This research was developed at the Universidade Federal de Pernambuco – UFPE – Recife (PE), Brazil.
(1) Post-Graduate Program (Doctorate) in Neuropsychiatry and Behavioral Sciences, Universidade Federal de Pernambuco – UFPE – Recife (PE), Brazil. (2) Speech, Language, Pathology and Audiology Department, Universidade Federal de Pernambuco – UFPE – Recife (PE), Brazil.
(3) Post-Graduate Program (Master’s degree) in Neuropsychiatry and Behavioral Sciences, Universidade Federal de Pernambuco – UFPE – Recife (PE), Brazil. Conflict of interests: No
Authors’ contribution: KPA main researcher, elaboration of the research, elaboration of the timeline, literature review, data collecting and analyzes, article’s writing, article’s submission and formalities; DCM adviser, elaboration of the research, elaboration of the timeline, data analyzes, article’s writing and correction, final version approval; FAP contributor researcher, literature review, data collecting and analyzes, article’s writing and revision; SMSG co-adviser, elaboration of the research, elaboration of the timeline, data analyzes, article’s writing correction, final version approval.
Correspondence address: Karina Paes Advíncula. R. Amaro Coutinho, 531/701, Encruzilhada, Recife (PE), Brazil, CEP: 52041-110. E-mail: kpadvincula@hotmail.com
Received: 1/3/2013; Accepted: 8/26/2013
Effect of modulation rate on masking release for speech
Percepção da fala em presença de ruído competitivo: o efeito da
taxa de modulação do ruído mascarante
Karina Paes Advíncula1, Denise Costa Menezes2, Fernando Augusto Pacífico3, Silvana Maria Sobral Griz2
ABSTRACT
Purpose: To investigate the effect of modulation rate on masking release for speech. Methods: Fifteen normal hearing subjects participated in the study. They were tested on speech perception in noise using the senten-ces of the HINT-Brazil. Speech recognition thresholds were obtained in the presence of steady masking and amplitude modulated masking at rates of 4, 8, 16, 32 and 64 Hz. The magnitude of masking release was obtained for each modulation rate, and results were compared. Results: Data showed significantly lower speech thresholds when the masking noise was amplitude modulated at rates of 4, 8, 16 and 32 Hz, when compared to thresholds obtained in steady noise or noise modulated at 64 Hz. Speech-to-masker ratios (SMR) were higher in steady masking noise, followed by modulated noise at 64 Hz, and lower for modulated rates of 32, 16, 8 and 4 Hz, respectively. Conclusion: The magnitude of masking release for speech does not seem to differ significantly among modulation rates of 4 to 32 Hz. However, for a modulation rate of 64 Hz the magnitude of masking release is significantly reduced.
Keywords: Hearing; Perceptual masking; Speech perception; Speech discrimination tests; Noise
RESUMO
Objetivo: Este estudo investigou o efeito das diferentes taxas de modu-lações do mascaramento na magnitude do masking release. Métodos: Quinze indivíduos jovens, com audição normal, foram submetidos ao teste de reconhecimento de sentença na presença de ruído, utilizando as listas de sentenças do HINT-Brasil. Foram obtidos limiares de reco-nhecimento de fala em presença de ruído estável e ruído modulado, em diferentes taxas de modulação (4, 8, 16, 32 e 64 Hz). A magnitude do
masking release foi obtida para cada modulação e foi realizada a análise comparativa dos resultados. Resultados: Os achados demonstraram me-lhores limiares de reconhecimento de sentenças quando o ruído masca-rante foi modulado em 4, 8, 16 e 32 Hz e piores limiares quando o ruído mascarante estava estável e em 64 Hz. No que diz respeito à análise da relação sinal/ruído, foram observados, no presente estudo, maiores valo-res para as tarefas que envolvem reconhecimento de sentenças com ruído estável, seguidos das tarefas que envolvem reconhecimento de sentenças com ruído modulado em 64 Hz, e menores valores para as tarefas que envolvem reconhecimento de sentenças com ruído modulado em 32, 16, 8 e 4 Hz, respectivamente. Conclusão: A magnitude do masking release
para sentenças não se diferencia com taxas de modulação em amplitude entre 4 e 32 Hz. No entanto, quando a taxa de modulação é elevada a 64 Hz, a magnitude do masking release diminui.
