Pontifícia Universidade Católica de São Paulo
PUC-SP
Everaldo Lopes Silva
Proposta de uma infraestrutura de baixo custo com multiprocessamento e
utilizando software aberto
Mestrado em tecnologias da inteligência e design digital
Pontifícia Universidade Católica de São Paulo
PUC-SP
Everaldo Lopes Silva
Proposta de uma infraestrutura de baixo custo com multiprocessamento e
utilizando software aberto
Mestrado em tecnologias da inteligência e design digital
Dissertação apresentada à Banca
Examinadora
da
Pontifícia
Universidade Católica de São Paulo,
como exigência parcial para obtenção
do título de Mestre em Tecnologias da
Inteligência e Design Digital sob a
orientação
do
Prof.
Dr.
Demi
Getschko.
iii
FICHA CATALOGRÁFICAAUTORIZO A CÓPIA E DIVULGAÇÃO TOTAL OU PARCIAL DESTE DOCUMENTO PARA FINS DE ESTUDO OU ACADÊMICOS, DESDE QUE CITADA A FONTE.
LOPES SILVA, Everaldo.
Proposta de uma infraestrutura de baixo custo com multiprocessamento e utilizando software aberto / Everaldo Lopes Silva; orientador Demi Getschko. -- São Paulo, 2012.
225f.
Dissertação (Mestrado). Área de Concentração: PUC-SP - TIDD.
1. Inteligência Coletiva
iv
Everaldo Lopes SilvaPROPOSTA DE UMA INFRAESTRUTURA DE BAIXO CUSTO COM MULTIPROCESSAMENTO E UTILIZANDO SOFTWARE ABERTO
Este trabalho refere-se à infraestrutura que seria um conjunto computadores/rede de comunicação onde se executaria sistemas de inteligência e Design Digital dentro do Programa de Estudos Pós-Graduados em Tecnologias da Inteligência e Design Digital - TIDD, com área de concentração
em “Inteligência Coletiva”, da Pontifícia
Universidade Católica de São Paulo – PUC/SP.
APROVADO em: __ / __ / __
_________________________
_________________________
_________________________
PROF. DR. DEMI GETSCHKO PUC-SP
(ORIENTADOR)
v
A meus pais,por iniciarem-me no interesse pela leitura e estudo; OFEREÇO
vi
AGRADECIMENTOSvii
“... buscai diligentemente e ensinai-vos uns aos outros palavras de sabedoria; sim nos melhores livros buscai palavras de sabedoria; procurai conhecimento, sim, pelo estudo e também pela fé."
viii
RESUMOEsta dissertação visa identificar os aspectos técnicos e teóricos que envolvem a utilização de cluster de computadores, tratando especialmente de plataformas com o
sistema operacional Linux. Serão apresentados alguns modelos de cluster em Linux,
reconhecendo suas vantagens e desvantagens e por fim indicando o modelo escolhido com a devida justificativa. Como parte do trabalho, proporemos um laboratório com um agrupamento de dois equipamentos conectados com duas interfaces de rede gigabit ethernet em cada um e um computador trabalhando isoladamente. Executaremos programas de Inteligência Artificial e Design Digital nesse cluster e compararemos o
seu desempenho com apenas um computador executando esses mesmos programas. As medições e análise servirão como base para análise para a verificação se um
cluster de Linux seria uma infraestrutura viável em termos técnicos e financeiros para
aplicações de Inteligência Artificial e Design Digital.
O método de pesquisa será naturalmente a pesquisa experimental e o método de abordagem será indutivo, pois através dos resultados da experimentação e da análise técnica se poderá aplicar o conhecimento obtido em situações semelhantes.
Para contextualizar a atividade experimental abordaremos as teorias de pesquisa mais significativas e contemporâneas para que se estabeleça de maneira clara a abordagem científica que norteará o trabalho como um todo.
ix
ABSTRACTThis dissertation has the objective of identifying the technical aspects that deal with the utilization of computer cluster, specially the platforms with Linux operational system. It
will be presented some cluster models in Linux, recognizing its advantages and its
disadvantages and finally indicating the chosen model with the due justification. As part of this work, we will propose a laboratory with a cluster of two equipments connected
with two gigabit interfaces each one and one computer working stand-alone. It will run Artificial Intelligence and Digital Design programs in this cluster, comparing its
performance with only one computer running the same programs. The measuring and analysis will indicate if the Linux cluster would be a feasible infrastructure in technical
and financial terms for AI and Digital Design application.
The research method will be naturally the experimental and the approach method will be inductive, for through the results of the experimentation and technical analysis, it will be able to apply the knowledge achieved in others similar environments.
For putting the experimental activity in the correct context, it will be used the more significant and contemporary research theories to establish in a clear way the scientific approach that it will lead the whole work.
x
LISTA DE FIGURASFigura 1 - Codificação de sinal de áudio analógico para sinal de áudio digital
Figura 2 - Intercâmbio de pacotes em sistemas multimídia
Figura 3 - Intercalamento de pacotes de dados e pacotes multimídia (Interleaving)
Figura 4 - Organização de arquivos multimídia não contíguos em discos rígidos
Figura 5 - Organização de arquivos multimídia não contíguos em discos rígidos
Figura 6 - Comparação entre o modelo ISO/OSI o protocolo TCP-IP
Figura 7 - Primitivas send e receive em passagem de mensagens (MPI)
Figura 8 - Comunicação entre servidor e cliente em RPC
Figura 9 - Memória Compartilhada Distribuída (DSM)
Figura 10 - Comunicação entre servidor e cliente em Sockets
Figura 11 - Diagrama de blocos simplificado de RPC em Sistema Microsoft
Figura 12 - Diagrama de blocos de exemplo de exemplo de RPC em Sistema Microsoft
Figura 13 - Digrama de explicativo de Race Passage
Figura 14 - Representação de Grafos para resolução do problema do “Drink dos Filósofos”
Figura 15 - Representação da Multiprogamação N-way
Figura 16 - Esquema lógico simplificado de um cluster Beowulf
Figura 17 - Esquema lógico simplificado de um cluster OSCAR
Figura 18 - Esquema lógico do laboratório
Figura 19 - Fotografia do laboratório
xi
Figura 21 - Execução das aplicações Breve e PovRay no Nó 00Figura 22 - Evidência de o cluster estar operacional
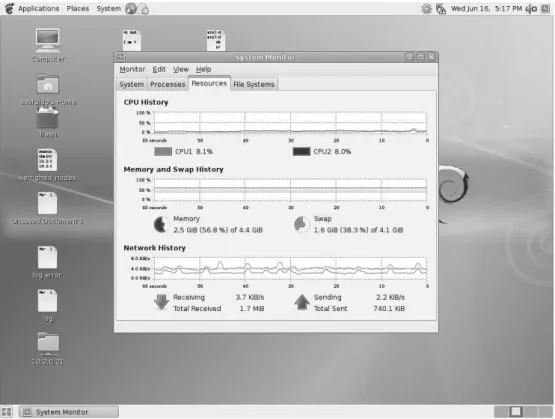
Figura 23 - Medições de utilização CPU, Memória e Rede no Nó 00
Figura 24 - Tempo de renderização do Benchmark.pov no Nó 00
Figura 25 - Execução da aplicação Breve no Nó 01
Figura 26 - Tempo de renderização do Benchmark.pov no Nó 01
Figura 27 - Finalização do teste de memória sem apresentar nenhum erro
Figura 28 - Medição do uso da memória durante a execução do memtester
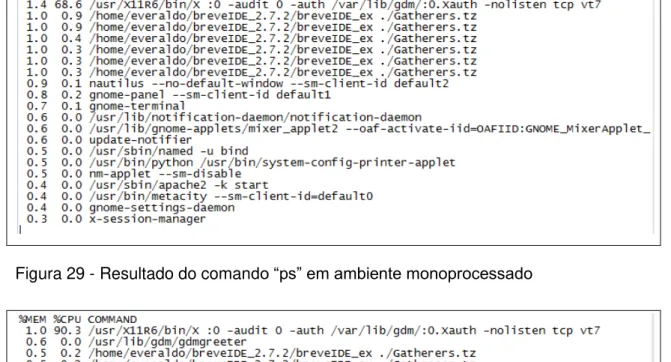
Figura 29 - Resultado do comando “ps” em ambiente monoprocessado com o Breve
xii
LISTA DE GRÁFICOSGráfico 1 - Medição de desempenho utilizando Zlib
Gráfico 2 - Medição de desempenho utilizando Fibonacci
Gráfico 3 - Medição de desempenho utilizando MD5
