Home Pesquisar: Autor Título Ano Evento Periódico Listar: Eventos Periódicos Trabalhos Recentes Curadoria Revista Brasileira de Redes de Computadores e Sistemas Distribuídos - Volume 1
7 registros retornados Número 1 - Ano 2008
Luci Pirmez, Lisandro Zambenedetti Granville. Edição completa. 1 - 73 Luci Pirmez, Lisandro Zambenedetti Granville. Carta dos editores. 7 - 8
Carlo K. S. Rodrigues, Luiz J. H. Filho, Rosa M. M. Leão. Técnicas para Sistemas de Vídeo sob Demanda Escaláveis. 9 - 22
André Soares, José Maranhão, William Giozza, Paulo Cunha. First Load Priority: A Wavelength Converter Placement Scheme for Optical
Networks. 23 - 35
Igor M. Moraes, Otto C. M. B. Duarte. Um Mecanismo de Controle de Admissão Baseado no Grau de Ocupação para Redes Ópticas. 37 -50
Regina Borges de Araujo, Leandro Villas, Azzedine Boukerche. Uma Solução de QoS com Processamento Centrado para Redes de
Atuadores e Sensores sem Fio. 51 - 60
André O. Castelucio, Ronaldo M. Salles, Artur Ziviani. Uma Rede Sobreposta no Nível de Sistemas Autônomos para Rastreamento de Tráfego IP. 61 - 73
Home Pesquisar: Autor Título Ano Evento Periódico Listar: Eventos Periódicos Trabalhos Recentes Curadoria
Biblioteca Digital Brasileira de Computação - Contato: [email protected]
Home Pesquisar: Autor Título Ano Evento Periódico Listar: Eventos Periódicos Trabalhos Recentes Curadoria
Técnicas para Sistemas de Vídeo sob Demanda Escaláveis Carlo K. S. Rodrigues, Luiz J. H. Filho, Rosa M. M. Leão.
Este trabalho apresenta a nova técnica de compartilhamento de banda chamada Merge Interativo (MI). Também são propostas duas novas políticas de gerência de buffer: Unique Buffer (UB) e Precise Buffer (PB). Por meio de simulações, usando cargas geradas a partir deservidores de multimídia reais, validamos nossas propostas e realizamos detalhadas análises competitivas com outras propostas da literatura. Os resultados mostram que combinando a técnica MI com as políticas de gerência de buffer podemos obter otimizações significativas nos valores de banda média, pico de banda e complexidade do sistema.
http://www.lbd.dcc.ufmg.br/colecoes/rbresd/1/1/003.pdf
Caso o link acima esteja inválido, faça uma busca pelo texto completo na Web: Buscar na Web
Home Pesquisar: Autor Título Ano Evento Periódico Listar: Eventos Periódicos Trabalhos Recentes Curadoria
Biblioteca Digital Brasileira de Computação Contato: [email protected]
sob Demanda Escaláveis
∗
Carlo K. S. Rodrigues
1,2, Luiz J. H. Filho
2& Rosa M. M. Leão
2 1Centro de Desenvolvimento de SistemasDepartamento de Ciência e Tecnologia Exército Brasileiro
QGEx - Bloco G - 20Piso - Ala Norte CEP 70630-901 - Brasília - DF - Brasil Fone: +55 (61) 3415-6800 - FAX: +55 (61) 3415-6848
{carlokleber}@gmail.com.br
2Programa de Engenharia e Sistemas de Computação - PESC/COPPE
Universidade Federal do Rio de Janeiro
CEP 21941-972 - CxP 68511 - Rio de Janeiro - RJ - Brasil Fone: +55 (21) 2562 8664 - FAX: +55 (21) 2562 8676
{ljhfilho | rosam }@land.ufrj.br
Abstract
This work introduces the novel bandwidth sharing technique denoted as Merge Interativo (MI). Addition-ally, two new policies for exploiting the client’s buffer-ing capability are also proposed: Unique Buffer (UB) and Precise Buffer (PB). Throughout trace-driven simu-lations, using workloads generated from real multimedia servers, we validate our proposals and carry out detailed competitive analyses with other proposals in the litera-ture. Our results show that combining the MI technique with the buffering policies makes it possible to achieve quite significant overall reductions at average bandwidth, peak bandwidth and system complexity.
Keywords: Video on Demand, Multicast, Multime-dia, Buffering, Bandwidth sharing
Resumo
Este trabalho apresenta a nova técnica de comparti-lhamento de banda chamada Merge Interativo (MI). Tam-bém são propostas duas novas políticas de gerência de buffer: Unique Buffer (UB) e Precise Buffer (PB). Por meio de simulações, usando cargas geradas a partir de servidores de multimídia reais, validamos nossas pro-postas e realizamos detalhadas análises competitivas com outras propostas da literatura. Os resultados mostram que combinando a técnica MI com as políticas de gerên-cia de buffer podemos obter otimizações significativas nos
∗Este trabalho é parcialmente financiado pelo CNPq e Faperj.
valores de banda média, pico de banda e complexidade do sistema.
Palavras-chave: Vídeo sob Demanda, Multicast,
Multimídia, Buffering, Compartilhamento de banda
1. I
NTRODUÇÃOOs sistemas de vídeo sob demanda (VoD – Video on Demand) com interatividade têm recebido crescente
atenção nos últimos anos. Idealmente, para implementar esses sistemas, o servidor deve alocar um canal de trans-missão de dados exclusivo para cada cliente, permitindo a emulação de ações de interatividade de um aparelho co-mum de DVD (Digital Video Disc). Entretanto, como
a banda do servidor é um recurso limitado, esta imple-mentação é inviável quando muitos usuários simultâneos precisam ser atendidos. Para fins de análise, vemos o aumento da escalabilidade desses sistemas em duas di-reções: técnicas de compartilhamento de banda [26, 25, 22, 13] e estratégias (políticas) de gerência debuffer[1,
21, 20].
intera-tividade do cliente, e a união de fluxos é conseguida pela escuta concomitante de dois fluxos. A proposta de [21] utiliza uma taxa de transmissão duas vezes maior que a normal para permitir a união de fluxos.
Os trabalhos de [18, 20, 22, 24, 25] são mais recentes e baseiam-se nos paradigmas de acesso seqüencial Patch-ing e Hierarchical Stream MergPatch-ing (HSM) [16, 13]. Estas técnicas diferenciam-se entre si na condição de que a es-trutura de união de fluxos tem um determinado número de níveis permitidos. Por exemplo, quando são permiti-dos três níveis, um dado cliente pode escutar um outro cliente que, por sua vez, escuta um outro cliente do sis-tema, constituindo assim uma árvore de altura três [5].
Em relação às estratégias de gerência de buffer, as
duas abordagens mais utilizadas na literatura são: Sim-ple Buffer (SB) [28, 8, 27] e ComSim-plete Buffer (CB) [20, 24, 22, 25, 27]. A primeira tem por principal finalidade permitir a sincronização da escuta de dois fluxos simultâ-neos que transmitem o mesmo objeto. O tamanho do
bufferlocal do cliente é determinado pelo tempo de
es-cuta simultânea permitido para o cliente, e nunca precisa ser maior que a metade da duração total do objeto [5]. O primeiro fluxo é utilizado para transmitir as informações (unidades de dados) que o cliente precisa visualizar in-stantaneamente. Já o segundo fluxo transmite unidades de dados que são visualizadas a partir de um instante futuro. As unidades de dados do segundo fluxo são armazenadas embufferlocal. No instante em que a unidade de dados
do primeiro fluxo alcançar a primeira unidade de dados armazenada embuffer(proveniente do segundo fluxo), o
cliente deixa de escutar o primeiro fluxo e passa a ler di-retamente de seubuffer. O primeiro fluxo pode então ser
extinto, redundando em economia de banda do sistema. O segundo fluxo permanece ativo e tendo suas unidades de dados armazenadas embufferlocal.
