Universidade do Minho
Escola de Engenharia
Artur Miguel Matos Mariano
Scheduling (ir)regular applications
on heterogeneous platforms
Universidade do Minho
Dissertação de Mestrado
Escola de Engenharia
Departamento de Informática
Artur Miguel Matos Mariano
Scheduling (ir)regular applications
on heterogeneous platforms
Mestrado em Engenharia Informática
Trabalho realizado sob orientação de
Alberto José Proença
João Garcia Barbosa
Acknowledgments
Ao meu orientador, Alberto Proen¸ca, pelo rigor que desde sempre lhe conheci e t˜ao bem
imprimiu na orienta¸c˜ao que me concedeu, quer durante a constru¸c˜ao da minha tese quer na
escrita desta disserta¸c˜ao. Ao meu co-orientador, Jo˜ao Barbosa, agrade¸co a oportunidade.
Ao professor Lu´ıs Paulo Santos endere¸co um particular agradecimento, pela incontest´avel
disponibilidade que mesmo sem lhe competir me demonstrou. Aos docentes que me mar-caram durante a minha jornada na Universidade do Minho, que agora finda, onde incluo
os professores Alberto Proen¸ca, Lu´ıs Paulo Santos, Jos´e Nuno Oliveira, Ant´onio Pina, Rui
Ralha, Pedro Nuno Sousa e Jos´e Bernardo Barros.
Ao LabCG que me acolheu no ´ultimo ano lectivo e a todo o pessoal que o integra, pelo
ambiente fant´astico. Ao Ricardo, ao Nuno, ao Waldir, e ao Jaime o meu obrigado. Um
especial agradecimento ao Roberto, pela disponibilidade e pelas discuss˜oes que mantivemos
durante o ano. Aos meus amigos Jo˜ao, Vences, Tiago, Jorge e Faber.
`
A Universidade do Minho, pela forma¸c˜ao de excelˆencia. `A Funda¸c˜ao para a Ciˆencia e
Tecnologia (FCT) e aos projectos por ela financiados que me concederam duas bolsas de
investiga¸c˜ao, permitindo-me assim, entre outras coisas, financiar a minha p´os-gradua¸c˜ao.
To several people from the University of Texas at Austin, including my advisors during my stay at UTexas, Dr. Andreas Gerstlauer and Dr. Derek Chiou. To some other people from UTexas as well, including Dr. Gregory Pogue, Dr. David Gibson and Lu´ıs Rodrigues, which were generous in sharing some of their precious time with me. To Kevin, from Michigan.
Mais que tudo, gostaria de agradecer `a minha fam´ılia, aos meus pais, irm˜ao e av´os, uma
vez que me motivam em cada dia da minha vida. Ao meu falecido tio Joaquim Corte, dedico esta tese.
iii
Em mem´oria de Joaquim Mariano Corte, 1946-2011
iv
Reflexion On June 7 of 1494, John II King of Portugal, the kings of Aragon and Austurias and the queen of Castile signed the treaty of Tordesillas, which divided “the newly discovered lands and the ones yet to be discovered” between the crowns of Portugal and Spain. Also due to this agreement, the Portuguese empire, the first global empire in history, expanded considerably and established itself as the world leading kingdom in economics and military power, during the fifteenth and until the beginning of the sixteenth centuries.
Coat of Arms of the Kingdom of Portugal (1139–1910)
The Portuguese discovered lands and maritime trades that defined the world map as it is known nowadays. The figure below shows the Portuguese discoveries and explorations, but it cannot show the effort they went into discovered (and in some cases conquest). To exploit the unknown is nowadays called research, which is precisely what was uniquely done by the Portuguese people more than 500 years ago. This makes of the Portuguese one of the bravest people in history, known worldwide as remarkable sailors and explorers.
Portuguese Discoveries and Explorations
Resumo
As plataformas computacionais actuais tornaram-se cada vez mais heterog´eneas e
parale-las nos ´ultimos anos, como consequˆencia de integrarem aceleradores cujas arquitecturas s˜ao
paralelas e distintas do CPU. Como resultado, v´arias frameworks foram desenvolvidas para
programar estas plataformas, com o objectivo de aumentar os n´ıveis de produtividade de
programa¸c˜ao. Neste sentido, a framework GAMA est´a a ser desenvolvida pelo grupo de
investiga¸c˜ao envolvido nesta tese, tendo como objectivo correr eficientemente algoritmos
reg-ulares e irregreg-ulares em plataformas heterog´eneas.
Um aspecto chave no contexto de frameworks cong´eneres ao GAMA ´e o escalonamento.
As solu¸c˜oes que comp˜oem o estado da arte de escalonamento em plataformas heterog´eneas s˜ao
eficientes para aplica¸c˜oes regulares, mas ineficientes para aplica¸c˜oes irregulares. O
escalona-mento destas ´e particularmente complexo devido `a imprevisibilidade e `as diferen¸cas no tempo
de computa¸c˜ao das tarefas computacionais que as comp˜oem.
Esta disserta¸c˜ao prop˜oe o design e valida¸c˜ao de um modelo de escalonamento e respectiva
implementa¸c˜ao, que endere¸ca tanto aplica¸c˜oes regulares como irregulares. O mecanismo de
escalonamento desenvolvido ´e validado na framework GAMA, executando algoritmos
cient´ı-ficos relevantes, que incluem a SAXPY, a Transformada R´apida de Fourier e dois algoritmos
de resolu¸c˜ao do problema n-Corpos. O mecanismo proposto ´e validado quanto `a sua eficiˆ
en-cia em encontrar boas decis˜oes de escalonamento e quanto `a eficiˆencia e escalabilidade do
GAMA, quando fazendo uso do mesmo.
Os resultados obtidos mostram que o modelo de escalonamento proposto ´e capaz de
ex-ecutar em plataformas heterog´eneas com alto grau de eficiˆencia, uma vez que encontra boas
decis˜oes de escalonamento na generalidade dos casos testados. Al´em de atingir a decis˜ao
de escalonamento que melhor representa o real poder computacional dos dispositivos na
plataforma, tamb´em permite ao GAMA atingir mais de 100% de eficiˆencia tal como definida
em [3], executando um importante algoritmo cient´ıfico irregular.
Integrando o modelo de escalonamento desenvolvido, o GAMA superou ainda bibliotecas
eficientes para CPU e GPU na execu¸c˜ao do SAXPY, um importante algoritmo cient´ıfico.
Foi tamb´em provada a escalabilidade do GAMA sob o modelo desenvolvido, que aproveitou
da melhor forma os recursos computacionais dispon´ıveis, em testes para um CPU-chip de 4
n´ucleos e dois GPUs.
Abstract
Current computational platforms have become continuously more and more heterogeneous and parallel over the last years, as a consequence of incorporating accelerators whose architec-tures are parallel and different from the CPU. As a result, several frameworks were developed to aid to program these platforms mainly targeting better productivity ratios. In this context, GAMA framework is being developed by the research group involved in this work, targeting both regular and irregular algorithms to efficiently run in heterogeneous platforms.
Scheduling is a key issue of GAMA-like frameworks. The state of the art solutions of scheduling on heterogeneous platforms are efficient for regular applications but lack adequate mechanisms for irregular ones. The scheduling of irregular applications is particularly com-plex due to the unpredictability and the differences on the execution time of their composing computational tasks.
This dissertation work comprises the design and validation of a dynamic scheduler’s model and implementation, to simultaneously address regular and irregular algorithms. The devised scheduling mechanism is validated within the GAMA framework, when running relevant sci-entific algorithms, which include the SAXPY, the Fast Fourier Transform and two n-Body solvers. The proposed mechanism is validated regarding its efficiency in finding good schedul-ing decisions and the efficiency and scalability of GAMA, when usschedul-ing it.