Gráfico 4 - Medição de desempenho utilizando SHA1
Gráfico 5 - Medição de desempenho utilizando Blowfish
Gráfico 6 - Medição de desempenho utilizando Raytracing
Gráfico 7 - Medição de tempo de execução do PovRay
Gráfico 8 - Instâncias benchmark.pov em cluster
Gráfico 9 - Instância benchmark.pov em computador standalone
xiii
LISTA DE TABELASTabela 1 - Arquivos criados na instalação do Kerrighed
Tabela 2 - Valores para a implementação do cluster do laboratório
Tabela 3 - Valores para a contratação de serviço de cloud
xiv
LISTA DE FÓRMULASFórmula 1 - Fórmula para escalonamento para sistemas em tempo real periódicos
Fórmula 2 - Performance teórica de pico
Fórmula 3 - Ganho de velocidade
Fórmula 4 - Fórmula de Amdahl
xv
LISTA DE SIGLAS E ACRÔNIMOSACM: Association for Computing Machinery
API: Application Programming Interface
BOINC: Berkeley Open Infrastructure for Network Computing
CAPTCHA: Completely Automated Public Turing test to tell Computers and Humans Apart
CIFS: Common Internet File System
CMG: Computer Measurement Group
CRT: Cathode Ray Tube
CVSS: Common Vulnerability Scoring System
DARPA: Defense Advanced Research Projects Agency
DCT: Discrete Cosine Transform
DDoS: Distributed Denial of Service
DFSA: Direct File System Access
DHCP: Dynamic Host Configuration Protocol
DoS: Denial of Service
DSL: Digital subscriber Line
DSM: Distributed Shared Memory
EDF: Earliest Deadline First
FEPAF: Fundação de Estudos e Pesquisas Agrícolas e Florestais
FTP: File Transfer Protocol
GPU: Graphics Processing Unit
xvi
HTTP: Hypertext Transfer ProtocolIA: Inteligência Artificial
IaaS: Infrastructure as a Service
IANA: Internet Assigned Numbers Authority
IDL: Interface Definition Language
IGMP: Internet Group Management Protocol
INRIA: Institut National de Recherche en Informatique et en Automatique
IPC: Interprocess Communication
IS-IS: Intermediate System to Intermediate System
ISO/OSI: International Standards Organization/Open Systems Interconnection
JFIF: JPEG File Interchange Format
JPEG: Joint Photographic Experts Group
LUI: Linux Utility for cluster InstalI
LVS: Linux Virtual Server
MAC: Medium Access Control
Mosix: Multicomputer Operating System UnIX
MP3: MPEG Layer 3
MPEG: Motion Picture Experts Group
MPI: Message Passing Interface
MPLS: Multi-protocol Label Switching
MPP: Massively Parallel Processing
NBX: Nugo Black Box
xvii
NP: Nondeterministic Polynomial TimeNSCS: National Supercomputing Centre in Shenzhen
NSF: National Science Foundation
NTSC: National Television System Committee
NUGO: Nutrigenomics Organization
OSCAR: Open Source Cluster Application Resources
PAL: Phase Alternating Line
PBS: Portable Batch System
PCM: Pulse Code Modulation
PCM: Pulse-Code Modulation
PDU: Protocol Data Unit
PovRay: Persistence of Vision Ray Tracer
PPM: Preempetive Process Migration
PVFS: Parallel Virtual File System
PVFS: Parallel Virtual File System
PVM: Parallel Virtual Machine
QoS: Quality of Service
RMS: Rate Monotonic Scheduling
ROI: Return of Investment
RPC: Remote Procedure Call
RPM: Red Hat Package Manager
RSTP: Real-time Streaming Protocol
xviii
RTCP: RTP Control ProtocolRTP: Real Time Protocol
RTP: Real-time Protocol
RTSP: Real Time Streaming Protocol
SDSC: San Diego Supercomputer Center
SIS: System Installation Suite
SLA: Service-Level Agreement
SMP: Symmetric Multiprocessing
SMT: Simultaneous Multithreading
SMTP: Simple Mail Transfer Protocol
SONET: Synchronous Digital NETwork
SSI: Single System Image
TCP-IP: Transport Control Protocol – Internet Protocol
TMT: Testing and Monitoring Tool
UDP: User Datagram Protocol
UHN: Unique Home-Node
UTP: Unshielded Twisted Pair
VLAN: Virtual Local Area Network
VNC: Virtual Network Computing
VoD: Vídeo on Demand
VoIP: Voice over IP
WFG: Wait-For-Graph
19
SUMÁRIOFICHA CATALOGRÁFICA ... iii
AGRADECIMENTOS ... vi
RESUMO ... viii
ABSTRACT ... ix
LISTA DE FIGURAS ... x
LISTA DE GRÁFICOS ... xii
LISTA DE TABELAS ... xiii
LISTA DE FÓRMULAS ... xiv
LISTA DE SIGLAS E ACRÔNIMOS ... xv
INTRODUÇÃO ... 21
METODOLOGIA ... 27
Capítulo 1 – Conceitos teóricos sobre processamento Monoprocessado e Distribuído ... 28
Características de um Cluster de Computadores ... 28
Fundamentos dos Sistemas Operacionais Convencionais ... 33
Dificuldades na manipulação de processos num ambiente monoprocessado ... 43
Escalonamento de processos ou threads ... 55
Escalonamento em sistemas em tempo real ... 62
Fundamentos de Sistemas Operacionais com Processamento Distribuído ... 82
Redes de Computadores ... 82
Processos e Threads ... 87
RPC (Remote Procedure Call) e MPI (Message Passing Interface)... 88
Gerenciamento de Memória: ... 93
Dispositivos de Entrada/Saída:... 96
Arquivos: ... 97
Chamadas de Sistema (System Calls) e Comunicação Interprocessos: ... 99
Dificuldades na manipulação de processos num ambiente de processamento distribuído ... 113
Aplicações Multimídia em Sistemas Distribuídos ... 124
Conclusão do Capítulo ... 131
Capítulo 2 – Apresentação de Cluster em Linux na Modalidade HPC com ênfase em Kerrighed ... 132
Classificação de Michael J. Flynn (FLYNN, 1972) das arquiteturas de Computadores ... 132
Tipos de clusters ... 133
Cluster Beowulf: ... 134
Cluster OSCAR (Open Source Cluster Application Resources): ... 137
Projeto Rocks ... 139
Cluster OpenMosix ... 141
Cluster Kerrighed ... 151
Conclusão do Capítulo ... 163
Capítulo 3 – Apresentação do Laboratório ... 164
Descrição do hardware utilizado ... 164
Descrição do Sistema Operacional utilizado ... 168
20
Descrição dos aplicativos para testes ... 171
Conclusão do capítulo ... 176
Capítulo 4 – Medições e análises ... 177
Performance teórica de pico ... 177
Performance das Aplicações ... 178
Performance da rede ... 179
Abordagem e ferramentas de análise do desempenho do cluster ... 180
Análise geral dos resultados... 181
Medição e análise do throughput real das conexões de rede. ... 181
Estresse do cluster e análise para confirmar a efetiva funcionalidade do mesmo... 182
Teste e medição de memória ... 186
Medição e análise do sistema em cluster e nos nós com ferramentas de benchmark apresentadas no aplicativo hardinfo ... 188
Medição e análise do sistema em cluster e monoprocessado utilizando um aplicativo de Design Digital (PovRay) ... 192
Medição e análise do sistema em cluster e monoprocessado utilizando um aplicativo de Inteligência Artificial (Breve) ... 194
Capítulo 5 – Conclusão ... 196
Viabilidade Econômica do Cluster Kerrighed ... 199
Viabilidade Técnica do cluster Kerrighed ... 203
Considerações Finais ... 205
Capítulo 6 - Um olhar para o presente e um olhar para o futuro da Tecnologia de Cluster ... 213
Um olhar para o presente ... 213
Um olhar para o futuro ... 216
Conclusão do capítulo ... 218
Referências: ... 219
21
INTRODUÇÃOAntes de adentrar na questão principal do trabalho, faz-se necessário estabelecermos alguns conceitos relacionados ao tema e o método de abordagem do mesmo.
