Universidade Federal do Cear´
a
Centro de Tecnologia
Departamento de Teleinform´
atica
Programa de P´
os-Gradua¸c˜
ao em Engenharia de Teleinform´
atica
UM MODELO DE DIAGN ´
OSTICO DISTRIBU´IDO E HIER´
ARQUICO
PARA TOLERˆ
ANCIA A ATAQUES DE MANIPULAC
¸ ˜
AO DE
RESULTADOS EM GRADES COMPUTACIONAIS
Felipe Sampaio Martins
DISSERTAC
¸ ˜
AO DE MESTRADO
Universidade Federal do Cear´
a
Centro de Tecnologia
Departamento de Teleinform´
atica
Felipe Sampaio Martins
UM MODELO DE DIAGN ´
OSTICO DISTRIBU´IDO E
HIER´
ARQUICO PARA TOLERˆ
ANCIA A ATAQUES DE
MANIPULAC
¸ ˜
AO DE RESULTADOS EM GRADES
COMPUTACIONAIS
Trabalho apresentado ao Programa de Programa de P´ os-Gradua¸c˜ao em Engenharia de Teleinform´atica do Depar-tamento de Teleinform´atica da Universidade Federal do Cear´a como requisito parcial para obten¸c˜ao do grau de Mestre em Engenharia de Teleinform´atica.
Orientador: Prof. Jos´e Neuman de Souza, DSc
Co-orientadores: Prof. Rossana M. de C. Andrade, PhD. e Prof. Aldri Luiz dos Santos, DSc.
M343m Martins, Felipe Sampaio
Um modelo de diagnóstico distribuído e hierárquico para tolerância a ataques de manipulação de resultados em grades computacionais / Felipe Sampaio Martins
113.:il.
Dissertação (Mestrado) Universidade Federal do Ceará, Centro de Tecnologia, Departamento de Teleinformática, Fortaleza-CE, 2006.
Orientador: Prof. José Neuman de Souza
1. Teleinformática 2. Redes e sistemas distribuídos. I.Título. II Orientador.
AGRADECIMENTOS
Gostaria de agradecer primeiramente aos meus professores orientadores Prof. Neuman, pela paciˆencia e seriedade com a qual me conduziu nessa empreitada; a Profa. Rossana, que me acolheu, me abriu as portas e tem investido em mim, uma mulher correta, per-severante e dona de suas pr´oprias conquistas; e ao Prof. Aldri, pela sua aten¸c˜ao nos momentos em que compartilhamos id´eias e pela pronta disposi¸c˜ao e motiva¸c˜ao que nele encontrei durante esse per´ıodo. Com vocˆes, Professores, aprendi o significado da palavra Mestre. Muito obrigado mesmo a todos vocˆes.
Aos professores Javam, Riverson, Miguel, Mauro e Jerffeson, membros do GREaT (Grupo de Redes de Computadores, Engenharia de Softwares e Sistemas), onde tive a oportuni-dade de trocar experiˆencias, al´em de cultivar amizades inesquec´ıveis. Muito obrigado a vocˆes todos, em especial, Lincoln, Fl´avio, Rute, Diana e Marcos.
Aos mais que colegas de trabalho do CENAPAD-NE (Centro Nacional de Processamento de Alto Desempenho no Nordeste): Bringel, pelo exemplo de car´ater e retid˜ao dado nesse per´ıodo de convivˆencia, Jo˜ao Marcelo, pelas risadas e descontra¸c˜ao no dia a dia, e ao Marcio Maia, cuja participa¸c˜ao foi decisiva na reta final do trabalho e une-se agora ao grupo, trazendo sua experiˆencia e alegria.
A Marcus Rodrigues, Moacyr Regys, Janine Costa e todos os ex-companheiros do LAR (Laborat´orio Multiinstitucional de Redes e Sistemas) do CEFET-CE, onde fui despertado para a pesquisa cient´ıfica.
Aos professores Walfredo, Fubica e todos do LSD (Laborat´orio de Sistemas Distribu´ıdos) na Universidade Federal de Campina Grande, sempre dispostos e receptivos nas dis-cuss˜oes. Aos professores Elias e Albini da Universidade Federal do Paran´a que leram os primeiros esbo¸cos da id´eia e me motivaram ainda mais para seguir em frente. Aos professores Heron e Helano da Universidade Federal do Cear´a, que me ofereceram cr´ıticas positivas que s´o vieram para melhorar este trabalho. Agrade¸co tamb´em a professora Mi-chele Nogueira que me socorreu com aten¸c˜ao e presteza em momentos de desespero.
A Jacinta Pereira, que, apesar do pouco contato, foi ´otima e essencial para o sucesso dos artigos aprovados.
AGRADECIMENTOS iv Aos meus amigos das noites (Adson, Alexandre, Aline, Ayla, Carla, Cot´o, Daniel, Denise, Edson, Eduardo, Elo´ıse, Emanuel, George, Gorete, Joelma, Josu´e, Juliana, Kelly, Leo-nardo, Manu, M´arcia, Marcus F´abio, Marley, Marquinhos, Saulo, S´ergio, Rafael, Renati-nha, Rob´erio, Thais, Ti˜ao, Tici, Ticiano e Wagner), que fizeram das situa¸c˜oes dram´aticas momentos felizes.
Ao Wraculles, amigo inspirador de todas as horas, sempre disposto a levantar o astral. A Adriana, minha amiga. Vocˆe me deu for¸cas e gra¸cas a vocˆe c´a estou.
A Larry Page e Sergey Brin.
A minha fam´ılia, em especial a minha querida av´o Jacyara, um exemplo de vida e de-dica¸c˜ao. Sou o que sou por sua causa, v´o.
A FUNCAP (Funda¸c˜ao Cearense de Apoio ao Desenvolvimento Cient´ıfico e Tecnol´ogico) pelo apoio financeiro sem o qual esse trabalho n˜ao teria sido poss´ıvel.
Se n˜ao tivesse o amor
Se n˜ao tivesse essa dor
E se n˜ao tivesse o sofrer
E se n˜ao tivesse o chorar
Melhor era tudo se acabar
RESUMO
A seguran¸ca da informa¸c˜ao em grades computacionais envolve requisitos que v˜ao al´em dos estabelecidos para as redes convencionais. Tratando-se especificamente de Integridade, a maioria das solu¸c˜oes existentes resolve essa quest˜ao apenas no escopo de transmiss˜ao, garantindo a n˜ao-viola¸c˜ao dos dados durante a comunica¸c˜ao entre as m´aquinas. Todavia, ´e preciso tamb´em garantir a integridade dos dados durante o seu processamento, de modo que os resultados das tarefas (jobs) processados em uma grade n˜ao sofram qualquer altera¸c˜ao indevida. De outra forma, a manipula¸c˜ao de resultados compromete a aplica¸c˜ao como um todo, incidindo num alto custo em termos de desempenho.
Para evitar que usu´arios obtenham resultados incorretos em virtude de elementos maliciosos, esta disserta¸c˜ao prop˜oe um modelo de diagn´ostico para tolerˆancia a falhas de seguran¸ca em grades computacionais de larga escala, abordando a verifica¸c˜ao de integri-dade na execu¸c˜ao dosjobs. Desta forma, ´e poss´ıvel excluir as unidades de processamento (n´os) de m´a conduta interessadas em comprometer as aplica¸c˜oes, oferecendo, portanto, um ambiente de computa¸c˜ao de alto desempenho formado apenas por n´os confi´aveis.
A utiliza¸c˜ao de diagn´ostico em n´ıvel de sistema como estrat´egia contra ataques de manipula¸c˜ao de resultados de jobs mostra-se uma solu¸c˜ao eficaz, visto que independe das plataformas de hardware utilizadas e ´e interoper´avel com solu¸c˜oes de seguran¸ca locais, o que viabiliza seu emprego na maioria das middlewares de grades computacionais. Al´em disso, o modelo de diagn´ostico aqui apresentado organiza os n´os em clusters l´ogicos, estabelecendo assim uma hierarquia entre os mesmos, de acordo com o papel de cada n´o (executor, testador ou ultra-confi´avel), atribu´ıdo segundo seu hist´orico comportamental no ambiente. Essa abordagem permite que o diagn´ostico seja feito de forma distribu´ıda com a participa¸c˜ao dos n´os que possuem um n´ıvel m´ınimo de confiabilidade.
Para validar esta estrat´egia, uma nova camada de seguran¸ca foi implementada em um simulador de grades, a fim de introduzir as asser¸c˜oes e os comportamentos descritos no modelo proposto. Os resultados obtidos atestam a sua efic´acia em cen´arios com diferentes taxas de n´os mal intencionados, oferecendo um ´ındice de detec¸c˜ao de 100% e acur´acia de 99,7% dos jobs processados, com 12,3% de custo de processamento.
ABSTRACT
Information security in grid computing involves requirements that go beyond the tradi-tional networks. Concerning specifically Integrity, most of existing solutions deal with it only during data transmission, ensuring non-violation of data in the communication between machines. Nevertheless, it is also necessary to guarantee data integrity during its processing, so that jobs results must not suffering any improper handling. Otherwise, the results manipulation compromises the application as a whole, also causing a high processing overhead.
In order to avoid that grid users obtain uncorrected results due to malicious elements, this work proposes a diagnosis model for tolerating security faults in large-scale computational grids, considering the integrity verification during job processing. In this way, it is possible to exclude those misbehaving processing units (nodes) interested in damaging the execution of processes, providing thus a high performance computing environment only formed by reliable nodes.
The usage of system-level diagnosis as a strategy against jobs results manipu-lation attacks reveals itself an efficient solution, since it does not depend on the hard-ware platform and it is interoperable with security local solutions. This feature allows the employment of the proposed model at the majority of grid computing middlewares. Furthermore, the proposed diagnosis model organizes the nodes into logical clusters, esta-blishing a hierarchy among them, in accordance to the role of each node (executor, tester or ultra-reliable), assigned through its historical behavior in the environment. This ap-proach enables diagnosis to be made in a distributed way with the participation of nodes that provide an expected degree of confidence.
To validate this strategy, a new security layer was implemented in a grid simulator in order to introduce the assertions and the behaviors described in the proposed model. The results testify the effectiveness of the model at scenarios with different quotas of malicious nodes, providing a rate of detection of 100% and accuracy of 99,7% of processed jobs, with 12,3% of overhead.
