Avaliação Estatística sobre o Reconhecimento de Dígitos Manuscritos
Everton B. Lacerda, Jefferson O. A. de Araújo, Roberto H. W. Pinheiro, Silvio S. Bandeira
Centro de InformáticaUniversidade Federal de Pernambuco Recife, Brasil
ebl3@cin.ufpe.br, joaa@cin.ufpe.br, rhwp@cin.ufpe.br, ssb@cin.ufpe.br
Abstract— The main goal of this work is to investigate the recognition of handwritten digits. This task is of capital importance in many applications and institutions as banks. Seven classifier configurations are presented and compared using samples from a known database. The performances of those configurations are tested using statistical methods to ensure comparison with mathematical grounding to determine the best configuration.
Palavras-chave; reconhecimento; dígitos manuscritos; máquinas de vetores de suporte; teste de hipótese
I. INTRODUÇÃO
O reconhecimento de caracteres é uma atividade de grande importância na sociedade. Principalmente, quando se considera a necessidade crescente de integração entre informações em meio físico e meio digital. O reconhecimento de caracteres manuscritos se torna uma tarefa bastante difícil devido à variedade de estilos de escrita entre pessoas diferentes, e até mesmo da mesma pessoa com o passar do tempo.
Nesse contexto, o reconhecimento de dígitos manuscritos se torna crucial em várias aplicações como: o processamento automático de cheques bancários [1], onde é necessário obter o valor correto do cheque, visto que caso contrário, haverá prejuízos para o banco ou para o cliente; o endereçamento automático de envelopes postais por meio da leitura do CEP (Código de Endereçamento Postal) [2], data ou dados de catálogo em documentos históricos, o que permitiria a indexação automática do acervo.
Devido aos altos custos envolvidos quando há erros de reconhecimento, sempre existe a demanda por classificadores mais precisos, ou de outra forma, com taxas de acerto mais altas.
Nesse cenário, foi proposto um classificador que obteve muito bom desempenho no reconhecimento de dígitos manuscritos em [3]. O método citado se baseia em um conjunto de SVMs (Máquinas de Vetores de Suporte) [4] que analisam cada par de dígitos possível (0 a 9), não importando a ordem em que eles aparecem, constituindo assim 45 pares e, por conseguinte, 45 SVMs.
Este trabalho faz uma investigação sobre a melhor configuração de parâmetros do classificador sob estudo, no que tange a seus parâmetros (função de kernel e respectivo
parâmetro interno). O texto se organiza da seguinte maneira: a Seção II apresenta os conceitos estatísticos relacionados à
comparação entre classificadores. A Seção III descreve os experimentos, e a Seção IV mostra a análise exploratória dos dados. Na Seção V, ilustram-se os resultados obtidos. Por fim, a Seção VI conclui o trabalho.
II. COMPARAÇÃO ENTRE CLASSIFICADORES No presente projeto, deseja-se comparar os desempenhos dos algoritmos de modo a determinar se algum ou alguns deles são superiores aos demais, com fundamentação matemática e não apenas com uma análise informal ou empírica. Os testes de hipóteses estatísticos são, portanto, adequados e fundamentais para essa comparação. Pode-se determinar, baseando-se em um número adequado de amostras, se os desempenhos são diferentes ou equivalentes, como também, quais são os melhores.
III. ESPECIFICAÇÕES DOS EXPERIMENTOS
A. Base de dados
As imagens de dígitos foram extraídas da base NIST SD19 [5], que é uma base de formulários numéricos, disponibilizada pelo NIST (National Institute of Standards and Technology, dos Estados Unidos da América). Cada
imagem contém variadas quantidades de dígitos, como se pode ver na Figura 1.
Figura 1: Exemplos da base NIST SD19.
Os dígitos foram isolados por um algoritmo de segmentação específico para esse fim, baseado em componentes conectados [6]. Isso foi feito para separar cada dígito e armazenar em uma imagem individual. Depois disso, cada número foi rotulado com sua saída desejada, para possibilitar o uso de aprendizagem supervisionada.
Como os dígitos não têm o mesmo tamanho realizou-se uma padronização, fazendo com que cada um fosse uma imagem 20x25 (Figura 2). Essas dimensões de imagem foram definidas empiricamente. O próximo passo consiste em encontrar as coordenadas que delimitam os dígitos usando projeções horizontais e verticais [7].