Quanto ao tema, é importante salientar que estamos trabalhando no campo da tecnologia, mas precisamos circunscrever o significado de tecnologia em relação aos conceitos de ciência e engenharia, estabelecendo os limites e abrangência de cada uma dessas atividades.
Numa visão conceitual podemos estabelecer que “ciência” é um corpo de conhecimento em determinada área de pesquisa, que procura descrever o mundo físico e suas propriedades através de uma metodologia. A engenharia busca soluções para problemas de natureza mais geral, utilizando o conhecimento gerado pela ciência dados certos recursos e limites. E por fim a tecnologia que é ciência e a engenharia aplicada visando à provisão de soluções para as necessidades humanas pontuais, usualmente utilizando o conhecimento construído pela engenharia, mas em algumas ocasiões, buscando as soluções diretamente do repositório de conhecimento da própria ciência. Usando como exemplo o próprio tema da pesquisa, a ciência descobriu as propriedades dos semicondutores e sua aplicação em circuitos digitais, especialmente na criação de operações de natureza binária e na transmissão de informações em meios elétricos e óticos. A engenharia desenvolve computadores,
softwares e equipamentos de comunicação de dados baseados nos conceitos
científicos, mas em ambiente de laboratório e não em larga escala.
A tecnologia desenvolve produtos para uso geral e em larga escala, baseados no conhecimento e técnicas desenvolvidas pela engenharia, no nosso caso, microcomputadores, sistemas operacionais, softwares e equipamentos de rede.
Porém apesar da área de pesquisa em questão ter uma ligação relativamente clara e interdependente entre a ciência, a engenharia e a tecnologia, isso não ocorre de modo geral, segundo Derek de Solla Price (PRICE, 1976). Ele coloca: “Em termos gerais, a
ciência não tem prestado grande auxílio à tecnologia, embora, uma e outra vez, deparemos com eventos anômalos e traumatizantes, como os transistores e a penicilina. Importa ser cauteloso: trata-se de grandes exceções, não a regra.”
22
Apesar da consciência de que sou um tecnologista, com as características próprias desse perfil, procurarei nesse trabalho utilizar a metodologia e a visão científica para analisar a pesquisa proposta, pois acredito que uma abordagem científica baseada num trabalho empírico-indutivo, conseguirá obter melhores resultados do que um simples benchmarking1.Estabelecido os conceitos, podemos seguir em frente com esse prólogo, abordando a agora a questão da metodologia indutiva. Apesar de adepto à experimentação, para Hume (HUME, 1999) a experimentação e em seguida a conclusão obtida através do método indutivo, não seriam adequadas, pois, segundo ele, não pode haver
argumentos lógicos válidos que nos permitam afirmar que “aqueles casos dos quais
não tivemos experiência alguma se assemelham àqueles que já experimentamos anteriormente”, consequentemente, “mesmo após observar uma associação constante ou frequente de objetos, não temos motivo para inferir algo que se refira a um objeto
que não experimentamos”. Em outras palavras, Hume não aceitava o método indutivo, pois, não sua visão, essa conclusão será de natureza psicológica, baseada no hábito de acreditar em leis, em assertivas que afirmam a regularidade de certos eventos.
1
23
Popper (POPPER, 1994) questiona essa posição, mas também tem reservas ao método indutivo e apresenta o que ele chama da teoria das “conjecturas e refutações”onde estabelece que ao invés de esperar passivamente que as repetições nos imponham suas regularidades e, por conseguinte a indução, nós devemos, segundo ele, de modo ativo impor regularidades ao mundo, tentando identificar similaridades e interpretá-las em termos da teoria que defendemos. Ele também estabelece que as teorias precisam ser testadas através de experimentos, mas não com o intuito de prová-las mas sim de refutá-las. Como Popper coloca “Só a falsidade de uma teoria pode ser inferida da evidência empírica, inferência que é puramente dedutiva”.
Kuhn (KUHN, 1978) na sua teoria da estrutura das revoluções científicas coloca que o princípio de falsificação de Popper é semelhante ao que na sua teoria ele chama de
experiências anômalas, isto é, “experiências que, ao evocarem crises, preparam o caminho para uma nova teoria”.
Porém, na visão de Kuhn “se todo e qualquer fracasso na tentativa de adaptar teoria e
dados fosse motivo para a rejeição de teorias, todas as teorias deveriam ser sempre
rejeitadas”.
Apenas para encerrar essas considerações sobre o método experimental, gostaria de acrescentar apenas a visão de Kant (KANT, 1999), que afirma que, apesar da experiência produzir conhecimento, existe um conhecimento “a priori” que não é
derivado de nenhuma experiência que se contrapõe ao conhecimento empírico ou “a posteriori”.
Diante dessas teorias e ideias, estabelecerei a minha estratégia de pesquisa. É importante ressaltar que minha pesquisa está totalmente no domínio da tecnologia e que alguns conceitos até agora apresentados referem-se mais propriamente à ciência. Apesar disso, considero salutar aplicar essas ideias e considerações a minha pesquisa para que a mesma se torne mais consistente e circunspecta.
Assim estarei atento quanto o grau de subjetividade na análise dos testes experimentais mesmo que os mesmos resultados se repitam numa frequência significativa assim como terei critério ao inferir um resultado ou conclusão, procurando fazê-lo se realmente a similaridade dos elementos comparados seja significativa e
clara. Também estabelecerei questionamentos que testem a “falsidade” das minhas
24
Terei também ciência que iniciarei os trabalhos com um conhecimento “a priori”
impuro, pois é fruto de certo empirismo obtido na minha experiência técnica.
Estabelecidas as diretrizes metodológicas da pesquisa, podemos introduzir o tema de minha pesquisa, que é verificar empiricamente se um sistema de cluster de
computadores com o sistema operacional Linux seria uma infraestrutura viável para aplicações de Design Digital e Inteligência Artificial. Sem dúvida que sistemas de
cluster já são largamente usados tanto nas instituições acadêmicas com nas
corporações, por exemplo, se acessarmos hoje o site www.top500.org que estabelece
um ranking de computadores mais poderosos do mundo, segundo seus critérios, temos um cluster na quarta posição com 120.640 processadores instalado no NSCS
(National Supercomputing Centre in Shenzhen) na China. Assim esse não é o foco da pesquisa, a viabilidade dos sistemas de cluster de modo geral, mas verificar de
maneira metódica o comportamento do mesmo ao executar aplicações especialistas de Design Digital e Inteligência Artificial com todas suas particularidades e características semelhantes em relação a aplicações de outra natureza.
