Dˆ
ENIS RICARDO XAVIER DE OLIVEIRA
O Problema de Detec¸
c˜
ao de
Clusters
Espaciais Irregulares: Uma Nova
Abordagem Multiobjetivo
Dˆ
ENIS RICARDO XAVIER DE OLIVEIRA
O Problema de Detec¸
c˜
ao de
Clusters
Espaciais
Irregulares: Uma Nova Abordagem Multiobjetivo
Disserta¸c˜ao apresentada ao Departa-mento de Computa¸c˜ao da Universidade Federal de Ouro Preto para obten¸c˜ao do t´ıtulo de Mestre em Ciˆencia da Computa¸c˜ao pelo Programa de P´os-gradua¸c˜ao em Ciˆencia da Computa¸c˜ao.
´
Area de concentra¸c˜ao: Ciˆencia da Com-puta¸c˜ao
Orientador: Prof. Dr. Gladston Juliano Prates Moreira
Catalogação: www.sisbin.ufop.br
Abordagem Multiobjetivo [manuscrito] / Dênis Ricardo Xavier de Oliveira. -2017.
75f.: il.: color; grafs; tabs; mapas.
Orientador: Prof. Dr. Gladston Juliano Prates Moreira.
Dissertação (Mestrado) - Universidade Federal de Ouro Preto. Instituto de Ciências Exatas e Biológicas. Departamento de Computação. Programa de Pós-Graduação em Ciência da Computação.
Área de Concentração: Ciência da Computação.
1. Problema de Detecção de Clusters Espaciais. 2. Particle Swarm
Optimization. 3. Otimização Multiobjetivo. 4. Funções de Penalização. I. Moreira, Gladston Juliano Prates. II. Universidade Federal de Ouro Preto. III. Titulo.
Ao Professor e Orientador Gladston Juliano Prates Moreira, pelo incentivo e orienta¸c˜ao.
`
A minha M˜ae Maria Aparecida e ao meu Pai Amantino (in memorian) e aos meus Irm˜aos Raquel e Raul.
`
A Tia Deolinda e Fam´ılia. `
A todos da Gerˆencia de Tecnologia da Informa¸c˜ao do Cˆampus Rio Pomba (GTI) e ao Professor Jo˜ao Paulo, pelo incentivo e por terem possibilitado o meu afastamento para a realiza¸c˜ao deste curso.
Ao Programa de P´os-Gradua¸c˜ao em Ciˆencia da Computa¸c˜ao (PPGCC) da Univer-sidade Federal de Ouro Preto.
Aos Professores Gladston e Eduardo coordenadores do CSI-Lab (Laborat´orio de Computa¸c˜ao de Sistemas Inteligentes), pelos recursos e infraestrutura disponibilizados.
Aos Professores e Funcion´arios do PPGCC.
Aos amigos da Turma do Caf´e Leandro, Paulo, Lauro, Tales, Adriano, Matheus, Rodolfo A., Rodolfo M. e Raul. E as amigas La´ıs e Priscila.
`
A todos os colegas e amigos, que ajudaram e contribu´ıram ao longo deste per´ıodo. Ao Cˆampus Rio Pomba do Instituto Federal de Educa¸c˜ao, Ciˆencia e Tecnologia do Sudeste de Minas Gerais (IF Sudeste MG), pelo programa de incentivo `a qualifica¸c˜ao dos Servidores T´ecnicos Administrativos.
`
A Universidade Federal de Ouro Preto, pelos recursos e infraestrutura disponibili-zados.
lutaste. ”
M´etodos visando a detec¸c˜ao e inferˆencia de clusters espaciais s˜ao de grande relevˆancia. Isso se deve a aplicabilidade em problemas de not´oria importˆancia como na sa´ude p´ublica, mas tamb´em pelo interesse cient´ıfico no desenvolvimento eficaz destes m´etodos. As principais t´ecnicas s˜ao baseadas na estat´ıstica espacial scan e muitas abordagens vinculam esta estat´ıstica a m´etodos estoc´asticos de otimiza¸c˜ao. Recentemente, em conjunto com a estat´ıstica, fun¸c˜oes de penaliza¸c˜ao tˆem sido propostas, com a finalidade de controlar a irregularidade excessiva da forma dos clusters candidatos. Este estudo apresenta um novo m´etodo baseado na estat´ıstica scan em conjunto com uma nova fun¸c˜ao de penaliza¸c˜ao geogr´afica dos clusters candidatos que apresentam enormes lacunas em suas ´areas, a fun¸c˜ao de Dispers˜ao. O objetivo principal ´e propor uma abordagem de otimiza¸c˜ao multiobjetivo para o problema visando maximizar o valor da estat´ıstica e minimizar o valor da nova fun¸c˜ao de penaliza¸c˜ao, usando a t´ecnica de computa¸c˜ao evolucion´aria Particle Swarm Optimization, resultando ao final em um conjunto de solu¸c˜oes n˜ao-dominadas representadas pela fronteira Pareto-´otimo. Resultados obtidos com a realiza¸c˜ao de experimentos usando um conjunto de aplica¸c˜oes do problema mostram que a abordagem multiobjetivo associada a fun¸c˜ao de dispers˜ao ´e um m´etodo satisfat´orio para o problema. Demonstrou-se que, em compara¸c˜ao com a fun¸c˜ao de penaliza¸c˜ao por n˜ao-conectividade e compacidade geom´etrica, a abordagem associada a fun¸c˜ao de dispers˜ao ´e r´apida e adequada para a detec¸c˜ao de
clusters espaciais irregulares.
Methods for the detection and inference of spatial clusters are of great relevance. It is due to its applicability in problems of notorious importance as in public health, but also for the scientific interest in the effective development of these methods. The main techniques are based on spatial scan statistics and many approaches link this statistic to stochastic optimization methods. Recently, in conjunction with this statistic, penalty functions have been proposed, for the purpose to control the excessive irregularity of the shape of candidate clusters. This study presents a new method based on scan statistics in conjunction with a new geographic penalization function of candidate clusters that present huge gaps in their areas, the Dispersion function. The main objective is to propose a multiobjective optimization approach to the problem aiming to maximize the value of the statistic and to minimize the value of the new penalty function using the evolutionary computation technique Particle Swarm Optimization, resulting in a set of non-dominated solutions represented by the Pareto-optimal front. Results obtained with experiments using a set of applications of the problem show that the multiobjective approach associated with the dispersion function is a satisfactory method for the problem. It has been shown that, comparing to the non-connectivity and geometric compactness penalty function, the approach associated with the dispersion function is faster and more appropriate for the detection of irregular shape spatial clusters.
Figura 1 – Uma poss´ıvel zona obtida para uma dada janela circular, Fonte: Moreira
(2011). . . 21
Figura 2 – Cluster encontrado pelo algoritmoSimulated Annealing sem penaliza¸c˜ao,
fonte: Can¸cado (2009) . . . 24
Figura 3 – Exemplo de dois subconjuntos de regi˜oes em destaque (cinza) que
assumem os formatos circular (a) e retangular (b). . . 28
Figura 4 – Exemplo de trˆes zonas (a), (b) e (c) em destaque e o subgrafo associado. 29
Figura 5 – Exemplo de um conjunto de centroides em um cluster e os considerados
para o c´alculo da fun¸c˜ao de penaliza¸c˜ao por Dispers˜ao. . . 31
Figura 6 – Clusters (a) e (b) dispostos em um espa¸co bidimensional (x, y) e
centroi-des associados e considerados para o c´alculo da fun¸c˜ao de penaliza¸c˜ao.
. . . 32
Figura 7 – Exemplo de rela¸c˜ao de dominˆancia e um conjunto de solu¸c˜oes
n˜ao-dominadas. . . 33
Figura 8 – Diagrama de blocos indicando o fluxo de execu¸c˜ao das principais etapas
do algoritmo PSO em seu modelo global. . . 36
Figura 9 – Fun¸c˜oes f1 e f2, e o conjunto O = {x1, x2, x3, x4} das solu¸c˜oes
n˜ao-dominadas e os espa¸cos R0 e R1. . . 39
Figura 10 – Mapa do Nordeste dos Estados Unidos: `A esquerda um mapa dividido
em um conjunto de regi˜oes; `A direita o grafo correspondente.. . . 42
Figura 11 – a) Exemplo de um conjunto de regi˜oes e uma zona em destaque (cinza);
b) Vetor de vari´aveis bin´arias associado a). . . 43
Figura 12 – C´alculo do valor da Crowding Distance Computation. . . 46
Figura 13 – Aplica¸c˜ao do operador de muta¸c˜ao em um indiv´ıduo (a): inclus˜ao de
v´ertice no indiv´ıduo (b); e exclus˜ao de v´ertice no indiv´ıduo(c). . . 50
Figura 14 – Clusters artificiais gerados no mapa do Nordeste dos EUA: A, B, C e D. 55
Figura 15 – Clusters artificiais gerados no mapa do Nordeste dos EUA: E e F. . . . 55
Figura 16 – Clusters artificiais gerados no mapa do Nordeste dos EUA: BOS, NYC
Gerais, Brasil, por regi˜ao em 2006: (a) mapa taxa de doen¸ca; (b) Mapa
da popula¸c˜ao em risco. . . 60
Figura 18 – Parte superior - (•) solu¸c˜oes n˜ao-dominadas, 999 conjuntos de solu¸c˜oes
n˜ao-dominadas simuladas sobre a hip´otese nula e a isolinha de p-valor
= 0,05; Parte inferior - mapa em escala de cinza para as solu¸c˜oes
n˜ao-dominadas observadas, obtidas pelo algoritmo MOBPSO-DP. . . . 62
Figura 19 – Parte superior - (•) solu¸c˜oes n˜ao dominadas, 999 conjuntos de solu¸c˜oes
n˜ao dominadas simuladas sob a hip´otese nula e a isolinha de p-valor
= 0,05; Parte inferior - mapa em escala de cinza para as solu¸c˜oes
n˜ao-dominadas observadas, obtidas pelo algoritmo MOBPSO-NC. . . . 63
Figura 20 – Parte superior - (•) solu¸c˜oes n˜ao dominadas, 999 conjuntos de solu¸c˜oes
n˜ao dominadas simuladas sob a hip´otese nula e a isolinha de p-valor=
0,05; Parte inferior - mapa em escala de cinza para as solu¸c˜oes
n˜ao-dominadas observadas, obtidas pelo algoritmo MOBPSO-CG. . . 64
Figura 21 – Cluster encontrado com maior valor obtido pela estat´ıstica de teste T
pelo algoritmo MOBPSO-DP. . . 65
Figura 22 – Cluster encontrado com maior valor obtido pela estat´ıstica de teste T
pelo algoritmo MOBPSO-NC e MOBPSO-CP. . . 66
Figura 23 – Cluster encontrado pelo m´etodo Scan El´ıptico com maior valor obtido
pela estat´ıstica de teste T, constitu´ıda por 86 regi˜oes. . . 67
Figura 24 – Parte superior - (•) solu¸c˜oes n˜ao dominadas, 999 conjuntos de solu¸c˜oes
n˜ao dominadas simuladas sobre a hip´otese nula e a isolinha de p-valor
= 0,05 ; Parte inferior - mapa em escala de cinza para as solu¸c˜oes
n˜ao-dominadas observadas, obtidas pelo m´etodo Scan El´ıptico. . . 68
Figura 25 – Fronteiras Pareto-´otimas obtidas pelos m´etodos MOBPSO-DP (C´ırculos)
Algoritmo 1 – - Pseudoc´odigo para a constru¸c˜ao gulosa da popula¸c˜ao de part´ıculas/indiv´ıduos. 45
Algoritmo 2 – - Pseudoc´odigo para a Crowding Distance Computation.. . . 47
Algoritmo 3 – - Pseudoc´odigo para o Operador de Muta¸c˜ao. . . 49
Algoritmo 4 – - Pseudoc´odigo do MOBPSO para o problema de detec¸c˜ao de clusters
Tabela 1 – Valores obtidos com o c´alculo do poder pelos algoritmos MOBPSO-DP,
MOBPSO-NC e MOBPSO-CP e pelo M´etodo Scan El´ıptico. . . 57
Tabela 2 – Valores obtidos com o c´alculo da Sensibilidade pelos algoritmos
MOBPSO-DP, MOBPSO-NC e MOBPSO-CP e pelo M´etodo Scan El´ıptico. . . . 58
Tabela 3 – Valores obtidos com o c´alculo do Valor Preditivo Positivo pelos
algorit-mos MOBPSO-DP, MOBPSO-NC e MOBPSO-CP e pelo M´etodo Scan
El´ıptico. . . 58
Tabela 4 – Tempo de execu¸c˜ao nas simula¸c˜oes na aplica¸c˜ao. . . 69
AGs Algoritmos Gen´eticos.
