06] POS tagging, parsin, etc Gratuita Biblioteca Python WordSmith (1996) [Sco96] Exploração de Corpora Comercial
XAIRA (2005) [Bur06] Exploração de Corpora Gratuita
Lingua::PT::PLNbase (2003) [JAR03] Segmentador e Atomizador Gratuita Biblioteca Perl Não suportadas atualmente
PALAVRAS (2000) [Bic00] Anotação POS Não disponível Usado no projeto ACDC Rembrandt (2006) [Car08] Reconhecimento de Entidades Gratuita Ferramenta
Capítulo 3
Processamento do arquivo de Notícias
A primeira tarefa desta dissertação aborda assim o processamento do arquivo de notícias do jornal online JPN, normalizando os textos e autores e anotando os artigos para posteriormente ser efetuada uma análise a vários níveis do arquivo.
3.1
JPN
Os artigos publicados pelo JPN obedecem à seguinte estrutura: • Título
• Autor
• Data de Publicação (D:M:A | H:m)
• Grupo de marcadores que identificam as notícias (Cultura, Economia, etc) • Subtítulo
• Corpo da notícia
• Comentários à notícia (gerados pelos leitores)
A extração das notícias do arquivo online foi realizada, guardando os artigos num ficheiro, formato XML, do ano de publicação respetivo. O arquivo estende-se desde o mês de março de 2004, no inicio do JPN, até março de 2015.
3.2
Processamento e anotação do arquivo
Depois de reunidas todas as notícias e comentários do arquivo, foi feito o processamento do corpus para estar pronto a ser analisado. As etiquetas de HTML do corpo da notícia são
Processamento do arquivo de Notícias
removidas e é feita a divisão de frases dos textos no título, subtítulo e corpo da notícia, usando a biblioteca Lingua-PT-PLNbase [JAR03] para Perl, disponível no CPAN. Esta biblioteca usa um algoritmo utilizado no projeto Natura que separa as frases de um texto, inserindo-as num nó de XML com a etiqueta <s>. Depois desta separação, cada frase é introduzida no marcador de partes da fala do LX-Suite, que para além de efetuar a atomização atribuindo a cada palavra uma etiqueta das presentes na Tabela 3.2. Este processo de anotação foi também efetuado nos comentários às notícias.
Quanto ao tipo de anotação, foi decidido usar um esquema de anotação embutida, de forma a simplificar tanto o processo de anotação como o de consulta. A maioria dos corpos discutidos no Capítulo 2 suportam também esta anotação, pelo que nos pareceu a escolha adequada.
3.2.1 Autores e Editores
O primeiro detalhe quanto ao tratamento dos arquivos é o uso de contas gerais para a publica-ção de notícias escritas por outros autores, provavelmente sem conta no site do JPN no momento da publicação. Isto leva a que muitas vezes o nome no campo de autor da notícia não seja o do seu criador, atuando apenas como um editor da notícia escrita por outrem (p. ex. aluno). O nome do(s) verdadeiro(s) autor(es) do artigo é colocado no fim do artigo, por vezes dentro de um “div"identificado com a classe autor, ou mesmo apenas envolvido em etiquetas de parágrafo (<p>). O conteúdo deste div apresenta, por vezes, ainda a informação sobre a fotografia ou fotógrafo res-ponsável. De forma a resolver este problema foi efetuada uma divisão por separadores HTML de parágrafo (<br/>), e posteriormente testada a correspondência com a seguinte expressão regular:
^( )*Foto(s?):(.*)
Esta expressão é responsável por detetar quando a caixa de autor está a mencionar o fotógrafo do artigo. Todos os outros casos são aceites como criadores da notícia. A prevalência deste estilo de autoria e publicação é menor nos anos mais recentes do arquivo. De forma a distinguir este tipo de publicação foi acrescentada a etiqueta <editor>, que identifica o responsável pela publicação da notícia. A etiqueta <creator> toma assim o significado correto de autor da notícia. Quando não existe um editor evidente da notícia, esta etiqueta toma o valor do autor do artigo.
3.2.2 Notícias Relacionadas
Cada notícia pode ter associada uma ou mais notícias anteriores relacionadas. Este relacio-namento é feito pelos autores da notícia e expõem alguns tópicos que são abordados ao longo de vários artigos. A notícia relacionada é anotada com uma etiqueta related, onde se inserem a etiqueta link, com o endereço da notícia relacionada, e a etiqueta linkName, que refere por sua vez o nome da notícia. O significado de cada etiqueta de XML pode ser verificado na Tabela 3.1.