Figura 2: Imagens de dígitos redimensionadas para 20x25.
B. Metodologia dos experimentos
A experimentação se baseia no esquema de holdout
estratificado [8]. O procedimento holdout consiste em
reservar certa quantidade de dados para teste, e o restante para treinamento. Normalmente, também sendo a configuração utilizada neste trabalho, usa-se 1/3 dos dados para teste e consequentemente 2/3 para a aprendizagem. Emprega-se uma amostragem estratificada para manter as proporções entre as classes da base como um todo em cada conjunto. Isso garante que se tenham exemplos de todas as classes nos conjuntos de treino e teste, além de facilitar a aprendizagem e também refletir a distribuição dos dados na construção da superfície de decisão.
Costuma-se repetir o holdout um número razoável de
vezes, visto que uma única execução pode trazer estimativas de desempenho não confiáveis. A ideia é que ao analisar o desempenho geral do método considerando todas as repetições, ter-se-á uma estimativa mais confiável do poder de generalização do modelo, ou seja, sua confiabilidade ao analisar novos exemplos.
Assim, teremos trinta taxas de acerto para cada um dos sete classificadores analisados. Esses dados correspondem às entradas para os testes de hipótese.
C. Implementações
As implementações deste trabalho foram realizadas em dois softwares/linguagens: o R [9] e o MATLAB [10].
Especificamente, no R se fez toda a parte de análise dos dados, e a maior parte dos testes de hipótese (com exceção do teste de Lilliefors, que foi feito no MATLAB).
D. Variáveis estudadas
Basicamente, a variável a ser estudada e analisada na pesquisa é a taxa de acerto média dos classificadores. Isso ocorre porque se deseja verificar se os desempenhos deles são equivalentes ou não, e de forma natural, determinar qual classificador apresenta melhor desempenho. Assim, os testes de hipótese visam dar suporte à determinação da melhor configuração de parâmetros do classificador de dígitos manuscritos utilizado.
Não se fez uma análise de tempo porque como estamos estudando várias configurações do mesmo algoritmo, os tempos de treinamento são praticamente os mesmos, não importando o classificador em questão.
IV. ANÁLISE EXPLORATÓRIA
Nesta seção descrevemos os dados da pesquisa, fazendo um estudo descritivo através das medidas estatísticas (apresentado na Tabela 1), gráficos box-plot das amostras
(Figura 3) e dos histogramas (Figura 4). Além disso, fazemos
os testes de aderência para verificação da normalidade dos dados.
A. Estatística descritiva
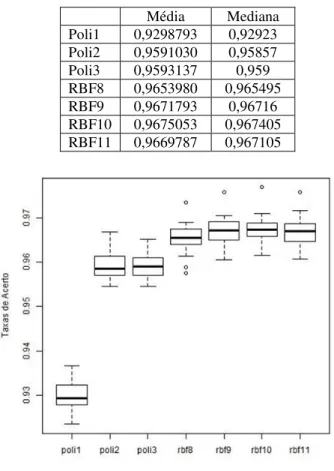
Calculamos a média, desvio padrão e mediana dos algoritmos em estudo (Tabela I). Não foi incluída a moda nas medidas pelo fato de os dados serem contínuos. Como pode se observar na Tabela I, as médias e medianas são bastante próximas para cada classificador. Isso indica certa tendência à normalidade visto que na distribuição normal, a média e a mediana são iguais.
TABELA 1: ESTATÍSTICA DESCRITIVA DOS ALGORITMOS
Média Mediana
Poli1 0,9298793 0,92923 Poli2 0,9591030 0,95857 Poli3 0,9593137 0,959 RBF8 0,9653980 0,965495 RBF9 0,9671793 0,96716 RBF10 0,9675053 0,967405 RBF11 0,9669787 0,967105
Figura 3: Gráficos box-plot das amostras.
A observação visual dos dados apresentados na Figura 3 já mostra uma tendência à normalidade, em especial os resultados dos algoritmos RBF.
Figura 4: Histogramas das amostras.