Já a abordagem Complete Buffer (CB) fundamenta-se na idéia de que o comportamento interativo do cliente o faz naturalmente realizar acessos a unidades de da-dos anteriormente já visualizadas. Sendo isso verdade, a otimização de banda pode ser conseguida ao se permi-tir que as unidades de dados transmitidas pelo servidor sejam permanentemente armazenadas embufferlocal
du-rante uma mesma sessão, i.e., enquanto o cliente estiver visualizando o objeto em uma mesma sessão, os dados de seubufferlocal não são removidos. Quando o cliente
re-aliza uma requisição para uma dada unidade de dados do objeto, primeiramente é verificado se a unidade de dados solicitada já não está embufferlocal. Se a resposta for
afirmativa, o cliente é atendido localmente, sem abertura de um novo fluxo e sem a tentativa de realizar compar-tilhamento com qualquer outro fluxo. Nessa estratégia o tamanho dobufferlocal é igual ao tamanho do objeto.
Este trabalho apresenta a nova técnica de comparti-lhamento de banda Merge Interativo (MI). Esta técnica é
baseada no paradigma de HSM [16, 13]. Também temos a apresentação de duas novas estratégias de gerência de
buffer: Unique Buffer (UB) e Precise Buffer (PB). A
primeira fundamenta-se na idéia de empregar um único
buffer compartilhado por todos os clientes de uma rede
local que desejam assistir a um mesmo objeto, e a se-gunda é baseada na condição de se verificar a quantidade de informação já disponível em bufferlocal para então
decidir sobre abertura e extinção de fluxos no sistema. Por meio de simulações, validamos as nossas propostas e realizamos análises comparativas detalhadas com out-ros trabalhos da literatura, utilizando diferentes métricas de performance. Dentre outras constatações, os resulta-dos obtiresulta-dos mostram principalmente que, em comparação com as abordagens mais convencionais, podemos obter otimizações no intervalo de5%−98%em valores médio
de banda, pico de banda e complexidade do sistema. O restante deste trabalho tem a seguinte organização. A Seção 2 revisa as mais recentes propostas de técnicas de compartilhamento de banda baseadas nos paradigmas de Patching e de HSM. A nova técnica Merge Interativo (MI) está na Seção 3. As novas estratégias de gerência debufferUB e PB estão na Seção 4. A Seção 5 traz os
mais importantes resultados de simulação então obtidos. Por último, as conclusões e as propostas para trabalhos futuros constituem a Seção 6.
2. C
OMPARTILHAMENTO DE BANDAConsidere um grupo de clientes recebendo fluxos de dados relativos a um objeto multimídia armazenado em um servidor através de uma rede de comunicação. O objeto é dividido em unidades de dados u de mesmo tamanho e de duração de uma unidade de tempo. A rede tem multicast implementado (camada IP ou camada de
aplicação). Os clientes têm acesso não-seqüencial, i.e., podem realizar ações de interatividade. O cliente possui
buffer local capaz de armazenar pelo menos metade do
objeto requisitado e sua banda corresponde a duas vezes a taxa de exibição desse objeto. Por fim, os fluxos de dados transmitem (individualmente) na mesma taxa de exibição do objeto. Doravante, salvo informado difer-entemente, assumimos estas suposições no restante deste texto [5, 2, 22, 18, 5].
essenci-ais: máxima eficiência e simplicidade.
2.1. TÉCNICAPATCHINGINTERATIVO– PI
Na técnica Patching Interativo (PI) a chegada de uma requisição é o único evento que pode provocar uma união de fluxos no sistema. SejauW a unidade de dados do ob-jeto correspondente ao tamanho da janela ótimaWda téc-nica Patching original [14, 7], (p. ex., seW= 12 s e o ob-jeto é dividido em unidades de 1 s cada, entãouW = 12), e sejaSW um fluxomulticastque transmite, no instante da chegada da requisição, uma unidade de dados anterior ou igual à uW. Para efeito de análise, assuma que uma requisição ocorre para uma dada unidade ur do objeto. A tomada de decisões neste algoritmo se dá em função de dois casos:ur= 1eur6= 1, onde1representa a primeira (inicial) unidade do objeto.
• Caso 1: ur = 1–SeSW existe e está transmitindo uma unidade de dados posterior àur, então a req-uisição é atendida pelo mesmo e as unidades even-tualmente perdidas (patch) são enviadas através de
um fluxounicast. SeSW não existe então um novo fluxomulticasté aberto para atender a requisição.
• Caso 2: ur 6= 1– Neste caso inicialmente é ver-ificado se existe um fluxo multicast Sbef ore, i.e., um fluxo transmitindo uma unidade de dados an-terior à ur dentro de um limiar de tempo δbef ore. Se este fluxo existe, então a requisição é atendida pelo mesmo. Caso contrário, é verificado se ex-iste um fluxomulticastSaf ter, i.e., um fluxo trans-mitindo uma unidade de dados posterior àure den-tro de um limiar de tempoδaf ter. Se este fluxo ex-iste então o servidor informa ao cliente para escutar Saf ter e abre um novo fluxounicastpara transmitir as unidades inicialmente perdidas (patch). Por outro
lado, seSaf ternão existe, então um novo fluxo
mul-ticastSnewé aberto para servir a requisição porur.
2.2. PATCHINGINTERATIVOEFICIENTE– PIE Semelhante à técnica PI, a chegada de uma requisição também é o único evento que provoca a união de fluxos na técnica Patching Interativo Eficiente (PIE). A seguir descrevemos sua operação.
Evento Único: Requisição para unidadeur. • Inicialmente busca-se um fluxo multicast Sbef ore,
i.e., um fluxo transmitindo uma unidade de dados igual ou anterior àur, dentro de um limiar de tempo δbef ore. Ou seja, Sbef ore pode estar transmitindo desde a unidadeur−δbef ore até a unidadeur. Se Sbef ore existe, então a requisição é atendida pelo mesmo.
• SeSbef orenão existe, é verificado se existe um fluxo
multicast Saf ter, i.e., um fluxo transmitindo uma
unidade de dados posterior àur, dentro de um lim-iar de tempo δaf ter. Ou seja, Saf ter pode estar transmitindo desde a unidadeur+ 1até a unidade ur +δaf ter. Se Saf ter existe, o servidor diz ao cliente para escutá-lo e abre um fluxounicast(i.e.,
umpatch) para transmitir as unidades perdidas
ini-cialmente.
• SeSaf ternão existe, um novo fluxomulticastSnew é aberto para servir a requisição porur. É ainda ver-ificado se existe um fluxomulticastSmerge, i.e., um fluxo transmitindo uma unidade de dados anterior à ur, dentro de um limiar de tempoδmerge. O fluxo Smerge não pode possuirpatches associados a ele, pois um dos objetivos é manter a estrutura de união de fluxos em no máximo dois níveis.
• SeSmerge existe, então o fluxo Snew é o seu alvo e os clientes de Smerge devem escutar também o fluxoSnewpara que, eventualmente,Smergese una ao fluxoSnew. CasoSmergenão exista, então nada mais precisa ser feito.
Note que o algoritmo de PIE é mais elaborado que o de PI por introduzir o conceito do fluxoSmerge, o que cria a expectativa de uma maior otimização de banda dado que é uma possibilidade a mais para a união de fluxos.
2.3. PATCHINGINTERATIVOCOMPLETO– PIC
A técnica Patching Interativo Completo (PIC) é mais elaborada que PI e PIE por possuir três eventos para união de fluxos, conforme explicamos a seguir.
• Evento 1: Requisição para a unidadeur.
Nesta situação o algoritmo procede de forma semel-hante ao de PIE com a diferença básica de que, em vez de buscar por um único fluxoSmerge, busca-se por um conjunto de fluxos desse tipo.
• Evento 2: Término de um fluxoSj que é o fluxo
alvo de um outro fluxomulticastSi.
Em outras palavras, Sj termina antes de ser al-cançado porSi. Os clientes deSi então tornam-se
órfãos (i.e., não possuem mais fluxo a alcançar) e
os conteúdos respectivamente armazenados em seus
buffers, devido à escuta deSj, são descartados. O servidor busca por um outro fluxo que transmite uma unidade de dados posterior àquela atual do fluxoSi e dentro do limiar de tempoδmerge. SejaSsubseste fluxo. Se este fluxo existe, então ele torna-se o novo alvo deSi. CasoSsubstambém termine antes de ser alcançado porSi, o processo de busca por um outro fluxoSsubsé repetido.