Processamento do arquivo de Notícias
3.2.3 Exemplo
Um exemplo de uma notícia do arquivo já completamente processada e anotada é o seguinte:
1 <item>
2 <title><![CDATA[Deutsche/PNM Bank/PNM acredita/V em_/PREP a/DA bolsa/CN portuguesa/
ADJ ]]></title>
3 <subtitle><s><![CDATA[Banco/PNM alemão/ADJ coloca/V bolsa/CN nacional/ADJ a_/PREP a
/DA frente/CN de_/V a/DA espanhola/ADJ .*//PNT ]]></s></subtitle>
4 <pubDate>Fri, 05 Mar 2004 14:57:09 +0000</pubDate>
5 <creator>pedrocandeias</creator>
6 <category>Destaques</category><category>Economia</category>
7 <related>
8 <link>http://jpn.up.pt/2013/12/17/680-bolsas-para-jovens-desempregados/</link>
9 <linkName>680 bolsas para jovens desempregados</linkName>
10 <content>
11
12 <s><![CDATA[Christophe/PNM Bernard/PNM ,*//PNT director/CN de_/PREP o/DA Deutsche/
PNM Bank/PNM \*,*//PNT afirma/V que/CJ Portugal/PNM beneficia/V de/PREP estí mulos/CN adicionais/ADJ que/REL o/CL aproximam/V de_/PREP os/DA grandes/ADJ mercados/CN europeus/ADJ ,*//PNT como/CJ é/V o/DA caso/CN de_/PREP o/DA Euro/CN
2004/DGT ,*//PNT de_/V o/DA baixo/ADJ valor/CN de_/PREP os/DA títulos/CN mais/ ADV importantes/ADJ e/CJ de_/PREP a/DA retoma/CN económica/ADJ .*//PNT ]]></s>
13
14 <s><![CDATA[Segundo/PREP o/DA director/CN de_/PREP o/DA banco/CN alemão/ADJ ,*//PNT
estes/DEM atractivos/CN vieram/V despertar/INF o/DA interesse/CN de_/PREP os/ DA investidores/CN europeus/ADJ que/REL até/ADV agora/ADV não/ADV estavam/V muito/ADV atentos/ADJ a_/PREP o/DA mercado/CN nacional/ADJ .*//PNT ]]></s>
15
16 <s><![CDATA[Christophe/PNM Bernard/PNM esclarece/V que/CJ o/DA Deutsche/PNM Bank/
PNM tem/VAUX estado/PPT atento/ADJ a/PREP Portugal/PNM enquanto/CJ país/CN integrado/PPA em_/PREP a/DA região/CN de_/PREP a/DA zona/CN euro/ADJ e/CJ devido/PPA a_/PREP o/DA crescimento/CN negativo/ADJ de_/PREP a/DA economia/CN portuguesa/ADJ em/PREP 2003/DGT .*//PNT ]]></s>
17 18
19 <s><![CDATA[Andreia/PNM Parente/PNM Fonte/PNM :*//PNT Diário/PNM Económico/PNM ]]><
/s>
20 </content>
21 </item>
A diferença quanto à categoria e ao marcador é a sua generalidade. Uma categoria é um mar-cador mais geral, enquanto que uma tag é usada numa coleção relativamente pequena de notícias.
Processamento do arquivo de Notícias
Marcador Parte da Notícia
title Título da Notícia
subtitle Subtítulo da Notícia pubDate Data de Publicação creator Autor da Notícia editor Editor da Notícia category Categoria da Notícia tag Tag/Marcador da Notícia content Corpo da Notícia related Notícia Relacionada
Processamento do arquivo de Notícias
Tag Categoria Exemplos
ADJ Adjetivos bom, brilhante, eficaz, . . .
ADV Adverbios hoje, já, sim, felizmente, . . .
CARD Cardinais zero, dez, cem, mil, . . .
CJ Conjunções e, ou, tal como, . . .
CL Clíticos o, lhe, se, . . .
CN Nomes Comuns computador, cidade, ideia, . . .
DA Artigos Definidos o, os, . . .
DEM Demonstrativos este, esses, aquele, . . .
DFR Denominadores de frações meio, terço, décimo, %, . . . DGTR Números Romanos VI, LX, MMIII, MCMXCIX, . . .
DGT Dígitos 0, 1, 42, 12345, 67890, . . .