BPSO Binary Particle Swarm Optimization.
MOPSO Multi-Objective Particle Swarm Optimization.
MOPSO-CD Multi-objective Particle Swarm Optimization with Crowding Distance.
NSGA-II Nondominated Sorting Genetic Algorithm II.
1
Introdu¸c˜
ao
. . . 161.1
Objetivos
. . . 181.1.1
Objetivo Geral
. . . 181.1.2
Objetivos Espec´ıficos
. . . 181.2
Estrutura do texto
. . . 192
Fundamenta¸c˜
ao Te´
orica
. . . 202.1
O Problema de Detec¸c˜
ao de
Clusters
Espaciais
. . . 202.1.1
Estat´ıstica Espacial
Scan
. . . 222.1.2
M´
etodos de detec¸
c˜
ao de
clusters
. . . 232.1.2.1
O M´etodo
Scan
El´ıptico
. . . 262.1.3
Fun¸c˜
oes de Penaliza¸
c˜
ao
. . . 262.1.3.1
Penaliza¸c˜ao por Compacidade Geom´etrica
. . . 272.1.3.2
Penaliza¸c˜ao por N˜ao-Conectividade
. . . 282.1.3.3
A Penaliza¸c˜ao por Dispers˜ao
. . . 302.2
Otimiza¸
c˜
ao Multiobjetivo
. . . 322.3
Particle Swarm Optimization
. . . 342.3.1
Binary Particle Swarm Optimization
. . . 372.4
C´
alculo de significˆ
ancia das solu¸c˜
oes
. . . 372.4.1
Fun¸c˜
oes de Aproveitamento
. . . 393
Algoritmo Proposto
. . . 413.1
Vis˜
ao Geral
. . . 413.2
Aspectos Estruturais
. . . 413.2.1
Vari´
aveis de decis˜
ao
. . . 433.3
Inicializa¸
c˜
ao
. . . 443.4
Defini¸
c˜
ao dos guias pBest e gBest
. . . 453.4.1
Crowding Distance Computation
. . . 463.5
Atualiza¸
c˜
oes da Velocidade e da Posi¸
c˜
ao
. . . 473.6
Operador de Muta¸
c˜
ao/Turbulˆ
encia
. . . 484.1
Configura¸
c˜
oes dos Algoritmos, do m´
etodo
Scan
El´ıptico
e do Ambiente de Execu¸
c˜
ao dos Experimentos
. . . 534.2
Avalia¸c˜
oes Num´
ericas
. . . 544.3
Ocorrˆ
encias de Casos Reais da Doen¸
ca de Chagas no
Estado de Minas Gerais
. . . 595
Conclus˜
oes
. . . 715.1
Trabalhos Publicados
. . . 72Referˆ
encias
1. . . 73
1 Introdu¸c˜
ao
O problema de detec¸c˜ao e inferˆencia de clusters (ou pela tradu¸c˜ao aglomerados) possui aplicabilidade em ´areas de evidente importˆancia como em problemas ligados `a sa´ude p´ublica (epidemiologia e vigilˆancia sindrˆomica), criminologia, pesquisas de mercado, entre outros. As an´alises das detec¸c˜oes podem ser realizadas em intervalos, que caracterizam as trˆes diferentes abordagens do problema, sendo elas no espa¸co (cluster espacial), no tempo (cluster temporal), ou em ambos (cluster espa¸co-temporal).
As an´alises tˆem como objetivo verificar se um n´umero de ocorrˆencias ´e discrepante em um subconjunto no espa¸co, no tempo ou em ambos em rela¸c˜ao a toda ´area em estudo. Estudos sobre a incidˆencia de doen¸cas s˜ao de grande interesse na comunidade cient´ıfica. Algoritmos para detec¸c˜ao e inferˆencia de clusters s˜ao ferramentas ´uteis para o alerta precoce de surtos de doen¸cas infecciosas (KULLDORFF et al., 2007).
Um cluster pode ser visto como um subconjunto limitado definido no espa¸co, no tempo ou em ambos, em que o risco da ocorrˆencia de um fenˆomeno de interesse (uma determinada doen¸ca, ocorrˆencias criminais, entre outros) ´e discrepante, ou seja, muito alta ou muito baixa quando comparada com o risco do conjunto como um todo, e simultaneamente significativo do ponto de vista estat´ıstico.
A Estat´ısticaScan proposta porKulldorff(1997) ´e o m´etodo mais usual, atualmente, empregado nos procedimentos de detec¸c˜ao de clusters em suas abordagens. O m´etodo ´e baseado em um teste da raz˜ao de verossimilhan¸cas. O valor m´aximo obtido pela estat´ıstica caracterizar´a a ocorrˆencia do cluster mais veross´ımil em um subconjunto limitado no espa¸co (ou tempo, ou em ambos) em estudo, ou seja, a solu¸c˜ao para o problema. Neste sentido o problema ´e facilmente modelado como um problema de otimiza¸c˜ao sendo a estat´ıstica Scan a principal fun¸c˜ao objetivo a ser otimizada.
A aplica¸c˜ao da estat´ısticascan, limitada `a abordagem espacial do problema, inde-pende da forma das solu¸c˜oes a serem pesquisadas, entretanto o delineamento dos clusters
trabalhos de (DUCZZMAL; ASSUNC¸ ˜AO, 2004; DUCZMAL et al., 2007; DUCZMAL; CANC¸ ADO; TAKAHASHI, 2008).
A importˆancia do desenvolvimento de m´etodos de detec¸c˜ao de clusters irregulares surge diante do fato do fenˆomeno de interesse muitas vezes estar atrelado a ´areas que comumente assumem formas diversas das convencionais. Exemplo dessa situa¸c˜ao podem ocorrer em um subconjunto de regi˜oes ligadas, como por exemplo, a curso de rios, rodovias, costas litorˆaneas, entre outros. Diante disso, e dos problemas anteriormente relatados, trabalhos recentes prop˜oem abordagens empregando t´ecnicas de otimiza¸c˜ao e fun¸c˜oes de penaliza¸c˜ao na tentativa da obten¸c˜ao de solu¸c˜oes satisfat´orias para o problema.
Um ponto chave no desenvolvimento de m´etodos para a detec¸c˜ao declusters espaciais de forma irregular ´e que, diante dos v´arios graus de liberdade inerente `as formas geom´etricas, algum mecanismo de corre¸c˜ao deve ser empregado objetivando compensar o aumento da flexibilidade, evitando a ocorrˆencia de falsos-positivos (DUCZMAL et al.,2007;DUCZMAL; KULLDORFF; HUANG, 2006). Este fato tem sido reconhecido desde o estudo inicial de clusters de forma el´ıptica (KULLDORFF et al.,2006). Neste sentido Yiannakoulias, Rosychuk e Hodgson (2007) propuseram uma fun¸c˜ao de penaliza¸c˜ao topol´ogica sobre os
clusters candidatos. Estas corre¸c˜oes tamb´em foram tratadas em abordagens multiobjetivo para o problema (DUCZMAL; CANC¸ ADO; TAKAHASHI, 2008; CANC¸ ADO et al.,2010;
DUARTE et al., 2010). No entanto, o custo computacional dos procedimentos ligados a tais funcionais tende a elevar, em geral, pois testes de conectividade das solu¸c˜oes precisam ser inclu´ıdos.
Particle Swarm Optimization (PSO) ´e uma t´ecnica de computa¸c˜ao evolutiva similar em alguns aspectos a Algoritmos Gen´eticos (AGs), sendo aplicada eficientemente em uma s´erie de problemas de otimiza¸c˜ao (KENNEDY; SPEARS, 1998). No problema de detec¸c˜ao de clusters abordagens baseadas em PSO foram pouco exploradas. Um estudo feito por Izakian e Pedrycz (2012) define uma estrutura geom´etrica para as janelas de busca aplicando posteriormente PSO como otimizador. Propostas multiobjetivo para o problema em estudo tˆem sido bem avaliadas como reportam o trabalho feito por Can¸cado et al. (2010) usando AGs. Em alguns problemas, como descrevemKennedy e Spears(1998), PSO tem como vantagens ser de f´acil implementa¸c˜ao, tem poucos parˆametros, requer menos recursos computacionais e pode convergir mais rapidamente. Em Eberhart e Yuhui
multiobjetivo baseadas em PSO n˜ao foram ainda exploradas, tonando-se assim, uma ´area promissora para estudos.
