Exploração de espaço de projeto para multicores heterogêneos com o uso
aprendizado de máquina: o estado da arte
Using machine learning to perform design space exploration of heterogeneous
multicore architectures: a state of art review
DOI:10.34117/bjdv6n5-215
Recebimento dos originais: 13/04/2020 Aceitação para publicação: 12/05/2020
Alba Sandyra Bezerra Lopes
Mestra em Sistemas e Computação pela Universidade Federal do Rio Grande do Norte Instituição: Instituto Federal do Rio Grande do Norte
Endereço: Rua Brusque, 2926, Bairro Potengi - Natal, RN, CEP: 59112-490 E-mail: [email protected]
Monica Magalhães Pereira
Doutora em Ciência da Computação pela Universidade Federal do Rio Grande do Sul Instituição: Universidade Federal do Rio Grande do Norte
Endereço: Av. Sen. Salgado Filho, 3000 - Candelária, Natal - RN, CEP: 59064-741 E-mail: [email protected]
RESUMO
A cada ano aumenta-se a demanda por recursos computacionais das aplicações que executam em sistemas embarcados. Para atender a essa demanda, os projetos desses sistemas têm feito uso da combinação de componentes diversificados, resultando em plataformas heterogêneas que buscam balancear o poder de processamento com o consumo de energia. Entretanto, uma questão chave no projeto desses sistemas é quais componentes combinar para atender ao desempenho esperado ao custo de área e energia adicionais. Realizar uma vasta exploração do espaço de projeto (DSE) permite mensurar previamente custo dessas plataformas antes da fase de fabricação. Entretanto a quantidade de possibilidades de soluções a ser avaliadas cresce de maneira exponencial. Avaliar o custo de uma dessas soluções através da síntese em hardware é uma tarefa extremamente custosa. E mesmo a alternativa de síntese em alto nível não permite sintetizar todas as soluções e atender ao time-to-market. O uso de técnicas de aprendizado de máquina na DSE reduz a quantidade de sínteses e simulações necessárias ao estimar novos valores a partir de um conjunto de dados de treinamento, possibilitando alcançar elevadas taxas de acurácia e atender ao time-to-market. Nesse trabalho é apresentada uma investigação do estado da arte do uso da técnica de aprendizado de máquina para a DSE de arquiteturas computacionais para sistemas embarcados.
Palavras-chave: exploração de espaço de projeto, sistemas embarcados, aprendizado de máquina.
ABSTRACT
Every year the demand of embedded applications for computational resources increases. To meet this demand, the embedded system designs have made use of the combination of diversified components, resulting in heterogeneous platforms that aims to balance the processing power with the energy consumption. However, a key question in the design of these systems is which components to combine to meet the expected performance at the cost of additional area and energy.
To perform a vast design space exploration allows to estimate the cost of these platforms before the manufacturing phase. However, the number of possibilities for solutions to be evaluated grows exponentially with the increasing diversity of components that can be integrated into a heterogeneous embedded system. Evaluating the cost of one of these solutions through hardware synthesis is an extremely costly task. And even the use of high-level synthesis tools as alternative does not allow to synthesize all the solution possibilities and meet the time-to-market. Using machine learning in DSE reduces the amount of syntheses and simulations required when estimating new values from a set of training data, making it possible to achieve high accuracy rates and meet the time-to-market. This work presents an investigation of the state of the art that uses machine learning technique for DSE of computational architectures for embedded systems.
Keywords: design space exploration, embedded systems, machine learning
1 INTRODUÇÃO
Sistemas embarcados estão cada dia mais presentes na sociedade moderna. Atualmente, cerca de 2% dos processadores vendidos no mundo são usados em computadores do tipo desktop laptops, enquanto os outros 98% são usados em sistemas embarcados. Nesse cenário, as aplicações que executam nesses sistemas também estão exigindo cada vez mais recursos computacionais, uma vez que possuem métricas críticas quanto a desempenho e consumo energético que devem ser levadas em consideração no fluxo do projeto dos sistemas embarcados. Os sistemas computacionais heterogêneos se apresentam como a solução mais promissora para prover os requisitos necessários à essa crescente demanda dessas aplicações (LEUPERS et al., 2019). Exemplos desses sistemas heterogêneos são os sistemas compostos por múltiplos núcleos processantes (multicores), tais como como o Nvidia Tegra (NVIDIA, 2019) e o Samsung Exynos (SAMSUNG, 2019), cujos núcleos processantes não são idênticos, e que estão incluídos em smartphones, tablets, consoles portáteis e sistemas automotivos modernos.
A diversidade de componentes que se pode integrar em um sistema multicore heterogêneo aumenta a cada ano, resultando na crescente expansão do espaço de projeto desses sistemas. A inclusão de componentes como aceleradores de hardware tem se tornando uma escolha frequente nos sistemas atuais que buscam cada vez mais o balanço entre desempenho e eficiência energética (WANG et al., 2017; GUI et al., 2019). Entretanto, uma questão chave no projeto de sistemas multicore heterogêneos é quando a combinação de processadores de propósito geral e aceleradores pode fornecer o desempenho esperado ao custo de área e energia adicionais. Responder essa questão implica em aumentar ainda mais o custo da exploração de espaço de projeto (WANG; SKADRON, 2016). A inclusão de novos componentes e quantidade de possibilidades de combinações quando se varia características microarquiteturais tanto de processadores quanto de aceleradores pode chegar facilmente à casa de milhões. Esse fato torna cada vez mais difícil para o
projetista avaliar todo o espaço de busca em tempo de projeto e encontrar a configuração arquitetural ideal que satisfaça aos requisitos iniciais.
Sintetizar em hardware uma dessas soluções ainda é uma tarefa extremamente custosa (DOPPA; ROSCA; BOGDAN, 2019). Seguindo essa linha, sintetizar todas essas possibilidades e atender ao time-to-market é uma tarefa inviável. Dentre as técnicas usadas para possibilitar a redução do tempo de exploração do espaço de projeto (DSE – do inglês Design Space Exploration) para sistemas computacionais está a predição do custo em área, potência e desempenho das possíveis soluções no espaço de projeto. Modelos de predição incluem técnicas de aprendizado de máquina e reduzem a quantidade de sínteses e simulações necessária, pois possibilitam a estimativa ou classificação de novos valores a partir de um conjunto de dados de treinamento (O’NEAL; BRISK, 2018). Essa técnica consolidada é encontrada em diversos trabalhos na literatura (ÏPEK et al., 2006; OZISIKYILMAZ; MEMIK; CHOUDHARY, 2008) e possibilita descobrir rapidamente soluções próximas do ótimo, satisfazendo aos múltiplos objetivos do sistema (KIM; DOPPA; PANDE, 2018).