The results show that the model of the devised dynamic scheduler is capable of working in heterogeneous systems with high efficiency and finding good scheduling decisions in the general tested cases. It achieves not only the scheduling decision that represents the real capacity of the devices in the platform, but also enables GAMA to achieve more than 100% of efficiency as defined in [3], when running a relevant scientific irregular algorithm.
Under the designed scheduling model, GAMA was also able to beat CPU and GPU ef-ficient libraries of SAXPY, an important scientific algorithm. It was also proved GAMA’s scalability under the devised dynamic scheduler, which properly leveraged the platform com-putational resources, in trials with one central quad-core CPU-chip and two GPU accelerators.
Contents
1 Introduction 7 1.1 Context . . . 7 1.2 Technological Background . . . 10 1.2.1 Hardware’s Perspective . . . 10 1.2.2 Software’s Perspective . . . 131.3 Motivation, Goals & Scientific Contribution . . . 15
1.4 Dissertation Structure . . . 17
2 The Problem Statement 18 2.1 The GAMA Framework . . . 18
2.2 Scheduling (Ir)regular Applications on HetPlats . . . 19
3 Scheduling on HetPlats: State of The Art 23 3.1 Performance Modeling . . . 24
3.2 Frameworks to Address Heterogeneous Platforms . . . 26
3.2.1 StarPU . . . 26 3.2.2 Qilin . . . 27 3.2.3 Harmony . . . 28 3.2.4 Merge . . . 29 3.2.5 MDR . . . 30 3.3 Other Studies . . . 31
3.3.1 Execution Time Awareness . . . 31
3.3.2 Device Contention Awareness . . . 34
3.3.3 Data Awareness . . . 34
3.4 Overview . . . 35
4 An (Ir)regularity-aware Scheduler for HetPlats 37 4.1 Conceptual Model . . . 38
4.1.1 Model’s Structure: Entities and their Interaction . . . 38
4.1.2 Assignment Policy . . . 40
4.1.3 Performance Modeling . . . 41
4.1.4 Run-time Execution Analysis . . . 41 vii
6 CONTENTS 4.2 Implementation . . . 42 4.2.1 Performance Model . . . 42 4.2.2 The Scheduler . . . 43 5 Validation 47 5.1 Case Studies . . . 47 5.1.1 SAXPY . . . 47
5.1.2 1D Fast Fourier Transform . . . 48
5.1.3 n-Body Solvers . . . 50
5.2 Experimental Environment . . . 51
5.3 Results . . . 52
5.3.1 Dynamic Scheduler’s Performance . . . 52
5.3.2 GAMA’s Efficiency . . . 57
5.3.3 GAMA’s Scalability . . . 61
6 Conclusions & Future Work 64 6.1 Conclusions . . . 64
6.2 Future Work . . . 66
Chapter 1
Introduction
This chapter introduces the dissertation work, contextualizing the state of the art of het-erogeneous platforms in high performance computing. It briefly presents the development and importance of both CPU-chips and GPU accelerators, and introduces the schedul-ing issue in heterogeneous environments. Section 1.3 presents the scientific motivation and the contributions of this thesis, whereas section 1.4 overviews the reminder of the dissertation.
1.1
Context
Heterogeneity is increasingly prevailing across High Performance Computing (HPC) plat-forms, which now include accelerators as co-processors to complement the general purpose central processing unit (CPU) chip. This success is justified by two main factors: (i) the wider spectrum of computing capabilities on heterogeneous systems, more suitable to appli-cations, sets of computational tasks with different computational requirements and (ii) good watt/performance and dollar/performance ratios.
The ever increasing programming capabilities of application specific co-processors, such as graphic processing unit (GPU) boards, are a major contributor to this heterogeneity. From the mid-nineties to the early XXI century, GPUs drastically moved from special-purpose non-programmable boards to powerful general-purpose non-programmable devices, simultaneously en-abling high levels of performance and power efficiency. This success was so significant that these boards influenced HPC hardware, as nowadays accelerated processing unit (APU) chips can prove.
Heterogeneity’s success became particularly noticeable in the TOP500’s1 November 2010
list where the chinese Milky Way No.1 GPU-based Tianhe-1A cluster, was considered the fastest supercomputer in the world. The latest TOP500’s list, published in June 2012, in-cludes 55 GPU-based clusters. Graphics boards emerged the general-purpose GPU (GPGPU) 1TOP500.org aims to deliver the list of the most powerful supercomputers in the world, twice in a year:
both in June and November.
8 CHAPTER 1. INTRODUCTION era, which motivated efficient implementations of data-parallel applications both in GPUs [54] and CPU+GPU platforms [72, 70].
Common accelerators include not only GPUs, but also both field programmable gate ar-ray (FPGA) devices and digital signal processors (DSP) units. Their architectures are not only different from the typical CPU but from one another. To extract the maximum per-formance out of these devices, time intensive hand-tuning may be required, along with a thorough knowledge of the their architecture. Additionally, these devices are tendentiously parallel, and only a small community of programmers are familiar with parallel programming. While it is hard to efficiently exploit accelerators separately or as a CPU co-processor, it is even harder to exploit platforms with several accelerators, especially if they differ from one another. These devices have different computing and programming models, as well as different architectures. This is especially relevant when determining the amount of
compu-tational work to assign to each computing unit (CU2) and managing data transfers. In this
context, frameworks were released to hide the burden of the required expertize to program these platforms.
This is not an isolated phenomenon in the history of computer science; the multi-core technology changed the way code must be written to get full advantage of the available parallelism in the chip, only possible on a multi-threaded fashion. To comply with this re-quirement, frameworks and libraries such as OpenMP [17], Intel Threading Building Blocks (TBB) [61] and Cilk [59] were released or adapted to relieve the end user from the required ex-pertize to effectively program multi-core chips. By ensuring efficient implementations, these
frameworks usually raise the level of both performance and productivity3.
In the past few years, especially between 2008 and 2009, relevant frameworks were de-signed to address systems populated by computing units including CPU-chips and acceler-ators, the so-called heterogeneous on-board platforms (HetPlats). Focused in data-parallel applications, these frameworks have been designed with high emphasis on their embedded schedulers, considered a key player in effectively exploiting the hardware platforms. These frameworks include StarPU [3], Qilin [47], Harmony [24], Merge [46] and more recently MDR [56]; section 3.2 overviews the key issues on these frameworks.
These frameworks usually represent the computational work by tasks, which are then assigned to the available computational resources. For regular workloads, frameworks that tackle multi-core chips and symmetric multiprocessor (SMP) devices are focused on both
2
In this dissertation the term computing unit (CU) refers to a chip or an entire board, whereas a processing element (PE) refers to a composing part (e.g. a CPU-core or a GPU Stream Multiprocessor (SM)).
3
In this context, productivity is defined as the ratio between the achieved performance and the man-hours spent in the implementation, similarly to economics, where it is calculated by the ratio between the developed product and time spent on it production.
1.1. CONTEXT 9 fairly and equally divide the computational work by the available resources, whereas frame-works addressing heterogeneous platforms must also consider the performance differences of each computing unit (CU) during the scheduling phase.
Scheduling may be defined as the assigning of computational tasks to CUs and the def-inition of their execution order [63], with respect to a specific target. These targets usually include to minimize the execution time of one application, also called its time-to-solution (TTS), to maximize the throughput and utilization of the system or to minimize the power consumption levels of the hardware, among others. This thesis work addresses the former.