1.1
Objetivos
1.1.1
Objetivo Geral
Esta disserta¸c˜ao tem como principal objetivo apresentar uma nova abordagem de otimiza¸c˜ao para o problema de detec¸c˜ao e inferˆencia de clusters espaciais irregulares e tamb´em propor uma fun¸c˜ao de penaliza¸c˜ao aplicada sobre a topologia das solu¸c˜oes candidatas. A abordagem utiliza como base a t´ecnica de computa¸c˜ao evolucion´ariaParticle Swarm Optimizationvers˜ao bin´aria e multiobjetivo visando maximizar o valor da estat´ıstica Espacial Scan e minimizar o valor da nova fun¸c˜ao de penaliza¸c˜ao.
1.1.2
Objetivos Espec´ıficos
Os objetivos espec´ıficos definidos com a realiza¸c˜ao desta disserta¸c˜ao s˜ao os seguintes:
• Realizar uma revis˜ao bibliogr´afica sobre o problema em estudo;
• Propor uma fun¸c˜ao de penaliza¸c˜ao sobre a topologia dos clusters candidatas.
• Desenvolver e implementar uma abordagem de otimiza¸c˜ao multiobjetivo para o problema com base na t´ecnica de computa¸c˜ao evolutivaParticle Swarm Optimization;
• Aplicar medidas de avalia¸c˜ao do porder detec¸c˜ao e qualidade da abordagem proposta;
• Aplicar o algoritmo multiobjetivo em um conjunto de dados reais do problema;
• Comparar os resultados obtidos com a fun¸c˜ao de penaliza¸c˜ao proposta com demais fun¸c˜oes descritas na literatura por meio do algoritmo multiobjetivo;
• Comparar os resultados obtidos pela abordagem com o m´etodo de defini¸c˜ao de janelas de busca de clusters, Scan El´ıptico; e
1.2
Estrutura do texto
2 Fundamenta¸c˜
ao Te´
orica
Este cap´ıtulo apresentada uma revis˜ao sobre os fundamentos te´oricos dos principais temas tratados e utilizados como base para o desenvolvimento deste trabalho de disserta¸c˜ao. A Se¸c˜ao 2.1descreve o problema de detec¸c˜ao e inferˆencia de clusters em sua abordagem espacial, a se¸c˜ao compreende a principal metodologia usada nos m´etodos detec¸c˜ao de
clusters (Subse¸c˜ao 2.1.1), um resumo sobre m´etodos de detec¸c˜ao (Subse¸c˜ao 2.1.2), o m´etodoScan El´ıptico (Subse¸c˜ao 2.1.2.1) e as fun¸c˜oes de penaliza¸c˜ao adotadas em m´etodos de detec¸c˜ao declusters de forma irregular (Subse¸c˜ao2.1.3). A Se¸c˜ao2.2descreve uma s´ıntese dos conceitos de otimiza¸c˜ao multiobjetivo. A Se¸c˜ao 2.3 relata a t´ecnica de computa¸c˜ao evolucion´aria Particle Swarm Optimization e sua extens˜ao para aplica¸c˜ao em problemas de otimiza¸c˜ao discretos (Subse¸c˜ao 2.3.1). E, por ´ultimo, a Se¸c˜ao 2.4 descreve a abordagem adotada para o c´alculo de significˆancia estat´ıstica das solu¸c˜oes obtidas pelo algoritmo proposto.
2.1
O Problema de Detec¸c˜
ao de
Clusters
Espaciais
Esta se¸c˜ao tem como objetivo apresentar as defini¸c˜oes que se limitam `a vers˜ao espacial do problema de detec¸c˜ao e inferˆencia de clusters. Em muitas aplica¸c˜oes frequente-mente existe a necessidade da delimita¸c˜ao de um subconjunto de regi˜oes em detrimento de outras onde a ocorrˆencia do n´umero de casos para um fenˆomeno de interesse seja maior ou menor do que o esperado e que ao mesmo tempo seja estatisticamente significativo. Muitas dessas aplica¸c˜oes est˜ao ligadas `a problemas relacionados a epidemiologia, vigilˆancia sindrˆomica, criminologia, entre outros. Esta quest˜ao ´e o objetivo primordial da abordagem espacial do problema de detec¸c˜ao de clusters.
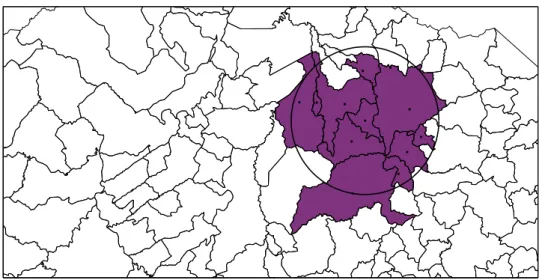
A Figura1 ilustra um exemplo de um subconjuntoz considerando as regi˜oes cujos centroides s˜ao internos a uma determinada janela circular sobrepondo a ´area do mapa em estudo.
Figura 1 – Uma poss´ıvel zona obtida para uma dada janela circular, Fonte:Moreira(2011).
Nestes termos um cluster espacial ´e um subconjunto de zonas geograficamente limitadas em que o risco de ocorrˆencia do fenˆomeno de interesse ´e alto ou baixo o suficiente para serem considerados significativos do ponto de vista estat´ıstico em rela¸c˜ao `a regi˜ao de estudo como um todo.
An´alises simpl´orias na tentativa de inferir quanto a significˆancia de um cluster
poderiam levar em conta simplesmente a incidˆencia de casos do fenˆomeno de interesse em cada zona, ou seja, o n´umero de casos observados dividido pela popula¸c˜ao, ou ainda o risco relativo que ´e o n´umero observado de casos dividido pelo n´umero esperado de casos (DUARTE, 2009). Apesar de parecer razo´avel, essa an´alise n˜ao resolve o problema de detec¸c˜ao de clusters, pois ´e poss´ıvel que clusters candidatos com popula¸c˜oes muito discrepantes possam apresentar uma mesma propor¸c˜ao de casos. Diante disso, estas solu¸c˜oes candidatas seriam comparadas em situa¸c˜ao de igualdade. Um aumento no risco relativo ´e t˜ao mais significativo quanto maior ´e a popula¸c˜ao de risco do cluster candidato. Isso significa que, embora uma regi˜ao, ou uma zona possa apresentar um alto risco relativo, se sua popula¸c˜ao ´e pequena, ela se torna pouca significativa.
Can¸cado(2009) exemplifica a ocorrˆencia deste problema diante do seguinte cen´ario, considere duas cidades X e Y com popula¸c˜oes de risco para um fenˆomeno de interesse
popula¸c˜ao total de risco do mapa igual a n= 10.000.000 e o n´umero total de casos reais igual a c= 100.000. Em um cen´ario sobre hipotese nula, ou seja, caso n˜ao haja cluster no mapa, a frequˆencia de casos esperados deve ser de 1 caso para cada 100 habitantes para todas as regi˜oes do mapa. Assim, o n´umero de casos esperados nas cidades X e Y devem ser ωx = 1 eωy = 10.000, respectivamente. Sejam os casos reais nas cidades X e Y iguais a cx = 2 e cy = 20.000, respectivamente. Neste cen´ario, ambas as cidades apresentam risco relativo, ou seja, o n´umero de casos reais dividido pelo n´umero de casos esperados, iguais a cx/ωx =cy/ωy = 2. Nesta situa¸c˜ao, atrav´es da an´alise pelo risco relativo as duas regi˜oes s˜ao equivalentes. Todavia, para a cidade Y uma varia¸c˜ao de 10.000 para 20.000 casos n˜ao deve ser considerada como uma simples flutua¸c˜ao estat´ıstica, necessitando-se de estudos mais detalhados.
A estat´ısticaScan proposta por Kulldorff (1997) resolve o problema descrito acima, sendo adotada atualmente como a principal t´ecnica nas abordagens de detec¸c˜ao e inferˆencia de clusters em suas vers˜oes. A se¸c˜ao 2.1.1 descreve os principais aspectos conceituais deste m´etodo.
2.1.1
Estat´ıstica Espacial
Scan
A estat´ıstica espacial scan proposta porKulldorff (1997), ´e atualmente o m´etodo mais usual empregado em abordagens de detec¸c˜ao e inferˆencia declusters espacial, temporal e espa¸co-temporal. A estat´ıstica ´e baseada em um teste de raz˜ao de verossimilhan¸cas que busca um subconjunto de regi˜oes ao longo de um mapa em estudo, o valor m´aximo para a estat´ıstica .
O logaritmo da raz˜ao de verossimilhan¸cas Λ(z) =log(L(Z)/L0) ´e, segundoKulldorff
(1997) definido pela equa¸c˜ao (1):
Λ(z) =
czlog
cz
µz
+ (C−cz) log
C−cz
C−µz
, se cz > µz
0, caso contr´ario
(1)
A fun¸c˜ao Λ(z) ´e maximizada sobre o conjunto de todas as zonas Z do mapa, identificando a zona que constitui o cluster mais veross´ımil. Logo se tem a estat´ıstica de teste que ´e dada por T =maxz∈ZΛ(z).
2.1.2
M´
etodos de detec¸
c˜
ao de
clusters
Definida a estat´ıstica de teste, a busca por solu¸c˜oes ´otimas, ou seja, aquelas que obt´em o valor m´aximo para a estat´ıstica, poderia ser feita dentro do conjuntoZ. Entretanto, o emprego de m´etodos baseados em busca completa (ou seja, for¸ca bruta) torna essa tarefa computacionalmente impratic´avel diante do grande n´umero de zonas poss´ıveis de serem formadas em mapa com n´umero de regi˜oes na ordem de algumas centenas. Em um mapa com n regi˜oes, dever˜ao ser analisados aproximadamente 2n subconjuntos de zonas fact´ıveis para o problema.
Para contornar esse problema, os m´etodos de detec¸c˜ao declusters espaciais normal-mente fazem uso de duas t´ecnicas:
• A redu¸c˜ao do conjunto das solu¸c˜oes em Z para um subconjuntoZ′ de Z das zonas promissoras ou que permita uma busca completa; e
• O emprego de m´etodos estoc´asticos de otimiza¸c˜ao.
