Resumo: Atualmente, educação a distância, em especial a educação
baseada na web, está se tornando mais importante na medida em que possibilita a disseminação de conhecimento e informação através da Internet de modo mais rápido e barato. Consequentemente, arquiteturas para sistemas de aprendizagem têm sido desenvolvidas e de modo a filtrar o que é mais relevante e/ou de interesse dos usuários, técnicas de personalização têm sido propostas e utilizadas. Em sistemas de aprendizagem, acesso ao conteúdo instrucional é sempre uma característica importante e a possibilidade de filtrar o conteúdo armazenado nestes repositórios é um aspecto essencial. Neste contexto, o trabalho descrito neste artigo enfoca o problema de reconhecer diferentes versões do mesmo conteúdo. Se diferentes versões são reconhecidas, então podem ser organizadas de acordo com diferentes características e é possível selecionar automaticamente a versão que melhor se adequa às necessidades do usuário. Este artigo descreve um serviço web – Serviço Agrupador de Resultados (objetos de aprendizagem) Semelhantes – que foi especificado para ser capaz de reconhecer versões de objetos de aprendizagem existentes baseados em seus registros de metadados. Um estudo de caso é descrito, em que as idéias apresentadas são ilustradas.
Palavras-chave: Objetos de Aprendizagem; Personalização; Perfil do
Usuário; Padrões de Metadados; Versões de Objetos de Aprendizagem; Agrupamento de Objetos Similares.
Abstract: Nowadays e-learning is becoming more important as it makes
possible the dissemination of knowledge and information through the internet in a faster and costless way. Therefore, architectures for e-learning systems have been developed and in order to filter what is more relevant and/or of users’ interest, personalization techniques have been proposed and adopted. In e-learning systems, access to instructional content is always an important feature and the possibility of filtering content stored in their repositories is an essential aspect. In this context, the work described in this paper addresses the problem of being able to recognize different versions of the same content. If different versions are recognized, then these versions can be organized according to different characteristics and it is possible to automatically select the version that suits best the user needs. This paper describes a web service – Similar LO Detection Service - that has been specified to be able to recognize versions of existing learning objects based on their metadata records. Besides that it also describes a case study where the ideas presented are showed.
Keywords: Learning Objects; Personalization; User Profile; Metadata
Standards; Versioning of Learning Objects; Grouping Similar Objects.
DE
O
BJETOS
DE
A
PRENDIZAGEM
S
EMELHANTES
Raphael Ghelman Software Development Microsoft
[email protected] Sean W. M. Siqueira
Depto Informática Aplicada UNIRIO
[email protected] Maria Helena L. B. Braz DECivil/IST/UTL - PT [email protected] Rubens N. Melo Depto. Informática PUC - Rio [email protected]
1. I
NTRODUÇÃOCom o avanço das tecnologias da informação e comunicação, bem como o crescimento da Sociedade da Informação através do uso da Internet, organizações e instituições utilizam cada vez mais técnicas sofisticadas para a geração e disseminação do conhecimento. Nesse contexto, o e-learning1 surge como uma área muito importante,
produzindo soluções avançadas, tais como as baseadas em objetos de aprendizagem (Learning Objects ou LOs).
Um LO é qualquer entidade digital ou não digital que possa ser usada, re-usada ou referenciada durante a aprendizagem baseada em Tecnologias da Informação [1]. Assim, um LO corresponde ao menor bloco de instrução ou informação, elaborado de forma independente, capaz de transmitir conhecimento. LOs são estruturados através da combinação do conteúdo didático (apostila, apresentação, tutorial, exercícios etc.) e seus respectivos metadados educacionais (título, autor, faixa etária etc.).
Este trabalho tem como motivação o projeto PGL [2], onde estão sendo desenvolvidos estudos, metodologias, técnicas, práticas e tecnologias relacionadas ao desenvolvimento/implementação de cursos em diversas áreas do conhecimento a serem disponibilizados na Web, com enfoque em LOs.
As instituições participantes do PGL visam compartilhar materiais educacionais para usuários com diferentes formações, habilidades e necessidades. Embora haja uma iniciativa em se desenvolver uma metodologia única de desenvolvimento de LOs para o consórcio, vários materiais já foram desenvolvidos em diferentes mídias e contextos e se encontram em um ambiente distribuído e heterogêneo, ou seja, são utilizadas diversas plataformas e ambientes de aprendizagem diferentes entre as instituições e nas próprias instituições participantes.