Scheduling is also a key concept in operating systems, which aims to balance the workload across the available resources. In cluster and grid environments, the job scheduling middle-ware usually aims to keep resources busy as much as possible [11]. Schedulers embedded either on frameworks or on applications, on the other hand, usually aim to run applications in or-der to maximize or minimize cost functions, where the execution time is particularly common. Schedulers can be classified as static, dynamic or adaptive. Static schedulers assign the workload to computational devices either at compile or launch-time on a single time. Dynamic schedulers start the workload assigning process in run-time, performing several assignments. Adaptive schedulers are dynamic, but they may change previously taken assignment decisions, usually for the purpose of correcting load imbalance on the system.
Directed acyclic graphs (DAGs), also called task-graphs, are a common and natural way to represent applications, since they can represent applications with arbitrary task and de-pendence structures [63]. In a DAG, each node represents a computation and each edge the communication cost between the incident nodes. DAGs have been used to adequately represent regular applications, but they have limitations to model parallelism in irregular algorithms [57].
In its general form, the scheduling is an NP-hard problem [69, 26], i.e., its decision problem is NP-complete and no optimal solutions can be find in polynomial time. Due to this inher-ent difficulty, scheduler decisions are usually based on heuristics, which produce reasonable or even near-optimal decisions, which can potentially be inaccurate. Schedulers overcome these limitations by usually embedding load-balancing schemes, such as work-stealing and task-donation schemes [10, 66, 25, 68].
Inaccuracy in scheduling decisions may also occur due to other factors. Schedulers must incur in low overheads, otherwise the potential performance gains will be lost. As decisions must be quickly taken, schedulers do not usually base their decisions in complex (and slow) algorithms to schedule. In heterogeneous platforms, schedulers must also consider (i) the different computational capabilities of each CU, thus taking different times to run a task and (ii) the distributed memory paradigm on these platforms, where data-movement is an
10 CHAPTER 1. INTRODUCTION expensive operation.
Since the effective mapping between tasks and CUs is crucial to achieve good levels of performance [31], (i) is a major issue on scheduling decisions. To consider the different com-putational capabilities of each CU, schedulers usually embody (per-task) performance models to estimate the execution time of a pair (task, device). These estimations are not only useful to decide which CU to assign a task, but also to estimate the relative performance differences among the available CUs, for each task. This matter is covered in detail in section 3.1.
Performance models are well behaved for regular applications and tasks, lacking accuracy for irregular applications. Current definitions for irregular applications differ from one an-other, but common definitions state that irregular applications either (i) access pointer-based data structures such as trees and graphs [45] or (ii) have data access patterns not known before execution time [51]; although related, (i) and (ii) are not exactly the same.
1.2
Technological Background
1.2.1 Hardware’s Perspective
CPU-chips
In 1965 Gordon Moore predicted that CPU-chips would double their number of transistors roughly every 1.5 years [49]. Although this was predicted to happen for approximately ten years, this rule became valid for half a century and is expected to remain valid at least up to 2015. This has enabled the processor clock frequencies to double every year and a half, which enabled software to run faster from one generation to another, just due to hardware developments.
However, in 2005, the clock frequencies started to stall, due to thermal dissipation, and manufacturers started to increase the number of cores within the CPU-chip, while keeping a steady clock frequency. This fact marked the beginning of the multi-core era and the in-creasing importance of parallel computing.
CPU-chips are general-purpose computing devices, formed by multiple highly-complex cores, each a processing element with local and fast memories, a small part of the memory hierarchy. High performance cores are highly pipelined with replicated functional units to support instruction level parallelism (ILP). CPU-cores also hide long external RAM latencies through complex multi-level caches, whose access latencies are considerable slower.
Additionally, these devices also have vector and super-scalar capabilities. The first enable vector processing, where the same instruction operate on multiple vectorized data sets, the so-called Single Instruction Multiple Data (SIMD) instructions. The latter allows faster CPU
1.2. TECHNOLOGICAL BACKGROUND 11 throughput, by executing more than one instruction in a clock cycle, which are dispatched to the replicated functional units on the processor.
GPU devices as accelerators
GPUs, driven by computer graphics, have evolved from non-programmable specific-purpose devices to programmable general-purpose devices. From 1994 to 2001 these devices pro-gressed from the simplest and specific pixel-drawing functions to implementing the full 3D pipeline: transforms, lighting, rasterization, texturing, depth testing, and display. Due to the industry’s demand for flexibility, to implement customized shaders, programmable units were added and increased programmability enabled the GPUs to be adopted by the HPC community in general, the so-called general-purpose GPU (GPGPU) era.
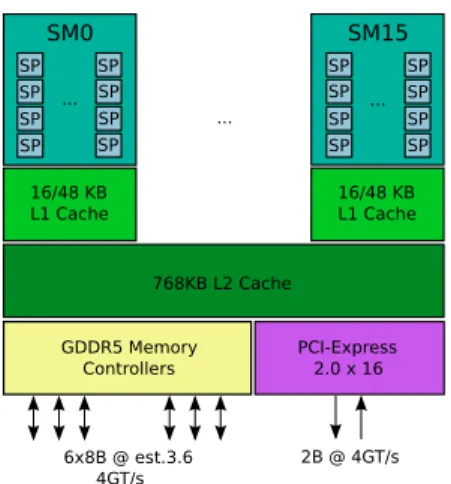
SM0 SM15 16/48 KB L1 Cache 16/48 KB L1 Cache 768KB L2 Cache GDDR5 Memory Controllers PCI-Express 2.0 x 16 2B @ 4GT/s 6x8B @ est.3.6 4GT/s ... 16/48 KB L1 Cache SP ... SM15 SP SP SP SP SP SP SP SP ... SP SP SP SP SP SP SP
Figure 1: NVIDIA’s Fermi architecture.
In particular, NVIDIA, a market leader sided by ATI, released the Fermi architecture in March 2010, formed by up to 512 Stream Processors (SP), clustered in up to 16 Stream Multiprocessors (SM) of 32 elements each. The SMs share a L2 cache, whereas SPs share a scratch-pad one another, within each SM (figure 1). A GDDR5 memory controller is also included in the device, which also supports DMA to system memory, through the PCIe bus. This massive data-parallel device is focused on delivering the higher possible throughput, simultaneously working at relatively low power consumptions.
In general, there is little benefit in running more threads on a CPU-chip than there are physical cores. GPUs, on the other hand, require thousands of threads to achieve several goals, including to hide the latency loads and texture fetches from DRAM. While CPUs rely on the memory hierarchy to hide long external RAM latencies, the GPU relies on switching threads whenever these stall, waiting for a load or texture fetch to complete: that can keep processors busy despite the long memory latency seen by individual threads [55].
12 CHAPTER 1. INTRODUCTION Another major feature on GPUs is their ability to efficiently schedule threads by hard-ware. The Fermi architecture includes a GigaThread global scheduler, and two schedulers per SM. The GigaThread global scheduler distributes thread blocks to SM thread schedulers. Each SM then schedules threads in groups of 32 parallel threads called warps. As warps execute independently and no dependencies have to be checked, this is considered a highly efficient process.
Despite their programming and computation model, general purpose GPUs achieved a widely acceptance and success on the HPC field, as the 37 GPU-based clusters in the Novem-ber 2011 TOP500 list proved. In particular, the chinese Milky way No.1 GPU-based, Tianhe-1A, became the most powerful cluster in the world, in October 2010, a position kept up to June 2011. Currently, and according to the latest TOP500 list, it is the fifth faster computer in the world, whereas also GPU-based Jaguar and Nebulae are sixth and tenth, respectively.