DM Marcas de Discurso olá, . . .
EADR Endereço Eletrónico http://www.di.fc.ul.pt, . . .
EOE Final de Enumeração etc
EXC Exclamativos ah, ei, ...
GER Gerúndios sendo, afirmando, vivendo, . . .
GERAUX Gerúndios ’ter/haver’ tendo, havendo . . .
IA Artigos Indefinidos uns, umas, . . .
IND Indefinidos tudo, alguém, ninguém, . . .
INF Infinitivos ser, afirmar, viver, . . .
INFAUX Infinitivos ’ter/haver’ ter, haver . . .
INT Interrogativos quem, como, quando, . . .
ITJ Interjeições bolas, caramba, . . .
LTR Letras a, b, c, . . .
MGT Classes de Magnitude unidade, dezena, dúzia, resma, . . .
MTH Meses Janeiro, Dezembro, . . .
NP Frases de Nome idem, . . .
ORD Ordinais primeiro, centésimo, penúltimo, . . .
PADR Parte de Endereço Rua, av., rot., . . .
PNM Parte de Nome Lisboa, António, João, . . .
PNT Marcas de Pontuação ., ?, (, . . .
POSS Possessivos meu, teu, seu, . . .
PPA Passado Particípio afirmados, vivida, . . .
PP Frases Preposicionais algures, . . .
PPT Passado Particípio composto sido, afirmado, vivido, . . .
PREP Preposições de, para, em redor de, . . .
PRS Pronomes Pessoais eu, tu, ele, . . .
QNT Quantificadores todos, muitos, nenhum, . . .
REL Relativos que, cujo, tal que, . . .
STT Títulos Sociais Presidente, dra., prof., . . .
SYB Símbolos @, #, &, . . .
TERMN Terminadores Opcionais (s), (as), . . .
UM "um"ou "uma" um, uma
UNIT Unidade Abreviada kg., km., . . .
VAUX ’Ter/Haver’ composto temos, haveriam, . . .
V Verbos falou, falaria, . . .
WD Dias da Semana segunda, terça-feira, sábado, . . . LADV1. . . LADVn Adverbios Multi-Palavra de facto, em suma, um pouco, . . . LCJ1. . . LCJn Conjunções Multi-Palavra assim como, já que, . . . LDEM1. . . LDEMn Demonstrativos Multi-Palavra o mesmo, . . . LDFR1. . . LDFRn Denominadores Multi-Palavra por cento LDM1. . . LDMn Marcas de Discurso Multi-Palavra pois não, até logo, . . . LITJ1. . . LITJn Interjeições Multi-Palavra meu Deus LPRS1. . . LPRSn Pessoais Multi-Palavra a gente, si mesmo, V. Exa., . . . LPREP1. . . LPREPn Preposições Multi-Palavra através de, a partir de, . . . LQD1. . . LQDn Quantificador Multi-Palavra uns quantos, . . . LREL1. . . LRELn Relativos Multi-Palavra tal como, . . .
Capítulo 4
Caracterização do Arquivo
Esta secção dedica-se à análise efetuada sobre o arquivo, desde a análise jornalística e mor-fológica até à análise efetuada sobre os autores responsáveis pelos textos. No entanto algumas análises são interdisciplinares, pelo que não se espera criar uma divisão clara entre cada análise, mas sim um guia estruturado à caracterização do corpus.
4.1
Vista geral
O arquivo do JPN é constituído por 19 072 artigos, ao longo de 132 meses (Março de 2004-Março 2015). No que diz respeito à distribuição dos artigos ao longo dos anos, apresenta-se o seguinte gráfico (Figura 4.1a). Para além dos artigos publicados durante o período em análise, o arquivo é composto de comentários efetuados pelos leitores às várias notícias. No total existem cerca de 5665 comentários durante os 11 anos de análise.
Caracterização do Arquivo
A autoria dos artigos divide-se entre 422 autores, alguns que só contribuem apenas para uma única peça, enquanto que outros regularmente publicam novo material. De forma a analisar a importância de cada tipo de autor para os métodos de publicação no jornal, foram usados grupos que agregam e representam todos os autores com um número de artigos entre um certo intervalo. O intervalo entre grupos é de 14 artigos e foi escolhido pois não é demasiado pequeno que aumente desnecessáriamente a complexidade da análise, e não é demasiado largo que resulte numa análise superficial e sem possibilidade da extração de conclusões. Foi acrescentado ainda o grupo ”1 artigo”, que representa os autores de intervenção única no jornal (Figura 4.1b). A média de artigos por autor é de cerca de 45 artigos.