• Evento 3: Término de todos os eventuais fluxos
Nesta situação o servidor tenta localizar um fluxo Smergeque transmite uma unidade de dados poste-rior àquela do fluxoSsourcee dentro de um limiar de tempoδmerge. Se este fluxo existe, então ele torna-se alvo deSsource. Ou seja, os clientes deSsource pas-sam a escutar também o fluxoSmergede tal sorte que SsourceeSmergepossam ser unidos mais à frente.
2.4. TÉCNICACLOSESTTARGET– CT
A técnica Closest Target (CT), por ser baseada no paradigma HSM, tem um mecanismo de tentativa de com-partilhamento de dados bem exaustivo. São considerados os três eventos descritos a seguir para união de fluxos no sistema.
• Evento 1: Requisição para a unidadeur.
O servidor abre um novo fluxomulticastSnew para atender esta requisição. Simultaneamente, o servi-dor também tenta localizar um outro fluxo em an-damento no sistema que esteja transmitindo uma unidade de dados posterior à ur, sem considerar qualquer limiar de tempo. SejaSteste fluxo. SeSt existe então o cliente deSnewtambém vai escutá-lo de tal sorte queSnew eStpossam, eventualmente, ser unidos mais à frente.
• Evento 2: Término de um fluxoSjque é o fluxo
alvo de um outro fluxoSi.
Neste caso o tratamento é análogo ao descrito no
EVENTO 2de PIC, sendo que aqui não se utiliza limiar de tempo para busca do substituto deSj.
• Evento 3: União do fluxoSie seu alvoSj. SejaSmo fluxo resultante desta união. Os eventu-ais conteúdos dosbuffers dos clientes de Sm, que originalmente eram clientes deSj, são descartados e o servidor imediatamente busca no sistema por um fluxo que esteja transmitindo uma unidade de dados posterior àquela do fluxoSm, sem considerar qual-quer limiar de tempo. SejaSteste fluxo. SeStexiste então os clientes deSmvão escutá-lo também de tal sorte queSmeStpossam ser unidos mais à frente.
Note que na técnica CT sempre buscamos por um fluxo para ser simultaneamente escutado com aquele que está efetivamente servindo a requisição por ur. Além disso, há ainda o fato de não haver qualquer limiar de tempo restritivo para a busca por fluxos no sistema, au-mentando as chances de localização de fluxos alvos.
OsEventos 1e3desta técnica dão à árvore de união de fluxos a característica de ter uma altura ilimitada. Por exemplo, um fluxoS1, recém aberto para atender a requi-sição porur, pode ter como alvo um outro fluxoS2que, por sua vez, já pode ter como alvo um outro fluxo S3, constituindo assim uma estrutura de profundidade três.
3. N
OVA TÉCNICA: M
ERGEI
NTERA -TIVO– MI
Aqui apresentamos a nova técnica Merge Interativo (MI). Assim como CT, esta nova técnica é baseada no paradigma de HSM e tem sua estrutura de união de fluxos com profundidade ilimitada (i.e., número de níveis ou al-tura ilimitada). Os três eventos descritos a seguir são con-siderados para a união de fluxos no sistema.
• Evento 1: Requisição para unidadeurdo objeto. Imediatamente abre-se um novo fluxo Snew para atender esta requisição. Simultaneamente, o servi-dor busca por um fluxo em andamento no sistema que esteja transmitindo uma unidade de dados pos-terior àur. SejaSteste fluxo. SeStexiste, então o cliente deSnewtambém vai escutá-lo de tal sorte queSneweStpossam ser unidos mais à frente.
• Evento 2: Término de um fluxoSj que é o fluxo
alvo de um outro fluxoSi.
Nesta situação, Sj termina antes de ser alcançado por Si. Os clientes de Si ficam órfãos (i.e., não possuem mais fluxo a alcançar) e os conteúdos ar-mazenados em seusbuffers, devido à escuta deSj, são descartados. O servidor busca um outro fluxo que transmite uma unidade de dados posterior àquela atual do fluxoSi. Seja Ssubs este fluxo. SeSsubs existe, ele se torna alvo deSi. CasoSsubs termine antes de ser alcançado porSi, a busca por um outro fluxoSsubsé repetida.
• Evento 3: União do fluxoSi e seu alvoSj. Seja Smo fluxo resultante.
O servidor imediatamente busca por um fluxo que esteja transmitindo uma unidade de dados posterior àquela do fluxoSm. SejaSteste fluxo. SeStexiste, os clientes deSm, que originalmente pertenciam ao fluxoSi, vão também escutá-lo para eventualmente se unir a ele. Já os clientes deSm, que originalmente pertenciam ao fluxoSj, não são afetados. CasoSt não exista, nada precisa ser feito.
A principal diferença entre a técnica MI e a técnica CT é que em MI não há a união de grupos de clientes pertencentes a fluxos distintos na ocorrência doEvento 3. A discussão a seguir justifica essa diferença para fins de se tentar obter uma maior otimização de uso da banda do sistema.
pertencentes àSj (enquanto estavam escutandoSk antes da ocorrência da união) é simplesmente descartada. Para um acesso seqüencial, esta decisão de descarte não au-menta a banda do servidor (embora impacte na banda do cliente), pois esta mesma informação precisa ser re-transmitida para atender os clientes originalmente perten-centes ao fluxoSi. Por outro lado, para um acesso não-seqüencial (i.e., com interatividade), esta decisão pode aumentar a banda do servidor, pois a informação descar-tada não é mais necessariamente retransmitida conforme explicamos a seguir.
Assuma que, logo após a união dos fluxos Si eSj, resultando no fluxoSm, todos os clientes originalmente pertencentes àSidecidam, por exemplo, realizar um salto para trás (ou para frente) do atual ponto em exibição do objeto. Se os clientes originalmente pertencentes à Sj descartarem a informação em buffer (recebida de Sk), como ocorre na técnica CT, esta mesma informação pre-cisará ser retransmitida novamente, não por causa dos clientes originalmente pertencentes àSi, mas por causa dos clientes originalmente pertencentes à Sj. A de-cisão de descarte nesta situação é então indevida, pois os clientes deSjjá tinham esta informação embufferantes da união. Para resolver isso, na técnica MI, conforme já explicamos, um fluxo alvoSté então selecionado e des-ignado exclusivamente para os clientes deSmque origi-nalmente pertenciam àSi, e os clientes que originalmente pertenciam àSjnão são afetados, i.e., não fazem descarte de dados e continuam tendoSk como fluxo alvo. Note queStpode ser um fluxo diferente deSk, pois os clientes têm um acesso não-seqüencial e assim podem, portanto, abrir fluxos de dados em qualquer instante e em qualquer unidade de dados do objeto que está sendo visualizado. Assim, em MI temos a possibilidade de um mesmo fluxo com diferentes grupos de clientes associados, cada grupo com um fluxo alvo distinto.
No entanto, é preciso dizer que existem duas situ-ações específicas que podem favorecer a técnica CT em relação à técnica MI. A primeira situação relaciona-se ao fato de que o eventual novo fluxo alvoSt, designado para os clientes deSi depois queSi se une àSj, pode estar relativamente mais próximo ao fluxo Sj do que aquele originalmente designado para o próprioSj. Por exem-plo, admita que, antes da união de Si comSj, o fluxo alvo de Sj, que é o fluxo Sk, esteja à distância de 20 unidades de dados. Admita que imediatamente antes da união de Si comSj, um novo fluxoSté aberto no sis-tema e este está à distância de apenas 3 unidades deSj. Considere que neste instante ocorre a união de Si com Sj, resultando no fluxo Sm. Considerando este cenário, analisemos a seguir o que ocorre nas técnicas MI e CT. Na técnica CT, todos os clientes deSm(originalmente per-tencentes àSiouSj) são beneficiados pelo fato da iden-tificação do novo alvo indicar o fluxo mais próximoSt.
Na técnica MI, os clientes deSm, originalmente perten-centes àSi, são beneficiados pela identificação do fluxo mais próximo St; entretanto, os clientes de Sm, origi-nalmente pertencentes àSj, permanecem tendoSkcomo fluxo alvo. Nesta situação, CT pode apresentar uma me-lhor otimização de banda que MI, pois o fluxo alvo mais próximo atende indistintamente a todos os clientes deSm. Note que uma maior proximidade do fluxo alvo leva a um menor número de fluxos no sistema, pois o fluxo que tenta alcançar o alvo pode ser extinto mais cedo.