A história de cluster de computadores se confunde com a história das próprias redes,
pois apenas através de redes de comunicação que foi possível computadores independentes trabalharem de maneira paralela como uma única entidade. Os primeiros clusters comerciais foram o ARCnet desenvolvido pela Datapoint em 1977 e
o VAX cluster desenvolvido pela DEC em 1984. Outros clusters que tiveram alguma
25
Com o surgimento da PVM (Parallel Virtual Machine) a construção de cluster tornou-semais acessível por ser uma arquitetura aberta (open source) baseada em TCP-IP,
podendo assim compor cluster com computadores heterogêneos totalmente
transparentes para o usuário final.
Após esse sucinto histórico da tecnologia, podemos apresentar como esse trabalho será estruturado. No capítulo 1, apresentaremos os conceitos de sistemas distribuídos tendo como contraponto os sistemas monoprocessados. No capítulo 2, abordaremos os principais modelos de cluster em sistemas operacionais Linux, esmiuçando o que
será o foco do nosso estudo que é “Kerrighed”. No capítulo 3, apresentaremos o nosso
laboratório com uma descrição detalhada de cada item do mesmo, assim como as configurações aplicadas aos computadores. Apresentaremos também as aplicações que serão executadas nesse sistema e suas características básicas no que concerne ao modo de processamento e alocação de recursos. No capítulo 4, descreveremos os testes de execução das aplicações previamente escolhidas e a devida medição, que envolverá em linhas gerais, utilização de CPU, de memória, de banda nas conexões de rede, tempo de resposta, a carga em cada nó do cluster, etc. Após a execução e
medição dos programas, analisaremos os resultados tendo como referência um computador com as mesmas características dos nós que compõe o cluster,
executando as mesmas aplicações. No quinto capítulo, a partir da análise realizada no capítulo anterior, chegaremos à conclusão ou pelo menos em indicações sobre a viabilidade do uso do sistema “Kerrighed” na execução de sistemas de Design Digital e Inteligência Artificial que foram executados em laboratório, utilizando como contraponto tecnologias alternativas de computação massiva como computação em
grid e computação em cloud. No sexto e último capítulo será apresentado como um
anexo, casos que representarão o estado da arte em tecnologia de cluster com um
olhar para o presente e um olhar para o futuro.
A fundamentação teórica desse trabalho visa ajudar aos pesquisadores e profissionais que não atuam com infraestrutura, subsídios para entender as especificidades técnicas dessa matéria, como suporte para a realização de suas atividades, como por exemplo, o desenvolvimento de códigos para Design Digital e Inteligência Artificial.
26
Uma proposição inicial seria que o sistema de cluster aumentaria a capacidade deprocessamento linearmente, isto é, na mesma medida em que adicionamos computadores ao cluster, aumentaríamos linearmente o desempenho do mesmo, a
ponto de considerarmos um cluster de servidores Linux uma infraestrutura viável para
implementação de aplicações de Inteligência Artificial e Design Digital. Porém sabemos que essa proposição não corresponde à realidade, assim consideraremos a agregação de 80% da capacidade computacional a cada novo nó inserido ao cluster,
prevendo alguma perda devido à latência da rede, dificuldade das aplicações realizarem processamento paralelo, gerenciamento de memória em ambientes distribuídos e os próprios recursos computacionais para as funcionalidades do cluster.
Iremos testar essa hipótese com a realização desse laboratório.
Inicialmente adotamos o projeto “OpenMosix” como sistema de cluster a ser utilizado
no laboratório idealizado para esse trabalho, porém o projeto foi encerrado em março de 2008 pelo professor Moshe Bar. Iniciamos os trabalhos de implementação do projeto em laboratório e ao consultar um dos autores mais proeminentes no Brasil em
cluster em Linux, Marcos Pitanga, fomos aconselhados a trabalhar com o cluster “Kerrighed” que também é SSI (Single System Image), sendo um projeto em franca atividade de implementação e aperfeiçoamento. Assim ao iniciarmos os trabalhos de laboratório, optamos por utilizar pelo clusterem Linux “Kerrighed”.
Objetivo final desse trabalho é verificar se uma plataforma de baixo custo de hardware,
utilizando software aberto é viável técnica e financeiramente para a execução de
27
METODOLOGIA28
Capítulo 1 – Conceitos teóricos sobre processamento Monoprocessado e
Distribuído
Considerações iniciais do capítulo
Além de apresentar as características básicas de um sistema em cluster, esse capítulo
tem como objetivo apresentar os componentes, tecnologias e desafios intrínsecos da computação monoprocessada e distribuída, apontando diferenças, semelhanças e relações. Acreditamos que essa fundamentação teórica será de grande valia ao estudarmos o foco desse trabalho em termos de solução, que seria o sistema em
cluster Kerrighed, que apesar de possuir técnicas próprias para algumas das
disciplinas da teoria da computação, como por exemplo, a alocação e o mapeamento de memória, as teorias convencionais sempre no servirão de base para o entendimento de novas abordagens seja por semelhança seja por contraponto.
Características de um Cluster de Computadores
Tanenbaum2 (TANENBAUM, 1995) coloca que “um sistema distribuído é uma coleção de computadores independentes que parecem aos usuários do sistema como um só computador”. Existem alguns autores como Gregory F. Pfister3 que fazem distinção entre sistemas distribuídos e clusters, mas nesse trabalho não faremos essa
diferenciação, pois além do tema ser controverso, em se tratando de cluster de alto
desempenho, essa distinção não se aplica a nossa abordagem do assunto.
2 Andrew Stuart Tanenbaum é o chefe do Departamento de sistemas de computação, na Universidade
Vrije, Amsterdã nos Países Baixos. Ele é o autor do Minix, um sistema operacional baseado no Unix com propósito educacional, e bastante conhecido por seus livros sobre ciência da computação.
Nasceu na cidade de Nova Iorque e cresceu em White Plains no estado de Nova Iorque. Recebeu o título de bacharelado pelo MIT e o doutorado pela UC Berkeley em 1971. Atualmente ministra aulas sobre Organização de Computadores e Sistemas Operacionais.
3 Gregory Y. Pfister obteve seu doutorado no MIT. Tendo sido instrutor nessa instituição, assim como
professor assistente na Universidade da California, Berkeley. Por muitos anos, ele foi membro da equipe de Pesquisa e Desenvolvimento da IBM num nível sênior. Ele detém inúmeras patentes em
29
Apenas título de registro Pfister (PFISTER, 1998) afirma que clusters são geralmentegrupos de computadores homogêneos em menor escala, dedicados a um número pequeno e bem definido de tarefas, nas quais o cluster atua como uma única máquina,
porém os clusters atualmente podem ser compostos de máquinas heterogêneas e de
um número grande de computadores, assim a definição de Pfister não se aplica ao nosso estudo e concepção de um cluster.
Tanenbaum (TANENBAUM, 1995) identifica características essenciais no desenvolvimento de sistemas distribuídos que são:
Transparência
Flexibilidade
Confiabilidade
Desempenho
Escalabilidade
Transparência
Transparência é capacidade do sistema em dar a impressão ao usuário de que ele está acessando apenas um computador convencional, quando na realidade há um
cluster de computadores realizando as tarefas.
A transparência pode ser vista sob os seguintes aspectos:
Transparência de localização: Os usuários não podem dizer onde os recursos estão localizados.
Transparência de migração: Os recursos podem se mover a qualquer momento sem mudarem seus nomes.
Transparência de replicação: Os usuários não podem dizer quantas cópias dos recursos existem.
Transparência de concorrência: Os usuários podem compartilhar os recursos automaticamente.
30
FlexibilidadePodemos dizer que temos duas vertentes para o desenvolvimento de estruturas de sistemas operacionais distribuídos. Temos os sistemas operacionais com o kernel
monolítico e temos os sistemas operacionais com microkernel.