INTRODUCTION
The ability to recognize speech in noise must be considered as an important issue to be clinically evaluated, especially for those who have hearing difficulties. In several daily listening situations, oral communication requires accurate perception of speech, and usually, the speech is masked by a background noise – a simultaneous competitive noise(1,2). This competitive
noise has multiple sources in a social environment and the listener has to ‘segregate’ speech from the masking noise(3,4).
Speech in noise recognition has been studied for years(5,6). One
example of this is the Articulation Index (AI), a metric used in acoustical studies to improve communication through the telephone, based in several experiments with different masking noises. This metric predicts intelligibility based on the available speech spectrum above the background noise(7,8).
For decades, studies have been comparing speech per-ception in the presence of different types of maskers where the acoustics characteristics of the noise are manipulated(1-12).
When an acoustic characteristic of the masker noise (usually an amplitude or frequency modulation) results in an improvement in speech recognition, this change is known as masking release. Several studies have shown that young normal hearing listeners perform better in recognition of a target speech when the masking noise is modulated in amplitude (amplitude mo-dulated – AM) or in its spectrum of frequencies (frequency modulated – FM). In other words, speech perception is opti-mized when the background noise is modulated, in comparison to steady noise(12,13). Regarding amplitude modulation across
time, masking release is due to the temporal intervals when there is a decrease in the noise intensity (modulation minima), improving, therefore, the signal to noise ratio(13,14). This situation
allows the listener to perceive better the target speech, exactly at the modulation minima, when the masking noise is lower in intensity. Therefore, the listener perceives brief fragments of the speech at the moment intensity decreases and receive more information in order to recognize what it has been said.
The magnitude of masking release is related to some of the physical characteristics of the masking noise. For example, its modulation rate across time(10,13-18). One study(18) shows an
im-provement of 15 dB to 25 dB in speech recognition thresholds among modulation rates from 8 to 20 Hz. A larger magnitude of masking release has been observed for low modulation rates(19),
ranging from 8 Hz to 25 Hz (especially 10 Hz)(13,14,20). Lower
modulation rates have longer temporal intervals of masker minima, which allow the listener to perceive more acoustical information of the speech(21).
The magnitude of masking release has been typically quan-tified as (a) the change in performance (percent correct) at a
specific signal-to-noise ratio (SNR) in steady and modulated noise, or as (b) the difference in SNR in steady and modulated noise at a specific percent correct value(22). Masking release for
speech is measured by using linguistic material, such as word or sentence lists from published tests, in the presence of masking noise. One of the tests used for this purpose is the Hearing in Noise Test (HINT)(23). This test investigated temporal aspects
of hearing, and more specifically, temporal masking (24).
In the Hearing in Noise Test (HINT), sentences are used to measure speech recognition thresholds in the presence of masking noise. It contains 25 lists of phonetically balanced sentences (10 sentences per list), and was developed for use evaluating speech recognition in noise. In 2008, researchers of the University of Sao Paulo, in Brazil published the Brazilian version of the HINT, the HINT-Brazil (25).
The HINT-Brazil is composed of 12 lists of 20 phonetically balanced Brazilian-Portuguese sentences and can be considered as an appropriate instrument to study the ability of recognizing speech in the presence of noise. However, the masking noise of the HINT-Brazil is a steady masker, which means that its intensity (amplitude) is steady across time. This masker can by amplitude modulated in different rates by an acoustic pro-cessor (RX6-Turker-Davis Technology). Therefore, sentences of HINT-Brazil can be used to investigate speech recognition thresholds in different rates of modulation noise and steady noise.