B. Testes de aderência
A confirmação das amostras seguirem uma distribuição normal foi obtida realizando os testes de aderência. Dois testes foram executados com as amostras padronizadas: Kolmogorov-Smirnov [11] e Lilliefors [12] (Tabela 2). A padronização dos dados foi necessária porque os testes se baseiam na diferença entre a distribuição normal padrão e a distribuição da amostra. Logo, se as amostras não são padronizadas, o resultado do teste tende a rejeitar a hipótese de normalidade, já que provavelmente não se tem amostras com média zero, e variância um, como a normal padrão.
Em todas as tabelas, adotamos a convenção “Poli” para os núcleos polinomiais, e o parâmetro interno de cada função
kernel é descrito pelo número ao lado do nome da função.
TABELA 2:P-VALUES DOS TESTES DE ADERÊNCIA
P-values
Kolmogorov-Smirnov Lilliefors
Poli1 0,7350677 0,2612
Poli2 0,9120706 0,5000*
Poli3 0,9595365 0,5000*
RBF8 0,8051991 0,3613
RBF9 0,8966829 0,5000*
RBF10 0,6535829 0,2236
RBF11 0,7211455 0,2981
Considerando que todos os p-values foram superiores ao
nível de significância empregado (5%), a hipótese nula não é rejeitada e, portanto ambos os testes de aderência indicam que as amostras se aproximam de uma distribuição normal.
V. RESULTADOS
A. Formulação das hipóteses
Como o objetivo da pesquisa é determinar se há diferença de desempenho entre os algoritmos e, em caso positivo, qual(is) é(são) o(s) melhor(es), precisamos testar os resultados dos algoritmos aos pares. Essa estratégia é justificada, inclusive, pelo fato de as mesmas 30 amostras terem sido usadas para todos os algoritmos.
Dessa forma, para cada par de algoritmos, testamos duas hipóteses, nesta ordem: médias iguais ou diferentes , médias iguais ou média do primeiro ser maior que a do segundo. Caso o segundo teste não rejeite a hipótese nula, conclui-se que a média do primeiro algoritmo é menor. Os testes foram realizados utilizando o t-student pareado [11], com nível de
significância 5%.
A decisão da comparação é dada pelo fluxograma da Figura 5.
B. Testes de hipóteses
O método de Friedman com o pós-teste de Nemenyi foi utilizado como teste alternativo para comparação entre classificadores. A distribuição de teste escolhida foi a chi-quadrado ao invés de Friedman, pois existem 30 amostras de 7 classificadores como aponta [13], com α = 0,05. Para o pós-teste de Nemenyi ,
q
0,05 = 2,949.Com p-value = 2,369791e-31, rejeitamos a hipótese de
que os classificadores eram iguais. Com o valor crítico de Nemenyi, CD = 1,644874, foi possível encontrar as diferenças críticas entre pares de classificadores isolados, apresentados na Tabela 3. A Tabela 4 mostra as diferenças entre os rankings na comparação par a par feita no pós-teste
de Nemenyi. Estes valores são usados para decidir se há diferença ou não entre os classificadores, comparando a diferença entre o par com o valor crítico (se for maior ou igual, há diferença significativa entre os classificadores).
TABELA 3:RESULTADOS DO TESTE DE FRIEDMAN
Poli2 Poli3 RBF8 RBF9 RBF10 RBF11
Poli1 ≈ ≈ ≠ ≠ ≠ ≠
Poli2 ≈ ≠ ≠ ≠ ≠
Poli3 ≠ ≠ ≠ ≠
RBF8 ≈ ≠ ≈
RBF9 ≈ ≈
RBF10 ≈
TABELA 4:DIFERENÇAS ENTRE RANKINGS.
Poli2 Poli3 RBF8 RBF9 RBF10 RBF11
Poli1 1.50000 1.56667 3.28333 4.91667 5.30000 4.43333
Poli2 0.06667 1.78333 3.41667 3.80000 2.93333
Poli3 1.71667 3.35000 3.73333 2.86667
RBF8 1.63333 2.01667 1.15000
RBF9 0.383333 0.483333
RBF10 0.866667
A comparação dos algoritmos aos pares está resumida na Tabela 5. Os sinais de menor, maior e equivalente dizem respeito à comparação do algoritmo da linha com o da coluna. Na Tabela 6 temos um ou dois p-values de acordo
com a quantidade de hipóteses testadas para se chegar ao resultado (vide Figura 5).