Deste modo, existem diferentes materiais educacionais que poderiam ser vistos de modo integrado, como grupos de versões de materiais e corresponderiam a possibilidades de seleção personalizada de acordo com o perfil dos usuários. Ou seja, os materiais poderiam ser agrupados, de modo que as versões que melhor correspondessem às necessidades/ habilidades dos usuários sejam selecionadas ou sugeridas automaticamente, facilitando o acesso à informação mais adequada e a recuperação dos materiais mais relevantes. Surge, então, a necessidade de se reconhecer essas diferentes versões, seja de mídia, língua ou autor de um mesmo material de ensino. Este trabalho descreve a abordagem seguida no desenvolvimento do Serviço Agrupador de Resultados Semelhantes, na tentativa de reconhecer diferentes versões de um mesmo LO, permitindo assim que um usuário execute uma consulta em que a resposta agrupa os LOs equivalentes, podendo destacar os que o sistema julga mais interessantes para aquele usuário, considerando o seu perfil.
Este trabalho está organizado da seguinte maneira: Na próxima seção são apresentados os padrões de metadados utilizados na definição do Serviço Agrupador de Resultados Semelhantes, que é, por sua vez, descrito na seção 3. A seção 4 descreve a implementação e um estudo de caso que foi desenvolvido para ilustrar as vantagens da solução proposta. Finalmente, na seção 5 são apresentadas algumas conclusões e sugestões para trabalhos futuros.
2. P
ADRÕESDEM
ETADADOSU
TILIZADOSMetadados, por definição, são dados que descrevem os dados e que têm como objetivo informar-nos sobre eles para tornar mais fácil a sua organização, busca e recuperação. “Metadados são dados estruturados e codificados que descrevem as características de entidades provedoras de informação para ajudar na identificação, na descoberta, na avaliação e na gerência das entidades descritas” [3].
2.1. IEEE-LOM
O IEEE LOM [1] é um padrão que busca especificar a sintaxe e a semântica dos metadados de objetos de aprendizagem (LOs), definindo os atributos necessários para descrevê-los adequadamente. No LOM, os LOs são definidos como entidades digitais ou não, que podem ser usadas ou referenciadas em cursos que utilizam recursos tecnológicos. Alguns exemplos desses tipos de curso são: ambientes de educação a distância, Intelligent
computer-aided instruction systems etc. Podemos citar alguns
exemplos de LOs: conteúdos multimídia, material didático digitalizado, avaliações, software de ensino e ferramentas de apoio a educação.
O IEEE LOM foi utilizado como base para a descrição de objetos de aprendizagem por ser, na verdade, resultante de outros esforços com objetivos semelhantes e ter sido já aprovado como padrão pela comunidade. Os principais grupos de trabalho que estiveram na gênese deste padrão foram essencialmente o IMS Global Learning Consortium (http:// www.imsglobal.org/), a Association of Remote Instructional Authoring and Distribution Networks for Europe (ARIADNE) (http://www.ariadne-eu.org) e o Dublin Core Metadata Initiative (DCMI) (http:// dublincore.org) que participaram ativamente no grupo IEEE Learning Technology Standards Committee (http:/ /ieeeltsc.org/) responsável pela publicação deste padrão. Atualmente, o IEEE LOM serve de base para outros padrões amplamente utilizados tais como o ADL SCORM (Sharable Content Object Reference Model) (http:// www.adlnet.gov/scorm/index.aspx).
O conjunto de metadados proposto no LOM busca definir o mínimo de atributos necessários para permitir que os LOs sejam gerenciados, avaliados e localizados.
Os elementos de dados que descrevem um LO são agrupados em 9 (nove) categorias, conforme definido no LOM v1.0 Base Schema (cláusula 6): [1]
1 Neste artigo, e-learning refere-se à utilização das tecnologias da
Internet para fornecer um amplo conjunto de soluções que melhoram o conhecimento e o desempenho [4], também é conhecido como Educação Baseada na Web (EBW).