Todavia, em ambas as t´ecnicas n˜ao existe a garantia do encontro da solu¸c˜ao ´otima global, mas comumente tendem a proporcionar solu¸c˜oes de boa qualidade. Um outro problema relacionado aos m´etodos de detec¸c˜ao de clusters est´a ligado `a forma das solu¸c˜oes encontradas.
Muitos m´etodos da literatura n˜ao s˜ao adequados para controlar a forma dosclusters
2009). As solu¸c˜oes que apresentam essa configura¸c˜ao claramente descaracterizam o signifi-cado de limita¸c˜ao geogr´afica do fenˆomeno em estudo. Esse cen´ario comumente ocorrer´a diante da falta de uma estrat´egia de penaliza¸c˜ao que deve ser incorporada aos m´etodos de detec¸c˜ao e inferˆencia de clusters, visto que essas abordagens tendem a obter o m´aximo valor para a estat´ıstica de teste T.
Figura 2 – Cluster encontrado pelo algoritmo Simulated Annealing sem penaliza¸c˜ao, fonte:
Can¸cado (2009) .
Em outros m´etodos existe somente a garantia do encontro de solu¸c˜oes com um formato espec´ıfico. Nesta linha h´a, por exemplo, o m´etodo Scan Circular proposto por
Kulldorff e Nagarwalla (1995) garante apenas a busca restrita de clusters de forma circular. Uma extens˜ao do formato circular visando uma maior cobertura das formas poss´ıveis
clusters candidatos ´e o Scan el´ıptico, proposto por Kulldorff et al.(2006).
No entanto, existem muitas situa¸c˜oes em que ocluster verdadeiro apresenta uma forma que n˜ao se ajusta em nenhum dos formatos prescritos anteriormente. Em muitos casos, o fenˆomeno de interesse pode estar atrelado a zonas que apresentam formas diversas das convencionais. Exemplos desta situa¸c˜ao poderia ser a ocorrˆencia do fenˆomeno de interesse ao longo do percurso de rios, estradas, rodovias, costas litorˆaneas e entre outros, o que daria, nestas circunstˆancias, uma forma mais alongada ao cluster verdadeiro.
adotada ´e o emprego de uma fun¸c˜ao de penaliza¸c˜ao para a forma ou topologia associada a estrutura do cluster candidato.
Can¸cado(2009) classifica os m´etodos de detec¸c˜ao declusters quanto `a geometria das solu¸c˜oes que podem ser encontradas, sendo os seguintes:
• Os clusters regulares, aqueles que possuem formato espec´ıfico, comumente o circular, o el´ıptico, e entre outros. Tais m´etodos s˜ao restritos em suas an´alises aos formatos predefinidos e fazem uso da t´ecnica de redu¸c˜ao do conjunto de solu¸c˜oes candidatas; e
• Os clusters irregulares, os que apresentam formas diversas. Existem m´etodos desta classe que fazem tanto o uso da redu¸c˜ao do conjunto de solu¸c˜oes candidatas quanto o uso de m´etodos estoc´asticos de otimiza¸c˜ao.
As t´ecnicas de computa¸c˜ao evolucion´aria s˜ao bem conhecidas pela sua habilidade de busca global, e tem sido amplamente aplicadas ao problema de detec¸c˜ao e inferˆencia de clusters espaciais (WU; GRUBESIC, 2010), (DUCZMAL et al., 2007) e (DUCZMAL; CANC¸ ADO; TAKAHASHI, 2008). Tais t´ecnicas s˜ao baseadas em um esquema que n˜ao restringe diretamente o conjunto de solu¸c˜oes, mas atrav´es de mecanismos espec´ıficos, pesquisam algumas das solu¸c˜oes candidatas durante o procedimento, descartando as solu¸c˜oes menos promissoras.
Algoritmos Gen´eticos (AGs) abordados em Duczmal et al. (2007) e Duczmal, Can¸cado e Takahashi (2008) especificamente implementados para o problema de detec¸c˜ao e inferˆencia de clusters, possuem operadores desenvolvidos especialmente para este problema. Os operadores gen´eticos promovem a busca de solu¸c˜oes que maximizam o valor da estat´ıstica de teste, todavia ocorrem em problemas semelhantes ao da abordagem implementada por meio da metaheur´ıstica Simulated Annealing.
Similar aos AGs, Particle swarm optimization ou pela tradu¸c˜ao Otimiza¸c˜ao por Enxame de Part´ıculas ´e uma t´ecnica de computa¸c˜ao evolutiva inicializada com uma popula¸c˜ao de solu¸c˜oes aleat´orias e que a cada solu¸c˜ao potencial tamb´em ´e atribu´ıda uma velocidade aleat´oria e essas solu¸c˜oes potenciais, denominadas de part´ıculas, sobrevoam o espa¸co de busca (EBERHART; KENNEDY, 1995a). E igualmente a outras abordagens de algoritmos de computa¸c˜ao evolutiva, PSO pode ser aplicada para resolver a maioria dos problemas de otimiza¸c˜ao (EBERHART; YUHUI, 2001).
a t´ecnica de otimiza¸c˜ao PSO multiobjetivo, visando maximizar o valor da estat´ıstica de teste T e minimizar a fun¸c˜ao de penaliza¸c˜ao tamb´em proposta neste trabalho que ser´a descrita na se¸c˜ao 2.1.3.3 .
2.1.2.1 O M´etodo
Scan
El´ıptico
O m´etodo Scan El´ıptico proposto por Kulldorff et al. (2006) surgiu como uma extens˜ao imediata ao Scan circular, definindo janelas em formas de elipses em suas an´alises de busca, n˜ao se restringindo com isso apenas `a forma circular.
Uma elipse pode ser definida pelos seguintes parˆametros: as coordenadasx e y de seu centroide, o comprimento de seus eixos maior e menor e o ˆangulo entre seu eixo maior e o eixo das abscissas. O m´etodo utiliza as janelas de busca no mapa em estudo analisando as zonas, cujos centroides s˜ao cobertos pela janela, e avaliando-as atrav´es da estat´ıstica espacial. A zona referente ao maior valor de a Λ(z) determinar´a a ocorrˆencia do cluster, ou seja, a solu¸c˜ao.
O Scan El´ıptico al´em de reduzir o conjunto de solu¸c˜oes candidatas atrav´es da utiliza¸c˜ao de janelas de busca de forma el´ıptica, tamb´em compreende a aplica¸c˜ao de varia¸c˜oes sobre as janelas, ligadas ao tamanho, `a orienta¸c˜ao e `a excentricidade, aumentando assim o range dos formatos dos potenciais clusters incidentes em um mapa sob estudo.
Todavia, como descrito na se¸c˜ao anterior, mesmo com a defini¸c˜ao pr´evia de diversos formatos para determina¸c˜ao das janelas de busca a delimita¸c˜ao do cluster real de formato qualquer ´e uma tarefa computacionalmente impratic´avel diante do tamanho do espa¸co de busca das solu¸c˜oes e dos variados graus inerentes `a liberdade da forma.
2.1.3
Fun¸c˜
oes de Penaliza¸
c˜
ao
As fun¸c˜oes de penaliza¸c˜ao constituem uma t´ecnica normalmente incorporada aos m´etodos de detec¸c˜ao de clusters espaciais de forma irregular, s˜ao aplicadas sobre a forma geom´etrica e/ou topol´ogica do subgrafo associado ao cluster candidato e s˜ao utilizadas tanto em abordagens de otimiza¸c˜ao mono-objetivo quanto multiobjetivo.
para a estat´ıstica de testeT. Em abordagens multiobjetivo a fun¸c˜ao de penaliza¸c˜ao torna-se um dos objetivos a serem otimizados no problema juntamente com Λ(z).
As se¸c˜oes seguintes trazem uma breve descri¸c˜ao sobre as fun¸c˜oes de penaliza¸c˜ao por Compacidade Geom´etrica e N˜ao-Conectividade. A ´ultima se¸c˜ao descreve a fun¸c˜ao proposta nesta disserta¸c˜ao, denominada Dispers˜ao.
2.1.3.1 Penaliza¸c˜ao por Compacidade Geom´etrica
A penaliza¸c˜ao por Compacidade Geom´etrica proposta por Duczmal, Kulldorff e Huang (2006) tem como finalidade penalizar os clusters candidatos que possuem um formato muito irregular, privilegiando os clusters cujo formato se aproxima da forma circular. Por defini¸c˜ao a Compacidade Geom´etrica K(z) de uma zona z ´e dada pela
Equa¸c˜ao 2:
K(z) = 4πA(z)
H(z)2 . (2)
em que A(z) ´e a ´area da zona z eH(z) o per´ımetro da zona z.
O valor da Compacidade Geom´etrica de uma zonaz n˜ao est´a ligada ao tamanho da zona mas sim a sua forma. O c´ırculo ´e o formato que possui o maior valor de compacidade, cujo valor ´e K(z) = 1. Quanto mais arredondado ´e o formato de uma zona mais pr´oximo de 1 ser´a seu valor. Por outro lado, quanto mais irregular for a forma, mais pr´oximo de 0 ser´a o valor da compacidade. O formato de um quadrado possui o valor de compacidade igual a K(z) = 0.785. J´a o valor para um retˆangulo com a base sendo o dobro da altura temos K(z) = 0.698.
(a)
(b)
Figura 3 – Exemplo de dois subconjuntos de regi˜oes em destaque (cinza) que assumem os formatos circular (a) e retangular (b).
2.1.3.2 Penaliza¸c˜ao por N˜ao-Conectividade
A penaliza¸c˜ao por N˜ao-Conectividade foi proposta por Yiannakoulias, Rosychuk e Hodgson (2007) e ´e baseada na rela¸c˜ao entre o n´umero de arestasa(z) e o n´umero de v´ertices v(z) do subgrafo associado `a zona z candidata.
A penaliza¸c˜ao por N˜ao-Conectividade de uma zonaz ´e definida pela Equa¸c˜ao 3:
Y(z) = a(z)
3(v(z)−2). (3)
n˜ao estar ligada `a forma geom´etrica do cluster candidato, mas sim ao grau de conexidade do subgrafo associado ao cluster candidato.