Other Computing Units
The set of accelerators in HPC is very likely to grow, as recently Texas Instruments (TI) C66x DSPs series have proved. These microprocessors became suitable to general purpose computing by being endowed with floating point capacity to support the 4G wireless standard [38]. Especially designed for power-efficiency, they can provide more than 500 Giga floating point operations per second (GFLOPS) of performance while consuming 50 Watts of power.
Similarly to TI’s DSPs, ARM processors, now leading the mobile industry, are likely
candidates to be soon adapted by the HPC community4. Also developed to deliver power
economy, these chips are now being designed also targeting high performance levels, moti-vated by the increasing complexity of both mobile applications and operating systems, such as Android or Symbian [40]. Currently limited to a 32-bit architecture, ARMv8 has already announced as a 64-bit ARM architecture.
The 50+ core Many Integrated Core (MIC) is Intel’s answer to NVIDIA and AMD’s GPU challenge. MIC is being used in experimental trials as a x86 accelerator, connected to the
CPU through a PCI bus5. In spite of the community’s familiarity with the x86 architecture
and the possibility of coding MIC using C, C++, Fortran and OpenMP, the facility of MIC’s programming and its sustained performance is yet to be proven.
4
e.g. the ARM-based Montblanc project will replace the MareNostrum in the Barcelona Supercomputing Center (BSC).
5
MIC is the basis of a 10-petaflop capable supercomputer, the Stampede, announced by Texas Advanced Computer Center (TACC) in September 2011. The Stampede’s heart is based on 50+ core Knights Corner (KNC) processor chips, packaged in a PCIe form factor.
1.2. TECHNOLOGICAL BACKGROUND 13
1.2.2 Software’s Perspective
pThreads
To fully exploit multi core features, the application algorithm and code may require a full re-design. Applications instantiated in processes can thus create multiple threads, since a single thread will eventually leave unused resources at some point. A thread is the smallest unit the operating system can schedule and one of the most important concepts in the history of computer science.
POSIX Threads, usually referred to as pThreads, is a POSIX standard for threads. Im-plementations are available for several Unix-like POSIX-conformant operating systems, such as GNU/Linux. The API provides thread management and synchronization primitives. Al-though this threading library is still on the top of the preferences of some computer scientists, the industry demanded higher-level libraries to explore parallelism, since with pThreads de-velopers are forced to deal with concurrency issues, such as deadlocks and race-conditions.
OpenMP, TBB & Cilk
OpenMP [17], Intel Threading Building Blocks (TBB) [61] and Cilk [59] have emerged to take advantage of the the multi-core technology from a higher abstraction level than direct threading APIs, as pThreads.
OpenMP is the most popular library across the industry to parallelize shared memory applications. This has been arguably due to its simplicity, since OpenMP is based on pre-processor directives. In OpenMP-based applications, the master thread creates a specified number of slave threads, which concurrently compute a task in a data-structure, while the operating system handles their allocation to the available processors. Task-sharing is done through the work-sharing scheme, which was popularized by OpenMP [34].
Other libraries, such as Cilk and TBB, employ stealing as part of their work-balancing mechanism. Work-stealing is described as a technique to implement runtime sched-ulers. A scheduler employs a specified number of threads, called workers. Each worker then maintains a local queue to store and retrieve tasks. When the local queue becomes empty at some synchronization point, its respective worker will try to steal a task from another busy worker. Each busy worker manages its private queue through synchronization-free pushes and pops.
Intel’s TBB [61] is a task-based threading library, which produces scalable parallel pro-gramming from standard C++. TBB is completely transversal across platforms and operating systems, only requiring a C++ compiler. The runtime system, automatically handles load balancing and cache optimization, while simultaneously offering parallel constructors and syn-chronization mechanisms to the programmer. The programmer specifies tasks, so the system
14 CHAPTER 1. INTRODUCTION can map such tasks on threads in an efficient manner. Unfortunately to expert programmers, TBB does not provide manual control over task locality.
Cilk/Cilk++ is a runtime system for multi-thread parallel programming in C/C++, de-signed by the MIT Laboratory for Computer Science and developed by Intel [59]. In this system, each processor maintains a stack of remaining work. When a procedure call is found, the current procedure’s state is recorded on the stack as an activation record, and the new procedure is executed. The last activation record is only executed as soon as the remaining procedures have been fully executed. As Cilk employs a work-stealing based scheduler, each stack can be dequeued by other processors that have executed all their work.
Chapel
Chapel is a new parallel, very high-level programming language developed by Cray [16]. It is focused on creating abstractions to data, by separating the algorithmic expression and data structure implementation details. In particular, Chapel creates the concept of “domain”, which contain the size and the location of data, used to perform intra and inter-domain operations. Domains and associated operations are then mapped across the available PEs, responsible to perform the algorithmic operations over them.
Message Passing Interface
Message Passing Interface (MPI) is a message-passing API, designed by both academia and industry researchers, to tackle distributed memory, parallel systems. It relies on processes running on each CU, communicating through the point-to-point and group message passing API, either in Fortran 77 or in C.
The parallel, scalable and large-scale applications designed with MPI must explicitly split the data among processes, where each process independently takes its execution. Successive applications have been designed using MPI to leverage several loosely coupled CUs at the same time, while using a shared-memory parallel library as OpenMP or TBB to parallelize each execution flow within each CU.
CUDA
The Compute Unified Device Architecture (CUDA) computing model was launched by NVIDIA, in 2007, aiming to provide an universal environment to address devices with similar archi-tectures to NVIDIA GPU devices. With a specific Instruction Set Architecture (ISA), the CUDA computing model enables users to program the resources (i.e. SPs and SMs) that compose the GPU-board.
CUDA model extends C and in a CUDA application, some parts can run on the CPU, the host, while some functions run on the GPU side, the device. GPU functions, called
ker-1.3. MOTIVATION, GOALS & SCIENTIFIC CONTRIBUTION 15 nels, are executed in parallel within the GPU, by a specified number of CUDA threads. The CUDA model defines a highly-semantical hierarchy of threads. Kernel calls generate a grid of blocks of threads. Both grids and blocks can be conceptually organized in 1-3 dimensions.
Figure 2: CUDA’s hierarchy of threads.
Figure 2 shows a bi-dimensional grid and block thread hierarchy organization. Each block and each thread is associated with bi-dimensional coordinates, which are later associated with specific computation. This hierarchy fashion provides a natural way to connect threads with vectors and matrices. Within the CUDA memory model, each thread has local memory and each block has shared memory, visible by all the threads within it. The complete range of launched threads can view and access both the global and constant memories.
The GPU massively parallel, single-instruction multiple-data/thread (SIMD/SIMT) ar-chitecture has achieved impressive performances for regular, data-parallel applications. This has led to GPUs wide acceptance on the HPC community, where a significant amount of problems are data-parallel. Nevertheless, a significant part of (client-side) applications are irregular [57], and some results have been recently presented, reporting good GPU perfor-mances in irregular applications [14, 48, 58], possible at cost of extensive hand-tuning.
1.3
Motivation, Goals & Scientific Contribution
Motivation
In the recent past years heterogeneous platforms have prevailed in the HPC field, with high acceptance by the scientific community in general. As much as predictable, computational systems will remain heterogeneous both within each chip [20] and as whole platforms [41]. Moreover, the variety of accelerators on HPC may grow, as the recent Intel’s MIC and TI
16 CHAPTER 1. INTRODUCTION C66x DSPs boards have proved.
Although heterogeneous computational platforms have been well accepted by the scien-tific community, due to their high, energy-efficient performance levels, programmers are facing tough times to reach the promised efficiency levels of single accelerators and heterogeneous platforms in general, only possible at the cost of algorithm’s re-design and/or dense code tuning, with a thorough knowledge of the underlying architecture [14, 58, 48].