SUM´
ARIO
Cap´ıtulo 1—Introdu¸c˜ao 1
1.1 Caracteriza¸c˜ao do Problema e Motiva¸c˜ao . . . 1
1.2 Objetivo e Contribui¸c˜ao . . . 3
1.3 Trabalhos Relacionados . . . 3
1.4 Estrutura da Disserta¸c˜ao . . . 7
Cap´ıtulo 2—Grades Computacionais 8 2.1 As Grades e os Servi¸cos de Alto Desempenho . . . 8
2.2 Arquiteturas de Processamento de Alto Desempenho . . . 11
2.3 Aspectos da Implementa¸c˜ao de Arquiteturas de Grade . . . 13
2.3.1 Descoberta de Servi¸cos . . . 14
2.3.2 Escalonamento de Aplica¸c˜oes . . . 15
2.3.3 Autentica¸c˜ao e Autoriza¸c˜ao . . . 17
2.3.4 Prote¸c˜ao dos Recursos e Aplica¸c˜oes . . . 18
2.4 Seguran¸ca em Grades . . . 19
2.4.1 Seguran¸ca no Globus Toolkit . . . 20
2.4.2 Seguran¸ca no OurGrid . . . 22
SUM ´ARIO ix
Cap´ıtulo 3—Diagn´ostico em N´ıvel de Sistema 25
3.1 Tipos de Falhas . . . 25
3.2 Classifica¸c˜ao de N´os com Mau Comportamento . . . 26
3.3 Confiabilidade e Seguran¸ca . . . 26
3.4 T´ecnicas para Verifica¸c˜ao de Integridade de Processamento . . . 27
3.5 Diagn´ostico . . . 29
3.5.1 Modelo PMC . . . 30
3.5.2 Algoritmo Adaptative-DSD . . . 32
3.5.3 Algoritmo Hi-ADSD . . . 33
3.5.4 Modelos Baseados em Compara¸c˜oes . . . 34
3.6 Diagn´ostico em Grades . . . 36
3.7 Conclus˜ao . . . 38
Cap´ıtulo 4—Um Modelo para Diagn´ostico em Grades 39 4.1 Caracter´ısticas do Modelo . . . 39
4.2 Especifica¸c˜ao . . . 40
4.3 Opera¸c˜ao de Diagn´ostico . . . 43
4.4 C´alculo da Reputa¸c˜ao . . . 46
4.5 Reconfigura¸c˜ao de Clusters . . . 48
4.6 Conclus˜ao . . . 49
Cap´ıtulo 5—Avalia¸c˜ao do Modelo 51 5.1 Caracteriza¸c˜ao da Simula¸c˜ao . . . 51
SUM ´ARIO x
5.1.2 Parˆametros Utilizados na Simula¸c˜ao . . . 52
5.2 Cen´arios Estudados . . . 53
5.2.1 Cen´ario sem Esquema de Reputa¸c˜ao . . . 53
5.2.2 Cen´ario com Esquema de Reputa¸c˜ao . . . 61
5.3 Conclus˜ao . . . 71
Cap´ıtulo 6—Conclus˜oes 73 6.1 Contribui¸c˜oes e Resultados . . . 73
6.2 Trabalhos Futuros . . . 74
Apˆendice A—Simuladores de Grades 86 A.1 OptorSim . . . 86
A.2 GridNet . . . 86
A.3 MicroGrid . . . 87
A.4 SimGrid . . . 87
A.5 GridSim . . . 88
A.6 Compara¸c˜ao Entre Simuladores . . . 88
Apˆendice B—Programa de Simula¸c˜ao 90 B.1 Execu¸c˜ao de uma Rodada de Testes . . . 90
B.2 Verifica¸c˜ao de uma Rodada de Testes . . . 91
B.3 Pesquisa por Padr˜ao de Comportamento do Testador . . . 92
B.4 Verifica¸c˜ao e Eleva¸c˜ao do Status dos N´os . . . 93
LISTA DE ABREVIATURAS
ACL - Access Control List
ADSD - Adaptative Distributed System-Level Diagnosis API - Application Program Interface
BoT - Bag-of-Tasks
CA - Certificate Authority CPU - Central Processing Unit FIFO - First In First Out
GSI - Globus Security Infrastructure GSS - Generic Security Services
Hi-ADSD - Hierarchical Adaptative Distributed System-Level Diagnosis HTC - High-Throughput Computing
HTTP - Hyper Text Transfer Protocol JVM - Java Virtual Machine
MM - Maeng, Malek
MPP - Massively Parallel Processors NoW - Network of Workstations NS - Network Simulator
P2P - Peer-to-Peer
LISTA DE ABREVIATURAS xii SOAP - Simple Object Access Protocol
SSL - Secure Socket Layer UC - Ultra-Confi´avel
UDDI - Universal Description, Discovery and Integration VO - Virtual Organizations
WQR - Workqueue with Replication
LISTA DE FIGURAS
2.1 Representa¸c˜ao da topologia de clusters . . . 8
2.2 VOs intercontinentais . . . 9
2.3 Grade de servi¸cos . . . 10
2.4 Arquitetura SMP . . . 11
2.5 Arquitetura MPP . . . 12
2.6 Arquitetura NoW . . . 12
2.7 Arquitetura de uma grade computacional de larga escala . . . 13
2.8 Descoberta dinˆamica de servi¸cos via Web Services . . . 15
2.9 Assinatura digital no GSI . . . 21
2.10 T´ecnica Sandbox . . . 23
3.1 Voto majorit´ario com 6 n´os fornecedores de recursos . . . 28
3.2 Poss´ıvel s´ındrome para um sistema baseado em testes distribu´ıdos . . . . 30
3.3 Exemplo de grafo do sistema e grafo de testes para 4 n´os . . . 31
3.4 Grafo de testes no ADSD . . . 32
3.5 Divis˜ao de clusters no Hi-ADSD . . . 33
3.6 Funcionamento do modelo MM . . . 35
3.7 Funcionamento do modelo de Compara¸c˜oes Generalizado . . . 35
LISTA DE FIGURAS xiv
4.1 Eleva¸c˜ao de status dos n´os . . . 41
4.2 Estrat´egia de testes aplicados aos n´os da grade . . . 43
5.1 Estrat´egia de diagn´ostico sem reputa¸c˜ao . . . 54
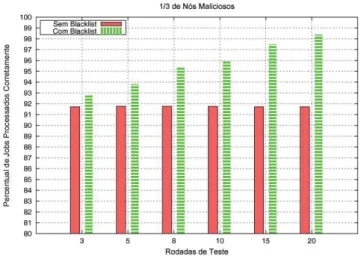
5.2 Acur´acia obtida com 1/6 dos n´os maliciosos . . . 55
5.3 Acur´acia obtida com 1/3 dos n´os maliciosos . . . 55
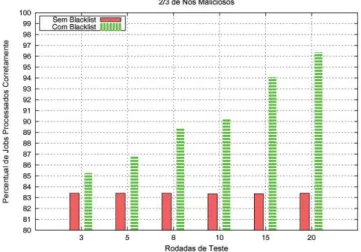
5.4 Acur´acia obtida com 2/3 dos n´os maliciosos . . . 56
5.5 Quantidade de n´os inseridos na blacklist . . . 57
5.6 N´os maliciosos detectados com 1/6 da grade comprometida . . . 58
5.7 N´os maliciosos detectados com 1/3 da grade comprometida . . . 58
5.8 N´os maliciosos detectados com 2/3 da grade comprometida . . . 59
5.9 Custo introduzido com 1/6 dos n´os maliciosos . . . 60
5.10 Custo introduzido com 1/3 dos n´os maliciosos . . . 60
5.11 Custo introduzido com 2/3 dos n´os maliciosos . . . 61
5.12 N´os inseridos na blacklist com 1/6 de maliciosos . . . 64
5.13 N´os inseridos na blacklist com 1/3 de maliciosos . . . 64
5.14 N´os inseridos na blacklist com 2/3 de maliciosos . . . 65
5.15 N´os maliciosos detectados com rodada de testes a cada 6h . . . 66
5.16 N´os maliciosos detectados com rodada de testes a cada 12h . . . 66
5.17 N´os maliciosos detectados com rodada de testes a cada 24h . . . 67
5.18 N´os maliciosos remanescentes com rodada de testes a cada 6h . . . 67
5.19 N´os maliciosos remanescentes com rodada de testes a cada 12h . . . 68
5.20 N´os maliciosos remanescentes com rodada de testes a cada 24h . . . 68
LISTA DE FIGURAS xv
LISTA DE TABELAS
3.1 Unidades testadoras falhas emitem resultados indeterminados . . . 30
4.1 Determina¸c˜ao de status dos n´os . . . 47
4.2 O vetor identifica o estado dos n´os em cada cluster . . . 49
5.1 N´os maliciosos detectados no pior e no melhor caso . . . 59
5.2 Valores para eleva¸c˜ao de status . . . 62
CAP´ITULO 1
INTRODUC
¸ ˜
AO
Esta disserta¸c˜ao apresenta um modelo de diagn´ostico para verifica¸c˜ao de integridade de resultados de tarefas (jobs) submetidas a um ambiente de grade computacional. Este modelo visa prover um eficiente mecanismo de tolerˆancia a ataques de manipula¸c˜ao, seja em plataformas de grades fechadas (e.g., Globus Toolkit) ou abertas (e.g., OurGrid), evi-tando a presen¸ca de elementos (n´os) maliciosos interessados em invalidar ou corromper o resultado dos jobs. Assim, atrav´es da detec¸c˜ao de manipula¸c˜ao maliciosa de resulta-dos, o modelo proposto permite que n´os mal intencionados sejam isolados da grade, n˜ao comprometendo o processamento das aplica¸c˜oes como um todo.
Neste cap´ıtulo, s˜ao apresentadas a justificativa e a motiva¸c˜ao para o desenvol-vimento desta disserta¸c˜ao, bem como os objetivos e as contribui¸c˜oes que se pretende alcan¸car. Em seguida, s˜ao discutidos os trabalhos relacionados nas ´areas de seguran¸ca em grades, sistemas de reputa¸c˜ao, diagn´ostico em n´ıvel de sistema e tolerˆancia a falhas em grades. Por fim, ´e dada uma descri¸c˜ao de como est´a organizado o restante desta disserta¸c˜ao.
1.1 CARACTERIZAC¸ ˜AO DO PROBLEMA E MOTIVAC¸ ˜AO
1.1. Caracteriza¸c˜ao do Problema e Motiva¸c˜ao 2
O provimento de seguran¸ca nas redes tradicionais envolve a utiliza¸c˜ao de meca-nismos que, em geral, impedem o acesso n˜ao autorizado de usu´arios e provˆeem sigilo e integridade dos dados transmitidos [2, 3]. No contexto da computa¸c˜ao em grade, a ado¸c˜ao de tais mecanismos ´e mais complexa, em virtude da intr´ınseca natureza heterogˆenea do ambiente, que incorpora requisitos de seguran¸ca diversos.