A fun¸c˜ao de N˜ao-Conectividade objetiva penalizar solu¸c˜oes candidatas cujo subgrafo associado possui estrutura baseada em ´arvores e priorizando solu¸c˜oes mais conexas (valores mais pr´oximos de 1 para Y(z)). Para exemplificar sua aplica¸c˜ao, a Figura 4 apresenta trˆes zonas (a), (b) e (c) e os respectivos subgrafos associados. A penaliza¸c˜ao por N˜ao-Conectividade ser´a na zona (a) considerando o n´umero de v´ertices v(z) = 7 e o n´umero de arestas a(z) = 6 o valor de aproximadamente Y(z) = 0,40, na zona (b) o n´umero de v´ertices v(z) = 8 e o n´umero de arestas a(z) = 7, assim Y(z) = 0,39 e na zona (c) o n´umero de v´ertices v(z) = 9 e o n´umero de arestas a(z) = 20 e Y(z) = 0,95.
(a)
(b)
(c)
Figura 4 – Exemplo de trˆes zonas (a), (b) e (c) em destaque e o subgrafo associado.
2.1.3.3 A Penaliza¸c˜ao por Dispers˜ao
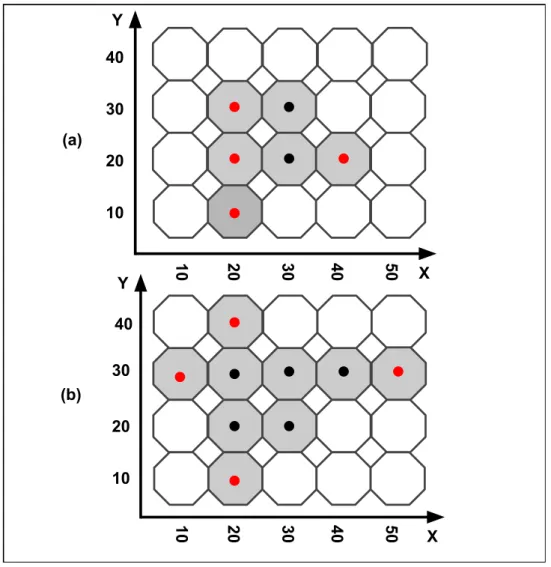
Esta se¸c˜ao prop˜oe uma nova fun¸c˜ao de penaliza¸c˜ao sobre a topologia do cluster
potencial a ser minimizada. Denomina-se penaliza¸c˜ao por dispers˜ao por estar ligada com a distribui¸c˜ao das regi˜oes da zona candidata no mapa dispostas em um espa¸co bidimensional (x, y).
Considere um mapa em estudo dividido emm regi˜oes, onde cada regi˜ao ´e associada a um ponto de coordenadas (x, y) denominado centroide, e uma zona z, ou seja, qualquer subconjunto de regi˜oes, com os centroides correspondentes (x1, y1), . . . ,(xnz, ynz), 1 ≤
nz ≤m. Seja x= max{xi} ex= min{xi} em que i∈ {1, . . . , nz} e defina d1 =x−x. Da mesma forma, defina-se d2 =y−y.
A fun¸c˜ao de penaliza¸c˜ao por dispers˜ao de uma zonaz ´e definido como:
D(z) = 2(d1d2)
d1+d2. (4)
Ou seja, ´e a m´edia harmˆonica do maior intervalo de coordenadas de centroides x e y da zona z, a ser minimizada e independente da forma do cluster.
Nota-se que uma zona z com valore alto para D(z) tendem ser um conjunto de regi˜oes com alto valor de verossimilhan¸ca que se espalham de forma aleat´oria por todo o mapa ou um conjunto de regi˜oes desconexas distantes geograficamente, ou seja, uma solu¸c˜ao indesej´avel na pr´atica. Por outro lado uma zona com valor mais baixo de D(z) pode representar um clusters de forma arbitr´aria sendo um conjunto de regi˜oes conexas ou desconexas, mas geograficamente pr´oximas (tamanho moderado).
Figura 5 – Exemplo de um conjunto de centroides em um cluster e os considerados para o c´alculo da fun¸c˜ao de penaliza¸c˜ao por Dispers˜ao.
Para demonstrar o comportamento da aplica¸c˜ao da fun¸c˜ao de penaliza¸c˜ao proposta, a Figura 6 exibe dois exemplos de clusters (a) e (b) dispostos em um espa¸co (x, y), cujas zonas est˜ao em destaque, e seus respectivos centroides. Para o c´alculo da Dispers˜ao no
(a)
Y X
X 10
20 30 40
10 20 30 40
10 20 30 40 50
10 20 30 40 50
Y
(b)
Figura 6 – Clusters (a) e (b) dispostos em um espa¸co bidimensional (x, y) e centroides associados e considerados para o c´alculo da fun¸c˜ao de penaliza¸c˜ao.
2.2
Otimiza¸
c˜
ao Multiobjetivo
min f(x) = (f1(x), f2(x), ..., fm(x))∈ Y ⊂ Rm
sujeito a:
Fx =
gi(x)≤0∀i= 1, ..., p
hj(x) = 0 ∀j = 1, ..., q
x∈ X
Quando temos dois ou mais objetivos conflitantes, pode ser imposs´ıvel encontrar uma solu¸c˜ao que satisfa¸ca todas elas. Uma forma de resolver este problema ´e encontrar um conjunto de solu¸c˜oes, cada um dos quais representando um compromisso (trade-off )
entre os objetivos, diretamente relacionado ao conceito de dominˆancia, definido a seguir:
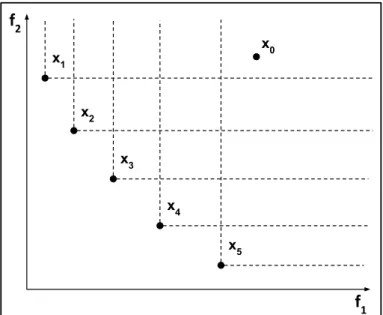
Defini¸c˜ao 1 (Rela¸c˜ao de Dominˆancia). Seja f(x) = (f1(x), f2(x), ..., fm(x)) uma fun¸c˜ao
definida em um espa¸co X. Um ponto x1 domina um ponto x0, denotado por, x1 ≺x0 e
x0, x1 ∈X se fi(x1)≤fi(x0), i= 1, ..., n e se existe pelo menos um ´ındice j ∈ {1, ..., m}
tal que fj(x1)< fj(x0).
A Figura7ilustra o conceito da rela¸c˜ao de dominˆancia para duas fun¸c˜oes objetivosf1
ef2 a serem minimizadas. No exemplo, o ponto x1 domina o pontox0, poisf1(x1)> f1(x0) e f2(x1) > f2(x0). O mesmo acontece quando x0 ´e comparado com os pontosx2, x3, x4
e x5. Por´em entre os pontos x1, x2, x3, x4 e x5 n˜ao existe essa rela¸c˜ao, esses pontos s˜ao n˜ao-dominados. f2 f1 x0 x5 x4 x3 x2 x1
A solu¸c˜ao para os problemas de otimiza¸c˜ao multiobjetivo consiste na determina¸c˜ao de solu¸c˜oes Pareto-´otimas.
Defini¸c˜ao 2 (Solu¸c˜ao Pareto-´otima). Diz-se que uma solu¸c˜ao x1 ∈f ´e Pareto-´otima se n˜ao existe x2 ∈f tal que x2 domina x1.
O conjunto YN D ⊂ Rm denota o conjunto de todas as solu¸c˜oes n˜ao-dominadas (espa¸co dos objetivos) e XE o conjunto de todas as solu¸c˜oes Pareto-´otimas (ou eficientes) (vari´aveis de decis˜ao).
Tradicionalmente as meta-heur´ısticas s˜ao boas t´ecnicas aplicadas na resolu¸c˜ao de problemas de otimiza¸c˜ao usadas para guiar outras heur´ısticas ou algoritmos em seus espa¸cos de busca aplicadas tanto em problemas de otimiza¸c˜ao mono-objetivo quanto multiobjetivo na convergˆencia de solu¸c˜oes (DONOSO; FABREGAT,2016).
2.3
Particle Swarm Optimization
Particle Swarm Optimization (PSO) ´e uma t´ecnica de computa¸c˜ao evolucion´aria desenvolvida por Kennedy e Eberhart em 1995. O PSO consiste em um m´etodo de otimiza¸c˜ao que visa simular um modelo social simplificado inspirado no comportamento da revoada de bando de p´assaros e no movimento de cardume de peixes (EBERHART; KENNEDY, 1995a).
A inten¸c˜ao inicial na concep¸c˜ao da t´ecnica era o de simular a coreografia da revoada de bandos de p´assaros e, todavia, em algum ponto do desenvolvimento do m´etodo foi obser-vado potencial de aplicabilidade do modelo como uma t´ecnica de otimiza¸c˜ao (EBERHART; KENNEDY, 1995b). A abordagem PSO ´e inicializada de forma aleat´oria, no espa¸co de busca do problema, com uma popula¸c˜ao de potenciais solu¸c˜oes denominadas part´ıculas. A cada part´ıcula ´e atribu´ıda uma velocidade tamb´em inicializada de forma aleat´oria.
Eberhart e Kennedy (1995a) apresentam duas vers˜oes de Particle Swarm Opti-mization. A primeira ´e o modelo da proposta original denominado Global (gbest) que adota o conjunto de todas as part´ıculas da popula¸c˜ao como vizinhan¸ca e a segunda ´e o modelo denominado Local (lbest) que adota subconjuntos de vizinhan¸cas de part´ıculas da popula¸c˜ao total.
fun¸c˜ao da posi¸c˜ao da part´ıcula no espa¸co de busca, obtido por cada part´ıcula at´e o momento recebe a denomina¸c˜ao de pbest. Outra posi¸c˜ao armazenada pelo PSO ´e o melhor valor global obtido at´e o momento por qualquer part´ıcula da popula¸c˜ao. Esse valor recebe a denomina¸c˜ao de gbest.
O modelo global da Particle Swarm Optimization segue a execu¸c˜ao das seguintes etapas:
1. Inicializar uma popula¸c˜ao P de part´ıculas com suas posi¸c˜oes pi e velocidades vi definidas de forma aleat´oria nas dimens˜oes d no espa¸co do problema.
2. Para cada part´ıcula pi, calcule sua fun¸c˜ao de aptid˜ao (f itness) nas dimens˜oes d. 3. Compare a fun¸c˜ao de aptid˜ao da part´ıcula pi com seu valor pbesti. Se o valor da
fun¸c˜ao de aptid˜ao for melhor que pbesti, ent˜ao defina o novo valor do pbesti para o valor atual obtido pela fun¸c˜ao de aptid˜ao, e a localiza¸c˜ao do pbesti igual a atual localiza¸c˜ao definida nas dimens˜oes d do espa¸co.