4.2
Análise Jornalística
4.2.1 Hábitos de Publicação
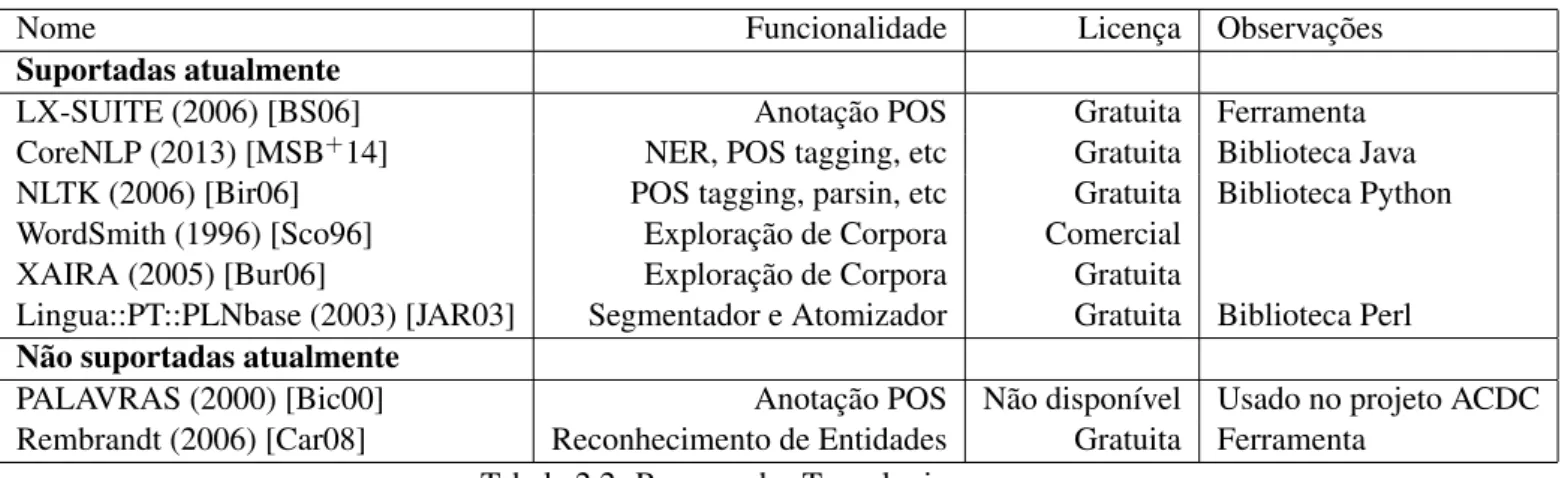
No que diz respeito aos hábitos de publicação do JPN, a Figura 4.2 mostra a distribuição dos artigos ao longo dos meses do ano, revelando uma maior frequência de publicação de novos artigos durante os meses de março, abril e maio, resultante do começo da atividade estagiária dos estudantes no jornal universitário. Estes meses registam aproximadamente 10 artigos por dia, enquanto que no mínimo de atividade do mês de agosto esta média é de apenas 1,4 artigos por dia.
Figura 4.2: Total número de artigos por mês
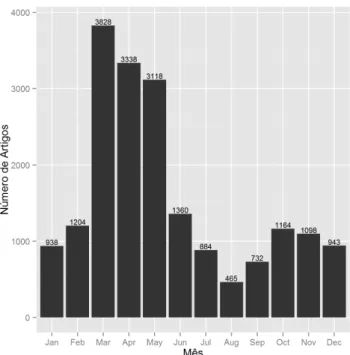
Em termos de publicações ao longo do dia, as 15, 16 e 17 horas são aquelas que apresentam maior atividade. Durante a manhã, novos artigos têm maior probabilidade de serem publicados às 10 horas. Durante a madrugada (da 1 até as 6 horas), foram publicados no total 168 artigos, que
Caracterização do Arquivo
representam 0,88% do total de artigos do arquivo. A Figura 4.3 mostra a restante distribuição das publicações durante o dia.
