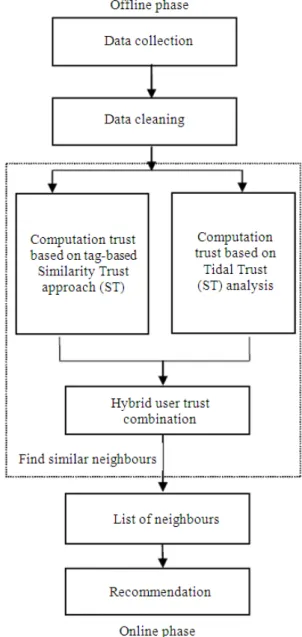
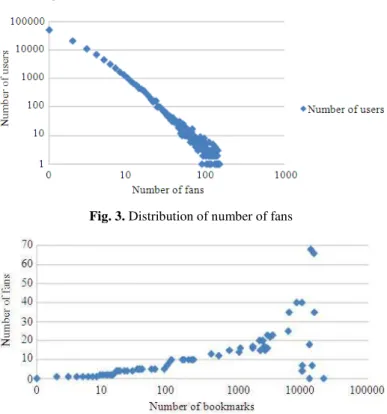
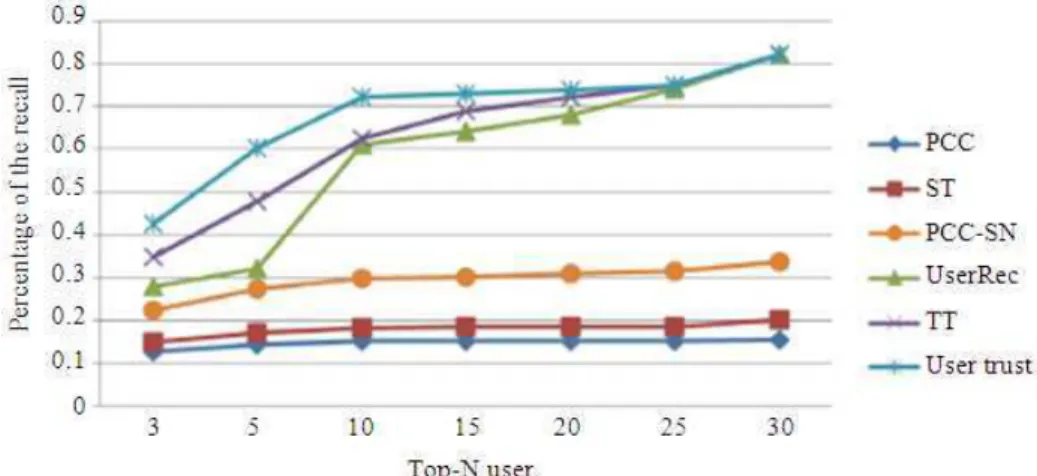
USER RECOMMENDATION ALGORITHM IN SOCIAL TAGGING SYSTEM BASED ON HYBRID USER TRUST
Texto
Imagem

Documentos relacionados
Our goal with this study is to discuss the changes in some hematological parameters in Brazilian Jiu Jitsu athletes who underwent training in two different levels of intensity
Posto isto, o objetivo deste estudo foi o de avaliar eventuais diferenças no perfil psicopatológico entre dois grupos de heroinómanos em TSO com Metadona:
Nesta fase, o conjunto de actividades desenvolvidas com os alunos visou, não só uma revisão/apresentação do quadro conceptual a abordar durante a visita (a
Quanto à coorte 1, os meninos apresentam médias superiores aos sete e nove anos de idade, ficando os 11 anos com superioridade do gênero feminino, todavia não foram
na decisão de colocar a página da empresa na Internet (questão 2.7 do questionário); influência/impacto mais provável da Internet nas agências de viagens e operadores
Shakyamuni, 0 Sutra de Lotus e 0 devoto san unos - realiza para 0 devoto 0 que as escolas estabelecidas do Budismo tentam pelas praticas tradicionais de medita~ao e disciplina
user interests based on the user‟s content and location preferences for the reranking. Again, the training process is performed on the server for its speed. The search
Tendo em vista a importância da regeneração de ambientes antropizados no semi-árido do nordeste brasileiro e a importância ecológica e econômica do componente herbáceo nesta