The present study investigated the effect of multiple masker modulation rates on masking release for speech in normal hearing young listeners. The speech material used was the HINT-Brazil.
METHODS
This is a quantitative, transversal and observational study, developed in the Research Laboratories of the Speech and Hearing Department of the Federal University of Pernambuco, from July to August, 2012. This study is part of a research pro-ject, titled as Temporal masking and speech recognition in the aging auditory system: US-BRAZIL, supported by the United StatesNational Institutes of Health (NIH), and conducted in a partnership between the University of North Carolina at Chapel Hill and the Federal University of Pernambuco. It was approved by the Institutional Review Board(11-1113), and the Ethical Committee on Research with Human Beings of the Federal University of Pernambuco (233/2012).
hearing/otologic, neurologic or psychiatric disorder. They all presented with normal otoscopy and normal hearing (thresholds lower than 20 dB HL for 250 Hz to 8000 Hz, including 3000 Hz and 6000 Hz)(26).
The subjects were submitted to speech-in-noise recognition tasks. As mentioned before, the speech material for these tasks were the 12 lists of 20 Brazilian-Portuguese sentences recorded at theHouse Research Institute (HRI) by a male speaker(25).
The masker noise was speech shaped noise (SSN) modulated by an acoustic processor (RX6-Tucker-Davis Technologies®). The SSN has a frequency spectrum ana-logous to that of the speech. The masker was squared-wave modulated between 65 and 30 dB SPL at rates of 4 Hz, 8 Hz, 16 Hz, 32 Hz and 64 Hz. The steady noise was presented at 65 dB SPL.
Subjects were positioned in an acoustic treated booth and instructed to listen carefully to all sentences and repeat as much as they understood. They were also informed that they would hear a masking noise. The researcher was positioned outside the booth, and controlled stimulus delivery and res-ponse registration by custom Matlab software scripts, 7.14 version (R2012a).
Speech signals and masking noise were processed by the same digital sound processor (RX6-Tucker-Davis Technologies®) and delivered monaurally through circum--aural earphones (Sennheiser-HD580) to the subject’s right ear or the better ear, when there was a difference of 5 dB or more between ears thresholds.
A correct response required the exact repetition of the test sentence. Any difference between the HINT sentence and the subject’s production was registered as an error, even when there was no semantic modification; for example, changes in the articles or in the verb conjugation, inclusion or exclusion of words.
In terms of the masker modulation rates, there were six test conditions: 0 Hz (steady), 4 Hz, 8 Hz, 16 Hz, 32 Hz and 64 Hz. Each subject was tested in two conditions resulting in three groups of five subjects: G1 (0 Hz and 4 Hz); G2 (8 Hz and 16 Hz) and G3 (32 Hz and 64 Hz). A subject’s speech threshold for each condition was taken as the average of four threshold replications. The result for each testing condition was the average across all group members.
The magnitude of masking release was computed as the difference between the mean speech recognition threshold in the steady masker (0 Hz modulation), taken as a reference, and the mean speech recognition threshold in each tested modulation rate.
Speech threshold was determined by an adaptive procedu-re, estimating 71% correct on the psychometric function. In
this adaptive procedure the signal level is presented according to the subject’s previous response(27-29).
Initial signal level was 70 dB SPL for the steady masking noise, and 60 dB SPL for the modulated masker in all rates. Signal level was adjusted following a two-down, one-up tracking rule(28). In this method, the level of the signal is
reduced by certain amount after two successive correct responses, and increased by the same amount after an in-correct response. For this study, signal level was reduced and increased by 2 dB.
Each threshold estimation track continued for a total of six reversals in signal level direction, where a reversal con-sisted of a change in the response course from decreasing to increasing or from increasing to decreasing.
In order to avoid learning effects, each sentence was presented only once to the subject. Subjects were randomly assigned to groups, and the order of conditions with group was random for each subject. The lists of sentences were also randomly selected.