4. Compare a fun¸c˜ao de aptid˜ao com o melhor global da popula¸c˜ao (gbest) definido. Se o valor da fun¸c˜ao de aptid˜ao for melhor do que a determinada por gbest redefina o valor de gbest para o valor obtido pela fun¸c˜ao de aptid˜ao.
5. Atualize a velocidade e a posi¸c˜ao das part´ıculas de acordo com as equa¸c˜oes (5) e (6), respectivamente:
vid=w∗vid+c1∗rand()∗(pbestid−xid) +c2∗rand()∗(gbestd−xid). (5)
xid=xid + vid. (6)
6. Se um crit´erio de parada n˜ao for atendido, geralmente associado a um bom valor para a fun¸c˜ao de aptid˜ao ou a um n´umero m´aximo de itera¸c˜oes, o processo deve ser repetido a partir da segunda etapa.
A velocidadevid das part´ıculas nas dimens˜oes do problema s˜ao limitadas a uma velocidade m´axima vmax definida pelo desenvolvedor:
if(vid> vmax){ vid=vmax }.
A velocidade m´axima consiste em um parˆametro importante, a defini¸c˜ao de um valor alto para vmax possibilita com que as part´ıculas explorem boas solu¸c˜oes e por outro lado a defini¸c˜ao de um valor baixo restringem o alcance de explora¸c˜ao das part´ıculas, podendo delimitar a busca a ´otimos locais no espa¸co do problema.
As constantes de acelera¸c˜aoc1 ec2 da equa¸c˜ao 5 representam os coeficientes dos termos de acelera¸c˜ao que direciona cada part´ıcula `as posi¸c˜oes pbest e gbest. O ajuste destas constantes altera a quantidade de tens˜ao no sistema. Em Eberhart e Yuhui (2001), os autores definem para as constante c1 e c2 o valor 2.0 para a maioria das aplica¸c˜oes desenvolvidas.
A figura8 apresenta uma diagrama indicando o fluxo de execu¸c˜ao das principais etapas definidas anteriormente do algoritmo PSO em seu modelo global.
Inicializar população e
velocidades.
Calcular
aptidão.
Definir os guias
pBest
e
gbest
.
Atualizar velocidade e
posição.
Critério
de
parada.
Fim.
Início.
Sim
Não
No modelo local deParticle Swarm Optimization, as part´ıculas tˆem a informa¸c˜ao de seu pbeste a melhor solu¸c˜ao obtida por seus vizinhos mais pr´oximos recebe a denomina¸c˜ao de lbest opondo-se nesta quest˜ao ao modelo global, o qual as part´ıculas compartilham a melhor solu¸c˜ao obtida com toda a popula¸c˜ao de part´ıculas.
2.3.1
Binary Particle Swarm Optimization
A t´ecnicaParticle Swarm Optimization foi proposta para a resolu¸c˜ao de problemas de otimiza¸c˜ao que ocorrem em espa¸co de busca real. Todavia, muitos problemas de otimiza¸c˜ao s˜ao caracterizados por ocorrerem em um espa¸co de busca discreto, ou bin´ario, como por exemplo o problema de detec¸c˜ao de clusters espaciais. Diante disso, Kennedy e Eberhart (1997) desenvolveram a Binary Particle Swarm Optimization (BPSO) uma adapta¸c˜ao do PSO voltada para a aplica¸c˜ao em problemas cujo espa¸co de busca ´e discreto. Nesta vers˜ao a equa¸c˜ao (5) de atualiza¸c˜ao da velocidade ainda ´e utilizada, em que
xid, pbestid, gbestd, est˜ao restritos a 0 ou 1. A velocidade nesta implementa¸c˜ao aponta a probabilidade de o elemento da posi¸c˜ao correspondente assumir o valor 1. Na atualiza¸c˜ao da posi¸c˜ao das part´ıculas uma fun¸c˜ao sigmoide (7) ´e introduzida para converter vid para o intervalo (0, 1).
A equa¸c˜ao (8) ´e utilizada para a atualiza¸c˜ao da posi¸c˜ao de cada part´ıcula da popula¸c˜ao:
s(vid) =
1
1 +exp−vid (7)
vid=
1, rand()< s(vid). 0, caso contrario.´
(8)
Em querand() ´e um gerador de n´umeros aleat´orios uniformes no intervalo [0.0,1.0]. E vid a nova posi¸c˜ao assumida pela part´ıcula no espa¸co.
2.4
C´
alculo de significˆ
ancia das solu¸c˜
oes
ser´a a que, dentre todas as analisadas, apresentar a maior valor de Λ(z). Antes de podermos afirmar que essa solu¸c˜ao ´e um cluster, devemos lembrar que um cluster deve apresentar um n´umero anormal de casos, ou seja, devemos comparar o mapa estudado contra v´arios mapas aleat´orios.
No caso mono-objetivo, se fosse conhecida a distribui¸c˜ao de probabilidade da estat´ıstica de teste T sob a hip´otese de n˜ao existˆencia de cluster no mapa em estudo, poderia ser determinado um valor cr´ıtico, Tcritico, resolvendo P(T > Tcritico) = α, com
α sendo a probabilidade de que T supere o valor cr´ıtico Tcritico, chamado de n´ıvel de significˆancia, tradicionalmente α = 0,05. Assim, um valor de T abaixo de Tcritico pode ocorrer por mero acaso 95% das vezes, mas um valor acima deTcritico s´o acontece por acaso com probabilidade menor que ou igual a 5% e, portanto, a solu¸c˜ao pode ser considerada um cluster. Essa probabilidade de que o valor observado da estat´ıstica de teste ocorra por mero acaso sob hip´otese nula ´e chamada de probabilidade de significˆancia do teste (p-valor). Se o p-valor de um cluster ´e menor que o n´ıvel de significˆancia α dizemos que a existˆencia daquele cluster ´e significativa ao n´ıvel α. Como, em princ´ıpio, essa distribui¸c˜ao de probabilidade ´e desconhecida, utiliza-se simula¸c˜oes de Monte Carlo (DWASS, 1957) para obter uma distribui¸c˜ao emp´ırica dos valores da estat´ıstica sob a hip´otese nula. Essas simula¸c˜oes s˜ao executadas v´arias vezes e os valores da estat´ıstica T obtidos s˜ao ordenados (o valor correspondente ao quantil de 95% ´e a estimativa do valor cr´ıtico a um n´ıvel de significˆancia de 5%). Dado o valor da estat´ıstica de teste dos casos observados, Tobs, a estimativa de seu p-valor ´e nobs+1
n , em que nobs ´e n´umero de vezes de T sob a hip´otese nula que s˜ao maiores que o valor de Tobs, em quen ´e o n´umero de simula¸c˜oes sob hip´otese nula.
Em abordagens de otimiza¸c˜ao multiobjetivo, de maneira an´aloga o c´alculo da significˆancia estat´ıstica dos clusters obtidos do mapa de casos observados ´e feita atrav´es da compara¸c˜ao com os clusters obtidos atrav´es de simula¸c˜oes de casos de v´arios mapas sob a hip´otese nula, geradas por meio de simula¸c˜oes de Monte Carlo. Sob a hip´otese nula, casos simulados s˜ao distribu´ıdos aleatoriamente ao longo do mapa em estudo conforme a distribui¸c˜ao de Poisson, de forma que cada regi˜ao receba, em m´edia, um n´umero de casos proporcional `a sua popula¸c˜ao. Com isso, a estat´ıstica de testeT ´e calculada para o conjunto Pareto e este procedimento ´e repetido n vezes (Em que n´e o n´umero de simula¸c˜oes).
encontrar uma curva cr´ıtica acima do qual consideramos que um cluster seja significativo. Essa curva cr´ıtica divide o plano em duas regi˜oes de maneira que um ponto do plano no espa¸co Λ(z)×P(z) ser´a considerado um cluster significativo se estiver acima dessa curva.
Can¸cado (2009) apresenta trˆes t´ecnicas utilizadas na estima¸c˜ao desta curva cr´ıtica, nos problemas de otimiza¸c˜ao multiobjetivo. Nesta disserta¸c˜ao adotou-se o conceito das fun¸c˜oes de aproveitamento (FONSECA; FONSECA; PAQUETE,2005) descrita na Se¸c˜ao
2.4.
2.4.1
Fun¸c˜
oes de Aproveitamento
Considere um problema de otimiza¸c˜ao biobjetivo, com as fun¸c˜oes f1 e f2, e O o conjunto das solu¸c˜oes n˜ao-dominadas definidas no espa¸co de objetivos de uma ´unica execu¸c˜ao do algoritmo (Veja a Figura 9). O conjuntoOest´a associado a uma fronteira que divide o espa¸co de objetivos em duas regi˜oes R1 e R0. R1 ´e a regi˜ao de pontos dominados por, ou iguais a, pelo menos, um ponto em O e R0 a regi˜ao dos pontos que n˜ao s˜ao dominados por nenhum ponto em O. Uma solu¸c˜aox que ´e dominada por pelo menos uma solu¸c˜ao de um determinado resultado O, ´e dita atingida por O. Na Figura 9, qualquer solu¸c˜ao localizada na regi˜ao R1 atingida por O.
f1 f2
R
1R
0x1
x2
x3
x4
Consideren execu¸c˜oes do algoritmo. Como cada execu¸c˜ao produz resultados dife-rentes podemos obter m´ultiplas fronteiras. Com isso, pode-se dividir o espa¸co objetivo em
n+ 1 tipos de regi˜oes de acordo com a frequˆencia com que estas regi˜oes s˜ao atingidas. Os limites dessas regi˜oes s˜ao denominadas fronteiras de aproveitamento. Estas frequˆencias s˜ao usadas para estimar a probabilidade de atingir um ponto no espa¸co de objetivos, quando um grande n´umero de execu¸c˜oes do algoritmo s˜ao realizados.
A fun¸c˜ao de aproveitamento avaliada em algum pontoO no espa¸co objetivo pode ser estimada pelos conjuntos de resultados O1,... ,On obtido atrav´es de n execu¸c˜oes independentes do algoritmo, como:
An(O) = 1
n
n X
i=1
I(OiDO) (9)
Em que o s´ımbolo ”D” significa que Oi atingiu O eI ´e a fun¸c˜ao indicadora, assumindo o valor 1 se OiDO, e 0 caso contr´ario.
No problema em estudo estamos interessados em estimar o p-valor das solu¸c˜oes n˜ao-dominadas de clusters candidatos representados por pontos (Λ(z), P(z)) no espa¸co objetivo, em que P(z) ´e uma fun¸c˜ao de penaliza¸c˜ao.