O primeiro possuindo a maioria dos serviços em si mesmo, tendo controle sobre sistemas de arquivos, conexão com a rede, etc. e o segundo realizando o mínimo de operações possíveis deixando que as outras tarefas necessárias para a obtenção dos resultados desejados, sejam realizadas fora do kernel, em nível de usuário do sistema.
Diferentemente dos sistemas monolíticos, o microkernel não provê um sistema de
arquivo ou diretórios, gerenciamento completo dos processos ou um manuseio considerável de chamadas de sistema.
Dessa maneira, os sistemas com microkernel são essencialmente mais flexíveis,
proporcionando um desenvolvimento modular de funções e serviços, podendo os mesmos estar fisicamente em recursos computacionais diferentes. Além disso, esse tipo de sistema torna a inclusão e manutenção dos serviços muito mais simples, pois não requer que o sistema seja parado para que se habilite um novo kernel com um
novo serviço.
A vantagem de um kernel monolítico é o desempenho, pois todas as instruções serão
realizadas na velocidade do barramento interno do computador, não necessitando de utilizar uma estrutura de rede para essa atividade.
O microkernel, na visão de Tanenbaum (TANENBAUM, 1995), seria a abordagem
mais adequada para o desenvolvimento de sistemas distribuídos.
Segue algumas funções básicas realizadas por sistemas microkernel:
Mecanismo de comunicação interprocessos;
Algum gerenciamento de memória;
Pequena quantidade processos de baixo nível responsáveis por gerenciamento e scheduling;
31
ConfiabilidadeUm dos primeiros objetivos de se construir sistemas distribuídos foi de fazê-los mais confiáveis que os sistemas monoprocessados. A ideia seria que se um computador ficasse fora de funcionamento, outro assumiria seu trabalho. Na teoria, a confiabilidade
de um sistema distribuído seria uma operação lógica “OU” das confiabilidades das
máquinas que o compõe. Por exemplo, se tivermos três servidores de arquivos com 0,95 de chance de estarem indisponíveis, a probabilidade dos três computadores estarem indisponíveis ao mesmo tempo seria de (1 - 0,053) = 0,999875, muito melhor do que qualquer servidor individual.
Na prática a função lógica “E” estaria mais próxima da realidade do que a operação
“OU”, porque manter num sistema distribuído todos os processos, arquivos, usuários
exatamente iguais em todos os computadores que o compõe, é uma tarefa árdua em termos técnicos e financeiros, aspectos como disponibilidade, segurança, consistência e tolerância a falhas são desafios para os desenvolvedores de sistemas distribuídos.
Em geral os sistemas distribuídos trabalham de modo a esconder do usuário do sistema que algum dos seus componentes não está disponível em dado momento.
Desempenho
No tema de sistemas distribuídos sempre teremos como pano de fundo o desempenho. Sempre buscaremos a condição de uma aplicação ser executada mais rapidamente num sistema distribuído do que num único servidor com capacidade computacional de um dos componentes desse cluster. Infelizmente, na prática a
obtenção desse objetivo não é tão fácil de ser alcançada.
A primeira questão é que na medição do desempenho (benchmarking), pode-se utilizar
várias métricas como tempo de resposta, vazão (número de Jobs por hora), utilização do sistema (recursos computacionais) e consumo da capacidade da rede. A consolidação dessas métricas nem sempre é uma atividade fácil de ser realizada assim como as conclusões derivadas dessa consolidação.
O tipo de operação escolhida também influencia em muitos nos resultados de um
benchmarking, por exemplo, trabalhar com um experimento computacional que
32
A infraestrutura de rede sempre será um elemento crítico num sistema distribuído. Uma comunicação entre duas máquinas na melhor das condições leva pelo menos um milissegundo, que comparado à taxa de transferência interna de um processador ou mesmo de um barramento de um computador, pode ser considerado um tempo extremamente longo, mesmo em conexões de LAN de 10 Gibabits.Quando falamos em desempenho em processamento distribuído temos que pensar na granularidade computacional. Utilizar um recurso computacional remoto de modo reduzido, como por exemplo, realizar uma operação lógica simples entre dois números, não será usualmente interessante em termos de desempenho num ambiente distribuído, devido ao overhead da comunicação de dados, por outro lado, se
realizarmos uma tarefa que exija um longo processamento computacional para uma mesma massa de dados, usualmente é um trabalho adequado para um processamento distribuído. Assim quando processos realizam poucas instruções e precisam comunicar-se muito, dizemos que são muitos granulares, quando realizam muitas instruções com pouca troca de informação, dizemos que são poucos granulares. Naturalmente num ambiente de processamento distribuído uma menor granularidade computacional, significa usualmente um melhor desempenho.
Escalabilidade
Falando em cluster em Linux temos na plataforma Beowulf no projeto Goddard Casse
Flight Center, um cluster com 199 servidores e na Caltech um sistema com 140 nós de cluster. Um dos clusters da “Yahoo” (Apache Hadoop Cluster) tem 910 nós, porém
esse é um sistema de cluster apenas para executar as funcionalidades de um servidor
web num modelo de grid, que é um agrupamento de computadores visando um
aumento de capacidade de processamento que estão geograficamente separados, porém podendo ou não estar disponíveis, para a realização de uma determinada tarefa computacional.
O grande desafio da escalabilidade não seria a quantidade de nós que poderiam ser agregados a um cluster e sim o desenvolvimento de sistemas operacionais e
33
Seguem algumas características de sistemas adequados para trabalhar num cluster:Nenhuma máquina tem uma completa informação sobre o estado de todo o sistema.
As máquinas tomam as “decisões” baseadas na informação local.
A falha numa máquina não afeta o funcionamento do sistema.
Não existe uma premissa implícita que exista um sistema global de sincronismo (clock).
Sobre o último tópico, estamos considerando o uso de cluster para fins gerais e não
para sistemas multimídia distribuídos que necessitam de um sincronismo adequado para operarem satisfatoriamente.
A escalabilidade só faz sentido quando as aplicações são compatíveis com um modelo de cluster de computadores. No nosso trabalho, em especial, buscaremos aplicações
de inteligência e Design Digital que satisfaçam esses requisitos.
Apesar dessas restrições, os sistemas de cluster são técnica e financeiramente viáveis
para uma grande quantidade de aplicações.
Fundamentos dos Sistemas Operacionais Convencionais
Para que possamos melhor compreender os princípios utilizados no processamento distribuído precisamos conhecer alguns componentes do processamento tradicional, isto é, computadores monoprocessados.
O objetivo dessa apresentação é apenas discorrer sobre os componentes e entidades do processamento convencional que necessitam ser adequadas ou pelo menos consideradas quando atuando com sistemas de processamento distribuído ou clusters.
34
Processos:Todo software executável num computador, algumas vezes incluindo o próprio sistema
operacional, é organizado num número de processos sequenciais. Um processo é um programa executável, com determinados valores nos contadores, registros e variáveis. Mesmo num sistema monoprocessado, temos a impressão de que os processos são executados paralelamente, mas na realidade eles compartilham uso da CPU em intervalos muito rápidos que nos dão essa impressão de um “pseudo-paralelismo”.
É importante ressaltar que em sistemas monoprocessados não podemos precisar exatamente quanto tempo um processo durará, caso seja executado mais de uma vez, pois não saberemos quanto tempo ele terá para fazer uso da CPU em cada execução. Essa falta uniformidade se acentua quando tratamos de sistemas distribuídos, questão iremos tratar no transcorrer desse trabalho. Existem trabalhos recentes onde se trabalha com mecanismos de scheduler mesmo em ambientes monoprocessados,
para que se tenha um maior controle do tempo de execução de cada processo. Podemos citar o trabalho de Silviu S. Craciunas, Christoph M. Kirsch e Harald Röck4, que trabalha com scheduler de chamadas de sistema para alcançar essa uniformidade
e melhor desempenho, baseando-se no princípio de Traffic Shaping utilizado em
roteadores.
