Universidade do Minho
Escola de Engenharia
Rui Pedro Araújo Vilas Boas
Desenvolvimento e optimização de
back-end de compilador criptográfico para
plataformas ARM
Universidade do Minho
Dissertação de Mestrado
Escola de Engenharia
Departamento de Informática
Rui Pedro Araújo Vilas Boas
Desenvolvimento e optimização de
back-end de compilador criptográfico para
plataformas ARM
Mestrado em Engenharia Informática
Trabalho realizado sob orientação de
Professor Manuel Bernardo Barbosa
Agradecimentos
Finda esta dissertação, gostaria de agradecer, em primeiro lugar, ao meu orientador Manuel Bernardo Barbosa, pela sua orientação, paciência, disponibilidade e boa disposição. Gostava também de agradecer ao Tiago Oliveira, pelas discussões de ideias que se revelaram muito importantes no desenvolvimento deste trabalho. Agradeço a todos os meus amigos, que fazem parte do meu dia-a-dia e que sempre me incentivaram a ser o meu melhor. Por fim, mas garantidamente não menos importante, agradeço aos meus pais que sempre acreditaram em mim e me apoiaram, foram eles que me possibilitaram ser tudo o que sou hoje.
Este trabalho foi apoiado pela seguinte bolsa de investigação.
Network Sensing for Critical Systems Monitoring (NORTE -01 -0124 -FEDER- 000058)
No âmbito do ON.2 IC&DT Programa Integrado “BEST CASE – Better Science Through Coo-perative Advanced Synergetic Efforts” Refª BI 2014_BestCase_RL3.2_UMINHO
Resumo
Devido à elevada proliferação tecnológica, existesoftwarecriptográfico implementado numa miríade de
plataformas. Plataformas essas que podem ter características de computação bastante diferentes. No
entanto, osoftwarecriptográfico deverá ser imperceptível ao utilizador final, uma vez que deve funcionar
como uma camada de protecção às tarefas que o utilizador possa estar a realizar e não aumentar a sua
pegada computacional. Essa exigência leva muitas vezes a que osoftware criptográfico tenha que ser
re-implementado de acordo com as capacidades computacionais da plataforma/dispositivo-alvo (sendo até
comum recorrer-se a assembly para atingir tal objectivo). O desenvolvimento de software criptográfico
também exige que o programador seja versado em diversas áreas da ciência, devendo assim ser realizado por criptógrafos especializados.
O CAO é uma DSL imperativa para a área da criptografia. Munido de um compilador, interpretador e
uma ferramenta de verificação formal, o CAO permite a passagem de conhecimento criptográfico para um programador com menos experiência na área da criptografia através da automatização da validação formal
das implementações. O compilador CAO possui umback-endaltamente configurável que permite geração
de executáveis dedicados às plataformas destino.
Com a grande utilização actual de processadores ARM, torna-se interessante estudar formas de explorar
as características destes processadores e desenvolver umback-endque as implemente com o objectivo de
obter melhor desempenho dosoftwarecriptográfico. Nesta dissertação explorou-se a utilização dos tipos
de dados vectoriais e instruções do co-processador NEON de forma a obter paralelismo ao nível dos dados. Também foi estudada a possibilidade de inclusão de paralelismo nativo ao nível das tarefas no CAO, de forma a tirar partido das arquitecturasmulti-core.
Abstract
Development and optimization of a cryptographic compiler
Back-end devised for ARM platforms
With the current technological proliferation, cryptography started to be incorporated in wide range of devices, from embedded processors to high-end servers. As cryptographic software needs to be as close to invisible as possible in terms of computational footprint, it must be highly optimised for each specific platform/device. It is not uncommon to see cryptographic code written in assembly to achieve such goal. Furthermore, the development of cryptographic software needs the programmer to be well-versed in various domains of science as mathematics, computer science and electrical engineering.
With that in mind, the CAO language was developed. The CAO language is a imperativeDSLtailored for the
cryptographic domain. Backed-up by a compiler, interactive interpreter and a formal verification tool, the CAO language is able to help an inexperienced programmer in the development of cryptographic software with the automisation of the formal validation of the implementations.
The CAO compiler has a highly-tunable back-end that can be optimized to deliver executables tailored for specific platforms/devices.
Since the ARM architectures are one of the most common processor architectures used in embedded devices, the main goal of this dissertation is the development of a CAO back-end that takes advantage of the characteristics of these processors in order to generate executables of higher performance for cryptographic software. This dissertation explores the usage of the NEON co-processor’s instructions and datatypes as means to attain data-level parallelism. It also studies the possibility of enabling the use of task-level parallelism as a feature of the CAO language, in order to better explore multi-core architectures.
Conteúdo
Conteúdo ix
Lista de Figuras xiii
Lista de Tabelas xv
Lista de Códigos-fonte xvii
1 Introdução 1 1.1 Motivação . . . 2 1.2 Principais resultados . . . 3 1.3 Estrutura do documento. . . 4 2 Revisão da Literatura 5 2.1 Linguagens Criptográficas . . . 5 2.2 Técnicas de optimização . . . 12 2.3 Computação algébrica . . . 17 3 Compilador CAO 21 3.1 Arquitectura do compilador . . . 21
3.2 Tipos de dados CAO . . . 22
3.3 Exemplos de código CAO . . . 24
3.4 Exemplo de compilação . . . 26
3.5 Estrutura da bibliotecaback-endgenérica . . . 28
4 Desenvolvimento de um back-end optimizado 31 4.1 Descrição da arquitectura-alvo . . . 31
4.3 Introdução do GMP . . . 37
4.4 Algumas considerações sobre as alterações . . . 38
4.5 ParalelismoThread-level . . . 39
5 Validação Experimental 45 5.1 Metodologia de obtenção dos resultados . . . 46
5.2 Plataformas utilizadas. . . 48
5.3 Funções de teste . . . 49
5.4 Novas implementações . . . 55
5.5 Testesmulti-threadem processadormulti-core . . . 75
6 Conclusões e trabalho futuro 77 6.1 Trabalho futuro . . . 78
Bibliografia 81 A Ficheiro.plat 85 B Código das funções de teste 87 B.1 Código CAO AES . . . 87
B.2 Código CAO Salsa20 . . . 99
B.3 Código CAO SHA-1 . . . 101
C Tabelas dos resultados obtidos (back-ends) 105 C.1 AES . . . 105
C.2 Salsa20 . . . 106
C.3 SHA-1 . . . 107
D Gráficos dos resultados obtidos (back-ends) 109 D.1 AES . . . 109
D.2 Salsa20 . . . 111
D.3 SHA-1 . . . 112
E O que são custos inclusivos e exclusivos (callgrind) 115
Siglas
AES Advanced Encryption Standard API Application Programming Interface AST Abstract Syntax Tree
CFG Control Flow Graph
CISC Complex Instruction Set Computer CPU Central Processing Unit
DES Data Encryption Standard DLP Data-level Parallelism DPA Differential Power Analysis DSL Domain-Specific Language ECB Electronic Codebook GCC GNU Compiler Collection