Al´em disso, deve-se considerar que as grades podem ser formadas por diferentes redes, com diferentes dom´ınios administrativos e, por conseg¨uinte, diferentes pol´ıticas de seguran¸ca. Desta maneira, garantir a seguran¸ca da informa¸c˜ao em ambientes deste tipo envolve novos requisitos, sendo assim uma tarefa complexa.
Tais requisitos tˆem sido atendidos e tratados de diferentes formas na literatura. Algumas solu¸c˜oes propostas visam, por exemplo, garantir confidencialidade e integridade na comunica¸c˜ao entre os elementos de rede que comp˜oem a grade [4, 5]. O controle de acesso aos recursos tamb´em tem sido bastante estudado [6, 7]. No que diz respeito `a integridade da informa¸c˜ao, a maioria dos trabalhos tˆem tratado essa quest˜ao apenas no ˆambito da transmiss˜ao, garantindo a n˜ao-viola¸c˜ao dos dados durante a comunica¸c˜ao entre as m´aquinas [8, 9].
Todavia, para oferecer seguran¸ca em grades ´e necess´ario tamb´em garantir a in-tegridade dos dados durante o seu processamento, de forma que os resultados dos jobs
processados em uma grade n˜ao devem sofrer qualquer altera¸c˜ao indevida. Logo, uma infra-estrutura deste porte precisa certificar-se de que as m´aquinas que comp˜oem a grade n˜ao s˜ao constitu´ıdas porhosts maliciosos interessados em invalidar ou corromper o resul-tado de umjob. Do contr´ario, a manipula¸c˜ao de resultados pode comprometer o processo como um todo, al´em de incidir num alto custo em termos de desempenho.
1.2. Objetivo e Contribui¸c˜ao 3
1.2 OBJETIVO E CONTRIBUIC¸ ˜AO
Este trabalho prop˜oe um modelo de diagn´ostico para tolerˆancia a falhas de seguran¸ca em grades computacionais de larga escala, abordando a verifica¸c˜ao de integridade na execu¸c˜ao dosjobs processados. O objetivo do modelo consiste em garantir a validade dos resultados dos jobs procesados e excluir os n´os de m´a conduta que estejam interessados em prejudicar a execu¸c˜ao dos processos e, desta forma, comprometer o desempenho das aplica¸c˜oes em grade.
A solu¸c˜ao aplica o paradigma de tolerˆancia a falhas no dom´ınio da seguran¸ca, `a medida que prop˜oe um modelo de diagn´ostico em n´ıvel de sistema, mediante uma abordagem distribu´ıda e hier´arquica para verifica¸c˜ao de integridade na execu¸c˜ao dos
jobs. Distribu´ıda porque o diagn´ostico ´e realizado por todos os n´os do sistema com o n´ıvel m´ınimo de confiabilidade requerido para tal, e hier´arquico porque os pap´eis dos n´os s˜ao atribu´ıdos de acordo com a reputa¸c˜ao adquirida atrav´es dos seus comportamentos dentro do ambiente.
A principal contribui¸c˜ao do modelo apresentado ´e a aplica¸c˜ao de t´ecnicas de to-lerˆancia a falhas de seguran¸ca para detec¸c˜ao de ataques de manipula¸c˜ao dos resultados dos jobs em grades computacionais. Este modelo pode ser integrado `as principais plata-formas de grades, tais como Globus [10] e OurGrid [11].
Para sua valida¸c˜ao, o modelo ´e submetido a uma ferramenta de simula¸c˜ao de ambientes de grades chamada GridSim, onde cen´arios representativos s˜ao avaliados a fim de determinar sua eficiˆencia e robustez. Assim, uma contribui¸c˜ao secund´aria ´e a extens˜ao do simulador de grades utilizado, visto que novos m´etodos foram incorporados, a fim de suportar os mecanismos empregados no modelo proposto.
1.3 TRABALHOS RELACIONADOS
sobre-1.3. Trabalhos Relacionados 4
carga, bugs de firmware, interrup¸c˜ao da comunica¸c˜ao e bad blocks de discos, excluindo, portanto, falhas de natureza intencionalmente maliciosas.
J´a em Duarte et al [13], os autores prop˜oem um mecanismo para identifica¸c˜ao das causas das falhas em ummiddleware de grade. Assim, atrav´es de uma abordagem baseada em diagn´ostico, pode-se conhecer os motivos que levaram determinados componentes de
software ao mau funcionamento e ent˜ao descobrir se as falhas sinalizadas por aquele componente foram originadas realmente por ele ou por um outro componente que lhe oferece algum servi¸co.
Um algoritmo para verifica¸c˜ao de integridade em grades ´e apresentada em Santos et al [14]. O Anti-Doping, como os seus autores o chamam, consiste em uma s´erie de testes executados por cada unidade de processamento provedora de recurso. O diagn´ostico ob-tido pelos testes pode ser utilizado para gerenciar informa¸c˜oes sobre os recursos dossites. O resultado dos testes ´e disponibilizado no formato XML para que cada administrador desite conhe¸ca o grau de confiabilidade de suas m´aquinas. Esta abordagem, no entanto, foi idealizada especificamente para a grade OurGrid e n˜ao chegou a ser implementada nem simulada.
Ainda tratando-se de tolerˆancia a falhas, um algoritmo de diagn´ostico tamb´em ´e apresentado em Caruso et al [15] para conhecer quais as unidades de processamento que est˜ao falhas em um sistema em grade. Entretanto, este trabalho considera como grade uma plataforma de hardware com diversos processadores interligados em malha, ou seja, n˜ao h´a heterogeneidade nem alta dispers˜ao geogr´afica e, portanto, os resultados dosjobs
n˜ao est˜ao sujeitos a ataques de manipula¸c˜ao.
Albini [16] prop˜oe um algoritmo para diagn´ostico de eventos baseado em com-para¸c˜oes, chamado Hi-Comp. Nessa proposta, um n´o envia uma tarefa para dois de seus filhos (n´os que possuem liga¸c˜ao direta) e ap´os receber os resultados, repete o processo para outros dois filhos, at´e que tenha passado por todos os n´os filhos. Ao diagnosticar um filho, o n´o testador tamb´em obt´em informa¸c˜oes de diagn´ostico do cluster ao qual o filho pertence. Embora o Hi-Comp seja capaz de diagnosticar outros tipos de falhas al´em decrash, ele assume que os n´os testadores sem-falhas informam resultados confi´aveis.
1.3. Trabalhos Relacionados 5
ambos podem qualificar um ao outro de maneira positiva, negativa ou neutra, de tal forma que a soma das qualifica¸c˜oes recebidas determina a reputa¸c˜ao do usu´ario. Neste sistema, o armazenamento e gerenciamento das qualifica¸c˜oes s˜ao comumente centraliza-dos, acarretando em problemas t´ıpicos desta arquitetura, como por exemplo, ponto ´unico de falha e gargalo no desempenho.
Em ambientes distribu´ıdos, como os sistemas Peer-to-Peer (P2P) para comparti-lhamento de arquivos, mecanismos de atribui¸c˜ao e verifica¸c˜ao de reputa¸c˜ao tˆem sido cada vez mais empregados, com o intuito de minimizar a presen¸ca de peers (pares) maliciosos interessados em difundir arquivos falsos ou incompletos, ou mesmo v´ırus e worms. As-sim, o esquema de reputa¸c˜ao permite que os pares participantes possam obter informa¸c˜ao confi´avel para o download de arquivos (recursos) de qualidade.
Nesse sentido, protocolos tˆem sido propostos para identificar pares maliciosos em ambientes P2P, tais como [18, 19, 20, 21]. Em geral, estas abordagens baseiam-se em certos crit´erios para estabelecer n´ıveis de confian¸ca `as entidades envolvidas, provendo assim uma informa¸c˜ao adicional que poder´a ser ´util ao usu´ario antes de realizar odownload
desejado. A informa¸c˜ao de reputa¸c˜ao de um par ´e dada a partir das suas intera¸c˜oes com a rede.
Em Kamvar et al [18], o algoritmo EigenTrust computa um valor de confian¸ca de um par com base nas opini˜oes dos demais pares que interagiram com ele, assumindo transitividade nas opini˜oes. Em Aberer et al [19], o protocolo proposto mant´em apenas informa¸c˜oes de feedbacks negativos que condenam a participa¸c˜ao do par, onde ele ´e sim-plesmente classificado em dois n´ıveis (confi´avel ou n˜ao-confi´avel). A proposta de Cornelli et al [20], chamada P2PRep, visa estimar a confian¸ca de um dado par na rede Gnutella, a partir de vota¸c˜ao entre os participantes. No entanto, al´em de necessitar de uma estrutura criptogr´afica para verificar as identidades dos pares, o trabalho n˜ao evidencia claramente as m´etricas utilizadas para o c´alculo da reputa¸c˜ao. O XRep, apresentado por Damiani et al [21], ´e uma extens˜ao do P2PRep que associa um valor de reputa¸c˜ao tanto para os pares quanto para os recursos. O XRep tamb´em utiliza vota¸c˜ao, mas tanto os votos dos pares confi´aveis quanto os dos n˜ao-confi´aveis tˆem o mesmo peso. Al´em disso, assim como as demais propostas, o XRep n˜ao leva em conta o tempo de vida dos pares no ambiente de rede.
1.3. Trabalhos Relacionados 6
ou usu´ario, ou seja, qual o n´ıvel de qualidade e confiabilidade no processamento de um resultado oferecido.
Em Sarmenta [22], o autor prop˜oe um esquema baseado na credibilidade para, atrav´es de c´alculos probabil´ısticos e combina¸c˜ao de t´ecnicas de tolerˆancia a falhas, ofe-recer prote¸c˜ao contra usu´arios maliciosos em um ambiente de computa¸c˜ao volunt´aria. Nesta abordagem, o cliente envia cada job a ser executado para diferentes unidades de processamento at´e que pelo menos um determinado n´umero m de resultados devolvidos sejam coincidentes. Atrav´es da compara¸c˜ao entre eles, a validade do resultado ´e atestada. Assim, as unidades de processamento provedoras de recursos ganham mais confian¸ca `a medida que agem corretamente no ambiente. Uma outra possibilidade de aplica¸c˜ao de testes, ´e o envio peri´odico de tarefas cujos resultados s˜ao previamente conhecidos para provar o comportamento das unidades de processamento.