This current programming workflow does not favor high levels of productivity, decreased by the long periods of implementation and tuning. Although some frameworks were released to address heterogeneous platforms, by automatically and efficiently orchestrate data man-agement and scheduling decisions, they lack adequate solutions for irregular applications, which compose a substantial slice of both scientific and technological applications in general [57].
These limitations motivated the design of a new framework to address irregular applica-tions on heterogeneous platforms. The scheduling of both regular and irregular applicaapplica-tions on these heterogeneous platforms was also identified as a key issue in such frameworks, be-cause good performance levels are proved to be strictly related with the effective mapping between the application and the available computing resources.
Goals
The main goals of this thesis are twofold: (i) to identify the proper mechanisms to address the key issues that arise on the scheduling of regular and irregular applications on heteroge-neous platforms, especially in CPU+GPU setups and (ii) to design, implement and validate a scheduler to effectively employ the mechanisms identified in (i), within the context of the GAMA framework, under development in the research group related with this thesis, and presented in section 2.1. This problem is described in detail in section 2.2.
As a result of the validation of the proposed scheduling mechanism, some other side questions are expected to be answered. In particular, it is expectable this dissertation (i) to characterize the class of algorithms that suits HetPlats whose accelerators are GPUs, (ii) to identify the relation between the accelerator’s usage and the application’s workload size, and (iii) to identify and characterize some issues with the scalability of applications in HetPlats. Scientific Contribution
With the thesis under this dissertation, it is expectable to produce and deliver a conceptual scheduling model to simultaneously and effectively address both regular and irregular appli-cations on heterogeneous platforms. The model is expectable to be validated on platforms with central computational units and accelerators, tightly connected one another through high-latency channels, and both regular and irregular algorithms.
1.4. DISSERTATION STRUCTURE 17
1.4
Dissertation Structure
This dissertation contains six chapters, whose summary is presented below:
- Introduction: introduced the dissertation work, contextualizing the state of the art of heterogeneous platforms in high performance computing. It briefly presents the devel-opment and importance of both CPU-chips and GPU accelerators, and introduces the scheduling issue in heterogeneous environments. Section 1.3 presents the scientific mo-tivation and the contributions of this thesis, whereas section 1.4 overviews the reminder of the dissertation.
- The problem statement: briefly presents the GAMA framework, and aims to identify and characterize the problem under study. It also frames the scheduling of irregular algorithms on heterogeneous platforms in a general context, while analyzing the key issues that arise on this type of scheduling.
- Scheduling on HetPlats: State of The Art: presents the state of the art of scheduling on heterogeneous platforms. This state of the art is mainly focused on two types of research work: (i) schedulers embedded in frameworks that address heterogeneous platforms (providing a high-level unified API and execution model to the users) and (ii) individual studies on scheduling over heterogeneous platforms. As scheduling decisions are usually supported by a performance model, the initial section addresses these models.
- An (Ir)regularity-aware Scheduler for HetPlats: presents the conceptual model and the implementation of the proposed scheduling mechanism. It addresses both regular and irregular applications on heterogeneous platforms, which contain CPU-chips and GPU devices as accelerators.
- Validation: validates the proposed scheduling mechanism on the GAMA framework, when scheduling some case study algorithms. It describes the case studies and the target platform, and presents the obtained results and their discussion. The proposed scheduling mechanism is compared with the best possible static scheduling and with commercial libraries that provide the implemented algorithms. GAMA’s efficiency is measured, both under dynamic and static scheduling.
- Conclusions and future work: concludes the dissertation, presenting an overview of the obtained results, related both with the proposed scheduling model, the performance of GAMA and the experience on heterogeneous platforms. Some guidelines of future work are suggested.
Chapter 2
The Problem Statement
This chapter briefly presents the GAMA framework, and aims to identify and charac-terize the problem under study. It also frames the scheduling of irregular algorithms on heterogeneous platforms in a general context, while analyzing the key issues that arise on this type of scheduling.
2.1
The GAMA Framework
The GPU And Multi-core Aware (GAMA) framework is an ongoing collaboration project between the University of Minho and the University of Texas at Austin. It mainly focuses to bridge the gap between different execution and programming models on a heterogeneous system formed by CPU-chips tightly coupled to accelerators. Theoretically designed to ad-dress a wide range of these devices, it currently supports x86 processors and CUDA-enabled devices (with compute capability 2.0 or higher).
Within the GAMA framework, applications are described as set of jobs, associated to a computational kernel, a data domain - where the computational kernel is applied - and a dicing description, that details how the data domain is diced to create smaller jobs. From the scheduler’s point of view, jobs are instantiated as tasks, which are assigned to the available CUs on the platform.
Jobs may have cross dependences, which are expressed by the programmer in the form of synchronization barriers, ensuring that no task of a job k + 1 is executed before of the end of all the tasks that belong to the k job. The run-time scheduler is responsible for ensuring synchronization, although it does not ensures any order of execution in applications without synchronization descriptions.
Memory System
GAMA employs a memory system and an address space on top of the devices memories within the system, which unifies the distributed address spaces and creates a distributed
2.2. SCHEDULING (IR)REGULAR APPLICATIONS ON HETPLATS 19 shared memory (DSM) system. This memory system is based on the release consistency model, which triggers implicit release-and-acquire operations on the data accessed by each thread.
GAMA’s memory system provides both private and shared memory, i.e., memory that can be visible and accessible by one or more threads at each time. Data is dynamically allocated and deallocated, following similar strategies to Hoard and xMalloc [8, 37], to favor both speed and scalability.
In the near future, it is planned GAMA to employ a software cache mechanism, enabling each device to maintain a piece of local and fast memory. This is expectable to reduce the memory access latencies for re-used data, which are currently accentuated since accelerators access to memory through high latency PCI-Express channels.
Job Definition and Execution
Each job is described by a class specialization in C++, in which the programmer mainly defines the execute and dice methods. In the first, the programmer defines the computation kernel executed on the data domain associated with such job. The second defines the data partition methodology to apply when dicing the data domain of that particular job.
2.2
Scheduling (Ir)regular Applications on HetPlats
Current GAMA scheduler assigns the application workload to the available CUs in a static and ungrounded fashion. It is intended to endow the GAMA framework with a scheduler that takes grounded assigning decisions, to minimize the execution time of each regular or irregular application on the running platform.
The scheduling of applications on heterogeneous platforms is still a challenging problem. In particular, the more irregular the application and the more heterogeneous the platform, the wider the spectrum of arising issues. Four types of scheduling can be identified when classifying both the platform and the application respectively as either homogeneous or het-erogeneous and as either regular or irregular. These scheduling types are shown in Table 1, whose complexity grows from the top to the bottom and from the left to the right.
(Regular & Homogeneous) (Regular & Heterogeneous)
(Irregular & Homogeneous) (Irregular & Heterogeneous)
Table 1: Types of scheduling in the form (application & platform).
20 CHAPTER 2. THE PROBLEM STATEMENT and simultaneously the most studied combination. Single core platforms and/or platforms formed by a single CU are usually homogeneous and these remained the most common plat-forms for several years. While scheduling one application on a single core may be a very low-level process (e.g. instruction level parallelism) and out of the scope of this thesis, the scheduling of regular applications on multi-core CPU-chips is based on assigning (relatively) equal amounts of workload to every core using programming models such as OpenMP and TBB.