Figura 4.3: Total número de artigos por hora
4.2.2 Vídeo Artigos
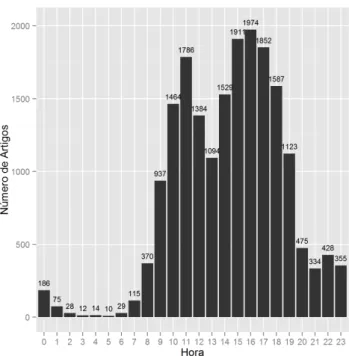
Como plataforma de jornalismo multimédia, o JPN publica ocasionalmente artigos onde o corpo da notícia é composto unicamente por uma vídeo-reportagem ou uma vídeo-entrevista. A identificação deste tipo de artigos pode ser feita ao isolar os artigos com a categoria “Vídeo” e um corpo da notícia vazio. A Figura 4.4 mostra a evolução do uso da vídeo-reportagem no JPN ao longo dos anos. O pico do uso do vídeo foi em 2008, com 3,8% dos artigos, tendo vindo a decrescer até 2,1% no ano de 2014. Até ao mês de março de 2015 nenhum artigo-vídeo foi publicado.
Do mesmo modo é interessante analisar quais as categorias de notícias que mais recorrem ao uso do vídeo (Figura 4.5). As notícias com destaque principal são alvo de vídeo-artigos mais frequentemente em relação a outras categorias. Da mesma forma, na categoria UP é usada por vezes a vídeo reportagem devido à facilidade da captação de imagem e opiniões sobre os temas discutidos, enquanto que, pela razão oposta, a categoria Mundo apenas excecionalmente apresenta notícias com recurso ao vídeo.
4.3
Análise dos Visitantes
Uma das partes da análise ao corpus e ao jornalismo praticado pelo JPN passa pela caracteriza-ção do tráfego do arquivo e dos leitores das notícias publicadas. De forma a atingir esse objetivo,
Caracterização do Arquivo
Figura 4.4: Percentagem de vídeo artigos ao longo dos anos
Caracterização do Arquivo
foram recolhidos alguns registos (logs) de servidor Apache, entre 28 de Março de 2012 e 31 de Outubro de 2014. De seguida são apresentadas algumas observações quanto ao uso do JPN pelos internautas.
4.3.1 Acessos e Visitantes
O termo acesso designa um pedido ao servidor Web. Um visitante pode efetuar vários acessos numa única sessão, e a leitura de uma notícia pode resultar em mais que um acesso (imagens, ficheiros, vídeos, etc). Desta forma, o número de acessos não representa uma medida de populari-dade de confiança, mas sim uma estatística quanto ao tráfego e tipo de estrutura de um website.
Os acessos podem ser ainda separados por acessos de visitantes e acessos de spiders, onde o primeiro representa um visitante humano enquanto que o segundo é realizado por um programa desenhado para examinar o conteúdo de um website. Durante o período em análise, o JPN recebeu mais de 254 milhões de acessos, 90,5 % destes provenientes de visitantes e 9,5% de spiders. Isto significa que durante os 947 dias da análise, o website recebeu em média 268 700 acessos por dia.
4.3.2 Visualizações de Páginas
No que diz respeito à visualização de páginas/notícias, o JPN apresenta um total de aproxima-damente 22 milhões de visualizações de páginas durante o período examinado. Isto resulta numa média de 23 272 páginas visualizadas por dia.
4.3.3 Atividade
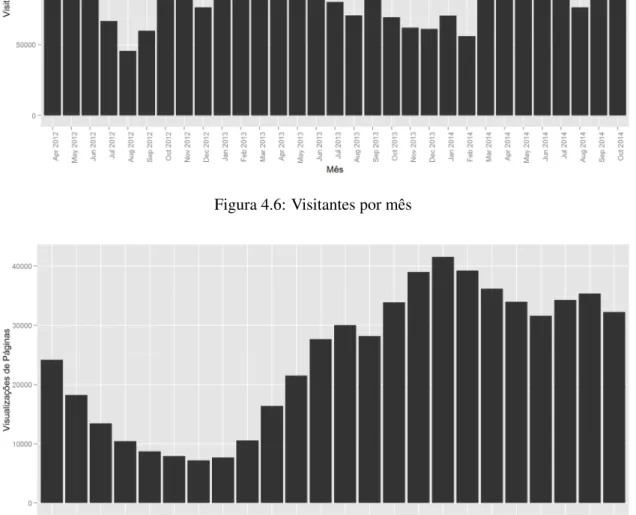
A atividade diária no website do JPN segue a distribuição na Figura 4.7, onde é possível observar a quebra de atividade durante a madrugada e o pico de atividade por volta das 16 horas. Quanto à atividade durante a semana, os visitantes utilizaram o JPN conforme a distribuição na Figura 4.8. Durante o ano, a atividade atingiu o seu máximo nos meses de março, abril e maio, tornando-se relativamente menor durante o período de Verão, como é evidente na Figura 4.6.