Tabela 1: Categorias do IEEE LOM
2.2. TRATAMENTODE VERSÕESDE OBJETOS
O versionamento de materiais de ensino é previsto no IEEE LOM através da categoria Relation, que é composta dos seguintes elementos: “tipo” e “recurso”. O recurso é descrito por um “identificador” (catálogo e entidade) e uma “descrição”. Assim, no campo “recurso” encontra-se o identificador para o outro material de ensino referenciado pelo atual e no campo “tipo” define-se qual é a relação entre o material de ensino atual e o que está sendo referenciado no campo “recurso”. Esse campo pode ser preenchido com os seguintes valores:
Tabela 2: Possíveis valores para o campo “tipo” da categoria Relation do IEEE LOM.
No contexto do trabalho apresentado neste artigo, a questão do versionamento torna-se mais complexa, pois deve ser capaz de lidar com materiais de ensino heterogêneos e armazenados em diversos repositórios (distribuídos) que não necessariamente conhecem um ao outro, portanto, os relacionamentos entre seus materiais de ensino não estão definidos.
Surge então uma necessidade de considerar uma semântica de identidade e similaridade de materiais de ensino com vista à detecção de versões. Foi assim criado o Serviço Agrupador de Resultados Semelhantes (Similar LO Detection Service) que agrupa os resultados semelhantes, ou seja, as versões de um mesmo material de ensino. Este serviço está inserido em um sistema de integração de repositórios de objetos de aprendizagem - LORIS [5], que é baseado na arquitetura de mediadores e tradutores e lida com a heterogeneidade dos conjuntos de metadados utilizados. LORIS foi desenvolvido no âmbito do projeto PGL e implementado através do uso de serviços web e ontologias. Sua extensão, AccessForAll-LORIS [6], foi desenvolvida para permitir acesso de forma integrada aos LOs em repositórios heterogêneos, de acordo com as necessidades de acessibilidade dos usuários. O Serviço Agrupador de Resultados Semelhantes foi inserido neste sistema, fazendo o reconhecimento de versões de LOs e seu agrupamento, além da recomendação dos LOs considerados mais adequados ao usuário.
3. O S
ERVIÇOA
GRUPADORDER
ESULTADOSS
EMELHANTES(SARS)
Neste tópico será abordada a questão das versões e explicado o processo utilizado na identificação de versões.
3.1. TRATAMENTO DE VERSÕES DE MATERIAIS EDUCACIONAIS
Versão é uma variante de alguma coisa original. No contexto de documentos, geralmente uma versão sempre é uma melhoria da versão anterior, sendo que o original é o menos evoluído.
A versão no contexto da informática se refere geralmente à versão do programa de computador, ou seja: a cada modificação no software que os programadores fazem é gerada uma nova versão.
No contexto deste trabalho Versões de Materiais Educacionais são diferentes Materiais Educacionais que tratam sobre o mesmo tema ou assunto e que sejam conceitualmente similares ou equivalentes. Sob essa ótica, o sistema não considera que apenas um Material Educacional melhorado ou alterado é uma versão do anterior.
Materiais Educacionais escritos em diversas línguas, utilizando diferentes mídias e diferentes autores, podem ser considerados versões de um mesmo Material Educacional conceitual, desde que eles tratem sobre o mesmo conteúdo semântico, envolvendo o mesmo tema ou assunto.
SARS utiliza essas premissas para integrar diferentes versões de um mesmo Material Educacional em um único
Material Educacional conceitual. O usuário ainda pode acessar a todas as versões individuais, porém elas aparecem agrupadas para que se tenha uma melhor visibilidade dos diferentes Materiais Educacionais retornados por uma consulta.
3.2. COMOO SARS RECONHECE VERSÕESDE MATERIAIS
EDUCACIONAIS
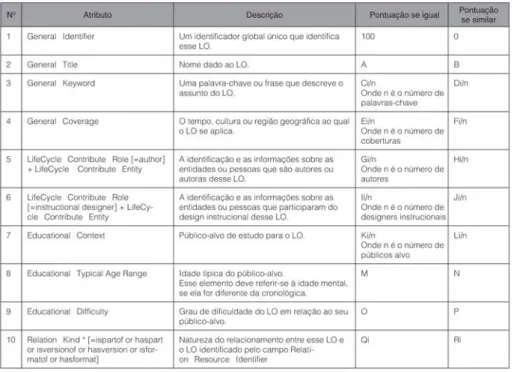
A abordagem utilizada para o reconhecimento de versões de um mesmo material de ensino foi por semelhança de seus metadados, ou seja, itens relevantes de seus metadados são comparados e a pontuação atribuída a cada um deles é somada quando eles são considerados iguais ou quando são considerados semelhantes, conforme a Tabela 3. Ao final do processo, se a pontuação atingida for superior a um valor pré-determinado, os objetos de aprendizagem em questão são considerados um versão do outro.