By default, OpenMP schedules parallel loops statically where an equal number of
iter-ations is given to each worker thread (e.g. I/T for I iterations and T running threads).
OpenMP’s dynamic scheduler, on the other hand, is based on the work-sharing scheme to distribute the workload among the available cores. Once a thread finishes a block of loop iterations, it retrieves another block from the top of the work queue. As a result, threads executing in equivalent cores will very likely execute the same amount of workload.
The scheduling of irregular applications on homogeneous platforms has also been previ-ously studied. The majority of this research can be found in implementations of irregular
ap-plications on OpenMP-like1 programming models, targeting (homogeneous) multi-core chips
[32, 35, 22]. Although several authors claimed that OpenMP has not the proper features to natively address this problem, some OpenMP extensions were proposed and validated to address this issue (e.g. the ability to cancel threads in a parallel region [65]).
Most of the work in the scheduling of regular applications on heterogeneous applications can be found on the state of the art frameworks designed to address heterogeneous platforms, described in detail in Chapter 3. Some of these proved that both static and dynamic schedul-ing approaches are able to achieve major levels of performance in some of the best known regular data-parallel algorithms.
The scheduling on these frameworks is usually based on per-task performance models [3], which train the scheduler with information about the execution time of each application’s task, either built transparently [2] or through reference runs [47]. This information mainly aims to provide the relative differences of performance of every CU within the system, which are later used by the scheduler to take assigning decisions.
The scheduling of irregular applications on heterogeneous platforms has not been ade-quately addressed and reported yet. As the complexity in Table 1 grows from the top to the bottom and from the left to the right, this is the most complex type of scheduling to solve. Some of the key issues that arise on this problem and that are intended to be addressed in this thesis are:
1
According to Tim Mattson, an OpenMP designer, OpenMP was not designed for irregular applications, but several studies achieved high performance levels in irregular algorithms on multi-cores, using OpenMP-like models.
2.2. SCHEDULING (IR)REGULAR APPLICATIONS ON HETPLATS 21 (i) Differences among CUs. On heterogeneous platforms there may exist computing units better tailored to perform specific sub-computations on applications, due to multiplicity of architecture features within the system. As a consequence, each CU will very likely perform these sub-computations (e.g. a task) differently, with respect to performance. It is thus essential to identify these relative differences among architectures, to achieve good levels of performance. In particular, this is a key problem in the scheduling regular applications on HetPlats, since good performance levels have been achieved by statically distributing the workload with basis on these relative differences [47, 52, 31].
(ii) Irregularity. Irregular algorithms are composed of tasks whose amount of computation and respective execution time is not known in advance. On data-parallel applications, formed by sets of tasks, this is equivalent to say that the execution times of such tasks might differ, even when executing on the same CU. Thus, the relative differences as shown in (i) may not provide enough information to effectively distribute the workload between the available CUs: defining the number of tasks to assign based only on these differences does not necessarily lead to a balanced distribution of computational load. Considering irregularity into a scheduling equation is far from simple, though, since it is very hard (or even impossible) to predict the execution time of irregular applications, which depend on factors such as run-time values and the input set.
(iii) Load imbalance. As it is very hard to define a good static policy taking both (i) and (ii) into account, the system may become imbalanced when statically assigning the workload. One approach to correct the workload imbalance is to follow a dynamic scheduling scheme, i.e. to schedule the workload multiple times, which may amortize the imbalance in run-time. This is done by considering the workload assignment to every device at every run-time assigning.
(iv) Data movement cost. Accelerators reintroduced the distributed memory paradigm and moving the workload among CUs is an expensive operation when the associated data resides at the local memory of a particular accelerator. This forces to move data between the accelerator and the main memory (or even a second accelerator), incurring in a non-negligible overhead, making work balancing methods too expensive. In GAMA, the task management is done exclusively on the CPU side, but due to data prefetching, each task’s data domain is copied to the local memory (if the case) of the device which will execute it. Correcting assignment decisions should thus be avoided and assignment decisions should be made with high certainty degrees.
(v) Data placement. As current accelerators have local memories, the data of each task may either be copied to such memories and accessed locally or be remotely accessed, through direct memory access (DMA). As result, assigning a task which accesses data stored in the local memory of an accelerator to another accelerator may incur in two memory copies (back and forth), which may severely affect performance. Thus and in general, an efficient scheduling policy would prefer to assign tasks to the device which already has the respective data.
22 CHAPTER 2. THE PROBLEM STATEMENT
Summary and conclusions:
After presenting the GAMA framework, this chapter identified and presented the four scheduling types, with respect the algorithm’s regularity and the platform’s heterogeneity. The scheduling of irregular applications on heterogeneous platforms, also under study in this thesis, is the most complex type, due to the hardware differences and software unpredictabil-ity. Several problems that arise from this kind of scheduling were identified and described.
The work in this thesis aims to design, implement and validate a mechanism to effectively schedule both regular and irregular applications on heterogeneous platforms, minimizing their execution time. It is thus expected this mechanism (i) to be aware of the differences of the platform’s CUs, (ii) to be aware of the application’s irregularity, (iii) to correct potential load imbalance, (iv) to minimize data movements and (v) to take data’s placement into account. This mechanism will be validated in the GAMA framework, when running both regular and irregular algorithms.
In Chapter 3 the state of the art of GAMA-like frameworks is described, with particular emphasis on their scheduling mechanisms. Chapter 4 presents the thesis, the model and the implementation of the scheduler mechanism proposed in this dissertation, whereas its validation is shown in Chapter 5, where the scheduler is compared with a baseline static scheduler and its performance on GAMA is compared with commercial libraries.
Chapter 3
Scheduling on HetPlats: State of
The Art
This chapter presents the state of the art of scheduling on heterogeneous platforms. This state of the art is mainly focused on two types of research work: (i) schedulers embedded in frameworks that address heterogeneous platforms (providing a high-level unified API and execution model to the users) and (ii) individual studies on scheduling over heterogeneous platforms. As scheduling decisions are usually supported by a performance model, the initial section addresses these models.
As programmers spend considerable amounts of time implementing applications on het-erogeneous platforms, frameworks were designed to take this burden, raising programmers productivity levels by lowering the implementation periods. In irregular applications this is even more noticed, because good scheduling and data management decisions depend on run-time values. Without these frameworks, programmers would be forced to design complex run-time systems to effectively take advantage of the platforms.
The embedded scheduler and the data management system (DMS) are crucial players in these frameworks. The former assigns workload to CUs, taking efficient decisions regarding a specific goal, such as performance. The latter moves data among the system memory banks (main and local memories), and manages prefetching and caching mechanisms. While this thesis is focused on scheduling, a parallel research activity focuses on the DMS of the GAMA framework.
Embedded schedulers are composed of several modules, including a load-balancer scheme, which corrects its decisions when inaccurate (e.g. work stealing), a work-management system, which is responsible to maintain the association of computational work and devices (e.g. a queuing system) and an assigner system, which is responsible to take assignment decisions, by mapping workload to CUs or PEs, according to some policy. This module may also include software and/or hardware modeling, usually called a performance model.
24 CHAPTER 3. SCHEDULING ON HETPLATS: STATE OF THE ART Section 3.1 covers the performance modeling theme, by classifying the current types of embedded schedulers based on their performance models. Section 3.2 presents the state of the art frameworks to address heterogeneous platforms, at the perspective of their scheduling and performance modeling systems. Section 3.3 presents schedulers for heterogeneous platforms not embedded in frameworks, which complements the previous section.