4.3.4 Pesquisas
As pesquisas representam as frases inseridas nos motores de busca que levaram os leitores às páginas do JPN. Em termos de motores de pesquisa usados, o Google domina sendo responsável por cerca de 94% das páginas visualizadas no JPN, seguido pelo motor de pesquisa português Sapo, com 2.3%. A Tabela 4.1 mostra as frases de pesquisa mais populares durante o período de análise.
4.3.5 Browsers Usados
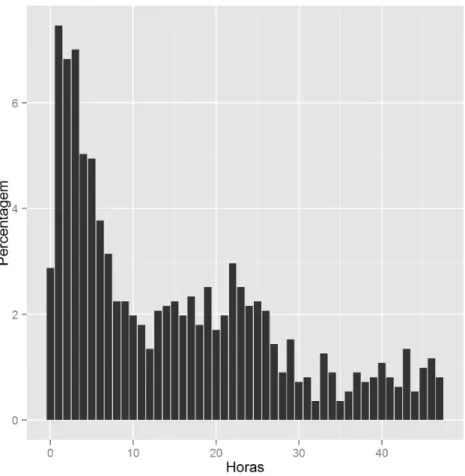
Os browsers utilizados para aceder ao arquivo do JPN são apresentados na Figura 4.9, onde se observa a competição entre o Internet Explorer e o Google Chrome, com 34,43% e 21.93% de visualizações respetivamente, seguidos pelo Firefox com 15,59%. O acesso através de dispositivos
Caracterização do Arquivo
Figura 4.6: Visitantes por mês
Figura 4.7: Visualizações de páginas por hora
móveis ao website do JPN é de aproximadamente 11% (Android Browser com 6,57% e o Mobile Safari com 4,42%).
4.3.6 Comentários
O website do JPN possibilita aos leitores comentar as notícias publicadas, abrindo a possibili-dade de uma análise ao nível do conteúdo gerado pelo público alvo do jornal. Durante o período de vida do arquivo (2004-2015), foram publicados cerca de 5665 comentários que tiveram como alvo 2178 artigos (11,4% do total de artigos). Se considerarmos apenas os artigos comentados, a média de comentários aproxima-se de 2.6 publicações por artigo. O máximo de comentários numa notícia é de 172, num artigo do ano de 2014. Existem 64 artigos com mais de 10 comentários.
Caracterização do Arquivo
Figura 4.8: Visualizações de páginas por dia da semana
Frase Número de Pesquisas
jpn 6251
resumo 3569
google nose 2968
dia da terra 2013 1834
queima das fitas porto 2012 1478
haxixe 1270
cartaz queima das fitas porto 2012 1160
strict 1135
dança contemporânea 1118
noticias 1045
Tabela 4.1: Frases de pesquisa mais utilizadas
Em termos de hora da publicação de comentários, a distribuição é apresentada na Figura 4.10a, onde é possível observar o pico de atividade durante a tarde. A sobreposição das horas de publica-ção de comentários com as horas de publicapublica-ção de novos artigos pode indicar-nos comportamentos interessantes da parte dos leitores do jornal. A Figura 4.10b mostra essa relação, revelando a in-clinação dos artigos para a publicação durante a tarde, enquanto que os comentários são feitos relativamente mais durante a noite. A relação entre artigos e comentários é o ponto mais interes-sante de analisar. Na Figura 4.11 é exibido o tempo desde a publicação de um novo artigo até ao primeiro comentário, onde é possível observar que o primeiro comentário é publicado mais frequentemente nas primeiras 3 horas.
Caracterização do Arquivo
Figura 4.9: Browsers mais usados (Maio 2014)
(a) Distribuição de Comentários por Hora (b) Comparação da publicação de novos artigos e co-mentários por Hora
4.4
Análise Morfológica e Lexical
No que diz respeito à análise da composição elementar dos textos, destaca-se a grande impor-tância das palavras dos artigos, assim como os comentários dos leitores, pois representam a sua parte escrita. Define-se por palavra toda a construção de letras separada por um espaço em branco, excluindo pontuação. O corpus apresenta assim aproximadamente 9 milhões de palavras. Cerca
Caracterização do Arquivo
Figura 4.11: Horas até ao primeiro comentário após a publicação da notícia
de 8,7 milhões constituem o texto jornalístico em que 2,2% fazem parte do título da notícia, 6,1% do subtítulo e os restantes 91,7% do corpo da notícia. As restantes 350 mil palavras constituem os comentários realizados às notícias.