Nesse contexto, esse trabalho apresenta o resultado da investigação do estado da arte do uso de aprendizado de máquina para a exploração de espaço de projeto de arquiteturas computacionais para sistemas embarcados, dando ênfase às arquiteturas compostas por múltiplos processadores e aceleradores em hardware. O restante desse trabalho está organizado da seguinte forma: a seção 2 apresenta o referencial teórico com os conceitos fundamentais para a compreensão do contexto dessa pesquisa. A seção 3 apresenta a metodologia adotada para o levantamento do estado da arte. A seção 4 detalha os resultados e discussões da busca pelos trabalhos que compõe o estado da arte. Por fim, a seção 5 apresenta as considerações finais.
2 REFERENCIAL TEÓRICO
Essa seção descreve os conceitos básicos e técnicas relacionados a essa pesquisa, apresentando os conceitos de projeto de sistemas embarcados compostos por múltiplos núcleos processantes. Bem como as metodologias usadas para a exploração de espaço de projeto desses sistemas, incluindo o uso de simuladores de alto nível e modelos de predição baseados em aprendizado de máquina.
2.1 PROJETOS DE SISTEMAS EMBARCADOS MULTICORE
Por muitos anos, os fabricantes de hardware replicaram as estruturas dos processadores para criar múltiplos caminhos permitindo que múltiplas instruções executassem de maneira concorrente. A duplicação de unidades aritméticas e unidades de ponto flutuante são exemplos dessa
metodologia (SCOGLAND et al., 2008). Os processadores multicore são o passo seguinte dessa replicação, onde duas ou mais unidades de execução independentes são integradas no mesmo circuito. Os multicores podem ser simétricos (homogêneos) ou assimétricos (heterogêneos) e estão representados na Figura 1, cujos simétricos, na Figura 1(a), são representados por blocos idênticos com a descrição CPU (Central Processing Unit) e os assimétricos, na Figura 1(b), são representados por blocos de tamanhos, cores e descrições diferentes, com GPU representado um núcleo do tipo Graphic Processing Unit e DSP representando um núcleo do tipo Digital Signal Processing.
Figura 1 – Representação de multicores (a) homogêneos (b) heterogêneos
Nos multicores homogêneos, todos os núcleos têm a mesma arquitetura, tamanho, poder de processamento e consomem a mesma quantidade de energia. Já nos multicores heterogêneos, existem núcleos que são computacionalmente mais poderosos do que outros (HILL; MARTY, 2008). A existência desses núcleos assimétricos visa balancear benefícios em termos de área, desempenho e energia. A heterogeneidade dos sistemas multicore pode ser classificada em funcional e de desempenho (REDDY et al., 2011). Na heterogeneidade funcional os núcleos são muito diferentes funcionalmente, possuindo conjuntos de instrução distintos. Nesse modelo de heterogeneidade, a vantagem se dá pelos padrões específicos de execução a fim de atender aos requisitos desempenho e energia. Já na heterogeneidade de desempenho, os núcleos possuem o mesmo conjunto de instruções, mas com características de desempenho e energia diferentes. Exemplo dessa heterogeneidade pode ser encontrada nos processadores ARM bit.LITTLE (ARM, 2020). Essas arquiteturas combinam núcleos com maior poder de processamento (big) e núcleos menores, com um menor poder de processamento (LITTLE) e, consequentemente, com menor consumo de energia.
Em adição a núcleos grandes e pequenos em sistemas multicore heterogêneos, a aceleração em hardware em forma de caminhos de dados e circuitos de controle customizados para algoritmos em particular também se tornou vastamente utilizada (CONG et al., 2014). É esperado que esses aceleradores entreguem benefícios em ordens de magnitude significativamente superior quando comparados aos processadores de propósito geral. Entretanto, o desenvolvimento de aceleradores específicos em hardware é custoso em termos financeiros, de tempo, e de mão de obra. Nesse contexto, a reconfiguração de hardware tem sido bastante utilizada no projeto de sistemas
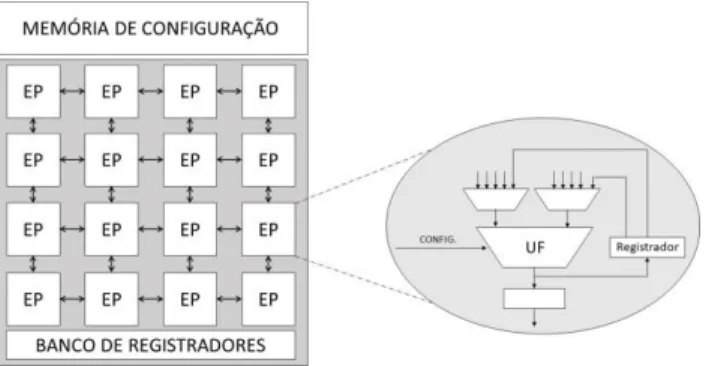
embarcados por ser um conjunto consolidado de metodologias, técnicas e ferramentas que tem como objetivo combinar a flexibilidade do software e a eficiência do hardware (COMPTON; HAUCK, 2002). Os dispositivos reconfiguráveis, representados na Figura 2, consistem em vários elementos de processamento (EPs) idênticos e modelos de interconexão que possibilitam a comunicação entre esses elementos (HARTENSTEIN, 2001).
Figura 2 - Representação de uma arquitetura reconfigurável
Esse fato permite uma alta exploração de paralelismo no nível de instrução (do inglês Instruction Level Paralellism – ILP). Nas aplicações com muito ILP, as operações podem ser distribuídas nos EPs para ser executadas em paralelo. Assim, por meio da customização do caminho de dados, as arquiteturas reconfiguráveis podem oferecer alto desempenho e com redução de consumo de energia. É importante destacar que os EPs não possuem um modelo arquitetural único e cada projeto encontrado na literatura define a arquitetura e organização dos seus EPs. No exemplo da Figura 2 é possível observar que cada EP possui uma unidade funcional (UF) que pode ser uma unidade para a realização de operações lógicas e aritméticas, um multiplicador ou outro componente; além de registradores e multiplexadores.
2.2 METODOLOGIAS E FERRAMENTAS PARA EXPLORAÇÃO DE ESPAÇO DE PROJETO De acordo com (PISCITELLI; PIMENTEL, 2012), os métodos para avaliar um ponto no espaço de projeto recaem em uma das três categorias a seguir: 1) mensurar o custo em uma implementação (protótipo); 2) medidas baseadas em simulação e 3) estimativas em algum tipo de modelo predição. A avaliação em uma implementação de protótipo provê a maior acurácia, mas implica em um longo tempo de desenvolvimento, o que é proibitivo. Esforços recentes no campo de DSE usam simulações ou modelos de predição junto com métodos de heurísticas de busca para realizar a busca no espaço de projeto. Abordagens baseadas em simulação estimam a performance de um programa ao executá-lo em um simulador, passando ao software a ideia de que está sendo executado em um hardware físico (BUTKO et al., 2012).
Esses simuladores podem ser simuladores funcionais ou simuladores com precisão do ciclo. Simuladores funcionais utilizam uma descrição abstrata da arquitetura do hardware e emulam cada instrução do conjunto de instruções do processador, buscando garantir que o sistema funciona de maneira correta, porém ignorando informações temporais. Exemplos desses simuladores são o Simics (MAGNUSSON et al., 2002), QEMU (BELLARD, 2005) e OVP (OVP, 2008).