Test time per subject was approximately 50 minutes. In order to avoid interference in the subject’s response caused by fatigue or discomfort, rest breaks were given as needed.
Data was analyzed at the Software Package for Statistical Analysis (SPSS) with the purpose to investigate the effect of multiple masker modulation on the masking release magnitude in normal hearing young adults. The significance of this data was evaluated by the analysis of variance, using the linear model with mixed effects. Modulation rate was considered as the fixed effect and the participants were considered as variable effect. Repeated measurements for each subject and for each testing condition were taken into account. The F-test was performed with a significance level of 95% to determine the effect of modulation rate. A Pairwise comparison, adjus-ted for multiple comparisons, was performed among mean thresholds for each modulation rate.
RESULTS
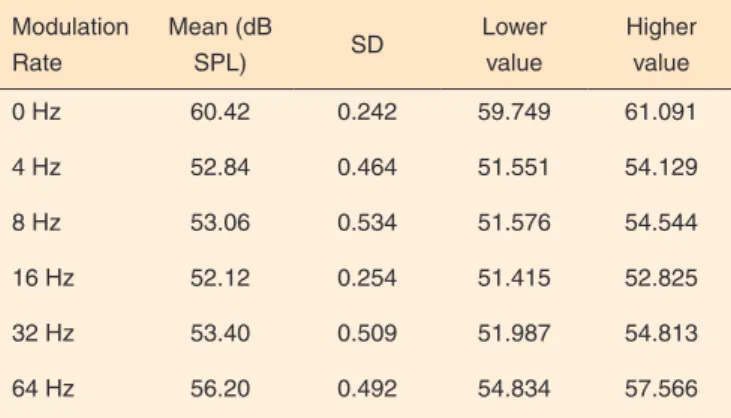
The averages of speech thresholds as a function of modu-lation rate are plotted in Figure 1.
of 4 Hz, 8 Hz, 16 Hz and 32 Hz, but lower than thresholds obtained with steady noise (Table 1).
A comparison of speech thresholds averages among all conditions (all modulation rates) shows significant main effect of modulation rate (F (5,6.5) = 207.4; p<0.01) shown in Table 2.
Pairwise comparisons among modulation rates, adjusted for multiple comparisons, resulted in the following pattern (p<0.05): speech thresholds measured in all modulated maskers (rates from 4 Hz to 64 Hz) were lower (better performance) than speech thresholds measured in steady masking noise; speech thresholds obtained at 4 Hz and 32 Hz modulation rates did not significantly differ from each other; speech thresholds obtained at 64 Hz modulation rate were significantly higher than thresholds obtained at all other modulation rates.
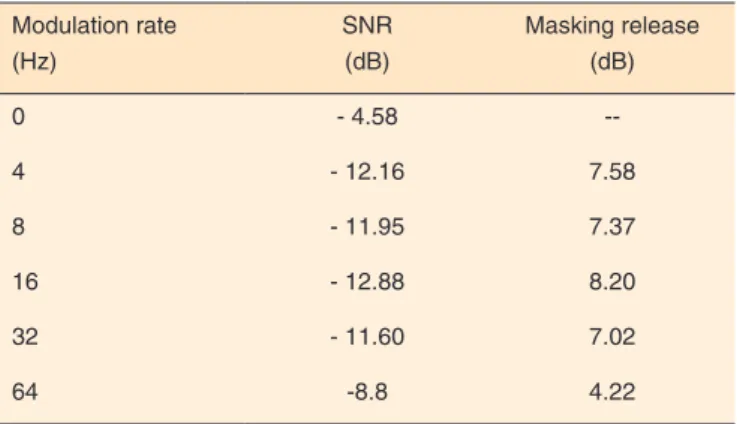
When expressed as signal-to-noise ratio (SNR), results were lower for steady noise and the 64 Hz modulation rate
Table 1. Speech thresholds for multiple modulation rates
Modulation Rate
Mean (dB
SPL) SD
Lower value
Higher value
0 Hz 60.42 0.242 59.749 61.091
4 Hz 52.84 0.464 51.551 54.129
8 Hz 53.06 0.534 51.576 54.544
16 Hz 52.12 0.254 51.415 52.825
32 Hz 53.40 0.509 51.987 54.813
64 Hz 56.20 0.492 54.834 57.566
Note: SD = standard deviation
Figure 1. Mean average of speech thresholds in a function of modu-lation rate
Table 2. Speech threshold comparison in different modulation rates
Modulation rate (Hz)
Modulation rate (Hz)
Mean
difference SD Significance**
0
4 7.58* 0.398 0.000
8 7.36* 0.587 0.000
16 8.30* 0.350 0.000
32 7.02* 0.563 0.000
64 4.22* 0.548 0.000
4
0 -7.58* 0.398 0.000
8 -0.22 0.708 0.764
16 0.72 0.529 0.221
32 -0.56 0.689 0.440
64 -3.36* 0.676 0.001
8
0 -7.36* 0.587 0.000
4 0.22 0.708 0.764