3 Algoritmo Proposto
Este cap´ıtulo tem como objetivo apresentar o algoritmo proposto nesta disserta¸c˜ao para a aplica¸c˜ao ao problema de detec¸c˜ao e inferˆencia de clusters espaciais irregulares. Utilizou-se como base a t´ecnica de computa¸c˜ao evolucion´aria Particle Swarm Optimization
adotando uma abordagem de otimiza¸c˜ao multiobjetivo visando maximizar a estat´ıstica de teste e minimizar a fun¸c˜ao de penaliza¸c˜ao por dispers˜ao. As principais estruturas e etapas do algoritmo s˜ao apresentadas ao longo das se¸c˜oes deste cap´ıtulo.
3.1
Vis˜
ao Geral
O algoritmo MOBPSO (Multi-Objective Binary Particle Swarm Optimization) para o problema de detec¸c˜ao e inferˆencia de clusters espaciais irregulares ´e baseado na t´ecnica de computa¸c˜ao evolucion´aria Particle Swarm Optimization em sua vers˜ao bin´aria (KENNEDY; EBERHART, 1997) e no algoritmo MOPSO-CD (Mult-Objective Particle Swarm Optimization with Crowding Distance) proposto por Raquel e Naval Jr. (2005) para aplica¸c˜ao em problemas de otimiza¸c˜ao multiobjetivo.
No tratamento do problema atrav´es de uma abordagem multiobjetivo o algoritmo MOBPSO encontrar´a as solu¸c˜oes (clusters) atrav´es da maximiza¸c˜ao da estat´ıstica Scan
e minimiza¸c˜ao da fun¸c˜ao de penaliza¸c˜ao por dispers˜ao (vide se¸c˜ao 2.1.3). Ao longo das gera¸c˜oes do algoritmo e do emprego do conceito de dominˆancia das solu¸c˜oes (vide se¸c˜ao
2.2) obt´em-se como resultado um subconjunto de solu¸c˜oes n˜ao-dominadas, representadas pela fronteira Pareto- ´Otimo. O par (Λ(z),D(z)) representa, respectivamente, os valores da estat´ıstica Scan e o da fun¸c˜ao de penaliza¸c˜ao, computados para cada part´ıcula da popula¸c˜ao.
3.2
Aspectos Estruturais
Defini¸c˜ao 3 ( Grafo ). Um Grafo G ´e um par (V, E), em que V ´e um conjunto finito e
E ´e uma rela¸c˜ao bin´aria em V. O conjunto V ´e denominado conjunto de v´ertices de G, e
seus elementos s˜ao denominados v´ertices. O conjunto E ´e denominado conjunto de arestas
de G, e seus elementos s˜ao denominados arestas.
Para o problema em estudo adotou-se o modelo de grafo n˜ao orientado. Em um Grafo G(V, E) n˜ao dirigido, o conjunto E de arestas ´e constitu´ıda por pares de v´ertices n˜ao ordenados, ou seja, {u, v}, em que u, v ∈ V e u 6= v e as arestas (u, v) e (v, u) s˜ao consideradas as mesmas.
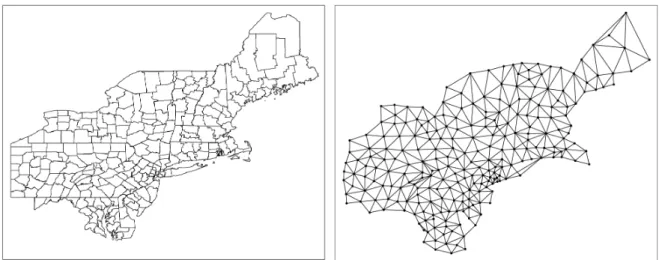
A Figura10 apresenta o mapa do nordeste dos Estados Unidos, dividido em um conjunto de regi˜oes (`a esquerda) e o grafo correspondente ao mapa (`a direita). Nesta representa¸c˜ao, as regi˜oes do mapa s˜ao simbolizadas pelo conjunto de V´ertices do Grafo. As rela¸c˜oes de vizinhan¸ca entre as regi˜oes, ou seja, quando uma regi˜ao r1 faz fronteira com uma regi˜ao r2 no mapa, s˜ao simbolizadas pelo conjunto de Arestas.
Figura 10 – Mapa do Nordeste dos Estados Unidos: `A esquerda um mapa dividido em um conjunto de regi˜oes; `A direita o grafo correspondente.
Solu¸c˜oes declusters adequadas para o problema s˜ao intrinsecamente caracterizadas pela conexidade das regi˜oes que o constitui. A representa¸c˜ao por meio de estruturas baseadas em grafos facilita a verifica¸c˜ao desta condi¸c˜ao diante do emprego do conceito de caminho.
Defini¸c˜ao 4 ( Caminho ). Um caminho de um v´ertice u a um v´ertice u′ em um Grafo
(V, E) ´e uma sequˆencia (v0, v1, v2, ..., vn) de v´ertices tais que u= v0, u′ =vn e (vi−1, vi)
Neste sentido, um grafo n˜ao dirigido ´e conexo se todo v´ertice pode ser alcan¸cado, ou seja, existe um caminho, por todos os outros v´ertices. Assim, a conexidade de um
cluster candidato representado como um subgrafo do grafo que representa as regi˜oes de um mapa em estudo pode ser validada.
3.2.1
Vari´
aveis de decis˜
ao
As solu¸c˜oes do problema em estudo podem ser representadas por meio de um vetor de vari´aveis bin´arias. Neste sentido, dado um mapa dividido emnregi˜oesR ={r1, r2, r3, ..., rn} e uma zona z como qualquer subconjunto de regi˜oes do mapa. Considere um vetor de vari´aveis bin´arias {x1, x2, x3, ..., xn}, em que xi = 1 se a i-´esima regi˜ao est´a presente na zona z ou xi = 0 caso contr´ario.
A Figura11simboliza a rela¸c˜ao descrita anteriormente em que (a) representa um conjunto de 12 regi˜oes e um subconjunto de regi˜oes ou zona em destaque (cinza) e (b) o vetor de vari´aveis bin´arias correspondente.
3.3
Inicializa¸
c˜
ao
A fase de inicializa¸c˜ao de um cl´assico algoritmo baseado na t´ecnica PSO compreende a gera¸c˜ao da popula¸c˜ao de part´ıculas (ou indiv´ıduos). Nesta fase, para cada part´ıcula ´e atribu´ıda uma posi¸c˜ao no espa¸co de busca do problema e uma velocidade, ambos de forma aleat´oria.
Todavia, na abordagem proposta, para o problema em estudo uma gera¸c˜ao aleat´oria comumente originar´a solu¸c˜oes invi´aveis implicando na necessidade de um maior n´umero de gera¸c˜oes para a convergˆencia de solu¸c˜oes vi´aveis. Uma estrat´egia adotada para contornar essa situa¸c˜ao ´e atrav´es de uma distribui¸c˜ao uniforme e gulosa da popula¸c˜ao de part´ıculas ao longo do mapa. Essa abordagem ´e utilizada no estudo de Can¸cado(2009) para o problema de detec¸c˜ao de clusters atrav´es do algoritmo gen´etico NSGA-II na gera¸c˜ao dos indiv´ıduos.
Nesta abordagem, como apresenta o Algoritmo 1, a popula¸c˜ao ´e gerada a partir de cada v´ertice vi do grafoG, que representa a instˆancia do mapa, gerando um subgrafo Gi. O processo de gera¸c˜ao continua com a constru¸c˜ao do conjunto de subgrafos Gis feita por meio de uma estrat´egia gulosa. Para cada v´erticevi, s˜ao selecionados os v´ertices vizinhos e escolhido aquele cuja zona tem maior valor da raz˜ao verossimilhan¸cas Λ(z) definida em1.
Algoritmo 1 - Pseudoc´odigo para a constru¸c˜ao gulosa da popula¸c˜ao de part´ıculas/indiv´ıduos.
1: function gerarPopulac¸˜ao(graf o G(V, E), pmgig)
2: n← N´umero de v´ertices do grafo G ( V, E );
3: for (i←1; i≤n; i←i+ 1) do
4: populacao[i] ← vi ∈Graf o G(V, E) ;
5: u1 ←vi;
6: for ( j ←2; j ≤pmgig; j ←j+ 1) do
7: uj ←v´ertice vizinho de uj−1 de maior Λ(z),uj ∈ {/ populacao[i]} ;
8: populacao[i] ← populacao[i] ∪ uj ;
9: returnpopulacao;
Apesar de parecer uma estrat´egia razo´avel para o problema em estudo, normalmente o m´etodo guloso, assim como para muitos problemas em que ele ´e aplicado, n˜ao encontra a solu¸c˜ao ´otima global, uma vez que o m´etodo n˜ao leva em conta todo o espa¸co de busca em que a fun¸c˜ao a ser otimizada est´a definida e restringe-se apenas a solu¸c˜oes ´otimas locais. Ocasionalmente, algumas das solu¸c˜oes encontradas pelo m´etodo guloso podem coincidir com a solu¸c˜ao ´otima global, todavia n˜ao existe garantia de que isso aconte¸ca (CANC¸ ADO,
2009).
3.4
Defini¸
c˜
ao dos guias pBest e gBest
O modelo global da t´ecnica PSO, adotado no algoritmo proposto para o problema desta disserta¸c˜ao, define duas principais m´etricas para a popula¸c˜ao de part´ıculas que s˜ao definidas ao longo das gera¸c˜oes, sendo eles os guias pBest egBest.
Na defini¸c˜ao do guiapBestem uma abordagem de otimiza¸c˜ao multiobjetivo aplica-se o conceito de dominˆancia das solu¸c˜oes (veja se¸c˜ao2.2). Em resumo, para uma determinada part´ıcula i se seu valor corrente pBesti for dominado pelo atual valor obtido pi por essa part´ıcula ent˜ao seu valor pBesti ´e atualizado para o novo valor obtido: pBesti =pi.
Crowding Distance (veja a se¸c˜ao3.4.1), definindo assim osgBesti para cada part´ıcula ida popula¸c˜ao.