Simuladores com precisão de ciclo constroem em software o pipeline completo do processador e simulam o fluxo de cada instrução através do pipeline para coletar informações mais precisas dos ciclos durante a execução. Apesar de acarretar maior custo de tempo em simulação, oferece uma maior precisão. Exemplos desses simuladores são o Simplescalar (AUSTIN; LARSON; ERNST, 2002), o PTLSim (YOURST, 2007) e o gem5 (BINKERT et al., 2011).
Muitos outros simuladores estão disponíveis e apesar dessas abordagens aumentarem a velocidade de simulação em muitas ordens de magnitude quando comparadas ao nível de transferência de registradores (do inglês Register Transfer Level - RTL), apenas o uso de simuladores de alto nível não é suficiente para atender à necessidade de um largo espaço de projeto de sistemas multiprocessados. Dessa forma, é necessária a utilização de um nível maior de abstração, como é o caso dos modelos de predição. Apesar de menos precisos do que simuladores de alto nível, os modelos de predição podem avaliar as possíveis soluções mais rapidamente. Para estimar o custo dos pontos no espaço de projeto utilizando predição, é preciso obter informações do perfil das aplicações. Essas informações são, então, usadas nos modelos de predição para estimar o custo da execução da aplicação em uma determinada plataforma alvo. Segundo (DIDONA et al., 2015), existem duas abordagens tradicionais usadas para a predição de custo de uma solução: 1) modelos analíticos e 2) aprendizado de máquina.
Modelos analíticos foram, por décadas, a técnica de referência para estimar o desempenho de plataformas computacionais. Essa técnica requer treinamento mínimo ou mesmo nenhum treinamento para realizar previsões operacionais no cenário alvo. Por outro lado, usam simplificações como suposições sobre como o sistema modelado e sua carga de trabalho se comportam, portanto, sua precisão pode ser seriamente contestada em condições específicas de carga de trabalho (DIDONA et al., 2015).
Já a técnica de aprendizado de máquina considera a construção de um modelo que uma vez treinado em um conjunto de pontos do espaço de projeto pode predizer o comportamento de diferentes configurações (BREUGHE; EYERMAN; EECKHOUT, 2015). Ao longo dos anos, diversos algoritmos poderosos foram sendo desenvolvidos e podem ser encontrados na literatura para a aquisição automática do conhecimento. Esses algoritmos variam nos seus objetivos, na disponibilidade de dados de treinamento, nas estratégias de aprendizagem e na linguagem que
empregam para representação do conhecimento. Dentre esses algoritmos encontram-se, por exemplo, algoritmos baseados em árvore de decisão, algoritmos baseados em regras, algoritmos de regressão linear e algoritmos de redes neurais.
Em arvores de decisão, cada possível valor de atributo gera um ramo na árvore, e uma decisão é tomada seguindo um caminho a partir do nó raiz até o nó folha. Uma das vantagens desse algoritmo é a simplicidade de compreensão e interpretação. Os algoritmos baseados em regras, por sua vez, são usados para encontrar relacionamentos ou padrões frequentes entre conjuntos de dados e definir um conjunto de regras que representem coletivamente o conhecimento capturado pelo sistema. Já a regressão linear busca encontrar a melhor linha de ajuste para modelar o conjunto de dados. Uma linha pode ser representada por uma equação, y = m * x + c onde y é a variável dependente e x é a variável independente. As teorias básicas de cálculo são aplicadas para encontrar os valores para m e c usando o conjunto de dados fornecido.
As redes neurais, por sua vez, são inspiradas no modelo biológico do sistema nervoso. A Figura 3 ilustra uma representação de uma rede neural, onde cada círculo representa um nó (neurônio) da rede que são organizados em camadas. Conexões ligam os neurônios entre si e essas conexões possuem pesos numéricos associados cujos valores vão sendo modificados de acordo com o processo de treinamento. A entrada para o neurônio pode vir de outros neurônios ou diretamente do dado na camada de entrada. Cada neurônio passa, então, o valor recebido multiplicado pelo peso da conexão e cada neurônio na camada seguinte recebe um valor que é a soma dos valores produzidos pelas conexões que levam até ele. A rede completa representa um conjunto complexo de interdependências que podem incorporar qualquer grau de não linearidade, permitindo que funções bem gerais sejam modeladas (FULKERSON, 1995).
Figura 3 – Representação de uma rede neural
Em complemento à estratégia de desenvolver algoritmos de aprendizado de máquina de maneira individual, a ideia de comitês de máquina, também chamados de ensembles, tem como foco resolver um problema particular através da reunião de um conjunto de algoritmos de aprendizagem. Esses ensembles buscam melhorar a acurácia dos modelos de predição e a chave do sucesso dessa estratégia está na diversidade dos componentes utilizados. Nessa estratégia, diferentes algoritmos
são treinados com o conjunto de dados e as saídas são combinadas para definição do resultado da predição (LI; YAO; WANG, 2018).
3 METODOLOGIA
Nessa seção será descrita a metodologia adotada para realizar a investigação do estado da arte dos trabalhos relacionados à exploração de espaço de projeto de arquiteturas computacionais para sistemas embarcados. Na metodologia foram considerados trabalhos que usam processadores de propósito geral em ambientes multicore combinados com aceleradores em hardware. A presente investigação do estado da arte foi realizada a partir de consulta retrospectiva, sem limites cronológicos utilizando a ferramenta de busca Google Scholar (Google Acadêmico), no período de setembro e outubro de 2019 e buscou responder as seguintes questões:
1) Há trabalhos que utilizam aprendizado de máquina para realizar a DSE de multicores compostos por processadores acoplados a aceleradores?
2) Os aceleradores abordados nos trabalhos são reconfiguráveis?
3) Quais são as técnicas de aprendizado de máquina abordadas nos trabalhos encontrados? 4) A exploração do espaço de projeto é multiobjetiva (considera mais de um objetivo
conflitante, como área, desempenho, energia)?
5) Os trabalhos com foco em multicore abordam multicores homogêneos ou heterogêneos? 6) Quais são os parâmetros microarquiteturais considerados nas DSEs dos trabalhos
encontrados?