Como no AccessForAll-LORIS [6], todos os metadados são convertidos para um esquema comum, a comparação dos metadados é feita somente sobre esse esquema integrador (baseado no IEEE LOM).
Na Tabela 3, onde a “Pontuação se igual” e a “Pontuação se similar” são atribuídas respectivamente quando o conteúdo dos atributos de metadados que estão sendo comparados é idêntico (para que os atributos sejam idênticos eles deverão possuir o mesmo tipo e o mesmo valor) ou similar. Valores proporcionais aos atributos considerados foram obtidos empiricamente. Embora ainda necessite uma formalização melhor ou testes mais detalhados, os valores estabelecidos foram: A = 60, B = 30, C = 60, D = 0, E = 20, F
= 0, G = 40, H = 0, I = 20, J = 0, K = 10, L = 0, M = 10, N = 10, O = 5, P = 5, Q = 100 e R = 0.
O título é considerado similar se não for idêntico, estiver descrito na mesma língua e se, ao removermos todas as preposições, o número de verbos, adjetivos e substantivos idênticos for maior que zero e a soma dos verbos, adjetivos e substantivos idênticos dividido pela soma de todos os verbos, adjetivos e substantivos (idênticos e diferentes) for maior ou igual a uma determinada porcentagem. Consideramos este valor igual a 0,5, ou seja, consideramos um título similar a outro se mais da metade de todos os verbos, adjetivos e substantivos existentes nos dois títulos for idêntica.
Na “Pontuação se igual” de alguns atributos aparece uma divisão por n. Em todas essas divisões, n é o maior número de itens do atributo em questão de cada metadado. Vale ressaltar que esta valoração só será efetuada caso haja 1 ou mais itens do atributo considerado (de modo a evitar uma divisão por zero). Por outro lado, i indica a quantidade de itens iguais. Por exemplo, se um atributo possuir 5 palavras-chave e estiver sendo comparado com outro que possua 3, então n será 5. Caso as 3 palavras-chave sejam idênticas a 3 existentes no atributo que possui 5, então i será igual a 3 e a “Pontuação se igual” será de (C*3)/5= (60*3)/5=36.
O atributo na linha número 5 possui um sinal “+” que significa que os valores do atributo LifeCycle’! Contribute’!Entity são utilizados na comparação quando o valor do atributo LifeCycle’!Contribute’!Role for igual a “author”. O mesmo ocorre na linha 6, exceto pelo fato de “author” ser substituído por “instructional designer”.
Tabela 3: Tabela de pontuação utilizada pelo SARS para o reconhecimento de versões de um mesmo material de ensino.
* Nesse caso a comparação é feita entre o atributo Relation’!Resource’!Identifier do primeiro LO e o atributo General’!Identifier do segundo LO. Obs. 1: i indica a quantidade de itens iguais, enquanto n indica a quantidade total de itens. Exemplo, se tivermos 5 palavras-chave (n = 5), sendo três iguais (i = 3), então o total será (C*3)/5 e supondo C = 60, então 60*3/5 = 36 pontos.
Obs. 2: as letras A .. R indicam um valor proporcional ao ser adicionado. Considerando que o mesmo identificador equivale a 100% ou 100 pontos, podemos indicar por exemplo que palavra-chave igual equivale a 60% deste total e portanto C = 60 para uma pontuação se igual.
A idade típica do público-alvo é considerada similar se a diferença não for maior do que três anos para mais ou para menos em termos de valores, ou caso se enquadrem em uma mesma faixa de grau de instrução. Esta variável depende do conjunto de valores utilizados e das regras de integração adotadas.
O grau de dificuldade em relação ao público-alvo é considerado similar se variar de apenas um nível para mais ou para menos. Assim, por exemplo: Muito fácil é considerado similar a fácil, porém fácil não é considerado similar a difícil. Os possíveis níveis, de acordo com a proposta do IEEE LOM, são: muito fácil, fácil, médio, difícil e muito difícil.