Um processo sempre tem um espaço de memória (address space) onde ele armazena
as informações que está manipulando que podem ser um programa executável, dados de um programa ou a própria pilha do processo. Também um processo sempre tem alguns registradores associados ao mesmo, que podem ser contadores, ponteiros de pilhas, registradores de hardware, etc. Usualmente um processo é inicializado através
de uma chamada de sistema (system call) que é constituída de diretivas que são
linhas de programação em C, se estamos falando em sistemas Unix e Linux, desenvolvidos para interagir com o sistema operacional e com a linguagem de máquina (Assembler), para realizar funções de baixo nível e de interação com o próprio sistema operacional.
4
35
Quando um processo faz uma chamada para a execução de outro processo, dizemos que o primeiro é um processo pai do segundo, daí a necessidade de comunicação interprocessos, que num ambiente monoprocessado que é consideravelmente mais simples do que em sistemas distribuídos.Threads
Embora tenham algumas semelhanças. Processos e threads são entidades distintas
com aplicações distintas. Os processos têm como função principal agrupar recursos e executar operações com eles. Em algumas situações é interessante separar o agrupamento dos recursos do processamento dos mesmos. Nesse cenário que temos as threads. Elas apenas executam operações, possuindo um contador para ter um
controle da execução, um registrador que armazena as variáveis de trabalho e uma pilha que contém um histórico da execução.
As threads acrescem aos processos a capacidade de realizar múltiplas execuções
num mesmo ambiente de processo, com um alto grau de independência. Tendo múltiplas threads sendo executadas num mesmo processo seria semelhante a ter múltiplos processos sendo executados num mesmo computador. As primeiras compartilham espaço de endereçamento, arquivos abertos, etc. Os últimos compartilham memória física, discos, impressoras, etc.
Quando temos um cenário de multi-thread, isto é, múltiplas threads associadas a um
único processo, temos também a impressão de um paralelismo, porém como os processos, na computação convencional, cada thread é executada por vez. Assim se
tivermos três threads sendo executadas sequencialmente por um processador, cada
uma terá apenas um terço da capacidade do mesmo.
Um motivo para utilizarmos threads seria aplicações que necessitem de processos
paralelos. Como as threads compartilham o mesmo espaço de memória e os próprios dados, elas são ideais para aplicações que necessitam dessa característica, como, por exemplo, um servidor de arquivos numa rede local.
Outra vantagem das threads é que como elas não possuem nenhum recurso
associado às mesmas, elas são criadas e finalizadas mais facilmente.
36
Gerenciamento de Memória:Todo sistema operacional precisa de uma memória principal onde os programas que estão sendo executados possam ser alojados. Em sistemas operacionais mais simples somente um programa por vez pode fazer usado no espaço de memória.
Nos sistemas mais sofisticados a memória pode ser compartilhada por mais de um programa, através da utilização do conceito de endereçamento de memória. Usualmente um processo tem um conjunto de endereços de memória com os quais ele pode trabalhar. Esse endereço pode ser de 32 ou 64 bits que significa respectivamente 232 e 264 bytes de tamanho de memória por endereço.
Outro mecanismo para aumentar a quantidade de memória disponível para os
processos é a memória virtual ou “paginação” que é a gravação temporária dos dados
da memória no disco rígido do computador, liberando a memória real para outras funções dos processos.
Dispositivos de Entrada/Saída:
Todo o computador tem dispositivos de E/S (Entrada/Saída), como teclado, impressoras, monitores, etc.
O sistema precisa gerenciar esses dispositivos na medida em que os processos e os programas solicitem uso de algum deles.
Num sistema de cluster, também esses recursos também precisarão receber as
requisições para o seu uso como que partissem de um único computador.
Arquivos:
Todo o sistema operacional possui um sistema de arquivos. Uma das principais funções de um sistema operacional é realizar uma abstração dos aspectos complexos do funcionamento real de um computador apresentando ao usuário ou mesmo programador uma interface amigável. Assim é com o sistema de arquivos.
37
Todo arquivo num sistema de arquivos possui um caminho (path) que é uma lista detodos os diretórios que necessita ser informada para acessar determinado arquivo.
Todo processo tem um diretório de trabalho que pode ser alterado através de uma chamada de sistema.
Novamente, o gerenciamento de um sistema arquivos num ambiente monoprocessado, apesar de ter certa complexidade não se compara às dificuldades em manter-se um sistema de arquivo num sistema de cluster, garantindo uma
uniformidade e coerência nos arquivos que estão espalhados entre os nós que compõe o mesmo.
Chamadas de Sistema (System Call):
A interface entre o sistema operacional e os programas dos usuários é definida por um grupo de chamadas de sistemas previamente definidas.
Apesar da maioria das chamadas de sistema ser altamente dependente das características do computador e usualmente escrita em linguagem de máquina (assembler), o desenvolvimento das mesmas foi simplificado através da criação de
bibliotecas de procedimentos (procedures libraries) que facilitam esse trabalho por se
poder utilizar linguagens de programação mais acessíveis como a C.
De forma simplificada podemos descrever os passos da execução de uma chamada de sistema como segue:
A chamada de sistema pertencente à biblioteca de procedimentos é chamada.
O programa que iniciou a chamada de sistema coloca os parâmetros fornecidos na respectiva pilha.
A chamada de sistema é executada com os parâmetros fornecidos.
38
Ocorre então uma instrução conhecida como TRAP, que é a mudança do modo usuário para o modo kernel (núcleo do Sistema Operacional) que inicia a execução dachamada de sistema.
O kernel verifica o número da chamada de sistema e o envia para o devido
manipulador de chamadas de sistema (system call handler).
O manipulador de chamadas de sistema é executado.
Após isso o sistema retorna para o modo usuário via instrução TRAP.
O programa que executou a chamada de sistema limpa a pilha utilizada para colher os parâmetros da mesma, procedimento usual nesse tipo de manipulação.
A quantidade de chamadas de sistema varia entre os sistemas operacionais. O Linux
kernel 2.6, por exemplo, tem 271 chamadas de sistema.
Dentre os vários serviços realizados pelas chamadas de sistema temos como os mais relevantes o gerenciamento de processos, de arquivos e de sistema de arquivos e diretórios.
Muitas das chamadas de sistemas em monoprocessamento podem ser usadas em processamento distribuído através de Remote Procedure Call (RPC). Os parâmetros
das chamadas de sistema ao invés de serem colocados num registrador, são colocados numa mensagem e o kernel envia a mensagem para a máquina que deseja
que execute a chamada de sistema que retorna o resultado através de outra mensagem para o computador que requisitou a execução remota, que do ponto de vista de RPC seria o client stub no processo e o executante o server stub.
39
Seguem agora alguns desafios que os desenvolvedores de sistemas operacionais enfrentam na implementação de processos e threads, considerando modelocomputacional de Von Neumann5.
IPC (Interprocess Communication)
Um componente muito crítico seja na computação tradicional seja na computação distribuída, é a comunicação entre processos.
Um exemplo típico de comunicação entre processos é o comando pipeline no
ambiente Unix, onde a saída de um processo alimenta a entrada do outro.
Existem muitas linhas de programação seja em linguagem de máquina seja em linguagem de alto nível para realizar esse comando que a primeira vista parece simples. Segue um exemplo de um código que escuta a função pipe. A função fork é
usada para criar um processo pai e um processo filho.