Essa t´ecnica, tamb´em conhecida como verifica¸c˜ao focalizada, assemelha-se `as abordagens encontradas em trabalhos como Casale et al [23] e Zhao et al [24]. No entanto, todas estas solu¸c˜oes s˜ao essencialmente centralizadas, o que ocasiona um custo para o
host gerente respons´avel pelos testes, tendo em vista que todo job de teste tamb´em ´e processado pelo gerente. No caso da verifica¸c˜ao baseada em replica¸c˜ao, ´e observado um alto overhead e desperd´ıcio de recursos, `a medida que os mesmos jobs s˜ao entregues a, no m´ınimo, m unidades de processamento.
A grade OurGrid tamb´em utiliza o conceito de reputa¸c˜ao, mas em outro contexto. Nesse caso, a verifica¸c˜ao de reputa¸c˜ao ´e empregada para incentivar a doa¸c˜ao de recursos computacionais ociosos e minimizar a presen¸ca de usu´arios que apenas consomem recur-sos, sem colaborar com a comunidade. Desta forma, o OurGrid monta o que ´e chamado de Rede de Favores [25], onde cada par calcula uma reputa¸c˜ao local para cada outro par, a partir do total de favores que ele fez e recebeu no passado. Este c´alculo permite que os pares doadores dˆeem maior prioridade de execu¸c˜ao `as entidades que mais contribuem com os outros participantes. No OurGrid este sistema autˆonomo permite que os pares utilizem somente informa¸c˜ao local para priorizar seus consumidores, eliminando a necessidade de obter um valor global de reputa¸c˜ao, diferentemente dos sistemas de gerenciamento de reputa¸c˜ao anteriormente discutidos. Reputa¸c˜ao autˆonoma tem se mostrado, portanto, um mecanismo eficiente em grades computacionais.
partici-1.4. Estrutura da Disserta¸c˜ao 7
pantes. Em vez disso, cada par analisa a credibilidade dos demais integrantes da grade conforme suas intera¸c˜oes passadas com os mesmos, eliminando a necessidade de um pro-tocolo de obten¸c˜ao da informa¸c˜ao de reputa¸c˜ao de um par e a preocupa¸c˜ao com a validade da informa¸c˜ao obtida, j´a que a mesma encontra-se `a disposi¸c˜ao localmente.
Com a introdu¸c˜ao desse conceito de reputa¸c˜ao ´e poss´ıvel ainda tornar o modelo hier´arquico, dificultando a possibilidade de um n´o com boa reputa¸c˜ao n˜ao ser apanhado ao fornecer resultados corrompidos. Al´em disso, o modelo proposto permite uma sens´ıvel economia de recursos j´a que n˜ao h´a replica¸c˜ao de jobs entre os n´os.
1.4 ESTRUTURA DA DISSERTAC¸ ˜AO
Este trabalho est´a organizado da seguinte forma: no Cap´ıtulo 2, s˜ao abordados os prin-cipais conceitos envolvidos em grades computacionais, evidenciando aspectos e funciona-lidades como descoberta de servi¸cos, autentica¸c˜ao e autoriza¸c˜ao dos usu´arios, escalona-mento e prote¸c˜ao das aplica¸c˜oes e m´aquinas. Al´em disso, s˜ao investigados os requisitos e mecanismos de seguran¸ca oferecidos por diferentes plataformas, em especial o Globus e o OurGrid.
O Cap´ıtulo 3 trata dos conceitos envolvidos em tolerˆancia a falhas e modelos de diagn´ostico em n´ıvel de sistema, discutindo as vantagens e desvantagens de cada modelo apresentado. Tamb´em s˜ao apresentados os tipos de falhas encontradas em grades, as t´ecnicas para verifica¸c˜ao de integridade de processamento que podem ser aplicadas nestes ambientes e uma breve taxonomia de n´os com mau comportamento.
No Cap´ıtulo 4 s˜ao explanadas as caracter´ısticas e funcionalidades do modelo de diagn´ostico proposto, apresentando sua especifica¸c˜ao, a estrat´egia utilizada para a aplica¸c˜ao de testes no processo de diagn´ostico e o c´alculo do ´ındice de confiabilidade dos n´os.
A valida¸c˜ao do modelo realizada atrav´es de simula¸c˜ao, bem como os resultados obtidos, s˜ao apresentados no Cap´ıtulo 5.
CAP´ITULO 2
GRADES COMPUTACIONAIS
Neste cap´ıtulo s˜ao discutidas as caracter´ısticas pertinentes a um ambiente de grade com-putacional, destacando funcionalidades como descoberta e acesso aos servi¸cos, auten-tica¸c˜ao/autoriza¸c˜ao dos usu´arios, e prote¸c˜ao dos dados. Tamb´em s˜ao abordadas as tec-nologias que permitem a cria¸c˜ao de uma infra-estrutura de grade e as especifica¸c˜oes para sua padroniza¸c˜ao, bem como os requisitos e mecanismos de seguran¸ca oferecidos por duas das principais plataformas de grades, Globus Toolkit e OurGrid.
2.1 AS GRADES E OS SERVIC¸ OS DE ALTO DESEMPENHO
At´e meados da d´ecada passada, a computa¸c˜ao de alto desempenho era realizada somente atrav´es do uso de supercomputadores. Por tratar-se de uma arquitetura robusta, com diversos processadores e grande quantidade de mem´oria, a aquisi¸c˜ao destas m´aquinas possui custo elevado e muitas vezes invi´avel.
Como alternativa, surgiu a proposta de dispor um conjunto de processadores interconectados por uma rede de alta velocidade, formando o que se chamacluster. Desta forma, os processos s˜ao divididos em tarefas (jobs) que s˜ao distribu´ıdas entre as unidades de processamento fornecedoras de recursos (n´os). Uma arquitetura baseada em clusters
´e normalmente constitu´ıda por ambientes locais, onde as unidades encontram-se em um mesmo dom´ınio administrativo. Esta abordagem ´e ilustrada pela Figura 2.1, onde os n´os, controladas pelo mesmofront-end, s˜ao respons´aveis pela execu¸c˜ao dos jobs.
2.1. As Grades e os Servi¸cos de Alto Desempenho 9
A necessidade de uma distribui¸c˜ao mais ampla da computa¸c˜ao de alto desem-penho, utilizando inclusive recursos ociosos de m´aquinas independentes e remotas em v´arios dom´ınios, motivou a cria¸c˜ao de uma tecnologia que fornecesse uma infra-estrutura descentralizada e flex´ıvel para execu¸c˜ao de aplica¸c˜oes paralelas.
Esta nova modalidade de computa¸c˜ao distribu´ıda, conhecida como computa¸c˜ao em grade (grid computing), requer a agrega¸c˜ao, sele¸c˜ao e coordena¸c˜ao dos recursos com-putacionais envolvidos nos diversos dom´ınios, visando a solu¸c˜ao de problemas de uma dada institui¸c˜ao de forma colaborativa. Logo, a principal diferen¸ca entre a computa¸c˜ao em grades e os sistemas distribu´ıdos convencionais ´e que a primeira preocupa-se com o compartilhamento de recursos em larga escala orientado ao alto desempenho [1]. N˜ao importa que tais recursos estejam geograficamente separados; mas sim que estes mes-mos recursos possam ser acessados de maneira transparente, possibilitando a cria¸c˜ao de verdadeiras “Organiza¸c˜oes Virtuais”.
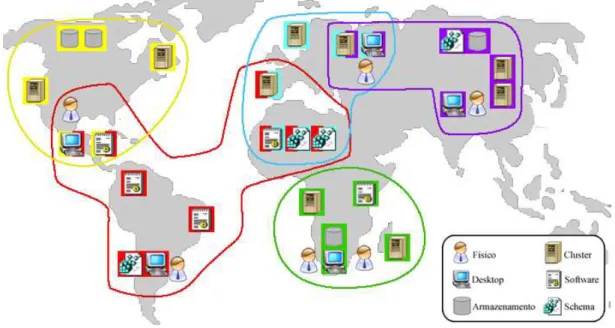
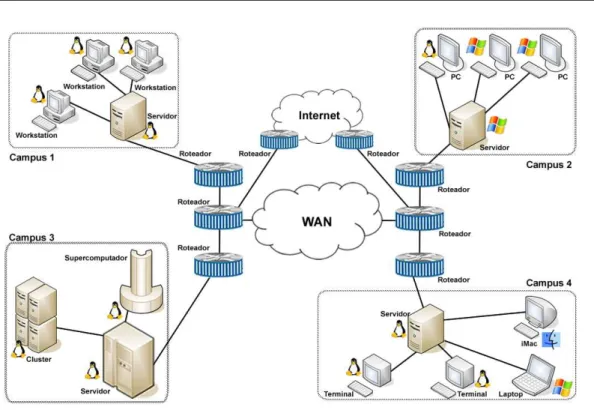
Sabendo que a computa¸c˜ao em grades aproveita-se dos diversos recursos pulveri-zados entre os diversos dom´ınios, o usu´ario membro de uma Organiza¸c˜ao Virtual (VO) constitu´ıda, por exemplo, de centros de computa¸c˜ao espalhados em universidades dos cinco continentes, pode submeter o seu problema computacional para a comunidade e, assim, utilizar os diferentes recursos de cada centro, permitindo, inclusive, o trabalho co-operativo entre os pesquisadores, como ilustrado na Figura 2.2, onde f´ısicos de diferentes institui¸c˜oes compartilham softwares, ciclos de CPU, espa¸co em disco e schemas.
2.1. As Grades e os Servi¸cos de Alto Desempenho 10
Em um n´ıvel mais alto de abstra¸c˜ao, as grades computacionais podem ser vistas como uma rede na qual o usu´ario se conecta a fim de obter servi¸cos computacionais que exigem recursos sob demanda para executar, de forma transparente, aplica¸c˜oes que tra-balham, por exemplo, com processamento de v´ıdeo, renderiza¸c˜ao de imagens e simula¸c˜oes f´ısico-qu´ımicas, como ilustrado a Figura 2.3.
Figura 2.3 Grade de servi¸cos
Pesquisas e implementa¸c˜oes tˆem sido realizadas e diversas grades, tais como Fu-sionGrid [26], GridPP [27] e GriPhyN [28], j´a est˜ao em produ¸c˜ao. Em paralelo ao seu desenvolvimento, as redes em grades tˆem despertado o interesse da comunidade cient´ıfica e da ind´ustria, posicionando-se como forte estrat´egia para a computa¸c˜ao em geral e n˜ao apenas para alto desempenho. Nos ´ultimos anos, grandes projetos como Globus Alliance [10] e TeraGrid [29] foram iniciados e aplica¸c˜oes vˆem sendo desenvolvidas para materia-lizar a vis˜ao das grades computacionais. Nesse sentido, a comunidade cient´ıfica tem se empenhado em estudos que visam a implementa¸c˜ao de sistemas complexos,frameworks e aplica¸c˜oes a partir da tecnologia em grades, tais como portaisweb [30, 31, 32], simula¸c˜ao de colis˜ao de buracos negros [33, 34], sistemas de tele-imers˜ao para visualiza¸c˜ao da qua-lidade da ´agua em ecossistemas [35], video-games interativos para m´ultiplos jogadores simultˆaneos [36], an´alise de conte´udo multim´ıdia [37], previs˜ao de cataclismos [38], entre outros.