16 0.94 0.649 0.221
32 -0.34 0.738 0.657
64 -3.14* 0.726 0.003
16
0 -8.30* 0.350 0.000
4 -0.72 0.529 0.221
8 -0.94 0.649 0.221
32 -1.28 0.569 0.066
64 -4. 8* 0.554 0.000
32
0 -7.02* 0.563 0.000
4 0.56 0.689 0.440
8 0.34 0.738 0.657
16 1.28 0.569 0.066
64 -2.80* 0.742 0.020
64
0 -4.22* 0.548 0.000
4 3.36* 0.676 0.001
8 3.14* 0.726 0.003
16 4.08* 0.554 0.000
32 2.80* 0.742 0.020
than for modulation rates at 4 Hz, 8 Hz, 16 Hz and 32 Hz. SNR observed in these conditions did not significantly differ from each other (Table 3).
The magnitude of masking release was observed for all masker modulation rates. However, magnitude was greater when the masking noise was modulated at 4 Hz, 8 Hz, 16 Hz and 32 Hz, and smaller at 64 Hz modulation rate (Table 3).
DISCUSSION
Speech recognition performance in noisy environments may vary according to the acoustic characteristics of the masking noise(2,9,13,14). Studies have shown better speech
re-cognition when the masking noise is modulated in amplitude across time and spectrum of frequencies(12,14,21,24).
When the noise is frequency modulated (FM), the spec-trum of the noise oscillates and becomes more or less similar to the spectrum of the target speech. When the noise spectrum is more different than the speech spectrum, more acoustic information of the speech is free from masking by the noise. Therefore, the listener can perceive more fragments of what is being said and, consequently, improve recognition perfor-mance. SNRs at threshold with FM maskers are usually lower than with steady noise(24).
When the noise amplitude is modulated, its intensity chan-ges across the time. The masker is less effective at the low levels of intensity (masker minima) permitting the listener to perceive more of the target information at these timing intervals. Once again, speech thresholds are lower when measured in AM noise than when measured in steady noise. As mentioned before, this improvement in speech recognition, cause by acoustical changes in the masker, is called masking releasing(10,13-21,23).
Amplitude modulation may also vary in its “shape”. Researchers have been using squared-wave or sinusoidal modulations. For a given rate, if the modulation is sinusoidal, the overall masking effectiveness is higher, and consequently
the magnitude of masking release is smaller, presumably because of the effectively shorter masker minima. In squared--wave modulation, the listener can hear more fragments of the speech, therefore, speech recognition performance is enhanced(12-14,21,24).
In this study, squared-wave modulation was used. The magnitude of masking release found here is higher than that shown in a study in which a 10 Hz sinusoidal modulation was used(2). Hall and collaborators show a masking release
magnitude around 5 dB, whereas the magnitude found here is approximately 7 to 8 dB.