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
#include <sys/wait.h>
int main()
{
char token[100];
FILE *fout;
int p[2];
int pid;
5
40
pipe( p ); /* “pipe” entre o pai e o filho */if((pid = fork()) == 0)
{/* executa o processo filho P1 */
close(p[1]); /* Fecha o fd (file descriptor) no final de escrita do pipe */
if(dup2(p[0], 0 ) == -1 ) /* Utiliza o stdin para ler o final do pipe */
{
perror( "dup2 failed" );
_exit(1);
}
close(p[0]); /* fecha o fd de final de leitura do pipe */
execl("Pipe_newB","Pipe_newB","CHILD", 0);
/* executa 'Pipe_newB' */
perror("execl Pipe_newB failed");
_exit(1);
}
else if(pid < 0)
{/* fork() failed */
perror("fork CHILD failed");
exit(1);
}
/* parent executes */
41
/* usa o fdopen() para associar o fluxo de escrita ao final de escrita do pipe entre o pai e filho */if( ( fout = fdopen( p[1], "w" ) ) == 0 )
{
perror( "fdopen failed" );
exit(1);
}
printf( "Please input a string:\n" );
while( scanf( "%s", token ) != EOF )
{
if( fprintf( fout, "%s-Parent\n", token ) == EOF )
{
perror( "fprintf failed" );
exit(1);
}
fflush( fout );
}
close(1); /* fecha a referência do pipe para enviar o ‘EOF” (End of File) */
wait(NULL);
return(0);
42
Vemos que o desenvolvimento de um código para prover uma comunicação entre processo não é trivial e envolve uma lógica considerável na comunicação em si, assim como na prevenção de problemas inerentes a esse tipo de operação, como, por exemplo, ao realizar a comunicação, um processo não poder interferir na execução do outro, necessitando assim que os processos sejam executados e troquem mensagens corretamente de modo a evitar conflitos na utilização dos recursos computacionais.O propósito desse trabalho não será entrar nos detalhes de programação, mas apenas para fins de exposição do princípio, vamos analisar de maneira não aprofundada o código acima. Temos a diretiva “include” que é usada para executar códigos de programa previamente desenvolvidos, que são tratados pelo pré-processador antes da execução do programa propriamente dito. Nesse caso temos, por exemplo, o código
“stdio.h” que é responsável por gerenciar os dispositivos padrões de entrada/saída.
Essas diretivas também são chamadas de bibliotecas da linguagem C. Dessas bibliotecas retiramos os comandos executados nos códigos C.
Após as bibliotecas haverem sido carregadas em memória, algumas variáveis são definidas, que para efeito de explanação do código, nos ateremos apenas nas
variáveis “p” que seria de processo e “pid” que seriam o identificador de processo. A
chamada de sistema pipe cria um tubo (pipe) entre um processo pai e um processo
filho. Basicamente realizar a função pipe seria usar a saída de padrão de um processo
como entrada para outro.
O processo filho tem o processo número 1 que é associado a um arquivo
“Pipe_newB”. É importante ressaltar o papel da função “dup2”, que além de fazer uma duplicação do processo filho original garante que o programa terá o uso da CPU sem interrupção, pela solicitação do kernel por algum outro processo, assim dizemos que
esse processo torna-se atômico porque até o mesmo ser finalizado, o sistema como um todo não visualiza a alteração que está sendo realizada. Caso o processo falhe na sua execução o sistema retorna a sua condição original. Retornando a função pipe,
43
O ponto mais importante na elucidação desse exemplo de comunicação interprocessos é conhecermos uma forma básica de processos comunicarem-se, trocando parâmetros e dados, assim como mostrar através de uma função, o tratamento da questão de um processo interferir na execução de outro, podendo gerar uma condição conhecida como race condition que veremos com mais detalhes àfrente.
É importante ressaltar que todas essas questões levantadas sobre a comunicação entre processos podem ser aplicadas também às threads.
Dificuldades na manipulação de processos num ambiente monoprocessado
Mesmo no processamento convencional, existem desafios no desenvolvimento ou aperfeiçoamento de sistemas operacionais, no gerenciamento dos recursos da CPU, memória, dispositivos de E/S em face aos vários processos que solicitam o uso dos mesmos, dando a impressão ao usuário que esses processos estão sendo executados paralelamente. Iremos abordar os principais problemas que são inerentes ao modelo computacional corrente e vivenciados na maioria das aplicações.
O objetivo é conhecer essas dificuldades na computação monoprocessada que usualmente são acentuadas num ambiente de processamento distribuído.
Vale a observação que estamos nos abstraindo nessa abordagem dos processadores que possuem dois núcleos (Dual-Core) ou mesmo os computadores multi-processados
(com mais de um processador em seu barramento), pois essas tecnologias não são foco principal dessa análise.
Race Condition
Race Condition é quando dois ou mais processos estão lendo ou escrevendo em
algum dado compartilhado e que o resultado vai depender do momento em que cada processo é executado, podendo um sobrescrever a ação do outro, causando resultados inesperados e incorretos.
44
A implementação de regiões ou seções críticas para cada processo e a premissa que dois ou mais processos não podem acessar essas regiões críticas ao mesmo tempo, ajudaria na minimização do problema de race condition, mas não o evitaria para todasas situações.
Para podermos ter “processos paralelos” compartilhando os mesmos recursos de uma forma mais produtiva sem a race condition, sugere-se quatro condições:
Dois processos não podem estar ao mesmo tempo em suas regiões críticas.
A não existência de premissas sobre velocidade ou número de CPU’s.
Nenhum processo sendo executado fora da sua região crítica pode bloquear outros.
Nenhum processo pode esperar indefinidamente para entrar em sua região crítica.
Deadlocks
Deadlock é um problema clássico na teoria e na prática da computação.
O deadlock é também um problema inerente ao modelo de computação convencional
relacionado à alocação de recursos por um sistema operacional. Um deadlock ocorre
quando num mesmo instante dois processos tentam acessar um recurso tanto de
hardware como de software que está sendo alocado pelo outro.
Por exemplo, se num banco de dados onde o processo “um” acessa o registro “um” e o processo “dois” acessa o registro “dois” e no próximo instante o processo “um” tenta acessar o registro “dois” e o processo “dois” tenta acessar o registro “um”, nesse momento os processos são bloqueados e ficarão nesse estado indefinidamente. Esse evento é conhecido como deadlock.
Coffman6 (COFFMAN, 1971) estabelece quatro condições para que ocorra um
deadlock:
Condição de exclusão mútua. Cada recurso, ou está correntemente designado exatamente para um dado processo, ou está disponível.
45
Condição de manutenção e espera. Processos que estão correntemente mantendo recursos anteriormente concedidos podem requisitar novos recursos.A falta de percepção de prioridade. Recursos previamente concedidos não podem ser forçosamente tirados de um processo. Eles precisam ser explicitamente liberados pelo o processo que os mantém.
Condição de espera circular. Deve haver uma corrente circular de dois ou mais processos, cada um esperando por um recurso mantido pelo próximo membro da corrente.
Conseguiremos evitar o deadlock quando conseguirmos fazer com que uma dessas
quatro condições não seja satisfeita. Existem várias técnicas e abordagens para a mitigação de deadlocks que não são foco do nosso trabalho, mas basta dizer que elas
passam por uma política de alocação de recurso criteriosa assim como uma composição de técnicas de detecção, anulação e prevenção e aplicação de soluções práticas com esse tipo abordagem, que evitariam, de modo eficiente, os deadlocks.
(HOWARD JR.7, 1972).
7
John Hayes Howard Jr. é autor do artigo “Mixed solutions for the deadlock problem” pela
46
Problema do Jantar dos FilósofosDijkstra8 (DIJKSTRA, 1971) elaborou um problema e concebeu uma solução para situações passíveis de se ocorrer no acesso aos recursos pelos processos. A ilustração é bem simples.
Temos cinco filósofos numa mesa de jantar com cinco pratos de espaguete e cinco garfos, porém o espaguete é muito escorregadio, sendo necessários dois garfos para poderem comê-lo.