A segunda situação é descrita a seguir. Na técnica MI, se os clientes de Sj não possuem um fluxo alvo, estes clientes ainda permanecerão sem um fluxo alvo mesmo após a união de Si com Sj. Na técnica CT, isso não ocorre, pois o fluxo alvo é escolhido para todos os clientes deSm, independentemente de originalmente pertencerem àSi ou àSj. Contudo, este fato, não traz considerável vantagem para CT. A explicação é que, devido à operação intrínseca do paradigma de HSM (abertura e busca por fluxos de forma exaustiva) e ainda à condição de termos interatividade, a probabilidade de um cliente não ter um fluxo alvo associado é praticamente desprezível.
4. N
OVAS GERÊNCIAS DE BUFFER 4.1. ESTRATÉGIAUNIQUEBUFFERA proposta Unique Buffer (UB) aproveita o efeito conjunto das requisições para um mesmo objeto devido aos vários clientes existentes no sistema e localizados em uma mesma rede local. O cliente deixa de ter umbuffer
local exclusivo, passando a existir apenas umbufferúnico
compartilhado – localizado em um nó (rede) de acesso – para atendimento de todos os clientes que desejam assis-tir a um mesmo objeto. As solicitações de um cliente no instantetpodem então se beneficiar de quaisquer solici-tações ocorridas em instantes anteriores at. Dessa forma, dois efeitos são percebidos: (i) o cliente se beneficia de suas próprias requisições anteriores, assim como na pro-posta original de CB, e (ii) o cliente se beneficia de req-uisições anteriores e provenientes de outros clientes. O tamanho dobufferúnico é igual ao tamanho do objeto.
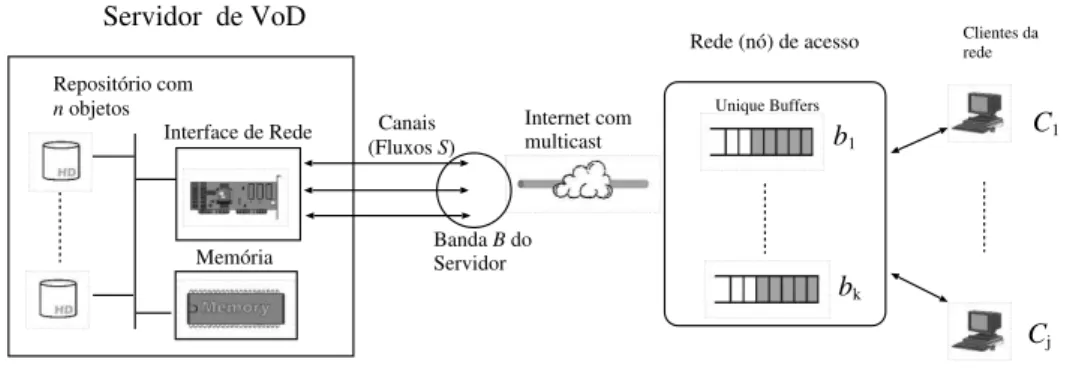
A Figura 1 ilustra um sistema no qual um servidor ar-mazenanobjetos de interesse de um total de j clientes
(C1, . . . , Cj), localizados remotamente em uma mesma
e estimado a partir da distribuição Zipf, que diz que a
probabilidade de selecionar o objeto de categoria β é igual a(β1−αPn
x=1x11−α)
−1, ondeαé denominado de
skewf actorda distribuição [18]. Oskbufferssão
aloca-dos dinamicamente segundo as requisições aloca-dos clientes. Quando todos oskbuffersestiverem alocados, as
requi-sições de outros objetos são atendidas por meio de um
bufferconvencional e local do cliente. A Figura 2(a)
ilus-tra os segmentos de dados armazenados em um dos k
buffersdevido a escuta de três fluxos distintos,
realiza-das por três clientes que vêem o mesmo objeto simul-taneamente. O fluxoS1 refere-se ao clienteC1, o fluxo S2 ao cliente C2, e o fluxo S3 deve-se ao cliente C3. As unidades armazenadas nobuffer podem ser
indistin-tamente utilizadas por qualquer um dosj clientes do sis-tema que queiram assistir ao mesmo objeto neste instante de tempo.
O compartilhamento eficiente de umbufferúnico, por
todos os clientes de uma rede local que desejam assistir a um mesmo objeto, exige o uso de métodos específicos de acesso aobuffer. Isto porque é provável termos mais
de um cliente realizando acesso simultaneamente. Esta questão pode ser modelada como oProblema do Produ-tor/Consumidor [29]. A princípio, vemos duas
aborda-gens para sua solução. A primeira é uma proposta de-nominada deSoftware Transactional Memory[19], a qual
baseia-se em conceitos da área de bancos de dados para controle de acesso, criando noções de atomicidade, con-sistência e isolamento de transações. A segunda, mais co-mum, relaciona-se à utilização de conceitos como semá-foros e/ou travas (locks) para o controle de acesso.
Na estratégia UB, o armazenamento de unidades de dados nobufferúnico é dinâmico, ou seja, é determinado
pelo acesso dos clientes às unidades do objeto que está sendo visualizado. Diferentemente de técnicas baseadas no emprego deproxies, na estratégia UB não há
necessi-dade de cópias de partes ou de todo o objeto do servidor multimídia sem que o cliente tenha requisitado, também não há premissa de uso de quaisquer tipos de codificação em camadas (layer-encoded streaming) visando a melhor
adaptação de qualidade dos fluxos. Uma análise compet-itiva mais detalhada com técnicas baseadas emproxiesé
considerada em trabalhos futuros.
4.2. ESTRATÉGIAPRECISEBUFFER
A principal motivação da estratégia PB está na ten-tativa de evitar que a fragmentação de informação no
bufferlocal do cliente comprometa a otimização do
sis-tema. A fragmentação se dá quando a informação ar-mazenada apresenta-se em pequenos segmentos espaça-dos entre si, fazendo com que na maioria das vezes o cliente não seja atendido por apenas um único segmento e, assim, necessite entrar em um ciclo de leitura: ora a partir debufferlocal, ora a partir de fluxos do sistema. Isso cria
uma maior dificuldade para o compartilhamento de dados, pois os fluxos passam a ter uma menor duração [23, 22]. Evitando os malefícios da fragmentação, podemos ainda esperar que haja uma minimização da variabilidade dos requisitos de banda (traffic smoothing [11]) e do over-head[5, 25] do servidor para o tratamento das mensagens
entre clientes e servidor, que se traduz em menor comple-xidade do sistema e é avaliada nos experimentos adiante. Na proposta PB, a requisição somente é atendida na condição de que o tamanho da informação contígua em
buffer (i.e., número de unidades consecutivas), a partir
da unidade de dados requisitada, seja suficiente para evi-tar que o cliente entre no ciclo de leitura descrito no úl-timo parágrafo. Seja então δB a variável que designa esse tamanho. A Figura 2(b) ilustra esta estratégia para um cliente que requisita a unidadeur1, sendo que ele já tem armazenado desde a unidadeur1 até a unidadeur2. Quandour2 −ur1 ≥ δB, a informação é utilizada para servir o cliente. Por outro lado, quandour2−ur1 < δB, a informação é ignorada e o cliente deve escutar fluxos de dados do servidor.
5. A
VALIAÇÃO DEP
ERFORMANCE 5.1. MÉTRICASAs principais métricas de performance aqui utilizadas são: consumo médio da banda, valor de pico da banda, distribuição da banda, razões competitivas e trabalho mé-dio.
Consumo médio e valor de pico da banda são duas métricas bastante freqüentes em experimentos compara-tivos. Já a distribuição da banda torna-se importante pelo fato de considerarmos em nossos experimentos a intera-tividade dos clientes. Isto faz com que a banda possa variar significativamente ao longo do tempo. Conseqüen-temente, o simples cômputo do valor médio ou do valor de pico não permitem uma análise mais detalhada das técnicas. As razões competitivas [6] aqui utilizadas são assim definidas [24]: RM ax = max(P[Banda>k]tec1
P[Banda>k]tec
2)
e RM in = min(P[Banda>k]tec1
P[Banda>k]tec2), para todo k inteiro desde que P[Banda > k] ≥ 10−4 (por precisão da
Servidor de VoD
Interface de Rede
Memória Repositório com n objetos
Canais (Fluxos S)
Internet com multicast
Rede (nó) de acesso
Banda B do Servidor
b1
bk
Clientes da rede
Unique Buffers
C1
Cj
Figura 1. Sistema de vídeo sob demanda.