2.2. Arquiteturas de Processamento de Alto Desempenho 11
Do ponto de vista de servi¸cos de seguran¸ca, falhas na especifica¸c˜ao das confi-gura¸c˜oes e pol´ıticas de acesso ao ambiente podem ser exploradas por usu´arios externos ou internos, a fim de obter acesso n˜ao autorizado aos recursos computacionais. Tais falhas nos sistemas em grade podem causar impacto em diferentes n´ıveis [39].
A seguir s˜ao discutidas a evolu¸c˜ao e as principais caracter´ısticas das arquiteturas existentes para o processamento de aplica¸c˜oes de alto desempenho.
2.2 ARQUITETURAS DE PROCESSAMENTO DE ALTO DESEMPENHO
No contexto de processamento de alto desempenho, as arquiteturas de execu¸c˜ao para aplica¸c˜oes paralelas podem diferir em diversos aspectos, tais como conectividade (atri-butos do canal de comunica¸c˜ao que interliga os processadores), heterogeneidade (dife-ren¸cas entre os processadores), escalabilidade (quantidade de processadores), entre ou-tros. Sendo assim, as arquiteturas de processamento paralelo podem ser classificadas em quatros grupos de acordo com essas caracter´ısticas [40].
O primeiro grupo ´e o SMP (Symmetric Multiprocessor), formado por m´aquinas multiprocessadas, cujas CPUs compartilham a mesma ´area de mem´oria e barramento, como ilustrado na Figura 2.4. Tal arquitetura ´e considerada fortemente acoplada, tendo em vista que se trata de processadores fisicamente pr´oximos e que interagem por meio de redes de comunica¸c˜ao de alta velocidade [41]. Embora esta forma de disposi¸c˜ao dos processadores apresente boa conectividade, ela possui limita¸c˜oes de escalabilidade, j´a que em geral ´e constitu´ıda por, no m´aximo, algumas poucas dezenas de processadores.
Figura 2.4 Arquitetura SMP
2.2. Arquiteturas de Processamento de Alto Desempenho 12
propriet´aria de alta velocidade e controladas por um escalonador de tarefas [42]. Tais m´aquinas s˜ao, portanto, altamente escal´aveis com suporte a in´umeros processadores, po-dendo chegar `a ordem de milhares, como no caso dos supercomputadores MPP de terceira gera¸c˜ao Cray XT3 [43].
Figura 2.5 Arquitetura MPP
No terceiro grupo, a arquitetura NoW (Network of Workstations), por sua vez, tamb´em agrega um conjunto de processadores independentes. No entanto, diferente-mente do MPP, em uma NoW cada unidade possui seu pr´oprio escalonador. Na verdade, uma arquitetura NoW ´e constitu´ıda por v´arias esta¸c˜oes de trabalho interligadas por uma rede tradicional (comumente Ethernet), como mostrado na Figura 2.6. Por esse motivo, as NoWs s˜ao consideradas arquiteturas fracamente acopladas. Essa disposi¸c˜ao “clusterizada” permite o uso de esta¸c˜oes de trabalho de prop´osito geral voltadas para a computa¸c˜ao de alto desempenho a um custo comparativamente baixo em rela¸c˜ao ao uso de supercomputadores.
Figura 2.6 Arquitetura NoW
2.3. Aspectos da Implementa¸c˜ao de Arquiteturas de Grade 13
Figura 2.7 Arquitetura de uma grade computacional de larga escala
Vale ressaltar que as caracter´ısticas arquiteturais de cada um dos grupos podem impactar no desempenho das aplica¸c˜oes. Por exemplo, uma aplica¸c˜ao paralela de alta granularidade (diversosjobs no mesmo contexto de uma tarefa, cooperando entre si) pode consumir maior tempo de execu¸c˜ao se submetida a uma arquitetura fortemente acoplada [41]. Al´em disso, ´e poss´ıvel afirmar que a evolu¸c˜ao das arquiteturas de processamento paralelo com vistas ao alto desempenho tem caminhado para uma maior distribui¸c˜ao dos componentes, agregando n˜ao s´o uma maior escalabilidade como tamb´em maior heteroge-neidade.
A se¸c˜ao seguinte aborda os aspectos fundamentais para implementa¸c˜ao de ar-quiteturas de grades, tais como descoberta de servi¸cos, escalonamento de aplica¸c˜oes e autentica¸c˜ao e autoriza¸c˜ao dos usu´arios.
2.3 ASPECTOS DA IMPLEMENTAC¸ ˜AO DE ARQUITETURAS DE GRADE
2.3. Aspectos da Implementa¸c˜ao de Arquiteturas de Grade 14
e coordena¸c˜ao do uso desses recursos compartilhados, a fim de solucionar problemas computacionais de determinadas Organiza¸c˜oes Virtuais.
Tendo em mente que as grades computacionais s˜ao plataformas de execu¸c˜ao para aplica¸c˜oes paralelas que congregam recursos dispersos geogr´afica e administrativamente [40], algumas arquiteturas tˆem sido criadas para a implementa¸c˜ao de grades, tais como Globus [10], Condor [44], Legion [45] e OurGrid [11]. Qualquer que seja a arquitetura de grade empregada, os servi¸cos computacionais oferecidos apresentam as seguintes carac-ter´ısticas [46]:
❼ heterogeneidade;
❼ alta dispers˜ao geogr´afica; ❼ compartilhamento de recursos; ❼ m´ultiplos dom´ınios administrativos; ❼ controle distribu´ıdo.
No entanto, o n˜ao-atendimento a algum desses aspectos n˜ao descaracteriza neces-sariamente uma determinada arquitetura como grade. Da mesma forma, cada arquitetura possui suas pr´oprias peculiaridades na maneira como implementa (ou n˜ao implementa) servi¸cos como escalonamento, contabiliza¸c˜ao e seguran¸ca. Assim, ao considerar as gra-des como arquiteturas orientadas a servi¸cos, certas funcionalidagra-des importantes para a implementa¸c˜ao dessas infra-estruturas devem ser abordadas, como explicado a seguir.
2.3.1 Descoberta de Servi¸cos
Uma grade pode se estender por diversos dom´ınios. Desta forma, a grade ´e fundamen-talmente uma grande inter-rede de dimens˜ao global, com caracter´ısticas dinˆamicas, onde os servi¸cos e recursos n˜ao s´o s˜ao heterogˆeneos como tamb´em extremamente vol´ateis, em vista do grande n´umero de entidades (e.g., usu´arios, esta¸c˜oes, recursos) que entram e saem do ambiente constantemente.
2.3. Aspectos da Implementa¸c˜ao de Arquiteturas de Grade 15
os usu´arios devem ser capazes de criar novos servi¸cos que possam interagir com outros servi¸cos, sem interven¸c˜ao do administrador [1]. A descoberta dinˆamica de servi¸cos pode ent˜ao ser vista como um meta-servi¸co, na medida em que permite que uma dada aplica¸c˜ao encontre os recursos e servi¸cos que atendam a sua demanda.
Nesse contexto, a tecnologia de Web Services tem sido cada vez mais empre-gada na cria¸c˜ao de arquiteturas de grades baseadas em servi¸cos [46], pois ela aproveita v´arios padr˜oes j´a estabelecidos, como o HTTP, e incorpora novos, como oUniversal Des-cription, Discovery and Integration (UDDI), o qual destina-se justamente `a descoberta dinˆamica de servi¸cos atrav´es da cria¸c˜ao de um cat´alogo global de todos os Web Services
compartilhados na Internet [46], como ilustrado na Figura 2.8.
Figura 2.8 Descoberta dinˆamica de servi¸cos via Web Services [47]
Inicialmente, o cliente utiliza o registro UDDI para conhecer quem ´e o servidor capaz de lhe prover um dado servi¸co X (passos 1 e 2). De posse da referˆencia para o servi¸co, o cliente comunica-se diretamente com o servidor respons´avel que disponibiliza um documento Web Services Description Language (WSDL), descrevendo os servi¸cos oferecidos e determinando como invoc´a-los (passos 3 a 6), atrav´es do protocolo Simple Object Access Protocol (SOAP).
2.3.2 Escalonamento de Aplica¸c˜oes
2.3. Aspectos da Implementa¸c˜ao de Arquiteturas de Grade 16
recursos, de tal forma que o escalonador precisa conhecer informa¸c˜oes sobre a grade e as aplica¸c˜oes em execu¸c˜ao. Em suma, ´e preciso conhecer as informa¸c˜oes de monitora¸c˜ao usa-das em previs˜oes de desempenho (quanto tempo cada tarefa consumir´a aquele recurso), o que n˜ao ´e f´acil, j´a que, segundo Santos Neto em [48], tais informa¸c˜oes s˜ao dinˆamicas e normalmente n˜ao se encontram dispon´ıveis no momento do escalonamento. O XSuffe-rage e Workqueue with Replication, discutidos a seguir, s˜ao exemplos de heur´ısticas de escalonamento aplicadas em grades.
O XSufferage ´e uma abordagem para escalonamento que ap´oia-se no conhecimento sobre o desempenho dos recursos [49]. Esta heur´ıstica de escalonamento d´a prioridade `as tarefas que seriam mais prejudicadas caso n˜ao fossem escalonadas, com base na diferen¸ca entre o melhor e o segundo melhor tempo de execu¸c˜ao previsto para cada tarefa em cada site. Desta maneira, a tarefa que apresentar maior diferen¸ca ter´a prioridade para ser escalonada no site que a executaria mais rapidamente [48]. Al´em disso, os dados de entrada utilizados para o c´alculo da diferen¸ca s˜ao reaproveitados no momento da aloca¸c˜ao de recursos, reduzindo o impacto de transferˆencias desnecess´arias. Por´em, para calcular a diferen¸ca o XSufferage precisa de informa¸c˜oes, como a carga da CPU, a largura de banda e os tempos de execu¸c˜ao de cada tarefa e, como mencionado anteriormente, essas informa¸c˜oes s˜ao de dif´ıcil obten¸c˜ao, tendo em vista a natureza dinˆamica das grades.