A pontuação descrita na tabela 3 foi definida através de um estudo empírico, por experimentação em um conjunto de LOs da comunidade PGL, de forma que os dois atributos de metadados que estejam sendo comparados sejam considerados versões um do outro se a pontuação for maior ou igual a 100. Por isso, por exemplo, a pontuação atribuída ao atributo identificador é 100, dado que esse identificador é único, o que significaria que se dois objetos estivessem sendo comparados e tivessem o mesmo identificador, eles seriam na verdade o mesmo objeto (portanto igualdade).
Por outro lado, caso os dois objetos em questão possuam identificadores diferentes, porém possuam um título similar, as mesmas palavras-chave e o mesmo público-alvo, eles seriam considerados similares.
4. I
MPLEMENTAÇÃODOP
ROTÓTIPOEE
STUDODEC
ASONesta seção é apresentada uma breve descrição da implementação do SARS que, como exposto anteriormente, é um serviço proposto na arquitetura AccessForAll-LORIS [6]. Também é descrito um estudo de caso, onde o SARS é utilizado para agrupar conteúdos instrucionais.
4.1. IMPLEMENTAÇÃODO SARS
O objetivo do SARS é identificar materiais de ensino iguais ou semelhantes e agrupá-los de forma que o usuário possa inicialmente ver ou utilizar apenas o material de ensino mais relevante de cada grupo (o que é determinado em função dos dados do seu perfil).
O SARS recebe como entrada o resultado da consulta submetida pelo usuário, definida no modelo global, acrescida dos metadados de acessibilidade e retorna o mesmo resultado com as respostas iguais ou semelhantes agrupadas.
Uma vez de posse do resultado da consulta submetida pelo usuário, o SARS faz uma comparação de cada um dos LOs obtidos (a partir de seus metadados) com todos os outros LOs obtidos (também a partir dos respectivos metadados) e atribui uma pontuação referente à similaridade de cada par de atributos de metadados (tal como apresentado em 3.2), gerando uma tabela semelhante à Tabela 4.
Tabela 4: Exemplo de pontuação referente à similaridade de cada
par de LOs a partir de seus metadados.
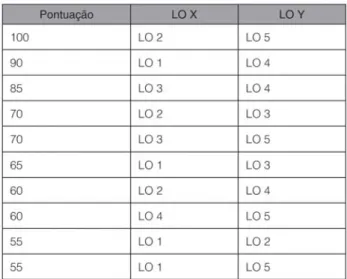
Uma vez gerada a tabela de pontuação de similaridade (ex.: Tabela 4), o SARS cria outra tabela ordenada de forma decrescente pela pontuação de similaridade dos dados acima da diagonal da tabela de similaridade, conforme ilustrado na Tabela 5.
Tabela 5: Exemplo de pontuação referente à similaridade de cada
par de LOs após a ordenação pela pontuação.
O SARS começa então a percorrer a tabela de pontuação (ex.: Tabela 5) e a identificar os grupos que poderão ser formados, o que se dá quando todos os integrantes de um determinado grupo possuem, entre si, uma pontuação de similaridade igual ou superior a um valor pré-determinado. O algoritmo utilizado para este agrupamento é apresentado abaixo.
ALGORITMO DE AGRUPAMENTO
Para cada linha da tabela onde a pontuação é maior que o
valor pré-determinado
Se os dois LOs não estiverem contidos simultâneamente em nenhum grupo
Crie um grupo com os dois LOs
Se o LO X estiver contido num grupo e o LO Y não Se o LO Y for semelhante a todos os outros elementos desse grupo
Adicione o LO Y ao grupo
Se o LO X for semelhante a todos os outros elementos desse grupo
Adicione o LO X ao grupo
Fim Para
No exemplo da Tabela 5, considerando-se o v a l o r p r é - d e t e r m i n a d o i g u a l a 7 0 , t e r í a m o s o s agrupamentos de materiais de ensino definidos da seguinte forma:
• 1 e 4 • 2, 3 e 5
O material de ensino 3 (LO 3) está agrupado aos itens 2 e 5 (LO 2 e LO 5), pois, apesar do LO 3 possuir 85 pontos de similaridade com o LO 4, ele possui apenas 65 pontos de similaridade com o LO 1 e, portanto, o LO 1 e o LO 4 não podem ser do mesmo grupo.