GMP GNU Multiple Precision Arithmetic Library GPL General-Purpose Language
ILP Instruction-level Parallelism IoT Internet of Things
ISA Instruction Set Architecture
MIMD Multiple Instruction Multiple Data
NIST National Institute of Standards and Technology NSA National Security Agency
NTL Number Theory Library OpenMP Open Multi-Processing
PAPI Performance Application Programming Interface PRF Pseudorandom function
RISC Reduced Instruction Set Computer SHA-1 Secure Hash Algorithm 1
SIMD Single Instruction Multiple Data SMT Simultaneous Multithreading SSA Static Single Assignment TAC Three-Address Code TLP Thread-level Parallelism
Lista de Figuras
3.1 Arquitectura do Compilador CAO . . . 21
4.1 Cifra por blocos emcounter mode . . . 41
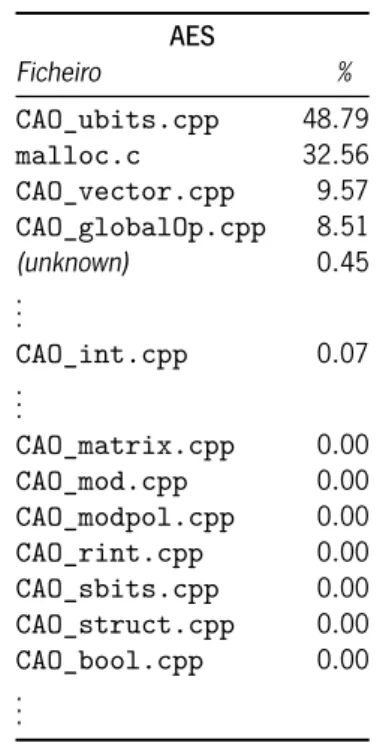
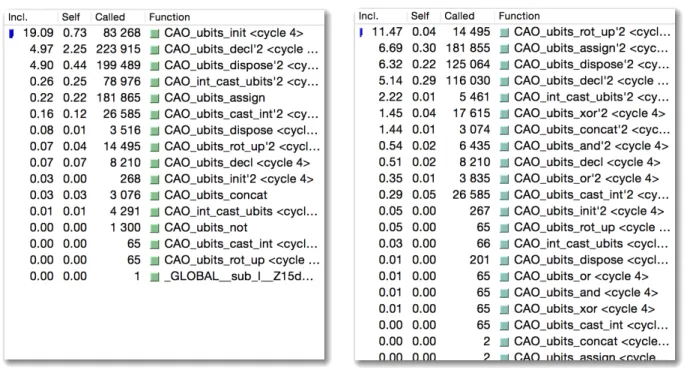
5.1 Custos e chamadas das funções do módulo CAO_ubits na função AES com oback-end
vec32 (O3) . . . 59
5.2 Custos e chamadas das funções do módulo CAO_ubits na função AES com oback-end
original (O2) . . . 59
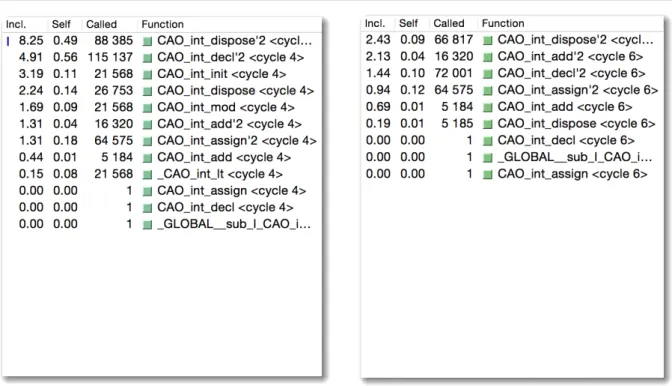
5.3 Custos e chamadas das funções do ficheiro arm_neon.h (O3) . . . 60
5.4 Custos e chamadas das funções do módulo CAO_ubits na função Salsa20 com o
back-endvec32 (O2) . . . 63
5.5 Custos e chamadas das funções do módulo CAO_ubits na função Salsa20 com o
back-endoriginal (O2) . . . 63
5.6 Custos e chamadas das funções do ficheiro arm_neon.h (O2) . . . 64
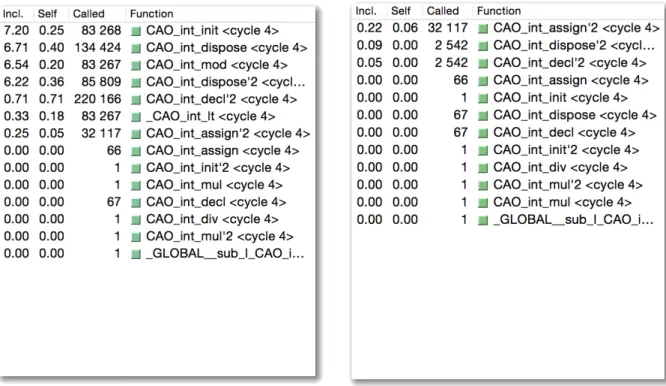
5.7 Custos e chamadas das funções do módulo CAO_int na função Salsa20 com oback-end
vec32 (O2) . . . 65
5.8 Custos e chamadas das funções do módulo CAO_int na função Salsa20 com oback-end
original (O2) . . . 65
5.9 Custos e chamadas das funções do módulo CAO_ubits na função SHA-1 com o
back-endvec32 (O3) . . . 70
5.10 Custos e chamadas das funções do módulo CAO_ubits na função SHA-1 com o
back-endoriginal (O2) . . . 70
5.11 Custos e chamadas das funções do ficheiro arm_neon.h (O3) . . . 70
5.12 Custos e chamadas das funções do módulo CAO_int na função SHA-1 com oback-end
vec32 (O3) . . . 71
5.13 Custos e chamadas das funções do módulo CAO_int na função SHA-1 com oback-end
5.14 Custos e chamadas das funções do módulo CAO_mod na função SHA-1 com oback-end
vec32 (O3) . . . 72
5.15 Custos e chamadas das funções do módulo CAO_mod na função SHA-1 com oback-end
original (O2) . . . 72
Lista de Tabelas
5.1 Resultados da função AES em milissegundos (ms) . . . 56
5.2 Rácios entre original em O2 e novas implementações em O3 para o AES . . . 56
5.3 Percentagem de utilização dossource files na função AES compilada em O0 com a
im-plementação vec32 e cominputde 4096bytes . . . 58
5.4 Percentagem de utilização dossource files na função AES compilada em O3 com a
im-plementação vec32 e cominputde 4096bytes . . . 58
5.5 Resultados da função Salsa20 em milissegundos (ms) . . . 61
5.6 Rácios entre original em O2 e novas implementações em O2 para o Salsa20 . . . 61
5.7 Percentagem de utilização dossource filesna função Salsa20 compilada em O0 com a
implementação vec32 e cominputde 4096bytes . . . 62
5.8 Percentagem de utilização dossource filesna função Salsa20 compilada em O2 com a
implementação vec32 e cominputde 4096bytes . . . 62
5.9 Resultados da função SHA-1 em milissegundos (ms) . . . 66
5.10 Rácios entre original em O2 e novas implementações em O3 para o SHA-1 . . . 67
5.11 Percentagem de utilização dos source files na função SHA-1 compilada em O0 com a
implementação vec32 e cominputde 4096bytes . . . 68
5.12 Percentagem de utilização dos source files na função SHA-1 compilada em O3 com a
implementação vec32 e cominputde 4096bytes . . . 68
5.13 Rácios médios da optimização obtida utilizando a implementação vec32 . . . 73
Lista de Códigos-fonte
1 Inicialização de matrizes, vectores e estruturas . . . 23
2 Inicialização de mods . . . 24
3 Implementação CAO da função curve25519 . . . 25
4 Implementação CAO da funçãobubble sort . . . 26
5 Código C gerado da funçãobubble sort . . . 27
6 Exemplo de utilização de parallel sections . . . 40
7 Exemplo sequencial do AES emcounter mode . . . 41
8 Exemplo paralelo do AES emcounter mode . . . 42
9 Excerto do código C gerado pela implementação AES com adição de directivas OpenMP 43 10 Sugestão de sintaxe CAO para paralelismo recorrendo a parallel sections . . . . 44
Capítulo 1
Introdução
Anteriormente ao século XX, a criptografia apenas se dedicava ao problema da comunicação secreta, ou seja, o conteúdo das mensagens comunicadas apenas deveria ser perceptível ao emissor e receptor, não vazando para terceiros. Nessa altura, a criptografia era vista como uma forma de arte uma vez que a criação de cifras apenas se apoiava no engenho e criatividade do seu criador, pois não havia conhecimento teórico que a pudesse sustentar. Porém, nos finais do século XX a criptografia passou a ser classificada como ciência devido ao aparecimento de teoria matemática que possibilitava a sua análise rigorosa. Assim sendo, na criptografia actual, à qual se chama criptografia moderna, a matemática assume um papel central na construção de criptossistemas seguros. A segurança destes sistemas passou a ser baseada em problemas matemáticos que se acreditam ser difíceis de resolver dado o contexto computacional existente. Enquanto que anteriormente a criptografia apenas tinha lugar dentro do contexto militar (a conhecida máquina Enigma utilizada na segunda guerra mundial é um exemplo disso), actualmente a criptografia pode ser encontrada em todo o lado, onde os seus utilizadores muitas vezes nem se apercebem que estão
dependentes dela, como por exemplo na comunicação segura no acesso a um website. Para além da
alteração do contexto da sua utilização, a sua extensão também se alargou. A criptografia deixou de cuidar apenas de confidencialidade para tratar também de outras propriedades de segurança como autenticidade, integridade, identificação, anonimato, não-repúdio,etc.
O desenvolvimento desoftwarecriptográfico é claramente distinto das outras áreas da engenharia de
software, uma vez que o desenho e implementação desoftwarecriptográfico implica o domínio de diversas áreas da ciência como a matemática, ciência da computação e engenharia electrónica. A isto acresce que a camada criptográfica deve ser imperceptível ao utilizador o que obriga a que osoftwareseja agressivamente
CAPÍTULO 1. INTRODUÇÃO
optimizado sem alterar as suas propriedades de segurança, o que muitas vezes pode implicar a obscuração do protocolo original e redução da sua genericidade. Actualmente, com a proliferação tecnológica existente,
a emergência da era da Internet of Things (IoT), a criptografia começou a ser introduzida em todo o tipo
de dispositivos de forma a garantir as suas propriedades de segurança. No entanto, esta vasta gama dispositivos pode apresentar características díspares, dado que estes podem variar entre processadores
embebidos com pouca capacidade computacional até servidores de alto-desempenho, tendo o software
criptográfico que ser adaptado ao ambiente onde vai ser executado.