2.3. Aspectos da Implementa¸c˜ao de Arquiteturas de Grade 17
2.3.3 Autentica¸c˜ao e Autoriza¸c˜ao
Ao tornar os seus recursos dispon´ıveis, o administrador daquele dom´ınio pode impor res-tri¸c˜oes na maneira como e quando seus recursos ser˜ao utilizados por outrem. Da mesma forma, um consumidor de recursos pode querer, por exemplo, utilizar somente recur-sos certificados como seguros. Faz-se necess´ario, portanto, mecanismos que garantam a identidade de um consumidor ou recursos (autentica¸c˜ao) e que determinem se uma dada opera¸c˜ao solicitada ´e ou n˜ao v´alida (autoriza¸c˜ao).
Por tratar-se de um ambiente bastante disperso e heterogˆeneo, as grades possuem certos requisitos de seguran¸ca mais complexos se comparados `as redes tradicionais. No que diz respeito `a autentica¸c˜ao e autoriza¸c˜ao, as grades devem oferecer mecanismos que permitam [1]:
❼ Assinatura ´unica (Single sign-on): para ter acessos aos recursos da grade, os usu´arios devem realizar o login, isto ´e, autenticar-se somente uma vez;
❼ Delega¸c˜ao: um determinado programa executado pelo usu´ario deve poder acessar recursos os quais s˜ao autorizados para aquele usu´ario;
❼ Integra¸c˜ao com solu¸c˜oes locais: as solu¸c˜oes de seguran¸ca da grade devem interoperar com as solu¸c˜oes de seguran¸ca dos provedores cujos recursos est˜ao sendo utilizados; ❼ Relacionamentos de confian¸ca baseado no usu´ario: se um usu´ario tem direito a utilizar os recursos de dois provedores distintos, ele pode desejar fazˆe-lo simulta-neamente, sem necessidade de intera¸c˜ao entre os administradores de seguran¸ca dos provedores.
Para que cada dom´ınio mantenha sua pr´opria pol´ıtica local de autentica¸c˜ao e autoriza¸c˜ao, e ao mesmo tempo exporte um servi¸co para autentica¸c˜ao e autoriza¸c˜ao de usu´arios externos, as atuais iniciativas de grades tˆem utilizado certificados digitais e esquemas baseados em chaves p´ublicas e privadas [46].
2.3. Aspectos da Implementa¸c˜ao de Arquiteturas de Grade 18
2.3.4 Prote¸c˜ao dos Recursos e Aplica¸c˜oes
Para encorajar uma maior participa¸c˜ao e disponibiliza¸c˜ao dos recursos, ´e preciso dar ga-rantias aos fornecedores de que seus recursos computacionais n˜ao ser˜ao comprometidos, j´a que suas m´aquinas est˜ao expostas a uma aplica¸c˜ao desconhecida que poderia muito bem, por exemplo, destruir o sistema de arquivos ou mesmo congestionar a rede. Nesse sentido, mecanismos de prote¸c˜ao dos recursos tˆem sido desenvolvidos para garantir que uma dada aplica¸c˜ao n˜ao contenha c´odigo malicioso que venha a prejudicar o pleno funcionamento das m´aquinas.
Embora n˜ao haja uma padroniza¸c˜ao, a tendˆencia observada na literatura ´e criar uma ´area com sistema de arquivos, processos e recursos de rede isolados, sem poder acessar outros processos. Em outras palavras, um determinado processo confinado nessa ´area s´o poder´a acessar os outros processos, o sistema de arquivos e os recursos de rede que se encontram em sua pr´opria ´area. Essa abordagem, conhecida como virtualiza¸c˜ao [51], ´e adotada em t´ecnicas como o Sandbox [52], que al´em de limitar as poss´ıveis a¸c˜oes do c´odigo de um processo, impedindo que o mesmo cause danos a outros programas e aos arquivos do usu´ario, tamb´em evita o consumo exagerado dos recursos dispon´ıveis. De outro modo, a execu¸c˜ao dos processos locais da m´aquina fornecedora de recursos estaria comprometida. Como mencionado anteriormente, n˜ao h´a padroniza¸c˜ao para prote¸c˜ao dos recursos, mas diversas iniciativas vˆem adotando solu¸c˜oes semelhantes, como no caso do Projeto OurGrid, que possui uma solu¸c˜ao baseada no Sandbox, intitulada Swan [46].
A respeito das aplica¸c˜oes, para algumas ´e primordial que os dados trafegando na grade sejam mantidos sob sigilo, pois o acesso n˜ao autorizado a informa¸c˜oes confidenciais pode comprometer os resultados. Contudo, atender esse requisito de confidencialidade ´e uma tarefa bastante complexa, ainda mais tratando-se de um ambiente amplamente dinˆamico e distribu´ıdo como as grades.
Al´em disso, a possibilidade de manipula¸c˜ao indevida dos resultados obtidos com o processamento ´e outro aspecto a ser considerado, visto que se os processos e seus resultados forem corrompidos, a aplica¸c˜ao ir´a incorrer em um alto custo em termos de desempenho. Nesse caso, ´e necess´ario um esquema que garanta n˜ao s´o a privacidade dos dados que trafegam na grade, mas tamb´em a integridade dos processos e resultados obtidos, certificando-se que as m´aquinas que comp˜oem a grade n˜ao s˜ao constitu´ıdas por
2.4. Seguran¸ca em Grades 19
apesar de tamb´em n˜ao existir qualquer padroniza¸c˜ao nesse sentido.
2.4 SEGURANC¸ A EM GRADES
Seguran¸ca em redes de computadores requer, tradicionalmente, princ´ıpios de auten-tica¸c˜ao, controle de acesso, integridade, privacidade e n˜ao-rep´udio [3]. Contudo, as grades computacionais, por serem de natureza dinˆamica e heterogˆenea, possuem requisitos de seguran¸ca adicionais, tais como [54, 55]:
❼ Assinatura ´unica: o usu´ario deve se autenticar uma vez, a fim de obter, utilizar e liberar os recursos dispon´ıveis, sem que o mesmo tenha que se autenticar novamente; ❼ Uniformidade e prote¸c˜ao de credenciais: informa¸c˜oes como senhas e chaves privadas
devem estar protegidas e codificadas de maneira padr˜ao;
❼ Interoperabilidade com solu¸c˜oes de seguran¸ca locais: as solu¸c˜oes de seguran¸ca de-vem fornecer mecanismos de acesso entre dom´ınios, sendo que o acesso a recursos de um dom´ınio local ´e determinado pelas suas pr´oprias pol´ıticas de seguran¸ca; ❼ Exportabilidade: o c´odigo deve ser export´avel de modo que possa ser executado em
qualquer site da grade, sem um esquema “pesado” de criptografia;
❼ Cria¸c˜ao dinˆamica de servi¸cos: os usu´arios devem ser capazes de criar novos servi¸cos que possam interagir com outros servi¸cos, sem interven¸c˜ao do administrador; ❼ Estabelecimento dinˆamico de dom´ınios confi´aveis: os diferentes dom´ınios precisam
estabelecer uma rela¸c˜ao de confian¸ca entre os seus usu´arios e recursos para garantir a coordena¸c˜ao de recursos.
Al´em dos requisitos acima citados, a dinamicidade do ambiente tamb´em deve ser levada em considera¸c˜ao, tendo em vista o grande n´umero de jobs e participantes que interagem com a grade constantemente. Existem, portanto, v´arios desafios para qualquer infra-estrutura de seguran¸ca em grade.
2.4. Seguran¸ca em Grades 20
Al´em disso, o Legion permite implementar pol´ıticas de seguran¸ca de acordo com a ne-cessidade, onde cada objeto possui um m´etodo chamado “MayI” que indica ao usu´ario os m´etodos do objeto aos quais ele tem acesso [7]. Em outras palavras, todo objeto ´e respons´avel por sua pr´opria pol´ıtica de controle de acesso. Pordefault, o m´etodo MayI im-plementa uma pol´ıtica baseada em checagem de credenciais e listas ACL (Access Control List).
J´a na plataforma Condor, cujo foco ´e voltado para a computa¸c˜ao de alta vaz˜ao (High-Throughput Computing - HTC) [56], ´e utilizado Secure Socket Layer (SSL) em conjunto com certificados X.509 para a autentica¸c˜ao, tal como na plataforma Globus (na verdade, parte da implementa¸c˜ao dos aspectos de seguran¸ca usados no Condor ´e originada do Globus [57]). Para a autoriza¸c˜ao, o Condor oferece um mecanismo que controla quais m´aquinas podem se unir `a grade, quais m´aquinas podem obter informa¸c˜oes sobre osite e quais m´aquinas do ambiente possuem privil´egios administrativos. No in´ıcio do projeto Condor, a autoriza¸c˜ao era baseada em informa¸c˜oes dohost (como endere¸co IP, por exemplo). Em sua vers˜ao est´avel mais recente, o Condor 6.6 trabalha com autoriza¸c˜ao baseada no usu´ario.
A seguir, ser˜ao discutidos em maiores detalhes os mecanismos e aspectos de se-guran¸ca observados nas plataformas Globus Toolkit e OurGrid.
2.4.1 Seguran¸ca no Globus Toolkit
A infra-estrutura oferecida pela plataforma Globus ´e atualmente a mais utilizada para constru¸c˜ao de Organiza¸c˜oes Virtuais montadas sobre grades computacionais. O projeto Globus ´e direcionado para a defini¸c˜ao e implementa¸c˜ao das camadas de mais baixo n´ıvel no desenvolvimento de grades computacionais, permitindo criar abstra¸c˜oes e diversas funcionalidades b´asicas [48]. A ferramenta desenvolvida no contexto do projeto Globus ´e conhecida como Globus Toolkit e hoje encontra-se em sua vers˜ao 4 (GT4).
O Globus Toolkit oferece uma API (Application Program Interface) que dispo-nibiliza um conjunto de mecanismos de seguran¸ca. Essa API, conhecida como Globus Security Infrastructure (GSI) foi implementada sobre o GSS (Generic Security Servi-ces)[58] e provˆe servi¸cos de seguran¸ca, tais como autentica¸c˜ao, autoriza¸c˜ao, n˜ao-rep´udio, confidencialidade e privacidade dos dados [4].
2.4. Seguran¸ca em Grades 21
usu´arios, esta¸c˜oes e recursos), o GSI utiliza o esquema de certificado digital de acordo com o padr˜ao X.509. Esses certificados s˜ao assinados por uma autoridade certificadora (Certificate Authority - CA), que exerce as fun¸c˜oes de administra¸c˜ao e armazenamento dos certificados. Dessa forma, o GSI atende o requisito de autentica¸c˜ao ´unica (single sign-on) atrav´es do uso de usu´arios proxies na estrutura interna da grade. Esse tipo de autentica¸c˜ao funciona da seguinte forma: no momento em que um usu´ario cadastrado se autentica na grade e envia algum processo para ser executado, um usu´arioproxy utiliza a identidade deste usu´ario autenticado e fica respons´avel por realizar todas as autentica¸c˜oes subseq¨uentes no ambiente interno, de forma independente da localiza¸c˜ao do dom´ınio des-tas entidades na grade. Al´em disso, o GSI provˆe autentica¸c˜ao m´utua atrav´es da troca de chaves entre as entidades envolvidas da grade, utilizando SSL. Logo ap´os a execu¸c˜ao do processo de autentica¸c˜ao e da comprova¸c˜ao da identidade das entidades, ´e criado um t´unel SSL respons´avel pela provis˜ao de integridade e confidencialidade na comunica¸c˜ao entre as entidades da grade.