Unique Buffer (UB)
uf play point
u1
u1
Unique Buffer play point
u1 Fluxo S1 devido
ao cliente C1
δp
uq1 uq2
up1 up2 play point
δq
δf
δf δq δp Fluxo S3 devido
ao cliente C3 Fluxo S2 devido
ao cliente C2
(a)
Precise Buffer (PB)
(b)
u1 Buffer do clienteδB
ur1 ur2 unidade requisitada
pelo cliente Caso (1) :
u1 Buffer do cliente
δB
ur1 ur2 unidade requisitada pelo cliente Caso (2) :
Figura 2. (a) Estratégia Unique Buffer; (b) Estratégia Precise Buffer.
busca por um fluxomulticast. Faz-se então a análise de
pior caso e admite-se que a operação de busca seja execu-tada em tempoO(n), ondené o número de fluxos multi-castem andamento no sistema. O servidor pode receber
quatro tipos de mensagens: requisição para uma unidade de dados (DR), requisição para o término de uma união de fluxos (MR), requisição para o término depatch(PR),
e requisição para fim de exibição (LR). A Tabela 1(a) sin-tetiza as complexidades de tempo relativas às operações devido a cada tipo de mensagem, ondeO(C)denota uma complexidade de tempo constante; a Tabela 1(b) apre-senta as equações para calcular o trabalho médio (detal-hes em [24]). Os valores den,E[DR],E[M R],E[P R], eE[LR]são obtidos a partir do modelo de simulação.
5.2. CARGAS
Consideramos quatro cargas sintéticas. Cada uma refere-se a um cenário de avaliação distinto no qual um objeto multimídia está sendo transmitido. Estas cargas são obtidas por meio de um gerador proposto no trabalho de [22] e referem-se aos servidores multimídia eTeach, MANIC e UniversoOnlineUOL [2, 9]. Os dois primeiros
servidores são de ensino a distância e o último é um servi-dor de conteúdo.
O gerador de carga sintética utilizado tem como en-trada umtracereal de sessões para um dado objeto com
uma certa taxa de requisições. Sua saída é umtrace
sin-tético com estatísticas semelhantes àquelas dotrace
Tabela 1. Complexidade de tempo e trabalho médio do servidor
Técnica DR MR PR LR
Patching O(n) — O(C) O(C) PI O(n) — O(C) O(C) PIE O(n) O(C) O(C) O(C) PIC O(2n) O(n) O(n) O(n) MI O(2n) O(n) — O(n) CT O(2n) O(n) — O(n)
(a) Complexidade de tempo
Técnica Fórmulas
Patching E[DR]∗n+E[P R] +E[LR] PI E[DR]∗n+E[P R] +E[LR] PIE E[DR]∗n+E[M R] +E[P R] +E[LR]
PIC E[DR]∗2n+ (E[M R] +E[P R] +E[LR])∗n
MI E[DR]∗2n+ (E[M R] +E[LR])∗n
CT E[DR]∗2n+ (E[M R] +E[LR])∗n (b) Trabalho médio
tamanho fixo do objeto. As probabilidades de início de uma sessão em cada segmento, assim como as probabili-dades de transição entre os estados, são calculadas a partir dotracereal. Umtracede sessões é então produzido
as-sumindo o início de sessão sendo dado por um processo de Poisson [2, 9], e o comportamento do cliente dentro de cada sessão é extraído a partir das características do cenário (trace) real. O cliente pode executar as seguintes
ações de interatividade: Play,Stop,Pause/Resume,Jump ForwardseJump Backwards.
As principais estatísticas das cargas sintéticas estão na Tabela 2. Para garantir um significativo espectro de análise, escolhemos cargas estatisticamente diferen-tes. Na Carga eTeach (Workload 1), o número de ações
Jump Backwards é bem razoável, resultando em
locali-dade de acesso, i.e., ocorre um grande número de re-tornos a unidades de dados anteriormente já visualizadas pelo cliente, o que deve favorecer às estratégias de gerên-cia de buffer onde o cliente armazena todos os dados
transmitidos pelo servidor. Outro aspecto interessante é que a maioria das unidades de dados são acessadas como primeira unidade do segmento. SejaX a variável aleatória que representa a primeira unidade acessada pelo cliente quando este faz um movimento, ou seja, quando requisita um novo segmento. Ter uma unidadeicomo a primeira unidade de um segmento significa que a variável aleatóriaXassume o valori. Por último, a distribuição de acesso a unidades é aproximadamente uniforme. Em re-lação à Carga MANIC-1 (Workload 2), o nível de interati-vidade (i.e., nr. de requisições por sessão) é relativamente baixo. Também a distribuição de acesso não é uniforme e apenas 24 unidades são acessadas como a primeira do segmento. Já na Carga MANIC-2 (Workload 3), pou-cas unidades são efetivamente acessadas como primeiras unidades do segmento. Existe ainda alguma uniformi-dade na distribuição de acesso. Finalmente, para a Carga UOL (Workload 4) há significativa localidade de acesso e a primeira unidade do objeto é bastante requisitada (pop-ular).
5.3. RESULTADOS E ANÁLISE
Os resultados de simulação são obtidos usando a fer-ramenta Tangram-II [12]. Esta ferfer-ramenta constitui-se
em um ambiente de modelagem e experimentação de sistemas computacionais/comunicações, desenvolvido na Universidade Federal do Rio de Janeiro (UFRJ), com par-ticipação de UCLA/USA, com propósitos de pesquisa e educação. Este ambiente combina uma interface de usuário sofisticada em um paradigma de orientação a ob-jeto e novas técnicas de solução para análise de perfor-mance e disponibilidade. O usuário especifica um mod-elo em termos de objetos que interagem por meio de um mecanismo de troca de mensagens. Um vez que o mod-elo seja compilado, pode ser resolvido analiticamente, se for Markoviano ou pertencer a uma classe de modelos não Markovianos, ou resolvido via simulação. É possível obter soluções tanto para estado estacionário como para estado transiente. Para facilidade de entendimento orga-nizamos a apresentação dos resultados em duas seções distintas. A Seção 5.3.1 dedica-se aos resultados prove-nientes da análise competitiva entre as técnicas de com-partilhamento de banda: Patching, PI, CT, PIE, PIC e MI. A Seção 5.3.2 dedica-se aos experimentos com as estraté-gias de gerência debufferSB, CB, UB e PB.
5.3.1. Análise das técnicas de compartilhamento:
Salvo informado diferentemente, aqui consideramos δaf ter = δmerge, e fazemosδbef ore =10 s. Estas su-posições são respaldadas nos resultados obtidos em [24, 25]. Devido a restrições de espaço, não ilustramos todos os experimentos realizados (resultados completos estão em [23]). Inicialmente analisamos as técnicas baseadas em Patching (i.e., PI, PIE e PIC) no intuito de obtermos aquela de melhor performance. Em seguida, de forma análoga, avaliamos as técnicas baseadas em HSM (i.e., CT e MI). Finalmente, temos uma análise competitiva considerando a mais eficiente técnica de cada paradigma. Também em nossas análises consideramos apenas os dois tipos mais comuns de gerência debuffer: Simple Buffer
(SB) e Complete Buffer (CB).
Tabela 2. CARGAS SINTÉTICAS
Estatística eTeach MANIC-1 MANIC-2 UOL
Tamanho do objetoT( s) 2199 4175 4126 226
Tamanho da unidade de dados ( s) 1 1 1 1
Nr. médio de requisições emT 98 99 100 97
Nr. total de requisições 5146 677 2366 1114
Nr. médio de requisições por sessão 10.29 1.35 4.73 2.23 Tamanho médio do SegmentoL( s) 118 1190 496 134
Desvio padrão deL( s) 143 1184 473 91
Coef. de variação deL 1.21 1.00 0.95 0.68
Nr. de valores diferentes da v.a.X 2199 24 98 24
PI-SB
PIE-SB PIC-SB
P[ Banda > k ]
k 0 5 10 15 20 25 0
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
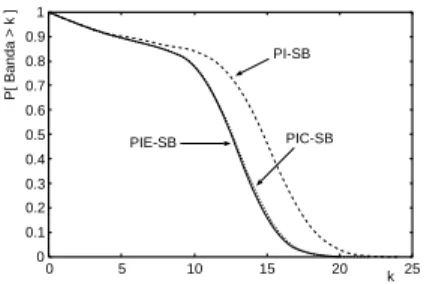
Figura 3. CCDF para PIE-SB, PIC-SB e PI-SB em MANIC-1.
meio das razões competitivas computadas:RM in= 1.0
eRM ax∈[120.2,3634.9].