A linguagem CAO, uma linguagem imperativa destinada à implementação de software criptográfico,
procura dar resposta a estes problemas levantados através da disponibilização de um compiladorsecurity–
awareque analisa, transforma e optimiza o código implementado nesta linguagem. A linguagem está
dese-nhada de forma a disponibilizar um conjunto de conceitos matemáticos como tiposfirst-class. Através da
inclusão destas noções matemáticas como tipos de dados, aliada a uma sintaxe imperativa é possibilitada ao programador comum a fácil implementação de componentes criptográficos. Por outro lado, a
lingua-gem possui um back-end altamente configurável que pode ser modificado de forma a gerar executáveis
optimizados para diferentes dispositivos-alvo. Desta forma elimina-se a necessidade de re-implementação do componente criptográfico original para optimizá-lo para cada dispositivo.
O mercado actual encontra-se inundado por dispositivos de pequeno porte como os smartphonese
tablets, entre outros. Comparativamente aos anos iniciais da informática, estes dispositivos já possuem uma grande capacidade de processamento tendo em conta o seu tamanho. Esta capacidade de proces-samento advém das evoluções ocorridas na área da arquitectura de processadores. Exemplos disso são a
inclusão de processamento vectorial dedicado à multimédia, através de instruçõesSIMDe as arquitecturas
multi-core. A grande maioria destes equipamentos utiliza processadores baseados em arquitecturasRISC
onde as arquitecturas ARM são líderes de mercado.
1.1 Motivação
Actualmente, existem doisback-ends desenvolvidos para o CAO. Um deles foi desenvolvido
especifi-camente para um processador proprietário, estando altamente optimizado para as suas propriedades. O
outro é umback-endgenérico de código-aberto. Dada a extrema necessidade de que osoftware
criptográ-fico seja o mais optimizado possível, e que as arquitecturas ARM estejam tão difundidas, é interessante
desenvolver um novoback-endque tire partido das propriedades destes processadores.
1.2. PRINCIPAIS RESULTADOS
Assim sendo, pretende-se estudar diferentes formas de tirar partido de funcionalidades específicas das
arquitecturas de processadores ARM, nomeadamente instruçõesSingle Instruction Multiple Data (SIMD)de
modo a obter benefícios do ponto de vista do desempenho. A utilização deste tipo de instruções também
se crê benéfica na protecção contra ataques side-channel. Os ataques side-channel são ataques que
tentam quebrar a segurança dos sistemas criptográficos não através de ataques força–bruta ou a possíveis fraquezas teóricas mas sim através da exploração de factores físicos das implementações. Exemplos disso
são os ataques por análise de tempo (timing attacks), por análises de consumo de energia e análises das
emissões de energia electromagnética. As instruçõesSIMDapresentam maior resiliência contra ataques
side-channel uma vez que o processamento simultâneo de diversos valores reduz a correlação entre o comportamento físico do processador e os valores individuais computados.
O objectivo final é obter implementações optimizadas para diferentes plataformas a partir do mesmo programa CAO e, para isso, é muito importante perceber como é que diferentes técnicas de optimização se comportam para diferentes programas/implementações CAO.
1.2 Principais resultados
Durante o desenvolvimento desta dissertação, foram criadas diversas implementações alternativas do
back-enddo compilador CAO. Tendo como ponto de partida oback-endgenérico, inicialmente foram utiliza-dos os tipos de dautiliza-dos vectoriais disponibilizautiliza-dos pelo co-processador NEON (que pode ser encontrado nos processadores ARM a partir da arquitectura ARMv7) para re-implementar os tipos de dados representativos dasbitstringssem sinal da linguagem CAO. Esta implementação foi replicada para os diferentes tamanhos de vector que este co-processador disponibiliza, por forma a encontrar qual o tamanho de dados mais eficiente. De seguida, foi trocada a biblioteca que implementa os inteiros CAO por uma com velocidades de processamento superiores. Por fim, foi re-implementado o tipo de dados que lida com inteiros módulo para que também possa fazer uso dos tipos de dados vectoriais NEON.
Posteriormente, cada uma destas implementações foi testada com diferentes casos representativos,
nomeadamente a cifra por blocos AES, a cifra sequencial Salsa20 e a função dehashSHA-1, com diferentes
tamanhos deinpute utilizando diferentes níveis de optimização do compilador C. Os dados destes testes
foram recolhidos e analisados de modo a que se possa identificar qual das implementações e nível de optimização é mais vantajosa, em termos de desempenho, para cada uma destas funções estudadas. No final, a partir das conclusões retiradas das execuções das diferentes funções, são apresentadas algumas
CAPÍTULO 1. INTRODUÇÃO
conclusões mais gerais.
Actualmente, a linguagem CAO não disponibiliza formas de explorar paralelismo. Assim sendo, são es-tudadas nesta dissertação formas introduzir formas paralelismo nativo na linguagem, mais concretamente paralelismo ao nível das tarefas. A partir do caso de estudo da paralelização de uma cifra por blocos, é apresentada uma sugestão de extensão à linguagem CAO para que seja incluída uma forma de criar
threads, para que se possa tirar partido das potencialidades das arquitecturasmulti-core.
1.3 Estrutura do documento
O restante desta dissertação está estruturado da seguinte forma:
Capítulo2 Neste capítulo é feita a revisão da literatura. Na primera parte, são aprofundados os
moti-vos para a existência deDSLs criptográficas e apresentadas duas linguagens deste tipo, o CAO e o
Cryptol. Na segunda parte, são estudadas e apresentadas diversas formas de obter melhor
desem-penho recorrendo a diferentes formas de paralelismo, com especial incidência nas instruçõesSIMD
e arquitecturasmulti-core. Finalmente, são apresentadas duas bibliotecas de computação algébrica.
Capítulo3 Neste capítulo é apresentada a estrutura do compilador CAO, os tipos de dados da linguagem
e a implementação genérica do back-end do compilador. É também apresentado um exemplo de
código CAO, o processo de compilação e o respectivo ficheiro gerado.
Capítulo4 É o capítulo onde são apresentadas as alterações realizadas noback-enddo compilador CAO
por forma a tirar partido das propriedades dos processadores ARM, na procura por melhor desem-penho. É também apresentado um teste simples de execução de código paralelo em processadores
multi-coree propostas alterações ao compilador CAO de forma a suportar este tipo de paralelismo de forma nativa.
Capítulo5 Neste capítulo são estudados os resultados obtidos da execução de três funções de teste
uti-lizando as novas implementações deback-endem diversos níveis de optimização, assim como do
testemulti-coreapresentado em4.
Capítulo6 Último capítulo onde são apresentadas as conclusões finais desta dissertação e propostas de
trabalho futuro.
Capítulo 2
Revisão da Literatura
2.1 Linguagens Criptográficas
UmaDomain-Specific Language(DSL) é uma linguagem de programação criada especificamente para
um campo científico. Estas linguagens contrastam com as sobejamente utilizadasGeneral-Purpose
Lan-guages (GPLs), como o C e o Java, que podem ser aplicadas a inúmeros domínios da ciência. Assim sendo,
umaDomain-Specific Language (DSL)permite utilização de conceitos abstractos pertencentes a esses
do-mínios científicos facilitando dessa forma a implementação de soluções, não havendo assim a necessidade
de ter em conta as limitações (técnicas) que umaGPLpossa ter. A existência de umaDSLpropicia também
a criação de ferramentas de suporte à ciência em questão, como por exemplo ferramentas de validação de correcção formal.
Desenvolversoftwarecriptográfico não é uma tarefa simples. Em primeiro lugar, o programador deve
ser versado em várias áreas da ciência, como a matemática, a computação, a engenharia electrónica,etc.,
pois a mais pequena falha em qualquer uma destas áreas pode ser explorada para quebrar a segurança de um sistema, e por essa razão, este trabalho deve ser apenas confiado a pessoas especializadas. Por
outro lado, o desempenho é fundamental uma vez que a camada criptográfica do software se deseja
totalmente invisível ao utilizador. Para atender a essa exigência, o programador é forçado a optimizar o seu
software. Na verdade, é bastante comum encontrar código implementado emassemblypara garantir tal
requerimento, o que exige ainda mais conhecimento do programador. No entanto, utilizarassemblypara
optimizar o código pode restringir o número de máquinas em que osoftwarepode executar, o que reduz
CAPÍTULO 2. REVISÃO DA LITERATURA
com a utilização deGPLspara desenvolversoftwarecriptográfico.
De seguida aprofundam-se as razões para a necessidade de umaDSLcriptográfica, abordando a
ques-tão sob diferentes perspectivas: desempenho, segurança e manutenção. Desempenho
Sob um prisma de abstracção, as linguagens de programação podem ser divididas em dois grupos: as linguagens de alto-nível (high-level) e as de baixo-nível (low-level). Esta abstracção é feita relativamente
ao Instruction Set Architecture (ISA), i.e., ao conjunto de instruções reconhecidas pelo processador. Isto
significa que quanto mais alto for o nível de abstracção, mais se aproxima da linguagem humana e se afasta da linguagem inteligível à máquina. Posto isto, facilmente se depreende que é mais fácil para o programador trabalhar sobre uma linguagem de alto-nível, que é o que acontece na grande maioria dos casos. Assim sendo, é necessário que esta abstracção seja eliminada para que o código possa ser executado pela máquina. Este é o trabalho do compilador.