4.4.1 POS Tags
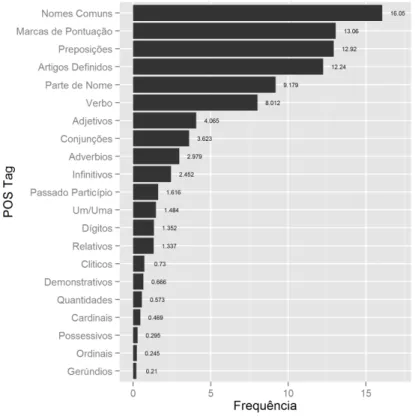
Uma anotação efetuada no corpus foi a marcação das partes do discurso (Part-of-Speech POS) nos textos, com recurso à ferramenta LX-SUITE [BS06]. Esta anotação fornece uma informação importante quanto ao uso pretendido da palavra, assim como ao estilo de escrita do autor do texto. A distribuição geral ao longo do corpus das principais etiquetas é apresentada na Figura 4.12. Com a figura é possível observar o destaque dos nomes comuns, assim como a presença dos elementos de construção de frases, como as preposições, os artigos, e as marcas de pontuação. Em termos da relação tipos e unidades, a Tabela 4.2 mostra a contagem para as principais etiquetas, assim com o rácio unidade para tipo, que permite observar o uso de uma etiqueta relativamente ao tamanho do seu léxico (número de tipos). Nesta tabela é possível observar a grande variedade de nomes comuns: cada tipo de nome comum aparece em média apenas 46 vezes no corpus, enquanto que categorias como as conjunções apresentam um grupo lexical muito menor, sendo muito mais reutilizadas. Os adjetivos também apresentam um grande conjunto de tipos. Esta
Caracterização do Arquivo
tabela tem apenas em consideração as palavras do corpus, resultando na disparidade entre a Figura 4.12, que calcula a percentagem contando com todas as etiqueta (incluindo marcas de pontuação).
Figura 4.12: Frequência de cada etiqueta POS no arquivo
Na Tabela 4.3 é apresentada a relação da distribuição de POS tags com outro corpus português: o Corpus de Referência do Português Contemporâneo (CRPC), de conteúdo geral. O CRPC usa o mesmo esquema de anotação que o corpus do JPN, o que facilita a comparação entre as várias categorias de partes da fala. Através da ferramenta disponível online1, foram criados sub corpora do CRPC compostos apenas com artigos de uma certa categoria, de forma a fazer a comparação com o nosso corpus jornalístico: sub corpus de textos políticos, sub corpus de textos literários e sub corpus de textos retirados de revistas. Para além da filtragem por tipo de texto, foram escolhidos apenas textos oriundos de Portugal, de forma a comparar os géneros de textos e não as diferenças linguísticas entre países.
POS Tipos Unidades Unidade por Tipo % no Corpus
Adjetivos 16357 371086 22,68 4,896
Advérbios 2105 271563 177,2 3,583
Conjunções 81 330221 4076 4,357
Nomes Comuns 31547 1463676 46,39 19,31
Parte de Nome 49913 836579 16,76 11,03
Tabela 4.2: Unidades e tipos de algumas partes de discurso no JPN
Caracterização do Arquivo
POS % no JPN % CRPC (Revista) % CRPC (Literário) % CRPC (Político)
Adjetivos 4,896 5,548 4,650 5,186 Advérbios 3,583 4,610 5,430 4,666 Nomes Comuns 19,310 19,210 17,330 16,800 Parte de Nome 11,030 6,070 3,477 8,980 Passado Particípio 1,943 2,100 1,81 1,880 Possessivos 0,355 0.736 1,170 0,706 Títulos Sociais 0,029 0,074 0,150 1,310
Tabela 4.3: Comparação das etiquetas POS com outros corpora
A tabela evidencia as diferenças na distribuição das POS tags entre os diferentes tipos de tex-tos. O texto jornalístico do JPN é o que mais usa os Nomes Próprios (conhecidos no tagset do LX—SUITE como “Partes de Nome”), devido principalmente à sua natureza expositiva e notici-osa. O texto jornalístico apresenta menos adjetivos que os outros tipos de textos à exceção do texto literário. Ao mesmo tempo é interessante reparar no menor uso nos advérbios e possessivos. O uso de títulos sociais (Presidente, dra. prof. ) também é relativamente pequeno e mais semelhante aos textos de revistas, ao contrário do grande uso no texto político. Os nomes comuns também estão em destaque no texto do JPN.