A study(1) has demonstrated a benefit of 4 to 8 dB for
sentence recognition in normal hearing subjects. In another study(22), researchers have observed an increase of 6 to 10 dB
in speech recognition thresholds. In 2006, two more studies reported 15 to 25 dB of masking release magnitude(17,18). The
masking release magnitude can be also presented as an incre-ase of signal-to-noise ratio at threshold(22) (Table 3).
Regarding the noise modulation rate, the results here show a significantly higher masking release magnitude for the lower rates (from 4 Hz to 32 Hz). Similar results are described in the literature on the firsts studies about masking release(30),
as well as in recent researches(13).
An explanation for these findings is that higher modulation rates make the noise more perceptually similar to a steady noi-se, providing the listener less intervals of minima masking(20).
Therefore, it seems that as the modulation rate increases, the chances for perceiving speech fragments decrease.
In 1950, a study presented a better speech recognition performance in modulated noise at 10 Hz(30). These researchers
also investigated masking release for several modulation rates and concluded that speech thresholds were equivalent between steady noise and modulated noise at higher rates. Results of the present study are in agreement with this pattern(30), as it
was found here higher values at steady noise and at 64 Hz than at the lower modulation rates.
Speech thresholds obtained for rates at 4 Hz, 8 Hz, 16 Hz and 32 Hz had no significant difference and were similar to the thresholds found in other studies in which a 10 Hz modu-lation rate was used(2,8,13,19). Regarding SNR analysis (Table
3), it was verified that SNR can be used to measure masking release magnitude.
CONCLUSION
The present study is innovative as sentences of the HINT-Brazil were used for the investigation of masking release at different rates of amplitude modulation. It can be concluded here that lower modulation rates of 4 Hz, 8 Hz, 16 Hz and 32
Table 3. SNR and masking release for multiple modulation rates
Modulation rate (Hz)
SNR (dB)
Masking release (dB)
0 - 4.58
--4 - 12.16 7.58
8 - 11.95 7.37
16 - 12.88 8.20
32 - 11.60 7.02
Hz provide greater masking release magnitude than a higher modulation rate of 64 Hz.
ACKNOWLEDGEMENTS
We acknowledge the assistance of Dr. John H. Grose (University of North Carolina at Chapel Hill) in imple-menting this study. This study was supported by part of his grant from the United States National Institutes of Health (R03-DC012278).
REFERENCES
1. Festen JM, Plomp R. Effects of fluctuating noise and interfering speech on the speech-reception threshold for impaired and normal hearing. J Acoust Soc Am. 1990;88(4):1725-36.
2. Hall JW, Buss E, Grose JH, Roush PA. Effects of age and hearing impairment on the ability to benefit from temporal and spectral modulation. Ear Hear. 2012;33(3):340-8.
3. Brungart DS. Informational and energetic masking effects in the perception of two simultaneous talkers. J Acoust Soc Am. 2001;109(3):1101-9.
4. Brungart DS, Simpson BD, Scott KR, Ericson MA. Informational and energetic masking effects in the perception of multiple simultaneous talkers. J Acoust Soc Am. 2001;110(5):2527-38. 5. Freyman RL, Balakrishnan U, Helfer KS. Effect of number of
masking talkers and auditory priming on informational masking in speech recognition. J Acoust Soc Am. 2004;115(5):2246-56. 6. Jacob RTS, Monteiro NFG, Molina SV, Bevilacqua MC, Lauris JRP,
Moret ALM. Percepção da fala em crianças em situação de ruído. Arq Int Otorrinolaringol. 2011;15(2):163-7.
7. Bernstein JG, Grant KW. Auditory and auditory-visual intelligibility of speech in fluctuating maskers for normal-hearing and hearing-impaired listeners. J Acoust Soc Am. 2009;125(5):3358-72. 8. Buss E, Hall JW3rd, Grose JH. Spectral integration of synchronous
and asynchronous cues to consoant indentification. J Acoust Soc Am. 2004;115(5):2278-85.