4.2 ESTUDO DE CASO
Para a realização do estudo de caso, foi considerado um conjunto de LOs da comunidade PGL, bem como LOs do The Math Library [7]. Foi executada a seguinte consulta:
• Quais são os materiais de ensino que possuem a palavra-chave “Math” ou que estejam escritos em francês, inglês britânico ou inglês australiano?
O objetivo da consulta era o de retornar materiais de ensino agrupáveis. Optou-se então por fazer uma consulta com a palavra-chave “Math”, para que a resposta contivesse materiais de ensino similares, e por considerar outras línguas. A consulta retornou 20 materiais de ensino que possuem os seguintes títulos:
• 0!
• Adding Integers
• Computation of Discrete Logarithms in Prime Fields
• Dave’s short course on Complex Numbers • e = 2.7182818285...
• Encyclopedia of Triangle Centers • Fibonacci Series and the Golden Section • Finding the Value of Pi Number
• How Robots Work
• Introduction to Fractions for Primary Students • Linear and Multilinear Algebra; Matrix Theory
(Finite and Infinite)
• No Matter What Shape Your Fractions Are In • Numerical Problems (Algorithm Design Manual) • Olimpíada Brasileira de Matemática
• Preconditioned Eigensolvers • Prune shrubs and small trees • The Fibonacci Series • The Pi Number Pages • Triangle Centers
• Wilfred Owen and Realism
Dos 20 materiais de ensino obtidos, 17 possuem a palavra-chave Math, um está escrito em francês, um em inglês britânico e um em inglês australiano.
Dentre os 20 materiais de ensino retornados pela consulta, o sistema agrupou satisfatoriamente 6 materiais de ensino em 3 grupos de 2, o que pode ser observado na Figura 1.
Esses resultados foram agrupados por possuírem títulos similares e palavras-chave e/ou autores idênticos, conforme descrito na seção 3.
Por exemplo, Fibonnaci Series and the Golden
Section foi considerado similar a The Fibonnaci Series por
ter obtido pontos conforme descrito na Tabela 6:
Tabela 6: Exemplo de comparação de The Fibonnaci Séries e
Fibonnaci Séries and the Golden Section.
O título (General’!Title) foi considerado similar, pois ambos estão escritos em inglês e ao se remover todas as suas preposições obteve-se “Fibonnaci Series
Golden Section” e “Fibonnaci Series”, onde a soma
dos verbos, adjetivos e substantivos idênticos é igual a 2 e a soma de todos os verbos, adjetivos e substantivos (idênticos e diferentes) é igual a 4. Sendo 4/2 = 0,5, esses títulos são similares.
Obteve-se 45 pontos no atributo General’!Keyword, pois ambos os materiais de ensino possuíam quatro palavras-chave (n=4), das quais três eram idênticas (i=3). Assim, temos 60i/n = (60*3) /4 = 45.
E, finalmente, estes materiais de ensino como um todo foram considerados similares, pois a soma da pontuação obtida (75) é maior ou igual ao valor pré-determinado (70, conforme descrito em 4.1).
Figura 1: Tela de resposta à consulta exemplificando o agrupamento de resultados.
5. C
ONCLUSÃOEste trabalho propôs a criação de um serviço capaz de lidar com o reconhecimento de diferentes versões de um mesmo conteúdo de aprendizagem, permitindo que a resposta a uma consulta do usuário possa vir agrupada em conjuntos de materiais similares, abrindo assim a possibilidade de selecionar aqueles que mais se enquadrem ao seu perfil. Esta escolha pode ser feita automaticamente em função dos dados do perfil do usuário
Esta possibilidade torna-se importante já que dentre os principais aspectos presentes numa comunidade de
e-learning, encontra-se a necessidade de se compartilhar
materiais educacionais para usuários com diferentes formações, habilidades e necessidades, que foram desenvolvidos em diferentes mídias e contextos e que se encontram em um ambiente distribuído e heterogêneo.
Na literatura pesquisada não foi encontrado nenhum trabalho explorando este aspecto. Sistemas de e-learning existentes tais como ATutor [8], Moodle [9] e Sakay [10], apesar de terem facilidades para consulta e tratarem algumas questões ligadas à personalização não tratam a questão de determinação de versões, principalmente considerando as questões de distribuição e heterogeneidade dos metadados.
Como contribuições e resultados deste trabalho é possível apontar:
• Definição de critérios para igualdade e similaridade de materiais de ensino, de modo a permitir a categorização de versões de objetos de ensino.