As técnicas PIE e PIC têm performances semelhan-tes em todas as cargas e são ambas, de forma geral, mais eficientes que PI. Esta superioridade em performance é quantificada por meio das razões competitivas com-putadas:RM in∈[0.5,1.0]eRM ax∈[1.6,25.8]. Tam-bém para ilustrar este fato apresentamos a distribuição (CCDF) da banda para PIE-SB, PIC-SB e PI-SB na Figura 3. Isto favorece enormemente PIE por ter uma implementação bem mais simples que PIC. Nestas avali-ações usamosδaf ter= 50%da janela ótimaW de Patch-ing [7, 14], entretanto, enfatizamos que as observações então feitas são válidas independentemente do valor ab-soluto deδaf terno intervalo de 0–100% deW ouL. Va-lores fora deste intervalo se mostram ineficientes.
Ao compararmos MI e CT, notamos que, na maioria dos cenários, MI é mais eficiente que CT quando usamos a estratégia de gerênciabufferCB e, de forma contrária,
quando usamos a gerência SB, a técnica CT torna-se mais eficiente que MI. Este resultado está embasado na difer-ença de MI com relação à CT. Em linhas gerais, quando usamos CB, existe uma tendência de termos um menor número de fluxos ativos no sistema e daí uma menor prob-abilidade de selecionar novos fluxos alvos, em substitu-ição a fluxos alvos originais, que de fato venham a prover economia de banda. Para ilustrar este ponto temos as
Fig-uras 4(a), 4(b) e 4(c). Nas duas primeiras figFig-uras temos a distribuição (CCDF) da banda quando usamos CB nas Cargas UOL e eTeach, respectivamente, onde vemos a vantagem de MI sobre CT. Na última figura temos o caso de emprego da gerência SB na Carga eTeach. A perfor-mance é justamente contrária: CT é mais eficiente que MI. Agora, desde que a implementação de CB é relati-vamente simples e vantajosa, devido à eventual economia de banda que pode ser atingida, decorre como conclusão natural que MI é uma melhor escolha para a maioria dos cenários examinados.
Por fim, comparamos a técnica mais eficiente no paradigma de Patching com a mais eficiente no paradigma de HSM: técnicas PIE e MI, respectivamente. Em todas as cargas, MI tem melhor performance que PIE. Este fato é ilustrado nas Figuras 5(a), 5(b) e 5(c). Para efeito de justiça, nesta análise utilizamos os valores ideais (obti-dos experimentalmente) do parâmetro δaf ter, explicita-dos nas próprias figuras em função do valor percentual da janela ótimaW de Patching (a saber: δbef ore =10.0 s e δaf ter =δmerge =117.0 s, 386.9 s, 271.9 s e 29.3 s para as Cargas eTeach, MANIC-1, MANIC-2 e UOL, respec-tivamente. Análises para derivação desses valores estão em [24, 25].) A título de ilustração, as Figuras 6(a) e 6(b) trazem as reduções (%) em relação ao consumo mé-dio de banda e aos valores de pico de banda, respecti-vamente, registrados por PIE e MI em relação à técnica Patching-SB. As reduções são de fato, como já esperado, bem expressivas, tanto para o consumo médio de banda (30%−68%), como para o valor de pico (18%−62%).
CT-CB
MI-CB P[ Banda > k ]
k 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5
0 5 10 15 20 25
(a)
CT-CB
MI-CB
P[ Banda > k ]
k 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
0 5 10 15 20 25 30 35 40 45
(b)
CT-SB MI-SB
P[ Banda > k ]
k 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0 5 10 15 20 25 30 35 40 45
(c)
Figura 4. (a) CCDF para MI-CB e CT-CB em UOL; (b) CCDF para MI-CB e CT-CB em eTeach; (c) CCDF para MI-SB e CT-SB em eTeach.
PIE-SB/40%
MI-SB
P[ Banda > k ]
k 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0 5 10 15 20 25 30 35 40 45 50
(a)
PIE-CB/70%
MI-CB
P[ Banda > k ]
k (b) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0 5 10 15 20
PIE-CB/50%
MI-CB
P[ Banda > k ]
k (c) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
0 5 10 15 20 25 30 35 40 45
Figura 5. Distribuição de banda para (a) PIE-SB e MI-SB em eTeach, (b) PIE-CB e MI-CB em MANIC-1, (c) PIE-CB e MI-CB em MANIC-2.
relação a MI-SB (MI-CB) em todas as cargas, exceto para UOL. Notamos ainda que, para tornar PIE mais eficiente que MI, o valor experimental obtido paraδbef ore é sem-pre maior no caso de uso da gerência debuffer CB do que no caso da gerência SB. Isso é explicado pelo fato de que, quando usamos CB, existe uma tendência de ter-mos um menor número de fluxos no sistema e, portanto, uma maior dificuldade para efetuar o compartilhamento de dados. Esta condição favorece à técnica MI por ter um mecanismo de busca mais exaustivo que PIE.
Por fim, a Figura 6(c) faz uma síntese gráfica compar-ativa entre MI-SB e PIE-SB considerando dois resultados: (i) o trabalho médio em função do nível de interatividade (número médio de requisições por sessão) e (ii) o valor deδbef ore para o qual temos praticamente a mesma dis-tribuição de banda em ambas as técnicas. Note que, con-forme o nível de interatividade aumenta, o trabalho médio de MI também aumenta enquanto que a descontinuidade introduzida porδbef orediminui. Comportamento semel-hante é obtido também para o caso de gerência CB. Este resultado geral mostra portanto que, apesar de MI ser de fato a técnica de melhor performance, PIE pode ser vista como uma técnica competitiva para cargas em que o nível de interatividade é relativamente alto.
5.3.2. Análise das Estratégias de Buffer: Aqui con-sideramos as estratégias de gerência de buffer SB, CB,
UB ePB empregadas em conjunto com as técnicas de compartilhamento de banda PIE e MI, por serem estas as mais eficientes, conforme observado nos experimentos anteriores. Especialmente em relação à técnica PIE,
uti-lizamos valores ideais (obtidos experimentalmente) para seus respectivos parâmetrosδe já indicados na seção an-terior. Para fins de facilidade de entendimento e orga-nização, resolvemos realizar dois conjuntos distintos de experimentos, conforme apresentado a seguir.
CONJUNTO 1: Análise Competitiva entre SB, CB, PB e UB
Aqui assumimos δB = L, onde L é o tamanho médio do segmento do objeto requisitado pelo cliente quando este faz uma requisição ao servidor. O valor de L (Tabela 2) pode ser estimado dinamicamente por medição durante a operação ou a partir de logs de clientes [25, 23, 22, 2, 9].
Valor Médio e Valor de Pico. As Figuras 7 e 8 re-sumem os resultados obtidos considerando estas métricas. A estratégiaUBé notadamente a de melhor desempenho, pois reduz significativamente os requisitos de banda mé-dia e valor de pico de banda, comparativamente às outras estratégias. Os requisitos de banda média são inferiores a 1 canal para todas as cargas consideradas. As reduções chegam até 98% em relação àSB. A estratégiaSB é a menos eficiente. Ainda notamos alguma equivalência nos resultados provenientes do uso de CBePB. No que se refere aos valores médios de banda, a diferença entreCB
Redução de Banda (%) 0 10 20 30 40 50 60 70 80
UOL MANIC-2 eTeach MANIC-1
UOL MANIC-2 eTeach MANIC-1
SIMPLE BUFFER COMPLETE BUFFER
PIE PIE PIE
PIE PIE PIE PIE PIE (a) MI MI MI MI MI MI MI MI 0 10 20 30 40 50 60 70 80
Redução de Pico (%)
UOL MANIC-2 eTeach MANIC-1
UOL MANIC-2 eTeach MANIC-1
SIMPLE BUFFER COMPLETE BUFFER
PIE PIE PIE PIE PIE PIE PIE PIE (b) MI MI MI MI MI MI MI MI
Nível de interatividade trabalho médio de MI-SB
δbefore(segundos)
trabalho médio de PIE-SB
10 100 1000 10000 100000
1 2 3 4 5 6 7 8 9 10 11
(c)
Figura 6. Otimizações de PIE e MI em relação à Patching-SB na (a) banda média e no (b) valor de pico; (c) Trabalho para MI-SB e PIE-SB.