9. Gustafsson HA, Arlinger SD. Masking of speech by amplitude-modulated noise. J Acoust Soc Am. 1994;95(1):518-29.
10. Nelson PB, Jin SH, Carney AE, Nelson DA. Understanding speech in modulated interference: cochlear implant users and normal hearing listeners. J Acoust Soc Am. 2003;113(2):961-8.
11. Anderson ES, Nelson DA, Kreft H, Nelson PB, Oxenham AJ. Comparing spatial tuning curves, spectral ripple resolution, and speech perception in cochlear implant users. J Acoust Soc Am. 2011;130(1):364-75.
12. Buss E, Whittle LN, Grose JH, Hall JW3rd. Masking release for words in amplitude-modulated noise as a function of modulation rate and task. J Acoust Soc Am. 2009;126(1):269-80.
13. Buss E, He S, Grose JH, Hall JW3rd. The monoaural temporal window based on masking period pattern data in school-aged children and adults. J Acoust Soc Am. 2013;133(3):1586-97. 14. Füllgrabe C, Berthommier F, Lorenzi C. Masking release for
consonant features in temporally fluctuating background noise. Hear Res. 2006;211(1-2):74-84.
15. Stuart A, Phillips DP. Word recognition in continuous and interrupted broadband noise by young normal-hearing, older normal-hearing, and presbyacusic listeners. Ear Hear. 1996;17(6):478-89.
16. Summers V, Molis MR. Speech recognition in fluctuating and continuous maskers: effects of hearing loss and presentation level. J Speech Lang Hear Res. 2004;47(2):245-56.
17. Rhebergen KS, Versfeld NJ, Dreschler WA. Extended speech intelligibility index for the prediction of the speech reception threshold in fluctuating noise. J Acoust Soc Am. 2006;120(6):3988-97.
18. George EL, Festen JM, Houtgast T. Factors affecting masking release for speech in modulated noise for normal-hearing and hearing-impaired listeners. J Acoust Soc Am. 2006;120(4):2295-311. 19. Desloge JG, Reed CM, Braida LD, Perez ZD, Delhorne LA. Speech
reception by listeners with real and simulated hearing impairment: effects of continuous and interrupted noise. J Acoust Soc Am. 2010;128(1):342-59.
20. Lorenzi C, Husson M, Ardoint M, Debruille X. Speech masking release in listeners with flat hearing loss: effects of masker fluctuation rate on identification scores and phonetic feature reception. Int J Audiol. 2006;45(9):487-95.
21. Shejf S, Yost WA. Discrimination of start phase with sinusoidal envelope modulation. J Acoustic Soc Am. 2007;121(2):84-9. 22. Kwon BJ, Perry TT, Wilhelm CL, Healy, EW. Sentence recognition
in noise promoting or suppressing masking release by normal-hearing and cochlear-implant listeners. J Acoust Soc Am. 2012;131(4):3111-9.
23. Nilsson M, Soli SD, Sullivan, JA. Development of the Hearing in Noise Test for the measurement of speech reception thresholds in quiet and in noise. J Acoust Soc Am. 1994;95(2):1085-99.
24. Grose JH, Mamo SK, Hall JW3rd. Age effects in temporal envelope processing: speech unmasking and auditory steady state responses. Ear Hear. 2009;30(5):568-75.
25. Bevilacqua MC, Banhara MR, Da Costa EA, Vignoly AB, Alvarenga KF. The Brazilian Portuguese hearing in noise test. Int J Audiol. 2008;47(6):364-5.
26. American National Institute (ANSI). (2004). American National Standart Specification for Audiometers. ANSI S3.6-2004. New York: ANSI, 2004.
27. Wetherill GB, Levitt H. Sequential estimation of points a psychometric function. Br J Math Stat Psychol. 1965;18:1-10. 28. Levitt H. Transformed up-down methods in psychoacoustics. J
29. Bode DL, Carhart R. Measurements of articulation functions using adaptive test procedures. IEE Trans Audiol Electroacoustic. 1973;21:196-201.