Esta conversão é possível porque o compilador consegue associar correctamente as operações com o devido efeito sobre as variáveis, permitindo manipular o código e gerar um executável optimizado. Desta forma, é possibilitada a existência da especificação do programa tanto em linguagem perceptível à máquina como em linguagem perceptível ao programador.
No entanto, quando se escrevesoftwarecriptográfico, é frequentemente necessário recorrer a noções
matemáticas abstractas (e.g. corpos finitos) que, programando com umaGPL, requerem a utilização de
bibliotecas externas para mais facilmente as manipular. A utilização deste tipo de bibliotecas levanta uma série de problemas de optimização, como por exemplo:
1. As variáveis não podem ser automaticamente alocadas a registos ou a registos temporários visto não serem de tipos de dados nativos e necessitam de ser alocadas manualmente para reduzir o espaço ocupado;
2. Não podem ser aplicadas técnicas de strength reductione é necessário trocar multiplicações por
constantes por cadeias de adição;
3. Eliminação de sub-expressões comuns (common sub-expression elimination) não pode ser realizada
e é necessário manualmente detectar e partilhar resultados intermédios.
2.1. LINGUAGENS CRIPTOGRÁFICAS
Portanto, sendo estas bibliotecas externas à linguagem, e por consequência, os seus tipos de dados não-nativos, o compilador não tem conhecimento sobre as suas semânticas operacionais, o que leva a que as optimizações que seriam expectáveis por parte deste não possam ocorrer.
Tudo isto representa um claro problema sob a perspectiva de desempenho. Se o programador pre-tender minorar os efeitos causados será sobrecarregado com trabalho extra e possivelmente ofuscará a implementação, pois deixará de representar o algoritmo original em favor de uma outra forma necessária para que se torne mais eficiente.
Segurança
É seguro dizer-se que é mais difícil diagnosticar e resolver problemas desoftwarerelativos a segurança do que problemas funcionais. Enquanto que os problemas funcionais normalmente se apresentam sob a
forma de umcrashou de um resultado errado, os problemas de segurança só se tornam visíveis quando
um utilizador explora indevidamente uma falha dedesign, (isto é, em linguagem corrente, “só se tornam
visíveis tarde demais”). Os problemas de segurança não surgem da normal utilização do softwaremas
sim através de uma utilização mal intencionada. Desta forma, é mais difícil prevenir e detectar problemas de segurança, pois requerem que o programador tenha o trabalho de “pensar como o atacante” e de se “defender” de todos os ângulos de ataque possíveis. Por fim, estes problemas diferem no sentido em que um único problema de segurança pode ser catastrófico enquanto que um problema funcional geral-mente não apresenta consequências tão graves, ou seja, enquanto que a mais ínfima falha de segurança pode comprometer o sistema completo e permitir ao atacante atingir o seu objectivo, normalmente uma falha funcional, apesar de poder ser terminal, pode não impedir que o programa continue a funcionar correctamente.
Este trabalho de detectar e prevenir falhas de segurança é claramente um exercício oneroso em que o programador poderia beneficiar do auxílio de alguma forma de assistência automática, assim como o dado pelos compiladores para erros funcionais através de mensagens de erro e de aviso. Esta mecanização
do processo oferece uma alternativa com maior garantia de qualidade dosoftwareatravés da redução da
possibilidade de erro. Este tipo de abordagem tem-se tornado cada vez mais comum e vários investigadores já desenvolveram ferramentas para detectar e prevenir vários tipos de ataques.
No campo dos métodos formais, têm vindo a ser desenvolvidos métodos que permitem a detecção
automática ou semi-automática de vulnerabilidades de segurança em protocolos criptográficos (e.g.
CAPÍTULO 2. REVISÃO DA LITERATURA
descrição do protocolo (numa forma deprocess algebra) e posteriormente essa descrição é avaliada por
software demodel checking que conclui se o protocolo é, ou não, seguro. Apesar da automatização de provas de segurança estar num patamar diferente do de mecanismos que possam auxiliar o
desenvolvi-mento desoftwarecriptográfico, e que, geralmente, quando se desenvolve código criptográfico já se segue
protocolos pré-estabelecidos, estes progressos na análise formal de programas começaram a ser
frutífe-ros quanto à área dos ataques side-channel[Kocher, 1996]. Embora já sejam conhecidas e formalmente
comprovadas várias formas de defesa contra estes ataques, a sua implementação fica sempre a cargo do programador. Desta forma, apesar de haver um vasto conhecimento sobre várias técnicas de ataque e de defesa, o programa fica sempre exposto ao perigo do erro humano. Faz então sentido transferir este
conhecimento para ferramentas automatizadas de forma a assistir na detecção de áreas dosoftwareque
sejam sensíveis a ataques side-channel, e na aplicação de contra-medidas, aliviando assim o trabalho do
programador. Manutenção
Após os problemas de optimização do desempenho e validação de segurança manuais, o próximo problema com que o programador se depara é o de manutenção. Numa primeira inspecção, torna-se evidente que a mais pequena alteração no código pode desperdiçar todo o esforço anterior e requerer uma nova optimização e reavaliação da segurança. No entanto, o problema adensa-se quando é necessário o
mesmo softwarecorrer em máquinas com características muito díspares. Devido aos recentes avanços
tecnológicos, existe uma grande quantidade de dispositivos com diferentes características computacionais: desde processadores embebidos, com capacidade computacional e de memória limitadas, até servidores de alto-desempenho com baixas-latências, necessitando todos eles de garantias de segurança. Assim sendo, para garantir um bom desempenho, é possível que sejam necessárias várias implementações de um mesmo programa, de forma a tirar partido completo das funcionalidades de cada uma das diferentes máquinas; o que nos leva de volta ao problema inicial. Manter e sincronizar todas estas versões torna-se uma tarefa complexa e o desfecho mais provável é que pequenas inconsistências de negligências acabem por tornar osoftwareineficiente e/ou inseguro.
Posto isto, surge a necessidade de desenvolver implementações de software genéricas e, portanto,
transversais a múltiplas plataformas e dispositivos. Pode parecer impossível a existência de uma linguagem universal onde se pode descrever os programas e depois compilá-los para cada dispositivo-alvo, no entanto, se o âmbito do problema for reduzido ao domínio da criptografia, devido à sua natureza matemática bem estruturada, torna-se possível uma aproximação a tal linguagem. Desta forma, a questão da manutenção dosoftwarefica resolvida, visto que se torna apenas necessário descrever okernelcriptográfico uma única
2.1. LINGUAGENS CRIPTOGRÁFICAS
vez e todo o trabalho de optimização e validação fica relegado ao compilador.
Nas seguintes secções apresentam-se duas DSLs criptográficas, o Cryptol1 e o CAO2, uma para o
paradigma funcional e outra para o imperativo.
2.1.1 Cryptol
O Cryptol [Lewis and Martin, 2003] é umaDSL puramente funcional para o domínio da criptografia
assente em métodos formais, desenvolvida nos laboratórios daGalois Connections com a consultoria de
criptógrafos da National Security Agency (NSA). A linguagem disponibiliza um conjunto de ferramentas
para validação das implementações, verificação formal das especificações, geração de vectores de teste e automação de testes.
Sendo uma linguagem puramente funcional, não possui estado global neminput/output, sendo apenas
dependente dos valores passados como parâmetro, não existindo assimside-effects,i.e. não é possível a
alteração de valores fora doscopeda função sem ser através dos valores devolvidos. Sendo uma linguagem
funcional, faz uso de conceitos como funções de ordem-superior efirst-class.
Actualmente, quando os algoritmos criptográficos são criados, são descritos através de notação ma-temática sobre a qual é possível fazer testes sobre a sua correcção formal. Mais tarde, quando esses algoritmos são aceites como seguros, são descritos por “implementações de referência” que variam entre pseudo-código, C ou até linguagem natural. Da utilização destas “linguagens” para descrição de imple-mentações de referência advêm alguns problemas:
1. Utilizar pseudo-código ou linguagem natural pode tornar as implementações ambíguas e/ou incom-pletas e não há possibilidade de validação.
2. Quando se usa pseudo-código, normalmente recorre-se a um tipo de “linguagem” processual que, em primeiro lugar, acaba por obscurecer os detalhes matemáticos e, em segundo, vai forçar uma ordem sequencial no algoritmo, o que não serve de boa base para uma implementação paralela.
3. Quando as implementações são descritas numa GPL, como C, normalmente tem que se ter em
conta os detalhes técnicos da linguagem. No caso do C, exemplo disso é a alocação dinâmica de
1https://cryptol.net/
CAPÍTULO 2. REVISÃO DA LITERATURA
memória que acaba por ofuscar o fluxo do algoritmo inicial.
Posto isto, uma das motivações para a criação da linguagem foi a possibilidade das implementações
se aproximarem o máximo das especificações matemáticas, reduzindo assim o gap existente entre as
implementações e as especificações, procurando assim aumentar a sua correcção e, por consequência, a sua segurança.