Os espaços em branco na diagonal principal da tabela representam o que seria a comparação de um algoritmo com ele mesmo. Os demais representam comparações já realizadas na parte superior à diagonal principal.
Os resultados das comparações nos levam à conclusão que o algoritmo RBF10 obteve o melhor desempenho no reconhecimento de dígitos manuscritos. Podemos ainda montar um ranking baseado nos desempenhos dos
algoritmos, como segue: 1. RBF10
2. RBF9, RBF11 3. RBF8 4. Poli3, Poli2 5. Poli1
TABELA 5:RESULTADOS DO TESTE T.
Poli2 Poli3 RBF8 RBF9 RBF10 RBF11
Poli1 < < < < < <
Poli2 ≈ < < < <
Poli3 < < < <
RBF8 < < <
RBF9 < ≈
RBF10 >
TABELA 6:P-VALUES DO TESTE T.
Poli2 Poli3 RBF8 RBF9 RBF10 RBF11
Poli1 8,481e-28 1,0000000 4,851e-27 1,0000000 9,382e-29 1,0000000 1,277e-29 1,0000000 2,960e-30 1,0000000 9,105e-30 1,0000000 Poli2
0,7636 1,0000000 7,367e-11 1,0000000 3,402e-14 1,0000000 5,526e-14 1,0000000 9,580e-13
Poli3 2,641e-13
1,0000000 1.855e-15 1,0000000 3.343e-16 1,0000000 4.377e-16 1,0000000
RBF8 4,542e-11
1,0000000 1,0000000 5,073e-09 0.9999971 5,850e-06
RBF9 0,0372400
0,98138 0,3696756
RBF10 0,000975
0,000487
VI. CONCLUSÕES
classificador baseado em um conjunto de SVMs, variando a função kernel e seu parâmetro interno.
Assim, fez-se a análise exploratória dos dados relativos ao desempenho dos classificadores, e construíram-se as hipóteses para fazer a avaliação dos mesmos. A partir da análise exploratória, e das hipóteses formuladas, aplicaram-se os testes adequados para determinar qual classificador obteve melhor desempenho.
Os resultados evidenciaram que a configuração com
kernel RBF e desvio igual a 10 foi superior às demais.
Portanto, pode-se dizer que essa configuração deve ser usada ao se empregar esse classificador para o reconhecimento de dígitos manuscritos.
REFERÊNCIAS
[1] C. A. B. Mello et al., “An efficient thresholding algorithm for
brazilian bank checks,” ICDAR 2007, Brazil, vol. 1, pp. 193-197. [2] T. Akiyama et al., “Handwritten address interpretation system
allowing for non-use of postal codes and omission of address elements,” IWFHR 2004, Japan, pp. 527-532.
[3] Neves et al., “A SVM based off-line digit recognizer,” SMC 2011,
Anchorage, USA, pp. 510-515.
[4] Cortes, C. and Vapnik, V. Support-Vector Networks. “Machine Learning”, vol. 20, no. 3, pp. 273-297, 1995.
[5] NIST Special Database 19. Handprinted Forms and Characters Database. Link: http://www.nist.gov/srd/nistsd19.cfm. Acessado em junho, 2013.
[6] E. R. Davies, “Machine Vision”, Morgan Kaufmann, 3rd ed, 2005. [7] J. R. Parker, “Algorithms for Image Processing and Computer Vision,
John Wiley and Sons, 1997.
[8] R. O. Duda, P. E. Hart and, D. G. Stork, “Pattern Classification”,
John Wiley and Sons, 2nd ed, 2001.
[9] R Project for Statistical Computing. Link: http://www.r-project.org/. Acessado em junho, 2013.
[10] MATLAB, Mathworks.The language of technical computing. Link: http://www.mathworks.com/products/matlab/. Acessado em junho, 2013.
[11] D. C. Montgomery and G. C. Runger, “Estatística Aplicada e Probabilidade para Engenheiros”, LTC, 5ª ed, 2012.
[12] H. W. Lilliefors, “On the Kolmogorov-Smirnov test for normality with mean and variance unknown.”,Journal of the American Statistical Association. vol. 62, pp. 399–402, 1967.