Para a busca por artigos foi elaborado um protocolo de busca que levou em consideração as seguintes palavras chave: “exploração de espaço de projeto”, “aprendizado de máquina”, “modelos de predição”, “inteligência artificial”, “multicore”, “mpsoc”, “aceleradores”, “arquiteturas reconfiguráveis”. Como idioma da busca, foi definido o idioma inglês e também foram utilizados sinônimos das palavras chave visando englobar um maior número de trabalhos. Na construção de um protocolo de busca utilizando o Google Scholar, os espaços representam palavras que devem aparecer simultaneamente nos resultados, sendo equivalente ao operador lógico E, enquanto a barra é referente ao operador lógico OU. Assim, o protocolo de busca elaborado e utilizado na consulta resultou em:
“design space exploration” | dse
“machine learning” | “predictive | prediction model | modeling” | “artificial intelligence” multicore | mpsoc | multiprocessor | cmp
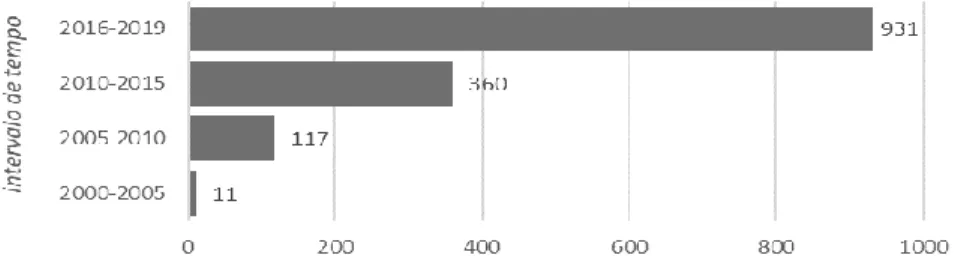
Após a definição, o protocolo foi executado na busca da ferramenta do Google Scholar, retornando 1.419 resultados, que são exibidos ordenados pelo critério de relevância. A Figura 4 apresenta a quantidade de trabalhos retornados categorizados por intervalo de tempo. Como é possível perceber, o maior volume de trabalho que envolve a temática pesquisada foi publicado nos últimos 4 anos.
Figura 4 - Quantidade de trabalhos por período
Em seguida, foram analisados os títulos e os resumos dos primeiros 300 artigos mais relevantes retornados pela busca e foram utilizados os seguintes critérios de inclusão e exclusão: critérios de inclusão – o trabalho realiza DSE em tempo de projeto; o foco da DSE é o processador, o acelerador em hardware ou multicore; critérios de exclusão – a aprendizagem foi utilizada para gerenciamento de recursos em tempo de execução; o foco do trabalho é em componentes específicos do projeto (ex: memória, barramento); o foco do trabalho é uma arquitetura específica para um algoritmo de aprendizado de máquina; artigo publicado em um veículo que não faz parte da base de consulta da universidade
Após a aplicação desses critérios, foram selecionados 132 artigos para serem lidos na íntegra, considerando que para alguns artigos, não foi possível aplicar o critério de exclusão apenas pela leitura do título e do resumo. Após a leitura dos artigos, foram selecionados 24 artigos que foram categorizados em: a) trabalhos que focam no projeto apenas de processadores de propósito geral; b) trabalhos que focam em projeto de aceleradores; e c) trabalhos, que abordam sistemas com múltiplos núcleos, homogêneos ou heterogêneos.
4 RESULTADOS E DISCUSSÕES
Essa seção apresenta os trabalhos encontrados após a aplicação da metodologia descrita na seção anterior, separados nas 3 categorias mencionadas.
4.1 DSE PARA PROCESSADORES
O trabalho (KHAN et al., 2007) faz a predição do comportamento de novas aplicações a partir de conhecimento sobre aplicações anteriores (cross-program). Redes neurais são usadas como
modelo de predição de energia e tempo de execução. Na técnica aplicada ao trabalho, são escolhidos pequenos conjuntos de configurações (chamadas canonical configurations) que são usadas para caracterizar a aplicação e os resultados de energia obtidos para essas configurações. Essa técnica requer a execução de y programas para obter y reações usadas como entrada do preditor. No trabalho, os autores provaram que com uma quantidade y de 8 aplicações (e até menos), ainda é possível obter predições precisas.
Em (OZISIKYILMAZ; MEMIK; CHOUDHARY, 2008) foram desenvolvidos modelos de predição para a exploração de espaço de projeto dos processadores Opteron Dual, Pentium 4 e Xeon. Os modelos foram baseados em redes neurais e regressão linear e foram utilizadas para a construção dos modelos com amostras randômicas entre 2% e 10% do espaço de projeto para validação. Dentre esses parâmetros utilizados na DSE estão: velocidade de processamento, tamanho da cache L2, tamanho da memória, frequência de operação e tamanho da cache de instrução L1.
(STOCKMAN; AWAD, 2010) apresenta um modelo de predição de potência usando Interval Based Hierarchical Support Vector Machine (IBH-SVM) para identificação de combinações ótimas de parâmetros microarquiteturais. Nesse trabalho, são considerados 13 parâmetros distintos. Os autores destacam que a vantagem da sua solução é oferecer ganhos tanto ao encontrar soluções eficientes energeticamente quanto em utilizar um número menor de simulações uma vez que configurações subótimas são eliminadas em estágios iniciais do processo de DSE.
Em (GUO et al., 2011), os autores desenvolveram um modelo denominado COMT, uma variação de árvore de decisão. Foi utilizado o Simplescalar como ferramenta para obter as informações de simulação de um conjunto de aplicações para utilizar como base de treinamento. Dez parâmetros foram usados na DSE, dentre os quais estão o tamanho das unidades de fetch/commit/issue, a quantidade de unidades funcionais inteiras e de ponto flutuante, os tamanhos das caches de instrução e de dados L1 e L2, tamanho do buffer de reordenamento e das filas de leitura/escrita na memória, com diferentes valores, totalizando mais de 70 milhões de configurações possíveis. Os autores comparam a solução proposta com uma rede neural e apresentam resultados de erro de predição para performance e energia inferiores a 4%.
4.2 DSE PARA ACELERADORES
O trabalho (MENG et al., 2016) apresenta o framework ATNE que utiliza aprendizado de máquina para DSE no contexto de OpenCL para FPGA. No trabalho, são discutidos os impactos dos parâmetros ajustáveis no OpenCL que influenciam na arquitetura em hardware, tais como: o fator de desenrolamento do laço, que influencia na replicação dos módulos de memória e no padrão de acesso à memória; e o número de variáveis privadas, que influencia na quantidade de
registradores. O foco do trabalho está em melhorar a qualidade do conjunto de pareto e os autores utilizaram Floresta de Decisão Aleatória (Random Forest) como modelo de aprendizado.
Em (GREATHOUSE; LOH, 2018), uma coleção de aplicações é executada em um hardware real de uma GPU (Graphics Processing Unit), considerando diferentes configurações. Os dados dessa execução são usados para treinar uma rede neural. E a partir de então, o comportamento de novas aplicações com relação a desempenho e energia pode ser predito em diferentes pontos do espaço de projeto.
Ferretti, Ansaloni e Pozzi (2018) realiza DSE para síntese de alto nível (HLS - do inglês high level synthesis), apresentando uma heurística baseada em cluster para dividir o espaço de projeto em regiões, focando na exploração apenas das regiões mais promissoras. A heurística é composta de dois estágios: um estágio de exploração intra-cluster que busca refinar a região de busca; e um estágio de exploração inter-cluster, que permite descobrir áreas não exploradas no espaço de projeto. O trabalho explora a diretiva de desenrolamento de laço e realiza a exploração variando o valor desse parâmetro em diferentes laços de diferentes aplicações. O trabalho utilizou como ferramenta a VivadoHLS e o FPGA Kintex7 como arquitetura alvo.