3.1
Performance Modeling
To take grounded scheduling decisions schedulers must estimate how tailored each task is to every CU or PE within the system, regarding a specific goal (e.g. performance, the fo-cus on this thesis). This capacity, provided by a performance model, enables the scheduler to efficiently perform the mapping between computational tasks and the available devices [31]. Heterogeneous systems are populated by different devices, with different architectures and computing capacities. They offer a wide spectrum of computational capabilities, more able to comply with the requirements of applications, sets of tasks, potentially with different computational requirements. This is the reason why high levels of performance are strictly dependent on an accurate mapping of computational tasks on devices.
A performance model estimates the “suitability” level of a tuple, typically a (task, device)1
pair. It is usually represented by a mathematical function f(x), where its domain would be the set of tuples (t,d) for every task t and device d on the system and its co-domain is typically a “suitability value”, either on N or R. Performance modeling is defined in this thesis as the act of building or using a performance model, whereas its refinement is called calibration.
The goal of performance modeling, also defined as the gain of understanding of a com-puter system’s performance on various applications [5], can be defined as the estimation of the suitability of various applications (or tasks) on a computer system (or device) [64]. Even reversing its definition, it is still true that the resulting model can be used to project perfor-mance to other application/system combinations, as defined in [5].
The mathematical function that represents the performance model may be formed by several weighted components. The more components are included in the function, the more accurate the function but the slower the model might be to execute. The range of possible components to include in the function is very wide (the wider the more heterogeneous the platform) and the performance model may be executed several times in run-time, a trade-off between the complexity and the accuracy of the model. As performance prediction has been proven to be so much time-consuming [15, 5, 31], schedulers usually resort to simplified per-formance models [15, 1].
3.1. PERFORMANCE MODELING 25 As a consequence of resorting to these less accurate performance models, schedulers may take less accurate, scheduling decisions. The error in each scheduling decision can be quan-tified as the difference between the optimal scheduling decision and the one taken by the scheduler. This introduced error is usually mitigated and controlled by a load balancing mechanism, which include popular schemes such as work stealing and donation [10, 68]. As these schemes introduce overhead to identify and solve the load imbalance, the error cannot be eliminated, but mitigated.
The more calibrated the performance model, the less the load-balancing scheme needs to act. Although load-balancing schemes can mitigate the scheduling errors by successfully mov-ing tasks between computmov-ing units on homogeneous systems, they are highly conditioned on heterogeneous systems. Accelerators re-introduced the distributed memory paradigm, and data-movement might be potentially expensive on these systems, in opposition to shared-memory systems, in which this cost may be negligible. This problem does also affect NUMA-based systems, and studies over OpenMP and TBB frameworks opted by either mitigating or preventing the work-stealing/donation [71, 13, 50].
Schedulers can build (and access) performance models either in compile or run-time (also called as off/on-line). In either case, these performance models may be dynamically cali-brated during the application’s life-time [2]. Performance models built off-line are designed considering the underlying architectures on the system and the code to execute [31]. Perfor-mance models built on-line, on the other hand, are usually based on dynamic learning, i.e., by increasing awareness during the application’s lifetime [2, 47, 39, 15]. Performance models may also be parameterized, with information provided by programmers.
Current schedulers may be classified based on their performance models. This thesis classifies as instrumented schedulers those that resort to dynamically (on-line) built per-formance models, because these are built based on run-time sensed values. On the other hand, schedulers that resort to compile-time (off-line) information are classified as predic-tors. These do not need the application to start to estimate the suitability of tasks and devices, which is done by matching the architectural properties of the system with the code to execute. Performance model’s calibration is inevitably an on-line process.
Instrumented schedulers resorts to instrumentation to measure the performance of tasks, which is then recorded in the performance model. This is an empirical operation, where the measurement of each task’s performance is highly dependent on the occupancy of the platform. Predictor schedulers are based on matching code properties (possibly extracted by a formal analysis of the code) with the hardware ones, usually by an analytical formula. They are usually based on lexical and syntactical analysis of the code, which can be made at compile-time, where compilers are very likely to perform these operations.
model-26 CHAPTER 3. SCHEDULING ON HETPLATS: STATE OF THE ART ing for GPUs, which has been made at the cost of dense analytical functions. One can find several studies in the literature, not only for performance modeling but also for other kinds of modeling for GPUs, as power modeling [53, 36]. Analytical GPU performance models consider a wide set of hardware constraints and features, well modeled in terms of latencies [43, 4, 36].
Presenting estimations with up to 13% of error, the latter work is designed resorting to variables that are gathered by the GPU PTX emulator Ocelot [42]. On the other hand, the authors in [4], have identified the major micro-architecture features for NVIDIA GPUs and built a predictor, which formally analyzes the code and builds a work flow graph (WFG). The combination of the several identified factors, through efficient symbolic evaluation, provide the final approximation to the execution time of the kernel.
3.2
Frameworks to Address Heterogeneous Platforms
An important slice of the state of the art in scheduling on heterogeneous platforms is related to frameworks that emerged on the last years to address these on-board systems. Besides the GAMA framework, current frameworks mainly target regular applications. They have been designed with high emphasis on their embedded schedulers, due to their major role in effectively exploiting the systems. Those frameworks, initially published between 2008 and 2009, include StarPU [3], Qilin [47], Harmony [24], Merge [46] and MDR [56].
3.2.1 StarPU
According to StarPU’s authors, approaches to run applications on regular cores with parts offloaded on accelerators are not sufficient to take full advantage of the hardware resources. The real challenge is to dynamically schedule an application over the entire system, across the available PEs [1]. StarPU’s scheduler is mainly focused on minimizing the cost of transfers between processing units and on using the data transfer cost prediction to improve the task scheduler decisions.
StarPU’s work team published two papers on its scheduler [1, 2], a major player in their framework. The former is focused on the devised performance modeling mechanism, whereas the latter is an extension to efficiently deal with multi-accelerator hardware configurations where data transfers are a key issue.
The authors argued that finding an explicit performance model for a kernel’s execution time is a tough task, due to the required extensive knowledge about the kernel and the under-lying architectures on the system. As a consequence, it is proposed an empirical, history-based performance model, resulting in an instrumented scheduler.
3.2. FRAMEWORKS TO ADDRESS HETEROGENEOUS PLATFORMS 27 Based on the Heterogeneous Earliest Finish Time (HEFT) heuristic [67], StarPU’s sched-uler reported super-linear speedups on a LU decomposition, when supported by the presented history-based scheme. The performance modeling is based on three steps: (i) the measure-ment of each task’s duration, a particular tough task on devices that overlap DMA transfers with computation, (ii) the identification of the tasks, based on the data layout, and (iii) feeding and accessing the model, based on a hash table per architecture.
A relevant part of this model is the “carefully chosen hash-function” that allows to access the performance model on a very efficient fashion. Although transparent to the programmer, this method is not applicable to irregular applications, since slightly different input sizes cannot be predicted based on one another. While introducing the performance model’s de-sign, the authors argued that analytical models are very hard to build even on homogeneous modern systems. They also argue that empirical models are most suitable, since they are realistic and can be calibrated, either at runtime using linear regression models or offline for non-linear models.
The latter paper is focused on the StarPU’s scheduler, an extension to efficiently deal with multi-accelerator hardware configurations where data transfers are a key issue. It also presents the implementation of data-prefetching on GPUs and a new scheduling policy that reduces the memory occupancy of the memory buses. This paper detailed the scheduler’s extension, namely to take data-transfers into account. It also introduced the asynchronous data request management capability, since CUs and PEs should ideally not stall, waiting for input data.