O Cryptol permite também a compilação dos algoritmos tanto para implementações de referência em
GPLs, como C ou Java, como para linguagens de descrição de hardware como VHDL e Verilog. Na sua
concepção, o Cryptol foi desenvolvido voltado para a criação de implementações em hardwarede
cripto-grafia simétrica formalmente verificadas. A natureza puramente funcional da linguagem proporciona uma
boa aproximação aohardware. Pois tanto as funções como os circuitos combinatórios correspondem a um
mapeamento deinputsaoutputs, a isto acresce que a não-sequencialidade do Cryptol permite tirar partido
das propriedades paralelas dohardware.
2.1.2 CAO
O CAO é uma DSLimperativa para o domínio da criptografia suportada por um compilador [Barbosa
et al., 2005], um interpretador interactivo e uma ferramenta de verificação formal (CAOVerif). O seu com-pilador executa um conjunto de análises, transformações e optimizações tendo em conta a segurança do sistema, traduzindo os programas descritos na linguagem CAO em implementações de alto-desempenho
em C. Essas implementações podem ser posteriormente integradas em projectos de softwaremais
com-plexos. Sob o ponto de vista de manutenção, isto é extremamente benéfico pois uma única especificação
em CAO pode ser traduzida em executáveis para diferentes dispositivos utilizando back-ends específicos
sem ser necessário o conhecimento prévio, por parte do programador, de quais são esses dispositivos. Na
sua essência, atoolchain está desenhada da seguinte forma: Em primeiro lugar é descrito um programa
na linguagem CAO e depois de compilado resulta uma especificação em C equivalente. Posteriormente
essa especificação será compilada peloGNU Compiler Collection (GCC)e executada no dispositivo-alvo. O
processo interior do compilador é descrito na secção3.1.
O foco da linguagem está restrito à implementação de componentes criptográficos como funções de
hash, cifras sequenciais e por blocos, protocolos de criptografia de chave pública, etc. Por essa razão,
um dos aspectos chave do design do CAO é o suporte de conceitos criptográficos como componentes
first-class da linguagem, i.e., permite que estes conceitos sejam passados como parâmetro, devolvidos
2.1. LINGUAGENS CRIPTOGRÁFICAS
por uma função, e atribuídos a uma variável de forma a facilitar a descrição dos programas e voltando a atenção do programador para aspectos da implementação que são críticos para a segurança. Daqui advém que, utilizando uma linguagem mais natural é permitido ao programador aumentar a sua produtividade e
reduzir a probabilidade de erro. O CAO é fortemente tipado e apresenta semânticacall-by-value, não sendo
também permitida a alocação dinâmica de memória de forma a evitar erros de gestão de memória. Sendo o seu foco a implementação de componentes criptográficos, não apresenta qualquer tipo de suporte de
input/outputno sentido de comunicação com o utilizador.
Pode-se dizer que o principal objectivo do CAO é permitir que um programador pouco versado em
criptografia possa desenvolversoftwareseguro através da transferência do conhecimento de programadores
experientes para uma ferramenta automática de análise e aplicação de técnicas de defesa. É importante ressalvar que o CAO não é um sistema invencível tanto da perspectiva de segurança como da perspectiva de desempenho. Por um lado é ingénuo assumir-se que é possível construir uma ferramenta automática que é capaz de se defender de todos os tipos de ataques existentes e formular defesas para formas de ataque que ainda não foram descobertas, por outro também não é consciente afirmar que o código gerado terá sempre melhor desempenho que outro escrito à mão.
CAPÍTULO 2. REVISÃO DA LITERATURA
2.2 Técnicas de optimização
O desempenho de um sistema computacional tem sido desde sempre uma preocupação,
independen-temente do seu uso final. De forma a responder a esta necessidade, osCentral Processing Units (CPUs)
evoluíram e tornaram-se cada vez mais rápidos, no entanto, isto revelou-se um custo na complexidade dos circuitos. Eventualmente tornou-se cada vez mais difícil atingir maiores frequências de relógio com circuitos tão complexos devido a problemas físicos inevitáveis como elevados consumos de energia, a
li-mitação da velocidade da luz, dissipação de calor, etc. Estes obstáculos obrigaram a uma alteração na
abordagem ao problema. As companhias de hardware decidiram simplificar os circuitos de começar a
introduzir múltiplas unidades de processamento num únicochip, originando assim as arquitecturas
multi-processador3. Esta decisão foi uma grande mudança de perspectiva, os fabricantes deixaram de depender
apenas emInstruction-level Parallelism (ILP)para começarem a empregar tambémData-level Parallelism
(DLP)eThread-level Parallelism (TLP).
Anteriormente à génese dos multi-processadores, o paralelismo existente (ILP) era implícito e ficava ao
cuidado do compilador e do hardwaree a única forma deTLPexistente era baseada em time slicing, ou
seja, o processador alterna entre diferentes threads de forma a dar a ilusão que estas estão a executar
em paralelo. O que não é na verdade paralelismo mas sim concorrência, pois existe um recurso a ser
disputado. Com a existência de CPUs multi-processador, as threads podem executar verdadeiramente
em paralelo se executarem simultaneamente em unidades de processamento diferentes. Enquanto que
o paralelismo recorrendo a ILP era implícito e levado a cabo pelo compilador e processador, as novas
formas de paralelismo requerem a interacção directa do programador. Os programadores passaram a ser obrigados a escrever e estruturar os programas de forma explicitamente paralela, o que muitas vezes se revela um fardo. Portanto, a necessidade de explorar as capacidades de paralelismo das arquitecturas multi-processador obrigou à criação de um novo modelo de programação que até então não existia.
Sob o ponto de vista da camada aplicacional, o paralelismo pode ser obtido de duas formas:
Data-level ParallelismeTask-level Parallelism. A primeira forma refere-se à possibilidade de operar sobre vários
sub-conjuntos de dados ao mesmo tempo, e a segunda refere-se ao processamento de múltiplas tarefas
(independentes entre si) em simultâneo. Assim sendo, através de DLPé possível dividir um conjunto de
dados em n sub-conjuntos e processá-los em simultâneo utilizando n unidades de processamento, dividindo assim o tempo de execução por n. Por outro lado, utilizandoTask-level Parallelism (TLP), é possível executar
3Note-se que o termo multi-processador é utilizado como termo lato para multi-processamento. Podendo referir-se tanto a
múltiplos processadores como a múltiploscoresnumchip.
2.2. TÉCNICAS DE OPTIMIZAÇÃO
n tarefas em n unidades de processamento independentes.
Já sob o ponto de vista da camada arquitectural, existem várias formas de obter essas duas formas de paralelismo (uma delas já foi mencionada anteriormente). Essas formas são:
Instruction-level Parallelism: como o próprio nome indica, ILPaplica paralelismo ao nível da instrução.
Ou seja, um processador super-escalar pode, através da ajuda do compilador, gerar as instruções de
forma a poder tirar partido depipelining, utilizando simultaneamente vários componentes do CPU.
Também é possível utilizar outras estratégias comospeculativeeout-of-order execution.
Arquitecturas vectoriais: as arquitecturas vectoriais são arquitecturas que têm os seus registos
organiza-dos como vectores. As arquitecturas vectoriais pertencem à classe de computadoresSIMDsegundo
a taxonomia de Flynn [Flynn, 1966]. Ao contrário das arquitecturas escalares, estas possuem um ins-truction setque permite aplicar uma mesma instrução a múltiplos registos simultaneamente. Desta
forma, as arquitecturas vectoriais permitem obterDLP, uma vez que vários dados são processados
ao mesmo tempo. Inicialmente as arquitecturas vectoriais eram representadas por processadores vectoriais mas com a evolução tecnológica dos processadores escalares a utilização de processado-res vectoriais caiu em desuso. Actualmente este tipo de arquitectura é repprocessado-resentada pelas extensões
SIMDpresentes na maioria dosCPUsactuais e pelosGraphic Processing Units (GPUs).
Thread-level Parallelism: permite obter, através de múltiplasthreads, tantoDLPcomoTask-level
Paralle-lism, uma vez que cada thread pode operar sobre o mesmo conjunto de dados ou simplesmente
executar tarefas distintas.
2.2.1 SIMD Instruction Set Extensions
As extensõesSIMD, são um tipo de instruções que permitem emular a arquitecturaSIMD utilizando
uma série de registos especiais para o efeito, permitindo assim a obtenção de DLP. Inspirados pelos
computadores vectoriais, os fabricantes de processadores começaram a introduzir extensões SIMD nos
seusinstruction setsde modo a aumentar o desempenho das aplicações multimédia. Apesar deste ter sido o objectivo inicial, estas instruções podem ser aplicadas a outras áreas como por exemplo a paralelização de cálculos sobre matrizes e vectores.
optimi-CAPÍTULO 2. REVISÃO DA LITERATURA
zação de primitivas criptográficas devido ao potencial de paralelismo que pode ser aproveitado uma vez
que estão presentes na maioria dos processadores modernos [Bernstein and Schwabe, 2012][Götzfried,
2013][Bos et al., 2014][Izu and Takagi, 2004]. A utilização de instruçõesSIMD é tradicionalmente tida
como proveitosa para a protecção contra ataquesside-channel, nomeadamenteDifferential Power Analysis
(DPA), uma vez que a computação simultânea de vários valores reduz a correlação entre o comportamento
físico do processador e os valores a ser computados.