0 5 10 15 20 PIE MI
SB CB PB UB Carga eTeach Banda Media (a) 0 5 10 15
20 Carga MANIC-1
Banda Media
PIE
MI
SB CB PB UB
(b)
0 5 10 15
20 Carga MANIC-2
Banda Media
PIE
MI
SB CB PB UB
(c)
0 5 10 15
20 Carga UOL
PIE
MI
SB CB PB UB
Banda Media
(d)
Figura 7. Valor da Banda Média:(a) eTeach; (b) MANIC-1; (c) MANIC-2; (d) UOL.
métrica.
Trabalho. Conforme podemos observar na Figura 9, a estratégiaUBé aqui também a mais eficiente. As duções chegam a até duas ordens de grandeza em re-lação à SB. Considerando CB e PB, podemos obser-var que, apesar da proximidade dos valores em ordem de grandeza, a estratégiaPBmostra-se geralmente mais eficiente que CB, pois apenas na Carga MANIC-1 não ocorre redução no valor desta métrica. Por exemplo, para MANIC-2 e técnica MI, o valor obtido porPBé aproxi-madamente três vezes menor que aquele de CB. As re-duções deCBcom relação àSBnão são expressivas. Há inclusive casos desfavoráveis, onde observamos aumen-tos. Estes casos são aqueles em que possivelmente ocorre a fragmentação da informação embuffer. Por fim, as
re-duções dePBem relação àSBsão um pouco mais atrati-vas. Por exemplo, para UOL e técnica MI, o valor relativo àPBé aproximadamente duas vezes menor que aquele registrado paraSB.
Distribuição. Os resultados desta métrica também confirmam queUBé a mais eficiente. A distribuição com-plementar (CCDF) para a estratégiaUBaparece sempre bem destacada das demais. A probabilidade do números de canais usados pelo servidor ser maior do que 2 é menor do que 0.1 para a grande maioria das cargas, enquanto que, para as outras estratégias de gerência debuffer, esta
probabilidade é maior que 0.7 na maioria dos cenários. Também, a partir das curvas da distribuição, observamos queSBé a estratégia menos eficiente. Para as estratégias
CBePB, os resultados aparecem divididos e não há signi-ficativa diferença entre elas. Por exemplo, para a técnica
MI, observamos que na Carga eTeach,CBmostra-se mais eficiente; por outro lado, na Carga MANIC-2,PBé mais eficiente. Alguns desses experimentos são ilustrados na Figura 10.
CONJUNTO 2: Análise do ParâmetroδBde PB Aqui variamos o valor deδB em função deL e ob-servamos as distribuições complementares da banda do servidor. Também consideramos o valor deδBem função do tamanho do objeto inteiroT. Observe que, quando δB → 0,PBtorna-se equivalente àCB; por outro lado, quandoδB →T,PBtorna-se equivalente àSB. O obje-tivo é então verificar a existência de um valor no intervalo
[0;T]que otimize a performance dePBe ainda estimar esse valor como função deL.
Para efeito de maior clareza e organização da análise, assumimos então dois casos: δB ≥ LeδB < L. No primeiro, não conseguimos verificar quaisquer otimiza-ções. Isso revela que o tamanho médio do segmentoLé possivelmente um valorupper boundpara as cargas
ex-aminadas. No segundo caso e considerando a maioria das cargas, alguma otimização foi produzida. Inclusive, houve situações em que PBpassou a ser mais eficiente queCB. O valor ideal deδB ≥ Lestabeleceu-se no in-tervalo de 25%–50% deL. Isso evidencia a importân-cia da determinação do valor ideal deδBpara o emprego da técnicaPB. Alguns resultados destes experimentos são ilustrados na Figura 11.
Em síntese, considerando ambos conjuntos de experi-mentos, constatamos que: (i) a estratégiaUBé a mais efi-ciente. As otimizações produzidas são bem expressivas, revelando um padrão de comportamento semelhante
0 10 20 30 40
50 Carga eTeach
PIE
MI
Pico de Banda
SB CB PB UB
(a)
0 10 20 30 40
50 Carga MANIC-1
SB CB PB UB
Pico de Banda
PIE
MI
(b)
0 10 20 30 40
50 Carga MANIC-2
PIE
MI
SB CB PB UB
Pico de Banda
(c)
0 10 20 30 40
50 Carga UOL
Pico de Banda
SB CB PB UB MI
PIE
(d)
Figura 8. Valor de Pico da Banda: (a) eTeach; (b) MANIC-1; (c) MANIC-2; (d) UOL.
0.1 1 10 100 1000 10000 100000
MI
PIE Carga eTeach
SB CB PB UB
Trabalho
(a)
0.1 1 10 100 1000 10000
100000 Carga MANIC-1
MI
PIE
SB CB PB UB
Trabalho
(b)
0.1 1 10 100 1000 10000 100000
MI
PIE Carga MANIC-2
SB CB PB UB
Trabalho
(c)
0.1 1 10 100 1000 10000
100000 Carga UOL
MI
PIE
SB CB PB UB
Trabalho
(d)
Figura 9. Trabalho (complexidade): (a) eTeach; (b) MANIC-1; (c) MANIC-2; (d) UOL.
tre clientes independentes que assistem a um mesmo ob-jeto; (ii) as estratégiasCBePBapresentam certa semel-hança nos resultados obtidos, exceto para a métrica tra-balho. Isto significa quePBtem uma menor complexi-dade de sistema queCB. A complexidade é estimada em função do número de mensagens trocadas entre clientes e servidor e das operações para tratamento das mesmas pelo servidor; (iii) a estratégiaPBé possível de ser otimizada determinando-se um valor ideal para o parâmetroδB, o qual na maioria das cargas utilizadas estabeleceu-se no intervalo de 25%–50%deL; (iv) a estratégiaSBé a mais simples, mas também é, em geral, a de performance mais sofrível. Esta desvantagem tende a tornar-se inclusive mais acentuada em cenários com alto nível de interativi-dade por parte dos clientes; (v) os valores de otimização que registramos enaltecem a importância do uso das es-tratégias de gerência debuffer.
6. CONCLUSÕES
Neste trabalho apresentamos a nova técnica de com-partilhamento de banda Merge Interativo (MI), cuja con-cepção baseia-se no paradigma de HSM. Também propo-mos duas novas estratégias de gerência debufferpara
sis-temas de VoD interativos: Unique Buffer (UB) e Precise Buffer (PB). Por meio de simulações, utilizando cargas sintéticas obtidas de servidores reais, validamos nossas propostas e realizamos análises competitivas com outras propostas da literatura.
Os resultados finais, os quais englobaram diferentes métricas de comparação de performance, mostraram prin-cipalmente que: (1) a nova técnica MI é de fato a de
maior eficiência, no entanto, o paradigma de Patching pode tornar-se bastante atrativo com a introdução de pe-quenas descontinuidades no serviço de atendimento de requisições; (2) a estratégia de gerência de bufferUB é
a mais eficiente, porém, pela maior simplicidade, as es-tratégias PB e CB também são consideradas competitivas. Em relação a outras propostas da literatura, alcançamos otimizações de 5%–98% em valores médio de banda, pico de banda e complexidade do sistema.
Como trabalhos futuros, podemos citar: (1) análise detalhada do desempenho da estratégia UB quando com-parada ao uso de umproxy, (2) avaliação das estratégias
propostas usando outras cargas sintéticas, (3) desenvolvi-mento de modelos analíticos para a análise de técnicas de compartilhamento de banda em ambientes com interativi-dade e, por fim, (4) desenvolvimento de novas técnicas de compartilhamento de banda conjuntamente com estraté-gias de gerência debufferobedecendo ao paradigma P2P
(Peer-to-Peer), criando um ambiente de transmissão
dis-tribuído.