(DUTTA; ADHINARAYANAN; FENG, 2018) utiliza aprendizado de máquina para predizer o comportamento de GPUs executando em diferentes níveis voltagem dinâmica e escala de frequência (DVFS - do inglês Dynamic Voltage and Frequency Scaling). Os autores inicialmente estudaram 8 técnicas de aprendizado de máquina (ZeroR, SLR, K-NN, bagging, random forest, SMOreg, árvore de decisão e redes neurais). Então compararam o erro médio predito pelos diferentes algoritmos, utilizando os resultados obtidos para a construção de comitês de máquina.
4.3 DSE PARA MULTICORES
Ïpek et al. (2006) realizam a predição de processadores e projeto de CMPs (do inglês chip multiprocessors) utilizando redes neurais. No projeto de processadores, os autores variam parâmetros como largura de fetch/commit/issue, tamanho do buffer de reordenamento, tamanho das caches L1 e L2, enquanto mantém fixos parâmetros como associatividade e tamanho dos blocos da cache. Já no projeto de CMPs, os autores variam o modelo do processador entre execução em ordem ou fora de ordem, a quantidade de núcleos no CMP, a frequência de operação dos processadores, associatividade e tamanho dos blocos da cache L2.
Em (KANG; KUMAR, 2008) é apresentado um framework para exploração de espaço de projeto de multicores heterogêneos. O trabalho utiliza uma biblioteca de núcleos dos quais são conhecidas características para possibilitar a categorização dos núcleos e das aplicações que serão
executadas. No processo de exploração, são passados limites de área e potência para a escolha do melhor núcleo ou do processador com k núcleos que satisfaçam os limites delimitados.
Em (MARIANI et al., 2012) é apresentada uma metodologia de otimização que explora a correlação espacial do espaço de projeto de multicore, denominada OSCAR. A OSCAR explora simulações reais para construir um RSM (do inglês response surface model) que permite: 1) a detecção dos pontos de projeto mais promissores e 2) a medição da incerteza do modelo em diferentes regiões do espaço de projeto. A plataforma alvo do trabalho consiste em um número variável de processadores fora de ordem, cujos parâmetros que podem ser modificados na exploração são a quantidade de processadores, a quantidade de instruções executadas por ciclo (issue width), tamanho e associatividade das caches L1 e L2 de dados e instrução, e tamanho dos blocos das caches L2.
(DAMAK et al., 2014) apresenta a proposta de sistemas heterogêneos compostos por aceleradores FPGA que podem ser privados ou compartilhados entre os processadores. A exploração do espaço de projeto apresentada no trabalho é relacionada às formas de compartilhamento dos processadores com os aceleradores, explorando o compromisso entre área, desempenho e potência. As soluções exploradas variam entre soluções apenas com aceleradores privados até soluções apenas com aceleradores compartilhados.
Sarma e Dutt (2015) realiza a poda do espaço de busca, reduzindo o tempo de simulação para multicores compostos por processadores heterogêneos de mesma arquitetura do conjunto de instruções. Usando regressão linear para a construção do modelo, foram variadas características do hardware, tais como: issue width, tamanho da fila de leitura e escrita, fila de instruções (IQ – instruction queue), buffer de reordenamento, quantidade de registradores inteiros e ponto flutuantes, tamanho das caches L1 e L2, frequência de operação, voltagem e área do núcleo.
O framework Lumos+ é apresentado em (WANG; SKADRON, 2016) como um framework analítico de potência e desempenho para arquiteturas heterogêneas com aceleradores. O Lumos+ é usado para explorar o impacto de se usar aceleradores fixos ou blocos reconfiguráveis. O estudo é feito para aplicações específicas e em seguida generalizado para qualquer conjunto de aplicações sintéticas. O trabalho assume o uso de um multicore homogêneo para explorar a heterogeneidade dos aceleradores. Um algoritmo genético é utilizado para percorrer o espaço de busca.
Sotiriou-Xanthopoulos et al. (2016) apresenta um framework para DSE de plataformas virtuais heterogêneas constituídas de muitos aceleradores (do inglês many-accelerator heterogeneous systems). Os autores utilizam como estudo de caso duas aplicações específicas: H.264 e Rician Denoise. Os aceleradores são dedicados às aplicações e a DSE é feita variando as características dos aceleradores, não havendo alteração no projeto dos processadores. O trabalho
utiliza modelos analíticos (regressão) construídos a partir de características extraídas da aplicação, combinados com o algoritmo evolutivo NSGA-II.
O trabalho (LIN et al., 2016) apresenta um método de estimação baseado em floresta de regressão aleatória (do inglês Regression Random Forests - RRF). O método reduz o tempo da exploração ao predizer com alta precisão o custo de pontos no espaço de busca, eliminando a necessidade de simulação desses pontos. Como estudo, o trabalho adotou três topologias de SoCs nos experimentos, mantendo fixas a quantidade de núcleos e a quantidade de memórias de alta velocidade. Para cada um dos três, varia outros parâmetros, tais como a largura da memória, a profundidade das filas de leitura e escrita e a frequência de operação das portas mestre, escravo e elementos de processamento.
Malazgirt e Yurdakul (2017) apresenta uma exploração de espaço de projeto de multicores com diversos níveis de cache. Em sua metodologia, utiliza as técnicas de algoritmo genético e K- means. E usa KNN (K-Nearest Neighbor) e SVM (Support Vector Machine) para treinar a rede com os parâmetros da arquitetura. No trabalho, é utilizado o conceito da clusterização dos pontos do espaço de projeto para reduzir o tempo de extração do conjunto de Pareto, reduzindo o tempo de simulação e estimação de dados. Já o
O trabalho em (KIM; DOPPA; PANDE, 2018) utiliza buscas locais como Simulated Anneling e NSGA-II como as abordagens principais para realizar a exploração do espaço de busca de sistemas manycore (multicores com centenas de núcleos) e incorporam técnicas de aprendizado de máquina para a tomada de decisão. A técnica utilizada é a de aprendizagem por reforço.
CHIŞ et al. (2018) utiliza a ferramenta FADSE para explorar o espaço de busca encontrando uma aproximação para a fronteira de Pareto através do uso de conhecimento do domínio por meio de regras de lógica fuzzy. O trabalho visa a otimização de 4 objetivos: área, desempenho, consumo de energia e comportamento térmico. No trabalho, as configurações são avaliadas utilizando simuladores do estado da arte (Sniper e McPAT).
A ferramenta AC-DSE é apresentada em (SHAHID et al., 2018). Nessa ferramenta o espaço de soluções é obtido inicialmente através da execução de um conjunto de 7 algoritmos multiobjetivos cujas saídas são usadas para treinar uma rede neural. A rede neural é então usada para retornar rapidamente suas soluções na forma de parâmetros do espaço de projeto. São usados dois parâmetros de entrada, que são os limites desejados de energia e desempenho; e três parâmetros de saída que são a quantidade núcleos no multicore, o tamanho da cache de configuração e a frequência de operação.