Actualmente, este tipo de instruções está presente na maioria dos processadores modernos. Assim
sendo, são uma fonte de paralelismo atractiva, principalmente quando se está a reformular um software
para correr num dispositivo onde ohardwarenão pode ser substituído facilmente.
O modelo de programação deste tipo de instruções assenta na utilização de bibliotecas específicas
ou pela utilização directa de assembly. No entanto, existem actualmente compiladores que permitem a
vectorização automática de código de forma a tirar partido destas instruções. Uma vantagem da utilização
de instruções SIMD é que o programador pode tirar partido de paralelismo sem deixar de raciocinar de
uma forma sequencial sobre a tarefa a cumprir.
2.2.2 Paralelismo Thread-level
Como o próprio nome indica, Thread-level Parallelismpermite obter paralelismo através da utilização
dethreads. No entanto, é preciso ter em atenção que podem existir aplicaçõesmulti-threadque não tirem
partido de paralelismo. Exemplo disso é quando se utilizathreadsem arquitecturas uni-processador. Neste
caso, as threadscompetem entre si por um recurso computacional obtendo assim concorrência, dando
a aparência de paralelismo (exceptuando o caso da utilização de Simultaneous Multithreading (SMT)).
Portanto, para que se possa obter verdadeiramente paralelismo através de threads, é necessário que a
arquitectura onde o programa está a executar possua mais que uma unidade de processamento e que as
diferentesthreadssejam atribuídas a cada uma delas. Este tipo de arquitecturas é normalmente apelidada
deMultiple Instruction Multiple Data (MIMD).
Asthreadspodem ser definidas como diferentes fios de execução a correr no interior dos processos,
podendo desempenhar diferentes tarefas. Ao contrário dos processos, as threads partilham o mesmo
espaço de endereçamento, pelo que este facto pode ser uma possível fonte de problemas se não for tido
em conta aquando da programação de um programamulti-threaded.
2.2. TÉCNICAS DE OPTIMIZAÇÃO
Thread-level Parallelismé normalmente utilizado para obterTask-level Parallelismmas também pode ser
utilizado para atingirData-level Parallelism. No entanto, a granularidade — representativa da quantidade
de trabalho a processar — deve ser suficientemente grande para que o desempenho obtido justifique o
overheadgerado na criação dasthreads.
2.2.2.1 Arquitecturas multi-core
Os multi-processadores podem ter dois tipos de organização de memória. Memória partilhada, onde todos os processadores têm igual acesso a uma memória central, ou memória distribuída onde cada processador tem a sua memória associada. Normalmente, o tipo de organização de memória utilizado num processador está relacionado com o número de processadores que possui. Sendo que os multi-processadores com menor número de multi-processadores geralmente utilizam memória partilhada, e os que têm um maior número de processadores utilizam memória distribuída como forma de diminuir a latência de acesso que poderia existir com um grande número de processadores a aceder à mesma memória.
As arquitecturas multi-core são um tipo de arquitectura multi-processador onde os processadores —
chamadoscores— se encontram no mesmochip. Na sua relação com o sistema operativo, os diferentes
coressão vistos como processadores individuais e atribui a cada um deles asthreadsque vão sendo
cria-das. Estescorespodem ter as mesmas ou diferentes características originando plataformas homogéneas
ou heterogéneas, respectivamente. Nos processadoresmulti-corea memória é partilhada, no entanto, a
or-ganização dascachesjá é variável consoante os modelos/fabricantes. As diferenças vão desde o número
decaches existentes ao tipo de acesso (se são privadas ou partilhadas). Normalmente o primeiro nível decache(L1) é privado e os seguintes níveis podem ser privados ou partilhados. A utilização de caches
privadas tem como vantagem a velocidade de acesso, tanto por proximidade como por exclusividade, mas causa o problema de manutenção de coerência dos dados. Por este motivo é necessária a existência de
protocolos que garantam a coerência dos dados nas diferentescaches.
2.2.2.2 OpenMP
OOpen Multi-Processing (OpenMP)4 é umaApplication Programming Interface (API)de programação
paralela orientada para o contexto de memória partilhada, que pode ser utilizada em C/C++ e Fortran. O
modelo de programação por trás do OpenMP é ofork-join. Inicialmente existe umamaster threada partir
CAPÍTULO 2. REVISÃO DA LITERATURA
da qual se criam outras —slave threads— assim que o programa encontra uma região paralela. No final
das regiões paralelas asslave threadssão terminadas e apenas amaster threadcontinua o processamento.
O OpenMP é composto por um conjunto de directivas de compilação (pragmasem C) que indicam as
secções de código que se deseja paralelizar, por variáveis de ambiente para definição de parâmetros de
funcionamento e por uma biblioteca que suporta a criação e gestão de threads, o que o torna simples
de usar. Esta simplicidade de utilização permite que o código possa ser paralelizado incrementalmente, não havendo necessidade de uma remodelação total do código de uma só vez. A isto acresce que as directivas de paralelismo são apenas lidas pelo pré-processador e ignoradas pelo compilador. Assim sendo, é possível a coexistência da versão sequencial e paralela no mesmo ficheiro e executada cada uma de acordo com a necessidade. Estas características tornam o OpenMP uma ferramenta bastante atractiva
para o desenvolvimento desoftwareparalelo.
2.3. COMPUTAÇÃO ALGÉBRICA
2.3 Computação algébrica
Grande parte da criptografia moderna assenta em conceitos matemáticos abstractos como por exemplo os corpos finitos, as curvas elípticas ou os grupos cíclicos. Desta forma, os criptógrafos necessitam de ter acesso a ferramentas que lhes permitam raciocinar e trabalhar sobre este tipo de noções matemáticas. Actualmente, existem diversas plataformas dedicadas à computação algébrica que o possibilitam. Alguns exemplos destas plataformas são o SageMath, Wolfram Mathematica e Magma. Destas referidas, o
Sage-Math é a única que éopen-source, tendo sido a motivação por trás da sua criação a disponibilização de
uma alternativaopen-sourceàs outras existentes.
Apesar destas plataformas possibilitarem a fácil manipulação de noções matemáticas de alto-nível, estas foram idealizadas para o plano científico, não sendo o seu objectivo a criação de executáveis de alto-desempenho que possam ser utilizados noutros dispositivos. Na procura por maior desempenho com-putacional é necessário recorrer a bibliotecas de nível inferior. Nas secções seguintes apresentam-se duas
bibliotecas para este efeito, aNumber Theory Library (NTL)e aGNU Multiple Precision Arithmetic Library
(GMP).
2.3.1 NTL
ONTL5, é uma biblioteca de alta-performancepara teoria dos números, como o próprio nome indica.
Está desenvolvida em C++ e pode ser utilizada em múltiplas plataformas e afirma serthreadeexception
safe.
Sendo uma biblioteca de teoria dos números, oNTLdisponibiliza estruturas de dados e algoritmos para
lidar com:
• aritmética sobre inteiros de comprimento arbitrário; • aritméticafloating-pointde precisão arbitrária;
• aritmética polinomial sobre os inteiros e corpos finitos; • redução de base de reticulados;
• álgebra linear (vectores e matrizes) sobre os inteiros, corpos finitos, e floating-point de precisão
arbitrária.
CAPÍTULO 2. REVISÃO DA LITERATURA
O NTLafirma, na sua páginaweb, ser uma das bibliotecas com a aritmética polinomial mais rápida
que existe, tendo esta obtido valoresrecordna factorização polinomial e determinação da ordem de curvas
elípticas. Também afirma ter uma das melhores implementações da redução de reticulados, tendo até já sido utilizada para quebrar a segurança de vários criptossistemas.
ONTLtem a particularidade de poder ser compilado em conjunto com aGMP(cf. § 2.3.2) para poder
utilizar internamente as suas funções de forma a obter melhor desempenho no global.
A suaAPIé simples, existindo uma classe representativa de cada tipo de dados matemático existente,
apetrechada com os métodos necessários para operar sobre os respectivos tipos de dados. Existem tam-bém outros módulos que permitem operar sobre grupos de tipos de dados mais simples, como é o caso das matrizes e vectores.
2.3.2 GMP
AGMP6é uma biblioteca de aritmética de precisão arbitrária desenvolvida em C no âmbito do projecto
GNU. No entanto também disponibiliza classeswrapperpara C++. Permite aritmética de precisão arbitrária
sobre inteiros, racionais e números de vírgula flutuante. Uma vez que pertence ao projecto GNU, a sua portabilidade está mais limitada. As plataformas para onde esta biblioteca está mais direccionada são as plataformas baseadas em unix como o GNU/Linux, Mac OS X/Darwin, BSD, Solaris, etc. No entanto, existem casos de compilações funcionais em Windows. A biblioteca foi desenvolvida com o intuito de
ser o mais rápida possível e para tal faz uso de códigoassemblyaltamente optimizado que é programado
manualmente para uma grande variedade de processadores, trocado assim simplicidade por eficácia. Outra característica interessante que é utilizada para aumentar o desempenho é a escolha dos algoritmos de
cálculo com base no tamanho dos operandos, eliminando/reduzindo desta forma ooverheadque poderia
surgir.