• Desenvolvimento de um protótipo do serviço de reconhecimento de versões de acordo com os princípios da arquitetura AccessForAll-LORIS. • Adoção de padrões web e de e-learning na
implementação do serviço proposto.
Como trabalhos futuros prevê-se a realização de um estudo da pontuação descrita na Tabela 3 quando aplicado a outros contextos, diferentes da comunidade PGL, possivelmente levando a uma formalização ou revisão da pontuação envolvida. Além disto, pretende-se avaliar o quanto nossa proposta está atendendo as expectativas dos usuários, bem como permitir um reagrupamento pelos próprios usuários. Outras questões relativas à melhoria do processo de pontuação estão sendo estudadas:
• Medição da quantidade de falso-positivos (a pontuação indica que os materiais de ensino em
questão são similares, quando na verdade não são) e de falso-negativos (a pontuação indica que os materiais de ensino em questão não são similares, quando na verdade são) obtidos com a pontuação atual e executando a mesma medição com outras pontuações para verificar se os resultados melhoram.
• Pode-se utilizar técnicas para distinção de similaridade baseadas no uso, técnicas estatísticas, mineração de texto etc. Isto poderia resultar na definição de um modelo mais robusto para a descoberta e categorização de versões. Outras vertentes de estudo envolvem a especificação de regras de inferência que possam enriquecer semanticamente a busca e o versionamento. Essas regras podem ser aplicadas aos relacionamentos entre LOs, conforme definido pelo padrão de metadados IEEE LOM, através da categoria relation. Considere como exemplo, três LOs cujos identificadores são: LO1, LO2 e LO3. Esses LOs estão relacionados da seguinte maneira: LO1 é pré-requisito de LO2 e LO2 é pré-requisito de LO3. A partir da definição desses relacionamentos e considerando a regra de transitividade válida para “pré-requisito”, conclui-se, através de inferência que LO1 é pré-requisito de LO
3.-R
EFERÊNCIAS[1] Institute of Electrical and Electronics Engineers, Inc. Draft Standard for Learning Object Metadata – IEEE (1484.12.1-2002). The Learning Technology Standards Committee. Disponível em: http://ltsc.ieee.org/wg12/ files/LOM_1484_12_1_v1_Final_Draft.pdf. Data de Acesso: 03 dez. 2007.
[2] PGL, Partnership in Global Learning (PGL), Disponível em: http://www.pgl.ufl.edu/. Data de Acesso: 03 dez. 2007.
[3] American Library Association. Summary Report. ALA/ALCTS/CCS Committee on Cataloging: Description and Access - Task Force on Meta-data, Summary, 1999. Disponível em: http:// www.libraries.psu.edu/tas/jca/ccda/tf-meta3.html. Data de Acesso: 03 dez. 2007.
[4] H. Hong, N. Albi, Kinshuk, X. He, A. Patel, C. Jesshope. Adaptivity in Web-based Educational System. In Proceedings International WWW Conference (10), Hong-Kong, 2001. Disponível em: http://www10.org/cdrom/posters/1052.pdf. Data do acesso: 03 dez. 2007.
[5] S. L. Moura. Uma arquitetura para Integração de Repositórios de Objetos de Aprendizagem baseada em Mediadores e Serviços Web. Dissertação de Mestrado, Pontifícia Universidade Católica do Rio de Janeiro, PUC-Rio, 2005.
[6] R. Ghelman, S. W. M. Siqueira, R. N. Melo. Providing Accessibility to Distributed and Heterogeneous Learning Objects. In Proceedings of the
Euro-American Conference on Telematics and Information Systems (EATIS 2006), Santa Martha, 2006.
[7] Drexel University University. The Math Forum Internet Mathematics Library. Disponível em: http:// mathforum.org/library/. Data de Acesso: 03 dez. 2007. [8] Adaptive Technology Resource Centre. ATutor Learning Content Management System. Disponível em: http://www.atutor.ca/. Data de Acesso: 03 dez. 2007.
[9] Moodle – A Free, Open Source Course Management System for Online Learning. Disponível em: http:// moodle.org/. Data de Acesso: 03 dez. 2007.
[10] FLUID Project. Sakai: Collaboration and Learning Environment for Education. Disponível em: http:// www.sakaiproject.org/. Data de Acesso: 03 dez. 2007.