O framework NAPEL é apresentado em (SINGH et al., 2019) e tem como foco a estimação de desempenho e energia de aplicações executando em arquiteturas NMC (do inglês near memory
computing). O trabalho constrói um modelo de predição baseado em comitê de máquina para predizer o comportamento de novas aplicações em um ambiente multicore homogêneo fixo. Assim, valores de desempenho e energia para aplicações desconhecidas são previstos a partir do conjunto de treinamento construído tomando por base a execução de diversas aplicações na plataforma alvo.
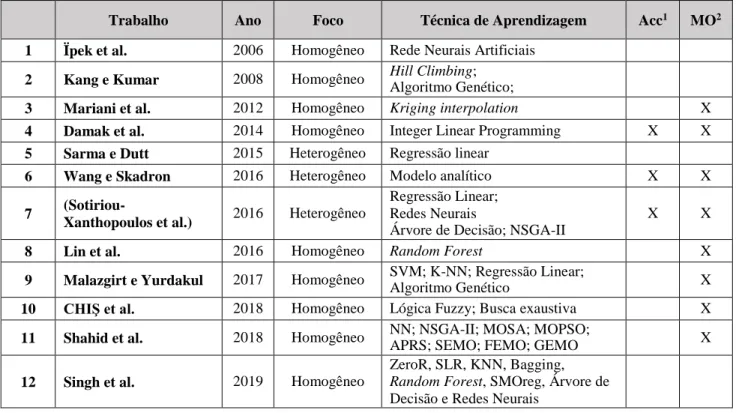
A Tabela 1 apresenta o quadro comparativo dos trabalhos encontrados que possuem foco em multicores, dos quais foram extraídas as seguintes características a) se o multicore abordado é homogêneo ou heterogêneo; b) quais técnicas de aprendizagem de máquina abordadas; c) se o multicore possui aceleradores; d) se a DSE é feita com carácter multiobjetivo.
Tabela 1 - Quadro comparativo dos trabalhos relacionados com foco em multicores
Trabalho Ano Foco Técnica de Aprendizagem Acc1 MO2 1 Ïpek et al. 2006 Homogêneo Rede Neurais Artificiais
2 Kang e Kumar 2008 Homogêneo Hill Climbing; Algoritmo Genético;
3 Mariani et al. 2012 Homogêneo Kriging interpolation X
4 Damak et al. 2014 Homogêneo Integer Linear Programming X X
5 Sarma e Dutt 2015 Heterogêneo Regressão linear
6 Wang e Skadron 2016 Heterogêneo Modelo analítico X X
7 (Sotiriou-
Xanthopoulos et al.) 2016 Heterogêneo
Regressão Linear; Redes Neurais
Árvore de Decisão; NSGA-II
X X
8 Lin et al. 2016 Homogêneo Random Forest X
9 Malazgirt e Yurdakul 2017 Homogêneo SVM; K-NN; Regressão Linear;
Algoritmo Genético X
10 CHIŞ et al. 2018 Homogêneo Lógica Fuzzy; Busca exaustiva X
11 Shahid et al. 2018 Homogêneo NN; NSGA-II; MOSA; MOPSO;
APRS; SEMO; FEMO; GEMO X
12 Singh et al. 2019 Homogêneo
ZeroR, SLR, KNN, Bagging,
Random Forest, SMOreg, Árvore de
Decisão e Redes Neurais
De acordo com os dados extraídos na tabela, a maioria dos trabalhos apresentados possuem foco em multicores homogêneos. Apenas os trabalhos de (DAMAK et al., 2014), (SARMA; DUTT, 2015) e (SOTIRIOU-XANTHOPOULOS et al., 2016) possuem foco em multicores heterogêneos. Com relação aos trabalhos que envolvem o uso de aceleradores, destacam-se os trabalhos de (DAMAK et al., 2014), (WANG; SKADRON, 2016) e (SOTIRIOU-XANTHOPOULOS et al., 2016). Os trabalhos de (DAMAK et al., 2014), (WANG; SKADRON, 2016) possuem como foco aceleradores reconfiguráveis de granularidade fina (FPGAs) enquanto o trabalho de (SOTIRIOU- XANTHOPOULOS et al., 2016) não especifica o modelo do acelerador.
1 Acelerador em hardware 2 Análise Multiobjetiva
Apesar dos trabalhos anteriores envolverem o uso de aceleradores, a DSE não considera simultaneamente a variação dos parâmetros microarquiteturais tanto dos processadores quanto dos aceleradores. Nos trabalhos investigados, a variação dos parâmetros é feita em apenas um dos componentes enquanto o outro componente é mantido com as características fixas. No que se refere à DSE multiobjetiva, com exceção dos trabalhos (ÏPEK et al., 2006; KANG; KUMAR, 2008; SARMA; DUTT, 2015; SINGH et al., 2019), os demais trabalhos consideram múltiplos objetivos conflitantes na exploração do espaço de projeto. Já ao considerar os métodos de aprendizagem de máquina, diversos métodos são usados pelos trabalhos, desde regressão linear a redes neurais artificiais. Foi identificado, entretanto, que poucos trabalhos combinam os métodos de aprendizagem em comitês de máquina com o intuito de melhorar a qualidade da predição. Os trabalhos que abordam esses métodos são os trabalhos de (LIN et al., 2016), (SHAHID et al., 2018) e (SINGH et al., 2019).
4.4 TENDÊNCIAS E PERSPECTIVAS NO CAMPO DE DSE PARA SISTEMAS EMBARCADOS
Com a crescente demanda dos sistemas atuais e a vasta aplicação dos sistemas embarcados nos mais diferentes domínios, a exploração de espaço de projeto desses sistemas é uma área que está distante de ser inesgotável. Existem diversos problemas em aberto no contexto de otimização arquitetural em tempo de projeto, tais como os que serão listados a seguir, o que demonstra o potencial para investigação de novas técnicas e ferramentas para realizar DSE de forma eficiente.
Otimização para diferentes atributos de qualidade: as arquiteturas atuais possuem atributos de qualidade considerados essenciais que norteiam o projeto dessas arquiteturas, tais como de área, desempenho e energia. A evidência do fim da escala de Dennard para a dissipação de potência deu início à era do silício negro e a preocupação com a quantidade de componentes que podem atuar no limite máximo da frequência ainda é um fator que demanda exploração. Além disso, a evolução tecnológica, provocou uma preocupação no desenvolvimento dos projetos visando atender a novos atributos de qualidade tais como tolerância a falha, confiabilidade e segurança em hardware (DOPPA; ROSCA; BOG-DAN, 2019; SCHAFER; WANG, 2019). A exploração de espaço de projeto e a definição de quais métricas para qualidade de serviço (QoS) devem ser utilizadas para relacionar os novos atributos com os atributos essenciais abre caminho para investigações mais aprofundadas na DSE e para a otimização dessas arquiteturas.