OGMPestá organizado por diferentes módulos para operar sobre os tipos de números referidos
anteri-ormente. Estes módulos podem ser divididos em módulos de alto-nível e baixo-nível. Os módulos alto-nível são os seguintes:
mpz: tipo de dados e aritmética sobre inteiros com sinal.
mpq: tipo de dados e aritmética para operar sobre números racionais. As funções mpz também podem
6https://gmplib.org/
2.3. COMPUTAÇÃO ALGÉBRICA
ser aqui utilizadas se aplicadas ao numerador e denominador em separado.
mpf: tipo de dados e aritmética para operar sobre número de vírgula flutuante.
O módulo de baixo-nível que existe é o mpn. As suas operações possuem um baixo grau deoverhead
e essas operações são utilizadas na maioria das implementações das funções dos outros módulos. Este módulo opera sobre inteiros de tamanho dowordsizedos registos e é de difícil utilização pois não cuida da
Capítulo 3
Compilador CAO
3.1 Arquitectura do compilador
O compilador CAO recebe comoinputum ficheiro CAO e transforma-o numa implementação
correspon-dente em C. O processo de compilação entre estes dois pontos está dividido em três partes: o front-end,
o middle-end e o back-end como se pode ver na figura3.1.
Nofront-endocorre a análise sintáctica dos ficheiros recebidos, da qual resulta uma representação
abs-tracta do código, ou seja, umaAbstract Syntax Tree (AST). É sobre esta representação que são verificadas
as regras de sintaxe da linguagem e deste processo resulta uma nova AST anotada que é utilizada nas
fases seguintes.
Código
CAO Front-end Middle-end Back-end
Código gerado
Compilador CAO
Figura 3.1: Arquitectura do Compilador CAO
Na fase domiddle-end, antes da geração do código C, é aplicado um conjunto de transformações àAST
CAPÍTULO 3. COMPILADOR CAO
mais fácil conversão para código C. Estas transformações ocorrem numa determinada ordem formando cinco etapas. A primeira etapa é a de expansão, que é uma etapa opcional, e o seu objectivo é fazer ounrolling dos ciclos existentes no código. Depois ocorre a avaliação onde são avaliadas as expressões que podem ser computadas estaticamente e posteriormente simplificadas através de propriedades dos
operadores (e.g. idempotência, cancelamento). Na etapa de simplificação são aplicadas transformações
sobre o código CAO de modo a gerar um formato de código intermédio mais simples e que se
asseme-lha aoThree-Address Code (TAC). Segue-se a optimização onde é inferido oControl Flow Graph (CFG)do
código e ao qual são aplicadas transformações de optimização na forma Static Single Assignment (SSA).
Por fim, são aplicadas medidas de protecção contra ataquesside-channel[Barbosa and Page, 2005]. Tais
contra-medidas garantem que o código gerado de duas funções potencialmente vulneráveis (por indicação do utilizador) é indiscernível fazendo-as executar as mesmas operações. Para tal, as instruções são
reor-denadas e, se necessário, são inseridas instruções postiças. É importante fazer notar, em primeiro lugar,
que esta etapa tem que ser obrigatoriamente a última pois qualquer transformação que fosse aplicada depois poderia inutilizar estas contra-medidas e em segundo, que estas apenas aumentam a resiliência das implementações e não garantem segurança contra todo o tipo de ataques.
Quando o código chega ao back-end é convertido para C. Como já foi referido, um dos objectivos
do CAO é que os executáveis resultantes da compilação possam ser aplicados a uma vasta gama de
plataformas/dispositivos sem que isso tenha custos no desempenho do software. Por isso, depois da
conversão, acontece a “linkagem” desse código a uma biblioteca estática onde estão definidos os tipos e
as operações implementadas. Desta forma, é possível que para cada plataforma/dispositivo esteja definida uma biblioteca diferente que vai ao encontro das suas características. Para cada uma destas bibliotecas
estáticas existe um ficheiro de configuração que permite explicitar as escolhas de implementação (e.g. o
return dos resultados por valor ou por referência) e quais as operações implementadas, o que permite que existam implementações incompletas e funcionais. Um excerto deste ficheiro pode ser consultado no
anexoAonde se pode ver as operações definidas para o módulo unsigned bitstrings. Mais uma vez,
a optimização do código é relegada para o compilador e não aplicada sobre o algoritmo inicial protegendo assim a sua genericidade.
3.2 Tipos de dados CAO
Um tipo de dados CAO pode pertencer a uma de duas categorias: escalares (ouprimitivos) ou
deriva-dos (ouconstruídos). Os escalares são os tipos básicos do CAO e os derivados são tipos mais complexos
3.2. TIPOS DE DADOS CAO
que são construídos à custa dos mais básicos. Os tipos de dados que permitem a construção de tipos
deri-vados são os vectores, matrizes e estruturas, representados pelaskeywordsvector, matrix e struct,
respectivamente. Como se pode adivinhar, o tipo de dados vector permite criar vectores, e o matrix matrizes, do mesmo tipo de dados. Já o tipo de dados struct, à semelhança do seu equivalente em C, permite criar um novo tipo de dados com vários tipos de dados diferentes, ou seja, enquanto que os vectores e as matrizes exigem que os tipos de dados contidos sejam do mesmo tipo, com as estruturas pode ser criado um tipo de dados novo que no seu interior contenha, por exemplo, uma matriz e um inteiro como se pode ver nalisting1.
1 def m : matrix[10,10] of int; 2 def v : vector[100] of int;
3 def s : struct[ def a: matrix[10,10] of int; def b: int];
Listing 1: Inicialização de matrizes, vectores e estruturas
Dentro dos tipos de dados escalares pode-se, de certa forma, considerar duas classes: uma de tipos simples e outra de complexos que permitem a construção de tipos matemáticos. Na primeira temos os booleanos, os inteiros de máquina (registo) e asbit strings(signedeunsigned), e na segunda os inteiros e o tipo de dados mod.
O tipo de dados booleano (bool), como em todas as linguagens de programação que o suportam, é um tipo de dados que pode tomar o valor de verdadeiro ou falso. Sobre ele estão implementadas operações de comparação e de álgebra booleana.
Os inteiros de máquina (register int), são inteiros que são convertidos para inteiros do C, o que quer
dizer que o seu tamanho máximo é limitado pela arquitectura do processador,i.e., para um processador de
32 bits, o maior inteiro (signed) que é possível representar é (231− 1) = 2147483647. Estes inteiros são
normalmente utilizados como contadores de ciclos e como índices, para evitar ooverheadda inicialização
dos outros inteiros mais complexos para este tipo de tarefas. O CAO suporta operações de comparação e aritmética simples sobre este tipo de inteiros.
Para fechar esta classe de tipos escalares mais simples, apresenta-se as bit strings. As bit strings
representam sequências de bits de tamanho n, sendo o tamanho definido aquando da inicialização da
variável e onde 0 representa o bit menos significativo e n− 1 o mais significativo. Estas podem existir
sobre o estado deunsigned(unsigned bits) ousigned(bits) onde a única diferença está na forma de
conversão para inteiro, ou seja, se éunsignedou complemento para dois, respectivamente. Sobre este tipo
CAPÍTULO 3. COMPILADOR CAO
como operações de selecção, atribuição e concatenação de bits. É importante fazer notar que, sendo as
bit stringsde tamanho limitado, as operações são fechadas sobre esse tamanho. Por exemplo, a aplicação
de umshiftde 8 bits para a esquerda a umabit stringde tamanho 8 resulta em 0.
O CAO permite a utilização de inteiros de precisão arbitrária (int). Se com os register ints o
tamanho máximo das variáveis era limitado peloword sizedo compilador, no caso dos ints, o seu tamanho
apenas é limitado pelo tamanho de memória disponível. Este tipo de inteiros é bastante útil particularmente em criptografia de chave-pública, onde muitas vezes é necessário raciocinar sobre números com centenas de dígitos.
O tipo mod permite operações sobre inteiros modulo um determinado número. Em criptografia, o
uso deste tipo de operações é bastante comum, como por exemplo no protocolo Diffie-Hellman [Diffie and
Hellman, 2006], na função RSA [Jonsson and Kaliski, 2003] e em criptografia sobre curvas elípticas [Cohen et al., 2012]. Através deste tipo dados é possível construir corpos finitos, extensões a corpos finitos e anéis polinomiais, tornando possível a utilização destas noções matemáticas como variáveisfirst-class.