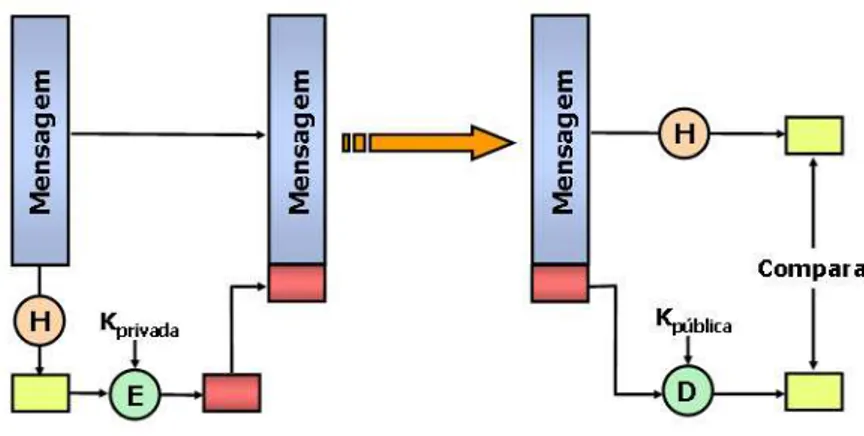
O GSI tamb´em disponibiliza um servi¸co de n˜ao-rep´udio atrav´es da utiliza¸c˜ao de assinaturas digitais, como ilustrado na Figura 2.9. No processo de cria¸c˜ao da assinatura, uma fun¸c˜ao hash (H) ´e utilizada para gerar um resumo da mensagem a ser assinada. Ap´os a gera¸c˜ao e assinatura do resumo com a chave K privada da entidade da grade, este ´e enviado juntamente com a pr´opria mensagem para a outra entidade participante da comunica¸c˜ao que realizar´a o processo de verifica¸c˜ao de assinatura, que acontece atrav´es da compara¸c˜ao entre o resumo gerado da mensagem e o resultado da decodifica¸c˜ao da assinatura via chave K p´ublica do emissor [4].
Figura 2.9 Assinatura digital no GSI
2.4. Seguran¸ca em Grades 22
tenha sido apropriadamente executado [59]. Assim, dentre as caracter´ısticas de seguran¸ca inerente ao GSI, observa-se a ausˆencia de um esquema que verifique a integridade dos
jobs em processamento, o que evidencia a necessidade de constru¸c˜ao de mecanismos de seguran¸ca no Globus que solucionem este problema de forma integrada ao GSI.
O Global Grid Forum [60], entidade padronizadora de tecnologias para grades formada por centros de pesquisa, institui¸c˜oes acadˆemicas e o setor corporativo, define que dentre os requisitos de seguran¸ca estabelecidos, h´a a necessidade de mecanismos que detectem intrus˜ao, identifiquem o mau uso da grade por parte de usu´arios maliciosos, protegendo o ambiente, inclusive, contra v´ırus e worms [61], e que tamb´em garantam a integridade das informa¸c˜oes, provendo confian¸ca nos resultados obtidos com o processa-mento.
2.4.2 Seguran¸ca no OurGrid
A plataforma OurGrid ´e uma solu¸c˜ao para a cria¸c˜ao de grades computacionais, com foco em aplica¸c˜oes chamadas Bag-of-Tasks (BoT), ou seja, aplica¸c˜oes cujas tarefas s˜ao independentes umas das outras [62]. Dessa forma, o OurGrid viabiliza uma rede P2P de troca de favores, onde, caso sejam solicitados, os recursos ociosos de um determinadosite
s˜ao fornecidos para outro, mediante uma pol´ıtica de quanto mais se doa recursos, maior a prioridade junto `a comunidade para obtˆe-los quando necess´ario [46].
O OurGrid oferece mecanismos para autentica¸c˜ao em n´ıvel desite local e remoto. No primeiro caso, a autentica¸c˜ao segue os procedimentos tradicionais (login e senha), j´a que trata-se de m´aquinas que encontram-se no mesmo dom´ınio ao qual o usu´ario pertence. Contudo, o acesso a recursos de outrossites passa pelofront-end de seu dom´ınio, ou seja, o OurGrid Peer local. Nesse caso, ´e utilizado o esquema de certificados X.509 [40].
2.5. Conclus˜ao 23
programas e aos arquivos do usu´ario dono da m´aquina fornecedora, j´a que estes mesmos
jobs est˜ao confinados em uma ´area onde s´o poder˜ao acessar outros processos, o sistema de arquivos e os recursos de rede que nela se encontram. Esta t´ecnica ´e ilustrada pela Figura 2.10.
Figura 2.10 T´ecnica Sandbox
Embora o OurGrid possua um mecanismo para a prote¸c˜ao dos recursos, n˜ao existe de fato um mecanismo que proteja tamb´em as aplica¸c˜oes. Portanto, essa plataforma n˜ao oferece garantias que os jobs executados pelas Gums sejam processados corretamente, sem a manipula¸c˜ao indevida dos seus resultados.
Assim como no Legion, no Condor e no Globus, nota-se a necessidade de uma solu¸c˜ao que garanta n˜ao s´o o bom uso dos recursos oferecidos, mas tamb´em a integri-dade dos processos e dos resultados obtidos, certificando-se assim que as m´aquinas que comp˜oem a grade n˜ao sejam constitu´ıdas por n´os maliciosos interessados em invalidar os dados.
2.5 CONCLUS˜AO
Este cap´ıtulo apresentou as principais caracter´ısticas das arquiteturas de sistemas dis-tribu´ıdos, com destaque para grades computacionais, discutindo aspectos como desco-berta de servi¸cos e escalonamento das aplica¸c˜oes. Al´em disso, tamb´em foram investiga-dos requisitos de seguran¸ca existentes para qualquer plataforma de grades, destacando os principais mecanismos de seguran¸ca oferecidos pelas plataformas Globus e OurGrid.
2.5. Conclus˜ao 24
CAP´ITULO 3
DIAGN ´
OSTICO EM N´IVEL DE SISTEMA
Neste cap´ıtulo s˜ao discutidos os principais modelos de falhas encontradas em grades, apresentando duas estrat´egias de tolerˆancia a falhas que podem ser aplicadas nesse am-biente com o intuito de detectar a manipula¸c˜ao dos resultados processados. Em seguida, s˜ao abordados modelos de diagn´ostico em n´ıvel de sistema, apontando seus conceitos, caracter´ısticas, vantagens e desvantagens.
3.1 TIPOS DE FALHAS
Ambientes distribu´ıdos e heterogˆeneos como os de grades s˜ao bastante suscet´ıveis a erros devido a sua complexidade. Quanto maior a grade, maior a possibilidade de falhas, j´a que um n´umero maior de componentes e elementos precisam estar continuamente interagindo. Assim, in´umeros tipos de falhas podem ocorrer nesse tipo de ambiente, como as falhas do tipo crash, por omiss˜ao, temporiza¸c˜ao e as falhas bizantinas [63].
3.2. Classifica¸c˜ao de N´os com Mau Comportamento 26
3.2 CLASSIFICAC¸ ˜AO DE N ´OS COM MAU COMPORTAMENTO
Conforme mencionado, as falhas ocasionadas por n´os maliciosos constituem apenas uma subclasse das falhas bizantinas decorrentes por mau comportamento. De acordo com Hollick et al em [65], as falhas originadas pelo mau comportamento envolvem componentes (n´os) que passam a agir de maneira inativa, ego´ısta ou maliciosa.
Os n´os inativos n˜ao cooperam com a rede, deixando de encaminhar pacotes, recusando-se a processar os jobs que lhe s˜ao entregues ou omitindo informa¸c˜oes sobre seus recursos dispon´ıveis. Os n´os considerados ego´ıstas negligenciam ajuda aos demais n´os, favorecendo apenas seus pr´oprios interesses. No contexto OurGrid, por exemplo, um n´o ego´ısta (chamado free-rider) ´e aquele que apenas consome recursos da comunidade, sem oferecer seus pr´oprios recursos quando solicitado. Embora ele n˜ao doe seus recursos, o n´o ego´ısta pode manter-se respondendo `as requisi¸c˜oes de descoberta de recursos a fim de permanecer ativo na grade. Quanto aos n´os maliciosos, estes possuem, por exemplo, interesse em subverter os recursos da grade, oferecer um resultado inv´alido ou mesmo em difundir worms ou v´ırus entre as m´aquinas do ambiente.
A classe de n´os maliciosos pode ainda ser subdividida em trˆes categorias [24]:
❼ N´os maliciosos tolos: sempre retornam resultados corrompidos;
❼ N´os maliciosos comuns: retornam resultados corrompidos com uma certa probabi-lidade;
❼ N´os maliciosos inteligentes: agem normalmente durante um certo per´ıodo para obter boa reputa¸c˜ao, at´e que passam deliberadamente a retornar resultados corrompidos com uma certa probabilidade.
Dentre as classifica¸c˜oes de mau comportamento apresentadas, as falhas de natu-reza maliciosa que geram resultados corrompidos, em especial os n´os maliciosos tolos e comuns, constituem o escopo desta disserta¸c˜ao.
3.3 CONFIABILIDADE E SEGURANC¸ A
3.4. T´ecnicas para Verifica¸c˜ao de Integridade de Processamento 27
como por exemplo, falta de energia el´etrica, bugs de software, degrada¸c˜ao do hardware, m´a configura¸c˜ao dos componentes, falhas na comunica¸c˜ao, entre outros [66]. J´a o con-ceito de seguran¸ca (security) est´a intimamente ligado a uma inten¸c˜ao maliciosa, como distribui¸c˜ao de v´ırus, invas˜ao de redes, quebra de chaves secretas, entre outros. Assim, a finalidade da seguran¸ca ´e evitar ou tolerar ataques desse tipo, protegendo as informa¸c˜oes e os servi¸cos oferecidos por um sistema.