Um ponto interessante a analisar é a evolução do uso de certas etiquetas ao longo dos anos do arquivo. Será que as notícias se tornam mais adjetivadas com o passar dos anos? Uso mais frequente da pontuação? O Gráfico 4.13 mostra a evolução do uso de algumas etiquetas desde o ano de 2004. Na Tabela 4.4 são apresentadas as diferenças em pontos percentuais do uso de algumas etiquetas no corpus. Foi usada uma janela de 10 anos (2004 - 2014) para comparação. O gráfico mostra um aumento no uso da pontuação, com alguma oscilação no uso de nomes comuns, advérbios e adjetivos. No entanto, recorrendo à Tabela 4.4, conclui-se que não houve grande alteração final na distribuição das etiquetas de POS entre os dois anos analisados.
POS 2004 2014 Diferença Adjetivos 4.407 3.987 -0.42 Advérbios 3.339 3.083 -0.26 Nomes Comuns 16.12 16.11 -0.01 Demonstrativos 0.821 0.767 -0.05 Gerúndios 0.185 0.185 0 Indefinidos 0.183 0.203 0.02 Infinitivos 2.378 2.654 0.28 Marcas de Pontuação 11.20 13.41 2.21 Passado Particípio 1.653 1.543 -0.11 Preposições 12.74 12.65 -0.08 Relativos 1.392 1.442 0.05 Verbo 8.369 8.125 -0.24 Ter/Haver 0.105 0.073 -0.03
Caracterização do Arquivo
Figura 4.13: Evolução das POS tags
A diferença na distribuição das POS tags no título, subtítulo e corpo da notícia está represen-tada na Figura 4.14, onde é possível observar as diferentes constituições de cada secção. Os títulos apresentam geralmente menos advérbios e verbos no infinitivo, ao mesmo tempo que são consti-tuídos por partes de nomes e verbos em geral, refletindo a natureza indicadora do título: apresentar os sujeitos e o que aconteceu. Por sua vez, os subtítulos apresentam a maior percentagem de no-mes comuns, artigos e preposições, focando-se no esclarecimento do tema da notícia. O corpo da notícia é composto por mais marcas de pontuação e advérbios, centrando-se na exposição com-pleta da notícia. Uma característica interessante a observar na Figura 4.14 é a natureza intermédia do subtítulo. Enquanto que por vezes é a secção com a maior presença de uma certa parte da fala, o subtítulo nunca é a secção com menor frequência nas POS apresentadas, tomando a maioria das vezes uma posição intermédia em relação ao título e ao corpo da notícia. Usando o exemplo dos verbos em que o título apresenta uma maior percentagem em relação ao corpo da notícia, é possível observar que a percentagem de verbos no subtítulo encaixa-se mesmo no meio das duas secções extremas. Isto suporta a ideia que a informação jornalística segue uma pirâmide inver-tida: o artigo foca-se na exposição da notícia em geral primeiramente, expandindo os detalhes no
Caracterização do Arquivo
seguinte texto. Esta estrutura pode surgir tanto no texto do corpo da notícia como na informação divulgada em cada secção do artigo, neste caso o título, subtítulo e corpo.
Figura 4.14: Percentagem de POS tag por cada secção
4.4.2 POS tags nos comentários
Os comentários efetuados às notícias representam um conjunto de textos livres merecedores de uma analise e comparação com os textos dos artigos. Na Figura 4.15 são apresentadas as principais etiquetas POS usadas nos comentários que, quando comparada com a Figura 4.12 representante da distribuição das partes da fala nas notícias, revela um menor uso de nomes comuns e marcas de pontuação mas um aumento significativo no uso de partes da fala como os verbos e advérbios. Os artigos definidos são outras etiquetas que se diferenciam: os comentadores utilizam-nos menos 3 pontos percentuais do que nos artigos de notícias. Outras variações que não estão presentes na figura mas que se revelam interessantes são o maior uso de interjeições, infinitivos, pronomes pessoais e demonstrativos nos comentários em relação ao texto jornalístico.