1 typedef a := mod[2]; 2 typedef b := mod[3**9];
3 typedef c := mod[ a<X> / X**8 + X**4 + X**3 + X + 1];
Listing 2: Inicialização de mods
3.3 Exemplos de código CAO
Para mais facilmente se poder perceber a sintaxe CAO, é apresentada nalisting3uma implementação
em CAO da função curve25519 [Bernstein, 2006], cuja sintaxe é agora brevemente explicada. Em
primeiro lugar há a definição de typedefs que, tal como noutras linguagens, dão umaliasa um tipo de
dados para facilitar a sua utilização. Pode-se observar a existência debit stringssem sinal, um vector de
bit string, uma extensão de um corpo finito (Fp) e um tipo derivado baptizado de MontRep composto por dois Fp. A função recebe como parâmetros uma chave secreta de 255 bits e um Fp e devolve um Fp.
Dentro da função é possível ver-se a declaração de variáveis dos tipos definidos em cima através da
utilização dakeyword def e do operador (:) para indicar o tipo da variável. Também se pode ver que o
acesso às variáveis interiores da estrutura é feito através do operador (.), tal como em C. Resta apenas salientar o seq, que representa um ciclo e que permite expressar de uma forma mais natural a sua condição
3.3. EXEMPLOS DE CÓDIGO CAO 1 typedef byte := unsigned bits[8];
2 typedef unpacked := unsigned bits[256];
3 typedef packed := vector[32] of unsigned bits[8];
4 typedef skey := unsigned bits[255];
5
6 typedef Fp := mod[2**255-19];
7 typedef MontRep := struct [ def x : Fp; def z : Fp; ];
8 9 (...)
10
11 def curve25519(n : skey, base : Fp) : Fp {
12
13 def mth, mp1th, one : MontRep;
14 one.x := base; 15 one.z := [1]; 16 mth := one; 17 mp1th := doubleMont(one); 18 19 seq i := 253 to 0 by -1 { 20 if (n[i] == 1) { 21 mth := addMont(mth, mp1th, one); 22 mp1th := doubleMont(mp1th); 23 } else { 24 mp1th := addMont(mth, mp1th, one); 25 mth := doubleMont(mth); 26 } 27 } 28 if (mth.z == [0]) { 29 return [0]; 30 } else { 31 return (mth.x/mth.z); 32 } 33 } 34 35 (...)
Listing 3: Implementação CAO da função curve25519
CAPÍTULO 3. COMPILADOR CAO
3.4 Exemplo de compilação
De forma a poder-se exemplificar o processo de compilação de um ficheiro CAO e consequente geração da mesma implementação em C, sem que se torne muito extenso, pode-se utilizar a implementação CAO
do algoritmobubble sortapresentado em4.
1 typedef int_vector := vector [10] of int ;
2
3 def bubble_sort ( v : int_vector ) : int_vector {
4 def temp : int ;
5 seq i := 8 to 0 by -1 { 6 seq j := 0 to i { 7 if ( v[j] > v[j+1]) { 8 temp := v[j]; 9 v[j] := v[j+1]; 10 v[j+1] := temp; 11 } 12 } 13 } 14 return v ; 15 }
Listing 4: Implementação CAO da funçãobubble sort
O compilador CAO é invocado utilizando o seguinte comando: $ cao comp --config=default.plat bubblesort.cao
Onde default.plat representa o ficheiro de configuração da plataforma previamente mencionado (onde estão especificados os tipos de dados e respectivas operações existentes), e bubblesort.cao
representa o ficheiro CAO onde está implementado o algoritmo. No excerto de código 5 podemos ver o
ficheiro C gerado pelo compilador1.
Na primeira linha de5podemos observar o typedef que é atribuído no respectivo código CAO,
pas-sando assim CAO_int_vector a descrever um novo tipo que representa um vector de inteiros, que é utilizado no resto da implementação. Posteriormente podemos observar a transformação da função em
várias chamadas a funções C que estão definidas no back-end. É importante adicionar que são sempre
criadas duas funções adicionais, uma init() e outra dispose() que fazem, respectivamente, a de-claração/inicialização e libertação de variáveis globais. Neste exemplo não existem variáveis externas à função, pelo que as funções init() e dispose() estão vazias.
1Note-se que osincludese as funções init() e dispose() foram removidos para poupar espaço
3.4. EXEMPLO DE COMPILAÇÃO 1 typedef CAO_vector CAO_int_vector;
2 CAO_RES c_bubble_sort(CAO_vector _r0, CAO_int_vector c_v)
3 { 4 CAO_REF c_t1028; 5 CAO_bool c_t1025; 6 CAO_int c_t1027; 7 CAO_int_decl(&c_t1027); 8 CAO_int c_t1026; 9 CAO_int_decl(&c_t1026); 10 CAO_int c_t1018; 11 CAO_int_decl(&c_t1018); 12 CAO_rint c_t1019; 13 CAO_int c_t1020; 14 CAO_int_decl(&c_t1020); 15 CAO_bool c_t1021; 16 CAO_rint c_t1022; 17 CAO_int c_t1023; 18 CAO_int_decl(&c_t1023); 19 CAO_rint c_t1024; 20 CAO_int c_temp;
21 CAO_int_decl(&c_temp);
22 CAO_rint c_i; 23 CAO_rint_init(c_i, 8); 24 CAO_rint_gte(c_t1025, c_i, 0); 25 while (c_t1025) 26 { 27 CAO_rint c_j; 28 CAO_rint_init(c_j, 0); 29 CAO_rint_lte(c_t1025, c_j, c_i); 30 while (c_t1025) 31 { 32 CAO_vector_select(c_t1018, c_v, c_j); 33 CAO_rint_add(c_t1019, c_j, 1); 34 CAO_vector_select(c_t1020, c_v, c_t1019); 35 CAO_int_assign(c_t1026, c_t1018); 36 CAO_int_assign(c_t1027, c_t1020); 37 CAO_int_gt(c_t1021, c_t1026, c_t1027); 38 if (c_t1021) 39 { 40 CAO_vector_select(c_temp, c_v, c_j); 41 CAO_rint_add(c_t1022, c_j, 1); 42 CAO_vector_select(c_t1023, c_v, c_t1022); 43 c_t1028 = CAO_vector_ref(c_v, c_j); 44 CAO_int_assign(c_t1028, c_t1023); 45 CAO_rint_add(c_t1024, c_j, 1); 46 c_t1028 = CAO_vector_ref(c_v, c_t1024); 47 CAO_int_assign(c_t1028, c_temp); 48 } 49 CAO_rint_add(c_j, c_j, 1); 50 CAO_rint_lte(c_t1025, c_j, c_i); 51 } 52 CAO_rint_add(c_i, c_i, -1); 53 CAO_rint_gte(c_t1025, c_i, 0); 54 } 55 CAO_vector_assign(_r0, c_v); 56 CAO_int_dispose(c_temp); 57 CAO_int_dispose(c_t1023); 58 CAO_int_dispose(c_t1020); 59 CAO_int_dispose(c_t1018); 60 CAO_int_dispose(c_t1026); 61 CAO_int_dispose(c_t1027); 62 return CAO_OK; 63 }
CAPÍTULO 3. COMPILADOR CAO
3.5 Estrutura da biblioteca back-end genérica
Todos os tipos de dados CAO referidos na secção3.2têm o seu tipo de dados mapeado nesta biblioteca,
como se pode observar no excerto de código5. Passa-se agora a explanar, sem entrar em profundo detalhe,
quais são e como estão implementados esses tipos de dados.
CAO_bool: a implementação em C do tipo de dados bool do CAO.
Na verdade, as funções implementadas sobre este tipo de dados são apenas macros sobre operações
bitwisesobre inteiros C de forma a emular operações booleanas.
CAO_rint: a implementação em C do tipo de dados register int do CAO.
Assim como os tipos de dados bool, a implementação dos register ints são apenas macros
sobre as operações sobre o tipo de dados int do C. Existe apenas a adição da função decastde
CAO_rint para CAO_int.
CAO_int: a implementação em C do tipo de dados int do CAO.
Osints estão implementadas recorrendo à classe ZZ doNTL. A classe ZZ é a classe que implementa
as operações sobre inteiros de precisão arbitrária. Portanto, a implementação do tipo de dados e das suas operações é bastante directa.
CAO_ubits: a implementação em C do tipo de dados unsigned bitstring do CAO.
Asubitssão representadas como inteiros e fazem-se acompanhar de uma variável que indica o seu
tamanho, para que se possa fazer oresizenecessário após algumas das operações. Assim sendo,
fazem uso da classe ZZ doNTLassim como os inteiros de precisão arbitrária.
CAO_sbits: a implementação em C do tipo de dados signed bitstring do CAO.
As sbits estão implementadas de forma semelhante às anteriores, i.e., fazendo uso também da
classe ZZ e utilizando uma variável indicando o tamanho dabitstring.
CAO_mod: a implementação em C do tipo de dados mod do CAO.
As operações com módulo estão implementadas utilizando a classe ZZ_p doNTL. A classe ZZ_p
permite o raciocínio sobre inteirosmodulop, onde p representa o valor passado aquando da
decla-ração da variável.
CAO_modpol: a implementação em C do tipo de dados que alberga polinómios modulares.