Embora possuam ˆenfases diferenciadas, ambas as ´areas preocupam-se com o cor-reto funcionamento dos sistemas computacionais, geralmente denominado como dependa-bility. Na realidade, seguran¸ca e confiabilidade interseccionam-se `a medida que seguran¸ca tamb´em pode tratar problemas de origem acidental, enquanto confiabilidade pode incluir problemas de origem maliciosa. Mecanismos cl´assicos, como controle de acesso e auten-tica¸c˜ao, t´ıpicos da ´area de seguran¸ca, podem ser utilizados para preven¸c˜ao de falhas, assim como ferramentas de tolerˆancia a intrus˜oes podem lan¸car m˜ao de conceitos comuns `a tolerˆancia a falhas [67].
Nesse contexto, o termo confiabilidade utilizado no restante deste trabalho refere-se justamente ao grau de integridade do comportamento de um determinado n´o (unidade de processamento) ao fornecer um resultado de umjob que ´e processado por ele na grade. Para isso, s˜ao utilizadas t´ecnicas de tolerˆancia a falhas.
3.4 T´ECNICAS PARA VERIFICAC¸ ˜AO DE INTEGRIDADE DE PROCESSAMENTO
Em sistemas distribu´ıdos, mais especificamente em grades computacionais, tolerˆancia a falhas tamb´em tem sido utilizada no dom´ınio da seguran¸ca. Assim, t´ecnicas de verifica¸c˜ao de integridade de processamento podem ser aplicadas utilizandojobs para testar periodi-camente os n´os da grade. Dependendo do sistema, osjobs de teste podem ser constitu´ıdos pelos pr´oprios jobs da aplica¸c˜ao. Por exemplo, o projeto Seti@home [68] (computa¸c˜ao volunt´aria para pesquisa de vida extra-terrena) adota o esquema de vota¸c˜ao majorit´aria (majority voting), onde osjobs da aplica¸c˜ao s˜ao replicados e distribu´ıdos entre os diversos
hosts volunt´arios do ambiente.
3.4. T´ecnicas para Verifica¸c˜ao de Integridade de Processamento 28
um resultado diferente da maioria. Assim, o n´o gerente assume x como resultado final v´alido e o n´o D como malicioso.
Embora seja relativamente simples de implementar, essa estrat´egia baseada em replica¸c˜ao ´e indicada somente em casos onde a taxa de erros ´e necessariamente baixa. Caso contr´ario, a replica¸c˜ao crescer´a excessivamente em fun¸c˜ao do n´umero m, e quanto maior o n´umero de r´eplicas, maior o desperd´ıcio de recursos e menor o desempenho.
Figura 3.1 Voto majorit´ario com 6 n´os fornecedores de recursos
Uma alternativa ao esquema de vota¸c˜ao majorit´aria ´e a t´ecnica baseada em veri-fica¸c˜ao focalizada (spot-checking), utilizado em trabalhos como o de Sarmenta [22]. Nesse caso, os n´os s˜ao testados aleatoriamente atrav´es da solicita¸c˜ao de execu¸c˜ao de umjob cujo resultado ´e previamente conhecido. Se o resultado divergir do esperado, os resultados an-teriores retornados por este n´o s˜ao descartados. A utiliza¸c˜ao de um mecanismo do tipo lista negra (blacklist) permite indicar quais n´os n˜ao s˜ao mais desejados na grade.
O trabalho de Casale et al [23] tamb´em emprega uma filosofia semelhante para tolerar ataques de manipula¸c˜ao em grades. Os n´os podem receber tantojobs de teste com resultados j´a conhecidos pelo n´o gerente, comojobsreplicados entre os diversos n´os do am-biente. Tais problemas s˜ao submetidos aos n´os em intervalos regulares pr´e-determinados. Segundo Casale et al, uma forma de diminuir o custo (overhead) introduzido por essas t´ecnicas seria a ado¸c˜ao de um esquema de reputa¸c˜ao que determine o grau de confiabili-dade de um dado n´o de acordo com o seu comportamento.
3.5. Diagn´ostico 29
comportamento dos n´os. Al´em disso, para grades ´e necess´ario obviamente aplicar testes mais sofisticados. Uma possibilidade ´e combinar diagn´ostico com verifica¸c˜ao focalizada, utilizando tamb´em uma lista negra e um esquema eficiente de reputa¸c˜ao.
3.5 DIAGN ´OSTICO
Algoritmos de diagn´ostico em n´ıvel de sistema s˜ao comumente utilizados como uma es-trat´egia de tolerˆancia a falhas, onde, a partir de uma s´erie de testes, determina-se quais unidades est˜ao falhas e quais est˜ao em pleno funcionamento, obtendo ao final um conjunto de respostas, chamado s´ındrome [69].
Os primeiros modelos de diagn´ostico que surgiram s˜ao do tipo centralizado, onde h´a a presen¸ca de uma unidade central respons´avel por testar os enlaces e estados das demais unidades do sistema. Esse modelo, embora pare¸ca de mais f´acil implementa¸c˜ao, possui a limita¸c˜ao de disponibilidade, pois caso ocorra uma falha na unidade central, todo o sistema ficar´a comprometido.
Como alternativa, surgiram os modelos distribu´ıdos, onde a responsabilidade de aplica¸c˜ao dos testes ´e passada para v´arias ou todas as unidades do sistema. Uma es-trat´egia simplificada para execu¸c˜ao de testes em modelos distribu´ıdos consiste no envio de est´ımulos das unidades testadoras para as unidades testadas [70]. Se as respostas das unidades testadas chegarem dentro de um intervalo de tempo limitado, a unidade testa-dora a considera como uma unidade sem-falha. Por outro lado, se a resposta n˜ao vier a tempo, a unidade testadora conclui que a unidade testada ´e falha.
Um algoritmo de diagn´ostico pode declarar todas as N unidades de um sistema como falhas, n˜ao falhas ou suspeitas. Em um modelo distribu´ıdo, ´e assumido que as unidades testadoras n˜ao falhas relatam resultados confi´aveis. Com rela¸c˜ao aos resultados das unidades falhas nada pode ser afirmado, como ilustra a Figura 3.2, com os resultados detalhados na Tabela 3.1.
3.5. Diagn´ostico 30
Figura 3.2 Poss´ıvel s´ındrome para um sistema baseado em testes distribu´ıdos
Testador Testado Resultado
N˜ao-Falho N˜ao-Falho 0 N˜ao-Falho Falho 1
Falho N˜ao-Falho X (0 ou 1) Falho Falho X (0 ou 1)
Tabela 3.1 Unidades testadoras falhas emitem resultados indeterminados
Na se¸c˜ao seguinte s˜ao discutidos os principais modelos de diagn´ostico em n´ıvel de sistema encontrados na literatura. Deste ponto em diante, as unidades do sistema s˜ao chamadas n´os. No escopo deste trabalho, cada n´o representa um recurso de processa-mento computacional.
3.5.1 Modelo PMC
Um dos modelos cl´assicos de diagn´ostico propostos ´e o modelo PMC [71], cujo nome deriva das iniciais dos seus autores (Preparata, Metze e Chien). Nesse modelo, os n´os testam uns aos outros e tais testes s˜ao realizados em intervalos pr´e-definidos. Os n´os sem-falhas que aplicam os testes s˜ao considerados confi´aveis e relatam resultados corretos. J´a os n´os testadores falhos s˜ao imprevis´ıveis, podendo dar um parecer arbitr´ario para o resultado do n´o testado. Os resultados dos testes possuem representa¸c˜ao bin´aria (0 para sem-falha, 1 para falha). Embora os testes sejam realizados de forma distribu´ıda, o diagn´ostico no modelo PMC ´e centralizado, visto que ´e assumida a existˆencia de uma entidade conhecida comoobservador central (ou or´aculo) com a atribui¸c˜ao de receber todos os resultados dos testes (s´ındrome), para em seguida determinar o diagn´ostico do sistema como um todo.
3.5. Diagn´ostico 31
status de falha de um n´o n˜ao muda durante o teste e o diagn´ostico. Embora este modelo n˜ao considere falhas transit´orias ou intermitentes, estas s˜ao as mais comuns e as mais dif´ıceis de diagnosticar [72]. Esse modelo foi adotado em trabalhos como [73, 74, 75].
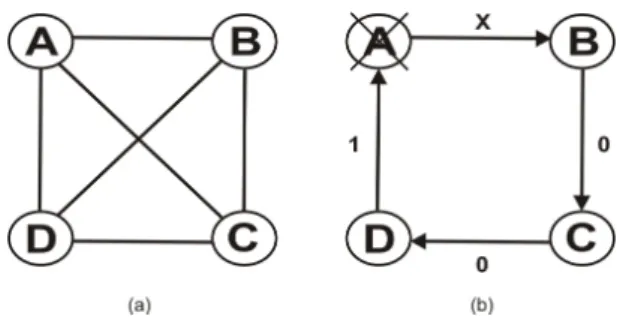
Para seu formalismo, o modelo utiliza a teoria de grafos, onde os v´ertices repre-sentam os n´os e as arestas indicam os enlaces com a dire¸c˜ao dos testes. Assim sendo, um sistema S, composto por N n´os totalmente conectados, ´e representado atrav´es de um grafo completo G=(V, E), onde V representa os v´ertices e E os enlaces. Um grafo completo para o modelo PMC com 4 n´os ´e ilustrado pela Figura 3.3 (a).
Figura 3.3 Exemplo de grafo do sistema e grafo de testes para 4 n´os
Na Figura 3.3 (b), o grafo direcionado de testes representa um sistema de 4 n´os, onde a aresta partindo do v´ertice A para o v´ertice B, por exemplo, representa um teste aplicado pelo n´o A sobre o n´o B (A → B), cujo resultado ´e X, isto ´e, indeterminado, podendo ser 0 ou 1, j´a que o n´o testador A est´a falho. O teste (B → C) identifica que o n´o C n˜ao possui falha (resultado 0). O mesmo para o teste (C → D). J´a o teste (D→A) indica que o A est´a falho (resultado 1). Assim, a s´ındrome do sistema pode ser representada pelo vetor de 4 bits X, 0, 0, 1, lembrando que no modelo PMC os n´os testa-dores sem-falhas s˜ao totalmente confi´aveis e sempre reportam resultados corretos. Esse conjunto de resultados ´e passado para o observador central, que tem a responsabilidade de oferecer o diagn´ostico do estado do sistema, o que nem sempre ´e trivial, j´a que n´os testadores podem dar resultados divergentes sobre um determinado n´o testado.
![Figura 2.8 Descoberta dinˆ amica de servi¸cos via Web Services [47]](https://thumb-eu.123doks.com/thumbv2/123dok_br/15301923.548136/33.892.224.664.454.725/figura-descoberta-dinˆ-amica-servi-cos-web-services.webp)