Since StarPU keeps track of each replicated data on the system, the scheduler can con-clude whether accessing some data requires a transfer or not. A rough estimation of the data transfer cost is based on both the latency and bandwidth between each pair or nodes. The HEFT policy is thus extended, so that the scheduler can take into account the data-transfer time of each task, along with the estimation of the task’s execution time, provided by the performance model. This is reported as significantly important to boost the performance of a stencil kernel and LU decomposition implementations.
However, the StarPU framework addresses only regular applications. Its scheduler and performance model are severely affected by irregular applications, since no assumptions can be made of the size of new input data-sets, even for the same algorithm, and they must be re-written to cover this class of applications.
3.2.2 Qilin
Qilin is described as a (experimental) heterogeneous programming system. The authors de-scribed a new type of empirical performance modeling, adaptive mapping, with reported speedups of 9.3x over the best serial implementation, by “judiciously” distributing work over
28 CHAPTER 3. SCHEDULING ON HETPLATS: STATE OF THE ART the CPU and the GPU. This implementation has been reported as 69% and 33% faster than using only the CPU and GPU, respectively, for a set of well-known benchmarks [47].
The adaptive mapping technique is reasoned on the likely unstable optimal mapping regarding different applications, different input problem sizes, and different hardware con-figurations. The authors have used the well-known matrix-multiplication operation as case study, generating static partitions for three different input data-sets, that ranged from CPU-only to GPU-CPU-only in multiples of 10%, as similar studies have also reported (e.g. [31]). Such method allows to validate a good approximation to the task/data partition.
The adaptive mapping is based on both training and reference runs. On the former, the
framework splits the application’s input size N into N1 and N2. Afterwards, these are broken
into smaller chunks (of different sizes), which are executed on the CPU and on the GPU. Their execution times are measured and used to feed a curve fitting process to determine the curves of each task, for both the CPU and the GPU. A reference run is then predicted through these curves, stored in a database, and the maximum time of these predictions is the estimated at run-time.
The authors empirically noticed that low computation-to-communication ratio renders the GPU less effective, which implicitly takes the bandwidth to the device into account. This metric, although relevant on these environments, has always been implicitly handled through the ratio between the data-transfer and computation on Qilin and on other similar work [31]. Unlike some similar-purpose research, the Qilin programming system relies on DAGs to express the dependencies of the application and on dynamic compilation, which builds the DAG of the application and decide the (task,device) mapping either using programmers restrictions or using the adaptive mapping technique. Before code generation, where the available data on the device is taken into account, the Qilin system optimizes the built DAG to reduce operation coalescing and unnecessary temporary arrays.
Qilin is not designed to address irregular applications, similarly to the reminder related work. While DAGs are not appropriate to model parallelism in irregular algorithms [57], the adaptive mapping technique is not suitable to these either, since the execution time of irregular applications cannot be statically predicted on a single reference or training run. Moreover, the adaptive mapping technique is neither applicable nor scalable for several and different accelerators.
3.2.3 Harmony
Harmony is focused on providing semantics to simplify the parallelism management, dynamic scheduling of compute intensive kernels to heterogeneous computing resources, and online monitoring-driven performance optimization for heterogeneous many core systems, with high
3.2. FRAMEWORKS TO ADDRESS HETEROGENEOUS PLATFORMS 29 focus on binary compatibility across the platform. The Harmony’s short paper provides lit-tle information on its scheduler. It does, however, acknowledge the importance of dynamic mapping and states that a priori prediction would improve the quality of the schedule [24].
Harmony’s dynamic scheduler is based on mapping kernels to PEs and variables to mem-ory spaces as the program is being executed [23]. The scheduling operation lasts while the window of kernels fetched from the program, continuously updated, is not empty. The sched-uler includes a performance model to predict the execution of kernels based on the used variables, the information about its PTX assembly code, and the history of previous execu-tion of the same or similar kernels.
This performance model allows to predict the execution of a kernel on any PE in the system, either as an absolute value or as a confidence interval. The other components of the Harmony runtime may use the performance model as its default behavior or query it again after a higher confidence prediction is obtained. The performance model is built by recording the execution times of kernels along with the machine parameters of the PE it is executed on, the size of the input data set and other values. These parameters are then used to feed a polynomial regression model to create a suitability function.
The kernel resorts to a dependence graph to get the set of fetched kernels that have not been scheduled yet. The scheduler is only responsible to define the PE where a
ker-nel should run, based on the list scheduling algorithm [29], with priority for critical kerker-nels2.
The scheduling decision may be re-computed in case of misspeculation, which removes kernels from the scheduling list, and load imbalance, where a list becomes empty for a PE whereas others have excess kernels.
Harmony’s performance model, whose authors refer to as “performance predictor”, is reported to spend >50% of the execution time of the whole Harmony’s execution model, whereas the dependence graph takes ∼20%. Other scheduling tasks, such as kernel dispatch take less than 5% of the overall execution time, while the kernel scheduling operation achieves negligible percentages (1%). The Harmony’s memory manager consumes ∼20% in this time breakdown. Consequently, its performance model is significantly more time consuming than the other tasks on the system.
3.2.4 Merge
The Merge framework relies on the map and reduce constructs as an efficient set of seman-tics for describing the potential concurrency in an algorithm. The MapReduce pattern is also responsible to keep the processors balanced with respect to their load, beyond providing transparency in parallelizing the code.
2Criticality in this context is defined as the sum of execution times of kernels that directly or indirectly
30 CHAPTER 3. SCHEDULING ON HETPLATS: STATE OF THE ART
To tackle portability, this framework uses EXOCHI to create an interface between the code and the accelerators, which makes this framework easily extensible [46]. This approach to load-balance and scheduling is different from the previous one and there is not much information regarding how this framework executes the associated performance modeling.
3.2.5 MDR
The model driven framework (MDR) is designed based on several performance models, which influence run-time decisions, including mapping and scheduling tasks to CUs and copying data between memory spaces [56]. It thus models task execution, while orchestrates the data-movement within the platform. The workloads are represented as parallel-operator di-rected acyclic graphs (PO-DAGs). The scheduling decisions are based on four identified criteria: suitability, locality, availability and criticality (SLAC).
During the run-time execution the MDR framework exploits coarse-grain parallelism across CUs, and fine-grained parallelism across PEs. These grains of parallelism correspond to inter-node and intra-node on the PO-DAG, respectively. To exploit intra-node, fine-grained parallelism, the MDR framework resorts to TBB and CUDA, for multi-core CPU-chips and GPU boards. Empirical performance models are used to estimate the execution time of each kernel, whereas the communication modeling is based on analytical models.
In their paper, the MDR’s authors detailed each criteria in the SLAC set:
- Suitability is considered a first-order effect, and is reported as based on the execution
time of each kernel on a CU; a kernel is thus better suited to PEi than a PEj if the
expected run-time on PEj is less than the one expected on PEj.
- Locality is based on the data locality/placement on the system, since each kernel’s execution time is not purely determined by its execution time but also the time required to move the associated data between different memory spaces.
- Availability of a PE is based on the estimated time for a PE to become free; as pointed out by the authors and also already considered, the availability allows one to address two scenarios: when a CU is free but a better scheduling decision would be to wait for another specific CU to schedule the task to it, and when it is a better decision to
schedule a task for a CUj even when its suitability is better on a CUi.
- Critically is based on the impact of the execution of one kernel in the overall execution time application.
Computational tasks on a critical path particularly increase the execution time of one application, when scheduled for a different CU than their preferable one. When using a DAG, the critical path is related with the graph’s structure, in addition to computation and