3.4.1
Crowding Distance Computation
O mecanismo Crowding Distance Computation ´e originalmente incorporado ao algoritmo NSGA-II objetivando garantir uma melhor distribui¸c˜ao das solu¸c˜oes ao longo da fronteira de Pareto. O valor da Crowding Distance de uma determinada solu¸c˜ao fornece uma estimativa da densidade das solu¸c˜oes circundante a essa solu¸c˜ao (DEB et al.,2002). A Figura 12apresenta o c´alculo daCrowding Distance do pontoicomo sendo uma estimativa do tamanho do maior delimitador cuboide isem incluir qualquer outro ponto.
O c´alculo daCrowding Distance ´e inicializada classificando o conjunto de solu¸c˜oes em ordem ascendente dos valores das fun¸c˜oes objetivo. O valor Crowding Distance de uma solu¸c˜ao i particular ´e a distˆancia m´edia das suas duas solu¸c˜oes vizinhas: (i−1)&(i+ 1). As solu¸c˜oes de limite que tˆem o maior e menor valor de fun¸c˜ao objetivo s˜ao atribu´ıdas “valores infinitos” para a Crowding Distance de maneira que essas solu¸c˜oes s˜ao sempre
selecionadas. Este processo ´e feito para cada fun¸c˜ao objetivo.
O valor final daCrowding Distance de uma determinada solu¸c˜aoi ´e calculada pela soma dos valores individuais deCrowding Distance para cada fun¸c˜ao objetivo do problema. Um pseudoc´odigo para a Crowding Distance pode ser visto em 2, onde A simboliza o arquivo externo de solu¸c˜oes n˜ao dominadas e nf o o n´umero de fun¸c˜oes objetivos.
Algoritmo 2 - Pseudoc´odigo para aCrowding Distance Computation. 1: function CrowdingDistanceComputation(A, nf o)
2: n←size(A);
3: for (i←1;i≤n;i←i+ 1) do 4: DIST AN CE(i)←0;
5: for (i←1;i≤nf o;i←i+ 1) do 6: Asort ←sort(A, i);
7: DIST AN CE(1)← ∞; 8: DIST AN CE(n)← ∞;
9: for (j ←2;j ≤n−1;j ←j + 1) do
10: DIST AN CE(j)←DIST AN CE(j) + (Asort(j+ 1)−Asort(j −1));
11: returnDISTANCE;
3.5
Atualiza¸
c˜
oes da Velocidade e da Posi¸
c˜
ao
A t´ecnica PSO possui duas opera¸c˜oes fundamentais, respons´aveis por determinar um novo valor no espa¸co de busca do problema para as part´ıculas da popula¸c˜ao que s˜ao executadas tamb´em ao longo das gera¸c˜oes do algoritmo, sendo elas a atualiza¸c˜ao da velocidade e da posi¸c˜ao.
Na atualiza¸c˜ao da velocidade foi incorporado `a opera¸c˜ao o fator de constri¸c˜ao (K) como pode ser visualizado na equa¸c˜ao (10). O trabalho desenvolvido por Clerc (1999) indica o uso do fator de constri¸c˜ao como necess´ario, em alguns casos, para assegurar a convergˆencia da t´ecnica PSO.
vt+1
id =K[w tvt
Na atualiza¸c˜ao da posi¸c˜ao das part´ıculas foi empregada a mesma equa¸c˜ao, como pode ser revista em (11), adotada na extens˜ao do PSO para a aplica¸c˜ao em problemas que ocorrem em espa¸co de busca discreto, ou seja, bin´ario.
xid=
1, rand()< s(vid)
0 caso contr´ario.
(11)
Em que s(vid) = 1+exp1−vid, e rand() um n´umero aleat´orio positivo de distribui¸c˜ao uniforme
entre [0; 1.0]. E K ´e o fator de Constri¸c˜ao definido como: k = 2
|2−ϕ−√ϕ2−4ϕ| em que
ϕ =c1+c2, ϕ >4.
Os parˆametros a serem ajustados foram definidos da seguinte forma: os coeficientes
c1 ec2 com o valor 2.05;r1 e r2 como sendo um n´umero aleat´orio positivo uniformemente distribu´ıdo no intervalo [0; 1.0]; e o coeficiente de in´ercia w pela f´ormula w = wmax− ((i)/ni)×(wmax−wmin), em que wmax = 0.3, wmin = 0.2, ni n´umero de itera¸c˜oes do sistema e i o valor da itera¸c˜ao corrente. A velocidade das part´ıculas s˜ao limitadas por um fator vmax = 2.0.
3.6
Operador de Muta¸
c˜
ao/Turbulˆ
encia
O operador de muta¸c˜ao ou turbulˆencia, como recebe a denomina¸c˜ao em PSO, implementado para o algoritmo MOBPSO segue uma abordagem semelhante aos operadores descritos nos trabalhos de Can¸cado (2009) para o problema de detec¸c˜ao de clusters
irregulares atrav´es do algoritmo NSGA-II e Coello, Pulido e Lechuga(2004) para aplica¸c˜ao em abordagens PSO multiobjetivo.
A inclus˜ao de um operador de muta¸c˜ao tem como finalidade proporcionar maior capacidade explorat´oria ao algoritmo. Ela constitui uma opera¸c˜ao computacionalmente cara para o problema em quest˜ao, diante da necessidade de verifica¸c˜ao de conexidade do subgrafo obtido quando o novo indiv´ıduo ´e gerado. Todavia sua aplica¸c˜ao possui abrangˆencia reduzida sobre a popula¸c˜ao ao longo das gera¸c˜oes do algoritmo.
acrescentar ou remover um v´ertice neste indiv´ıduo, respeitando a restri¸c˜ao de que o subgrafo permane¸ca conexo. A escolha de acrescentar ou remover um v´ertice ´e aleat´oria, do mesmo modo que a escolha do v´ertice a ser acrescentado ou removido.
O Algoritmo3apresenta as principais etapas do operador de muta¸c˜ao implementado. As vari´aveistxpetxptbsimbolizam a subpopula¸c˜ao selecionada para a aplica¸c˜ao da muta¸c˜ao e a taxa de pertuba¸c˜ao que ser´a aplicada sobre os indiv´ıduos selecionados, respectivamente. A Figura13ilustra a aplica¸c˜ao do operador de muta¸c˜ao em um indiv´ıduo a um pertuba¸c˜ao inicial. Em b) um v´ertice ´e inclu´ıdo ao indiv´ıduo e em c) um v´ertice ´e exclu´ıdo do indiv´ıduo.
Algoritmo 3 - Pseudoc´odigo para o Operador de Muta¸c˜ao. 1: function OperadorDeMutacao(txp, txptb)
2: n← tamanho de txp;
3: for (i←1;i≤n;i←i+ 1) do
4: pi ←indiv´ıduo i detxp;
5: for (j ←1;j ≤txptb;j ←j+ 1) do
6: v ← selecione aleatoriamente um v´ertice de pi;
7: r ← aleat´orio( 0 , 1 );
8: if (r= 1) then
9: vz ← selecione aleatoriamente um v´ertice vizinho dev;
10: M P ← {vz} ∪pi;
11: if (r= 0) then 12: M P ← pi\ {v};
13: if M P nao ´e um graf o conexothen 14: M P ←pi;
15: pi ←M P;
2
3 4 5 6
7 8 9 10
11 12
1
2
3 4 5 6
7 8 9 10
11 12
1 2
3 4 5 6
7 8 9 10
11 12
1 a)
c) b)
Figura 13 – Aplica¸c˜ao do operador de muta¸c˜ao em um indiv´ıduo (a): inclus˜ao de v´ertice no indiv´ıduo (b); e exclus˜ao de v´ertice no indiv´ıduo(c).
3.7
Pseudoc´
odigo do MOBPSO
O Algoritmo4 descreve a sequˆencia de execu¸c˜ao das principais etapas do algoritmo MOBPSO para o problema de detec¸c˜ao e inferˆencia de clusters espaciais, que foram descritas previamente nas se¸c˜oes deste cap´ıtulo.
A linha 2 ´e respons´avel pela chamada ao m´etodo gerador da popula¸c˜ao inicialP das part´ıculas pela estrat´egia gulosa descrita na se¸c˜ao 3.3. A linha 3 inicializa a velocidade V
ocorre a defini¸c˜ao do guia gbest para as part´ıculas da popula¸c˜ao P como relata a se¸c˜ao
3.4. Nas linhas 11 a 13 ocorrem a aplica¸c˜ao das opera¸c˜oes de atualiza¸c˜ao de velocidade e posi¸c˜ao das part´ıculas em P, se¸c˜ao3.5. E por ´ultimo, na linha 14, ocorre a incidˆencia do operador de muta¸c˜ao em P como definido na se¸c˜ao 3.6.
Algoritmo 4 - Pseudoc´odigo do MOBPSO para o problema de detec¸c˜ao de clusters
espaciais irregulares.
1: function MOBPSO(c1, c2, vmax, np, nd, ng, pmut, pmgig )
2: P ← Gerar a popula¸c˜ao de part´ıculas pelo m´etodo guloso;
3: V ← Inicializar a velocidade de cada part´ıcula deP de forma aleat´oria;
4: for (i←1;i≤ng;i←i+ 1) do
5: Calcular o valor para o componente de in´erciaw;
6: Avaliar as part´ıculas deP;
7: Selecionar o guia pBestde cada part´ıcula de P;
8: Armazenar as solu¸c˜oes n˜ao dominadas em um arquivo externo A;
9: Calcular a Crowding Distance das solu¸c˜oes de A e classific´a-las em ordem decrescente do valor;
10: Selecionar aleatoriamente de uma por¸c˜ao especifica de 10% do topo de A o guia gBest para cada part´ıcula de P;
11: Atualizar a velocidade v e a posi¸c˜aox de cada part´ıcula de P de acordo com as equa¸c˜oes:
12:
vtid+1 =K[wtvtid+c1r1(pid−xtid) +c2r2(gid−xtid)]
13:
xid = (
1, rand()< s(vid) 0 caso contr´ario.
14: Aplicar o operador de Muta¸c˜ao em P;
Uma das etapas fundamentais na concep¸c˜ao do algoritmo envolve a configura¸c˜ao ou ajuste dos parˆametros respons´aveis pelo correto funcionamento e que se adequam ao tipo de problema. Os principais parˆametros a serem definidos no algoritmo MOBPSO s˜ao:
• w, c1 e c2 : componentes de in´ercia, cognitivo e social, respectivamente;
• np: N´umero de part´ıculas da popula¸c˜ao;
• nd: N´umero de dimens˜oes do problema;
• ng: N´umero de gera¸c˜oes;
• pmut: Probabilidade de muta¸c˜ao; e
• vmax: Velocidade m´axima.