Referências
[1] E. L. Abram-Profeta and K. G. Shin. Providing unrestricted VCR functions in multicast video-on-demand servers. In Proc. of IEEE ICMCS, pages
66–75, Austin, Texas, June 1998.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0 5 10 15 20 25 30 35 40 45
SB PB
UB CB
k Carga eTeach (MI)
P[Banda > k]
(a) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0 5 10 15 20 25 Carga MANIC - 1 (PIE)
k
P[Banda > k]
UB CB
SB e PB
(b) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0 5 10 15 20 25 30 35 40 UB
PB CB SB Carga MANIC-2 (MI)
k
P[Banda > k]
(c) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0 5 10 15 20 25 Carga UOL (PIE)
UB CB
PB SB
k
P[Banda > k]
(d)
Figura 10. Distribuição (CCDF): (a) eTeach; (b) MANIC-1; (c) MANIC-2; (d) UOL.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
δΒ =100%L=
5.37%T (PB)
δΒ = 25%L=
1.35%T
δΒ = 0%L= 0%T (CB)
Carga eTeach (PIE)
k
P[Banda > k]
δΒ > 50% T =
932% L (SB)
0 5 10 15 20 25 30 35 40 45 50 (a) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
1 Carga MANIC-1 (PIE)
k
P[Banda > k]
δB = 0%L= 0%T (CB)
δB = 25%L= 7.14%T
δB > 50%L = 14.25%T (SB e PB)
0 5 10 15 20 25 (b) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
1 Carga eTeach (MI)
k
P[Banda > k] δB > 932%L = 50%T (SB)
δB =100%L =
5.37%T (PB) δB = 50%L=
2.69%T δB = 0%T=
0%L (CB)
0 5 10 15 20 25 30 35 40 45
(c) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
1 Carga MANIC-2 (MI)
k
P[Banda > k]
δB > 416%L= 50%T (SB)
δB = 0%L = 0%T (CB)
δB =100%L= 12%T (PB)
δB = 50%L= 6%T 10%L=1.22%T
0 5 10 15 20 25 30 35 40 (d)
Figura 11. Distribuição (CCDF): (a) eTeach; (b) MANIC-1; (c) eTeach; (d) MANIC-2.
[3] K. C. Almeroth and M. H. Ammar. The use of multicast delivery to provide a scalable and interac-tive video-on-demand service. IEEE Journal on Se-lected Areas in Communications, 14(5):1110–1122, August 1996.
[4] R. O. Banker and et al. Method of providing video-on-demand with VCR-like functions. U. S. Patent 5357276, 1994.
[5] A. Bar-Noy, G. Goshi, R. E. Ladner, and K. Tam. Comparison of stream merging algorithms for media-on-demand. In Proc. Multimedia Comput-ing and NetworkComput-ing (MMCN’02), pages 18–25, San Jose, CA, January 2002.
[6] A. Borodin and R. El-Yaniv. On-line computation and competitive analysis. Cambridge University Press, The Pitt Building, Trumpington Street, Cam-bridge, United Kingdom, 1998.
[7] Y. Cai, K. Hua, and K. Vu. Optimizing patching per-formance. InProc. SPIE/ACM Conference on Multi-media Computing and Networking, pages 204–215, January 1999.
[8] S.-H. Gary Chan and Edward Chang. Provid-ing scalable on-demand interactive video service by means of multicast and client buffering. In Proc. IEEE ICC, pages 11–15, Helsinki, June 2001.
[9] C. Costa, I. Cunha, A. Borges, C. Ramos, M. Rocha, J. M. Almeida, and B. Ribeiro-Neto. Analyzing client interactivity in streaming media. InProc. 13th ACM Int’l World Wide Web Conference, pages 534– 543, May 2004.
[10] A. Dan, D. Sitaram, P. Shahabuddin, and D. Towsley. Channel allocation under batch-ing and VCR control in movie-on-demand servers. Journal of Parallel and Distributed Computing, 30(2):168–179, November 1995.
[11] E. de Souza e Silva, R. M. M. Leão, Berthier A. Ribeiro-Neto, and S. V. A. Campos. Performance issues of multimedia applications. InPerformance Evaluation of Complex Systems: Techniques and Tools, Performance 2002, Tutorial Lectures, pages 374–404, London, UK, 2002. Springer-Verlag.
[12] E. de Souza e Silva and Rosa M. M. Leão. The Tangram-II Environment. In Proc.11th Int’l Con-ference TOOLS2000, pages 366–369, 2000.
[13] D. Eager, M. Vernon, and J. Zahorjan. Opti-mal and efficient merging schedules for video-on-demand servers. InProc. 7th ACM Int’l Multimedia Conference (ACM Multimedia’99), pages 199–202, November 1999.
[14] L. Gao and D. Towsley. Supplying instantaneous video-on-demand services using controlled multi-cast. InProc. IEEE Multimedia Computing Systems, pages 117–121, June 1999.
[15] M. L. Gorza. Uma técnica de compartilhamento de recursos para transmissão de vídeo com alta intera-tividade e experiemntos. Tese de mestrado, UFF, Departamento de Ciência da Computação, Dezem-bro 2003.
Proc. 6th ACM Int’l Multimedia Conference (ACM MULTIMEDIA’98), pages 191–200, 1998.
[17] W. Liao and V. O. K. Li. The split and merge pro-tocol for interactive video-on-demand. IEEE Multi-media, 4(4):51–62, Oct 1997.
[18] Huadong Ma and K. G. Shin. A new scheduling scheme for multicast true VoD service. Lecture Notes in Computer Science, 2195:708–715, 2001.
[19] V. J. Marathe, M. F. Spear, C. Heriot, A. Acharya, D. Eisenstat, W. N. Scherer III, and M. L. Scott. Lowering the overhead of nonblocking software transactional memory. InWorkshop on Languages, Compilers, and Hardware Support for Transac-tional Computing (TRANSACT), 2006.
[20] B. C. M. Netto. Patching interativo: Um novo método de compartilhamento de recursos para trans-missão de vídeo com alta interatividade. Tese Mestrado, UFRJ, COPPE/PESC, Fevereiro 2004.
[21] W. Wing-Fai Poon and Kwok-Tung Lo. De-sign of multicast delivery for providing VCR func-tionality in interactive video-on-demand systems.
IEEE Transactions on Broadcasting, 45(1):141–
148, March 1999.
[22] M. Rocha, M. Maia, I. Cunha, J. Almeida, and S. Campos. Scalable Media Streaming to Interac-tive Users. In MULTIMEDIA’05: Proceedings of the 13th annual ACM international conference on Multimedia, Singapore, November 2005.
[23] C. K. S. Rodrigues. Mecanismos de compar-tilhamento de recursos para aplicações de mídia contínua na Internet. Tese de Doutorado, UFRJ, COPPE/PESC, Abril 2006.
[24] C. K. S. Rodrigues and R. M. M. Leão. Novas técnicas de compartilhamento de banda para servi-dores de vídeo sob demanda com interatividade. In XXIII Simpósio Brasileiro de Redes de Com-putadores (SBRC2005), Fortaleza, CE, Brasil, Maio
2005.
[25] C. K. S. Rodrigues and R. M. M. Leão. Técnicas para sistemas de vídeo sob demanda escaláveis. In
XXIV Simpósio Brasileiro de Redes de Computa-dores (SBRC2006), pages 247–262, Curitiba, PR,
Brasil, Maio 2006.
[26] C. K. S. Rodrigues and R. M. M. Leão. Band-width usage distribution of multimedia servers us-ing patchus-ing. Computer Networks, 51(3):569–587,
February 2007.
[27] C. K. S. Rodrigues and R. M. M. Leão. Buffer-ing para otimização de sistemas interativos de VoD. InXXV Simpósio Brasileiro de Redes de Computa-dores (SBRC2007), pages 941–954, Belém, PA,
Brasil, Maio 2007.
[28] S. Viswanathan and T. Imielinski. Pyramid broad-casting for video-on-demand service. In Proc. SPIE Multimedia Computing and Networking Con-ference, pages 66–77, February 1995.
[29] I. Yang and W. Moloney. Concurrent reading and writing with replicated data objects. In CSC ’88: Proceedings of the 1988 ACM sixteenth annual con-ference on Computer science, pages 414–417, New