À primeira vista, a solução do problema seria simples, teríamos que ter apenas um algoritmo que testasse quando os dois garfos estivessem disponíveis, assim o filósofo poderia utilizá-los. Infelizmente a solução não é tão simples assim. Imaginem se os cinco filósofos ao mesmo tempo verificassem que os garfos estão disponíveis e consequentemente tentam utilizá-los. Eles não terão os dois garfos disponíveis para si e os processos entrarão em deadlock.
Podemos aprimorar essa solução não exitosa colocando a premissa de que ao pegar o garfo ao lado esquerdo do prato, o filósofo verifica se o garfo ao lado direito está disponível, caso negativo, ele devolve o garfo do lado esquerdo à mesa. Essa parece ser uma boa abordagem para o problema, mas imagine se os cinco filósofos resolvam ao mesmo tempo pegar o garfo a sua esquerda e testar se o garfo a sua direita está disponível. Eles irão constatar que o garfo a sua direita não está disponível e devolverão à mesa o garfo a sua esquerda. Essa situação continuará indefinidamente, entrando os processos numa condição conhecida como starvation quando os
programas são executados continuamente, sem, porém, conseguir realizar qualquer progresso efetivo no andamento dos mesmos, em suma, o programa simplesmente não é executado.
Uma ideia seria os filósofos (processos) esperando um tempo aleatório para pegar o garfo a sua esquerda, como é feito em redes locais. Antes de pegar qualquer garfo, o filósofo entraria numa condição de down num semáforo “mutex” (exclusão mútua),
assim nenhum outro filósofo (processo) tentaria pegar qualquer garfo até que o primeiro colocasse os garfos de volta à mesa e entrasse num estado de up liberando
assim os recursos (garfos) para os outros processos (filósofos).
8
47
Essa solução previne efetivamente os deadlocks e starvation, porém não é eficaz, poisconsiderando os recursos (pratos e garfos), dois filósofos poderiam comer ao mesmo tempo e nesse caso apenas um comeria por vez.
Uma solução mais eficaz para o problema do Jantar dos Filósofos seria utilizarmos um
array que controla os estados dos filósofos que seriam: comendo, pensando ou com
fome (tentando pegar os dois garfos). Um filósofo só poderia pegar os garfos se nenhum de seus vizinhos estiver comendo.
Essa solução contempla um array de semáforos para cada filósofo. São definidas
macros para identificar os vizinhos de cada filósofo. Por exemplo, se o processo do filósofo é o dois, seu vizinho da direita seria 1 e o da esquerda 3.
Segue um código que aplica a solução para o problema do Jantar dos Filósofos:
#define N 5 /* número de filósofos */
#define LEFT (i+N−1)%N /* número de i's à esquerda do vizinho */
#define RIGHT (i+1)%N /* número de i's à direita do vizinho */
#define THINKING 0 /* filósofo está pensando */
#define HUNGRY 1 /* filósofo está tentando pegar os garfos */
#define EATING 2 /* filósofo está comendo */
typedef int semaphore; /* os semáforos são tipos de especiais de int */
int state[N]; /* array para verificar o estado de todos os filósofos */
semaphore mutex = 1; /* mutual exclusão para região críticas */
semaphore s[N]; /* um semáforo por filósofo */
void philosopher (int i) /* i número de filósofo, de 0 a N−1 */
{
while (TRUE) { /* repete indefinidamente*/
48
take_forks(i); /* pega dois garfos ou bloqueia */eat(); /* comendo espaguete */
put_forks(i); /* coloca os garfos de volta à mesa */
}
}
void take_forks(int i) /* i número de filósofo, de 0 a N−1 */
{
down(&mutex); /* entra em região crítica */
state[i] = HUNGRY; /* registra que o filósofo i está com fome */
test(i); /* tenta pegar os dois garfos */
up(&mutex); /* sai da região crítica */
down(&s[i]); /* bloqueia se os garfos não foram pegos */
}
void put_forks(i) /* i número de filósofo, de 0 a N−1 */
{
down(&mutex); /* entra em região crítica */
state[i] = THINKING; /* filósofo termina de comer */
test(LEFT); /* verifica se o vizinho da esquerda pode comer agora */
test(RIGHT); /* verifica se o vizinho da direita pode comer agora */
up(&mutex); /* sai da região crítica */
}
void test(i) /* i número de filósofo, de 0 a N−1 */
49
if (state[i] == HUNGRY && state[LEFT] != EATING && state[RIGHT] != EATING) {state[i] = EATING;
up(&s[i]);
}
}
Os comentários sobre código acima são autoexplicativos, porém algumas linhas do código valem ser ressaltadas. Temos um “while” principal com funções para as quatro atividades dos filósofos que são: pensando, pegando os garfos, comendo e colocando os garfos de volta na mesa. Na função “take_forks”, vemos um teste para verificar se os garfos estão disponíveis e a decisão de pegar os talheres ou não associadas à colocação do semáforo no estado de down ou up. Na função “put_forks” vemos a
execução da função “test” para verificar se o filósofo vizinho da direita ou dá esquerda podem pegar os garfos, assim a função “test” verifica se os vizinhos não estão comendo, para que o filósofo possa entrar do estado de EATING.
Existem abordagens mais recentes para esse problema como Software Visualization
que é uma programação visual, baseada em semiótica e os recursos de linguagens de programação como a Parlog86.
Problemas de leitores e escritores
Esse problema está muito ligado ao acesso a banco de dados. Quando temos um banco de dados, podemos ter vários acessos de leitura, mas apenas um de escrita por questões óbvias, pois se tivermos vários acessos de escrita mesmo em registros diferentes ou ainda no mesmo registro, mas em intervalos muito pequenos, teremos um banco de dados inconsistente, além disso, essa condição seria muito propícia a
deadlocks.
A solução clássica para esse problema é relativamente simples. Temos dois semáforos, um que poderia ser chamado “db” e outro “mutex”, o primeiro para
controlar o acesso de escrita ao banco e o segundo para controlar os acessos de leitura. Quando o primeiro leitor acessar o banco, coloca em down o semáforo “db” e
50
Na medida em que outros leitores foram acessando o banco de dados, o contador é incrementado, quando eles deixam de acessar o banco, o contador é decrementado. Quando o último leitor deixa o acesso, ele muda a condição do semáforo “db” para upe assim um escritor do banco de dados, caso exista algum nesse momento, está livre para fazer um acesso de escrita.
Essa abordagem é eficiente caso não tenhamos uma quantidade muito elevada de acessos de leitura ao banco, pois do contrário, nunca ocorrerá um acesso de escrita devido à condição de mútua exclusão entre os dois processos.
Uma solução para essa fragilidade do algoritmo seria quando um leitor for acessar o banco e já houver um processo de escrita esperando a liberação do mesmo, esse processo é colocado em espera, sendo executado só após a liberação e execução do processo de escrita, dessa forma o escritor só esperaria pelos processos de leitura que já estivessem em execução na sua chegada. Um ponto fraco dessa abordagem é que, apesar dela diminuir a concorrência entre processos, tem o desempenho comprometido.
Segue o código que apresenta a solução descrita acima para o problema de acessos de leitura e escrita:
typedef int semaphore; /* os semáforos são tipos de especiais de int */
semaphore mutex = 1; /* controla o acesso ao 'rc' */
semaphore db = 1; /* controla o acesso ao banco de dados */
int rc = 0; /* número de processos de leitura ou desejando ler */
void reader(void)
{
while (TRUE) { /* repete indefinidamente */
down(&mutex); /* obtém acesso exclusivo ao 'rc' */
rc = rc + 1; /* mais um leitor agora */
if (re == 1) down(&db); /* se esse é o primeiro leitor… */