Uso de comitês de máquina (ensembles): Muitos dos trabalhos atuais de exploração de espaço de projeto que usam aprendizado de máquina ainda focam em modelos individuais de predição. A técnica de comitês de máquina tem sido largamente explorada em outros domínios no
contexto de aprendizado supervisionado o (AL-RAKHAMI et al., 2019; MUNG; PHYU, 2020) e podem apresentar ganhos significativos em acurácia se aplicadas ao contexto de DSE de sistemas embarcados. Existem três razões fundamentais que validam o uso desses comitês. A primeira razão é estatística. O uso dos comitês pode realizar uma média das diferentes respostas obtidas por algoritmos individuais, reduzindo o risco de escolher hipóteses errôneas. A segunda razão é computacional. Muitos algoritmos caem em mínimos locais por restringir o espaço de busca. Com comitês, a busca é iniciada em diferentes pontos, permitindo a melhor aproximação da função objetivo. A última razão é a representacional, considerando a dificuldade de generalização além dos dados treinados. O uso dos comitês evita que a representação fique restrita ao conjunto finito de hipóteses.
Evolução das arquiteturas embarcadas para aplicações específicas: muitos dos projetos de arquiteturas embarcadas atuais tem sido voltadas para classes de aplicações específicas, tais como internet das coisas (IoT) (NIKOLOV; NAKOV, 2019) e computação de borda (LIU et al., 2019). A explosão da IoT levou a uma demanda em larga escala por processamento em servidores centralizados na nuvem, que extrapolou os recursos de rede e infraestrutura disponíveis. A computação de borda oferece uma alternativa mais eficiente: os dados são processados e analisados nos sistemas embarcados, sendo mais perto do ponto no qual foram criados, reduzindo significativamente a latência e otimizando a experiência do cliente. Nesse contexto, a exploração de espaço de projeto das arquiteturas embarcadas abre espaço para investigar além de arquiteturas de propósito geral, buscando contribuir com a identificação automatizada dos projetos otimizados para arquiteturas específicas de IoT e computação de borda. Essa tendência exige cada vez mais foco na exploração de arquiteturas heterogêneas.
5 CONSIDERAÇÕES FINAIS
Realizar a exploração de espaço de projeto em estágios iniciais do fluxo de projeto permite estimar o custo da fabricação do sistema embarcado e entregar o poder de processamento exigido pelas aplicações que irão executar no sistema, balanceando o consumo de área e energia. Entretanto, com a diversidade de componentes que se pode integrar nesses sistemas, o tempo de realizar essa exploração através de ferramentas de síntese em hardware e mesmo com ferramentas de síntese de alto nível limita o tamanho do espaço de projeto investigado. Nesse trabalho foi apresentada uma revisão literária que resultou no levantamento do estado da arte de propostas de uso de técnicas de aprendizado de máquina na exploração de espaço de projeto de arquiteturas computacionais para sistemas embarcados.
A partir dos trabalhos investigados, foi possível identificar que poucos trabalhos abordam essa técnica para a DSE de multicores heterogêneos compostos por processadores de propósito geral acoplados a aceleradores em hardware. E, quando abordam, é feita a variação de parâmetros de apenas um dos componentes, seja o processador ou o acelerador. Além disso, também foram encontrados poucos trabalhos que combinam as técnicas de aprendizagem em comitês de máquina visando aumentar a acurácia da predição. Esses apontamentos abrem caminhos de possibilidades de projetos futuros como a exploração dessa técnica na construção de ferramentas automatizadas para a exploração de espaço de projeto multicores heterogêneos integrados a aceleradores reconfiguráveis utilizando a técnica de comitês de máquina para elevar a acurácia na predição.
REFERÊNCIAS
AL-RAKHAMI, M. et al. An ensemble learning approach for accurate energy load prediction in residential buildings. IEEE Access, IEEE, v. 7, p. 48328–48338, 2019.
ARM. Arm big.little technologies. <https://www.arm.com/why-arm/technologies/big-little>. Accesso em: 14/04/2020.
AUSTIN, T.; LARSON, E.; ERNST, D. Simplescalar: An infrastructure for computer system modeling. Computer, IEEE, n. 2, p. 59–67, 2002.
BELLARD, F. Qemu, a fast and portable dynamic translator. In: USENIX Annual Technical Conference, FREENIX Track. [S.l.: s.n.], 2005. v. 41, p. 46.
BINKERT, N. et al. The gem5 simulator. ACM SIGARCH Computer Architecture News, ACM, v. 39, n. 2, p. 1–7, 2011.
BREUGHE, M. B.; EYERMAN, S.; EECKHOUT, L. Mechanistic analytical modeling of superscalar in-order processor performance. ACM Transactions on Architecture and Code Optimization (TACO), ACM, v. 11, n. 4, p. 50, 2015.
BUTKO, A. et al. Accuracy evaluation of gem5 simulator system. In: IEEE. 7th International Workshop on Reconfigurable and Communication-Centric Systems-on-Chip (ReCoSoC). [S.l.], 2012. p. 1–7.
CHIŞ, R. et al. Multi-objective optimization for an enhanced multi-core sniper simulator. 2018. COMPTON, K.; HAUCK, S. Reconfigurable computing: a survey of systems and software. ACM Computing Surveys (csuR), ACM, v. 34, n. 2, p. 171–210, 2002.
CONG, J. et al. Accelerator-rich architectures: Opportunities and progresses. In: ACM. Proceedings of the 51st Annual Design Automation Conference. [S.l.], 2014. p. 1–6.
DAMAK, B. et al. Design space exploration for customized asymmetric heterogeneous mpsoc. In: IEEE. 2014 17th Euromicro Conference on Digital System Design. [S.l.], 2014. p. 50–57.
DIDONA, D. et al. Enhancing performance prediction robustness by combining analytical modeling and machine learning. In: ACM. Proceedings of the 6th ACM/SPEC International conference on performance engineering. [S.l.], 2015. p. 145–156.
DOPPA, J. R.; ROSCA, J.; BOGDAN, P. Autonomous design space exploration of computing systems for sustainability: Opportunities and challenges. IEEE Design & Test, IEEE, v. 36, n. 5, p. 35–43, 2019
DUTTA, B.; ADHINARAYANAN, V.; FENG, W.-c. Gpu power prediction via ensemble machine learning for dvfs space exploration. In: ACM. Proceedings of the 15th ACM International Conference on Computing Frontiers. [S.l.], 2018. p. 240–243.
FERRETTI, L.; ANSALONI, G.; POZZI, L. Cluster-based heuristic for high level synthesis design space exploration. IEEE Transactions on Emerging Topics in Computing, IEEE, 2018.
FULKERSON, B. Machine learning, neural and statistical classification. [S.l.]: Taylor & Francis, 1995.
GREATHOUSE, J. L.; LOH, G. H. Machine learning for performance and power modeling of heterogeneous systems. In: IEEE. 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD). [S.l.], 2018. p. 1–6.
GUI, C.-Y. et al. A survey on graph processing accelerators: Challenges and opportunities. Journal of Computer Science and Technology, Springer, v. 34, n. 2, p. 339–371, 2019.
GUO, Q. et al. Effective and efficient microprocessor design space exploration using unlabeled design configurations. In: Twenty-Second International Joint Conference on Artificial Intelligence. [S.l.: s.n.], 2011.
HARTENSTEIN, R. Coarse grain reconfigurable architecture (embedded tutorial). In: Proceedings of the 2001 Asia and South Pacific Design Automation Conference. New York,NY, USA: ACM, 2001. (ASP-DAC ’01), p. 564–570. ISBN 0-7803-6634-4.
HILL, M. D.; MARTY, M. R. Amdahl’s law in the multicore era. Computer, IEEE, v. 41, n. 7, p. 33–38, 2008.
ÏPEK, E. et al. Efficiently exploring architectural design spaces via predictive modeling. [S.l.]: ACM, 2006. v. 41.
KANG, S.; KUMAR, R. Magellan: a search and machine learning-based framework for fast multi- core design space exploration and optimization. In: IEEE. 2008 Design, Automation and Test in Europe. [S.l.], 2008. p. 1432–1437.
KHAN, S. et al. Using predictive modeling for cross-program design space exploration in multicore systems. In: IEEE COMPUTER SOCIETY. Proceedings of the 16th International Conference on Parallel Architecture and Compilation Techniques. [S.l.], 2007. p. 327–338.
KIM, R. G.; DOPPA, J. R.; PANDE, P. P. Machine learning for design space exploration and optimization of manycore systems. In: IEEE. 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD). [S.l.], 2018. p. 1–6.
LEUPERS, R. et al. Software compilation techniques for heterogeneous embedded multi-core systems. In: Handbook of Signal Processing Systems. [S.l.]: Springer, 2019. p.1021–1062
LI, D.; YAO, S.; WANG, Y. Processor design space exploration via statistical sampling and semi- supervised ensemble learning. IEEE Access, IEEE, v. 6, p. 25495–25505, 2018.
LIN, C. et al. An efficient and effective performance estimation method for dse. In: IEEE. 2016 International Symposium on VLSI Design, Automation and Test (VLSI-DAT). [S.l.], 2016. p. 1–4. LIU, F. et al. A survey on edge computing systems and tools. Proceedings of the IEEE,IEEE, v. 107, n. 8, p. 1537–1562, 2019.
MADSEN, J. et al. Multi-objective design space exploration of embedded system platforms. In: SPRINGER. IFIP Working Conference on Distributed and Parallel Embedded Systems. [S.l.], 2006. p. 185–194.
MAGNUSSON, P. S. et al. Simics: A full system simulation platform. Computer, IEEE, v. 35, n. 2, p. 50–58, 2002.
MALAZGIRT, G. A.; YURDAKUL, A. Prenaut: Design space exploration for embedded symmetric multiprocessing with various on-chip architectures. Journal of Systems Architecture, Elsevier, v. 72, p. 3–18, 2017.
MARIANI, G. et al. Oscar: An optimization methodology exploiting spatial correlation in multicore design spaces. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, IEEE, v. 31, n. 5, p. 740–753, 2012.
MENG, P. et al. Adaptive threshold non-pareto elimination: Re-thinking machine learning for system level design space exploration on fpgas. In: EDA CONSORTIUM. Proceedings of the 2016 Conference on Design, Automation & Test in Europe. [S.l.], 2016. p. 918–923.
MUNG, P. S.; PHYU, S. Effective analytics on healthcare big data using ensemble learning. In: IEEE.2020 IEEE Conference on Computer Applications (ICCA). [S.l.], 2020.p. 1–4.
NIKOLOV, N.; NAKOV, O. Creating architecture and software of embedded systems with constrained resources and their communication to the iot cloud. In: IEEE. 2019 X National Conference with International Participation (ELECTRONICA). [S.l.], 2019.p. 1–4
NVIDIA. Tegra mobile processors. 2019. <http://www.nvidia.com/>. Accesso em: 29-06-2019. O’NEAL, K.; BRISK, P. Predictive modeling for cpu, gpu, and fpga performance and power consumption: A survey. In: IEEE. 2018 IEEE Computer Society Annual Symposium on VLSI (ISVLSI). [S.l.], 2018. p. 763–768.
OVP. Open Vitual Platform. 2008. <http://www.ovpworld.org/>. Acesso em: 2019-12-09.
OZISIKYILMAZ, B.; MEMIK, G.; CHOUDHARY, A. Efficient system design space exploration using machine learning techniques. In: ACM. Proceedings of the 45th annual design automation conference. [S.l.], 2008. p. 966–969.
PISCITELLI, R.; PIMENTEL, A. D. Design space pruning through hybrid analysis in system-level design space exploration. In: EDA CONSORTIUM. Proceedings of the Conference on Design, Automation and Test in Europe. [S.l.], 2012. p. 781–786.
REDDY, D. et al. Bridging functional heterogeneity in multicore architectures. ACM SIGOPS Operating Systems Review, ACM New York, NY, USA, v. 45, n. 1, p. 21–33, 2011.
SAMSUNG. The Samsung Reference Platform. 2019. <http://www.samsung.com/>. Accesso em: 02/06/2019.
SARMA, S.; DUTT, N. Cross-layer exploration of heterogeneous multicore processor configurations. In: IEEE. 2015 28th International Conference on VLSI Design. [S.l.], 2015. p. 147– 152.
SCHAFER, B. C.; WANG, Z. High-level synthesis design space exploration: Past, present and future. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, IEEE, 2019
SCOGLAND, T. et al. Asymmetric interactions in symmetric multi-core systems: analysis, enhancements and evaluation. In: IEEE. SC’08: Proceedings of the 2008 ACM/IEEE Conference on Supercomputing. [S.l.], 2008. p. 1–12.
SHAHID, A. et al. Ac-dse: approximate computing for the design space exploration of reconfigurable mpsocs. Journal of Circuits, Systems and Computers, World Scientific, v. 27, n. 09, p. 1850145, 2018.
SINGH, G. et al. Napel: Near-memory computing application performance prediction via ensemble learning. In: ACM. Proceedings of the 56th Annual Design Automation Conference 2019. [S.l.], 2019. p. 27.
SOTIRIOU-XANTHOPOULOS, E. et al. An integrated exploration and virtual platform framework for many-accelerator heterogeneous systems. ACM Transactions on Embedded Computing Systems (TECS), ACM, v. 15, n. 3, p. 43, 2016.
STOCKMAN, M.; AWAD, M. Predicting microarchitectural power using interval based hierarchical support vector machine. In: IEEE. 2010 International Conference on Energy Aware Computing. [S.l.], 2010. p. 1–3.
WANG, C. et al. Reconfigurable hardware accelerators: Opportunities, trends, and challenges. arXiv preprint arXiv:1712.04771, 2017.
WANG, L.; SKADRON, K. Lumos+: Rapid, pre-rtl design space exploration on accelerator-rich heterogeneous architectures with reconfigurable logic. In: IEEE. 2016 IEEE 34th International Conference on Computer Design (ICCD). [S.l.], 2016. p. 328–335.
YOURST, M. T. Ptlsim: A cycle accurate full system x86-64 microarchitectural simulator. In: IEEE. 2007 IEEE International Symposium on Performance Analysis of Systems & Software. [S.l.], 2007. p. 23–34.